| БрМЭЦМі: |
| РДдДгкcnblogsЃЌНщЩмСЫЪ§ОнЕМШыКЭЕМГіЃЌЬсШЁКЭЩИбЁашвЊЕФЪ§ОнЃЌЭГМЦУшЪіЃЌЪ§ОнДІРэЕШЁЃ |
|

ЧАбдЃКИїжжКЭЪ§ОнЗжЮіЯрЙиpythonПтЕФНщЩм
1.NumpyЃК
NumpyЪЧpythonПЦбЇМЦЫуЕФЛљДЁАќЃЌЫќЬсЙЉвдЯТЙІФмЃЈВЛЯогкДЫЃЉЃК
(1)ПьЫйИпаЇЕФЖрЮЌЪ§зщЖдЯѓnaarray
(2)гУгкЖдЪ§зщжДаадЊЫиМЖМЦЫувдМАжБНгЖдЪ§зщжДааЪ§бЇдЫЫуЕФКЏЪ§
(3)гУгкЖСаДгВХЬЩЯЛљгкЪ§зщЕФЪ§ОнМЏЕФЙЄОп
(4)ЯпадДњЪ§дЫЫуЁЂИЕРявЖБфЛЛЃЌвдМАЫцЛњЪ§ЩњГЩ
(5)гУгкНЋCЁЂC++ЁЂFortranДњТыМЏГЩЕНpythonЕФЙЄОп
2.pandas
pandasЬсЙЉСЫЪЙЮвУЧФмЙЛПьЫйБуНнЕиДІРэНсЙЙЛЏЪ§ОнЕФДѓСПЪ§ОнНсЙЙКЭКЏЪ§ЁЃpandasМцОпNumpyИпадФмЕФЪ§зщМЦЫуЙІФмвдМАЕчзгБэИёКЭЙиЯЕаЭЪ§ОнЃЈШчSQLЃЉСщЛюЕФЪ§ОнДІРэФмСІЁЃЫќЬсЙЉСЫИДдгОЋЯИЕФЫїв§ЙІФмЃЌвдБуИќЮЊБуНнЕиЭъГЩжиЫмЁЂЧаЦЌКЭЧаПщЁЂОлКЯвдМАбЁШЁЪ§ОнзгМЏЕШВйзїЁЃ
ЖдгкН№ШкаавЕЕФгУЛЇЃЌpandasЬсЙЉСЫДѓСПЪЪгУгкН№ШкЪ§ОнЕФИпадФмЪБМфађСаЙІФмКЭЙЄОпЁЃ
DataFrameЪЧpandasЕФвЛИіЖдЯѓЃЌЫќЪЧвЛИіУцЯђСаЕФЖўЮЌБэНсЙЙЃЌЧвКЌгаааБъКЭСаБъЁЃ
ps.в§гУвЛЖЮЭјЩЯЕФЛАЫЕУїDataFrameЕФЧПДѓжЎДІЃК
Excel 2007МАЦфвдКѓЕФАцБОЕФзюДѓааЪ§ЪЧ1048576ЃЌзюДѓСаЪ§ЪЧ16384ЃЌГЌЙ§етИіЙцФЃЕФЪ§ОнExcelОЭЛсЕЏГіИіПђПђЁАДЫЮФБОАќКЌЖрааЮФБОЃЌЮоЗЈЗХжУдквЛИіЙЄзїБэжаЁБЁЃPandasДІРэЩЯЧЇЭђЕФЪ§ОнЪЧвзШчЗДеЦЕФЪТЧщЃЌЭЌЪБЫцКѓЮвУЧвВНЋПДЕНЫќБШSQLгаИќЧПЕФБэДяФмСІЃЌПЩвдзіКмЖрИДдгЕФВйзїЃЌвЊаДЕФcodeвВИќЩйЁЃ
ЫЕСЫвЛДѓЖбЫќЕФКУДІЃЌвЊЪЕМЪИаДЅЛЙЕУЖЏЪжТыДњТыЁЃ
3.matplotlib
matplotlibЪЧзюСїааЕФгУгкЛцжЦЪ§ОнЭМБэЕФpythonПтЁЃ
4.Scipy
ScipyЪЧвЛзщзЈУХНтОіПЦбЇМЦЫужаИїжжБъзМЮЪЬтгђЕФАќЕФМЏКЯЁЃ
5.statsmodelsЃК https://github.com/statsmodels/statsmodels
6.scikit-learnЃК http://scikit-learn.org/stable/
вЛ.Ъ§ОнЕМШыКЭЕМГі
ЃЈвЛЃЉЖСШЁcsvЮФМў
1.БОЕиЖСШЁ
import pandas
as pd
df = pd.read_csv('E:\\tips.csv') #ИљОнздМКЪ§ОнЮФМўБЃДцЕФТЗОЖЬюаД(p.s.
pythonЬюаДТЗОЖЪБЃЌвЊУДЪЙгУ/ЃЌвЊУДЪЙгУ\\)
#ЪфГіЃК
total_bill tip sex smoker day time size
16.99 1.01 Female No Sun Dinner 2
10.34 1.66 Male No Sun Dinner 3
21.01 3.50 Male No Sun Dinner 3
23.68 3.31 Male No Sun Dinner 2
24.59 3.61 Female No Sun Dinner 4
25.29 4.71 Male No Sun Dinner 4
.. ... ... ... ... ... ... ...
27.18 2.00 Female Yes Sat Dinner 2
22.67 2.00 Male Yes Sat Dinner 2
17.82 1.75 Male No Sat Dinner 2
18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns] |
2.ЭјТчЖСШЁ
import pandas
as pd
data_url = "https: //raw. githubusercontent
.com / mwaskom /seaborn- data/master /tips.csv"
#ЬюаДurlЖСШЁ
df = pd.read_csv(data_url)
#ЪфГіЭЌЩЯ |
3.read_csvЯъНт
ЙІФмЃК Read CSV (comma-separated) file into DataFrame
| read_ csv(filepath_
or_buffer, sep =',', dialect =None , compression=
'infer', doublequote= True, escapechar= None,
quotechar ='"', quoting= 0, skipinitialspace=
False, lineterminator= None, header= 'infer',
index_col= None, names= None, prefix= None, skiprows=
None, skipfooter =None, skip_ footer= 0, na_values=
None, true_values= None , false_ values= None,
delimiter= None, converters =None, dtype= None,
usecols None, engine =None, delim _whitespace
=False, as_ recarray =False, na_ filter= True,
compact_ ints= False, use_ unsigned =False, low
_memory= True, buffer _lines= None, warn _bad_lines
=True, error_ bad_lines =True, keep_ default _na=
True, thousands = None, comment = None, decimal
='.', parse_ dates= False, keep _date_col =False,
dayfirst = False, date_parser= None, memory _map=
False, float _precision =None, nrows =None, iterator
=False , chunksize= None, verbose= False, encoding=
None, squeeze= False, mangle_dupe_cols = True,
tupleize_ cols= False, infer_ datetime _ format
= False, skip _blank_ lines= True) |
ВЮЪ§ЯъНтЃК
http: //pandas.pydata.org /pandas-docs
/stable/generated /pandas.read_csv.html
(Жў)ЖСШЁMysqlЪ§Он
МйЩшЪ§ОнПтАВзАдкБОЕиЃЌгУЛЇУћЮЊmyusername,УмТыЮЊmypassword,вЊЖСШЁmydbЪ§ОнПтжаЕФЪ§Он
import pandas
as pd
import MySQLdb
mysql_cn= MySQLdb.connect (host='localhost', port=
3306,user ='myusername', passwd= 'mypassword',
db= 'mydb ')
df = pd.read_sql('select * from test;', con= mysql_
cn)
mysql_ cn.close() |
ЩЯУцЕФДњТыЖСШЁСЫtestБэжаЫљгаЕФЪ§ОнЕНdfжаЃЌЖјdfЕФЪ§ОнНсЙЙЮЊDataframeЁЃ
ps.MySQLНЬГЬ:http://www.runoob.com/mysql/mysql-tutorial.html
(Ш§)ЖСШЁexcelЮФМў
вЊЖСШЁexcelЮФМўЛЙашвЊАВзАxlrdФЃПщЃЌpip install xlrdМДПЩЁЃ
| df = pd.read_excel('E:\\tips.xls') |
(ЫФ)Ъ§ОнЕМГіЕНcsvЮФМў
df.to_csv('E:\\
demo.csv', encoding= 'utf-8', index = False)
#index=False БэЪОЕМГіЪБШЅЕєааУћГЦЃЌШчЙћЪ§ОнжаКЌгажаЮФЃЌвЛАуencoding жИЖЈЮЊЁЎutf-8ЁЏ |
(Юх)ЖСаДSQLЪ§ОнПт
import pandas
as pd
import sqlite3
con = sqlite3.connect('...')
sql = '...'
df = pd.read_sql(sql,con)
#helpЮФМў
help (sqlite3.connect)
#ЪфГі
Help on built- in function connect in module _
sqlite3 :
connect(...)
connect(database[, timeout, isolation_level, detect
_types, factory])
Opens a connection to the SQLite database file
*database *. You can use
":memory :" to open a database connection
to a database that resides in
RAM instead of on disk.
#############
help(pd.read_sql)
#ЪфГі
Help on function read_ sql in module pandas.io.
sql :
read_sq l(sql, con, index_col= None, coerce_float=
True, params= None, parse_ dates= None, columns=
None, chunksize= None)
Read SQL query or database table into a DataFrame. |
ps.Ъ§ОнПтЕФДњТыЪЧЮвжБНгДгЭјТчЩЯеГЬљЙ§РДЕФЃЌУЛгаВтЪдЙ§ЪЧВЛЪЧПЩааЃЌЯШЬљЩЯРДЁЃ
Ъ§ОнПтЮвЛЙдкУўЫїжаЃЌбЇЯАаФЕУбЇЯАБЪМЧжЎРрЕФДѓМвПЩвдвЛЦ№ЗжЯэ23333~
Жў.ЬсШЁКЭЩИбЁашвЊЕФЪ§Он
ЃЈвЛЃЉЬсШЁКЭВщПДЯргІЪ§Он ЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps:
//github .com/mwaskom /seaborn- dataЃЉ
print df.head()
#ДђгЁЪ§ОнЧАЮхаа
#ЪфГі
total_ bill tip sex smoker day time size
16.99 1.01 Female No Sun Dinner 2
10.34 1.66 Male No Sun Dinner 3
21.01 3.50 Male No Sun Dinner 3
23.68 3.31 Male No Sun Dinner 2
24.59 3.61 Female No Sun Dinner 4 |
print df.tail()
#ДђгЁЪ§ОнКѓ5аа
#ЪфГі
total_bill tip sex smoker day time size
29.03 5.92 Male No Sat Dinner 3
27.18 2.00 Female Yes Sat Dinner 2
22.67 2.00 Male Yes Sat Dinner 2
17.82 1.75 Male No Sat Dinner 2
18.78 3.00 Female No Thur Dinner 2! |
print df.columns
#ДђгЁСаУћ
#ЪфГі
Index ([u'total_bill', u'tip', u'sex', u'smoker',
u'day', u'time', u'size'], dtype ='object') |
print df.index
#ДђгЁааУћ
#ЪфГі
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
...
234, 235, 236, 237, 238, 239, 240, 241, 242, 243],
dtype='int64', length= 244) |
print df.ix[10:20,
0:3] #ДђгЁ10~20ааЧАШ§СаЪ§Он
#ЪфГі
total_bill tip sex
10.27 1.71 Male
35.26 5.00 Female
15.42 1.57 Male
18.43 3.00 Male
14.83 3.02 Female
21.58 3.92 Male
10.33 1.67 Female
16.29 3.71 Male
16.97 3.50 Female
20.65 3.35 Male
17.92 4.08 Male |
#ЬсШЁВЛСЌајааКЭСаЕФЪ§ОнЃЌетИіР§згЬсШЁЕФЪЧЕк1,3,5ааЃЌЕк2,4СаЕФЪ§Он
df.iloc[[1,3,5],[2,4]]
#ЪфГі
sex day
Male Sun
Male Sun
Male Sun |
#зЈУХЬсШЁФГвЛИіЪ§ОнЃЌетИіР§згЬсШЁЕФЪЧЕкШ§ааЃЌЕкЖўСаЪ§ОнЃЈФЌШЯДг0ПЊЪМЫуЙўЃЉ
df.iat[3,2]
#ЪфГі
'Male'
|
print df.drop(df.columns[1,
2], axis = 1) #ЩсЦњЪ§ОнЧАСНСа
print df.drop(df.columns[[1, 2]], axis = 0)
#ЩсЦњЪ§ОнЧАСНаа
#ЮЊСЫНкЪЁЦЊЗљНсЙћОЭВЛЬљГіРДСЫЙў~
|
print df.shape
#ДђгЁЮЌЖШ
#ЪфГі
(244, 7) |
df.iloc[3]
#бЁШЁЕк3аа
#ЪфГі1
total_bill 23.68
tip 3.31
sex Male
smoker No
day Sun
time Dinner
size 2
Name: 3, dtype: object
df.iloc[2:4] #бЁШЁЕк2ЕНЕк3аа
#ЪфГі2
total_bill tip sex smoker day time size
21.01 3.50 Male No Sun Dinner 3
23.68 3.31 Male No Sun Dinner 2
df.iloc[0,1] #бЁШЁЕк0аа1СаЕФдЊЫи
#ЪфГі3
1.01 |
(Жў)ЩИбЁГіашвЊЕФЪ§ОнЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps:
//github.com /mwaskom /seaborn- dataЃЉ
#example:МйЩшЮвУЧвЊЩИбЁГіаЁЗбДѓгк$8ЕФЪ§Он
df[df.tip>8]
#ЪфГі
total_bill tip sex smoker day time size
50.81 10 Male Yes Sat Dinner 3
48.33 9 Male No Sat Dinner 4 |
#Ъ§ОнЩИбЁЭЌбљПЩвдгУЁБЛђЁАКЭЁБЧвЁАзїЮЊЩИбЁЬѕМўЃЌБШШч
#1
df[(df.tip>7)|(df.total_bill>50)] #ЩИбЁГіаЁЗбДѓгк$7
ЛђзмеЫЕЅДѓгк$50ЕФЪ§Он
#ЪфГі
total_bill tip sex smoker day time size
39.42 7.58 Male No Sat Dinner 4
50.81 10.00 Male Yes Sat Dinner 3
48.33 9.00 Male No Sat Dinner 4
#2
df [(df.tip>7)&(df.total_ bill>50)]#ЩИбЁГіаЁЗбДѓгк$7ЧвзмеЫЕЅДѓгк$50ЕФЪ§Он
#ЪфГі
total_bill tip sex smoker day time size
50.81 10 Male Yes Sat Dinner 3 |
#НгЩЯ
#МйШчМгШыСЫЩИбЁЬѕМўКѓЃЌЮвУЧжЛЙиаФdayКЭtime
df[['day','time']][(df.tip>7)|(df.total_bill>50)]
#ЪфГі
day time
Sat Dinner
Sat Dinner
Sat Dinner |
Ш§.ЭГМЦУшЪіЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps://github.com/mwaskom/seaborn-dataЃЉ
print df.describe() #УшЪіадЭГМЦ
#ЪфГі ИїжИБъЖМБШНЯМђЕЅОЭВЛНтЪЭСЫЙў
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000 |
ЫФ.Ъ§ОнДІРэ(вЛ)Ъ§ОнзЊжУЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps:
//github.com /mwaskom /seaborn- dataЃЉ
print df.T
#output
1 2 3 4 5 6 7 \
total_bill 16.99 10.34 21.01 23.68 24.59 25.29
8.77 26.88
tip 1.01 1.66 3.5 3.31 3.61 4.71 2 3.12
sex Female Male Male Male Female Male Male Male
smoker No No No No No No No No
day Sun Sun Sun Sun Sun Sun Sun Sun
time Dinner Dinner Dinner Dinner Dinner Dinner
Dinner Dinner
size 2 3 3 2 4 4 2 4
9 ... 234 235 236 237 238 \
total_bill 15.04 14.78 ... 15.53 10.07 12.6 32.83
35.83
tip 1.96 3.23 ... 3 1.25 1 1.17 4.67
sex Male Male ... Male Male Male Male Female
smoker No No ... Yes No Yes Yes No
day Sun Sun ... Sat Sat Sat Sat Sat
time Dinner Dinner ... Dinner Dinner Dinner Dinner
Dinner
size 2 2 ... 2 2 2 2 3
240 241 242 243
total_bill 29.03 27.18 22.67 17.82 18.78
tip 5.92 2 2 1.75 3
sex Male Female Male Male Female
smoker No Yes Yes No No
day Sat Sat Sat Sat Thur
time Dinner Dinner Dinner Dinner Dinner
size 3 2 2 2 2
[7 rows x 244 columns] |
(Жў)Ъ§ОнХХађЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps:
//github.com/mwaskom /seaborn-data ЃЉ
df.sort_values(by='tip')
#АДtipСаЩ§ађХХађ
#ЪфГіЃЈЮЊСЫВЛеМЦЊЗљЮвМђЛЏСЫвЛВПЗжЃЉ
total_bill tip sex smoker day time size
3.07 1.00 Female Yes Sat Dinner 1
12.60 1.00 Male Yes Sat Dinner 2
5.75 1.00 Female Yes Fri Dinner 2
7.25 1.00 Female No Sat Dinner 1
16.99 1.01 Female No Sun Dinner 2
.. ... ... ... ... ... ... ...
28.17 6.50 Female Yes Sat Dinner 3
34.30 6.70 Male No Thur Lunch 6
48.27 6.73 Male No Sat Dinner 4
39.42 7.58 Male No Sat Dinner 4
48.33 9.00 Male No Sat Dinner 4
50.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns] |
(Ш§)ШБЪЇжЕДІРэ1.ЬюГфШБЪЇжЕ(Ъ§ОнРДздЁЖРћгУpythonНјааЪ§ОнЗжЮіЁЗЕкЖўеТ
usagov_ bitly_ data 2012-03-16- 1331923249.txtЃЌашвЊЕФЭЌбЇПЩвдевЮввЊ)
import json
#pythonгааэЖрФкжУЛђЕкШ§ЗНФЃПщПЩвдНЋJSONзжЗћДЎзЊЛЛГЩpythonзжЕфЖдЯѓ
import pandas as pd
import numpy as np
from pandas import DataFrame
path = 'F: \PycharmProjects\pydata-book-master\
ch02\ usagov_bitly_ data2012-03-16-1331923249.txt'
#ИљОнздМКЕФТЗОЖЬюаД
records = [json.loads(line) for line in open (path)]
frame = DataFrame(records)
frame ['tz']
#ЪфГіЃЈЮЊСЫНкЪЁЦЊЗљЮвЩОГ§СЫВПЗжЪфГіНсЙћЃЉ
America/New_York
America/Denver
America/New_York
America/Sao_Paulo
America/New_York
America/New_York
Europe/Warsaw
America/Los_Angeles
America/New_York
America/New_York
NaN
...
Name: tz, dtype: object |
ДгвдЩЯЪфГіжЕПЩвдПДГіЪ§ОнДцдкЮДжЊЛђШБЪЇжЕЃЌНгзХдлУЧРДДІРэШБЪЇжЕЁЃ
print frame['tz'].fillna(1111111111111)
#вдЪ§зжДњЬцШБЪЇжЕ
#ЪфГіНсЙћЃЈЮЊСЫНкЪЁЦЊЗљЮвЩОГ§СЫВПЗжЪфГіНсЙћЃЉ
America/New_York
America/Denver
America/New_York
America/Sao_Paulo
America/New_York
America/New_York
Europe/Warsaw
America/Los_Angeles
America/New_York
America/New_York
1111111111111
Name: tz, dtype: object |
print frame
['tz'].fillna ('YuJie2333333333333') #гУзжЗћДЎДњЬцШБЪЇжЕ
#ЪфГіЃЈЮЊСЫНкЪЁЦЊЗљЮвЩОГ§СЫВПЗжЪфГіНсЙћЃЉ
America/New_York
America/Denver
America/New_York
America/Sao_Paulo
America/New_York
America/New_York
Europe/Warsaw
America/Los_Angeles
America/New_York
America/New_York
YuJie2333333333333
Name: tz, dtype: object |
ЛЙгаЃК
print frame['tz'].fillna(method='pad')
#гУЧАвЛИіЪ§ОнДњЬцШБЪЇжЕ
print frame['tz'].fillna(method='bfill') #гУКѓвЛИіЪ§ОнДњЬцШБЪЇжЕ
|
2.ЩОГ§ШБЪЇжЕ ЃЈЪ§ОнЭЌЩЯЃЉ
print frame['tz'].dropna(axis=0)
#ЩОГ§ШБЪЇаа
print frame['tz'].dropna(axis=1) #ЩОГ§ШБЪЇСа
|
3.ВхжЕЗЈЬюВЙШБЪЇжЕ
гЩгкУЛгаЪ§ОнЃЌетЖљВхВЅвЛИіаЁжЊЪЖЕуЃКДДНЈвЛИіЫцЛњЕФЪ§ОнПђ
import pandas
as pd
import numpy as np
#ДДНЈвЛИі6*4ЕФЪ§ОнПђЃЌrandnКЏЪ§гУгкДДНЈЫцЛњЪ§
czf_data = pd.DataFrame (np.random .randn (6,4),columns=
list('ABCD'))
czf_ data
#ЪфГі
A B C D
0.355690 1.165004 0.810392 -0.818982
0.496757 -0.490954 -0.407960 -0.493502
-0.202123 -0.842278 -0.948464 0.223771
0.969445 1.357910 -0.479598 -1.199428
0.125290 0.943056 -0.082404 -0.363640
-1.762905 -1.471447 0.351570 -1.546152 |
КУРВЃЌЪ§ОнОЭГіРДСЫЁЃНгзХЮвУЧгУПежЕЬцЛЛЪ§жЕЃЌДДдьГівЛИіКЌгаПежЕЕФDataFrameЁЃ
#АбЕкЖўСаЪ§ОнЩшжУЮЊШБЪЇжЕ
czf_data.ix [2,:]=np.nan
czf_data
#ЪфГі
A B C D
0.355690 1.165004 0.810392 -0.818982
0.496757 -0.490954 -0.407960 -0.493502
NaN NaN NaN NaN
0.969445 1.357910 -0.479598 -1.199428
0.125290 0.943056 -0.082404 -0.363640
-1.762905 -1.471447 0.351570 -1.546152 |
#НгзХОЭПЩвдРћгУВхжЕЗЈЬюВЙПеШБжЕСЫ~
print czf_ data.interpolate()
#ЪфГі
A B C D
0.355690 1.165004 0.810392 -0.818982
0.496757 -0.490954 -0.407960 -0.493502
0.733101 0.433478 -0.443779 -0.846465
0.969445 1.357910 -0.479598 -1.199428
0.125290 0.943056 -0.082404 -0.363640
-1.762905 -1.471447 0.351570 -1.546152 |
(ЫФ)Ъ§ОнЗжзщЃЈгУЕФЪЧtips.csvЕФЪ§ОнЃЌЪ§ОнРДдДЃКhttps:
//github.com/mwaskom /seaborn-data ЃЉ
group = df.groupby('day') #АДdayетвЛСаНјааЗжзщ
#1
print group.first ()#ДђгЁУПвЛзщЕФЕквЛааЪ§Он
#ЪфГі
total_bill tip sex smoker time size
day
Fri 28.97 3.00 Male Yes Dinner 2
Sat 20.65 3.35 Male No Dinner 3
Sun 16.99 1.01 Female No Dinner 2
Thur 27.20 4.00 Male No Lunch 4
#2
print group.last()#ДђгЁУПвЛзщЕФзюКѓвЛааЪ§Он
#ЪфГі
total_bill tip sex smoker time size
day
Fri 10.09 2.00 Female Yes Lunch 2
Sat 17.82 1.75 Male No Dinner 2
Sun 15.69 1.50 Male Yes Dinner 2
Thur 18.78 3.00 Female No Dinner 2 |
(Юх)жЕЬцЛЛ
import pandas as pd
import numpy as np
#ЪзЯШДДдьвЛИіSeriesЃЈУЛгаЪ§ОнЧщПіЯТЕФИЃвє233ЃЉ
Series = pd.Series([0,1,2,3,4,5])
#ЪфГі
Series
0
1
2
3
4
5
dtype: int64 |
#Ъ§жЕЬцЛЛЃЌР§ШчНЋ0ЛЛГЩ10000000000000
print Series.replace(0,10000000000000)
#ЪфГі
10000000000000
1
2
3
4
5
dtype: int64 |
#СаКЭСаЕФЬцЛЛЭЌРэ
print Series.replace([0,1,2,3,4,5]ЃЌ[11111,222222,3333333,44444,55555,666666])
#ЪфГі
11111
222222
3333333
44444
55555
666666
dtype: int64 |
Юх.ЭГМЦЗжЮі
(вЛ)tМьбщ
1.ЖРСЂбљБОtМьбщ
СНЖРСЂбљБОtМьбщОЭЪЧИљОнбљБОЪ§ОнЖдСНИібљБОРДздЕФСНЖРСЂзмЬхЕФОљжЕЪЧЗёгаЯджјВювьНјааЭЦЖЯЃЛНјааСНЖРСЂбљБОtМьбщЕФЬѕМўЪЧЃЌСНбљБОЕФзмЬхЯрЛЅЖРСЂЧвЗћКЯе§ЬЌЗжВМЁЃ
ПЊЪМевВЛЕНКЯЪЪЕФЪ§ОнЃЌЮвОЭдкЭјЩЯЫцБуеЊГСЫИіspssзіЖРСЂбљБОtМьбщЕФЪЕР§Ъ§ОнзїЮЊР§згДѓМвднЪБПДзХАЩевЕНКЯЪЪЕФР§згдйИјДѓМвОй~
Ъ§ОнШчЯТЃЌЮвНЋЪ§ОнБЃДцЮЊБОЕиxlsxИёЪНЃК
group data
1 34
1 37
1 28
1 36
1 30
2 43
2 45
2 47
2 49
2 39 |
import pandas
as pd
from scipy.stats import ttest_ind
IS_t_test = pd.read_excel('E:\\IS_t_test.xlsx')
Group1 = IS_t_test[IS_t_test['group']==1]['data']
Group2 = IS_t_test[IS_t_test['group']==2]['data']
print ttest_ind(Group1,Group2)
#ЪфГі
(-4.7515451390104353, 0.0014423819408438474) |
ЪфГіНсЙћЕФЕквЛИідЊЫиЮЊtжЕЃЌЕкЖўИідЊЫиЮЊp-value
ttest_indФЌШЯСНзщЪ§ОнЗНВюЦыадЕФЃЌШчЙћЯывЊЩшжУФЌШЯЗНВюВЛЦыЃЌПЩвдЩшжУequal_var=False
print ttest_ind(Group1,Group2,equal_var=True)
print ttest_ind(Group1,Group2,equal_var=False)
#ЪфГі
(-4.7515451390104353, 0.0014423819408438474)
(-4.7515451390104353, 0.0014425608643614844) |
2.ХфЖдбљБОtМьбщ
ЭЌбљевВЛЕНЪ§ОнЃЌШУЮвУЧднЧвМйЩшЩЯБпЖРСЂбљБОЪЧХфЖдбљБОАЩЃЌЪЙгУЭЌбљЕФЪ§ОнЁЃ
import pandas
as pd
from scipy.stats import ttest_rel
IS_t_test = pd.read_excel('E:\\IS_t_test.xlsx')
Group1 = IS_t_test[IS_t_test['group']==1]['data']
Group2 = IS_t_test[IS_t_test['group']==2]['data']
print ttest_rel(Group1,Group2)
#ЪфГі
(-5.6873679190073361, 0.00471961872448184) |
ЭЌбљЕФЃЌЪфГіНсЙћЕФЕквЛИідЊЫиЮЊtжЕЃЌЕкЖўИідЊЫиЮЊp-valueЁЃ
(Жў)ЗНВюЗжЮі
1.ЕЅвђЫиЗНВюЗжЮі
етРявРШЛбигУtМьбщЕФЪ§Он
import pandas
as pd
from scipy import stats
IS_t_test = pd.read_excel('E:\\IS_t_test.xlsx')
Group1 = IS_t_test[IS_t_test['group']==1]['data']
Group2 = IS_t_test[IS_t_test['group']==2]['data']
w,p = stats.levene(*args)
#leveneЗНВюЦыадМьбщЁЃlevene(*args, **kwds) Perform Levene
test for equal variances.ШчЙћp<0.05ЃЌдђЗНВюВЛЦы
print w,p
#НјааЗНВюЗжЮі
f,p = stats.f_oneway(*args)
print f,p
#ЪфГі
(0.019607843137254936, 0.89209916055865535)
22.5771812081 0.00144238194084 |
2.ЖрвђЫиЗНВюЗжЮі
Ъ§ОнЪЧЮвДгЭјЩЯевЕФЖрвђЫиЗНВюЗжЮіЕФвЛИіР§згЃЌбаОПЧјзщКЭгЊбјЫиЖдЬхжиЕФгАЯьЁЃЮвзіГЩСЫexcelЮФМўЃЌашвЊЕФЭЌбЇПЩвдЮЪЮввЊЙў~зіЖрвђЫиЗНВюЗжЮіашвЊМгдиstatsmodelsФЃПщЃЌШчЙћЕчФдУЛгаАВзАПЩвдpip
installвЛЯТЁЃ
#Ъ§ОнЕМШы
import pandas as pd
MANOVA=pd.read_excel('E:\\MANOVA.xlsx')
MANOVA
#ЪфГіЃЈЮЊСЫНкЪЁЦЊЗљЩОЕєСЫжаМфВПЗжЕФЪфГіНсЙћЃЉ
id nutrient weight
1 1 50.1
2 1 47.8
3 1 53.1
4 1 63.5
5 1 71.2
6 1 41.4
.......................
6 3 38.5
7 3 51.2
8 3 46.2 |
#ЖрвђЫиЗНВюЗжЮі
from statsmodels.formula.api import ols
from statsmodels. stats.anova import anova_lm
formula = 'weight~C (id)+ C(nutrient) +C(id):
C (nutrient) '
anova_results = anova_lm (ols (formula ,MANOVA)
.fit ())
print anova_results
#output
df sum_sq mean_sq F PR (>F)
C(id) 7 2.373613e +03 339.087619 0 NaN
C(nutrient) 2 1.456133e+02 72.806667 0 NaN
C(id):C(nutrient) 14 3.391667e +02 24.226190 0
NaN
Residual 0 8.077936e-27 inf NaN NaN |
вВаэЪ§ОнбЁЕУВЛЖдЃЌp-valueШЋЪЧПежЕ23333ЃЌД§ЮвевИіКУЕуЖљЕФЪ§ОндйзівЛДЮЖрвђЫиЗНВюЗжЮіЁЃ
3.жиИДВтСПЩшМЦЕФЗНВюЗжЮіЃЈЕЅвђЫиЃЉ ********Д§ЭъЩЦ
жиИДВтСПЩшМЦЪЧЖдЭЌвЛвђБфСПНјаажиИДВтЖШЃЌжиИДВтСПЩшМЦЕФЗНВюЗжЮіПЩвдЪЧЭЌвЛЬѕМўЯТНјааЕФжиИДВтЖШЃЌвВПЩвдЪЧВЛЭЌЬѕМўЯТЕФжиИДВтСПЁЃ
ДњТыКЭЖрвђЫиЗНВюЗжЮівЛбљЃЌЫМТЗВЛвЛбљЖјвб~ЕЋЮвЛЙевВЛЕНЖрвђЫиЗНВюЗжЮіКЯЪЪЕФЪ§ОнЫљвдетЖљОЭЯШВЛаДСЫ2333
4.ЛьКЯЩшМЦЕФЗНВюЗжЮі ********Д§ЭъЩЦ
#########ЭГМЦбЇбЇЕУКУЕФЭЌбЇУЧЃЌНЬНЬЮвАЩЁЃЁЃ
(Ш§)ПЈЗНМьбщ
ПЈЗНМьбщОЭЪЧЭГМЦбљБОЕФЪЕМЪЙлВтжЕгыРэТлЭЦЖЯжЕжЎМфЕФЦЋРыГЬЖШЃЌЪЕМЪЙлВтжЕгыРэТлЭЦЖЯжЕжЎМфЕФЦЋРыГЬЖШОЭОіЖЈПЈЗНжЕЕФДѓаЁЃЌПЈЗНжЕдНДѓЃЌдНВЛЗћКЯЃЛПЈЗНжЕдНаЁЃЌЦЋВюдНаЁЃЌдНЧїгкЗћКЯЃЌШєСНИіжЕЭъШЋЯрЕШЪБЃЌПЈЗНжЕОЭЮЊ0ЃЌБэУїРэТлжЕЭъШЋЗћКЯЁЃЃЈfrom
АйЖШАйПЦ2333ЃЉ
1.ЕЅвђЫиПЈЗНМьбщ
Ъ§ОндДгкЭјТчЃЌФаХЎЛЏзБгыВЛЛЏзБШЫЪ§ЕФРэТлжЕгыЪЕМЪжЕЁЃ
import numpy as np
from scipy import stats
from scipy.stats import chisquare
observed = np.array([15,95])
#ЙлВтжЕЃК110бЇЩњжаЛЏзБЕФХЎЩњ95ШЫЃЌЛЏзБЕФФаЩњ15ШЫ
expected = np.array([55,55])
#РэТлжЕЃК110бЇЩњжаЛЏзБЕФХЎЩњ55ШЫЃЌЛЏзБЕФФаЩњ55ШЫ
chisquare(observed,expected)
#output
(58.18181818181818, 2.389775628860044e-14) |
2.ЖрвђЫиПЈЗНМьбщ*****е§дкбаОПжаЃЌбЇЛсСЫЭъЩЦетвЛПщ~
(ЫФ)МЦЪ§ЭГМЦЃЈгУЕФЪ§ОнЮЊtips.csvЃЉ
#exampleЃКЭГМЦадБ№
count = df['sex'].value_counts()
#ЪфГі
print count
Male 157
Female 87
Name: sex, dtype: int64 |
(Юх)ЛиЙщЗжЮі *****Д§бЇЯАЃК Ъ§ОнФтКЯЃЌЙувхЯпадЛиЙщЁЃЁЃЁЃЁЃЕШЕШ
Сљ.ПЩЪгЛЏ
ЮвОѕЕУАЩЃЌЦфЪЕПДзХexcelОЭПЩвдЪЕЯжЕФЙІФмЮЊКЮФЧУДИДдгЃЌexcelШЗЪЕЙЛЭЈгУЙЛБуНнЃЌЕЋЪЧДІРэКмДѓЪ§ОнСПЕФЛАвВаэГдВЛЯћАЩЁЃбЇбЇpythonЛцЭМвВВЛРЕЃЌЖјЧвНВецЃЌгаЕФГЩаЇецЕФЭІКУПДЕФЁЃ
(вЛ)Seaborn
ЮвбЇЪ§ОнЗжЮіПЩЪгЛЏЪЧДгбЇЯАSeabornШыУХЕФЃЌSeabornЪЧЛљгкmatplotlibЕФPythonПЩЪгЛЏПтЃЌИеПЊЪМБуНгДЅmatplotlibФбУтгааЉГдСІЃЌВЮЪ§ЖрЧвФбРэНтЃЌЕЋЪЧТ§Т§РДзмЛсбЇЛсЕФЁЃЛЙгаЙиМќЕФвЛЕуЪЧЃЌseabornЛГіРДЕФЭМКУКУПДЁЃЁЃ
#ЛљДЁЕМШы
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt |
#аЁЗбЪ§ОнецЕФЭІКУЕФЃЌетЖљгУtipsзїЮЊexample
tips = sns.load_dataset('tips') #ДгЭјТчЛЗОГЕМШыЪ§Онtips |
1.lmplotКЏЪ§
lmplot(x, y, data, hue =None, col=None,
row=None, palette =None, col_wrap=None, size=5, aspect=1,
markers ='o', sharex=True, sharey=True, hue _order=None,
col_order=None, row_ order =None, legend=True, legend_out=True,
x_ estimator= None, x_bins=None, x_ci='ci', scatter
= True, fit_reg=True, ci=95, n_boot= 1000, units=
None, order=1, logistic= False , lowess =False, robust
=False, logx= False, x_partial=None, y_partial=None,
truncate = False , x_ jitter=None, y_jitter=None,
scatter_kws=None, line_kws= None)
ЙІФмЃКPlot data and regression model fits across a FacetGrid.
ЯТУцОЭВЛЭЌЕФР§згЃЌЖдlmplotЕФВЮЪ§НјааНтЪЭ
Р§зг1. ЛГізмеЫЕЅКЭаЁЗбЛиЙщЙиЯЕЭМ
гУЕНСЫlmplot(x, y, data,scatter_kwsЃЉ
x,y,dataвЛФПСЫШЛетЖљОЭВЛЖрНтЪЭСЫЃЌscatter_kwsКЭline_kwsЕФЙйЗННтЪЭШчЯТЃК
{scatter,line}_kws : dictionarie
Additional keyword arguments to pass to plt.scatter
and plt.plot.
scatterЮЊЕуЃЌlineЮЊЯпЁЃЦфЪЕОЭЪЧгУзжЕфШЅЯоЖЈЕуКЭЯпЕФИїжжЪєадЃЌШчР§згЫљЪОЃЌЩЂЕуЕФбеЩЋЮЊЛвЪЏЩЋЃЌЯпЬѕЕФбеЩЋЮЊгЁЖШКьЃЌГЩЯёаЇЙћОЭЪЧетбљЕуЯпбеЩЋЗжРыЃЌеЙЯжаЇЙћКмКУЁЃДѓМввВПЩвдЛЛЩЯздМКЯывЊЕФЭМЦЌЪєадЁЃ
sns.lmplot("total_bill",
"tip", tips,
scatter_kws= {"marker": ".",
"color": "slategray"},
line_ kws= {"linewidth": 1, "color":
"indianred" }).savefig ('picture2')
|
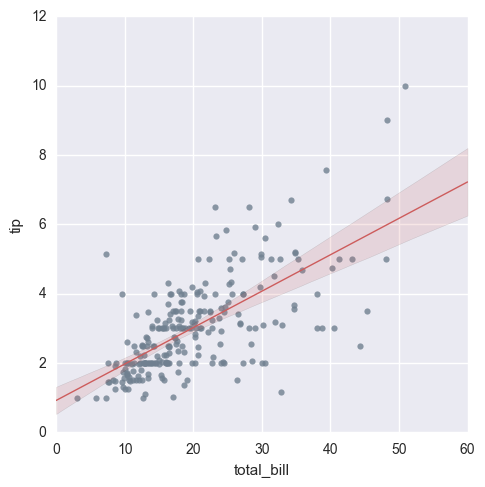
СэЭтЃКбеЩЋЛЙПЩвдЪЙгУRGBДњТыЃЌОпЬхЖдееБэПЩвдВЮПМетИіЭјеОЃЌПЩвдздМКДюХфбеЩЋЃК
http: //www.114la.com /other/rgb.htm
markerвВПЩвдгаЖржжбљЪНЃЌОпЬхШчЯТЃК
. Point marker
, Pixel marker
o Circle marker
v Triangle down marker
^ Triangle up marker
< Triangle left marker
> Triangle right marker
1 Tripod down marker
2 Tripod up marker
3 Tripod left marker
4 Tripod right marker
s Square marker
p Pentagon marker
* Star marker
h Hexagon marker
H Rotated hexagon D Diamond marker
d Thin diamond marker
| Vertical line (vlinesymbol) marker
_ Horizontal line (hline symbol) marker
+ Plus marker
x Cross (x) marker
sns.lmplot("total_bill",
"tip", tips,
scatter_ kws= {"marker": ".","color":"#FF7F00"},
line _ kws= {"linewidth": 1, "color":
"#BF3EFF" }). savefig ('s1')
ps.ЮваоИФmakerЪєадВЛГЩЙІВЛжЊЮЊКЮЃЌЧѓНтД№ |

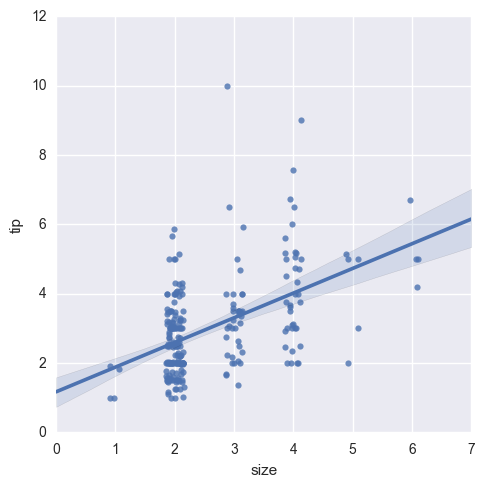
Р§зг2.гУВЭШЫЪ§(size)КЭаЁЗб(tip)ЕФЙиЯЕЭМ
ЙйЗННтЪЭЃК
x_estimator : callable that maps vector -> scalar,
optional
Apply this function to each unique value of x and
plot the resulting estimate. This is useful when x
is a discrete variable. If x_ci is not None, this
estimate will be bootstrapped and a confidence interval
will be drawn.
ДѓИХНтЪЭОЭЪЧЃКЖдгЕгаЯрЭЌxЫЎЦНЕФyжЕНјаагГЩф
plt.figure()
sns.lmplot ('size', 'tip', tips, x_estimator =
np .mean ). savefig('picture3') |

{x,y}_jitter : floats, optional
Add uniform random noise of this size to either
the x or y variables. The noise is added to a copy
of the data after fitting the regression, and only
influences the look of the scatterplot. This can be
helpful when plotting variables that take discrete
values.
jitterЪЧИіКмгавтЫМЕФВЮЪ§, ЬиБ№ЪЧДІРэАаЪ§ОнЕФoverlappingЙ§гкбЯжиЕФЧщПіЪБ,
ЭЈЙ§діМгвЛЖЈГЬЖШЕФдыЩљ(noise)ЪЕЯжЪ§ОнЕФЧјИєЛЏ, етбљдЪМЪ§ОнЪЧШєИЩ ЕуДи БфГЩвЛЯЕСаУмМЏСкНќЕФЕуШК.
СэЭт, гаЕФШЫЛсОГЃНЋ rug гы jitter НсКЯЪЙгУ. етвРШЫАЩ.ЖдгкКсжсШЁРыЩЂЫЎЦНЕФЪБКђ,
гУx_jitter ПЩвдШУЪ§ОнЕуЗЂЩњЫЎЦНЕФШХЖЏ.ЕЋШХЖЏЕФЗљЖШВЛвЫЙ§ДѓЁЃ
| sns.lmplot('size',
'tip', tips, x_jitter= .15). savefig ('picture4') |
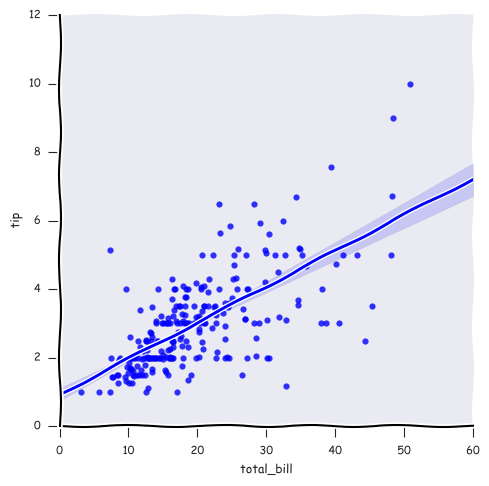
seabornЛЙПЩвдзіГіxkcdЗчИёЕФЭМЦЌЃЌЛЙЭІгавтЫМЕФ
with plt.xkcd():
sns.color_ palette('husl', 8)
sns.set_ context('paper')
sns.lmplot (x='total_bill', y='tip', data= tips,
ci= 65).savefig ('picture1') |
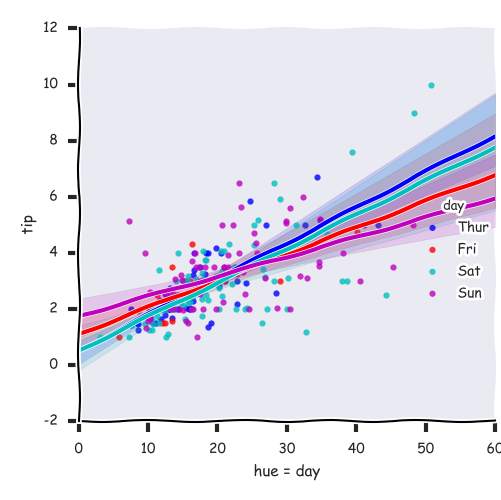
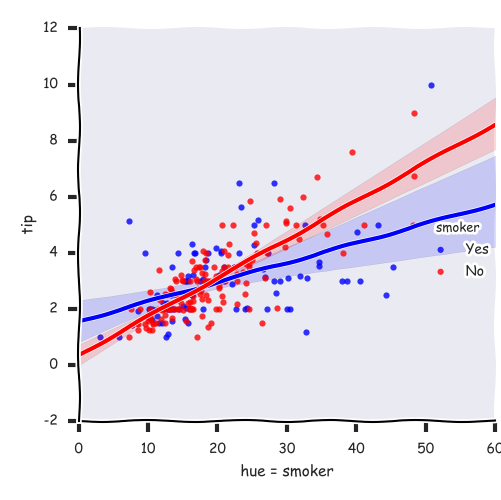
with plt.xkcd():
sns.lmplot('total_ bill', 'tip', data =tips, hue=
'day ')
plt.xlabel('hue = day')
plt.savefig('picture5') |
with plt.xkcd():
sns.lmplot ('total_bill', 'tip', data=tips, hue=
'smoker')
plt.xlabel('hue = smoker')
plt.savefig('picture6') |
sns.set_style('dark')
sns.set_context('talk')
sns.lmplot('size', 'total_ bill', tips, order=2)
plt.title('# poly order = 2')
plt.savefig ('picture7')
plt.figure()
sns.lmplot('size', 'total_bill', tips, order=3)
plt.title ('# poly order = 3')
plt.savefig('picture8') |
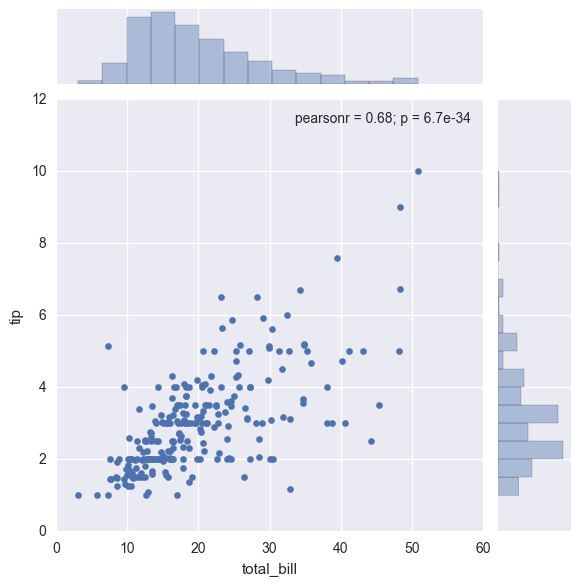
| sns.jointplot("total_bill",
"tip", tips). savefig( 'picture9 ') |
(Жў)matplotlib ********Д§ЭъЩЦ
Цп.ЦфЫќ~
(вЛ)ЕїгУR
ШУPythonжБНгЕїгУRЕФКЏЪ§ЃЌЯТдиАВзАrpy2ФЃПщМДПЩ~
ОпЬхВНжшЃКhttp://www.geome.cn/posts/python-%E9%80%9A%E8%BF%87rpy2%E8%B0%83%E7%94%A8-r%E8%AF%AD%E8%A8%80/ |









