| БрМЭЦМі: |
| БОЮФРДздгкe-learn,ЮФеТжївЊЬНОПвЛЯТScrapyПђМмЭЈгУХРГцЕФЪЕЯжЗНЗЈЕШЯрЙиФкШнЃЌЯЃЭћЖдФњЕФбЇЯАФмгаЫљАяжњЁЃ |
|
ЭЈЙ§ScrapyЃЌЮвУЧПЩвдЧсЫЩЕиЭъГЩвЛИіеОЕуХРГцЕФБраДЁЃЕЋШчЙћзЅШЁЕФеОЕуСПЗЧГЃДѓЃЌБШШчХРШЁИїДѓУНЬхЕФаТЮХаХЯЂЃЌЖрИіSpiderдђПЩФмАќКЌКмЖржиИДДњТыЁЃ
ШчЙћЮвУЧНЋИїИіеОЕуЕФSpiderЕФЙЋЙВВПЗжБЃСєЯТРДЃЌВЛЭЌЕФВПЗжЬсШЁГіРДзїЮЊЕЅЖРЕФХфжУЃЌШчХРШЁЙцдђЁЂвГУцНтЮіЗНЪНЕШГщРыГіРДзіГЩвЛИіХфжУЮФМўЃЌФЧУДЮвУЧдкаТдівЛИіХРГцЕФЪБКђЃЌжЛашвЊЪЕЯжетаЉЭјеОЕФХРШЁЙцдђКЭЬсШЁЙцдђМДПЩЁЃ
БОНкЮвУЧОЭРДЬНОПвЛЯТScrapyЭЈгУХРГцЕФЪЕЯжЗНЗЈЁЃ
вЛЁЂCrawlSpider
дкЪЕЯжЭЈгУХРГцжЎЧАЃЌЮвУЧашвЊЯШСЫНтвЛЯТCrawlSpiderЃЌЦфЙйЗНЮФЕЕСДНгЮЊЃКhttp://scrapy.readthedocs.
io/en/latest/topics/spiders.html#crawlspiderЁЃ
CrawlSpiderЪЧScrapyЬсЙЉЕФвЛИіЭЈгУSpiderЁЃдкSpiderРяЃЌЮвУЧПЩвджИЖЈвЛаЉХРШЁЙцдђРДЪЕЯжвГУцЕФЬсШЁЃЌетаЉХРШЁЙцдђгЩвЛИізЈУХЕФЪ§ОнНсЙЙRuleБэЪОЁЃRuleРяАќКЌЬсШЁКЭИњНјвГУцЕФХфжУЃЌSpiderЛсИљОнRuleРДШЗЖЈЕБЧАвГУцжаЕФФФаЉСДНгашвЊМЬајХРШЁЁЂФФаЉвГУцЕФХРШЁНсЙћашвЊгУФФИіЗНЗЈНтЮіЕШЁЃ
CrawlSpiderМЬГаздSpiderРрЁЃГ§СЫSpiderРрЕФЫљгаЗНЗЈКЭЪєадЃЌЫќЛЙЬсЙЉСЫвЛИіЗЧГЃживЊЕФЪєадКЭЗНЗЈЁЃ
rulesЃЌЫќЪЧХРШЁЙцдђЪєадЃЌЪЧАќКЌвЛИіЛђЖрИіRuleЖдЯѓЕФСаБэЁЃУПИіRuleЖдХРШЁЭјеОЕФЖЏзїЖМзіСЫЖЈвхЃЌCrawlSpiderЛсЖСШЁrulesЕФУПвЛИіRuleВЂНјааНтЮіЁЃ
parse_start_url()ЃЌЫќЪЧвЛИіПЩжиаДЕФЗНЗЈЁЃЕБstart_urlsРяЖдгІЕФRequestЕУЕНResponseЪБЃЌИУЗНЗЈБЛЕїгУЃЌЫќЛсЗжЮіResponseВЂБиаыЗЕЛиItemЖдЯѓЛђепRequestЖдЯѓЁЃ
етРязюживЊЕФФкШнФЊЙ§гкRuleЕФЖЈвхСЫЃЌЫќЕФЖЈвхКЭВЮЪ§ШчЯТЫљЪОЃК
| class scrapy.contrib.spiders.Rule(link_extractor,
callback=None, cb_kwargs=None, follow=None, process_links=None,
process_request=None) |
ЯТУцНЋвРДЮЫЕУїRuleЕФВЮЪ§ЁЃ
link_extractorЃКЪЧLink ExtractorЖдЯѓЁЃЭЈЙ§ЫќЃЌSpiderПЩвджЊЕРДгХРШЁЕФвГУцжаЬсШЁФФаЉСДНгЁЃЬсШЁГіЕФСДНгЛсздЖЏЩњГЩRequestЁЃЫќгжЪЧвЛИіЪ§ОнНсЙЙЃЌвЛАуГЃгУLxmlLinkExtractorЖдЯѓзїЮЊВЮЪ§ЃЌЦфЖЈвхКЭВЮЪ§ШчЯТЫљЪОЃК
| class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(),
deny=(), allow_domains=(), deny_domains=(), deny_extensions=None,
restrict_xpaths=(), restrict_css=(), tags=('a',
'area'), attrs=('href', ), canonicalize=False,
unique=True, process_value=None, strip=True) |
allowЪЧвЛИіе§дђБэДяЪНЛђе§дђБэДяЪНСаБэЃЌЫќЖЈвхСЫДгЕБЧАвГУцЬсШЁГіЕФСДНгФФаЉЪЧЗћКЯвЊЧѓЕФЃЌжЛгаЗћКЯвЊЧѓЕФСДНгВХЛсБЛИњНјЁЃdenyдђЯрЗДЁЃallow_domainsЖЈвхСЫЗћКЯвЊЧѓЕФгђУћЃЌжЛгаДЫгђУћЕФСДНгВХЛсБЛИњНјЩњГЩаТЕФRequestЃЌЫќЯрЕБгкгђУћАзУћЕЅЁЃdeny_domainsдђЯрЗДЃЌЯрЕБгкгђУћКкУћЕЅЁЃrestrict_xpathsЖЈвхСЫДгЕБЧАвГУцжаXPathЦЅХфЕФЧјгђЬсШЁСДНгЃЌЦфжЕЪЧXPathБэДяЪНЛђXPathБэДяЪНСаБэЁЃrestrict_cssЖЈвхСЫДгЕБЧАвГУцжаCSSбЁдёЦїЦЅХфЕФЧјгђЬсШЁСДНгЃЌЦфжЕЪЧCSSбЁдёЦїЛђCSSбЁдёЦїСаБэЁЃЛЙгавЛаЉЦфЫћВЮЪ§ДњБэСЫЬсШЁСДНгЕФБъЧЉЁЂЪЧЗёШЅжиЁЂСДНгЕФДІРэЕШФкШнЃЌЪЙгУЕФЦЕТЪВЛИпЁЃПЩвдВЮПМЮФЕЕЕФВЮЪ§ЫЕУїЃКhttp://scrapy.readthedocs.io
/en/latest/topics/link-extractors.html #module-scrapy.linkextractors.lxmlhtmlЁЃ
callbackЃКМДЛиЕїКЏЪ§ЃЌКЭжЎЧАЖЈвхRequestЕФcallbackгаЯрЭЌЕФвтвхЁЃУПДЮДгlink_extractorжаЛёШЁЕНСДНгЪБЃЌИУКЏЪ§НЋЛсЕїгУЁЃИУЛиЕїКЏЪ§НгЪевЛИіresponseзїЮЊЦфЕквЛИіВЮЪ§ЃЌВЂЗЕЛивЛИіАќКЌItemЛђRequestЖдЯѓЕФСаБэЁЃзЂвтЃЌБмУтЪЙгУparse()зїЮЊЛиЕїКЏЪ§ЁЃгЩгкCrawlSpiderЪЙгУparse()ЗНЗЈРДЪЕЯжЦфТпМЃЌШчЙћparse()ЗНЗЈИВИЧСЫЃЌCrawlSpiderНЋЛсдЫааЪЇАмЁЃ
cb_kwargsЃКзжЕфЃЌЫќАќКЌДЋЕнИјЛиЕїКЏЪ§ЕФВЮЪ§ЁЃ
followЃКВМЖћжЕЃЌМДTrueЛђFalseЃЌЫќжИЖЈИљОнИУЙцдђДгresponseЬсШЁЕФСДНгЪЧЗёашвЊИњНјЁЃШчЙћcallbackВЮЪ§ЮЊNoneЃЌfollowФЌШЯЩшжУЮЊTrueЃЌЗёдђФЌШЯЮЊFalseЁЃ
process_linksЃКжИЖЈДІРэКЏЪ§ЃЌДгlink_extractorжаЛёШЁЕНСДНгСаБэЪБЃЌИУКЏЪ§НЋЛсЕїгУЃЌЫќжївЊгУгкЙ§ТЫЁЃ
process_requestЃКЭЌбљЪЧжИЖЈДІРэКЏЪ§ЃЌИљОнИУRuleЬсШЁЕНУПИіRequestЪБЃЌИУКЏЪ§ЖМЛсЕїгУЃЌЖдRequestНјааДІРэЁЃИУКЏЪ§БиаыЗЕЛиRequestЛђепNoneЁЃ
вдЩЯФкШнБуЪЧCrawlSpiderжаЕФКЫаФRuleЕФЛљБОгУЗЈЁЃЕЋетаЉФкШнПЩФмЛЙВЛзувдЭъГЩвЛИіCrawlSpiderХРГцЁЃЯТУцЮвУЧРћгУCrawlSpiderЪЕЯжаТЮХЭјеОЕФХРШЁЪЕР§ЃЌРДИќКУЕиРэНтRuleЕФгУЗЈЁЃ
ЖўЁЂItem Loader
ЮвУЧСЫНтСЫРћгУCrawlSpiderЕФRuleРДЖЈвхвГУцЕФХРШЁТпМЃЌетЪЧПЩХфжУЛЏЕФвЛВПЗжФкШнЁЃЕЋЪЧЃЌRuleВЂУЛгаЖдItemЕФЬсШЁЗНЪНзіЙцдђЖЈвхЁЃЖдгкItemЕФЬсШЁЃЌЮвУЧашвЊНшжњСэвЛИіФЃПщItem
LoaderРДЪЕЯжЁЃ
Item LoaderЬсЙЉвЛжжБуНнЕФЛњжЦРДАяжњЮвУЧЗНБуЕиЬсШЁItemЁЃЫќЬсЙЉЕФвЛЯЕСаAPIПЩвдЗжЮідЪМЪ§ОнЖдItemНјааИГжЕЁЃItemЬсЙЉЕФЪЧБЃДцзЅШЁЪ§ОнЕФШнЦїЃЌЖјItem
LoaderЬсЙЉЕФЪЧЬюГфШнЦїЕФЛњжЦЁЃгаСЫЫќЃЌЪ§ОнЕФЬсШЁЛсБфЕУИќМгЙцдђЛЏЁЃ
Item LoaderЕФAPIШчЯТЫљЪОЃК
| class scrapy.loader.ItemLoader([item,
selector, response, ] **kwargs) |
Item LoaderЕФAPIЗЕЛивЛИіаТЕФItem LoaderРДЬюГфИјЖЈЕФItemЁЃШчЙћУЛгаИјГіItemЃЌдђЪЙгУжаЕФРрздЖЏЪЕР§ЛЏdefault_item_classЁЃСэЭтЃЌЫќДЋШыselectorКЭresponseВЮЪ§РДЪЙгУбЁдёЦїЛђЯьгІВЮЪ§ЪЕР§ЛЏЁЃ
ЯТУцНЋвРДЮЫЕУїItem LoaderЕФAPIВЮЪ§ЁЃ
itemЃКЫќЪЧItemЖдЯѓЃЌПЩвдЕїгУadd_xpath()ЁЂadd_css()Лђadd_value()ЕШЗНЗЈРДЬюГфItemЖдЯѓЁЃ
selectorЃКЫќЪЧSelectorЖдЯѓЃЌгУРДЬсШЁЬюГфЪ§ОнЕФбЁдёЦїЁЃ
responseЃКЫќЪЧResponseЖдЯѓЃЌгУгкЪЙгУЙЙдьбЁдёЦїЕФResponseЁЃ
вЛИіБШНЯЕфаЭЕФItem LoaderЪЕР§ШчЯТЫљЪОЃК
from scrapy.loader
import ItemLoader
from project.items import Product
def parse(self, response):
loader = ItemLoader(item=Product(), response=response)
loader.add_xpath('name', '//div[@class="product_name"]')
loader.add_xpath('name', '//div[@class="product_title"]')
loader.add_xpath('price', '//p[@id="price"]')
loader.add_css('stock', 'p#stock]')
loader.add_value('last_updated', 'today')
return loader.load_item() |
етРяЪзЯШЩљУївЛИіProduct ItemЃЌгУИУItemКЭResponseЖдЯѓЪЕР§ЛЏItemLoaderЃЌЕїгУadd_xpath()ЗНЗЈАбРДздСНИіВЛЭЌЮЛжУЕФЪ§ОнЬсШЁГіРДЃЌЗжХфИјnameЪєадЃЌдйгУadd_xpath()ЁЂadd_css()ЁЂadd_value()ЕШЗНЗЈЖдВЛЭЌЪєадвРДЮИГжЕЃЌзюКѓЕїгУload_item()ЗНЗЈЪЕЯжItemЕФНтЮіЁЃетжжЗНЪНБШНЯЙцдђЛЏЃЌЮвУЧПЩвдАбвЛаЉВЮЪ§КЭЙцдђЕЅЖРЬсШЁГіРДзіГЩХфжУЮФМўЛђДцЕНЪ§ОнПтЃЌМДПЩЪЕЯжПЩХфжУЛЏЁЃ
СэЭтЃЌItem LoaderУПИізжЖЮжаЖМАќКЌСЫвЛИіInput ProcessorЃЈЪфШыДІРэЦїЃЉКЭвЛИіOutput
ProcessorЃЈЪфГіДІРэЦїЃЉЁЃInput ProcessorЪеЕНЪ§ОнЪБСЂПЬЬсШЁЪ§ОнЃЌInput
ProcessorЕФНсЙћБЛЪеМЏЦ№РДВЂЧвБЃДцдкItemLoaderФкЃЌЕЋЪЧВЛЗжХфИјItemЁЃЪеМЏЕНЫљгаЕФЪ§ОнКѓЃЌload_item()ЗНЗЈБЛЕїгУРДЬюГфдйЩњГЩItemЖдЯѓЁЃдкЕїгУЪБЛсЯШЕїгУOutput
ProcessorРДДІРэжЎЧАЪеМЏЕНЕФЪ§ОнЃЌШЛКѓдйДцШыItemжаЃЌетбљОЭЩњГЩСЫItemЁЃ
ЯТУцНЋНщЩмвЛаЉФкжУЕФЕФProcessorЁЃ
1. Identity
IdentityЪЧзюМђЕЅЕФProcessorЃЌВЛНјааШЮКЮДІРэЃЌжБНгЗЕЛидРДЕФЪ§ОнЁЃ
2. TakeFirst
TakeFirstЗЕЛиСаБэЕФЕквЛИіЗЧПежЕЃЌРрЫЦextract_first()ЕФЙІФмЃЌГЃгУзїOutput
ProcessorЃЌШчЯТЫљЪОЃК
from scrapy.loader.processors
import TakeFirst
processor = TakeFirst()
print(processor(['', 1, 2, 3])) |
ЪфГіНсЙћШчЯТЫљЪОЃК
ОЙ§ДЫProcessorДІРэКѓЕФНсЙћЗЕЛиСЫЕквЛИіВЛЮЊПеЕФжЕЁЃ
3. Join
JoinЗНЗЈЯрЕБгкзжЗћДЎЕФjoin()ЗНЗЈЃЌПЩвдАбСаБэЦДКЯГЩзжЗћДЎЃЌзжЗћДЎФЌШЯЪЙгУПеИёЗжИєЃЌШчЯТЫљЪОЃК
from scrapy.loader.processors
import Join
processor = Join()
print(processor(['one', 'two', 'three'])) |
ЪфГіНсЙћШчЯТЫљЪОЃК
ЫќвВПЩвдЭЈЙ§ВЮЪ§ИќИФФЌШЯЕФЗжИєЗћЃЌР§ШчИФГЩЖККХЃК
from scrapy.loader.processors
import Join
processor = Join(',')
print(processor(['one', 'two', 'three'])) |
дЫааНсЙћШчЯТЫљЪОЃК
ComposeЪЧгУИјЖЈЕФЖрИіКЏЪ§ЕФзщКЯЖјЙЙдьЕФProcessorЃЌУПИіЪфШыжЕБЛДЋЕнЕНЕквЛИіКЏЪ§ЃЌЦфЪфГідйДЋЕнЕНЕкЖўИіКЏЪ§ЃЌвРДЮРрЭЦЃЌжБЕНзюКѓвЛИіКЏЪ§ЗЕЛиећИіДІРэЦїЕФЪфГіЃЌШчЯТЫљЪОЃК
from scrapy.loader.processors
import Compose
processor = Compose(str.upper, lambda s: s.strip())
print(processor(' hello world')) |
дЫааНсЙћШчЯТЫљЪОЃК
дкетРяЮвУЧЙЙдьСЫвЛИіCompose ProcessorЃЌДЋШывЛИіПЊЭЗДјгаПеИёЕФзжЗћДЎЁЃCompose
ProcessorЕФВЮЪ§гаСНИіЃКЕквЛИіЪЧstr.upperЃЌЫќПЩвдНЋзжФИШЋВПзЊЮЊДѓаДЃЛЕкЖўИіЪЧвЛИіФфУћКЏЪ§ЃЌЫќЕїгУstrip()ЗНЗЈШЅГ§ЭЗЮВПеАззжЗћЁЃComposeЛсЫГДЮЕїгУСНИіВЮЪ§ЃЌзюКѓЗЕЛиНсЙћЕФзжЗћДЎШЋВПзЊЛЏЮЊДѓаДВЂЧвШЅГ§СЫПЊЭЗЕФПеИёЁЃ
5. MapCompose
гыComposeРрЫЦЃЌMapComposeПЩвдЕќДњДІРэвЛИіСаБэЪфШыжЕЃЌШчЯТЫљЪОЃК
from scrapy.loader.processors
import MapCompose
processor = MapCompose(str.upper, lambda s: s.strip())
print(processor(['Hello', 'World', 'Python'])) |
дЫааНсЙћШчЯТЫљЪОЃК
| ['HELLO', 'WORLD',
'PYTHON'] |
БЛДІРэЕФФкШнЪЧвЛИіПЩЕќДњЖдЯѓЃЌMapComposeЛсНЋИУЖдЯѓБщРњШЛКѓвРДЮДІРэЁЃ
6. SelectJmes
SelectJmesПЩвдВщбЏJSONЃЌДЋШыKeyЃЌЗЕЛиВщбЏЫљЕУЕФValueЁЃВЛЙ§ашвЊЯШАВзАJmespathПтВХПЩвдЪЙгУЫќЃЌУќСюШчЯТЫљЪОЃК
АВзАКУJmespathжЎКѓЃЌБуПЩвдЪЙгУетИіProcessorСЫЃЌШчЯТЫљЪОЃК
from scrapy.loader.processors
import SelectJmes
proc = SelectJmes('foo')
processor = SelectJmes('foo')
print(processor({'foo': 'bar'})) |
дЫааНсЙћШчЯТЫљЪОЃК
вдЩЯФкШнБуЪЧвЛаЉГЃгУЕФProcessorЃЌдкБОНкЕФЪЕР§жаЮвУЧЛсЪЙгУProcessorРДНјааЪ§ОнЕФДІРэЁЃ
НгЯТРДЃЌЮвУЧгУвЛИіЪЕР§РДСЫНтItem LoaderЕФгУЗЈЁЃ
Ш§ЁЂБОНкФПБъ
ЮвУЧвджаЛЊЭјПЦММРраТЮХЮЊР§ЃЌРДСЫНтCrawlSpiderКЭItem
LoaderЕФгУЗЈЃЌдйЬсШЁЦфПЩХфжУаХЯЂЪЕЯжПЩХфжУЛЏЁЃЙйЭјСДНгЮЊЃКhttp://tech.china.com/ЁЃЮвУЧашвЊХРШЁЫќЕФПЦММРраТЮХФкШнЃЌСДНгЮЊЃКhttp://tech.china.com/articles/ЃЌвГУцШчЯТЭМЫљЪОЁЃ
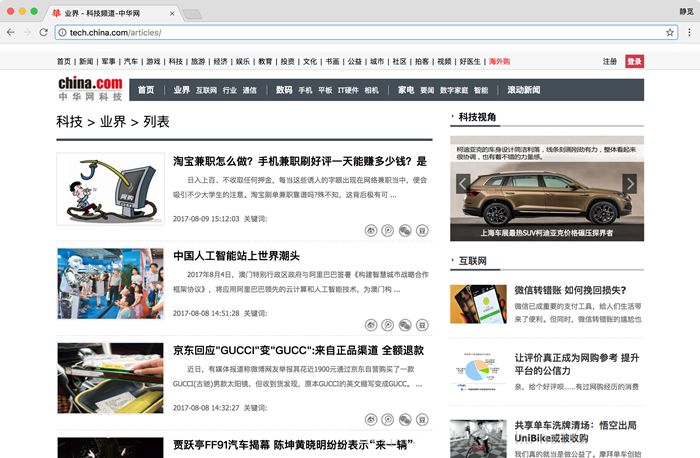
ЮвУЧвЊзЅШЁаТЮХСаБэжаЕФЫљгаЗжвГЕФаТЮХЯъЧщЃЌАќРЈБъЬтЁЂе§ЮФЁЂЪБМфЁЂРДдДЕШаХЯЂЁЃ
ЫФЁЂаТНЈЯюФП
ЪзЯШаТНЈвЛИіScrapyЯюФПЃЌУћЮЊscrapyuniversalЃЌШчЯТЫљЪОЃК
| scrapy startproject
scrapyuniversal |
ДДНЈвЛИіCrawlSpiderЃЌашвЊЯШжЦЖЈвЛИіФЃАхЁЃЮвУЧПЩвдЯШПДПДгаФФаЉПЩгУФЃАхЃЌУќСюШчЯТЫљЪОЃК
дЫааНсЙћШчЯТЫљЪОЃК
| Available templates:
basic crawl csvfeed xmlfeed |
жЎЧАДДНЈSpiderЕФЪБКђЃЌЮвУЧФЌШЯЪЙгУСЫЕквЛИіФЃАхbasicЁЃетДЮвЊДДНЈCrawlSpiderЃЌОЭашвЊЪЙгУЕкЖўИіФЃАхcrawlЃЌДДНЈУќСюШчЯТЫљЪОЃК
| scrapy genspider
-t crawl china tech.china.com |
дЫаажЎКѓБуЛсЩњГЩвЛИіCrawlSpiderЃЌЦфФкШнШчЯТЫљЪОЃК
from scrapy.linkextractors
import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ChinaSpider(CrawlSpider):
name = 'china'
allowed_domains = ['tech.china.com']
start_urls = ['http://tech.china.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item',
follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i |
етДЮЩњГЩЕФSpiderФкШнЖрСЫвЛИіrulesЪєадЕФЖЈвхЁЃRuleЕФЕквЛИіВЮЪ§ЪЧLinkExtractorЃЌОЭЪЧЩЯЮФЫљЫЕЕФLxmlLinkExtractorЃЌжЛЪЧУћГЦВЛЭЌЁЃЭЌЪБЃЌФЌШЯЕФЛиЕїКЏЪ§вВВЛдйЪЧparseЃЌЖјЪЧparse_itemЁЃ
ЮхЁЂЖЈвхRule
вЊЪЕЯжаТЮХЕФХРШЁЃЌЮвУЧашвЊзіЕФОЭЪЧЖЈвхКУRuleЃЌШЛКѓЪЕЯжНтЮіКЏЪ§ЁЃЯТУцЮвУЧОЭРДвЛВНВНЪЕЯжетИіЙ§ГЬЁЃ
ЪзЯШНЋstart_urlsаоИФЮЊЦ№ЪМСДНгЃЌДњТыШчЯТЫљЪОЃК
| start_urls =
['http://tech.china.com/articles/'] |
жЎКѓЃЌSpiderХРШЁstart_urlsРяУцЕФУПвЛИіСДНгЁЃЫљвдетРяЕквЛИіХРШЁЕФвГУцОЭЪЧЮвУЧИеВХЫљЖЈвхЕФСДНгЁЃЕУЕНResponseжЎКѓЃЌSpiderОЭЛсИљОнУПвЛИіRuleРДЬсШЁетИівГУцФкЕФГЌСДНгЃЌШЅЩњГЩНјвЛВНЕФRequestЁЃНгЯТРДЃЌЮвУЧОЭашвЊЖЈвхRuleРДжИЖЈЬсШЁФФаЉСДНгЁЃ
ЕБЧАвГУцШчЯТЭМЫљЪОЁЃ
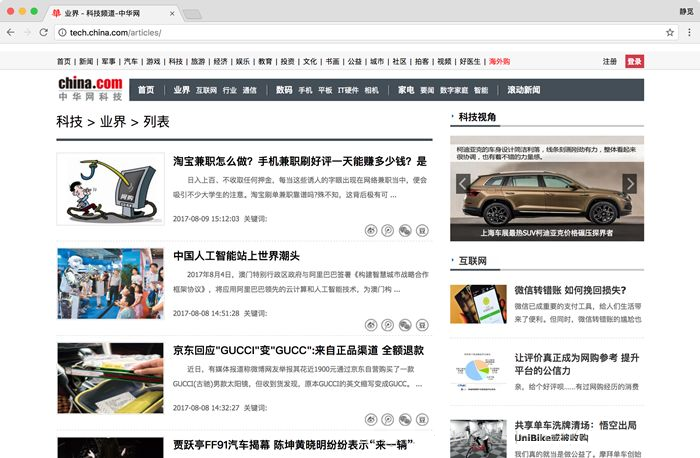
етЪЧаТЮХЕФСаБэвГЃЌЯТвЛВНздШЛОЭЪЧНЋСаБэжаЕФУПЬѕаТЮХЯъЧщЕФСДНгЬсШЁГіРДЁЃетРяжБНгжИЖЈетаЉСДНгЫљдкЧјгђМДПЩЁЃВщПДдДДњТыЃЌЫљгаСДНгЖМдкIDЮЊleft_sideЕФНкЕуФкЃЌОпЬхРДЫЕЪЧЫќФкВПЕФclassЮЊcon_itemЕФНкЕуЃЌШчЯТЭМЫљЪОЁЃ

ДЫДІЮвУЧПЩвдгУLinkExtractorЕФrestrict_xpathsЪєадРДжИЖЈЃЌжЎКѓSpiderОЭЛсДгетИіЧјгђЬсШЁЫљгаЕФГЌСДНгВЂЩњГЩRequestЁЃЕЋЪЧЃЌУПЦЊЮФеТЕФЕМКНжаПЩФмЛЙгавЛаЉЦфЫћЕФГЌСДНгБъЧЉЃЌЮвУЧжЛЯыАбашвЊЕФаТЮХСДНгЬсШЁГіРДЁЃеце§ЕФаТЮХСДНгТЗОЖЖМЪЧвдarticleПЊЭЗЕФЃЌЮвУЧгУвЛИіе§дђБэДяЪННЋЦфЦЅХфГіРДдйИГжЕИјallowВЮЪ§МДПЩЁЃСэЭтЃЌетаЉСДНгЖдгІЕФвГУцЦфЪЕОЭЪЧЖдгІЕФаТЮХЯъЧщвГЃЌЖјЮвУЧашвЊНтЮіЕФОЭЪЧаТЮХЕФЯъЧщаХЯЂЃЌЫљвдДЫДІЛЙашвЊжИЖЈвЛИіЛиЕїКЏЪ§callbackЁЃ
ЕНЯждкЮвУЧОЭПЩвдЙЙдьГівЛИіRuleСЫЃЌДњТыШчЯТЫљЪОЃК
| Rule(LinkExtractor(allow=
'article\/.*\.html', restrict_xpaths=' //div[@id="left_side"]
//div[@class="con_item"]'), callback='parse_item') |
НгЯТРДЃЌЮвУЧЛЙвЊШУЕБЧАвГУцЪЕЯжЗжвГЙІФмЃЌЫљвдЛЙашвЊЬсШЁЯТвЛвГЕФСДНгЁЃЗжЮіЭјвГдДТыжЎКѓПЩвдЗЂЯжЯТвЛвГСДНгЪЧдкIDЮЊpageStyleЕФНкЕуФкЃЌШчЯТЭМЫљЪОЁЃ
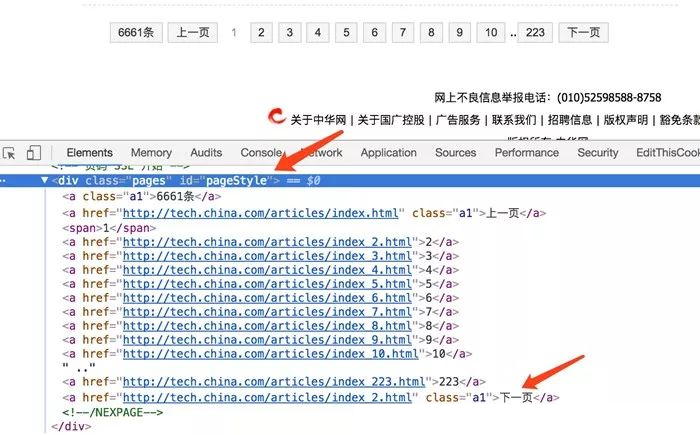
ЕЋЪЧЃЌЯТвЛвГНкЕуКЭЦфЫћЗжвГСДНгЧјЗжЖШВЛИпЃЌвЊШЁГіДЫСДНгЮвУЧПЩвджБНггУXPathЕФЮФБОЦЅХфЗНЪНЃЌЫљвдетРяЮвУЧжБНггУLinkExtractorЕФrestrict_xpathsЪєадРДжИЖЈЬсШЁЕФСДНгМДПЩЁЃСэЭтЃЌЮвУЧВЛашвЊЯёаТЮХЯъЧщвГвЛбљШЅЬсШЁДЫЗжвГСДНгЖдгІЕФвГУцЯъЧщаХЯЂЃЌвВОЭЪЧВЛашвЊЩњГЩItemЃЌЫљвдВЛашвЊМгcallbackВЮЪ§ЁЃСэЭтетЯТвЛвГЕФвГУцШчЙћЧыЧѓГЩЙІСЫОЭашвЊМЬајЯёЩЯЪіЧщПівЛбљЗжЮіЃЌЫљвдЫќЛЙашвЊМгвЛИіfollowВЮЪ§ЮЊTrueЃЌДњБэМЬајИњНјЦЅХфЗжЮіЁЃЦфЪЕЃЌfollowВЮЪ§вВПЩвдВЛМгЃЌвђЮЊЕБcallbackЮЊПеЕФЪБКђЃЌfollowФЌШЯЮЊTrueЁЃДЫДІRuleЖЈвхЮЊШчЯТЫљЪОЃК
| Rule(LinkExtractor(restrict_xpaths=
'//div[@id="pageStyle"]//a[contains(.,
"ЯТвЛвГ")]')) |
ЫљвдЯждкrulesОЭБфГЩСЫЃК
rules = (
Rule(LinkExtractor(allow='article\/.*\.html',
restrict_xpaths='//div[@id="left_side"]
//div[@class="con_item"]'), callback='parse_item'),
Rule(LinkExtractor(restrict_xpaths=' //div[@id="pageStyle"]//a[contains(.,
"ЯТвЛвГ")]'))
) |
НгзХЮвУЧдЫааДњТыЃЌУќСюШчЯТЫљЪОЃК
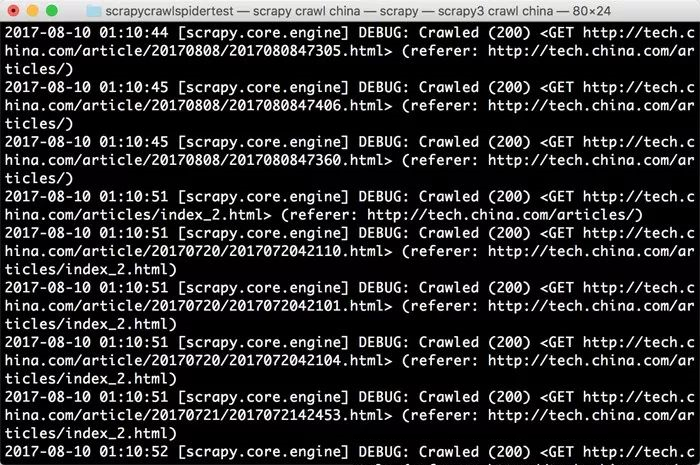
ЯждквбОЪЕЯжвГУцЕФЗвГКЭЯъЧщвГЕФзЅШЁСЫЃЌЮвУЧНіНіЭЈЙ§ЖЈвхСЫСНИіRuleМДЪЕЯжСЫетбљЕФЙІФмЃЌдЫаааЇЙћШчЯТЭМЫљЪОЁЃ
СљЁЂНтЮівГУц
НгЯТРДЮвУЧашвЊзіЕФОЭЪЧНтЮівГУцФкШнСЫЃЌНЋБъЬтЁЂЗЂВМЪБМфЁЂе§ЮФЁЂРДдДЬсШЁГіРДМДПЩЁЃЪзЯШЖЈвхвЛИіItemЃЌШчЯТЫљЪОЃК
from scrapy
import Field, Item
class NewsItem(Item):
title = Field()
url = Field()
text = Field()
datetime = Field()
source = Field()
website = Field() |
етРяЕФзжЖЮЗжБ№жИаТЮХБъЬтЁЂСДНгЁЂе§ЮФЁЂЗЂВМЪБМфЁЂРДдДЁЂеОЕуУћГЦЃЌЦфжаеОЕуУћГЦжБНгИГжЕЮЊжаЛЊЭјЁЃвђЮЊМШШЛЪЧЭЈгУХРГцЃЌПЯЖЈЛЙгаКмЖрХРГцвВРДХРШЁЭЌбљНсЙЙЕФЦфЫћеОЕуЕФаТЮХФкШнЃЌЫљвдашвЊвЛИізжЖЮРДЧјЗжвЛЯТеОЕуУћГЦЁЃ
ЯъЧщвГЕФдЄРРЭМШчЯТЭМЫљЪОЁЃ
ШчЙћЯёжЎЧАвЛбљЬсШЁФкШнЃЌОЭжБНгЕїгУresponseБфСПЕФxpath()ЁЂcss()ЕШЗНЗЈМДПЩЁЃетРяparse_item()ЗНЗЈЕФЪЕЯжШчЯТЫљЪОЃК
def parse_item(self,
response):
item = NewsItem()
item['title'] = response.xpath ('//h1[@id="chan_newsTitle"
]/text()').extract_first()
item['url'] = response.url
item['text'] = ''.join(response.xpath(' //div
[@id="chan_newsDetail"] //text()').extract()).strip()
item['datetime'] = response.xpath ( //div[@id="chan_newsInfo"]/text()').
re_first('(\d+-\d+-\d+\s\d+:\d+:\d+)')
item['source'] = response.xpath ('//div[@id="chan_newsInfo"]/text()').
re_first('РДдДЃК(.*)').strip()
item['website'] = 'жаЛЊЭј'
yield item |
етбљЮвУЧОЭАбУПЬѕаТЮХЕФаХЯЂЬсШЁаЮГЩСЫвЛИіNewsItemЖдЯѓЁЃ
етЪБЪЕМЪЩЯЮвУЧОЭвбОЭъГЩСЫItemЕФЬсШЁЁЃдйдЫаавЛЯТSpiderЃЌШчЯТЫљЪОЃК
ЪфГіФкШнШчЯТЭМЫљЪОЁЃ

ЯждкЮвУЧОЭПЩвдГЩЙІНЋУПЬѕаТЮХЕФаХЯЂЬсШЁГіРДЁЃ
ВЛЙ§ЮвУЧЗЂЯжетжжЬсШЁЗНЪНЗЧГЃВЛЙцећЁЃЯТУцЮвУЧдйгУItem LoaderЃЌЭЈЙ§add_xpath()ЁЂadd_css()ЁЂadd_value()ЕШЗНЪНЪЕЯжХфжУЛЏЬсШЁЁЃЮвУЧПЩвдИФаДparse_item()ЃЌШчЯТЫљЪОЃК
def parse_item(self,
response):
loader = ChinaLoader(item=NewsItem(), response=response)
loader.add_xpath('title', '//h1[@id="chan_newsTitle"]/text()')
loader.add_value('url', response.url)
loader.add_xpath('text', '//div[@id="chan_newsDetail"]//text()')
loader.add_xpath('datetime', '//div[@id="chan_newsInfo"]/text()',
re='(\d+-\d+-\d+\s\d+:\d+:\d+)')
loader.add_xpath('source', '//div[@id="chan_newsInfo"]/text()',
re='РДдДЃК(.*)')
loader.add_value('website', 'жаЛЊЭј')
yield loader.load_item() |
етРяЮвУЧЖЈвхСЫвЛИіItemLoaderЕФзгРрЃЌУћЮЊChinaLoaderЃЌЦфЪЕЯжШчЯТЫљЪОЃК
from scrapy.loader
import ItemLoader
from scrapy.loader.processors import TakeFirst,
Join, Compose
class NewsLoader(ItemLoader):
default_output_processor = TakeFirst()
class ChinaLoader(NewsLoader):
text_out = Compose(Join(), lambda s: s.strip())
source_out = Compose(Join(), lambda s: s.strip()) |
ChinaLoaderМЬГаСЫNewsLoaderРрЃЌЦфФкЖЈвхСЫвЛИіЭЈгУЕФOut
ProcessorЮЊTakeFirstЃЌетЯрЕБгкжЎЧАЫљЖЈвхЕФextract_first()ЗНЗЈЕФЙІФмЁЃЮвУЧдкChinaLoaderжаЖЈвхСЫtext_outКЭsource_outзжЖЮЁЃетРяЪЙгУСЫвЛИіCompose
ProcessorЃЌЫќгаСНИіВЮЪ§ЃКЕквЛИіВЮЪ§JoinвВЪЧвЛИіProcessorЃЌЫќПЩвдАбСаБэЦДКЯГЩвЛИізжЗћДЎЃЛЕкЖўИіВЮЪ§ЪЧвЛИіФфУћКЏЪ§ЃЌПЩвдНЋзжЗћДЎЕФЭЗЮВПеАззжЗћШЅЕєЁЃОЙ§етвЛЯЕСаДІРэжЎКѓЃЌЮвУЧОЭНЋСаБэаЮЪНЕФЬсШЁНсЙћзЊЛЏЮЊШЅжиЭЗЮВПеАззжЗћЕФзжЗћДЎЁЃ
ДњТыжиаТдЫааЃЌЬсШЁаЇЙћЪЧЭъШЋвЛбљЕФЁЃ
жСДЫЃЌЮвУЧвбОЪЕЯжСЫХРГцЕФАыЭЈгУЛЏХфжУЁЃ
ЦпЁЂЭЈгУХфжУГщШЁ
ЮЊЪВУДЯждкжЛзіЕНСЫАыЭЈгУЛЏЃПШчЙћЮвУЧашвЊРЉеЙЦфЫћеОЕуЃЌШдШЛашвЊДДНЈвЛИіаТЕФCrawlSpiderЃЌЖЈвхетИіеОЕуЕФRuleЃЌЕЅЖРЪЕЯжparse_item()ЗНЗЈЁЃЛЙгаКмЖрДњТыЪЧжиИДЕФЃЌШчCrawlSpiderЕФБфСПЁЂЗНЗЈУћМИКѕЖМЪЧвЛбљЕФЁЃФЧУДЮвУЧПЩВЛПЩвдАбЖрИіРрЫЦЕФМИИіХРГцЕФДњТыЙВгУЃЌАбЭъШЋВЛЯрЭЌЕФЕиЗНГщРыГіРДЃЌзіГЩПЩХфжУЮФМўФиЃП
ЕБШЛПЩвдЁЃФЧЮвУЧПЩвдГщРыГіФФаЉВПЗжЃПЫљгаЕФБфСПЖМПЩвдГщШЁЃЌШчnameЁЂallowed_domainsЁЂstart_urlsЁЂrulesЕШЁЃетаЉБфСПдкCrawlSpiderГѕЪМЛЏЕФЪБКђИГжЕМДПЩЁЃЮвУЧОЭПЩвдаТНЈвЛИіЭЈгУЕФSpiderРДЪЕЯжетИіЙІФмЃЌУќСюШчЯТЫљЪОЃК
| scrapy genspider
-t crawl universal universal |
етИіШЋаТЕФSpiderУћЮЊuniversalЁЃНгЯТРДЃЌЮвУЧНЋИеВХЫљаДЕФSpiderФкЕФЪєадГщРыГіРДХфжУГЩвЛИіJSONЃЌУќУћЮЊchina.jsonЃЌЗХЕНconfigsЮФМўМаФкЃЌКЭspidersЮФМўМаВЂСаЃЌДњТыШчЯТЫљЪОЃК
{
"spider":
"universal",
"website":
"жаЛЊЭјПЦММ",
"type": "аТЮХ",
"index": "http://tech.china.com/",
"settings": {
"USER_AGENT":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90
Safari/537.36"
},
"start_urls": [
"http://tech.china.com/articles/"
],
"allowed_domains": [
"tech.china.com"
],
"rules": "china"
} |
ЕквЛИізжЖЮspiderМДSpiderЕФУћГЦЃЌдкетРяЪЧuniversalЁЃКѓУцЪЧеОЕуЕФУшЪіЃЌБШШчеОЕуУћГЦЁЂРраЭЁЂЪзвГЕШЁЃЫцКѓЕФsettingsЪЧИУSpiderЬигаЕФsettingsХфжУЃЌШчЙћвЊИВИЧШЋОжЯюФПЃЌsettings.pyФкЕФХфжУПЩвдЕЅЖРЮЊЦфХфжУЁЃЫцКѓЪЧSpiderЕФвЛаЉЪєадЃЌШчstart_urlsЁЂallowed_domainsЁЂrulesЕШЁЃrulesвВПЩвдЕЅЖРЖЈвхГЩвЛИіrules.pyЮФМўЃЌзіГЩХфжУЮФМўЃЌЪЕЯжRuleЕФЗжРыЃЌШчЯТЫљЪОЃК
from scrapy.linkextractors
import LinkExtractor
from scrapy.spiders import Rule
rules = {
'china': (
Rule(LinkExtractor(allow= 'article\/.*\.html',
restrict_xpaths=' //div[@id="left_side"]//div[@class="con_item"]'),
callback='parse_item'),
Rule(LinkExtractor (restrict_xpaths=' //div[@id="pageStyle"]//a[contains(.,
"ЯТвЛвГ")]'))
)
} |
етбљЮвУЧНЋЛљБОЕФХфжУГщШЁГіРДЁЃШчЙћвЊЦєЖЏХРГцЃЌжЛашвЊДгИУХфжУЮФМўжаЖСШЁШЛКѓЖЏЬЌМгдиЕНSpiderжаМДПЩЁЃЫљвдЮвУЧашвЊЖЈвхвЛИіЖСШЁИУJSONЮФМўЕФЗНЗЈЃЌШчЯТЫљЪОЃК
from os.path
import realpath, dirname
import json
def get_config(name):
path = dirname(realpath(__file__)) + '/configs/'
+ name + '.json'
with open(path, 'r', encoding='utf-8') as f:
return json.loads(f.read()) |
ЖЈвхСЫget_config()ЗНЗЈжЎКѓЃЌЮвУЧжЛашвЊЯђЦфДЋШыJSONХфжУЮФМўЕФУћГЦМДПЩЛёШЁДЫJSONХфжУаХЯЂЁЃЫцКѓЮвУЧЖЈвхШыПкЮФМўrun.pyЃЌАбЫќЗХдкЯюФПИљФПТМЯТЃЌЫќЕФзїгУЪЧЦєЖЏSpiderЃЌШчЯТЫљЪОЃК
import sys
from scrapy.utils.project import get_project_settings
from scrapyuniversal.spiders.universal import
UniversalSpider
from scrapyuniversal.utils import get_config
from scrapy.crawler import CrawlerProcess
def run():
name = sys.argv[1]
custom_settings = get_config(name)
# ХРШЁЪЙгУЕФSpiderУћГЦ
spider = custom_settings.get('spider', 'universal')
project_settings = get_project_settings()
settings = dict(project_settings.copy())
# КЯВЂХфжУ
settings.update(custom_settings.get('settings'))
process = CrawlerProcess(settings)
# ЦєЖЏХРГц
process.crawl(spider, **{'name': name})
process.start()
if __name__ == '__main__':
run() |
дЫааШыПкЮЊrun()ЁЃЪзЯШЛёШЁУќСюааЕФВЮЪ§ВЂИГжЕЮЊnameЃЌnameОЭЪЧJSONЮФМўЕФУћГЦЃЌЦфЪЕОЭЪЧвЊХРШЁЕФФПБъЭјеОЕФУћГЦЁЃЮвУЧЪзЯШРћгУget_config()ЗНЗЈЃЌДЋШыИУУћГЦЖСШЁИеВХЖЈвхЕФХфжУЮФМўЁЃЛёШЁХРШЁЪЙгУЕФspiderЕФУћГЦЁЂХфжУЮФМўжаЕФsettingsХфжУЃЌШЛКѓНЋЛёШЁЕНЕФsettingsХфжУКЭЯюФПШЋОжЕФsettingsХфжУзіСЫКЯВЂЁЃаТНЈвЛИіCrawlerProcessЃЌДЋШыХРШЁЪЙгУЕФХфжУЁЃЕїгУcrawl()КЭstart()ЗНЗЈМДПЩЦєЖЏХРШЁЁЃ
дкuniversalжаЃЌЮвУЧаТНЈвЛИі__init__()ЗНЗЈЃЌНјааГѕЪМЛЏХфжУЃЌЪЕЯжШчЯТЫљЪОЃК
from scrapy.linkextractors
import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapyuniversal.utils import get_config
from scrapyuniversal.rules import rules
class UniversalSpider(CrawlSpider):
name = 'universal'
def __init__(self, name, *args, **kwargs):
config = get_config(name)
self.config = config
self.rules = rules.get(config.get('rules'))
self.start_urls = config.get('start_urls')
self.allowed_domains = config.get('allowed_domains')
super(UniversalSpider, self).__init__(*args, **kwargs)
def parse_item(self, response):
i = {}
return i |
дк__init__()ЗНЗЈжаЃЌstart_urlsЁЂallowed_domainsЁЂrulesЕШЪєадБЛИГжЕЁЃЦфжаЃЌrulesЪєадСэЭтЖСШЁСЫrules.pyЕФХфжУЃЌетбљОЭГЩЙІЪЕЯжХРГцЕФЛљДЁХфжУЁЃ
НгЯТРДЃЌжДааШчЯТУќСюдЫааХРГцЃК
ГЬађЛсЪзЯШЖСШЁJSONХфжУЮФМўЃЌНЋХфжУжаЕФвЛаЉЪєадИГжЕИјSpiderЃЌШЛКѓЦєЖЏХРШЁЁЃдЫаааЇЙћЭъШЋЯрЭЌЃЌдЫааНсЙћШчЯТЭМЫљЪОЁЃ

ЯждкЮвУЧвбОЖдSpiderЕФЛљДЁЪєадЪЕЯжСЫПЩХфжУЛЏЁЃЪЃЯТЕФНтЮіВПЗжЭЌбљашвЊЪЕЯжПЩХфжУЛЏЃЌдРДЕФНтЮіКЏЪ§ШчЯТЫљЪОЃК
def parse_item(self,
response):
loader = ChinaLoader(item=NewsItem(), response=response)
loader.add_xpath('title', '//h1[@id="chan_newsTitle"]/text()')
loader.add_value('url', response.url)
loader.add_xpath('text', '//div[@id="chan_newsDetail"]//text()')
loader.add_xpath('datetime', '//div[@id="chan_newsInfo"]/text()',
re='(\d+-\d+-\d+\s\d+:\d+:\d+)')
loader.add_xpath('source', '//div[@id="chan_newsInfo"]/text()',
re='РДдДЃК(.*)')
loader.add_value('website', 'жаЛЊЭј')
yield loader.load_item() |
ЮвУЧашвЊНЋетаЉХфжУвВГщРыГіРДЁЃетРяЕФБфСПжївЊгаItem LoaderРрЕФбЁгУЁЂItemРрЕФбЁгУЁЂItem
LoaderЗНЗЈВЮЪ§ЕФЖЈвхЃЌЮвУЧПЩвддкJSONЮФМўжаЬэМгШчЯТitemЕФХфжУЃК
| "item":
{ "class": "NewsItem", "loader":
"ChinaLoader", "attrs": {
"title": [ { "method": "xpath",
"args": [ "//h1[@id='chan_newsTitle']/text()"
] } ], "url": [ { "method":
"attr", "args": [ "url"
] } ], "text": [ { "method":
"xpath", "args": [ "//div[@id='chan_newsDetail']//text()"
] } ], "datetime": [ { "method":
"xpath", "args": [ "//div[@id='chan_newsInfo']/text()"
], "re": "(\\d+-\\d+-\\d+\\s\\d+:\\d+:\\d+)"
} ], "source": [ { "method":
"xpath", "args": [ "//div[@id='chan_newsInfo']/text()"
], "re": "РДдДЃК(.*)" } ], "website":
[ { "method": "value", "args":
[ "жаЛЊЭј" ] } ] }} |
етРяЖЈвхСЫclassКЭloaderЪєадЃЌЫќУЧЗжБ№ДњБэItemКЭItem
LoaderЫљЪЙгУЕФРрЁЃЖЈвхСЫattrsЪєадРДЖЈвхУПИізжЖЮЕФЬсШЁЙцдђЃЌР§ШчЃЌtitleЖЈвхЕФУПвЛЯюЖМАќКЌвЛИіmethodЪєадЃЌЫќДњБэЪЙгУЕФЬсШЁЗНЗЈЃЌШчxpathМДДњБэЕїгУItem
LoaderЕФadd_xpath()ЗНЗЈЁЃargsМДВЮЪ§ЃЌОЭЪЧadd_xpath()ЕФЕкЖўИіВЮЪ§ЃЌМДXPathБэДяЪНЁЃеыЖдdatetimeзжЖЮЃЌЮвУЧЛЙгУСЫвЛДЮе§дђЬсШЁЃЌЫљвдетРяЛЙПЩвдЖЈвхвЛИіreВЮЪ§РДДЋЕнЬсШЁЪБЫљЪЙгУЕФе§дђБэДяЪНЁЃ
ЮвУЧЛЙвЊНЋетаЉХфжУжЎКѓЖЏЬЌМгдиЕНparse_item()ЗНЗЈРяЁЃзюКѓЃЌзюживЊЕФОЭЪЧЪЕЯжparse_item()ЗНЗЈЃЌШчЯТЫљЪОЃК
def parse_item(self,
response):
item = self.config.get('item')
if item:
cls = eval(item.get('class'))()
loader = eval(item.get('loader'))(cls, response=response)
# ЖЏЬЌЛёШЁЪєадХфжУ
for key, value in item.get('attrs').items():
for extractor in value:
if extractor.get('method') == 'xpath':
loader.add_xpath(key, *extractor.get('args'),
**{'re': extractor.get('re')})
if extractor.get('method') == 'css':
loader.add_css(key, *extractor.get('args'), **{'re':
extractor.get('re')})
if extractor.get('method') == 'value':
loader.add_value(key, *extractor.get('args'),
**{'re': extractor.get('re')})
if extractor.get('method') == 'attr':
loader.add_value(key, getattr(response, *extractor.get('args')))
yield loader.load_item() |
етРяЪзЯШЛёШЁItemЕФХфжУаХЯЂЃЌШЛКѓЛёШЁclassЕФХфжУЃЌНЋЦфГѕЪМЛЏЃЌГѕЪМЛЏItem
LoaderЃЌБщРњItemЕФИїИіЪєадвРДЮНјааЬсШЁЁЃХаЖЯmethodзжЖЮЃЌЕїгУЖдгІЕФДІРэЗНЗЈНјааДІРэЁЃШчmethodЮЊcssЃЌОЭЕїгУItem
LoaderЕФadd_css()ЗНЗЈНјааЬсШЁЁЃЫљгаХфжУЖЏЬЌМгдиЭъБЯжЎКѓЃЌЕїгУload_item()ЗНЗЈНЋItemЬсШЁГіРДЁЃ
жиаТдЫааГЬађЃЌНсЙћШчЯТЭМЫљЪОЁЃ

дЫааНсЙћЪЧЭъШЋЯрЭЌЕФЁЃ
ЮвУЧдйЛиЙ§ЭЗПДвЛЯТstart_urlsЕФХфжУЁЃетРяstart_urlsжЛПЩвдХфжУОпЬхЕФСДНгЁЃШчЙћетаЉСДНгга100ИіЁЂ1000ИіЃЌЮвУЧзмВЛФмНЋЫљгаЕФСДНгШЋВПСаГіРДАЩЃПдкФГаЉЧщПіЯТЃЌstart_urlsвВашвЊЖЏЬЌХфжУЁЃЮвУЧНЋstart_urlsЗжГЩСНжжЃЌвЛжжЪЧжБНгХфжУURLСаБэЃЌвЛжжЪЧЕїгУЗНЗЈЩњГЩЃЌЫќУЧЗжБ№ЖЈвхЮЊstaticКЭdynamicРраЭЁЃ
БОР§жаЕФstart_urlsКмУїЯдЪЧstaticРраЭЕФЃЌЫљвдstart_urlsХфжУИФаДШчЯТЫљЪОЃК
| "start_urls":
{ "type": "static", "value":
[ "http://tech.china.com/articles/"
]} |
ШчЙћstart_urlsЪЧЖЏЬЌЩњГЩЕФЃЌЮвУЧПЩвдЕїгУЗНЗЈДЋВЮЪ§ЃЌШчЯТЫљЪОЃК
| "start_urls":
{ "type": "dynamic", "method":
"china", "args": [ 5, 10 ]} |
етРяstart_urlsЖЈвхЮЊdynamicРраЭЃЌжИЖЈЗНЗЈЮЊurls_china()ЃЌШЛКѓДЋШыВЮЪ§5КЭ10ЃЌРДЩњГЩЕк5ЕН10вГЕФСДНгЁЃетбљЮвУЧжЛашвЊЪЕЯжИУЗНЗЈМДПЩЃЌЭГвЛаТНЈвЛИіurls.pyЮФМўЃЌШчЯТЫљЪОЃК
def china(start,
end):
for page in range(start, end + 1):
yield 'http://tech.china.com/articles/index_'
+ str(page) + '.html' |
ЦфЫћеОЕуПЩвдздааХфжУЁЃШчФГаЉСДНгашвЊгУЕНЪБМфДСЃЌМгУмВЮЪ§ЕШЃЌОљПЩЭЈЙ§здЖЈвхЗНЗЈЪЕЯжЁЃ
НгЯТРДдкSpiderЕФ__init__()ЗНЗЈжаЃЌstart_urlsЕФХфжУИФаДШчЯТЫљЪОЃК
from scrapyuniversal
import urls
start_urls = config.get('start_urls')
if start_urls:
if start_urls.get('type') == 'static':
self.start_urls = start_urls.get('value')
elif start_urls.get('type') == 'dynamic':
self.start_urls = list(eval('urls.' + start_urls.get('method'))(*start_urls.get('args',
[]))) |
етРяЭЈЙ§ХаЖЈstart_urlsЕФРраЭЗжБ№НјааВЛЭЌЕФДІРэЃЌетбљЮвУЧОЭПЩвдЪЕЯжstart_urlsЕФХфжУСЫЁЃ
жСДЫЃЌSpiderЕФЩшжУЁЂЦ№ЪМСДНгЁЂЪєадЁЂЬсШЁЗНЗЈЖМвбОЪЕЯжСЫШЋВПЕФПЩХфжУЛЏЁЃ
злЩЯЫљЪіЃЌећИіЯюФПЕФХфжУАќРЈШчЯТФкШнЁЃ
spiderЃКжИЖЈЫљЪЙгУЕФSpiderЕФУћГЦЁЃ
settingsЃКПЩвдзЈУХЮЊSpiderЖЈжЦХфжУаХЯЂЃЌЛсИВИЧЯюФПМЖБ№ЕФХфжУЁЃ
start_urlsЃКжИЖЈХРГцХРШЁЕФЦ№ЪМСДНгЁЃ
allowed_domainsЃКдЪаэХРШЁЕФеОЕуЁЃ
rulesЃКеОЕуЕФХРШЁЙцдђЁЃ
itemЃКЪ§ОнЕФЬсШЁЙцдђЁЃ
ЮвУЧЪЕЯжСЫScrapyЕФЭЈгУХРГцЃЌУПИіеОЕужЛашвЊаоИФJSONЮФМўМДПЩЪЕЯжздгЩХфжУЁЃ
АЫЁЂБОНкДњТы
БОНкДњТыЕижЗЮЊЃКhttps://github.com/Python3WebSpider/ScrapyUniversalЁЃ
ОХЁЂНсгя
БОНкНщЩмСЫScrapyЭЈгУХРГцЕФЪЕЯжЁЃЮвУЧНЋЫљгаХфжУГщРыГіРДЃЌУПдіМгвЛИіХРГцЃЌОЭжЛашвЊдіМгвЛИіJSONЮФМўХфжУЁЃжЎКѓЮвУЧжЛашвЊЮЌЛЄетаЉХфжУЮФМўМДПЩЁЃШчЙћвЊИќМгЗНБуЕФЙмРэЃЌПЩвдНЋЙцдђДцШыЪ§ОнПтЃЌдйЖдНгПЩЪгЛЏЙмРэвГУцМДПЩЁЃ
|









