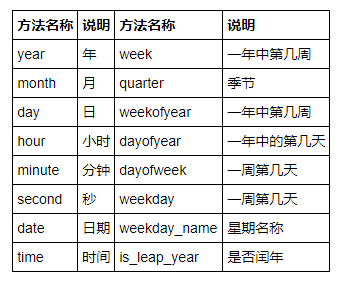
| БрМЭЦМі: |
| БОЮФРДздгкcnblogs,ЮФеТНщЩмСЫNumpyЃЌScipyЃЌpandasЕФЧјБ№ЃЌPandasЕФЪ§ОнЖСШЁвдМАЪ§ОнаДГіЕФЯрЙиФкШнЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
КмЖрШЫЖМЗжВЛЧхNumpyЃЌScipyЃЌpandasШ§ИіПтЕФЧјБ№ЁЃ
дкетРяМђЕЅЗжБ№вЛЯТЃК
NumPyЃКЪ§бЇМЦЫуПтЃЌвдОиеѓЮЊЛљДЁЕФЪ§бЇМЦЫуФЃПщЃЌАќРЈЛљБОЕФЫФдђдЫааЃЌЗНГЬЪНвдМАЦфЫћЗНУцЕФМЦЫуЪВУДЕФЃЌДПЪ§бЇЃЛ
SciPy ЃКПЦбЇМЦЫуПтЃЌгавЛаЉИпНзГщЯѓКЭЮяРэФЃаЭЃЌдкNumPyЛљДЁЩЯЃЌЗтзАСЫвЛВуЃЌУЛгаФЧУДДПЪ§бЇЃЌЬсЙЉЗНЗЈжБНгМЦЫуНсЙћЃЛ
БШШчЃК
зіИіИЕСЂвЖБфЛЛЃЌетЪЧДПЪ§бЇЕФЃЌгУNumpyЃЛ
зіИіТЫВЈЦїЃЌетЪєгкаХКХДІРэФЃаЭСЫЃЌгУScipyЁЃ
PandasЃКЬсЙЉУћЮЊDataFrameЕФЪ§ОнНсЙЙЃЌБШНЯЦѕКЯЭГМЦЗжЮіжаЕФБэНсЙЙЃЌзіЪ§ОнЗжЮігУЕФЃЌжївЊЪЧзіБэИёЪ§ОнГЪЯжЁЃ
ФПЧАРДЫЕЃЌЫцзХPandasИќаТЃЌNumpyДѓВПЗжЙІФмвбОжБНгКЭPandasШкКЯСЫЁЃ
ЕЋШчЙћФуВЛЪЧДПЪ§бЇзЈвЕЃЌЖјЧвЯызіЪ§ОнЗжЮіЕФЛАЃЌГЂЪдзХДг Pandas ШыЪжБШНЯКУЁЃ
НгЯТРДНВPandasЁЃ
1Ъ§ОнНсЙЙ
SeriesЃКвЛЮЌЪ§зщЃЌгыNumpyжаЕФвЛЮЌarrayРрЫЦЁЃ
Time- SeriesЃКвдЪБМфЮЊЫїв§ЕФSeriesЁЃ
DataFrameЃКЖўЮЌЕФБэИёаЭЪ§ОнНсЙЙЁЃПЩвдНЋDataFrameРэНтЮЊSeriesЕФШнЦїЁЃ
Panel ЃКШ§ЮЌЕФЪ§зщЃЌПЩвдРэНтЮЊDataFrameЕФШнЦїЁЃ
# ЕМШыБ№Ућ
import pandas as pd
pd.Series([1,2,3,4]) |
2Ъ§ОнЖСШЁ
2.1 csvЮФМўЖСШЁ
| read_csv(filepath_or_buffer,
sep=',', delimiter=None, header='infer', names=None,
index_col=None, usecols=None, squeeze=False, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, nrows=None,
na_values=None, keep_default_na=True, na_filter=True,
verbose=False, skip_blank_lines=True, parse_dates=False,
infer_datetime_format=False, keep_date_col=False,
date_parser=None, dayfirst=False, iterator=False,
chunksize=None, compression='infer', thousands=None,
decimal=b'.', lineterminator=None, quotechar='"',
quoting=0, escapechar=None, comment=None, encoding=None,
dialect=None, tupleize_cols=False, error_bad_lines=True,
warn_bad_lines=True, skipfooter=0, skip_footer=0,
doublequote=True, delim_whitespace=False, as_recarray=False,
compact_ints=False, use_unsigned=False, low_memory=True,
buffer_lines=None, memory_map=False, float_precision=None) |
filepath_or_bufferЃКЮФМўТЗОЖЃЌНЈвщЪЙгУЯрЖдТЗОЖ
headerЃК ФЌШЯздЖЏЪЖБ№ЪзааЮЊСаУћЃЈЬиеїУћЃЉЃЌдкЪ§ОнУЛгаСаУћЕФЧщПіЯТ header = none,
ЛЙПЩвдЩшжУЮЊЦфЫћааЃЌР§Шч header = 5 БэЪОЫїв§ЮЛжУЮЊ5ЕФаазїЮЊЦ№ЪМСаУћ
sepЃК БэЪОcsvЮФМўЕФЗжИєЗћЃЌФЌШЯЮЊ','
namesЃК БэЪОЩшжУЕФзжЖЮУћЃЌФЌШЯЮЊ'infer'
index_colЃКБэЪОзїЮЊЫїв§ЕФСаЃЌФЌШЯЮЊ0-ааЪ§ЕФЕШВюЪ§СаЁЃ
engineЃКБэЪОНтЮів§ЧцЃЌПЩвдЮЊ'c'Лђеп'python'
encodingЃКБэЪОЮФМўЕФБрТыЃЌФЌШЯЮЊ'utf-8'ЁЃ
nrowsЃКБэЪОЖСШЁЕФааЪ§ЃЌФЌШЯЮЊШЋВПЖСШЁ
# ЖСШЁcsvЃЌВЮЪ§ПЩЩО
data = pd.read_csv('./data/test.csv',sep = ',',header
= 'infer',names = range(5,18),index_col = [0,2],engine
= 'python',encoding = 'gbk',nrows = 100) |
# ЖСШЁcsvЃЌВЮЪ§ПЩЩО
data = pd.read_table('./data/test.csv',sep = ',',header
= 'infer',names = range(5,18),index_col = [0,2],engine
= 'python',encoding = 'gbk',nrows = 100) |
2.2Excel Ъ§ОнЖСШЁ
| read_excel(io,
sheetname=0, header=0, skiprows=None, skip_footer=0,
index_col=None, names=None, parse_cols=None, parse_dates=False,
date_parser=None, na_values=None, thousands=None,
convert_float=True, has_index_names=None, converters=None,
dtype=None, true_values=None, false_values=None,
engine=None, squeeze=False, **kwds) |
ioЃКЮФМўТЗОЖ+ШЋГЦЃЌЮоФЌШЯ
sheetnameЃКЙЄзїВОЕФУћзжЃЌФЌШЯЮЊ0
headerЃК ФЌШЯздЖЏЪЖБ№ЪзааЮЊСаУћЃЈЬиеїУћЃЉЃЌдкЪ§ОнУЛгаСаУћЕФЧщПіЯТ header = none,
ЛЙПЩвдЩшжУЮЊЦфЫћааЃЌР§Шч header = 5 БэЪОЫїв§ЮЛжУЮЊ5ЕФаазїЮЊЦ№ЪМСаУћ
namesЃК БэЪОЩшжУЕФзжЖЮУћЃЌФЌШЯЮЊ'infer'
index_colЃКБэЪОзїЮЊЫїв§ЕФСаЃЌФЌШЯЮЊ0-ааЪ§ЕФЕШВюЪ§Са
engineЃКБэЪОНтЮів§ЧцЃЌПЩвдЮЊ'c'Лђеп'python'
| data = pd.read_excel('./data/test.xls',sheetname='дЪМЪ§Он',header
= 0,index_col = [5,6]) |
2.3Ъ§ОнПтЪ§ОнЖСШЁ
| read_sql_query(sql,
con, index_col=None, coerce_float=True, params=None,
parse_dates=None, chunksize=None) |
sqlЃКБэЪОГщШЁЪ§ОнЕФSQLгяОфЃЌР§Шч'select * from БэУћ'
conЃКБэЪОЪ§ОнПтСЌНгЕФУћГЦ
index_colЃКБэЪОзїЮЊЫїв§ЕФСаЃЌФЌШЯЮЊ0-ааЪ§ЕФЕШВюЪ§Са
| read_sql_table(table_name,
con, schema=None, index_col=None, coerce_float=True,
parse_dates=None, columns=None, chunksize=None) |
table_nameЃКБэЪОГщШЁЪ§ОнЕФБэУћ
conЃКБэЪОЪ§ОнПтСЌНгЕФУћГЦ
index_colЃКБэЪОзїЮЊЫїв§ЕФСаЃЌФЌШЯЮЊ0-ааЪ§ЕФЕШВюЪ§Са
columnsЃКЪ§ОнПтЪ§ОнЖСШЁКѓЕФСаУћЁЃ
| read_sql(sql,
con, index_col=None, coerce_float=True, params=None,
parse_dates=None, columns=None, chunksize=None) |
sqlЃКБэЪОГщШЁЪ§ОнЕФБэУћЛђепГщШЁЪ§ОнЕФSQLгяОфЃЌР§Шч'select * from БэУћ'
conЃКБэЪОЪ§ОнПтСЌНгЕФУћГЦ
index_colЃКБэЪОзїЮЊЫїв§ЕФСаЃЌФЌШЯЮЊ0-ааЪ§ЕФЕШВюЪ§Са
columnsЃКЪ§ОнПтЪ§ОнЖСШЁКѓЕФСаУћЁЃ
НЈвщЃКгУЧАСНИі
# ЖСШЁЪ§ОнПт
from sqlalchemy import create_engine
conn = create_engine('mysql+pymysql://root:root@127.0.0.1/test?charset=utf8',
encoding='utf-8', echo=True)
# data1 = pd.read_sql_query('select * from data',
con=conn)
# print(data1.head())
data2 = pd.read_sql_table('data', con=conn)
print(data2.tail())
print(data2['X'][1]) |
Ъ§ОнПтСЌНгзжЗћДЎИїВЮЪ§ЫЕУї
'mysql+pymysql://root:root@127.0.0.1/test?charset=utf8'
СЌНгЦї://гУЛЇУћ:УмТы@Ъ§ОнПтЫљдкIP/ЗУЮЪЕФЪ§ОнПтУћГЦ?зжЗћМЏ
3Ъ§ОнаДГі
3.1НЋЪ§ОнаДГіЮЊcsv
| DataFrame.to_csv(path_or_buf=None,
sep=',', na_rep='', float_format=None, columns=None,
header=True, index=True, index_label=None, mode='w',
encoding=None, compression=None, quoting=None,
quotechar='"', line_terminator='\n', chunksize=None,
tupleize_cols=False, date_format=None, doublequote=True,
escapechar=None, decimal='.') |
path_or_bufЃКЪ§ОнДцДЂТЗОЖЃЌКЌЮФМўШЋУћР§Шч'./data.csv'
sepЃКБэЪОЪ§ОнДцДЂЪБЪЙгУЕФЗжИєЗћ
headerЃКЪЧЗёЕМГіСаУћЃЌTrueЕМГіЃЌFalseВЛЕМГі
indexЃК ЪЧЗёЕМГіЫїв§ЃЌTrueЕМГіЃЌFalseВЛЕМГі
modeЃКЪ§ОнЕМГіФЃЪНЃЌ'w'ЮЊаД
encodingЃКЪ§ОнЕМГіЕФБрТы
import pandas
as pd
data.to_csv('data.csv',index = False) |
3.2НЋЪ§ОнаДГіЮЊexcel
| DataFrame.to_excel(excel_writer,
sheet_name='Sheet1', na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None,
startrow=0, startcol=0, engine=None, merge_cells=True,
encoding=None, inf_rep='inf', verbose=True, freeze_panes=None) |
excel_writerЃКЪ§ОнДцДЂТЗОЖЃЌКЌЮФМўШЋУћР§Шч'./data.xlsx'
sheet_nameЃКБэЪОЪ§ОнДцДЂЕФЙЄзїВОУћГЦ
headerЃКЪЧЗёЕМГіСаУћЃЌTrueЕМГіЃЌFalseВЛЕМГі
indexЃК ЪЧЗёЕМГіЫїв§ЃЌTrueЕМГіЃЌFalseВЛЕМГі
encodingЃКЪ§ОнЕМГіЕФБрТы
| data.to_excel('data.xlsx',index=False) |
3.3НЋЪ§ОнаДШыЪ§ОнПт
| DataFrame.to_sql(name,
con, flavor=None, schema=None, if_exists='fail',
index=True, index_label=None, chunksize=None,
dtype=None) |
nameЃКЪ§ОнДцДЂБэУћ
conЃКБэЪОЪ§ОнСЌНг
if_existsЃКХаЖЯЪЧЗёвбОДцдкИУБэЃЌ'fail'БэЪОДцдкОЭБЈДэЃЛ'replace'БэЪОДцдкОЭИВИЧЃЛ'append'БэЪОдкЮВВПзЗМг
indexЃК ЪЧЗёЕМГіЫїв§ЃЌTrueЕМГіЃЌFalseВЛЕМГі
from sqlalchemy
import create_engine
conn =create_engine('mysql+pymysql: //root:root@127.0.0.1/data?charset=utf8',
encoding='utf-8', echo=True)
data.to_sql('data',con = conn) |
4Ъ§ОнДІРэ
4.1Ъ§ОнВщПД
# ВщПДЧА5аа,5ЮЊЪ§ФПЃЌВЛЪЧЫїв§ЃЌФЌШЯЮЊ5
data.head()
# ВщПДзюКѓ6ааЃЌ6ЮЊЪ§ФПЃЌВЛЪЧЫїв§ЃЌФЌШЯЮЊ5
data.tail(6)
# ВщПДЪ§ОнЕФаЮзД
data.shape
# ВщПДЪ§ОнЕФСаЪ§ЃЌ0ЮЊаа1ЮЛСа
data.shape[1]
# ВщПДЫљгаЕФСаУћ
data.columns
# ВщПДЫїв§
data.index
# ВщПДУПвЛСаЪ§ОнЕФРраЭ
data.dtypes
# ВщПДЪ§ОнЕФЮЌЖШ
data.ndim |
## ВщПДЪ§ОнЛљБОЧщПі
data.describe()
'''
countЃКЗЧПежЕЕФЪ§ФП
meanЃКЪ§жЕаЭЪ§ОнЕФОљжЕ
stdЃКЪ§жЕаЭЪ§ОнЕФБъзМВю
minЃКЪ§жЕаЭЪ§ОнЕФзюаЁжЕ
25%ЃКЪ§жЕаЭЪ§ОнЕФЯТЫФЗжЮЛЪ§
50%ЃКЪ§жЕаЭЪ§ОнЕФжаЮЛЪ§
75%ЃКЪ§жЕаЭЪ§ОнЕФЩЯЫФЗжЮЛЪ§
maxЃКЪ§жЕаЭЪ§ОнЕФзюДѓжЕ
''' |
4.2Ъ§ОнЫїв§
# ШЁГіЕЅЖРФГвЛСа
X = data['X']
# ШЁГіЖрСа
XY = data[['X','Y']]
# ШЁГіФГСаЕФФГвЛаа
data['X'][1]
# ШЁГіФГСаЕФФГМИаа
data['X'][:10]
# ШЁГіФГМИСаЕФФГМИаа
data[['X','Y']][:10]
# locЗНЗЈЫїв§
'''
DataFrame.loc[ааУћ,СаУћ]
'''
# ШЁГіФГМИСаЕФФГвЛаа
data.loc[1,['X','дТЗн']]
# ШЁГіФГМИСаЕФФГМИааЃЈСЌајЃЉ
data.loc[1:5,['X','дТЗн']]
# ШЁГіФГМИСаЕФФГМИааЃЈСЌајЃЉ
data.loc[[1,3,5],['X','дТЗн']]
# ШЁГі x ,FFMC ,DCЕФ0-20ааЫљгаЫїв§УћГЦЮЊХМЪ§ЕФЪ§Он
data.loc[range(0,21,2),['X','FFMC','DC']]
# ilocЗНЗЈЫїв§
'''
DataFrame.iloc[ааЮЛжУ,СаЮЛжУ]
'''
# ШЁГіФГМИСаЕФФГвЛаа
data.iloc[1,[1,4]]
# ШЁГіСаЮЛжУЮЊХМЪ§ЃЌааЮЛжУЮЊ0-20ЕФХМЪ§ЕФЪ§Он
data.iloc[0:21:2,0:data.shape[1]:2]
# ixЗНЗЈЫїв§
'''
DataFrame.ix[ааЮЛжУ/ааУћ,СаЮЛжУ/СаУћ]
'''
## ШЁГіФГМИСаЕФФГвЛаа
data.ix[1:4,[1,4]]
data.ix[1:4,1:4] |
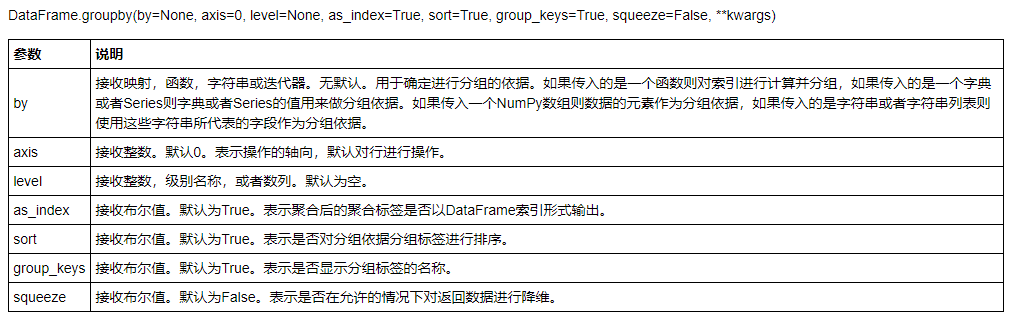
loc,iloc,ixЕФЧјБ№
locЪЙгУУћГЦЫїв§ЃЌБеЧјМф
ilocЪЙгУЮЛжУЫїв§ЃЌЧАБеКѓПЊЧјМф
ixЪЙгУУћГЦЛђЮЛжУЫїв§ЃЌЧвгХЯШЪЖБ№УћГЦЃЌЦфЧјМфИљОнУћГЦ/ЮЛжУРДИФБф
злКЯЩЯЪіЫљбдЃЌВЛНЈвщЪЙгУixЃЌШнвзЗЂЩњЛьЯ§ЕФЧщПіЃЌВЂЧвдЫаааЇТЪЕЭгкlocКЭilocЃЌpandasПМТЧдкКѓЦкЛсвЦГ§етвЛЫїв§ЗНЗЈ
4.3Ъ§ОнаоИФ
# аоИФСаУћ
list1 = list(data.columns)
list1[0] = 'ЕквЛСа'
data.columns = list1
data['аТдіСа'] = True
data.loc['аТдівЛаа',:] = True
data.drop('аТдіСа',axis=1,inplace=True)
data.drop('аТдівЛаа',axis=0,inplace=True) |
import pandas
as pd
data = pd.read_excel('./data/test.xls')
# ЪБМфРраЭЪ§ОнзЊЛЛ
data['ЗЂЩњЪБМф'] = pd.to_datetime(data['ЗЂЩњЪБМф'],format='%Y%m%d%H%M%S')
# ЬсШЁday
data.loc[1,'ЗЂЩњЪБМф'].day
# ЬсШЁШеЦкаХЯЂаТНЈвЛСа
data['ШеЦк'] = [i.day for i in data['ЗЂЩњЪБМф']]
year_data = [i.is_leap_year for i in data['ЗЂЩњЪБМф']] |
4.4ЗжзщОлКЯ
4.4.1Зжзщ
# Зжзщ
group1 = data.groupby('адБ№')
group2 = data.groupby(['ШыжАЪБМф','адБ№'])
# ВщПДгаЖрЩйзщ
group1.size() |
БЪМЧЃК
гУgroupbyЗНЗЈЗжзщКѓЕФНсЙћВЂВЛФмжБНгВщПДЃЌЖјЪЧБЛДцдкФкДцжаЃЌЪфГіЕФЪЧФкДцЕижЗЁЃЪЕМЪЩЯЗжзщКѓЕФЪ§ОнЖд
ЯѓGroupByРрЫЦSeriesгыDataFrameЃЌЪЧpandasЬсЙЉЕФвЛжжЖдЯѓЁЃ
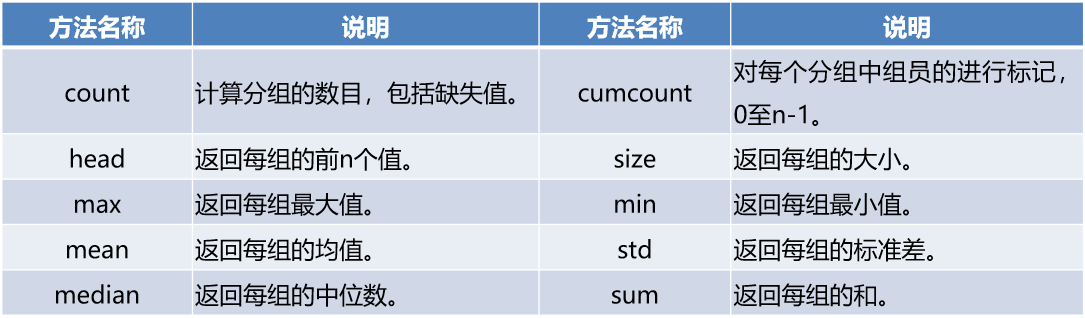
4.4.2GroupbyЖдЯѓГЃМћЗНЗЈ
4.4.3GroupedЖдЯѓЕФaggЗНЗЈ
Grouped.agg(КЏЪ§ЛђАќКЌСЫзжЖЮУћКЭКЏЪ§ЕФзжЕф)
# ЕквЛжжЧщПі
group[['ФъСф','ЙЄзЪ']].agg(min)
# ЖдВЛЭЌЕФСаНјааВЛЭЌЕФОлКЯВйзї
group.agg({'ФъСф':max,'ЙЄзЪ':sum})
# ЩЯЪіЙ§ГЬжаЪЙгУЕФКЏЪ§ОљЮЊЯЕЭГmathПтЫљДјЕФКЏЪ§ЃЌШєашвЊЪЙгУpandasЕФКЏЪ§дђашвЊзіШчЯТВйзї
group.agg({'ФъСф':lambda x:x.max(),'ЙЄзЪ':lambda
x:x.sum()}) |
4.4.4GroupedЖдЯѓЕФapplyОлКЯЗНЗЈ
Grouped.apply(КЏЪ§Вйзї)
жЛФмЖдЫљгаСажДааЭЌвЛжжВйзї
| group.apply(lambda
x:x.max()) |
4.4.5GroupedЖдЯѓЕФtransformЗНЗЈ
grouped.transform(КЏЪ§Вйзї)
transformВйзїЪБЕФЖдЯѓВЛдйЪЧУПвЛзщЃЌЖјЪЧУПвЛИідЊЫи
# УПвЛПеЬэМгзжЗћ
group['ФъСф'].transform(lambda x: x.astype(str)+'Ыъ').head()
# зщФкБъзМЛЏ
group1['ЙЄзЪ'].transform(lambda x:(x.mean()-x.min())/(x.max()-x.min())).head() |
|









