| БрМЭЦМі: |
| РДдДгкcnblogsЃЌБОЮФНщЩмСЫPythonЖдгкЯпГЬЕФжЇГжЃЌАќРЈЁАбЇЛсЁБЖрЯпГЬБрГЬашвЊеЦЮеЕФЛљДЁвдМАPythonСНИіЯпГЬБъзМПтЕФЭъећНщЩмМАЪЙгУЪОР§ЁЃ |
|
ЛњЦїбЇЯАЪЧвЛЯюОбщММФмЃЌОбщдНЖрдНКУЁЃдкЯюФПНЈСЂЕФЙ§ГЬжаЃЌЪЕМљЪЧеЦЮеЛњЦїбЇЯАЕФзюМбЪжЖЮЁЃдкЪЕМљЙ§ГЬжаЃЌЭЈЙ§ЪЕМЪВйзїМгЩюЖдЗжРрКЭЛиЙщЮЪЬтЕФУПвЛИіВНжшЕФРэНтЃЌДяЕНбЇЯАЛњЦїбЇЯАЕФФПЕФЁЃ
дЄВтФЃаЭЯюФПФЃАх
ВЛФмжЛЭЈЙ§дФЖСРДеЦЮеЛњЦїбЇЯАЕФММФмЃЌашвЊНјааДѓСПЕФСЗЯАЁЃБОЮФНЋНщЩмвЛИіЭЈгУЕФЛњЦїбЇЯАЕФЯюФПФЃАхЃЌДДНЈетИіФЃАхзмЙВгаСљИіВНжшЁЃЭЈЙ§БОЮФНЋбЇЕНЃК
ЖЫЕНЖЫЕидЄВтЃЈЗжРргыЛиЙщЃЉФЃаЭЕФЯюФПНсЙЙЁЃ
ШчКЮНЋЧАУцбЇЕНЕФФкШнв§ШыЕНЯюФПжаЁЃ
ШчКЮЭЈЙ§етИіЯюФПФЃАхРДЕУЕНвЛИіИпзМШЗЖШЕФФЃАхЁЃ
ЛњЦїбЇЯАЪЧеыЖдЪ§ОнНјааздЖЏЭкОђЃЌевГіЪ§ОнЕФФкдкЙцТЩЃЌВЂгІгУетИіЙцТЩРДдЄВтаТЪ§ОнЃЌШчЭМ19-1ЫљЪОЁЃ
ЭМ19-1
дкЯюФПжаЪЕМљЛњЦїбЇЯА
ЖЫЕНЖЫЕиНтОіЛњЦїбЇЯАЕФЮЪЬтЪЧЗЧГЃживЊЕФЁЃПЩвдбЇЯАЛњЦїбЇЯАЕФжЊЪЖЃЌПЩвдЪЕМљЛњЦїбЇЯАЕФФГИіЗНУцЃЌЕЋЪЧжЛгаеыЖдФГвЛИіЮЪЬтЃЌДгЮЪЬтЖЈвхПЊЪМЕНФЃаЭВПЪ№ЮЊжЙЃЌЭЈЙ§ЪЕМљЛњЦїбЇЯАЕФИїИіЗНУцЃЌВХФмеце§еЦЮеВЂгІгУЛњЦїбЇЯАРДНтОіЪЕМЪЮЪЬтЁЃ
дкВПЪ№вЛИіЯюФПЪБЃЌШЋГЬВЮгыЕНЯюФПжаПЩвдИќМгЩюШыЕиЫМПМШчКЮЪЙгУФЃаЭЃЌвдМАгТгкГЂЪдгУЛњЦїбЇЯАНтОіЮЪЬтЕФИїИіЗНУцЃЌЖјВЛНіНіЪЧВЮгыЕНздМКИааЫШЄЛђЩУГЄЕФЗНУцЁЃвЛИіКмКУЕФЪЕМљЛњЦїбЇЯАЯюФПЕФЗНЗЈЪЧЃЌЪЙгУДг
UCIЛњЦїбЇЯАВжПтЃЈhttp://archive.ics.uci.edu/ml/datasets.htmlЃЉ
ЛёШЁЕФЪ§ОнМЏПЊЦєвЛИіЛњЦїбЇЯАЯюФПЁЃШчЙћДгвЛИіЪ§ОнМЏПЊЪМЪЕМљЛњЦїбЇЯАЃЌгІИУШчКЮНЋбЇЕНЕФЫљгаММЧЩКЭЗНЗЈећКЯЕНвЛЦ№РДДІРэЛњЦїбЇЯАЕФЮЪЬтФиЃП
ЗжРрЛђЛиЙщФЃаЭЕФЛњЦїбЇЯАЯюФППЩвдЗжГЩвдЯТСљИіВНжшЃК
ЃЈ1ЃЉЖЈвхЮЪЬтЁЃ
ЃЈ2ЃЉРэНтЪ§ОнЁЃ
ЃЈ3ЃЉЪ§ОнзМБИЁЃ
ЃЈ4ЃЉЦРЙРЫуЗЈЁЃ
ЃЈ5ЃЉгХЛЏФЃаЭЁЃ
ЃЈ6ЃЉНсЙћВПЪ№ЁЃ
гаЪБетаЉВНжшПЩФмБЛКЯВЂЛђНјвЛВНЗжНтЃЌЕЋЭЈГЃЪЧАДЩЯЪіСљИіВНжшРДПЊеЙЛњЦїбЇЯАЯюФПЕФЁЃЮЊСЫЗћКЯPythonЕФЯАЙпЃЌдкЯТУцЕФPythonЯюФПФЃАхжаЃЌАДееетСљИіВНжшЗжНтећИіЯюФПЃЌдкНгЯТРДЕФВПЗжЛсУїШЗИїИіВНжшЛђзгВНжшжаЫљвЊЪЕЯжЕФЙІФмЁЃ
ЛњЦїбЇЯАЯюФПЕФPythonФЃАх
ЯТУцЛсИјГівЛИіЛњЦїбЇЯАЯюФПЕФPythonФЃАхЁЃДњТыШчЯТЃК
| # PythonЛњЦїбЇЯАЯюФПЕФФЃАх
# 1. ЖЈвхЮЪЬт
# a) ЕМШыРрПт
# b) ЕМШыЪ§ОнМЏ
# 2. РэНтЪ§Он
# a) УшЪіадЭГМЦ
# b) Ъ§ОнПЩЪгЛЏ
# 3. Ъ§ОнзМБИ
# a) Ъ§ОнЧхЯД
# b) ЬиеїбЁдё
# c) Ъ§ОнзЊЛЛ
# 4. ЦРЙРЫуЗЈ
# a) ЗжРыЪ§ОнМЏ
# b) ЖЈвхФЃаЭЦРЙРБъзМ
# c) ЫуЗЈЩѓВщ
# d) ЫуЗЈБШНЯ
# 5. гХЛЏФЃаЭ
# a) ЫуЗЈЕїВЮ
# b) МЏГЩЫуЗЈ
# 6. НсЙћВПЪ№
# a) дЄВтЦРЙРЪ§ОнМЏ
# b) РћгУећИіЪ§ОнМЏЩњГЩФЃаЭ
# c) ађСаЛЏФЃаЭ |
ЕБгааТЕФЛњЦїбЇЯАЯюФПЪБЃЌаТНЈвЛИіPythonЮФМўЃЌВЂНЋетИіФЃАхеГЬљНјШЅЃЌдйАДееЧАУцеТНкНщЩмЕФЗНЗЈНЋЦфЬюГфЕНУПвЛИіВНжшжаЁЃ
ИїВНжшЕФЯъЯИЫЕУї
НгЯТРДНЋЯъЯИНщЩмЯюФПФЃАхЕФИїИіВНжшЁЃ
ВНжш1ЃКЖЈвхЮЪЬт
жївЊЪЧЕМШыдкЛњЦїбЇЯАЯюФПжаЫљашвЊЕФРрПтКЭЪ§ОнМЏЕШЃЌвдБуЭъГЩЛњЦїбЇЯАЕФЯюФПЃЌАќРЈЕМШыPythonЕФРрПтЁЂРрКЭЗНЗЈЃЌвдМАЕМШыЪ§ОнЁЃЭЌЪБетвВЪЧЫљгаЕФХфжУВЮЪ§ЕФХфжУФЃПщЁЃЕБЪ§ОнМЏЙ§ДѓЪБЃЌПЩвддкетРяЖдЪ§ОнМЏНјааЪнЩэДІРэЃЌРэЯызДЬЌЪЧПЩвддк1ЗжжгФкЃЌЩѕжСЪЧ30УыФкЭъГЩФЃаЭЕФНЈСЂЛђПЩЪгЛЏЪ§ОнМЏЁЃ
ВНжш2ЃКРэНтЪ§Он
етЪЧМгЧПЖдЪ§ОнРэНтЕФВНжшЃЌАќРЈЭЈЙ§УшЪіадЭГМЦРДЗжЮіЪ§ОнКЭЭЈЙ§ПЩЪгЛЏРДЙлВьЪ§ОнЁЃдкетвЛВНашвЊЛЈЗбЪБМфЖрЮЪМИИіЮЪЬтЃЌЩшЖЈМйЩшЬѕМўВЂЕїВщЗжЮівЛЯТЃЌетЖдФЃаЭЕФНЈСЂЛсгаКмДѓЕФАяжњЁЃ
ВНжш3ЃКЪ§ОнзМБИ
Ъ§ОнзМБИжївЊЪЧдЄДІРэЪ§ОнЃЌвдБуШУЪ§ОнПЩвдИќКУЕиеЙЪОЮЪЬтЃЌвдМАЪьЯЄЪфШыгыЪфГіНсЙћЕФЙиЯЕЁЃАќРЈЃК
ЭЈЙ§ЩОГ§жиИДЪ§ОнЁЂБъМЧДэЮѓЪ§жЕЃЌЩѕжСБъМЧДэЮѓЕФЪфШыЪ§ОнРДЧхЯДЪ§ОнЁЃ
ЬиеїбЁдёЃЌАќРЈвЦГ§ЖргрЕФЬиеїЪєадКЭдіМгаТЕФЬиеїЪєадЁЃ
Ъ§ОнзЊЛЏЃЌЖдЪ§ОнГпЖШНјааЕїећЃЌЛђепЕїећЪ§ОнЕФЗжВМЃЌвдБуИќКУЕиеЙЪОЮЪЬтЁЃ
вЊВЛЖЯЕижиИДетИіВНжшКЭЯТвЛИіВНжшЃЌжБЕНевЕНзуЙЛзМШЗЕФЫуЗЈЩњГЩФЃаЭЁЃ
ВНжш4ЃКЦРЙРЫуЗЈ
ЦРЙРЫуЗЈжївЊЪЧЮЊСЫбАевзюМбЕФЫуЗЈзгМЏЃЌАќРЈЃК
ЗжРыГіЦРЙРЪ§ОнМЏЃЌвдБугкбщжЄФЃаЭЁЃ
ЖЈвхФЃаЭЦРЙРБъзМЃЌгУРДЦРЙРЫуЗЈФЃаЭЁЃ
ГщбљЩѓВщЯпадЫуЗЈКЭЗЧЯпадЫуЗЈЁЃ
БШНЯЫуЗЈЕФзМШЗЖШЁЃ
дкУцЖдвЛИіЛњЦїбЇЯАЕФЮЪЬтЕФЪБКђЃЌашвЊЛЈЗбДѓСПЕФЪБМфдкЦРЙРЫуЗЈКЭзМБИЪ§ОнЩЯЃЌжБЕНевЕН3~5жжзМШЗЖШзуЙЛЕФЫуЗЈЮЊжЙЁЃ
ВНжш5ЃКгХЛЏФЃаЭ
ЕБЕУЕНвЛИізМШЗЖШзуЙЛЕФЫуЗЈСаБэКѓЃЌвЊДгжаевГізюКЯЪЪЕФЫуЗЈЃЌЭЈГЃгаСНжжЗНЗЈПЩвдЬсИпЫуЗЈЕФзМШЗЖШЃК
ЖдУПвЛжжЫуЗЈНјааЕїВЮЃЌЕУЕНзюМбНсЙћЁЃ
ЪЙгУМЏКЯЫуЗЈРДЬсИпЫуЗЈФЃаЭЕФзМШЗЖШЁЃ
ВНжш6ЃКНсЙћВПЪ№
вЛЕЉШЯЮЊФЃаЭЕФзМШЗЖШзуЙЛИпЃЌОЭПЩвдНЋетИіФЃаЭађСаЛЏЃЌвдБугааТЪ§ОнЪБЪЙгУИУФЃаЭРДдЄВтЪ§ОнЁЃ
ЭЈЙ§бщжЄЪ§ОнМЏРДбщжЄБЛгХЛЏЙ§ЕФФЃаЭЁЃ
ЭЈЙ§ећИіЪ§ОнМЏРДЩњГЩФЃаЭЁЃ
НЋФЃаЭађСаЛЏЃЌвдБугкдЄВтаТЪ§ОнЁЃ
зіЕНетвЛВНЕФЪБКђЃЌОЭПЩвдНЋФЃаЭеЙЪОВЂЗЂВМИјЯрЙиШЫдБЁЃЕБгааТЪ§ОнВњЩњЪБЃЌОЭПЩвдВЩгУетИіФЃаЭРДдЄВтаТЪ§ОнЁЃ
ЪЙгУФЃАхЕФаЁММЧЩ
ПьЫйжДаавЛБщЃКЪзЯШвЊПьЫйЕидкЯюФПжаНЋФЃАхжаЕФУПвЛИіВНжшжДаавЛБщЃЌетбљЛсМгЧПЖдЯюФПУПвЛВПЗжЕФРэНтВЂИјШчКЮИФНјДјРДСщИаЁЃ
бЛЗЃКећИіСїГЬВЛЪЧЯпадЕФЃЌЖјЪЧбЛЗНјааЕФЃЌвЊЛЈЗбДѓСПЕФЪБМфРДжиИДИїИіВНжшЃЌгШЦфЪЧВНжш3ЛђВНжш4ЃЈЛђВНжш3ЁЋВНжш5ЃЉЃЌжБЕНевЕНвЛИізМШЗЖШзуЙЛЕФФЃаЭЃЌЛђепДяЕНдЄЖЈЕФжмЦкЁЃ
ГЂЪдУПвЛИіВНжшЃКЬјЙ§ФГИіВНжшКмМђЕЅЃЌгШЦфЪЧВЛЪьЯЄЁЂВЛЩУГЄЕФВНжшЁЃМсГждкетИіФЃАхЕФУПвЛИіВНжшжазіаЉЙЄзїЃЌМДЪЙетаЉЙЄзїВЛФмЬсИпЫуЗЈЕФзМШЗЖШЃЌЕЋвВаэдкКѓУцЕФВйзїОЭПЩвдИФНјВЂЬсИпЫуЗЈЕФзМШЗЖШЁЃМДЪЙОѕЕУетИіВНжшВЛЪЪгУЃЌвВВЛвЊЬјЙ§етИіВНжшЃЌЖјЪЧМѕЩйИУВНжшЫљзіЕФЙБЯзЁЃ
ЖЈЯђзМШЗЖШЃКЛњЦїбЇЯАЯюФПЕФФПБъЪЧЕУЕНвЛИізМШЗЖШзуЙЛИпЕФФЃаЭЁЃУПвЛИіВНжшЖМвЊЮЊЪЕЯжетИіФПБъзіГіЙБЯзЁЃвЊШЗБЃУПДЮИФБфЖМЛсИјНсЙћДјРДе§ЯђЕФгАЯьЃЌЛђепЖдЦфЫћЕФВНжшДјРДе§ЯђЕФгАЯьЁЃдкећИіЯюФПЕФУПИіВНжшжаЃЌзМШЗЖШжЛФмЯђБфКУЕФЗНЯђвЦЖЏЁЃ
АДашЪЪгУЃКПЩвдАДееЯюФПЕФашвЊРДаоИФВНжшЃЌгШЦфЪЧЖдФЃАхжаЕФИїИіВНжшЗЧГЃЪьЯЄжЎКѓЁЃашвЊАбЮеЕФддђЪЧЃЌУПвЛДЮИФНјЖМвдЬсИпЫуЗЈФЃаЭЕФзМШЗЖШЮЊЧАЬсЁЃ
змНс
БОеТНщЩмСЫдЄВтФЃаЭЯюФПЕФФЃАхЃЌетИіФЃАхЪЪгУгкЗжРрЛђЛиЙщЮЪЬтЁЃНгЯТРДНЋНщЩмЛњЦїбЇЯАжаЕФвЛИіЛиЙщЮЪЬтЕФЯюФПЃЌетИіЯюФПБШЧАУцНщЩмЕФ№АЮВЛЈЕФР§згИќМгИДдгЃЌЛсРћгУЕНБОеТНщЩмЕФУПИіВНжшЁЃ
ЛиЙщЯюФПЪЕР§
ЛњЦїбЇЯАЪЧвЛЯюОбщММФмЃЌЪЕМљЪЧеЦЮеЛњЦїбЇЯАЁЂЬсИпРћгУЛњЦїбЇЯАНтОіЮЪЬтЕФФмСІЕФгааЇЗНЗЈжЎвЛЁЃФЧУДШчКЮЭЈЙ§ЛњЦїбЇЯАРДНтОіЮЪЬтФиЃПБОеТНЋЭЈЙ§вЛИіЪЕР§РДвЛВНвЛВНЕиНщЩмвЛИіЛиЙщЮЪЬтЁЃБОеТжївЊНщЩмвдЯТФкШнЃК
ШчКЮЖЫЕНЖЫЕиЭъГЩвЛИіЛиЙщЮЪЬтЕФФЃаЭЁЃ
ШчКЮЭЈЙ§Ъ§ОнзЊЛЛЬсИпФЃаЭЕФзМШЗЖШЁЃ
ШчКЮЭЈЙ§ЕїВЮЬсИпФЃаЭЕФзМШЗЖШЁЃ
ШчКЮЭЈЙ§МЏГЩЫуЗЈЬсИпФЃаЭЕФзМШЗЖШЁЃ
ЖЈвхЮЪЬт
дкетИіЯюФПжаНЋЗжЮібаОПВЈЪПЖйЗПМлЃЈBoston House PriceЃЉЪ§ОнМЏЃЌетИіЪ§ОнМЏжаЕФУПвЛааЪ§ОнЖМЪЧЖдВЈЪПЖйжмБпЛђГЧеђЗПМлЕФУшЪіЁЃЪ§ОнЪЧ1978ФъЭГМЦЪеМЏЕФЁЃЪ§ОнжаАќКЌвдЯТ14ИіЬиеїКЭ506ЬѕЪ§ОнЃЈUCIЛњЦїбЇЯАВжПтжаЕФЖЈвхЃЉЁЃ
CRIMЃКГЧеђШЫОљЗИзяТЪЁЃ
ZNЃКзЁеЌгУЕиЫљеМБШР§ЁЃ
INDUSЃКГЧеђжаЗЧзЁеЌгУЕиЫљеМБШР§ЁЃ
CHASЃКCHASащФтБфСПЃЌгУгкЛиЙщЗжЮіЁЃ
NOXЃКЛЗБЃжИЪ§ЁЃ
RMЃКУПЖАзЁеЌЕФЗПМфЪ§ЁЃ
AGEЃК1940ФъвдЧАНЈГЩЕФздзЁЕЅЮЛЕФБШР§ЁЃ
DISЃКОрРы5ИіВЈЪПЖйЕФОЭвЕжааФЕФМгШЈОрРыЁЃ
RADЃКОрРыИпЫйЙЋТЗЕФБуРћжИЪ§ЁЃ
TAXЃКУПвЛЭђУРдЊЕФВЛЖЏВњЫАТЪЁЃ
PRTATIOЃКГЧеђжаЕФНЬЪІбЇЩњБШР§ЁЃ
BЃКГЧеђжаЕФКкШЫБШР§ЁЃ
LSTATЃКЕиЧјжагаЖрЩйЗПЖЋЪєгкЕЭЪеШыШЫШКЁЃ
MEDVЃКздзЁЗПЮнЗПМлжаЮЛЪ§ЁЃ
ЭЈЙ§ЖдетаЉЬиеїЪєадЕФУшЪіЃЌЮвУЧПЩвдЗЂЯжЪфШыЕФЬиеїЪєадЕФЖШСПЕЅЮЛЪЧВЛЭГвЛЕФЃЌвВаэашвЊЖдЪ§ОнНјааЖШСПЕЅЮЛЕФЕїећЁЃ
ЕМШыЪ§Он
ЪзЯШЕМШыдкЯюФПжаашвЊЕФРрПтЁЃДњТыШчЯТЃК
# ЕМШыРрПт
import numpy as np
from numpy import arange
from matplotlib import pyplot
from pandas import read_csv
from pandas import set_option
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error |
НгЯТРДЕМШыЪ§ОнМЏЕНPythonжаЃЌетИіЪ§ОнМЏвВПЩвдДгUCIЛњЦїбЇЯАВжПтЯТдиЃЌдкЕМШыЪ§ОнМЏЪБЛЙЩшЖЈСЫЪ§ОнЪєадЬиеїЕФУћзжЁЃДњТыШчЯТЃК
# ЕМШыЪ§Он
filename = 'housing.csv'
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX',
'RM', 'AGE', 'DIS',
'RAD', 'TAX', 'PRTATIO', 'B', 'LSTAT', 'MEDV']
data = read_csv(filename, names=names, delim_whitespace=True) |
дкетРяЖдУПвЛИіЬиеїЪєадЩшЖЈСЫвЛИіУћГЦЃЌвдБугкдкКѓУцЕФГЬађжаЪЙгУЫќУЧЁЃвђЮЊCSVЮФМўЪЧЪЙгУПеИёМќзіЗжИєЗћЕФЃЌвђДЫЖСШыCSVЮФМўЪБжИЖЈЗжИєЗћЮЊПеИёМќЃЈdelim_whitespace=TrueЃЉЁЃ
РэНтЪ§Он
ЖдЕМШыЕФЪ§ОнНјааЗжЮіЃЌБугкЙЙНЈКЯЪЪЕФФЃаЭЁЃ
ЪзЯШПДвЛЯТЪ§ОнЮЌЖШЃЌР§ШчЪ§ОнМЏжагаЖрЩйЬѕМЧТМЁЂгаЖрЩйИіЪ§ОнЬиеїЁЃДњТыШчЯТЃК
# Ъ§ОнЮЌЖШ
print(dataset.shape) |
жДаажЎКѓЮвУЧПЩвдПДЕНзмЙВга506ЬѕМЧТМКЭ14ИіЬиеїЪєадЃЌетгыUCIЬсЙЉЕФаХЯЂвЛжТЁЃ
дйВщПДИїИіЬиеїЪєадЕФзжЖЮРраЭЁЃДњТыШчЯТЃК
# ЬиеїЪєадЕФзжЖЮРраЭ
print(dataset.dtypes) |
ПЩвдПДЕНЫљгаЕФЬиеїЪєадЖМЪЧЪ§зжЃЌЖјЧвДѓВПЗжЬиеїЪєадЖМЪЧИЁЕуЪ§ЃЌвВгавЛВПЗжЬиеїЪєадЪЧећЪ§РраЭЕФЁЃжДааНсЙћШчЯТЃК
CRIM float64
ZN float64
INDUS float64
CHAS int64
NOX float64
RM float64
AGE float64
DIS float64
RAD int64
TAX float64
PRTATIO float64
B float64
LSTAT float64
MEDV float64
dtype: object |
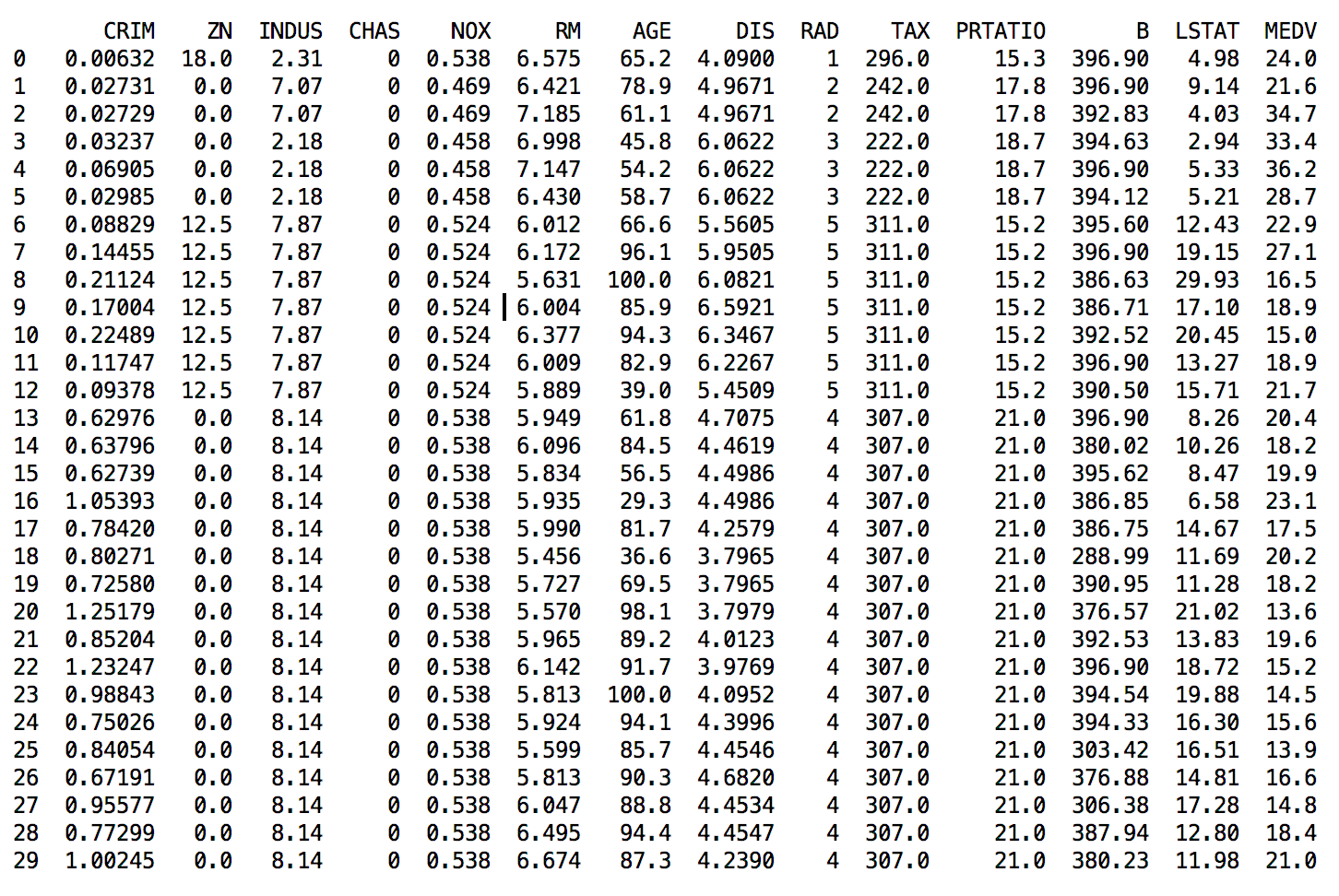
НгЯТРДЖдЪ§ОнНјаавЛДЮМђЕЅЕФВщПДЃЌдкетРяЮвУЧВщПДвЛЯТзюПЊЪМЕФ30ЬѕМЧТМЁЃДњТыШчЯТЃК
# ВщПДзюПЊЪМЕФ30ЬѕМЧТМ
set_option('display.line_width', 120)
print(dataset.head(30)) |
етРяжИЖЈЪфГіЕФПэЖШЮЊ120ИізжЗћЃЌвдШЗБЃНЋЫљгаЬиеїЪєаджЕЯдЪОдквЛааФкЁЃЖјЧветаЉЪ§ОнВЛЪЧгУЯрЭЌЕФЕЅЮЛДцДЂЕФЃЌНјааКѓУцЕФВйзїЪБЃЌвВаэашвЊНЋЪ§ОнећРэЮЊЯрЭЌЕФЖШСПЕЅЮЛЁЃжДааНсЙћШчЭМ20-1ЫљЪОЁЃ
ЭМ20-1
НгЯТРДПДвЛЯТЪ§ОнЕФУшЪіадЭГМЦаХЯЂЁЃДњТыШчЯТЃК
# УшЪіадЭГМЦаХЯЂ
set_option('precision', 1)
print(dataset.describe()) |
дкУшЪіадЭГМЦаХЯЂжаАќКЌЪ§ОнЕФзюДѓжЕЁЂзюаЁжЕЁЂжаЮЛжЕЁЂЫФЗжЮЛжЕЕШЃЌЗжЮіетаЉЪ§ОнФмЙЛМгЩюЖдЪ§ОнЗжВМЁЂЪ§ОнНсЙЙЕШЕФРэНтЁЃНсЙћШчЭМ20-2ЫљЪОЁЃ

ЭМ20-2
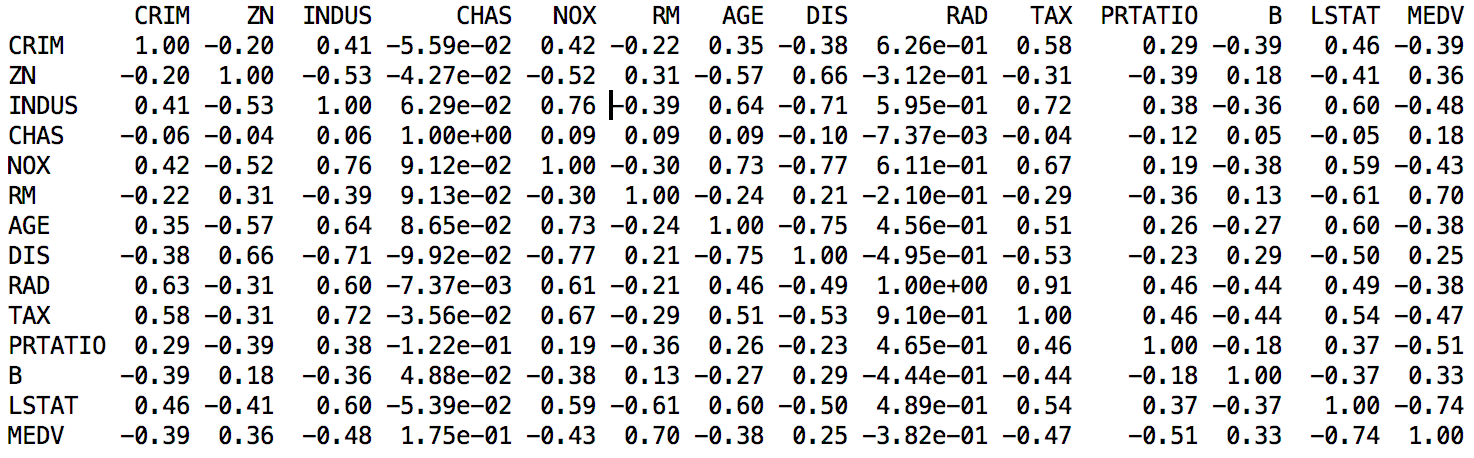
НгЯТРДПДвЛЯТЪ§ОнЬиеїжЎМфЕФСНСНЙиСЊЙиЯЕЃЌетРяВщПДЪ§ОнЕФЦЄЖћбЗЯрЙиЯЕЪ§ЁЃДњТыШчЯТЃК
# ЙиСЊЙиЯЕ
set_option('precision', 2)
print(dataset.corr(method='pearson')) |
жДааНсЙћШчЭМ20-3ЫљЪОЁЃ
ЭМ20-3
ЭЈЙ§ЩЯУцЕФНсЙћПЩвдПДЕНЃЌгааЉЬиеїЪєаджЎМфОпгаЧПЙиСЊЙиЯЕЃЈ>0.7Лђ<-0.7ЃЉЃЌШчЃК
NOXгыINDUSжЎМфЕФЦЄЖћбЗЯрЙиЯЕЪ§ЪЧ0.76ЁЃ
DISгыINDUSжЎМфЕФЦЄЖћбЗЯрЙиЯЕЪ§ЪЧ-0.71ЁЃ
TAXгыINDUSжЎМфЕФЦЄЖћбЗЯрЙиЯЕЪ§ЪЧ0.72ЁЃ
AGEгыNOXжЎМфЕФЦЄЖћбЗЯрЙиЯЕЪ§ЪЧ0.73ЁЃ
DISгыNOXжЎМфЕФЦЄЖћбЗЯрЙиЯЕЪ§ЪЧ-0.77ЁЃ
Ъ§ОнПЩЪгЛЏ
ЕЅвЛЬиеїЭМБэ
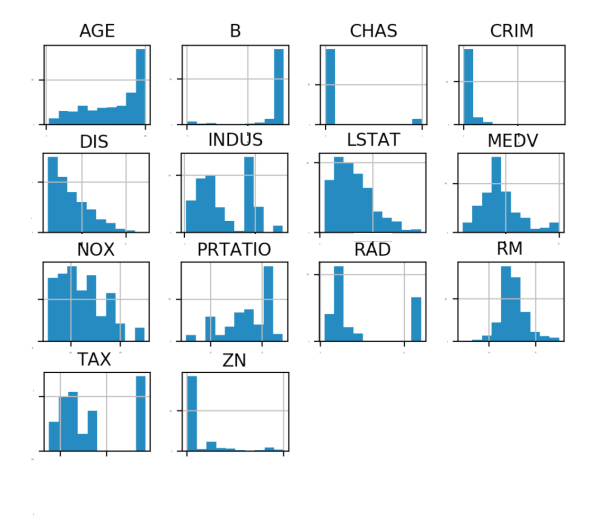
ЪзЯШВщПДУПвЛИіЪ§ОнЬиеїЕЅЖРЕФЗжВМЭМЃЌЖрВщПДМИжжВЛЭЌЕФЭМБэгажњгкЗЂЯжИќКУЕФЗНЗЈЁЃЮвУЧПЩвдЭЈЙ§ВщПДИїИіЪ§ОнЬиеїЕФжБЗНЭМЃЌРДИаЪмвЛЯТЪ§ОнЕФЗжВМЧщПіЁЃДњТыШчЯТЃК
# жБЗНЭМ
dataset.hist(sharex=False, sharey=False, xlabelsize=1,
ylabelsize=1)
pyplot.show() |
жДааНсЙћШчЭМ20-4ЫљЪОЃЌДгЭМжаПЩвдПДЕНгааЉЪ§ОнГЪжИЪ§ЗжВМЃЌШчCRIMЁЂZNЁЂAGEКЭBЃЛгааЉЪ§ОнЬиеїГЪЫЋЗхЗжВМЃЌШчRADКЭTAXЁЃ
ЭМ20-4
ЭЈЙ§УмЖШЭМПЩвдеЙЪОетаЉЪ§ОнЕФЬиеїЪєадЃЌУмЖШЭМБШжБЗНЭМИќМгЦНЛЌЕиеЙЪОСЫетаЉЪ§ОнЬиеїЁЃДњТыШчЯТЃК
# УмЖШЭМ
dataset.plot(kind='density', subplots=True, layout=(4,4),
sharex=False, fontsize=1)
pyplot.show() |
дкУмЖШЭМжаЃЌжИЖЈlayout=(4, 4)ЃЌетЫЕУївЊЛвЛИіЫФааЫФСаЕФЭМаЮЁЃжДааНсЙћШчЭМ20-5ЫљЪОЁЃ
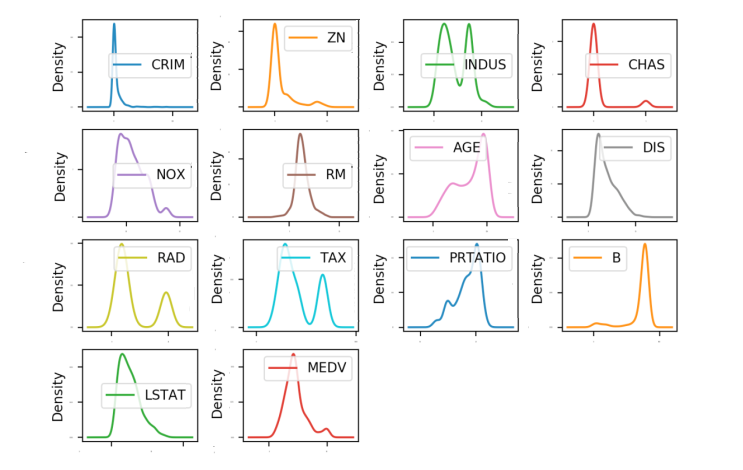
ЭМ20-5
ЭЈЙ§ЯфЯпЭМПЩвдВщПДУПвЛИіЪ§ОнЬиеїЕФзДПіЃЌвВПЩвдКмЗНБуЕиПДГіЪ§ОнЗжВМЕФЦЋЬЌГЬЖШЁЃДњТыШчЯТЃК
#ЯфЯпЭМ
dataset.plot(kind='box', subplots=True, layout=(4,4),
sharex=False, sharey=False, fontsize=8)
pyplot.show()
|
жДааНсЙћШчЭМ20-6ЫљЪОЁЃ
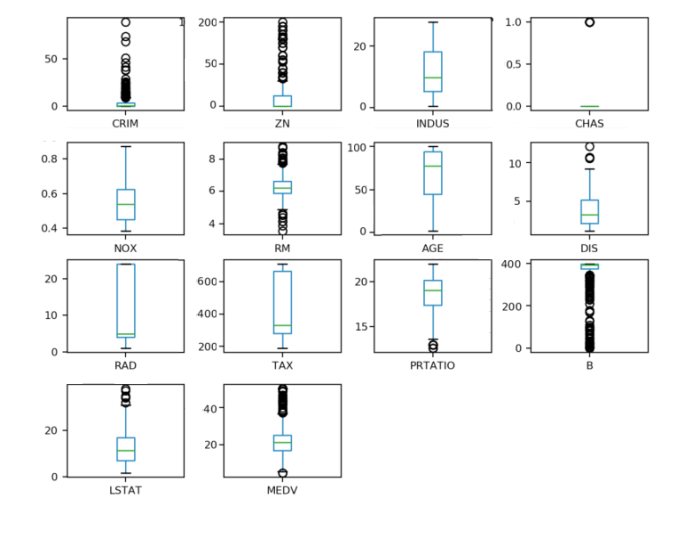
ЭМ20-6
ЖржиЪ§ОнЭМБэ
НгЯТРДРћгУЖржиЪ§ОнЭМБэРДВщПДВЛЭЌЪ§ОнЬиеїжЎМфЕФЯрЛЅгАЯьЙиЯЕЁЃЪзЯШПДвЛЯТЩЂЕуОиеѓЭМЁЃДњТыШчЯТЃК
# ЩЂЕуОиеѓЭМ
scatter_matrix(dataset)
pyplot.show() |
ЭЈЙ§ЩЂЕуОиеѓЭМПЩвдПДЕНЃЌЫфШЛгааЉЪ§ОнЬиеїжЎМфЕФЙиСЊЙиЯЕКмЧПЃЌЕЋЪЧетаЉЪ§ОнЗжВМНсЙЙвВКмКУЁЃМДЪЙВЛЪЧЯпадЗжВМНсЙЙЃЌвВЪЧПЩвдКмЗНБуНјаадЄВтЕФЗжВМНсЙЙЃЌжДааНсЙћШчЭМ20-7ЫљЪОЁЃ
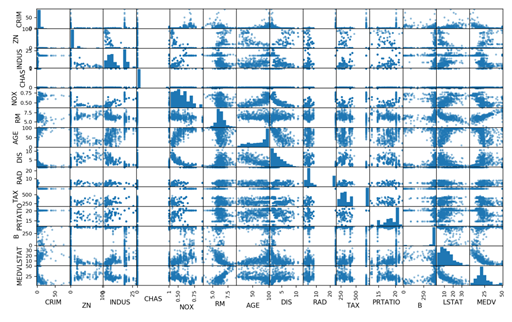
ЭМ20-7
дйПДвЛЯТЪ§ОнЯрЛЅгАЯьЕФЯрЙиОиеѓЭМЁЃДњТыШчЯТЃК
# ЯрЙиОиеѓЭМ
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(dataset.corr(), vmin=-1, vmax=1,
interpolation='none')
fig.colorbar(cax)
ticks = np.arange(0, 14, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show() |
жДааНсЙћШчЭМ20-8ЫљЪОЃЌИљОнЭМР§ПЩвдПДЕНЃЌЪ§ОнЬиеїЪєаджЎМфЕФСНСНЯрЙиадЃЌгааЉЪєаджЎМфЪЧЧПЯрЙиЕФЃЌНЈвщдкКѓајЕФДІРэжавЦГ§етаЉЬиеїЪєадЃЌвдЬсИпЫуЗЈЕФзМШЗЖШЁЃ
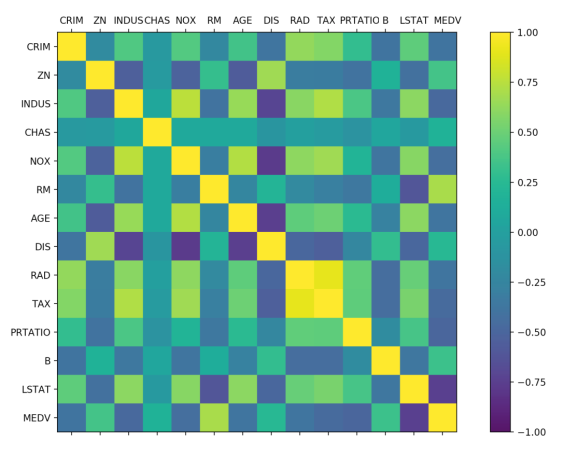
ЭМ20-8
ЫМТЗзмНс
ЭЈЙ§Ъ§ОнЕФЯрЙиадКЭЪ§ОнЕФЗжВМЕШЗЂЯжЃЌЪ§ОнМЏжаЕФЪ§ОнНсЙЙБШНЯИДдгЃЌашвЊПМТЧЖдЪ§ОнНјаазЊЛЛЃЌвдЬсИпФЃаЭЕФзМШЗЖШЁЃПЩвдГЂЪдДгвдЯТМИИіЗНУцЖдЪ§ОнНјааДІРэЃК
ЭЈЙ§ЬиеїбЁдёРДМѕЩйДѓВПЗжЯрЙиадИпЕФЬиеїЁЃ
ЭЈЙ§БъзМЛЏЪ§ОнРДНЕЕЭВЛЭЌЪ§ОнЖШСПЕЅЮЛДјРДЕФгАЯьЁЃ
ЭЈЙ§е§ЬЌЛЏЪ§ОнРДНЕЕЭВЛЭЌЕФЪ§ОнЗжВМНсЙЙЃЌвдЬсИпЫуЗЈЕФзМШЗЖШЁЃ
ПЩвдНјвЛВНВщПДЪ§ОнЕФПЩФмадЗжМЖЃЈРыЩЂЛЏЃЉЃЌЫќПЩвдАяжњЬсИпОіВпЪїЫуЗЈЕФзМШЗЖШЁЃ
ЗжРыЦРЙРЪ§ОнМЏ
ЗжРыГівЛИіЦРЙРЪ§ОнМЏЪЧвЛИіКмКУЕФжївтЃЌетбљПЩвдШЗБЃЗжРыГіЕФЪ§ОнМЏгыбЕСЗФЃаЭЕФЪ§ОнМЏЭъШЋИєРыЃЌгажњгкзюжеХаЖЯКЭБЈИцФЃаЭЕФзМШЗЖШЁЃдкНјааЕНЯюФПЕФзюКѓвЛВНДІРэЪБЃЌЛсЪЙгУетИіЦРЙРЪ§ОнМЏРДШЗШЯФЃаЭЕФзМШЗЖШЁЃетРяЗжРыГі20%ЕФЪ§ОнзїЮЊЦРЙРЪ§ОнМЏЃЌ80%ЕФЪ§ОнзїЮЊбЕСЗЪ§ОнМЏЁЃДњТыШчЯТЃК
# ЗжРыЪ§ОнМЏ
array = dataset.values
X = array[:, 0:13]
Y = array[:, 13]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation =
train_test_split(X, Y,test_size=validation_size,
random_state=seed) |
ЦРЙРЫуЗЈ
ЦРЙРЫуЗЈЁЊЁЊдЪМЪ§Он
ЗжЮіЭъЪ§ОнВЛФмСЂПЬбЁдёГіФФИіЫуЗЈЖдашвЊНтОіЕФЮЪЬтзюгааЇЁЃЮвУЧжБЙлЩЯШЯЮЊЃЌгЩгкВПЗжЪ§ОнЕФЯпадЗжВМЃЌЯпадЛиЙщЫуЗЈКЭЕЏадЭјТчЛиЙщЫуЗЈЖдНтОіЮЪЬтПЩФмБШНЯгааЇЁЃСэЭтЃЌгЩгкЪ§ОнЕФРыЩЂЛЏЃЌЭЈЙ§ОіВпЪїЫуЗЈЛђжЇГжЯђСПЛњЫуЗЈвВаэПЩвдЩњГЩИпзМШЗЖШЕФФЃаЭЁЃЕНетРяЃЌвРШЛВЛЧхГўФФИіЫуЗЈЛсЩњГЩзМШЗЖШзюИпЕФФЃаЭЃЌвђДЫашвЊЩшМЦвЛИіЦРЙРПђМмРДбЁдёКЯЪЪЕФЫуЗЈЁЃЮвУЧВЩгУ10елНЛВцбщжЄРДЗжРыЪ§ОнЃЌЭЈЙ§ОљЗНЮѓВюРДБШНЯЫуЗЈЕФзМШЗЖШЁЃОљЗНЮѓВюдНЧїНќгк0ЃЌЫуЗЈзМШЗЖШдНИпЁЃДњТыШчЯТЃК
# ЦРЙРЫуЗЈ ЁЊЁЊ ЦРЙРБъзМ
num_folds = 10
seed = 7
scoring = 'neg_mean_squared_error' |
ЖддЪМЪ§ОнВЛзіШЮКЮДІРэЃЌЖдЫуЗЈНјаавЛИіЦРЙРЃЌаЮГЩвЛИіЫуЗЈЕФЦРЙРЛљзМЁЃетИіЛљзМжЕЪЧЖдКѓајЫуЗЈИФЩЦгХСгБШНЯЕФЛљзМжЕЁЃЮвУЧбЁдёШ§ИіЯпадЫуЗЈКЭШ§ИіЗЧЯпадЫуЗЈРДНјааБШНЯЁЃ
ЯпадЫуЗЈЃКЯпадЛиЙщЃЈLRЃЉЁЂЬзЫїЛиЙщЃЈLASSOЃЉКЭЕЏадЭјТчЛиЙщЃЈENЃЉЁЃ
ЗЧЯпадЫуЗЈЃКЗжРргыЛиЙщЪїЃЈCARTЃЉЁЂжЇГжЯђСПЛњЃЈSVMЃЉКЭKНќСкЫуЗЈЃЈKNNЃЉЁЃ
ЫуЗЈФЃаЭГѕЪМЛЏЕФДњТыШчЯТЃК
# ЦРЙРЫуЗЈ - baseline
models = {}
models['LR'] = LinearRegression()
models['LASSO'] = Lasso()
models['EN'] = ElasticNet()
models['KNN'] = KNeighborsRegressor()
models['CART'] = DecisionTreeRegressor()
models['SVM'] = SVR() |
ЖдЫљгаЕФЫуЗЈЪЙгУФЌШЯВЮЪ§ЃЌВЂБШНЯЫуЗЈЕФзМШЗЖШЃЌДЫДІБШНЯЕФЪЧОљЗНЮѓВюЕФОљжЕКЭБъзМЗНВюЁЃДњТыШчЯТЃК
# ЦРЙРЫуЗЈ
results = []
for key in models:
kfold = KFold(n_splits=num_folds, random_state=seed)
cv_result = cross_val_score(models[key], X_train,
Y_train, cv=kfold, scoring=scoring)
results.append(cv_result)
print('%s: %f (%f)' % (key, cv_result.mean(),
cv_result.std())) |
ДгжДааНсЙћРДПДЃЌЯпадЛиЙщЃЈLRЃЉОпгазюгХЕФMSEЃЌНгЯТРДЪЧЗжРргыЛиЙщЪї ЃЈCARTЃЉЫуЗЈЁЃжДааНсЙћШчЯТЃК
LR: -21.379856
(9.414264)
LASSO: -26.423561 (11.651110)
EN: -27.502259 (12.305022)
KNN: -41.896488 (13.901688)
CART: -26.608476 (12.250800)
SVM: -85.518342 (31.994798) |
дйВщПДЫљгаЕФ10елНЛВцЗжРыбщжЄЕФНсЙћЁЃДњТыШчЯТЃК
#ЦРЙРЫуЗЈЁЊЁЊЯфЯпЭМ
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show() |
жДааНсЙћШчЭМ20-9ЫљЪОЃЌДгЭМжаПЩвдПДЕНЃЌЯпадЫуЗЈЕФЗжВМБШНЯРрЫЦЃЌВЂЧвKНќСкЫуЗЈЕФНсЙћЗжВМЗЧГЃНєДеЁЃ
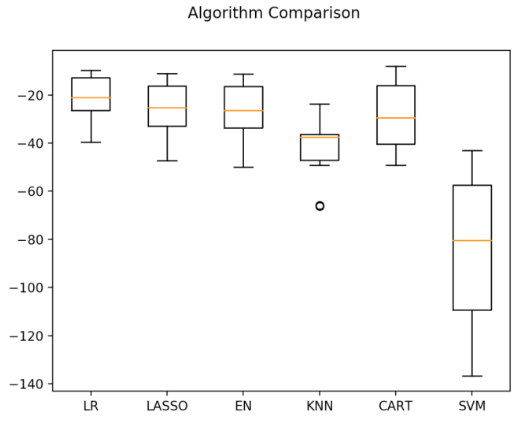
ЭМ20-9
ВЛЭЌЕФЪ§ОнЖШСПЕЅЮЛЃЌвВаэЪЧKНќСкЫуЗЈКЭжЇГжЯђСПЛњЫуЗЈБэЯжВЛМбЕФжївЊдвђЁЃЯТУцНЋЖдЪ§ОнНјаае§ЬЌЛЏДІРэЃЌдйДЮБШНЯЫуЗЈЕФНсЙћЁЃ
ЦРЙРЫуЗЈЁЊЁЊе§ЬЌЛЏЪ§Он
дкетРяВТВтвВаэвђЮЊдЪМЪ§ОнжаВЛЭЌЬиеїЪєадЕФЖШСПЕЅЮЛВЛвЛбљЃЌЕМжТгаЕФЫуЗЈЕФНсЙћВЛЪЧКмКУЁЃНгЯТРДЭЈЙ§ЖдЪ§ОнНјаае§ЬЌЛЏЃЌдйДЮЦРЙРетаЉЫуЗЈЁЃдкетРяЖдбЕСЗЪ§ОнМЏНјааЪ§ОнзЊЛЛДІРэЃЌНЋЫљгаЕФЪ§ОнЬиеїжЕзЊЛЏГЩЁА0ЁБЮЊжаЮЛжЕЁЂБъзМВюЮЊЁА1ЁБЕФЪ§ОнЁЃЖдЪ§Оне§ЬЌЛЏЪБЃЌЮЊСЫЗРжЙЪ§ОнаЙТЖЃЌВЩгУPipelineРДе§ЬЌЛЏЪ§ОнКЭЖдФЃаЭНјааЦРЙРЁЃЮЊСЫгыЧАУцЕФНсЙћНјааБШНЯЃЌДЫДІВЩгУЯрЭЌЕФЦРЙРПђМмРДЦРЙРЫуЗЈФЃаЭЁЃДњТыШчЯТЃК
# ЦРЙРЫуЗЈЁЊЁЊе§ЬЌЛЏЪ§Он
pipelines = {}
pipelines['ScalerLR'] = Pipeline([('Scaler', StandardScaler()),
('LR', LinearRegression())])
pipelines['ScalerLASSO'] = Pipeline([('Scaler',
StandardScaler()), ('LASSO', Lasso())])
pipelines['ScalerEN'] = Pipeline([('Scaler',
StandardScaler()), ('EN', ElasticNet())])
pipelines['ScalerKNN'] = Pipeline([('Scaler',
StandardScaler()), ('KNN', KNeighborsRegressor())])
pipelines['ScalerCART'] = Pipeline([('Scaler',
StandardScaler()), ('CART', DecisionTreeRegressor())])
pipelines['ScalerSVM'] = Pipeline([('Scaler',
StandardScaler()), ('SVM', SVR())])
results = []
for key in pipelines:
kfold = KFold(n_splits=num_folds, random_state=seed)
cv_result = cross_val_score(pipelines[key], X_train,
Y_train, cv=kfold, scoring=scoring)
results.append(cv_result)
print('%s: %f (%f)' % (key, cv_result.mean(),
cv_result.std())) |
жДааКѓЗЂЯжKНќСкЫуЗЈОпгазюгХЕФMSEЁЃжДааНсЙћШчЯТЃК
ScalerLR: -21.379856
(9.414264)
ScalerLASSO: -26.607314 (8.978761)
ScalerEN: -27.932372 (10.587490)
ScalerKNN: -20.107620 (12.376949)
ScalerCART: -26.978716 (12.164366)
ScalerSVM: -29.633086 (17.009186) |
НгЯТРДПДвЛЯТЫљгаЕФ10елНЛВцЗжРыбщжЄЕФНсЙћЁЃДњТыШчЯТЃК
#ЦРЙРЫуЗЈЁЊЁЊЯфЯпЭМ
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show() |
жДааНсЙћЃЌЩњГЩЕФЯфЯпЭМШчЭМ20-10ЫљЪОЃЌПЩвдПДЕНKНќСкЫуЗЈОпгазюгХЕФMSEКЭзюНєДеЕФЪ§ОнЗжВМЁЃ
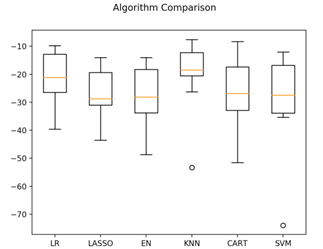
ЕїВЮИФЩЦЫуЗЈ
ФПЧАРДПДЃЌKНќСкЫуЗЈЖдзіЙ§Ъ§ОнзЊЛЛЕФЪ§ОнМЏгаКмКУЕФНсЙћЃЌЕЋЪЧЪЧЗёПЩвдНјвЛВНЖдНсЙћзівЛаЉгХЛЏФиЃПKНќСкЫуЗЈЕФФЌШЯВЮЪ§НќСкИіЪ§ЃЈn_neighborsЃЉЪЧ5ЃЌЯТУцЭЈЙ§ЭјИёЫбЫїЫуЗЈРДгХЛЏВЮЪ§ЁЃДњТыШчЯТЃК
# ЕїВЮИФЩЦЫуЗЈЁЊЁЊKNN
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_neighbors': [1, 3, 5, 7, 9, 11,
13, 15, 17, 19, 21]}
model = KNeighborsRegressor()
kfold = KFold(n_splits=num_folds, random_state=seed)
grid = GridSearchCV(estimator=model,
param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)
print('зюгХЃК%s ЪЙгУ%s' % (grid_result.best_score_,
grid_result.best_params_))
cv_results =
zip(grid_result.cv_results_['mean_test_score'],
grid_result.cv_results_['std_test_score'],
grid_result.cv_results_['params'])
for mean, std, param in cv_results:
print('%f (%f) with %r' % (mean, std, param)) |
зюгХНсЙћЁЊЁЊKНќСкЫуЗЈЕФФЌШЯВЮЪ§НќСкИіЪ§ЃЈn_neighborsЃЉЪЧ3ЁЃжДааНсЙћШчЯТЃК
зюгХЃК-18.1721369637
ЪЙгУ{'n_neighbors': 3}
-20.208663 (15.029652) with {'n_neighbors': 1}
-18.172137 (12.950570) with {'n_neighbors': 3}
-20.131163 (12.203697) with {'n_neighbors': 5}
-20.575845 (12.345886) with {'n_neighbors': 7}
-20.368264 (11.621738) with {'n_neighbors': 9}
-21.009204 (11.610012) with {'n_neighbors': 11}
-21.151809 (11.943318) with {'n_neighbors': 13}
-21.557400 (11.536339) with {'n_neighbors': 15}
-22.789938 (11.566861) with {'n_neighbors': 17}
-23.871873 (11.340389) with {'n_neighbors': 19}
-24.361362 (11.914786) with {'n_neighbors': 21} |
МЏГЩЫуЗЈ
Г§ЕїВЮжЎЭтЃЌЬсИпФЃаЭзМШЗЖШЕФЗНЗЈЪЧЪЙгУМЏГЩЫуЗЈЁЃЯТУцЛсЖдБэЯжБШНЯКУЕФЯпадЛиЙщЁЂKНќСкЁЂЗжРргыЛиЙщЪїЫуЗЈНјааМЏГЩЃЌРДПДПДЫуЗЈФмЗёЬсИпЁЃ
зАДќЫуЗЈЃКЫцЛњЩСжЃЈRFЃЉКЭМЋЖЫЫцЛњЪїЃЈETЃЉЁЃ
ЬсЩ§ЫуЗЈЃКAdaBoostЃЈABЃЉКЭЫцЛњЬнЖШЩЯЩ§ЃЈGBMЃЉЁЃ
вРШЛВЩгУКЭЧАУцЭЌбљЕФЦРЙРПђМмКЭе§ЬЌЛЏжЎКѓЕФЪ§ОнРДЗжЮіЯрЙиЕФЫуЗЈЁЃДњТыШчЯТЃК
# МЏГЩЫуЗЈ
ensembles = {}
ensembles['ScaledAB'] = Pipeline([('Scaler',
StandardScaler()), ('AB', AdaBoostRegressor())])
ensembles['ScaledAB-KNN'] = Pipeline([('Scaler',
StandardScaler()), ('ABKNN', AdaBoostRegressor
(base_estimator= KNeighborsRegressor(n_neighbors=3)))])
ensembles['ScaledAB-LR'] = Pipeline([('Scaler',
StandardScaler()), ('ABLR',
AdaBoostRegressor(LinearRegression()))])
ensembles['ScaledRFR'] = Pipeline([('Scaler',
StandardScaler()), ('RFR', RandomForestRegressor())])
ensembles['ScaledETR'] = Pipeline([('Scaler',
StandardScaler()), ('ETR', ExtraTreesRegressor())])
ensembles['ScaledGBR'] = Pipeline([('Scaler',
StandardScaler()), ('RBR', GradientBoostingRegressor())])
results = []
for key in ensembles:
kfold = KFold(n_splits=num_folds, random_state=seed)
cv_result = cross_val_score(ensembles[key],
X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_result)
print('%s: %f (%f)' % (key, cv_result.mean(),
cv_result.std())) |
гыЧАУцЕФЯпадЫуЗЈКЭЗЧЯпадЫуЗЈЯрБШЃЌетДЮЕФзМШЗЖШЖМгаСЫНЯДѓЕФЬсИпЁЃжДааНсЙћШчЯТЃК
ScaledAB: -15.244803
(6.272186)
ScaledAB-KNN: -15.794844 (10.565933)
ScaledAB-LR: -24.108881 (10.165026)
ScaledRFR: -13.279674 (6.724465)
ScaledETR: -10.464980 (5.476443)
ScaledGBR: -10.256544 (4.605660) |
НгЯТРДЭЈЙ§ЯфЯпЭМПДвЛЯТМЏГЩЫуЗЈдк10елНЛВцбщжЄжаОљЗНЮѓВюЕФЗжВМзДПіЁЃДњТыШчЯТЃК
# МЏГЩЫуЗЈЁЊЁЊЯфЯпЭМ
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(ensembles.keys())
pyplot.show() |
жДааНсЙћШчЭМ20-11ЫљЪОЃЌЫцЛњЬнЖШЩЯЩ§ЫуЗЈКЭМЋЖЫЫцЛњЪїЫуЗЈОпгаНЯИпЕФжаЮЛжЕКЭЗжВМзДПіЁЃ
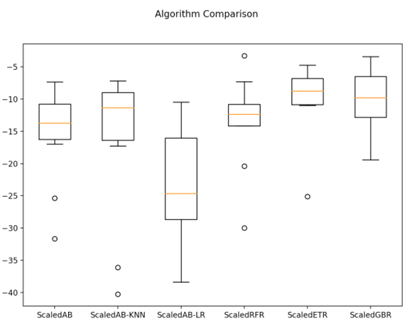
ЭМ20-11
МЏГЩЫуЗЈЕїВЮ
МЏГЩЫуЗЈЖМгавЛИіВЮЪ§n_estimatorsЃЌетЪЧвЛИіКмКУЕФПЩвдгУРДЕїећЕФВЮЪ§ЁЃЖдгкМЏГЩВЮЪ§РДЫЕЃЌn_estimatorsЛсДјРДИќзМШЗЕФНсЙћЃЌЕБШЛетвВгавЛЖЈЕФЯоЖШЁЃЯТУцЖдЫцЛњЬнЖШЩЯЩ§ЃЈGBMЃЉКЭМЋЖЫЫцЛњЪїЃЈETЃЉЫуЗЈНјааЕїВЮЃЌдйДЮБШНЯетСНИіЫуЗЈФЃаЭЕФзМШЗЖШЃЌРДШЗЖЈзюжеЕФЫуЗЈФЃаЭЁЃДњТыШчЯТЃК
# МЏГЩЫуЗЈGBMЁЊЁЊЕїВЮ
caler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_estimators': [10, 50, 100, 200,
300, 400, 500, 600, 700, 800, 900]}
model = GradientBoostingRegressor()
kfold = KFold(n_splits=num_folds, random_state=seed)
grid = GridSearchCV(estimator=model,
param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)
print('зюгХЃК%s ЪЙгУ%s' % (grid_result.best_score_,
grid_result.best_params_))
# МЏГЩЫуЗЈETЁЊЁЊЕїВЮ
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_estimators': [5, 10, 20, 30,
40, 50, 60, 70, 80, 90, 100]}
model = ExtraTreesRegressor()
kfold = KFold(n_splits=num_folds, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid,
scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)
print('зюгХЃК%s ЪЙгУ%s' % (grid_result.best_score_,
grid_result.best_params_)) |
ЖдгкЫцЛњЬнЖШЩЯЩ§ЃЈGBMЃЉЫуЗЈРДЫЕЃЌзюгХЕФn_estimatorsЪЧ500ЃЛЖдгкМЋЖЫЫцЛњЪїЃЈETЃЉЫуЗЈРДЫЕЃЌзюгХЕФn_estimatorsЪЧ80ЁЃжДааНсЙћЃЌМЋЖЫЫцЛњЪїЃЈETЃЉЫуЗЈТдгХгкЫцЛњЬнЖШЩЯЩ§ЃЈGBMЃЉЫуЗЈЃЌвђДЫВЩгУМЋЖЫЫцЛњЪїЃЈETЃЉЫуЗЈРДбЕСЗзюжеЕФФЃаЭЁЃжДааНсЙћШчЯТЃК
зюгХЃК-9.3078229754
ЪЙгУ{'n_estimators': 500}
зюгХЃК-8.99113433246 ЪЙгУ{'n_estimators': 80} |
вВаэашвЊжДааЖрДЮетИіЙ§ГЬВХФмевЕНзюгХВЮЪ§ЁЃетРягавЛИіММЧЩЃЌЕБзюгХВЮЪ§ЪЧparam_gridЕФБпНчжЕЪБЃЌгаБивЊЕїећparam_gridНјааЯТвЛДЮЕїВЮЁЃ
ШЗЖЈзюжеФЃаЭ
ЮвУЧвбОШЗЖЈСЫЪЙгУМЋЖЫЫцЛњЪїЃЈETЃЉЫуЗЈРДЩњГЩФЃаЭЃЌЯТУцОЭЖдИУЫуЗЈНјаабЕСЗКЭЩњГЩФЃаЭЃЌВЂМЦЫуФЃаЭЕФзМШЗЖШЁЃДњТыШчЯТЃК
#бЕСЗФЃаЭ
caler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
gbr = ExtraTreesRegressor(n_estimators=80)
gbr.fit(X=rescaledX, y=Y_train) |
дйЭЈЙ§ЦРЙРЪ§ОнМЏРДЦРЙРЫуЗЈЕФзМШЗЖШЁЃ
# ЦРЙРЫуЗЈФЃаЭ
rescaledX_validation = scaler.transform(X_validation)
predictions = gbr.predict(rescaledX_validation)
print(mean_squared_error(Y_validation, predictions)) |
жДааНсЙћШчЯТЃК
змНс
БОЯюФПЪЕР§ДгЮЪЬтЖЈвхПЊЪМЃЌжБЕНзюКѓЕФФЃаЭЩњГЩЮЊжЙЃЌЭъГЩСЫвЛИіЭъећЕФЛњЦїбЇЯАЯюФПЁЃЭЈЙ§етИіЯюФПЃЌРэНтСЫЩЯвЛеТжаНщЩмЕФЛњЦїбЇЯАЯюФПЕФФЃАхЃЌвдМАећИіЛњЦїбЇЯАФЃаЭНЈСЂЕФСїГЬЁЃНгЯТРДЛсНщЩмвЛИіЛњЦїбЇЯАЕФЖўЗжРрЮЪЬтЃЌвдНјвЛВНМгЩюЖдетИіФЃАхЕФРэНтЁЃ
|









