| БрМЭЦМі: |
| БОЮФРДдДpythonЩчЧјЃЌБОЮФЬжТлЕФБГОАЪЧLinuxЛЗОГЯТЕФnetwork
IO,вдМА,ЪТМўЧ§ЖЏаЭГЬађФЃаЭЕФСїГЬЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
вЛЁЂЪТМўЧ§ЖЏФЃаЭНщЩм
1ЁЂДЋЭГЕФБрГЬФЃЪН
Р§ШчЃКЯпадФЃЪНДѓжТСїГЬ
ПЊЪМ--->ДњТыПщA--->ДњТыПщB--->ДњТыПщC--->ДњТыПщD--->......--->НсЪј
УПвЛИіДњТыПщРяЪЧЭъГЩИїжжИїбљЪТЧщЕФДњТыЃЌЕЋБрГЬепжЊЕРДњТыПщA,B,C,D...ЕФжДааЫГађЃЌЮЈвЛФмЙЛИФБфетИіСїГЬЕФЪЧЪ§ОнЁЃЪфШыВЛЭЌЕФЪ§ОнЃЌИљОнЬѕМўгяОфХаЖЯЃЌСїГЬЛђаэОЭИФЮЊA--->C--->E...--->НсЪјЁЃУПвЛДЮГЬађдЫааЫГађЛђаэЖМВЛЭЌЃЌЕЋЫќЕФПижЦСїГЬЪЧгЩЪфШыЪ§ОнКЭФуБраДЕФГЬађОіЖЈЕФЁЃШчЙћФужЊЕРетИіГЬађЕБЧАЕФдЫаазДЬЌЃЈАќРЈЪфШыЪ§ОнКЭГЬађБОЩэЃЉЃЌФЧФуОЭжЊЕРНгЯТРДЩѕжСвЛжБЕННсЪјЫќЕФдЫааСїГЬЁЃ
Р§ШчЃКЪТМўЧ§ЖЏаЭГЬађФЃаЭДѓжТСїГЬ
ПЊЪМ--->ГѕЪМЛЏ--->ЕШД§
гыЩЯУцДЋЭГБрГЬФЃЪНВЛЭЌЃЌЪТМўЧ§ЖЏГЬађдкЦєЖЏжЎКѓЃЌОЭдкФЧЕШД§ЃЌЕШД§ЪВУДФиЃПЕШД§БЛЪТМўДЅЗЂЁЃДЋЭГБрГЬЯТвВгаЁАЕШД§ЁБЕФЪБКђЃЌБШШчдкДњТыПщDжаЃЌФуЖЈвхСЫвЛИіinput()ЃЌашвЊгУЛЇЪфШыЪ§ОнЁЃЕЋетгыЯТУцЕФЕШД§ВЛЭЌЃЌДЋЭГБрГЬЕФЁАЕШД§ЁБЃЌБШШчinput()ЃЌФузїЮЊГЬађБраДепЪЧжЊЕРЛђепЧПжЦгУЛЇЪфШыФГИіЖЋЮїЕФЃЌЛђаэЪЧЪ§зжЃЌЛђаэЪЧЮФМўУћГЦЃЌШчЙћгУЛЇЪфШыДэЮѓЃЌФуЛЙашвЊЬсабЫћЃЌВЂЧыЫћжиаТЪфШыЁЃЪТМўЧ§ЖЏГЬађЕФЕШД§дђЪЧЭъШЋВЛжЊЕРЃЌвВВЛЧПжЦгУЛЇЪфШыЛђепИЩЪВУДЁЃжЛвЊФГвЛЪТМўЗЂЩњЃЌФЧГЬађОЭЛсзіГіЯргІЕФЁАЗДгІЁБЁЃетаЉЪТМўАќРЈЃКЪфШыаХЯЂЁЂЪѓБъЁЂЧУЛїМќХЬЩЯФГИіМќЛЙгаЯЕЭГФкВПЖЈЪБЦїДЅЗЂЁЃ
2ЁЂЪТМўЧ§ЖЏФЃаЭ
ЭЈГЃЃЌЮвУЧаДЗўЮёЦїДІРэФЃаЭЕФГЬађЪБЃЌгавдЯТМИжжФЃаЭЃК
ЃЈ1ЃЉУПЪеЕНвЛИіЧыЧѓЃЌДДНЈвЛИіаТЕФНјГЬЃЌРДДІРэИУЧыЧѓЃЛ
ЃЈ2ЃЉУПЪеЕНвЛИіЧыЧѓЃЌДДНЈвЛИіаТЕФЯпГЬЃЌРДДІРэИУЧыЧѓЃЛ
ЃЈ3ЃЉУПЪеЕНвЛИіЧыЧѓЃЌЗХШывЛИіЪТМўСаБэЃЌШУжїНјГЬЭЈЙ§ЗЧзшШћI/OЗНЪНРДДІРэЧыЧѓ
3ЁЂЕкШ§жжОЭЪЧаГЬЁЂЪТМўЧ§ЖЏЕФЗНЪНЃЌвЛАуЦеБщШЯЮЊЕкЃЈ3ЃЉжжЗНЪНЪЧДѓЖрЪ§ЭјТчЗўЮёЦїВЩгУЕФЗНЪН
ЪОР§ЃК
| 1
#ЪТМўЧ§ЖЏжЎЪѓБъЕуЛїЪТМўзЂВс
2
3 <!DOCTYPE html>
4 <html lang="en">
5 <head>
6 <meta charset="UTF-8">
7 <title>Title</title>
8
9 </head>
10 <body>
11
12 <p onclick="fun()">ЕуЮвбН</p>
13
14
15 <script type="text/javascript">
16 function fun() {
17 alert('дМТ№?')
18 }
19 </script>
20 </body>
21
22 </html> |
жДааНсЙћЃК
дкUIБрГЬжаЃЌГЃГЃвЊЖдЪѓБъЕуЛїНјааЯргІЃЌЪзЯШШчКЮЛёЕУЪѓБъЕуЛїФиЃП
СНжжЗНЪНЃК
1ЁЂДДНЈвЛИіЯпГЬбЛЗМьВтЪЧЗёгаЪѓБъЕуЛї
ФЧУДетИіЗНЪНгавдЯТМИИіШБЕуЃК
CPUзЪдДРЫЗбЃЌПЩФмЪѓБъЕуЛїЕФЦЕТЪЗЧГЃаЁЃЌЕЋЪЧЩЈУшЯпГЬЛЙЪЧЛсвЛжБбЛЗМьВтЃЌетЛсдьГЩКмЖрЕФCPUзЪдДРЫЗбЃЛШчЙћЩЈУшЪѓБъЕуЛїЕФНгПкЪЧзшШћЕФФиЃП
ШчЙћЪЧЖТШћЕФЃЌгжЛсГіЯжЯТУцетбљЕФЮЪЬтЃЌШчЙћЮвУЧВЛЕЋвЊЩЈУшЪѓБъЕуЛїЃЌЛЙвЊЩЈУшМќХЬЪЧЗёАДЯТЃЌгЩгкЩЈУшЪѓБъЪББЛЖТШћСЫЃЌФЧУДПЩФмгРдЖВЛЛсШЅЩЈУшМќХЬЃЛ
ШчЙћвЛИібЛЗашвЊЩЈУшЕФЩшБИЗЧГЃЖрЃЌетгжЛсв§РДЯьгІЪБМфЕФЮЪЬтЃЛ
ЫљвдЃЌИУЗНЪНЪЧЗЧГЃВЛКУЕФЁЃ
2ЁЂЪТМўЧ§ЖЏФЃаЭ
ФПЧАДѓВПЗжЕФUIБрГЬЖМЪЧЪТМўЧ§ЖЏФЃаЭЃЌШчКмЖрUIЦНЬЈЖМЛсЬсЙЉonClick()ЪТМўЃЌетИіЪТМўОЭДњБэЪѓБъАДЯТЪТМўЁЃЪТМўЧ§ЖЏФЃаЭДѓЬхЫМТЗШчЯТЃК
1.гавЛИіЪТМўЃЈЯћЯЂЃЉЖгСаЃЛ
2.ЪѓБъАДЯТЪБЃЌЭљетИіЖгСажадіМгвЛИіЕуЛїЪТМўЃЈЯћЯЂЃЉЃЛ
3.гаИібЛЗЃЌВЛЖЯДгЖгСаШЁГіЪТМўЃЌИљОнВЛЭЌЕФЪТМўЃЌЕїгУВЛЭЌЕФКЏЪ§ЃЌШчonClick()ЁЂonKeyDown()ЕШЃЛ
4.ЪТМўЃЈЯћЯЂЃЉвЛАуЖМИїздБЃДцИїздЕФДІРэКЏЪ§жИеыЃЌетбљЃЌУПИіЯћЯЂЖМгаЖРСЂЕФДІРэКЏЪ§ЃЛ
ЪВУДЪЧЪТМўЧ§ЖЏФЃаЭ ЃП
ФПЧАДѓВПЗжЕФUIБрГЬЖМЪЧЪТМўЧ§ЖЏФЃаЭЃЌШчКмЖрUIЦНЬЈЖМЛсЬсЙЉonClick()ЪТМўЃЌетИіЪТМўОЭДњБэЪѓБъАДЯТЪТМўЁЃЪТМўЧ§ЖЏФЃаЭДѓЬхЫМТЗШчЯТЃК
1.гавЛИіЪТМўЃЈЯћЯЂЃЉЖгСаЃЛ
2.ЪѓБъАДЯТЪБЃЌЭљетИіЖгСажадіМгвЛИіЕуЛїЪТМўЃЈЯћЯЂЃЉЃЛ
3.гаИібЛЗЃЌВЛЖЯДгЖгСаШЁГіЪТМўЃЌИљОнВЛЭЌЕФЪТМўЃЌЕїгУВЛЭЌЕФКЏЪ§ЃЌШчonClick()ЁЂonKeyDown()ЕШЃЛ
4.ЪТМўЃЈЯћЯЂЃЉвЛАуЖМИїздБЃДцИїздЕФДІРэКЏЪ§жИеыЃЌетбљЃЌУПИіЯћЯЂЖМгаЖРСЂЕФДІРэКЏЪ§ЃЛ
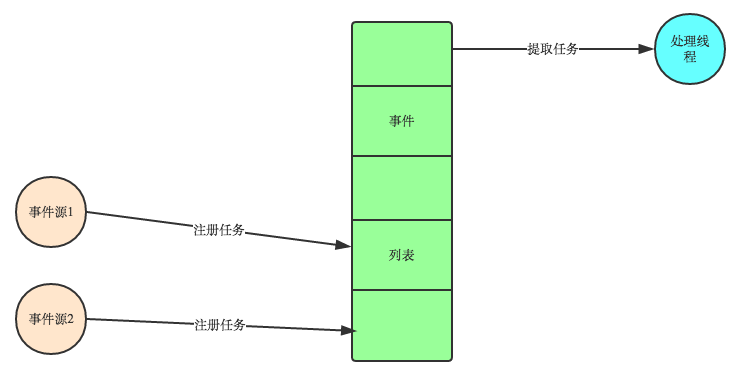
ЪТМўЧ§ЖЏБрГЬЪЧвЛжжБрГЬЗЖЪНЃЌетРяГЬађЕФжДааСїгЩЭтВПЪТМўРДОіЖЈЁЃЫќЕФЬиЕуЪЧАќКЌвЛИіЪТМўбЛЗЃЌЕБЭтВПЪТМўЗЂЩњЪБЪЙгУЛиЕїЛњжЦРДДЅЗЂЯргІЕФДІРэЁЃСэЭтСНжжГЃМћЕФБрГЬЗЖЪНЪЧЃЈЕЅЯпГЬЃЉЭЌВНвдМАЖрЯпГЬБрГЬЁЃ
ашжЊЃКУПИіcpuЖМгаЦфвЛЬзПЩжДааЕФзЈУХжИСюМЏЃЌШчSPARCКЭPentiumЃЌЦфЪЕУПИігВМўжЎЩЯЖМвЊгавЛИіПижЦГЬађЃЌcpuЕФжИСюМЏОЭЪЧcpuЕФПижЦГЬађЁЃ
ЖўЁЂIOФЃаЭзМБИ
дкНјааНтЪЭжЎЧАЃЌЪзЯШвЊЫЕУїМИИіИХФюЃК
1.гУЛЇПеМфКЭФкКЫПеМф
2.НјГЬЧаЛЛ
3.НјГЬЕФзшШћ
4.ЮФМўУшЪіЗћ
5.ЛКДц I/O
1ЁЂгУЛЇПеМфКЭФкКЫПеМф
Р§ШчЃКВЩгУащФтДцДЂЦїЃЌЖдгк32bitВйзїЯЕЭГЃЌЫќЕФбАжЗПеМф(ащФтДцДЂПеМфЮЊ4GЃЌМД2ЕФ32ДЮЗН)ЁЃ
ВйзїЯЕЭГЕФКЫаФЪЧФкКЫЃЌЖРСЂгкЦеЭЈЕФгІгУГЬађЃЌПЩвдЗУЮЪЪмБЃЛЄЕФФкДцПеМфЃЌвВПЩвдЗУЮЪЕзВугВМўЕФЫљгаШЈЯоЁЃ
ЮЊСЫБЃжЄгУЛЇНјГЬВЛФмжБНгВйзїФкКЫ(kernel),БЃжЄФкКЫЕФАВШЋЃЌВйзїЯЕЭГНЋащФтПеМфЛЎЗжЮЊСНВПЗжЃКвЛВПЗжЮЊФкКЫПеМфЃЌСэвЛВПЗжЮЊгУЛЇПеМфЁЃ
ФЧУДВйзїЯЕЭГЪЧШчКЮЗжХфПеМфЕФЃПетРяОЭЛсЩцМАЕНФкКЫЬЌКЭгУЛЇЬЌЕФСНжжЙЄзїзДЬЌЁЃ
1GЃК 0 --->ФкКЫЬЌ
3GЃК 1 --->гУЛЇЬЌ
CPUЕФжИСюМЏЃЌЪЧЭЈЙ§0КЭ1 ОіЖЈФуЪЧгУЛЇЬЌЃЌЛЙЪЧФкКЫЬЌ
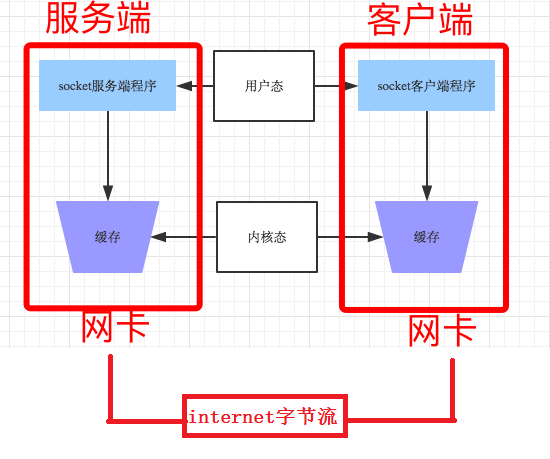
МЦЫуЛњЕФСНжжЙЄзїзДЬЌ: ФкКЫЬЌКЭгУЛЇЬЌ
cpuЕФСНжжЙЄзїзДЬЌЃК
ЯждкЕФВйзїЯЕЭГЖМЪЧЗжЪБВйзїЯЕЭГЃЌЗжЪБЕФИљдДЃЌРДздгкгВМўВуУцВйзїЯЕЭГФкКЫеМгУЕФФкДцгыгІгУГЬађеМгУЕФФкДцБЫДЫжЎМфИєРыЁЃcpuЭЈЙ§pswЃЈГЬађзДЬЌМФДцЦїЃЉжаЕФвЛИі2НјжЦЮЛРДПижЦcpuБОЩэЕФЙЄзїзДЬЌЃЌМДФкКЫЬЌгыгУЛЇЬЌЁЃ
ФкКЫЬЌЃКВйзїЯЕЭГФкКЫжЛФмдЫзїгкcpuЕФФкКЫЬЌЃЌетжжзДЬЌвтЮЖзХПЩвджДааcpuЫљгаЕФжИСюЃЌПЩвджДааcpuЫљгаЕФжИСюЃЌетвВвтЮЖзХЖдМЦЫуЛњгВМўзЪдДгазХЭъШЋЕФПижЦШЈЯоЃЌВЂЧвПЩвдПижЦcpuЙЄзїзДЬЌгЩФкКЫЬЌзЊГЩгУЛЇЬЌЁЃ
гУЛЇЬЌЃКгІгУГЬађжЛФмдЫзїгкcpuЕФгУЛЇЬЌЃЌетжжзДЬЌвтЮЖзХжЛФмжДааcpuЫљгаЕФжИСюЕФвЛаЁВПЗжЃЈЛђепГЦЮЊЫљгажИСюЕФвЛИізгМЏЃЉЃЌетвЛаЁВПЗжжИСюЖдМЦЫуЛњЕФгВМўзЪдДУЛгаЗУЮЪШЈЯоЃЈБШШчI/OЃЉЃЌВЂЧвВЛФмПижЦгЩгУЛЇЬЌзЊГЩФкКЫЬЌЁЃ
2ЁЂНјГЬЧаЛЛ
ЮЊСЫПижЦНјГЬЕФжДааЃЌФкКЫБиаыгаФмСІЙвЦ№е§дкCPUЩЯжДааЕФНјГЬЃЌВЂЛжИДвдЧАЙвЦ№ЕФФГИіНјГЬЕФжДааЃЌетжжааЮЊОЭБЛГЦЮЊНјГЬЧаЛЛЁЃ
змНсЃКНјГЬЧаЛЛЪЧКмЯћКФзЪдДЕФЁЃ
3ЁЂНјГЬЕФзшШћ
е§дкжДааЕФНјГЬЃЌгЩгкЦкД§ЕФФГаЉЪТМўЮДЗЂЩњЃЌШчЧыЧѓЯЕЭГзЪдДЪЇАмЁЂЕШД§ФГжжВйзїЕФЭъГЩЁЂаТЪ§ОнЩаЮДЕНДяЛђЮоаТЙЄзїзіЕШЃЌдђгЩЯЕЭГздЖЏжДаазшШћдгя(Block)ЃЌЪЙздМКгЩдЫаазДЬЌБфЮЊзшШћзДЬЌЁЃПЩМћЃЌНјГЬЕФзшШћЪЧНјГЬздЩэЕФвЛжжжїЖЏааЮЊЃЌвВвђДЫжЛгаДІгкдЫааЬЌЕФНјГЬЃЈЛёЕУCPUЃЉЃЌВХПЩФмНЋЦфзЊЮЊзшШћзДЬЌЁЃЕБНјГЬНјШызшШћзДЬЌЃЌЪЧВЛеМгУCPUзЪдДЕФЁЃ
4ЁЂЮФМўУшЪіЗћfd
ЮФМўУшЪіЗћЃЈFile descriptorЃЉЪЧМЦЫуЛњПЦбЇжаЕФвЛИіЪѕгяЃЌЪЧвЛИігУгкБэЪіжИЯђЮФМўЕФв§гУЕФГщЯѓЛЏИХФюЁЃ
ЮФМўУшЪіЗћдкаЮЪНЩЯЪЧвЛИіЗЧИКећЪ§ЁЃЪЕМЪЩЯЃЌЫќЪЧвЛИіЫїв§жЕЃЌжИЯђФкКЫЮЊУПвЛИіНјГЬЫљЮЌЛЄЕФИУНјГЬДђПЊЮФМўЕФМЧТМБэЁЃЕБГЬађДђПЊвЛИіЯжгаЮФМўЛђепДДНЈвЛИіаТЮФМўЪБЃЌФкКЫЯђНјГЬЗЕЛивЛИіЮФМўУшЪіЗћЁЃдкГЬађЩшМЦжаЃЌвЛаЉЩцМАЕзВуЕФГЬађБраДЭљЭљЛсЮЇШЦзХЮФМўУшЪіЗћеЙПЊЁЃЕЋЪЧЮФМўУшЪіЗћетвЛИХФюЭљЭљжЛЪЪгУгкUNIXЁЂLinuxетбљЕФВйзїЯЕЭГЁЃ
5ЁЂЛКДц I/O
ЛКДц I/O гжБЛГЦзїБъзМ I/OЃЌДѓЖрЪ§ЮФМўЯЕЭГЕФФЌШЯ I/O ВйзїЖМЪЧЛКДц
I/OЁЃдк Linux ЕФЛКДц I/O ЛњжЦжаЃЌВйзїЯЕЭГЛсНЋ I/O ЕФЪ§ОнЛКДцдкЮФМўЯЕЭГЕФвГЛКДцЃЈ
page cache ЃЉжаЃЌвВОЭЪЧЫЕЃЌЪ§ОнЛсЯШБЛПНБДЕНВйзїЯЕЭГФкКЫЕФЛКГхЧјжаЃЌШЛКѓВХЛсДгВйзїЯЕЭГФкКЫЕФЛКГхЧјПНБДЕНгІгУГЬађЕФЕижЗПеМфЁЃгУЛЇПеМфУЛЗЈжБНгЗУЮЪФкКЫПеМфЕФЃЌФкКЫЬЌЕНгУЛЇЬЌЕФЪ§ОнПНБДЁЃ
ЛКДц I/O ЕФШБЕуЃК
Ъ§ОндкДЋЪфЙ§ГЬжаашвЊдкгІгУГЬађЕижЗПеМфКЭФкКЫНјааЖрДЮЪ§ОнПНБДВйзїЃЌетаЉЪ§ОнПНБДВйзїЫљДјРДЕФ
CPU вдМАФкДцПЊЯњЪЧЗЧГЃДѓЕФЁЃ
БОЮФЬжТлЕФБГОАЪЧLinuxЛЗОГЯТЕФnetwork IOЁЃ
IOЗЂЩњЪБЩцМАЕФЖдЯѓКЭВНжшЃК
ЖдгквЛИіnetwork IO (етРяЮвУЧвдreadОйР§)ЃЌЫќЛсЩцМАЕНСНИіЯЕЭГЖдЯѓЃЌ
1ЁЂвЛИіЪЧЕїгУетИіIOЕФprocess (or thread)ЃЌ
2ЁЂСэвЛИіОЭЪЧЯЕЭГФкКЫ(kernel)ЁЃ
ЕБвЛИіreadВйзїЗЂЩњЪБЃЌЫќЛсОРњСНИіНзЖЮЃК
1ЁЂЕШД§Ъ§ОнзМБИ (Waiting for the data to
be ready)
2ЁЂНЋЪ§ОнДгФкКЫПНБДЕННјГЬжа (Copying the data
from the kernel to the process)
МЧзЁетСНЕуКмживЊЃЌвђЮЊетаЉIO ModelЕФЧјБ№ОЭЪЧдкСНИіНзЖЮЩЯИїгаВЛЭЌЕФЧщПіЁЃ
ГЃМћЕФМИжжIO ФЃаЭЃК
1.blocking IO ЃЈзшШћIOЃЉ
2.nonblocking IO ЃЈЗЧзшШћIOЃЉ
3.IO multiplexing ЃЈIOЖрТЗИДгУЃЉ
4.signal driven IO ЃЈаХКХЧ§ЖЏЪНIOЃЉ
5.asynchronous IO ЃЈвьВНIOЃЉ
вЛЁЂВЛГЃгУЕФIOФЃаЭ
1ЁЂаХКХЧ§ЖЏIOФЃаЭЃЈSignal-driven IOЃЉ
ЪЙгУаХКХЃЌШУФкКЫдкУшЪіЗћОЭаїЪБЗЂЫЭSIGIOаХКХЭЈжЊгІгУГЬађЃЌГЦетжжФЃаЭЮЊаХКХЧ§ЖЏЪНI/OЃЈsignal-driven
I/OЃЉЁЃ
дРэЭМЃК
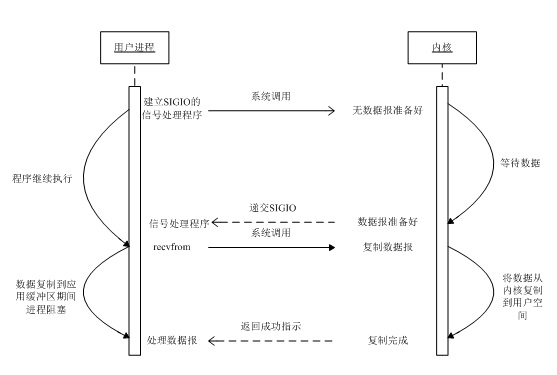
ЪзЯШПЊЦєЬзНгзжЕФаХКХЧ§ЖЏЪНI/OЙІФмЃЌВЂЭЈЙ§sigactionЯЕЭГЕїгУАВзАвЛИіаХКХДІРэКЏЪ§ЁЃИУЯЕЭГЕїгУНЋСЂМДЗЕЛиЃЌЮвУЧЕФНјГЬМЬајЙЄзїЃЌвВОЭЪЧЫЕНјГЬУЛгаБЛзшШћЁЃЕБЪ§ОнБЈзМБИКУЖСШЁЪБЃЌФкКЫОЭЮЊИУНјГЬВњЩњвЛИіSIGIOаХКХЁЃЫцКѓОЭПЩвддкаХКХДІРэКЏЪ§жаЕїгУrecvfromЖСШЁЪ§ОнБЈЃЌВЂЭЈжЊжїбЛЗЪ§ОнвбОзМБИКУД§ДІРэЃЌвВПЩвдСЂМДЭЈжЊжїбЛЗЃЌШУЫќЖСШЁЪ§ОнБЈЁЃ
ЮоТлШчКЮДІРэSIGIOаХКХЃЌетжжФЃаЭЕФгХЪЦдкгкЕШД§Ъ§ОнБЈЕНДяЦкМфНјГЬВЛБЛзшШћЁЃжїбЛЗПЩвдМЬајжДаа
ЃЌжЛвЊЕШЕНРДздаХКХДІРэКЏЪ§ЕФЭЈжЊЃКМШПЩвдЪЧЪ§ОнвбзМБИКУБЛДІРэЃЌвВПЩвдЪЧЪ§ОнБЈвбзМБИКУБЛЖСШЁЁЃ
ЖўЁЂГЃгУЕФЫФжжIOФЃаЭЃК
1ЁЂ blocking IOЃЈзшШћIOФЃаЭЃЉ
дРэЭМЃК
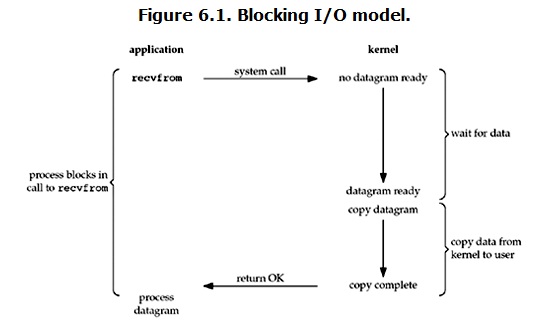
ЪОР§ЃКвЛЪевЛЗЂГЬађЛсНјШыЫРбЛЗ
server.py
| 1
#!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #Author: nulige
4
5 import socket
6
7 sk=socket.socket()
8
9 sk.bind(("127.0.0.1",8080))
10
11 sk.listen(5)
12
13 while 1:
14 conn,addr=sk.accept()
15
16 while 1:
17 conn.send("hello client".encode("utf8"))
18 data=conn.recv(1024)
19 print(data.decode("utf8")) |
client.py
| 1
#!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 #Author: nulige
4
5 import socket
6
7 sk=socket.socket()
8
9 sk.connect(("127.0.0.1",8080))
10
11 while 1:
12 data=sk.recv(1024)
13 print(data.decode("utf8"))
14 sk.send(b"hello server") |
ЕБгУЛЇНјГЬЕїгУСЫrecvfromетИіЯЕЭГЕїгУЃЌkernelОЭПЊЪМСЫIOЕФЕквЛИіНзЖЮЃКзМБИЪ§ОнЁЃЖдгкnetwork
ioРДЫЕЃЌКмЖрЪБКђЪ§ОндквЛПЊЪМЛЙУЛгаЕНДяЃЈБШШчЃЌЛЙУЛгаЪеЕНвЛИіЭъећЕФUDPАќЃЉЃЌетИіЪБКђkernelОЭвЊЕШД§зуЙЛЕФЪ§ОнЕНРДЁЃЖјдкгУЛЇНјГЬетБпЃЌећИіНјГЬЛсБЛзшШћЁЃЕБkernelвЛжБЕШЕНЪ§ОнзМБИКУСЫЃЌЫќОЭЛсНЋЪ§ОнДгkernelжаПНБДЕНгУЛЇФкДцЃЌШЛКѓkernelЗЕЛиНсЙћЃЌгУЛЇНјГЬВХНтГ§blockЕФзДЬЌЃЌжиаТдЫааЦ№РДЁЃ
ЫљвдЃЌblocking IOЕФЬиЕуОЭЪЧдкIOжДааЕФСНИіНзЖЮЖМБЛblockСЫЁЃ
2ЁЂnon-blocking IO(ЗЧзшШћIO)
дРэЭМЃК
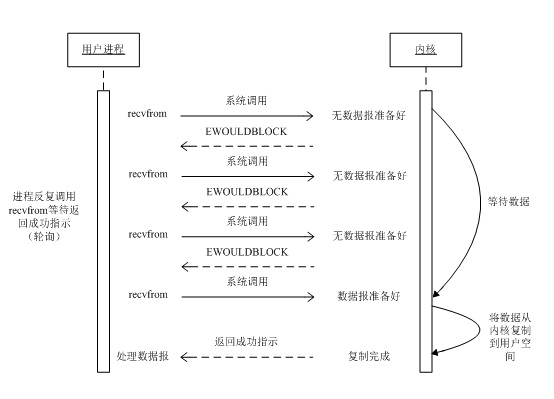
ДгЭМжаПЩвдПДГіЃЌЕБгУЛЇНјГЬЗЂГіreadВйзїЪБЃЌШчЙћkernelжаЕФЪ§ОнЛЙУЛгазМБИКУЃЌФЧУДЫќВЂВЛЛсblockгУЛЇНјГЬЃЌЖјЪЧСЂПЬЗЕЛивЛИіerrorЁЃДггУЛЇНјГЬНЧЖШНВ
ЃЌЫќЗЂЦ№вЛИіreadВйзїКѓЃЌВЂВЛашвЊЕШД§ЃЌЖјЪЧТэЩЯОЭЕУЕНСЫвЛИіНсЙћЁЃгУЛЇНјГЬХаЖЯНсЙћЪЧвЛИіerrorЪБЃЌЫќОЭжЊЕРЪ§ОнЛЙУЛгазМБИКУЃЌгкЪЧЫќПЩвддйДЮЗЂЫЭreadВйзїЁЃвЛЕЉkernelжаЕФЪ§ОнзМБИКУСЫЃЌВЂЧвгждйДЮЪеЕНСЫгУЛЇНјГЬЕФsystem
callЃЌФЧУДЫќТэЩЯОЭНЋЪ§ОнПНБДЕНСЫгУЛЇФкДцЃЌШЛКѓЗЕЛиЁЃ
ЫљвдЃЌгУЛЇНјГЬЦфЪЕЪЧашвЊВЛЖЯЕФжїЖЏбЏЮЪkernelЪ§ОнКУСЫУЛгаЁЃ
зЂвтЃК
дкЭјТчIOЪБКђЃЌЗЧзшШћIOвВЛсНјааrecvformЯЕЭГЕїгУЃЌМьВщЪ§ОнЪЧЗёзМБИКУЃЌгызшШћIOВЛвЛбљЃЌЁБЗЧзшШћНЋДѓЕФећЦЌЪБМфЕФзшШћЗжГЩNЖрЕФаЁЕФзшШћ,
ЫљвдНјГЬВЛЖЯЕигаЛњЛс ЁЎБЛЁЏ CPUЙтЙЫЁБЁЃМДУПДЮrecvformЯЕЭГЕїгУжЎМфЃЌcpuЕФШЈЯоЛЙдкНјГЬЪжжаЃЌетЖЮЪБМфЪЧПЩвдзіЦфЫћЪТЧщЕФЃЌ
вВОЭЪЧЫЕЗЧзшШћЕФrecvformЯЕЭГЕїгУЕїгУжЎКѓЃЌНјГЬВЂУЛгаБЛзшШћЃЌФкКЫТэЩЯЗЕЛиИјНјГЬЃЌШчЙћЪ§ОнЛЙУЛзМБИКУЃЌДЫЪБЛсЗЕЛивЛИіerrorЁЃНјГЬдкЗЕЛижЎКѓЃЌПЩвдИЩЕуБ№ЕФЪТЧщЃЌШЛКѓдйЗЂЦ№recvformЯЕЭГЕїгУЁЃжиИДЩЯУцЕФЙ§ГЬЃЌбЛЗЭљИДЕФНјааrecvformЯЕЭГЕїгУЁЃетИіЙ§ГЬЭЈГЃБЛГЦжЎЮЊТжбЏЁЃТжбЏМьВщФкКЫЪ§ОнЃЌжБЕНЪ§ОнзМБИКУЃЌдйПНБДЪ§ОнЕННјГЬЃЌНјааЪ§ОнДІРэЁЃашвЊзЂвтЃЌПНБДЪ§ОнећИіЙ§ГЬЃЌНјГЬШдШЛЪЧЪєгкзшШћЕФзДЬЌЁЃ
ЪОР§ЃК
ЗўЮёЖЫЃК
| 1
import time
2 import socket
3 sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
4 sk.bind(('127.0.0.1',6667))
5 sk.listen(5)
6 sk.setblocking(False) #ЩшжУГЩЗЧзшШћзДЬЌ
7 while True:
8 try:
9 print ('waiting client connection .......')
10 connection,address = sk.accept() # НјГЬжїЖЏТжбЏ
11 print("+++",address)
12 client_messge = connection.recv(1024)
13 print(str(client_messge,'utf8'))
14 connection.close()
15 except Exception as e: #ВЖзНДэЮѓ
16 print (e)
17 time.sleep(4) #УП4УыДђгЁвЛИіВЖзНЕНЕФДэЮѓ |
ПЭЛЇЖЫЃК
| 1
import time
2 import socket
3 sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
4
5 while True:
6 sk.connect(('127.0.0.1',6667))
7 print("hello")
8 sk.sendall(bytes("hello","utf8"))
9 time.sleep(2)
10 break |
ШБЕуЃК
1ЁЂЗЂЫЭСЫЬЋЖрЯЕЭГЕїгУЪ§Он
2ЁЂЪ§ОнДІРэВЛМАЪБ
3ЁЂIO multiplexingЃЈIOЖрТЗИДгУЃЉ
IO multiplexingетИіДЪПЩФмгаЕуФАЩњЃЌЕЋЪЧШчЙћЮвЫЕselectЃЌepollЃЌДѓИХОЭЖМФмУїАзСЫЁЃгааЉЕиЗНвВГЦетжжIOЗНЪНЮЊevent
driven IOЁЃЮвУЧЖМжЊЕРЃЌselect/epollЕФКУДІОЭдкгкЕЅИіprocessОЭПЩвдЭЌЪБДІРэЖрИіЭјТчСЌНгЕФIOЁЃЫќЕФЛљБОдРэОЭЪЧselect/epollетИіfunctionЛсВЛЖЯЕФТжбЏЫљИКд№ЕФЫљгаsocketЃЌЕБФГИіsocketгаЪ§ОнЕНДяСЫЃЌОЭЭЈжЊгУЛЇНјГЬЁЃ
IOЖрТЗИДгУЕФШ§жжЗНЪНЃК
1ЁЂselect--->аЇТЪзюЕЭЃЌЕЋгазюДѓУшЪіЗћЯожЦЃЌдкlinuxЮЊ1024ЁЃ
2ЁЂpoll ---->КЭselectвЛбљЃЌЕЋУЛгазюДѓУшЪіЗћЯожЦЁЃ
3ЁЂepoll --->аЇТЪзюИпЃЌУЛгазюДѓУшЪіЗћЯожЦЃЌжЇГжЫЎЦНДЅЗЂгыБпдЕДЅЗЂЁЃ
IOЖрТЗИДгУЕФгХЪЦЃКЭЌЪБПЩвдМрЬ§ЖрИіСЌНгЃЌгУЕФЪЧЕЅЯпГЬЃЌРћгУПеЯаЪБМфЪЕЯжВЂЗЂЁЃ

зЂвтЃК
LinuxЯЕЭГЃК selectЁЂpollЁЂepoll
WindowsЯЕЭГЃКselect
MacЯЕЭГЃКselectЁЂpoll
дРэЭМЃК
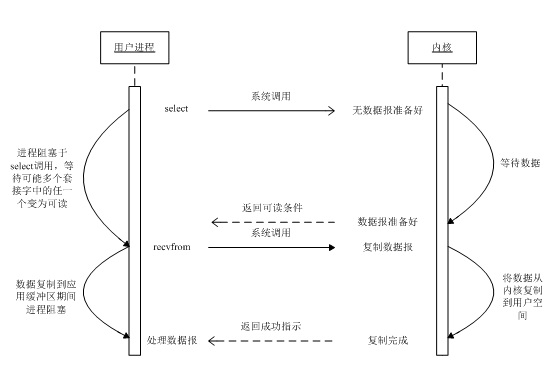
ЕБгУЛЇНјГЬЕїгУСЫselectЃЌФЧУДећИіНјГЬЛсБЛblockЃЌЖјЭЌЪБЃЌkernelЛсЁАМрЪгЁБЫљгаselectИКд№ЕФsocketЃЌЕБШЮКЮвЛИіsocketжаЕФЪ§ОнзМБИКУСЫЃЌselectОЭЛсЗЕЛиЁЃетИіЪБКђгУЛЇНјГЬдйЕїгУreadВйзїЃЌНЋЪ§ОнДгkernelПНБДЕНгУЛЇНјГЬЁЃ
етИіЭМКЭblocking IOЕФЭМЦфЪЕВЂУЛгаЬЋДѓЕФВЛЭЌЃЌЪТЪЕЩЯЃЌЛЙИќВювЛаЉЁЃвђЮЊетРяашвЊЪЙгУСНИіsystem
call (select КЭ recvfrom)ЃЌЖјblocking IOжЛЕїгУСЫвЛИіsystem
call (recvfrom)ЁЃЕЋЪЧЃЌгУselectЕФгХЪЦдкгкЫќПЩвдЭЌЪБДІРэЖрИіconnectionЁЃЃЈЖрЫЕвЛОфЁЃЫљвдЃЌШчЙћДІРэЕФСЌНгЪ§ВЛЪЧКмИпЕФЛАЃЌЪЙгУselect/epollЕФweb
serverВЛвЛЖЈБШЪЙгУmulti-threading + blocking IOЕФweb serverадФмИќКУЃЌПЩФмбгГйЛЙИќДѓЁЃselect/epollЕФгХЪЦВЂВЛЪЧЖдгкЕЅИіСЌНгФмДІРэЕУИќПьЃЌЖјЪЧдкгкФмДІРэИќЖрЕФСЌНгЁЃЃЉ
дкIO multiplexing ModelжаЃЌЪЕМЪжаЃЌЖдгкУПвЛИіsocketЃЌвЛАуЖМЩшжУГЩЮЊnon-blockingЃЌЕЋЪЧЃЌШчЩЯЭМЫљЪОЃЌећИігУЛЇЕФprocessЦфЪЕЪЧвЛжББЛblockЕФЁЃжЛВЛЙ§processЪЧБЛselectетИіКЏЪ§blockЃЌЖјВЛЪЧБЛsocket
IOИјblockЁЃ
зЂвт1ЃКselectКЏЪ§ЗЕЛиНсЙћжаШчЙћгаЮФМўПЩЖССЫЃЌФЧУДНјГЬОЭПЩвдЭЈЙ§ЕїгУaccept()Лђrecv()РДШУkernelНЋЮЛгкФкКЫжазМБИЕНЕФЪ§ОнcopyЕНгУЛЇЧјЁЃ
зЂвт2: selectЕФгХЪЦдкгкПЩвдДІРэЖрИіСЌНгЃЌВЛЪЪгУгкЕЅИіСЌНг
ЪОР§ЃК
server.py
|
1 #server.py
2
3 import socket
4 import select
5 sk=socket.socket()
6 sk.bind(("127.0.0.1",9904))
7 sk.listen(5)
8
9 while True:
10 # sk.accept() #ЮФМўУшЪіЗћ
11 r,w,e=select.select([sk,],[],[],5) #ЪфШыСаБэЃЌЪфГіСаБэЃЌДэЮѓСаБэ,5:
ЪЧМрЬ§5Уы
12 for i in r: #[sk,]
13 conn,add=i.accept()
14 print(conn)
15 print("hello")
16 print('>>>>>>') |
client.py
| 1
import socket
2
3 sk=socket.socket()
4
5 sk.connect(("127.0.0.1",9904))
6
7 while 1:
8 inp=input(">>").strip()
9 sk.send(inp.encode("utf8"))
10 data=sk.recv(1024)
11 print(data.decode("utf8")) |
IOЖрТЗИДгУжаЕФСНжжДЅЗЂЗНЪНЃК
ЫЎЦНДЅЗЂ:ШчЙћЮФМўУшЪіЗћвбООЭаїПЩвдЗЧзшШћЕФжДааIOВйзїСЫ,ДЫЪБЛсДЅЗЂЭЈжЊ.дЪаэдкШЮвтЪБПЬжиИДМьВтIOЕФзДЬЌ,
УЛгаБивЊУПДЮУшЪіЗћОЭаїКѓОЁПЩФмЖрЕФжДааIO.select,pollОЭЪєгкЫЎЦНДЅЗЂЁЃ
БпдЕДЅЗЂ:ШчЙћЮФМўУшЪіЗћздЩЯДЮзДЬЌИФБфКѓгааТЕФIOЛюЖЏЕНРД,ДЫЪБЛсДЅЗЂЭЈжЊ.дкЪеЕНвЛИіIOЪТМўЭЈжЊКѓвЊОЁПЩФм
ЖрЕФжДааIOВйзї,вђЮЊШчЙћдквЛДЮЭЈжЊжаУЛгажДааЭъIOФЧУДОЭашвЊЕШЕНЯТвЛДЮаТЕФIOЛюЖЏЕНРДВХФмЛёШЁЕНОЭаїЕФУшЪі
Зћ.аХКХЧ§ЖЏЪНIOОЭЪєгкБпдЕДЅЗЂЁЃ
epollЃКМДПЩвдВЩгУЫЎЦНДЅЗЂ,вВПЩвдВЩгУБпдЕДЅЗЂЁЃ
1ЁЂЫЎЦНДЅЗЂ
жЛгаИпЕчЦНЛђЕЭЕчЦНЕФЪБКђВХДЅЗЂ
1-----ИпЕчЦН---ДЅЗЂ
0-----ЕЭЕчЦН---ВЛДЅЗЂ
ЪОР§ЃК
serverЗўЮёЖЫ
| 1
#ЫЎЦНДЅЗЂ
2 import socket
3 import select
4 sk=socket.socket()
5 sk.bind(("127.0.0.1",9904))
6 sk.listen(5)
7
8 while True:
9 r,w,e=select.select([sk,],[],[],5) #inputЪфШыСаБэЃЌoutputЪфГіСаБэЃЌerronДэЮѓСаБэ,5:
ЪЧМрЬ§5Уы
10 for i in r: #[sk,]
11 print("hello")
12
13 print('>>>>>>') |
clientПЭЛЇЖЫ
| 1
import socket
2
3 sk=socket.socket()
4
5 sk.connect(("127.0.0.1",9904))
6
7 while 1:
8 inp=input(">>").strip()
9 sk.send(inp.encode("utf8"))
10 data=sk.recv(1024)
11 print(data.decode("utf8")) |
2ЁЂБпдЕДЅЗЂ
1---------ИпЕчЦН--------ДЅЗЂ
0---------ЕЭЕчЦН--------ДЅЗЂ
IOЖрТЗИДгУгХЪЦЃКЭЌЪБПЩвдМрЬ§ЖрИіСЌНг
ЪОР§ЃКselectПЩвдМрПиЖрИіЖдЯѓ
ЗўЮёЖЫ
| 1
#гХЪЦ
2 import socket
3 import select
4 sk=socket.socket()
5 sk.bind(("127.0.0.1",9904))
6 sk.listen(5)
7 inp=[sk,]
8
9 while True:
10 r,w,e=select.select(inp,[],[],5) #[sk,conn]ЃЌ5ЪЧУПИєМИУыМрЬ§вЛДЮ
11
12 for i in r: #[sk,]
13 conn,add=i.accept() #ЗЂЫЭЯЕЭГЕїгУ
14 print(conn)
15 print("hello")
16 inp.append(conn)
17 # conn.recv(1024)
18 print('>>>>>>') |
ПЭЛЇЖЫЃК
| 1
import socket
2
3 sk=socket.socket()
4
5 sk.connect(("127.0.0.1",9904))
6
7 while 1:
8 inp=input(">>").strip()
9 sk.send(inp.encode("utf8"))
10 data=sk.recv(1024)
11 print(data.decode("utf8")) |
ЖрСЫвЛИіХаЖЯЃЌгУselectЗНЪНЪЕЯжЕФВЂЗЂ
ЪОР§ЃКЪЕЯжВЂЗЂСФЬьЙІФм (select+IOЖрТЗИДгУЃЌЪЕЯжВЂЗЂЃЉ
ЗўЮёЖЫЃК
|
1 import socket
2 import select
3 sk=socket.socket()
4 sk.bind(("127.0.0.1",8801))
5 sk.listen(5)
6 inputs=[sk,]
7 while True: #МрЬ§skКЭconn
8 r,w,e=select.select(inputs,[],[],5) #connЗЂЩњБфЛЏ,skВЛБфЛЏОЭзпelse
9 print(len(r))
10 #ХаЖЯsk or conn ЫЗЂЩњСЫБфЛЏ
11 for obj in r:
12 if obj==sk:
13 conn,add=obj.accept()
14 print(conn)
15 inputs.append(conn)
16 else:
17 data_byte=obj.recv(1024)
18 print(str(data_byte,'utf8'))
19 inp=input('ЛиД№%sКХПЭЛЇ>>>'%inputs.index(obj))
20 obj.sendall(bytes(inp,'utf8'))
21
22 print('>>',r) |
ПЭЛЇЖЫЃК
| 1
import socket
2 sk=socket.socket()
3 sk.connect(('127.0.0.1',8801))
4
5 while True:
6 inp=input(">>>>")
7 sk.sendall(bytes(inp,"utf8"))
8 data=sk.recv(1024)
9 print(str(data,'utf8')) |
жДааНсЙћЃК
ЯШдЫааЗўЮёЖЫЃЌдйдЫааЖрИіПЭЛЇЖЫЃЌОЭПЩвдСФЬьРВЁЃЃЈПЩвдНгЪеЖрИіПЭЛЇЖЫЯћЯЂЃЉ
|
1 #server
2 >> [<socket.socket fd=276, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8801)>]
3 1
4 hello
5 ЛиД№1КХПЭЛЇ>>>word
6 >> [<socket.socket fd=344, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8801), raddr=('127.0.0.1', 54388)>]
7 1
8
9 #clinet
10 >>>>hello
11 word |
4ЁЂAsynchronous I/OЃЈвьВНIOЃЉ
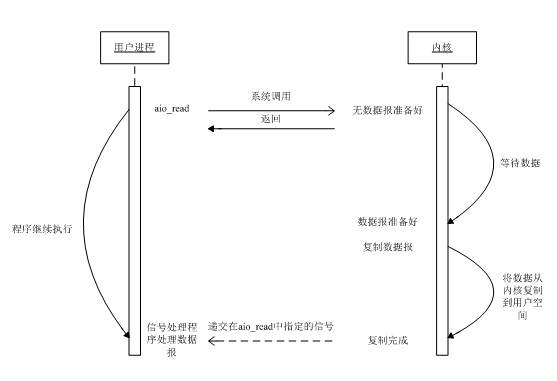
гУЛЇНјГЬЗЂЦ№readВйзїжЎКѓЃЌСЂПЬОЭПЩвдПЊЪМШЅзіЦфЫќЕФЪТЁЃЖјСэвЛЗНУцЃЌДгkernelЕФНЧЖШЃЌЕБЫќЪмЕНвЛИіasynchronous
readжЎКѓЃЌЪзЯШЫќЛсСЂПЬЗЕЛиЃЌЫљвдВЛЛсЖдгУЛЇНјГЬВњЩњШЮКЮblockЁЃШЛКѓЃЌkernelЛсЕШД§Ъ§ОнзМБИЭъГЩЃЌШЛКѓНЋЪ§ОнПНБДЕНгУЛЇФкДцЃЌЕБетвЛЧаЖМЭъГЩжЎКѓЃЌkernelЛсИјгУЛЇНјГЬЗЂЫЭвЛИіsignalЃЌИцЫпЫќreadВйзїЭъГЩСЫЁЃ
вьВНзюДѓЬиЕуЃКШЋГЬЮозшШћ
synchronous IOЃЈЭЌВНIO)КЭasynchronous IO(вьВНIO)ЕФЧјБ№ЃК
1.A synchronous I/O operation causes
the requesting process to be blocked until that I/O
operationcompletes;
2.An asynchronous I/O operation does
not cause the requesting process to be blocked;
СНепЕФЧјБ№ОЭдкгкsynchronous IOзіЁБIO operationЁБЕФЪБКђЛсНЋprocessзшШћЁЃЃЈгавЛЖЁЕузшШћЃЌЖМЪЧЭЌВНIOЃЉАДееетИіЖЈвхЃЌжЎЧАЫљЪіЕФblocking
IOЃЌnon-blocking IOЃЌIO multiplexingЖМЪєгкsynchronous IOЃЈЭЌВНIOЃЉЁЃ
ЭЌВНIOЃКАќРЈ blocking IOЁЂnon-blockingЁЂselectЁЂpollЁЂepollЃЈЙЪ:epoolжЛЪЧЮБвьВНЖјвбЃЉЃЈгазшШћЃЉ
вьВНIOЃКАќРЈ:asynchronous ЃЈЮозшШћЃЉ
ЮхжжIOФЃаЭБШНЯЃК
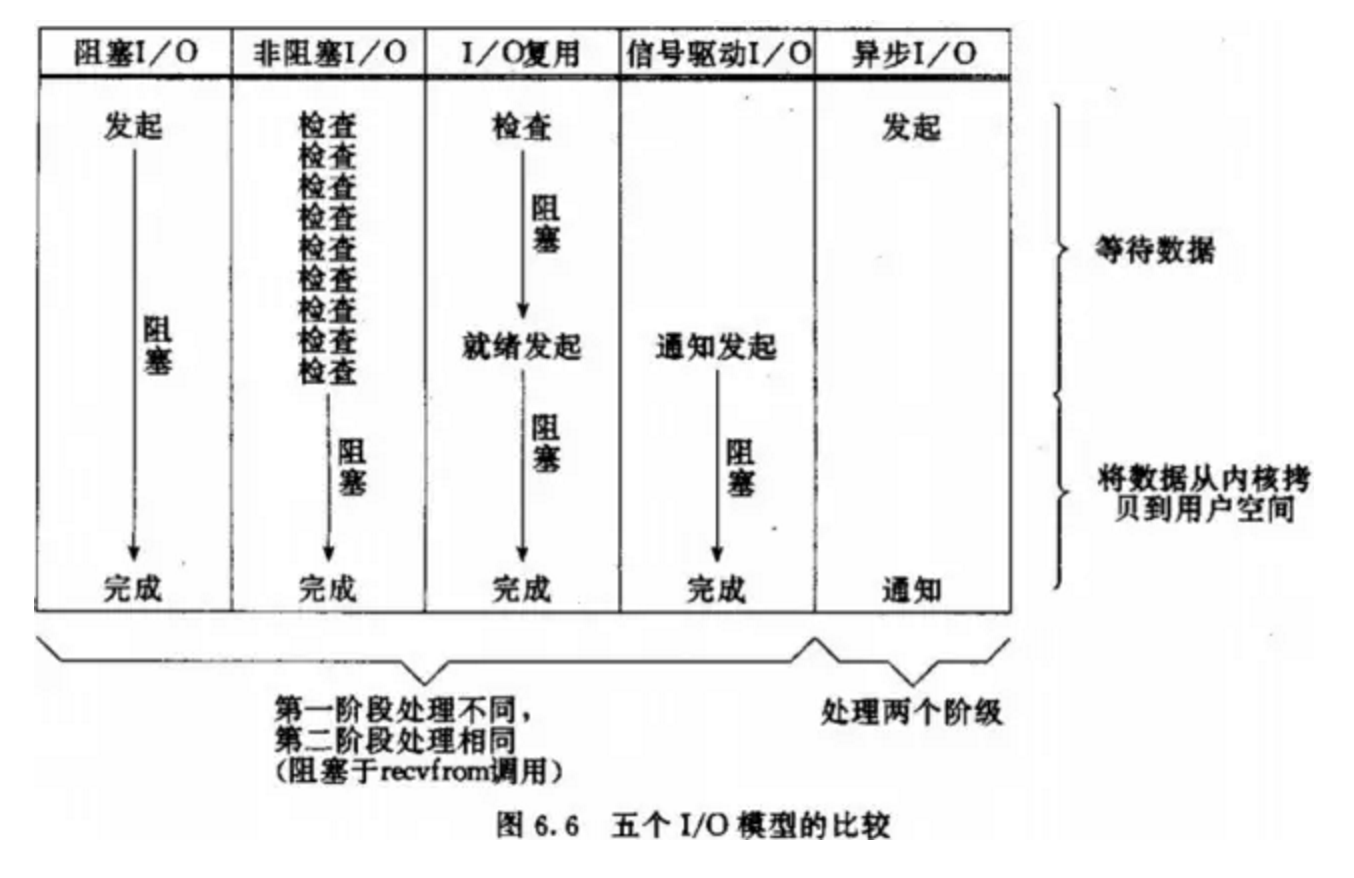
ОЙ§ЩЯУцЕФНщЩмЃЌЛсЗЂЯжnon-blocking IOКЭasynchronous
IOЕФЧјБ№ЛЙЪЧКмУїЯдЕФЁЃдкnon-blocking IOжаЃЌЫфШЛНјГЬДѓВПЗжЪБМфЖМВЛЛсБЛblockЃЌЕЋЪЧЫќШдШЛвЊЧѓНјГЬШЅжїЖЏЕФcheckЃЌВЂЧвЕБЪ§ОнзМБИЭъГЩвдКѓЃЌвВашвЊНјГЬжїЖЏЕФдйДЮЕїгУrecvfromРДНЋЪ§ОнПНБДЕНгУЛЇФкДцЁЃЖјasynchronous
IOдђЭъШЋВЛЭЌЁЃЫќОЭЯёЪЧгУЛЇНјГЬНЋећИіIOВйзїНЛИјСЫЫћШЫЃЈkernelЃЉЭъГЩЃЌШЛКѓЫћШЫзіЭъКѓЗЂаХКХЭЈжЊЁЃдкДЫЦкМфЃЌгУЛЇНјГЬВЛашвЊШЅМьВщIOВйзїЕФзДЬЌЃЌвВВЛашвЊжїЖЏЕФШЅПНБДЪ§ОнЁЃ
5ЁЂselectorsФЃПщгІгУ
pythonЗтзАКУЕФФЃПщЃКselectors
selectorsФЃПщ: ЛсбЁдёвЛИізюгХЕФВйзїЯЕЭГЪЕЯжЗНЪН
ЪОР§ЃК
select_module.py
|
1 import selectors
2 import socket
3
4 sel = selectors.DefaultSelector()
5
6 def accept(sock, mask):
7 conn, addr = sock.accept() # Should be ready
8 print('accepted', conn, 'from', addr)
9 conn.setblocking(False) #ЩшжУГЩЗЧзшШћ
10 sel.register(conn, selectors.EVENT_READ,
read) #connАѓЖЈЕФЪЧread
11
12 def read(conn, mask):
13 try:
14 data = conn.recv(1000) # Should be ready
15 if not data:
16 raise Exception
17 print('echoing', repr(data), 'to', conn)
18 conn.send(data) # Hope it won't block
19 except Exception as e:
20 print('closing', conn)
21 sel.unregister(conn) #НтГ§зЂВс
22 conn.close()
23
24 sock = socket.socket()
25 sock.bind(('localhost', 8090))
26 sock.listen(100)
27 sock.setblocking(False)
28 #зЂВс
29 sel.register(sock, selectors.EVENT_READ,
accept)
30 print("server....")
31
32 while True:
33 events = sel.select() #МрЬ§[sock,conn1,conn2]
34 print("events",events)
35 #ФУЕН2ИідЊЫиЃЌвЛИіkey,вЛИіmask
36 for key, mask in events:
37 # print("key",key)
38 # print("mask",mask)
39 callback = key.data #АѓЖЈЕФЪЧreadКЏЪ§
40 # print("callback",callback)
41 callback(key.fileobj, mask) #key.fileobj=sock,conn1,conn2 |
client.py
|
1 import socket
2
3 sk=socket.socket()
4
5 sk.connect(("127.0.0.1",8090))
6 while 1:
7 inp=input(">>>")
8 sk.send(inp.encode("utf8")) #ЗЂЫЭФкШн
9 data=sk.recv(1024) #НгЪеаХЯЂ
10 print(data.decode("utf8")) #ДђгЁГіРД |
жДааНсЙћЃК
ЯШдЫааselect_module.pyЃЌдйдЫааclinet.py
|
1 #server
2
3 server....
4 events [(SelectorKey(fileobj=<socket.socket
fd=312, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090)>, fd=312,
events=1, data=<function accept at 0x01512F60>),
1)]
5 accepted <socket.socket fd=376, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8090), raddr=('127.0.0.1', 57638)> from ('127.0.0.1',
57638)
6 events [(SelectorKey(fileobj=<socket.socket
fd=376, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57638)>, fd=376, events=1, data=<function
read at 0x015C26A8>), 1)]
7 echoing b'hello' to <socket.socket fd=376,
family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57638)>
8 events [(SelectorKey(fileobj=<socket.socket
fd=312, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090)>, fd=312,
events=1, data=<function accept at 0x01512F60>),
1)]
9 accepted <socket.socket fd=324, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8090), raddr=('127.0.0.1', 57675)> from ('127.0.0.1',
57675)
10 events [(SelectorKey(fileobj=<socket.socket
fd=324, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57675)>, fd=324, events=1, data=<function
read at 0x015C26A8>), 1)]
11 echoing b'uuuu' to <socket.socket fd=324,
family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57675)>
12 events [(SelectorKey(fileobj=<socket.socket
fd=324, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57675)>, fd=324, events=1, data=<function
read at 0x015C26A8>), 1)]
13 closing <socket.socket fd=324, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8090), raddr=('127.0.0.1', 57675)>
14 events [(SelectorKey(fileobj=<socket.socket
fd=312, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090)>, fd=312,
events=1, data=<function accept at 0x01512F60>),
1)]
15 accepted <socket.socket fd=324, family=AddressFamily.AF_INET,
type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1',
8090), raddr=('127.0.0.1', 57876)> from ('127.0.0.1',
57876)
16 events [(SelectorKey(fileobj=<socket.socket
fd=324, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57876)>, fd=324, events=1, data=<function
read at 0x015C26A8>), 1)]
17 echoing b'welcome' to <socket.socket fd=324,
family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
proto=0, laddr=('127.0.0.1', 8090), raddr=('127.0.0.1',
57876)>
18
19 #clinet (ЦєЖЏСНИіclient)
20 >>>hello
21 hello
22
23 >>>welcome
24 welcome |
6ЁЂI/OЖрТЗИДгУЕФгІгУГЁОА
ЃЈ1ЃЉЕБПЭЛЇДІРэЖрИіУшЪізжЪБЃЈвЛАуЪЧНЛЛЅЪНЪфШыКЭЭјТчЬзНгПкЃЉЃЌБиаыЪЙгУI/OИДгУЁЃ
ЃЈ2ЃЉЕБвЛИіПЭЛЇЭЌЪБДІРэЖрИіЬзНгПкЪБЃЌЖјетжжЧщПіЪЧПЩФмЕФЃЌЕЋКмЩйГіЯжЁЃ
ЃЈ3ЃЉШчЙћвЛИіTCPЗўЮёЦїМШвЊДІРэМрЬ§ЬзНгПкЃЌгжвЊДІРэвбСЌНгЬзНгПкЃЌвЛАувВвЊгУЕНI/OИДгУЁЃ
ЃЈ4ЃЉШчЙћвЛИіЗўЮёЦїМДвЊДІРэTCPЃЌгжвЊДІРэUDPЃЌвЛАувЊЪЙгУI/OИДгУЁЃ
ЃЈ5ЃЉШчЙћвЛИіЗўЮёЦївЊДІРэЖрИіЗўЮёЛђЖрИіавщЃЌвЛАувЊЪЙгУI/OИДгУЁЃ
'''гыЖрНјГЬКЭЖрЯпГЬММЪѕЯрБШЃЌI/OЖрТЗИДгУММЪѕЕФзюДѓгХЪЦЪЧЯЕЭГПЊЯњаЁЃЌЯЕЭГВЛБиДДНЈНјГЬ/ЯпГЬЃЌвВВЛБиЮЌЛЄетаЉНјГЬ/ЯпГЬЃЌДгЖјДѓДѓМѕаЁСЫЯЕЭГЕФПЊЯњЁЃ'''
зюКѓЃЌдйОйМИИіВЛЪЧКмЧЁЕБЕФР§згРДЫЕУїетЫФИіIO Model:
гаAЃЌBЃЌCЃЌDЫФИіШЫдкЕігуЃК
AгУЕФЪЧзюРЯЪНЕФгуИЭЃЌЫљвдФиЃЌЕУвЛжБЪизХЃЌЕШЕНгуЩЯЙГСЫдйРИЫЃЛЁОзшШћЁП
BЕФгуИЭгаИіЙІФмЃЌФмЙЛЯдЪОЪЧЗёгагуЩЯЙГЃЈетИіЯдЪОЙІФмвЛжБШЅХаЖЯгуЪЧЗёЩЯЙГЃЉЃЌЫљвдФиЃЌBОЭКЭХдБпЕФMMСФЬьЃЌИєЛсдйПДПДгаУЛгагуЩЯЙГЃЌгаЕФЛАОЭбИЫйРИЫЃЛЁОЗЧзшШћЁП
CгУЕФгуИЭКЭBВюВЛЖрЃЌЕЋЫћЯыСЫвЛИіКУАьЗЈЃЌОЭЪЧЭЌЪБЗХКУМИИљгуИЭЃЌШЛКѓЪидкХдБпЃЌвЛЕЉгаЯдЪОЫЕгуЩЯЙГСЫЃЌЫќОЭНЋЖдгІЕФгуИЭРЦ№РДЃЛЁОЭЌВНЁП
DЪЧИігаЧЎШЫЃЌИЩДрЙЭСЫвЛИіШЫАяЫћЕігуЃЌвЛЕЉФЧИіШЫАбгуЕіЩЯРДСЫЃЌОЭИјDЗЂИіЖЬаХЃЈЯћЯЂЛиЕєЛњжЦЃЌжїЖЏИцжЊЃЉЁЃЁОвьВНЁП
|









