在运营系统中经常用到异步方式来处理我们的任务,比如将业务上线流程串成任务再写入队列,通过后台作业节点去调度执行。比较典型的案例为腾讯的蓝鲸、织云、云智慧等平台。本译文结合Django+Celery+Redis实现一个定期从Flickr 获取图片并展示的简单案例,方便大家理解实现异步对列任务的过程。
刚接触django的时候,我经历过的最让人沮丧的事情是需要定期运行一段代码。我写了一个需要每天上午12点执行一个动作的不错的函数。很简单是不是?错了。事实证明,这对我来说是一个巨大的困难点,因为,那时我使用Cpane类型的虚拟主机管理系统,它能专门提供一个很友好,很方便的图形用户界面来设置cron作业。
经过反复研究,我发现了一个很好的解决方案 - Celery,一个用于在后台运行任务的强大的异步作业队列。但是,这也导致了其它的问题,因为我无法找到一系列简单的指令将celery集成到Django项目中。
当然,我最终还是设法成功搞定了它 - 这正是本文将介绍的内容:如何将celery集成到一个Django项目,创建周期性任务。
该项目利用Python3.4,Django的1.8.2,celery3.1.18和Redis3.0.2.
一、概述
由于大篇幅的文字,为了您的方便,请参阅下表中的每一步的简要信息,并获取相关的代码。
步骤 概要 Git标签
样板 样板下载 V1
建立 集成Celery和Django V2
Celery任务 添加基本的Celery任务 V3
周期性任务 添加周期性任务 V4
本地运行 本地运行我们的应用程序 V5
远程运行 远程运行我们的应用程序 V5
二、什么是Celery
“Celery是一个异步任务队列/基于分布式消息传递的作业队列。它侧重于实时操作,但对调度的支持也很好。”本文,我们将重点讲解周期性执行任务的调度特点。
为什么这一点有用呢?
回想一下你不得不在将来运行某一特定任务的经历。也许你需要每隔一小时访问一个API。或者,也许你需要在这一天结束时发送一批电子邮件。不论任务大小,Celery都可以使得调度周期性任务变的很容易。
你永远不希望终端用户等待那些不必要的页面加载或动作执行完成。如果你的应用程序工作流的一部分是一个需要很长时间的程序,当资源可用时,你就可以使用Celery在后台执行这段程序,从而使你的应用程序可以继续响应客户端的请求。这样可以使任务在应用程序的环境之外运行。
三、构建项目
在深入了解Celery之前,先从Github库中获取开始项目。确保激活一个虚拟的环境,安装必要的软件,并运行迁移。然后启动服务器,通过你的浏览器导航到http://localhost:8000/。你应当能看到‘恭喜你的第一个Django页面’。完成后,关闭服务器。
接下来,我们开始安装celery。
$ pip install celery==3.1.18
$ pip freeze > requirements.txt |
现在,我们通过简单的三步将celery集成到django项目中。
步骤一:创建celery.py
在“picha“目录下,创建celery.py,代码如下:
view plain print ?
from __future__ import absolute_import
import os
from celery import Celery
from django.conf import settings
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'picha.settings')
app = Celery('picha')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request)) |
请注意代码中的注释。
步骤二:引入celery应用
为了确保在django启动时加载了celery应用,在settings.py旁边新建__init__.py,并添加以下代码到__init__.py中。
view plain print ?
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
|
完成以上步骤后,你的项目目录应该是这样的:
├── manage.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── requirements.txt |
步骤三:安装 Redis作为Celery的“中间件”
Celery使用中间件在django项目与celery监控者之间传递消息。在本教程中,我们使用redis作为消息中间代理。
首先,从官方下载页面或通过brew(BREW安装Redis)安装Redis,然后打开你的终端上,在一个新的终端窗口,启动服务器:
$ redis-server
你可以通过在终端中输入如下命令测试Redis是否正常工作。
$ redis-cli ping
Redis应该回复PONG - 试试吧!
一旦Redis正常启动了,把下面的代码添加到你的settings.py文件中:
view plain print ?
# CELERY STUFF
BROKER_URL = 'redis://localhost:6379'
CELERY_RESULT_BACKEND = 'redis://localhost:6379'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Africa/Nairobi' |
你还需要添加Redis的作为Django项目的依赖:
$ pip install redis==2.10.3
$ pip freeze > requirements.txt |
就是这样了!你现在应该能够在Django中使用Celery。有关设置Celery与Django的更多信息,请查看官方Celery文档。
在继续下面步骤之前,让我们进行一些完整性检查,以确保一切都是正常的。
测试Celery worker已准备好接收任务:
view plain print ?
$ celery -A picha worker -l info
...
[2015-07-07 14:07:07,398: INFO/MainProcess] Connected to redis://localhost:6379//
[2015-07-07 14:07:07,410: INFO/MainProcess] mingle: searching for neighbors
[2015-07-07 14:07:08,419: INFO/MainProcess] mingle: all alone |
使用CTRL-C杀死该段程序。现在,测试Celery任务调度程序是否已经准备好:
$ celery -A picha beat -l info
...
[2015-07-07 14:08:23,054: INFO/MainProcess] beat: Starting... |
在上述完成时再次终止该进程。
1、Celery任务
Celery利用celery调用的常规Python函数作为任务。
例如,让我们把这个基本函数变为celery的任务:
view plain print ?
def add(x, y):
return x + y |
首先,添加一个装饰器。
view plain print ?
from celery.decorators import task
@task(name="sum_two_numbers")
def add(x, y):
return x + y |
然后你可以通过以下方式利用celery异步运行该任务:
add.delay(7, 8)
很简单,对不对?
所以,这对于解决类似你要加载一个网页,而不需要用户等待一些后台程序的完成这些类型的任务来说是非常完美的。
让我们来看一个例子...
让我们再回到Django项目的版本3,它包括一个接受来自用户的反馈的应用程序,人们形象地称之为反馈:
├── feedback
│ ├── __init__.py
│ ├── admin.py
│ ├── emails.py
│ ├── forms.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── requirements.txt
└── templates
├── base.html
└── feedback
├── contact.html
└── email
├── feedback_email_body.txt
└── feedback_email_subject.txt |
安装新的必要软件,启动应用程序,并导航到http://localhost:8000/feedback/。你应该看到如下结果:

让我们连接celery任务。
2、添加任务
基本上,用户提交反馈表后,我们希望让他继续以他舒服的方式往下进行,而我们在后台进行处理反馈,发送电子邮件等等。
要做到这一点,首先添加一个叫tasks.py的文件到“feedback”目录:
view plain print ?
from celery.decorators import task
from celery.utils.log import get_task_logger
from feedback.emails import send_feedback_email
logger = get_task_logger(__name__)
@task(name="send_feedback_email_task")
def send_feedback_email_task(email, message):
"""sends an email when feedback form is filled successfully"""
logger.info("Sent feedback email")
return send_feedback_email(email, message) |
然后按照如下内容更新forms.py:
view plain print ?
from django import forms
from feedback.tasks import send_feedback_email_task
class FeedbackForm(forms.Form):
email = forms.EmailField(label="Email Address")
message = forms.CharField(
label="Message", widget=forms.Textarea(attrs={'rows': 5}))
honeypot = forms.CharField(widget=forms.HiddenInput(), required=False)
def send_email(self):
# try to trick spammers by checking whether the honeypot field is
# filled in; not super complicated/effective but it works
if self.cleaned_data['honeypot']:
return False
send_feedback_email_task.delay(
self.cleaned_data['email'], self.cleaned_data['message']) |
大体上,send_feedback_email_task.delay(email, message)的函数过程,并发送反馈电子邮件等都是在用户继续使用该网站的同时作为后台进程运行。
注:在views.py中的success_url被设置为将用户重定向到/ 目录,这个目录还不存在。我们会在下一节设置这个终点启动。
3、周期任务
通常情况下,你经常需要安排一个任务在特定的时间运行 - 例如,一个web scraper 可能需要每天都运行。这样的任务,被称为周期性任务,很容易建立利用celery启动。
celery使用“celery beat”来安排定期任务。celery beat定期运行任务,然后由celery worker执行任务。
例如,下面的任务计划每15分钟运行一次:
view plain print ?
from celery.task.schedules import crontab
from celery.decorators import periodic_task
@periodic_task(run_every=(crontab(minute='*/15')), name="some_task", ignore_result=True)
def some_task():
# do something |
让我们通过往Django项目中添加功能来看一个更强大的例子。
回到Django项目版本4,它包括另一个新的应用程序,叫做photos,这个应用程序使用 Flickr API获取新照片用来显示在网站:
├── feedback
│ ├── __init__.py
│ ├── admin.py
│ ├── emails.py
│ ├── forms.py
│ ├── models.py
│ ├── tasks.py
│ ├── tests.py
│ └── views.py
├── manage.py
├── photos
│ ├── __init__.py
│ ├── admin.py
│ ├── models.py
│ ├── settings.py
│ ├── tests.py
│ ├── utils.py
│ └── views.py
├── picha
│ ├── __init__.py
│ ├── celery.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── requirements.txt
└── templates
├── base.html
├── feedback
│ ├── contact.html
│ └── email
│ ├── feedback_email_body.txt
│ └── feedback_email_subject.txt
└── photos
└── photo_list.html |
安装新的必要软件,运行迁移,然后启动服务器,以确保一切都是好的。重新测试反馈表。这次,它应该重定向好了。
下一步是什么?
既然我们需要周期性的调用Flickr API,以获取更多的照片添加到我们的网站,我们可以添加一个celery任务。
4、添加任务
往photos应用中添加一个tasks.py。
view plain print ?
from celery.task.schedules import crontab
from celery.decorators import periodic_task
from celery.utils.log import get_task_logger
from photos.utils import save_latest_flickr_image
logger = get_task_logger(__name__)
@periodic_task(
run_every=(crontab(minute='*/15')),
name="task_save_latest_flickr_image",
ignore_result=True
)
def task_save_latest_flickr_image():
"""
Saves latest image from Flickr
"""
save_latest_flickr_image()
logger.info("Saved image from Flickr") |
在这里,我们通过在一个task中包装这个函数,来实现每15分钟运行一次save_latest_flickr_image()函数。该@periodic_task装饰器抽象出代码来运行celery任务,使得tasks.py干净,易于阅读!
5、本地运行
准备开始运行了?
在Django应用程序和Redis运行的前提下,打开两个新的终端窗口/标签。在每一个新的窗口中,导航到你的项目目录,激活你的虚拟环境,然后运行下面的命令(每个窗口一个):
$ celery -A picha worker -l info
$ celery -A picha beat -l info |
当你访问http://127.0.0.1:8000/ 网址的时候,你现在应该能看到一个图片。我们的应用程序每15分钟从Flickr 获取一张图片。
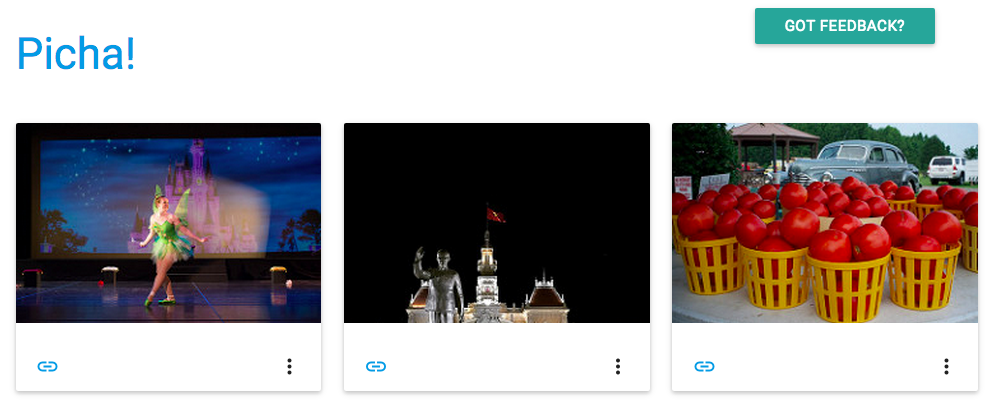
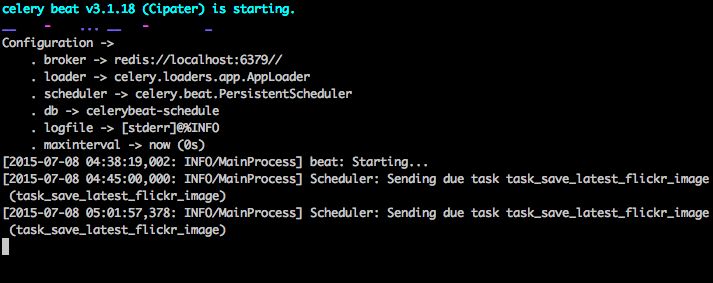
通过photos/tasks.py查看代码。点击“Feedback”按钮发送一些反馈意见:
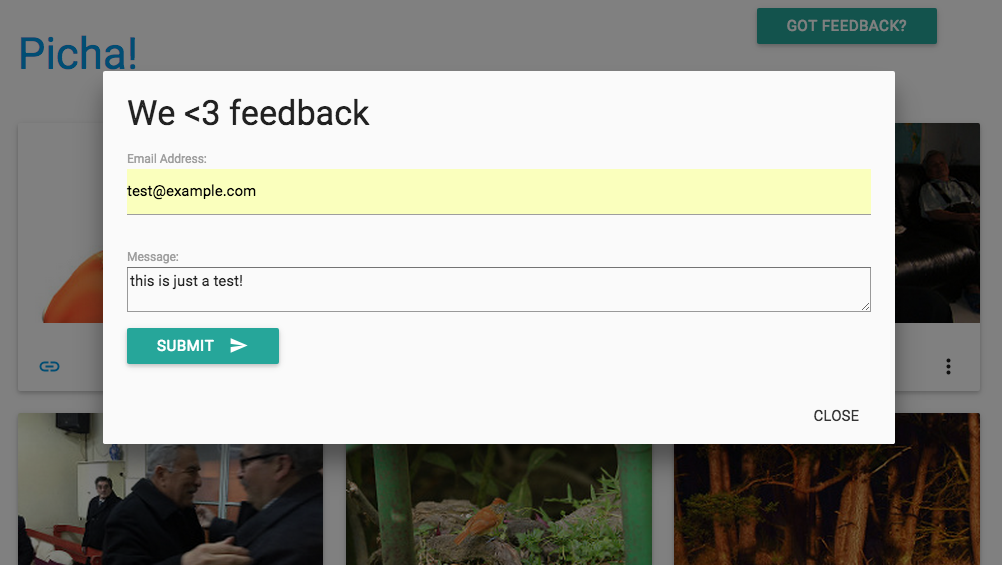
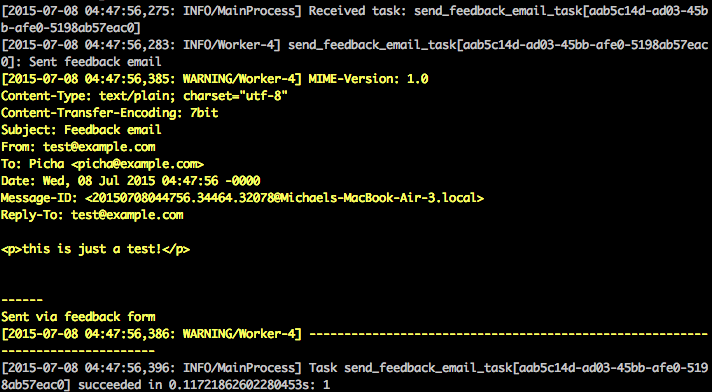
以上是通过celery任务运行的。更多的请查看feedback/tasks.py。
就这样,你成功的启动并运行了 Picha项目!
当你本地开发Django项目时,这是一个很好的测试,但是当你需要部署到生产环境- 就像 DigitalOcean时,就不那么合适了。为此,建议你通过使用Supervisor在后台作为一个守护进程运行celery worker和调度器。
6、远程运行
安装很简单。从版本库中获取版本5(如果你还没有的话)。然后,SSH到远程服务器,并运行:
$ sudo apt-get install supervisor
然后,通过在远程服务器上“/etc/supervisor/conf.d/” 目录下添加配置文件来告知Supervisor celery的workers。在我们的例子中,我们需要两个这样的配置文件 - 一个用于Celery worker,一个是Celery scheduler。
在本地,在项目的根目录下创建一个“supervisor”的文件夹,然后添加下面的文件。
Celery Worker: picha_celery.conf
view plain print ?
; ==================================
; celery worker supervisor example
; ==================================
; the name of your supervisord program
[program:pichacelery]
; Set full path to celery program if using virtualenv
command=/home/mosh/.virtualenvs/picha/bin/celery worker -A picha --loglevel=INFO
; The directory to your Django project
directory=/home/mosh/sites/picha
; If supervisord is run as the root user, switch users to this UNIX user account
; before doing any processing.
user=mosh
; Supervisor will start as many instances of this program as named by numprocs
numprocs=1
; Put process stdout output in this file
stdout_logfile=/var/log/celery/picha_worker.log
; Put process stderr output in this file
stderr_logfile=/var/log/celery/picha_worker.log
; If true, this program will start automatically when supervisord is started
autostart=true
; May be one of false, unexpected, or true. If false, the process will never
; be autorestarted. If unexpected, the process will be restart when the program
; exits with an exit code that is not one of the exit codes associated with this
; process’ configuration (see exitcodes). If true, the process will be
; unconditionally restarted when it exits, without regard to its exit code.
autorestart=true
; The total number of seconds which the program needs to stay running after
; a startup to consider the start successful.
startsecs=10
; Need to wait for currently executing tasks to finish at shutdown.
; Increase this if you have very long running tasks.
stopwaitsecs = 600
; When resorting to send SIGKILL to the program to terminate it
; send SIGKILL to its whole process group instead,
; taking care of its children as well.
killasgroup=true
; if your broker is supervised, set its priority higher
; so it starts first
priority=998 |
Celery Scheduler: picha_celerybeat.conf
view plain print ?
; ================================
; celery beat supervisor example
; ================================
; the name of your supervisord program
[program:pichacelerybeat]
; Set full path to celery program if using virtualenv
command=/home/mosh/.virtualenvs/picha/bin/celerybeat -A picha --loglevel=INFO
; The directory to your Django project
directory=/home/mosh/sites/picha
; If supervisord is run as the root user, switch users to this UNIX user account
; before doing any processing.
user=mosh
; Supervisor will start as many instances of this program as named by numprocs
numprocs=1
; Put process stdout output in this file
stdout_logfile=/var/log/celery/picha_beat.log
; Put process stderr output in this file
stderr_logfile=/var/log/celery/picha_beat.log
; If true, this program will start automatically when supervisord is started
autostart=true
; May be one of false, unexpected, or true. If false, the process will never
; be autorestarted. If unexpected, the process will be restart when the program
; exits with an exit code that is not one of the exit codes associated with this
; process’ configuration (see exitcodes). If true, the process will be
; unconditionally restarted when it exits, without regard to its exit code.
autorestart=true
; The total number of seconds which the program needs to stay running after
; a startup to consider the start successful.
startsecs=10
; if your broker is supervised, set its priority higher
; so it starts first
priority=999 |
注:确保更新这些文件的路径,以匹配你的远程服务器的文件系统。
基本上,这些supervisor 配置文件告诉supervisord如何运行并管理我们的'programs'(因为它们是由supervisord调用)。
在上面的例子中,我们已经创建了两个名为“pichacelery”和“pichacelerybeat”的supervisord程序。
现在,只需将这些文件拷贝到远程服务器的/etc/supervisor/conf.d/目录下。
我们还需要在远程服务器上创建上面脚本中提到的日志文件:
$ touch /var/log/celery/picha_worker.log
$ touch /var/log/celery/picha_beat.log |
最后,运行以下命令,使 Supervisor 知道它所管理的程序的存在 - 例如,pichacelery和pichacelerybeat:
$ sudo supervisorctl reread
$ sudo supervisorctl update |
运行以下命令停止,启动,和/或检查pichacelery程序的状态:
$ sudo supervisorctl stop pichacelery
$ sudo supervisorctl start pichacelery
$ sudo supervisorctl status pichacelery |
你可以通过阅读官方文档获取Supervisor的更多信息。
7、最后提示
1. 千万不要传递Django模型对象到celery任务。为了避免模型对象在传递给celery任务之前已经改变了,传递celery的主键给celery。然后,在运行之前使用主键从数据库中获取对象。
2. 默认celery调度会在本地创建一些文件存储它的调度表。这些文件是“celerybeat-schedule.db”和“celerybeat.pid”。如果你在使用版本控制系统,比如Git(你应该使用!),请忽略这个文件,不要将它们添加到你的代码库中,因为它们是为本地运行的进程服务的。
8、下一步
以上就是将celery集成到一个django项目的基本介绍。
想要更多?
1. 深入研究官方celery用户指南,以了解更多信息。
2. 创建一个Fabfile来设置Supervisor和配置文件。确保添加命令到reread和 update Supervisor。
3. 从repo中获取这个项目,并打开一个Pull 请求来添加一个新的celery任务。
编码快乐! |









