| БрМЭЦМі: |
| БОЮФРДздгкМђЪщ,ЮФеТжївЊНщЩмСЫNumPyЮФБОЮФМўЖСаДЕШЙІФмВЂИЈвдЪЕР§НјааНВНтЁЃ |
|
БъЬтжаЕФгЂЮФЪззжФИДѓаДБШНЯЙцЗЖЃЌЕЋдкpythonЪЕМЪЪЙгУжаОљЮЊаЁаДЁЃ
бЇЯАФкШнЃК
1.ДгЮФМўжаЖСШЁЪ§Он
2.НЋЪ§ОнаДШыЮФМў
3.РћгУЪ§бЇКЭЭГМЦЗжЮіКЏЪ§ЭъГЩЪЕМЪЭГМЦЗжЮігІгУ
4.еЦЮеЪ§зщЯрЙиЕФГЃгУКЏЪ§
1.ЮФБОЮФМўЖСаД
1.1ЪЙгУnumpy.savetxtЗНЗЈаДШыЮФБОЮФМў
numpy.savetxtЗНЗЈашвЊ2ИіВЮЪ§ЃКЕк1ИіВЮЪ§ЪЧЮФМўУћЃЌЪ§ОнРраЭЮЊзжЗћДЎstrЃЛ
Ек2ИіВЮЪ§ЪЧБЛаДШыЮФМўЕФndaЪ§ОнЃЌЪ§ОнРраЭЮЊndarrayЖдЯѓЁЃ
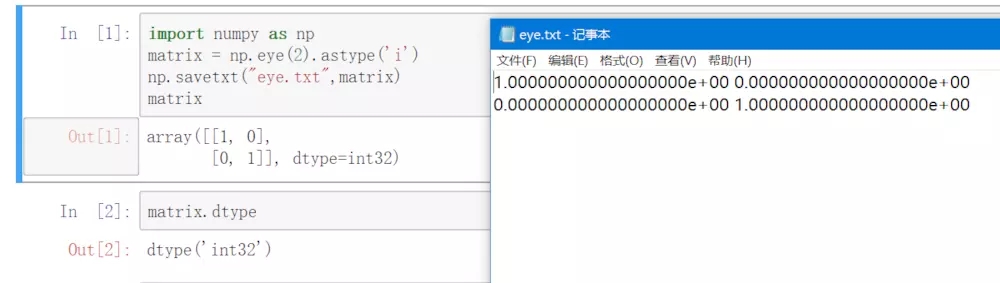
аДШыЮФМўНсЙћ.png
ДгЩЯЭМПЩвдПДГіЃЌndarrayЖдЯѓжаЕФдЊЫиЪ§ОнРраЭдБОЮЊint,ЕЋаДШыЮФМўЪБзЊБфЮЊfloatЁЃ
1.2ЪЙгУnumpy.loadtxtЗНЗЈЖСШЁЮФБОЮФМў
numpy.loadtxtЗНЗЈашвЊ1ИіВЮЪ§ЃКВЮЪ§ЪЙЮФМўУћЃЌЪ§ОнРраЭЮЊзжЗћДЎstrЁЃ
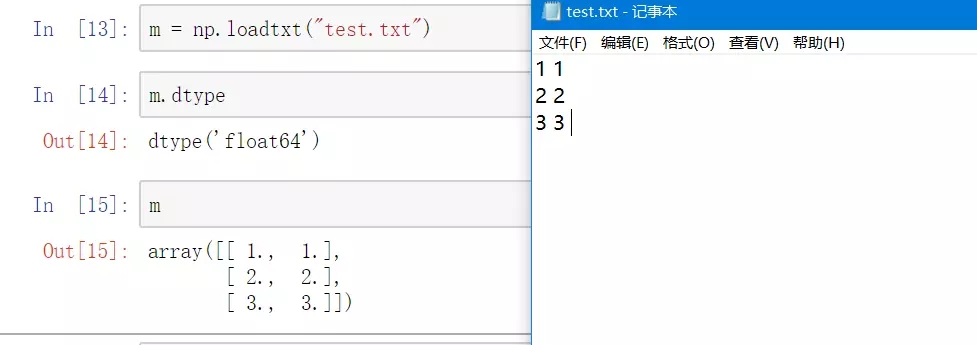
ЖСШЁЮФМўНсЙћ.png
ДгЩЯЭМПЩвдПДГіЃЌЪЙгУnumpy.loadtxtЗНЗЈдиШыЕФЪ§ОнИГжЕИјmБфСПЃЌmБфСПЕФЪ§ОнРраЭЮЊndarrayЖдЯѓЁЃ
дБОtest.txtЮФБОжаЪ§ОнЕФЪ§ОнРраЭЮЊintЃЌЕЋРћгУnumpy.loadtxtЗНЗЈКѓЪ§ОнРраЭЮЊfloat64ЁЃ
2.ЪЙгУnumpy.loadtxtЗНЗЈЖСШЁCSVЮФМў
CSVЮФМўИёЪНИХФюЃКCSVИёЪНЪЧвЛжжГЃМћЕФЮФМўИёЪНЁЃЭЈГЃЃЌЪ§ОнПтЕФзЊДцЮФМўОЭЪЧCSVИёЪНЕФЃЌЮФМўжаЕФИїИізжЖЮЖдгІгкЪ§ОнПтжаЕФСаЁЃЖјЧвMircosoft
ExcelвВПЩвдДІРэCSVЮФМў
ЯТУцСЗЯАашвЊгУЕНЕФdata.csvЮФМўЯТдиСДНг: https://pan.baidu.com/s/1bo-PLzYICmF6Hc87tMG1uA
УмТы: spwr
ЮФМўЯТдиКѓДђПЊШчЯТЭМЫљЪОЃК
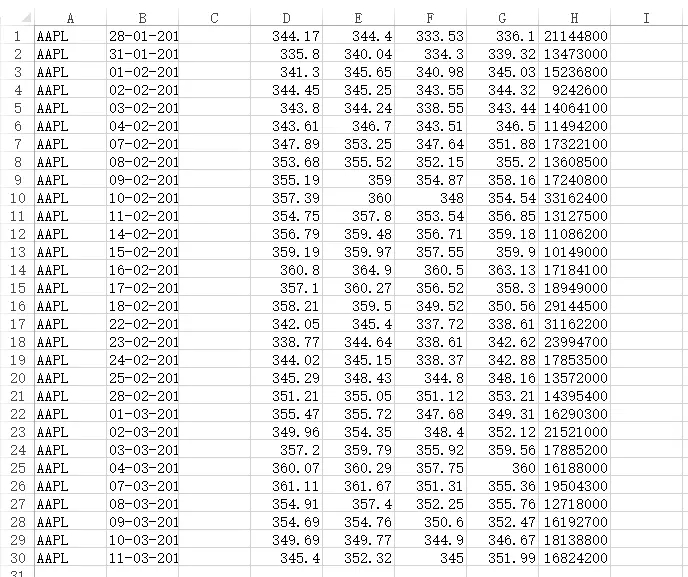
image.png
Ек4-8СаЃЌМДEXCELБэИёжаЕФD-HСаЃЌЗжБ№ЮЊЙЩЦБЕФПЊХЬМлЃЌзюИпМлЃЌзюЕЭМлЃЌЪеХЬМлЃЌГЩНЛСПЁЃ
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (6,7),
unpack = True
)
endPrice,turnover = np.loadtxt(**params)
print(endPrice)
print(turnover) |
numpy.loadtxtашвЊДЋШы4ИіЙиМќзжВЮЪ§ЃК
1.fnameЪЧЮФМўУћЃЌЪ§ОнРраЭЮЊзжЗћДЎstrЃЛ
2.delimiterЪЧЗжИєЗћЃЌЪ§ОнРраЭЮЊзжЗћДЎstrЃЛ
3.usecolsЪЧЖСШЁЕФСаЪ§ЃЌЪ§ОнРраЭЮЊдЊзщtuple,ЦфжадЊЫиИіЪ§гаЖрЩйИіЃЌдђбЁГіЖрЩйСаЃЛ
4.unpackЪЧЪЧЗёНтАќЃЌЪ§ОнРраЭЮЊВМЖћboolЁЃ
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЭМЫљЪОЃК
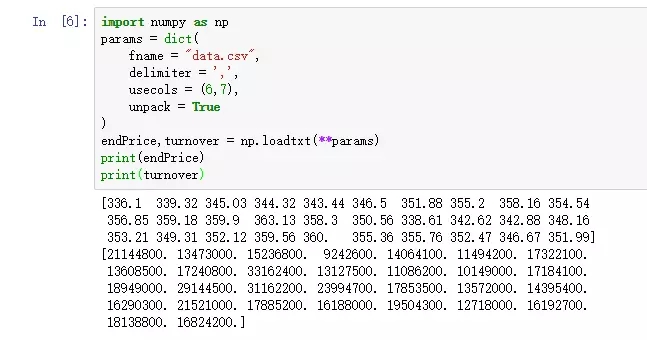
ЖСШЁcsvЮФМўНсЙћ.png
3.ЛљгкNumpyЕФЙЩМлЭГМЦЗжЮігІгУ
дкЕк2НкЕФЛљДЁЩЯЃЌЖдЙЩМлНјааЭГМЦЗжЮі
3.1 МЦЫуГЩНЛСПМгШЈЦНОљМлИё
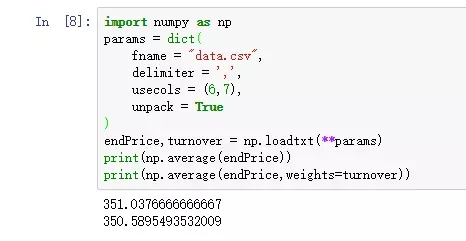
ИХФюЃКГЩНЛСПМгШЈЦНОљМлИёЃЌгЂЮФУћVWAP(Volume-Weighted Average PriceЃЌГЩНЛСПМгШЈЦНОљМлИёЃЉЪЧвЛИіЗЧГЃживЊЕФОМУбЇСПЃЌДњБэзХН№ШкзЪВњЕФЁАЦНОљЁБМлИёЁЃ
ФГИіМлИёЕФГЩНЛСПдНДѓЃЌИУМлИёЫљеМЕФШЈжиОЭдНДѓЁЃVWAPОЭЪЧвдГЩНЛСПЮЊШЈжиМЦЫуГіРДЕФМгШЈЦНОљжЕЁЃ
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (6,7),
unpack = True
)
endPrice,turnover = np.loadtxt(**params)
print(np.average(endPrice))
print(np.average(endPrice,weights=turnover)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
ГЩНЛСПМгШЈЦНОљМлИё.png
ДгЩЯУцЕФдЫааНсЙћПЩвдПДГіЃК
1.Ждгкnumpy.averageЗНЗЈЃЌЪЧЗёМгШЈжиweightsЃЌНсЙћЛсгаЧјБ№ЁЃ
2.ШчЙћnumpy.averageЗНЗЈУЛгаweightsВЮЪ§ЃЌгыnumpy.meanЗНЗЈаЇЙћЯрЭЌЁЃ
3.ОЙ§зїепЪЕбщЃЌnp.mean(endPrice)КЭendPrice.mean()аЇЙћЯрЭЌЁЃ
3.2 МЦЫузюДѓжЕКЭзюаЁжЕ
ЪЙгУЗНЗЈЃКnumpy.max(highPrice)КЭhighPrice.max()ЯрЭЌ
numpy.min(lowPrice)КЭlowPrice.min()ЯрЭЌ
МЦЫуЙЩМлНќЦкзюИпМлЕФзюДѓжЕКЭзюЕЭМлЕФзюаЁжЕ
зюИпМлЮЛгкexcelжаЕФЕк4СаЃЌзюЕЭМлЮЛгкexcelжаЕФЕк5СаЃЌЫљвдusecols=(4,5)
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (4,5),
unpack = True
)
highPrice,lowPrice = np.loadtxt(**params)
print("max=",highPrice.max())
print("min=",lowPrice.min()) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
max= 364.9
min= 333.53
3.3 МЦЫуМЋВю
ЪЙгУЗНЗЈЃКnumpy.ptp(highPrice)КЭhighPrice.ptp()ЯрЭЌ
МЦЫуЙЩМлНќЦкзюИпМлЕФзюДѓжЕКЭзюаЁжЕЕФВюжЕ
МЦЫуЙЩМлНќЦкзюЕЭМлЕФзюДѓжЕКЭзюаЁжЕЕФВюжЕ
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (4,5),
unpack = True
)
highPrice,lowPrice = np.loadtxt(**params)
print("max - min of high price:", highPrice.ptp())
print("max - min of low price:", lowPrice.ptp()) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
max - min of high price: 24.859999999999957
max - min of low price: 26.970000000000027
3.4МЦЫужаЮЛЪ§
ЪЙгУЗНЗЈЃКВЛФмЪЙгУendPrice.median()ЃЌПЩвдЪЙгУnumpy.median(endPrice)
МЦЫуЪеХЬМлЕФжаЮЛЪ§
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
print("median =",np.median(endPrice)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
median = 352.055
3.5МЦЫуЗНВю
ЪЙгУЗНЗЈЃКendPrice.var()КЭnumpy.var(endPrice)аЇЙћЯрЭЌ
МЦЫуЪеХЬМлЕФЗНВю
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
print("variance =",np.var(endPrice))
print("variance =",endPrice.var()) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
variance = 50.126517888888884
variance = 50.126517888888884
3.6МЦЫуЙЩЦБЪевцТЪЁЂФъВЈЖЏТЪМАдТВЈЖЏТЪ
дкЭЖзЪбЇжаЃЌВЈЖЏТЪЪЧЖдМлИёБфЖЏЕФвЛжжЖШСПЃЌРњЪЗВЈЖЏТЪПЩвдИљОнРњЪЗМлИёЪ§ОнМЦЫуЕУГіЁЃМЦЫуРњЪЗВЈЖЏТЪЪБЃЌашвЊгУЕНЖдЪ§ЪевцТЪЁЃ
ФъВЈЖЏТЪЕШгкЖдЪ§ЪевцТЪЕФБъзМВюГ§вдЦфОљжЕЃЌдйГЫвдНЛвзШеЕФЦНЗНИљЃЌЭЈГЃНЛвзШеШЁ252ЬьЁЃ
дТВЈЖЏТЪЕШгкЖдЪ§ЪевцТЪЕФБъзМВюГ§вдЦфОљжЕЃЌдйГЫвдНЛвздТЕФЦНЗНИљЁЃЭЈГЃНЛвздТШЁ12дТЁЃ
ЯТУцДњТыжаЧѓЕУЖдЪ§ЪевцТЪИГжЕИј
import numpy
as np
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = 6,
)
endprice = np.loadtxt(**params)
logReturns = np.diff(np.log(endPrice))
annual_volatility = logReturns.std()/logReturns.mean()*np.sqrt(252)
monthly_volatility = logReturn.std()/logReturns.mean()*np.sqrt(12)
print("ФъВЈЖЏТЪ",annual_volatility)
print("дТВЈЖЏТЪ",monthly_volatility |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
ФъВЈЖЏТЪ 129.27478991115134
дТВЈЖЏТЪ 28.210071915112593
4.ЦфЫћГЃгУКЏЪ§
4.1 МЦЫуНзГЫ
import numpy
as np
a = np.arange(1,8)
print("a is:", a)
print("a.prod is:", a.prod())
print("a.cumprod is:", a.cumprod()) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
a is: [1 2 3 4 5 6 7]
a.prod is: 5040
a.cumprod is: [ 1 2 6 24 120 720 5040]
4.2 аоМє
РћгУndarrayЖдЯѓЕФclipЗНЗЈЃЌНЋЫљгаБШИјЖЈжЕЛЙДѓЕФдЊЫиШЋВПЩшЮЊИјЖЈЕФзюДѓжЕЃЌНЋЫљгаБШИјЖЈжЕЛЙаЁЕФдЊЫиШЋВПЩшЖЈЮЊИјЖЈЕФзюаЁжЕЁЃ
import numpy
as np
a = np.arange(1,20)
print("a is:",a)
print("a.clip(5,15) is:",a.clip(5,15)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
a is: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19]
a.clip(5,15) is: [ 5 5 5 5 5 6 7 8 9 10 11 12 13 14
15 15 15 15 15]
4.3 бЙЫѕ
бЁГіndarrayЖдЯѓжаТњзуЬѕМўЕФЪ§
import numpy
as np
a = np.arange(1,20)
print("a is:",a)
print("a>10 is:", a>10)
print("a[a>10] is:",a[a>10])
print("a.compress(a>10 is:", a.compress(a>10)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
a is: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
18 19]
a>10 is: [False False False False False False False
False False False True True
True True True True True True True]
a[a>10] is: [11 12 13 14 15 16 17 18 19]
a.compress(a>10 is: [11 12 13 14 15 16 17 18 19]
ДгдЫааНсЙћПЩвдПДГіa[a>10]КЭa.compress(a>10)аЇЙћЯрЭЌЃЌa>10ЪЧдЊЫиЮЊВМЖћboolЕФndarrayЖдЯѓЁЃ
СЗЯА
СЗЯА1.ЙЩЦБЭГМЦЗжЮі
ЮФМўжаЕФЪ§ОнЮЊИјЖЈЪБМфЗЖЮЇФкФГЙЩЦБЕФЪ§ОнЃЌЯжвЊЧѓЃК
1.ЛёШЁИУЪБМфЗЖЮЇФкНЛвзШежмвЛЁЂжмЖўЁЂжмШ§ЁЂжмЫФЁЂжмЮхЗжБ№ЖдгІЕФЦНОљЪеХЬМл
2.ЦНОљЪеХЬМлзюЕЭЃЌзюИпЗжБ№ЮЊаЧЦкМИ
import numpy
as np
import datetime
def dateStr2num(s):
s = s.decode("utf-8")
return datetime.datetime.strptime(s, "%d-%m-%Y").weekday()
params = dict(
fname = "data.csv",
delimiter = ',',
usecols = (1,6),
converters = {1:dateStr2num},
unpack = True
)
date, closePrice = np.loadtxt(**params)
average = []
for i in range(5):
average.append(closePrice[date==i].mean())
print("аЧЦк%dЕФЦНОљЪеХЬМлЮЊ:" %(i+1), average[i])
print("\nЦНОљЪеХЬМлзюЕЭЪЧаЧЦк%d" %(np.argmin(average)+1))
print("ЦНОљЪеХЬМлзюИпЪЧаЧЦк%d" %(np.argmax(average)+1)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
аЧЦк1ЕФЦНОљЪеХЬМлЮЊ: 351.7900000000001
аЧЦк2ЕФЦНОљЪеХЬМлЮЊ: 350.63500000000005
аЧЦк3ЕФЦНОљЪеХЬМлЮЊ: 352.1366666666666
аЧЦк4ЕФЦНОљЪеХЬМлЮЊ: 350.8983333333333
аЧЦк5ЕФЦНОљЪеХЬМлЮЊ: 350.0228571428571
ЦНОљЪеХЬМлзюЕЭЪЧаЧЦк5
ЦНОљЪеХЬМлзюИпЪЧаЧЦк3
СЗЯА2. offerЕФбЁдё
аЁУїНгЪеЕНСНМвЙЋЫОЕФofferЃЌОРНсИУШЅФФМв?
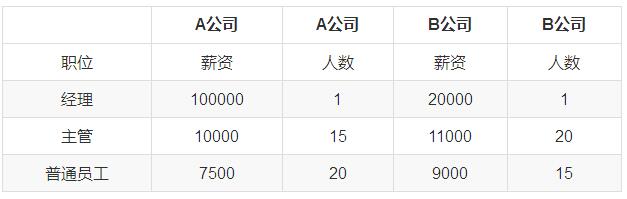
companyA = np.array([100000]
+ [10000] * 15 + [7500] * 20)
companyB = np.array([20000] + [11000] * 20 + [9000]
* 15)
print("ДјШЈЦНОљжЕЖдБШЃК")
print("AЙЋЫОЃК%.2f" %companyA.mean(),"BЙЋЫОЃК%.2f"
%companyB.mean())
print("жаЮЛЪ§ЖдБШЃК")
print("AЙЋЫОЃК",np.median(companyA),"BЙЋЫОЃК",np.median(companyB)) |
ЩЯУцвЛЖЮДњТыЕФдЫааНсЙћШчЯТЃК
ДјШЈЦНОљжЕЖдБШЃК
AЙЋЫОЃК11111.11 BЙЋЫОЃК10416.67
жаЮЛЪ§ЖдБШЃК
AЙЋЫОЃК 7500.0 BЙЋЫОЃК 11000.0
ДгЩЯУцЕФЗжЮіПЩвдПДГіЃЌBЙЋЫОЙЄзЪЕФжаЮЛЪ§ИќДѓЁЃ
ЫљвдзїЮЊвЛУћЦеЭЈдБЙЄЃЌаЁУїгІИУбЁдёШЅBЙЋЫОЁЃ
|









