| БрМЭЦМі: |
| БОЮФРДздгкCSDN,жївЊНВЕФШЋеЛPythonБрГЬБиБИжЊЪЖЃЌШчгяЗЈЁЂЪ§ОнРраЭЁЂРргыМЬГаЁЂАќгыФЃПщЁЂУќУћЙцЗЖЁЂЕќДњЦїЁЂЩњГЩЦїЕШЕШЁЃ |
|
ОнЫЕЃК
2019ФъЃЌ еуНаХЯЂММЪѕИпПМПЩвдПМpythonСЫЃЛ
2018ФъЃЌ Python НјШыСЫаЁбЇЩњЕФНЬВФЃЛ
2018ФъЃЌ ШЋЙњМЦЫуЛњЕШМЖПМЪдЃЌПЩвдПМpython СЫЃЛ
ОнЭтУНБЈЕРЃЌЮЂШэе§ПМТЧЬэМг Python ЮЊЙйЗНЕФвЛжж Excel НХБОгябд
ЁЁ
PythonзїЮЊвЛжжБрГЬгябдЃЌБЛГЦЮЊЁАНКЫЎгябдЁБЃЌИќБЛгЕѕЛУЧгўЮЊЁАзюУРРіЁБЕФБрГЬгябдЃЌДгдЦЖЫЕНПЭЛЇЖЫЃЌдйЕНЮяСЊЭјжеЖЫЃЌЮоЫљВЛдкЃЌЭЌЪБЛЙЪЧШЫЙЄжЧФмгХбЁЕФБрГЬгябдЁЃ
вђДЫЃЌДгШЋеЛЕФНЧЖШПДЃЌ Python ЪЧвЛУХБиБИЕФгябдЃЌвђЮЊЫќЪЧГ§СЫЧ§ЖЏКЭВйзїЯЕЭГЭтЃЌЦфЫћЖМПЩвдзіКУЁЃ
ВЛЛ§ѕЭВНЮовджСЧЇРяЃЌВЛЛ§аЁСїЮовдГЩНКЃЁЃЁЊЁЊ мїзгЁЖШАбЇЁЗ
гяЗЈ
PythonЪЙгУПеИёЛђжЦБэЗћЫѕНјЕФЗНЪНЗжИєДњТыЃЌPython 2 Ніга31ИіБЃСєзжЃЌЖјЧвУЛгаЗжКХЁЂbeginЁЂendЕШБъМЧЁЃ
>>> help("keywords")
Here is a list of the Python keywords. Enter any keyword to get more help.
and elif if print
as else import raise
assert except in return
break exec is try
class finally lambda while
continue for not with
def from or yield
del global pass
>>> |
ПЩвдзщжЏГЩДђгЭЪЋЃЌ ИќЗНБуМЧвфЃК
Global is classЃЌdef not passЁЃ
if eilf elseЃЌ del as breakЁЃ
raise in whileЃЌimport from yieldЃЌ
try for printЃЌreturn and assertЁЃ
exec except with lambda,
finally or continueЁЁ
pythonжаУЛгаЬсЙЉЖЈвхГЃСПЕФБЃСєзжЃЌПЩвдздМКЖЈвхвЛИіГЃСПРрРДЪЕЯжГЃСПЕФЙІФмЁЃpythonжага3жжБэЪОзжЗћДЎРраЭЕФЗНЪНЃЌМДЕЅв§КХЁЂЫЋв§КХЁЂШ§в§КХЁЃЕЅв§КХКЭЫЋв§КХЕФзїгУЪЧЯрЭЌЕФЃЌpythonГЬађдБИќЯВЛЖгУЕЅв§КХЃЌC/JavaГЬађдБдђЯАЙпЪЙгУЫЋв§КХБэЪОзжЗћДЎЁЃШ§в§КХжаПЩвдЪфШыЕЅв§КХЁЂЫЋв§КХЛђЛЛааЕШзжЗћЁЃpythonВЛжЇГжзддідЫЫуЗћКЭздМѕдЫЫуЗћЃЌЦфЫћдЫЫуЗћКЭБэДяЪНЖМЪЧРрЫЦЕФЃЌгШЦфЪЧЗжжЇХаЖЯКЭбЛЗЁЃ
PythonЕФЮФМўРраЭЗжЮЊ3жжЃЌМДдДДњТыЁЂзжНкДњТыКЭгХЛЏДњТыЁЃетаЉЖМПЩвджБНгдЫааЃЌВЛашвЊНјаадЄБрвыЛђСЌНгЁЃ
Ъ§ОнРраЭ
PythonжаЕФЛљБОЪ§ОнРраЭгаВМЖћРраЭЃЌећЪ§ЃЌИЁЕуЪ§КЭзжЗћДЎЕШЁЃ
Python жаЕФЪ§ОнНсЙЙжївЊгадЊзщЃЈtupleЃЉЃЌСаБэЃЈlistЃЉКЭзжЕфЃЈdictionaryЃЉЁЃдЊзщЁЂСаБэКЭзжЗћДЎЖМЪєгкађСа,ЪЧОпгаЫїв§КЭЧаЦЌФмСІЕФМЏКЯЁЃ
дЊзщГѕЪМЛЏКѓВЛПЩаоИФЃЌЪЧаДБЃЛЄЕФЁЃдЊзщЭљЭљДњБэвЛааЪ§ОнЃЌЖјдЊзщжаЕФдЊЫиДњБэВЛЭЌЕФЪ§ОнЯюЃЌПЩвдАбдЊзщПДзіВЛПЩаоИФЕФЪ§зщЁЃ
| tuple_name=(ЁАyouЁБ,ЁБmeЁБ,ЁБhimЁБ,ЁБherЁБ) |
СаБэПЩзЊЛЛЮЊдЊзщЃЌЪЧДЋЭГвтвхЩЯЕФЪ§зщЃЌПЩвдЪЕЯжЬэМгЁЂЩОГ§КЭВщевВйзїЃЌдЊЫиЕФжЕПЩвдБЛаоИФЁЃ
| list_name=[ЁАyouЁБ,ЁБmeЁБ,ЁБhimЁБ,ЁБherЁБ] |
зжЕфЪЧМќжЕЖд,ЯрЖдгкЙўЯЃБэЁЃ
| dict_name={ЁАyЁБ:ЁБyouЁБ, ЁАmЁБ:ЁБmeЁБ, ЁАhiЁБ:ЁБhimЁБ, ЁАheЁБ:ЁБherЁБ} |
СаБэЭЦЕМЃЈList ComprehensionsЃЉЪЧЙЙНЈСаБэЕФПьНнЗНЪН, ПЩЖСадНЯКУЧваЇТЪИќИп. дЫгУСаБэЩњГЩЪНЃЌПЩвдПьЫйЩњГЩlistЃЌР§Шч ЕУЕНЕБЧАФПТМЯТЕФЫљгаФПТМКЭЮФМўЃК
>>> import os
>>> [d for d in os.listdir('.')] |
вВПЩвдЭЈЙ§вЛИіlistЭЦЕМГіСэвЛИіlistЃЌДњТыМђНрЃЌР§Шч НЋвЛИіСаБэжаЕФдЊЫиЖМБфГЩаЁаДЃК
>>> L = ['Hello', 'World', 'IBM', 'Apple']
>>> [s.lower() for s in L] |
ЭЈЙ§етаЉЛљБОРраЭЃЌПЩвдзщГЩИќгаеыЖдадашЧѓЕФЪ§ОнНсЙЙЃЌР§ШчзжЕфЧЖЬзаЮГЩЕФЪїЕШЃЌ еыЖдИќИДдгЕФЪ§ОнНсЙЙЃЌ Python жаЬсЙЉСЫДѓСПЕФПтЁЃ
РргыМЬГа
pythonгУclassРДЖЈвхвЛИіРрЃЌЕБЫљашЕФЪ§ОнНсЙЙВЛФмгУМђЕЅРраЭРДБэЪОЪБЃЌОЭашвЊЖЈвхРрЃЌШЛКѓРћгУЖЈвхЕФРрДДНЈЖдЯѓЁЃЕБвЛИіЖдЯѓБЛДДНЈКѓЃЌАќКЌСЫШ§ЗНУцЕФЬиадЃЌМДЖдЯѓЕФОфБњЁЂЪєадКЭЗНЗЈЁЃДДНЈЖдЯѓЕФЗНЗЈЃК
РрЕФЗНЗЈЭЌбљЗжЮЊЙЋгаЗНЗЈКЭЫНгаЗНЗЈЁЃЫНгаКЏЪ§ВЛФмБЛИУРржЎЭтЕФКЏЪ§ЕїгУЃЌЫНгаЕФЗНЗЈвВВЛФмБЛЭтВПЕФРрЛђКЏЪ§ЕїгУЁЃpythonЪЙгУКЏЪ§ЁБstaticmethod()ЁАЛђЁБ@ staticmethodЁАЕФЗНЗЈАбЦеЭЈЕФКЏЪ§зЊЛЛЮЊОВЬЌЗНЗЈЃЌЯрЕБгкШЋОжКЏЪ§ЁЃpythonЕФЙЙдьКЏЪ§УћЮЊinitЃЌЮіЙЙКЏЪ§УћЮЊdelЁЃМЬГаЕФЪЙгУЗНЗЈЃК
class AbelApp(abel): ЁЁЁЁ
def Ё
|
Python жаЕФБфСПУћНтЮізёбLEGBддђЃЌБОЕизїгУгђЃЈLocalЃЉЃЌЩЯвЛВуНсЙЙжаЕФdefЛђLambdaЕФБОЕизїгУгђЃЈEnclosingЃЉЃЌШЋОжзїгУгђЃЈGlobalЃЉЃЌФкжУзїгУгђЃЈBuiltinЃЉЃЌАДЫГађВщевЁЃ
КЭБфСПНтЮіВЛЭЌЃЌPython ЛсАДееЬиЖЈЕФЫГађБщРњМЬГаЪїЃЌОЭЪЧЗНЗЈНтЮіЫГађЃЈMethod Resolution OrderЃЌMROЃЉЁЃРрЖМгавЛИіУћЮЊmro ЕФЪєадЃЌжЕЪЧвЛИідЊзщЃЌАДееЗНЗЈНтЮіЫГађСаГіИїИіГЌРрЃЌДгЕБЧАРрвЛжБЯђЩЯЃЌжБЕН object РрЁЃ
Python жагавЛжжЬиЪтЕФРрЪЧдЊРрЃЈmetaclassЃЉЁЃдЊРрЪЧгЩЁАtypeЁБбмЩњЖјГіЃЌЫљвдИИРрашвЊДЋШыtypeЃЌдЊРрЕФВйзїЖМдк newжаЭъГЩЁЃЭЈЙ§дЊРрДДНЈЕФРрЃЌЕквЛИіВЮЪ§ЪЧИИРрЃЌЕкЖўИіВЮЪ§ЪЧmetaclassЁЃ
АќгыФЃПщ
pythonГЬађгЩАќ(package)ЁЂФЃПщ(module)КЭКЏЪ§зщГЩЁЃАќЪЧгЩвЛЯЕСаФЃПщзщГЩЕФМЏКЯЁЃАќБиаыКЌгавЛИіinit.pyЮФМўЃЌЫќгУгкБъЪЖЕБЧАЮФМўМаЪЧвЛИіАќЁЃ
ФЃПщЪЧДІРэФГвЛРрЮЪЬтЕФКЏЪ§КЭРрЕФМЏКЯЁЃФЃПщАбвЛзщЯрЙиЕФКЏЪ§ЛђДњТызщжЏЕНвЛИіЮФМўжаЃЌвЛИіЮФМўМДЪЧвЛИіФЃПщЁЃФЃПщгЩДњТыЁЂКЏЪ§КЭРрзщГЩЁЃЕМШыФЃПщЪЙгУimportгяОфЃЌВЛЙ§ФЃПщВЛЯогкДЫЃЌЛЙПЩвдБЛ import гяОфЕМШыЕФФЃПщЙВгавдЯТЫФРр:
- ЪЙгУPythonаДЕФГЬађ( .pyЮФМў)
- CЛђC++РЉеЙ(вбБрвыЮЊЙВЯэПтЛђDLLЮФМў)
- Аќ(АќКЌЖрИіФЃПщ)
- ФкНЈФЃПщ(ЪЙгУCБраДВЂвбСДНгЕНPythonНтЪЭЦїФк)
Python ЬсЙЉФкНЈКЏЪ§__import__ЖЏЬЌМгди module,import БОжЪЩЯЪЧЕїгУ __import__Мгди module ЕФЃЌ КЏЪ§даЭШчЯТЃК
| __import__(name, globals={}, locals={}, fromlist=[], level=-1) |
Р§ШчЃЌМгдиУћЮЊ abelЕФФПТМЯТЫљгаФЃПщЃК
def loadModules():
res = {}
import os
lst = os.listdir("abel")
dir = []
for d in lst:
s = os.path.abspath("abel") + os.sep + d
if os.path.isdir(s) and os.path.exists(s + os.sep + "__init__.py"):
dir.append(d)
# load the modules
for d in dir:
res[d] = __import__("abel." + d, fromlist = ["*"])
return res |
ашвЊзЂвтЕФЪЧЃЌШчЙћЪфШыЕФВЮЪ§ШчЙћДјга ЁА.ЁБЃЌВЩгУ __import__жБНгЕМШы module ШнвздьГЩвтЯыВЛЕНЕФНсЙћЁЃ OpenStack ЕФ oslo.utils ЗтзАСЫ __import__ЃЌжЇГжЖЏЬЌЕМШы class, object ЕШЁЃ
УќУћЙцЗЖ
Python жаЕФnaming convention вдМА coding standard гаКмЖрКУЕФЪЕМљЃЌР§ШчGoogle ЕФPython БрГЬЙцЗЖЕШЁЃ ОЭУќУћЙцЗЖЖјбдЃЌ ПЩвдВЮМћPythonжЎИИGuidoЭЦМіЕФЙцЗЖЃЌМћЯТБэЃК
| Type |
Public |
Internal |
| Modules |
lower_with_under |
_lower_with_under |
| Packages |
lower_with_under |
|
| Classes |
CapWords |
_CapWords |
| Exceptions |
CapWords |
|
| Functions |
lower_with_under() |
_lower_with_under() |
| Global/Class Constants |
CAPS_WITH_UNDER |
_CAPS_WITH_UNDER |
| Global/Class Variables |
lower_with_under |
_lower_with_under |
| Instance Variables |
lower_with_under |
_lower_with_under (protected) Лђ__lower_with_under (private) |
| Method Names |
lower_with_under() |
_lower_with_under() (protected) Лђ __lower_with_under() (private) |
| Function/Method Parameters |
lower_with_under |
|
| Local Variables |
lower_with_under |
|
ЕќДњЦї
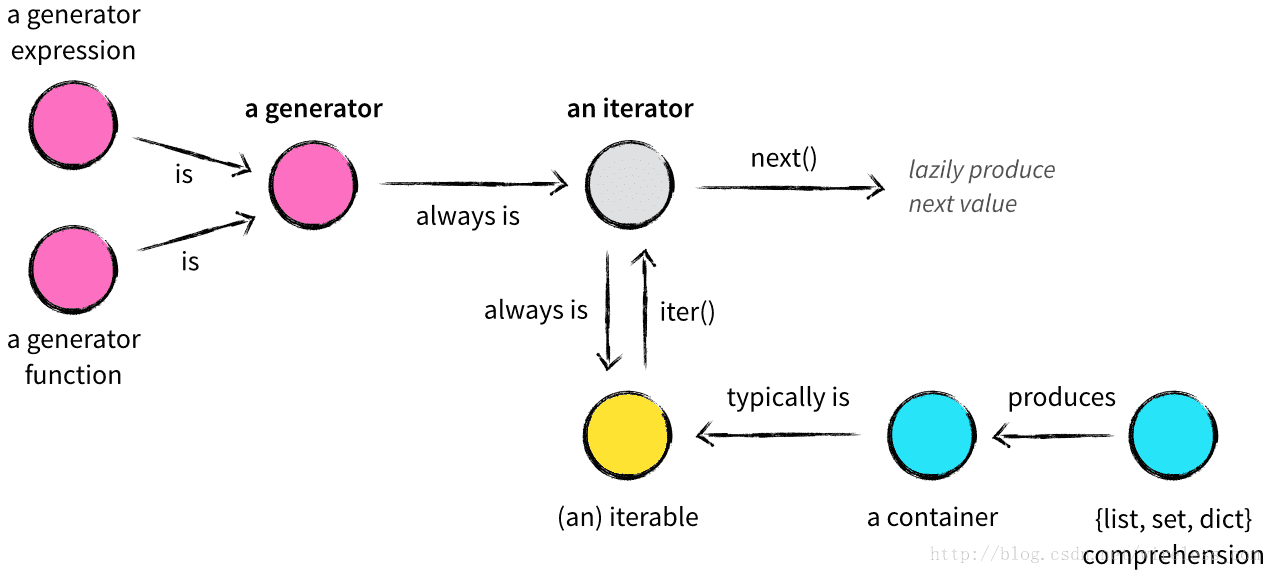
ЕќДњЪЧЪ§ОнДІРэЕФЛљДЁЃЌ ВЩгУвЛжжЖшадЛёШЁЪ§ОнЕФЗНЪН, МДАДашвЛДЮЛёШЁвЛИіЪ§ОнЃЌетОЭЪЧЕќДњЦїФЃЪН. ЕќДњЦїЪЧвЛИіДјзДЬЌЕФЖдЯѓЃЌМьВщвЛИіЖдЯѓ a ЪЧЗёЪЧЕќДњЖдЯѓ, зюзМШЗЕФЗНЗЈЪЧЕїгУ iter(a) , ШчЙћВЛПЩЕќДњ, дђХзГі TypeError вьГЃ.
БъзМЕФЕќДњЦїНгПкгаСНИіЗНЗЈ:
- __next__: ЗЕЛиЯТвЛИіПЩгУдЊЫи, ШчУЛга, ХзГіStopIteration вьГЃ.
- __iter__: ЗЕЛиself , вдБудкгІИУЪЙгУПЩЕќДњЖдЯѓЕФЕиЗНЪЙгУЕќДњЦї.
ПЩЕќДњЖдЯѓвЛЖЈВЛФмЪЧздЩэЕФЕќДњЦї. вВОЭЪЧЫЕ, ПЩЕќДњЖдЯѓБиаыЪЕЯж __iter__ЗНЗЈ, ЕЋВЛФмЪЕЯж __next__ ЗНЗЈ.
ЪЕЯжвЛИіьГВЈФЧЦѕЪ§СаЕФЕќДњЦїР§згШчЯТЃК
class Fibonacci:
def __init__(self):
self.prevous = 0
self.current = 1
def __iter__(self):
return self
def __next__(self):
value = self.current
self.current = self.prevous + self.current
self.prevous = value
return value |
ЕќДњЦїОЭЪЧЪЕЯжСЫЙЄГЇФЃЪНЕФЖдЯѓЃЌгаКмЖрЙигкЕќДњЦїЕФР§згЃЌБШШчitertoolsКЏЪ§ЗЕЛиЕФЖМЪЧЕќДњЦїЖдЯѓЁЃ
ЩњГЩЦї
ЩњГЩЦїЫуЕУЩЯЪЧPythonжазюЮќв§ШЫЕФЬиаджЎвЛЃЌЩњГЩЦїЦфЪЕЪЧвЛжжЬиЪтЕФЕќДњЦїЃЌЕЋВЛашвЊаД__iter__()КЭ__next__()ЗНЗЈСЫЃЌжЛашвЊвЛИіyiledЙиМќзжМДПЩЁЃpythonжаЕФ yield ЙиМќзж, гУгкЙЙНЈЩњГЩЦї(generator), ЦфзїгУгыЕќДњЦївЛбљ. ЛЙвдьГВЈФЧЦѕЪ§СаЮЊР§ЃК
def Fibonacci():
prevous, current = 0, 1
while True:
yield current
prevous, current = current, current + prevous |
ЫљгаЕФЩњГЩЦїЖМЪЧЕќДњЦї, ЖМЪЕЯжСЫЕќДњЦїЕФНгПкЁЃ вЛАуЕиЃЌжЛвЊpythonКЏЪ§ЕФЖЈвхЬхжаЪЙгУСЫ yield ЙиМќзж, ИУКЏЪ§ОЭЪЧЩњГЩЦїКЏЪ§. ЕїгУЩњГЩЦїКЏЪ§ЪБ, ЛсЗЕЛивЛИіЩњГЩЦїЖдЯѓЁЃвВОЭЪЧЫЕ, ЩњГЩЦїКЏЪ§ЪЧЩњГЩЦїЙЄГЇЁЃ
ЩњГЩЦїКЏЪ§ЛсДДНЈвЛИіЩњГЩЦїЖдЯѓ, АќзАЩњГЩЦїКЏЪ§ЕФЖЈвхЬх. АбЩњГЩЦїДЋИј next(Ё) КЏЪ§ЪБ, ЩњГЩЦїКЏЪ§ЛсЯђЧАжДааКЏЪ§ЬхжаЯТвЛИі yield гяОф, ЗЕЛиВњГіЕФжЕ, ВЂдкКЏЪ§ЖЈвхЬхЕФЕБЧАЮЛжУднЭЃ.
ашвЊзЂвтЕФЪЧЃЌ дкаГЬжа, yield ЭЈГЃГіЯждкБэДяЪНЕФгвБп(data = yield), ПЩвдВњГіжЕ, вВПЩвдВЛВњГі(ШчЙћyieldКѓУцУЛгаБэДяЪН, ФЧУДЛсГіNone)ЁЃ аГЬПЩФмЛсДгЕїгУЗННгЪеЪ§Он, ЕїгУЗНАбЪ§ОнЬсЙЉИјаГЬЪЙгУ ЭЈЙ§ЕФЪЧ .send(data) ЗНЗЈ. ЖјВЛЪЧ next(Ё) . ЭЈГЃ, ЕїгУЗНЛсАбжЕЭЦЫЭИјаГЬ.
ЩњГЩЦїЕїгУЗНЪЧвЛжБЛёШЁЪ§Он, ЖјаГЬЕїгУЗНПЩвдЯђЫќДЋШыЪ§Он, аГЬвВВЛвЛЖЈвЊВњГіЪ§ОнЁЃВЛЙмЪ§ОнШчКЮСїЖЏ, yield ЖМЪЧвЛжжСїГЬПижЦЙЄОп, ЪЙгУЫќПЩвдЪЕЯжаДзїЪНЖрШЮЮёМДЃЌаГЬПЩвдАбПижЦЦїШУВНИјжааФЕїЖШГЬађ, ДгЖјМЄЛюЦфЫћЕФаГЬ.
УшЪіЗћ
УшЪіЗћЪЧвЛжжДДНЈЭаЙмЪєадЕФЗНЗЈЃЌЭаЙмЪєадЛЙПЩгУгкБЃЛЄЪєадВЛЪмаоИФЃЌЛђздЖЏИќаТФГИівРРЕЪєадЕФжЕЁЃУшЪіЗћЪЧвЛжждкЖрИіЪєадЩЯжиИДРћгУЭЌвЛИіДцШЁТпМЕФЗНЪНЃЌФмНйГжФЧаЉБОгІЖдгкself.__dict__ЕФВйзїЁЃдкЦфЫћБрГЬгябджаЃЌУшЪіЗћБЛГЦзї setter КЭ getterЃЌгУгкЛёЕУ (Get) КЭЩшжУ (Set) вЛИіЫНгаБфСПЁЃPython УЛгаЫНгаБфСПЕФИХФюЃЌЖјУшЪіЗћПЩвдзїЮЊвЛжж Python ЕФЗНЪНРДЪЕЯжгыЫНгаБфСПРрЫЦЕФЙІФмЁЃ
ОВЬЌЗНЗЈЁЂРрЗНЗЈЁЂpropertyЖМЪЧЙЙНЈУшЪіЗћЕФРрЁЃДДНЈУшЪіЗћЕФЗНЪНжївЊга3жжЃК
1.ДДНЈвЛИіРрВЂИВИЧШЮвтвЛИіУшЪіЗћЗНЗЈЃК__set__ЁЂ__ get__ КЭ __delete__ЁЃЕБашвЊФГИіУшЪіЗћПчЖрИіВЛЭЌЕФРрКЭЪєадЕФЪБКђЃЌР§ШчРраЭбщжЄЃЌдђЪЙгУИУЗНЗЈЃЌР§ШчЃК
class MyNameDescriptor(object):
def __init__(self):
self._myname = ''
def __get__(self, instance, owner):
return self._myname
def __set__(self, instance, myname):
self._myname = myname.getText()
def __delete__(self, instance):
del self._myname |
2.ЪЙгУЪєадРраЭПЩвдИќМгМђЕЅЁЂСщЛюЕиДДНЈУшЪіЗћЁЃЭЈЙ§ЪЙгУ property()ЃЌПЩвдЧсЫЩЕиЮЊШЮвтЪєадДДНЈПЩгУЕФУшЪіЗћЁЃ
class Student(object):
def __init__(self):
self._sname = ''
def fget(self):
return self._sname
def fset(self, value):
self._sname = value.title()
def fdel(self):
del self._sname
name = property(fget, fset, fdel, "This is the property.") |
3.ЪЙгУЪєадУшЪіЗћЃЌЫќНсКЯСЫЪєадРраЭЗНЗЈКЭ PythonзАЪЮЦїЁЃ
class Student(object):
def __init__(self):
self._sname = ''
@property
def name(self):
return self._sname
@name.setter
def name(self, value):
self._sname = value.title()
@name.deleter
def name(self):
del self._sname |
СэЭтЃЌЛЙПЩвддкдЫааЪБЖЏЬЌДДНЈУшЪіЗћЁЃ УшЪіЗћгаКмЖрОЕфЕФгІгУЃЌР§ШчProtobufЁЃ
зАЪЮЦї
зАЪЮЦї(Decorator)ЪЧПЩЕїгУЕФЖдЯѓ, ЦфВЮЪ§ЪЧСэвЛИіКЏЪ§(БЛзАЪЮЕФКЏЪ§). зАЪЮЦїПЩФмЛсДІРэБЛзАЪЮЕФКЏЪ§, ШЛКѓАбЫќЗЕЛи, ЛђепНЋЦфЬцЛЛГЩСэвЛИіКЏЪ§ЛђПЩЕїгУЖдЯѓ.ЪЕМЪЩЯзАЪЮЦїОЭЪЧвЛИіИпНзКЏЪ§ЃЌЫќНгЪевЛИіКЏЪ§зїЮЊВЮЪ§ЃЌШЛКѓЗЕЛивЛИіаТКЏЪ§ЁЃ
зАЪЮЦїгаСНДѓЬиеї:
- АбБЛзАЪЮЕФКЏЪ§ЬцЛЛГЩЦфЫћКЏЪ§
- зАЪЮЦїдкМгдиФЃПщЪБСЂМДжДаа
pythonФкжУСЫШ§ИігУгкзАЪЮЗНЗЈЕФКЏЪ§: propertyЁЂclassmethod КЭ staticmethod. ЕБзАЪЮЦїВЛЙиаФБЛзАЪЮКЏЪ§ЕФВЮЪ§ЃЌЛђЪЧБЛзАЪЮКЏЪ§ЕФВЮЪ§ЖржжЖрбљЕФЪБКђЃЌПЩБфВЮЪ§ЗЧГЃЪЪКЯЪЙгУЁЃ
ШчЙћвЛИіКЏЪ§БЛЖрИізАЪЮЦїаоЪЮЃЌЦфЪЕгІИУЪЧИУКЏЪ§ЯШБЛзюРяУцЕФзАЪЮЦїаоЪЮЃЌБфГЩСэвЛИіКЏЪ§КѓЃЌдйДЮБЛзАЪЮЦїаоЪЮЁЃР§ШчЃК
def second(func):
print "running 2nd decorator"
def wrapper():
func()
return wrapper
def fisrt(func):
print "running 1st decorator"
def wrapper():
func()
return wrapper
@second
@first
def myfunction():
print "running myfunction" |
ОЭРЉеЙЙІФмЖјбдЃЌзАЪЮЦїФЃЪНБШзгРрЛЏИќМгСщЛюЁЃ
дкЩшМЦФЃЪНжаЃЌОпЬхЕФзАЪЮЦїЪЕР§вЊАќзАОпЬхзщМўЕФЪЕР§ЃЌМДзАЪЮЦїКЭЫљзАЪЮЕФзщМўНгПквЛжТЃЌЖдЪЙгУИУзщМўЕФПЭЛЇЖЫЭИУїЃЌВЂНЋПЭЛЇЖЫЕФЧыЧѓзЊЗЂИјИУзщМўЃЌВЂЧвПЩФмдкзЊЗЂЧАКѓжДаавЛаЉЖюЭтЕФВйзїЃЌЭИУїадЪЙЕУПЩвдЕнЙщЧЖЬзЖрИізАЪЮЦїЃЌДгЖјПЩвдЬэМгШЮвтЖрИіЙІФмЁЃзАЪЮЦїФЃЪНКЭPythonзАЪЮЦїжЎМфВЂВЛЪЧвЛЖдвЛЕФЕШМлЙиЯЕЃЌPythonзАЪЮЦїКЏЪ§ИќЮЊЧПДѓЃЌВЛНіНіПЩвдЪЕЯжзАЪЮЦїФЃЪНЁЃ
Lambda
Python ВЛЪЧДПнЭЕФКЏЪ§ЪНБрГЬгябдЃЌЕЋБОЩэЬсЙЉСЫвЛаЉКЏЪ§ЪНБрГЬЕФЬиадЃЌЯё mapЁЂreduceЁЂfilterЕШЖМжЇГжКЏЪ§зїЮЊВЮЪ§ЃЌlambda КЏЪ§КЏЪ§дђЪЧКЏЪ§ЪНБрГЬжаЕФЧЬГўЁЃ
Lambda КЏЪ§гжГЦФфУћКЏЪ§ЃЌдкФГжжвтвхЩЯЃЌreturnгяОфвўКЌдкlambdaжаЁЃКЭЦфЫћКмЖргябдЯрБШЃЌPython ЕФ lambda ЯожЦКмЖрЃЌзюбЯжиЕФЪЧЫќжЛФмгЩвЛЬѕБэДяЪНзщГЩЁЃlambdaЙцЗЖБиаыАќКЌжЛгавЛИіБэДяЪНЃЌБэДяЪНБиаыЗЕЛивЛИіжЕЃЌгЩlambdaДДНЈвЛИіФфУћКЏЪ§вўЪНЕиЗЕЛиБэДяЪНЕФЗЕЛижЕЁЃ
дкPySpark жаОГЃЛсгУЕНЪЙгУLambda ЕФВйзїЃЌР§ШчЃК
li = [1, 2, 3, 4, 5]
### СаБэжаЙњФъЕФУПИідЊЫиМг5
map(lambda x: x+5, li)
### ЗЕЛиЦфжаЕФХМЪ§
filter(lambda x: x % 2 == 0, li) # [2, 4]
### ЗЕЛиЫљгадЊЫиЕФГЫЛ§
reduce(lambda x, y: x * y, li) |
lambda ПЩвдНгЪеШЮвтЖрИіВЮЪ§ (АќРЈПЩбЁВЮЪ§) ВЂЧвЗЕЛиЕЅИіБэДяЪНЕФжЕЁЃ
БОжЪЩЯЃЌLambda КЏЪ§ЪЧвЛИіжЛгыЪфШыВЮЪ§гаЙиЕФГщЯѓДњТыЪїЦЌЖЮЁЃдкКмЖргябдРяЃЌlambda КЏЪ§ЕФЕїгУЛсБЛЬзЩЯвЛВуНгПкЃЌЛЙЛсаЮГЩБеАќЃЌдк lambda КЏЪ§ЙЙдьЕФЭЌЪБОЭПЩвдЭъГЩЃЌжЎКѓ lambda КЏЪ§ФкВПОЭЪЧЭъШЋОВЬЌЕФЁЃЖјвЛАуЕФКЏЪ§ЛЙвЊМгЩЯДцДЂОжВПБфСПЕФЧјгђЃЌЖдЭтВПЛЗОГЕФВйзїЃЌвдМАУќУћЃЌДѓВПЗжгябдЧПжЦСЫвЛАуКЏЪ§БиаыгыУћзжАѓЖЈЁЃ
ЯпГЬ
pythonЪЧжЇГжЖрЯпГЬЕФ, pythonЕФЯпГЬОЭЪЧCгябдЕФвЛИіpthreadЃЌВЂЭЈЙ§ВйзїЯЕЭГЕїЖШЫуЗЈНјааЕїЖШЁЃ python ЕФthreadФЃПщЪЧЧсСПМЖЕФЃЌЖјthreadingФЃПщЪЧЖдthreadзіСЫвЛаЉЗтзАЃЌЗНБуЪЙгУЁЃthreading ОГЃКЭQueueНсКЯЪЙгУ,QueueФЃПщжаЬсЙЉСЫЭЌВНЕФЁЂЯпГЬАВШЋЕФЖгСаРрЃЌАќРЈFIFOЖгСаЃЌLIFOЖгСаЃЌКЭгХЯШМЖЖгСаЕШЁЃетаЉЖгСаЖМЪЕЯжСЫЫјЃЌФмЙЛдкЖрЯпГЬжажБНгЪЙгУЃЌПЩвдЪЙгУЖгСаРДЪЕЯжЯпГЬМфЕФЭЌВНЁЃ
дЫааЯпГЬ(ЯпГЬжаАќКЌnameЪєад)ЕФСНжжГЃгУЗНЪНШчЯТ:
- дкЙЙдьКЏЪ§жаДЋШыгУгкЯпГЬдЫааЕФКЏЪ§
- дкзгРржажиаДthreading.ThreadЛљРржаrun()ЗНЗЈ(жЛашжиаДinit()КЭrun()ЗНЗЈ)
ЪЕЯжвЛИіЪиЛЄЯпГЬЕФМђЕЅР§згШчЯТЃК
class MyThread(threading.Thread):
def run(self):
time.sleep(30)
print 'thread %s finished.' % self.name
def MyDaemons():
print 'start thread:'
for i in range(5):
t = MyThread()
t.setDaemon(1)
t.start()
print 'end thread.'
if __name__ == '__main__':
MyDaemons() |
ЮЊСЫБмУтЯпГЬВЛЭЌВНдьГЩЪ§ОнВЛЭЌВНЃЌПЩвдЖдзЪдДНјааМгЫјЃЌвВОЭЪЧЗУЮЪзЪдДЕФЯпГЬашвЊЛёЕУЫјЃЌВХФмЗУЮЪЁЃthreading ФЃПщжаЬсЙЉСЫвЛИі Lock ЙІФмЁЃДгPython3.XПЊЪМЃЌБъзМПтЮЊЬсЙЉСЫconcurrent.futuresФЃПщЃЌЦфжаЕФThreadPoolExecutorКЭProcessPoolExecutorСНИіРрЃЌЪЕЯжСЫЖдthreadingКЭmultiprocessingЕФНјвЛВНГщЯѓЃЌЖдБраДЯпГЬГиЬсЙЉСЫжБНгжЇГжЁЃ
ЯпГЬдкpython БЛкИВЁЕФЪЧЃЌгЩгкGILЕФЛњжЦжТЪЙЖрЯпГЬВЛФмРћгУЛњЦїЖрКЫЕФЬиадЁЃЦфЪЕЃЌGILВЂВЛЪЧPythonЕФЬиадЃЌжЛЪЧдкЪЕЯжPythonНтЮіЦї(CPython)ЕФЪБКюЫљв§ШыЕФЁЃОЁЙмPythonЭъШЋжЇГжЖрЯпГЬБрГЬЃЌ ЕЋНтЪЭЦїЕФCгябдЪЕЯжВПЗждкЭъШЋВЂаажДааЪБВЂВЛЪЧЯпГЬАВШЋЕФЃЌНтЪЭЦїБЛвЛИіШЋОжЫјМДGILБЃЛЄзХЃЌЫќШЗБЃШЮКЮЪБКђЖМжЛгавЛИіPythonЯпГЬжДааЁЃ
дкЖрЯпГЬЛЗОГжаЃЌPython ащФтЛњАДвдЯТЗНЪНжДаа:
- ЩшжУGIL
- ЧаЛЛЕНвЛИіЯпГЬШЅжДаа
- дЫаажИЖЈЕФзжНкТыжИСюМЏКЯ
- ЯпГЬжїЖЏШУГіПижЦ
- АбЯпГЬЩшжУЭъЫЏУпзДЬЌ
- НтЫјGIL
- дйДЮжиИДвдЩЯВНжш
вђДЫЃЌPythonЕФЖрЯпГЬдкЖрКЫCPUЩЯЃЌжЛЖдгкIOУмМЏаЭМЦЫуВњЩње§УцаЇЙћЃЛЖјЕБгажСЩйгавЛИіCPUУмМЏаЭЯпГЬДцдкЃЌФЧУДЖрЯпГЬаЇТЪЛсгЩгкGILЖјДѓЗљЯТНЕЁЃ
GC
Python жаЕФGCЮЊПЩХфжУЕФРЌЛјЛиЪеЦїЬсЙЉСЫвЛИіНгПкЁЃЭЈЙ§ЫќПЩвдНћгУЛиЪеЦїЁЂЕїећЛиЪеЦЕТЪвдМАЩшжУdebugбЁЯюЃЌвВЮЊгУЛЇФмЙЛВщПДФЧаЉЮоЗЈЛиЪеЕФЖдЯѓЁЃ
ашвЊСЫНтGC ЕФСНИіживЊКЏЪ§ЪЧgc.collectЃЈЃЉ КЭ gc.set_thresholdЃЈЃЉЁЃ
gc.collect([generation])ДЅЗЂЛиЪеааЮЊЃЌЗЕЛиunreachable objectЕФЪ§СПЁЃgenerationПЩбЁВЮЪ§ЃЌгУгкжИЖЈЛиЪеЕкМИДњРЌЛјЛиЪеЃЌгЩДЫвВПЩПДГіpythonЪЙгУЕФЪЧЗжДњРЌЛјЛиЪеЁЃШчЙћВЛЬсЙЉВЮЪ§ЃЌБэЪОЖдећИіЖбНјааЛиЪеЃЌМДFull GCЁЃ
gc.set_threshold(threshold0[,threshold1[,threshold2)ЩшжУВЛЭЌДњЕФЛиЪеЦЕТЪЃЌGCЛсАбЩњУќжмЦкВЛЭЌЕФЖдЯѓЗжБ№ЗХЕН3жжДњШЅЙмРэЛиЪеЃЌgeneration 0МДДЋЫЕжаЕФФъЧсДњЃЌgeneration 1ЮЊРЯФъДњЕШЁЃ
вЛАуЕиЃЌЭЈЙ§БШНЯЩЯДЮЛиЪежЎКѓЃЌБШНЯЗжХфЕФзЪдДЪ§КЭЪЭЗХЕФзЪдДЪ§РДОіЖЈЪЧЗёЦєЖЏЛиЪеЃЌБШШчЃЌЕБЗжХфЕФзЪдДМѕШЅЪЭЗХЕФзЪдДЪ§ГЌЙ§уажЕ0ЪБЃЌЛиЪеФъЧсДњЕФЖдЯѓЁЃЯргІЕФЃЌПЩвдЭЈЙ§gc.get_referents(*objs)ЕУЕНЖдobjsШЮвЛЖдЯѓв§гУЕФЫљгаЖдЯѓСаБэЁЃ
дквЊЧѓМЋЯоадФмЕФЧщПіЯТЃЌВЂШЗБЃГЬађВЛЛсдьГЩЖдЯѓбЛЗв§гУЕФЪБКђЃЌПЩвдНћЕєРЌЛјЛиЪеЦїЁЃЭЈЙ§ЪЙгУgc.disable()ЃЌПЩвдНћЕєздЖЏРЌЛјЛиЪеЦїЁЃ
1. gc.enable()ЃКМЄЛюGC
2. gc.disable()ЃКНћгУGC
3. gc.isenabled():МьВщЪЧЗёМЄЛю |
ЭЌЪБЃЌПЩвдгУgc.set_debug(gc.DEBUG_LEAK)РДЕїЪдгаФкДцаЙТЖЕФГЬађЁЃГ§ДЫжЎЭтЃЌЛЙгаDEBUG_SAVEALLЃЌИУбЁЯюФмЙЛШУБЛЛиЪеЕФЖдЯѓБЃДцдкgc.garbageРяУцЃЌвдБуМьВщЁЃ
ЕїЪд
iPDBЪЧвЛИіВЛДэЕФЙЄОпЃЌЭЈЙ§ pip install ipdb АВзАИУЙЄОпЃЌШЛКѓдкФуЕФДњТыжаimport ipdb; ipdb.set_trace()ЃЌШЛКѓдкГЬађдЫааЪБЃЌЛсЛёЕУвЛИіНЛЛЅЪНЬсЪОЃЌУПДЮжДааГЬађЕФвЛааВЂЧвМьВщБфСПЁЃЪОР§ДњТыШчЯТЃК
import ipdb
ipdb.set_trace()
ipdb.set_trace(context=5) # will show five lines of code
# instead of the default three lines
ipdb.pm()
ipdb.run('x[0] = 3')
result = ipdb.runcall(function, arg0, arg1, kwarg='foo')
result = ipdb.runeval('f(1,2) - 3') |
СэЭтЃЌpythonФкжУСЫвЛИіКмКУЕФзЗзйФЃПщЃЌЕБЯЃЭћИуЧхЦфЫћГЬађЕФФкВПЙЙдьЕФЪБКђЃЌетИіЙІФмЗЧГЃгагУЁЃ
| python -m trace --trace tracing.py |
дквЛаЉГЁКЯЃЌПЩвдЪЙгУpycallgraphРДзЗзйадФмЮЪЬтЃЌЫќПЩвдДДНЈКЏЪ§ЕїгУЪБМфКЭДЮЪ§ЕФЭМБэЁЃЭЌЪБЃЌobjgraphЖдгкВщевФкДцаЙТЖЗЧГЃгагУЁЃ
ЕБШЛЃЌ дкPython ГЬађдБАЫШйАЫГмжаЬИЕНЁАвдДђгЁШежОЮЊШй , вдЕЅВНИњзйЮЊГмЁАЃЌШежОдкКмЖрЪБКђЖМЪЧЕїЪдЕФВЛЖўЗЈУХЁЃ
адФмгХЛЏжаЕФЕёГцаЁММ
ДгЪБПеЕФНЧЖШПДЃЌгХЛЏЭЈГЃАќКЌСНЗНУцЕФФкШнЃКМѕаЁДњТыЕФЬхЛ§ЃЌЬсИпДњТыЕФдЫаааЇТЪЁЃ
вЛИіСМКУЕФЫуЗЈЭљЭљЖдадФмЦ№ЕНЙиМќзїгУЃЌвђДЫадФмИФНјЕФЪзвЊЕуЪЧЖдЫуЗЈЕФИФНјЁЃдкЫуЗЈЕФЪБМфИДдгЖШХХађЩЯвРДЮЪЧЃК
| O(1) -> O(log n) -> O(n) -> O(n log n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
|
вђДЫФмдкЪБМфИДдгЖШЩЯЖдЫуЗЈНјаавЛЖЈЕФИФНјЃЌЖдадФмЕФЬсИпВЛбдЖјгїЁЃ
Python зжЕфжаВщевВйзїЕФИДдгЖШЮЊO(1)ЃЌЖјlist ЪЕМЪЪЧИіЪ§зщЃЌдкlist жаВщевашвЊБщРњећИіБэЃЌЦфИДдгЖШЮЊO(n)ЃЌвђДЫЖдГЩдБЕФЖСВйзїзжЕфвЊБШСаБэ ИќПьЁЃдкашвЊЖрЪ§ОнГЩдБНјааЦЕЗБЗУЮЪЕФЪБКђЃЌзжЕфЪЧвЛИіНЯКУЕФбЁдёЁЃsetЕФunionЃЌ intersectionЃЌdifferenceВйзївЊБШlistЕФЕќДњвЊПьЁЃвђДЫШчЙћЩцМАЕНЧѓlistНЛМЏЃЌВЂМЏЛђепВюЕФЮЪЬтПЩвдзЊЛЛЮЊsetРДВйзїЁЃ
ЖдбЛЗЕФгХЛЏЫљзёбЕФддђЪЧОЁСПМѕЩйбЛЗЙ§ГЬжаЕФМЦЫуСПЃЌгаЖржибЛЗЕФОЁСПНЋФкВуЕФМЦЫуЬсЕНЩЯвЛВуЁЃ дкбЛЗЕФЪБКђЪЙгУ xrange ЖјВЛЪЧ rangeЃЌвђЮЊ xrange() дкађСажаУПДЮЕїгУжЛВњЩњвЛИіећЪ§дЊЫиЁЃЖј range() НЋжБНгЗЕЛиЭъећЕФдЊЫиСаБэЃЌгУгкбЛЗЪБЛсгаВЛБивЊЕФПЊЯњЁЃСэЭтЃЌwhile 1 вЊБШ while True ИќПьЁЃСэЭтЃЌвЊГфЗжРћгУLazy if-evaluationЕФЬиадЃЌвВОЭЪЧЫЕШчЙћДцдкЬѕМўБэДяЪНif x and yЃЌдк x ЮЊfalseЕФЧщПіЯТyБэДяЪНЕФжЕНЋВЛдйМЦЫуЁЃ
pythonжаЕФзжЗћДЎЖдЯѓЪЧВЛПЩИФБфЕФЃЌвђДЫЖдШЮКЮзжЗћДЎЕФВйзїШчЦДНгЃЌаоИФЕШЖМНЋВњЩњвЛИіаТЕФзжЗћДЎЖдЯѓЃЌЖјВЛЪЧЛљгкдзжЗћДЎЃЌвђДЫетжжГжајЕФcopyЛсдквЛЖЈГЬЖШЩЯгАЯьpythonЕФадФмЁЃвђДЫЃЌдкзжЗћДЎСЌНгЕФЪЙгУОЁСПЪЙгУjoin()ЖјВЛЪЧ+ЃЌЕБЖдзжЗћДЎДІРэЕФЪБКђЃЌЪзбЁФкжУКЏЪ§ЃЌЖдзжЗћНјааИёЪНЛЏБШжБНгДЎСЊЖСШЁвЊПьЃЌОЁСПЪЙгУСаБэЭЦЕМКЭЩњГЩЦїБэДяЪНЁЃ
гХЛЏЕФЧАЬсЪЧашвЊСЫНтадФмЦПОБдкЪВУДЕиЗНЃЌЖдгкБШНЯИДдгЕФДњТыПЩвдНшжњвЛаЉЙЄОпРДЖЈЮЛЃЌШчprofileЁЃprofileЕФЪЙгУЗЧГЃМђЕЅЃЌжЛашвЊдкЪЙгУжЎЧАНјааimportМДПЩЁЃЖдгкprofileЕФЦЪЮіЪ§ОнЃЌШчЙћвдЖўНјжЦЮФМўЕФЪБКђБЃДцНсЙћЕФЪБКђЃЌПЩвдЭЈЙ§pstatsФЃПщНјааЮФБОБЈБэЗжЮіЃЌЫќжЇГжЖржжаЮЪНЕФБЈБэЪфГіЃЌЪЧЮФБОНчУцЯТвЛИіНЯЮЊЪЕгУЕФЙЄОпЁЃ
PythonадФмгХЛЏГ§СЫИФНјЫуЗЈЃЌбЁгУКЯЪЪЕФЪ§ОнНсЙЙжЎЭтЃЌЛЙПЩвдНЋЙиМќpythonДњТыВПЗжжиаДГЩCРЉеЙФЃПщЃЌЛђепбЁгУдкадФмЩЯИќЮЊгХЛЏЕФНтЪЭЦїЕШЁЃ
ЧПДѓЕФПт
PythonзюАєЕФЕиЗНжЎвЛЃЌОЭЪЧДѓСПЕФЕкШ§ЗНПтЃЌИВИЧжЎЙуЃЌСюШЫОЊЬОЁЃPython ПтгавЛИіШБЯнОЭЪЧФЌШЯЛсНјааШЋОжАВзАЁЃЮЊСЫЪЙУПИіЯюФПЖМгавЛИіЖРСЂЕФЛЗОГЃЌашвЊЪЙгУЙЄОпvirtualenvЃЌдйгУАќЙмРэЙЄОпpipКЭvirtualenvХфКЯЙЄзїЁЃ
ОЁЙмЖМПЩвдЧѓжњгкgoogleЛђепbaiduЃЌЕЋЛЙвЊВЛздСПСІЃЌАДееИіШЫШЯжЊИјГівЛИіСаБэЃЌШчЯТЃК
| Сьгђ |
МђвЊЫЕУї |
ЪОР§Пт |
| АќЙмРэ |
ЙмРэАќКЭвРРЕЕФЙЄОп |
pipЃЌconda ЕШ |
| ЗжЗЂгыАВзА |
ДђАќЮЊПЩжДааЮФМў |
PyInstaller ЕШ |
| ЙЙНЈ |
НЋдДТыБрвыГЩШэМў |
BitBakeЃЌPlatformIO ЕШ |
| НтЪЭЦї |
НЛЛЅЪН Python НтЮіЦї |
IPython ЕШ |
| БрМЦї |
Python ДњТыБрМЦї |
AnacondaЃЌPython-mode ЕШ |
| IDE |
МЏГЩПЊЗЂЛЗОГ |
pydevЃЌSpyder ЕШ |
| НјГЬ |
ВйзїЯЕЭГНјГЬЦєЖЏМАЭЈаХПт |
envoyЃЌsh ЕШ |
| ВЂЗЂ |
гУвдНјааВЂЗЂКЭВЂааВйзїЕФПт |
geventЃЌeventlet ЕШ |
| ЭјТч |
гУгкЭјТчБрГЬЕФПт |
TwistedЃЌpyzmq ЕШ |
| WebSocket |
гУгкЭјТчБрГЬЕФПт |
AutobahnPythonЃЌCrossbar ЕШ |
| RPC |
МцШн RPC ЕФЗўЮёЦї |
SimpleJSONRPCServerЃЌzeroRPC ЕШ |
| ШэМўЖЈвхЭјТч |
ЭјТчПЩЪгЛЏКЭSDNЕФЙЄОпКЭПт |
PyreticЃЌPOX ЕШ |
| гВМў |
ЖдгВМўНјааБрГЬЕФПт |
inoЃЌPyro ЕШ |
| GUI |
ДДНЈЭМаЮгУЛЇНчУцГЬађЕФПт |
wxPythonЃЌPyQtЃЌPySide ЕШ |
| ЮФМў |
ЮФМўЙмРэКЭ MIMEРраЭМьВт |
mimetypesЃЌwatchdog ЕШ |
| ЮФБОДІРэ |
гУгкНтЮіКЭВйзїЮФБОЕФПт |
chardetЃЌsimplejsonЃЌpyparsing ЕШ |
| ЬиЪтЮФБОИёЪН |
вЛаЉгУРДНтЮіКЭВйзїЬиЪтЮФБОИёЪНЕФПт |
python-docxЃЌPDFMinerЃЌPyYAML ЕШ |
| ЮФЕЕ |
гУвдЩњГЩЯюФПЮФЕЕЕФПт |
Sphinx ЕШ |
| ХфжУЮФМў |
гУРДБЃДцКЭНтЮіХфжУЮФМўЕФПт |
ConfigParser ЕШ |
| ЭМЯёДІРэ |
гУРДВйзїЭМЯёЕФПт |
PILЃЌImageMagicЃЌpython-qrcode ЕШ |
| вєЦЕ |
гУРДВйзївєЦЕЕФПт |
eyeD3ЃЌaudioread ЕШ |
| ЪгЦЕ |
гУРДВйзїЪгЦЕКЭGIFЕФПт |
moviepyЃЌscikit-video ЕШ |
| ЕиРэаХЯЂ |
ЕиРэБрТыЕижЗвдМАгУРДДІРэОЮГЖШЕФПт |
GeoIPЃЌGeoDjango ЕШ |
| УмТыбЇ |
ИїжжМгНтУмЙЄОпПт |
cryptographyЃЌPyCrypto ЕШ |
| ЫуЗЈ |
Python ЪЕЯжЕФЫуЗЈКЭЩшМЦФЃЪН |
algorithmsЃЌpython-patterns ЕШ |
| гЮЯЗПЊЗЂ |
гЮЯЗПЊЗЂПт |
Cocos2dЃЌPygameЃЌPanda3D ЕШ |
| ШежО |
гЮЯЗПЊЗЂПт |
SentryЃЌlogbook ЕШ |
| Ъ§ОнПтЧ§ЖЏ |
гУРДСЌНгКЭВйзїЪ§ОнПтЕФПт |
PyMySQLЃЌpsycopg2 ЕШ |
| ЙиЯЕаЭORM |
ЪЕЯжЙиЯЕаЭЪ§ОнгГЩфЕФПт |
SQLAlchemy ЕШ |
| NoSQLקƏ |
гУРДСЌНгКЭВйзїNoSQLЕФПт |
PyMongoЃЌredis-pyЃЌpy2neoЃЌHappyBase ЕШ |
| NoSQL ORM |
ЪЕЯжNoSQLЪ§ОнгГЩфЕФПт |
MongoEngineЃЌHot-redis ЕШ |
| HTTP |
HTTPавщЕФЙЄОпПт |
requestsЃЌurllib3 ЕШ |
| Restful API |
гУРДПЊЗЂRESTful APIЕФПт |
flask-restfulЃЌfalcon ЕШ |
| URL ДІРэ |
НтЮіurlЕФПт |
webargsЃЌfurl ЕШ |
| HTMLДІРэ |
ДІРэ HTMLКЭXMLЕФПт |
BeautifulSoupЃЌcssutilsЃЌhtml5lib ЕШ |
| ЭјвГДІРэ |
гУгкНјааЭјвГФкШнЬсШЁЕФПт |
opengraphЃЌHaul ЕШ |
| ЭјвГДІРэ |
гУгкНјааЭјвГФкШнЬсШЁЕФПт |
opengraphЃЌHaul ЕШ |
| ЭјвГЩњГЩ |
гУгкНјааЭјвГФкШнЬсШЁЕФПт |
PelicanЃЌHyde ЕШ |
| БэЕЅДІРэ |
ХРШЁЭјТчеОЕуЕФПт |
DeformЃЌWTForms ЕШ |
| Ъ§ОнбщжЄ |
Ъ§ОнбщжЄПтЃЌПЩгУгкБэЕЅбщжЄ |
CerberusЃЌschema ЕШ |
| ЙмРэУцАх |
Ъ§ОнбщжЄПтЃЌПЩгУгкБэЕЅбщжЄ |
AjentiЃЌflask-admin ЕШ |
| ЪкШЈбщжЄ |
ЪЕЯжбщжЄЗНАИЕФПт |
OAuthLibЃЌpython-oauth2 ЕШ |
| ФЃАцв§Чц |
ФЃАхЩњГЩКЭДЪЗЈНтЮіЕФПтКЭЙЄОп |
Jinja2ЃЌMako ЕШ |
| ЖгСа |
ДІРэЪТМўвдМАШЮЮёЖгСаЕФПт |
celeryЃЌmrq ЕШ |
| ЫбЫїв§Чц |
ЖдЪ§ОнНјааЫїв§КЭжДааЫбЫїВщбЏЕФПт |
elasticsearch-pyЃЌsolrpy ЕШ |
| Feed ЯћЯЂ |
гУРДДДНЈгУЛЇЛюЖЏЕФПт |
Stream-Framework ЕШ |
| WebПђМм |
МцШн WSGI ЕФ web ЗўЮёЦї |
gunicornЃЌuwsgiЕШ |
| WSGI |
ЗсИЛЕФЛЅСЊЭјгІгУ |
DjangoЃЌFlaskЃЌTornadoЕШ |
| зЪдДЙмРэ |
ЗсИЛЕФЛЅСЊЭјгІгУ |
fanstaticЃЌjinja-assets-compressorЕШ |
| ЛКДц |
ЛКДцЪ§ОнЕФПт |
django-cache-machineЃЌdjango-cacheopЕШ |
| CMS |
ФкШнЙмРэЯЕЭГ |
django-cmsЕШ |
| ЕчзгЩЬЮё |
гУгкЕчзгЩЬЮёвдМАжЇИЖЕФПђМмКЭПт |
django-shopЃЌmerchantЕШ |
| ЕчзггЪМў |
гУРДЗЂЫЭКЭНтЮіЕчзггЪМўЕФПт |
envelopesЃЌinboxЕШ |
| ЙњМЪЛЏ |
гУРДНјааЙњМЪЛЏЕФПт |
BabelЕШ |
| ВтЪдПђМм |
ЕЅдЊВтЪдПт |
noseЃЌpytestЃЌRobot FrameworkЕШ |
| WebВтЪд |
webгІгУВтЪдПт |
SeleniumЃЌsixpackЕШ |
| mockВтЪд |
MockВтЪдПт |
mockЃЌhttpprettyЕШ |
| ВтЪдЪ§Он |
ЩњГЩВтЪдЪ§ОнЕФПт |
mixerЃЌfakerЕШ |
| ДњТыЗжЮі |
гУгкДњТыЗжЮіМАПЩЪгЛЏЕФПт |
pycallgraphЃЌpysonar2ЃЌcoverageЕШ |
| LintЙЄОп |
гУгкОВЬЌДњТыЗжЮіЕФПт |
Flake8ЃЌpylintЕШ |
| ЕїЪдЙЄОп |
гУгкdebugЕФПт |
ipdbЃЌwdbЕШ |
| адФмЙЄОп |
ИЈжњШЗЖЈадФмЦПОБЕФПт |
profilingЃЌMemory ProfilerЕШ |
| ИпадФм |
ШУ Python ИќПьЕФПт |
cythonЃЌpypyЕШ |
| devops |
ИЈгУгк DevOps ЕФШэМўКЭПт |
AnsibleЃЌFabricЃЌpexpectЕШ |
| CI |
ГжајМЏГЩЙЄОпПт |
CircleCIЃЌWerckerЕШ |
| ШЮЮёЕїЖШ |
ШЮЮёЕїЖШПт |
APSchedulerЃЌTaskFlowЕШ |
| ПЦбЇМЦЫу |
ПЦбЇМЦЫуЕФПт |
numpyЃЌpandasЃЌblazeЃЌscipyЕШ |
| бЇПЦзЈЪє |
ЬьЮФЃЌЛЏбЇЃЌЩњЮябЇЕШЕФПт |
astropyЃЌcclibЃЌBiopythonЕШ |
| Ъ§ОнПЩЪгЛЏ |
НјааЪ§ОнПЩЪгЛЏЕФПт |
matplotlibЃЌggplotЃЌbokerЕШ |
| OCR |
ЙтбЇзжЗћЪЖБ№Пт |
pytesseract ЕШ |
| МЦЫуЛњЪгОѕ |
МЦЫуЛњЪгОѕПт |
OpenCVЃЌSimpleCV ЕШ |
| здШЛгябдДІРэ |
NLPЯрЙиЕФpythonПт |
NLTKЃЌJieba ЕШ |
| ЛњЦїбЇЯА |
ЛњЦїбЇЯАПт |
scikit-learnЃЌtensorflowЃЌtheanoЕШ |
| ДѓЪ§Он |
MapReduce ПђМмКЭПт |
PySparkЃЌstreamparseЕШ |
| дЦЖЫЙЄОп |
дЦЗўЮёЯрЙиЕФpythonПт |
aws-cliЃЌapache-libcloudЕШ |
| дЦЙЙНЈ |
гУгкЙЙНЈЫНгаКЭЙЋгадЦЕФПт |
OpenStackЃЌDocker ComposeЕШ |
ЫфШЛТоСаКмЖрЃЌЕЋжеЙщЪЧВзКЃвЛЫкЃЌживЊЕФЪЧЃЌетаЉЖМЪЧПЊдДЕФЁЃ
ВЛЪЧаЁНсЕФаЁНс
гяЗЈЪ§ОнЃЌРргыМЬГаЃЛ
АќгыФЃПщЃЌЙцЗЖУќУћЃЛ
УшЪізАЪЮЃЌЕќДњЩњГЩЃЛ
Lambda GCЃЌ ВЂЗЂЯпГЬЃЛ
ЕїЪдгХЛЏЃЌРрПтЮоЧюЃЛ
ШЫЩњПрЖЬЃЌPython БрГЬЁЃ
|









