| БрМЭЦМі: |
| РДдДгкcsdnЃЌвЛПЊЪМНщЩмЮЊжїЃЌШЛКѓНщЩмЕФИХФюЮЊжїЃЌзюКѓНсКЯвНСЦЪЕР§ЯъЯИНщЩмЕФЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ |
|
жмЫФЭэЩЯКњИчИјДѓМвМђЕЅХрбЕСЫвЛЯТnlpЕФвЛаЉЫуЗЈЃЌИаОѕЪмвцЗЫЧГЁЃЛиШЅжЎКѓЗДЪЁСЫвЛЯТЃЌгаЖЮЪБМфУЛПДЛњЦїбЇЯАЕФЖЋЮїСЫЃЌnlpвЊзЅЃЌЛњЦїбЇЯАвВвЊбЇЁЃПЊИіПгЃЌМЧТМКЭЗжЯэвЛЯТбЇЯАФкШнЃЈЪщМЎЮЊЁЖpythonЛњЦїбЇЯАМАЪЕМљЁЗЃЉЁЃ
ЪзЯШЯШвдНщЩмЮЊжїЁЃ
1959ФъЃЌУРЙњЕФЧАIBMдБЙЄШћчбЖћПЊЗЂСЫвЛИіЮїбѓЦхГЬађЃЌетИіГЬађПЩвддкгкШЫРрЦхЪжЖдоФЕФЙ§ГЬжаЃЌВЛЖЯИФЩЦздМКЕФЦхвеЁЃдк4ФъжЎКѓЃЌетИіГЬађеНЪЄСЫЩшМЦепБОШЫЃЛВЂЧвгжЙ§СЫ3ФъЃЌеНЪЄСЫУРЙњвЛЮЛБЃГж8ФъГЃЪЄВЛАмЕФзЈвЕЦхЪжЁЃ
зюНќЙШИшЕФDeepMindбаОПЭХЖге§ЪНаћВМЦфДДдьКЭзЋаДЕФЛњЦїбЇЯАГЬађAlphaGoвд4:1ЕФзмБШЗжЛїАмСЫЪРНчЖЅМЖбЁЪжРюЪРЪЏЃЌКѓРДНјЛЏКѓЕФAlphaGoгжвд3:0ЕФзмБШЗжЛїАмСЫЪРНчХХУћЕквЛЕФПТНрЁЃ
ИљОнЛњЦїбЇЯАРэТлЯШЧ§ЁЂчбШќЖћЯШЩњЕФЫЕЗЈЃЌЫћВЂУЛгаБраДОпЬхЕФГЬађИцЫпЮїбѓЦхГЬађШчКЮааЦхЁЃЪТЪЕЩЯЃЌетвВЪЧВЛПЩФмЕФЃЌвђЮЊЯТЦхВпТдЧЇБфЭђЛЏЃЌЮвУЧЮоЗЈЭЈЙ§БраДЭъБИЕФЃЌФФХТЪЧЙЬЖЈЕФжДааЙцГЬРДЬєеНШЫРрЦхЪжЁЃДгШћчбЖћЕФЮїбѓЦхГЬађЃЌЕНЙШИшЕФAlphaGoЃЌЮвУЧПЩвдзмНсГіЛњЦїбЇЯАЯЕЭГЕФШчЯТЬиЕуЃК
1ЃЉаэЖрЛњЦїбЇЯАЯЕЭГЫљНтОіЕФЖМЪЧЮоЗЈжБНгЪЙгУЙЬЖЈЙцдђЛђепСїГЬДњТыЭъГЩЕФЮЪЬтЃЌЭЈГЃетРрЮЪЬтЖдШЫРрЖјбдКмМђЕЅЁЃБШШчЃЌМЦЫуЛњКЭЪжЛњРяЕФМЦЫуЦїОЭВЛЪєгкОпБИжЧФмЕФЯЕЭГЃЌвђЮЊРяУцЕФМЦЫуЗНЗЈЖМгаЧхГўЖјЧвЙЬЖЈЕФЙцГЬЃЛЕЋЪЧШчЙћвЊЧѓвЛЬЈЛњЦїШЅБцБ№вЛеХЯрЦЌжагаФФаЉШЫКЭЮяЬхЃЌетЖдШЫРДНВКмШнвзЃЌЛњЦїШДКмФбзіЕНЁЃ
2ЃЉЫљЮНОпБИЁАбЇЯАЁБФмСІЕФГЬађЖМЪЧжИЫќФмЙЛВЛЖЯЕиДгОРњКЭЪ§ОнжаЮќШЁОбщНЬбЕЃЌДгЖјгІЖдЮДРДЕФдЄВтШЮЮёЁЃЮвУЧЯАЙпАбетжжЖдЮЊЮДжЊЕФдЄВтФмСІНазіЗКЛЏСІЁЃ
3ЃЉЛњЦїбЇЯАИќМггеШЫЕФЕиЗНдкгкЃЌЫќОпБИВЛЖЯИФЩЦздЩэгІЖдОпЬхШЮЮёЕФФмСІЁЃЮвУЧЯАЙпАбетжжЭъГЩШЮЮёЕФФмСІГЦЮЊадФмЁЃШћчбЖћЕФЮїбѓЦхГЬађКЭЙШИшЕФAlphaGoЖМЪЧЕфаЭЕФНшжњЙ§ШЅЖдоФЕФОбщЛђЦхЦзЃЌВЛЖЯЬсИпздЩэадФмЕФЛњЦїбЇЯАЯЕЭГЁЃ
вдЩЯЪЧЭЈЙ§ЮїбѓЦхГЬађЕФР§згзмНсЕФвЛаЉЛњЦїбЇЯАЯЕЭГЫљОпБИЕФЬиаЇЃЌЕЋЪЧетРядйв§ЪівЛЯТУРЙњПЈФкЛљУЗТЁДѓбЇЃЈДѓбЇбЇЕФПЮГЬЪЧМИФъЧАв§ШыЕФcmuЕФНЬГЬЁЃЁЃЛАЫЕКмЯлФНШЅcmuЖСбаЕФаЁЛяАщЃЌзюНќЛЙФУСЫЮЂШэЕФspecial
offerЃЉЛњЦїбЇЯАСьгђЕФжјУћНЬЪкTom MitchellЕФОЕфЖЈвхРДВћЪіЛњЦїбЇЯАРэТлЕФПЊЦЊЃК
гЂЮФдЛАетРяОЭВЛДђСЫЃЌИааЫШЄПЩвдздМКШЅАйЖШЃЌДЫДІЗХЗвыЃКШчЙћвЛИіГЬађдкЪЙгУМШгаЕФОбщЃЈEЃЉжДааФГРрШЮЮёЃЈTЃЉЕФЙ§ГЬжаБЛШЯЖЈЮЊЁАОпБИбЇЯАФмСІЕФЁБЃЌФЧУДЫќвЛЖЈашвЊеЙЯжГіЃКРћгУЯжгаЕФОбщЃЈEЃЉЃЌВЛЖЯИФЩЦЦфЭъГЩМШЖЈШЮЮёЃЈTЃЉЕФадФмЃЈPЃЉЕФЬижЪЁЃ
ЫЕАзСЫЃЌОЭЪЧЫЕЁАжЛгаФмРћгУЯжгаОбщВЛЖЯЭъЩЦздЩэадФмЕФГЬађВХгазЪИёГЦЮЊЛњЦїбЇЯАГЬађЁЃЁБ
МЬајвдНщЩмЮЊжї
ШЮЮёЃК
ЛњЦїбЇЯАЕФШЮЮёгаКмЖрЃЌетРяЮвУЧВржигкЖдСНРрОЕфЕФШЮЮёНјааНВНтКЭЪЕМљЃКМрЖНбЇЯАКЭЗЧМрЖНбЇЯАЁЃЙигкетСНепЕФИХФюЃЌВЛЧхГўЕФПЩвдШЅПДМрЖНбЇЯАКЭЗЧМрЖНбЇЯАЕФЧјБ№ЁЃ
етРяВЙГфвЛЕуЗЧМрЖНбЇЯАЕФФкШнЃЌЗЧМрЖНбЇЯАГЃгУЕФММЪѕАќРЈЪ§ОнНЕЮЌКЭОлРрЮЪЬтЕШЁЃжївЊВЙГфЪ§ОнНЕЮЌЕФИХФюЃЌЪ§ОнНЕЮЌЪЧЖдЪТЮяЕФЬиадНјаабЙЫѕКЭЩИбЁЃЌетЯюШЮЮёЯрЖдБШНЯГщЯѓЁЃШчЙћЮвУЧУЛгаЬиЖЈЕФСьгђжЊЪЖЃЌЪЧЮоЗЈдЄЯШЯШШЗЖЈВЩбљФФаЉЪ§ОнЕФЃЛЖјШчНёЃЌДЋИаЩшБИЕФВЩбљГЩБОЯрЖдНЯЕЭЃЌЯрЗДЃЌЩИбЁгааЇаХЯЂЕФГЩБОИќИпЁЃБШШчЃЌдкЪЖБ№ЭМЯёжаШЫСГЕФШЮЮёжаЃЌЮвУЧПЩвджБНгЖСШЁЕНЭМЯёЯёЫиаХЯЂЃЌШєЪЧжБНгЪЙгУетаЉЯёЫиаХЯЂЃЌФЧУДЪ§ОнЕФЮЌЖШЛсЗЧГЃИпЃЌЬиБ№ЪЧдкЭМЯёЗжБцТЪдНРДдНИпЕФНёЬьЁЃвђДЫЃЌЮвУЧЭЈГЃЛсЪЙгУЪ§ОнНЕЮЌЕФММЪѕЖдЭМЯёНјааНЕЮЌЃЌБЃСєзюОпгаЧјЗжЖШЕФЯёЫизщКЯЁЃ
ОбщЃК
ЮвУЧЯАЙпадЕиАбЪ§ОнЪгзїОбщЃЛЪТЪЕЩЯЃЌжЛгаФЧаЉЖдбЇЯАШЮЮёгагУЕФЬиЖЈаХЯЂВХЛсБЛСаШыПМТЧЗЖЮЇЁЃЖјЮвУЧЭЈГЃАбетаЉЗДгГЪ§ОнФкдкЙцТЩЕФаХЯЂНазіЬиеїЁЃБШШчЧАУцЬсЕНЕФШЫСГЭМЯёЪЖБ№ШЮЮёжаЃЌЮвУЧКмЩйжБНгАбЭМЯёзюдЪМЕФЯёЫиаХЯЂзїЮЊОбщНЛИјбЇЯАЯЕЭГЃЛЖјЪЧЭЈЙ§НЕЮЌЃЌЩѕжСвЛаЉИќЮЊИДдгЕФЪ§ОнДІРэЗНЗЈЕУЕНИќМггажњгкШЫСГЪЖБ№ЕФТжРЊЬиеїЁЃ
ЖдгкМрЖНбЇЯАЮЪЬтЃЌЮвУЧЫљгЕгаЕФОбщАќРЈЬиеїКЭБъМЧ/ФПБъСНИіВПЗжЁЃЮвУЧвЛАугУвЛИіЬиеїЯђСПРДУшЪівЛИіЪ§ОнбљБОЃЛБъМЧ/ФПБъЕФБэЯжаЮЪНдђШЁОігкМрЖНбЇЯАЕФжжРрЁЃ
ЮоМрЖНбЇЯАЮЪЬтздШЛУЛгаБъМЧ/ФПБъЃЌвђДЫЮоЗЈДгЪТдЄВтШЮЮёЃЌШДИќЪЪКЯЖдЪ§ОнНсЙЙЕФЗжЮіЁЃе§ЪЧвђЮЊетИіЧјБ№ЃЌЮвУЧОГЃПЩвдЛёЕУДѓСПЕФЮоМрЖНЪ§ОнЃЛЖјМрЖНЪ§ОнЕФБъзЂвђЮЊОГЃКФЗбДѓСПЕФЪБМфЁЂН№ЧЎКЭШЫСІЃЌЫљвдЪ§ОнСПЯрЖдНЯЩйЁЃ
адФмЃК
ЫљЮНадФмЃЌБуЪЧЦРМлЫљЭъГЩШЮЮёжЪСПЕФжИБъЁЃЮЊСЫЦРМлбЇЯАФЃаЭЭъГЩШЮЮёЕФжЪСПЃЌЮвУЧашвЊОпБИЯрЭЌЬиеїЕФЪ§ОнЃЌВЂНЋФЃаЭЕФдЄВтНсЙћЭЌЯрЖдгІЕФе§ШЗД№АИНјааБШЖдЁЃЮвУЧГЦетбљЕФЪ§ОнМЏЮЊВтЪдМЏЁЃЖјЧвИќЮЊживЊЕФЪЧЃЌЮвУЧашвЊБЃжЄЃЌГіЯждкВтЪдМЏжаЕФЪ§ОнбљБОвЛЖЈВЛФмБЛгУгкФЃаЭбЕСЗЁЃМђЖјбджЎЃЌбЕСЗМЏКЭВтЪдМЏжЎМфЪЧЛЅГтЕФЁЃ
ЖдгкдЄВтаджЪЕФЮЪЬтЃЌЮвУЧОГЃЙизЂдЄВтЕФОЋЖШЁЃОпЬхРДНВЃКЗжРрЮЪЬтЃЌЮвУЧвЊИљОндЄВте§ШЗРрБ№ЕФАйЗжБШРДЦРМлЦфадФмЃЌетИіжИБъЭЈГЃБЛГЦзїзМШЗадЃЛЛиЙщЮЪЬтдђЮоЗЈЪЙгУРрЫЦЕФжИБъЃЌЮвУЧЭЈГЃЛсКтСПдЄВтжЕгыЪЕМЪжЕжЎМфЕФЦЋВюДѓаЁЁЃ
вдЯТОЭвЊНсКЯОпЬхpythonДњТыКЭРУДѓНжЕФжзСідЄВтЮЪЬтСЫЁЃ
ИљОнЩЯЪіЕФУшЪіЃЌДѓМвПЩвдШЗЖЈЁАСМ/ЖёадШщЯйАЉжзСідЄВтЁБЕФЮЪЬтЪєгкЖўЗжРрШЮЮёЁЃД§дЄВтЕФРрБ№ЗжБ№ЪЧСМадШщЯйАЉжзСіКЭЖёадШщЯйАЉжзСіЁЃЭЈГЃЮвУЧЪЙгУРыЩЂЕФећЪ§РДДњБэРрБ№ЁЃШчЯТБэЃЌЁАжзСіРраЭЁБвЛСаСаГіСЫжзСіЕФРраЭЃЛ0ДњБэСМадЃЌ1ДњБэЖёадЁЃ

ЭъећЕФЪ§ОнМЏжзСіЕФЬиеїВЛжЙетСНИіЃЌЕЋЪЧдкетИіР§згжаЮвУЧжЛШЁетСНИіЬиеїЃЌВЂЧвВтЪдМЏЪ§СПЮЊ175ЬѕЁЃЮвУЧЯШПДвЛЯТет175ЬѕжзСібљБОдкЖўЮЌЬиеїПеМфЕФЗжВМЧщПіЃЌШчЯТЭМЫљЪОЁЃXДњБэЖёаджзСіЃЌOДњБэСМаджзСіЁЃ
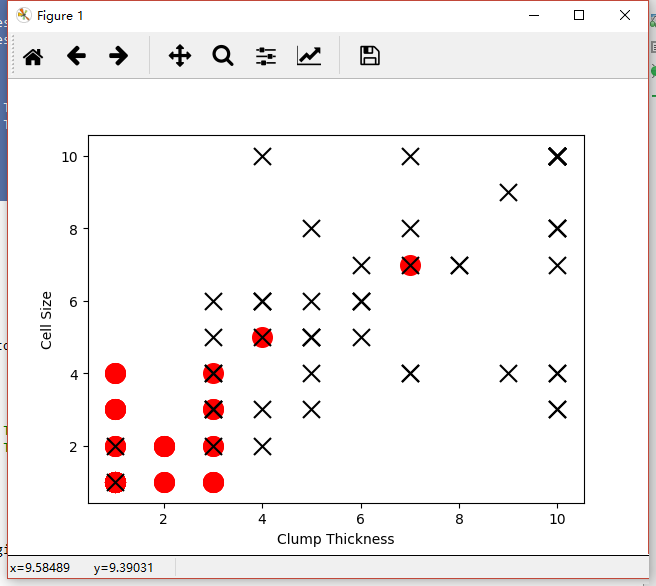
ЛцжЦетеХЭМЕФДњТыШчЯТЃК
# -*- coding:utf-8
-*-
# ЕМШыpandasАќЃЌБ№УћЮЊpd
import pandas as pd
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋбЕСЗМЏЖСШЁНјРДВЂДцжСБфСПdf_train
df_train = pd.read_csv('breast-cancer-train.csv')
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋВтЪдМЏЖСШЁНјРДВЂДцжСБфСПdf_test
df_test = pd.read_csv('breast-cancer-test.csv')
# бЁШЁClump ThicknessКЭCell SizeзїЮЊЬиеїЃЌЙЙНЈВтЪдМЏжаЕФе§ИКЗжРрбљБО
df_test_negative = df_test.loc[df_test['Type']
== 0][['Clump Thickness', 'Cell Size']]
df_test_positive = df_test.loc[df_test['Type']
== 1][['Clump Thickness', 'Cell Size']]
# ЕМШыmatplotlibЙЄОпАќжаЕФpyplotВЂУќУћЮЊplt
import matplotlib.pyplot as plt
# ЛцжЦЭМжаЕФСМаджзСібљБОЕуЃЌБъМЧЮЊКьЩЋЕФo
plt.scatter(df_test_negative['Clump Thickness'],
df_test_negative['Cell Size'], marker='o', s=200,
c='red')
# ЛцжЦЭМжаЕФЖёаФжзСібљБОЕуЃЌБъМЧЮЊКкЩЋЕФx
plt.scatter(df_test_positive['Clump Thickness'],
df_test_positive['Cell Size'], marker='x', s=150,
c='black')
# ЛцжЦxЃЌyжсЫЕУї
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
# ЯдЪОЭМ
plt.show() |
ЫцКѓЮвУЧЫцЛњГѕЪМЛЏвЛИіЖўРрЗжРрЦїЃЌетИіЗжРрЦїгУвЛЬѕжБЯпРДЛЎЗжСМ/ЖёаджзСіЁЃОіЖЈетЬѕжБЯпЕФзпЯђгаСНИівђЫиЃКжБЯпЕФаБТЪКЭНиОрЁЃетаЉБЛЮвУЧГЦЮЊФЃаЭЕФВЮЪ§ЃЌвВЪЧЗжРрЦїашвЊЭЈЙ§бЇЯАДгбЕСЗЪ§ОнжаЕУЕНЕФЁЃзюГѕЃЌЫцЛњГѕЪМЛЏВЮЪ§ЕФЗжРрЦїЕФадФмБэЯжШчЯТЭМЫљЪОЃК
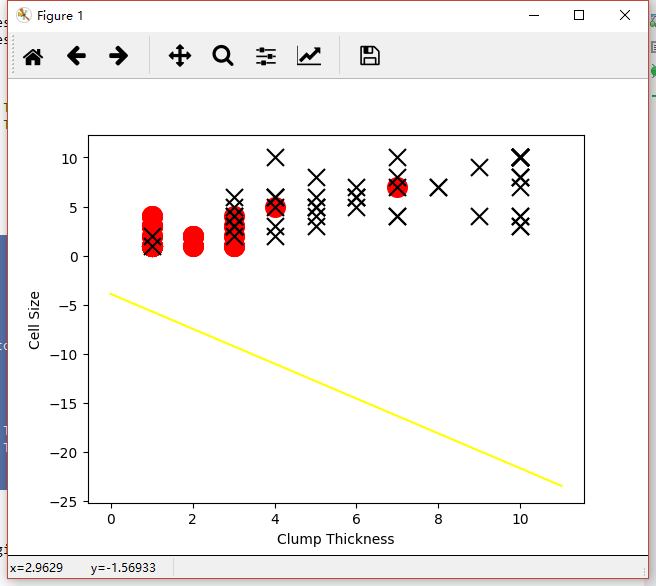
ЛцжЦетеХЭМЕФДњТыШчЯТЃК
<span style="font-size:12px;">#
-*- coding:utf-8 -*-
# ЕМШыpandasАќЃЌБ№УћЮЊpd
import pandas as pd
# ЕМШыmatplotlibЙЄОпАќжаЕФpyplotВЂУќУћЮЊplt
import matplotlib.pyplot as plt
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋбЕСЗМЏЖСШЁНјРДВЂДцжСБфСПdf_train
df_train = pd.read_csv('breast-cancer-train.csv')
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋВтЪдМЏЖСШЁНјРДВЂДцжСБфСПdf_test
df_test = pd.read_csv('breast-cancer-test.csv')
# бЁШЁClump ThicknessКЭCell SizeзїЮЊЬиеїЃЌЙЙНЈВтЪдМЏжаЕФе§ИКЗжРрбљБО
df_test_negative = df_test.loc[df_test['Type']
== 0][['Clump Thickness', 'Cell Size']]
df_test_positive = df_test.loc[df_test['Type']
== 1][['Clump Thickness', 'Cell Size']]
# ЕМШыnumpyЙЄОпАќЃЌжиУќУћЮЊnp
import numpy as np
# РћгУnumpyжаЕФrandomКЏЪ§ЫцЛњВЩбљжБЯпЕФНиОрКЭЯЕЪ§
intercept = np.random.random([1])
coef = np.random.random([2])
lx = np.arange(0, 12)
ly = (-intercept - lx * coef[0]) / coef[1]
# ЛцжЦвЛЬѕЫцЛњжБЯп
plt.plot(lx, ly, c='yellow')
plt.scatter(df_test_negative['Clump Thickness'],
df_test_negative['Cell Size'], marker='o', s=200,
c='red')
plt.scatter(df_test_positive['Clump Thickness'],
df_test_positive['Cell Size'], marker='x', s=150,
c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()</span> |
ЫцКѓЮвУЧЪЙгУвЛЖЈСПбЕСЗбљБОЃЌЗжРрЦїЫљБэЯжЕФадФмгаСЫДѓЗљЖШЕФЬсЪОЃЌШчЯТЭМЃК
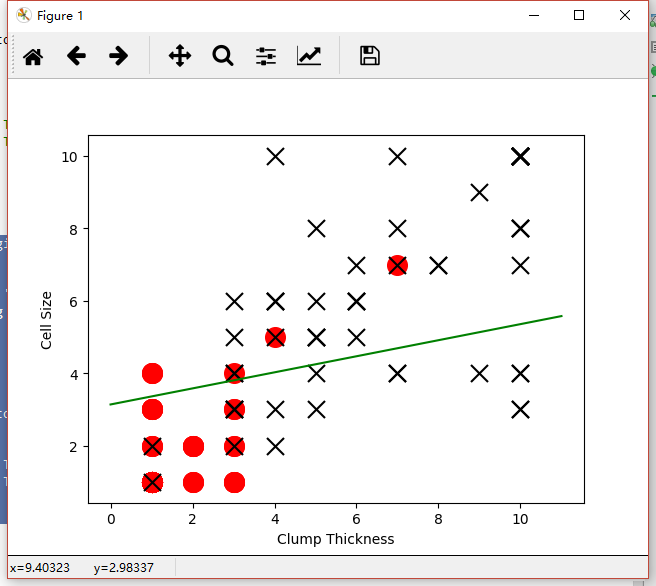
ЛцжЦетеХЭМЕФДњТыШчЯТЃК
<span style="font-size:12px;">#
-*- coding:utf-8 -*-
# ЕМШыpandasАќЃЌБ№УћЮЊpd
import pandas as pd
# ЕМШыnumpyЙЄОпАќЃЌжиУќУћЮЊnp
import numpy as np
# ЕМШыmatplotlibЙЄОпАќжаЕФpyplotВЂУќУћЮЊplt
import matplotlib.pyplot as plt
# ЕМШыsklearnжаЕФТпМЫЙЕйЛиЙщЗжРрЦї
from sklearn.linear_model import LogisticRegression
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋбЕСЗМЏЖСШЁНјРДВЂДцжСБфСПdf_train
df_train = pd.read_csv('breast-cancer-train.csv')
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋВтЪдМЏЖСШЁНјРДВЂДцжСБфСПdf_test
df_test = pd.read_csv('breast-cancer-test.csv')
# бЁШЁClump ThicknessКЭCell SizeзїЮЊЬиеїЃЌЙЙНЈВтЪдМЏжаЕФе§ИКЗжРрбљБО
df_test_negative = df_test.loc[df_test['Type']
== 0][['Clump Thickness', 'Cell Size']]
df_test_positive = df_test.loc[df_test['Type']
== 1][['Clump Thickness', 'Cell Size']]
lr = LogisticRegression()
# ЪЙгУЧА10ЬѕбЕСЗбљБОбЇЯАжБЯпЕФЯЕЪ§КЭНиОр
lr.fit(df_train[['Clump Thickness', 'Cell Size']][:10],
df_train['Type'][:10])
print 'Testing accuracy (10 training samples):',
lr.score(df_test[['Clump Thickness', 'Cell Size']],
df_test['Type'])
intercept = lr.intercept_
coef = lr.coef_[0, :]
lx = np.arange(0, 12)
# дБОетИіЗжРрУцгІИУЪЧlx*coef[0] + ly*coef[1] + intercept=0
гГЩфЕН2ЮЌЦНУцЩЯжЎКѓЃЌгІИУЪЧЃК
ly = (-intercept - lx * coef[0]) / coef[1]
plt.plot(lx, ly, c='green')
plt.scatter(df_test_negative['Clump Thickness'],
df_test_negative['Cell Size'], marker='o', s=200,
c='red')
plt.scatter(df_test_positive['Clump Thickness'],
df_test_positive['Cell Size'], marker='x', s=150,
c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show()</span> |
printЕФжЕЮЊЃКTesting accuracy (10 training samples): 0.868571428571
ШчЩЯЭМЫљЪОЃЌЕБбЇЯАСЫ10ЬѕбЕСЗбљБОЪБЃЌЗжРрЦїЕФадФмИФНјСЫвЛаЉЃЌВтЪдМЏЩЯЕФЗжРрзМШЗадЮЊ86.9%ЃЛЮвУЧМЬајбЇЯАЫљгабЕСЗбљБОЃЌЗжРрЦїЕФадФмНјвЛВНЬсЩ§ЃЌдкВтЪдМЏЩЯЕФЗжРрзМШЗадзюжеДяЕН93.7%ЃЌШчЯТЭМЃК
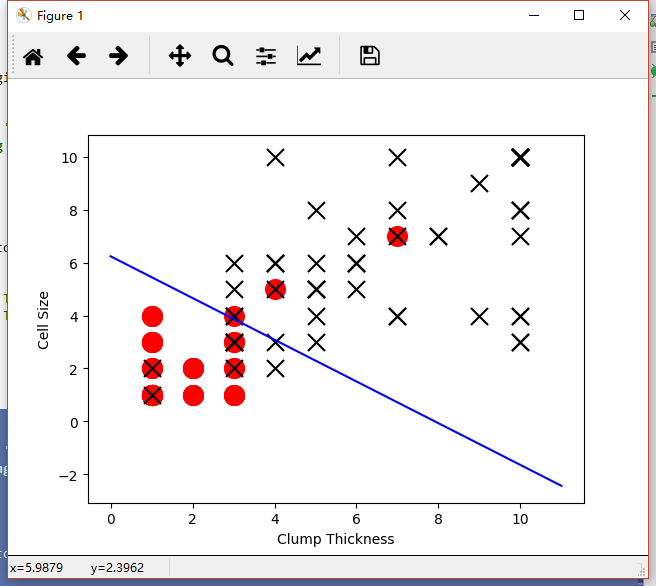
ЛцжЦетеХЭМЕФДњТыШчЯТЃК
# -*- coding:utf-8
-*-
# ЕМШыpandasАќЃЌБ№УћЮЊpd
import pandas as pd
# ЕМШыnumpyЙЄОпАќЃЌжиУќУћЮЊnp
import numpy as np
# ЕМШыmatplotlibЙЄОпАќжаЕФpyplotВЂУќУћЮЊplt
import matplotlib.pyplot as plt
# ЕМШыsklearnжаЕФТпМЫЙЕйЛиЙщЗжРрЦї
from sklearn.linear_model import LogisticRegression
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋбЕСЗМЏЖСШЁНјРДВЂДцжСБфСПdf_train
df_train = pd.read_csv('breast-cancer-train.csv')
# ЪЙгУpandasЕФread_csvКЏЪ§ЃЌНЋВтЪдМЏЖСШЁНјРДВЂДцжСБфСПdf_test
df_test = pd.read_csv('breast-cancer-test.csv')
# бЁШЁClump ThicknessКЭCell SizeзїЮЊЬиеїЃЌЙЙНЈВтЪдМЏжаЕФе§ИКЗжРрбљБО
df_test_negative = df_test.loc[df_test['Type']
== 0][['Clump Thickness', 'Cell Size']]
df_test_positive = df_test.loc[df_test['Type']
== 1][['Clump Thickness', 'Cell Size']]
lr = LogisticRegression()
# ЪЙгУЧА10ЬѕбЕСЗбљБОбЇЯАжБЯпЕФЯЕЪ§КЭНиОр
lr.fit(df_train[['Clump Thickness', 'Cell Size']],
df_train['Type'])
print 'Testing accuracy (10 training samples):',
lr.score(df_test[['Clump Thickness', 'Cell Size']],
df_test['Type'])
intercept = lr.intercept_
coef = lr.coef_[0, :]
lx = np.arange(0, 12)
# дБОетИіЗжРрУцгІИУЪЧlx*coef[0] + ly*coef[1] + intercept=0
гГЩфЕН2ЮЌЦНУцЩЯжЎКѓЃЌгІИУЪЧЃК
ly = (-intercept - lx * coef[0]) / coef[1]
plt.plot(lx, ly, c='green')
plt.scatter(df_test_negative['Clump Thickness'],
df_test_negative['Cell Size'], marker='o', s=200,
c='red')
plt.scatter(df_test_positive['Clump Thickness'],
df_test_positive['Cell Size'], marker='x', s=150,
c='black')
plt.xlabel('Clump Thickness')
plt.ylabel('Cell Size')
plt.show() |
printЕФжЕЮЊTesting accuracy (10 training samples): 0.937142857143
етЗнДњТыжЛЪЧАяДѓМвРэЧхвЛЯТзюЮЊЛљДЁЕФpythonБрГЬвЊЫиЃЌЗНБуЖдКѓУцЕФЪЕР§НјааРэНтКЭЪЕМљЁЃ
Ъ§ОнЕижЗhttp://pan.baidu.com/s/1jI00k8QЃЌДѓМвПЩвдШЅЯТдиЁЃ
|









