| БрМЭЦМі: |
| БОЮФРДдДгкcnblogs
ЃЌНщЩмСЫ time ЃЌdatetime ЃЌrandom ЃЌos ЃЌsys ЃЌ shutil
ЃЌjson&pickle ЃЌlogging ФЃПщЕШжЊЪЖЁЃ |
|
вЛЁЂtimeгыdatetimeФЃПщ
дкPythonжаЃЌЭЈГЃгаетМИжжЗНЪНРДБэЪОЪБМфЃК
ЪБМфДС(timestamp)ЃКЭЈГЃРДЫЕЃЌЪБМфДСБэЪОЕФЪЧДг1970Фъ1дТ1Ше00:00:00ПЊЪМАДУыМЦЫуЕФЦЋвЦСПЁЃЮвУЧдЫааЁАtype(time.time())ЁБЃЌЗЕЛиЕФЪЧfloatРраЭЁЃ
ИёЪНЛЏЕФЪБМфзжЗћДЎ(Format String)
НсЙЙЛЏЕФЪБМф(struct_time)ЃКstruct_timeдЊзщЙВга9ИідЊЫиЙВОХИідЊЫи:(ФъЃЌдТЃЌШеЃЌЪБЃЌЗжЃЌУыЃЌвЛФъжаЕкМИжмЃЌвЛФъжаЕкМИЬьЃЌЯФСюЪБ)
import time
#--------------------------ЮвУЧЯШвдЕБЧАЪБМфЮЊзМ,ШУДѓМвПьЫйШЯЪЖШ§жжаЮЪНЕФЪБМф
print (time.time()) # ЪБМфДС :1487130156.419527
print (time.strftime("%Y-%m-%d %X"))
# ИёЪНЛЏЕФЪБМфзжЗћДЎ :'2017-02-15 11:40:53'
print (time.localtime()) #БОЕиЪБЧјЕФ struct_time
print (time.gmtime()) #UTCЪБЧјЕФ struct_time |
%a LocaleЁЏs
abbreviated weekday name.
%A LocaleЁЏs full weekday name.
%b LocaleЁЏs abbreviated month name.
%B LocaleЁЏs full month name.
%c LocaleЁЏs appropriate date and time representation.
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%I Hour (12-hour clock) as a decimal number [01,12].
%j Day of the year as a decimal number [001,366].
%m Month as a decimal number [01,12].
%M Minute as a decimal number [00,59].
%p LocaleЁЏs equivalent of either AM or PM. (1)
%S Second as a decimal number [00,61]. (2)
%U Week number of the year (Sunday as the first
day of the week) as a decimal number [00,53].
All days in a new year preceding the first Sunday
are considered to be in week 0. (3)
%w Weekday as a decimal number [0 (Sunday),6].
%W Week number of the year (Monday as the first
day of the week) as a decimal number [00,53].
All days in a new year preceding the first Monday
are considered to be in week 0. (3)
%x LocaleЁЏs appropriate date representation.
%X LocaleЁЏs appropriate time representation.
%y Year without century as a decimal number 00
,99 ].
%Y Year with century as a decimal number.
%z Time zone offset indicating a positive or negative
time difference from UTC /GMT of the form + HHMM
or - HHMM, where H represents decimal hour digits
and M represents decimal minute digits [ - 23:59,
+ 23:59 ].
%Z Time zone name (no characters if no time zone
exists) .
%% A literal '%' character.
ИёЪНЛЏзжЗћДЎЕФЪБМфИёЪН |
ЦфжаМЦЫуЛњШЯЪЖЕФЪБМфжЛФмЪЧ'ЪБМфДС'ИёЪНЃЌЖјГЬађдБПЩДІРэЕФЛђепЫЕШЫРрФмПДЖЎЕФЪБМфга: 'ИёЪНЛЏЕФЪБМфзжЗћДЎ'ЃЌ'НсЙЙЛЏЕФЪБМф'
ЃЌгкЪЧгаСЫЯТЭМЕФзЊЛЛЙиЯЕ
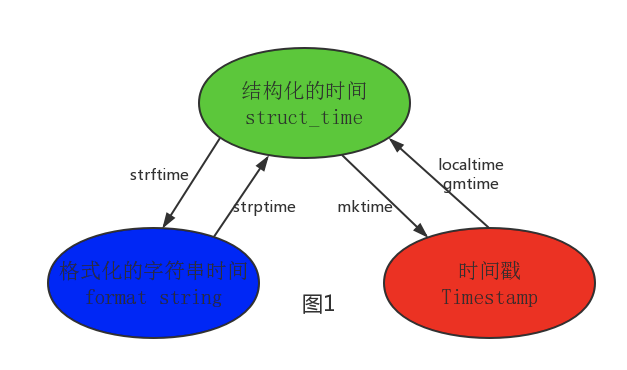
#--------------------------АДЭМ1зЊЛЛЪБМф
# localtime ([secs])
# НЋвЛИіЪБМфДСзЊЛЛЮЊЕБЧАЪБЧјЕФ struct_timeЁЃsecs ВЮЪ§ЮДЬсЙЉ ЃЌдђвдЕБЧАЪБМфЮЊзМЁЃ
time.localtime ()
time.localtime (1473525444.037215)
# gmtime ([secs]) КЭlocaltime()ЗНЗЈРрЫЦЃЌgmtime () ЗНЗЈЪЧНЋвЛИіЪБМфДСзЊЛЛЮЊUTCЪБЧјЃЈ0ЪБЧјЃЉЕФstruct
_ timeЁЃ
# mktime(t) : НЋвЛИі struct_time зЊЛЏЮЊЪБМфДСЁЃ
print (time.mktime (time.localtime ()) ) # 1473525749
.0
# strftime (format[, t]) : АбвЛИіДњБэЪБМфЕФдЊзщЛђепstruct_timeЃЈШчгЩtime.localtime
()КЭ # time. gmtime () ЗЕЛи ЃЉзЊЛЏЮЊИёЪНЛЏЕФЪБМфзжЗћДЎЁЃШчЙћtЮДжИЖЈЃЌНЋДЋШыtime.localtime
()ЁЃШчЙћдЊзщжаШЮКЮвЛИі
# дЊЫидННчЃЌValueError ЕФДэЮѓНЋЛсБЛХзГіЁЃ
print(time.strftime ("%Y-%m-%d %X",
time. localtime ( )))#2016-09-11 00:49:56
# time. strptime (string[, format])
# АбвЛИіИёЪНЛЏЪБМфзжЗћДЎзЊЛЏЮЊ struct_time ЁЃЪЕМЪЩЯЫќКЭstrftime ()ЪЧФцВйзїЁЃ
print (time.strptime ('2011-05-05 16:37:06', '%Y-%m
- %d %X'))
#time.struct_time (tm_year=2011, tm_mon = 5, tm_mday
= 5, tm_hour = 16, tm_min = 37, tm_sec = 6,
# tm_wday = 3, tm_yday = 125, tm_isdst = -1)
#дкетИіКЏЪ§жаЃЌformat ФЌШЯЮЊЃК"%a %b %d %H:%M:%S %Y"
ЁЃ |
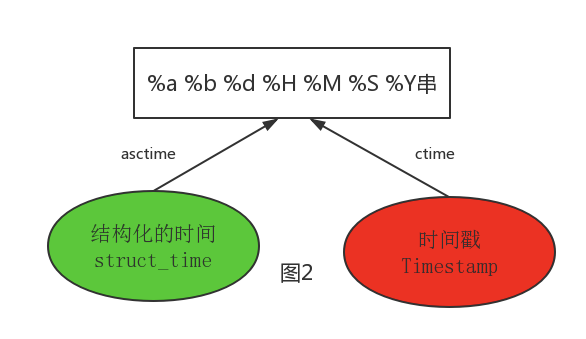
#--------------------------АДЭМ2зЊЛЛЪБМф
# asctime([t]) : АбвЛИіБэЪОЪБМфЕФдЊзщЛђепstruct_ time БэЪОЮЊетжжаЮЪНЃК'Sun
Jun 20 23:21:05 1993 'ЁЃ
# ШчЙћУЛгаВЮЪ§ЃЌНЋЛсНЋtime.localtime ()зїЮЊВЮЪ§ДЋШыЁЃ
print (time.asctime() ) #Sun Sep 11 00:43:43 2016
# ctime ([secs]) : АбвЛИіЪБМфДСЃЈАДУыМЦЫуЕФИЁЕуЪ§ЃЉзЊЛЏЮЊtime.asctime()ЕФаЮЪНЁЃШчЙћВЮЪ§ЮДИјЛђепЮЊ
# NoneЕФЪБКђЃЌНЋЛсФЌШЯ time.time ()ЮЊВЮЪ§ЁЃЫќЕФзїгУЯрЕБгкtime.asctime
(time.localtime(secs))ЁЃ
print (time.ctime()) # Sun Sep 11 00:46:38 2016
print (time.ctime(time.time())) # Sun Sep 11
00:46:38 2016 |
1 #--------------------------ЦфЫћгУЗЈ
2 # sleep(secs)
3 # ЯпГЬЭЦГйжИЖЈЕФЪБМфдЫааЃЌЕЅЮЛЮЊУыЁЃ |
datetimeФЃПщ
#ЪБМфМгМѕ
import datetime
# print (datetime.datetime.now()) #ЗЕЛи 2016-08-19
12 : 47 : 03.941925
#print (datetime.date.fromtimestamp (time .time
() ) ) # ЪБМфДСжБНгзЊГЩШеЦкИёЪН 2016-08-19
# print (datetime.datetime.now() )
# print (datetime.datetime.now() + datetime.timedelta
(3)) #ЕБЧАЪБМф+3Ьь
# print (datetime.datetime.now() + datetime.timedelta
(-3)) #ЕБЧАЪБМф-3Ьь
# print (datetime.datetime.now() + datetime.timedelta
(hours=3)) #ЕБЧАЪБМф+3аЁЪБ
# print (datetime.datetime.now() + datetime.timedelta
(minutes=30)) #ЕБЧАЪБМф+30Зж
#
# c_time = datetime.datetime.now ()
# print (c_time.replace (minute=3,hour=2)) #ЪБМфЬцЛЛ |
ЖўЁЂrandomФЃПщ
import random
print (random.random())#(0,1)----float Дѓгк0ЧваЁгк1жЎМфЕФаЁЪ§
print (random.randint(1,3)) #[1,3] ДѓгкЕШгк1ЧваЁгкЕШгк3жЎМфЕФећЪ§
print (random.randrange(1,3)) #[1,3) ДѓгкЕШгк1ЧваЁгк3жЎМфЕФећЪ§
print (random.choice([1,'23',[4,5]]))#1Лђеп23Лђеп[4,5]
print (random.sample([1,'23',[4,5]],2))#СаБэдЊЫиШЮвт2ИізщКЯ
print (random.uniform(1,3))#Дѓгк1аЁгк3ЕФаЁЪ§ЃЌШч1.927109612082716
item = [1,3,5,7,9]
random.shuffle (item) #ДђТвitemЕФЫГађ,ЯрЕБгк"ЯДХЦ"
print (item) |
import random
def make_code (n):
res=''
for i in range(n):
s1 = chr (random.randint(65,90))
s2 = str (random.randint(0,9))
res += random.choice([s1,s2])
return res
print (make_code(9))
ЩњГЩЫцЛњбщжЄТы |
Ш§ЁЂosФЃПщ
osФЃПщЪЧгыВйзїЯЕЭГНЛЛЅЕФвЛИіНгПк
os.getcwd()
ЛёШЁЕБЧАЙЄзїФПТМЃЌМДЕБЧАpythonНХБОЙЄзїЕФФПТМТЗОЖ
os.chdir ("dirname") ИФБфЕБЧАНХБОЙЄзїФПТМЃЛЯрЕБгк
shellЯТcd
os.curdir ЗЕЛиЕБЧАФПТМ: ('.')
os.pardir ЛёШЁЕБЧАФПТМЕФИИФПТМзжЗћДЎУћЃК('..')
os.makedirs ('dirname1/dirname2') ПЩЩњГЩЖрВуЕнЙщФПТМ
os.removedirs ('dirname1') ШєФПТМЮЊПеЃЌдђЩОГ§ЃЌВЂЕнЙщЕНЩЯвЛМЖФПТМЃЌШчШєвВЮЊПеЃЌдђЩОГ§ЃЌвРДЫРрЭЦ
os.mkdir ('dirname') ЩњГЩЕЅМЖФПТМЃЛЯрЕБгкshellжаmkdir dirname
os.rmdir ('dirname') ЩОГ§ЕЅМЖПеФПТМЃЌШєФПТМВЛЮЊПедђЮоЗЈЩОГ§ЃЌБЈДэЃЛЯрЕБгкshellжаrmdir
dirname
os.listdir ('dirname') СаГіжИЖЈФПТМЯТЕФЫљгаЮФМўКЭзгФПТМЃЌАќРЈвўВиЮФМўЃЌВЂвдСаБэЗНЪНДђгЁ
os.remove () ЩОГ§вЛИіЮФМў
os.rename ("oldname","newname")
жиУќУћЮФМў/ФПТМ
os.stat ( 'path/filename') ЛёШЁЮФМў/ФПТМаХЯЂ
os.sep ЪфГіВйзїЯЕЭГЬиЖЈЕФТЗОЖЗжИєЗћЃЌwinЯТЮЊ"\\ ",LinuxЯТЮЊ
"/"
os.linesep ЪфГіЕБЧАЦНЬЈЪЙгУЕФаажежЙЗћЃЌwinЯТЮЊ"\ t\n ",LinuxЯТЮЊ
"\n"
os.pathsep ЪфГігУгкЗжИюЮФМўТЗОЖЕФзжЗћДЎ winЯТЮЊ; , Linux ЯТЮЊ:
os.name ЪфГізжЗћДЎжИЪОЕБЧАЪЙгУЦНЬЈЁЃwin- >'nt'; Linux- >'posix'
os.system ("bash command") дЫааshellУќСюЃЌжБНгЯдЪО
os.environ ЛёШЁЯЕЭГЛЗОГБфСП
os.path.abspath (path) ЗЕЛиpathЙцЗЖЛЏЕФОјЖдТЗОЖ
os.path.split (path) НЋpathЗжИюГЩФПТМКЭЮФМўУћЖўдЊзщЗЕЛи
os.path.dirname (path) ЗЕЛиpathЕФФПТМЁЃЦфЪЕОЭЪЧos.path.split
(path)ЕФЕквЛИідЊЫи
os.path.basename (path) ЗЕЛиpathзюКѓЕФЮФМўУћЁЃШчКЮpathвдЃЏ
Лђ\ НсЮВЃЌФЧУДОЭЛсЗЕЛиПежЕЁЃМДos. path . split (path)ЕФЕкЖўИідЊЫи
os.path.exists (path) ШчЙћpathДцдкЃЌЗЕЛи TrueЃЛШчЙћ pathВЛДцдкЃЌЗЕЛи
False
os.path.isabs (path) ШчЙћ path ЪЧОјЖдТЗОЖЃЌЗЕЛиTrue
os.path.isfile (path) ШчЙћ path ЪЧвЛИіДцдкЕФЮФМўЃЌЗЕЛиTrueЁЃЗёдђЗЕЛиFalse
os.path.isdir (path) ШчЙћ path ЪЧвЛИіДцдкЕФФПТМЃЌдђЗЕЛи TrueЁЃЗёдђЗЕЛи
False
os.path.join (path1[, path2[, ...]]) НЋЖрИіТЗОЖзщКЯКѓЗЕЛиЃЌЕквЛИіОјЖдТЗОЖжЎЧАЕФВЮЪ§НЋБЛКіТд
os. path.getatime (path) ЗЕЛиpathЫљжИЯђЕФЮФМўЛђепФПТМЕФзюКѓДцШЁЪБМф
os.path.getmtime (path) ЗЕЛиpathЫљжИЯђЕФЮФМўЛђепФПТМЕФзюКѓаоИФЪБМф
os.path.getsize (path) ЗЕЛиpathЕФДѓаЁ |
дкLinuxКЭMacЦНЬЈЩЯЃЌИУКЏЪ§ЛсдбљЗЕЛи
pathЃЌдкwindows ЦНЬЈЩЯЛсНЋТЗОЖжаЫљгазжЗћзЊЛЛЮЊаЁаДЃЌВЂНЋЫљгааБИмзЊЛЛЮЊЗЙаБИмЁЃ
>>> os.path.normcase ('c:/windows\\system32\\')
'c : \\ windows\\system32\\'
ЙцЗЖЛЏТЗОЖЃЌШч..КЭ/
>>> os.path.normpath ('c://windows \\System32
\\../ Temp /')
'c:\\windows\\Temp'
>>> a= '/Users/jieli /test1/\\\a1/\\\\aa.py/../..'
>>> print (os.path.normpath(a))
/Users /jieli/test1 |
osТЗОЖДІРэ
#ЗНЪНвЛЃКЭЦМіЪЙгУ
import os
#ОпЬхгІгУ
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath (__file__),
os.pardir, #ЩЯвЛМЖ
os.pardir,
os.pardir
))
sys.path.insert (0,possible_topdir)
#ЗНЪНЖўЃКВЛЭЦМіЪЙгУ
os.path.dirname (os.path.dirname (os .path. dirname
(os.path. abspath (__file__) ))) |
ЫФЁЂsysФЃПщ
sys.argv УќСюааВЮЪ§ListЃЌЕквЛИідЊЫиЪЧГЬађБОЩэТЗОЖ
sys.exit (n) ЭЫГіГЬађЃЌе§ГЃЭЫГіЪБexit(0)
sys.version ЛёШЁ Python НтЪЭГЬађЕФАцБОаХЯЂ
sys.maxint зюДѓЕФ Int жЕ
sys.path ЗЕЛиФЃПщЕФЫбЫїТЗОЖЃЌГѕЪМЛЏЪБЪЙгУPYTHONPATH ЛЗОГБфСПЕФжЕ
sys.platform ЗЕЛиВйзїЯЕЭГЦНЬЈУћГЦ |
ДђгЁНјЖШЬѕ
#=========жЊЪЖДЂБИ==========
#НјЖШЬѕЕФаЇЙћ
[# ]
[## ]
[### ]
[#### ]
#жИЖЈПэЖШ
print ('[%-15s]' %'#')
print ('[%-15s]' %'##')
print ('[%-15s]' %'###')
print ('[%-15s]' %'####')
#ДђгЁ%
print ('%s%%' %(100)) #ЕкЖўИі%КХДњБэШЁЯћЕквЛИі%ЕФЬиЪтвтвх
#ПЩДЋВЮРДПижЦПэЖШ
print ('[%%-%ds]' %50) #[%-50s]
print (('[%%-%ds]' %50) %'#')
print (('[%%-%ds]' %50) %'##')
print (('[%%-%ds]' %50) %'###')
#=========ЪЕЯжДђгЁНјЖШЬѕКЏЪ§==========
import sys
import time
def progress (percent,width=50):
if percent >= 1:
percent = 1
show_str = ('[%%-%ds]' %width) % (int(width*percent)*'#')
print ('\r%s %d%%' %(show_str,int (100*percent)
),file = sys . stdout ,flush = True,end='')
#=========гІгУ==========
data_size= 1025
recv_size= 0
while recv_size < data_size:
time.sleep (0.1) #ФЃФтЪ§ОнЕФДЋЪфбгГй
recv_size+= 1024 #УПДЮЪе1024
percent = recv_size/data_size #НгЪеЕФБШР§
progress (percent,width=70) #НјЖШЬѕЕФПэЖШ70
гХЛЏАцБОЃК
def progress (percent,width=50):
if percent > 1:
percent = 1
show_str = ('[%%-%ds]' %width) % (int(width*percent)
* '#')
print( '\r%s %d%%' % (show_str,int(100*percent)),end='')
import time
recv_size = 0
total_size = 100
while recv_size < total_size:
time.sleep (0.1)
recv_size += 1
percent = recv_size / total_size
progress (percent) |
ЮхЁЂshutilФЃПщ
ИпМЖЕФ ЮФМўЁЂЮФМўМаЁЂбЙЫѕАќ ДІРэФЃПщ
shutil.copyfileobj(fsrc, fdst[, length])
НЋЮФМўФкШнПНБДЕНСэвЛИіЮФМўжа
import shutil
shutil.copyfileobj (open('old.xml','r'), open
('new . xml', 'w')) |
shutil.copyfile(src, dst)
ПНБДЮФМў
| shutil.copyfile
('f1.log', 'f2.log') #ФПБъЮФМўЮоашДцдк |
shutil.copymode(src, dst)
НіПНБДШЈЯоЁЃФкШнЁЂзщЁЂгУЛЇОљВЛБф
| Hello World!shutil.copymode
('f1.log', 'f2.log') #ФПБъЮФМўБиаыДцдк |
shutil.copystat(src, dst)
НіПНБДзДЬЌЕФаХЯЂЃЌАќРЈЃКmode bits, atime, mtime, flags
| shutil.copystat
('f1.log', 'f2.log') #ФПБъЮФМўБиаыДцдк |
shutil.copy(src, dst)
ПНБДЮФМўКЭШЈЯо
import shutil
shutil.copy ('f1.log', 'f2.log') |
shutil.copy2(src, dst)
ПНБДЮФМўКЭзДЬЌаХЯЂ
import shutil
shutil.copy2('f1.log', 'f2.log') |
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
ЕнЙщЕФШЅПНБДЮФМўМа
import shutil
shutil.copytree ('folder1', 'folder2', ignore
= shutil .ignore _ patterns ('*.pyc', 'tmp*'))
#ФПБъФПТМВЛФмДцдкЃЌзЂвтЖд folder2ФПТМИИМЖФПТМвЊгаПЩаДШЈЯоЃЌignore ЕФвтЫМЪЧХХГ§
|
import shutil
shutil.copytree ('f1', 'f2', symlinks=True, ignore
= shutil.ignore_patterns('*.pyc', 'tmp*' ) )
'''
ЭЈГЃЕФПНБДЖМАбШэСЌНгПНБДГЩгВСДНгЃЌМДЖдД§ШэСЌНгРДЫЕЃЌДДНЈаТЕФЮФМў
'''
ПНБДШэСДНг |
shutil.rmtree(path[, ignore_errors[, onerror]])
ЕнЙщЕФШЅЩОГ§ЮФМў
import shutil
shutil.rmtree('folder1') |
shutil.move(src, dst)
ЕнЙщЕФШЅвЦЖЏЮФМўЃЌЫќРрЫЦmvУќСюЃЌЦфЪЕОЭЪЧжиУќУћЁЃ
import shutil
shutil.move('folder1', 'folder3') |
shutil.make_archive(base_name, format,...)
ДДНЈбЙЫѕАќВЂЗЕЛиЮФМўТЗОЖЃЌР§ШчЃКzipЁЂtar
ДДНЈбЙЫѕАќВЂЗЕЛиЮФМўТЗОЖЃЌР§ШчЃКzipЁЂtar
base_nameЃК бЙЫѕАќЕФЮФМўУћЃЌвВПЩвдЪЧбЙЫѕАќЕФТЗОЖЁЃжЛЪЧЮФМўУћЪБЃЌдђБЃДцжСЕБЧАФПТМЃЌЗёдђБЃДцжСжИЖЈТЗОЖЃЌ
Шч data_bak =>БЃДцжСЕБЧАТЗОЖ
ШчЃК/tmp/data_bak =>БЃДцжС/tmp/
formatЃК бЙЫѕАќжжРрЃЌЁАzipЁБ, ЁАtarЁБ, ЁАbztarЁБЃЌЁАgztarЁБ
root_dirЃК вЊбЙЫѕЕФЮФМўМаТЗОЖЃЈФЌШЯЕБЧАФПТМЃЉ
ownerЃК гУЛЇЃЌФЌШЯЕБЧАгУЛЇ
groupЃК зщЃЌФЌШЯЕБЧАзщ
loggerЃК гУгкМЧТМШежОЃЌЭЈГЃЪЧlogging.LoggerЖдЯѓ
#НЋ /data ЯТЕФЮФМўДђАќЗХжУЕБЧАГЬађФПТМ
import shutil
ret = shutil.make_archive ("data_bak",
'gztar', root _ dir= '/data')
#НЋ /dataЯТЕФЮФМўДђАќЗХжУ /tmp/ФПТМ
import shutil
ret = shutil.make_archive ("/tmp/data_bak",
'gztar', root_ dir= '/data') |
shutil ЖдбЙЫѕАќЕФДІРэЪЧЕїгУ ZipFile КЭ TarFile СНИіФЃПщРДНјааЕФЃЌЯъЯИЃК
import zipfile
# бЙЫѕ
z = zipfile.ZipFile ('laxi.zip', 'w')
z.write ('a.log')
z.write ('data.data')
z.close()
# НтбЙ
z = zipfile.ZipFile ('laxi.zip', 'r')
z.extractall (path='.')
z.close()
zipfileбЙЫѕНтбЙЫѕ |
import tarfile
# бЙЫѕ
>>> t=tarfile.open ('/tmp/egon.tar','w')
>>> t.add ('/test1/a.py',arcname='a.bak')
>>> t.add ('/test1/b.py',arcname='b.bak')
>>> t.close ()
# НтбЙ
>>> t=tarfile.open ('/tmp/egon.tar','r')
>>> t.extractall ('/egon')
>>> t.close ()
tarfile бЙЫѕНтбЙЫѕ |
СљЁЂjson&pickleФЃПщ
жЎЧАЮвУЧбЇЯАЙ§гУevalФкжУЗНЗЈПЩвдНЋвЛИізжЗћДЎзЊГЩpythonЖдЯѓЃЌВЛЙ§ЃЌevalЗНЗЈЪЧгаОжЯоадЕФЃЌЖдгкЦеЭЈЕФЪ§ОнРраЭЃЌjson.loadsКЭevalЖМФмгУЃЌЕЋгіЕНЬиЪтРраЭЕФЪБКђЃЌevalОЭВЛЙмгУСЫ,ЫљвдevalЕФжиЕуЛЙЪЧЭЈГЃгУРДжДаавЛИізжЗћДЎБэДяЪНЃЌВЂЗЕЛиБэДяЪНЕФжЕЁЃ
import json
x= "[null,true,false,1]"
print (eval(x)) #БЈДэЃЌЮоЗЈНтЮіnullРраЭЃЌЖјjson ОЭПЩвд
print (json.loads(x)) |
ЪВУДЪЧађСаЛЏЃП
ЮвУЧАбЖдЯѓ(БфСП)ДгФкДцжаБфГЩПЩДцДЂЛђДЋЪфЕФЙ§ГЬГЦжЎЮЊађСаЛЏЃЌдкPythonжаНаpicklingЃЌдкЦфЫћгябджавВБЛГЦжЎЮЊserializationЃЌmarshallingЃЌflatteningЕШЕШЃЌЖМЪЧвЛИівтЫМЁЃ
ЮЊЪВУДвЊађСаЛЏЃП
1ЃКГжОУБЃДцзДЬЌ
ашжЊвЛИіШэМў/ГЬађЕФжДааОЭдкДІРэвЛЯЕСазДЬЌЕФБфЛЏЃЌдкБрГЬгябджаЃЌ'зДЬЌ'ЛсвдИїжжИїбљгаНсЙЙЕФЪ§ОнРраЭ(вВПЩМђЕЅЕФРэНтЮЊБфСП)ЕФаЮЪНБЛБЃДцдкФкДцжаЁЃ
ФкДцЪЧЮоЗЈгРОУБЃДцЪ§ОнЕФЃЌЕБГЬађдЫааСЫвЛЖЮЪБМфЃЌЮвУЧЖЯЕчЛђепжиЦєГЬађЃЌФкДцжаЙигкетИіГЬађЕФжЎЧАвЛЖЮЪБМфЕФЪ§ОнЃЈгаНсЙЙЃЉЖМБЛЧхПеСЫЁЃ
дкЖЯЕчЛђжиЦєГЬађжЎЧАНЋГЬађЕБЧАФкДцжаЫљгаЕФЪ§ОнЖМБЃДцЯТРДЃЈБЃДцЕНЮФМўжаЃЉЃЌвдБугкЯТДЮГЬађжДааФмЙЛДгЮФМўжадиШыжЎЧАЕФЪ§ОнЃЌШЛКѓМЬајжДааЃЌетОЭЪЧађСаЛЏЁЃ
ОпЬхЕФРДЫЕЃЌФуЭцЪЙУќейЛНДГЕНСЫЕк13ЙиЃЌФуБЃДцгЮЯЗзДЬЌЃЌЙиЛњзпШЫЃЌЯТДЮдйЭцЃЌЛЙФмДгЩЯДЮЕФЮЛжУПЊЪММЬајДГЙиЁЃЛђШчЃЌащФтЛњзДЬЌЕФЙвЦ№ЕШЁЃ
2ЃКПчЦНЬЈЪ§ОнНЛЛЅ
ађСаЛЏжЎКѓЃЌВЛНіПЩвдАбађСаЛЏКѓЕФФкШнаДШыДХХЬЃЌЛЙПЩвдЭЈЙ§ЭјТчДЋЪфЕНБ№ЕФЛњЦїЩЯЃЌШчЙћЪеЗЂЕФЫЋЗНдМЖЈКУЪЕгУвЛжжађСаЛЏЕФИёЪНЃЌФЧУДБуДђЦЦСЫЦНЬЈ/гябдВювьЛЏДјРДЕФЯожЦЃЌЪЕЯжСЫПчЦНЬЈЪ§ОнНЛЛЅЁЃ
ЗДЙ§РДЃЌАбБфСПФкШнДгађСаЛЏЕФЖдЯѓжиаТЖСЕНФкДцРяГЦжЎЮЊЗДађСаЛЏЃЌМДunpicklingЁЃ
ШчКЮађСаЛЏжЎjsonКЭpickle:
json
ШчЙћЮвУЧвЊдкВЛЭЌЕФБрГЬгябджЎМфДЋЕнЖдЯѓЃЌОЭБиаыАбЖдЯѓађСаЛЏЮЊБъзМИёЪНЃЌБШШчXMLЃЌЕЋИќКУЕФЗНЗЈЪЧађСаЛЏЮЊJSONЃЌвђЮЊJSONБэЪОГіРДОЭЪЧвЛИізжЗћДЎЃЌПЩвдБЛЫљгагябдЖСШЁЃЌвВПЩвдЗНБуЕиДцДЂЕНДХХЬЛђепЭЈЙ§ЭјТчДЋЪфЁЃJSONВЛНіЪЧБъзМИёЪНЃЌВЂЧвБШXMLИќПьЃЌЖјЧвПЩвджБНгдкWebвГУцжаЖСШЁЃЌЗЧГЃЗНБуЁЃ
JSONБэЪОЕФЖдЯѓОЭЪЧБъзМЕФJavaScriptгябдЕФЖдЯѓЃЌJSONКЭPythonФкжУЕФЪ§ОнРраЭЖдгІШчЯТЃК
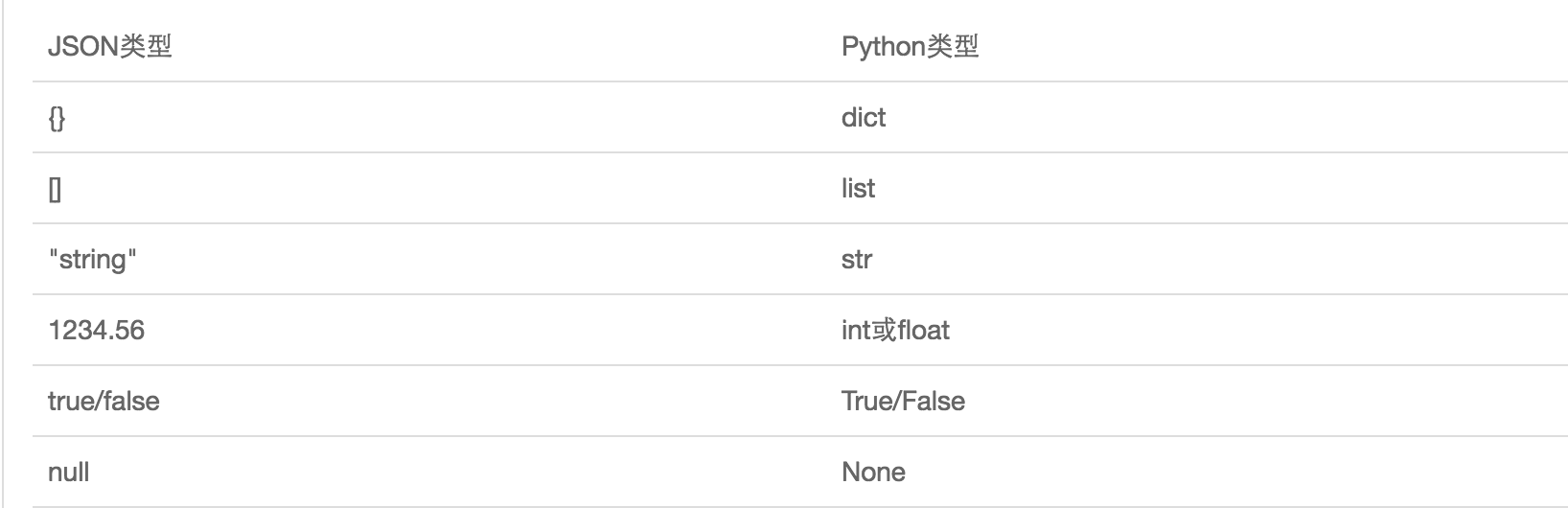

JsonФЃПщЬсЙЉСЫЫФИіЙІФмЃКdumpsЁЂdumpЁЂloadsЁЂload
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #ађСаЛЏЃКНЋвЛИізжЕфзЊЛЛГЩвЛИізжЗћДЎ
print (type(str_dic),str_dic) #<class 'str'>
{"k3" : "v3", "k1":
"v1", "k2": "v2"
}
#зЂвтЃЌ json зЊЛЛЭъЕФзжЗћДЎРраЭЕФзжЕфжаЕФзжЗћДЎЪЧгЩ""БэЪОЕФ
dic2 = json.loads (str_dic) #ЗДађСаЛЏЃКНЋвЛИізжЗћДЎИёЪНЕФзжЕфзЊЛЛГЩвЛИізжЕф
#зЂвтЃЌвЊгУ json ЕФloadsЙІФмДІРэЕФзжЗћДЎРраЭЕФзжЕфжаЕФзжЗћДЎБиаыгЩ""БэЪО
print (type(dic2) ,dic2) # <class 'dict'>
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
list_dic = [1, ['a','b','c'], 3, {'k1': 'v1','k2'
:'v2'} ]
str_dic = json.dumps (list_dic) #вВПЩвдДІРэЧЖЬзЕФЪ§ОнРраЭ
print (type(str_dic),str_dic) # <class 'str'>
[1, ["a", "b", "c"]
, 3, {"k1": "v1", "k2":
"v2"}]
list_dic2 = json.loads (str_dic)
print (type (list_dic2),list_dic2) # <class
'list '> [1, ['a', 'b', 'c'], 3, {'k1': 'v1',
'k2': 'v2' }]
loads КЭ dumps |
import json
f = open ('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump (dic,f) #dumpЗНЗЈНгЪевЛИіЮФМўОфБњЃЌжБНгНЋзжЕфзЊЛЛГЩ json
зжЗћДЎаДШыЮФМў
f.close ()
f = open ('json_file')
dic2 = json.load (f) #load ЗНЗЈНгЪевЛИіЮФМўОфБњЃЌжБНгНЋЮФМўжаЕФjsonзжЗћДЎзЊЛЛГЩЪ§ОнНсЙЙЗЕЛи
f.close ()
print (type(dic2),dic2)
load КЭ dump |
import json
#dct= "{'1':111}"#json ВЛШЯЕЅв§КХ
#dct=str ({"1":111}) #БЈДэ,вђЮЊЩњГЩЕФЪ§ОнЛЙЪЧЕЅв§КХ:{'one':
1}
dct ='{"1":"111"}'
print (json.loads(dct))
#conclusion:
# ЮоТлЪ§ОнЪЧдѕбљДДНЈЕФЃЌжЛвЊТњзуjsonИёЪНЃЌОЭПЩвдjson.loadsГіРД,ВЛвЛЖЈЗЧвЊ
dumpsЕФЪ§ОнВХФм loads
зЂвтЕу |
pickle

import pickle
dic = {'name':'alvin','age':23,'sex':'male'}
print (type(dic))#<class 'dict'>
j= pickle.dumps (dic)
print(type(j)) #<class 'bytes'>
f=open ('ађСаЛЏЖдЯѓ_pickle','wb')#зЂвтЪЧwЪЧаДШыstr,wb ЪЧаДШы
bytes,jЪЧ 'bytes'
f.write (j) #-------------------ЕШМлгкpickle.dump
(dic ,f)
f.close ()
#-------------------------ЗДађСаЛЏ
import pickle
f=open ('ађСаЛЏЖдЯѓ_pickle','rb')
data = pickle.loads (f.read())# ЕШМлгкdata = pickle
.load (f)
print ( data['age'] ) |
PickleЕФЮЪЬтКЭЫљгаЦфЫћБрГЬгябдЬигаЕФађСаЛЏЮЪЬтвЛбљЃЌОЭЪЧЫќжЛФмгУгкPythonЃЌВЂЧвПЩФмВЛЭЌАцБОЕФPythonБЫДЫЖМВЛМцШнЃЌвђДЫЃЌжЛФмгУPickleБЃДцФЧаЉВЛживЊЕФЪ§ОнЃЌВЛФмГЩЙІЕиЗДађСаЛЏвВУЛЙиЯЕЁЃ
ЦпЁЂloggingФЃПщ
ШежОМЖБ№
CRITICAL =
50 #FATAL = CRITICAL
ERROR = 40
WARNING = 30 #WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 #ВЛЩшжУ |
ФЌШЯМЖБ№ЮЊwarning,ФЌШЯДђгЁЕНжеЖЫ
import logging
logging.debug ('ЕїЪдdebug')
logging.info ('ЯћЯЂinfo')
logging.warning ('ОЏИцwarn')
logging.error ('ДэЮѓerror')
logging.critical ('бЯжиcritical')
'''
WARNING:root: ОЏИц warn
ERROR:root :ДэЮѓ error
CRITICAL:root: бЯжи critical
''' |
ЮЊloggingФЃПщжИЖЈШЋОжХфжУЃЌеыЖдЫљгаloggerгааЇЃЌПижЦДђгЁЕНЮФМўжа
ПЩдк logging.basicConfig
( ) КЏЪ§жаЭЈЙ§ОпЬхВЮЪ§РДИќИФ logging ФЃПщФЌШЯааЮЊЃЌПЩгУВЮЪ§га
filename ЃКгУжИЖЈЕФЮФМўУћДДНЈ FiledHandlerЃЈКѓБпЛсОпЬхНВНт handler
ЕФИХФюЃЉЃЌетбљШежОЛсБЛДцДЂдкжИЖЈЕФЮФМўжаЁЃ
filemodeЃКЮФМўДђПЊЗНЪНЃЌдкжИЖЈСЫ filename ЪБЪЙгУетИіВЮЪ§ЃЌФЌШЯжЕЮЊЁАaЁБЛЙПЩжИЖЈЮЊЁАwЁБЁЃ
formatЃКжИЖЈ handler ЪЙгУЕФШежОЯдЪОИёЪНЁЃ
datefmtЃКжИЖЈШеЦкЪБМфИёЪНЁЃ
levelЃКЩшжУ rootloggerЃЈКѓБпЛсНВНтОпЬхИХФюЃЉЕФШежОМЖБ№
streamЃКгУжИЖЈЕФ stream ДДНЈ StreamHandler ЁЃПЩвджИЖЈЪфГіЕН sys.stderr,sys.stdout
ЛђепЮФМўЃЌФЌШЯЮЊsys.stderrЁЃШєЭЌЪБСаГіСЫ filename КЭ stream СНИіВЮЪ§ЃЌдђ
stream ВЮЪ§ЛсБЛКіТдЁЃ
#ИёЪН
%(name)sЃКLogger ЕФУћзжЃЌВЂЗЧгУЛЇУћЃЌЯъЯИВщПД
%(levelno)sЃКЪ§зжаЮЪНЕФШежОМЖБ№
%(levelname)sЃКЮФБОаЮЪНЕФШежОМЖБ№
%(pathname)sЃКЕїгУШежОЪфГіКЏЪ§ЕФФЃПщЕФЭъећТЗОЖУћЃЌПЩФмУЛга
%(filename)sЃКЕїгУШежОЪфГіКЏЪ§ЕФФЃПщЕФЮФМўУћ
%(module)sЃКЕїгУШежОЪфГіКЏЪ§ЕФФЃПщУћ
%(funcName)sЃКЕїгУШежОЪфГіКЏЪ§ЕФКЏЪ§Ућ
%(lineno)dЃКЕїгУШежОЪфГіКЏЪ§ЕФгяОфЫљдкЕФДњТыаа
%(created)fЃКЕБЧАЪБМфЃЌгУUNIXБъзМЕФБэЪОЪБМфЕФИЁ ЕуЪ§БэЪО
%(relativeCreated) dЃКЪфГіШежОаХЯЂЪБЕФЃЌздLoggerДДНЈвд РДЕФКСУыЪ§
%(asctime)sЃКзжЗћДЎаЮЪНЕФЕБЧАЪБМфЁЃФЌШЯИёЪНЪЧ ЁА2003-07-08 16:49:45,896ЁБЁЃЖККХКѓУцЕФЪЧКСУы
%(thread)dЃКЯпГЬIDЁЃПЩФмУЛга
%(threadName)sЃКЯпГЬУћЁЃПЩФмУЛга
%(process)dЃКНјГЬIDЁЃПЩФмУЛга
%(message)sЃКгУЛЇЪфГіЕФЯћЯЂ
formatВЮЪ§жаПЩФмгУЕНЕФИёЪНЛЏДЎЃК
%(name)s LoggerЕФУћзж
%(levelno)s Ъ§зжаЮЪНЕФШежОМЖБ№
%(levelname)s ЮФБОаЮЪНЕФШежОМЖБ№
%(pathname)s ЕїгУШежОЪфГіКЏЪ§ЕФФЃПщЕФЭъећТЗОЖУћЃЌПЩФмУЛга
%(filename)s ЕїгУШежОЪфГіКЏЪ§ЕФФЃПщЕФЮФМўУћ
%(module)s ЕїгУШежОЪфГіКЏЪ§ЕФФЃПщУћ
%(funcName)s ЕїгУШежОЪфГіКЏЪ§ЕФКЏЪ§Ућ
%(lineno)d ЕїгУШежОЪфГіКЏЪ§ЕФгяОфЫљдкЕФДњТыаа
%(created)f ЕБЧАЪБМфЃЌгУUNIXБъзМЕФБэЪОЪБМфЕФИЁ ЕуЪ§БэЪО
%(relativeCreated)d ЪфГіШежОаХЯЂЪБЕФЃЌздLoggerДДНЈвд РДЕФКСУыЪ§
%(asctime)s зжЗћДЎаЮЪНЕФЕБЧАЪБМфЁЃФЌШЯИёЪНЪЧ ЁА2003-07-08 16:49:45,896ЁБЁЃЖККХКѓУцЕФЪЧКСУы
%(thread)d ЯпГЬIDЁЃПЩФмУЛга
%(threadName)s ЯпГЬУћЁЃПЩФмУЛга
%(process)d НјГЬIDЁЃПЩФмУЛга
%(message)sгУЛЇЪфГіЕФЯћЯЂ
#========ЪЙгУ
import logging
logging.basicConfig (filename='access.log',
format = '% (asctime)s - %(name)s - %(levelname)s
-% (module)s: %(message)s',
datefmt = '%Y-%m-%d %H:%M:%S %p',
level = 10)
logging.debug ('ЕїЪдdebug')
logging.info ('ЯћЯЂinfo')
logging.warning ('ОЏИцwarn')
logging.error ('ДэЮѓerror')
logging.critical ('бЯжиcritical')
#========НсЙћ
access.logФкШн:
2017-07-28 20:32:17 PM - root - DEBUG -test:
ЕїЪдdebug
2017-07-28 20:32:17 PM - root - INFO -test:
ЯћЯЂinfo
2017-07-28 20:32:17 PM - root - WARNING -test:
ОЏИцwarn
2017-07-28 20:32:17 PM - root - ERROR -test:
ДэЮѓerror
2017-07-28 20:32:17 PM - root - CRITICAL -test:
бЯжиcritical
part2: ПЩвдЮЊlogging ФЃПщжИЖЈФЃПщМЖЕФХфжУ,МДЫљгаloggerЕФХфжУ |
loggingФЃПщЕФFormatter,HandlerЃЌLoggerЃЌFilterЖдЯѓ
дРэЭМЃК
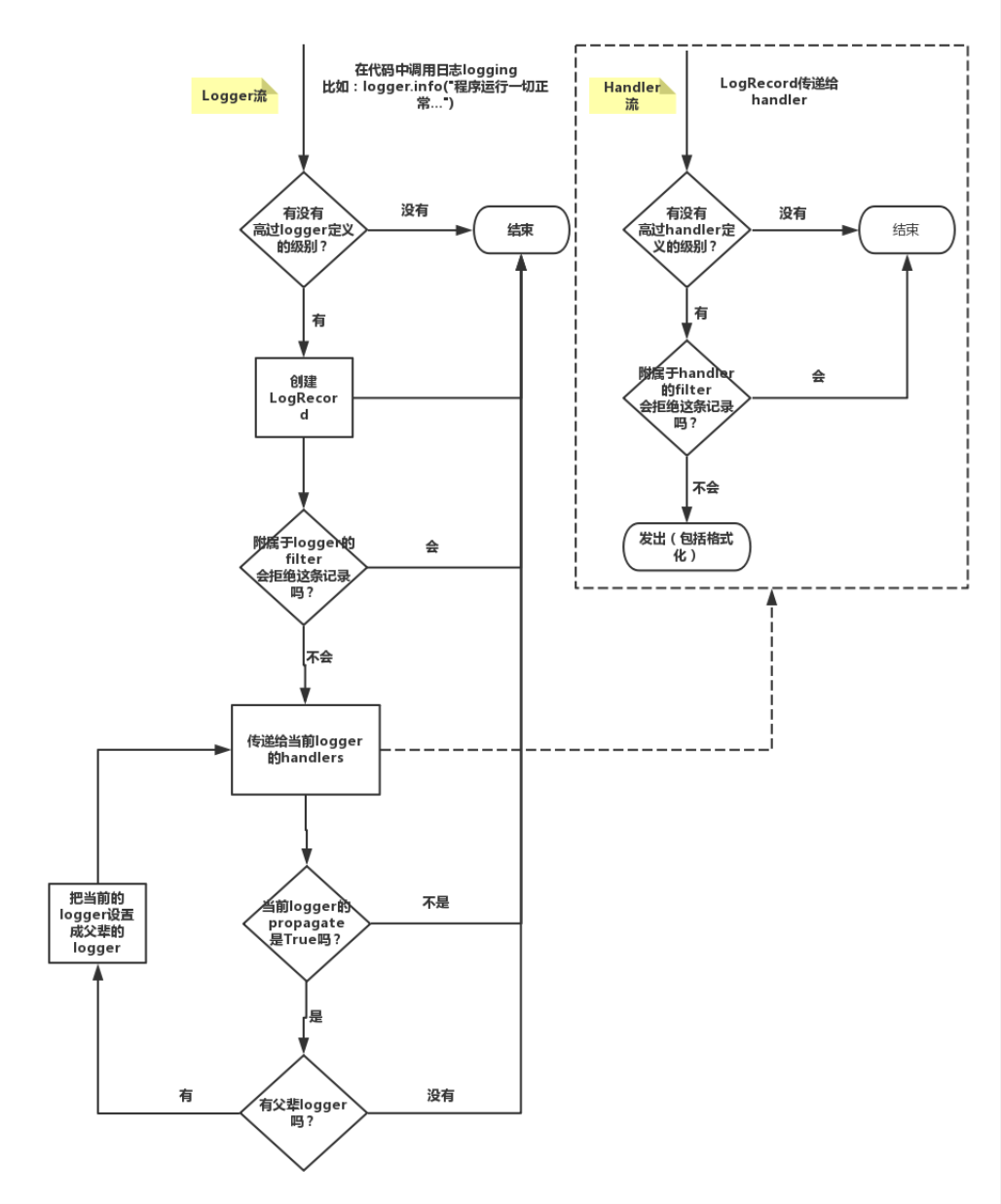
loggerЃКВњЩњШежОЕФЖдЯѓ
Filter:Й§ТЫШежОЕФЖдЯѓ
Handler:НгЪеШежОШЛКѓПижЦДђгЁЕНВЛЭЌЕФЕиЗНЃЌFileHandlerгУРДДђгЁЕНЮФМўжаЃЌStreamHandler
гУРДДђгЁЕНжеЖЫ
Formatter ЖдЯѓЃКПЩвдЖЈжЦВЛЭЌЕФШежОИёЪНЖдЯѓЃЌШЛКѓАѓЖЈИјВЛЭЌЕФ Handler ЖдЯѓЪЙгУЃЌвдДЫРДПижЦВЛЭЌЕФHandler
ЕФШежОИёЪН
'''
critical=50
error =40
warning =30
info = 20
debug =10
'''
import logging
#1ЁЂloggerЖдЯѓЃКИКд№ВњЩњШежОЃЌШЛКѓНЛИј Filter Й§ТЫЃЌШЛКѓНЛИјВЛЭЌЕФHandlerЪфГі
logger = logging.getLogger (__file__)
#2ЁЂFilter ЖдЯѓЃКВЛГЃгУЃЌТд
#3ЁЂHandler ЖдЯѓЃКНгЪе logger ДЋРДЕФШежОЃЌШЛКѓПижЦЪфГі
h1=logging.FileHandler ('t1.log') #ДђгЁЕНЮФМў
h2=logging.FileHandler ('t2.log') #ДђгЁЕНЮФМў
h3=logging.StreamHandler () # ДђгЁЕНжеЖЫ
#4ЁЂFormatterЖдЯѓЃКШежОИёЪН
formmater1 = logging.Formatter ('%(asctime)s -
%(name) s - % (levelname)s -% (module)s: % ( message)
s',
datefmt = '%Y-%m-%d %H:%M:%S %p',)
formmater2 = logging.Formatter ('%(asctime)s :
% ( message) s',
datefmt = '%Y-%m-%d %H:%M:%S %p',)
formmater3 = logging.Formatter ('%(name)s %( message)s',)
#5ЁЂЮЊ Handler ЖдЯѓАѓЖЈИёЪН
h1.setFormatter (formmater1)
h2.setFormatter (formmater2)
h3.setFormatter (formmater3)
#6ЁЂНЋHandlerЬэМгИј logger ВЂЩшжУШежОМЖБ№
logger.addHandler (h1)
logger.addHandler (h2)
logger.addHandler (h3)
logger.setLevel (10)
#7ЁЂВтЪд
logger.debug ('debug')
logger.info ('info')
logger.warning ('warning')
logger.error ('error')
logger.critical ('critical') |
LoggerгыHandlerЕФМЖБ№
loggerЪЧЕквЛМЖЙ§ТЫЃЌШЛКѓВХФмЕНhandlerЃЌЮвУЧПЩвдИјloggerКЭhandlerЭЌЪБЩшжУlevelЃЌЕЋЪЧашвЊзЂвтЕФЪЧ
Logger is also
the first to filter the message based on a level
ЁЊ if you set the logger to INFO, and all handlers
to DEBUG, you still won't receive DEBUG messages
on handlers ЁЊ they'll be rejected by the logger
itself. If you set logger to DEBUG, but all handlers
to INFO, you won't receive any DEBUG messages
either ЁЊ because while the logger says "ok,
process this", the handlers reject it (DEBUG
< INFO).
#бщжЄ
import logging
form=logging.Formatter ('%(asctime)s - %(name)s
- % (levelname)s -%(module)s: %(message)s',
datefmt = '%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler ()
ch.setFormatter (form)
# ch.setLevel (10)
ch.setLevel (20)
l1=logging.getLogger ('root')
# l1.setLevel (20)
l1.setLevel (10)
l1.addHandler (ch)
l1.debug ('l1 debug')
живЊЃЌживЊЃЌживЊЃЁЃЁЃЁ |
LoggerЕФМЬГа(СЫНт)
import logging
formatter=logging.Formatter('%(asctime)s -
%(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(formatter)
logger1=logging.getLogger('root')
logger2=logging.getLogger('root.child1')
logger3=logging.getLogger('root.child1.child2')
logger1.addHandler(ch)
logger2.addHandler(ch)
logger3.addHandler(ch)
logger1.setLevel(10)
logger2.setLevel(10)
logger3.setLevel(10)
logger1.debug('log1 debug')
logger2.debug('log2 debug')
logger3.debug('log3 debug')
'''
2017-07-28 22:22:05 PM - root - DEBUG -test:
log1 debug
2017-07-28 22:22:05 PM - root.child1 - DEBUG
-test: log2 debug
2017-07-28 22:22:05 PM - root.child1 - DEBUG
-test: log2 debug
2017-07-28 22:22:05 PM - root.child1.child2
- DEBUG -test: log3 debug
2017-07-28 22:22:05 PM - root.child1.child2
- DEBUG -test: log3 debug
2017-07-28 22:22:05 PM - root.child1.child2
- DEBUG -test: log3 debug
'''
СЫНтМДПЩ |
loggingгІгУ
"""
loggingХфжУ
"""
import os
import logging.config
# ЖЈвхШ§жжШежОЪфГіИёЪН ПЊЪМ
standard_format = '[%(asctime)s] [%(threadName)s:
%(thread)d] [task_id:%(name)s] [%(filename)s:
% (lineno)d]' \
'[%(levelname)s] [%(message)s]' # ЦфжаnameЮЊgetloggerжИЖЈЕФУћзж
simple_format = '[%(levelname)s] [%(asctime)s]
[%(filename)s: %(lineno)d] %(message)s'
id_simple_format = '[%(levelname)s] [%(asctime)s]
%(message)s'
# ЖЈвхШежОЪфГіИёЪН НсЪј
logfile_dir = os.path.dirname (os.path.abspath(__file__))
# logЮФМўЕФФПТМ
logfile_name = 'all2.log' # logЮФМўУћ
# ШчЙћВЛДцдкЖЈвхЕФШежОФПТМОЭДДНЈвЛИі
if not os.path.isdir (logfile_dir):
os.mkdir (logfile_dir)
# logЮФМўЕФШЋТЗОЖ
logfile_path = os.path.join (logfile_dir, logfile_name)
# logХфжУзжЕф
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#ДђгЁЕНжеЖЫЕФШежО
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # ДђгЁЕНЦСФЛ
'formatter': 'simple'
},
#ДђгЁЕНЮФМўЕФШежО,ЪеМЏinfoМАвдЩЯЕФШежО
'default': {
'level': 'DEBUG',
'class': 'logging.handlers. RotatingFileHandler',
# БЃДцЕНЮФМў
'formatter': 'standard',
'filename': logfile_path, # ШежОЮФМў
'maxBytes': 1024*1024*5, # ШежОДѓаЁ 5M
'backupCount': 5,
'encoding': 'utf-8', # ШежОЮФМўЕФБрТыЃЌдйвВВЛгУЕЃаФжаЮФlogТвТыСЫ
},
},
'loggers': {
#logging.getLogger (__name__)ФУЕНЕФloggerХфжУ
'': {
'handlers': ['default', 'console'], # етРяАбЩЯУцЖЈвхЕФСНИіhandlerЖММгЩЯЃЌМДlogЪ§ОнМШаДШыЮФМўгжДђгЁЕНЦСФЛ
'level': 'DEBUG',
'propagate': True, # ЯђЩЯЃЈИќИпlevelЕФloggerЃЉДЋЕн
},
},
}
def load_ my_logging_cfg ():
logging. config.dictConfig (LOGGING_DIC) # ЕМШыЩЯУцЖЈвхЕФloggingХфжУ
logger = logging.getLogger (__name__) # ЩњГЩвЛИіlogЪЕР§
logger. info ('It works!') # МЧТМИУЮФМўЕФдЫаазДЬЌ
if __name__ = = '__main__':
load_my_logging_ cfg ()
logging ХфжУЮФМў |
"""
MyLogging Test
"""
import time
import logging
import my_logging # ЕМШыздЖЈвхЕФloggingХфжУ
logger = logging.getLogger(__name__) # ЩњГЩloggerЪЕР§
def demo():
logger.debug ("start range... time:{}".format(time.time()))
logger.info ("жаЮФВтЪдПЊЪМЁЃЁЃЁЃ")
for i in range(10):
logger.debug ("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug ("over range... time:{}".format
(time.time()))
logger.info("жаЮФВтЪдНсЪјЁЃЁЃЁЃ")
if __name__ == "__main__":
my_logging.load_my_logging_cfg() # дкФуГЬађЮФМўЕФШыПкМгдиздЖЈвхloggingХфжУ
demo ()
гІгУ |
зЂвтзЂвтзЂвтЃК
#1ЁЂгаСЫЩЯЪіЗНЪНЮвУЧЕФКУДІЪЧЃКЫљгагы logging ФЃПщгаЙиЕФХфжУЖМаДЕНзжЕфжаОЭПЩвдСЫЃЌИќМгЧхЮњЃЌЗНБуЙмРэ
#2ЁЂЮвУЧашвЊНтОіЕФЮЪЬтЪЧЃК
1ЁЂДгзжЕфМгдиХфжУЃКlogging.config.dictConfig ( settings
.LOGGING_DIC)
2ЁЂФУЕНloggerЖдЯѓРДВњЩњШежО
logger ЖдЯѓЖМЪЧХфжУЕНзжЕфЕФ loggers МќЖдгІЕФзгзжЕфжаЕФ
АДееЮвУЧЖд logging ФЃПщЕФРэНтЃЌвЊЯыЛёШЁФГИіЖЋЮїЖМЪЧЭЈЙ§УћзжЃЌвВОЭЪЧkeyРДЛёШЁЕФ
гкЪЧЮвУЧвЊЛёШЁВЛЭЌЕФ logger ЖдЯѓОЭЪЧ
logge r= logging .getLogger ('loggersзгзжЕфЕФkeyУћ')
ЕЋЮЪЬтЪЧЃКШчЙћЮвУЧЯывЊВЛЭЌ loggerУћЕФ loggerЖдЯѓЖМЙВгУвЛЖЮХфжУЃЌФЧУДПЯЖЈВЛФмдк
loggersзгзжЕфжаЖЈвхnИіkey
'loggers': {
'l1': {
'handlers': ['default', 'console'], #
'level': 'DEBUG',
'propagate': True, # ЯђЩЯЃЈИќИпlevelЕФloggerЃЉДЋЕн
},
'l2: {
'handlers': ['default', 'console' ],
'level': 'DEBUG',
'propagate': False, # ЯђЩЯЃЈИќИпlevelЕФloggerЃЉДЋЕн
},
'l3': {
'handlers': ['default', 'console'], #
'level': 'DEBUG',
'propagate': True, # ЯђЩЯЃЈИќИпlevelЕФloggerЃЉДЋЕн
},
}
#ЮвУЧЕФНтОіЗНЪНЪЧЃЌЖЈвхвЛИіПеЕФkey
'loggers': {
'': {
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': True,
},
}
етбљЮвУЧдйШЁloggerЖдЯѓЪБ
logging. getLogger (__name__)ЃЌВЛЭЌЕФЮФМў__name__ВЛЭЌЃЌетБЃжЄСЫДђгЁШежОЪББъЪЖаХЯЂВЛЭЌЃЌЕЋЪЧФУзХИУУћзжШЅ
loggersРяев keyУћЪБШДЗЂЯжевВЛЕНЃЌгкЪЧФЌШЯЪЙгУkey =''ЕФХфжУ
!!!ЙигкШчКЮФУЕН logger ЖдЯѓЕФЯъЯИНтЪЭЃЁЃЁЃЁ |
СэЭтвЛИіdjangoЕФХфжУЃЌУщвЛблОЭПЩвдЃЌИњЩЯУцЕФвЛбљ
#logging_config.py
LOGGING = {
'version': 1,
'disable_ existing_loggers': False,
'formatters': {
'standard': {
'format': '[%(asctime)s] [%(threadName)s :% (thread)
d] [task_id:%(name)s] [%(filename)s :% (lineno)d]'
'[%(levelname)s] [%(message)s]'
},
'simple': {
'format': '[%(levelname)s] [%(asctime)s] [%( filename)s:
%(lineno)d] %(message)s'
},
'collect': {
'format': '%(message)s'
}
},
'filters': {
'require_debug_true': {
'()' : 'django.utils .log. RequireDebugTrue',
},
},
'handlers': {
#ДђгЁЕНжеЖЫЕФШежО
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class' : 'logging .StreamHandler',
'formatter': 'simple'
},
#ДђгЁЕНЮФМўЕФШежО,ЪеМЏinfoМАвдЩЯЕФШежО
'default': {
'level': 'INFO',
'class': 'logging.handlers. RotatingFileHandler',
# БЃДцЕНЮФМўЃЌздЖЏЧа
'filename': os.path.join (BASE_LOG_DIR, "xxx_
info.log "), # ШежОЮФМў
'maxBytes': 1024 * 1024 * 5, # ШежОДѓаЁ 5M
'backupCount': 3,
'formatter': 'standard',
'encoding': 'utf-8',
},
#ДђгЁЕНЮФМўЕФШежО:ЪеМЏДэЮѓМАвдЩЯЕФШежО
'error': {
'level': 'ERROR',
'class': 'logging.handlers .RotatingFileHandler',
# БЃДцЕНЮФМўЃЌздЖЏЧа
'filename': os.path.join (BASE_LOG_DIR, "xxx_err.log"),
# ШежОЮФМў
'maxBytes': 1024 * 1024 * 5, # ШежОДѓаЁ 5M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
#ДђгЁЕНЮФМўЕФШежО
'collect': {
'level': 'INFO',
'class': 'logging.handlers .RotatingFileHandler',
# БЃДцЕНЮФМўЃЌздЖЏЧа
'filename': os.path.join (BASE_LOG_DIR, "xxx_collect.log"),
'maxBytes': 1024 * 1024 * 5, # ШежОДѓаЁ 5M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
'loggers': {
#logging.getLogger (__name__)ФУЕНЕФloggerХфжУ
'': {
'handlers': ['default', 'console', 'error'],
'level': 'DEBUG',
'propagate': True,
},
#logging.getLogger ('collect')ФУЕНЕФloggerХфжУ
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
}
# -----------
# гУЗЈ:ФУЕНСЉИіlogger
logger = logging.getLogger (__name__) #ЯпЩЯе§ГЃЕФШежО
collect_logger = logging.getLogger ("collect")
#СьЕМЫЕ,ашвЊЮЊСьЕМУЧЕЅЖРЖЈжЦСьЕМУЧПДЕФШежО |
|









