| БрМЭЦМі: |
| БОЮФРДдДcsdnЃЌБОЮФжївЊНщЩмЛЈЪНЫїв§КЭВМЖћаЭЫїв§ЩцМАЕНИДжЦВйзїЃЌЦфЫћЕФЖМЪЧЗЕЛидДЪ§ОнЕФЪгЭМЁЃ |
|
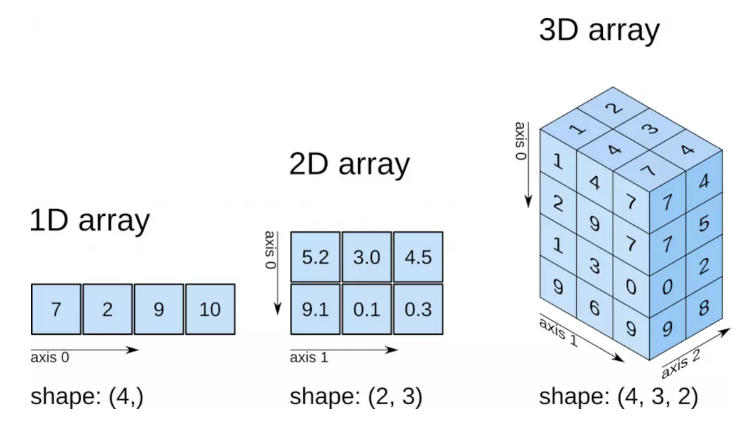
NumPyЃЈNumerical PythonЕФЛљДЁЃЉЪЧИпадФмПЦбЇМЦЫуКЭЪ§ОнЗжЮіЕФЛљДЁАќЁЃЦфВПЗжЙІФмШчЯТЃК
1.ndarrayЃЌвЛИіОпгаЪИСПЫуЪѕдЫЫуКЭИДдгЙуВЅФмСІЕФПьЫйЧвНкЪЁПеМфЕФЖрЮЌЪ§зщЁЃ
2.гУгкЖдЪ§зщЪ§ОнНјааПьЫйдЫЫуЕФБъзМЪ§бЇКЏЪ§ЃЈЮоађБраДбЛЗЃЉЁЃ
3.гУгкЖСаДДХХЬЪ§ОнЕФЙЄОпМАЦфгУгкВйзїФкДцгГЩфЮФМўЕФЙЄОпЁЃ
4.ЯпадДњЪ§ЁЂЫцЛњЪ§ЩњГЩвдМАИЕРявЖБфЛЛЙІФмЁЃ
5.гУгкМЏГЩгЩCЁЂC++ЁЂFortranЕШгябдБраДЕФДњТыЕФЙЄОпЁЃ
ДДНЈndarray
ДДНЈЪ§зщзюМђЕЅЕФАьЗЈОЭЪЧЪЙгУarrayКЏЪ§ЁЃЫќНгЪмвЛЧаађСааЭЕФЖдЯѓЃЈАќРЈЦфЫћЪ§зщЃЉЃЌШЛКѓВњЩњвЛИіаТЕФКЌгаДЋШыЪ§ОнЕФNumPyЪ§зщЁЃ
СаБэЕФзЊЛЛЃК
| data1
= [6,7.5,8,0,1]
arr1 = np.array(data1)
# array([ 6. , 7.5, 8. , 0. , 1. ]) |
ЧЖЬзађСаЃЈБШШчгЩвЛзщЕШГЄСаБэзщГЩЕФСаБэЃЉНЋЛсБЛзЊЮЊвЛИіЖрЮЌЪ§зщЃК
| data2
= [[1,2,3,4],[5,6,7,8]]
arr2 = np.array(data2)
# array([[1, 2, 3, 4],
# [5, 6, 7, 8]]) |
data2ЪЧвЛИіlist of lists, Ыљвдarr2ЮЌЖШЮЊ2ЁЃЮвУЧФмгУndimКЭshapeЪєадРДШЗШЯвЛЯТЃК
Г§ЗЧжїЖЏЩљУїЃЌЗёдђnp.arrayЛсздЖЏИјdataДюХфЪЪКЯЕФРраЭЃЌВЂБЃДцдкdtypeРяЃК
| arr1.dtype
# dtype('float64') |
| arr2.dtype
# dtype('int64') |
Г§СЫnp.arrayЃЌЛЙгавЛаЉЦфЫћКЏЪ§ФмДДНЈЪ§зщЁЃБШШчzeros,ones,СэЭтЛЙПЩвддквЛИіtupleРяжИЖЈshapeЃК
| np.zeros(10)
# array([ 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.]) |
| np.zeros((3,6))
# array([[ 0., 0., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 0., 0.]]) |
| np.empty((2,3,2))
# array([[[ 0.00000000e+000, 0.00000000e+000],
# [ 2.16538378e-314, 2.16514681e-314],
# [ 2.16511832e-314, 2.16072529e-314]],
# [[ 0.00000000e+000, 0.00000000e+000],
# [ 2.14037397e-314, 6.36598737e-311],
# [ 0.00000000e+000, 0.00000000e+000]]])
|
np.emptyВЂВЛФмБЃжЄЗЕЛиЫљгаЪЧ0ЕФЪ§зщЃЌФГаЉЧщПіЯТЃЌЛсЗЕЛиЮЊГѕЪМЛЏЕФРЌЛјЪ§жЕЃЌШчЩЯЁЃ
arangeЪЧвЛИіЪ§зщАцЕФpython rangeКЏЪ§ЃК
| np.arange(15)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14]) |
вЛаЉДДНЈЪ§зщЕФКЏЪ§ЃК
ndarrayЕФЪ§ОнРраЭ
dtypeБЃДцЪ§ОнЕФРраЭЃК
| arr1
= np.array([1, 2, 3], dtype=np.float64)
arr2 = np.array([1, 2, 3], dtype=np.int32)
arr1.dtype
# dtype('float64')
arr2.dtype
# dtype('int32')
|
dtypeВХЪЧnumpyФмСщЛюДІРэЦфЫћЭтНчЪ§ОнЕФдвђЁЃ


ПЩвдгУastypeРДзЊЛЛРраЭЃК
| arr
= np.array([1, 2, 3, 4, 5])
arr.dtype
# dtype('int64')
float_arr = arr.astype(np.float64)
float_arr.dtype
# dtype('float64') |
ЩЯУцЪЧАбintБфЮЊfloatЁЃШчЙћЪЧАбfloatБфЮЊintЃЌаЁЪ§ЕуКѓЕФВПЗжЛсБЛЖЊЦњЃК
| arr
= np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
arr
# array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
arr.astype(np.int32)
# array([ 3, -1, -2, 0, 12, 10], dtype=int32
|
ЛЙПЩвдгУastypeАбstringРяЕФЪ§зжБфЮЊЪЕМЪЕФЪ§зжЃК
| numeric_strings
= np.array(['1.25', '-9.6', '42'], dtype=np.string_)
numeric_strings
# array([b'1.25', b'-9.6', b'42'],
# dtype='|S4')
numeric_strings.astype(float)
# array([ 1.25, -9.6 , 42. ])
|
вЊЪЎЗжзЂвтnumpy.string_РраЭЃЌетжжРраЭЕФГЄЖШЪЧЙЬЖЈЕФЃЌЫљвдПЩФмЛсжБНгНиШЁВПЗжЪфШыЖјВЛИјОЏИцЁЃ
ШчЙћзЊЛЛЃЈcastingЃЉЪЇАмЕФЛАЃЌЛсИјГівЛИіValueErrorЬсЪОЁЃ
ПЩвдгУЦфЫћЪ§зщЕФdtypeжБНгРДжЦЖЈРраЭЃК
| int_array
= np.arange(10)
calibers = np.array([.22, .270, .357, .380,
.44, .50], dtype=np.float64)
int_array.astype(calibers.dtype)
# array([ 0., 1., 2., 3., 4., 5., 6., 7., 8.,
9.])
|
ЛЙПЩвдРћгУРраЭЕФЫѕаДЃЌБШШчu4ОЭДњБэunit32ЃК
| empty_unit32
= np.empty(8, dtype='u4')
empty_unit32
# array([0, 0, 0, 0, 0, 0, 0, 0], dtype=uint32) |
astypeзмЪЧЛсЗЕЛивЛИіаТЕФЪ§зщЁЃ
Ъ§зщКЭБъСПжЎМфЕФдЫЫу
Ъ§зщКмживЊЃЌвђЮЊЫќЪЙФуВЛгУБраДбЛЗМДПЩЖдЪ§ОнжДааХњСПдЫЫуЁЃНазіЪИСПЛЏЁЃДѓаЁЯрЕШЕФЪ§зщжЎМфЕФШЮКЮЫуЪѕдЫЫуЖМЛсНЋдЫЫугІгУЕНдЊЫиМЖЃК
| arr
= np.array([[1., 2., 3.], [4., 5., 6.]])
arr
# array([[ 1., 2., 3.],
# [ 4., 5., 6.]]
arr * arr
# array([[ 1., 4., 9.],
# [ 16., 25., 36.]])
arr - arr
# array([[ 0., 0., 0.],
# [ 0., 0., 0.]])
|
Ъ§зщгыБъСПЕФЫуЪѕдЫЫувВЛсНЋФЧИіБъСПжЕДЋВЅЕНИїИідЊЫи:
| 1
/ arr
# array([[ 1. , 0.5 , 0.33333333],
# [ 0.25 , 0.2 , 0.16666667]])
arr ** 0.5
# array([[ 1. , 1.41421356, 1.73205081],
# [ 2. , 2.23606798, 2.44948974]])
|
ВЛЭЌДѓаЁЕФЪ§зщжЎМфЕФдЫЫуНазіЙуВЅЃЈbroadcastingЃЉЁЃ
ЛљБОЕФЫїв§КЭЧаЦЌ
NumPyЪ§зщЕФЫїв§бЁШЁЪ§ОнзгМЏЛђЕЅИідЊЫиЕФЗНЪНгаКмЖрЁЃвЛЮЌЪ§зщКЭPythonСаБэЙІФмВюВЛЖрЃК
| arr
= np.arange(10)
arr
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5]
# 5
arr[5:8]
# array([5, 6, 7])
arr[5:8] = 12
arr
# array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
|
ЕБФуНЋвЛИіБъСПжЕИГИјвЛИіЧаЦЌЪБЃЈШчarr[5:8]=12ЃЉЃЌИУжЕЛсздЖЏДЋВЅЃЈЁАЙуВЅЁБЃЉЕНећИібЁЧјЁЃКЭPythonСаБэВЛЭЌЕФЪЧЃЌЪ§зщЧаЦЌЪЧдЪМЪ§зщЕФЪгЭМЁЃетвтЮЖзХЪ§ОнВЛЛсБЛИДжЦЃЌШЮКЮаоИФЖМЛсЗДгІЕНдДЪ§зщЩЯЁЃ
| arr_slice
= arr[5:8]
arr_slice
# array([12, 12, 12])
arr_slice[1] = 12345
# array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9])
arr_slice[:] = 64
arr
# array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
|
ШєЯыЕУЕНndarrayЧаЦЌЕФвЛЗнИББОЃЌОЭашвЊЯдЪНЕиНјааИДжЦВйзїЃЌР§Шчarr[5:8].copy()
дквЛИіЖўЮЌЪ§зщжаЃЌИїЫїв§ЮЛжУЩЯЕФдЊЫиВЛдйЪЧБъСПЖјЪЧвЛЮЌЪ§зщЃК
| arr2d
= np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr2d[2]
# array([7, 8, 9]) |
гаСНжжЗНЪНПЩвдЗУЮЪЕЅвЛдЊЫи:
| arr2d[0][2]
# 3
arr2d[0, 2]
# 3 |
ЖўЮЌЪ§зщЕФЫїв§ЗНЪНЃК
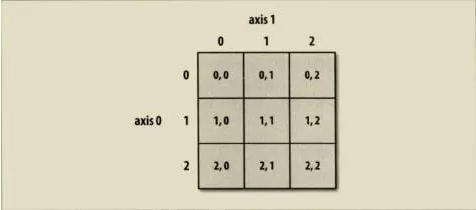
ЖдгкЖрЮЌЪ§зщЃЌШчЙћЪЁТдКѓУцЕФЫїв§ЃЌЗЕЛиЕФНЋЪЧвЛИіЕЭЮГЖШЕФЖрЮЌЪ§зщЁЃР§ШчЃЌвЛИі2
x 2 x 3Ъ§зщ
| arr3d
= np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8,
9], [10, 11, 12]]])
arr3d
# array([[[ 1, 2, 3],
# [ 4, 5, 6]],
# [[ 7, 8, 9],
# [10, 11, 12]]])
|
arr3d[0]ЪЧвЛИі2x3Ъ§зщЃК
| arr3d[0]
# array([[1, 2, 3],
# [4, 5, 6]]) |
БъСПКЭЪ§зщЖМФмИГИјarr3d[0]:
| old_values
= arr3d[0].copy()
arr3d[0] = 42
arr3d
# array([[[42, 42, 42],
# [42, 42, 42]],
# [[ 7, 8, 9],
# [10, 11, 12]]])
arr3d[0] = old_values
arr3d
# array([[[ 1, 2, 3],
# [ 4, 5, 6]],
# [[ 7, 8, 9],
# [10, 11, 12]]])
|
arr3d[1, 0]ЛсИјЗЕЛивЛИі(1, 0)ЕФвЛЮЌЪ§зщЃК
| arr3d[1,
0]
# array([7, 8, 9]) |
зЂвтЃЌЩЯЪібЁШЁЪ§зщзгМЏЕФР§згЗЕЛиЕФЖМЪЧЪгЭМЃЈВЛЪЧИББОЃЌЪЧБОз№ЃЉЁЃ
ЧаЦЌЫїв§
ndarrayЕФЧаЦЌгяЗЈКЭPythonСаБэетбљЕФвЛЮЌЖдЯѓВюВЛЖрЁЃ
ИпЮЌЖдЯѓПЩвддйвЛИіЛђЖрИіжсЩЯНјааЧаЦЌЃЌвВПЩвдИњећЪ§Ыїв§ЛьКЯЪЙгУЁЃ
| arr2d
# array([[1,2,3],
# [4,5,6]
# [7,8,9]])
arr2d[:2]
# array([[1,2,3],
# [4,5,6]]) |
ПЩвдПДГіЃЌЫќЪЧбизХaxis 0ЃЈааЃЉРДДІРэЕФЁЃПЩвдвЛДЮДЋШыЖрИіЧаЦЌЃЌОЭЯёДЋШыЖрИіЫїв§ФЧбљЃК
| arr2d[:2,
1:]
# array([[2, 3],
# [5, 6]]) |
ШчДЫЧаЦЌЃЌжЛФмЕУЕНЯрЭЌЮЌЪ§ЕФЪ§зщЪгЭМЁЃЁЃНЋећЪ§Ыїв§КЭЧаЦЌЛьКЯЃЌПЩвдЕУЕНЕЭЮГЖШЧаЦЌЃК
| arr2d[1,
:2]
# array([4, 5]) |
зЂвтЃЌжЛгаУАКХБэЪОбЁШЁећИіжсЃЌР§ШчЃК
| arr2d[:,
:1]
# array([[1],
# [4],
# [7]]) |
ЖдЧаЦЌБэДяЪНЕФИГжЕВйзївВЛсРЉЩЂЕНећИібЁЧјЃК
| arr2d[:2,
1:] = 0
arr2d
# array([[1, 0, 0],
# [4, 0, 0],
# [7, 8, 9]]) |
ВМЖћаЭЫїв§
МйЩшЮвУЧгавЛИігУгкДцДЂЪ§ОнЕФЪ§зщвдМАвЛИіДцДЂаеУћЕФЪ§зщЃЈКЌгажиИДЯюЃЉЁЃБШШчЫЕЃК
| names
= np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will',
'Joe', 'Joe'])
names
# array(['Bob', 'Joe', 'Will', 'Bob', 'Will',
'Joe', 'Joe'],
# dtype='<U4')
data = np.random.randn(7, 4)
data
# array([[ 0.06226591, -0.27507719, 0.39229467,
1.0592541 ],
# [ 0.29856009, -0.287806 , -1.06875432, -0.33292789],
# [-0.48500348, -0.10072345, -1.76972263, -0.27355081],
# [ 0.23004649, -0.76163183, 0.24673954, -0.47700137],
# [ 1.54353606, -0.17964118, -0.7093982 , -1.55488714],
# [ 0.17778785, 1.25049472, 1.92926838, 0.49794146],
# [ 0.11571349, -1.28075539, -1.15407468, 0.86778147]])
|
МйЩшУПИіУћзжЖдгІdataЪ§зщжаЕФвЛааЃЌЮвУЧЯывЊбЁГіЖдгІгкУћзж'Bob'ЕФЫљгаааЁЃКЭЫуЪѕдЫЫувЛбљЃЌЪ§зщЕФБШНЯдЫЫуЃЈШч==ЃЉвВЪЧЪИСПЛЏЕФЁЃвђДЫЃЌЖдnamesКЭзжЗћДЎЁАBobЁБЕФБШНЯдЫЫуЛсВњЩњвЛИіВМЖћаЭЪ§зщЃК
| names
== 'Bob'
# array([ True, False, False, True, False,
False, False], dtype=bool) |
ВМЖћаЭЪ§зщПЩгУгкЪ§зщЫїв§ЃК
| data[names
== 'Bob']
# array([[ 0.02584271, -1.53529621, 0.73143988,
-0.34086189],
# [-0.48632936, 0.63817756, -0.40792716, -1.48037389]])
|
ВМЖћаЭЪ§зщЕФГЄЖШБиаыИњБЛЫїв§ЕФжсГЄЖШвЛжТЁЃЛЙПЩвдНЋВМЖћаЭЪ§зщИњЧаЦЌЁЂећЪ§ЃЈЛђећЪ§ађСаЃЉЛьКЯЪЙгУЃК
| data[names
== 'Bob', 2:]
# array([[ 0.73143988, -0.34086189],
# [-0.40792716, -1.48037389]])
data[names == 'Bob', 3]
# array([-0.34086189, -1.48037389])
|
бЁжаГ§СЫ'Bob'ЭтЕФЫљгаааЃЌПЩвдгУ!=Лђеп~ЃК
| names
!= 'Bob'
# array([False, True, True, False, True, True,
True], dtype=bool)
data[~(names == 'Bob')]
# array([[ 0.40864782, 0.53476799, 1.09620596,
0.4846564 ],
# [ 1.95024076, -0.37291038, -0.40424703, 0.30297059],
# [-0.81976335, -1.10162466, -0.59823212, -0.10926744],
# [-0.5212113 , 0.29449179, 2.0568032 , 2.00515735],
# [-2.36066876, -0.3294302 , -0.24464646, -0.81432884]])
|
бЁШЁетШ§ИіУћзжжаЕФСНИіашвЊзщКЯгІгУЖрИіВМЖћЬѕМўЃЌШч&ЃЈгыЃЉЁЂ|ЃЈЛђЃЉжЎРрЕФВМЖћдЫЫуЗћЁЃ
| names
# array(['Bob', 'Joe', 'Will', 'Bob', 'Will',
'Joe', 'Joe'],
# dtype='<U4')
mask = (names == 'Bob') | (names == 'Will')
mask
# array([ True, False, True, True, True, False,
False], dtype=bool)
data[mask]
# array([[ 0.02584271, -1.53529621, 0.73143988,
-0.34086189],
# [ 1.95024076, -0.37291038, -0.40424703, 0.30297059],
# [-0.48632936, 0.63817756, -0.40792716, -1.48037389],
# [-0.81976335, -1.10162466, -0.59823212, -0.10926744]])
|
ЭЈЙ§ВМЖћаЭЫїв§бЁШЁЪ§зщжаЕФЪ§ОнЃЌзмЪЧДДНЈЪ§ОнЕФИББОЃЌМДЪЙЗЕЛивЛУўвЛбљЕФЪ§зщвВЪЧШчДЫЁЃ
ЭЈЙ§ВМЖћаЭЪ§зщЩшжУжЕЪЧвЛжжГЃгУЪжЖЮЃЌЮЊСЫНЋdataжаЕФЫљгаИКжЕЩшжУЮЊ0ЃЌжЛашЃК
| data[data
< 0] = 0
data
# array([[ 0.02584271, 0. , 0.73143988, 0. ],
# [ 0.40864782, 0.53476799, 1.09620596, 0.4846564
],
# [ 1.95024076, 0. , 0. , 0.30297059],
# [ 0. , 0.63817756, 0. , 0. ],
# [ 0. , 0. , 0. , 0. ],
# [ 0. , 0.29449179, 2.0568032 , 2.00515735],
# [ 0. , 0. , 0. , 0. ]])
|
ЭЈЙ§вЛЮЌВМЖћЪ§зщЩшжУећааЛђСаЕФжЕвВКмМђЕЅЃК
| data[names
!= 'Joe'] = 7
data
# array([[ 7. , 7. , 7. , 7. ],
# [ 0.40864782, 0.53476799, 1.09620596, 0.4846564
],
# [ 7. , 7. , 7. , 7. ],
# [ 7. , 7. , 7. , 7. ],
# [ 7. , 7. , 7. , 7. ],
# [ 0. , 0.29449179, 2.0568032 , 2.00515735],
# [ 0. , 0. , 0. , 0. ]])
|
ЛЈЪНЫїв§
ЛЈЪНЫїв§ЪЧвЛИіNumPyЪѕгяЃЌЫќжИЕФЪЧРћгУећЪ§Ъ§зщНјааЫїв§ЁЃМйЩшгавЛИі8 x 4ЕФЪ§зщЃК
| arr
= np.empty((8, 4))
for i in range(8):
arr[i] = i
arr
# array([[ 0., 0., 0., 0.],
# [ 1., 1., 1., 1.],
# [ 2., 2., 2., 2.],
# [ 3., 3., 3., 3.],
# [ 4., 4., 4., 4.],
# [ 5., 5., 5., 5.],
# [ 6., 6., 6., 6.],
# [ 7., 7., 7., 7.]])
|
ЮЊСЫвдЬиЖЈЫГађбЁШЁзгМЏЃЌжЛашДЋШывЛИіжИЖЈЫГађЕФећЪ§СаБэЛђndarrayМДПЩЃК
| arr[[4,
3, 0, 6]]
# array([[ 4., 4., 4., 4.],
# [ 3., 3., 3., 3.],
# [ 0., 0., 0., 0.],
# [ 6., 6., 6., 6.]])
|
ЪЙгУИКЪ§Ыїв§НЋДгФЉЮВПЊЪМбЁааЃК
| arr[[-3,
-5, -7]]
# array([[ 5., 5., 5., 5.],
# [ 3., 3., 3., 3.],
# [ 1., 1., 1., 1.]]) |
вЛДЮВєШыЖрИіЫїв§Ъ§зщЛсгавЛЕуЬиБ№ЁЃЦфЗЕЛиЕФЪЧвЛИівЛЮЌЪ§зщЃЌЦфжаЕФдЊЫиЖдгІИїИіЫїв§дЊзщЃК
| arr
= np.arange(32).reshape((8, 4))
arr
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23],
3 [24, 25, 26, 27],
# [28, 29, 30, 31]])
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
# array([ 4, 23, 29, 10])
|
вдПДЕН[ 4, 23, 29, 10]ЗжБ№ЖдгІ(1, 0), (5, 3), (7, 1), (2,
2)ЁЃВЛТлЪ§зщгаЖрЩйЮЌЃЌЛЈЪНЫїв§ЕФНсЙћзмЪЧвЛЮЌЁЃбЁШЁОиеѓЕФааСазгМЏПЩвдЪЙгУШчЯТЗНЪНЃК
| arr[[1,
5, 7, 2]][:, [0, 3, 1, 2]]
# array([[ 4, 7, 5, 6],
# [20, 23, 21, 22],
# [28, 31, 29, 30],
# [ 8, 11, 9, 10]])
|
ЩЯУцЕФвтЫМЪЧЃЌЯШДгarrжабЁГі[1, 5, 7, 2]етЫФааЃК
| array([[
4, 5, 6, 7],
[20, 21, 22, 23],
[28, 29, 30, 31],
[ 8, 9, 10, 11]]) |
ШЛКѓ[:, [0, 3, 1, 2]]БэЪОбЁжаЫљгаааЃЌЕЋЪЧСаЕФЫГађвЊАД0,3,1,2РДХХЁЃгкЪЧЕУЕНЃК
| array([[
4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]]) |
ЛЈЪНЫїв§ИњЧаЦЌВЛЭЌЃЌзмЪЧНЋЪ§ОнИДжЦЕНаТЪ§зщжаЁЃ
Ъ§зщзЊжУКЭжсЖдЛЛ
зЊжУЪЧжиЫмЕФвЛжжЬиЪтаЮЪНЃЌЦфЗЕЛидДЪ§ОнЕФЪгЭМЃЈВЛЛсНјааШЮКЮИДжЦВйзїЃЉЁЃгаСНжжЗНЪНЃЌвЛЪЧtransposeЗНЗЈЃЌЖўЪЧTЪєадЁЃ
| arr
= np.arange(15).reshape((3, 5))
arr
# array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
arr.T
# array([[ 0, 5, 10],
# [ 1, 6, 11],
# [ 2, 7, 12],
# [ 3, 8, 13],
# [ 4, 9, 14]])
|
дйНјааОиеѓМЦЫуЪБЃЌГЃашвЊИУВйзїЃЌШчРћгУnp.dotМЦЫуФкЛ§ЃК
| arr
= np.random.randn(6,3)
np.dot(arr.T,arr)
# array([[ 1.8717599 , -1.66444711, -0.65044072],
# [-1.66444711, 6.02759713, 0.05453921],
# [-0.65044072, 0.05453921, 3.65394036]])
|
ЖдгкИпЮЌЪ§зщЃЌtransposeашвЊЕУЕНвЛИігЩжсБрКХзщГЩЕФдЊзщВХФмЖдетаЉжсНјаазЊжУЃЈБШНЯЗбВщПЫРЃЉЃК
| arr
= np.arange(16).reshape((2, 2, 4))
arr
# array([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7]],
# [[ 8, 9, 10, 11],
# [12, 13, 14, 15]]])
arr.transpose((1, 0, 2))
# array([[[ 0, 1, 2, 3],
# [ 8, 9, 10, 11]],
# [[ 4, 5, 6, 7],
# [12, 13, 14, 15]]])
|
ЦфЪЕОЭЪЧАбдБОЕФжсАДдЊзщРяЕФФкШнжиХХвЛЯТЁЃМђЕЅЕФзЊжУПЩвдгУ.TЁЃndarrayЛЙгавЛИіswapaxesЗНЗЈЃЌашвЊНгЪмвЛЖджсБрКХЃК
| arr
# array([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7]],
# [[ 8, 9, 10, 11],
# [12, 13, 14, 15]]])
arr.swapaxes(1, 2)
# array([[[ 0, 4],
# [ 1, 5],
# [ 2, 6],
# [ 3, 7]],
# [[ 8, 12],
# [ 9, 13],
# [10, 14],
# [11, 15]]])
|
swapaxesвВЪЧЗЕЛиЪ§ОнЕФЪгЭМЃЈВЛЛсНјааШЮКЮИДжЦВйзїЃЉЁЃ
|









