| БрМЭЦМі: |
| РДдДВЎРждкЯпЃЌдкетаЉВЉЮФжаЃЌзїепЛсЬжТлвЛаЉЛљДЁжЊЪЖЁЃБШШчШчКЮгУpandasДгбХЛЂВЦОЛёЕУЪ§ОнЃЌ
ПЩЪгЛЏЙЩЪаЪ§ОнЃЌЦНОжЪ§жИБъЕФЖЈвхЃЌЩшМЦвЦЖЏЦНОљНЛЛуЕуЗжЮівЦЖЏЦНОљЯпЕФЗНЗЈЃЌЛиЫнВтЪдЃЌ
ЛљзМЗжЮіЗЈЁЃ |
|
в§бд
Н№ШквЕЪЙгУИпЕШЪ§бЇКЭЭГМЦвбОгаЖЮЪБШеЁЃдчдкАЫЪЎФъДњвдЧАЃЌвјаавЕКЭН№ШквЕБЛШЯЮЊЪЧЁАПндяЁБЕФЃЛЭЖзЪвјааИњЩЬвЕвјааЪЧЗжПЊЕФ,вЕНчжївЊЕФШЮЮёЪЧДІРэЁАМђЕЅЕФЁБЃЈИњЕБНёЯрБШЃЉЕФН№ШкжАФмЃЌР§ШчДћПюЁЃРяИљеўИЎЕФМѕЩйЕїПиКЭЪ§бЇЕФгІгУЃЌЪЙИУаавЕДгПндяЕФвјаавЕБфЮЊНёЬьЕФФЃбљЁЃдкФЧжЎКѓЃЌН№ШкѕвЩэПЦбЇЃЌГЩЮЊЭЦЖЏЪ§бЇбаОПКЭЗЂеЙЕФСІСПЁЃР§ШчЪ§бЇЩЯвЛИіжиДѓНјеЙЪЧВМРГПЫ-ЪцЖћЫЙЙЋЪНЕФЭЦЕМЁЃЫќБЛгУРДЙЩЦБЖЈМл
(вЛЗнИГгшЙЩЦБГжгаепвдвЛЖЈЕФМлИёДгЙЩЦБЗЂааепЪжжаТђШыКЭТєГіЕФКЯЭЌЃЉЁЃЕЋЪЧ, ВЛКУЕФЭГМЦФЃаЭЃЌАќРЈВМРГПЫ-ЪцЖћЫЙФЃаЭЃЌ
БГИКСЫВПЗжЕМжТ2008Н№ШкЮЃЛњЕФТюУћЁЃ
НќФъРДЃЌМЦЫуЛњПЦбЇМгШыСЫИпЕШЪ§бЇЕФеѓгЊЃЌЮЊН№ШкКЭжЄШЏНЛвзЃЈЮЊСЫгЏРћЖјНјааЕФН№ШкВњЦЗТђШыТєГіааЮЊЃЉДјРДСЫИяУќадЕФБфЛЏЁЃШчНёНЛвзжївЊгЩМЦЫуЛњРДЭъГЩЃКЫуЗЈФмвдШЫРрФбвдДяЕНЕФЫйЖШзіГіНЛвзОіВпЃЈВЮПДЙтЫйЕФЯожЦвбОГЩЮЊЯЕЭГЩшМЦжаЕФЦПОБЃЉЁЃЛњЦїбЇЯАКЭЪ§ОнЭкОђвВБЛдНРДдНЙуЗКЕФгУЕНН№ШкСьгђжаЃЌФПВтетИіЪЦЭЗЛсБЃГжЯТШЅЁЃЪТЪЕЩЯКмДѓвЛВПЗжЕФЫуЗЈНЛвзЖМЪЧИпЦЕНЛвзЃЈHFTЃЉЁЃЫфШЛЫуЗЈБШШЫЙЄПьЃЌЕЋетаЉММЪѕЛЙЪЧКмаТЃЌЖјЧвБЛгІгУдквЛИівдВЛЮШЖЈЃЌИпЗчЯежјГЦЕФСьгђЁЃОнвЛЬѕБЛКкПЭЦиЙтЕФАзЙЌЯрЙиУНЬхЭЦЬиБэУїHFTгІИУЖд2010
ЩСЕчЪНБРХЬ and a 2013 ЩСЕчЪНБРХЬ ИКд№ЁЃ
ВЛЙ§етНкПЮВЛЪЧЙигкШчКЮРћгУВЛКУЕФЪ§бЇФЃаЭРДДнЛйжЄШЏЪаГЁЁЃЯрЗДЕФЃЌЮвНЋЬсЙЉвЛаЉЛљБОЕФPythonЙЄОпРДДІРэКЭЗжЮіЙЩЪаЪ§ОнЁЃЮвЛсНВЕНвЦЖЏЦНОљжЕЃЌШчКЮРћгУвЦЖЏЦНОљжЕРДжЦЖЈНЛвзВпТдЃЌШчКЮжЦЖЈНјШыКЭГЗГіЙЩЪаЕФОіВпЃЌМЧвфШчКЮРћгУЛиЫнВтЪдРДЦРЙРвЛИіОіВпЁЃ
Утд№ЩъУїЃКетВЛЪЧЭЖзЪНЈвщЁЃЭЌЪБЮвЫНШЫЭъШЋУЛгаНЛвзОбщЃЈЮФжаЯрЙиЕФжЊЪЖДѓВПЗжРДздЮвдкбЮКўГЧЩчЧјДѓбЇВЮМгЕФвЛИібЇЦкЙигкЙЩЪаНЛвзЕФПЮГЬЃЉЃЁетРяНіНіЪЧЛљБОИХФюжЊЪЖЃЌВЛзувдгУгкЪЕМЪНЛвзЕФЙЩЦБЁЃЙЩЦБНЛвзПЩвдШУФуЪмЕНЫ№ЪЇЃЈвбгаЬЋЖрАИР§ЃЉЃЌФувЊЮЊздМКЕФааЮЊИКд№ЁЃ
ЛёШЁВЂПЩЪгЛЏЙЩЪаЪ§Он
ДгбХЛЂН№ШкЛёШЁЪ§Он
дкЗжЮіЪ§ОнжЎЧАЕУЯШЕУЕНЪ§ОнЁЃЙЩЪаЪ§ОнПЩвдДгYahoo! FinanceЁЂ Google FinanceвдМАЦфЫћЕФЕиЗНФУЕНЁЃЭЌЪБЃЌpandasАќЬсЙЉСЫЧсЫЩДгвдЩЯЭјеОЛёШЁЪ§ОнЕФЗНЗЈЁЃетНкПЮЮвУЧЪЙгУбХЛЂН№ШкЕФЪ§ОнЁЃ
ЯТУцЕФДњТыеЙЪОСЫШчКЮжБНгДДНЈвЛИіКЌгаЙЩЪаЪ§ОнЕФDataFrameЁЃЃЈИќЖрЙигкдЖГЬЛёШЁЪ§ОнЕФаХЯЂЃЌЕуЛїетРяЃЉ
import pandas
as pd
import pandas.io.data as web # Package and modules
for importing data; this code may change depending
on pandas version
import datetime
# We will look at stock prices over the past year,
starting at January 1, 2016
start = datetime.datetime(2016,1,1)
end = datetime.date.today()
# Let's get Apple stock data; Apple's ticker symbol
is AAPL
# First argument is the series we want, second
is the source ("yahoo" for Yahoo! Finance),
third is the start date, fourth is the end date
apple = web.DataReader("AAPL", "yahoo",
start, end)
type(apple) |
C:\Anaconda3\lib\site-packages\pandas\io\data.py:35:
FutureWarning:
The pandas.io.data module is moved to a separate
package (pandas-datareader) and will be removed
from pandas in a future version.
After installing the pandas-datareader package
(https://github.com/pydata/pandas-datareader),
you can change the import ``from pandas.io import
data, wb`` to ``from pandas_datareader import
data, wb``.
FutureWarning)
pandas.core.frame.DataFrame |
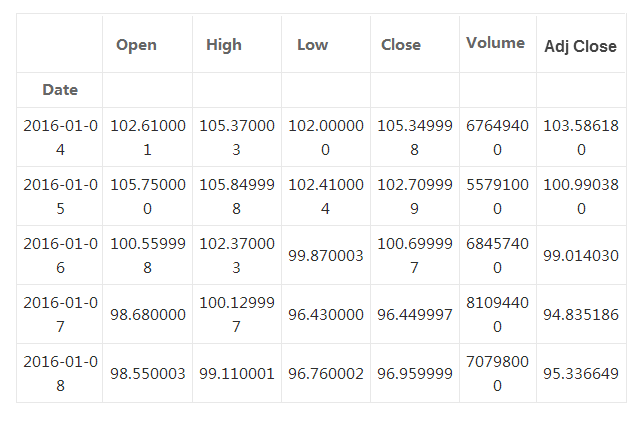
ШУЮвУЧМђЕЅЫЕвЛЯТЪ§ОнФкШнЁЃOpenЪЧЕБЬьЕФПЊЪММлИёЃЈВЛЪЧЧАвЛЬьБеЪаЕФМлИёЃЉЃЛhighЪЧЙЩЦБЕБЬьЕФзюИпМлЃЛlowЪЧЙЩЦБЕБЬьЕФзюЕЭМлЃЛcloseЪЧБеЪаЪБМфЕФЙЩЦБМлИёЁЃVolumeжИНЛвзЪ§СПЁЃAdjust
closeЪЧИљОнЗЈШЫааЮЊЕїећжЎКѓЕФБеЪаМлИёЁЃЫфШЛЙЩЦБМлИёЛљБОЩЯЪЧгЩНЛвзепОіЖЈЕФЃЌstock splits
ЃЈВ№ЙЩЁЃжИЩЯЪаЙЋЫОНЋЯжгаЙЩЦБвЛВ№ЮЊЖўЃЌаТЙЩМлИёЮЊдЙЩЕФвЛАыЕФааЮЊЃЉвдМАdividendsЃЈЗжКьЁЃУПвЛЙЩЕФЗжКьЃЉЭЌбљвВЛсгАЯьЙЩЦБМлИёЃЌвВгІИУдкФЃаЭжаБЛПМТЧЕНЁЃ
ПЩЪгЛЏЙЩЪаЪ§Он
ЛёЕУЪ§ОнжЎКѓШУЮвУЧПМТЧНЋЦфПЩЪгЛЏЁЃЯТУцЮвЛсбнЪОШчКЮЪЙгУmatplotlibАќЁЃжЕЕУзЂвтЕФЪЧappleDataFrameЖдЯѓгавЛИіplot()ЗНЗЈШУЛЭМБфЕУИќМђЕЅЁЃ
import matplotlib.pyplot
as plt # Import matplotlib
# This line is necessary for the plot to appear
in a Jupyter notebook
%matplotlib inline
# Control the default size of figures in this
Jupyter notebook
%pylab inline
pylab.rcParams['figure.figsize'] = (15, 9) # Change
the size of plots
apple["Adj Close"].plot(grid = True)
# Plot the adjusted closing price of AAPL
|
|
Populating the interactive namespace from numpy
and matplotlib |
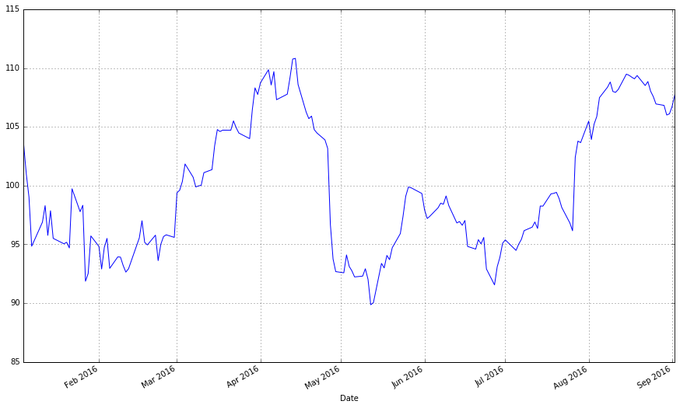
ЯпЖЮЭМЪЧПЩааЕФЃЌЕЋЪЧУПвЛЬьЕФЪ§ОнжСЩйгаЫФИіБфСПЃЈПЊЪаЃЌЙЩЦБзюИпМлЃЌЙЩЦБзюЕЭМлКЭБеЪаЃЉЃЌЮвУЧЯЃЭћевЕНвЛжжВЛашвЊЮвУЧЛЫФЬѕВЛЭЌЕФЯпОЭФмПДЕНетЫФИіБфСПзпЪЦЕФПЩЪгЛЏЗНЗЈЁЃвЛАуРДЫЕЮвУЧЪЙгУжђжљЭМЃЈвВГЦЮЊШеБОвѕбєжђЭМБэЃЉРДПЩЪгЛЏН№ШкЪ§ОнЃЌжђжљЭМзюдчдк18ЪРМЭБЛШеБОЕФЕОУзЩЬШЫЫљЪЙгУЁЃПЩвдгУmatplotlibРДзїЭМЃЌЕЋЪЧашвЊЗбаЉЙІЗђЁЃ
ФуУЧПЩвдЪЙгУЮвЪЕЯжЕФвЛИіКЏЪ§ИќШнвзЕиЛжђжљЭМЃЌЫќНгЪмpandasЕФdata frameзїЮЊЪ§ОнРДдДЁЃЃЈГЬађЛљгкетИіР§зг,
ФуПЩвдДгетРяевЕНЯрЙиКЏЪ§ЕФЮФЕЕЁЃЃЉ
from matplotlib.dates
import DateFormatter, WeekdayLocator,\
DayLocator, MONDAY
from matplotlib.finance import candlestick_ohlc
def pandas_candlestick_ohlc(dat, stick = "day",
otherseries = None):
"""
:param dat: pandas DataFrame object with datetime64
index, and float columns "Open", "High",
"Low", and "Close", likely
created via DataReader from "yahoo"
:param stick: A string or number indicating the
period of time covered by a single candlestick.
Valid string inputs include "day", "week",
"month", and "year", ("day"
default), and any numeric input indicates the
number of trading days included in a period
:param otherseries: An iterable that will be coerced
into a list, containing the columns of dat that
hold other series to be plotted as lines
This will show a Japanese candlestick plot for
stock data stored in dat, also plotting other
series if passed.
"""
mondays = WeekdayLocator(MONDAY) # major ticks
on the mondays
alldays = DayLocator() # minor ticks on the days
dayFormatter = DateFormatter('%d') # e.g., 12
# Create a new DataFrame which includes OHLC data
for each period specified by stick input
transdat = dat.loc[:,["Open", "High",
"Low", "Close"]]
if (type(stick) == str):
if stick == "day":
plotdat = transdat
stick = 1 # Used for plotting
elif stick in ["week", "month",
"year"]:
if stick == "week":
transdat["week"] = pd.to_datetime(transdat.index).map(lambda
x: x.isocalendar()[1]) # Identify weeks
elif stick == "month":
transdat["month"] = pd.to_datetime(transdat.index).map(lambda
x: x.month) # Identify months
transdat["year"] = pd.to_datetime(transdat.index).map(lambda
x: x.isocalendar()[0]) # Identify years
grouped = transdat.groupby(list(set(["year",stick])))
# Group by year and other appropriate variable
plotdat = pd.DataFrame({"Open": [],
"High": [], "Low": [], "Close":
[]}) # Create empty data frame containing what
will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open":
group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close":
group.iloc[-1,3]},
index = [group.index[0]]))
if stick == "week": stick = 5
elif stick == "month": stick = 30
elif stick == "year": stick = 365
elif (type(stick) == int and stick >= 1):
transdat["stick"] = [np.floor(i / stick)
for i in range(len(transdat.index))]
grouped = transdat.groupby("stick")
plotdat = pd.DataFrame({"Open": [],
"High": [], "Low": [], "Close":
[]}) # Create empty data frame containing what
will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open":
group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close":
group.iloc[-1,3]},
index = [group.index[0]]))
else:
raise ValueError('Valid inputs to argument "stick"
include the strings "day", "week",
"month", "year", or a positive
integer')
# Set plot parameters, including the axis object
ax used for plotting
fig, ax = plt.subplots()
fig.subplots_adjust(bottom=0.2)
if plotdat.index[-1] - plotdat.index[0] < pd.Timedelta('730
days'):
weekFormatter = DateFormatter('%b %d') # e.g.,
Jan 12
ax.xaxis.set_major_locator(mondays)
ax.xaxis.set_minor_locator(alldays)
else:
weekFormatter = DateFormatter('%b %d, %Y')
ax.xaxis.set_major_formatter(weekFormatter)
ax.grid(True)
# Create the candelstick chart
candlestick_ohlc(ax, list(zip(list(date2num(plotdat.index.tolist())),
plotdat["Open"].tolist(), plotdat["High"].tolist(),
plotdat["Low"].tolist(), plotdat["Close"].tolist())),
colorup = "black", colordown = "red",
width = stick * .4)
# Plot other series (such as moving averages)
as lines
if otherseries != None:
if type(otherseries) != list:
otherseries = [otherseries]
dat.loc[:,otherseries].plot(ax = ax, lw = 1.3,
grid = True)
ax.xaxis_date()
ax.autoscale_view()
plt.setp(plt.gca().get_xticklabels(), rotation=45,
horizontalalignment='right')
plt.show()
pandas_candlestick_ohlc(apple) |
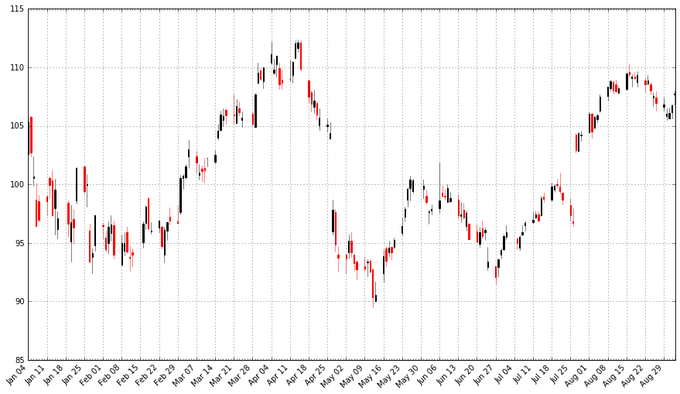
жђзДЭМжаКкЩЋЯпЬѕДњБэИУНЛвзШеБеЪаМлИёИпгкПЊЪаМлИёЃЈгЏРћЃЉЃЌКьЩЋЯпЬѕДњБэИУНЛвзШеПЊЪаМлИёИпгкБеЪаМлИёЃЈПїЫ№ЃЉЁЃПЬЖШЯпДњБэЕБЬьНЛвзЕФзюИпМлКЭзюЕЭМлЃЈгАЯпгУРДжИУїжђЩэЕФФФЖЫЪЧПЊЪаЃЌФФЖЫЪЧБеЪаЃЉЁЃжђзДЭМдкН№ШкКЭММЪѕЗжЮіжаБЛЙуЗКЪЙгУдкНЛвзОіВпЩЯЃЌРћгУжђЩэЕФаЮзДЃЌбеЩЋКЭЮЛжУЁЃЮвНёЬьВЛЛсЩцМАЕНВпТдЁЃ
ЮвУЧвВаэЯывЊАбВЛЭЌЕФН№ШкЩЬЦЗГЪЯждквЛеХЭМЩЯЃКетбљЮвУЧПЩвдБШНЯВЛЭЌЕФЙЩЦБЃЌБШНЯЙЩЦБИњЪаГЁЕФЙиЯЕЃЌЛђепПЩвдПДЦфЫћжЄШЏЃЌР§ШчНЛвзЫљНЛвзЛљН№(ETFs)ЁЃдкКѓУцЕФФкШнжаЃЌЮвУЧНЋЛсбЇЕНШчКЮЛН№ШкжЄШЏИњвЛаЉжИЪ§ЃЈвЦЖЏЦНОљЃЉЕФЙиЯЕЁЃНьЪБФуашвЊЪЙгУЯпЖЮЭМЖјВЛЪЧжђзДЭМЁЃЃЈЪдЯыФуШчКЮжиЕўВЛЭЌЕФжђзДЭМЖјШУЭМБэБЃГжећНрЃПЃЉ
ЯТУцЮвеЙЪОСЫВЛЭЌММЪѕЙЋЫОЙЩЦБЕФЪ§ОнЃЌвдМАШчКЮЕїећЪ§ОнШУЪ§ОнЯпОлдквЛЦ№ЁЃ
microsoft = web.DataReader("MSFT",
"yahoo", start, end)
google = web.DataReader("GOOG", "yahoo",
start, end)
# Below I create a DataFrame consisting of the
adjusted closing price of these stocks, first
by making a list of these objects and using the
join method
stocks = pd.DataFrame({"AAPL": apple["Adj
Close"],
"MSFT": microsoft["Adj
Close"],
"GOOG": google["Adj
Close"]})
stocks.head() |
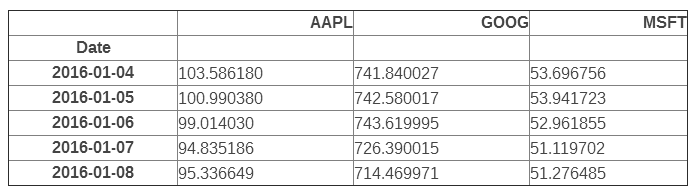
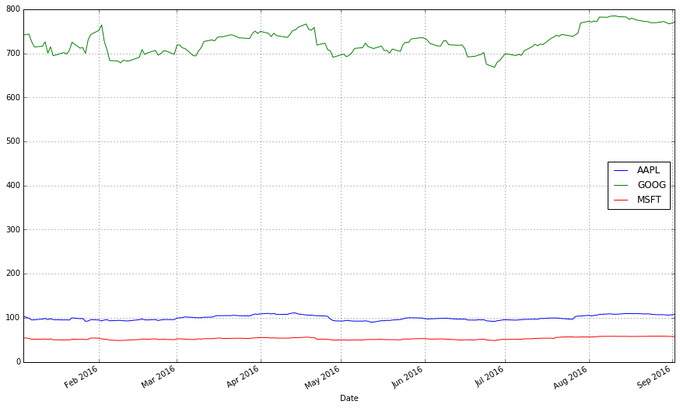
етеХЭМБэЕФЮЪЬтдкФФРяФиЃПЫфШЛМлИёЕФОјЖджЕКмживЊЃЈАКЙѓЕФЙЩЦБКмФбЙКЕУЃЌетВЛНіЛсгАЯьЫќУЧЕФВЈЖЏадЃЌвВЛсгАЯьФуНЛвзЫќУЧЕФФбвзЖШЃЉЃЌЕЋЪЧдкНЛвзжаЃЌЮвУЧИќЙизЂУПжЇЙЩЦБМлИёЕФБфЛЏЖјВЛЪЧЫќЕФМлИёЁЃGoogleЕФЙЩЦБМлИёБШЦЛЙћЮЂШэЕФЖМИпЃЌетИіВюБ№ШУЦЛЙћКЭЮЂШэЕФЙЩЦБЯдЕУВЈЖЏадКмЕЭЃЌЖјЪТЪЕВЂВЛЪЧФЧбљЁЃ
вЛИіНтОіАьЗЈОЭЪЧгУСНИіВЛЭЌЕФБъЖШРДзїЭМЁЃвЛИіБъЖШгУгкЦЛЙћКЭЮЂШэЕФЪ§ОнЃЛСэвЛИіБъЖШгУРДБэЪОGoogleЕФЪ§ОнЁЃ
| stocks.plot(secondary_y
= ["AAPL", "MSFT"], grid =
True) |
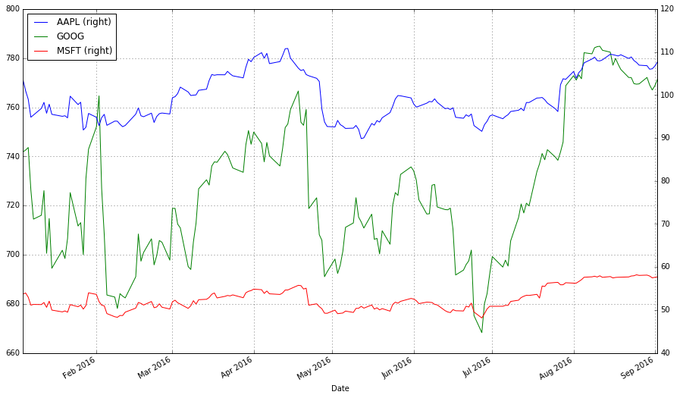
вЛИіЁАИќКУЁБЕФНтОіЗНЗЈЪЧПЩЪгЛЏЮвУЧЪЕМЪЙиаФЕФаХЯЂЃКЙЩЦБЕФЪевцЁЃеташвЊЮвУЧНјааБивЊЕФЪ§ОнзЊЛЏЁЃЪ§ОнзЊЛЏЕФЗНЗЈКмЖрЁЃЦфжавЛИізЊЛЏЗНЗЈЪЧНЋУПИіНЛвзШеЕФЙЩЦБНЛИіИњБШНЯЮвУЧЫљЙиаФЕФЪБМфЖЮПЊЪМЕФЙЩЦБМлИёЯрБШНЯЁЃвВОЭЪЧЃК
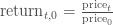
еташвЊзЊЛЏstockЖдЯѓжаЕФЪ§ОнЃЌВйзїШчЯТЃК
# df.apply(arg) will apply the function arg to
each column in df, and return a DataFrame with
the result
# Recall that lambda x is an anonymous function
accepting parameter x; in this case, x will be
a pandas Series object
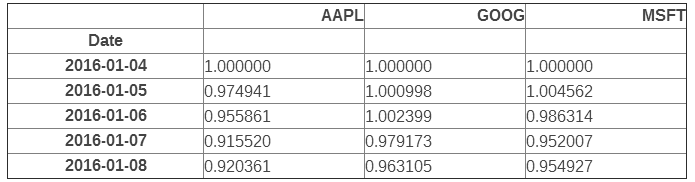
stock_return = stocks.apply(lambda x: x / x[0])
stock_return.head() |
| tock_return.plot(grid
= True).axhline(y = 1, color = "black",
lw = 2) |
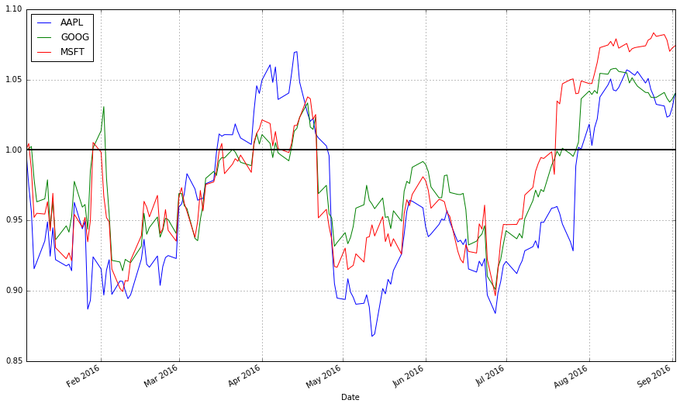
етИіЭМОЭгагУЖрСЫЁЃЯждкЮвУЧПЩвдПДЕНДгЮвУЧЫљЙиаФЕФШеЦкЫуЦ№ЃЌУПжЇЙЩЦБЕФЪевцгаЖрИпЁЃЖјЧвЮвУЧПЩвдПДЕНетаЉЙЩЦБжЎМфЕФЯрЙиадКмИпЁЃЫќУЧЛљБОЩЯГЏЭЌвЛИіЗНЯђвЦЖЏЃЌдкЦфЫћРраЭЕФЭМБэжаКмФбЙлВьЕНетвЛЯжЯѓЁЃ
ЮвУЧЛЙПЩвдгУУПЬьЕФЙЩжЕБфЛЏзїЭМЁЃвЛИіПЩааЕФЗНЗЈЪЧЮвУЧЪЙгУКѓвЛЬь$t + 1$КЭЕБЬь$t$ЕФЙЩжЕБфЛЏеМЕБЬьЙЩМлЕФБШР§ЃК
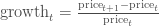
ЮвУЧвВПЩвдБШНЯЕБЬьИњЧАвЛЬьЕФМлИёЃК
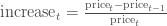
вдЩЯЕФЙЋЪНВЂВЛЯрЭЌЃЌПЩФмЛсШУЮвУЧЕУЕНВЛЭЌЕФНсТлЃЌЕЋЪЧЮвУЧПЩвдЪЙгУЖдЪ§ВювьРДБэЪОЙЩЦБМлИёБфЛЏЃК
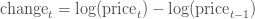
(етРяЕФlog ЪЧздШЛЖдЪ§,ЮвУЧЕФЖЈвхВЛЭъШЋШЁОігкЪЙгУ 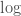 ЛЙЪЧ ЛЙЪЧ
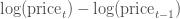 ЪЙгУЖдЪ§ВювьЕФКУДІЪЧИУВювьжЕПЩвдБЛНтЪЭЮЊЙЩЦБЕФАйЗжБШВювьЃЌЕЋЪЧВЛЪмЗжФИЕФгАЯьЁЃ ЪЙгУЖдЪ§ВювьЕФКУДІЪЧИУВювьжЕПЩвдБЛНтЪЭЮЊЙЩЦБЕФАйЗжБШВювьЃЌЕЋЪЧВЛЪмЗжФИЕФгАЯьЁЃ
ЯТУцЕФДњТыбнЪОСЫШчКЮМЦЫуКЭПЩЪгЛЏЙЩЦБЕФЖдЪ§ВювьЃК
# Let's use NumPy's
log function, though math's log function would
work just as well
import numpy as np
stock_change = stocks.apply(lambda x: np.log(x)
- np.log(x.shift(1))) # shift moves dates back
by 1.
stock_change.head() |
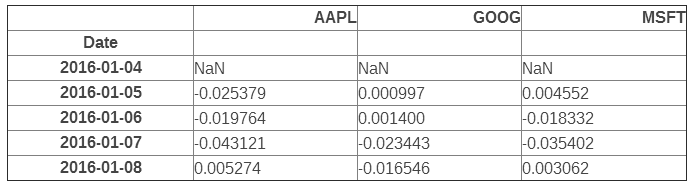
| stock_change.plot(grid
= True).axhline(y = 0, color = "black",
lw = 2) |
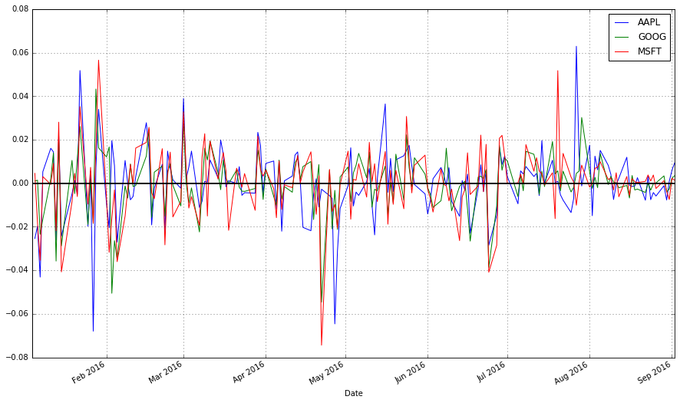
ЗНЗЈФиЃПДгЯрЖдЪБМфЖЮПЊЪМШеЕФЪевцВюОрПЩвдУїЯдПДГіВЛЭЌжЄШЏЕФзмЬхзпЪЦЁЃВЛЭЌНЛвзШежЎМфЕФВюОрБЛгУгкИќЖрдЄВтЙЩЪаааЧщЕФЗНЗЈжаЃЌЫќУЧЪЧВЛШнБЛКіЪгЕФЁЃ
вЦЖЏЦНОљжЕ
ЭМБэЗЧГЃгагУЁЃдкЯжЪЕЩњЛюжаЃЌгааЉНЛвзШЫдкзіОіВпЕФЪБКђМИКѕЭъШЋЛљгкЭМБэЃЈетаЉШЫЪЧЁАММЪѕШЫдБЁБЃЌДгЭМБэжаевЕНЙцТЩВЂжЦЖЈНЛвзВпТдБЛГЦзїММЪѕЗжЮіЃЌЫќЪЧНЛвзЕФЛљБОНЬвхжЎвЛЁЃЃЉЯТУцШУЮвУЧРДПДПДШчКЮевЕНЙЩЦБМлИёЕФБфЛЏЧїЪЦЁЃ
вЛИіqЬьЕФвЦЖЏЦНОљжЕЃЈгУ 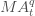 РДБэЪОЃЉЖЈвхЮЊЃКЖдгкФГвЛИіЪБМфЕуtЃЌЫќжЎЧАqЬьЕФЦНОљжЕЁЃ РДБэЪОЃЉЖЈвхЮЊЃКЖдгкФГвЛИіЪБМфЕуtЃЌЫќжЎЧАqЬьЕФЦНОљжЕЁЃ
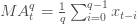
вЦЖЏЦНОљжЕПЩвдШУвЛИіЯЕСаЕФЪ§ОнБфЕУИќЦНЛЌЃЌгажњгкЮвУЧевЕНЧїЪЦЁЃqжЕдНДѓЃЌвЦЖЏЦНОљЖдЖЬЦкЕФВЈЖЏдНВЛУєИаЁЃвЦЖЏЦНОљЕФЛљБОФПЕФОЭЪЧДгдывєжаЪЖБ№ЧїЪЦЁЃПьЫйЕФвЦЖЏЦНОљгаЦЋаЁЕФqЃЌЫќУЧИќНгНќЙЩЦБМлИёЃЛЖјТ§ЫйЕФвЦЖЏЦНОљгаНЯДѓЕФqжЕЃЌетЪЙЕУЫќУЧЖдВЈЖЏВЛУєИаДгЖјИќМгЮШЖЈЁЃ
pandasЬсЙЉСЫМЦЫувЦЖЏЦНОљЕФКЏЪ§ЁЃЯТУцЮвНЋбнЪОЪЙгУетИіКЏЪ§РДМЦЫуЦЛЙћЙЋЫОЙЩЦБМлИёЕФ20ЬьЃЈвЛИідТЃЉвЦЖЏЦНОљжЕЃЌВЂНЋЫќИњЙЩЦБМлИёЛдквЛЦ№ЁЃ
apple["20d"]
= np.round(apple["Close"].rolling(window
= 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],
otherseries = "20d") |
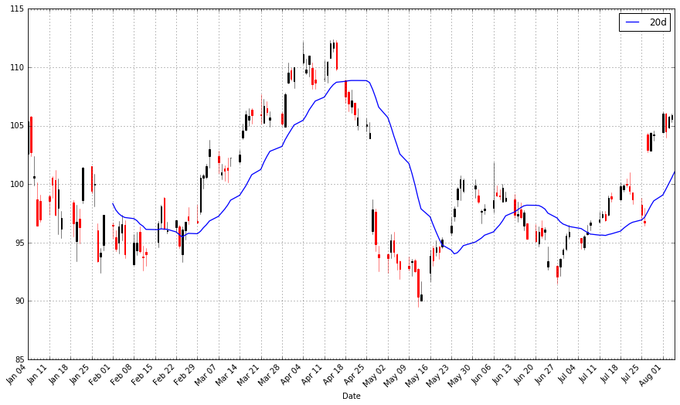
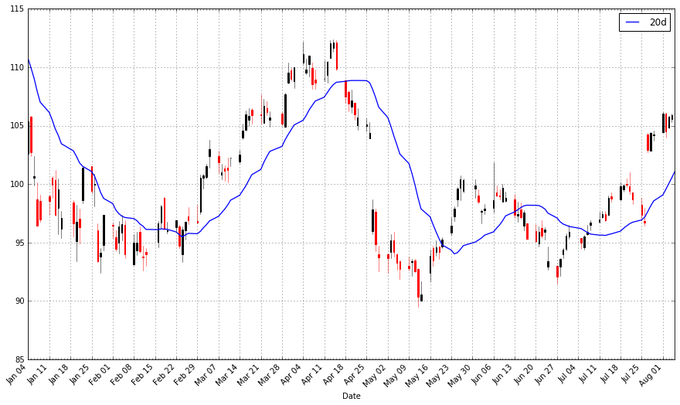
зЂвтЕНЦНОљжЕЕФЦ№ЪМЕуЪБМфЪЧКмГйЕФЁЃЮвУЧБиаыЕШЕН20ЬьжЎКѓВХФмПЊЪММЦЫуИУжЕЁЃетИіЮЪЬтЖдгкИќГЄЪБМфЖЮЕФвЦЖЏЦНОљРДЫЕЪЧИіИќМгбЯжиЕФЮЪЬтЁЃвђЮЊЮвЯЃЭћЮвПЩвдМЦЫу200ЬьЕФвЦЖЏЦНОљЃЌЮвНЋРЉеЙЮвУЧЫљЕУЕНЕФЦЛЙћЙЋЫОЙЩЦБЕФЪ§ОнЃЌЕЋЮвУЧжївЊЛЙЪЧжЛЙизЂ2016ЁЃ
start = datetime.datetime(2010,1,1)
apple = web.DataReader("AAPL", "yahoo",
start, end)
apple["20d"] = np.round(apple["Close"].rolling(window
= 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],
otherseries = "20d") |
ФуЛсЗЂЯжвЦЖЏЦНОљБШецЪЕЕФЙЩЦБМлИёЪ§ОнЦНЛЌКмЖрЁЃЖјЧветИіжИЪ§ЪЧЗЧГЃФбИФБфЕФЃКвЛжЇЙЩЦБЕФМлИёашвЊБфЕНЦНОжжЕжЎЩЯЛђжЎЯТВХФмИФБфвЦЖЏЦНОљЯпЕФЗНЯђЁЃвђДЫЦНОљЯпЕФНЛВцЕуДњБэСЫЧБдкЕФЧїЪЦБфЛЏЃЌашвЊМгвдзЂвтЁЃ
НЛвзепЭљЭљЖдВЛЭЌЕФвЦЖЏЦНОљИааЫШЄЃЌР§Шч20ЬьЃЌ50ЬьКЭ200ЬьЁЃвЊЭЌЪБЩњГЩЖрЬѕвЦЖЏЦНОљЯпвВВЛФбЃК
apple["50d"]
= np.round(apple["Close"].rolling(window
= 50, center = False).mean(), 2)
apple["200d"] = np.round(apple["Close"].rolling(window
= 200, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:],
otherseries = ["20d", "50d",
"200d"])
|
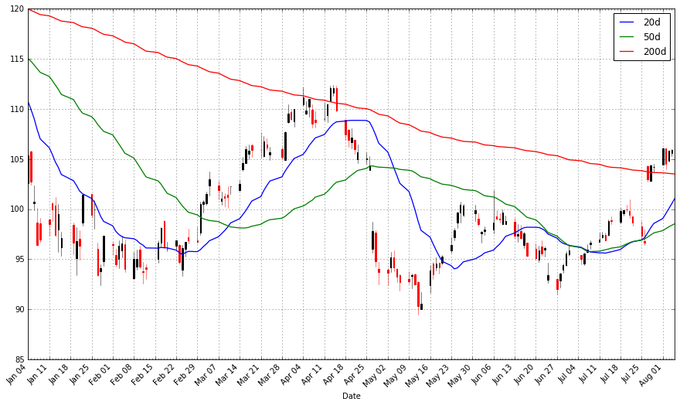
20ЬьЕФвЦЖЏЦНОљЯпЖдаЁЕФБфЛЏЗЧГЃУєИаЃЌЖј200ЬьЕФвЦЖЏЦНОљЯпВЈЖЏзюаЁЁЃетРяЕФ200ЬьЦНОљЯпЯдЪОГіРДзмЬхЕФамЪаЧїЪЦЃКЙЩжЕзмЬхРДЫЕвЛжБдкЯТНЕЁЃ20ЬьвЦЖЏЦНОљЯпЫљДњБэЕФаХЯЂЪЧамЪаХЃЪаНЛЬцЃЌНгЯТРДгаПЩФмЪЧХЃЪаЁЃетаЉЦНОљЯпЕФНЛВцЕуОЭЪЧНЛвзаХЯЂЕуЃЌЫќУЧДњБэЙЩЦБМлИёЕФЧїЪЦЛсгаЫљИФБфвђЖјФуашвЊзїГіФмгЏРћЕФЯргІОіВпЁЃ |









