в§бдКЭЪ§Он
ЛЖгдФЖС Python ЛњЦїбЇЯАЯЕСаНЬГЬЕФЛиЙщВПЗжЁЃетРяЃЌФугІИУвбОАВзАСЫ Scikit-LearnЁЃШчЙћУЛгаЃЌАВзАЫќЃЌвдМА
Pandas КЭ MatplotlibЁЃ
| pip install numpy
pip install scipy
pip install scikit-learn
pip install matplotlib
pip install pandas |
Г§СЫетаЉНЬГЬЗЖЮЇЕФЕМШыжЎЭтЃЌЮвУЧЛЙвЊдкетРяЪЙгУ QuandlЃК
ЪзЯШЃЌЖдгкЮвУЧНЋЦфгУгкЛњЦїбЇЯАЖјбдЃЌЪВУДЪЧЛиЙщФиЃПЫќЕФФПБъЪЧНгЪмСЌајЪ§ОнЃЌбАевзюЪЪКЯЪ§ОнЕФЗНГЬЃЌВЂФмЙЛЖдЬиЖЈжЕНјаадЄВтЁЃЪЙгУМђЕЅЕФЯпадЛиЙщЃЌФуПЩвдНіНіЭЈЙ§ДДНЈзюМбФтКЯжБЯпЃЌРДЪЕЯжЫќЁЃ
етРяЃЌЮвУЧПЩвдЪЙгУетЬѕжБЯпЕФЗНГЬЃЌРДдЄВтЮДРДЕФМлИёЃЌЦфжаШеЦкЪЧ x жсЁЃ
ЛиЙщЕФШШУХгУЗЈЪЧдЄВтЙЩЦБМлИёЁЃгЩгкЮвУЧЛсПМТЧМлИёЫцЪБМфЕФСїЖЏЃЌВЂЧвЪЙгУСЌајЕФЪ§ОнМЏЃЌГЂЪддЄВтЮДРДЕФЯТвЛИіСїЖЏМлИёЃЌЫљвдПЩвдетбљзіЁЃ
ЛиЙщЪЧМрЖНЕФЛњЦїбЇЯАЕФвЛжжЃЌвВОЭЪЧЫЕЃЌПЦбЇМвЯђЦфеЙЪОЬиеїЃЌжЎКѓЯђЦфеЙЪОе§ШЗД№АИРДНЬЛсЛњЦїЁЃвЛЕЉНЬЛсСЫЛњЦїЃЌПЦбЇМвОЭФмЙЛЪЙгУвЛаЉВЛПЩМћЕФЪ§ОнРДВтЪдЛњЦїЃЌЦфжаПЦбЇМвжЊЕРе§ШЗД№АИЃЌЕЋЪЧЛњЦїВЛжЊЕРЁЃЛњЦїЕФД№АИЛсгывбжЊД№АИЖдБШЃЌВЂЧвЖШСПЛњЦїЕФзМШЗТЪЁЃШчЙћзМШЗТЪзуЙЛИпЃЌПЦбЇМвОЭЛсПМТЧНЋЦфЫуЗЈгУгкецЪЕЪРНчЁЃ
гЩгкЛиЙщЙуЗКгУгкЙЩЦБМлИёЃЌЮвУЧПЩвдЪЙгУвЛИіЪОР§ДгетРяПЊЪМЁЃзюПЊЪМЃЌЮвУЧашвЊЪ§ОнЁЃгаЪБКђЪ§ОнвзгкЛёШЁЃЌгаЪБФуашвЊГіШЅВЂЧзздЪеМЏЁЃЮвУЧетРяЃЌЮвУЧжСЩйФмЙЛвдМђЕЅЕФЙЩЦБМлИёКЭГЩНЛСПаХЯЂПЊЪМЃЌЫќУЧРДзд
QuandlЁЃЮвУЧЛсзЅШЁ Google ЕФЙЩЦБМлИёЃЌЫќЕФДњТыЪЧGOOGLЃК
| import
pandas as pd
import quandl
df = quandl.get("WIKI/GOOGL")
print(df.head())
|
зЂвтЃКаДетЦЊЮФеТЕФЪБКђЃЌQuandl ЕФФЃПщЪЙгУДѓаД Q в§гУЃЌЕЋЯждкЪЧаЁаД qЃЌЫљвдimport
quandlЁЃ
ЕНетРяЃЌЮвУЧгЕгаЃК
| Open
High Low Close Volume Ex-Dividend \
Date
2004-08-19 100.00 104.06 95.96 100.34 44659000
0
2004-08-20 101.01 109.08 100.50 108.31 22834300
0
2004-08-23 110.75 113.48 109.05 109.40 18256100
0
2004-08-24 111.24 111.60 103.57 104.87 15247300
0
2004-08-25 104.96 108.00 103.88 106.00 9188600
0
Split Ratio Adj. Open Adj. High Adj. Low Adj.
Close \
Date
2004-08-19 1 50.000 52.03 47.980 50.170
2004-08-20 1 50.505 54.54 50.250 54.155
2004-08-23 1 55.375 56.74 54.525 54.700
2004-08-24 1 55.620 55.80 51.785 52.435
2004-08-25 1 52.480 54.00 51.940 53.000
Adj. Volume
Date
2004-08-19 44659000
2004-08-20 22834300
2004-08-23 18256100
2004-08-24 15247300
2004-08-25 9188600
|
етЪЧИіЗЧГЃКУЕФПЊЪМЃЌЮвУЧгЕгаСЫЪ§ОнЃЌЕЋЪЧгаЕуЖрСЫЁЃ
етРяЃЌЮвУЧгаКмЖрСаЃЌаэЖрЖМЪЧЖргрЕФЃЌЛЙгааЉВЛдѕУДБфЛЏЁЃЮвУЧПЩвдПДЕНЃЌГЃЙцКЭаое§ЃЈAdjЃЉЕФСаЪЧжиИДЕФЁЃаое§ЕФСаПДЦ№РДИќМгРэЯыЁЃГЃЙцЕФСаЪЧЕБЬьЕФМлИёЃЌЕЋЪЧЙЩЦБгаИіНазіЗжВ№ЕФЖЋЮїЃЌЦфжавЛЙЩЭЛШЛОЭБфГЩСЫСНЙЩЃЌЫљвдвЛЙЩЕФМлИёвЊМѕАыЃЌЕЋЪЧЙЋЫОЕФМлжЕВЛБфЁЃаое§ЕФСаЮЊЙЩЦБЗжВ№ЖјЕїећЃЌетЪЙЕУЫќУЧЖдгкЗжЮіИќМгПЩППЁЃ
ЫљвдЃЌШУЮвУЧМЬајЃЌЯїМѕдЪМЕФ DataFrameЁЃ
| df
= df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
|
ЯждкЮвУЧгЕгаСЫаое§ЕФСаЃЌвдМАГЩНЛСПЁЃгавЛаЉЖЋЮїашвЊзЂвтЁЃаэЖрШЫЬИТлЛђепЬ§ЫЕЛњЦїбЇЯАЃЌОЭЯёЮожаЩњгаЕФКкФЇЗЈЁЃЛњЦїбЇЯАПЩвдЭЛГівбгаЕФЪ§ОнЃЌЕЋЪЧЪ§ОнашвЊЯШДцдкЁЃФуашвЊгавтвхЕФЪ§ОнЁЃЫљвдФудѕУДжЊЕРЪЧЗёгавтвхФиЃПЮвЕФзюМбНЈвщОЭЪЧЃЌНіНіМђЛЏФуЕФДѓФдЁЃПМТЧвЛЯТЃЌРњЪЗМлИёЛсОіЖЈЮДРДМлИёТ№ЃПгааЉШЫетУДШЯЮЊЃЌЕЋЪЧОУЖјОУжЎетБЛжЄЪЕЪЧДэЮѓЕФЁЃЕЋЪЧРњЪЗЙцТЩФиЃПЭЛГіЕФЪБКђЛсгавтвхЃЈЛњЦїбЇЯАЛсгаЫљАяжњЃЉЃЌЕЋЪЧЛЙЪЧЬЋШѕСЫЁЃФЧУДЃЌМлИёБфЛЏКЭГЩНЛСПЫцЪБМфЕФЙиЯЕЃЌдйМгЩЯРњЪЗЙцТЩФиЃППЩФмИќКУвЛЕуЁЃЫљвдЃЌФувбОФмЙЛПДЕНЃЌВЂВЛЪЧЪ§ОндНЖрдНКУЃЌЖјЪЧЮвУЧашвЊЪЙгУгагУДІЕФЪ§ОнЁЃЭЌЪБЃЌдЪМЪ§ОнгІИУзівЛаЉзЊЛЛЁЃ
ПМТЧУПШеВЈЖЏЃЌР§ШчзюИпМлМѕзюЕЭМлЕФАйЗжБШВюжЕШчКЮЃПУПШеЕФАйЗжБШБфЛЏгжШчКЮФиЃПФуОѕЕУOpen, High,
Low, CloseетжжМђЕЅЪ§ОнЃЌЛЙЪЧClose, Spread/Volatility, %change
dailyИќКУЃПЮвОѕЕУКѓепИќКУвЛЕуЁЃЧАепЖМЪЧЗЧГЃЯрЫЦЕФЪ§ОнЕуЃЌКѓепЛљгкЧАепЕФЭГвЛЪ§ОнДДНЈЃЌЕЋЪЧДјгаИќМггаМлжЕЕФаХЯЂЁЃ
ЫљвдЃЌВЂВЛЪЧФугЕгаЕФЫљгаЪ§ОнЖМЪЧгагУЕФЃЌВЂЧвгаЪБФуашвЊЖдФуЕФЪ§ОнжДааНјвЛВНЕФВйзїЃЌВЂЪЙЦфИќМггаМлжЕЃЌжЎКѓВХФмЬсЙЉИјЛњЦїбЇЯАЫуЗЈЁЃШУЮвУЧМЬајВЂзЊЛЛЮвУЧЕФЪ§ОнЃК
| df['HL_PCT']
= (df['Adj. High'] - df['Adj. Low']) / df['Adj.
Close'] * 100.0 |
етЛсДДНЈвЛИіаТЕФСаЃЌЫќЪЧЛљгкЪеХЬМлЕФАйЗжБШМЋВюЃЌетЪЧЮвУЧЖдгкВЈЖЏЕФДжВкЖШСПЁЃЯТУцЃЌЮвУЧЛсМЦЫуУПШеАйЗжБШБфЛЏЃК
| df['PCT_change']
= (df['Adj. Close'] - df['Adj. Open']) / df['Adj.
Open'] * 100.0 |
ЯждкЮвУЧЛсЖЈвхвЛИіаТЕФ DataFrameЃК
| df
= df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
print(df.head()) |
|
Adj. Close HL_PCT PCT_change Adj. Volume
Date
2004-08-19 50.170 8.072553 0.340000 44659000
2004-08-20 54.155 7.921706 7.227007 22834300
2004-08-23 54.700 4.049360 -1.218962 18256100
2004-08-24 52.435 7.657099 -5.726357 15247300
2004-08-25 53.000 3.886792 0.990854 9188600 |
ЬиеїКЭБъЧЉ
ЛљгкЩЯвЛЦЊЛњЦїбЇЯАЛиЙщНЬГЬЃЌЮвУЧНЋвЊЖдЮвУЧЕФЙЩЦБМлИёЪ§ОнжДааЛиЙщЁЃФПЧАЕФДњТыЃК
| import
quandl
import pandas as pd
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low'])
/ df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj.
Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
print(df.head()) |
етРяЮвУЧвбОЛёШЁСЫЪ§ОнЃЌХаЖЯГігаМлжЕЕФЪ§ОнЃЌВЂЭЈЙ§ВйзїДДНЈСЫвЛаЉЁЃЮвУЧЯждквбОзМБИКУЪЙгУЛиЙщПЊЪМЛњЦїбЇЯАЕФЙ§ГЬЁЃЪзЯШЃЌЮвУЧашвЊвЛаЉИќЖрЕФЕМШыЁЃЫљгаЕФЕМШыЪЧЃК
| import
quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation,
svm
from sklearn.linear_model import LinearRegression |
ЮвУЧЛсЪЙгУnumpyФЃПщРДНЋЪ§ОнзЊЛЛЮЊ NumPy Ъ§зщЃЌЫќЪЧ Sklearn ЕФдЄЦкЁЃЮвУЧдкгУЕНpreprocessingКЭcross_validationЪБЃЌЛсЩюШыЬИТлЫћУЧЃЌЕЋЪЧдЄДІРэЪЧгУгкдкЛњЦїбЇЯАжЎЧАЃЌЖдЪ§ОнЧхЯДКЭЫѕЗХЕФФЃПщЁЃНЛВцбщжЄдкВтЪдНзЖЮЪЙгУЁЃзюКѓЃЌЮвУЧвВДг
Sklearn ЕМШыСЫLinearRegressionЫуЗЈЃЌвдМАsvmЁЃЫќУЧгУзїЮвУЧЕФЛњЦїбЇЯАЫуЗЈРДеЙЪОНсЙћЁЃ
етРяЃЌЮвУЧвбОЛёШЁСЫЮвУЧШЯЮЊгагУЕФЪ§ОнЁЃецЪЕЕФЛњЦїбЇЯАШчКЮЙЄзїФиЃПЪЙгУМрЖНЪНбЇЯАЃЌФуашвЊЬиеїКЭБъЧЉЁЃЬиеїОЭЪЧУшЪіадЪєадЃЌБъЧЉОЭЪЧФуГЂЪддЄВтЕФНсЙћЁЃСэвЛИіГЃМћЕФЛиЙщЪОР§ОЭЪЧГЂЪдЮЊФГИіШЫдЄВтБЃЯеЕФБЃЗбЁЃБЃЯеЙЋЫОЛсЪеМЏФуЕФФъСфЁЂМнЪЛЮЅЙцааЮЊЁЂЙЋЙВЗИзяМЧТМЃЌвдМАФуЕФаХгУЦРЗжЁЃЙЋЫОЛсЪЙгУРЯПЭЛЇЃЌЛёШЁЪ§ОнЃЌВЂЕУГігІИУИјПЭЛЇЕФЁАРэЯыБЃЗбЁБЃЌЛђепШчЙћЫћУЧОѕЕУгаРћПЩЭМЕФЛАЃЌЫћУЧЛсЪЙгУЪЕМЪЪЙгУЕФПЭЛЇЁЃ
ЫљвдЃЌЖдгкбЕСЗЛњЦїбЇЯАЗжРрЦїРДЫЕЃЌЬиеїЪЧПЭЛЇЪєадЃЌБъЧЉЪЧКЭетаЉЪєадЯрЙиЕФБЃЗбЁЃ
ЮвУЧетРяЃЌЪВУДЪЧЬиеїКЭБъЧЉФиЃПЮвУЧГЂЪддЄВтМлИёЃЌЫљвдМлИёОЭЪЧБъЧЉЃПШчЙћетбљЃЌЪВУДЪЧЬиеїФиЃПЖдгкдЄВтЮвУЧЕФМлИёРДЫЕЃЌЮвУЧЕФБъЧЉЃЌОЭЪЧЮвУЧДђЫудЄВтЕФЖЋЮїЃЌЪЕМЪЩЯЪЧЮДРДМлИёЁЃетбљЃЌЮвУЧЕФЬиеїЪЕМЪЩЯЪЧЃКЕБЧАМлИёЁЂHL
АйЗжБШКЭАйЗжБШБфЛЏЁЃБъЧЉМлИёЪЧЮДРДФГИіЕуЕФМлИёЁЃШУЮвУЧМЬајЬэМгаТЕФааЃК
| forecast_col
= 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df))) |
етРяЃЌЮвУЧЖЈвхСЫдЄВтСаЃЌжЎКѓЮвУЧНЋШЮКЮ NaN Ъ§ОнЬюГфЮЊ -99999ЁЃЖдгкШчКЮДІРэШБЪЇЪ§ОнЃЌФугавЛаЉбЁдёЃЌФуВЛФмНіНіНЋ
NaNЃЈВЛЪЧЪ§жЕЃЉЪ§ОнЕуДЋИјЛњЦїбЇЯАЗжРрЮїЃЌФуашвЊДІРэЫќЁЃвЛИіжїСїбЁЯюОЭЪЧНЋШБЪЇжЕЬюГфЮЊ -99999ЁЃдкаэЖрЛњЦїбЇЯАЗжРрЦїжаЃЌЛсНЋЦфЪЧБЛЮЊРыШКЕуЁЃФувВПЩвдНіНіЖЊЦњАќКЌШБЪЇжЕЕФЫљгаЬиеїЛђБъЧЉЃЌЕЋЪЧетбљФуПЩФмЛсЖЊЕєДѓСПЕФЪ§ОнЁЃ
ецЪЕЪРНчжаЃЌаэЖрЪ§ОнМЏЖМКмЛьТвЁЃЖрЪ§ЙЩМлЛђГЩНЛСПЪ§ОнЖМКмИЩОЛЃЌКмЩйгаШБЪЇЪ§ОнЃЌЕЋЪЧаэЖрЪ§ОнМЏЛсгаДѓСПШБЪЇЪ§ОнЁЃЮвМћЙ§вЛаЉЪ§ОнМЏЃЌДѓСПЕФааКЌгаШБЪЇЪ§ОнЁЃФуВЂВЛвЛЖЈЯывЊЪЇШЅЫљгаВЛДэЕФЪ§ОнЃЌШчЙћФуЕФбљР§Ъ§ОнгавЛаЉШБЪЇЃЌФуПЩФмЛсВТВтецЪЕЪРНчЕФгУР§вВгавЛаЉШБЪЇЁЃФуашвЊбЕСЗЁЂВтЪдВЂвРРЕЯрЭЌЪ§ОнЃЌвдМАЪ§ОнЕФЬиеїЁЃ
зюКѓЃЌЮвУЧЖЈвхЮвУЧашвЊдЄВтЕФЖЋЮїЁЃаэЖрЧщПіЯТЃЌОЭЯёГЂЪддЄВтПЭЛЇЕФБЃЗбЕФАИР§жаЃЌФуНіНіашвЊвЛИіЪ§зжЃЌЕЋЪЧЖдгкдЄВтРДЫЕЃЌФуашвЊдЄВтжИЖЈЪ§СПЕФЪ§ОнЕуЁЃЮвУЧМйЩшЮвУЧДђЫудЄВтЪ§ОнМЏећИіГЄЖШЕФ
1%ЁЃвђДЫЃЌШчЙћЮвУЧЕФЪ§ОнЪЧ 100 ЬьЕФЙЩЦБМлИёЃЌЮвУЧашвЊФмЙЛдЄВтЮДРДвЛЬьЕФМлИёЁЃбЁдёФуЯывЊЕФФЧИіЁЃШчЙћФужЛЪЧГЂЪддЄВтУїЬьЕФМлИёЃЌФугІИУбЁШЁвЛЬьжЎКѓЕФЪ§ОнЃЌЖјЧввВжЛФмвЛЬьжЎКѓЕФЪ§ОнЁЃШчЙћФуДђЫудЄВт
10 ЬьЃЌЮвУЧПЩвдЮЊУПвЛЬьЩњГЩвЛИідЄВтЁЃ
ЮвУЧетРяЃЌЮвУЧОіЖЈСЫЃЌЬиеїЪЧвЛЯЕСаЕБЧАжЕЃЌБъЧЉЪЧЮДРДЕФМлИёЃЌЦфжаЮДРДЪЧЪ§ОнМЏећИіГЄЖШЕФ 1%ЁЃЮвУЧМйЩшЫљгаЕБЧАСаЖМЪЧЮвУЧЕФЬиеїЃЌЫљвдЮвУЧЪЙгУвЛИіМђЕЅЕФ
Pnadas ВйзїЬэМгвЛИіаТЕФСаЃК
| df['label']
= df[forecast_col].shift(-forecast_out) |
ЯждкЮвУЧгЕгаСЫЪ§ОнЃЌАќКЌЬиеїКЭБъЧЉЁЃЯТУцЮвУЧдкЪЕМЪдЫааШЮКЮЖЋЮїжЎЧАЃЌЮвУЧашвЊзівЛаЉдЄДІРэКЭзюжеВНжшЃЌЮвУЧдкЯТвЛЦЊНЬГЬЛсЙизЂЁЃ
бЕСЗКЭВтЪд
ЛЖгдФЖС Python ЛњЦїбЇЯАЯЕСаНЬГЬЕФЕкЫФВПЗжЁЃдкЩЯвЛИіНЬГЬжаЃЌЮвУЧЛёШЁСЫГѕЪМЪ§ОнЃЌАДееЮвУЧЕФЯВКУВйзїКЭзЊЛЛЪ§ОнЃЌжЎКѓЮвУЧЖЈвхСЫЮвУЧЕФЬиеїЁЃScikit
ВЛашвЊДІРэ Pandas КЭ DataFrameЃЌЮвГігкздМКЕФЯВКУЖјДІРэЫќЃЌвђЮЊЫќПьВЂЧвИпаЇЁЃЗДжЎЃЌSklearn
ЪЕМЪЩЯашвЊ NumPy Ъ§зщЁЃPandas ЕФ DataFrame ПЩвдЧсвззЊЛЛЮЊ NumPy Ъ§зщЃЌЫљвдЪТЧщОЭЪЧетбљЕФЁЃ
ФПЧАЮЊжЙЮвУЧЕФДњТыЃК
| import
quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation,
svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
print(df.head())
#print(df.tail())
df = df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj.
Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj.
Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
print(df.head())
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out) |
ЮвУЧжЎКѓвЊЖЊЦњЫљгаШдОЩЪЧ NaN ЕФаХЯЂЁЃ
ЖдгкЛњЦїбЇЯАРДЫЕЃЌЭЈГЃвЊЖЈвхXЃЈДѓаДЃЉзїЮЊЬиеїЃЌКЭyЃЈаЁаДЃЉзїЮЊЖдгкЬиеїЕФБъЧЉЁЃетбљЃЌЮвУЧПЩвдЖЈвхЮвУЧЕФЬиеїКЭБъЧЉЃЌЯёетбљЃК
| X
= np.array(df.drop(['label'], 1))
y = np.array(df['label']) |
ЩЯУцЃЌЮвУЧЫљзіЕФОЭЪЧЖЈвхXЃЈЬиеїЃЉЃЌЪЧЮвУЧећИіЕФ DataFrameЃЌГ§СЫlabelСаЃЌВЂзЊЛЛЮЊ NumPy
Ъ§зщЁЃЮвУЧЪЙгУdropЗНЗЈЃЌПЩвдгУгк DataFrameЃЌЫќЗЕЛивЛИіаТЕФ DataFrameЁЃЯТУцЃЌЮвУЧЖЈвхЮвУЧЕФyБфСПЃЌЫќЪЧЮвУЧЕФБъЧЉЃЌНіНіЪЧ
DataFrame ЕФБъЧЉСаЃЌВЂзЊЛЛЮЊ NumPy Ъ§зщЁЃ
ЯждкЮвУЧОЭФмИцвЛЖЮТфЃЌзЊЯђбЕСЗКЭВтЪдСЫЃЌЕЋЪЧЮвУЧДђЫузівЛаЉдЄДІРэЁЃЭЈГЃЃЌФуЯЃЭћФуЕФЬиеїдк -1 ЕН
1 ЕФЗЖЮЇФкЁЃетПЩФмВЛЦ№зїгУЃЌЕЋЪЧЭЈГЃЛсМгЫйДІРэЙ§ГЬЃЌВЂгажњгкзМШЗадЁЃвђЮЊДѓМвЖМЪЙгУетИіЗЖЮЇЃЌЫќАќКЌдкСЫ
Sklearn ЕФpreprocessingФЃПщжаЁЃЮЊСЫЪЙгУЫќЃЌФуашвЊЖдФуЕФXБфСПЕїгУpreprocessing.scaleЁЃ
| X
= preprocessing.scale(X) |
ЯТУцЃЌДДНЈБъЧЉyЃК
| y
= np.array(df['label']) |
ЯждкОЭЪЧбЕСЗКЭВтЪдЕФЪБКђСЫЁЃЗНЪНОЭЪЧбЁШЁ 75% ЕФЪ§ОнгУгкбЕСЗЛњЦїбЇЯАЗжРрЦїЁЃжЎКѓбЁШЁЪЃЯТЕФ 25%
ЕФЪ§ОнгУгкВтЪдЗжРрЦїЁЃгЩгкетЪЧФуЕФбљР§Ъ§ОнЃЌФугІИУгЕгаЬиеїКЭвЛжББъЧЉЁЃвђДЫЃЌШчЙћФуВтЪдКѓ 25% ЕФЪ§ОнЃЌФуОЭЛсЕУЕНвЛжжзМШЗЖШКЭПЩППадЃЌНазіжУаХЖШЁЃгааэЖрЗНЪНПЩвдЪЕЯжЫќЃЌЕЋЪЧЃЌзюКУЕФЗНЪНПЩФмОЭЪЧЪЙгУФкНЈЕФcross_validationЃЌвђЮЊЫќвВЛсЮЊФуДђТвЪ§ОнЁЃДњТыЪЧетбљЃК
| X_train,
X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.2) |
етРяЕФЗЕЛижЕЪЧЬиеїЕФбЕСЗМЏЁЂВтЪдМЏЁЂБъЧЉЕФбЕСЗМЏКЭВтЪдМЏЁЃЯждкЃЌЮвУЧвбОЖЈвхКУСЫЗжРрЦїЁЃSklearn
ЬсЙЉСЫаэЖрЭЈгУЕФЗжРрЦїЃЌгавЛаЉПЩвдгУгкЛиЙщЁЃЮвУЧЛсдкетИіР§згжаеЙЪОвЛаЉЃЌЕЋЪЧЯждкЃЌШУЮвУЧЪЙгУsvmАќжаЕФжЇГжЯђСПЛиЙщЁЃ
ЮвУЧетРяНіНіЪЙгУФЌШЯбЁЯюРДЪЙЪТЧщМђЕЅЃЌЕЋЪЧФуПЩвддкsklearn.svm.SVRЕФЮФЕЕжаСЫНтИќЖрЁЃ
вЛЕЉФуЖЈвхСЫЗжРрЦїЃЌФуОЭПЩвдбЕСЗЫќСЫЁЃдк Sklearn жаЃЌЪЙгУfitРДбЕСЗЁЃ
| clf.fit(X_train,
y_train)1 |
етРяЃЌЮвУЧФтКЯСЫЮвУЧЕФбЕСЗЬиеїКЭбЕСЗБъЧЉЁЃ
ЮвУЧЕФЗжРрЦїЯждкбЕСЗЭъБЯЁЃетЗЧГЃМђЕЅЃЌЯждкЮвУЧПЩвдВтЪдСЫЁЃ
| confidence
= clf.score(X_test, y_test) |
МгдиВтЪдЃЌжЎКѓЃК
| print(confidence)
# 0.960075071072 |
ЫљвдетРяЃЌЮвУЧПЩвдПДЕНзМШЗТЪМИКѕЪЧ 96%ЁЃУЛгаЪВУДПЩЫЕЕФЃЌШУЮвУЧГЂЪдСэвЛИіЗжРрЦїЃЌетвЛДЮЪЙгУLinearRegressionЃК
| clf
= LinearRegression()
# 0.963311624499 |
ИќКУвЛЕуЃЌЕЋЪЧЛљБОвЛбљЁЃЫљвдзїЮЊПЦбЇМвЃЌЮвУЧШчКЮжЊЕРЃЌбЁдёФФИіЫуЗЈФиЃПВЛОУЃЌФуЛсЪьЯЄЪВУДдкЖрЪ§ЧщПіЯТЖМЙЄзїЃЌЪВУДВЛЙЄзїЁЃФуПЩвдДг
Scikit ЕФеОЕуЩЯВщПДбЁдёе§ШЗЕФЦРЙРЙЄОпЁЃетгажњгкФуфЏРРвЛаЉЛљБОЕФбЁЯюЁЃШчЙћФубЏЮЪИуЛњЦїбЇЯАЕФШЫЃЌЫќЭъШЋЪЧЪдбщКЭГіДэЁЃФуЛсГЂЪдДѓСПЕФЫуЗЈВЂЧвНіНібЁШЁзюКУЕФФЧИіЁЃвЊзЂвтЕФСэвЛМўЪТЧщОЭЪЧЃЌвЛаЉЫуЗЈБиаыЯпаддЫааЃЌЦфЫќЕФВЛЪЧЁЃВЛвЊАбЯпадЛиЙщКЭЯпаддЫааИуЛьСЫЁЃЫљвдетаЉвтЮЖзХЪВУДФиЃПвЛаЉЛњЦїбЇЯАЫуЗЈЛсвЛДЮДІРэвЛВНЃЌУЛгаЖрЯпГЬЃЌЦфЫќЕФЪЙгУЖрЯпГЬЃЌВЂЧвПЩвдРћгУФуЛњЦїЩЯЕФЖрКЫЁЃФуПЩвдЩюШыСЫНтУПИіЫуЗЈЃЌРДХЊЧхГўФФИіПЩвдЖрЯпГЬЃЌЛђепФуПЩвддФЖСЮФЕЕЃЌВЂВщПДn_jobsВЮЪ§ЁЃШчЙћгЕгаn_jobsЃЌФуОЭПЩвдШУЫуЗЈЭЈЙ§ЖрЯпГЬРДЛёШЁИќИпЕФадФмЁЃШчЙћУЛгаЃЌОЭКмВЛзпдЫСЫЁЃЫљвдЃЌШчЙћФуДІРэДѓСПЕФЪ§ОнЃЌЛђепашвЊДІРэжаЕШЙцФЃЕФЪ§ОнЃЌЕЋЪЧашвЊКмИпЕФЫйЖШЃЌФуОЭПЩФмЯывЊЯпГЬМгЫйЁЃШУЮвУЧПДПДетСНИіЫуЗЈЁЃ
ЗУЮЪsklearn.svm.SVRЕФЮФЕЕЃЌВЂВщПДВЮЪ§ЃЌПДЕНn_jobsСЫТяЃПЗДе§ЮвУЛПДЕНЃЌЫљвдЫќОЭВЛФмЪЙгУЯпГЬЁЃФуПЩФмЛсПДЕНЃЌдкЮвУЧЕФаЁаЭЪ§ОнМЏЩЯЃЌВювьВЛДѓЁЃЕЋЪЧЃЌМйЩшЪ§ОнМЏгЩ
20MBЃЌВювьОЭКмУїЯдЁЃШЛКѓЃЌЮвУЧВщПДLinearRegressionЫуЗЈЃЌПДЕНn_jobsСЫТяЃПЕБШЛЃЌЫљвдетРяЃЌФуПЩвджИЖЈФуЯЃЭћЖрЩйЯпГЬЁЃШчЙћФуДЋШы-1ЃЌЫуЗЈЛсЪЙгУЫљгаПЩгУЕФЯпГЬЁЃ
етбљЃК
| clf
= LinearRegression(n_jobs=-1) |
ОЭЙЛСЫЁЃЫфШЛЮвШУФузіСЫКмЩйЕФЪТЧщЃЈВщПДЮФЕЕЃЉЃЌШУЮвИјФуЫЕИіЪТЪЕАЩЃЌНіНігЩгкЛњЦїбЇЯАЫуЗЈЪЙгУФЌШЯВЮЪ§ЙЄзїЃЌВЛДњБэФуПЩвдКіТдЫќУЧЁЃР§ШчЃЌШУЮвУЧЛиЙЫsvm.SVRЁЃSVR
ЪЧжЇГжЯђСПЛиЙщЃЌдкжДааЛњЦїбЇЯАЪБЃЌЫќЪЧвЛжжМмЙЙЁЃЮвЗЧГЃЙФРјФЧаЉгааЫШЄбЇЯАИќЖрЕФШЫЃЌШЅбаОПетИіжїЬтЃЌвдМАЯђБШЮвбЇРњИќИпЕФШЫбЇЯАЛљДЁЁЃЮвЛсОЁСІАбЖЋЮїНтЪЭЕУИќМђЕЅЃЌЕЋЪЧЮвВЂВЛЪЧзЈМвЁЃЛиЕНИеВХЕФЛАЬтЃЌsvm.SVRгавЛИіВЮЪ§НазіkernelЁЃетИіЪЧЪВУДФиЃПКЫОЭЯрЕБгкФуЕФЪ§ОнЕФзЊЛЛЁЃетЪЙЕУДІРэЙ§ГЬИќМгбИЫйЁЃдкsvm.SVRЕФР§згжаЃЌФЌШЯжЕЪЧrbfЃЌетЪЧКЫЕФвЛИіРраЭЃЌФугавЛаЉбЁдёЁЃВщПДЮФЕЕЃЌФуПЩвдбЁдё'linear',
'poly', 'rbf', 'sigmoid', 'precomputed'ЛђепвЛИіПЩЕїгУЖдЯѓЁЃЭЌбљЃЌОЭЯёГЂЪдВЛЭЌЕФ
ML ЫуЗЈвЛбљЃЌФуПЩвдзіФуЯызіЕФШЮКЮЪТЧщЃЌГЂЪдвЛЯТВЛЭЌЕФКЫАЩЁЃ
| for
k in ['linear','poly','rbf','sigmoid']:
clf = svm.SVR(kernel=k)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(k,confidence)1
linear 0.960075071072
poly 0.63712232551
rbf 0.802831714511
sigmoid -0.125347960903
|
ЮвУЧПЩвдПДЕНЃЌЯпадЕФКЫБэЯжзюКУЃЌжЎКѓЪЧrbfЃЌжЎКѓЪЧpolyЃЌsigmoidКмЯдШЛЪЧИіАкЩшЃЌВЂЧвгІИУвЦГ§ЁЃ
ЫљвдЮвУЧбЕСЗВЂВтЪдСЫЪ§ОнМЏЁЃЮвУЧвбОга 71% ЕФТњвтЖШСЫЁЃЯТУцЮвУЧзіЪВУДФиЃПЯждкЮвУЧашвЊдйНјвЛВНЃЌзівЛаЉдЄВтЃЌЯТвЛеТЛсЩцМАЫќЁЃ
дЄВт
ЛЖгдФЖСЛњЦїбЇЯАЯЕСаНЬГЬЕФЕкЮхеТЃЌЕБЧАЩцМАЕНЛиЙщЁЃФПЧАЮЊжЙЃЌЮвУЧЪеМЏВЂаоИФСЫЪ§ОнЃЌбЕСЗВЂВтЪдСЫЗжРрЦїЁЃетвЛеТжаЃЌЮвУЧДђЫуЪЙгУЮвУЧЕФЗжРрЦїРДЪЕМЪзівЛаЉдЄВтЁЃЮвУЧФПЧАЫљЪЙгУЕФДњТыЮЊЃК
| import
quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation,
svm
from sklearn.linear_model import LinearRegression
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low'])
/ df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj.
Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence) |
ЮвЛсЧПЕїЃЌзМШЗТЪДѓгк 95% ЕФЯпадФЃаЭВЂВЛЪЧФЧУДКУЁЃЮвЕБШЛВЛЛсгУЫќРДНЛвзЙЩЦБЁЃШдШЛгавЛаЉашвЊПМТЧЕФЮЪЬтЃЌЬиБ№ЪЧВЛЭЌЙЋЫОгаВЛЭЌЕФМлИёЙьМЃЁЃGoogle
ЗЧГЃЯпадЃЌЯђгвЩЯНЧвЦЖЏЃЌаэЖрЙЋЫОВЛЪЧетбљЃЌЫљвдвЊМЧзЁЁЃЯждкЃЌЮЊСЫзідЄВтЃЌЮвУЧашвЊвЛаЉЪ§ОнЁЃЮвУЧОіЖЈдЄВт
1% ЕФЪ§ОнЃЌвђДЫЮвУЧДђЫуЃЌЛђепжСЩйФмЙЛдЄВтЪ§ОнМЏЕФКѓ 1%ЁЃЫљвдЮвУЧЪВУДПЩвдетбљзіФиЃПЮвУЧЪВУДЪБКђПЩвдЪЖБ№етаЉЪ§ОнЃПЮвУЧЯждкОЭПЩвдЃЌЕЋЪЧвЊзЂвтЮвУЧГЂЪддЄВтЕФЪ§ОнЃЌВЂУЛгаЯёбЕСЗМЏФЧбљЫѕЗХЁЃКУЕФЃЌФЧУДзіЪВУДФиЃПЪЧЗёвЊЖдКѓ
1% ЕїгУpreprocessing.scale()ЃПЫѕЗХЗНЗЈЛљгкЫљгаИјЫќЕФвбжЊЪ§ОнМЏЁЃРэЯыЧщПіЯТЃЌФугІИУвЛЭЌЫѕЗХбЕСЗМЏЁЂВтЪдМЏКЭгУгкдЄВтЕФЪ§ОнЁЃетгРдЖЪЧПЩФмЛђКЯРэЕФТяЃПВЛЪЧЃЌШчЙћФуПЩвдетУДзіЃЌФуОЭгІИУетУДзіЁЃЕЋЪЧЃЌЮвУЧетРяЃЌЮвУЧПЩвдетУДзіЁЃЮвУЧЕФЪ§ОнзуЙЛаЁЃЌВЂЧвДІРэЪБМфзуЙЛЕЭЃЌЫљвдЮвУЧЛсвЛДЮаддЄДІРэВЂЫѕЗХЪ§ОнЁЃ
дкаэЖрР§згжаЃЌФуВЛФметУДзіЁЃЯыЯѓШчЙћФуЪЙгУМИИі GB ЕФЪ§ОнРДбЕСЗЗжРрЦїЁЃбЕСЗЗжРрЦїЛсЛЈЗбМИЬьЃЌВЛФмдкУПДЮЯывЊзіГідЄВтЕФЪБКђЖМетУДзіЁЃвђДЫЃЌФуПЩФмашвЊВЛЫѕЗХШЮКЮЖЋЮїЃЌЛђепЕЅЖРЫѕЗХЪ§ОнЁЃЭЈГЃЃЌФуПЩФмЯЃЭћВтЪдетСНИібЁЯюЃЌВЂПДПДФЧИіЖдгкФуЕФЬиЖЈАИР§ИќКУЁЃ
вЊМЧзЁЫќЃЌШУЮвУЧдкЖЈвхXЕФЪБКђДІРэЫљгаааЃК
| X
= np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(confidence) |
вЊзЂвтЮвУЧЪзЯШЛёШЁЫљгаЪ§ОнЃЌдЄДІРэЃЌжЎКѓдйЗжИюЁЃЮвУЧЕФX_latelyБфСПАќКЌзюНќЕФЬиеїЃЌЮвУЧашвЊЖдЦфНјаадЄВтЁЃФПЧАФуПЩвдПДЕНЃЌЖЈвхЗжРрЦїЁЂбЕСЗЁЂКЭВтЪдЖМЗЧГЃМђЕЅЁЃдЄВт
| forecast_set
= clf.predict(X_lately) |
вВЗЧГЃМђЕЅЃК
forecast_setЪЧдЄВтжЕЕФЪ§зщЃЌБэУїФуВЛНіНіПЩвдзіГіЕЅИідЄВтЃЌЛЙПЩвдвЛДЮаддЄВтЖрИіжЕЁЃПДПДЮвУЧФПЧАгЕгаЪВУДЃК
| [
745.67829395 737.55633261 736.32921413 717.03929303
718.59047951
731.26376715 737.84381394 751.28161162 756.31775293
756.76751056
763.20185946 764.52651181 760.91320031 768.0072636
766.67038016
763.83749414 761.36173409 760.08514166 770.61581391
774.13939706
768.78733341 775.04458624 771.10782342 765.13955723
773.93369548
766.05507556 765.4984563 763.59630529 770.0057166
777.60915879] 0.956987938167 30 |
ЫљвдетаЉОЭЪЧЮвУЧЕФдЄВтНсЙћЃЌШЛКѓФиЃПвбОЛљБОЭъГЩСЫЃЌЕЋЪЧЮвУЧПЩвдНЋЦфПЩЪгЛЏЁЃЙЩЦБМлИёЪЧУПвЛЬьЕФЃЌвЛжм
5 ЬьЃЌжмФЉУЛгаЁЃЮвжЊЕРетИіЪТЪЕЃЌЕЋЪЧЮвУЧДђЫуНЋЦфМђЛЏЃЌАбУПИідЄВтжЕЕБГЩУПвЛЬьЕФЁЃШчЙћФуДђЫуДІРэжмФЉЕФМфИєЃЈВЛвЊЭќСЫМйЦкЃЉЃЌОЭШЅзіАЩЃЌЕЋЪЧЮветРяЛсНЋЦфМђЛЏЁЃзюПЊЪМЃЌЮвУЧЬэМгвЛаЉаТЕФЕМШыЃК
| import
datetime
import matplotlib.pyplot as plt
from matplotlib import style |
ЮвЕМШыСЫdatetimeРДДІРэdatetimeЖдЯѓЃЌMatplotlib ЕФpyplotАќгУгкЛцЭМЃЌвдМАstyleРДЪЙЮвУЧЕФЛцЭМИќМгЪБїжЁЃШУЮвУЧЩшжУвЛИібљЪНЃК
жЎКѓЃЌЮвУЧЬэМгвЛИіаТЕФСаЃЌforecastСаЃК
ЮвУЧЪзЯШНЋжЕЩшжУЮЊ NaNЃЌЕЋЪЧЮвУЧжЎКѓЛсЬюГфЫћЁЃ
дЄВтМЏЕФБъЧЉе§КУДгУїЬьПЊЪМЁЃвђЮЊЮвУЧвЊдЄВтЮДРДm = 0.1 * len(df)ЬьЕФЪ§ОнЃЌЯрЕБгкАбЪеХЬМлЭљЧАвЦЖЏmЬьЩњГЩБъЧЉЁЃФЧУДЪ§ОнМЏЕФКѓmИіЪЧВЛФмгУзїбЕСЗМЏКЭВтЪдМЏЕФЃЌвђЮЊУЛгаБъЧЉЁЃгкЪЧЮвУЧНЋКѓmИіЪ§ОнгУзїдЄВтМЏЁЃдЄВтМЏЕФЕквЛИіЪ§ОнЃЌвВОЭЪЧЪ§ОнМЏЕФЕкn
- mИіЪ§ОнЃЌЫќЕФБъЧЉгІИУЪЧn - m + m = nЬьЕФЪеХЬМлЃЌЮвУЧжЊЕРНёЬьдкdfРяУцЪЧЕкn -
1ЬьЃЌФЧУДЫќОЭЪЧУїЬьЁЃ
ЮвУЧЪзЯШашвЊзЅШЁ DataFrame ЕФзюКѓвЛЬьЃЌНЋУПвЛИіаТЕФдЄВтжЕИГИјаТЕФШеЦкЁЃЮвУЧЛсетбљПЊЪМЁЃ
| last_date
= df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day |
ЯждкЮвУЧгЕгаСЫдЄВтМЏЕФЦ№ЪМШеЦкЃЌВЂЧввЛЬьга 86400 УыЁЃЯждкЮвУЧНЋдЄВтЬэМгЕНЯжгаЕФ DataFrame
жаЁЃ
| for
i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i] |
ЮвУЧетРяЫљзіЕФЪЧЃЌЕќДњдЄВтМЏЕФБъЧЉЃЌЛёШЁУПИідЄВтжЕКЭШеЦкЃЌжЎКѓНЋетаЉжЕЗХШы DataFrameЃЈЪЙдЄВтМЏЕФЬиеїЮЊ
NaNЃЉЁЃзюКѓвЛааЕФДњТыДДНЈ DataFrame жаЕФвЛааЃЌЫљгадЊЫижУЮЊ NaNЃЌШЛКѓНЋзюКѓвЛИідЊЫижУЮЊiЃЈетРяЪЧдЄВтМЏЕФБъЧЉЃЉЁЃЮвбЁдёСЫетжжЕЅааЕФforбЛЗЃЌвдБудкИФЖЏ
DataFrame КЭЬиеїжЎКѓЃЌДњТыЛЙФме§ГЃЙЄзїЁЃЫљгаЖЋЮїЖМзіЭъСЫТ№ЃПНЋЦфЛцжЦГіРДЁЃ
| df['Adj.
Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show() |
ЭъећЕФДњТыЃК
| import
Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation,
svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low'])
/ df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj.
Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.2)
clf = LinearRegression(n_jobs=-1)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show() |
НсЙћЃК
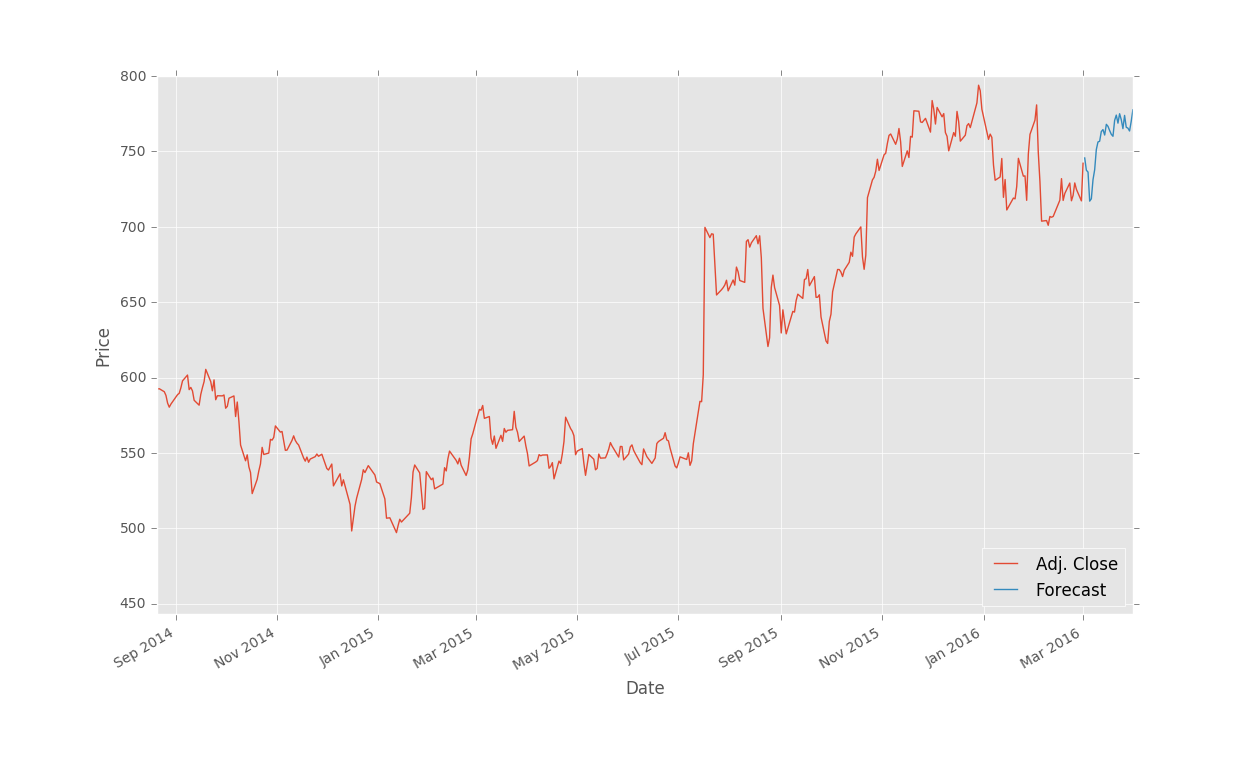
БЃДцКЭРЉеЙ
ЩЯвЛЦЊНЬГЬжаЃЌЮвУЧЪЙгУЛиЙщЭъГЩСЫЖдЙЩЦБМлИёЕФдЄВтЃЌВЂЪЙгУ Matplotlib ПЩЪгЛЏЁЃетИіНЬГЬжаЃЌЮвУЧЛсЬжТлвЛаЉНгЯТРДЕФВНжшЁЃ
ЮвМЧЕУЮвЕквЛДЮГЂЪдбЇЯАЛњЦїбЇЯАЕФЪБКђЃЌЖрЪ§ЪОР§НіНіЩцМАЕНбЕСЗКЭВтЪдЕФВПЗжЃЌЭъШЋЬјЙ§СЫдЄВтВПЗжЁЃЖдгкФЧаЉАќКЌбЕСЗЁЂВтЪдКЭдЄВтВПЗжЕФНЬГЬРДЫЕЃЌЮвУЛгаевЕНвЛЦЊНтЪЭБЃДцЫуЗЈЕФЮФеТЁЃдкФЧаЉР§згжаЃЌЪ§ОнЭЈГЃЗЧГЃаЁЃЌЫљвдбЕСЗЁЂВтЪдКЭдЄВтЙ§ГЬЖМКмПьЁЃдкецЪЕЪРНчжаЃЌЪ§ОнЖМЗЧГЃДѓЃЌВЂЧвЛЈЗбИќГЄЪБМфРДДІРэЁЃгЩгкУЛгавЛЦЊНЬГЬеце§ЬИТлЕНетвЛживЊЕФЙ§ГЬЃЌЮвДђЫуАќКЌвЛаЉДІРэЪБМфКЭБЃДцЫуЗЈЕФаХЯЂЁЃ
ЫфШЛЮвУЧЕФЛњЦїбЇЯАЗжРрЦїЛЈЗбМИУыРДбЕСЗЃЌдквЛаЉЧщПіЯТЃЌбЕСЗЗжРрЦїашвЊМИИіаЁЪБЩѕжСЪЧМИЬьЁЃЯыЯѓФуЯывЊдЄВтМлИёЕФУПЬьЖМашвЊетУДзіЁЃетВЛЪЧБивЊЕФЃЌвђЮЊЮвУЧФиПЩвдЪЙгУ
Pickle ФЃПщРДБЃДцЗжРрЦїЁЃЪзЯШШЗБЃФуЕМШыСЫЫќЃК
ЪЙгУ PickleЃЌФуПЩвдБЃДц Python ЖдЯѓЃЌОЭЯёЮвУЧЕФЗжРрЦїФЧбљЁЃдкЖЈвхЁЂбЕСЗКЭВтЪдФуЕФЗжРрЦїжЎКѓЃЌЬэМгЃК
| with
open('linearregression.pickle','wb') as f:
pickle.dump(clf, f) |
ЯждкЃЌдйДЮжДааНХБОЃЌФугІИУЕУЕНСЫlinearregression.pickleЃЌЫќЪЧЗжРрЦїЕФађСаЛЏЪ§ОнЁЃЯждкЃЌФуашвЊзіЕФЫљгаЪТЧщОЭЪЧМгдиpickleЮФМўЃЌНЋЦфБЃДцЕНclfЃЌВЂееГЃЪЙгУЃЌР§ШчЃК
| pickle_in
= open('linearregression.pickle','rb')
clf = pickle.load(pickle_in) |
ДњТыжаЃК
| import
Quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation,
svm
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from matplotlib import style
import datetime
import pickle
style.use('ggplot')
df = Quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low',
'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low'])
/ df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj.
Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change',
'Adj. Volume']]
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.1 * len(df)))
df['label'] = df[forecast_col].shift(-forecast_out)
X = np.array(df.drop(['label'], 1))
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.2)
#COMMENTED OUT:
##clf = svm.SVR(kernel='linear')
##clf.fit(X_train, y_train)
##confidence = clf.score(X_test, y_test)
##print(confidence)
pickle_in = open('linearregression.pickle','rb')
clf = pickle.load(pickle_in)
forecast_set = clf.predict(X_lately)
df['Forecast'] = np.nan
last_date = df.iloc[-1].name
last_unix = last_date.timestamp()
one_day = 86400
next_unix = last_unix + one_day
for i in forecast_set:
next_date = datetime.datetime.fromtimestamp(next_unix)
next_unix += 86400
df.loc[next_date] = [np.nan for _ in range(len(df.columns)-1)]+[i]
df['Adj. Close'].plot()
df['Forecast'].plot()
plt.legend(loc=4)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show() |
вЊзЂвтЮвУЧзЂЪЭЕєСЫЗжРрЦїЕФдЪМЖЈвхЃЌВЂЬцЛЛЮЊМгдиЮвУЧБЃДцЕФЗжРрЦїЁЃОЭЪЧетУДМђЕЅЁЃ
зюКѓЃЌЮвУЧвЊЬжТлвЛЯТаЇТЪКЭБЃДцЪБМфЃЌЧАМИЬьЮвДђЫуЬсГівЛИіЯрЖдНЯЕЭЕФЗЖЪНЃЌетОЭЪЧСйЪБЕФГЌМЖМЦЫуЛњЁЃбЯЫрЕиЫЕЃЌЫцзХАДашжїЛњЗўЮёЕФаЫЦ№ЃЌР§Шч
AWSЁЂDO КЭ LinodeЃЌФуФмЙЛАДееаЁЪБРДЙКТђжїЛњЁЃащФтЗўЮёЦїПЩвддк 60 УыФкНЈСЂЃЌЫљашЕФФЃПщПЩвддк
15 ЗжжгФкАВзАЃЌЫљвдЗЧГЃгаЯоЁЃФуПЩвдаДвЛИі shell НХБОЛђепЪВУДЖЋЮїРДИјЫќМгЫйЁЃПМТЧФуашвЊДѓСПЕФДІРэЃЌВЂЧвЛЙУЛгавЛЬЈЖЅМЖМЦЫуЛњЃЌЛђепФуЪЙгУБЪМЧБОЁЃУЛгаЮЪЬтЃЌжЛашвЊЦєЖЏвЛЬЈЗўЮёЦїЁЃ
ЮвЖдетИіЗНЪНЕФзюКѓвЛИізЂНтЪЧЃЌЪЙгУШЮКЮжїЛњЃЌФуЭЈГЃЖМПЩвдНЈСЂвЛИіЗЧГЃаЁаЭЕФЗўЮёЦїЃЌМгдиЫљашЕФЖЋЮїЃЌжЎКѓРЉеЙетИіЗўЮёЦїЁЃЮвЯВЛЖвдвЛИіаЁаЭЗўЮёЦїПЊЪМЃЌжЎКѓЃЌЮвзМБИКУЕФЪБКђЃЌЮвЛсИФБфЫќЕФГпДчЃЌИјЫќЩ§МЖЁЃЭъГЩжЎКѓЃЌВЛвЊЭќСЫзЂЯњЛђепНЕМЖФуЕФЗўЮёЦїЁЃ
РэТлвдМАЙЄзїдРэ
ЛЖгдФЖСЕкЦпЦЊНЬГЬЁЃФПЧАЮЊжЙЃЌФувбОПДЕНСЫЯпадЛиЙщЕФМлжЕЃЌвдМАШчКЮЪЙгУ Sklearn РДгІгУЫќЁЃЯждкЮвУЧДђЫуЩюШыСЫНтЫќШчКЮМЦЫуЁЃЫфШЛЮвОѕЕУВЛБивЊЩюШыЕНУПИіЛњЦїбЇЯАЫуЗЈЪ§бЇжаЃЈФугаУЛгаНјШыЕНФузюЯВЛЖЕФФЃПщЕФдДТыжаЃЌПДПДЫќЪЧШчКЮЪЕЯжЕФЃПЃЉЃЌЯпадДњЪ§ЪЧЛњЦїбЇЯАЕФБОжЪЃЌВЂЧвЖдгкРэНтЛњЦїбЇЯАЕФЙЙНЈЛљДЁЪЎЗжЪЕгУЁЃ
ЯпадДњЪ§ЕФФПБъЪЧМЦЫуЯђСППеМфжаЕФЕуЕФЙиЯЕЁЃетПЩвдгУгкКмЖрЪТЧщЃЌЕЋЪЧФГЬьЃЌгаИіШЫгаСЫИіЗЧГЃПёвАЕФЯыЗЈЃЌФУЫћДІРэЪ§ОнМЏЕФЬиеїЁЃЮвУЧвВПЩвдЁЃМЧЕУжЎЧАЮвУЧЖЈвхЪ§ОнРраЭЕФЪБКђЃЌЯпадЛиЙщДІРэСЌајЪ§ОнТ№ЃПетВЂВЛЪЧвђЮЊЪЙгУЯпадЛиЙщЕФШЫЃЌЖјЪЧвђЮЊзщГЩЫќЕФЪ§бЇЁЃМђЕЅЕФЯпадЛиЙщПЩгУгкбАевЪ§ОнМЏЕФзюМбФтКЯжБЯпЁЃШчЙћЪ§ОнВЛЪЧСЌајЕФЃЌОЭВЛЪЧзюМбФтКЯжБЯпЁЃШУЮвУЧПДПДвЛаЉЪОР§ЁЃ
аЗНВю
ЩЯУцЕФЭМЯёЯдШЛгЕгаСМКУЕФаЗНВюЁЃШчЙћФуЭЈЙ§ЙРМЦЛвЛЬѕзюМбФтКЯжБЯпЃЌФугІИУФмЙЛЧсвзЛГіРДЃК
ШчЙћЭМЯёЪЧетбљФиЃП
ВЂВЛКЭжЎЧАвЛбљЃЌЕЋЪЧЪЧЧхГўЕФИКЯрЙиЁЃФуПЩФмФмЙЛЛГізюМбФтКЯжБЯпЃЌЕЋЪЧИќПЩФмЛВЛГіРДЁЃ
зюКѓЃЌетИіФиЃП
ЩЖЃПЕФШЗгазюМбФтКЯжБЯпЃЌЕЋЪЧашвЊдЫЦјНЋЦфЛГіРДЁЃ
НЋЩЯУцЕФЭМЯёПДзіЬиеїЕФЭМЯёЃЌЫљвд X зјБъЪЧЬиеїЃЌY зјБъЪЧЯрЙиЕФБъЧЉЁЃX КЭ Y ЪЧЗёгаШЮКЮаЮЪНЕФНсЙЙЛЏЙиЯЕФиЃПЫфШЛЮвУЧПЩвдзМШЗМЦЫуЙиЯЕЃЌЮДРДЮвУЧОЭВЛЬЋПЩФмгЕгаетУДЖржЕСЫЁЃ
дкЦфЫќЭМЯёЕФАИР§жаЃЌX КЭ Y жЎМфЯдШЛДцдкЙиЯЕЁЃЮвУЧЪЕМЪЩЯПЩвдЬНЫїетжжЙиЯЕЃЌжЎКѓбизХЮвУЧЯЃЭћЕФШЮКЮЕуЛцЭМЁЃЮвУЧПЩвдФУ
Y РДдЄВт XЃЌЛђепФУ X РДдЄВт YЃЌЖдгкШЮКЮЮвУЧПЩвдЯыЕНЕФЕуЁЃЮвУЧвВПЩвддЄВтЮвУЧЕФФЃаЭгаЖрЩйЕФЮѓВюЃЌМДЪЙФЃаЭжЛгавЛИіЕуЁЃЮвУЧШчКЮЪЕЯжетИіФЇЗЈФиЃПЕБШЛЪЧЯпадДњЪ§ЁЃ
ЪзЯШЃЌШУЮвУЧЛиЕНжабЇЃЌЮвУЧдкФЧРяИДЯАжБЯпЕФЖЈвхЃКy = mx + bЃЌЦфжаmЪЧаБТЪЃЌbЪЧзнНиОрЁЃетПЩвдЪЧгУгкЧѓНтyЕФЗНГЬЃЌЮвУЧПЩвдНЋЦфБфаЮРДЧѓНтxЃЌЪЙгУЛљБОЕФДњЪ§ддђЃКx
= (y-b)/mЁЃ
КУЕФЃЌЫљвдЃЌЮвУЧЕФФПБъЪЧбАевзюМбФтКЯжБЯпЁЃВЛЪЧНіНіЪЧФтКЯСМКУЕФжБЯпЃЌЖјЪЧзюКУЕФФЧЬѕЁЃетЬѕжБЯпЕФЖЈвхОЭЪЧy
= mx + bЁЃyОЭЪЧД№АИЃЈЮвУЧЦфЫћЕФзјБъЃЌЛђепЩѕжСЪЧЮвУЧЕФЬиеїЃЉЃЌЫљвдЮвУЧШдШЛашвЊmЃЈаБТЪЃЉКЭbЃЈзнНиОрЃЉЃЌгЩгкxПЩФмЮЊби
x жсЕФШЮвЛЕуЃЌЫљвдЫќЪЧвбжЊЕФЁЃ
зюМбФтКЯжБЯпЕФаБТЪmЖЈвхЮЊЃК
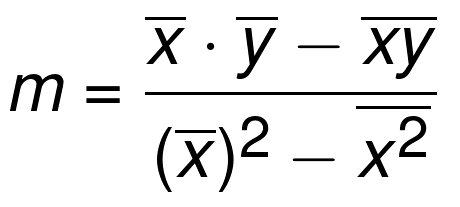
зЂЃКПЩМђаДЮЊm = cov(x, y) / var(x)ЁЃ
ЗћКХЩЯУцЕФКсИмДњБэОљжЕЁЃШчЙћСНИіЗћКХАЄзХЃЌОЭНЋЦфЯрГЫЁЃxs КЭ ys
ЪЧЫљгавбжЊзјБъЁЃЫљвдЮвУЧЯждкЧѓГіСЫy=mx+bзюМбФтКЯжБЯпЖЈвхЕФmЃЈаБТЪЃЉЃЌЯждкЮвУЧНіНіашвЊbЃЈзнНиОрЃЉЁЃетРяЪЧЙЋЪНЃК
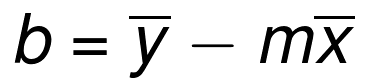
КУЕФЁЃећИіВПЗжВЛЪЧИіЪ§бЇНЬГЬЃЌЖјЪЧИіБрГЬНЬГЬЁЃЯТвЛИіНЬГЬжаЃЌЮвУЧДђЫуетбљзіЃЌВЂЧвНтЪЭЮЊЪВУДЮввЊБрГЬЪЕЯжЫќЃЌЖјВЛЪЧжБНггУФЃПщЁЃ
БрГЬМЦЫуаБТЪ
ЛЖгдФЖСЕкАЫЦЊНЬГЬЃЌЮвУЧИеИевтЪЖЕНЃЌЮвУЧашвЊЪЙгУ Python жиИДБраДвЛаЉБШНЯживЊЕФЫуЗЈЃЌРДГЂЪдИјЖЈЪ§ОнМЏЕФМЦЫузюМбФтКЯжБЯпЁЃ
дкЮвУЧПЊЪМжЎЧАЃЌЮЊЪВУДЮвУЧЛсгавЛаЉаЁТщЗГФиЃПЯпадЛиЙщЪЧЛњЦїбЇЯАЕФЙЙНЈЛљДЁЁЃЫќМИКѕгУгкУПИіЕЅЖРЕФжїСїЛњЦїбЇЯАЫуЗЈжЎжаЃЌЫљвдЖдЫќЕФРэНтгажњгкФуеЦЮеЖрЪ§жїСїЛњЦїбЇЯАЫуЗЈЁЃГігкЮвУЧЕФШШЧщЃЌРэНтЯпадЛиЙщКЭЯпадДњЪ§ЃЌЪЧБраДФуздМКЕФЛњЦїбЇЯАЫуЗЈЃЌвдМАПчШыЛњЦїбЇЯАЧАбиЃЌЪЙгУЕБЧАзюМбЕФДІРэЙ§ГЬЕФЕквЛВНЁЃгЩгкДІРэЙ§ГЬЕФгХЛЏКЭгВМўМмЙЙЕФИФБфЁЃгУгкЛњЦїбЇЯАЕФЗНЗЈТлвВЛсИФБфЁЃзюНќГіЯжЕФЩёОЭјТчЃЌЪЙгУДѓСП
GPU РДЭъГЩЙЄзїЁЃФуЯыжЊЕРЪВУДЪЧЩёОЭјТчЕФКЫаФТ№ЃПФуВТЖдСЫЃЌЯпадДњЪ§ЁЃ
ШчЙћФуФмМЧЕУЃЌзюМбФтКЯжБЯпЕФаБТЪmЃК
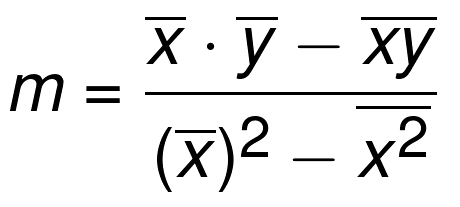
ЪЧЕФЃЌЮвУЧЛсНЋЦфВ№ГЩЦЌЖЮЁЃЪзЯШЃЌНјаавЛаЉЕМШыЃК
| from
statistics import mean
import numpy as np |
ЮвУЧДгstatisticsЕМШыmeanЃЌЫљвдЮвУЧПЩвдЧсвзЛёШЁСаБэЕФОљжЕЁЃЯТУцЃЌЮвУЧЪЙnumpy
as npЃЌЫљвдЮвУЧПЩвдЦфДДНЈ NumPy Ъ§зщЁЃЮвУЧПЩвдЖдСаБэзіКмЖрЪТЧщЃЌЕЋЪЧЮвУЧашвЊФмЙЛзівЛаЉМђЕЅЕФОиеѓдЫЫуЃЌЫќВЂВЛЖдМђЕЅСаБэЬсЙЉЃЌЫљвдЮвУЧЪЙгУ
NumPyЁЃЮвУЧдкетИіНзЖЮВЛЛсЪЙгУЬЋИДдгЕФ NumPyЃЌЕЋЪЧжЎКѓ NumPy ОЭЛсГЩЮЊФуЕФзюМбЛяАщЁЃЯТУцЃЌШУЮвУЧЖЈвхвЛаЉЦ№ЪМЕуАЩЁЃ
| xs
= [1,2,3,4,5]
ys = [5,4,6,5,6] |
ЫљвдетРягавЛаЉЮвУЧвЊЪЙгУЕФЪ§ОнЕуЃЌxsКЭysЁЃФуПЩвдШЯЮЊxsОЭЪЧЬиеїЃЌysОЭЪЧБъЧЉЃЌЛђепЫћУЧЖМЪЧЬиеїЃЌЮвУЧЯывЊНЈСЂЫћУЧЕФСЊЯЕЁЃжЎЧАЬсЕНЙ§ЃЌЮвУЧЪЕМЪЩЯАбЫќУЧБфГЩ
NumPy Ъ§зщЃЌвдБужДааОиеѓдЫЫуЁЃЫљвдШУЮвУЧаоИФетСНааЃК
| xs
= np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64) |
ЯждкЫћУЧЖМЪЧ NumPy Ъ§зщСЫЁЃЮвУЧвВЯдЪНЩљУїСЫЪ§ОнРраЭЁЃМђЕЅНВвЛЯТЃЌЪ§ОнРраЭгаЬиадЪЧЪєадЃЌетаЉЪєадОіЖЈСЫЪ§ОнБОЩэШчКЮДЂДцКЭВйзїЁЃЯждкЫќВЛЪЧЪВУДЮЪЬтЃЌЕЋЪЧШчЙћЮвУЧжДааДѓСПдЫЫуЃЌВЂЯЃЭћЫћУЧХмдк
GPU ЖјВЛЪЧ CPU ЩЯОЭЪЧСЫЁЃ
НЋЦфЛГіРДЃЌЫћУЧЪЧЃК
ЯждкЮвУЧзМБИКУЙЙНЈКЏЪ§РДМЦЫуmЃЌвВОЭЪЧЮвУЧЕФжБЯпаБТЪЃК
| def
best_fit_slope(xs,ys):
return m
m = best_fit_slope(xs,ys) |
КУСЫЁЃПЊИіЭцаІЃЌЫљвдетЪЧЮвУЧЕФПђМмЃЌЯждкЮвУЧвЊЬюГфСЫЁЃ
ЮвУЧЕФЕквЛИіТпМОЭЪЧМЦЫуxsЕФОљжЕЃЌдйГЫЩЯysЕФОљжЕЁЃМЬајЬюГфЮвУЧЕФПђМмЃК
| def
best_fit_slope(xs,ys):
m = (mean(xs) * mean(ys))
return m |
ФПЧАЮЊжЙЛЙКмМђЕЅЁЃФуПЩвдЖдСаБэЁЂдЊзщЛђепЪ§зщЪЙгУmeanКЏЪ§ЁЃвЊзЂвтЮветРяЪЙгУСЫРЈКХЁЃPython
ЕФзёбдЫЫуЗћЕФЪ§бЇгХЯШМЖЁЃЫљвдШчЙћФуДђЫуБЃжЄЫГађЃЌвЊЯдЪНЪЙгУРЈКХЁЃвЊМЧзЁФуЕФдЫЫуЙцдђЁЃ
ЯТУцЮвУЧашвЊНЋЦфМѕШЅx*yЕФОљжЕЁЃетМШЪЧЮвУЧЕФОиеѓдЫЫуmean(xs*ys)ЁЃЯждкЕФДњТыЪЧЃК
| def
best_fit_slope(xs,ys):
m = ( (mean(xs)*mean(ys)) - mean(xs*ys) )
return m |
ЮвУЧЭъГЩСЫЙЋЪНЕФЗжзгВПЗжЃЌЯждкЮвУЧМЬајДІРэЕФЗжФИЃЌвдxЕФОљжЕЦНЗНПЊЪМЃК(mean(xs)*mean(xs))ЁЃPython
жЇГж** 2ЃЌФмЙЛДІРэЮвУЧЕФ NumPy Ъ§зщЕФfloat64РраЭЁЃЬэМгетаЉЖЋЮїЃК
| def
best_fit_slope(xs,ys):
m = ( ((mean(xs)*mean(ys)) - mean(xs*ys)) /
(mean(xs)**2))
return m |
ЫфШЛИљОндЫЫуЗћгХЯШМЖЃЌЯђећИіБэДяЪНЬэМгРЈКХЪЧВЛБивЊЕФЁЃЮветРяетбљзіЃЌЫљвдЮвПЩвддкГ§ЗЈКѓУцЬэМгвЛааЃЌЪЙећИіЪНзгИќМгвзЖСКЭвзРэНтЁЃВЛетбљЕФЛАЃЌЮвУЧЛсдкаТЕФвЛааЕУЕНгяЗЈДэЮѓЁЃЮвУЧМИКѕЭъГЩСЫЃЌЯждкЮвУЧжЛашвЊНЋxЕФОљжЕЦНЗНКЭxЕФЦНЗНОљжЕЃЈmean(xs*xs)ЃЉЯрМѕЁЃШЋВПДњТыЮЊЃК
| def
best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs*xs)))
return m |
КУЕФЃЌЯждкЮвУЧЕФЭъећНХБОЮЊЃК
| from
statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)**2) - mean(xs**2)))
return m
m = best_fit_slope(xs,ys)
print(m)
# 0.3 |
ЯТУцИЩЪВУДЃПЮвУЧашвЊМЦЫузнНиОрbЁЃЮвУЧЛсдкЯТвЛИіНЬГЬжаДІРэЫќЃЌВЂЭъГЩЭъећЕФзюМбФтКЯжБЯпМЦЫуЁЃЫќБШаБТЪИќМбвзгкМЦЫуЃЌГЂЪдБраДФуздМКЕФКЏЪ§РДМЦЫуЫќЁЃШчЙћФузіЕНСЫЃЌвВВЛвЊЬјЙ§ЯТвЛИіНЬГЬЃЌЮвУЧЛсзівЛаЉБ№ЕФЪТЧщЁЃ
МЦЫузнНиОр
ЛЖгдФЖСЕкОХЦЊНЬГЬЁЃЮвУЧЕБЧАе§дкЮЊИјЖЈЕФЪ§ОнМЏЃЌЪЙгУ Python
МЦЫуЛиЙщЛђепзюМбФтКЯжБЯпЁЃжЎЧАЃЌЮвУЧБраДСЫвЛИіКЏЪ§РДМЦЫуаБТЪЃЌЯждкЮвУЧашвЊМЦЫузнНиОрЁЃЮвУЧФПЧАЕФДњТыЪЧЃК
| from
statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
return m
m = best_fit_slope(xs,ys)
print(m) |
ЧыЛивфЃЌзюМбФтКЯжБЯпЕФзнНиОрЪЧЃК
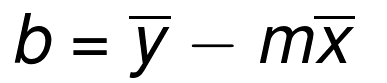
етИіБШаБТЪМђЕЅЖрСЫЁЃЮвУЧПЩвдНЋЦфаДЕНЭЌвЛИіКЏЪ§РДНкЪЁМИааДњТыЁЃЮвУЧНЋКЏЪ§жиУќУћЮЊbest_fit_slope_and_interceptЁЃ
ЯТУцЃЌЮвУЧПЩвдЬюГфb = mean(ys) - (m*mean(xs))ЃЌВЂЗЕЛиm, bЃК
| def
best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b |
ЯждкЮвУЧПЩвдЕїгУЫќЃК
| best_fit_slope_and_intercept(xs,ys) |
ЮвУЧФПЧАЮЊжЙЕФДњТыЃК
| from
statistics import mean
import numpy as np
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
m, b = best_fit_slope_and_intercept(xs,ys)
print(m,b)
# 0.3, 4.3 |
ЯждкЮвУЧНіНіашвЊЮЊЪ§ОнДДНЈвЛЬѕжБЯпЃК
вЊМЧзЁy=mx+bЃЌЮвУЧФмЙЛЮЊДЫБраДвЛИіКЏЪ§ЃЌЛђепНіНіЪЙгУвЛааЕФforбЛЗЁЃ
| regression_line
= [(m*x)+b for x in xs] |
ЩЯУцЕФвЛааforбЛЗКЭетИіЯрЭЌЃК
| regression_line
= []
for x in xs:
regression_line.append((m*x)+b) |
КУЕФЃЌШУЮвУЧЪеШЁЮвУЧЕФРЭЖЏЙћЪЕАЩЁЃЬэМгЯТУцЕФЕМШыЃК
| import
matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot') |
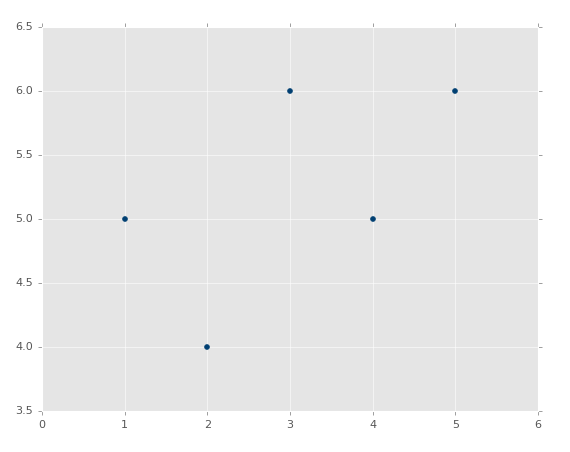
ЮвУЧПЩвдЛцжЦЭМЯёЃЌВЂЧвВЛЛсЬиБИФбПДЁЃЯждкЃК
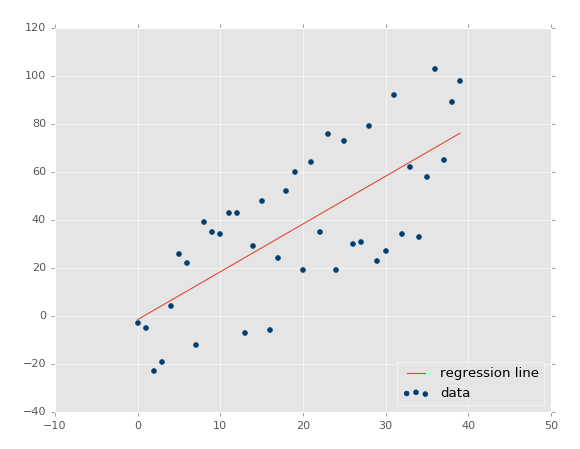
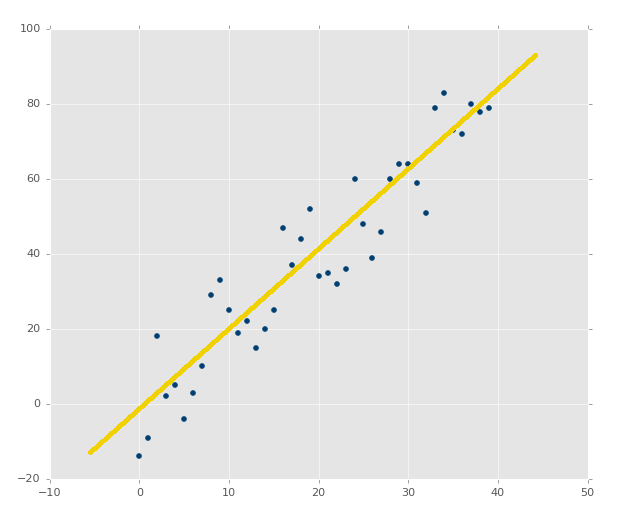
| plt.scatter(xs,ys,color='#003F72')
plt.plot(xs, regression_line)
plt.show() |
ЪзЯШЮвУЧЛцжЦСЫЯжгаЪ§ОнЕФЩЂЕуЭМЃЌжЎКѓЮвУЧЛцжЦСЫЮвУЧЕФЛиЙщжБЯпЃЌжЎКѓеЙЪОЫќЁЃШчЙћФуВЛЪьЯЄЃЌПЩвдВщПД Matplotlib
НЬГЬМЏЁЃ
ЪфГіЃК
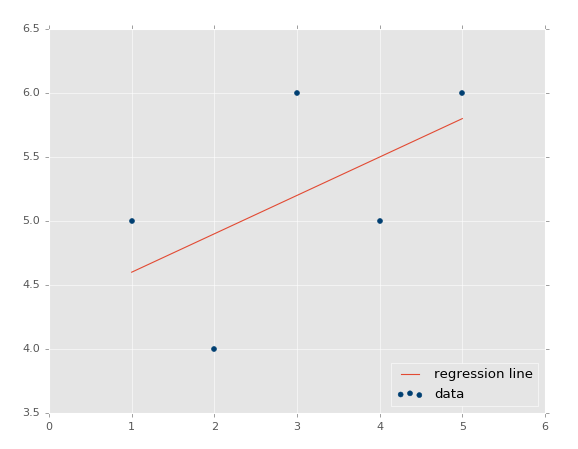
ЙЇЯВЙЇЯВЁЃЫљвдЃЌШчКЮЛљДЁетИіФЃаЭРДзівЛаЉЪЕМЪЕФдЄВтФиЃПКмМђЕЅЃЌФугЕгаСЫФЃаЭЃЌжЛвЊЬюГфxОЭааСЫЁЃР§ШчЃЌШУЮвУЧдЄВтвЛаЉЕуЃК
ЮвУЧЪфШыСЫЪ§ОнЃЌвВОЭЪЧЮвУЧЕФЬиеїЁЃФЧУДБъЧЉФиЃП
| predict_y
= (m*predict_x)+b
print(predict_y)
# 6.4 |
ЮвУЧвВПЩвдЛцжЦЫќЃК
| predict_x
= 7
predict_y = (m*predict_x)+b
plt.scatter(xs,ys,color='#003F72',label='data')
plt.plot(xs, regression_line, label='regression
line')
plt.legend(loc=4)
plt.show() |
ЪфГіЃК
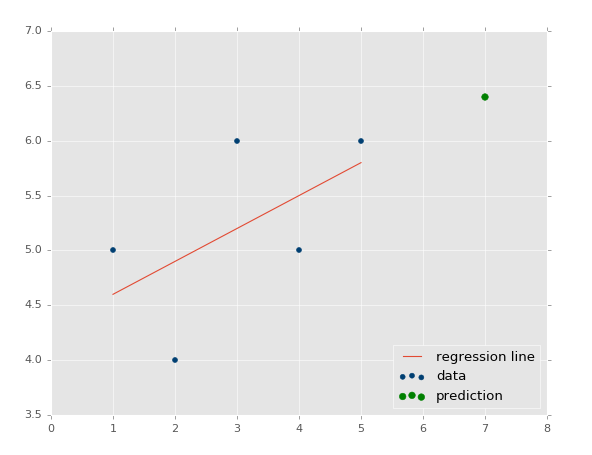
ЮвУЧЯждкжЊЕРСЫШчКЮДДНЈздМКЕФФЃаЭЃЌетКмКУЃЌЕЋЪЧЮвУЧШдОЩШБЩйСЫвЛаЉЖЋЮїЃЌЮвУЧЕФФЃаЭгаЖрОЋШЗЃПетОЭЪЧЯТвЛИіНЬГЬЕФЛАЬтСЫЁЃ
R ЦНЗНКЭХаЖЈЯЕЪ§дРэ
ЛЖгдФЖСЕкЪЎЦЊНЬГЬЁЃЮвУЧИеИеЭъГЩСЫЯпадФЃаЭЕФДДНЈКЭДІРэЃЌЯждкЮвУЧКУЦцНгЯТРДвЊИЩЪВУДЁЃЯждкЃЌЮвУЧПЩвдЧсвзЙлВьЪ§ЃЌВЂОіЖЈЯпадЛиЙщФЃаЭгаЖрУДзМШЗЁЃЕЋЪЧЃЌШчЙћФуЕФЯпадЛиЙщФЃаЭЪЧФУЩёОЭјТчЕФ
20 ИіВуМЖзіГіРДЕФФиЃПВЛНіНіЪЧетбљЃЌФуЕФФЃаЭвдВНжшЛђепДАПкЙЄзїЃЌвВОЭЪЧвЛЙВ 5 АйЭђИіЪ§ОнЕуЃЌвЛДЮжЛЯдЪО
100 ИіЃЌЛсдѕУДбљЃПФуашвЊвЛаЉздЖЏЛЏЕФЗНЪНРДХаЖЯФуЕФзюМбФтКЯжБЯпгаЖрКУЁЃ
ЛивфжЎЧАЃЌЮвУЧеЙЪОМИИіЛцЭМЕФЪБКђЃЌФувбОПДЕНЃЌзюМбФтКЯжБЯпКУЛЙЪЧВЛКУЁЃЯёетбљЃК
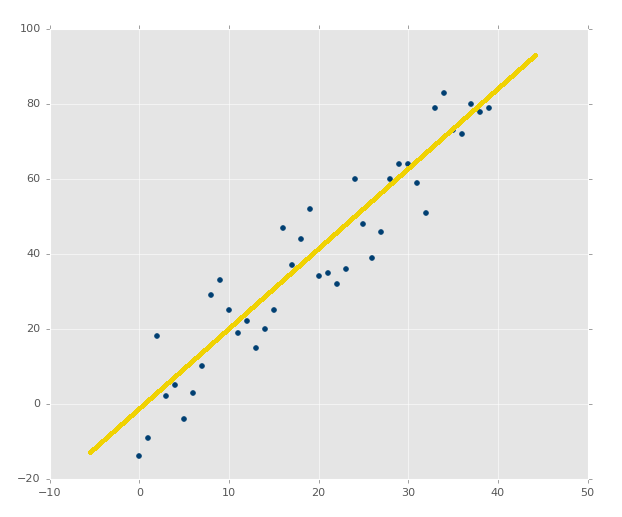
гыетИіЯрБШЃК
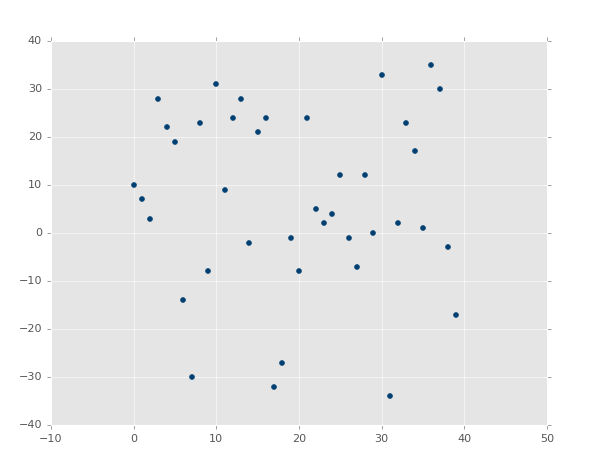
ЕкЖўеХЭМЦЌжаЃЌЕФШЗгазюМбФтКЯжБЯпЃЌЕЋЪЧУЛгаШЫдквтЁЃМДЪЙЪЧзюМбФтКЯжБЯпвВЪЧУЛгагУЕФЁЃВЂЧвЃЌЮвУЧЯыдкЛЈЗбДѓСПМЦЫуФмСІжЎЧАОЭжЊЕРЫќЁЃ
МьВщЮѓВюЕФБъзМЗНЪНОЭЪЧЪЙгУЦНЗНЮѓВюЁЃФуПЩФмжЎЧАЬ§ЫЕЙ§ЃЌетИіЗНЗЈНазі
R ЦНЗНЛђепХаЖЈЯЕЪ§ЁЃЪВУДНаЦНЗНЮѓВюФиЃП
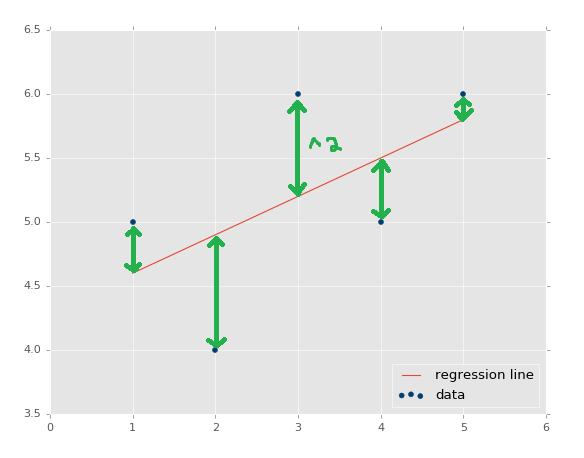
ЛиЙщжБЯпКЭЪ§ОнЕФyжЕЕФОрРыЃЌОЭНазіЮѓВюЃЌЮвУЧНЋЦфЦНЗНЁЃжБЯпЕФЦНЗНЮѓВюЪЧЫќУЧЕФЦНОљЛђепКЭЁЃЮвУЧМђЕЅЧѓКЭАЩЁЃ
ЮвУЧЪЕМЪЩЯвбОНтГ§СЫЦНЗНЮѓВюМйЩшЁЃЮвУЧЕФзюМбФтКЯжБЯпЗНГЬЃЌгУгкМЦЫузюМбФтКЯЛиЙщжБЯпЃЌОЭЪЧжЄУїНсЙћЁЃЦфжаЛиЙщжБЯпОЭЪЧгЕгазюаЁЦНЗНЮѓВюЕФжБЯпЃЈЫљвдЫќВХНазізюаЁЖўГЫЗЈЃЉЁЃФуПЩвдЫбЫїЁАЛиЙщжЄУїЁБЃЌЛђепЁАзюМбФтКЯжБЯпжЄУїЁБРДРэНтЫќЁЃЫќКмвжгєРэНтЃЌЕЋЪЧашвЊДњЪ§БфаЮФмСІРДЕУГіНсЙћЁЃ
ЮЊЩЖЪЧЦНЗНЮѓВюЃПЮЊЪВУДВЛНіНіНЋЦфМгЦ№РДЃПЪзЯШЃЌЮвУЧЯывЊвЛжжЗНЪНЃЌНЋЮѓВюЙцЗЖЛЏЮЊОрРыЃЌЫљвдЮѓВюПЩФмЪЧ
-5ЃЌЕЋЪЧЃЌЦНЗНжЎКѓЃЌЫќОЭЪЧе§Ъ§СЫЁЃСэвЛИідвђЪЧвЊНјвЛВНГЭЗЃРыШКЕуЁЃНјвЛВНЕФвтЫМЪЧЃЌЫќгАЯьЮѓВюЕФГЬЖШИќДѓЁЃетОЭЪЧШЫУЧЫљЪЙгУЕФБъзМЗНЪНЁЃФувВПЩвдЪЙгУ4,
6, 8ЕФУнЃЌЛђепЦфЫћЁЃФувВПЩвдНіНіЪЙгУЮѓВюЕФОјЖджЕЁЃШчЙћФужЛгавЛИіЬєеНЃЌвВаэОЭЪЧДцдквЛаЉРыШКЕуЃЌЕЋЪЧФуВЂВЛДђЫуЙмЫќУЧЃЌФуОЭПЩвдПМТЧЪЙгУОјЖджЕЁЃШчЙћФуБШНЯдквтРыШКЕуЃЌФуОЭПЩвдЪЙгУИќИпНзЕФжИЪ§ЁЃЮвУЧЛсЪЙгУЦНЗНЃЌвђЮЊетЪЧДѓЖрЪ§ШЫЫљЪЙгУЕФЁЃ
КУЕФЃЌЫљвдЮвУЧМЦЫуЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌЪВУДМЦЫуФиЃПетЪЧЪВУДвтЫМЃПЦНЗНЮѓВюЭъШЋКЭЪ§ОнМЏЯрЙиЃЌЫљвдЮвУЧВЛдйашвЊБ№ЕФЖЋЮїСЫЁЃетОЭЪЧ
R ЦНЗНв§ШыЕФЪБКђСЫЃЌвВНазїХаЖЈЯЕЪ§ЁЃЗНГЬЪЧЃК
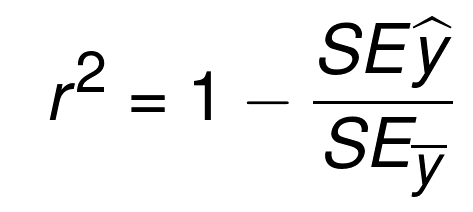
| y_hat
= x * m + b
r_sq = 1 - np.sum((y - y_hat) ** 2) / np.sum((y
- y.mean()) ** 2) |
етИіЗНГЬЕФЕФБОжЪОЭЪЧЃЌ1 МѕШЅЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌБШЩЯ y ЦНОљжБЯпЕФЦНЗНЮѓВюЁЃ y ЦНОљжБЯпОЭЪЧЪ§ОнМЏжаЫљга
y жЕЕФОљжЕЃЌШчЙћФуНЋЦфЛГіРДЃЌЫќЪЧвЛИіЫЎЦНЕФжБЯпЁЃЫљвдЃЌЮвУЧМЦЫу y ЦНОљжБЯпЃЌКЭЛиЙщжБЯпЕФЦНЗНЮѓВюЁЃетРяЕФФПБъЪЧЪЖБ№ЃЌгыЧЗФтКЯЕФжБЯпЯрБШЃЌЪ§ОнЬиеїЕФБфЛЏВњЩњСЫЖрЩйЮѓВюЁЃ
ЫљвдХаЖЈЯЕЪ§ОЭЪЧЩЯУцФЧИіЗНГЬЃЌШчКЮХаЖЈЫќЪЧКУЪЧЛЕЃПЮвУЧПДЕНСЫЫќЪЧ 1 МѕШЅвЛаЉЖЋЮїЁЃЭЈГЃЃЌдкЪ§бЇжаЃЌФуПДЕНЫћЕФЪБКђЃЌЫќЗЕЛиСЫвЛИіАйЗжБШЃЌЫќЪЧ
0 ~ 1 жЎМфЕФЪ§жЕЁЃФуШЯЮЊЪВУДЪЧКУЕФ R ЦНЗНЛђепХаЖЈЯЕЪ§ФиЃПШУЮвУЧМйЩшетРяЕФ R ЦНЗНЪЧ 0.8ЃЌЫќЪЧКУЪЧЛЕФиЃПЫќБШ
0.3 ЪЧКУЛЙЪЧЛЕЃПЖдгк 0.8 ЕФ R ЦНЗНЃЌетОЭвтЮЖзХЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌБШЩЯ y ОљжЕЕФЦНЗНЮѓВюЪЧ
2 БШ 10ЁЃетОЭЪЧЫЕЛиЙщжБЯпЕФЮѓВюЗЧГЃаЁгк y ОљжЕЕФЮѓВюЁЃЬ§Ц№РДВЛДэЁЃЫљвд 0.8 ЗЧГЃКУЁЃ
ФЧУДгыХаЖЈЯЕЪ§ЕФжЕ 0.3 ЯрБШФиЃПетРяЃЌЫќвтЮЖзХЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌБШЩЯ y ОљжЕЕФЦНЗНЮѓВюЪЧ
7 БШ 10ЁЃЦфжа 7 БШ 10 вЊЛЕгк 2 БШ 10ЃЌ7 КЭ 2 ЖМЪЧЛиЙщжБЯпЕФЦНЗНЮѓВюЁЃвђДЫЃЌФПБъЪЧМЦЫу
R ЦНЗНжЕЃЌЛђепНазіХаЖЈЯЕЪ§ЃЌЪЙЦфОЁСПНгНќ 1ЁЃ
БрГЬМЦЫу R ЦНЗН
ЛЖгдФЖСЕкЪЎвЛЦЊНЬГЬЁЃМШШЛЮвУЧжЊЕРСЫЮвУЧбАевЕФЖЋЮїЃЌШУЮвУЧЪЕМЪдк Python жаМЦЫуЫќАЩЁЃЕквЛВНОЭЪЧМЦЫуЦНЗНЮѓВюЁЃКЏЪ§ПЩФмЪЧетбљЃК
| def
squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line -
ys_orig)) |
ЪЙгУЩЯУцЕФКЏЪ§ЃЌЮвУЧПЩвдМЦЫуГіШЮКЮЪЕЯжЕНЪ§ОнЕуЕФЦНЗНЮѓВюЁЃЫљвдЮвУЧПЩвдНЋетИігяЗЈгУгкЛиЙщжБЯпКЭ y
ОљжЕжБЯпЁЃвВОЭЪЧЫЕЃЌЦНЗНЮѓВюжЛЪЧХаЖЈЯЕЪ§ЕФвЛВПЗжЃЌЫљвдШУЮвУЧЙЙНЈФЧИіКЏЪ§АЩЁЃгЩгкЦНЗНЮѓВюКЏЪ§жЛгавЛааЃЌФуПЩвдбЁдёНЋЦфЧЖШыЕНХаЖЈЯЕЪ§КЏЪ§жаЃЌЕЋЪЧЦНЗНЮѓВюЪЧФудкетИіКЏЪ§жЎЭтМЦЫуЕФЖЋЮїЃЌЫљвдЮвбЁдёНЋЦфЕЅЖРаДГЩвЛИіКЏЪ§ЁЃЖдгк
R ЦНЗНЃК
| def
coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig,
ys_line)
squared_error_y_mean = squared_error(ys_orig,
y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean) |
ЮвУЧЫљзіЕФЪЧЃЌМЦЫу y ОљжЕжБЯпЃЌЪЙгУЕЅааЕФforбЛЗЃЈЦфЪЕЪЧВЛБивЊЕФЃЉЁЃжЎКѓЮвУЧМЦЫуСЫ y ОљжЕЕФЦНЗНЮѓВюЃЌвдМАЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌЪЙгУЩЯУцЕФКЏЪ§ЁЃЯждкЃЌЮвУЧашвЊзіЕФОЭЪЧМЦЫуГі
R ЦНЗНжЎЃЌЫќНіНіЪЧ 1 МѕШЅЛиЙщжБЯпЕФЦНЗНЮѓВюЃЌГ§вд y ОљжЕжБЯпЕФЦНЗНЮѓВюЁЃЮвУЧЗЕЛиИУжЕЃЌШЛКѓОЭЭъГЩСЫЁЃзщКЯЦ№РДВЂЬјЙ§ЛцЭМВПЗжЃЌДњТыЮЊЃК
| from
statistics import mean
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
xs = np.array([1,2,3,4,5], dtype=np.float64)
ys = np.array([5,4,6,5,6], dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def squared_error(ys_orig,ys_line):
return sum((ys_line - ys_orig) * (ys_line -
ys_orig))
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = squared_error(ys_orig,
ys_line)
squared_error_y_mean = squared_error(ys_orig,
y_mean_line)
return 1 - (squared_error_regr/squared_error_y_mean)
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
# 0.321428571429
##plt.scatter(xs,ys,color='#003F72',label='data')
##plt.plot(xs, regression_line, label='regression
line')
##plt.legend(loc=4)
##plt.show() |
етЪЧИіКмЕЭЕФжЕЃЌЫљвдИљОнетИіЖШСПЃЌЮвУЧЕФзюМбФтКЯжБЯпВЂВЛЪЧКмКУЁЃетРяЕФ R ЦНЗНЪЧИіКмКУЕФЖШСПЪжЖЮТ№ЃППЩФмШЁОігкЮвУЧЕФФПБъЁЃЖрЪ§ЧщПіЯТЃЌШчЙћЮвУЧЙиаФзМШЗдЄВтЮДРДЕФжЕЃЌR
ЦНЗНЕФШЗКмгагУЁЃШчЙћФуЖддЄВтЖЏЛњЛђепЧїЪЦИааЫШЄЃЌЮвУЧЕФзюМбФтКЯжБЯпЪЕМЪЩЯвбОКмКУСЫЁЃR ЦНЗНВЛгІИУШчДЫживЊЁЃПДвЛПДЮвУЧЪЕМЪЕФЪ§ОнМЏЃЌЮвУЧБЛвЛИіНЯЕЭЕФЪ§жЕПЈзЁСЫЁЃжЕгыжЕжЎМфЕФБфЛЏдкФГаЉЕуЩЯЪЧ
20% ~ 50%ЃЌетвбОЗЧГЃИпСЫЁЃЮвУЧЭъШЋВЛгІИУИаЕНвтЭтЃЌЪЙгУетИіМђЕЅЕФЪ§ОнМЏЃЌЮвУЧЕФзюМбФтКЯжБЯпВЂВЛФмУшЪіецЪЕЪ§ОнЁЃ
ЕЋЪЧЃЌЮвУЧИеВХЫЕЕФЪЧвЛИіМйЩшЁЃЫфШЛЮвУЧТпМЩЯЭГвЛетИіМйЩшЃЌЮвУЧашвЊЬсГівЛИіаТЕФЗНЗЈЃЌРДбщжЄМйЩшЁЃЕНФПЧАЮЊжЙЕФЫуЗЈЗЧГЃЛљДЁЃЌЮвУЧЯждкжЛФмзіКмЩйЕФЪТЧщЃЌЫљвдУЛгаЪВУДПеМфРДИФНјЮѓВюСЫЃЌЕЋЪЧжЎКѓЃЌФуЛсдкПеМфжЎЩЯЗЂЯжПеМфЁЃВЛНіНівЊПМТЧЫуЗЈБОЩэЕФВуДЮПеМфЃЌЛЙгагЩКмЖрЫуЗЈВуДЮзщКЯЖјГЩЕФЫуЗЈЁЃЦфжаЃЌЮвУЧашвЊВтЪдЫќУЧРДШЗБЃЮвУЧЕФМйЩшЃЌЙигкЫуЗЈЪЧИЩЪВУДгУЕФЃЌЪЧе§ШЗЕФЁЃПМТЧАбВйзїзщГЩГЩКЏЪ§гЩЖрУДМђЕЅЃЌжЎКѓЃЌДгетРяПЊЪМЃЌНЋећИібщжЄЗжНтГЩЪ§ЧЇааДњТыЁЃ
ЮвУЧдкЯТвЛЦЊНЬГЬЫљзіЕФЪЧЃЌЙЙНЈвЛИіЯрЖдМђЕЅЕФЪ§ОнМЏЩњГЩЦїЃЌИљОнЮвУЧЕФВЮЪ§РДЩњГЩЪ§ОнЁЃЮвУЧПЩвдЪЙгУЫќРДАДеевтдИВйзїЪ§ОнЃЌжЎКѓЖдетаЉЪ§ОнМЏВтЪдЮвУЧЕФЫуЗЈЃЌИљОнЮвУЧЕФМйЩшаоИФВЮЪ§ЃЌгІИУЛсВњЩњвЛаЉгАЯьЁЃЮвУЧжЎКѓПЩвдНЋЮвУЧЕФМйЩшКЭецЪЕЧщПіБШНЯЃЌВЂЯЃЭћЫћУЧЦЅХфЁЃетРяЕФР§згжаЃЌМйЩшЪЧЮвУЧе§ШЗБраДетаЉЫуЗЈЃЌВЂЧвХаЖЈЯЕЪ§ЕЭЕФдвђЪЧЃЌy
жЕЕФЗНВюЬЋДѓСЫЁЃЮвУЧЛсдкЯТвЛИіНЬГЬжабщжЄетИіМйЩшЁЃ
ЮЊВтЪдДДНЈбљР§Ъ§ОнМЏ
ЛЖгдФЖСЕкЪЎЖўЦЊНЬГЬЁЃЮвУЧвбОСЫНтСЫЛиЙщЃЌЩѕжСБраДСЫЮвУЧздМКЕФМђЕЅЯпадЛиЙщЫуЗЈЁЃВЂЧвЃЌЮвУЧвВЙЙНЈСЫХаЖЈЯЕЪ§ЫуЗЈРДМьВщзюМбФтКЯжБЯпЕФзМШЗЖШКЭПЩППадЁЃЮвУЧжЎЧАЬжТлКЭеЙЪОЙ§ЃЌзюМбФтКЯжБЯпПЩФмВЛЪЧзюКУЕФФтКЯЃЌвВНтЪЭСЫЮЊЪВУДЮвУЧЕФЪОР§ЗНЯђЩЯЪЧе§ШЗЕФЃЌМДЪЙВЂВЛзМШЗЁЃЕЋЪЧЯждкЃЌЮвУЧЪЙгУСНИіЖЅМЖЫуЗЈЃЌЫќУЧгЩвЛаЉаЁаЭЫуЗЈзщГЩЁЃЫцзХЮвУЧМЬајЙЙдьетжжЫуЗЈВуДЮЃЌШчЙћЫќУЧжЎжагаИіаЁДэЮѓЃЌЮвУЧОЭЛсгіЕНТщЗГЃЌЫљвдЮвУЧДђЫубщжЄЮвУЧЕФМйЩшЁЃ
дкБрГЬЕФЪРНчжаЃЌЯЕЭГЛЏЕФГЬађВтЪдЭЈГЃНазіЁАЕЅдЊВтЪдЁБЁЃетОЭЪЧДѓаЭГЬађЙЙНЈЕФЗНЪНЃЌУПИіаЁаЭЕФзгЯЕЭГЖМВЛЖЯМьВщЁЃЫцзХДѓаЭГЬађЕФЩ§МЖКЭИќаТЃЌПЩвдЧсвзвЦГ§вЛаЉКЭжЎЧАЯЕЭГГхЭЛЕФЙЄОпЁЃЪЙгУЛњЦїбЇЯАЃЌетвВЪЧИіЮЪЬтЃЌЕЋЪЧЮвУЧЕФжївЊЙизЂЕуНіНіЪЧВтЪдЮвУЧЕФМйЩшЁЃзюКѓЃЌФугІИУзуЙЛДЯУїЃЌПЩвдЮЊФуЕФећИіЛњЦїбЇЯАЯЕЭГДДНЈЕЅдЊВтЪдЃЌЕЋЪЧФПЧАЮЊжЙЃЌЮвУЧашвЊОЁПЩФмМђЕЅЁЃ
ЮвУЧЕФМйЩшЪЧЃЌЮвУЧДДНЈСЫзюМњheжБЯпЃЌжЎКѓЪЙгУХаЖЈЯЕЪ§ЗЈРДВтСПЁЃЮвУЧжЊЕРЃЈЪ§бЇЩЯЃЉЃЌR ЦНЗНЕФжЕдНЕЭЃЌзюМбФтКЯжБЯпОЭдНВЛКУЃЌВЂЧвдНИпЃЈНгНќ
1ЃЉОЭдНКУЁЃЮвУЧЕФМйЩшЪЧЃЌЮвУЧЙЙНЈСЫвЛИіетбљЙЄзїЕФЯЕЭГЃЌЮвУЧЕФЯЕЭГгааэЖрВПЗжЃЌМДЪЙЪЧвЛИіаЁЕФВйзїДэЮѓЖМЛсВњЩњКмДѓЕФТщЗГЁЃЮвУЧШчКЮВтЪдЫуЗЈЕФааЮЊЃЌБЃжЄШЮКЮЖЋЮїЖМдЄЦкЙЄзїФиЃП
етРяЕФРэФюЪЧДДНЈвЛИібљР§Ъ§ОнМЏЃЌгЩЮвУЧЖЈвхЃЌШчЙћЮвУЧгавЛИіе§ЯрЙиЕФЪ§ОнМЏЃЌЯрЙиадЗЧГЃЧПЃЌШчЙћЯрЙиадКмШѕЕФЛАЃЌЕувВВЛЪЧКмНєУмЁЃЮвУЧгУблОІКмШнвзЦРВтетИіжБЯпЃЌЕЋЪЧЛњЦїгІИУзіЕУИќКУЁЃШУЮвУЧЙЙНЈвЛИіЯЕЭГЃЌЩњГЩЪОР§Ъ§ОнЃЌЮвУЧПЩвдЕїећетаЉВЮЪ§ЁЃ
зюПЊЪМЃЌЮвУЧЙЙНЈвЛИіПђМмКЏЪ§ЃЌФЃФтЮвУЧЕФзюжеФПБъЃК
| def
create_dataset(hm,variance,step=2,correlation=False):
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64) |
ЮвУЧВщПДКЏЪ§ЕФПЊЭЗЃЌЫќНгЪмЯТСаВЮЪ§ЃК
1.hmЃЈhow muchЃЉЃКетЪЧЩњГЩЖрЩйИіЪ§ОнЕуЁЃР§ШчЮвУЧПЩвдбЁдё
10ЃЌЛђепвЛЧЇЭђЁЃ
2.varianceЃКОіЖЈУПИіЪ§ОнЕуКЭжЎЧАЕФЪ§ОнЕуЯрБШЃЌгаЖрДѓБфЛЏЁЃБфЛЏдНДѓЃЌОЭдНВЛНєУмЁЃ
3.stepЃКУПИіЕуОрРыОљжЕгаЖрдЖЃЌФЌШЯЮЊ 2ЁЃ
4.correlationЃКПЩвдЮЊFalseЁЂposЛђепnegЃЌОіЖЈВЛЯрЙиЁЂе§ЯрЙиКЭИКЯрЙиЁЃ
вЊзЂвтЃЌЮвУЧвВЕМШыСЫrandomЃЌетЛсАяжњЮвУЧЩњГЩЃЈЮБЃЉЫцЛњЪ§ОнМЏЁЃ
ЯждкЮвУЧвЊПЊЪМЬюГфКЏЪ§СЫЁЃ
| def
create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y) |
ЗЧГЃМђЕЅЃЌЮвУЧНіНіЪЙгУhmБфСПЃЌЕќДњЮвУЧЫљбЁЕФЗЖЮЇЃЌНЋЕБЧАжЕМгЩЯвЛИіИКВюжЕЕНжЄВюжЕЕФЫцЛњЗЖЮЇЁЃетЛсВњЩњЪ§ОнЃЌЕЋЪЧШчЙћЮвУЧЯывЊЕФЛАЃЌЫќУЛгаЯрЙиадЁЃШУЮвУЧетбљЃК
| def
create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step |
ЗЧГЃАєСЫЃЌЯждкЮвУЧЖЈвхКУСЫ y жЕЁЃЯТУцЃЌШУЮвУЧДДНЈ xЃЌЫќИќМђЕЅЃЌжЛЪЧЗЕЛиЫљгаЖЋЮїЁЃ
| def
create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64) |
ЮвУЧзМБИКУСЫЁЃЮЊСЫДДНЈбљР§Ъ§ОнМЏЃЌЮвУЧЫљашЕФОЭЪЧЃК
| xs,
ys = create_dataset(40,40,2,correlation='pos') |
ШУЮвУЧНЋжЎЧАЯпадЛиЙщНЬГЬЕФДњТыЗХЕНвЛЦ№ЃК
| from
statistics import mean
import numpy as np
import random
import matplotlib.pyplot as plt
from matplotlib import style
style.use('ggplot')
def create_dataset(hm,variance,step=2,correlation=False):
val = 1
ys = []
for i in range(hm):
y = val + random.randrange(-variance,variance)
ys.append(y)
if correlation and correlation == 'pos':
val+=step
elif correlation and correlation == 'neg':
val-=step
xs = [i for i in range(len(ys))]
return np.array(xs, dtype=np.float64),np.array(ys,dtype=np.float64)
def best_fit_slope_and_intercept(xs,ys):
m = (((mean(xs)*mean(ys)) - mean(xs*ys)) /
((mean(xs)*mean(xs)) - mean(xs*xs)))
b = mean(ys) - m*mean(xs)
return m, b
def coefficient_of_determination(ys_orig,ys_line):
y_mean_line = [mean(ys_orig) for y in ys_orig]
squared_error_regr = sum((ys_line - ys_orig)
* (ys_line - ys_orig))
squared_error_y_mean = sum((y_mean_line - ys_orig)
* (y_mean_line - ys_orig))
print(squared_error_regr)
print(squared_error_y_mean)
r_squared = 1 - (squared_error_regr/squared_error_y_mean)
return r_squared
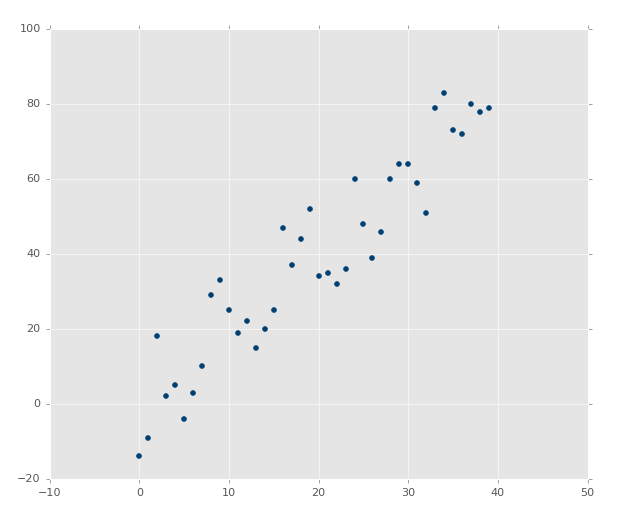
xs, ys = create_dataset(40,40,2,correlation='pos')
m, b = best_fit_slope_and_intercept(xs,ys)
regression_line = [(m*x)+b for x in xs]
r_squared = coefficient_of_determination(ys,regression_line)
print(r_squared)
plt.scatter(xs,ys,color='#003F72', label =
'data')
plt.plot(xs, regression_line, label = 'regression
line')
plt.legend(loc=4)
plt.show() |
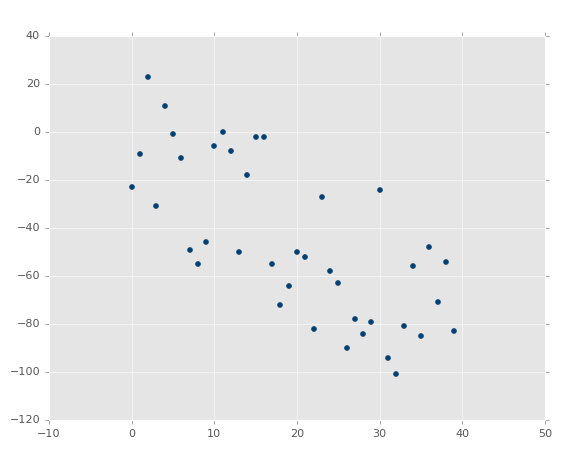
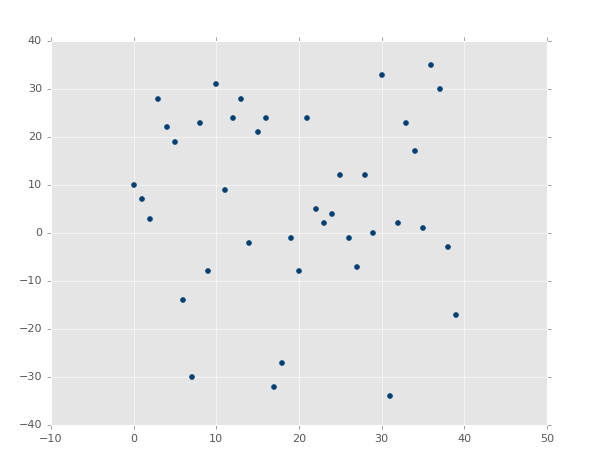
жДааДњТыЃЌФуЛсПДЕНЃК
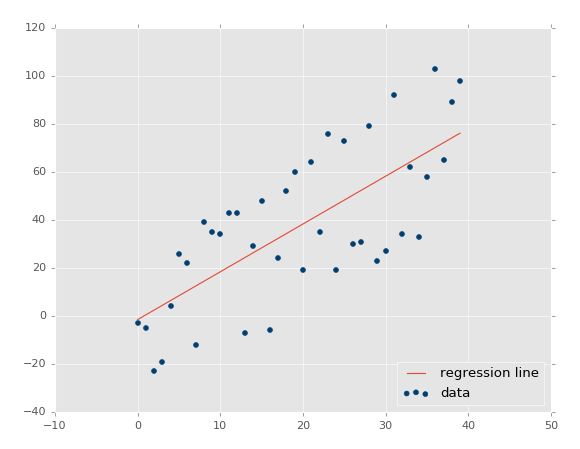
ХаЖЈЯЕЪ§ЪЧ 0.516508576011ЃЈвЊзЂвтФуЕФНсЙћВЛЛсЯрЭЌЃЌвђЮЊЮвУЧЪЙгУСЫЫцЛњЪ§ЗЖЮЇЃЉЁЃ
ВЛДэЃЌЫљвдЮвУЧЕФМйЩшЪЧЃЌШчЙћЮвУЧЩњГЩвЛИіИќМгНєУмЯрЙиЕФЪ§ОнМЏЃЌЮвУЧЕФ
R ЦНЗНЛђХаЖЈЯЕЪ§гІИУИќКУЁЃШчКЮЪЕЯжЫќФиЃПКмМђЕЅЃЌАбЗЖЮЇЕїЕЭЁЃ
| xs,
ys = create_dataset(40,10,2,correlation='pos') |
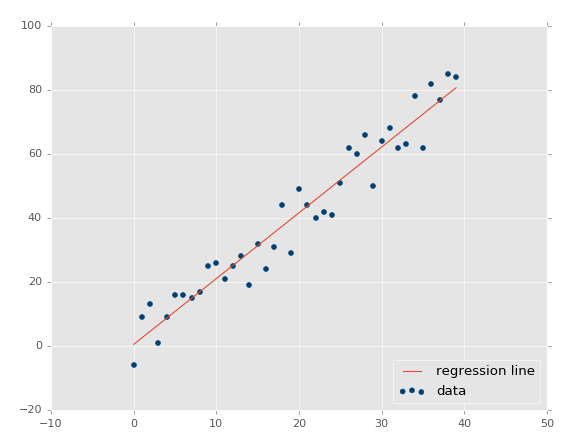
ЯждкЮвУЧЕФ R ЦНЗНжЕЮЊ 0.939865240568ЃЌЗЧГЃВЛДэЃЌОЭЯёдЄЦквЛбљЁЃШУЮвУЧВтЪдИКЯрЙиЃК
| xs,
ys = create_dataset(40,10,2,correlation='neg') |
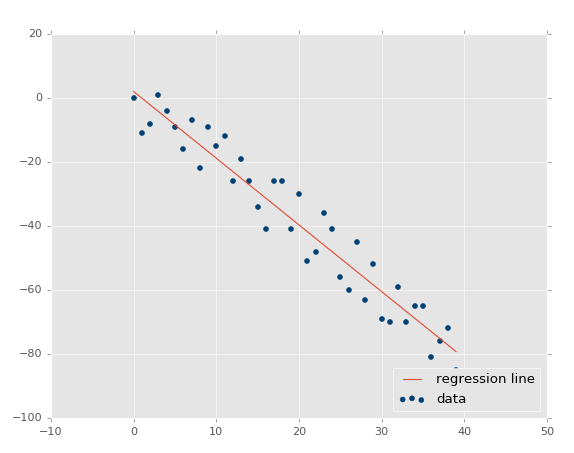
R ЦНЗНжЕЪЧ 0.930242442156ЃЌИњжЎЧАвЛбљКУЃЌгЩгкЫќУЧВЮЪ§ЯрЭЌЃЌжЛЪЧЗНЯђВЛЭЌЁЃ
етРяЃЌЮвУЧЕФМйЩшжЄЪЕСЫЃКБфЛЏдНаЁ R жЕКЭХаЖЈЯЕЪ§дНИпЃЌБфЛЏдНДѓ
R жЕдНЕЭЁЃШчЙћЪЧВЛЯрЙиФиЃПгІИУКмЕЭЃЌНгНќгк 0ЃЌГ§ЗЧЮвУЧЕФЫцЛњЪ§ХХСаЪЕМЪЩЯгаЯрЙиадЁЃШУЮвУЧВтЪдЃК
| xs,
ys = create_dataset(40,10,2,correlation=False) |
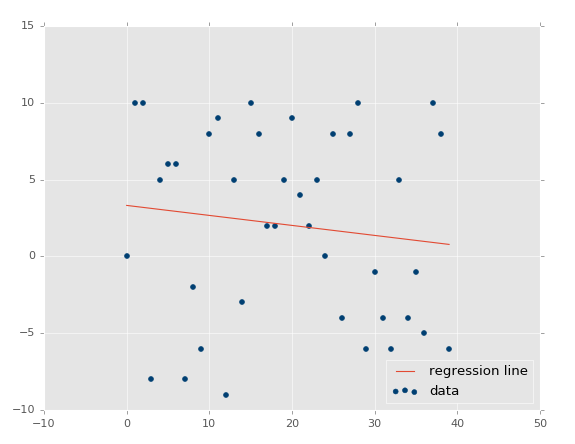
ХаЖЈЯЕЪ§ЮЊ 0.0152650900427ЁЃ
ЯждкЮЊжЙЃЌЮвОѕЕУЮвУЧгІИУИаЕНздаХЃЌвђЮЊЪТЧщЖМЗћКЯЮвУЧЕФдЄЦкЁЃ
МШШЛЮвУЧвбОЖдМђЕЅЕФЯпадЛиЙщКмЪьЯЄСЫЃЌЯТИіНЬГЬжаЮвУЧПЊЪМНВНтЗжРрЁЃ
|









