| БрМЭЦМі: |
| БОЮФРДздгкsegmentfault.com,жївЊДг3ИіЗНУцНщЩмЃЌДгЛЗОГДюНЈЁЂШчКЮДгвГУцзЅШЁЪ§ОнвдМАЭМЦЌДІРэЃЌЯЕЭГЕФДјДѓМвШыУХЁЃ |
|
Лљгк Python ЕФ Scrapy ХРГцШыУХЃКЛЗОГДюНЈ
зїЮЊвЛИіШЋеЛЙЄГЬЪІЃЈ:-) HoHoЃЉЃЌЧАЖЫКѓЬЈЖМЖЎЕуЪЧБиаыЕФЃЌЕЋЪЧPython КмВЫЃЌScrapy ИќВЫЃЌУЛДэЃЌетОЭЪЧ
Full Stack Developer ЕФЬиЕуЃЌЪВУДЖМЖЎЕуЃЌЪВУДЖМВЛОЋЃЌЮвУЧЕФЬиЕуОЭЪЧЩЯЪжПьЃЌЭќЕУвВКмПьЃЌВЛЙ§ХфКЯЧПДѓЕФЫбЫїв§ЧцЃЌаДаЉаЁЖЋЮїГіРДЪЧВЛГЩЮЪЬтЕФЃЁ
бдЙще§ДЋЃЌзюНќЯыгУХРГцзЅШЁвЛаЉФкШнРДГфЪЕздМКЕФВЉПЭЃЌвдЧАгУЙ§ phpspiderЃЌЛљБОФмТњзувЊЧѓЃЌЕЋЪЧВЛЙЛЧПДѓЃЌЫљвдбЁгУ
ScrapyЃЌЫГБуЛивфвЛЯТПьЭќЙтЕФ PythonЃЌЫШУЫќетУДЛ№ФиЁЃ
вЛЁЂЛљДЁЛЗОГ
гЩгкВЛЪЧжАвЕЕФWebПЊЗЂепЃЌвђДЫЛЗОГЪЧЛљгкWindowsЕФЁЃ
1. Python АВзА
ЕН python.org ЯТдизюаТАц Python АВзААќЃЌЮвЪЙгУЕФЪЧ3.6.3 32ЮЛАцБОЃЌзЂвтШчЙћАВзАСЫ64ЮЛАцБОЃЌвдКѓЫљЪЙгУЕФАќвВЖМашвЊ64ЮЛЁЃАВзАГЬађФЌШЯАВзАpipАќЙмРэЙЄОпЃЌВЂЩшжУСЫЯрЙиЛЗОГБфСПЃКЬэМг
%Python% МА %Python%\Scripts ЕН PATH жаЃЈ%Python%ЪЧФуЕФАВзАФПТМЃЉЃЌФудЫааЕФ
Python ГЬађЛђНХБОЖМдк Scripts жаЃЌАќЖМАВзАдк Lib\site-packages жаЁЃ
2. ХфжУ pip ЙњФкОЕЯёдД
PythonжЎЫљвдЧПДѓе§ЪЧвђЮЊИїжжЙІФмЦыШЋЕФПЊЗЂАќЃЌгЩгкжкЫљжмжЊЕФдвђ pipЯТдиФЃПщЫйЖШКмТ§ЃЌвђДЫЮЊСЫБЃжЄpipЯТдиЫГРћЃЌНЈвщЬцЛЛГЩЙњФкЕФАВзАдДОЕЯёЃК
ДДНЈЮФМў %HOMEPATH%\pip\pip.iniЃЌФкШнШчЯТЃК
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple |
ЩЯУцетИіЪЧЧхЛЊДѓбЇЕФОЕЯёЃЌСэЭтИНЩЯЦфЫћМИИіКУгУЕФЃЌОнЫЕУП30ЗжжгЭЌВНЙйЭј
АЂРядЦЃКhttp://mirrors.aliyun.com/pypi/simple/
ЖЙАъЭјЃКhttp://pypi.doubanio.com/simple/
ПЦММДѓбЇЃКhttp://mirrors.ustc.edu.cn/pypi/web/simple/ |
ШчЙћВЛЯгТщЗГЕФЛАвВПЩвдУПДЮАВзАЪБжИЖЈЃК
| pip -i http://pypi.douban.com/simple
install Flask |
3. ЛЛвЛИіГУЪжЕФУќСюаа
гЩгкPythonжаОГЃвЊгУЕНУќСюааЙЄОпЃЌЕЋWindowsздДјЕФcmdЛђPowerShellБЦИёЬЋЕЭЃЌЛЛИізжЬхЛЙЕУелЬкДѓАыЬьЃЌвђДЫгаБивЊЛЛвЛИіКУгУЕФЃЌЭЦМіcmder
miniАцЃКhttps://github.com/cmderdev/c...ЃЌPythonЪфГіЕФЕїЪдаХЯЂПЩвдИљОнбеЩЋЧјЗжЃЌВЛгУЯёcmdФЧбљевАыЬьСЫЁЃ
4. АВзАЛљДЁАќ
virtualenv
ЛљБОЩЯPythonУПИіЯюФПЖМЛсгУЕНДѓСПЕФФЃПщЃЌБШШчБОЮФжаЕФScrapyХРГцЃЌpip install
scrapyКѓГ§СЫScrapyБОЩэЭтЃЌЛЙЛсЯТдиЪ§ЪЎИівРРЕАќЃЌШчЙћОГЃгУPythonзіИїжжПЊЗЂЃЌsite-packagesЛсдНРДдНХгДѓЃЌПЩФмгааЉАќжЛдквЛИіЯюФПжагУЕНЃЌЛђепЩОГ§АќКѓвРРЕАќВЂУЛгаБЛЩОГ§ЃЌзмжЎВЛЬЋКУЙмРэЃЌзїЮЊЧПЦШжЂЛМепЪЧОіВЛФмШЬЪмЕФЁЃ
КУдкгавЛИіЙЄОп virtualenv ПЩвдЗНБуЙмРэ Python ЕФЛЗОГЃЌЫќПЩвдДДНЈвЛИіИєРыЕФPythonащФтПЊЗЂЛЗОГЃЌЪЙгУЫќФуПЩвдЭЌЪБАВзАЖрИіPythonАцБОЃЌЗНБуЭЌЪБЖрИіЯюФПЕФПЊЗЂЃЌУПИіЯюФПжЎМфЕФАќАВзАгыЪЙгУЖМЪЧЖРСЂЕФЃЌЛЅВЛИЩШХЃЌЭЈЙ§УќСюПЩвдЫцЪБЧаЛЛИїИіащФтЛЗОГЃЌШчЙћВЛдйЪЙгУЃЌАбећИіащФтЛЗОГЩОГ§МДПЩЭЌЪБЩОГ§ЦфжаЫљгаЕФФЃПщАќЃЌБЃГжШЋОжЛЗОГЕФИЩОЛЁЃ
ЮЊСЫБугкЪЙгУЃЌЮвбЁдёАВзАvirtualenvwrapper-winФЃПщЃЌЫќвРРЕгкvirtualenvЃЌАќКЌWindowsЯТУцвзгкЪЙгУЕФХњДІРэНХБОЃЌЦфЪЕжЛЪЧЕїгУСЫ
virtualenv ЙІФмЖјвбЃК
pip install virtualenvwrapper-win
virtualenvwrapper ГЃгУУќСюЃК
workon: СаГіащФтЛЗОГСаБэ
lsvirtualenv: ЭЌЩЯ
mkvirtualenv: аТНЈащФтЛЗОГ
workon [ащФтЛЗОГУћГЦ]: ЧаЛЛащФтЛЗОГ
rmvirtualenv: ЩОГ§ащФтЛЗОГ
deactivate: РыПЊащФтЛЗОГ
wheel
wheel ЪЧpythonжаЕФНтАќКЭДђАќЙЄОпЃЌвђДЫгаБивЊАВзАЕНШЋОжЛЗОГжаЃЌгааЉФЃПщЪЙгУpipАВзАзмЪЧЪЇАмЃЌПЩвдГЂЪдЯШЯТдиwhlЮФМўЃЌдйЪЙгУwheelБОЕиАВзАЕФЗНЪНАВзАЁЃ
pip install wheel
pypiwin32
МШШЛдкWindowsЯТПЊЗЂЃЌwin32apiвВЪЧБиВЛПЩЩйЕФАќЃЌвђДЫвВзАЕНШЋОжЛЗОГжаЃЌЯТДЮаТНЈащФтЯюФПЛЗОГгУЕНЪБОЭВЛБиУПДЮдйЯТдивЛДЮСЫЁЃ
ЕБШЛЃЌвдЩЯ2ЃЌ3ЃЌ4ЦфЪЕЖМВЛЪЧБиаыЕФЃЌЕЋЪЧНЈКУЛљБОЛЗОГгаРћгквдКѓЕФПЊЗЂЩйЖЕШІзгЁЃ
ЖўЁЂScrapy АВзА
ДђПЊcmderУќСюааЙЄОп
ДДНЈScrapyащФтЛЗОГЃК mkvirtualenv ScrapyЃЌФЌШЯЧщПіЯТЛсДДНЈ%HOMEPATH%\EnvsФПТМЃЌЫљгаЕФащФтЛЗОГЖМЛсВњЩњвЛИізгФПТМБЃДцдкДЫЃЌРяУцАќКЌPythonЛљБОГЬађЮФМўвдМАpip,wheel,setuptoolsПтЮФМўЁЃШчЙћЯыаоИФEnvsФЌШЯТЗОЖЃЌдкWindowsжаПЩЬэМгвЛИі
%WORKON_HOME% ЛЗОГБфСПжИЖЈаТЕФФПТМЁЃ
ЧаЛЛЕНScrapyЛЗОГЃКworkon scrapy ЃЌжДааКѓдкУќСюааЬсЪОЗћЧАУцЛсЖрГі (Scrapy)
зжЗћЃЌБэЪОЕБЧАДІгкScrapyащФтЛЗОГжаЃЌЭЌЪБЬэМгСЫЕБЧАЛЗОГжаЕФЯрЙиТЗОЖдкЯЕЭГ %PATH% ЫбЫїТЗОЖжаЁЃ
АВзАScrapyАќЃКpip install scrapyЃЌздМККУМИДЮЖМгіЕНTwistedФЃПщАВзАЪЇАмЕФЮЪЬтЃЌУВЫЦЪЧБрвыЪЇАмЃЌШБЩйMicrosoft
Visual C++ 14.0ЕМжТЃК
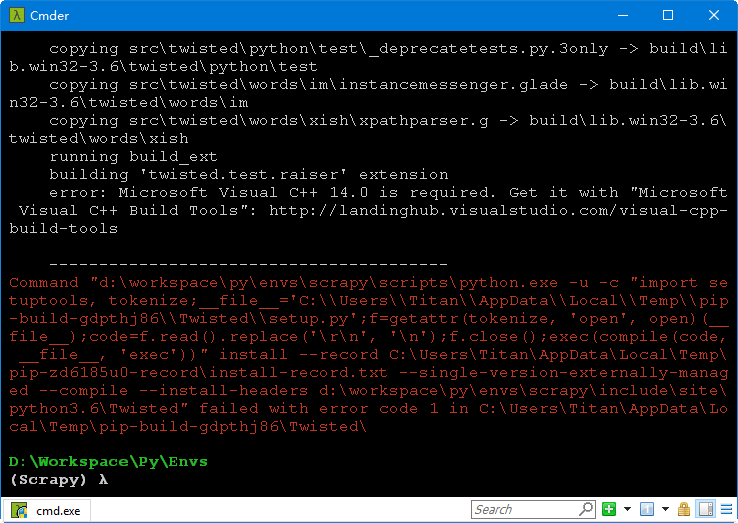
ЮвУЛгаАДвЊЧѓАВзАMicrosoft Visual C++ 14.0БрвыЙЄОпЃЌЖјЪЧЯТдиwhlЮФМўБОЕиАВзАЭъГЩЖдЃЌДЫЪБwheelБуХЩЩЯСЫгУГЁЃЌЕН
https://www.lfd.uci.edu/~gohl... ЯТдиtwistedЕФwhlЮФМўЃЈзЂвтЖдгІPythonАцБОЃЉ

дйЪЙгУ pip install Twisted?17.9.0?cp36?cp36m?win32.whl
РДНјааАВзАЃЌБОЕиАВзАtwistedГЩЙІЃЌгЩгкжЎЧАБЛДэЮѓжаЖЯЃЌНЈвщдйжДаавЛДЮ pip install
scrapy ЗРжЙгавРРЕАќУЛгаАВзАЕНЁЃ
зЂвтЃКWindowsЦНЬЈашвЊЖюЭтАВзА pypiwin32 ФЃПщЃЌЗёдђдкScrapyжДааХРГцЪБЛсБЈДэЃК
ModuleNotFoundError: No module named 'win32api'
жСДЫ Scrapy ЛЗОГДюНЈЭъГЩЃЌЫљгаЕФФЃПщДцЗХдк %HOMEPATH%\Envs\Scrapy жаЃЌШчЙћВЛдйЪЙгУЃЌжЛашвЊУќСюаажДаа
rmvirtualenv scrapyЃЌећИіФПТМЖМЛсБЛЩОГ§ЃЌЫљгавРРЕФЃПщЖМЛсБЛЧхРэИЩОЛЁЃ
Лљгк Python ЕФ Scrapy ХРГцШыУХЃКвГУцЬсШЁ
вЛЁЂФкШнЗжЮі
ДђПЊ ЭМГцЭјЃЌЖЅВПВЫЕЅЁАЗЂЯжЁБ ЁАБъЧЉЁБРяУцЪЧЖдИїжжЭМЦЌЕФЗжРрЃЌЕуЛївЛИіБъЧЉЃЌБШШчЁАУРХЎЁБЃЌЭјвГЕФСДНгЮЊЃКhttps://tuchong.com/tags/УРХЎ/ЃЌЮвУЧвдДЫзїЮЊХРГцШыПкЃЌЗжЮівЛЯТИУвГУцЃК
ДђПЊвГУцКѓГіЯжвЛИіИіЕФЭММЏЃЌЕуЛїЭММЏПЩШЋЦСфЏРРЭМЦЌЃЌЯђЯТЙіЖЏвГУцЛсГіЯжИќЖрЕФЭММЏЃЌУЛгавГТыЗвГЕФЩшжУЁЃChromeгвМќЁАМьВщдЊЫиЁБДђПЊПЊЗЂепЙЄОпЃЌМьВщвГУцдДТыЃЌФкШнВПЗжШчЯТЃК
<div class="content">
<div class="widget-gallery">
<ul class="pagelist-wrapper">
<li class="gallery-item... |
ПЩвдХаЖЯУПвЛИіli.gallery-itemЪЧвЛИіЭММЏЕФШыПкЃЌДцЗХдкul.pagelist-wrapperЯТЃЌdiv.widget-galleryЪЧвЛИіШнЦїЃЌШчЙћЪЙгУ
xpath бЁШЁгІИУЪЧЃК//div[@class="widget-gallery"]/ul/liЃЌАДеевЛАувГУцЕФТпМЃЌдкli.gallery-itemЯТУцевЕНЖдгІЕФСДНгЕижЗЃЌдйЭљЯТЩюШывЛВувГУцзЅШЁЭМЦЌЁЃ
ЕЋЪЧШчЙћгУРрЫЦ Postman ЕФHTTPЕїЪдЙЄОпЧыЧѓИУвГУцЃЌЕУЕНЕФФкШнЪЧЃК
<div class="content">
<div class="widget-gallery"></div>
</div> |
вВОЭЪЧВЂУЛгаЪЕМЪЕФЭММЏФкШнЃЌвђДЫПЩвдЖЯЖЈвГУцЪЙгУСЫAjaxЧыЧѓЃЌжЛгадкфЏРРЦїдиШывГУцЪБВХЛсЧыЧѓЭММЏФкШнВЂМгШыdiv.widget-galleryжаЃЌЭЈЙ§ПЊЗЂепЙЄОпВщПДXHRЧыЧѓЕижЗЮЊЃК
| https://tuchong.com/rest/tags/УРХЎ/posts?page=1&count=20&order=weekly&before_timestamp= |
ВЮЪ§КмМђЕЅЃЌpageЪЧвГТыЃЌcountЪЧУПвГЭММЏЪ§СПЃЌorderЪЧХХађЃЌbefore_timestampЮЊПеЃЌЭМГцвђЮЊЪЧЭЦЫЭФкШнЪНЕФЭјеОЃЌвђДЫbefore_timestampгІИУЪЧвЛИіЪБМфжЕЃЌВЛЭЌЕФЪБМфЛсЯдЪОВЛЭЌЕФФкШнЃЌетРяЮвУЧАбЫќЖЊЦњЃЌВЛПМТЧЪБМфжБНгДгзюаТЕФвГУцЯђЧАзЅШЁЁЃ
ЧыЧѓНсЙћЮЊJSONИёЪНФкШнЃЌНЕЕЭСЫзЅШЁФбЖШЃЌНсЙћШчЯТЃК
{
"postList":
[
{
"post_id": "15624611",
"type": "multi-photo",
"url": "https://weishexi.tuchong.com/15624611/",
"site_id": "443122",
"author_id":
"443122",
"published_at":
"2017-10-28 18:01:03",
"excerpt":
"10дТ18Ше",
"favorites":
4052,
"comments": 353,
"rewardable":
true,
"parent_comments": "165",
"rewards": "2",
"views":
52709,
"title": "ЮЂЗчВЛдя Чявте§КУ",
"image_count": 15,
"images":
[
{
"img_id": 11585752,
"user_id":
443122,
"title": "",
"excerpt": "",
"width":
5016,
"height": 3840
},
{
"img_id": 11585737,
"user_id":
443122,
"title": "",
"excerpt": "",
"width":
3840,
"height": 5760
},
...
],
"title_image": null,
"tags":
[
{
"tag_id": 131,
"type":
"subject",
"tag_name":
"ШЫЯё",
"event_type": "",
"vote": ""
},
{
"tag_id": 564,
"type":
"subject",
"tag_name":
"УРХЎ",
"event_type": "",
"vote": ""
}
],
"favorite_list_prefix": [],
"reward_list_prefix": [],
"comment_list_prefix":
[],
"cover_image_src": "https://photo.tuchong.com/443122/g/11585752.webp",
"is_favorite": false
}
],
"siteList": {...},
"following":
false,
"coverUrl": "https://photo.tuchong.com/443122/ft640/11585752.webp",
"tag_name": "УРХЎ",
"tag_id":
"564",
"url": "https://tuchong.com/tags/%E7%BE%8E%E5%A5%B3/",
"more": true,
"result":
"SUCCESS"
} |
ИљОнЪєадУћГЦКмШнвзжЊЕРЖдгІЕФФкШнКЌвхЃЌетРяЮвУЧжЛашЙиаФ postlist етИіЪєадЃЌЫќЖдгІЕФвЛИіЪ§зщдЊЫиБуЪЧвЛИіЭММЏЃЌЭММЏдЊЫижагаМИЯюЪєадЮвУЧашвЊгУЕНЃК
urlЃКЕЅИіЭММЏфЏРРЕФвГУцЕижЗ
post_idЃКЭММЏБрКХЃЌдкЭјеОжагІИУЪЧЮЈвЛЕФЃЌПЩвдгУРДХаЖЯЪЧЗёвбОзЅШЁЙ§ИУФкШн
site_idЃКзїепеОЕуБрКХ ЃЌЙЙНЈЭМЦЌРДдДСДНгвЊгУЕН
titleЃКБъЬт
excerptЃКеЊвЊЮФзж
typeЃКЭММЏРраЭЃЌФПЧАЗЂЯжСНжжЃЌвЛжжmulti-photoЪЧДПееЦЌЃЌвЛжжtextЪЧЮФзжгыЭМЦЌЛьКЯЕФЮФеТЪНвГУцЃЌСНжжФкШнНсЙЙВЛЭЌЃЌашвЊВЛЭЌЕФзЅШЁЗНЪНЃЌБОР§жажЛзЅШЁДПееЦЌРраЭЃЌtextРраЭжБНгЖЊЦњ
tagsЃКЭММЏБъЧЉЃЌгаЖрИі
image_countЃКЭМЦЌЪ§СП
imagesЃКЭМЦЌСаБэЃЌЫќЪЧвЛИіЖдЯѓЪ§зщЃЌУПИіЖдЯѓжаАќКЌвЛИіimg_idЪєадашвЊгУЕН
ИљОнЭМЦЌфЏРРвГУцЗжЮіЃЌЛљБОЩЯЭМЦЌЕФЕижЗЖМЪЧетжжИёЪНЃК https://photo.tuchong.com/{site_id}/f/{img_id}.jpg
ЃЌКмШнвзЭЈЙ§ЩЯУцЕФаХЯЂКЯГЩЁЃ
ЖўЁЂДДНЈЯюФП
НјШыcmderУќСюааЙЄОпЃЌЪфШыworkon scrapy НјШыжЎЧАНЈСЂЕФащФтЛЗОГЃЌДЫЪБУќСюааЬсЪОЗћЧАЛсГіЯж(Scrapy)
БъЪЖЃЌБъЪЖДІгкИУащФтЛЗОГжаЃЌЯрЙиЕФТЗОЖЖМЛсЬэМгЕНPATHЛЗОГБфСПжаБугкПЊЗЂМАЪЙгУЁЃ
ЪфШы scrapy startproject tuchong ДДНЈЯюФП tuchong
НјШыЯюФПжїФПТМЃЌЪфШы scrapy genspider photo tuchong.com ДДНЈвЛИіХРГцУћГЦНа
photo (ВЛФмгыЯюФПЭЌУћ)ЃЌХРШЁ tuchong.com гђУћЃЈетИіашвЊаоИФЃЌДЫДІЯШЪфИіДѓИХЕижЗЃЉЃЌЕФвЛИіЯюФПФкПЩвдАќКЌЖрИіХРГц
ОЙ§вдЩЯВНжшЃЌЯюФПздЖЏНЈСЂСЫвЛаЉЮФМўМАЩшжУЃЌФПТМНсЙЙШчЯТЃК
(PROJECT)
ЉІ scrapy.cfg
ЉІ
ЉИЉЄtuchong
ЉІ items.py
ЉІ middlewares.py
ЉІ pipelines.py
ЉІ settings.py
ЉІ __init__.py
ЉІ
ЉРЉЄspiders
ЉІ ЉІ photo.py
ЉІ ЉІ __init__.py
ЉІ ЉІ
ЉІ ЉИЉЄ__pycache__
ЉІ __init__.cpython-36.pyc
ЉІ
ЉИЉЄ__pycache__
settings.cpython-36.pyc
__init__.cpython-36.pyc |
scrapy.cfgЃКЛљДЁЩшжУ
items.pyЃКзЅШЁЬѕФПЕФНсЙЙЖЈвх
middlewares.pyЃКжаМфМўЖЈвхЃЌДЫР§жаЮоашИФЖЏ
pipelines.pyЃКЙмЕРЖЈвхЃЌгУгкзЅШЁЪ§ОнКѓЕФДІРэ
settings.pyЃКШЋОжЩшжУ
spiders\photo.pyЃКХРГцжїЬхЃЌЖЈвхШчКЮзЅШЁашвЊЕФЪ§Он
Ш§ЁЂжївЊДњТы
items.py жаДДНЈвЛИіTuchongItemРрВЂЖЈвхашвЊЕФЪєадЃЌЪєадМЬГазд scrapy.Field
жЕПЩвдЪЧзжЗћЁЂЪ§зжЛђепСаБэЛђзжЕфЕШЕШЃК
| import scrapy
class TuchongItem(scrapy.Item):
post_id = scrapy.Field()
site_id = scrapy.Field()
title = scrapy.Field()
type = scrapy.Field()
url = scrapy.Field()
image_count = scrapy.Field()
images = scrapy.Field()
tags = scrapy.Field()
excerpt = scrapy.Field()
... |
етаЉЪєадЕФжЕНЋдкХРГцжїЬхжаИГгшЁЃ
spiders\photo.py етИіЮФМўЪЧЭЈЙ§УќСю scrapy genspider photo
tuchong.com здЖЏДДНЈЕФЃЌРяУцЕФГѕЪМФкШнШчЯТЃК
| import scrapy
class PhotoSpider(scrapy.Spider):
name = 'photo'
allowed_domains = ['tuchong.com']
start_urls = ['http://tuchong.com/']
def parse(self, response):
pass |
ХРГцУћ nameЃЌдЪаэЕФгђУћ allowed_domainsЃЈШчЙћСДНгВЛЪєгкДЫгђУћНЋЖЊЦњЃЌдЪаэЖрИіЃЉ
ЃЌЦ№ЪМЕижЗ start_urls НЋДгетРяЖЈвхЕФЕижЗзЅШЁЃЈдЪаэЖрИіЃЉ
КЏЪ§ parse ЪЧДІРэЧыЧѓФкШнЕФФЌШЯЛиЕїКЏЪ§ЃЌВЮЪ§ response ЮЊЧыЧѓФкШнЃЌвГУцФкШнЮФБОБЃДцдк
response.body жаЃЌЮвУЧашвЊЖдФЌШЯДњТыЩдМгаоИФЃЌШУЦфТњзуЖрвГУцбЛЗЗЂЫЭЧыЧѓЃЌеташвЊжиди
start_requests КЏЪ§ЃЌЭЈЙ§бЛЗгяОфЙЙНЈЖрвГЕФСДНгЧыЧѓЃЌаоИФКѓДњТыШчЯТЃК
import scrapy,
json
from ..items import TuchongItem
class PhotoSpider(scrapy.Spider):
name = 'photo'
# allowed_domains = ['tuchong.com']
# start_urls = ['http://tuchong.com/']
def start_requests(self):
url = 'https://tuchong.com/rest/tags/%s/posts?page=%d&count=20&order=weekly';
# зЅШЁ10ИівГУцЃЌУПвГ20ИіЭММЏ
# жИЖЈ parse зїЮЊЛиЕїКЏЪ§ВЂЗЕЛи Requests ЧыЧѓЖдЯѓ
for page in range(1, 11):
yield scrapy.Request(url=url % ('УРХЎ', page),
callback=self.parse)
# ЛиЕїКЏЪ§ЃЌДІРэзЅШЁФкШнЬюГф TuchongItem Ъєад
def parse(self, response):
body = json.loads(response.body_as_unicode())
items = []
for post in body['postList']:
item = TuchongItem()
item['type'] = post['type']
item['post_id'] = post['post_id']
item['site_id'] = post['site_id']
item['title'] = post['title']
item['url'] = post['url']
item['excerpt'] = post['excerpt']
item['image_count'] = int(post['image_count'])
item['images'] = {}
# НЋ images ДІРэГЩ {img_id: img_url} ЖдЯѓЪ§зщ
for img in post.get('images', ''):
img_id = img['img_id']
url = 'https://photo.tuchong.com/%s/f/%s.jpg'
% (item['site_id'], img_id)
item['images'][img_id] = url
item['tags'] = []
# НЋ tags ДІРэГЩ tag_name Ъ§зщ
for tag in post.get('tags', ''):
item['tags'].append(tag['tag_name'])
items.append(item)
return items |
ОЙ§етаЉВНжшЃЌзЅШЁЕФЪ§ОнНЋБЛБЃДцдк TuchongItem РржаЃЌзїЮЊНсЙЙЛЏЕФЪ§ОнБугкДІРэМАБЃДцЁЃ
ЧАУцЫЕЙ§ЃЌВЂВЛЪЧЫљгазЅШЁЕФЬѕФПЖМашвЊЃЌР§ШчБОР§жаЮвУЧжЛашвЊ type="multi_photo
РраЭЕФЭММЏЃЌВЂЧвЭМЦЌЬЋЩйЕФвВВЛашвЊЃЌетаЉзЅШЁЬѕФПЕФЩИбЁВйзївдМАШчКЮБЃДцашвЊдкpipelines.pyжаДІРэЃЌИУЮФМўжаФЌШЯвбДДНЈРр
TuchongPipeline ВЂжидиСЫ process_item КЏЪ§ЃЌЭЈЙ§аоИФИУКЏЪ§жЛЗЕЛиФЧаЉЗћКЯЬѕМўЕФ
itemЃЌДњТыШчЯТЃК
...
def process_item(self, item, spider):
# ВЛЗћКЯЬѕМўДЅЗЂ scrapy.exceptions.DropItem вьГЃЃЌЗћКЯЬѕМўЕФЪфГіЕижЗ
if int(item['image_count']) < 3:
raise DropItem("УРХЎЬЋЩй: " + item['url'])
elif item['type'] != 'multi-photo':
raise DropItem("ИёЪНВЛЖд: " + + item['url'])
else:
print(item['url'])
return item
... |
ЕБШЛШчЙћВЛгУЙмЕРжБНгдк parse жаДІРэвВЪЧвЛбљЕФЃЌжЛВЛЙ§етбљНсЙЙИќЧхЮњвЛаЉЃЌЖјЧвЛЙгаЙІФмИќЖрЕФFilePipelinesКЭImagePipelinesПЩЙЉЪЙгУЃЌprocess_itemНЋдкУПвЛИіЬѕФПзЅШЁКѓДЅЗЂЃЌЭЌЪБЛЙга
open_spider МА close_spider КЏЪ§ПЩвджидиЃЌгУгкДІРэХРГцДђПЊМАЙиБеЪБЕФЖЏзїЁЃ
зЂвтЃКЙмЕРашвЊдкЯюФПжазЂВсВХФмЪЙгУЃЌдк settings.py жаЬэМгЃК
ITEM_PIPELINES = {
'tuchong.pipelines.TuchongPipeline': 300, # ЙмЕРУћГЦ:
дЫаагХЯШМЖ(Ъ§зжаЁгХЯШ)
}
СэЭтЃЌДѓЖрЪ§ЭјеОЖМгаЗДХРГцЕФ Robots.txt ХХГ§авщЃЌЩшжУ ROBOTSTXT_OBEY =
True ПЩвдКіТдетаЉавщЃЌЪЧЕФЃЌетКУЯёжЛЪЧИіО§згаЖЈЁЃШчЙћЭјеОЩшжУСЫфЏРРЦїUser AgentЛђепIPЕижЗМьВтРДЗДХРГцЃЌФЧОЭашвЊИќИпМЖЕФScrapyЙІФмЃЌБОЮФВЛзіНВНтЁЃ
ЫФЁЂдЫаа
ЗЕЛи cmder УќСюааНјШыЯюФПФПТМЃЌЪфШыУќСюЃК
жеЖЫЛсЪфГіЫљгаЕФХРааНсЙћМАЕїЪдаХЯЂЃЌВЂдкзюКѓСаГіХРГцдЫааЕФЭГМЦаХЯЂЃЌР§ШчЃК
[scrapy.statscollectors]
INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 491,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 10224,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 11, 27,
7, 20, 24, 414201),
'item_dropped_count': 5,
'item_dropped_reasons_count/DropItem': 5,
'item_scraped_count': 15,
'log_count/DEBUG': 18,
'log_count/INFO': 8,
'log_count/WARNING': 5,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 11, 27,
7, 20, 23, 867300)} |
жївЊЙизЂERRORМАWARNINGСНЯюЃЌетРяЕФ Warning ЦфЪЕЪЧВЛЗћКЯЬѕМўЖјДЅЗЂЕФ DropItem
вьГЃЁЃ
ЮхЁЂБЃДцНсЙћ
ДѓЖрЪ§ЧщПіЯТЖМашвЊЖдзЅШЁЕФНсЙћНјааБЃДцЃЌФЌШЯЧщПіЯТ item.py жаЖЈвхЕФЪєадПЩвдБЃДцЕНЮФМўжаЃЌжЛашвЊУќСюааМгВЮЪ§
-o {filename} МДПЩЃК
scrapy crawl
photo -o output.json # ЪфГіЮЊJSONЮФМў
scrapy crawl photo -o output.csv # ЪфГіЮЊCSVЮФМў |
зЂвтЃКЪфГіжСЮФМўжаЕФЯюФПЪЧЮДОЙ§ TuchongPipeline ЩИбЁЕФЯюФПЃЌжЛвЊдк parse КЏЪ§жаЗЕЛиЕФ
Item ЖМЛсЪфГіЃЌвђДЫвВПЩвддк parse жаЙ§ТЫжЛЗЕЛиашвЊЕФЯюФП
ШчЙћашвЊБЃДцжСЪ§ОнПтЃЌдђашвЊЬэМгЖюЭтДњТыДІРэЃЌБШШчПЩвддк pipelines.py жа process_item
КѓЬэМг:
...
def process_item(self, item, spider):
...
else:
print(item['url'])
self.myblog.add_post(item) # myblog ЪЧвЛИіЪ§ОнПтРрЃЌгУгкДІРэЪ§ОнПтВйзї
return item
... |
ЮЊСЫдкВхШыЪ§ОнПтВйзїжаХХГ§жиИДЕФФкШнЃЌПЩвдЪЙгУ item['post_id'] НјааХаЖЯЃЌШчЙћДцдкдђЬјЙ§ЁЃ
БОЯюФПжаЕФзЅШЁФкШнжЛЩцМАСЫЮФБОМАЭМЦЌСДНгЃЌВЂЮДЯТдиЭМЦЌЮФМўЃЌШчашЯТдиЭМЦЌЃЌПЩвдЭЈЙ§СНжжЗНЪНЃК
АВзА Requests ФЃПщЃЌдк process_item КЏЪ§жаЯТдиЭМЦЌФкШнЃЌЭЌЪБдкБЃДцЪ§ОнПтЪБЬцЛЛЮЊБОЕиЭМЦЌТЗОЖЁЃ
ЪЙгУ ImagePipelines ЙмЕРЯТдиЭМЦЌЃЌОпЬхЪЙгУЗНЗЈЯТЛиНВНтЁЃ
Лљгк Python ЕФ Scrapy ХРГцШыУХЃКЭМЦЌДІРэ
ЩЯЮФжаНВНтСЫШчКЮДгЭјеОвГУцзЅШЁЫљашвЊЕФЪ§ОнЃЌКмавдЫЗЖР§жаЫљашЕФЪ§ОнЪЧЭЈЙ§ Ajax ЧыЧѓЗЕЛиЕФ
JSON НсЙЙЛЏЪ§ОнЃЌДІРэЦ№РДКмМђЕЅЃЌЭМЦЌФкШнвВжЛШЁСЫвЛИіСДНгЃЌЖдгкЮвзюГѕЕФФПБъЁААбетаЉЭММЏЬэМгЕНздМКЕФВЉПЭеОЕужаЁБетвбОЙЛСЫЃЌЫЕАзСЫОЭЪЧЁАЕССДЁБТяЃЌШчЙћгавЛЬьЭјеОзіСЫЗРЕССДДыЪЉЃЌФЧетаЉГРДЕФЭММЏОЭЖМзїЗЯСЫЃЌБЃЯеЕФЗНЗЈОЭЪЧАбЭМЦЌвВЯТдиЕНБОЕиЃЌдйАбЭМЦЌСДНгЬцЛЛЮЊБОЕиЭМЦЌЁЃ
ЯТдиЭМЦЌ
ЯТдиЭМЦЌгаСНжжЗНЪНЃЌвЛжжЪЧЭЈЙ§ Requests ФЃПщЗЂЫЭ get ЧыЧѓЯТдиЃЌСэвЛжжЪЧЪЙгУ Scrapy
ЕФ ImagesPipeline ЭМЦЌЙмЕРРрЃЌетРяжївЊНВКѓепЁЃ
АВзА Scrapy ЪБВЂУЛгаАВзАЭМЯёДІРэвРРЕАќ PillowЃЌашЪжЖЏАВзАЗёдђдЫааХРГцГіДэЁЃ
ЪзЯШдк settings.py жаЩшжУЭМЦЌЕФДцДЂТЗОЖЃК
ЭМЦЌДІРэЯрЙиЕФбЁЯюЛЙгаЃК
# ЭМЦЌзюаЁИпЖШКЭПэЖШЩшжУЃЌПЩвдЙ§ТЫЬЋаЁЕФЭМЦЌ
IMAGES_MIN_HEIGHT = 110
IMAGES_MIN_WIDTH = 110
# ЩњГЩЫѕТдЭМбЁЯю
IMAGES_THUMBS = {
'small': (50, 50),
'big': (270, 270),
} |
ИќЖрбЁЯюЧыВЮПМЃКhttps://doc.scrapy.org/en/lat...
жЎЧАвбОДцдкЬсШЁФкШнЕФ TuchongPipeline РрЃЌШчЙћЪЙгУ ImagePipeline ПЩвдНЋЬсШЁФкШнЕФВйзїЖМКЯВЂЙ§РДЃЌЕЋЪЧЮЊСЫИќКУЕФЫЕУїЭМЦЌЙмЕРЕФзїгУЃЌЮвУЧдйЕЅЖРДДНЈвЛИі
ImagePipeline РрЃЌМгЕН pipelines.py ЮФМўжаЃЌЭЌЪБжидиКЏЪ§ get_media_requestsЃК
class PhotoGalleryPipeline(object):
...
class PhotoPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for (id, url) in item['images'].items():
yield scrapy.Request(url) |
ЩЯЦЊЮФеТжаЮвУЧАбЭМЦЌЕФURLБЃДцдкСЫ item['images'] жаЃЌЫќЪЧвЛИізжЕфРраЭЕФЪ§зщЃЌаЮШчЃК[{img_id:
img_url}, ...]ЃЌДЫКЏЪ§жаашвЊАб img_url ШЁГіВЂЙЙНЈЮЊ scrapy.Request
ЧыЧѓЖдЯѓВЂЗЕЛиЃЌУПвЛИіЧыЧѓЖМНЋДЅЗЂвЛДЮЯТдиЭМЦЌЕФВйзїЁЃ
ЕН settings.py жазЂВс PhotoPipelineЃЌВЂАбгХЯШМЖЩшЕФБШЬсШЁФкШнЕФЙмЕРвЊИпвЛаЉЃЌБЃжЄЭМЦЌЯТдигХЯШгкФкШнДІРэЃЌФПЕФЪЧШчЙћгаЭМЦЌЯТдиЮДГЩЙІЃЌЭЈЙ§ДЅЗЂ
DropItem вьГЃПЩвджаЖЯетвЛИі Item ЕФДІРэЃЌЗРжЙВЛЭъећЕФЪ§ОнНјШыЯТвЛЙмЕРЃК
ITEM_PIPELINES
= {
'Toutiao.pipelines.PhotoGalleryPipeline': 300,
'Toutiao.pipelines.PhotoPipeline': 200,
} |
жДааХРГц scrapy crawl photo ЃЌШчЮоДэЮѓЃЌдкЩшЖЈЕФДцДЂФПТМжаЛсГіЯжвЛИі full
ФПТМЃЌРяУцЪЧЯТдиКѓЕФЭМЦЌЁЃ
ЮФМўУћДІРэ
ЯТдиЕФЮФМўУћЪЧвдЭМЦЌURLЭЈЙ§ sha1 БрТыЕУЕНЕФзжЗћЃЌРрЫЦ 0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg
ВЛЪЧЬЋгбКУЃЌПЩвдЭЈЙ§жиди file_path КЏЪ§здЖЈвхЮФМўУћЃЌБШШчПЩвдетбљБЃСєдЮФМўУћЃК
...
def file_path(self, request, response=None, info=None):
file_name = request.url.split('/')[-1]
return 'full/%s' % (file_name)
... |
ЩЯУцетбљДІРэФбУтЛсгажиУћЕФЮФМўБЛИВИЧЃЌЕЋВЮЪ§ request жаУЛгаЙ§ЖрЕФаХЯЂЃЌВЛБугкЖдЭМЦЌЗжРрЃЌвђДЫПЩвдИФЮЊжиди
item_completed КЏЪ§ЃЌдкЯТдиЭъГЩКѓЖдЭМЦЌНјааЗжРрВйзїЁЃ
КЏЪ§ item_completed ЕФЖЈвхЃК
| def item_completed(self,
results, item, info) |
ВЮЪ§жаАќКЌ item ЃЌгаЮвУЧзЅШЁЕФЫљгааХЯЂЃЌВЮЪ§ results ЮЊЯТдиЭМЦЌЕФНсЙћЪ§зщЃЌАќКЌЯТдиКѓЕФТЗОЖвдМАЪЧЗёГЩЙІЯТдиЃЌФкШнШчЯТЃК
[(True,
{'checksum': '2b00042f7481c7b056c4b410d28f33cf',
'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg',
'url': 'http://www.example.com/files/product1.pdf'}),
(False,
Failure(...))] |
жидиИУКЏЪ§НЋЯТдиЭМЦЌзЊвЦЕНЗжРрФПТМжаЃЌЭЌЪБЙиСЊЮФМўТЗОЖЕН item жаЃЌБЃГжФкШнгыЭМЦЌЮЊвЛИіећЬхЃК
def item_completed(self,
results, item, info):
image_paths = {x['url'].split('/')[-1]: x['path']
for ok, x in results if ok}
if not image_paths:
# ЯТдиЪЇАмКіТдИУ Item ЕФКѓајДІРэ
raise DropItem("Item contains no files")
else:
# НЋЭМЦЌзЊвЦжСвд post_id ЮЊУћЕФзгФПТМжа
for (dest, src) in image_paths.items():
dir = settings.IMAGES_STORE
newdir = dir + os.path.dirname(src) + '/' + item['post_id']
+ '/'
if not os.path.exists(newdir):
os.makedirs(newdir)
os.rename(dir + src, newdir + dest)
# НЋБЃДцТЗОЖБЃДцгк item жаЃЈimage_paths ашвЊдк items.py жаЖЈвхЃЉ
item['image_paths'] = image_paths
return item |
НгЯТРДдкд TuchongPipeline РржааДШыЪ§ОнПтЕФВйзїжаЃЌЭЈЙ§ item['image_paths']
ТЗОЖаХЯЂаДШыБОЕиЭМЦЌСДНгЁЃ
Г§СЫ ImagesPipeline ДІРэЭМЦЌЭтЃЌЛЙга FilesPipeline ПЩвдДІРэЮФМўЃЌЪЙгУЗНЗЈгыЭМЦЌРрЫЦЃЌЪТЪЕЩЯ
ImagesPipeline ЪЧ FilesPipeline ЕФзгРрЃЌвђЮЊЭМЦЌвВЪЧЮФМўЕФвЛжжЁЃ |









