| БрМЭЦМі: |
| ЮФеТРДдДгк51ctoЃЌЯъЯИНВЪіЙ§ФтКЯЕФИХФюКЭгУМИжжгУгкНтОіЙ§ФтКЯЮЪЬтЕФе§дђЛЏЗНЗЈЃЌВЂИЈвдPythonАИР§НВНтЁЃ |
|
ЪВУДЪЧе§дђЛЏ
дкЩюШыЬНЬжетИіЛАЬтжЎЧАЃЌЧыПДвЛЯТетеХЭМЦЌЃК
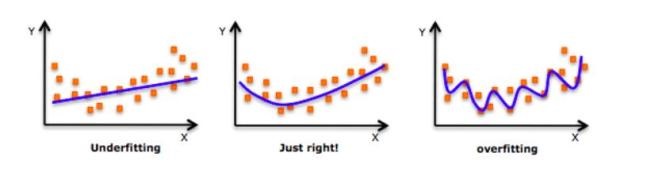
УПДЮЬИМАЙ§ФтКЯЃЌетеХЭМЦЌОЭЛсЪБВЛЪБЕиБЛРГіРДЁАБоЪЌЁБЁЃШчЩЯЭМЫљЪОЃЌИеПЊЪМЕФЪБКђЃЌФЃаЭЛЙВЛФмКмКУЕиФтКЯЫљгаЪ§ОнЕуЃЌМДЮоЗЈЗДгГЪ§ОнЗжВМЃЌетЪБЫќЪЧЧЗФтКЯЕФЁЃЖјЫцзХбЕСЗДЮЪ§діЖрЃЌЫќТ§Т§евГіСЫЪ§ОнЕФФЃЪНЃЌФмдкОЁПЩФмЖрЕиФтКЯЪ§ОнЕуЕФЭЌЪБЗДгГЪ§ОнЧїЪЦЃЌетЪБЫќЪЧвЛИіадФмНЯКУЕФФЃаЭЁЃдкетЛљДЁЩЯЃЌШчЙћЮвУЧМЬајбЕСЗЃЌФЧФЃаЭОЭЛсНјвЛВНЭкОђбЕСЗЪ§ОнжаЕФЯИНкКЭдыЩљЃЌЮЊСЫФтКЯЫљгаЪ§ОнЕуЁАВЛдёЪжЖЮЁБЃЌетЪБЫќОЭЙ§ФтКЯСЫЁЃ
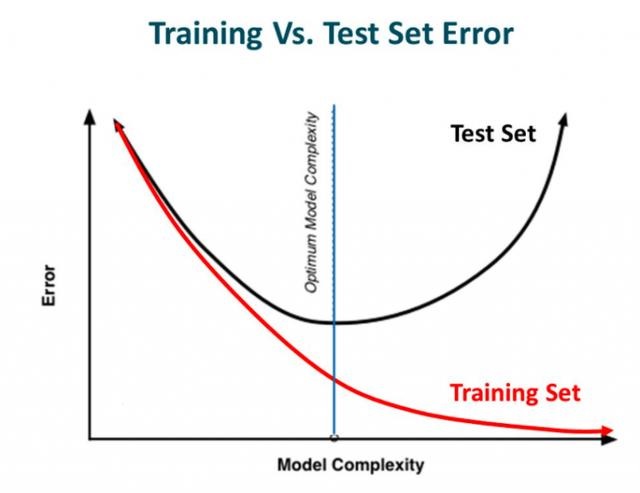
ЛЛОфЛАЫЕЃЌДгзѓЭљгвПДЃЌФЃаЭЕФИДдгЖШж№НЅЬсИпЃЌдкбЕСЗМЏЩЯЕФдЄВтДэЮѓж№НЅМѕЩйЃЌЕЋЫќдкВтЪдМЏЩЯЕФДэЮѓТЪШДГЪЯжвЛЬѕЯТЭЙЧњЯпЁЃ
РДдДЃКSlideplayer
ШчЙћФужЎЧАЙЙНЈЙ§ЩёОЭјТчЃЌЯыБиФувбОЕУЕНСЫетИіНЬбЕЃКЭјТчгаЖрИДдгЃЌЙ§ФтКЯОЭгаЖрШнвзЁЃЮЊСЫЪЙФЃаЭдкФтКЯЪ§ОнЕФЭЌЪБИќОпЭЦЙуадЃЌЮвУЧПЩвдгУе§дђЛЏЖдбЇЯАЫуЗЈзівЛаЉЯИЮЂаоИФЃЌДгЖјЬсИпФЃаЭЕФећЬхадФмЁЃ
е§дђЛЏКЭЙ§ФтКЯ
Й§ФтКЯКЭЩёОЭјТчЕФЩшМЦУмЧаЯрЙиЃЌвђДЫЮвУЧЯШРДПДвЛИіЙ§ФтКЯЕФЩёОЭјТчЃК
ШчЙћФужЎЧАдФЖСЙ§ЮвУЧЕФДгСубЇЯАЃКДгPythonКЭRРэНтКЭБрТыЩёОЭјТчЃЈЭъећАцЃЉЃЌЛђЖдЩёОЭјТче§дђЛЏИХФюгаГѕВНСЫНтЃЌФугІИУжЊЕРЩЯЭМжаДјМ§ЭЗЕФЯпЪЕМЪЩЯЖМДјгаШЈжиЃЌЖјЩёОдЊЪЧДЂДцЪфШыЪфГіЕФЕиЗНЁЃЮЊСЫЙЋЦНЦ№МћЃЌвВОЭЪЧЮЊСЫЗРжЙЭјТчдкгХЛЏЗНЯђЩЯЙ§гкЗХЗЩздЮвЃЌетРяЮвУЧЛЙашвЊМгШывЛИіЯШбщЁЊЁЊе§дђЛЏГЭЗЃЯюЃЌгУРДГЭЗЃЩёОдЊЕФМгШЈОиеѓЁЃ
ШчЙћЮвУЧЩшЕФе§дђЛЏЯЕЪ§КмДѓЃЌЕМжТвЛаЉМгШЈОиеѓЕФжЕМИКѕЮЊСуЁЊЁЊФЧзюКѓЮвУЧЕУЕНЕФЪЧвЛИіИќМђЕЅЕФЯпадЭјТчЃЌЫќКмПЩФмЪЧЧЗФтКЯЕФЁЃ
вђДЫетИіЯЕЪ§ВЂВЛЪЧдНДѓдНКУЁЃЮвУЧашвЊгХЛЏетИіе§дђЛЏЯЕЪ§ЕФжЕЃЌвдБуЛёЕУвЛИіСМКУФтКЯЕФФЃаЭЃЌШчЯТЭМЫљЪОЁЃ
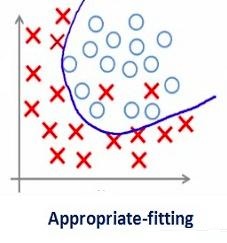
ЩюЖШбЇЯАжаЕФе§дђЛЏ
L2КЭL1е§дђЛЏ
L1КЭL2ЪЧзюГЃМћЕФе§дђЛЏЗНЗЈЃЌЫќУЧЕФзіЗЈЪЧдкДњМлКЏЪ§КѓУцдйМгЩЯвЛИіе§дђЛЏЯюЁЃ
ДњМлКЏЪ§ = Ы№ЪЇЃЈШчЖўдЊНЛВцьиЃЉ + е§дђЛЏЯю
гЩгкЬэМгСЫетИіе§дђЛЏЯюЃЌИїШЈжЕБЛМѕаЁСЫЃЌЛЛОфЛАЫЕЃЌОЭЪЧЩёОЭјТчЕФИДдгЖШНЕЕЭСЫЃЌНсКЯЁАЭјТчгаЖрИДдгЃЌЙ§ФтКЯОЭгаЖрШнвзЁБЕФЫМЯыЃЌДгРэТлЩЯРДЫЕЃЌетбљзіЕШгкжБНгЗРжЙЙ§ФтКЯЃЈАТПЈФЗЬъЕЖЗЈдђЃЉЁЃ
ЕБШЛЃЌетИіе§дђЛЏЯюдкL1КЭL2РяЪЧВЛвЛбљЕФЁЃ
ЖдгкL2ЃЌЫќЕФДњМлКЏЪ§ПЩБэЪОЮЊЃК
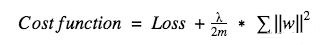
етРяІЫОЭЪЧе§дђЛЏЯЕЪ§ЃЌЫќЪЧвЛИіГЌВЮЪ§ЃЌПЩвдБЛгХЛЏвдЛёЕУИќКУЕФНсЙћЁЃЖдЩЯЪНЧѓЕМКѓЃЌШЈжиwЧАЕФЯЕЪ§ЮЊ1?ІЧІЫ/mЃЌвђЮЊІЧЁЂІЫЁЂmЖМЪЧе§Ъ§ЃЌ1?ІЧІЫ/mаЁгк1ЃЌwЕФЧїЪЦЪЧМѕаЁЃЌЫљвдL2е§дђЛЏвВБЛГЦЮЊШЈжиЫЅМѕЁЃ
ЖјЖдгкL1ЃЌЫќЕФДњМлКЏЪ§ПЩБэЪОЮЊЃК
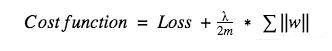
КЭL2ВЛЭЌЃЌетРяЮвУЧГЭЗЃЕФЪЧШЈжиwЕФОјЖджЕЁЃЖдЩЯЪНЧѓЕМКѓЃЌЮвУЧЕУЕНЕФЕШЪНРяАќКЌвЛЯю-sgn(w)ЃЌетвтЮЖзХЕБwЪЧе§Ъ§ЪБЃЌwМѕаЁЧїЯђгк0ЃЛЕБwЪЧИКЪ§ЪБЃЌwдіДѓЧїЯђгк0ЁЃЫљвдL1ЕФЫМТЗОЭЪЧАбШЈжиЭљ0ППЃЌДгЖјНЕЕЭЭјТчИДдгЖШЁЃ
вђДЫЕБЮвУЧЯывЊбЙЫѕФЃаЭЪБЃЌL1ЕФаЇЙћЛсКмКУЃЌЕЋШчЙћжЛЪЧМђЕЅЗРжЙЙ§ФтКЯЃЌвЛАуЧщПіЯТЛЙЪЧЛсгУL2ЁЃдкKerasжаЃЌЮвУЧПЩвджБНгЕїгУregularizersдкШЮвтВузіе§дђЛЏЁЃ
Р§ЃКдкШЋСЌНгВуЪЙгУL2е§дђЛЏЕФДњТыЃК
| from keras import
regularizersmodel .add (Dense ( 64 , input_dim
= 64, kernel _ regularizer = regularizers .l2
(0.01) |
зЂЃКетРяЕФ0.01ЪЧе§дђЛЏЯЕЪ§ІЫЕФжЕЃЌЮвУЧПЩвдЭЈЙ§ЭјИёЫбЫїЖдЫќзіНјвЛВНгХЛЏЁЃ
Dropout
DropoutГЦЕУЩЯЪЧе§дђЛЏЗНЗЈжазюгаШЄЕФвЛжжЃЌЫќЕФаЇЙћвВКмКУЃЌЫљвдЪЧЩюЖШбЇЯАСьгђГЃгУЕФЗНЗЈжЎвЛЁЃЮЊСЫИќКУЕиНтЪЭЫќЃЌЮвУЧЯШМйЩшЮвУЧЕФЩёОЭјТчГЄетбљЃК
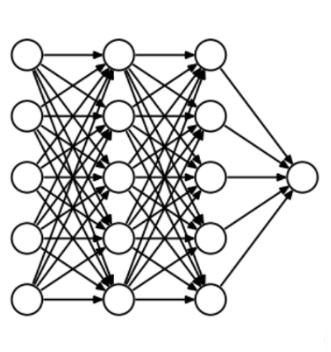
ФЧУДDropoutЕНЕзdropСЫЪВУДЃПЮвУЧРДПДЯТУцетЗљЭМЃКдкУПДЮЕќДњжаЃЌЫќЛсЫцЛњбЁдёвЛаЉЩёОдЊЃЌВЂАбЫќУЧЁАТњУХГеЖЁБЁЊЁЊАбЩёОдЊСЌЭЌЯргІЕФЪфШыЪфГівЛВЂЁАЩОГ§ЁБЁЃ
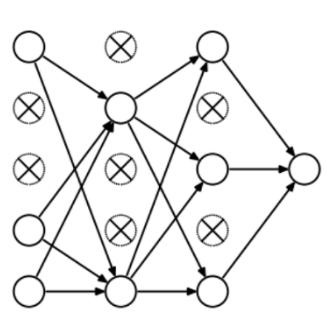
БШЦ№L1КЭL2ЖдДњМлКЏЪ§ЕФаоИФЃЌDropoutИќЯёЪЧбЕСЗЭјТчЕФвЛжжММЧЩЁЃЫцзХбЕСЗНјааЃЌЩёОЭјТчдкУПвЛДЮЕќДњжаЖМЛсКіЪгвЛаЉЃЈГЌВЮЪ§ЃЌГЃЙцЪЧвЛАыЃЉвўВиВу/ЪфШыВуЕФЩёОдЊЃЌетОЭЕМжТВЛЭЌЕФЪфГіЃЌЦфжагаЕФЪЧе§ШЗЕФЃЌгаЕФЪЧДэЮѓЕФЁЃ
етИізіЗЈгаЕуРрЫЦМЏГЩбЇЯАЃЌЫќФмИќЖрЕиВЖЛёИќЖрЕФЫцЛњадЁЃМЏГЩбЇЯАЗжРрЦїЭЈГЃБШЕЅвЛЗжРрЦїаЇЙћИќКУЃЌЭЌбљЕФЃЌвђЮЊЭјТчвЊФтКЯЪ§ОнЗжВМЃЌЫљвдDropoutКѓФЃаЭДѓВПЗжЕФЪфГіПЯЖЈЪЧе§ШЗЕФЃЌЖјдыЩљЪ§ОнгАЯьжЛеМвЛаЁВПЗжЃЌВЛЛсЖдзюжеНсЙћдьГЩЬЋДѓгАЯьЁЃ
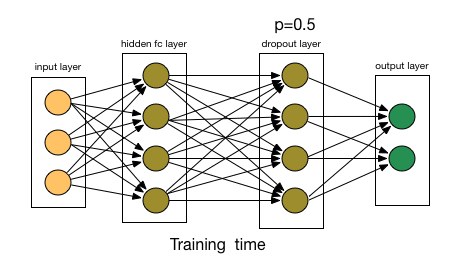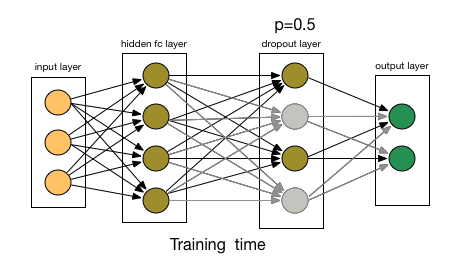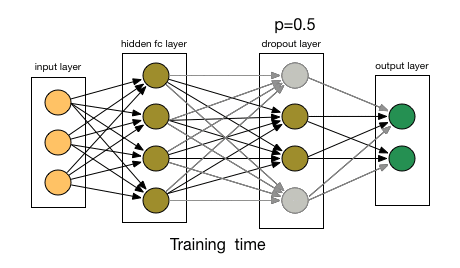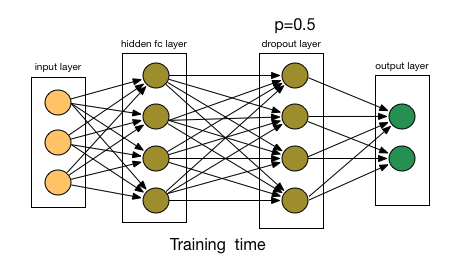
гЩгкетаЉвђЫиЃЌЕБЮвУЧЕФЩёОЭјТчНЯДѓЧвЫцЛњадИќЖрЪБЃЌЮвУЧвЛАугУDropoutЁЃ
дкKerasжаЃЌЮвУЧПЩвдЪЙгУkeras core layerЪЕЯжdropoutЁЃЯТУцЪЧЫќЕФPythonДњТыЃК
| from keras.layers.core
import Dropoutmodel = Sequential ([Dense (output_
dim= hidden1_ num_ units, input_ dim= input_ num_
units, activation ='relu' ),Dropout (0.25), Dense
(output_ dim= output _ num_ units , input _dim=
hidden5_ num_ units, activation ='softmax'),])
|
зЂЃКетРяЮвУЧАб0.25ЩшЮЊDropoutЕФГЌВЮЪ§ЃЈУПДЮЁАЩОЁБ1/4ЃЉЃЌЮвУЧПЩвдЭЈЙ§ЭјИёЫбЫїЖдЫќзіНјвЛВНгХЛЏЁЃ
Ъ§ОндіЧП
МШШЛЙ§ФтКЯЪЧФЃаЭЖдЪ§ОнМЏжадыЩљКЭЯИНкЕФЙ§ЖШВЖзНЃЌФЧУДЗРжЙЙ§ФтКЯзюМђЕЅЕФЗНЗЈОЭЪЧдіМгбЕСЗЪ§ОнСПЁЃЕЋЪЧдкЛњЦїбЇЯАШЮЮёжаЃЌдіМгЪ§ОнСПВЂВЛЪЧФЧУДШнвзЪЕЯжЕФЃЌвђЮЊЫбМЏЁЂБъМЧЪ§ОнЕФГЩБОЬЋИпСЫЁЃ
МйЩшЮвУЧе§дкДІРэЕФвЛаЉЪжаДЪ§зжЭМЯёЃЌЮЊСЫРЉДѓбЕСЗМЏЃЌЮвУЧФмВЩШЁЕФЗНЗЈгаЁЊЁЊа§зЊЁЂЗзЊЁЂЫѕаЁ/ЗХДѓЁЂЮЛвЦЁЂНиШЁЁЂЬэМгЫцЛњдыЩљЁЂЬэМгЛћБфЕШЁЃЯТУцЪЧвЛаЉДІРэЙ§ЕФЭМЃК

етаЉЗНЪНОЭЪЧЪ§ОндіЧПЁЃДгФГжжвтвхЩЯРДЫЕЃЌЛњЦїбЇЯАФЃаЭЕФадФмЪЧППЪ§ОнСПЖбГіРДЕФЃЌвђДЫЪ§ОндіЧППЩвдЮЊФЃаЭдЄВтЕФзМШЗТЪЬсЙЉОоДѓЬсЩ§ЁЃгаЪБЮЊСЫИФНјФЃаЭЃЌетвВЪЧвЛжжБигУЕФММЧЩЁЃ
дкKerasжаЃЌЮвУЧПЩвдЪЙгУImageDataGeneratorжДааЫљгаетаЉзЊЛЛЃЌЫќЬсЙЉСЫвЛДѓЖбПЩвдгУРДдЄДІРэбЕСЗЪ§ОнЕФВЮЪ§СаБэЁЃвдЯТЪЧЪЕЯжЫќЕФЪОР§ДњТыЃК
| from keras.preprocessing.image
import ImageData Generatordatagen = ImageDataGenerator
( horizontal flip = True) datagen.fit(train) |
дчЭЃЗЈ
етЪЧвЛжжНЛВцбщжЄВпТдЁЃбЕСЗЧАЃЌЮвУЧДгбЕСЗМЏжаГщГівЛВПЗжзїЮЊбщжЄМЏЃЌЫцзХбЕСЗЕФНјааЃЌЕБФЃаЭдкбщжЄМЏЩЯЕФадФмдНРДдНВюЪБЃЌЮвУЧСЂМДЪжЖЏЭЃжЙбЕСЗЃЌетжжЬсЧАЭЃжЙЕФЗНЗЈОЭЪЧдчЭЃЗЈЁЃ
дкЩЯЭМжаЃЌЮвУЧгІИУдкащЯпЮЛжУОЭЭЃжЙбЕСЗЃЌвђЮЊдкФЧжЎКѓЃЌФЃаЭОЭПЊЪМЙ§ФтКЯСЫЁЃ
дкKerasжаЃЌЮвУЧПЩвдЕїгУcallbacksКЏЪ§ЬсЧАЭЃжЙбЕСЗЃЌвдЯТЪЧЫќЕФЪОР§ДњТыЃК
| from keras.callbacks
import EarlyStopping EarlyStopping (monitor ='val_err',
patience=5) |
дкетРяЃЌmonitorжИЕФЪЧашвЊМрПиЕФepochЪ§СПЃЛval_errБэЪОбщжЄДэЮѓЃЈvalidation
errorЃЉЁЃ
patienceБэЪООЙ§5ИіСЌајepochКѓФЃаЭдЄВтНсЙћУЛгаНјвЛВНИФЩЦЁЃНсКЯЩЯЭМНјааРэНтЃЌОЭЪЧдкащЯпКѓЃЌФЃаЭУПбЕСЗвЛИіepochОЭЛсгаИќИпЕФбщжЄДэЮѓЃЈИќЕЭЕФбщжЄзМШЗТЪЃЉЃЌвђДЫСЌајбЕСЗ5ИіepochКѓЃЌЫќЛсЬсЧАЭЃжЙбЕСЗЁЃ |









