| БрМЭЦМі: |
| БОЮФРДздгкcsdn,ЮФеТжївЊНщЩмСЫScrapyПђМмЪЧЪВУДЃЌвдМАScrapyШчКЮНјааАВзАКЭЪЙгУЕФЯъЯИВйзїЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
ScrapyПђМмЪЧФПЧАPythonжазюЪмЛЖгЕФХРГцПђМмжЎвЛ,ФЧУДЮвУЧНёЬьОЭРДОпЬхСЫНтвЛЯТScrapyПђМм
ЪВУДЪЧScrapyПђМм
ScrapyЪЧвЛИіПьЫйЁЂИпВуДЮЁЂЧсСПМЖЕФЦСФЛзЅШЁКЭwebзЅШЁЕФpythonХРГцПђМм
ScrapyЕФгУЭО:
ScrapyгУЭОЗЧГЃЙуЗК,жївЊгУгкзЅШЁЬиЖЈwebеОЕуЕФаХЯЂВЂДгжаЬсШЁЬиЖЈНсЙЙЕФЪ§Он,Г§ДЫжЎЭт,ЛЙПЩгУгкЪ§ОнЭкОђЁЂМрВтЁЂздЖЏЛЏВтЪдЁЂаХЯЂДІРэКЭРњЪЗЦЌЖЮ(РњЪЗМЧТМ)ДђАќЕШ
СЫНтЭъScrapyПђМмКѓ,ЮвУЧОЭРДПДПДдѕУДАВзАКЭЪЙгУАЩ
АВзАScrapy
АВзАЗНЗЈгаСНжж:
1. ШчЙћФуЕчФдЩЯгаAnacondaЕФЛА,ПЩвдЪЙгУетжжЗНЗЈ
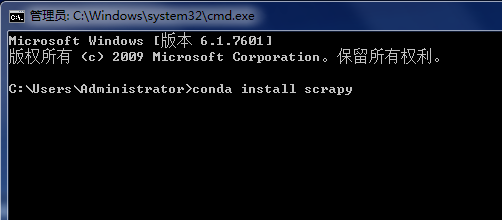
windows+r >>> cmd >>> conda install
scrapy >>> ЛиГЕ
2.ЕкЖўжжЗНЗЈЪЙгУpipАВзА,ВЛЙ§ФуашвЊЯШЯТдиTwistedВхМў
ЯТдиЕижЗ:https://www.lfd.uci.edu/~gohlke
/pythonlibs/#twisted
(1)ЕуЛїЯТдиЕижЗ,НјШыКѓАД ctrl+f ,ЫбЫїtwisted,ШЛКѓЯТдиЖдгІАцБО
cp27:БэЪОpython2.7АцБО cp36:БэЪОpython3.6АцБО
win32:БэЪОWindows32ЮЛВйзїЯЕЭГ
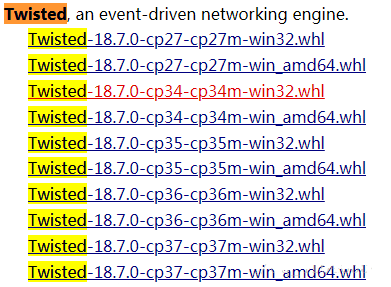
(2)ЯТдиЭъГЩКѓНјШыжеЖЫ,ЪфШыpip installTwisted-18.7.0-cp36-cp36m-win32.whl
Twisted-18.7.0-cp36-cp36m-win32.whl:ЮФМўУћ(ФуЯТдиФФИіЮФМўОЭЪфШыФФИіЮФМўЕФЮФМўУћ,вЊЪфШыШЋВПТЗОЖ)
АВзАЭъГЩКѓдйЪфШыpip install scrapy,ЛиГЕ
МьВтscrapyАВзАЪЧЗёГЩЙІ:дкжеЖЫЪфШыscrapy,ГіЯжвдЯТФкШнОЭДњБэАВзАГЩЙІ

ScrapyгУЗЈ
АВзАЭъГЩКѓ,ОЭРДПДПДШчКЮЪЙгУscrapyПђМмАЩ
ашвЊзЂвтЕФЪЧ:scrapyЕФЫљгаУќСюЖМЪЧдкwindowsЕФжеЖЫРяЭъГЩЕФ
1.ScrapyПЩвджДааЕФУќСю
дкжеЖЫжаЪфШы scrapy,ПЩвдВщПДЫљгаПЩжДааЕФУќСю,ЯждкЮвУЧРДОпЬхПДвЛЯТетаЉУќСю
bench:адФмВтЪд
fetch:ЖСШЁдДДњТы
genspider:ЩњГЩХРГцЮФМў
runspider:дЫааХРГцЮФМў
settings:ХРГцЩшжУ
shell:жеЖЫВйзї
startproject:ДДНЈЯюФП
version:ВщПДАцБО
вдЩЯетаЉУќСюжЛвЊЮвУЧАВзАscrapyОЭПЩвджДаа
ЕЋЪЧ,вдЯТМИжжУќСюашвЊЮвУЧДДНЈОпЬхЕФpyЮФМўжЎКѓВХФмжДаа,ШчКЮДДНЈpyЮФМўЧыВЮПМЯТЮФ
check:МьВщДњТыЪЧЗёГіДэ
crawl:дЫаавЛИіХРГц
edit:БрМХРГц
list:СаГігааЇЕФХРГц
parse:НтЮіurlВЂДђгЁГіНсЙћ
2.ДДНЈвЛИіscrapyПђМм,етЪЧЫљгаВйзїЕФЧАЬс
(1)дкБрвыЦї(етРявдPyCharmЮЊР§)РяДДНЈвЛИіЮФМў,ЮФМўУћОЭУќУћЮЊScrapyАЩ
(2)ДДНЈscrapyПђМмжЎЧА,ЪзЯШвЊШЗБЃАбПђМмДДНЈдкЮвУЧИеИеаТНЈЕФЮФМўМаScrapyжа
ДђПЊМЦЫуЛњжеЖЫ:ЪфШыcd КѓУцИњвЛИіПеИё ШЛКѓАбФуаТНЈЕФScrapyЮФМўжБНгЭЯзЇНјжеЖЫРя
cd:change directory аоИФЮЛжУЕНжИЖЈЮФМўМажа
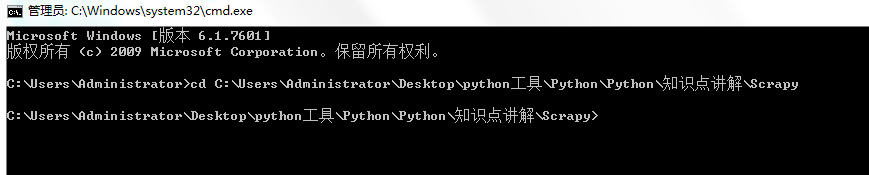
ЕквЛааЪЧУќСю,ЕкЖўааЪЧНсЙћ
(3)ДДНЈscrapyПђМм,дкжеЖЫжаЪфШы:scrapy startproject Demo
scrapy startproject:БэЪОвЊжДааДДНЈвЛИіаТЯюФПЕФУќСю Demo:ЯюФПУћ,ПЩвдздЖЈвхУќУћ
УќСюжДааЭъГЩКѓ,ЮвУЧЛиЕНPyCharmжа,ПЩвдПДЕНScrapyЮФМўздЖЏГіЯжСЫаэЖраТЕФЮФМў

етРяРДНтЪЭвЛЯТИїИіЮФМўЕФзїгУ:
items.py:ЖЈвхХРГцГЬађЕФЪ§ОнФЃаЭ
middlewares.py:ЖЈвхЪ§ОнФЃаЭжаЕФжаМфМў
pipelines.py:ЙмЕРЮФМў,ИКд№ЖдХРГцЗЕЛиЪ§ОнЕФДІРэ
settings.py:ХРГцГЬађЩшжУ,жївЊЪЧвЛаЉгХЯШМЖЩшжУ,гХЯШМЖдНИп,жЕдНаЁ
scrapy.cfg:ФкШнЮЊscrapyЕФЛљДЁХфжУ
етРяЮвУЧвЊИФвЛЯТsettings.pyРяЕФФкШн:
(1)ДђПЊЮФМў,евЕНДњТыЕФЕк22аа,Аб ROBOTSTXT_OBEY=True ИФЮЊ False,етааДњТыБэЪОЪЧЗёзёбХРГцавщ,ШчЙћЪЧTureЕФПЩФмгааЉФкШнЮоЗЈХРШЁ
(2)НЋЕк67ЕН69ааДњТыНтзЂЪЭ,ВЂАб300ИФЮЊ1,етЪЧгХЯШМЖЩшжУ
жСДЫ,вЛИіscrapyПђМмвбОГѕВНДДНЈГЩЙІСЫЁЃ
Яждк,ЮвУЧРДОпЬхСЫНтвЛЯТscrapyПђМмЪЧШчКЮЙЙГЩКЭШчКЮдЫааЕФЁЃ
ScrapyПђМмЭМ ТЬЩЋЪЧЪ§ОнСїЯђ
(зЂ:вдЯТЭМЦЌРДдДгкЭјТч)
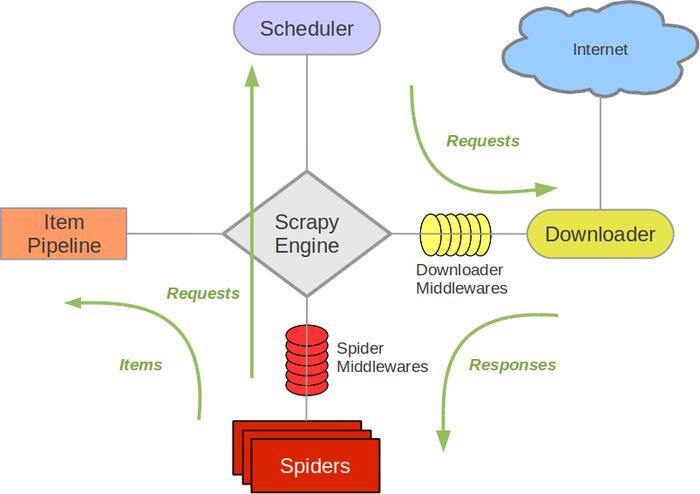
Scrapy Engine:в§Чц,ДІРэећИіПђМмЕФЪ§ОнСї
Scheduler:ЕїЖШЦї,НгЪев§ЧцЗЂЙ§РДЕФЧыЧѓ,НЋЦфХХжСЖгСажа,ЕБв§ЧцдйДЮЧыЧѓЪБЗЕЛи
Downloader:ЯТдиЦї,ЯТдиЫљгав§ЧцЗЂЫЭЕФЧыЧѓ,ВЂНЋЛёШЁЕФдДДњТыЗЕЛиИјв§Чц,жЎКѓгЩв§ЧцНЛИјХРГцДІРэ
Spiders:ХРГц,НгЪеВЂДІРэЫљгав§ЧцЗЂЫЭЙ§РДЕФдДДњТы,ДгжаЗжЮіВЂЬсШЁitemзжЖЮЫљашвЊЕФЪ§Он,ВЂНЋашвЊИњНјЕФurlЬсНЛИјв§Чц,дйДЮНјШыЕїЖШЦї
Item Pipeline:ЙмЕР,ИКд№ДІРэДгХРГцжаЛёШЁЕФItem,ВЂНјааКѓЦкДІРэ
Downloader Middlewares:ЯТдижаМфМў,ПЩвдРэНтЮЊздЖЈвхРЉеЙЯТдиЙІФмЕФзщМў
Spider Middlewares:SpiderжаМфМў,здЖЈвхРЉеЙКЭВйзїв§ЧцгыХРГцжЎМфЭЈаХЕФЙІФмзщМў
ScrapyЪ§ОнДІРэСїГЬ:
1. ЕБашвЊДђПЊвЛИігђУћЪБ,ХРГцПЊЪМЛёШЁЕквЛИіurl,ВЂЗЕЛиИјв§Чц
2.в§ЧцАбurlзїЮЊвЛИіЧыЧѓНЛИјЕїЖШЦї
3.в§ЧцдйДЮЖдЕїЖШЦїЗЂГіЧыЧѓ,ВЂНгЪеЩЯвЛДЮШУЕїЖШЦїДІРэЕФЧыЧѓ
4.в§ЧцНЋЧыЧѓНЛИјЯТдиЦї
5.ЯТдиЦїЯТдиЭъГЩКѓ,зїЮЊЯьгІЗЕЛиИјв§Чц
6.в§ЧцАбЯьгІНЛИјХРГц,ХРГцПЊЪМНјвЛВНДІРэ,ДІРэЭъГЩКѓгаСНИіЪ§Он,вЛИіЪЧашвЊИњНјЕФurl,СэвЛИіЪЧЛёШЁЕНЕФitemЪ§Он,ШЛКѓАбНсЙћЗЕЛиИјв§Чц
7.в§ЧцАбашвЊИњНјЕФurlИјЕїЖШЦї,АбЛёШЁЕФitemЪ§ОнИјЙмЕР
8.ШЛКѓДгЕк2ВНПЊЪМбЛЗ,жЊЕРЛёШЁаХЯЂЭъБЯЁЃжЛгаЕїЖШЦїжаУЛгаШЮКЮЧыЧѓЪБ,ГЬађВХЛсЭЃжЙ
3.ScrapyЕФОпЬхВйзї
(1)ЮвУЧвЊдкspidersЮФМўМажаДДНЈХРГцГЬађ,ЕЋЪЧЯждкЕФЕБЧАЮФМўЪЧScrapy,ЫљвдЮвУЧвЊЯШИФБфЕБЧАЮФМўЮЛжУжСspidersжа
ЗНЗЈЭЌЩЯ,дкжеЖЫжаЪфШы:cd КѓУцМгвЛИіПеИё ШЛКѓАбspidersЮФМўЭЯЙ§ШЅЛиГЕМДПЩ
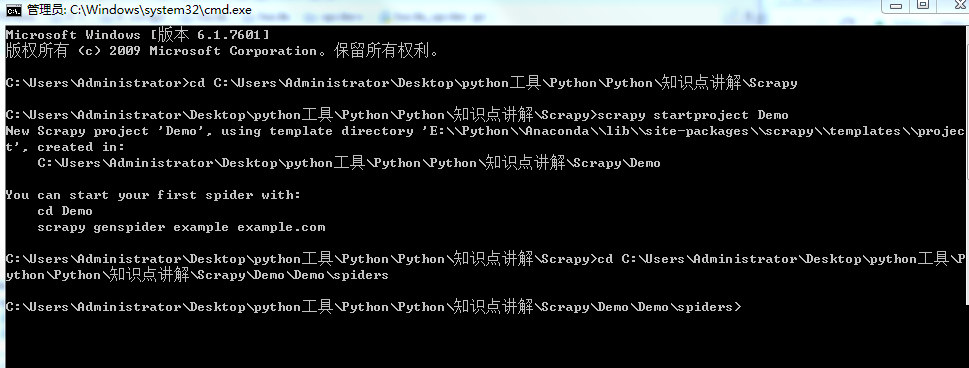
(2)ПЊЪМДДНЈХРГцЮФМў,етРяЕФгђУћвдАйЖШЮЊР§
дкжеЖЫжаЪфШы:scrapy genspider baidu_spider baidu.com Цфжа:baidu_spider ЪЧЮФМўУћ,ПЩвдздЖЈвх,ЕЋЪЧВЛФмгыЯюФПУћвЛбљ
ЛиГЕКѓЛсдкspidersЮФМўМаЯТДДНЈвЛИіbaidu_spider.pyЮФМў,жЎКѓЫљгаЕФВйзїЖМЛсдкетИіЮФМўжаЕФdef
parseжажДаа

baidu_spider.pyЮФМўФкШн:

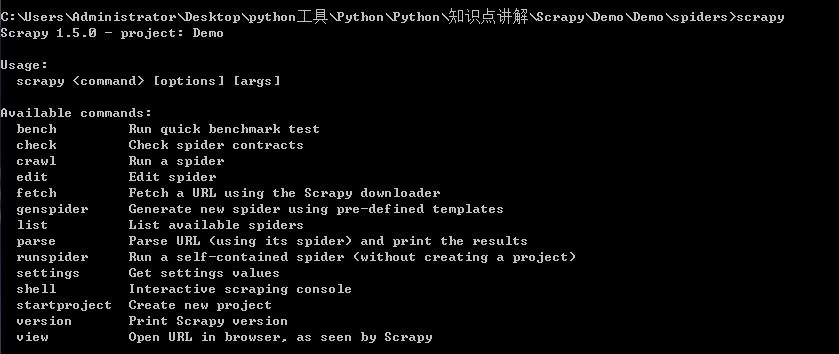
ЕБДДНЈpyЮФМўГЩЙІКѓ,ЮвУЧдйДЮЪфШыУќСю:scrapy ЛсЗЂЯжЖрСЫcheck,crawl,edit,list,parseет5ИіЗНЗЈ,ОпЬхзїгУЧыВЮПМЩЯЮФ
(3)ВЙШЋurlВЂДђгЁНсЙћ,вђЮЊscrapyЛсздЖЏХРГц,ЫљвдЮвУЧжЛашвЊЪфГіНсЙћОЭааСЫ

дкжеЖЫжаЪфШы:scrapy crawl baidu_spider
ШчЙћГЩЙІЛсГіЯжФПБъurlЕФЭјвГдДТы

НёЬьЙигкScrapyЕФНВНтОЭЕНетРяСЫ,ЙигкШчКЮгУScrapyЛёШЁОпЬхЕФЪ§ОнжЎКѓЮвЛсМЬајНВНтЁЃ
|









