МђНщ
ЕБФудкЛњЦїЩЯЦєЖЏФГИіГЬађЪБЃЌЫќжЛЪЧдкздМКЕФЁАbubbleЁБРяУцдЫааЃЌетИіЦјХнЕФзїгУОЭЪЧгУРДНЋЭЌвЛЪБПЬдЫааЕФЫљгаГЬађНјааЗжРыЁЃетИіЁАbubbleЁБвВПЩвдГЦжЎЮЊНјГЬЃЌАќКЌСЫЙмРэИУГЬађЕїгУЫљашвЊЕФвЛЧаЁЃ
Р§ШчЃЌетИіЫљЮНЕФНјГЬЛЗОГАќРЈИУНјГЬЪЙгУЕФФкДцвГЃЌДІРэИУНјГЬДђПЊЕФЮФМўЃЌгУЛЇКЭзщЕФЗУЮЪШЈЯоЃЌвдМАЫќЕФећИіУќСюааЕїгУЃЌАќРЈИјЖЈЕФВЮЪ§ЁЃ
ДЫаХЯЂБЃДцдкUNIX/LinuxЯЕЭГЕФСїГЬЮФМўЯЕЭГжаЃЌИУЯЕЭГЪЧвЛИіащФтЮФМўЯЕЭГЃЌПЩЭЈЙ§/procФПТМНјааЗУЮЪЁЃЬѕФПЖМвбОИљОнНјГЬIDХХЙ§ађСЫЃЌИУIDЪЧУПИіНјГЬЕФЮЈвЛБъЪЖЗћЁЃЪОР§1ЯдЪОСЫОпгаНјГЬID#177ЕФШЮвтбЁдёЕФНјГЬЁЃ
ЪОР§1:ПЩгУгкНјГЬЕФаХЯЂ
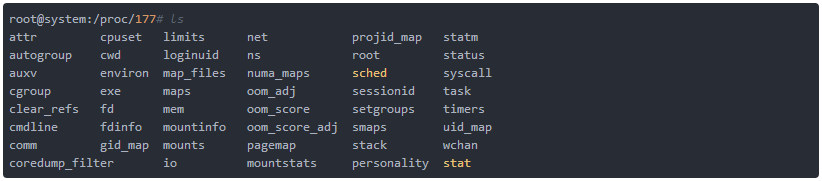
ЙЙНЈГЬађДњТывдМАЪ§Он
ГЬађдНИДдгЃЌОЭдНгажњгкНЋЦфЗжГЩНЯаЁЕФФЃПщЁЃВЛНіНідДДњТыЪЧетбљЃЌдкЛњЦїЩЯжДааЕФДњТывВЭЌбљЪЪгУгкетЬѕЙцдђЁЃИУЙцдђЕФЕфаЭЗЖР§ОЭЪЧЪЙгУзгНјГЬВЂаажДааЁЃетБГКѓЕФЯыЗЈОЭЪЧЃК
- ЕЅИіНјГЬАќКЌСЫПЩвдЕЅЖРдЫааЕФДњТыЖЮ
- ФГаЉДњТыЖЮПЩвдЭЌЪБдЫааЃЌвђДЫддђЩЯдЪаэВЂаа
- ЪЙгУЯжДњДІРэЦїКЭВйзїЯЕЭГЕФЬиадЃЌР§ШчПЩвдЪЙгУДІРэЦїЕФЫљгаКЫаФЃЌетбљОЭПЩвдМѕЩйГЬађЕФзмжДааЪБМф
- МѕЩйГЬађ/ДњТыЕФИДдгадЃЌВЂНЋЙЄзїЭтАќзЈУХЕФДњРэ
ЪЙгУзгНјГЬашвЊжиаТПМТЧГЬађЕФжДааЗНЪНЃЌДгЯпадЕНВЂааЁЃЫќРрЫЦгкНЋЙЋЫОЕФЙЄзїЪгНЧДгЦеЭЈдБЙЄзЊБфЮЊОРэЁЊЁЊФуБиаыЙизЂЫдкзіЪВУДЃЌФГИіВНжшашвЊЖрГЄЪБМфЃЌвдМАжаМфНсЙћжЎМфЕФвРРЕЙиЯЕЁЃ
етгаРћгкНЋДњТыЗжИюГЩИќаЁЕФВПЗжЃЌетаЉИќаЁЕФВПЗжПЩвдгЩзЈУХгУгкДЫШЮЮёЕФДњРэжДааЁЃШчЙћЛЙУЛгаЯыЧхГўЃЌЪдЯывЛЯТЪ§ОнМЏЕФЙЙдьдРэЃЌЫќвВЪЧЭЌбљЕФЕРРэЃЌетбљОЭПЩвдгЩЕЅИіДњРэНјаагааЇЕФДІРэЁЃЕЋЪЧетвВв§ГіСЫвЛаЉЮЪЬтЃК
- ЮЊЪВУДвЊНЋДњТыВЂааЛЏ?ТфЪЕЕНОпЬхАИР§жаЛђепдкХЌСІЕФЙ§ГЬжаЃЌЫМПМетИіЮЪЬтгавтвхТ№?
- ГЬађЪЧЗёДђЫужЛдЫаавЛДЮЃЌЛЙЪЧЛсЖЈЦкдЫаадкРрЫЦЕФЪ§ОнМЏЩЯ?
- ФмАбЫуЗЈЗжГЩМИИіЕЅЖРЕФжДааВНжшТ№?
- Ъ§ОнЪЧЗёдЪаэВЂааЛЏ?ШчЙћВЛдЪаэЃЌФЧУДЪ§ОнзщжЏНЋвдКЮжжЗНЪННјааЕїећ?
- МЦЫуЕФжаМфНсЙћЪЧЗёЯрЛЅвРРЕ?
- ашвЊЖдгВМўНјааЕїећТ№?
- дкгВМўЛђЫуЗЈжаЪЧЗёДцдкЦПОБЃЌШчКЮБмУтЛђепзюаЁЛЏетаЉвђЫиЕФгАЯь?
- ВЂааЛЏЕФЦфЫћИБзїгУгаФФаЉ?
ПЩФмЕФгУР§ОЭЪЧжїНјГЬЃЌвдМАКѓЬЈдЫааЕФЕШД§БЛМЄЛюЕФЪиЛЄНјГЬ(жї/Дг)ЁЃДЫЭтЃЌетПЩФмЪЧЦєЖЏАДашдЫааЕФЙЄзїНјГЬЕФвЛИіжївЊЙ§ГЬЁЃдкЪЕМљжаЃЌжївЊЕФЙ§ГЬЪЧвЛИіРЁЯпЙ§ГЬЃЌЫќПижЦСНИіЛђЖрИіБЛРЁЫЭЪ§ОнВПЗжЕФДњРэЃЌВЂдкИјЖЈЕФВПЗжНјааМЦЫуЁЃ
ЧыМЧзЁЃЌгЩгкВйзїЯЕЭГЫљашвЊЕФзгНјГЬЕФПЊЯњЃЌВЂааВйзїМШАКЙѓгжКФЪБЁЃгывдЯпадЗНЪНдЫааСНИіЛђЖрИіШЮЮёЯрБШЃЌдкВЂааЕФЧщПіЯТЃЌИљОнФњЕФгУР§ЃЌПЩвддкУПИізгЙ§ГЬжаНкЪЁ25%ЕН30%ЕФЪБМфЁЃР§ШчЃЌШчЙћдкЯЕСажажДааСЫСНЯюЯћКФ5УыЕФШЮЮёЃЌФЧУДзмЙВашвЊ10УыЕФЪБМфЃЌВЂЧвдкВЂааЛЏЕФЧщПіЯТЃЌдкЖрКЫЛњЦїЩЯЦНОљашвЊ8УыЁЃга3УыЪЧгУгкИїжжПЊЯњЃЌМДетВПЗжЪЧЮоЗЈбЙЫѕКЭгХЛЏЕФЃЌЫљвдЫйЖШЬсИпЪЧгаМЋЯоЕФЁЃ
дЫаагыPythonВЂааЕФКЏЪ§
PythonЬсЙЉСЫЫФжжПЩФмЕФДІРэЗНЪНЁЃЪзЯШПЩвдЪЙгУmultiprocessingФЃПщВЂаажДааЙІФмЁЃЕкЖўЃЌНјГЬЕФЬцДњЗНЗЈЪЧЯпГЬЁЃДгММЪѕЩЯНВЃЌетаЉЖМЪЧЧсСПМЖЕФНјГЬЃЌВЛдкБОЮФЕФЗЖЮЇжЎФкЁЃЯыСЫНтИќМгЯъЯИЕФФкШнЃЌПЩвдПДПДPythonЕФЯпГЬФЃПщЁЃЕкШ§ЃЌПЩвдЪЙгУosФЃПщЕФsystem()ЗНЗЈЛђsubprocessФЃПщЬсЙЉЕФЗНЗЈЕїгУЭтВПГЬађЃЌШЛКѓЪеМЏНсЙћЁЃ
multiprocessingФЃПщКИЧСЫвЛЯЕСаЗНЗЈРДДІРэВЂаажДааР§ГЬЁЃетАќРЈНјГЬЃЌДњРэГиЃЌЖгСавдМАЙмЕРЁЃ
ЧхЕЅ1ЪЙгУСЫЮхИіДњРэГЬађГиЃЌЭЌЪБДІРэШ§ИіжЕЕФПщЁЃЖдгкДњРэЕФЪ§СПКЭЖдchunksizeЕФжЕЖМЪЧШЮвтбЁдёЕФЃЌгУгкбнЪОФПЕФЁЃИљОнДІРэЦїжаКЫаФЕФЪ§СПРДЕїећетаЉжЕЁЃ
Pool.map()ЗНЗЈашвЊШ§ИіВЮЪ§ - дкЪ§ОнМЏЕФУПИідЊЫиЩЯЕїгУЕФКЏЪ§ЃЌЪ§ОнМЏБОЩэКЭchunksizeЁЃдкЧхЕЅ1жаЃЌЮвУЧЪЙгУsquareКЏЪ§ЃЌВЂМЦЫуИјЖЈећЪ§жЕЕФЦНЗНЁЃДЫЭтЃЌchunksizeВЛЪЧБиаыЕФЁЃШчЙћЮДУїШЗЩшжУЃЌдђФЌШЯchunksizeЮЊ1ЁЃ
ЧызЂвтЃЌДњРэЩЬЕФжДааЖЉЕЅВЛФмБЃжЄЃЌЕЋНсЙћМЏЕФЫГађЪЧе§ШЗЕФЁЃЫќИљОндЪМЪ§ОнМЏЕФдЊЫиЕФЫГађАќКЌЦНЗНжЕЁЃ
ЧхЕЅ1ЃКВЂаадЫааКЏЪ§
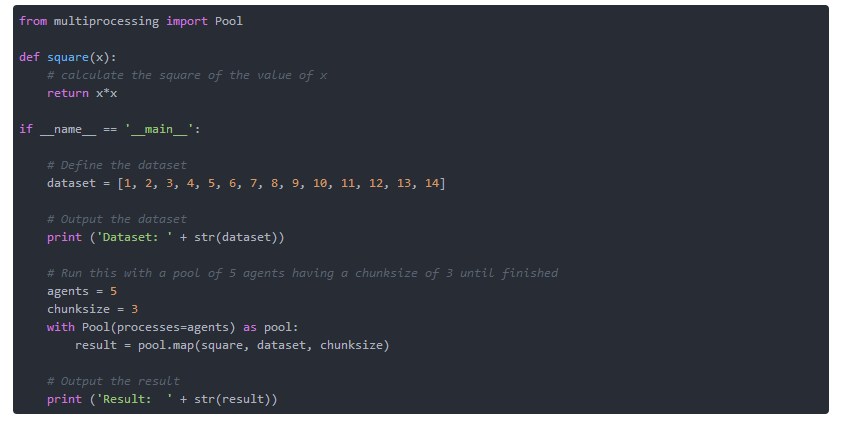
дЫааДЫДњТыгІИУВњЩњвдЯТЪфГіЃК

зЂвтЃКЮвУЧНЋЪЙгУPython 3зїЮЊетаЉР§згЁЃ
ЪЙгУЖгСадЫааЖрИіКЏЪ§
зїЮЊЪ§ОнНсЙЙЃЌЖгСаЪЧЗЧГЃЦеБщЕФЃЌВЂЧввдЖржжЗНЪНДцдкЁЃ ЫќБЛзщжЏЮЊЯШНјЯШГіЃЈFIFOЃЉЛђЯШНјЯШГіЃЈLIFOЃЉ/ЖбеЛЃЌвдМАгаКЭУЛгагХЯШМЖЃЈгХЯШМЖЖгСаЃЉЁЃ Ъ§ОнНсЙЙБЛЪЕЯжЮЊОпгаЙЬЖЈЪ§СПЬѕФПЕФЪ§зщЃЌЛђзїЮЊАќКЌПЩБфЪ§СПЕФЕЅИідЊЫиЕФСаБэЁЃ
дкСаБэ2.1-2.7жаЃЌЮвУЧЪЙгУFIFOЖгСаЁЃ ЫќБЛЪЕЯжЮЊвбОгЩРДздmultiprocessingФЃПщЕФЯргІРрЬсЙЉЕФСаБэЁЃДЫЭтЃЌtimeФЃПщБЛМгдиВЂгУгкФЃФтЙЄзїИКдиЁЃ
ЧхЕЅ2.1ЃКвЊЪЙгУЕФФЃПщ

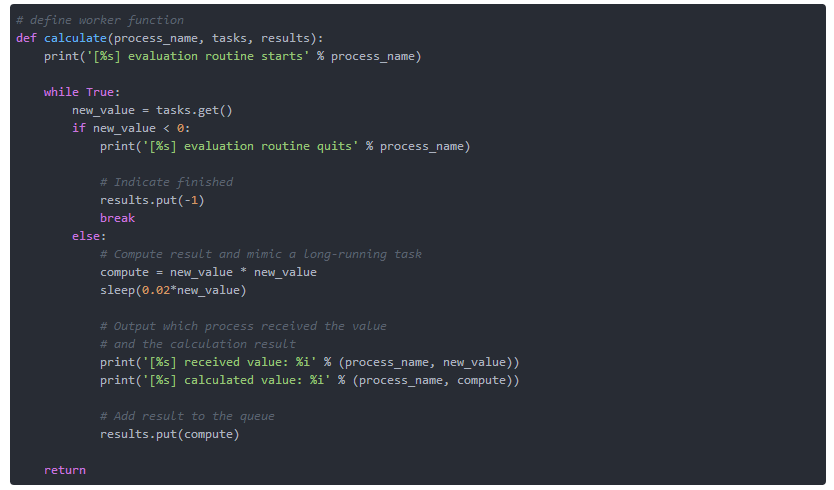
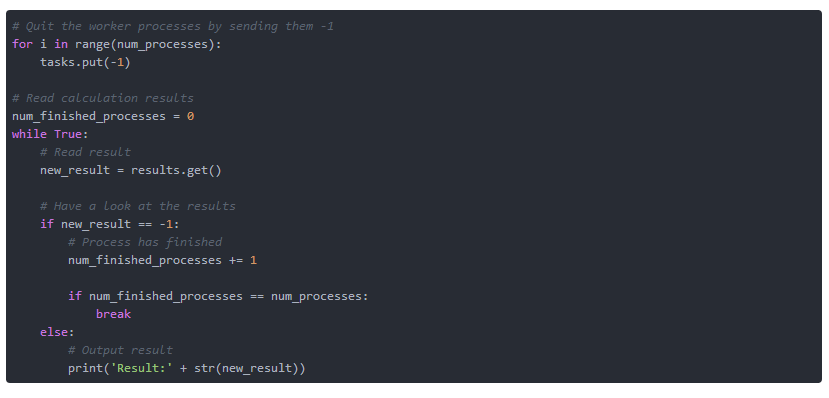
НгЯТРДЃЌЖЈвхвЛИіworkerКЏЪ§ЃЈЧхЕЅ2.2ЃЉЁЃ ИУКЏЪ§ЪЕМЪЩЯДњБэДњРэЃЌашвЊШ§ИіВЮЪ§ЁЃНјГЬУћГЦжИЪОЫќЪЧФФИіНјГЬЃЌtasksКЭresultsЖМжИЯђЯргІЕФЖгСаЁЃ
дкЙЄзїКЏЪ§РяУцЪЧвЛИіwhileбЛЗЁЃtasksКЭresultsЖМЪЧдкжїГЬађжаЖЈвхЕФЖгСаЁЃtasks.get()ДгвЊДІРэЕФШЮЮёЖгСажаЗЕЛиЕБЧАШЮЮёЁЃаЁгк0ЕФШЮЮёжЕЭЫГіwhileбЛЗЃЌЗЕЛижЕЮЊ-1ЁЃШЮКЮЦфЫћШЮЮёжЕЖМНЋжДаавЛИіМЦЫуЃЈЦНЗНЃЉЃЌВЂЗЕЛиДЫжЕЁЃНЋжЕЗЕЛиЕНжїГЬађЪЕЯжЮЊresult.put()ЁЃетНЋдкresultsЖгСаЕФФЉЮВЬэМгМЦЫужЕЁЃ
ЧхЕЅ2.2ЃКworkerКЏЪ§
ЯТвЛВНЪЧжїбЛЗЃЈВЮМћЧхЕЅ2.3ЃЉЁЃЪзЯШЃЌЖЈвхСЫНјГЬМфЭЈаХЃЈIPCЃЉЕФОРэЁЃНгЯТРДЃЌЬэМгСНИіЖгСаЃЌвЛИіБЃСєШЮЮёЃЌСэвЛИігУгкНсЙћЁЃ
ЧхЕЅ2.3ЃКIPCКЭЖгСа

ЭъГЩДЫЩшжУКѓЃЌЮвУЧЖЈвхвЛИіОпгаЫФИіЙЄзїНјГЬЃЈДњРэЃЉЕФНјГЬГиЁЃЮвУЧЪЙгУРрmultiprocessing.Pool()ЃЌВЂДДНЈвЛИіЫќЕФЪЕР§ЁЃ НгЯТРДЃЌЮвУЧЖЈвхвЛИіПеЕФНјГЬСаБэЃЈМћЧхЕЅ2.4ЃЉЁЃ
ЧхЕЅ2.4ЃКЖЈвхвЛИіНјГЬГи

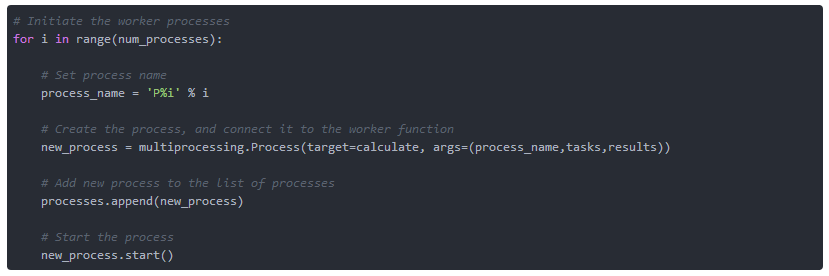
зїЮЊвдЯТВНжшЃЌЮвУЧЦєЖЏСЫЫФИіЙЄзїНјГЬЃЈДњРэЃЉЁЃ ЮЊСЫМђЕЅЦ№МћЃЌЫќУЧБЛУќУћЮЊЁАP0ЁБЕНЁАP3ЁБЁЃЪЙгУmultiprocessing.Pool()ЭъГЩДДНЈЫФИіЙЄзїНјГЬЁЃетНЋЫќУЧжаЕФУПвЛИіСЌНгЕНworkerЙІФмвдМАШЮЮёКЭНсЙћЖгСаЁЃ зюКѓЃЌЮвУЧдкНјГЬСаБэЕФФЉЮВЬэМгаТГѕЪМЛЏЕФНјГЬЃЌВЂЪЙгУnew_process.start()ЦєЖЏаТНјГЬЃЈВЮМћЧхЕЅ2.5ЃЉЁЃ
ЧхЕЅ2.5ЃКзМБИworkerНјГЬ
ЮвУЧЕФЙЄзїНјГЬе§дкЕШД§ЙЄзїЁЃЮвУЧЖЈвхвЛИіШЮЮёСаБэЃЌдкЮвУЧЕФР§згжаЪЧШЮвтбЁдёЕФећЪ§ЁЃетаЉжЕНЋЪЙгУtasks.put()ЬэМгЕНШЮЮёСаБэжаЁЃУПИіЙЄзїНјГЬЕШД§ШЮЮёЃЌВЂДгШЮЮёСаБэжабЁдёЯТвЛИіПЩгУШЮЮёЁЃ етгЩЖгСаБОЩэДІРэЃЈМћЧхЕЅ2.6ЃЉЁЃ
ЧхЕЅ2.6ЃКзМБИШЮЮёЖгСа

Й§СЫвЛЛсЖљЃЌЮвУЧЯЃЭћЮвУЧЕФДњРэЭъГЩЁЃ УПИіЙЄзїНјГЬЖджЕЮЊ-1ЕФШЮЮёзіГіЗДгІЁЃ ЫќНЋДЫжЕНтЪЭЮЊжежЙаХКХЃЌДЫКѓЫРЭіЁЃ етОЭЪЧЮЊЪВУДЮвУЧдкШЮЮёЖгСажаЗХжУОЁПЩФмЖрЕФ-1ЃЌвђЮЊЮвУЧгаНјГЬдЫааЁЃ дкЫРЛњжЎЧАЃЌжежЙЕФНјГЬЛсдкНсЙћЖгСажаЗХжУ-1ЁЃ етвтЮЖзХЪЧДњРэе§дкжежЙЕФжїбЛЗЕФШЗШЯаХКХЁЃ
дкжїбЛЗжаЃЌЮвУЧДгИУЖгСаЖСШЁЃЌВЂМЦЪ§-1ЁЃ вЛЕЉЮвУЧМЦЫуСЫЮвУЧгаЙ§ГЬЕФжежЙШЗШЯЪ§СПЃЌжїбЛЗОЭЛсЭЫГіЁЃ ЗёдђЃЌЮвУЧДгЖгСажаЪфГіМЦЫуНсЙћЁЃ
ЧхЕЅ2.7ЃКНсЙћЕФжежЙКЭЪфГі
ЪОР§2ЯдЪОСЫPythonГЬађЕФЪфГіЁЃ дЫааГЬађВЛжЙвЛДЮЃЌФњПЩФмЛсзЂвтЕНЃЌЙЄзїНјГЬЦєЖЏЕФЫГађгыДгЖгСажабЁдёШЮЮёЕФНјГЬБОЩэВЛПЩдЄВтЁЃ ЕЋЪЧЃЌвЛЕЉЭъГЩНсЙћЖгСаЕФдЊЫиЕФЫГађгыШЮЮёЖгСаЕФдЊЫиЕФЫГађЯрЦЅХфЁЃ
ЪОР§2
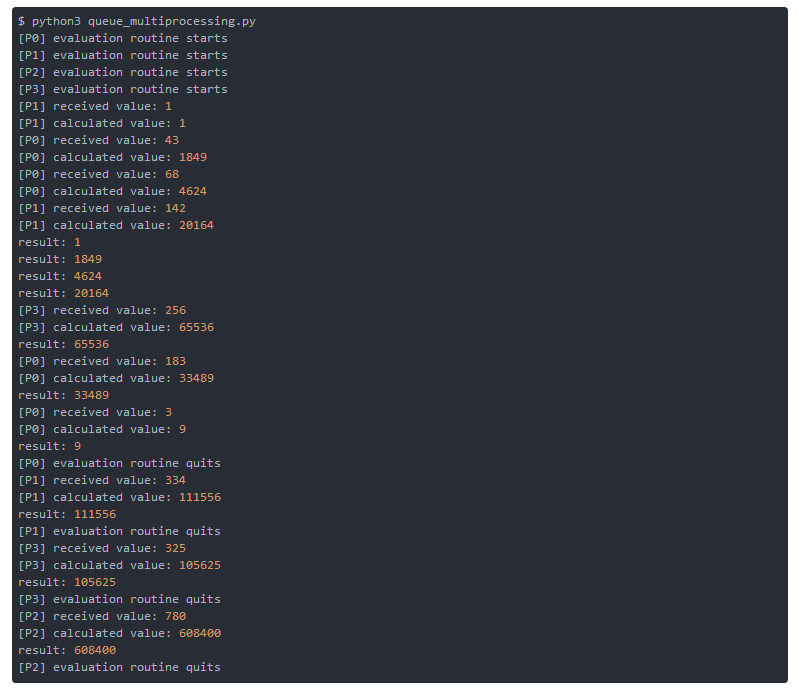
зЂвтЃКШчЧАЫљЪіЃЌгЩгкжДааЫГађВЛПЩдЄВтЃЌФњЕФЪфГіПЩФмгыЩЯУцЯдЪОЕФЪфГіВЛвЛжТЁЃ
ЪЙгУos.system()ЗНЗЈ
system()ЗНЗЈЪЧosФЃПщЕФвЛВПЗжЃЌЫќдЪаэдкгыPythonГЬађЕФЕЅЖРНјГЬжажДааЭтВПУќСюааГЬађЁЃsystem()ЗНЗЈЪЧвЛИізшШћЕїгУЃЌФуБиаыЕШЕНЕїгУЭъГЩВЂЗЕЛиЁЃ зїЮЊUNIX / LinuxАнЮяНЬЭНЃЌФњжЊЕРПЩвддкКѓЬЈдЫааУќСюЃЌВЂНЋМЦЫуНсЙћаДШыжиЖЈЯђЕНетбљЕФЮФМўЕФЪфГіСїЃЈВЮМћЪОР§3ЃЉЃК
ЪОР§3ЃКДјгаЪфГіжиЖЈЯђЕФУќСю

дкPythonГЬађжаЃЌФњжЛашМђЕЅЕиЗтзАДЫЕїгУЃЌШчЯТЫљЪОЃК
ЧхЕЅ3ЃКЪЙгУosФЃПщНјааМђЕЅЕФЯЕЭГЕїгУ

ДЫЯЕЭГЕїгУДДНЈвЛИігыЕБЧАPythonГЬађВЂаадЫааЕФНјГЬЁЃ ЛёШЁНсЙћПЩФмЛсБфЕУгаЕуМЌЪжЃЌвђЮЊетИіЕїгУПЩФмЛсдкФуЕФPythonГЬађНсЪјКѓжежЙ - ФугРдЖЖМВЛЛсжЊЕРЁЃ
ЪЙгУетжжЗНЗЈБШЮвУшЪіЕФЯШЧАЗНЗЈвЊЙѓЕУЖрЁЃ ЪзЯШЃЌПЊЯњвЊДѓЕУЖрЃЈНјГЬЧаЛЛЃЉЃЌЦфДЮЃЌЫќНЋЪ§ОнаДШыЮяРэФкДцЃЌБШШчвЛИіашвЊИќГЄЪБМфЕФДХХЬЁЃ ЫфШЛетЪЧвЛИіИќКУЕФбЁдёЃЌФуЕФФкДцгаЯоЃЈЯёRAMЃЉЃЌЖјЪЧПЩвдНЋДѓСПЪфГіЪ§ОнаДШыЙЬЬЌДХХЬЁЃ
ЪЙгУзгНјГЬФЃПщ
ИУФЃПщжМдкЬцЛЛos.system()КЭos.spawn()ЕїгУЁЃзгЙ§ГЬЕФЯыЗЈЪЧМђЛЏВњТбЙ§ГЬЃЌЭЈЙ§ЙмЕРКЭаХКХгыЫћУЧНјааЭЈаХЃЌВЂЪеМЏЫћУЧЩњГЩЕФЪфГіАќРЈДэЮѓЯћЯЂЁЃ
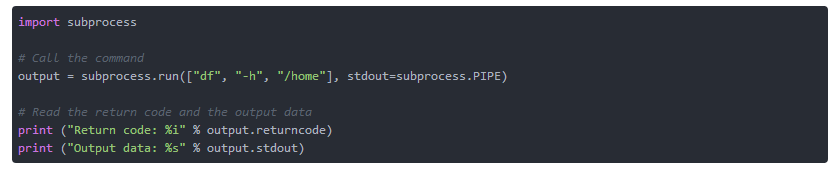
ДгPython 3.5ПЊЪМЃЌзгНјГЬАќКЌЗНЗЈsubprocess.run()РДЦєЖЏвЛИіЭтВПУќСюЃЌЫќЪЧЕзВуsubprocess.Popen()РрЕФАќзАЦїЁЃ зїЮЊЪОР§ЃЌЮвУЧЦєЖЏUNIX/LinuxУќСюdf -hЃЌвдВщевЛњЦїЕФ/ homeЗжЧјЩЯШдШЛгаЖрЩйДХХЬПеМфЁЃдкPythonГЬађжаЃЌФњПЩвджДааШчЯТЫљЪОЕФЕїгУЃЈЧхЕЅ4ЃЉЁЃ
ЧхЕЅ4ЃКдЫааЭтВПУќСюЕФЛљБОЪОР§

етЪЧЛљБОЕФЕїгУЃЌЗЧГЃРрЫЦгкдкжеЖЫжажДааЕФУќСюdf -h / homeЁЃЧызЂвтЃЌВЮЪ§БЛЗжИєЮЊСаБэЖјВЛЪЧЕЅИізжЗћДЎЁЃЪфГіНЋгыЪОР§4ЯрЫЦЁЃгыДЫФЃПщЕФЙйЗНPythonЮФЕЕЯрБШЃЌГ§СЫЕїгУЕФЗЕЛижЕжЎЭтЃЌЫќНЋЕїгУНсЙћЪфГіЕНstdoutЁЃ
ЪОР§4ЯдЪОСЫЮвУЧЕФКєНаЕФЪфГіЁЃЪфГіЕФзюКѓвЛааЯдЪОУќСюЕФГЩЙІжДааЁЃЕїгУsubprocess.run()ЗЕЛивЛИіРрCompletedProcessЕФЪЕР§ЃЌЫќгаСНИіУћЮЊargsЃЈУќСюааВЮЪ§ЃЉЕФЪєадКЭreturncodeЃЈУќСюЕФЗЕЛижЕЃЉЁЃ
ЪОР§4ЃКдЫааЧхЕЅ4жаЕФPythonНХБО

вЊвжжЦЪфГіЕНstdoutЃЌВЂВЖЛёЪфГіКЭЗЕЛижЕНјааНјвЛВНЕФЦРЙРЃЌsubprocess.run()ЕФЕїгУБиаыЩдзїаоИФЁЃУЛгаНјвЛВНаоИФЃЌsubprocess.run()НЋжДааЕФУќСюЕФЪфГіЗЂЫЭЕНstdoutЃЌетЪЧЕзВуPythonНјГЬЕФЪфГіЭЈЕРЁЃ вЊЛёШЁЪфГіЃЌЮвУЧБиаыИќИФДЫжЕЃЌВЂНЋЪфГіЭЈЕРЩшжУЮЊдЄЖЈвхжЕsubprocess.PIPEЁЃЧхЕЅ5ЯдЪОСЫШчКЮзіЕНетвЛЕуЁЃ
ЧхЕЅ5ЃКзЅШЁЙмЕРжаЕФЪфГі
ШчЧАЫљЪіЃЌsubprocess.run()ЗЕЛивЛИіРрCompletedProcessЕФЪЕР§ЁЃдкЧхЕЅ5жаЃЌетИіЪЕР§ЪЧвЛИіМђЕЅУќУћЮЊoutputЕФБфСПЁЃИУУќСюЕФЗЕЛиТыБЃДцдкЪєадoutput.returncodeжаЃЌДђгЁЕНstdoutЕФЪфГіПЩвддкЪєадoutput.stdoutжаевЕНЁЃ ЧызЂвтЃЌетВЛАќРЈДІРэДэЮѓЯћЯЂЃЌвђЮЊЮвУЧУЛгаИќИФЪфГіЧўЕРЁЃ
НсТл
гЩгкЯждкЕФгВМўвбОКмРїКІСЫЃЌвђДЫвВИјВЂааДІРэЬсЙЉСЫОјМбЕФЛњЛсЁЃPythonвВЪЙЕУгУЛЇМДЪЙдкЗЧГЃИДдгЕФМЖБ№ЃЌвВПЩвдЗУЮЪетаЉЗНЗЈЁЃе§ШчдкmultiprocessingКЭsubprocessФЃПщжЎЧАПДЕНЕФФЧбљЃЌПЩвдШУФуКмЧсЫЩЕФЖдИУжїЬтгаКмЩюШыЕФСЫНтЁЃ |









