| БрМЭЦМі: |
| БОЮФРДздгкsegmentfault,ЮФеТжївЊНщЩмСЫScrapyПђМмЪЧЪВУДЃЌScrapyЕФМмЙЙСїГЬЭМ,вдМАScrapyПђМмЕФАВзАЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
Scrapy ЪЧгУPythonЪЕЯжвЛИіЮЊХРШЁЭјеОЪ§ОнЁЂЬсШЁНсЙЙадЪ§ОнЖјБраДЕФгІгУПђМмЁЃ
вЛЁЂScrapyПђМмМђНщ
ScrapyЪЧвЛИіЮЊСЫХРШЁЭјеОЪ§ОнЃЌЬсШЁНсЙЙадЪ§ОнЖјБраДЕФгІгУПђМмЁЃ ПЩвдгІгУдкАќРЈЪ§ОнЭкОђЃЌаХЯЂДІРэЛђДцДЂРњЪЗЪ§ОнЕШвЛЯЕСаЕФГЬађжаЁЃ
ЦфзюГѕЪЧЮЊСЫ вГУцзЅШЁ (ИќШЗЧаРДЫЕ, ЭјТчзЅШЁ )ЫљЩшМЦЕФЃЌ вВПЩвдгІгУдкЛёШЁAPIЫљЗЕЛиЕФЪ§Он(Р§Шч
Amazon Associates Web Services ) ЛђепЭЈгУЕФЭјТчХРГцЁЃ
ЖўЁЂМмЙЙСїГЬЭМ
НгЯТРДЕФЭМБэеЙЯжСЫScrapyЕФМмЙЙЃЌАќРЈзщМўМАдкЯЕЭГжаЗЂЩњЕФЪ§ОнСїЕФИХРР(ТЬЩЋМ§ЭЗЫљЪО)ЁЃ ЯТУцЖдУПИізщМўЖМзіСЫМђЕЅНщЩмЃЌВЂИјГіСЫЯъЯИФкШнЕФСДНгЁЃЪ§ОнСїШчЯТЫљУшЪіЁЃ
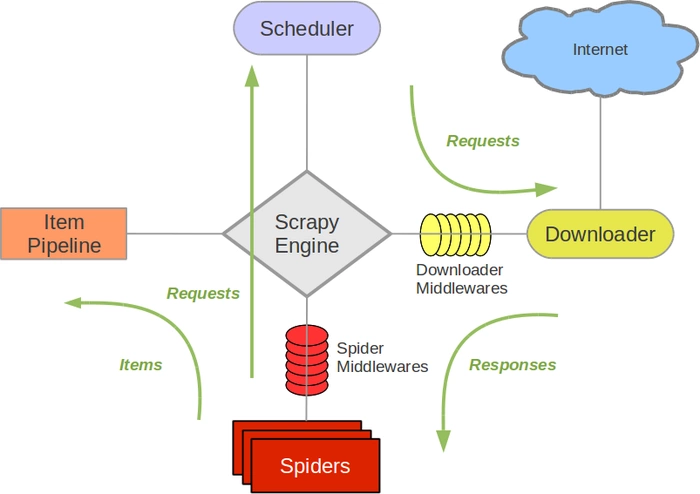
1ЁЂзщМў
Scrapy Engine
в§ЧцИКд№ПижЦЪ§ОнСїдкЯЕЭГжаЫљгазщМўжаСїЖЏЃЌВЂдкЯргІЖЏзїЗЂЩњЪБДЅЗЂЪТМўЁЃ ЯъЯИФкШнВщПДЯТУцЕФЪ§ОнСї(Data
Flow)ВПЗжЁЃ
ЕїЖШЦї(Scheduler)
ЕїЖШЦїДгв§ЧцНгЪмrequestВЂНЋЫћУЧШыЖгЃЌвдБужЎКѓв§ЧцЧыЧѓЫћУЧЪБЬсЙЉИјв§ЧцЁЃ
ЯТдиЦї(Downloader)
ЯТдиЦїИКд№ЛёШЁвГУцЪ§ОнВЂЬсЙЉИјв§ЧцЃЌЖјКѓЬсЙЉИјspiderЁЃ
Spiders
SpiderЪЧScrapyгУЛЇБраДгУгкЗжЮіresponseВЂЬсШЁitem(МДЛёШЁЕНЕФitem)ЛђЖюЭтИњНјЕФURLЕФРрЁЃ
УПИіspiderИКд№ДІРэвЛИіЬиЖЈ(ЛђвЛаЉ)ЭјеОЁЃ ИќЖрФкШнЧыПД Spiders ЁЃ
Item Pipeline
Item PipelineИКд№ДІРэБЛspiderЬсШЁГіРДЕФitemЁЃЕфаЭЕФДІРэгаЧхРэЁЂ бщжЄМАГжОУЛЏ(Р§ШчДцШЁЕНЪ§ОнПтжа)ЁЃ
ИќЖрФкШнВщПД Item Pipeline ЁЃ
ЯТдиЦїжаМфМў(Downloader middlewares)
ЯТдиЦїжаМфМўЪЧдкв§ЧцМАЯТдиЦїжЎМфЕФЬиЖЈЙГзг(specific hook)ЃЌДІРэDownloaderДЋЕнИјв§ЧцЕФresponseЁЃ
ЦфЬсЙЉСЫвЛИіМђБуЕФЛњжЦЃЌЭЈЙ§ВхШыздЖЈвхДњТыРДРЉеЙScrapyЙІФмЁЃИќЖрФкШнЧыПД ЯТдиЦїжаМфМў(Downloader
Middleware) ЁЃ
SpiderжаМфМў(Spider middlewares)
SpiderжаМфМўЪЧдкв§ЧцМАSpiderжЎМфЕФЬиЖЈЙГзг(specific hook)ЃЌДІРэspiderЕФЪфШы(response)КЭЪфГі(itemsМАrequests)ЁЃ
ЦфЬсЙЉСЫвЛИіМђБуЕФЛњжЦЃЌЭЈЙ§ВхШыздЖЈвхДњТыРДРЉеЙScrapyЙІФмЁЃИќЖрФкШнЧыПД SpiderжаМфМў(Middleware)
ЁЃ
2ЁЂЪ§ОнСї(Data flow)
ScrapyжаЕФЪ§ОнСїгЩжДаав§ЧцПижЦЃЌЦфЙ§ГЬШчЯТ:
в§ЧцДђПЊвЛИіЭјеО(open a domain)ЃЌевЕНДІРэИУЭјеОЕФSpiderВЂЯђИУspiderЧыЧѓЕквЛИівЊХРШЁЕФURL(s)ЁЃ
в§ЧцДгSpiderжаЛёШЁЕНЕквЛИівЊХРШЁЕФURLВЂдкЕїЖШЦї(Scheduler)вдRequestЕїЖШЁЃ
в§ЧцЯђЕїЖШЦїЧыЧѓЯТвЛИівЊХРШЁЕФURLЁЃ
ЕїЖШЦїЗЕЛиЯТвЛИівЊХРШЁЕФURLИјв§ЧцЃЌв§ЧцНЋURLЭЈЙ§ЯТдижаМфМў(ЧыЧѓ(request)ЗНЯђ)зЊЗЂИјЯТдиЦї(Downloader)ЁЃ
вЛЕЉвГУцЯТдиЭъБЯЃЌЯТдиЦїЩњГЩвЛИіИУвГУцЕФResponseЃЌВЂНЋЦфЭЈЙ§ЯТдижаМфМў(ЗЕЛи(response)ЗНЯђ)ЗЂЫЭИјв§ЧцЁЃ
в§ЧцДгЯТдиЦїжаНгЪеЕНResponseВЂЭЈЙ§SpiderжаМфМў(ЪфШыЗНЯђ)ЗЂЫЭИјSpiderДІРэЁЃ
SpiderДІРэResponseВЂЗЕЛиХРШЁЕНЕФItemМА(ИњНјЕФ)аТЕФRequestИјв§ЧцЁЃ
в§ЧцНЋ(SpiderЗЕЛиЕФ)ХРШЁЕНЕФItemИјItem PipelineЃЌНЋ(SpiderЗЕЛиЕФ)RequestИјЕїЖШЦїЁЃ
(ДгЕкЖўВН)жиИДжБЕНЕїЖШЦїжаУЛгаИќЖрЕиrequestЃЌв§ЧцЙиБеИУЭјеОЁЃ
3ЁЂЪТМўЧ§ЖЏЭјТч(Event-driven networking)
ScrapyЛљгкЪТМўЧ§ЖЏЭјТчПђМм Twisted БраДЁЃвђДЫЃЌScrapyЛљгкВЂЗЂадПМТЧгЩЗЧзшШћ(МДвьВН)ЕФЪЕЯжЁЃ
ЙигквьВНБрГЬМАTwistedИќЖрЕФФкШнЧыВщПДЯТСаСДНг:
Ш§ЁЂ4ВНжЦзїХРГц
аТНЈЯюФПЃЈscrapy startproject xxxЃЉ:аТНЈвЛИіаТЕФХРГцЯюФП
УїШЗФПБъЃЈБраДitems.pyЃЉ:УїШЗФуЯывЊзЅШЁЕФФПБъ
жЦзїХРГцЃЈspiders/xxsp der.pyЃЉ:жЦзїХРГцПЊЪМХРШЁЭјвГ
ДцДЂФкШнЃЈpipelines.pyЃЉ:ЩшМЦЙмЕРДцДЂХРШЁФкШн
ЫФЁЂАВзАПђМм
етРяЮвУЧЪЙгУ conda РДНјааАВзАЃК
ЛђепЪЙгУ pip НјааАВзАЃК
ВщПДАВзАЃК
spider scrapy
-h
Scrapy 1.4.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined
templates
runspider Run a self-contained spider (without
creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run
from project directory
Use "scrapy <command> -h" to
see more info about a command |
1.ДДНЈЯюФП
spider scrapy
startproject SF
New Scrapy project 'SF', using template directory
'/Users/kaiyiwang/anaconda2/lib/python2.7/site-packages/scrapy/templates/project',
created in:
/Users/kaiyiwang/Code/python/spider/SF
You can start your first spider with:
cd SF
scrapy genspider example example.com
spider |
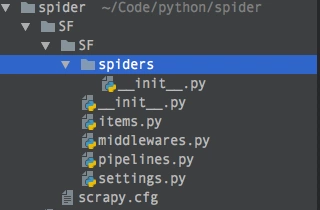
ЪЙгУ tree УќСюПЩвдВщПДЯюФПНсЙЙЃК
SF tree
.
ЉРЉЄЉЄ SF
ЉІ ЉРЉЄЉЄ __init__.py
ЉІ ЉРЉЄЉЄ items.py
ЉІ ЉРЉЄЉЄ middlewares.py
ЉІ ЉРЉЄЉЄ pipelines.py
ЉІ ЉРЉЄЉЄ settings.py
ЉІ ЉИЉЄЉЄ spiders
ЉІ ЉИЉЄЉЄ __init__.py
ЉИЉЄЉЄ scrapy.cfg |
2.дкspiders ФПТМЯТДДНЈФЃАх
spiders scrapy
genspider sf "https://segmentfault.com"
Created spider 'sf' using template 'basic' in
module:
SF.spiders.sf
spiders |
етбљЃЌОЭЩњГЩСЫвЛИіЯюФПЮФМў sf.py
# -*- coding:
utf-8 -*-
import scrapy
from SF.items import SfItem
class SfSpider(scrapy.Spider):
name = 'sf'
allowed_domains = ['https://segmentfault.com']
start_urls = ['https://segmentfault.com/']
def parse(self, response):
# print response.body
# pass
node_list = response.xpath("//h2[@class='title']")
# гУРДДцДЂЫљгаЕФitemзжЖЮЕФ
# items = []
for node in node_list:
# ДДНЈitemзжЖЮЖдЯѓЃЌгУРДДцДЂаХЯЂ
item = SfItem()
# .extract() НЋxpathЖдЯѓзЊЛЛЮЊ UnicodeзжЗћДЎ
title = node.xpath("./a/text()").extract()
item['title'] = title[0]
# ЗЕЛизЅШЁЕНЕФitemЪ§ОнЃЌИјЙмЕРЮФМўДІРэЃЌЭЌЪБЛЙЛиРДМЬајжДааКѓБпЕФДњТы
yield.item
#return item
#return scrapy.Request(url)
#items.append(item)
|
УќСюЃК
# ВтЪдХРГцЪЧЗёе§ГЃ,
sfЮЊХРГцЕФУћГЦ
scrapy check sf
s
# дЫааХРГц
scrapy crawl sf |
3.item pipeline
ЕБ item дкSpiderжаБЛЪеМЏжЎКѓЃЌЫќНЋЛсБЛДЋЕнЕН item Pipeline, етаЉ item
Pipeline зщМўАДЖЈвхЕФЫГађДІРэ item.
УПИі Item Pipeline ЖМЪЧЪЕЯжСЫМђЕЅЗНЗЈЕФPython РрЃЌБШШчОіЖЈДЫItemЪЧЖЊЦњЛђДцДЂЃЌвдЯТЪЧ
item pipeline ЕФвЛаЉЕфаЭгІгУЃК
бщжЄХРШЁЕУЪ§ОнЃЈМьВщitemАќКЌФГаЉзжЖЮЃЌБШШчЫЕnameзжЖЮЃЉ
ВщжиЃЈВЂЖЊЦњЃЉ
НЋХРШЁНсЙћБЃДцЕНЮФМўЛђепЪ§ОнПтзмЃЈЪ§ОнГжОУЛЏЃЉ
БраД item pipeline
БраД item pipeline КмМђЕЅЃЌitem pipeline
зщМўЪЧвЛИіЖРСЂЕФPythonРрЃЌЦфжа process_item()ЗНЗЈБиаыЪЕЯжЁЃ
from scrapy.exceptions
import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s"
% item) |
4.бЁдёЦї(Selectors)
ЕБзЅШЁЭјвГЪБЃЌФузіЕФзюГЃМћЕФШЮЮёЪЧДгHTMLдДТыжаЬсШЁЪ§ОнЁЃ
Selector гаЫФИіЛљБОЕФЗНЗЈЃЌзюГЃгУЕФЛЙЪЧXpath
xpath():ДЋШыxpathБэДяЪНЃЌЗЕЛиИУБэДяЪНЫљЖдгІЕФЫљгаНкЕуЕФselector list СаБэЁЃ
extract(): ађСаЛЏИУНкЕуЮЊUnicodeзжЗћДЎВЂЗЕЛиlist
css():ДЋШыCSSБэДяЪНЃЌЗЕЛиИУБэДяЪНЫљЖдгІЕФЫљгаНкЕуЕФselector list СаБэЃЌгяЗЈЭЌ
BeautifulSoup4
re():ИљОнДЋШыЕФе§дђБэДяЪНЖдЪ§ОнНјааЬсШЁЃЌЗЕЛиUnicode зжЗћДЎlist СаБэ
ScrapyЬсШЁЪ§ОнгаздМКЕФвЛЬзЛњжЦЁЃЫќУЧБЛГЦзїбЁдёЦї(seletors)ЃЌвђЮЊЫћУЧЭЈЙ§ЬиЖЈЕФ XPath
Лђеп CSS БэДяЪНРДЁАбЁдёЁБ HTMLЮФМўжаЕФФГИіВПЗжЁЃ
XPath ЪЧвЛУХгУРДдкXMLЮФМўжабЁдёНкЕуЕФгябдЃЌвВПЩвдгУдкHTMLЩЯЁЃ CSS ЪЧвЛУХНЋHTMLЮФЕЕбљЪНЛЏЕФгябдЁЃбЁдёЦїгЩЫќЖЈвхЃЌВЂгыЬиЖЈЕФHTMLдЊЫиЕФбљЪНЯрЙиСЌЁЃ
ScrapyбЁдёЦїЙЙНЈгк lxml ПтжЎЩЯЃЌетвтЮЖзХЫќУЧдкЫйЖШКЭНтЮізМШЗадЩЯЗЧГЃЯрЫЦЁЃ
XPathБэДяЪНЕФР§згЃК
/html/head/title:
бЁдё<HTML>ЮФЕЕжа<head>БъЧЉФкЕФ<title>дЊЫи
/html/head/title/text(): бЁдёЩЯУцЬсЕНЕФ<title>дЊЫиЕФЮЪЬт
//td: бЁдёЫљгаЕФ<td> дЊЫи
//div[@class="mine"]:бЁдёЫљгаОпга class="mine"
ЪєадЕФ div дЊЫи |
ЮхЁЂХРШЁеаЦИаХЯЂ
1.ХРШЁЬкбЖеаЦИаХЯЂ
ХРШЁЕФЕижЗЃКhttp://hr.tencent.com/positio...
1.1 ДДНЈЯюФП
> scrapy
startproject Tencent
You can start your first spider with:
cd Tencent
scrapy genspider example example.com |

ашвЊзЅШЁЭјвГЕФдЊЫиЃК
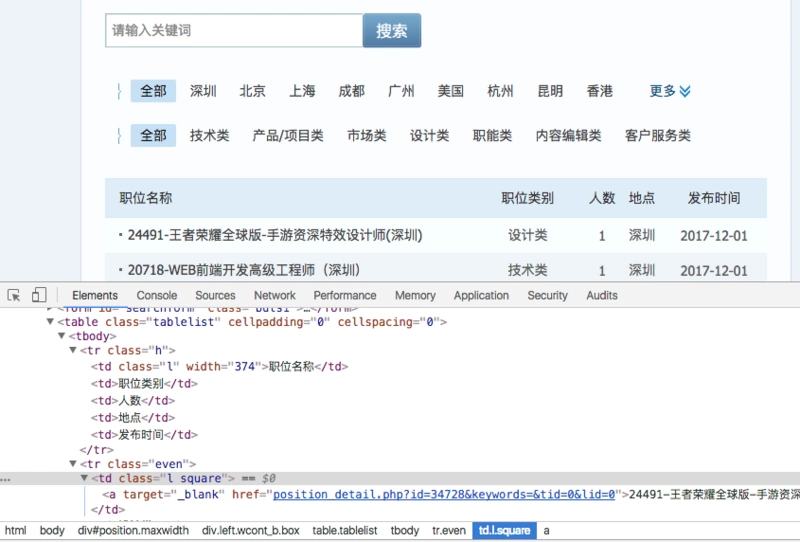
ЮвУЧашвЊХРШЁвдЯТаХЯЂЃК
жАЮЛУћЃКpositionName
жАЮЛСДНгЃКpositionLink
жАЮЛРраЭЃКpositionType
жАЮЛШЫЪ§ЃКpositionNumber
ЙЄзїЕиЕуЃКworkLocation
ЗЂВМЪБЕуЃКpublishTime
дк items.py ЮФМўжаЖЈвхХРШЁЕФзжЖЮЃК
# -*- coding:
utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
# ЖЈвхзжЖЮ
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# жАЮЛУћ
positionName = scrapy.Field()
# жАЮЛСДНг
positionLink = scrapy.Field()
# жАЮЛРраЭ
positionType = scrapy.Field()
# жАЮЛШЫЪ§
positionNumber = scrapy.Field()
# ЙЄзїЕиЕу
workLocation = scrapy.Field()
# ЗЂВМЪБЕу
publishTime = scrapy.Field()
pass |
1.2 аДspiderХРГц
ЪЙгУУќСюДДНЈ
Tencent scrapy
genspider tencent "tencent.com"
Created spider 'tencent' using template 'basic'
in module:
Tencent.spiders.tencent |
ЩњГЩЕФ spider дкЕБЧАФПТМЯТЕФ spiders/tencent.py
Tencent tree
.
ЉРЉЄЉЄ __init__.py
ЉРЉЄЉЄ __init__.pyc
ЉРЉЄЉЄ items.py
ЉРЉЄЉЄ middlewares.py
ЉРЉЄЉЄ pipelines.py
ЉРЉЄЉЄ settings.py
ЉРЉЄЉЄ settings.pyc
ЉИЉЄЉЄ spiders
ЉРЉЄЉЄ __init__.py
ЉРЉЄЉЄ __init__.pyc
ЉИЉЄЉЄ tencent.py |
ЮвУЧПЩвдПДЯТЩњГЩЕФетИіГѕЪМЛЏЮФМў tencent.py
# -*- coding:
utf-8 -*-
import scrapy
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
start_urls = ['http://tencent.com/']
def parse(self, response):
pass |
ЖдГѕЪЖЮФМўtencent.pyНјаааоИФЃК
# -*- coding:
utf-8 -*-
import scrapy
from Tencent.items import TencentItem
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
baseURL = "http://hr.tencent.com/position.php?&start="
offset = 0 # ЦЋвЦСП
start_urls = [baseURL + str(offset)]
def parse(self, response):
# ЧыЧѓЯьгІ
# node_list = response.xpath("//tr[@class='even']
or //tr[@class='odd']")
node_list = response.xpath("//tr[@class='even']
| //tr[@class='odd']")
for node in node_list:
item = TencentItem() # в§ШызжЖЮРр
# ЮФБОФкШн, ШЁСаБэЕФЕквЛИідЊЫи[0], ВЂЧвНЋЬсШЁГіРДЕФUnicodeБрТы зЊЮЊ
utf-8
item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0].encode("utf-8")
item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0].encode("utf-8")
# СДНгЪєад
item['positionType'] = node.xpath("./td[2]/text()").extract()[0].encode("utf-8")
item['positionNumber'] = node.xpath("./td[3]/text()").extract()[0].encode("utf-8")
item['workLocation'] = node.xpath("./td[4]/text()").extract()[0].encode("utf-8")
item['publishTime'] = node.xpath("./td[5]/text()").extract()[0].encode("utf-8")
# ЗЕЛиИјЙмЕРДІРэ
yield item
# ЯШХР 2000 вГЪ§Он
if self.offset < 2000:
self.offset += 10
url = self.baseURL + self.offset
yield scrapy.Request(url, callback = self.parse)
#pass
|
аДЙмЕРЮФМў pipelines.pyЃК
# -*- coding:
utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES
setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class TencentPipeline(object):
def __init__(self):
self.f = open("tencent.json", "w")
# ЫљгаЕФitemЪЙгУЙВЭЌЕФЙмЕР
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii
= False) + ",\n"
self.f.write(content)
return item
def close_spider(self, spider):
self.f.close() |
ЙмЕРаДКУжЎКѓЃЌдк settings.py жаЦєгУЙмЕР
# Configure
item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
} |
дЫааЃК
> scrapy
crawl tencent
File "/Users/kaiyiwang/Code /python/spider
/Tencent/Tencent/spiders/tencent.py", line
21, in parse
item['positionName'] = node.xpath("./td[1]/a/text()").
extract()[0].encode("utf-8")
IndexError: list index out of range |
ЧыЧѓЯьгІетРяаДЕФгаЮЪЬтЃЌXpathЛђгІИУЮЊетжжаДЗЈЃК
# ЧыЧѓЯьгІ
# node_list = response.xpath("//tr[@class='even']
or //tr[@class='odd']")
node_list = response.xpath("//tr[@class='even']
| //tr[@class='odd']") |
ШЛКѓдйжДааУќСюЃК
жДааНсЙћЮФМў tencent.json ЃК
{"positionName":
"23673-ВЦОдЫгЊжааФШШЕудЫгЊзщБрМ", "publishTime":
"2017-12-02", "positionLink":
"position_detail.php?id=32718&keywords=&tid=0&lid=0",
"positionType": "ФкШнБрМРр", "workLocation":
"ББОЉ", "positionNumber": "1"},
{"positionName": "MIG03-ЬкбЖЕиЭМИпМЖЫуЗЈЦРВтЙЄГЬЪІЃЈББОЉЃЉ",
"publishTime": "2017-12-02",
"positionLink": "position_detail.php?id=30276&keywords=&tid=0&lid=0",
"positionType": "ММЪѕРр", "workLocation":
"ББОЉ", "positionNumber": "1"},
{"positionName": "MIG10-ЮЂЛиЪеЧўЕРВњЦЗдЫгЊОРэЃЈЩюлкЃЉ",
"publishTime": "2017-12-02",
"positionLink": "position_detail.php?id=32720&keywords=&tid=0&lid=0",
"positionType": "ВњЦЗ/ЯюФПРр",
"workLocation": "Щюлк", "positionNumber":
"1"},
{"positionName": "MIG03-iOSВтЪдПЊЗЂЙЄГЬЪІЃЈББОЉЃЉ",
"publishTime": "2017-12-02",
"positionLink": "position_detail.php?id=32715&keywords=&tid=0&lid=0",
"positionType": "ММЪѕРр", "workLocation":
"ББОЉ", "positionNumber": "1"},
{"positionName": "19332-ИпМЖPHPПЊЗЂЙЄГЬЪІЃЈЩЯКЃЃЉ",
"publishTime": "2017-12-02",
"positionLink": "position_detail.php?id=31967&keywords=&tid=0&lid=0",
"positionType": "ММЪѕРр", "workLocation":
"ЩЯКЃ", "positionNumber": "2"} |
1.3 ЭЈЙ§ЯТвЛвГХРШЁ
ЮвУЧЩЯБпЪЧЭЈЙ§змЕФвГЪ§РДзЅШЁУПвГЪ§ОнЕФЃЌЕЋЪЧУЛгаПМТЧЕНУПЬьЕФЪ§ОнЪЧБфЛЏЕФЃЌЫљвдЃЌашвЊХРШЁЕФзмвГЪ§ВЛФмаДЫРЃЌФЧИУдѕУДХаЖЯЪЧЗёХРЭъСЫЪ§ОнФиЃПЦфЪЕКмМђЕЅЃЌЮвУЧПЩвдИљОнЯТвЛвГРДХРШЁЃЌжЛвЊЯТвЛвГУЛгаЪ§ОнСЫЃЌОЭЫЕУїЪ§ОнвбОХРЭъСЫЁЃ
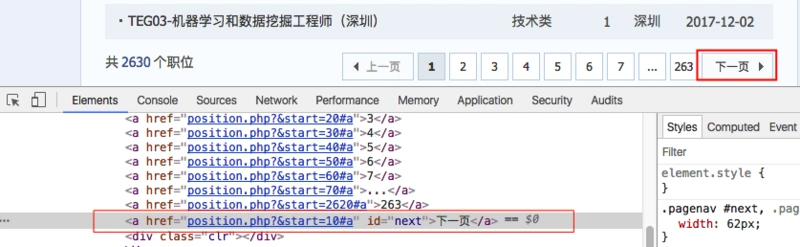
ЮвУЧЭЈЙ§ ЯТвЛвГ ПДЯТзюКѓвЛвГЕФЬиеїЃК

ЯТвЛвГЕФАДХЅЮЊЛвЩЋЃЌВЂЧвСДНгЮЊ class='noactive'ЪєадСЫЃЌЮвУЧПЩвдИљОнДЫЬиадРДХаЖЯЪЧЗёЕНзюКѓвЛвГСЫЁЃ
# аДЫРзмвГЪ§ЃЌЯШХР 100
вГЪ§Он
"""
if self.offset < 100:
self.offset += 10
url = self.baseURL + str(self.offset)
yield scrapy.Request(url, callback = self.parse)
"""
# ЪЙгУЯТвЛвГХРШЁЪ§Он
if len(response.xpath("//a[@class='noactive'
and @id='next']")) == 0:
url = response.xpath("//a[@id='next']/@href").extract()[0]
yield scrapy.Request("http://hr.tencent.com/"
+ url, callback = self.parse) |
аоИФКѓЕФtencent.pyЮФМўЃК
# -*- coding:
utf-8 -*-
import scrapy
from Tencent.items import TencentItem
class TencentSpider(scrapy.Spider):
# ХРГцУћ
name = 'tencent'
# ХРГцХРШЁЪ§ОнЕФгђЗЖЮЇ
allowed_domains = ['tencent.com']
# 1.ашвЊЦДНгЕФURL
baseURL = "http://hr.tencent.com/position.php?&start="
# ашвЊЦДНгЕФURLЕижЗЕФЦЋвЦСП
offset = 0 # ЦЋвЦСП
# ХРГцЦєЖЏЪБЃЌЖСШЁЕФURLЕижЗСаБэ
start_urls = [baseURL + str(offset)]
# гУРДДІРэresponse
def parse(self, response):
# ЬсШЁУПИіresponseЕФЪ§Он
node_list = response.xpath("//tr[@class='even']
| //tr[@class='odd']")
for node in node_list:
# ЙЙНЈitemЖдЯѓЃЌгУРДБЃДцЪ§Он
item = TencentItem()
# ЮФБОФкШн, ШЁСаБэЕФЕквЛИідЊЫи[0], ВЂЧвНЋЬсШЁГіРДЕФUnicodeБрТы зЊЮЊ
utf-8
print node.xpath("./td[1]/a/text()").extract()
item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0].encode("utf-8")
item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0].encode("utf-8")
# СДНгЪєад
# НјааЪЧЗёЮЊПеХаЖЯ
if len(node.xpath("./td[2]/text()")):
item['positionType'] = node.xpath("./td[2]/text()").extract()[0].encode("utf-8")
else:
item['positionType'] = ""
item['positionNumber'] = node.xpath("./td[3]/text()").extract()[0].encode("utf-8")
item['workLocation'] = node.xpath("./td[4]/text()").extract()[0].encode("utf-8")
item['publishTime'] = node.xpath("./td[5]/text()").extract()[0].encode("utf-8")
# yieldЕФживЊадЃЌЪЧЗЕЛиЪ§ОнКѓЛЙФмЛиРДНгзХжДааДњТыЃЌЗЕЛиИјЙмЕРДІРэЃЌШчЙћЮЊreturn
ећИіКЏЪ§ЖМЭЫГіСЫ
yield item
# ЕквЛжжаДЗЈЃКЦДНгURLЃЌЪЪгУГЁОАЃКвГУцУЛгаПЩвдЕуЛїЕФЧыЧѓСДНгЃЌБиаыЭЈЙ§ЦДНгURLВХФмЛёШЁЯьгІ
"""
if self.offset < 100:
self.offset += 10
url = self.baseURL + str(self.offset)
yield scrapy.Request(url, callback = self.parse)
"""
<
# ЕкЖўжжаДЗЈЃКжБНгДгresponseЛёШЁашвЊХРШЁЕФСЌНгЃЌВЂЗЂЫЭЧыЧѓДІРэЃЌжБЕНСЌНгШЋВПЬсШЁЭъЃЈЪЙгУЯТвЛвГХРШЁЪ§ОнЃЉ
if len(response.xpath("//a[@class='noactive'
and @id='next']")) == 0:
url = response.xpath("//a[@id='next']/@href").extract()[0]
yield scrapy.Request("http://hr.tencent.com/"
+ url, callback = self.parse)
#pass |
OKЃЌЭЈЙ§ ИљОнЯТвЛвГЮвУЧГЩЙІХРЭъеаЦИаХЯЂЕФЫљгаЪ§ОнЁЃ
1.4 аЁНс
ХРГцВНжшЃК
1.ДДНЈЯюФП scrapy project XXX
2.scarpy genspider xxx "http://www.xxx.com"
3.БраД items.py, УїШЗашвЊЬсШЁЕФЪ§Он
4.БраД spiders/xxx.py, БраДХРГцЮФМўЃЌДІРэЧыЧѓКЭЯьгІЃЌвдМАЬсШЁЪ§ОнЃЈyield itemЃЉ
5.БраД pipelines.py, БраДЙмЕРЮФМўЃЌДІРэspiderЗЕЛиitemЪ§Он,БШШчБОЕиЪ§ОнГжОУЛЏЃЌаДЮФМўЛђДцЕНБэжаЁЃ
6.БраД settings.pyЃЌЦєЖЏЙмЕРзщМўITEM_PIPELINESЃЌвдМАЦфЫћЯрЙиЩшжУ
7.жДааХРГц scrapy crawl xxx
гаЪБКђБЛХРШЁЕФЭјеОПЩФмзіСЫКмЖрЯожЦЃЌЫљвдЃЌЮвУЧЧыЧѓЪБПЩвдЬэМгЧыЧѓБЈЭЗЃЌscrapy
ИјЮвУЧЬсЙЉСЫвЛИіКмЗНБуЕФБЈЭЗХфжУЕФЕиЗНЃЌsettings.py жаЃЌЮвУЧПЩвдПЊЦє:
# Crawl responsibly
by identifying yourself (and your website) on
the user-agent
USER_AGENT = 'Tencent (+http://www.yourdomain.com)'
User-AGENT = "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_11_6)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/62.0.3202.94 Safari/537.36"
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml, application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
} |
scrapy зюДѓЕФЪЪгУГЁОАЪЧХРШЁОВЬЌвГУцЃЌадФмЗЧГЃЧПКЗЃЌЕЋШчЙћвЊХРШЁЖЏЬЌЕФjsonЪ§ОнЃЌФЧОЭУЛБивЊСЫЁЃ
|









