| БрМЭЦМі: |
| РДдДгкcnblogsЃЌЮФеТвбДњТыЕФаЮЪНеЙПЊЃЌжївЊНтОівдЯТЮЪЬтЃЌИХФюЃЌpy2ЕФstringБрТыЃЌpy3ЕФstringБрТыЃЌЮФМўДгДХХЬЕНФкДцЕФБрТы(******)ЕШЕШЁЃ |
|
ЫЕЦ№pythonБрТыЃЌецЪЧОфОфаФЫсЁЃЫуЦ№РДЃЌЗДИДелЬкСНИіРДдТСЫЁЃЭђавЕФЪЧЃЌжегкЪсРэЧхГўСЫЁЃзїЮЊвЛИіЙВВњжївхепЃЌвЛЖЈвЊЗжЯэИјДѓМвЁЃШчЙћФуЛЙдквђЮЊБрТыЖјЭЗЭДЃЌФЧУДИЯНєИњзХЮвдлУЧвЛЦ№РДНвПЊpyБрТыЕФецЯрАЩЃЁ

вЛ ЪВУДЪЧБрТыЃП
ЛљБОИХФюКмМђЕЅЁЃЪзЯШЃЌЮвУЧДгвЛЖЮаХЯЂМДЯћЯЂЫЕЦ№ЃЌЯћЯЂвдШЫРрПЩвдРэНтЁЂвзЖЎЕФБэЪОДцдкЁЃЮвДђЫуНЋетжжБэЪОГЦЮЊЁАУїЮФЁБЃЈplain
textЃЉЁЃЖдгкЫЕгЂгяЕФШЫЃЌжНеХЩЯДђгЁЕФЛђЦСФЛЩЯЯдЪОЕФгЂЮФЕЅДЪЖМЫузїУїЮФЁЃ
ЦфДЮЃЌЮвУЧашвЊФмНЋУїЮФБэЪОЕФЯћЯЂзЊГЩСэЭтФГжжБэЪОЃЌЮвУЧЛЙашвЊФмНЋБрТыЮФБОзЊЛиГЩУїЮФЁЃДгУїЮФЕНБрТыЮФБОЕФзЊЛЛГЦЮЊЁАБрТыЁБЃЌДгБрТыЮФБОгжзЊЛиГЩУїЮФдђЮЊЁАНтТыЁБЁЃ
БрТыЮЪЬтЪЧИіДѓЮЪЬтЃЌШчЙћВЛГЙЕзНтОіЃЌЫќОЭЛсЯёвўВидкДдСжжаЕФаЁЩпЃЌЪБВЛЪБЕивЇФувЛПкЁЃ
ФЧУДЕНЕзЪВУДЪЧБрТыФиЃП
//ASCII
МЧзЁвЛОфЛАЃКМЦЫуЛњжаЕФЫљгаЪ§ОнЃЌВЛТлЪЧЮФзжЁЂЭМЦЌЁЂЪгЦЕЁЂЛЙЪЧвєЦЕЮФМўЃЌБОжЪЩЯзюжеЖМЪЧАДееРрЫЦ 01010101
ЕФЖўНјжЦДцДЂЕФЁЃ
дйЫЕМђЕЅЕуЃЌМЦЫуЛњжЛЖЎЖўНјжЦЪ§зжЃЁ
ЫљвдЃЌФПЕФУїШЗСЫЃКШчКЮНЋЮвУЧФмЪЖБ№ЕФЗћКХЮЈвЛЕФгывЛзщЖўНјжЦЪ§зжЖдгІЩЯЃПгкЪЧУРРћМсЕФЭЌжОЯыЕНЭЈЙ§вЛИіЕчЦНЕФИпЕЭзДЬЌРДДњжИ0Лђ1ЃЌ
АЫИіЕчЦНзіЮЊвЛзщОЭПЩвдБэЪОГі
256жжВЛЭЌзДЬЌЃЌУПжжзДЬЌОЭЮЈвЛЖдгІвЛИізжЗћЃЌБШШчA--->00010001,ЖјгЂЮФжЛга26ИізжЗћЃЌЫуЩЯвЛаЉЬиЪтзжЗћКЭЪ§зжЃЌ128ИізДЬЌвВЙЛ
гУСЫЃЛУПИіЕчЦНГЦЮЊвЛИіБШЬиЮЊЃЌдМЖЈ8ИіБШЬиЮЛЙЙГЩвЛИізжНкЃЌетбљМЦЫуЛњОЭПЩвдгУ127ИіВЛЭЌзжНкРДДцДЂгЂгяЕФЮФзжСЫЁЃетОЭЪЧASCIIБрТыЁЃ
РЉеЙANSIБрТы
ИеВХЫЕСЫЃЌзюПЊЪМЃЌвЛИізжНкгаАЫЮЛЃЌЕЋЪЧзюИпЮЛУЛгУЩЯЃЌФЌШЯЮЊ0ЃЛКѓРДЮЊСЫМЦЫуЛњвВПЩвдБэЪОРЖЁЮФЃЌОЭНЋзюКѓвЛЮЛвВгУЩЯСЫЃЌ
Дг128ЕН255ЕФзжЗћМЏЖдгІРЖЁЮФРВЁЃжСДЫЃЌвЛИізжНкОЭгУТњСЫЃЁ
//GB2312
МЦЫуЛњЦЏбѓЙ§КЃРДЕНжаЙњКѓЃЌЮЪЬтРДСЫЃЌМЦЫуЛњВЛШЯЪЖжаЮФЃЌЕБШЛвВУЛЗЈЯдЪОжаЮФЃЛЖјЧввЛИізжНкЫљгазДЬЌЖМБЛеМТњСЫЃЌЭђЖёЕФЕлЙњжївхЭі
ЮвжЎаФВЛЫРАЁЃЁЮвЕГвВЪЧАєЃЌздСІИќЩњЃЌздМКжиаДвЛеХБэЃЌжБНгЩњУЭЕиНЋРЉеЙЕФЕкАЫЮЛЖдгІРЖЁЮФШЋВПЩОЕєЃЌЙцЖЈвЛИіаЁгк127ЕФзжЗћЕФвт
вхгыдРДЯрЭЌЃЌЕЋСНИіДѓгк127ЕФзжЗћСЌдквЛЦ№ЪБЃЌОЭБэЪОвЛИіККзжЃЌЧАУцЕФвЛИізжНкЃЈЫћГЦжЎЮЊИпзжНкЃЉДг0xA1гУЕН0xF7ЃЌКѓУцвЛИізжНк
ЃЈЕЭзжНкЃЉДг0xA1ЕН0xFEЃЌетбљЮвУЧОЭПЩвдзщКЯГіДѓдМ7000ЖрИіМђЬхККзжСЫЃЛетжжККзжЗНАИНазі ЁАGB2312ЁБЁЃGB2312
ЪЧЖд ASCII ЕФжаЮФРЉеЙЁЃ
//GBK КЭ GB18030БрТы
ЕЋЪЧККзжЬЋЖрСЫЃЌGB2312вВВЛЙЛгУЃЌгкЪЧЙцЖЈЃКжЛвЊЕквЛИізжНкЪЧДѓгк127ОЭЙЬЖЈБэЪОетЪЧвЛИіККзжЕФПЊЪМЃЌВЛЙмКѓУцИњЕФЪЧВЛЪЧРЉеЙзжЗћМЏРяЕФ
ФкШнЁЃНсЙћРЉеЙжЎКѓЕФБрТыЗНАИБЛГЦЮЊ GBK БъзМЃЌGBK АќРЈСЫ GB2312 ЕФЫљгаФкШнЃЌЭЌЪБгждіМгСЫНќ20000ИіаТЕФККзжЃЈАќРЈЗБЬхзжЃЉКЭЗћКХЁЃ
//UNICODEБрТыЃК
КмЖрЦфЫќЙњМвЖМИуГіздМКЕФБрТыБъзМЃЌБЫДЫМфШДЯрЛЅВЛжЇГжЁЃетОЭДјРДСЫКмЖрЮЪЬтЁЃгкЪЧЃЌЙњМЪБъЫЛЏзщжЏЮЊСЫЭГвЛБрТыЃКЬсГіСЫБъзМБрТызМ
дђЃКUNICODE ЁЃ
UNICODEЪЧгУСНИізжНкРДБэЪОЮЊвЛИізжЗћЃЌЫќзмЙВПЩвдзщКЯГі65535ВЛЭЌЕФзжЗћЃЌетзувдИВИЧЪРНчЩЯЫљгаЗћКХЃЈАќРЈМзЙЧЮФЃЉ
//utf8:
unicodeЖМвЛЭГЬьЯТСЫЃЌЮЊЪВУДЛЙвЊгавЛИіutf8ЕФБрТыФиЃП
ДѓМвЯыЃЌЖдгкгЂЮФЪРНчЕФШЫУЧРДНВЃЌвЛИізжНкЭъШЋЙЛСЫЃЌБШШчвЊДцДЂA,БОРД00010001ОЭПЩвдСЫЃЌЯждкГдЩЯСЫunicodeЕФДѓЙјЗЙЃЌ
ЕУгУСНИізжНкЃК00000000 00010001ВХааЃЌРЫЗбЬЋбЯжиЃЁ
ЛљгкДЫЃЌУРРћМсЕФПЦбЇМвУЧЬсГіСЫЬьВХЕФЯыЗЈЃКutf8.
UTF-8ЃЈ8-bit Unicode Transformation FormatЃЉЪЧвЛжжеыЖдUnicodeЕФПЩБфГЄЖШзжЗћБрТыЃЌЫќПЩвдЪЙгУ1~4ИізжНкБэЪОвЛИіЗћКХЃЌИљОн
ВЛЭЌЕФЗћКХЖјБфЛЏзжНкГЄЖШЃЌЕБзжЗћдкASCIIТыЕФЗЖЮЇЪБЃЌОЭгУвЛИізжНкБэЪОЃЌЫљвдЪЧМцШнASCIIБрТыЕФЁЃ
етбљЯджјЕФКУДІЪЧЃЌЫфШЛдкЮвУЧФкДцжаЕФЪ§ОнЖМЪЧunicodeЃЌЕЋЕБЪ§ОнвЊБЃДцЕНДХХЬЛђепгУгкЭјТчДЋЪфЪБЃЌжБНгЪЙгУunicodeОЭдЖВЛШчutf8ЪЁПеМфРВЃЁ
етвВЪЧЮЊЪВУДutf8ЪЧЮвУЧЕФЭЦМіБрТыЗНЪНЁЃ
Unicodeгыutf8ЕФЙиЯЕЃК
вЛбдвдБЮжЎЃКUnicodeЪЧФкДцБрТыБэЪОЗНАИЃЈЪЧЙцЗЖЃЉЃЌЖјUTFЪЧШчКЮБЃДцКЭДЋЪфUnicodeЕФЗНАИЃЈЪЧЪЕЯжЃЉетвВЪЧUTFгыUnicodeЕФЧјБ№ЁЃ
ВЙГфЃКutf8ЪЧШчКЮНкдМгВХЬКЭСїСПЕФ
ФуПДЕНЕФunicodeзжЗћМЏЪЧетбљЕФБрТыБэЃК
I 0049
' 0027
m 006d
0020
дЗ 82d1
ъЛ 660a |
УПвЛИізжЗћЖдгІвЛИіЪЎСљНјжЦЪ§зжЁЃ
МЦЫуЛњжЛЖЎЖўНјжЦЃЌвђДЫЃЌбЯИёАДееunicodeЕФЗНЪН(UCS-2)ЃЌгІИУетбљДцДЂЃК
I 00000000 01001001
' 00000000 00100111
m 00000000 01101101
00000000 00100000
дЗ 10000010 11010001
ъЛ 01100110 00001010 |
етИізжЗћДЎзмЙВеМгУСЫ12ИізжНкЃЌЕЋЪЧЖдБШжагЂЮФЕФЖўНјжЦТыЃЌПЩвдЗЂЯжЃЌгЂЮФЧА9ЮЛЖМЪЧ0ЃЁРЫЗбАЁЃЌРЫЗбгВХЬЃЌРЫЗбСїСПЁЃдѕУДАьЃПUTF8:
I 01001001
' 00100111
m 01101101
00100000
дЗ 11101000 10001011 10010001
ъЛ 11100110 10011000 10001010 |
utf8гУСЫ10ИізжНкЃЌЖдБШunicodeЃЌЩйСЫСНИіЃЌвђЮЊЮвУЧЕФГЬађгЂЮФЛсдЖЖргкжаЮФЃЌЫљвдПеМфЛсЬсИпКмЖрЃЁ
МЧзЁЃКвЛЧаЖМЪЧЮЊСЫНкЪЁФуЕФгВХЬКЭСїСПЁЃЁЁЁЁ
Жў py2ЕФstringБрТы
дкpy2жаЃЌгаСНжжзжЗћДЎРраЭЃКstrРраЭКЭunicodeРраЭЃЛзЂвтЃЌетНіНіЪЧСНИіУћзжЃЌpythonЖЈвхЕФСНИіУћзжЃЌЙиМќЪЧетСНжжЪ§ОнРраЭдкГЬађдЫааЪБДцдкФкДцЕижЗЕФЪЧЪВУДЃП
ЮвУЧРДПДвЛЯТЃК
#coding:utf8
s1='дЗ'
print type(s1) # <type 'str'>
print repr(s1) #'\xe8\x8b\x91
s2=u'дЗ'
print type(s2) # <type 'unicode'>
print repr(s2) # u'\u82d1' |
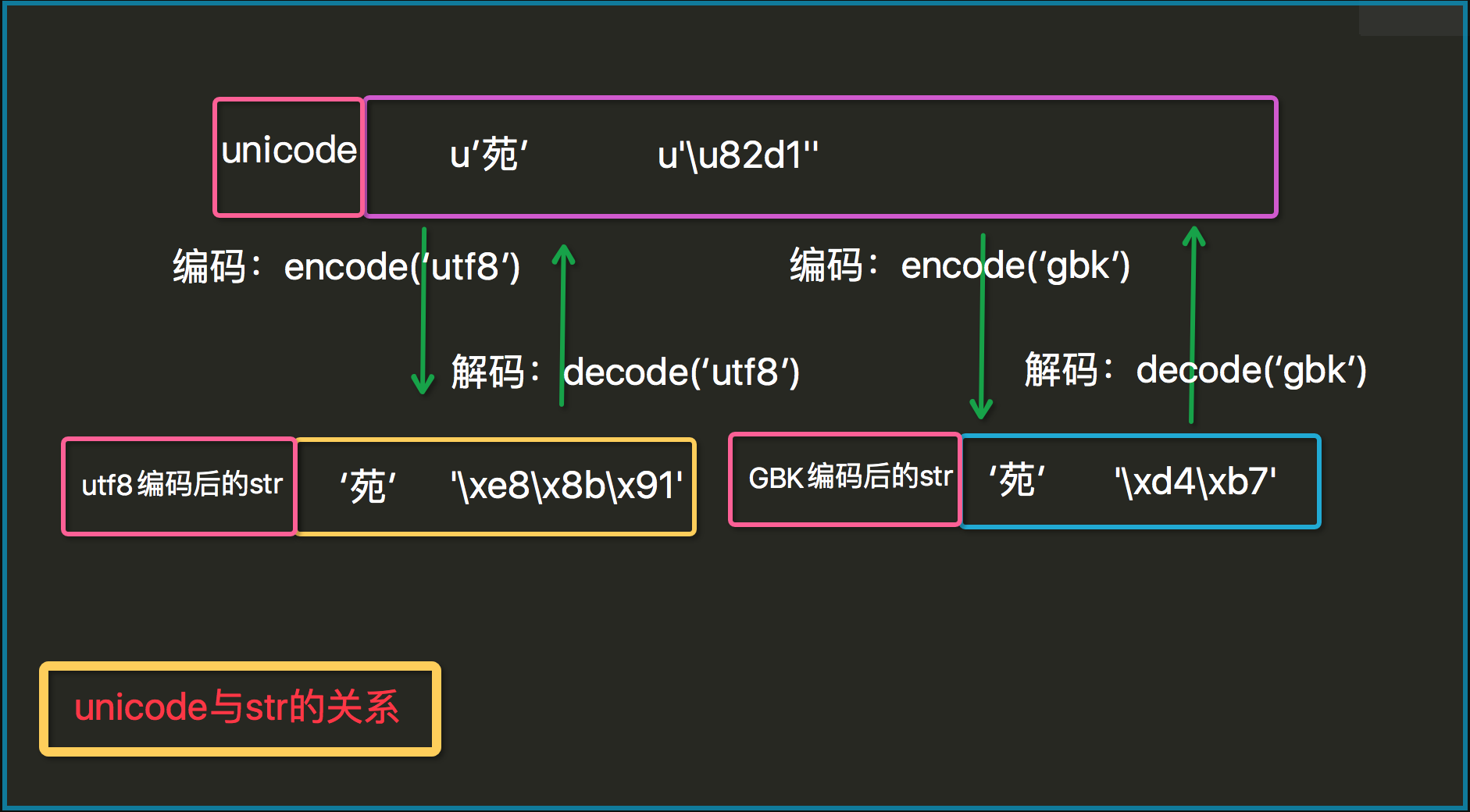
ФкжУКЏЪ§reprПЩвдАяЮвУЧдкетРяЯдЪОДцДЂФкШнЁЃдРДЃЌstrКЭunicodeЗжБ№ДцЕФЪЧзжНкЪ§ОнКЭunicodeЪ§ОнЃЛФЧУДСНжжЪ§ОнжЎМфЪЧЪВУДЙиаФФиЃПШчКЮзЊЛЛФи?етРяОЭЩцМАЕНБрТы(encode)КЭНтТы(decode)СЫ
s1=u'дЗ'
print repr(s1) #u'\u82d1'
b=s1.encode('utf8')
print b
print type(b) #<type 'str'>
print repr(b) #'\xe8\x8b\x91'
s2='дЗъЛ'
u=s2.decode('utf8')
print u # дЗъЛ
print type(u) # <type 'unicode'>
print repr(u) # u'\u82d1\u660a'
#зЂвт
u2=s2.decode('gbk')
print u2 #шц
print len('дЗъЛ') #6 |
ЮоТлЪЧutf8ЛЙЪЧgbkЖМжЛЪЧвЛжжБрТыЙцдђЃЌвЛжжАбunicodeЪ§ОнБрТыГЩзжНкЪ§ОнЕФЙцдђЃЌЫљвдutf8БрТыЕФзжНквЛЖЈвЊгУutf8ЕФЙцдђНтТыЃЌЗёдђОЭЛсГіЯжТвТыЛђепБЈДэЕФЧщПіЁЃ
py2БрТыЕФЬиЩЋЃК
#coding:utf8
print 'дЗъЛ' # дЗъЛ
print repr('дЗъЛ')#'\xe8\x8b\x91\xe6\x98\x8a'
print (u"hello"+"yuan")
#print (u'дЗъЛ'+'зюЫЇ') #UnicodeDecodeError: 'ascii'
codec can't decode byte 0xe6
# in position 0: ordinal not in range(128) |
Python 2 ЧФЧФбкИЧЕєСЫ byte ЕН unicode ЕФзЊЛЛЃЌжЛвЊЪ§ОнШЋВПЪЧ ASCII ЕФЛАЃЌЫљгаЕФзЊЛЛЖМЪЧе§ШЗЕФЃЌвЛЕЉвЛИіЗЧ
ASCII зжЗћЭЕЭЕНјШыФуЕФГЬађЃЌФЧУДФЌШЯЕФНтТыНЋЛсЪЇаЇЃЌДгЖјдьГЩ UnicodeDecodeError
ЕФДэЮѓЁЃpy2БрТыШУГЬађдкДІРэ ASCII ЕФЪБКђИќМгМђЕЅЁЃФуИДГіЕФДњМлОЭЪЧдкДІРэЗЧ ASCII ЕФЪБКђНЋЛсЪЇАмЁЃ
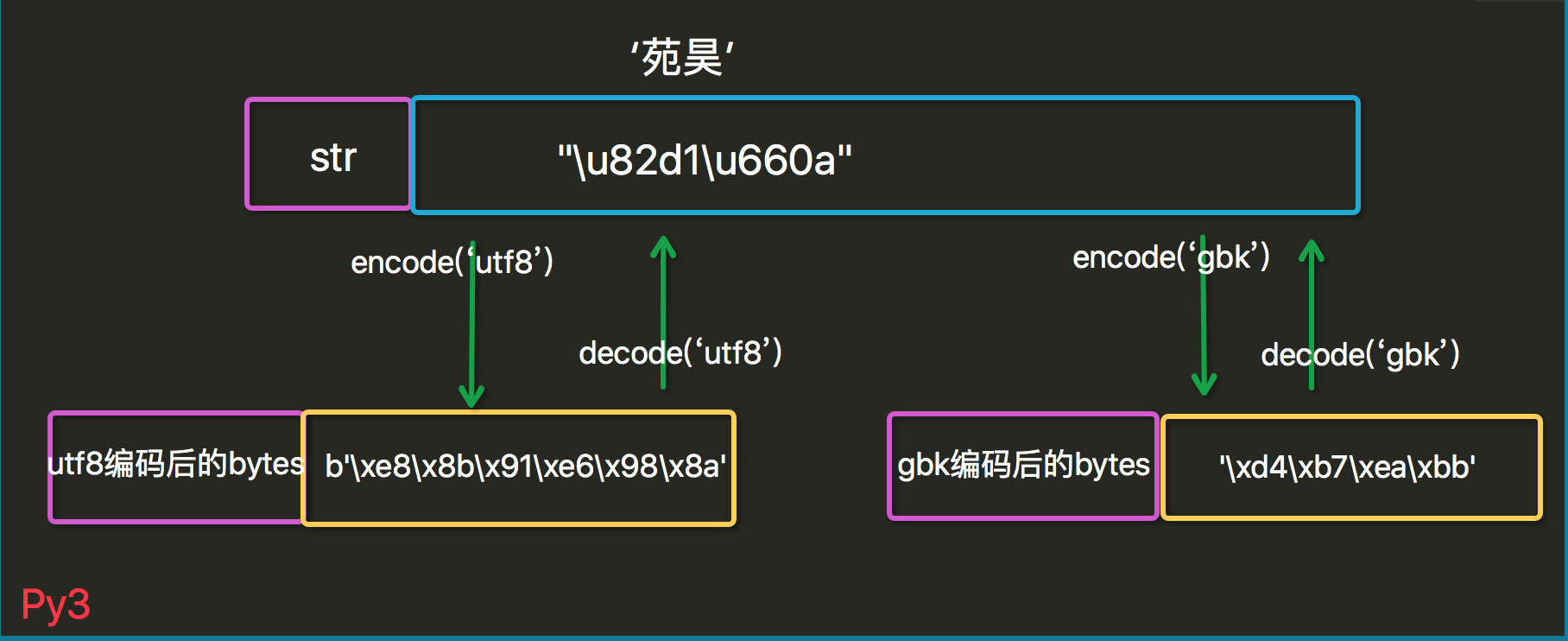
Ш§ py3ЕФstringБрТы
python3 renamed the unicode type to str ,the old
str type has been replaced by bytes.
py3вВгаСНжжЪ§ОнРраЭЃКstrКЭbytesЃЛ strРраЭДцunicodeЪ§ОнЃЌbytseРраЭДцbytesЪ§ОнЃЌгыpy2БШжЛЪЧЛЛСЫвЛЯТУћзжЖјвбЁЃ
| import json
s='дЗъЛ'
print(type(s)) #<class 'str'>
print(json.dumps(s)) # "\u82d1\u660a"
b=s.encode('utf8')
print(type(b)) # <class 'bytes'>
print(b) # b'\xe8\x8b\x91\xe6\x98\x8a'
u=b.decode('utf8')
print(type(u)) #<class 'str'>
print(u) #дЗъЛ
print(json.dumps(u)) #"\u82d1\u660a"
print(len('дЗъЛ')) # 2
|
py3ЕФБрТыембЇЃК
Python 3зюживЊЕФаТЬиадДѓИХвЊЫуЪЧЖдЮФБОКЭЖўНјжЦЪ§ОнзїСЫИќЮЊЧхЮњЕФЧјЗжЃЌВЛдйЛсЖдbytesзжНкДЎНјааздЖЏНтТыЁЃЮФБОзмЪЧUnicodeЃЌгЩstrРраЭБэЪОЃЌЖўНјжЦЪ§ОндђгЩbytesРраЭБэЪОЁЃPython
3ВЛЛсвдШЮвтвўЪНЕФЗНЪНЛьгУstrКЭbytesЃЌе§ЪЧетЪЙЕУСНепЕФЧјЗжЬиБ№ЧхЮњЁЃФуВЛФмЦДНгзжЗћДЎКЭзжНкАќЃЌвВЮоЗЈдкзжНкАќРяЫбЫїзжЗћДЎЃЈЗДжЎврШЛЃЉЃЌвВВЛФмНЋзжЗћДЎДЋШыВЮЪ§ЮЊзжНкАќЕФКЏЪ§ЃЈЗДжЎврШЛЃЉЁЃ
#print('alvin'+u'yuan')#зжНкДЎКЭunicodeСЌНг
py2:alvinyuan
print(b'alvin'+'yuan')#зжНкДЎКЭunicodeСЌНг py3:БЈДэ can't
concat bytes to str |
зЂвтЃКЮоТлpy2ЃЌЛЙЪЧpy3,гыУїЮФжБНгЖдгІЕФОЭЪЧunicodeЪ§ОнЃЌДђгЁunicodeЪ§ОнОЭЛсЯдЪОЯргІЕФУїЮФ(АќРЈгЂЮФКЭжаЮФ)
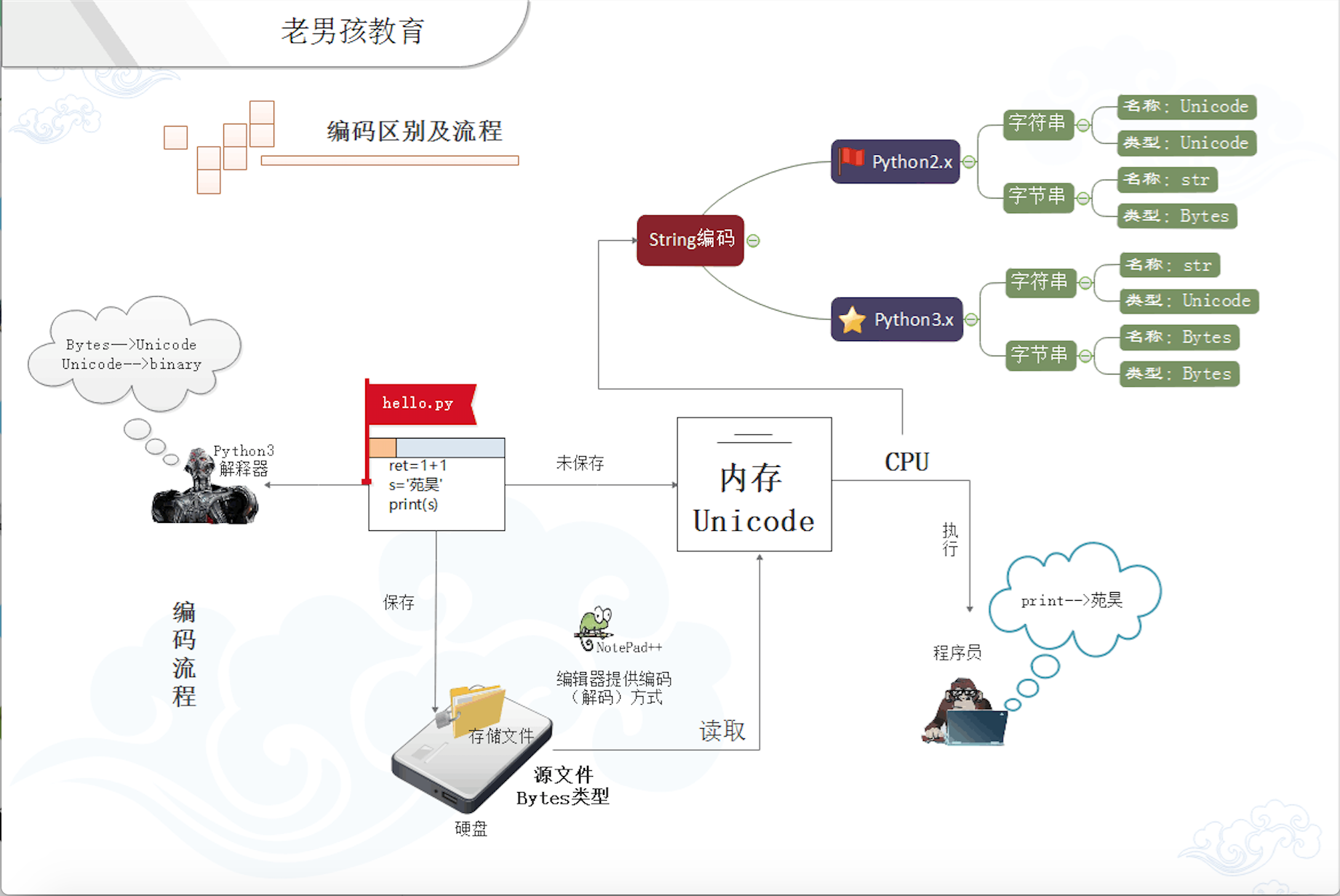
ЫФ ЮФМўДгДХХЬЕНФкДцЕФБрТы(******)
ЫЕЕНетЃЌВХРДЕНЮвУЧЕФжиЕуЃЁ
ХзПЊжДаажДааГЬађЃЌЧыЮЪДѓМвЃЌЮФБОБрМЦїДѓМвЖМЪЧгУЙ§АЩЃЌШчЙћВЛЖЎЪЧЪВУДЃЌФЧУДwordзмгУЙ§АЩЃЌokЃЌЕБЮвУЧдкwordЩЯБрМЮФзжЕФЪБКђЃЌВЛЙмЪЧжаЮФЛЙЪЧгЂЮФЃЌМЦЫуЛњЖМЪЧВЛШЯЪЖЕФЃЌФЧУДдкБЃДцжЎЧАЪ§ОнЪЧЭЈЙ§ЪВУДаЮЪНДцдкФкДцЕФФиЃПyesЃЌОЭЪЧunicodeЪ§ОнЃЌЮЊЪВУДвЊДцunicodeЪ§ОнЃЌетЪЧвђЮЊЫќЕФУћзжзюХЃКЭђЙњТыЃЁНтЪЭЦ№РДОЭЪЧЮоТлгЂЮФЃЌжаЮФЃЌШеЮФЃЌРЖЁЮФЃЌЪРНчЩЯЕФШЮКЮзжЗћЫќЖМгаЮЈвЛБрТыЖдгІЃЌЫљвдМцШнадЪЧзюКУЕФЁЃ
КУЃЌФЧЕБЮвУЧБЃДцСЫДцЕНДХХЬЩЯЕФЪ§ОнгжЪЧЪВУДФиЃП
Д№АИЪЧЭЈЙ§ФГжжБрТыЗНЪНБрТыЕФbytesзжНкДЎЁЃБШШчutf8-ЃЃвЛжжПЩБфГЄБрТыЃЌКмКУЕФНкЪЁСЫПеМфЃЛЕБШЛЛЙгаРњЪЗВњЮяЕФgbkБрТыЕШЕШЁЃгкЪЧЃЌдкЮвУЧЕФЮФБОБрМЦїШэМўЖМгаФЌШЯЕФБЃДцЮФМўЕФБрТыЗНЪНЃЌБШШчutf8ЃЌБШШчgbkЁЃЕБЮвУЧЕуЛїБЃДцЕФЪБКђЃЌетаЉБрМШэМўвбО"ФЌФЌЕи"АяЮвУЧзіСЫБрТыЙЄзїЁЃ
ФЧЕБЮвУЧдйДђПЊетИіЮФМўЪБЃЌШэМўгжФЌФЌЕиИјЮвУЧзіСЫНтТыЕФЙЄзїЃЌНЋЪ§ОндйНтТыГЩunicode,ШЛКѓОЭПЩвдГЪЯжУїЮФИјгУЛЇСЫЃЁЫљвдЃЌunicodeЪЧРыгУЛЇИќНќЕФЪ§ОнЃЌbytesЪЧРыМЦЫуЛњИќНќЕФЪ§ОнЁЃ
ЫЕСЫетУДЖрЃЌКЭЮвУЧГЬађжДаагаЪВУДЙиЯЕФиЃП
ЯШУїШЗвЛИіИХФюЃКpyНтЪЭЦїБОЩэОЭЪЧвЛИіШэМўЃЌвЛИіРрЫЦгкЮФБОБрМЦївЛбљЕФШэМўЃЁ
ЯждкШУЮвУЧвЛЦ№ЛЙдвЛИіpyЮФМўДгДДНЈЕНжДааЕФБрТыЙ§ГЬЃК
ДђПЊpycharmЃЌДДНЈhello.pyЮФМўЃЌаДШы
ret=1+1
s='дЗъЛ'
print(s) |
ЕБЮвУЧБЃДцЕФЕФЪБКђЃЌhello.pyЮФМўОЭвдpycharmФЌШЯЕФБрТыЗНЪНБЃДцЕНСЫДХХЬЃЛЙиБеЮФМўКѓдйДђПЊЃЌpycharmОЭдйвдФЌШЯЕФБрТыЗНЪНЖдИУЮФМўДђПЊКѓЖСЕНЕФФкШнНјааНтТыЃЌзЊГЩunicodeЕНФкДцЮвУЧОЭПДЕНСЫЮвУЧЕФУїЮФЃЛ
ЖјШчЙћЮвУЧЕуЛїдЫааАДХЅЛђепдкУќСюаадЫааИУЮФМўЪБЃЌpyНтЪЭЦїетИіШэМўОЭЛсБЛЕїгУЃЌДђПЊЮФМўЃЌШЛКѓНтТыДцдкДХХЬЩЯЕФbytesЪ§ОнГЩunicodeЪ§ОнЃЌетИіЙ§ГЬКЭБрМЦїЪЧвЛбљЕФЃЌВЛЭЌЕФЪЧНтЪЭЦїЛсдйНЋетаЉunicodeЪ§ОнЗвыГЩCДњТыдйзЊГЩЖўНјжЦЕФЪ§ОнСїЃЌзюКѓЭЈЙ§ПижЦВйзїЯЕЭГЕїгУcpuРДжДааетаЉЖўНјжЦЪ§ОнЃЌећИіЙ§ГЬВХЫуНсЪјЁЃ
ФЧУДЮЪЬтРДСЫЃЌЮвУЧЕФЮФБОБрМЦїгаздМКФЌШЯЕФБрТыНтТыЗНЪНЃЌЮвУЧЕФНтЪЭЦїгаТ№ЃП
ЕБШЛгаРВЃЌpy2ФЌШЯASCIIТыЃЌpy3ФЌШЯЕФutf8ЃЌПЩвдЭЈЙ§ШчЯТЗНЪНВщбЏ
import sys
print(sys.getdefaultencoding()) |
ДѓМвЛЙМЧЕУетИіЩљУїТ№ЃП
ЪЧЕФЃЌетОЭЪЧвђЮЊШчЙћpy2НтЪЭЦїШЅжДаавЛИіutf8БрТыЕФЮФМўЃЌОЭЛсвдФЌШЯЕиASCIIШЅНтТыutf8ЃЌвЛЕЉГЬађжагажаЮФЃЌздШЛОЭНтТыДэЮѓСЫЃЌЫљвдЮвУЧдкЮФМўПЊЭЗЮЛжУЩљУїЁЁ#coding:utf8ЃЌЦфЪЕОЭЪЧИцЫпНтЪЭЦїЃЌФуВЛвЊвдФЌШЯЕФБрТыЗНЪНШЅНтТыетИіЮФМўЃЌЖјЪЧвдutf8РДНтТыЁЃЖјpy3ЕФНтЪЭЦївђЮЊФЌШЯutf8БрТыЃЌЫљвдОЭЗНБуКмЖрСЫЁЃ
зЂвтЃКЮвУЧЩЯУцНВЕФstringБрТыЪЧдкcpuжДааГЬађЪБЕФДцДЂзДЬЌЃЌЪЧСэЭтвЛИіЙ§ГЬЃЌВЛвЊЛьЯ§ЃЁ
Юх ГЃМћЕФБрТыЮЪЬт
1 cmdЯТЕФТвТыЮЪЬт
#coding:utf8
print ('дЗъЛ') |
ЮФМўБЃДцЪБЕФБрТывВЮЊutf8ЁЃ
ЫМПМЃКЮЊЪВУДдкIDEЯТгУ2Лђ3жДааЖМУЛЮЪЬтЃЌдкcmd.exeЯТ3е§ШЗЃЌ2ТвТыФиЃП
ЮвУЧдкwinЯТЕФжеЖЫМДcmd.exeШЅжДааЃЌДѓМвзЂвтЃЌcmd.exeБОЩэвВвЛИіШэМўЃЛЕБЮвУЧpython2
hello.pyЪБЃЌpython2НтЪЭЦї(ФЌШЯASCIIБрТы)ШЅАДЩљУїЕФutf8БрТыЮФМўЃЌЖјЮФМўгжЪЧutf8БЃДцЕФЃЌЫљвдУЛЮЪЬтЃЛЮЪЬтГідкЕБЮвУЧprint'дЗъЛ'ЪБЃЌНтЪЭЦїетБпе§ГЃжДааЃЌвВВЛЛсБЈДэЃЌжЛЪЧprintЕФФкШнЛсДЋЕнИјcmd.exeгУРДЯдЪОЃЌЖјдкpy2РяетИіФкШнОЭЪЧutf8БрТыЕФзжНкЪ§ОнЃЌПЩетИіШэМўФЌШЯЕФБрТыНтТыЗНЪНЪЧGBKЃЌЫљвдcmd.exeгУGBKЕФНтТыЗНЪНШЅНтТыutf8здШЛЛсТвТыЁЃ
py3е§ШЗЕФдвђЪЧДЋЕнИјcmdЕФЪЧunicodeЪ§ОнЃЌcmd.exeПЩвдЪЖБ№ФкШнЃЌЫљвдЯдЪОУЛЮЪЬтЁЃ
УїАздРэСЫЃЌаоИФОЭгаКмЖрЗНЪНЃЌБШШчЃК
ИФГЩетбљКѓЃЌcmdЯТгУ2вВВЛЛсгаЮЪЬтСЫЁЃ
2 open()жаЕФБрТыЮЪЬт
ДДНЈвЛИіhelloЮФБОЃЌБЃДцГЩutf8ЃК
ЭЌФПТМЯТДДНЈвЛИіindex.py
f=open('hello')
print(f.read()) |
ЮЊЪВУД дкlinuxЯТЃЌНсЙће§ГЃЃКдЗъЛЃЌдкwinЯТЃЌТвТыЃКшцЃЈpy3НтЪЭЦїЃЉЃП
вђЮЊФуЕФwinЕФВйзїЯЕЭГАВзАЪБЪЧФЌШЯЕФgbkБрТыЃЌЖјlinuxВйзїЯЕЭГФЌШЯЕФЪЧutf8БрТыЃЛ
ЕБжДааopenКЏЪ§ЪБЃЌЕїгУЕФЪЧВйзїЯЕЭГДђПЊЮФМўЃЌВйзїЯЕЭГгУФЌШЯЕФgbkБрТыШЅНтТыutf8ЕФЮФМўЃЌздШЛТвТыЁЃ
НтОіАьЗЈЃК
f=open('hello',encoding='utf8')
print(f.read()) |
ШчЙћФуЕФЮФМўБЃДцЕФЪЧgbkБрТыЃЌдкwin ЯТОЭВЛгУжИЖЈencodingСЫЁЃ
СэЭтЃЌШчЙћФуЕФwinЩЯВЛашвЊжИЖЈИјВйзїЯЕЭГencoding='utf8'ЃЌФЧОЭЪЧФуАВзАЪБОЭЪЧФЌШЯЕФutf8БрТыЛђепвбОЭЈЙ§УќСюаоИФГЩСЫutf8БрТыЁЃ
зЂвтЃКopenетИіКЏЪ§дкpy2РяКЭpy3жаЪЧВЛЭЌЕФЃЌpy3жагаСЫвЛИіencodingЃНNoneВЮЪ§ЁЃ
|









