| БрМЭЦМі: |
РДдДгкжЊКѕЃЌБОЮФОЭЛиЙщЪїЕФЛљБОдРэНјааНВНтЃЌВЂЪжАбЪжЁЂМчВЂМчЕиДјФњЪЕЯжетвЛЫуЗЈЁЃ |
|
1. дРэЦЊ
ЮвУЧгУШЫЛАЖјВЛЪЧДѓЖЮЕФЪ§бЇЙЋЪНРДНВНВЛиЙщЪїЪЧдѕУДвЛЛиЪТЁЃ
1.1 зюМђЕЅЕФФЃаЭ
ШчЙћдЄВтФГИіСЌајБфСПЕФДѓаЁЃЌзюМђЕЅЕФФЃаЭжЎвЛОЭЪЧгУЦНОљжЕЁЃБШШчЭЌЪТЕФЦНОљФъСфЪЧ28ЫъЃЌФЧУДаТРДСЫвЛХњЭЌЪТЃЌдкВЛжЊЕРетаЉЭЌЪТЕФШЮКЮаХЯЂЕФЧщПіЯТЃЌжБОѕЩЯгУЦНОљжЕ28РДдЄВтЪЧБШНЯзМШЗЕФЃЌжСЩйБШ0ЫъЛђеп100ЫъвЊППЦзвЛаЉЁЃЮвУЧВЛЗСжЄУївЛЯТЮвУЧЕФжБОѕЃК
1.ЖЈвхЫ№ЪЇКЏЪ§LЃЌЦфжаy_hatЪЧЖдyдЄВтжЕЃЌЪЙгУMSEРДЦРЙРЫ№ЪЇЃК

2.Ждy_hatЧѓЕМ:

3.СюЕМЪ§ЕШгк0ЃЌзюаЁЛЏMSEЃЌдђ:

4.ЫљвдЃЌ

5.НсТлЃЌШчЙћвЊгУвЛИіГЃСПРДдЄВтyЃЌгУyЕФОљжЕЪЧвЛИізюМбЕФбЁдёЁЃ
1.2 МгвЛЕуФбЖШ
ШдШЛЪЧдЄВтЭЌЪТФъСфЃЌетДЮЮвУЧдЄЯШжЊЕРСЫЭЌЪТЕФжАМЖЃЌМйЩшжАМЖЕФЗЖЮЇЪЧећЪ§1-10ЃЌШчКЮФмШУетИіаХЯЂАяжњЮвУЧИќМгзМШЗЕФдЄВтФъСфФиЃП
вЛИіЫМТЗЪЧИљОнжАМЖАбЭЌЪТЗжЮЊСНзщЃЌетСНзщЗжБ№гІгУЮвУЧжЎЧАЬсЕНЕФЁАЦНОљжЕЁБФЃаЭЁЃБШШчжАМЖаЁгк5ЕФЭЌЪТЗжЕНAзщЃЌДѓгкЛђЕШгк5ЕФЗжЕНBзщЃЌAзщЕФЦНОљФъСфЪЧ25ЫъЃЌBзщЕФЦНОљФъСфЪЧ35ЫъЁЃШчЙћаТРДСЫвЛИіЭЌЪТЃЌжАМЖЪЧ3ЃЌгІИУБЛЗжЕНAзщЃЌЮвУЧОЭдЄВтЫћЕФФъСфЪЧ25ЫъЁЃ
1.3 зюМбЗжИюЕу
ЛЙгавЛИіЮЪЬтД§НтОіЃЌШчКЮШЁвЛИізюМбЕФЗжИюЕуЖдВЛЭЌжАМЖЕФЭЌЪТНјааЗжзщФиЃП ЮвУЧГЂЪдЫљгаmИіПЩФмЕФЗжИюЕуP_iЃЌбигУжЎЧАЕФЫ№ЪЇКЏЪ§ЃЌЖдAЁЂBСНзщЗжБ№МЦЫуLossВЂЯрМгЕУЕНL_iЁЃзюаЁЕФL_iЫљЖдгІЕФP_iОЭЪЧЮвУЧвЊевЕФЁАзюМбЗжИюЕуЁБЁЃ
1.4 дЫгУЖрИіБфСП
дйИДдгвЛаЉЃЌШчЙћЮвУЧВЛНіНіжЊЕРСЫЭЌЪТЕФжАМЖЃЌЛЙжЊЕРСЫЭЌЪТЕФЙЄзЪЃЈУВЫЦВЛПЦбЇЃЉЃЌИУШчКЮдЄВтЭЌЪТЕФФъСфФиЃП
ЮвУЧПЩвдЗжБ№ИљОнжАМЖЁЂЙЄзЪМЦЫуГіжАМЖКЭЙЄзЪЕФзюМбЗжИюЕуP_1, P_2ЃЌЖдгІЕФLoss L_1,
L_2ЁЃШЛКѓБШНЯL_1КЭL2ЃЌШЁНЯаЁепЁЃМйЩшL_1 < L_2ЃЌФЧУДАДееP_1АбВЛЭЌжАМЖЕФЭЌЪТЗжЮЊAЁЂBСНзщЁЃдкAЁЂBзщФкЗжБ№МЦЫуЙЄзЪЫљЖдгІЕФЗжИюЕуЃЌдйЗжЮЊCЁЂDСНзщЁЃетбљЮвУЧОЭЕУЕНСЫAC,
AD, BC, BDЫФзщЭЌЪТвдМАЖдгІЕФЦНОљФъСфгУгкдЄВтЁЃ
1.5 Д№АИНвЯў
ШчКЮЪЕЯжетжж1 to 2, 2 to 4, 4 to 8ЕФЫуЗЈФиЃП
ЪьЯЄЪ§ОнНсЙЙЕФЭЌбЇздШЛЛсЯыЕНЖўВцЪїЃЌетжжЪїБЛГЦЮЊЛиЙщЪїЃЌЙЫУћЫМвхРћгУЪїаЮНсЙЙЧѓНтЛиЙщЮЪЬтЁЃ
2. ЪЕЯжЦЊ
БОШЫгУШЋгюжцзюМђЕЅЕФБрГЬгябдЁЊЁЊPythonЪЕЯжСЫЛиЙщЪїЫуЗЈЃЌУЛгавРРЕШЮКЮЕкШ§ЗНПтЃЌБугкбЇЯАКЭЪЙгУЁЃМђЕЅЫЕУївЛЯТЪЕЯжЙ§ГЬЃЌИќЯъЯИЕФзЂЪЭЧыВЮПМБОШЫgithubЩЯЕФДњТыЁЃ
2.1 ДДНЈNodeРр
ГѕЪМЛЏЃЌДцДЂдЄВтжЕЁЂзѓгвНсЕуЁЂЬиеїКЭЗжИюЕу
class Node(object):
def __init__(self, score=None):
self.score = score
self.left = None
self.right = None
self.feature = None
self.split = None |
2.2 ДДНЈЛиЙщЪїРр
ГѕЪМЛЏЃЌДцДЂИљНкЕуКЭЪїЕФИпЖШЁЃ
class RegressionTree(object):
def __init__(self):
self.root = Node()
self.height = 0 |
2.3 МЦЫуЗжИюЕуЁЂMSE
ИљОнздБфСПXЁЂвђБфСПyЁЂXдЊЫижаБЛШЁГіЕФааКХidxЃЌСаКХfeatureвдМАЗжИюЕуsplitЃЌМЦЫуЗжИюКѓЕФMSEЁЃзЂвтетРяЮЊСЫМѕЩйМЦЫуСПЃЌгУЕНСЫЗНВюЙЋЪНЃК ![D(X) = E{[X-E(X)]^2} = E(X^2)-[E(X)]^2](https://www.zhihu.com/equation?tex=D%28X%29+%3D+E%7B%5BX-E%28X%29%5D%5E2%7D+%3D+E%28X%5E2%29-%5BE%28X%29%5D%5E2)
def _get_split_mse(self,
X, y, idx, feature, split):
split_sum = [0, 0]
split_cnt = [0, 0]
split_sqr_sum = [0, 0]
for i in idx:
xi, yi = X[i][feature], y[i]
if xi < split:
split_cnt[0] += 1
split_sum[0] += yi
split_sqr_sum[0] += yi ** 2
else:
split_cnt[1] += 1
split_sum[1] += yi
split_sqr_sum[1] += yi ** 2
split_avg = [split_sum[0] / split_cnt[0],
split_sum[1] / split_cnt[1]]
split_mse = [split_sqr_sum[0] - split_sum[0]
* split_avg[0],
split_sqr_sum[1] - split_sum[1] * split_avg[1]]
return sum(split_mse), split, split_avg |
2.4 МЦЫузюМбЗжИюЕу
БщРњЬиеїФГвЛСаЕФЫљгаЕФВЛжиИДЕФЕуЃЌевГіMSEзюаЁЕФЕузїЮЊзюМбЗжИюЕуЁЃШчЙћЬиеїжаУЛгаВЛжиИДЕФдЊЫидђЗЕЛиNoneЁЃ
def _choose_split_point(self,
X, y, idx, feature):
unique = set([X[i][feature] for i in idx])
if len(unique) == 1:
return None
unique.remove(min(unique))
mse, split, split_avg = min(
(self._get_split_mse(X, y, idx, feature, split)
for split in unique), key=lambda x: x[0])
return mse, feature, split, split_avg |
2.5 бЁдёзюМбЬиеї
БщРњЫљгаЬиеїЃЌМЦЫузюМбЗжИюЕуЖдгІЕФMSEЃЌевГіMSEзюаЁЕФЬиеїЁЂЖдгІЕФЗжИюЕуЃЌзѓгвзгНкЕуЖдгІЕФОљжЕКЭааКХЁЃШчЙћЫљгаЕФЬиеїЖМУЛгаВЛжиИДдЊЫидђЗЕЛиNone
def _choose_feature(self,
X, y, idx):
m = len(X[0])
split_rets = [x for x in map(lambda x: self._choose_split_point(
X, y, idx, x), range(m)) if x is not None]
if split_rets == []:
return None
_, feature, split, split_avg = min(
split_rets, key=lambda x: x[0])
idx_split = [[], []]
while idx:
i = idx.pop()
xi = X[i][feature]
if xi < split:
idx_split[0].append(i)
else:
idx_split[1].append(i)
return feature, split, split_avg, idx_split |
2.6 ЙцдђзЊЮФзж
НЋЙцдђгУЮФзжБэДяГіРДЃЌЗНБуЮвУЧВщПДЙцдђЁЃ
def _expr2literal(self,
expr):
feature, op, split = expr
op = ">=" if op == 1 else "<"
return "Feature%d %s %.4f" % (feature,
op, split) |
2.7 ЛёШЁЙцдђ
НЋЛиЙщЪїЕФЫљгаЙцдђЖМгУЮФзжБэДяГіРДЃЌЗНБуЮвУЧСЫНтЪїЕФШЋУВЁЃетРягУЕНСЫЖгСа+ЙуЖШгХЯШЫбЫїЁЃгааЫШЄвВПЩвдЪдЪдЕнЙщЛђепЩюЖШгХЯШЫбЫїЁЃ
def _get_rules(self):
que = [[self.root, []]]
self.rules = []
while que:
nd, exprs = que.pop(0)
if not(nd.left or nd.right):
literals = list(map(self._expr2literal, exprs))
self.rules.append([literals, nd.score])
if nd.left:
rule_left = copy(exprs)
rule_left.append([nd.feature, -1, nd.split])
que.append([nd.left, rule_left])
if nd.right:
rule_right = copy(exprs)
rule_right.append ([nd.feature, 1, nd.split])
que.append([nd.right, rule_right]) |
2.8 бЕСЗФЃаЭ
ШдШЛЪЙгУЖгСа+ЙуЖШгХЯШЫбЫїЃЌбЕСЗФЃаЭЕФЙ§ГЬжаашвЊзЂвтЃК 1. ПижЦЪїЕФзюДѓЩюЖШmax_depthЃЛ
2. ПижЦЗжСбЪБзюЩйЕФбљБОСПmin_samples_splitЃЛ 3. вЖзгНсЕужСЩйгаСНИіВЛжиИДЕФyжЕЃЛ
4. жСЩйгавЛИіЬиеїЪЧУЛгажиИДжЕЕФЁЃ
def fit (self,
X, y, max_depth=5, min_ samples _ split = 2 ):
self.root = Node()
que = [[0, self.root, list (range(len(y)))]]
while que:
depth, nd, idx = que.pop(0)
if depth == max_depth:
break
if len(idx) < min_samples_split or \
set (map (lambda i: y[i], idx)) == 1:
continue
feature_rets = self._ choose_feature(X, y,
idx)
if feature _rets is None:
continue
nd.feature, nd.split, split_avg, idx_split
= feature _ rets
nd.left = Node (split_avg[0])
nd.right = Node(split_avg[1])
que.append ([depth+1, nd.left, idx_split[0]])
que.append ([depth+1, nd.right, idx_split[1]])
self.height = depth
self._get_rules() |
2.9 ДђгЁЙцдђ
ФЃаЭбЕСЗЭъБЯЃЌВщПДвЛЯТФЃаЭЩњГЩЕФЙцдђ
def print_rules(self):
for i, rule in enumerate (self.rules):
literals, score = rule
print("Rule %d: " % i, ' | '.join(
literals) + ' => split_hat %.4f' % score) |
2.10 дЄВтвЛИібљБО
def _ predict(self,
row):
nd = self.root
while nd.left and nd.right:
if row[nd.feature] < nd.split:
nd = nd.left
else:
nd = nd.right
return nd.score |
2.11 дЄВтЖрИібљБО
def predict(self,
X):
return [self._predict(Xi) for Xi in X] |
3 аЇЙћЦРЙР
3.1 mainКЏЪ§
ЪЙгУжјУћЕФВЈЪПЖйЗПМлЪ§ОнМЏЃЌАДее7:3ЕФБШЧ¹ЗжЮЊбЕСЗМЏКЭВтЪдМЏЃЌбЕСЗФЃаЭЃЌВЂЭГМЦзМШЗЖШЁЃ
@run_time
def main():
print ("Tesing the accuracy of RegressionTree...")
X, y = load_boston_house_prices()
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=10)
reg = RegressionTree()
reg.fit(X= X_train, y=y_ train, max_depth=4)
reg.print_rules()
get_r2(reg, X_test, y_test) |
3.2 аЇЙћеЙЪО
зюжеЩњГЩСЫ15ЬѕЙцдђЃЌФтКЯгХЖШ0.801ЃЌдЫааЪБМф1.74УыЃЌаЇЙћЛЙЫуВЛДэ~
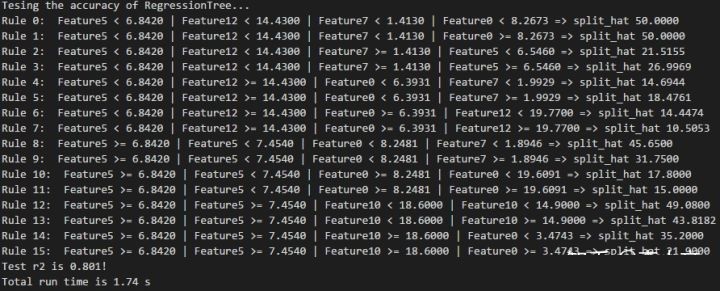
3.3 ЙЄОпКЏЪ§
БОШЫздЖЈвхСЫвЛаЉЙЄОпКЏЪ§ЃЌПЩвддкgithubЩЯВщПД
1. run_time - ВтЪдКЏЪ§дЫааЪБМф
2. load_boston_house_prices - МгдиВЈЪПЖйЗПМлЪ§Он
3. train_test_split - В№ЗжбЕСЗМЏЁЂВтЪдМЏ
4. get_r2 - МЦЫуФтКЯгХЖШ
змНс
ЛиЙщЪїЕФдРэЃК
Ы№ЪЇзюаЁЛЏЃЌЦНОљжЕДѓЗЈЁЃ зюМбаагыСаЃЌаЇЙћЖЅпЩпЩЁЃ
ЛиЙщЪїЕФЪЕЯжЃК
вЛЖйВйзїУЭШчЛЂЃЌМгМѕГЫГ§ЖўВцЪїЁЃ |









