| БрМЭЦМі: |
| БОЮФРДздгкЭјТч,ЮФеТжївЊНщЩмСЫPandsЪ§ОнНсЙЙЃЌВЂЖдSeriesКЭDataFrameНјааСЫЯъЯИВћЪіЁЃ |
|
PandasЪЧЪВУДЃП
1ЁЂвЛИіЧПДѓЕФЗжЮі НсЙЙЛЏЪ§Он ЕФЙЄОпМЏ
2ЁЂЛљДЁЪЧNumPyЃЌЬсЙЉСЫ ИпадФмОиеѓ ЕФдЫЫу
3ЁЂгІгУдкЪ§бЇЭкОђЃЌЪ§ОнЗжЮіЁЃБШШчЃЌбЇЩњГЩМЈЗжЮіЃЌЙЩЦБЪ§ОнЗжЮіЕШ
4ЁЂЬсЙЉЪ§ОнЧхЯДЙІФм
#ЪЙгУ
import pandas as pd |
PandsЪ§ОнНсЙЙЃЌжївЊЗжЮЊСНжжЃЌSeriesКЭDataFrame
Series
1ЁЂРрЫЦвЛЮЌЪ§зщЕФЖдЯѓ
2ЁЂЭЈЙ§listЙЙНЈSeries
ser_obj = pd.Series(rang(10))
3ЁЂгЩЪ§ОнКЭЫїв§зщГЩ
Ыїв§дкзѓЃЌЪ§Ондкгв
Ыїв§ЪЧздЖЏДДНЈЕФ
4ЁЂЛёШЁЪ§ОнКЭЫїв§
ser_obj.index
ser_obj.values |
5ЁЂдЄРРЪ§Он(ШЁЧАМИИі)
ser_obj.head(n)
6ЁЂЭЈЙ§Ыїв§ЛёШЁЪ§Он

7ЁЂЫїв§гыЪ§ОнЕФЖдгІЙиЯЕШдБЃГждкЪ§зщдЫЫуЕФНсЙћжаЃЈЙ§ТЫseriesжаЕФЪ§ОнЃЉ
| print(ser_obj[ser_obj
> 15]) |
8ЁЂЭЈЙ§dictЙЙНЈSeries
year_data =
{2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data)
print(ser_obj2.head())
print(ser_obj2.index)
ser_obj2.name = 'temp'
#жИЖЈnameУћГЦЃЈЯрЕБгкБэЭЗЃЉ
ser_obj2.index.name = 'year'
print(ser_obj2.head())
=================================
2001 17.8
2002 20.1
2003 16.5
dtype: float64
Int64Index([2001, 2002, 2003], dtype='int64')
year
2001 17.8
2002 20.1
2003 16.5
Name: temp, dtype: float64 |
DataFrame
1ЁЂРрЫЦЖрЮЌЪ§зщ/БэИёЪ§Он
2ЁЂУПСаЪ§ОнПЩвдЪЧВЛЭЌЕФРраЭ
3ЁЂЫїв§АќРЈааЫїв§КЭСаЫїв§ 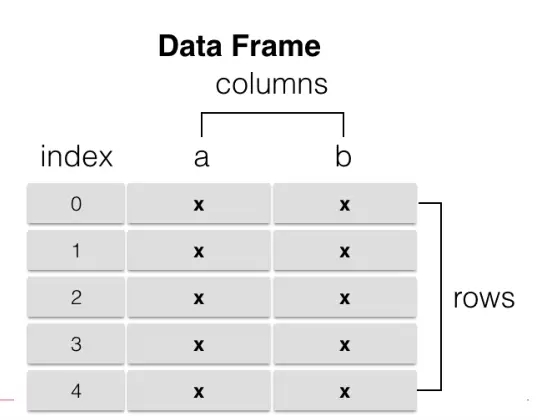
import numpy
as np
# ЭЈЙ§ndarrayЙЙНЈDataFrame
array = np.random.randn(5,4)
print(array)
df_obj = pd.DataFrame(array)
print(df_obj)
# ЭЈЙ§dictЙЙНЈDataFrame
dict_data = {'A': 1.,
'B': pd.Timestamp('20161217'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["Python","Java","C++","C#"]),
'F' : 'ChinaHadoop' }
#print dict_data
df_obj2 = pd.DataFrame(dict_data)
print(df_obj2.head())
# ЭЈЙ§СаЫїв§ЛёШЁСаЪ§Он(dataFrameгХЯШЭЈЙ§СаЫїв§ЗУЮЪЪ§Он)
print(df_obj2['A'])
#ЭЈЙ§Ыїв§ЗУЮЪЪ§Он
print(df_obj2.values[2])
#УПСаЖМЪЧвЛИіseries
print(type(df_obj2['A']))
#ЭЈЙ§ЖдЯѓЪєадЗУЮЪ
print(df_obj2.A)
# діМгСаЃЌРрЫЦdictЬэМгkey-value
df_obj2['G'] = df_obj2['D'] + 4
print(df_obj2.head())
# ЩОГ§Са
del(df_obj2['G'] )
print(df_obj2.head()) |
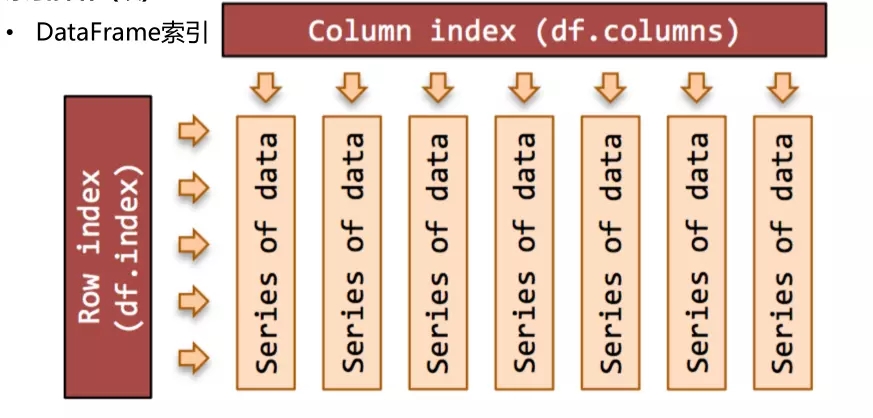
Index Ыїв§ЖдЯѓ
1ЁЂSeriesКЭDataFrameжаЕФЫїв§ЖМЪЧIndexЖдЯѓ
2ЁЂIndexОпгаВЛПЩБфадЃЈimmutableЃЉЃЌМДSeriesКЭDataFrameжаЕФvalueПЩвдИФБфЃЌЕЋЪЧЫїв§ВЛПЩБфЃЌБЃжЄСЫЪ§ОнЕФАВШЋ
3ЁЂГЃМћЕФIndexжжРр
Index Int64Index MultiIndex(ВуМЖЫїв§) DatatimeIndex(ЪБМфДСРраЭ)
print(type(ser_obj.index))
print(type(df_obj2.index))
print(df_obj2.index)
=====================================
<class 'pandas.core.indexes.range.RangeIndex'>
<class 'pandas.core.indexes.numeric.Int64Index'>
Int64Index([0, 1, 2, 3], dtype='int64') |
SeriesЪ§ОнВйзї
import pandas
as pd
#index,жИЖЈЫїв§УћГЦ
ser_obj = pd.Series(range(5), index = ['a', 'b',
'c', 'd', 'e'])
print(ser_obj.head())
# ЭЈЙ§Ыїв§ШЁжЕ ser_obj['label'],ser_obj[pos]
print(ser_obj['a']) //ЭЈЙ§Ыїв§УћШЁжЕ
print(ser_obj[0]) //ЭЈЙ§ЮЛжУЫїв§ШЁжЕ
# ЧаЦЌЫїв§
print(ser_obj[1:3]) // ЧАПЊКѓБеЃЌМДЃЌШЁЕНСНИіжЕ
print(ser_obj['b':'d']) //ЧАБеКѓБеЃЌМДЃЌШЁЕНШ§ИіжЕ
# ВЛСЌајЫїв§
print(ser_obj[[0, 2, 4]]) // ФкВПЪЧlist
print(ser_obj[['a', 'e']]) //ФкВПЪЧlist
# ВМЖћЫїв§
ser_bool = ser_obj > 2
print(ser_bool)
print(ser_obj[ser_bool])
print(ser_obj[ser_obj > 2]) |
DataFrameЪ§ОнВйзї
import numpy
as np
# colmns жИЖЈСаУћ
df_obj = pd.DataFrame(np.random.randn(5,4), columns
= ['a', 'b', 'c', 'd'])
print(df_obj.head())
# СаЫїв§
print('СаЫїв§')
print(df_obj['a']) # ЗЕЛиSeriesРраЭ
print(type(df_obj)) # ЗЕЛиDataFrameРраЭ
# ВЛСЌајЫїв§
print('ВЛСЌајЫїв§')
print(df_obj[['a','c']]) # ЗЕЛиЕквЛСаКЭЕкШ§Са |
Ыїв§ВйзїзмНс
PandasЕФЫїв§ВйзїПЩЙщФЩЮЊ3жж
.locЃКБъЧЉЫїв§ЃЈБъЧЉЕФЧаЦЌЫїв§ЪЧАќКЌФЉЮВЮЛжУЕФЃЌЩЯУцЕФЧАБеКѓБеЃЉ
.iloc: ЮЛжУЫїв§
.ixЃК БъЧЉгыЮЛжУЛьКЯЫїв§
-------------ЯШАДБъЧЉЫїв§ГЂЪдВйзїЃЌШЛКѓдйАДееЮЛжУЫїв§ГЂЪдВйзї
# БъЧЉЫїв§ loc
# Series
print(ser_obj['b':'d'])
print(ser_obj.loc['b':'d'])
# DataFrame
print(df_obj['a'])
print(df_obj.loc[0:2, 'a'])
# ећаЭЮЛжУЫїв§ iloc
print(ser_obj[1:3])
print(ser_obj.iloc[1:3])
# DataFrame
ЕквЛИіВЮЪ§ЃЌБэЪОЕФЪЧЕк1ааКЭЕкЖўааЃЌЕкЖўИі0БэЪОЕФФФвЛСа
print(df_obj.iloc[0:2, 0]) # зЂвтКЭdf_obj.loc[0:2,
'a']ЕФЧјБ№ |
дЫЫугыЖдЦы
АДЫїв§ЖдЦыдЫЫуЃЌУЛЖдЦыЕФЮЛжУВЙNaN
s1 = pd.Series(range(10,
20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
# Series ЖдЦыдЫЫу,SeriesАДааЫїв§ЖдЦыЃЌУЛЖдЦыЕФЮЛжУВЙNaN
print(s1 + s2)
==================================================
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
================================================
import numpy as np
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a',
'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a',
'b', 'c'])
# DataFrameЖдЦыВйзї
print(df1 + df2)
=============================
a b c
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
================================
# ЬюГфЮДЖдЦыЕФЪ§ОнНјаадЫЫу
#ЪЙгУadd,sub,div,mulЃЛЭЌЪБЭЈЙ§fill_valueжИЖЈЬюГфжЕ
s1.add(s2, fill_value = 1)
df1.sub(df2, fill_value = 2.)
# ЬюГфNaN
s3 = s1 + s2
s3_filled = s3.fillna(-1)//АбЫљгаЕФNaNЪЙгУ-1ЬюГф
df3 = df1 + df2
df3.fillna(100, inplace = True)//АбЫљгаЕФNaNЪЙгУ100ЬюГф |
КЏЪ§гІгУ
# Numpy ufunc
КЏЪ§
df = pd.DataFrame(np.random.randn(5,4) - 1)
#ЧѓОјЖджЕЃЌзїгУгкdfжаУПИіЪ§Он
print(np.abs(df))
# ЪЙгУapplyгІгУааЛђСаЪ§Он
#ШчЙћУЛгажИЖЈaxisЗНЯђЃЌФЌШЯАДСаЃЌaxis =0
print(df.apply(lambda x : x.max()))
# жИЖЈжсЗНЯђ
print(df.apply(lambda x : x.max(), axis=1))
# ЪЙгУapplymapгІгУЕНУПИіЪ§Он
f2 = lambda x : '%.2f' % x
print(df.applymap(f2)) |
ХХађ
s4 = pd.Series(range(10,
15), index = np.random.randint(5, size=5))
# Ыїв§ХХађ
s4.sort_index()
df4 = pd.DataFrame(np.random.randn(3, 4),
index=np.random.randint(3, size=3),
columns=np.random.randint(4, size=4))
df4.sort_index(axis=1)
# АДжЕХХађ sort_values(by='label')
df4.sort_values(by=1) |
ДІРэШБЪЇЪ§Он
import numpy
as np
df_data = pd.DataFrame([np.random.randn(3), [1.,
np.nan, np.nan],
[4., np.nan, np.nan], [1., np.nan, 2.]])
df_data.head()
# isnull
df_data.isnull()
# dropna ЖЊЦњШБЪЇЪ§Он
df_data.dropna()
#df_data.dropna(axis=1)
# fillna ЬюГфШБЪЇЪ§Он
df_data.fillna(-100.) |
|









