| БрМЭЦМі: |
| БОЮФРДздгкcsdn,ЮФеТНщЩмСЫгУгкЪЕЬхЪЖБ№ЕФЛљБОММЪѕЪЧЗжПщЃЌУќУћЪЕЬхЪЖБ№ЃЈNERЃЉвдМАЙиЯЕГщШЁЕШЯрЙиФкШнЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
ЛиД№ЯТСаЮЪЬтЃК
ЁЁЁЁЃЈЃБЃЉШчКЮФмЙЙНЈвЛИіЯЕЭГЃЌвджСДгЗЧНсЙЙЛЏЮФБОжаЬсШЁНсЙЙЛЏЪ§ОнЃП
ЁЁЁЁЃЈЃВЃЉгаФФаЉЮШНЁЕФЗНЗЈЪЖБ№вЛИіЮФБОУшЪіЕФЪЕЬхКЭЙиЯЕЃП
ЁЁЁЁЃЈЃГЃЉФФаЉгяСЯПтЪЪКЯетЯюЙЄзїЃЌШчКЮЪЙгУЫќУЧРДбЕСЗКЭЦРЙРФЃаЭЃП
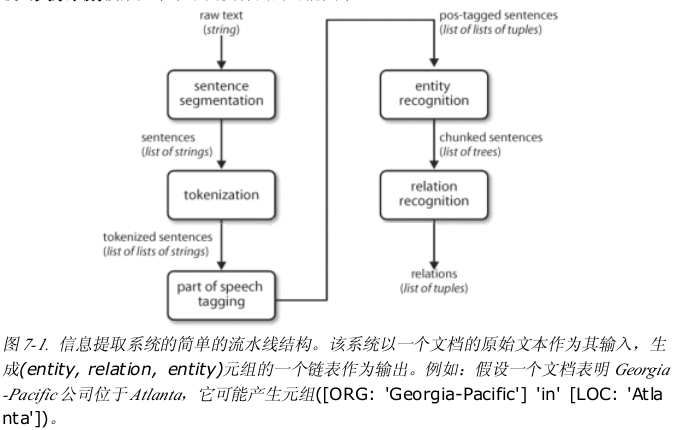
вЛЁЁаХЯЂЬсШЁ
аХЯЂгаКмЖржжЁБаЮзДЁАКЭЁБДѓаЁЁАЃЌвЛИіживЊЕФаЮЪНЪЧНсЙЙЛЏЪ§ОнЃКЪЕЬхКЭЙиЯЕЕФЙцЗЖКЭПЩдЄВтЕФзщжЏЁЃР§ШчЃКЮвУЧПЩФмЖдЙЋЫОКЭЕиЕужЎМфЕФЙиЯЕЃЌПЩгУЙиЯЕЪ§ОнПтДцДЂЁЃ
ЕЋШчЙћЮвУЧГЂЪдДгЮФБОжаЛёЕУЯрЫЦЕФаХЯЂЃЌЪТЧщОЭБШНЯТщЗГСЫЁЃШчКЮДгвЛЖЮЮФзжжаЗЂЯжвЛИіЪЕЬхКЭЙиЯЕЕФБэФиЃП
ШЛКѓЃЌРћгУЧПДѓЕФВщбЏЙЄОпЃЌШчЃгЃбЃЬЃЌетжжДгЮФБОЛёШЁвтвхЕФЗНЗЈБЛГЦЮЊЁАаХЯЂЬсШЁЁБ
аХЯЂЬсШЁгааэЖргІгУЃЌАќРЈЩЬвЕжЧФмЁЂМђРњЪеЛёЁЂУНЬхЗжЮіЁЂЧщИаМьВтЁЂзЈРћМьЫїМАЕчзггЪМўЩЈУшЁЃЕБЧАбаОПЕФвЛИіЬиБ№живЊЕФСьгђЪЧЬсШЁГіЕчзгПЦбЇЮФЯзЕФНсЙЙЛЏЪ§ОнЃЌЬиБ№ЪЧдкЩњЮябЇКЭвНбЇСьгђЁЃ
ЃЃаХЯЂЬсШЁНсЙЙ
вЊжДааЧАУцЃГИіШЮЮёЃЌОфзгЗжИюЦїЁЂЗжДЪЦїКЭДЪадБъзЂЦї
import nltk,
re, pprint
def ie_preprocess(document):
sentences = nltk.sent_tokenize(document) #ОфзгЗжИю
sentences = [nltk.word_tokenize(sent) for sent
in sentences] #ЗжДЪ
sentences = [nltk.pos_tag(sent) for sent in sentence]
#ДЪадБъзЂЦї |
ЖўЁЁЗжПщ
гУгкЪЕЬхЪЖБ№ЕФЛљБОММЪѕЪЧЗжПщ(chunking)
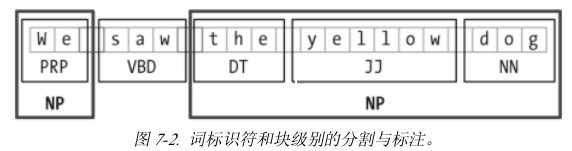
аЁПђЯдЪОДЪМЖБъЪЖЗћКЭДЪадБъзЂЃЌЭЌЪБЃЌДѓПђЯдЪОНЯИпМЖЕФГЬађЗжПщ
дкБОНкЩЯЃЌЮвУЧНЋдкНЯЩюЕФВуУцЩЯЬНЬжГЬађЗжПщЃЌвдзщПщЕФЖЈвхКЭБэЪОПЊЪМЃЌЮвУЧНЋПДЕНе§дђБэДяЪНКЭn-gramЗНЗЈЗжПщЃЌЪЙгУCoNLL-2000ЗжПщгяСЯПтПЊЗЂКЭЦРЙРЗжПщЦїЁЃ
ЃЃУћДЪЖЬгяЗжПщ
NP-chunkingЃЈУћДЪЖЬгяЗжПщЃЉЃЌбАевЕЅЖРУћДЪЖЬгяЖдгІЕФПщ
NPЃЗжПщаХЯЂзюгагУЕФРДдДжЎвЛЪЧДЪадБъМЧЁЃетЪЧдкаХЯЂЬсШЁЯЕЭГжаНјааДЪадБъзЂЕФЖЏЛњжЎвЛЁЃ
ЮЊСЫДДНЈNPЃЗжПщЃЌЪзЯШЖЈвхЗжПщгяЗЈЃЌЙцЖЈОфзггІШчКЮЗжПщЁЃдкБОР§жаЃЌЪЙгУвЛИіе§дђБэДяЪНЙцдђЖЈвхвЛИіМђЕЅЕФгяЗЈЁЃ
етЬѕЙцдђЪЧNP-ЗжПщгаПЩбЁЕФЧвКѓУцИњзХШЮвтЪ§ФПаЮШнДЪЕФЯоЖЈДЪКЭУћДЪзщГЩЁЃЪЙгУДЫгяЗЈЃЌЮвУЧДДНЈСЫзщПщЗжЮіЦїЃЌВтЪдЮвУХЕФР§ОфЁЃНсЙћЕУЕНЪїзДЭМЃЌПЩвдЪфГіЛђЯдЪОЭМаЮЁЃ
sentence = [("the","DT"),("little","JJ"),("yellow","JJ")
,("dog","NN"),("barked","VBD"),
("at","IN"),("the","DT"),("cat","NN")]
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print result
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN)) |

ЃЃБъМЧФЃЪН
ЪЙгУЭМаЮНчУцnltk.app.chunkparser()
ЃЃгУе§дђБэДяЪНЗжПщ
grammer = r"""
NP: {<DT|PP\$>?<JJ>*<NN>} #ЦЅХфвЛИіПЩбЁЕФЯоЖЈДЪЛђЫљгаИёДњУћДЪ
{<NNP>+} #ЦЅХфвЛИіЛђЖрИізЈгаУћДЪ
"""
cp = nltk.RegexpParser(grammer)
sentence = [("Rapunzel","NNP"),("let","VBD"),("down",
"RP"),("her","PP$"),("long","JJ"),("golden","JJ"),("hair","NN")]
print cp.parse(sentence)
(S
(NP Rapunzel/NNP)
let/VBD
down/RP
(NP her/PP$ long/JJ golden/JJ hair/NN)) |
nouns = [("money","NN"),("market","NN"),("fund","NN")]
grammar = "NP: {<NN><NN>}"
#ШчЙћНЋЦЅХфСНИіСЌајУћДЪЕФЮФБОЕФЙцдђгІгУЕНАќКЌЃГИіСЌајУћДЪЕФЮФБОжаЃЌдђжЛгаЧАСНИіУћДЪБЛЗжПщ
cp = nltk.RegexpParser(grammar)
print cp.parse(nouns)
(S (NP money/NN market/NN) fund/NN) |
ЃЃЬНЫїЮФБОгяСЯПт
ЪЙгУЗжПщЦїПЩвддквбБъзЂЕФгяСЯПтжаЬсШЁЦЅХфЬиЖЈДЪадБъМЧађСаЕФЖЬгя
cp = nltk.RegexpParser('CHUNK:
{<V.*> <TO> <V.*>}')
brown = nltk.corpus.brown
for sent in brown.tagged_sents():
tree = cp.parse(sent)
for subtree in tree.subtrees():
if subtree.label() == 'CHUNK':
print subtree
(CHUNK combined/VBN to/TO achieve/VB)
(CHUNK continue/VB to/TO place/VB)
(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB)
(CHUNK allowed/VBN to/TO place/VB)
...... |
ЃЃЗьЯЖ
ЮЊВЛАќРЈдкДѓПщжаЕФБъЪЖЗћађСаЖЈвхвЛИіЗьЯЖ
МгЗьЯЖЪЧДгДѓПщжаШЅГ§БъЪЖЗћађСаЕФЙ§ГЬ
grammar = r"""
NP:
{<.*>+}
}<VBD|IN>+{"""
sentence = [("the","DT"),("little","JJ"),
("yellow","JJ"),("dog","NN"),("barked","VBD"),
("at","IN"),("the","DT"),("cat","NN")]
cp = nltk.RegexpParser(grammar)
print cp.parse(sentence)
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN)) |
ЃЃЗжПщЕФБэЪОЃКБъМЧгыЪїзДЭМ
зїЮЊБъзЂКЭЗжЮіжЎМфЕФжаМфзДЬЌЃЌПщНсЙЙПЩвдЪЙгУБъМЧЛђЪїзДЭМРДБэЪОЁЃЪЙгУзюЙуЗКЕФБэЪОЪЧIOBБъМЧ
дкетИіЗНАИжаЃЌУПИіБъЪЖЗћБЛгУЃГИіЬиЪтЕФПщБъЧЉжЎвЛБъзЂЃЌЃЩЃЈinsideЃЌФкВПЃЉЃЌЃЯЃЈoutsideЃЌЭтВПЃЉЛђЃТЃЈbeginЃЌПЊЪМЃЉЁЃ
ЃТБъжОзХЫќЪЧЗжПщЕФПЊЪМЁЃПщФкЕФБъЪЖЗћзгађСаБЛБъжОЮЊЃЩЃЌЦфЫћЮЊЃЯ
ЃТКЭЃЩБъМЧЪЧПщРраЭЕФКѓзКЃЌШчB-NP, I-NPЁЃ
NLTKгУЪїзДЭМзїЮЊЗжПщЕФФкВПБэЪОЃЌШДЬсЙЉетаЉЪїзДЭМгыIOBжЎМфИёЪНзЊЛЛЕФЗНЗЈ
ЃГЁЁПЊЗЂКЭЦРЙРЗжПщЦї
ШчКЮЦРЙРЗжПщЦї
ЃЃЖСШЁIOBИёЪНгыCoNLL2000ЗжПщгяСЯПт
CoNLL2000ЗжПщгяСЯПтАќКЌ27ЭђДЪЕФЁЖЛЊЖћНжШеБЈЮФБОЁЗЃЌЗжЮЊЁАбЕСЗЁБКЭЁАВтЪдЁБСНВПЗжЃЌБъзЂгаДЪадБъМЧКЭIOBИёЪНЗжПщБъМЧЁЃ
from nltk.corpus import conll2000
print conll2000.chunked_sents('train.txt')[99]
(S
(PP Over/IN)
(NP a/DT cup/NN)
(PP of/IN)
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
(VP told/VBD)
(NP his/PRP$ story/NN)
./.) |
АќКЌЃГжаЗжПщРраЭЃКNPЗжПщЃЌVPЗжПщЃЌPPЗжПщ
| print conll2000.chunked_sents('train.txt',
chunk_types=['NP'])[99] #жЛбЁдёNPЗжПщ |
ЃЃМђЕЅЦРЙРКЭЛљзМ
cp = nltk.RegexpParser("")
#ВЛЗжПщ
test_sents = conll2000.chunked_sents('test.txt',chunk_types=['NP'])
print cp.evaluate(test_sents) #ЦРЙРНсЙћ
ChunkParse score:
IOB Accuracy: 43.4%%
Precision: 0.0%%
Recall: 0.0%%
F-Measure: 0.0%% |
grammar = r"NP:
{<[CDJNP].*>+}"
cp = nltk.RegexpParser(grammar) #ГѕМЖЕФе§дђБэДяЪНЗжПщЦї
test_sents = conll2000.chunked_sents('test.txt')
print cp.evaluate(test_sents) #ЦРЙРНсЙћ
ChunkParse score:
IOB Accuracy: 62.5%%
Precision: 70.6%%
Recall: 38.5%%
F-Measure: 49.8%% |
ЪЙгУunigramБъзЂЦїЖдУћДЪЖЬгяЗжПщ
#ЪЙгУбЕСЗгяСЯевЕНЖдУПИіДЪадБъМЧзюгаПЩФмЕФПщБъМЧЃЈЃЩЁЂЃЯЛђЃТЃЉ
#ПЩвдгУunigramБъзЂЦїНЈСЂвЛИіЗжПщЦїЃЌЕЋВЛЪЧвЊШЗЖЈУПИіДЪЕФе§ШЗДЪадБъМЧЃЌЖјЪЧИјЖЈУПИіДЪЕФДЪадБъМЧЃЌГЂЪдШЗЖЈе§ШЗЕФПщБъМЧ
class UnigramChunker(nltk.ChunkParserI):
def __init__(self, train_sents):
train_data = [[(t,c) for w,t,c in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = nltk.UnigramTagger(train_data)
def parse(self, sentence):
pos_tags = [pos for (word,pos) in sentence]
tagged_pos_tags = self.tagger.tag(pos_tags)
chunktags = [chunktag for (pos, chunktag) in tagged_pos_tags]
#ЮЊДЪадБъзЂIOBПщБъМЧ
conlltags = [(word, pos, chunktag) for ((word,pos),chunktag)
in zip(sentence, chunktags)]
return nltk.chunk.conlltags2tree(conlltags) #зЊЛЛГЩЗжПщЪїзДЭМ |
#ЪЙгУCoNLL2000ЗжПщгяСЯПтбЕСЗ
test_sents = conll2000.chunked_sents('test.txt',
chunk_types=['NP'])
train_sents = conll2000.chunked_sents('train.txt',
chunk_types=['NP'])
unigram_chunker = UnigramChunker(train_sents)
print unigram_chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 92.9%%
Precision: 79.9%%
Recall: 86.8%%
F-Measure: 83.2%% |
postags = sorted(set(pos
for sent in train_sents for (word,pos) in sent.leaves()))
print unigram_chunker.tagger.tag(postags)
[(u'#', u'B-NP'), (u'$', u'B-NP'), (u"''",
u'O'), (u'(', u'O'), (u')', u'O'), (u',', u'O'),
(u'.', u'O'), (u':', u'O'), (u'CC', u'O'), (u'CD',
u'I-NP'), (u'DT', u'B-NP'), (u'EX', u'B-NP'),
(u'FW', u'I-NP'), (u'IN', u'O'), (u'JJ', u'I-NP'),
(u'JJR', u'B-NP'), (u'JJS', u'I-NP'), (u'MD',
u'O'), (u'NN', u'I-NP'), (u'NNP', u'I-NP'), (u'NNPS',
u'I-NP'), (u'NNS', u'I-NP'), (u'PDT', u'B-NP'),
(u'POS', u'B-NP'), (u'PRP', u'B-NP'), (u'PRP$',
u'B-NP'), (u'RB', u'O'), (u'RBR', u'O'), (u'RBS',
u'B-NP'), (u'RP', u'O'), (u'SYM', u'O'), (u'TO',
u'O'), (u'UH', u'O'), (u'VB', u'O'), (u'VBD',
u'O'), (u'VBG', u'O'), (u'VBN', u'O'), (u'VBP',
u'O'), (u'VBZ', u'O'), (u'WDT', u'B-NP'), (u'WP',
u'B-NP'), (u'WP$', u'B-NP'), (u'WRB', u'O'), (u'``',
u'O')] |
#ЪЙгУбЕСЗгяСЯевЕНЖдУПИіДЪадБъМЧзюгаПЩФмЕФПщБъМЧЃЈЃЩЁЂЃЯЛђЃТЃЉ
#ПЩвдгУbigramБъзЂЦїНЈСЂвЛИіЗжПщЦїЃЌЕЋВЛЪЧвЊШЗЖЈУПИіДЪЕФе§ШЗДЪадБъМЧЃЌЖјЪЧИјЖЈУПИіДЪЕФДЪадБъМЧЃЌГЂЪдШЗЖЈе§ШЗЕФПщБъМЧ
class BigramChunker(nltk.ChunkParserI):
def __init__(self, train_sents):
train_data = [[(t,c) for w,t,c in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = nltk.BigramTagger(train_data)
def parse(self, sentence):
pos_tags = [pos for (word,pos) in sentence]
tagged_pos_tags = self.tagger.tag(pos_tags)
chunktags = [chunktag for (pos, chunktag) in tagged_pos_tags]
#ЮЊДЪадБъзЂIOBПщБъМЧ
conlltags = [(word, pos, chunktag) for ((word,pos),chunktag)
in zip(sentence, chunktags)]
return nltk.chunk.conlltags2tree(conlltags) #зЊЛЛГЩЗжПщЪїзДЭМ
bigram_chunker = BigramChunker(train_sents)
print bigram_chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 93.3%%
Precision: 82.3%%
Recall: 86.8%%
F-Measure: 84.5%% |
ЃЃбЕСЗЛљгкЗжРрЦїЕФЗжПщЦї
гаЪБДЪадБъМЧВЛзувдШЗЖЈвЛИіОфзггІШчКЮЗжПщ
АВзАocaml
АВзАmaxnet зюДѓьи
class ConsecutiveNPChunkTagger(nltk.TaggerI):
def __init__(self, train_sents):
train_set = []
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word,tag) in enumerate(tagged_sent):
featureset = npchunk_features(untagged_sent, i,
history)
train_set.append( (featureset, tag) )
history.append(tag)
self.classifier = nltk.MaxentClassifier.train(train_set,
algorithm='megam', trace=0)ЁЁ#зюДѓьи
def tag(self, sentence):
history = []
for i, word in enumerate(sentence):
featureset = npchunk_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
return zip(sentence, history)
class ConsecutiveNPChunker(nltk.ChunkParserI):
def __init__(self, train_sents):
tagged_sents = [[((w,t),c) for (w,t,c) in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = ConsecutiveNPChunkTagger(tagged_sents)
def parse(self, sentence):
tagged_sents = self.tagger.tag(sentence)
conlltags = [(w,t,c) for ((w,t),c) in tagged_sents]
return nltk.chunk.conlltags2tree(conlltags)
|
def npchunk_features(sentence,
i, history):
word, pos = sentence[i]
return {"pos": pos} #жЛЬсЙЉЕБЧАБъЪЖЗћЕФДЪадБъМЧ |
chunker = ConsecutiveNPChunker(train_sents)
print chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 92.9%%
Precision: 79.9%%
Recall: 86.7%%
F-Measure: 83.2%% |
def npchunk_features(sentence,
i, history):
word, pos = sentence[i]
if i == 0:
prevword, prevpos = "<START>",
"<START>"
else:
prevword, prevpos = sentence[i-1] |
| return {"pos":
pos, "prevpos": prevpos} #ФЃФтЯрСкБъМЧжЎМфЕФЯрЛЅзїгУ |
chunker = ConsecutiveNPChunker(train_sents)
print chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 93.7%%
Precision: 82.1%%
Recall: 87.2%%
F-Measure: 84.5%% |
def npchunk_features(sentence,
i, history):
word, pos = sentence[i]
if i == 0:
prevword, prevpos = "<START>",
"<START>"
else:
prevword, prevpos = sentence[i-1]
return {"pos": pos, "word":
word, "prevpos": prevpos} #діМгДЪЕФФкШн
chunker = ConsecutiveNPChunker(train_sents)
print chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 94.2%%
Precision: 83.2%%
Recall: 88.3%%
F-Measure: 85.7%% |
def npchunk_features(sentence,
i, history):
word, pos = sentence[i]
if i == 0:
prevword, prevpos = "<START>",
"<START>"
else:
prevword, prevpos = sentence[i-1]
if i == len(sentence)-1:
nextword, nextpos = "<END>", "<END>"
else:
nextword, nextpos = sentence[i+1]
return {"pos": pos,
"word":
word,
"prevpos": prevpos,
"nextpos":
nextpos,
"prevpos+pos": "%s+%s"
% (prevpos, pos),
"pos+nextpos":
"%s+%s" % (pos, nextpos),
"tags-since-dt":
tags_since_dt(sentence, i)} #дЄШЁЬиеїЁЂХфЖдЙІФмКЭИДдгЕФгяОГЬиеї
def tags_since_dt(sentence, i):
tags = set()
for word, pos in sentence[:i]:
if pos == "DT":
tags = set()
else:
tags.add(pos)
return '+'.join(sorted(tags))
chunker = ConsecutiveNPChunker(train_sents)
print chunker.evaluate(test_sents)
ChunkParse score:
IOB Accuracy: 96.0%%
Precision: 88.8%%
Recall: 91.1%%
F-Measure: 89.9%% |
ЫФЁЁгябдНсЙЙжаЕФЕнЙщ
ЃЃгУМЖСЊЗжПщЦїЙЙНЈЧЖЬзНсЙЙ
жЛашДДНЈвЛИіАќКЌЕнЙщЙцдђЕФЖрМЖЕФЗжПщгяЗЈЃЌОЭПЩвдНЈСЂШЮвтЩюЖШЕФЗжПщНсЙЙ
Р§згеЙЪОУћДЪЖЬгяЁЂНщДЪЖЬгяЁЂЖЏДЪЖЬгяКЭОфзгЕФФЃЪН
grammar = r"""
NP: {<DT|JJ|NN.*>+}
PP: {<IN><NP>}
VP: {<VB.*><NP|PP|CLAUSE>+$}
CLAUSE: {<NP><VP>}
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Mary","NN"),
("saw","VBD"),("the","DT"),("cat","NN"),
("sit","VB"),("on","IN"),("the","DT"),("mat","NN")]
print cp.parse(sentence)
(S
(NP Mary/NN)
saw/VBD #ЮоЗЈЪЖБ№VP
(CLAUSE
(NP the/DT cat/NN)
(VP sit/VB (PP on/IN (NP the/DT mat/NN))))) |
cp = nltk.RegexpParser(grammar,
loop=2) #ЬэМгбЛЗ
print cp.parse(sentence)
(S
(CLAUSE
(NP Mary/NN)
(VP
saw/VBD
(CLAUSE
(NP the/DT cat/NN)
(VP sit/VB (PP on/IN (NP the/DT mat/NN))))))) |
ЃЃЪїзДЭМ
дкNLTKжаЃЌДДНЈЪїзДЭМЃЌЗНЗЈЪЧИјНкЕуЬэМгБъЧЉКЭвЛИізгСДБэ
ЃЃЪїБщРњ
ЪЙгУЕнЙщКЏЪ§РДБщРњЪїЪЧБъзМЕФзіЗЈ
ЮхЁЁУќУћЪЕЬхЪЖБ№
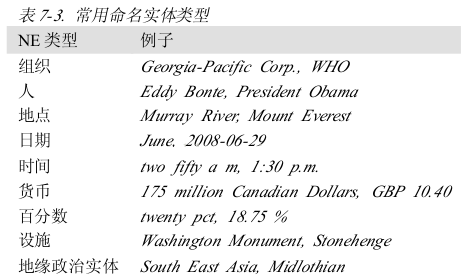
УќУћЪЕЬхЪЖБ№ЃЈNERЃЉЯЕЭГЕФФПБъЪЧЪЖБ№ЫљгаЮФзжЬсМАЕФУќУћЪЕЬхЁЃетПЩвдЗжНтГЩСНИізгШЮЮёЃКШЗЖЈNEЕФБпНчКЭШЗЖЈЦфРраЭЁЃУќУћЪЕЬхЪЖБ№ОГЃЪЧаХЯЂЬсШЁжаЙиЯЕЪЖБ№ЕФЧАзрЃЌвВгажњгкЦфЫћШЮЮёЁЃР§ШчЃКдкЮЪД№ЯЕЭГЃЈQAЃЉжаЃЌЮвУЧЪдЭМЬсИпаХЯЂМьЫїЕФОЋШЗЖШЃЌВЛгУЗЕЛиећИівГУцЖјжЛЪЧАќКЌгУЛЇЮЪЬтЕФД№АИЕФФЧВПЗжЁЃДѓЖрЪ§QAЯЕЭГРћгУБъзМаХЯЂМьЫїЗЕЛиЕФЮФМўЃЌШЛКѓГЂЪдЗжРыЮФЕЕжаАќКЌД№АИЕФзюаЁЕФЮФБОЗжЖЮЁЃP303ЃЌР§ШчЮЪЬтЃКWho
was the first President of the USЃПБЛМьЫїЕФЮФЕЕжаАќКЌД№АИЃЌЕЋЮвУЧЯыЕУЕНЕФД№АИгІИУЪЧX
was the first President of the USЕФаЮЪНЃЌЦфжаXВЛНіЪЧвЛИіУћДЪЖЬгявВЪЧвЛИіPERРраЭЕФУќУћЪЕЬхЁЃ
ШчКЮЪЖБ№УќУћЪЕЬхФиЃПвЛжжЗНЗЈЪЧВщевЪЪЕБЕФУћГЦСаБэЃЌЕЋЮЪЬтЪЧаэЖрЪЕЬхДыДЧгаЦчвхЃЌШчMayКЭNorthПЩФмЪЧШеЦкКЭЕиЕу
вђДЫЮвУЧашвЊФмЙЛЪЖБ№ЖрБъЪЖЗћађСаЕФПЊЭЗКЭНсЮВ
NERЪЧвЛИіЗЧГЃЪЪКЯгУгкЗжРрЦїРраЭЕФЗНЗЈЁЃ
NLTKЬсЙЉСЫвЛИівбОбЕСЗКУЕФПЩвдЪЖБ№УќУћЪЕЬхЕФЗжРрЦїЃЌЪЙгУКЏЪ§nltk.ne_chunk()ЗУЮЪЁЃ
sent = nltk.corpus.treebank.tagged_sents()[22]
print nltk.ne_chunk(sent, binary=True) #ШчЙћЩшжУВЮЪ§binary=TrueЃЌФЧУДУќУћЪЕЬхжЛБЛБъзЂЮЊNE
(S
The/DT
(NE U.S./NNP)
is/VBZ
one/CD
of/IN |
print nltk.ne_chunk(sent)
#PERSON, ORGANIZATION and GPE
(S
The/DT
(GPE U.S./NNP)
is/VBZ
......
(PERSON Brooke/NNP T./NNP Mossman/NNP)
,/,
a/DT
professor/NN
of/IN
pathlogy/NN
at/IN
the/DT
(ORGANIZATION University/NNP)
of/IN
(PERSON Vermont/NNP College/NNP)
of/IN
(GPE Medicine/NNP) |
СљЁЁЙиЯЕГщШЁ
жЛвЊЮФБОжаЕФУќУћЪЕЬхБЛЪЖБ№ЃЌЮвУЧОЭПЩвдЬсШЁЫќУЧжЎМфДцдкЕФЙиЯЕЁЃ
ЗНЗЈжЎвЛЪЧЪзЯШбАевЫљга(X, a, Y)аЮЪНЕФШ§дЊзщЃЌЦфжаXКЭYЪЧжИЖЈРраЭЕФУќУћЪЕЬхЃЌaБэЪОXКЭYжЎМфЙиЯЕЕФзжЗћДЎ
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC',
doc, corpus='ieer', pattern=IN):
print nltk.sem.relextract.rtuple(rel)
[ORG: u'WHYY'] u'in' [LOC: u'Philadelphia']
[ORG: u'McGlashan & Sarrail'] u'firm in' [LOC:
u'San Mateo']
[ORG: u'Freedom Forum'] u'in' [LOC: u'Arlington']
[ORG: u'Brookings Institution'] u', the research
group in' [LOC: u'Washington']
[ORG: u'Idealab'] u', a self-described business
incubator based in' [LOC: u'Los Angeles']
[ORG: u'Open Text'] u', based in' [LOC: u'Waterloo'] |
|









