| БрМЭЦМі: |
| БОЮФРДздгкjikexueyuan,ЮФеТжївЊНщЩмСЫЛљгк
NumPy ЕФвЛИіЗЧГЃКУгУЕФПтЁЊЁЊPandasвдМАЛљБОЪЙгУЕШЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
Pandas ЪЧЛљгк NumPy ЕФвЛИіЗЧГЃКУгУЕФПтЃЌе§ШчУћзжвЛбљЃЌШЫМћШЫАЎЁЃжЎЫљвдШчДЫЃЌОЭдкгкВЛТлЪЧЖСШЁЁЂДІРэЪ§ОнЃЌгУЫќЖМЗЧГЃМђЕЅЁЃ
ЛљБОЕФЪ§ОнНсЙЙ
Pandas гаСНжжздМКЖРгаЕФЛљБОЪ§ОнНсЙЙЁЃЖСепгІИУзЂвтЕФЪЧЃЌЫќЙЬШЛгазХСНжжЪ§ОнНсЙЙЃЌвђЮЊЫќвРШЛЪЧ
Python ЕФвЛИіПтЃЌЫљвдЃЌPython жагаЕФЪ§ОнРраЭдкетРявРШЛЪЪгУЃЌвВЭЌбљЛЙПЩвдЪЙгУРрздМКЖЈвхЪ§ОнРраЭЁЃжЛВЛЙ§ЃЌPandas
РяУцгжЖЈвхСЫСНжжЪ§ОнРраЭЃКSeries КЭ DataFrameЃЌЫќУЧШУЪ§ОнВйзїИќМђЕЅСЫЁЃ
вдЯТВйзїЖМЪЧЛљгкЃК

ЮЊСЫЪЁЪТЃЌКѓУцОЭВЛдкЯдЪОСЫЁЃВЂЧвШчЙћФуИњЮввЛбљЪЧЪЙгУ ipython notebookЃЌжЛашвЊПЊЪМв§ШыФЃПщМДПЩЁЃ
Series
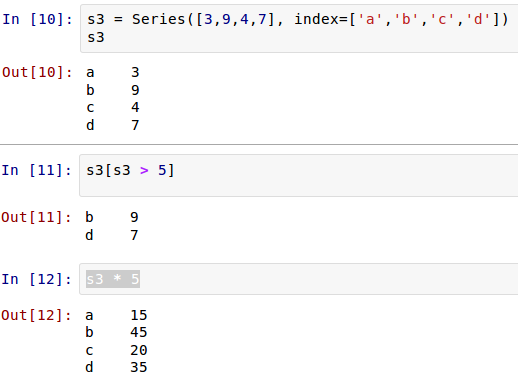
Series ОЭШчЭЌСаБэвЛбљЃЌвЛЯЕСаЪ§ОнЃЌУПИіЪ§ОнЖдгІвЛИіЫїв§жЕЁЃБШШчетбљвЛИіСаБэЃК[9, 3, 8]ЃЌШчЙћИњЫїв§жЕаДЕНвЛЦ№ЃЌОЭЪЧЃК
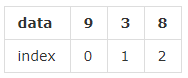
етжжбљЪНЮвУЧвбОЪьЯЄСЫЃЌВЛЙ§ЃЌдкгааЉЪБКђЃЌашвЊАбЫќЪњЙ§РДБэЪОЃК
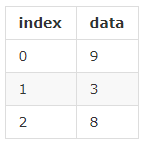
ЩЯУцСНжжЃЌжЛЪЧБэЯжаЮЪНЩЯЕФВюБ№АеСЫЁЃ
Series ОЭЪЧЁАЪњЦ№РДЁБЕФ listЃК
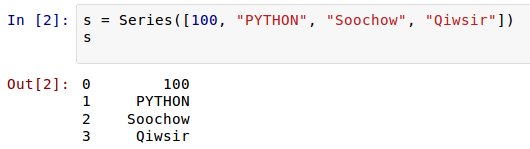
СэЭтвЛЕувВКмЯёСаБэЃЌОЭЪЧРяУцЕФдЊЫиЕФРраЭЃЌгЩФуШЮвтОіЖЈЃЈЦфЪЕЪЧгЩашвЊРДОіЖЈЃЉЁЃ
етРяЃЌЮвУЧЪЕжЪЩЯДДНЈСЫвЛИі Series ЖдЯѓЃЌетИіЖдЯѓЕБШЛОЭгаЦфЪєадКЭЗНЗЈСЫЁЃБШШчЃЌЯТУцЕФСНИіЪєадвРДЮПЩвдЯдЪО
Series ЖдЯѓЕФЪ§ОнжЕКЭЫїв§ЃК
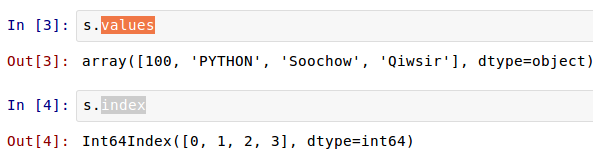
СаБэЕФЫїв§жЛФмЪЧДг 0 ПЊЪМЕФећЪ§ЃЌSeries Ъ§ОнРраЭдкФЌШЯЧщПіЯТЃЌЦфЫїв§вВЪЧШчДЫЁЃВЛЙ§ЃЌЧјБ№гкСаБэЕФЪЧЃЌSeries
ПЩвдздЖЈвхЫїв§ЃК


здЖЈвхЫїв§ЃЌЕФШЗБШНЯгавтЫМЁЃОЭЦОетИіЃЌвВЪЧБиаыЕФЁЃ
УПИідЊЫиЖМгаСЫЫїв§ЃЌОЭПЩвдИљОнЫїв§ВйзїдЊЫиСЫЁЃЛЙМЧЕУ list жаЕФВйзїТ№ЃПSeries жаЃЌвВгаРрЫЦЕФВйзїЁЃЯШПДМђЕЅЕФЃЌИљОнЫїв§ВщПДЦфжЕКЭаоИФЦфжЕЃК
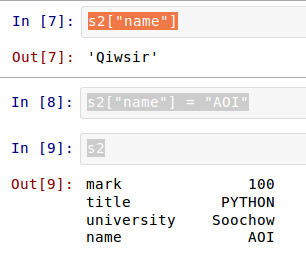
етЪЧВЛЪЧгжгаЕуРрЫЦ dict Ъ§ОнСЫФиЃПЕФШЗШчДЫЁЃПДЯТУцОЭРэНтСЫЁЃ
ЖСепЪЧЗёзЂвтЕНЃЌЧАУцЖЈвх Series ЖдЯѓЕФЪБКђЃЌгУЕФЪЧСаБэЃЌМД Series() ЗНЗЈЕФВЮЪ§жаЃЌЕквЛИіСаБэОЭЪЧЦфЪ§ОнжЕЃЌШчЙћашвЊЖЈвх
indexЃЌЗХдкКѓУцЃЌвРШЛЪЧвЛИіСаБэЁЃГ§СЫетжжЗНЗЈжЎЭтЃЌЛЙПЩвдгУЯТУцЕФЗНЗЈЖЈвх Series ЖдЯѓЃК
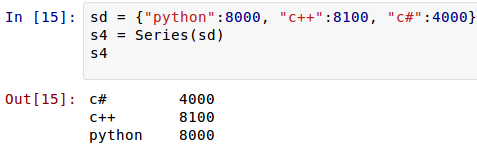
ЯждкЪЧЗёРэНтЮЊЪВУДЧАУцФЧИіРрЫЦ dict СЫЃПвђЮЊБОРДОЭЪЧПЩвдетбљЖЈвхЕФЁЃ
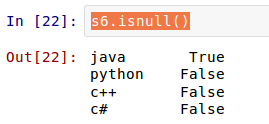
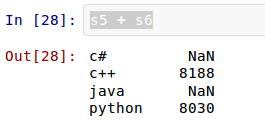
етЪБКђЃЌЫїв§вРШЛПЩвдздЖЈвхЁЃPandas ЕФгХЪЦдкетРяЬхЯжГіРДЃЌШчЙћздЖЈвхСЫЫїв§ЃЌздЖЈЕФЫїв§ЛсздЖЏбАевдРДЕФЫїв§ЃЌШчЙћвЛбљЕФЃЌОЭШЁдРДЫїв§ЖдгІЕФжЕЃЌетИіПЩвдМђГЦЮЊЁАздЖЏЖдЦыЁБЁЃ
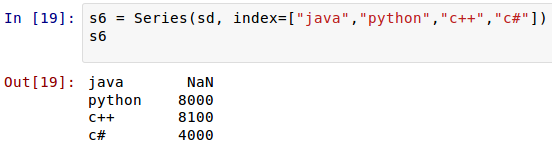
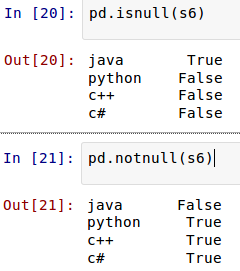
дк sd жаЃЌжЛга'python':8000, 'c++':8100, 'c#':4000ЃЌУЛга"java"ЃЌЕЋЪЧдкЫїв§ВЮЪ§жагаЃЌгкЪЧЦфЫќФмЙЛЁАздЖЏЖдЦыЁБЕФееАсджЕЃЌУЛгаЕФФЧИі"java"ЃЌвРШЛдкаТ
Series ЖдЯѓЕФЫїв§жаДцдкЃЌВЂЧвздЖЏЮЊЦфИГжЕ NaNЁЃдк Pandas жаЃЌШчЙћУЛгажЕЃЌЖМЖдЦыИГИј
NaNЁЃРДвЛИіИќЬиЪтЕФЃК
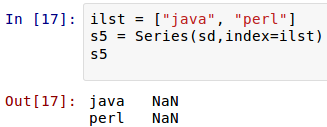
аТЕУЕНЕФ Series ЖдЯѓЫїв§гы sd ЖдЯѓвЛИівВВЛЖдгІЃЌЫљвдЖМЪЧ NaNЁЃ
Pandas газЈУХЕФЗНЗЈРДХаЖЯжЕЪЧЗёЮЊПеЁЃ
ДЫЭтЃЌSeries ЖдЯѓвВгаЭЌбљЕФЗНЗЈЃК
ЦфЪЕЃЌЖдЫїв§ЕФУћзжЃЌЪЧПЩвдДгаТЖЈвхЕФЃК
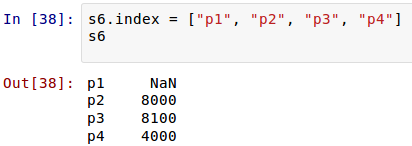
Ждгк Series Ъ§ОнЃЌвВПЩвдзіРрЫЦЯТУцЕФдЫЫуЃЈЙигкдЫЫуЃЌКѓУцЛЙвЊЯъЯИНщЩмЃЉЃК
ЩЯУцЕФбнЪОжаЃЌЖМЪЧдк ipython notebook жаНјааЕФЃЌЫљвдНиЭМСЫЁЃдкбЇЯА Series
Ъ§ОнРраЭЭЌЪБСЫНтСЫ ipyton notebookЁЃЖдгкКѓУцЕФЫљгаВйзїЃЌЖСепЖМПЩвддк ipython
notebook жаНјааЁЃЕЋЪЧЃЌЮвЕФНВЪіПЩФмЛсдк Python НЛЛЅФЃЪНжаНјааЁЃ
DataFrame
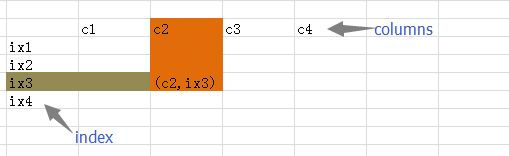
DataFrame ЪЧвЛжжЖўЮЌЕФЪ§ОнНсЙЙЃЌЗЧГЃНгНќгкЕчзгБэИёЛђепРрЫЦ mysql Ъ§ОнПтЕФаЮЪНЁЃЫќЕФЪњааГЦжЎЮЊ
columnsЃЌКсааИњЧАУцЕФ Series вЛбљЃЌГЦжЎЮЊ indexЃЌвВОЭЪЧЫЕПЩвдЭЈЙ§ columns
КЭ index РДШЗЖЈвЛИіжїОфЕФЮЛжУЁЃЃЈгаШЫАб DataFrame ЗвыЮЊЁАЪ§ОнПђЁБЃЌЪЧВЛЪЧЛЙПЩвдГЦжЎЮЊЁАП№ЁБФиЃПЯђРяУцзАЪ§ОнТяЁЃ)
ЯТУцЕФбнЪОЃЌЪЧдк Python НЛЛЅФЃЪНЯТНјааЃЌЖСепШдШЛПЩвддк ipython
notebook ЛЗОГжаВтЪдЁЃ
>>>
import pandas as pd
>>> from pandas import Series, DataFrame
>>> data = {"name":["yahoo","google","facebook"],
"marks":[200,400,800], "price":[9,
3, 7]}
>>> f1 = DataFrame(data)
>>> f1
marks name price
0 200 yahoo 9
1 400 google 3
2 800 facebook 7 |
етЪЧЖЈвхвЛИі DataFrame ЖдЯѓЕФГЃгУЗНЗЈЁЊЁЊЪЙгУ dict ЖЈвхЁЃзжЕфЕФЁАМќЁБЃЈ"name"ЃЌ"marks"ЃЌ"price"ЃЉОЭЪЧ
DataFrame ЕФ columns ЕФжЕЃЈУћГЦЃЉЃЌзжЕфжаУПИіЁАМќЁБЕФЁАжЕЁБЪЧвЛИіСаБэЃЌЫќУЧОЭЪЧФЧвЛЪњСажаЕФОпЬхЬюГфЪ§ОнЁЃЩЯУцЕФЖЈвхжаУЛгаШЗЖЈЫїв§ЃЌЫљвдЃЌАДееЙпР§ЃЈSeries
жавбОаЮГЩЕФЙпР§ЃЉОЭЪЧДг 0 ПЊЪМЕФећЪ§ЁЃДгЩЯУцЕФНсЙћжаКмУїЯдБэЪОГіРДЃЌетОЭЪЧвЛИіЖўЮЌЕФЪ§ОнНсЙЙЃЈРрЫЦ
excel Лђеп mysql жаЕФВщПДаЇЙћЃЉЁЃ
ЩЯУцЕФЪ§ОнЯдЪОжаЃЌcolumns ЕФЫГађУЛгаЙцЖЈЃЌОЭШчЭЌзжЕфжаМќЕФЫГађвЛбљЃЌЕЋЪЧдк
DataFrame жаЃЌcolumns ИњзжЕфМќЯрБШЃЌгавЛИіУїЯдВЛЭЌЃЌОЭЪЧЦфЫГађПЩвдБЛЙцЖЈЃЌЯђЯТУцетбљзіЃК
>>>
f2 = DataFrame(data, columns=['name','price','marks'])
>>> f2
name price marks
0 yahoo 9 200
1 google 3 400
2 facebook 7 800 |
Ињ Series РрЫЦЕФЃЌDataFrame Ъ§ОнЕФЫїв§вВФмЙЛздЖЈвхЁЃ
>>>
f3 = DataFrame(data, columns=['name', 'price',
'marks', 'debt'], index=['a','b','c','d'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py",
line 283, in __init__
mgr = self._init_dict(data, index, columns, dtype=dtype)
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py",
line 368, in _init_dict
mgr = BlockManager(blocks, axes)
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py",
line 285, in __init__
self._verify_integrity()
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py",
line 367, in _verify_integrity
assert(block.values.shape[1:] == mgr_shape[1:])
AssertionError |
БЈДэСЫЁЃетИіБЈДэаХЯЂОЭЬЋВЛгбКУСЫЃЌвВУЛгаЬсЙЉЪВУДЯпЫїЁЃетОЭЪЧНЛЛЅФЃЪНЕФВЛРћжЎДІЁЃаоИФжЎЃЌДэЮѓдкгк
index ЕФжЕЁЊЁЊСаБэЁЊЁЊЕФЪ§ОнЯюЖрСЫвЛИіЃЌdata жаЪЧШ§ааЃЌетРяИјГіСЫЫФИіЯюЃЈ['a','b','c','d']ЃЉЁЃ
>>>
f3 = DataFrame(data, columns=['name', 'price',
'marks', 'debt'], index=['a','b','c'])
>>> f3
name price marks debt
a yahoo 9 200 NaN
b google 3 400 NaN
c facebook 7 800 NaN |
ЖСепЛЙвЊзЂвтЙлВьЩЯУцЕФЯдЪОНсЙћЁЃвђЮЊдкЖЈвх f3 ЕФЪБКђЃЌcolumns ЕФВЮЪ§жаЃЌБШвдЭљЖрСЫвЛЯю('debt')ЃЌЕЋЪЧетЯюдк
data етИізжЕфжаВЂУЛгаЃЌЫљвд debt етвЛЪњСаЕФжЕЖМЪЧПеЕФЃЌдк Pandas жаЃЌПеОЭгУ NaN
РДДњБэСЫЁЃ
ЖЈвх DataFrame ЕФЗНЗЈЃЌГ§СЫЩЯУцЕФжЎЭтЃЌЛЙПЩвдЪЙгУЁАзжЕфЬззжЕфЁБЕФЗНЪНЁЃ
>>>
newdata = {"lang":{"firstline":"python","secondline":"java"},
"price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN |
дкзжЕфжаОЭЙцЖЈКУЪ§СаУћГЦЃЈЕквЛВуМќЃЉКЭУПКсааЫїв§ЃЈЕкЖўВузжЕфМќЃЉвдМАЖдгІЕФЪ§ОнЃЈЕкЖўВузжЕфжЕЃЉЃЌвВОЭЪЧдкзжЕфжаЙцЖЈКУСЫУПИіЪ§ОнИёзгжаЕФЪ§ОнЃЌУЛгаЙцЖЈЕФЖМЪЧПеЁЃ
>>>
DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN |
ШчЙћЖюЭтШЗЖЈСЫЫїв§ЃЌОЭШчЭЌЩЯУцЯдЪОвЛбљЃЌГ§ЗЧдкзжЕфжагаЯргІЕФЫїв§ФкШнЃЌЗёдђЖМЪЧ NaNЁЃ
ЧАУцЖЈвхСЫ DataFrame Ъ§ОнЃЈПЩвдЭЈЙ§СНжжЗНЗЈЃЉЃЌЫќвВЪЧвЛжжЖдЯѓРраЭЃЌБШШчБфСП
f3 в§гУСЫвЛИіЖдЯѓЃЌЫќЕФРраЭЪЧ DataFrameЁЃГаНгвдЧАЕФЫМЮЌЗНЗЈЃКЖдЯѓгаЪєадКЭЗНЗЈЁЃ
>>>
f3.columns
Index(['name', 'price', 'marks', 'debt'], dtype=object)
|
DataFrame ЖдЯѓЕФ columns ЪєадЃЌФмЙЛЯдЪОЫигаЕФ
columns УћГЦЁЃВЂЧвЃЌЛЙФмгУЯТУцРрЫЦзжЕфЕФЗНЪНЃЌЕУЕНФГЪњСаЕФШЋВПФкШнЃЈЕБШЛАќКЌЫїв§ЃЉЃК
>>>
f3['name']
a yahoo
b google
c facebook
Name: name |
етЪЧЪВУДЃПетЦфЪЕОЭЪЧвЛИі SeriesЃЌЛђепЫЕЃЌПЩвдНЋ DataFrame РэНтЮЊЪЧгавЛИівЛИіЕФ Series
зщГЩЕФЁЃ
вЛжБЙЂЙЂгкЛГУЛгаЪ§жЕЕФФЧвЛСаЃЌЯТУцЕФВйзїЪЧЭГвЛИјФЧвЛСаИГжЕЃК
>>>
f3['debt'] = 89.2
>>> f3
name price marks debt
a yahoo 9 200 89.2
b google 3 400 89.2
c facebook 7 800 89.2 |
Г§СЫФмЙЛЭГвЛИГжЕжЎЭтЃЌЛЙФмЙЛЁАЕуЖдЕуЁБЬэМгЪ§жЕЃЌНсКЯЧАУцЕФ SeriesЃЌМШШЛ
DataFrame ЖдЯѓЕФУПЪњСаЖМЪЧвЛИі Series ЖдЯѓЃЌФЧУДПЩвдЯШЖЈвхвЛИі Series ЖдЯѓЃЌШЛКѓАбЫќЗХЕН
DataFrame ЖдЯѓжаЁЃШчЯТЃК
>>>
sdebt = Series([2.2, 3.3], index=["a","c"])
#зЂвтЫїв§
>>> f3['debt'] = sdebt |
НЋ Series ЖдЯѓ(sdebt БфСПЫљв§гУ) ИГИј f3['debt']СаЃЌPandas
ЕФвЛИіживЊЬиадЁЊЁЊздЖЏЖдЦыЁЊЁЊдкетРяЦ№зігУСЫЃЌдк Series жаЃЌжЛгаСНИіЫїв§ЃЈ"a","c"ЃЉЃЌЫќУЧНЋКЭ
DataFrame жаЕФЫїв§здЖЏЖдЦыЁЃгкЪЧКѕЃК
>>>
f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 7 800 3.3 |
здЖЏЖдЦыжЎКѓЃЌУЛгаБЛИДжЦЕФвРШЛБЃГж NaNЁЃ
ЛЙПЩвдИќОЋзМЕФаоИФЪ§ОнТ№ЃПЕБШЛПЩвдЃЌЭъШЋЗТеезжЕфЕФВйзїЃК
>>>
f3["price"]["c"]= 300
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 300 800 3.3 |
етаЉВйзїЪЧВЛЪЧЖМВЛФАЩњбНЃЌетОЭЪЧ Pandas жаЕФСНжжЪ§ОнЖдЯѓЁЃ
|









