| БрМЭЦМі: |
| БОЮФРДдДcsdnЃЌБОЮФжївЊЖдPythonЕФЕкШ§ЗНПтPandasЃЌНјааИпадФмвзгУЪ§ОнРраЭКЭЗжЮіЁЃ |
|
1.Pandas МђНщ
1.1 pandasЪЧЪВУД
PandasЪЧPythonЕкШ§ЗНПтЃЌЬсЙЉИпадФмвзгУЪ§ОнРраЭКЭЗжЮіЙЄОп
PandasЛљгкNumPyЪЕЯж ЃЌГЃгыNumPyКЭMatplotlibвЛЭЌЪЙгУ
1.2 pandas vs numpy

2.PandasПтЕФSeriesРраЭ
2.1 SeriesЕФНсЙЙ
| #ЖрЮЌвЛСаЃЌаЮЪНЪЧЃКЫїв§+жЕЁЃЃЈЪЁТдindexЛсздЖЏЩњГЩЃЌДг0ПЊЪМЃЉ
>>> pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
a 1
b 2
c 3
d 4
e 5
dtype: int64 |
2.2 SeriesЕФДДНЈ
SeriesРраЭПЩвдгЩШчЯТРраЭДДНЈЃК
1.PythonСаБэ
2.БъСПжЕ
3.PythonзжЕф
4.ndarray
5.ЦфЫћКЏЪ§ЃЌrange()ЕШ
| #БъСПжЕ
>>> pd.Series(5)
0 5
dtype: int64
#БъСПжЕ+index НсЙћЛсИљОнЫїв§жиаТХХађ
pd.Series(5,index=['a','v','c','d','e'])
a 5
v 5
c 5
d 5
e 5
dtype: int64
#зжЕф
>>> pd.Series({'a':999,'v':888,'c':756,
'd':7,'e':437})
a 999
c 756
d 7
e 437
v 888
dtype: int64
#зжЕф+index
>>>pd.Series({'a':999,'v':888,'c':756,
'd':7,'e':437},index=['a','v'])
a 999
v 888
dtype: int64
#гУndarrayДДНЈ
>>> pd.Series(np.arange(5),index=np.
arange(14,9,-1))
14 0
13 1
12 2
11 3
10 4
dtype: int32 |
SeriesdЕФДДНЈзмНсЃК
1.SeriesРраЭПЩвдгЩШчЯТРраЭДДНЈЃК
2.PythonСаБэЃЌindexгыСаБэдЊЫиИіЪ§вЛжТ
3.БъСПжЕЃЌindexБэДяSeriesРраЭЕФГпДч
4.PythonзжЕфЃЌМќжЕЖджаЕФЁАМќЁБЪЧЫїв§ЃЌindexДгзжЕфжаНјаабЁдёВйзї
5.ndarrayЃЌЫїв§КЭЪ§ОнЖМПЩвдЭЈЙ§ndarrayРраЭДДНЈ
6.ЦфЫћКЏЪ§ЃЌrange()КЏЪ§ЕШ
2.3 SeriesЛљБОВйзї
1.SeriesРраЭАќРЈindexКЭvaluesСНВПЗж
2.SeriesРраЭЕФВйзїРрЫЦndarrayРраЭ
3.SeriesРраЭЕФВйзїРрЫЦPythonзжЕфРраЭ
ЃЈ1ЃЉSeriesЛљБОВйзї
| #SeriesЛљБОВйзї
>>>a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a.index
Index(['a', 'c', 'd', 'e', 'v'], dtype='object')
>>> a.values
array([1, 3, 4, 5, 2], dtype=int64)
#СНЬзЫїв§ВЂДцЃЌЕЋВЛФмЛьгУ
>>> a[['a','v']]
a 1
v 2
dtype: int64
>>> a[[0,4]]
a 1
v 2
dtype: int64
#ЛьгУЃЌвдППЧАЕФЮЊзМ
>>> a[['a',4]]
a 1.0
4 NaN
dtype: float64 |
(2)SeriesРраЭЕФВйзїРрЫЦndarrayРраЭЃК
Ыїв§ЗНЗЈЯрЭЌЃЌВЩгУ [ ]
ПЩвдЭЈЙ§здЖЈвхЫїв§ЕФСаБэНјааЧаЦЌ
ПЩвдЭЈЙ§здЖЏЫїв§НјааЧаЦЌЃЌШчЙћДцдкздЖЈвхЫїв§ЃЌдђвЛЭЌБЛЧаЦЌ
| #ВЩгУ
[]ЧаЦЌ
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a[:3]
a 1
c 3
d 4
dtype: int64
#дкЫїв§ЧАНјаадЫЫу
>>> a[a>a.median()]
d 4
e 5
dtype: int64
#вдздШЛГЃЪ§eЮЊЕзЕФжИЪ§КЏЪ§
>>> np.exp(a)
a 2.718282
c 20.085537
d 54.598150
e 148.413159
v 7.389056
dtype: float64 |
(3)SeriesРраЭЕФВйзї(РрЫЦPython)ЃК
ЭЈЙ§здЖЈвхЫїв§ЗУЮЪ
БЃСєзжinВйзї
ЪЙгУ.get()ЗНЗЈ
| #БЃСєзжin
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> 'a' in a
True
>>> 'v' in a
True
#жЛЦЅХфЫїв§
>>> 1 in a
False |
2.4 SeriesЖдЦыВйзї
| #SeriesРраЭдкдЫЫужаЛсздЖЏЖдЦыВЛЭЌЫїв§ЕФЪ§Он.(МДЖдВЛЦыЃЌОЭЕБШБЪЇЯюДІРэ)
>>> a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> b=pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5})
>>> a+b
a 2.0
b NaN
c 6.0
d 8.0
e 10.0
v NaN
dtype: float64 |
2.5 SeriesЕФnameЪєад
| #SeriesЖдЯѓКЭЫїв§ЖМПЩвдгавЛИіУћзжЃЌДцДЂдкЪєад.nameжа
a=pd.Series({'a':1,'v':2,'c':3,'d':4,'e':5})
>>> a.name
>>> a.name="ОЋжвЬјЫЎЖг"
>>> a.name
'ОЋжвЬјЫЎЖг'
>>> a
a 1
c 3
d 4
e 5
v 2
Name: ОЋжвЬјЫЎЖг, dtype: int64 |
2.6 SeriesаЁНс
SeriesЪЧвЛЮЌДјЁАБъЧЉЁБЪ§зщ
index_0 Ёњ data_a
SeriesЛљБОВйзїРрЫЦndarrayКЭзжЕфЃЌИљОнЫїв§ЖдЦы
3.PandasПтЕФDataFrameРраЭ
3.1 DataFrameНсЙЙ
| #DataFrameЪЧвЛИіБэИёаЭЕФЪ§ОнРраЭЃЌУПСажЕРраЭПЩвдВЛЭЌ
#DataFrameМШгаааЫїв§ЁЂвВгаСаЫїв§
>>> df = pd.DataFrame(np.random.randint(1,10,(4,5)))
>>> df
0 1 2 3 4
0 8 5 4 1 1
1 3 4 2 7 3
2 4 3 8 9 9
3 7 8 9 1 7 |
3.2 DataFrameЕФДДНЈ
DataFrameРраЭПЩвдгЩШчЯТРраЭДДНЈЃК
ndarrayЖдЯѓ
гЩвЛЮЌndarrayЁЂСаБэЁЂзжЕфЁЂдЊзщЛђSeriesЙЙГЩЕФзжЕф
SeriesРраЭ
ЦфЫћЕФDataFrameРраЭ
| #гЩзжЕфДДНЈ
ЃЈздЖЈвхааСаЫїв§ЃЌЛсздЖЏВЙЦыШБЪЇЕФжЕЮЊNANЃЉ
>>> df=pd.DataFrame({'one':pd.Series([1,2,3],index=
['a','v','c']),'two':pd.Series([1,2,3,4,5],index=
['a','b','c','d','e'])})
>>> df
one two
a 1.0 1.0
b NaN 2.0
c 3.0 3.0
d NaN 4.0
e NaN 5.0
v 2.0 NaN
#гЩзжЕф+СаБэДДНЈЁЃЭГвЛindexЃЌГпДчБиаыЯрЭЌ
>>> df=pd.DataFrame({'one':[1,2,3],'two':[2,2,3],'three'
:[3,2,3]},index=['a','b','c'])
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
#Ыїв§ЃЈРрЫЦSeriesЃЌвРОнааСаЫїв§ЃЉ
>>> df['one']['a']
1
>>> df['three']['c']
3 |
3.3 pandasЪ§ОнРраЭВйзїЁЊЁЊжиаТЫїв§
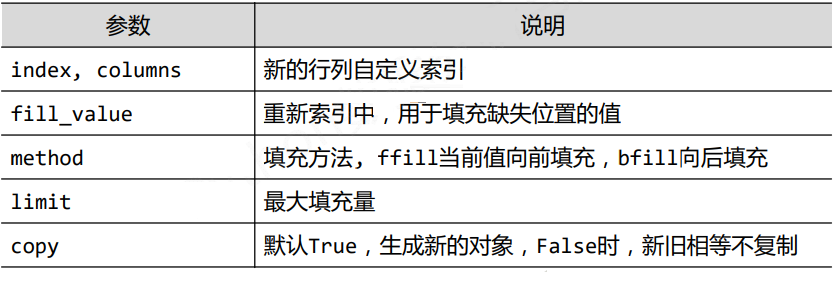
| #гЩa
b cИФЮЊc a b
>>> df.reindex(['c','a','b'])
one three two
c 3 3 3
a 1 3 2
b 2 2 2
#жиХХВЂдіМгСа
>>> df.reindex(columns=['three','two','one','two'])
three two one two
a 3 2 1 2
b 2 2 2 2
c 3 3 3 3
#дЪМЕФЪ§Он
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
#ВхШыСа
>>> newc=df.columns.insert(3,'аТді')
>>> newc
Index(['one', 'three', 'two', 'аТді'], dtype='object')
#ВхШыаТЪ§Он
>>> newd=df.reindex(columns=newc,fill_value=99)
>>> newd
one three two аТді
a 1 3 2 99
b 2 2 2 99
c 3 3 3 99 |
3.4pandasЪ§ОнРраЭВйзїЁЊЁЊЫїв§РраЭ
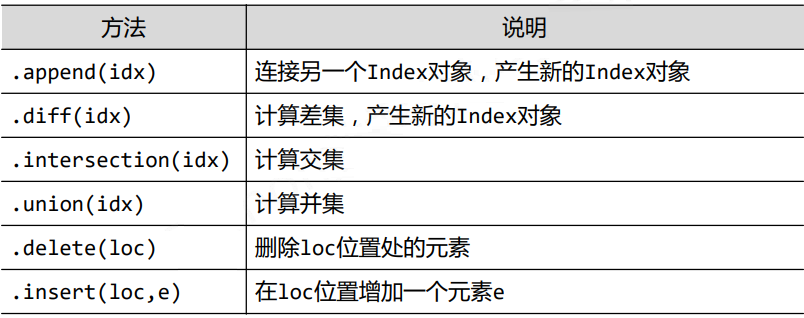
| >>>
df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
>>> nc=df.columns.delete(1)
>>> ni=df.index.insert(3,'new_index')
#ЮоЬюГф
>>> df.reindex(columns=nc,index=ni)
one two
a 1.0 2.0
b 2.0 2.0
c 3.0 3.0
new_index NaN NaN
#гаЬюГф
>>> df.reindex(columns=nc,index=ni,method='ffill')
one two
a 1 2
b 2 2
c 3 3
new_index 3 3
#ЩОГ§ааСа
#ФЌШЯЩО Г§аа
>>> df.drop('b')
one three two
a 1 3 2
c 3 3 3
#жс1ЮЊСа
>>> df.drop('three',axis=1)
one two
a 1 2
b 2 2
c 3 3 |
3.5pandasЪ§ОнРраЭдЫЫуЁЊЁЊЫуЪ§дЫЫу
ЫуЪ§дЫЫуЗЈдђЃК
ЫуЪѕдЫЫуИљОнааСаЫїв§ЃЌВЙЦыКѓдЫЫуЃЌдЫЫуФЌШЯВњЩњИЁЕуЪ§
ВЙЦыЪБШБЯюЬюГфNaN (ПежЕ)
ЖўЮЌКЭвЛЮЌЁЂвЛЮЌКЭСуЮЌМфЮЊЙуВЅдЫЫу
ВЩгУ+ Љ\ * /ЗћКХНјааЕФЖўдЊдЫЫуВњЩњаТЕФЖдЯѓ
ЃЈ1ЃЉВЩгУ+ Љ\ * /ЗћКХНјааЕФЖўдЊдЫЫуЃК
| #гУЗћКХдЫЫуЃЌЮоЗЈДІРэШБЪЇжЕ
>>> df1 =pd.DataFrame({'one':[1,2,3],'two':
[4,5,6]},index=['a','b','c'])
>>> df2 =pd.DataFrame({'one':[1,2,3]},
index=['a','b','c'])
>>> df1+df2
one two
a 2 NaN
b 4 NaN
c 6 NaN |
ЃЈ2ЃЉВЩгУЗНЗЈаЮЪННјааЖўдЊдЫЫуЃК

| >>>
df1 =pd.DataFrame({'one':[1,2,3],'two':[4,5,6]},
index=['a','b','c'])
>>> df2 =pd.DataFrame({'one':[1,2,3]},index=['a','b','c'])
#гУЗНЗЈНјаадЫЫуЃЌПЩбЁВЮЪ§ДІРэШБЪЇжЕ
>>> df1.add(df2,fill_value=0)
one two
a 2 4.0
b 4 5.0
c 6 6.0 |
| #дЫЫуЗНЪН
#жЛЖдЖдгІЮЌЖШМАЖдгІЮЛжУНјаадЫЫуЃЌГЃЪ§дђНјааЙуВЅдЫЫуЁЃ
ЮоЦЅХфЮЛжУЃЌдђжУЮЊNAN
df =pd.DataFrame({'one':[1,2,3],'two':[2,2,3],'three'
:[3,2,3]},index=['a','b','c'])
df3=df=pd.DataFrame({'one':[1,2,3]},index=['a','b','c'])
df4=pd.DataFrame({'two':[2,2,3]},index=['a','b','c'])
#ГЃЪ§
>>> df3-1
one
a 0
b 1
c 2
>>> df -1
one three two
a 0 2 1
b 1 1 1
c 2 2 2
#ЖдгІЮЌЖШ
>>> df3 -df
one three two
a 0 NaN NaN
b 0 NaN NaN
c 0 NaN NaN
>>> df-df4
one three two
a NaN NaN 0
b NaN NaN 0
c NaN NaN 0 |
3.6pandasЪ§ОнРраЭдЫЫуЁЊЁЊБШНЯдЫЫу
ЃЈ1ЃЉЗЈдђ
БШНЯдЫЫужЛФмБШНЯЯрЭЌЫїв§ЕФдЊЫиЃЌВЛНјааВЙЦы
ЖўЮЌКЭвЛЮЌЁЂвЛЮЌКЭСуЮЌМфЮЊЙуВЅдЫЫу
ВЩгУ>ЁЂ<ЁЂ >=ЁЂ <= ЁЂ==ЁЂ !=ЕШЗћКХНјааЕФЖўдЊдЫЫуВњЩњВМЖћЖдЯѓ
| >>>
dfx
one three two
a 1 3 2
b 1 3 2
c 1 3 2
>>> df
one three two
a 1 3 2
b 2 2 2
c 3 3 3
>>> df>dfx
one three two
a False False False
b True False False
c True False True |
4.PandasЪ§ОнРраЭаЁНс
1.ОнРраЭгыЫїв§ЕФЙиЯЕЃЌВйзїЫїв§МДВйзїЪ§Он
2.Series = Ыїв§+ вЛЮЌЪ§Он
3.DataFrame = ааСаЫїв§+ ЖрЮЌЪ§Он
4.жиаТЫїв§ЁЂЪ§ОнЩОГ§ЁЂЫуЪѕдЫЫуЁЂБШНЯдЫЫу
5.ЯёЖдД§ЕЅвЛЪ§ОнвЛбљЖдД§SeriesКЭDataFrameЖдЯѓ |






