| 编辑推荐: |
本文主要探讨了本体论(Ontology)与模型驱动工程(MDE)在软件开发中的关联与定位,希望对你的学习有帮助。
本文来源于Digital Engineering ,由火龙果软件Alice编辑,推荐。 |
|
编者按:
有朋友半夜发来个链接,似乎希望能看我吐个槽。好吧,满足你的愿望,但下不为例哈。“上等人”就喜欢看这种斗鸡撕逼游戏吗?
先看一组数据,MathWorks公司是个什么概念。据去年他们向美国商务部提交的数据显示,他们发展了四十多年,现在用100多种产品和数百种第三方产品,服务于世界范围内10万机构的500万专业用户。
据金山办公2025年半年度报告显示,截至2025年6月30日,WPS国内累计年度付费用户数4179万,海外年度付费个人用户数189万。
所以,当一个领域专业工具的开发商宣称要面向X千万工科生、X千万工程师开发产品时,他的站位已经高于工信部+教育部+工程院。如果这不是疯言疯语,要为他让路的岂止是MATLAB?
据《新闻战线》2025年9月刊文显示,“学习强国”注册用户数达3.7亿,日均浏览人次近7亿。据公开数据显示,2025年11月,豆包月活用户数约为1.68亿。
所以说,这是想追求多高的估值,要让这些苦哈哈的年轻人承担这样离谱的责任? 试想1.1亿人,每人拿个计算器拖拉拽求解常微分方程,这画面太美直追大炼钢铁土法炼钢。
真是MATLAB躺平任踩,龙傲天看了也直摇头。
人心都是肉长的,别PUA了,放了孩子们吧。 再次提醒把笑话端到我面前的朋友,下次再发这种荒唐链接给我看,我可要收费了。这种互吹冒料的帖子自身是释放从而吸引阴性能量的,我得写多少材料、念多少经文来阴阳对冲啊!
以上是文字原创内容。
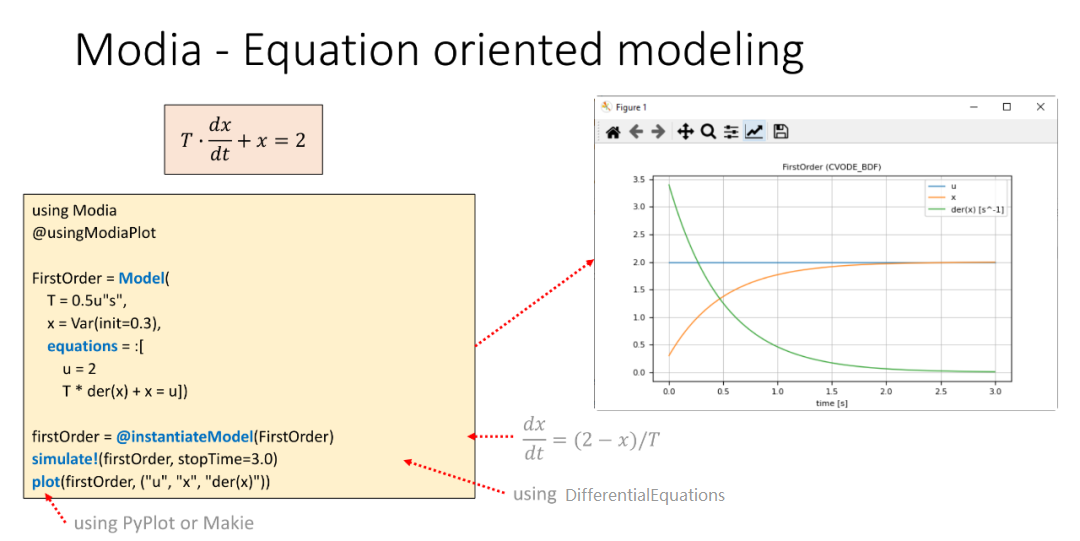
真是没办法,混淆我的文风,好好地研究本体,给我乱入一段。来都来了,那就继续放点相关内容吧。Modelica之父讲的建模课。
话说人家瑞典的学生们还是挺仗义的,时不时还会想着拉祖师爷的后裔一把。
看起来这堂课主要是基于Modia讲的,这是Julia生态中的系统建模仿真产品,Modelica之父十分喜欢。瑞典人就是开放啊。
结构与符号处理”(Structural and Symbolic Processing)的流程步骤 ,通常用于复杂系统(如微分代数方程系统、工程建模等场景)的求解与代码生成,各步骤的含义及作用如下:
- 构建 关联矩阵 (Build incidence matrix) 用矩阵表示系统中 “方程 - 变量” 等元素的关联关系,是后续结构分析的基础。
- 执行别名消除(Perform alias elimination) 去除系统中重复、冗余的变量 / 标识,简化模型复杂度。
- 为每个方程分配变量(Assign a variable to each equation) 明确方程与待求解变量的对应关系,是方程组求解的前置匹配步骤。
- 对等式排序并分组(BLT) 通过 “块下三角(Block Lower Triangular)” 排序,将方程组划分为块结构,降低求解难度。
- 通过撕裂法减小块大小(Reduce block size by tearing) 拆分大型方程组的块,进一步简化每一块的求解复杂度。
- 执行索引约简(Perform Index reduction) 常用于微分代数方程(DAE)的处理,降低方程的 “索引” 以转化为更易求解的形式(如常微分方程)。
- 符号求解未知量(Symbolically solve for the unknowns) 用符号计算的方式推导未知量的解析解(而非数值近似)。
- 对特定方程进行符号微分(Symbolically differentiate certain equations) 通过微分操作处理方程(如 DAE 中需微分转化为可求解形式)。
- 生成可执行代码(Generate executable code) 将处理后的模型转化为可运行的代码,用于实际仿真、计算。
整体而言,这是一套 从系统结构分析、方程简化,到符号计算、最终生成执行代码 的完整流程,核心目的是高效处理复杂方程组(尤其是微分代数系统)的求解问题。
“关联矩阵(Incidence Matrix)” 在微分代数方程(DAE)结构分析中的应用,包含定义说明、矩阵示例及相关补充说明。
关联矩阵是表示系统中 方程与变量之间依赖关系 的矩阵,是结构与符号处理流程(如前序提到的 “Build incidence matrix” 步骤)的基础工具,用于可视化和分析方程组的拓扑结构。
矩阵结构规则
- 列(Column) :对应一个变量(Variable),每列代表系统中的一个待求解变量。
- 行(Row) :对应一个方程(Equation),每行代表系统中的一个方程。
- 矩阵元素 :若某变量存在于某方程中(即方程依赖该变量),则对应位置标记为非零值(图中以蓝色方块表示),否则为零(空白)。
实例解析(右侧矩阵图)
图中展示了一个具体的关联矩阵实例,矩阵右侧标注了 “connections”(变量关联)和 “equations”(方程),蓝色方块的分布直观呈现了:
- 例如,第 1 行(方程 1)的蓝色方块对应列 25 和 27,表明方程 1 依赖变量 25 和 27(原文标注:“Equation 1 is a function of variables 25 and 27”)。
- 矩阵整体呈现稀疏分布(Sparse representation),符合实际工程系统中 “每个方程仅依赖少量变量” 的特点。
数学表示与扩展说明
- 数学定义 :用集合表示为 G = {(1,25), (1,27), (2,21), ...} ,其中每个元组 (行,列) 表示 “行对应方程依赖列对应变量”。
- 图论本质 :关联矩阵等价于一个 “二部图”(Bipartite graph)的表示,其中一行对应图中的一个 “方程节点”,一列对应一个 “变量节点”,非零元素表示节点间的边(依赖关系)。
应用价值
通过关联矩阵可快速识别方程组的 耦合关系 、 冗余方程 / 变量 ,为后续 “别名消除”“方程分组(BLT)”“撕裂法简化” 等步骤提供结构依据,是复杂系统建模与求解的关键前置分析工具。
别名消除(Alias Elimination) —— 这是 Modelica 工具处理微分代数方程(DAE)时的第一步简化操作,核心是移除冗余方程、替换 “别名变量” 以精简系统。
1. 核心简化规则
Modelica 工具通过两种方式简化 DAE:
- 规则 1( v = 0 形式方程) 移除 v = 0 的方程,将系统中所有出现 v 的位置替换为 0 ,再简化相关方程。
- 规则 2(变量等价形式方程) 移除 v1 = v2 、 v1 = -v2 、 0 = v1+v2 这类方程(其中 v1 被称为 “别名变量”),将系统中所有 v1 替换为 v2 (或 -v2 ),再简化相关方程。
2. 示例解析
左侧是 被移除的冗余方程 (如 ground.p.v = 0 、 V.n.v = ground.p.v 等);右侧是工具 内部保留的赋值信息 :
- 由 ground.p.v = 0 ,可得 ground.p.v := 0 ,进而推导得 V.n.v := 0 、 C.n.v = 0 ;
- 结合 C.v = C.p.v - C.n.v 与 C.n.v = 0 ,可推得 C.p.v := C.v ;
- 最终仅保留 C.v (因为它包含导数项 der(C.v) ,无法被替换),其他变量(如 C.p.v )均被替换 / 移除。
3. 符号含义
- expr1 = expr2 表示等式左右两侧的表达式相等;
- v := expr 表示将右侧表达式的计算结果赋值给左侧变量。
这个操作的作用是 消除系统中的冗余变量与方程 ,降低后续方程组求解的复杂度。
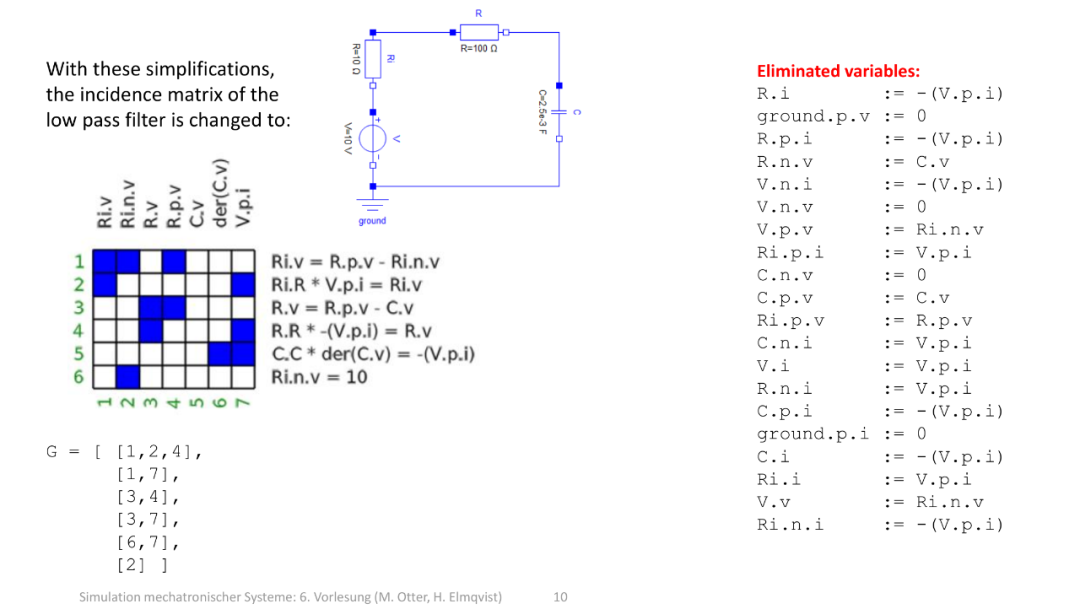
机电系统仿真课程中 “低通滤波器的电路建模” 相关内容,核心是用 关联矩阵(Incidence Matrix)+ 变量消元 的方法建立电路的数学模型,方便后续仿真计算。
1. 核心对象:低通滤波器电路(中间图)
电路包含:
- 电压源( V i = 10 V )、内阻 R i = 0Ω (理想电压源)
- 电阻 R = 100Ω
- 电容 C = 25.53 F
- 接地端(ground)
2. 关联矩阵(左侧)
关联矩阵用于描述 电路元件与节点、变量之间的连接 / 约束关系 (基于基尔霍夫定律 / KCL/KVL、元件伏安特性):
- 矩阵的行 / 列对应不同元件的变量(如 R i . v 、 R . p . v 等,代表电阻 / 电容的端口电压、电流)。
- 蓝色方块表示变量间存在约束,旁边的方程是具体约束关系(比如 R i . v = R . p . v − R i . n . v 是电压的节点约束)。
3. 变量消元(右侧)
通过方程化简, 消去冗余变量 ,得到精简的变量关系(比如 R . i := − ( V . p . i ) 表示电阻电流与电压源端口电流的关系),目的是减少未知量,便于建立系统的微分方程 / 仿真模型。
4. 关联矩阵的节点连接列表(底部 G)
用列表形式描述 元件与电路节点的连接关系 (比如 [1,2,4] 表示某元件连接节点 1、2、4),是关联矩阵的 “节点连接” 表达方式。
整体是课程中 “电路系统的数学建模(用于仿真)” 的步骤:用关联矩阵描述电路约束→消去冗余变量→得到可计算的系统模型。
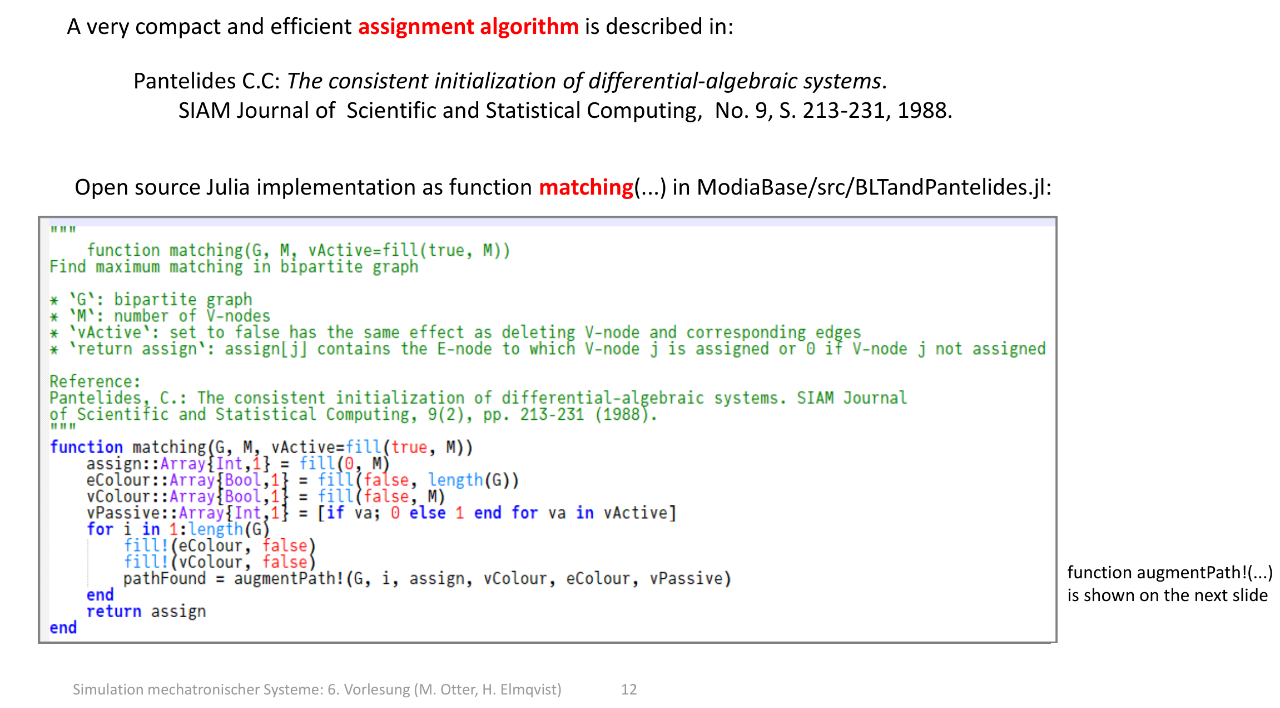
整体是 “电路建模自动化” 的关键步骤:通过算法自动匹配 “未知变量 - 求解方程”,避免手动分配的繁琐,为后续求解电路的微分方程 / 仿真做准备。
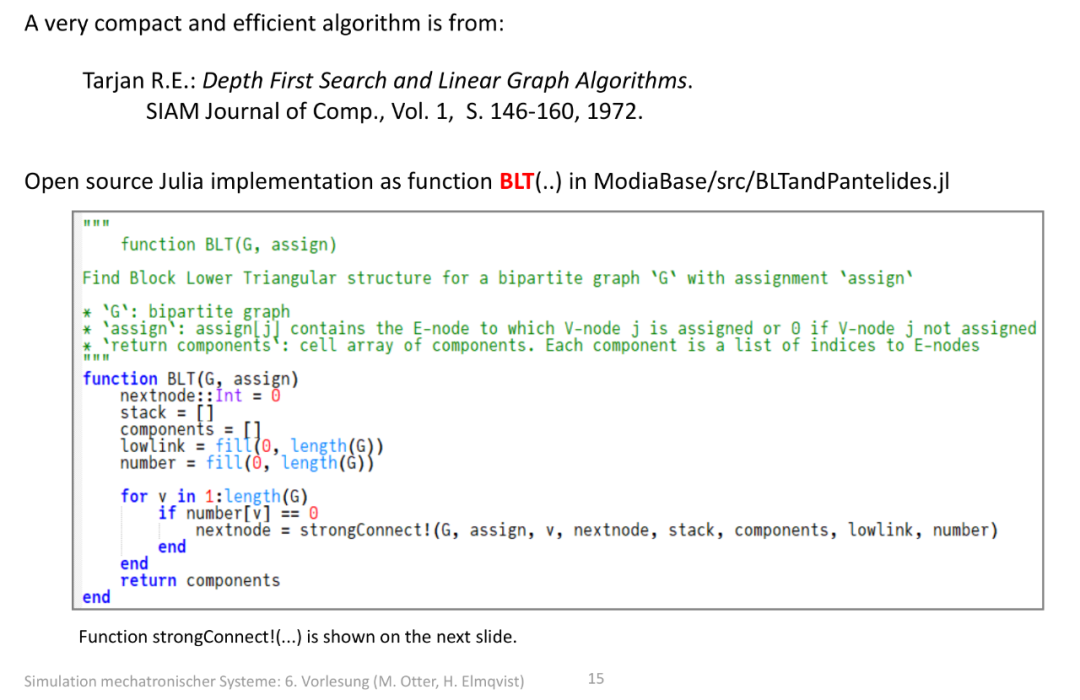
1. 算法来源
这里用到的 紧凑高效的分配算法 ,出自论文:Pantelides C.C. 1988 年发表的《微分代数系统的一致初始化》(发表于 SIAM 科学与统计计算期刊)。这个算法是处理 “微分代数系统(如电路,同时包含微分方程和代数约束)” 的核心工具之一,用于解决 “变量与约束方程的匹配 / 分配” 问题。
2. 开源实现(Julia 代码)
这个算法被封装为 Julia 函数 matching(...) ,位于开源库 ModiaBase 的 BLTandPantelides.jl 文件中,作用是 在 “变量 - 方程” 构成的二分图中,找到最大匹配 (即给尽可能多的未知变量分配对应的求解方程)。
函数参数与含义:
- G :表示 “变量 - 方程” 关系的 二分图 (对应之前电路的关联矩阵,描述变量和方程的连接);
- M :变量节点(V-nodes)的数量;
- vActive :标记变量是否 “活跃(未知)”—— false 表示变量已知,相当于删除该变量及对应的边;
- 返回值 assign :数组, assign[j] 表示第 j 个变量对应的求解方程(E-node), 0 表示未分配。
3. 代码逻辑
函数的核心是 增广路径法(通过 augmentPath 函数实现) (二分图最大匹配的经典算法):
- 初始化 assign 数组(默认所有变量未分配,值为 0);
- 初始化 “访问标记”( eColour 、 vColour )和 “被动变量标记”( vPassive );
- 遍历每个方程,重置标记后调用 augmentPath 找增广路径,完成变量与方程的匹配;
- 返回最终的变量 - 方程分配结果。
这个算法是 “电路建模自动化求解” 的关键:通过它能自动完成变量与方程的匹配,解决微分代数系统的 “一致初始化” 问题(确保系统有唯一解)。
对,就是这个算法,是PSE创始人搞出来的。据说当年H跟他师兄在开会,他师兄看H为这个问题感到为难,就将这个算法随手写在纸上给了H,解决了这个问题。然后这位师兄转手又提出了一种新算法。
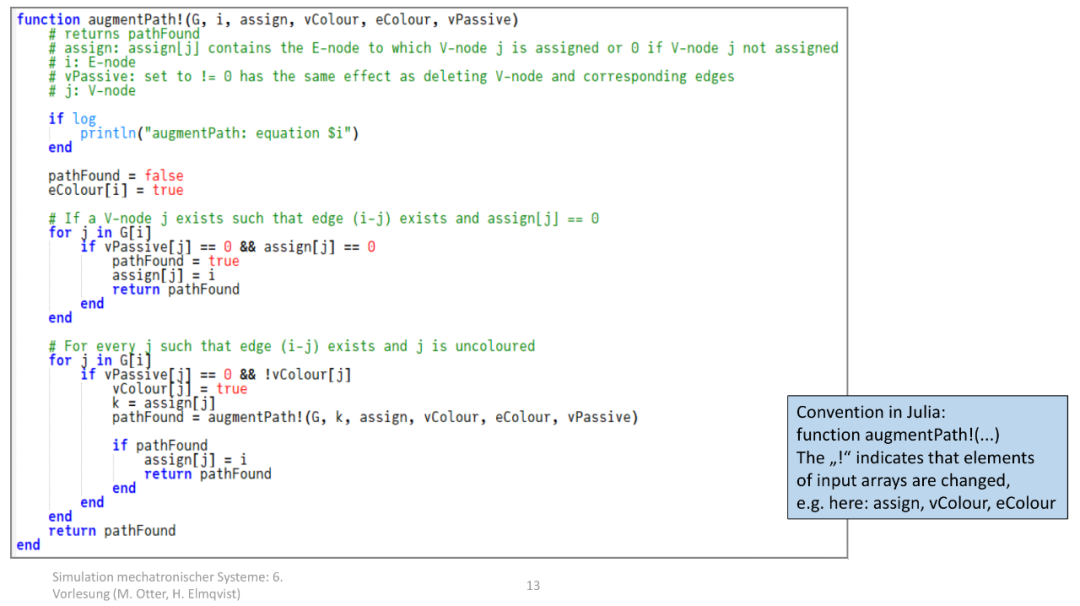
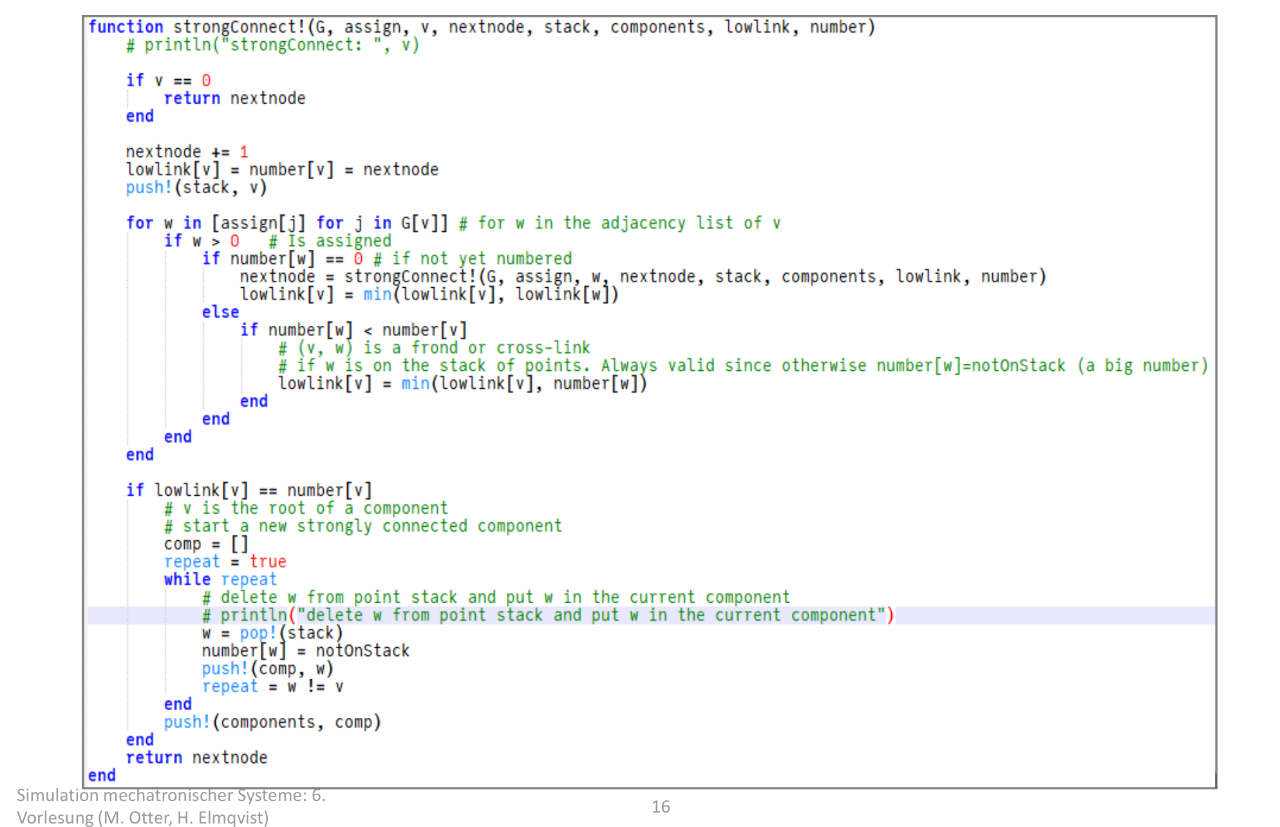
机电系统仿真中 “增广路径函数(augmentPath!)” 的实现 —— 它是之前 matching 函数的核心子函数,用于在 “变量 - 方程” 二分图中找到 增广路径 (实现二分图最大匹配),是 Pantelides 算法(解决微分代数系统一致初始化)的关键步骤。 这个函数的作用是实现 “变量 - 方程” 的最大匹配,确保电路(微分代数系统)的所有未知变量都能对应到唯一的约束方程,为后续求解系统方程铺路。
机电系统仿真中 “BLT 变换(BLT transformation)” 的应用 ,核心是将电路的约束方程组 分解为求解块 ,同时识别 “代数环(algebraic loop)”(方程间相互依赖的循环,需联立求解),具体拆解如下:
1. BLT 变换的作用
BLT 变换是处理 ** 微分代数系统(如电路)** 的关键步骤:它会把电路的约束方程组分解成若干 “求解块”,同时识别出 “代数环”—— 即方程之间相互依赖、无法顺序求解的循环,这类方程需要联立求解。
2. 左侧:矩阵与标记含义
矩阵的 行对应电路方程 , 列对应变量 ,不同标记代表不同信息:
- 🔴红色方块:已分配的变量(对应之前 matching 函数的变量 - 方程匹配结果);
- 🔵蓝色方块:该变量是对应行方程的组成部分;
- 🟤灰色区域:标记 “代数环”—— 这里方程 3、4、2、1 相互依赖,形成循环(比如方程 1 的变量依赖方程 2,方程 2 的变量又依赖方程 1),无法逐个顺序求解,必须联立。
3. 右侧:代码与变换结果
- 电路:还是之前的 低通滤波器 (电压源、内阻、电阻、电容);
- Julia 代码:调用 BLT(G, assign) ,输入是第 10 张幻灯片的二分图 G (变量 - 方程连接关系)、第 20 张幻灯片的变量分配结果 assign ;
- 结果 blt = [[6], [3,4,2,1], [5]] :表示方程组被分成 3 个 “求解块”:
- 块 1:方程 6(可单独求解);
- 块 2:方程 3、4、2、1(构成代数环,需联立求解);
- 块 3:方程 5(可单独求解)。
BLT 变换的价值是 简化电路方程组的求解逻辑 :把独立方程和依赖方程(代数环)分开,独立方程顺序解,代数环联立解,让仿真计算更高效。
在Julia中的实现。
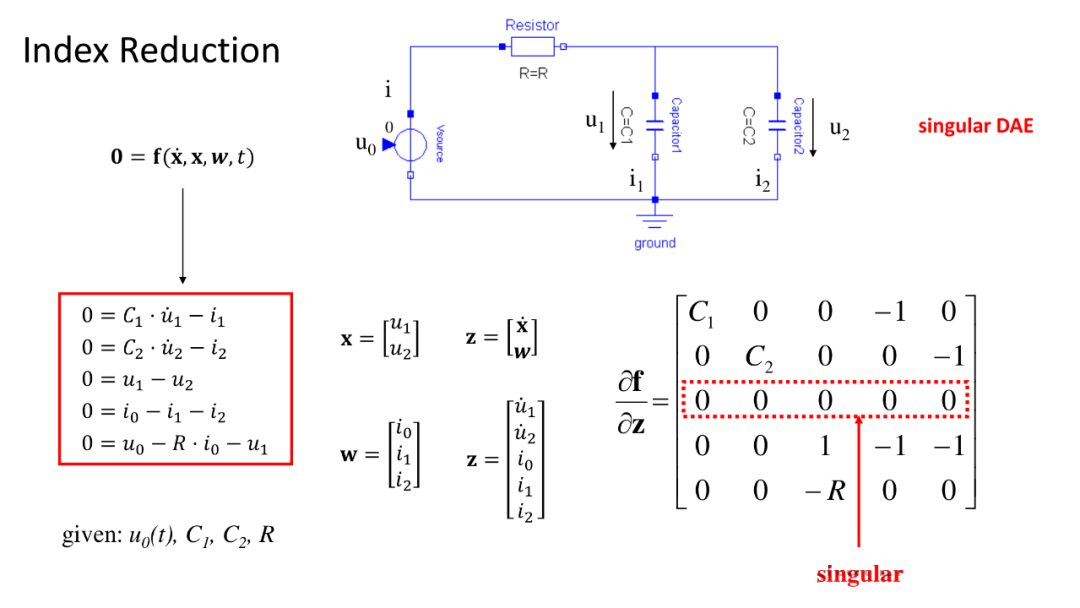
指标约减方法,吴义忠和陈立平两位先生写的那本书上,第一章介绍了三种约减方法。上面是第一种,第二种是H的师兄写出来的“哑导”法,第三种是在“哑导”法基础上做的一种方法。大概是这样,时间久远了。
奇异微分代数系统(singular DAE,如复杂电路对应的数学模型)的自动化求解通用流程 ,核心是通过四步将高指标的奇异 DAE 转化为可高效数值求解的形式,具体拆解如下:
步骤 1:识别需要求导的方程
- 目的:通过 结构算法(Pantelides 算法) ,找出奇异 DAE 中需要求导的代数方程(求导是降低 DAE 指标的核心操作)。
- 实现工具:开源库 ModiaBase 中的函数 pantelides! 。
步骤 2:对识别的方程做解析求导
- 目的:对步骤 1 选中的方程进行 解析求导 ,得到新的约束方程,以此降低 DAE 的指标(高指标→低指标)。
- 实现工具: ModiaBase 中的函数 derivative 。
步骤 3:选择状态变量 + 排序方程
- 目的:从系统中筛选 “真实状态变量”(去掉冗余变量),并将 原始方程 + 求导后的方程 重新排序,此时系统会转化为 正则 DAE(低指标) ,甚至可以进一步转化为常微分方程(ODE)。
- 实现工具: ModiaBase 中的函数 getSortedAndSolvedAST 。
步骤 4:生成仿真代码
- 目的:自动生成包含 “线性 / 非线性方程组数值求解逻辑” 的代码,最终可用于仿真计算。
- 实现工具:
- ModiaLang 包的 generate_getDerivatives! 函数,生成 getDerivatives! (计算导数的核心函数);
- 结合 DifferentialEquations 包(提供各类积分器),完成系统的数值仿真。
整个流程是 **“自动处理奇异 DAE→生成可仿真代码”** 的全链路工具链,适配机电系统等复杂 DAE 模型的自动化仿真需求。
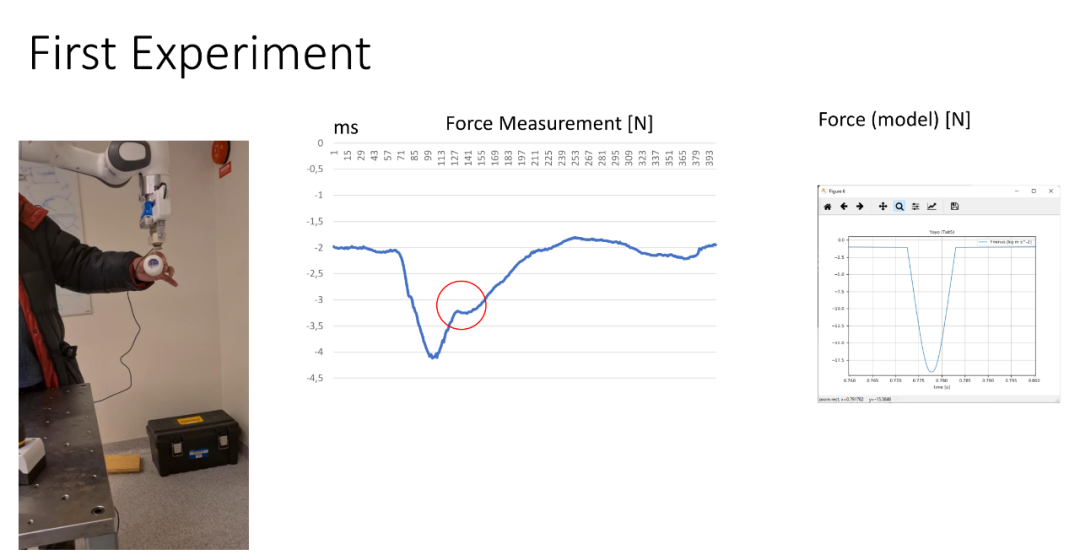
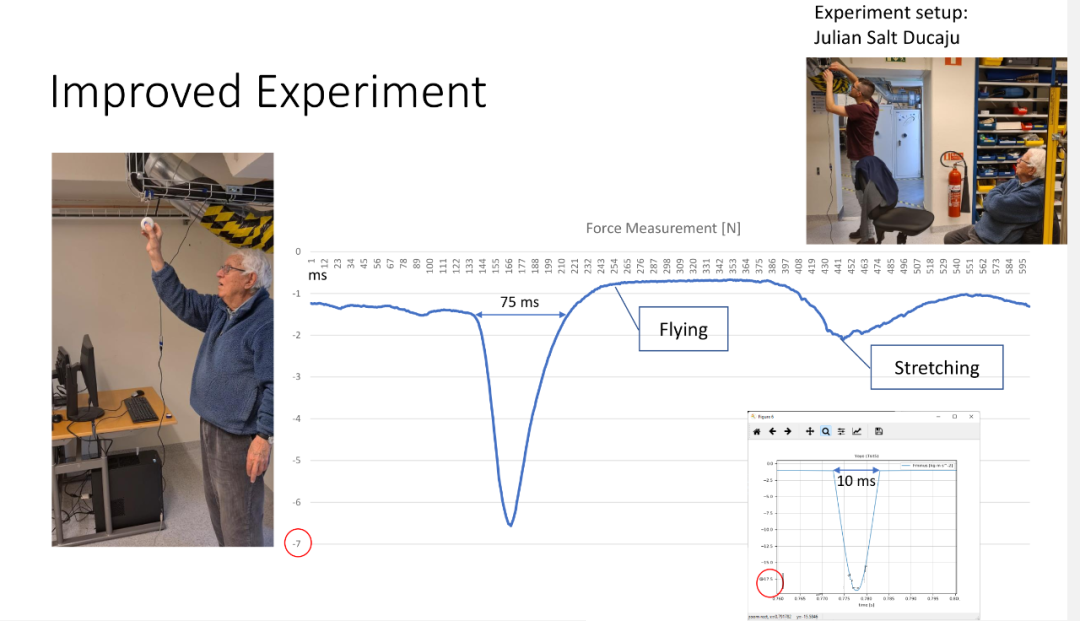
被吹得神乎其神的“基于方程建模”,就这么点核心内容,老先生们当年写书的时候,连三章的篇幅都凑不起来。 接下来就是举例说明了。例子就不赘述了。 只是里面有些画面真的很美。
大人者,不失其赤子之心。各种意义上,爷爷看孙子的即视感。 接下来就是讲“面向对象建模”了。
理想连接语义(Ideal Connection semantic)的根源 —— 即不同物理系统(电学、力学、流体)中,“连接点(节点 /junction)” 遵循的 守恒规则 ,这些规则是机电液等系统建模时 “理想连接” 的理论基础,具体拆解如下:
核心概念:理想连接语义
“理想连接” 是系统建模(比如机电液一体化仿真)的统一逻辑: 不同物理系统的 “连接点”,都会遵循某种 “流量 / 作用量的守恒” ,这是各类系统模型能统一描述的基础。
分领域的根源定律
1. 电学领域
- 基础定律: 基尔霍夫电流定律(1845 年)
- 理想连接规则:电路节点(junction)处的 电流之和为零 (电流的守恒)。
- 配图对应:电路接头(多线连接的节点)+ 基尔霍夫的肖像。
2. 力学领域
- 基础定律: 牛顿第二定律(1687) (力的矢量和 = 质量 × 加速度)、 欧拉第二定律(约 1737) (角动量变化率 = 力矩之和)。
- 理想连接规则:忽略连接点的质量 / 转动惯量,因此连接点处的 力之和为零、力矩之和为零 (力与力矩的守恒)。
- 配图对应:机械结构的连接节点(比如桁架接头)+ 牛顿、欧拉的肖像。
3. 流体系统领域
- 基础逻辑:考虑连接点的小体积单元。
- 理想连接规则:
- 质量守恒: 质量流量之和为零 ;
- 能量守恒: 能量流量之和为零 。
- 配图对应:流体管道的连接节点(T 型管接头)+ 对应的流场示意图。
这些领域的 “连接点守恒规则”,共同构成了 “理想连接语义” 的核心 —— 不同物理系统的连接,都能用 “守恒和为零” 的逻辑统一建模。
多领域建模语言 Modelica 的历史根源 ,核心是早期学者提出的物理系统跨领域类比方法(这些方法是 Modelica 实现 “多领域统一建模” 的思想基础),具体内容分三部分:
1. 麦克斯韦(1873):力 - 电压类比
- 引入 “势(effort)” 和 “流(flow)” 两类核心变量;
- 把机械领域的 “质量” 类比为电气领域的 “电感”;
- 建立领域连接规则:电气元件的串联,对应机械元件的并联(反之亦然);
- 后续 Paynter(1960)在此基础上提出 “键图(Bond graphs)”—— 这是多领域建模的经典工具之一。
2. Firestone(1933):力 - 电流类比(幻灯片标绿的核心内容)
- 定义 “跨接(across,相对量)” 和 “通过(through)” 两类变量;
- 把机械领域的 “质量” 类比为电气领域的 “电容”(注:质量以 “地” 为参考);
- 借鉴电路的基尔霍夫电流定律,规定 “通过变量的和为零”。
3. Trent(1955):
- 建立 “有向线性图” 与 “集总物理系统” 的同构关系,为物理系统的图形化建模提供了理论支撑。
这些早期的跨领域类比、建模工具(如键图)、图形 - 系统的同构理论,共同构成了 Modelica 的核心思想根源 —— 实现电、机械等不同物理领域的统一建模与分析。
基于 Julia 语言的多领域建模工具 Modia/Modia3D ,内容分为 “发展历程” 和 “核心特性” 两部分:
1. Modia 的发展历程
- 2016 年:开始在 Julia 编程语言中开展实验开发,推出了 Modia 0.3 版本;
- 2020 年秋季:启动全新设计迭代,后续更新至 Modia 0.5 版本。
2. 核心特性(Essentials)
- 建模构造的简化与统一:让建模的组件、语法更简洁通用;
- 非因果模型与多体系统的耦合:将 Modia 的 “非因果建模”(无需预先指定信号流向,是 Modelica 类工具的核心特点),与 Modia3D 的 “3D 多体机械系统建模” 结合,支持跨领域(如机电 + 3D 机械)的统一仿真;
- 注重可扩展性:能支撑更大规模的模型仿真;
- 采用 DifferentialEquations.jl 工具:将模型转化为 ** 常微分方程(ODE)** 求解(而非更复杂的微分代数方程 DAE),提升了仿真的效率与稳定性。
这里面有个问题,懂得大佬可以留言解释一下。为什么Modelica之父放弃了DAE,转向ODE?前两天有个老师留言,说大家不用Julia是因为Julia的积分求解不稳定。有懂的大佬可以留言解释一下。
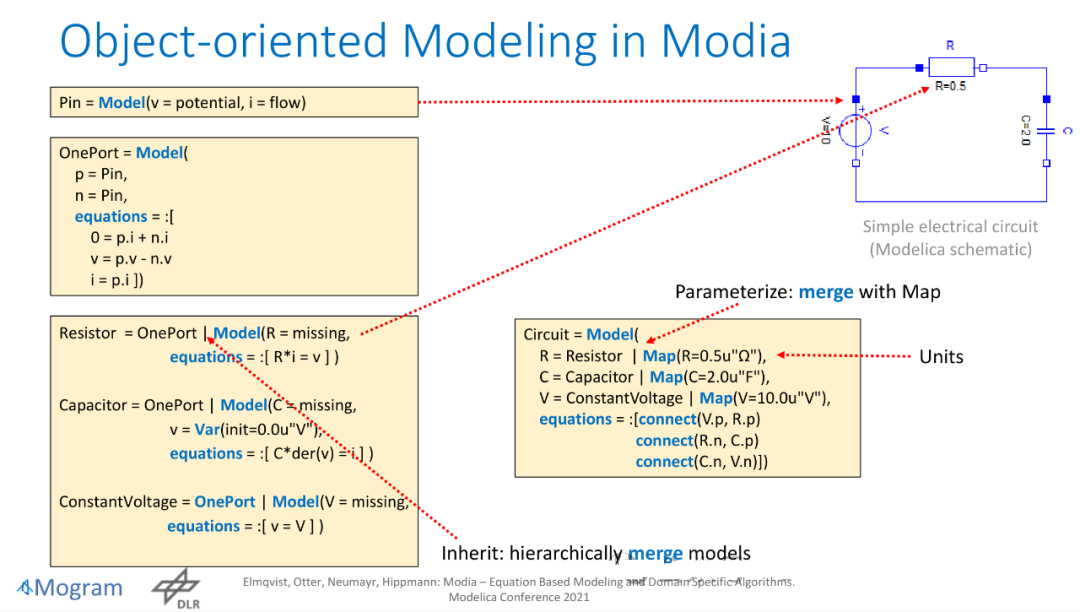
Modia中的面向对象建模。 后面介绍了Modia的一些新特性,以及练习。站在今天看,似乎Modelica社区另一位大佬Tiller基于Julia语言开发的系统建模与仿真软件混得更好一点。 接下来该切入正题,讲本体了。 我硬是把公众号写成了读书笔记。
以下内容节选自这本书的第9章。
9 本体论、元模型与模型驱动范式
9.1 引言
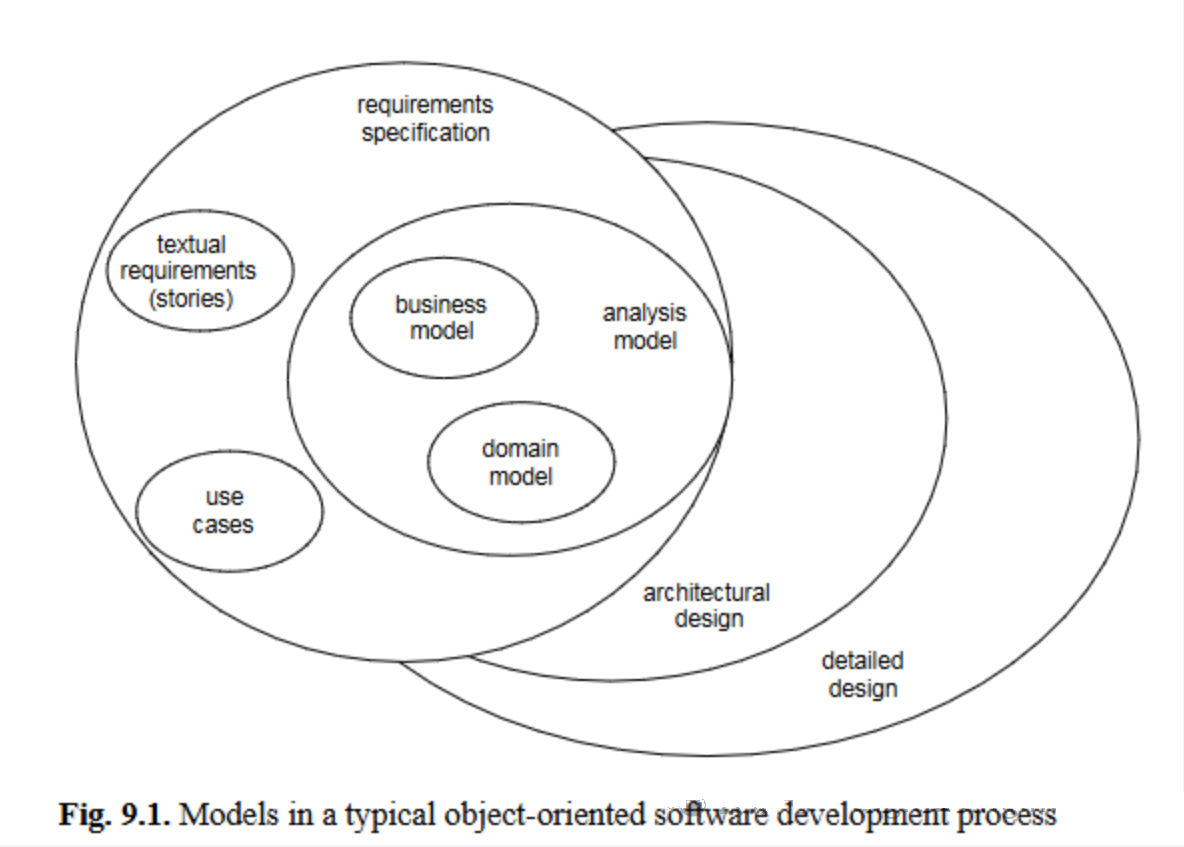
基于精化的软件开发以生成多个模型为核心,这些模型从抽象逐步过渡到具体(图9.1),最终以实现作为最精细的模型收尾[45]。抽象模型中的构造会逐步精化为更具体的模型元素。大致而言,开发过程可分为两个阶段:分析阶段基于领域模型、业务模型和上下文模型,构建描述用户所有期望功能的需求规格说明;随后的设计阶段生成架构设计规格说明和详细设计规格说明;最后在实现阶段,根据设计规格说明完成软件系统的开发实现。
模型驱动工程(MDE)是这种基于精化的软件开发的一种变体。在MDE中,模型不再是松散耦合的,而是以系统化的方式相互关联[9,10]。一方面,MDE对20世纪70年代的软件精化方法进行了改进,细分了更具体的开发阶段;另一方面,每个阶段不仅通过手动精化,还通过半自动或自动转换生成更具体的模型。为此,模型之间必须建立关联,即模型元素需能在抽象模型与具体模型之间双向追溯。这一目标通过元建模实现:元模型定义了有效模型的集合,为模型的转换、序列化和交换提供了支持。
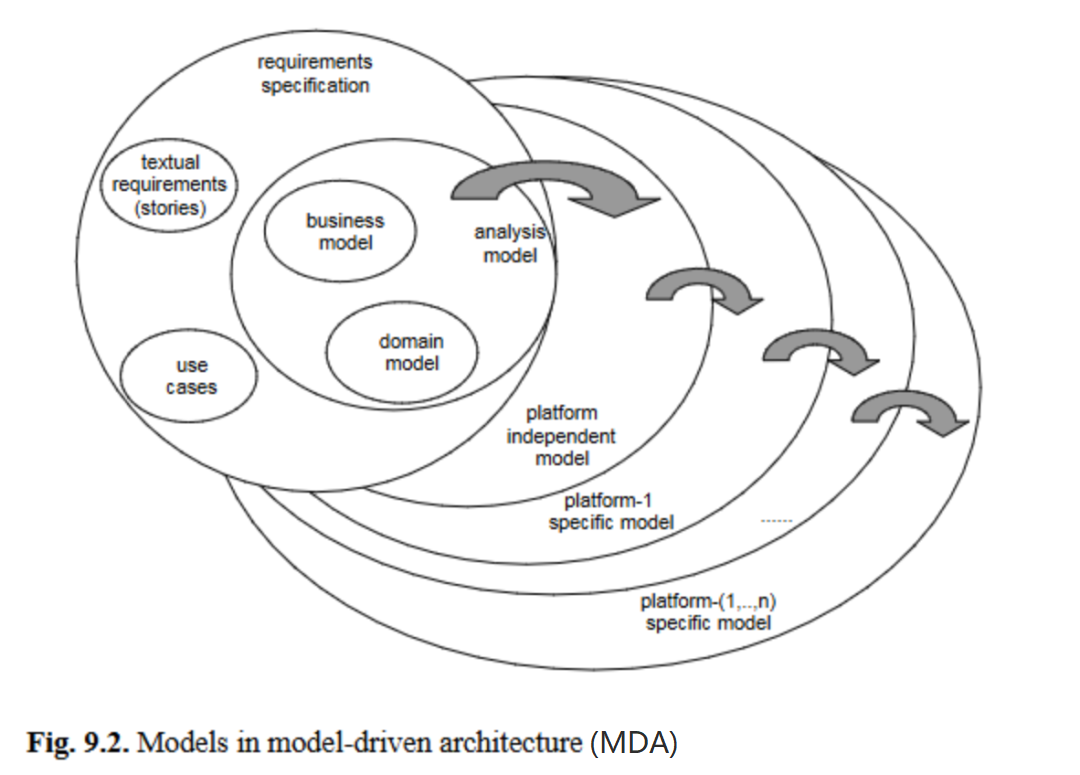
近年来,模型驱动工程通过一种特定形式——模型驱动架构(MDA)得到了广泛推广。在这一过程中,一类特定的模型信息——平台信息——发挥着重要作用。在MDA中,模型的差异在于其包含的平台信息多少(图9.2)。例如,一种平台可能指系统的编程语言,另一种可能是所采用的库或框架,第三种则可能是二进制组件模型。设计人员从一个抽象了各类平台问题的高层模型入手,通过迭代将模型转换为更具体的形式,逐步引入更多平台相关信息。因此,所有与编程语言、框架或组件模型相关的信息,都会通过平台相关扩展添加到平台无关模型中。
本质上,MDA区分了三种模型视角[30]:计算无关(CI)视角从用户角度看待系统,并体现在计算无关模型( CIM )中。该模型是典型的分析模型,以问题领域的术语表述:
计算无关视角聚焦于系统的运行环境和系统需求,系统的结构与处理细节则被隐藏或尚未确定[30]。
CIM包含领域模型(描述领域中的概念及其相互关系)、业务模型(描述企业的业务规则)以及需求说明。平台无关(PI)视角从设计人员角度看待系统,抽象了系统可能运行的所有平台,最终形成平台无关模型(PIM)。大致来说,PIM包含架构模型,并附加了足够详细的平台通用实现相关信息。最后,平台相关视角通过添加平台相关扩展,生成平台相关模型(PSM)。该模型既可以直接执行,也可用于代码生成。
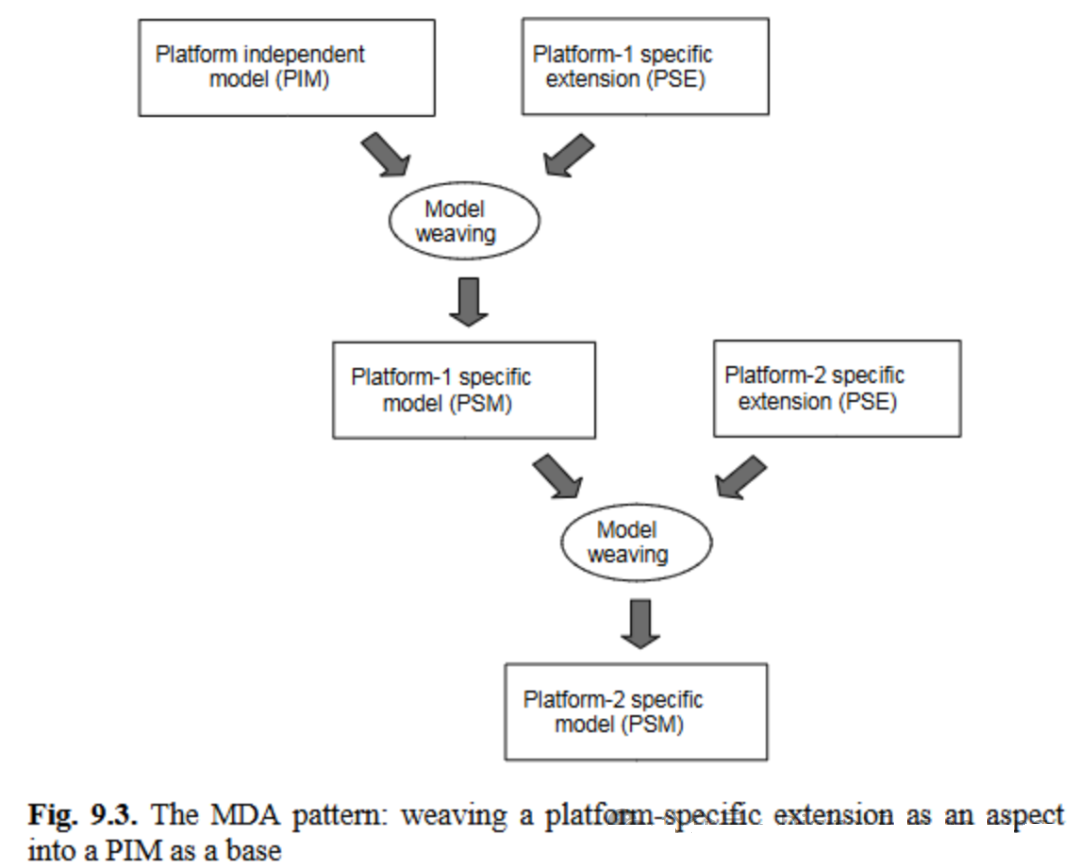
要得到PSM,需为PIM添加平台相关信息,具体方式是将PIM与多个平台相关扩展(PSE)进行合并(图9.3)。
由于平台相关扩展(PSE)可被视为横切平台无关信息的关注点[24],因此这一过程可称为模型编织。这种通过PIM与PSE编织生成PSM的MDA模式可在多个层级重复应用。通常,系统可能涉及多种类型的平台,且需要在这些平台实例的所有组合上实现系统变体;例如,一个系统既支持C #和Java语言 ,又能运行于Web和GUI客户端平台。多级MDA的核心思想是在多个层级重复模型编织过程(图9.3),即每个层级的PSM都可被重新解释为下一级平台的新PIM。
可能会有持不同意见者认为,MDA(进而MDE)并非新技术,只是基于精化的软件开发。然而,由于MDA将平台相关信息视为精化的主要标准,整个过程相比20世纪70年代的“自由式”精化更加结构化。此外,MDA中的所有模型均基于图形,而传统精化主要适用于语法树。
近年来,语义网推广了另一种模型概念——本体论。本体论是“共享概念化的形式化显式规范”[18],其核心是描述领域中的概念,这与CIM中的领域模型类似。尽管本体论目前主要应用于语义网,但在通用软件开发中也可能发挥作用[1,8]。这就引出了一个问题:本体论应如何融入MDE,尤其是MDA的过程架构中?这正是本章后续内容要探讨的核心。9.2节将本体论与通用模型进行对比,得出本体论描述现实而模型定义工件的核心结论;9.3节进一步深入分析这些关系,并阐释如何利用“实例关系”(instance-of)构建模型层级结构(即所谓的IRDS元金字塔);9.4节将本体论融入元金字塔,区分出描述维度;最后通过相关工作对比总结全文。
9.2 模型与本体论
本节将探讨“模型”和“本体论”这两个核心术语,分析它们的主要共性与差异。首先介绍两者的定义,接着讨论模型的一个基本属性——描述性与规定性,最后基于这一区分明确本体论与其他软件模型的差异。
9.2.1 模型的本质
模型是对事物的表示、描述和规范。皮德(Pidd)给出的定义如下:
模型是为特定目的而对现实的一种表示[34]。
因此,模型表示现实(下文用“被表示关系”(is-represented-by)表示这一关联)。
模型与所建模的现实部分存在因果关联:模型必须形成真实或忠实的表示,以便对模型的查询能得出关于现实的可靠结论,或对模型的操作能实现对现实的可靠调整。皮德对这一特性的描述如下:
模型是人们对现实某一部分的外部显式表示,使用者借助该模型来理解、改变、管理和控制这部分现实[34]。
其次,尽管模型需忠实表示现实,但可能会抽象掉无关细节。例如,模型虽是有限描述,却可能表征无限语言(即无限的事物或系统集合)。通常,这需要借助抽象手段——例如对语言中元素的数量进行抽象。
模型可表示多种不同类型的现实,如领域、语言,尤其是系统。因此,可区分领域模型与系统模型:系统模型是对一组系统进行描述或控制的模型:
系统模型是为特定目的而对该系统及其环境的描述或规范[31]。
其中,系统的环境由领域模型描述。
模型可分为结构模型和行为模型。结构模型描述现实中的概念及其相互关系、领域的静态语义、其上下文无关或上下文相关结构,良构规则(完整性约束)则描述现实的有效配置。
示例1 :UML类图常与对象约束语言(OCL)[31]结合使用。OCL完整性约束用于描述UML类模型中类与对象的有效配置及相互关系。
行为模型除包含抽象概念及其相互关系外,还规定了它们的行为和动态语义。在这种情况下,模型可能对领域中事物或某些系统的行为做出断言。这类断言可通过概念化方式或转换方式表达:前者将系统的动态特性表示为概念,并通过约束解释其相互关系;后者则通过状态空间上的转换[23]或指称语义的修改[42]来表达动态特性及其关系。
有时,这些转换或修改可进一步通过逻辑表示。然而,如下例所示,这并非总是合适的。若动态语义的状态空间是连续的,则语义更适合通过数值方法(如微分方程)表达。
示例2 :Modelica是一种多领域建模语言,用于技术系统的仿真、可视化和控制。因此,它是一种用于描述技术系统动态语义的规定性建模语言[13]。
9.2.2 本体论的本质
近年来,语义网推广了另一种模型概念——本体论。引用最广泛的定义如下:
本体论是“共享概念化的形式化显式规范”[18]。
由于概念是抽象的,且在模型中发挥重要作用,因此本体论无疑是一种特殊的模型。但两者的具体差异是什么?要回答这一问题,需引入模型的其他属性。
根据上述定义,本体论是特定领域中一组人共享的模型。这包括国际组织标准化的本体论(如都柏林核心本体论[27])、大型用户群体共享的本体论(如基因本体论[3]),以及企业与其客户之间共享的本体论(如葡萄酒本体论[28])。一般而言,模型并非必须共享。例如,某产品的设计模型若仅在小公司的少数开发人员之间共享,则不应被视为本体论,而应视为普通的工件模型。当然,“共享性”是一个相对概念:模型的用户群体是否足够大以使其成为该群体的本体论,往往带有主观性。
本体论的一个重要属性是所谓的“开放世界假设”[20]。直观而言,该假设认为本体论中未明确表达的任何内容都是未知的。因此,本体论将部分描述或欠规范作为重要的抽象手段。相比之下,大多数系统模型遵循“封闭世界假设”——即未明确规范的内容要么被默认禁止,要么被默认允许——以限制系统的任意扩展(这种扩展可能导致不一致)。 区分模型是描述现实还是控制现实至关重要。描述性模型用于监控现实,形成真实或忠实的抽象;规定性模型用于控制现实,即制定现实构建完成后应满足的良构条件。也可以说,这类模型是现实的模板或模式。因此,模型的一个最基本特征是其描述性或规定性[38]:描述性模型仅描述现实,但现实并非基于该模型构建;规定性模型则规定现实的结构或行为,现实需根据该模型构建,即模型是现实的规范。法夫尔(Favre)[11]指出,描述性模型的真实性源于现实,而规定性模型的真实性源于模型本身。描述性模型常用于分析和逆向工程,规定性模型(规范)则用于设计和正向工程。由于大多数规范是对系统的建模,因此规定性系统模型也被称为系统规范。 模型是为特定目的而对现实的抽象[34],本体论是一种特殊的模型。软件开发和设计中使用的大多数模型都是规定性的,它们作为后续系统实现的模板。相比之下,由于本体论遵循开放世界假设,应被视为描述性模型。这是因为开放世界假设不允许完整且最终的描述:任何未明确说明的内容都是未知的。两个差异显著的系统可能都满足同一本体论,只要它们的差异体现在本体论未明确提及的领域。
另一方面,我们承认本体论也可以(且经常)被用作规定性用途。但我们认为,此时它们更适合被称为规范模型,而非本体论。当模型被用作系统的规范时,它应限制系统的合法结构,而这需要封闭世界假设的支持。至少在开发的某个阶段,必须“封闭世界”——即引入额外假设:所有未明确规范或无法推导的内容都是无效的。这种世界封闭不仅难以理解(因为它改变了底层逻辑的语义),还可能需要在数据库中添加额外事实或修改逻辑推理器。
综合上述讨论,我们给出以下定义:
- 本体论是一种共享的、描述性的结构模型,在开放世界假设下,通过一组概念、概念间的相互关系及约束来表示现实。
- 规范模型是一种规定性模型,在封闭世界假设下,通过一组概念、概念间的相互关系及约束来表示一组工件。
这些定义需要进一步阐释。对比核心文献(如[18]和[38])可以发现,规范模型与本体论非常相似:两者都提供语言词汇表,并为语言元素定义有效性规则;两者都使用完整性约束来限制领域的有效实例³²。
然而,两者也存在差异:本体论是共享知识,即必须在特定群体中标准化;本体论并非规范模型,而是赛德维茨(Seidewitz)意义上的描述性模型;本体论不描述系统,仅描述领域。因此,在软件工程过程中,本体论应扮演分析模型的角色,而非设计或实现模型。这一观点与德韦德齐奇(Devedzic)的主张——“一般而言,本体论是描述如何构建模型的元模型”[8]——以及格鲁伯(Gruber)认为“本体论是规范”[18]的观点相悖。但这种概念区分能为本体论在模型驱动工程中找到自然的定位,这将在9.4节中详细阐述。
综上,我们做出如下假设:规范模型侧重于系统的规范、控制和生成,本体论侧重于事物的描述和概念化(结构建模)。两种模型的共同属性是抽象性和因果关联性。那么,在这种情况下,本体论与规范模型如何在模型驱动工程中共存?
9.3 相似关系与元建模
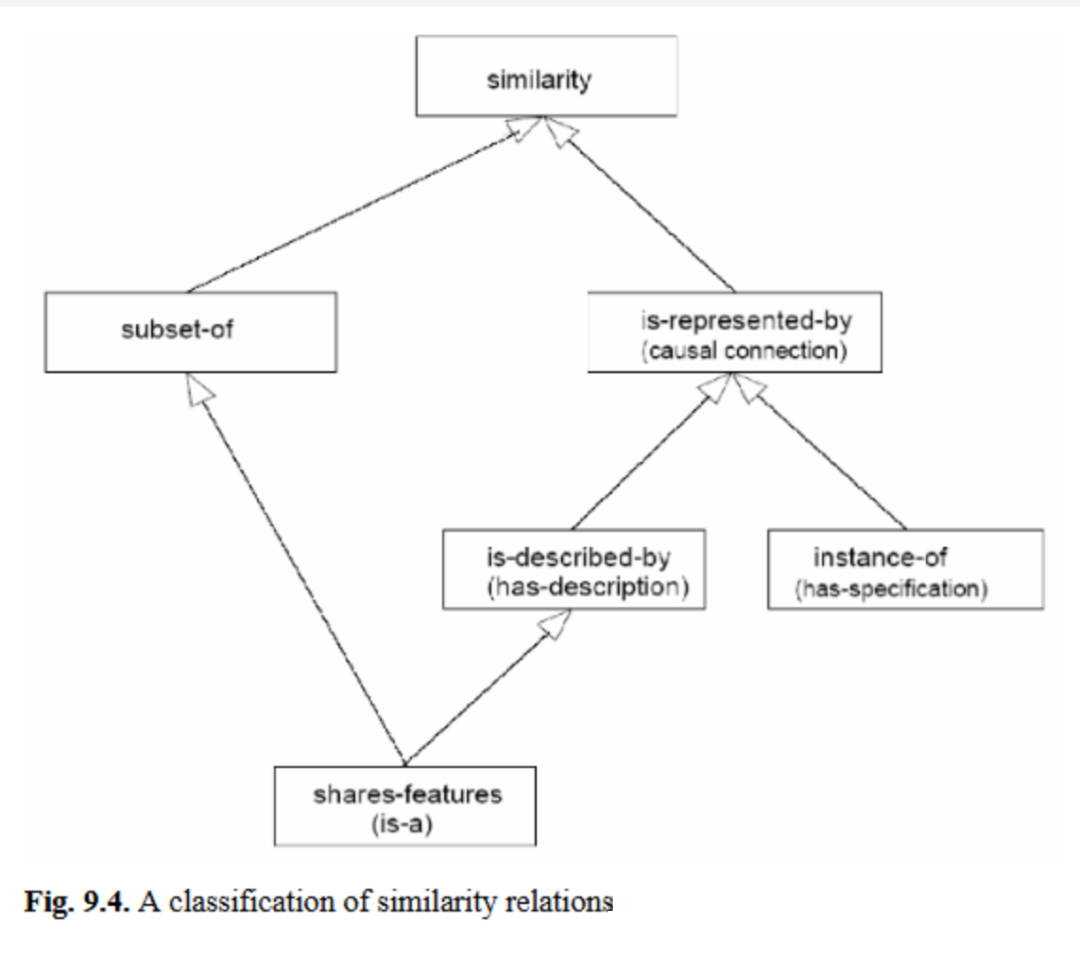
上述讨论使得我们能够区分模型与对应现实部分之间“被表示关系”的两种基本含义(图9.4)。在描述性模型(如本体论)中,模型描述世界,即世界中的对象与描述性模型的概念之间存在“被描述关系”(is-described-by);在规范模型中,系统对象基于模型创建,即对象是模型元素的“实例”(instance-of)。两种关系都是表示关系:一种是描述性的,另一种是规定性的。它们的泛化形式“被表示关系”是一种相似关系,在被表示事物与表示模型之间定义了因果关联——能够得出真实且忠实的结论。此外,还可定义更多相似关系:例如,两个事物可能共享特征(通常用“是-关系”(is-a)表示,即结构或行为继承),或可能属于集合层级结构(集合包含、子集关系(subset-of))。在图9.4中,“是-关系”被定义为子集关系的子关系,因为继承通常具有基于集合的语义——即子类中的所有对象也是超类的成员;同时,“是-关系”也是被描述关系的子关系,因为超类也描述子类中的所有对象。相比之下,“是-关系”不能作为实例关系的子关系,因为超类不一定能被视为子类的模板、模式或规范。
9.3.1 元模型
在MDE中,“实例关系”这一规范关系具有特殊地位。当规范原则被重复应用时,模型本身被视为研究的现实或系统,从而可以定义用于规范模型的模型——即元模型。元模型表示并规范模型,即描述模型的有效组成部分。更精确地说:
元模型规定了特定建模语言的有效模型中可以表达的内容[38]。
因此,元模型是建模语言的规定性模型[38]。一般而言,元模型是语言规范,不仅适用于建模语言,也适用于任意语言。在MDE的当前阶段,元模型主要关注静态语义——即模型的上下文相关语法、完整性和良构约束。然而,用于动态语义的建模语言也可用于构建元模型[42]。
元模型中的语言概念或构造由元类捕获:元类的结构和嵌入方式描述语言构造的静态语义,元类的方法描述语言构造的动态行为。通常,元类被组织在行为元模型(即元对象协议(MOP)[25])中,这是一种描述语言解释器的反射元模型。
元建模的一个主要推动力是计算机辅助软件工程(CASE)工具供应商对模型交换的需求[32]。由于元模型描述(更准确地说是规范)建模语言的有效实例(模型),因此能够控制模型的结构和有效性。如果两个 CASE工具 采用相同的元模型,它们将为模型施加相同的结构,从而便于模型的交换。
元模型所描述的语言可能具有特定的应用目的或领域,这些目的或建模领域被称为元模型的“主题领域”[12]。
示例3 :例如,公共仓库元模型(CWM)[29]定义了一种数据规范语言,是面向数据和信息系统应用的元模型;工作流系统是另一个特殊的主题领域,其数据、功能和任务也可通过元模型描述[36];作为特定工作流的软件过程,可通过元建模[14]用于构建软件环境[5]。
主题领域可以组织为层级结构或偏序结构。此时,特定主题领域的元模型可基于较低层级主题领域的元模型构建,从而使复杂语言能够复用简单语言[12]。
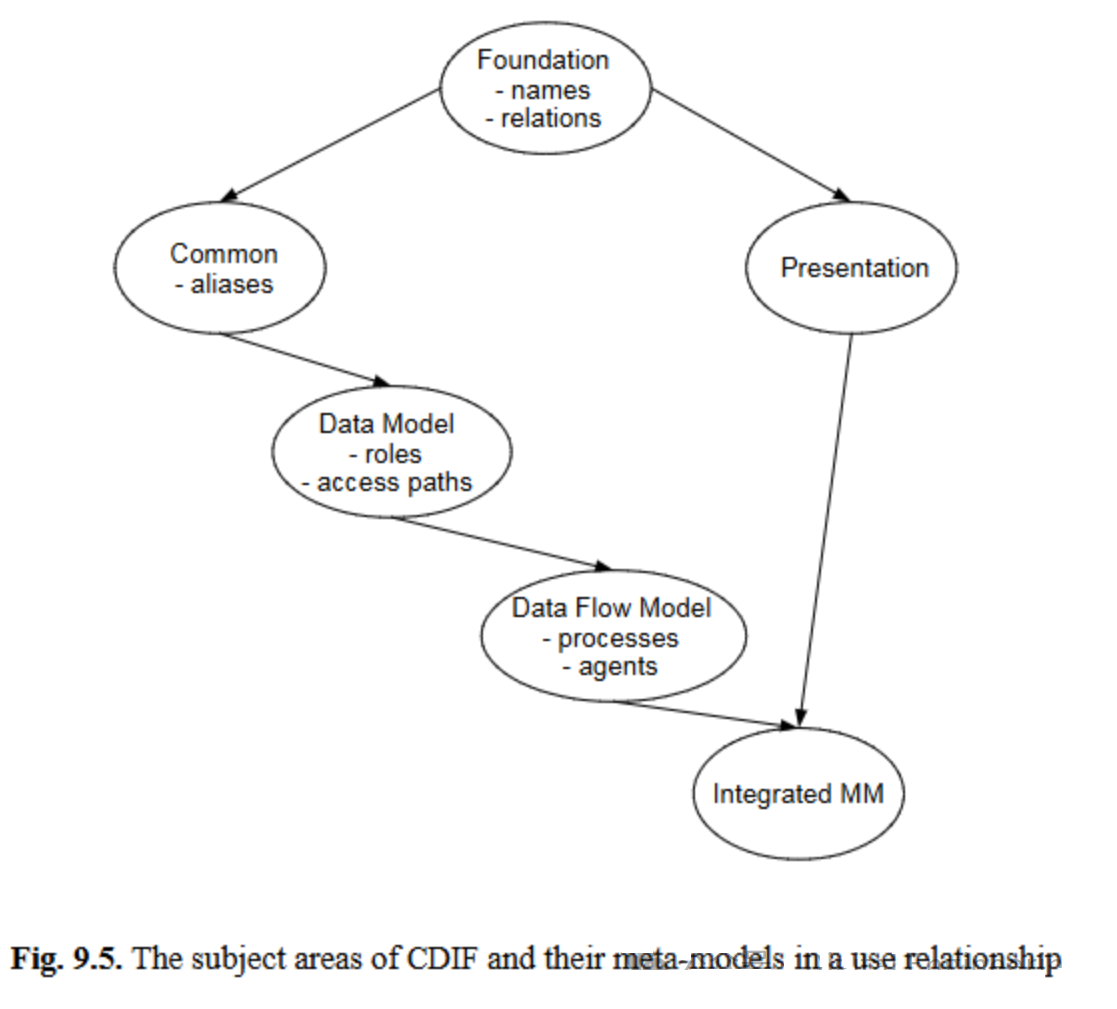
示例4 :CASE数据交换格式(CDIF)将其元模型划分为多个主题领域(图9.5):基础模块(Foundation)包含名称和关系相关信息;通用模块(Common)定义对象的名称别名;数据模块(Data Model)描述数据的访问路径和对象的角色;基于这些模块,可定义数据流(数据流模块(Data Flow Model));另一个模块规定了对象的呈现机制;最终,完整的集成元模型(Integrated MM)整合了所有其他模块的概念,为用户提供统一的访问接口。
9.3.2 元-元模型
规范原则可被重复应用:元-元模型表示并规范元模型,即描述元模型的有效组成部分。元-元模型规范语言,因此是一种语言规范语言(元语言)。
为了实现有用的建模,这种最小化的元语言应包含以下概念[12]:
- 类(概念);
- 类的属性(或特性)(包含在类中);
- 类之间的二元关系。
因此,实体-关系图(ERD)语言[6]可作为一种非常简单的元语言,用于定义建模概念、它们的属性和关系。此外,还存在其他用于描述特定形式语言或特定方面的元语言:
- 语法规范语言(如EBNF),用于规范基于文本的语言的具体或抽象语法[17];
- 属性语法,以语法树的属性规则形式描述上下文相关语法[7];
- 自然语义,可用于类型系统,也能规范系统的动态语义[23];
- 在SGML[16]中,可定义标记语言;XML[44]是SGML的变体,允许定义上下文无关的标记语言;
- EXPRESS[37]是一种类似于UML的建模语言,常用于机械工程领域。
9.3.3 元金字塔:MDE的建模架构
基于元原则,可定义所谓的“元金字塔”,系统地展示上述模型和元模型的层级结构[22]。本质上,元金字塔是通过实例关系链接的规范层级结构,其中上层元模型以某种方式规范下层模型集合。由于模型集合可被视为语言,因此元金字塔是语言规范的层级结构。
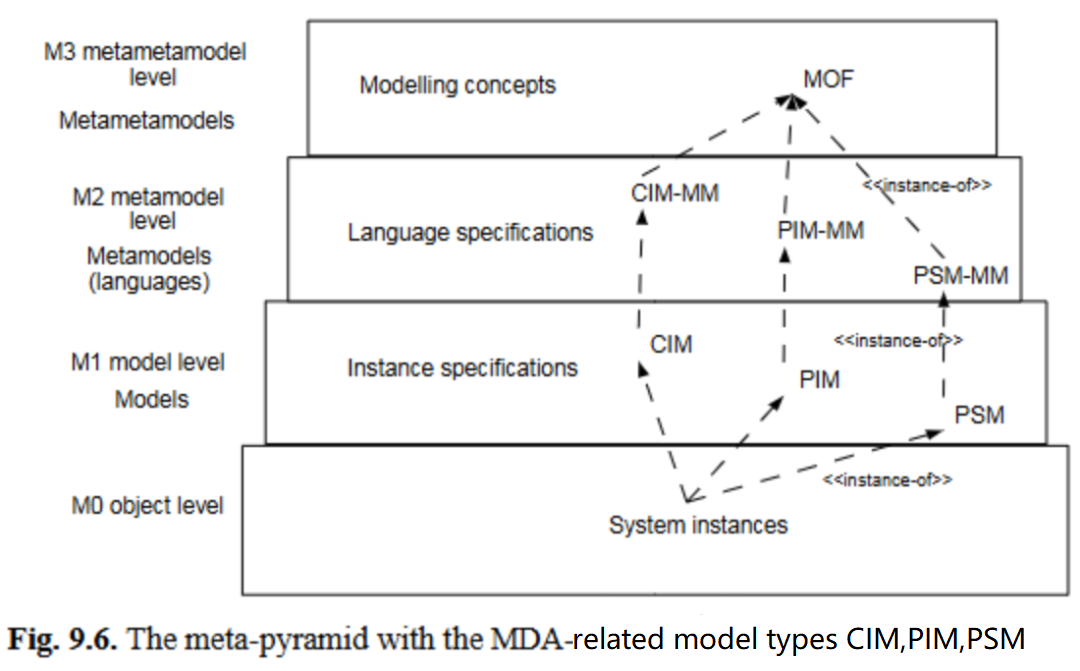
本章重点讨论OMG的标准元金字塔,该元金字塔最初在ISO信息资源字典系统(IRDS)标准[22]中提出(图9.6),包含四个层级:M0层(对象)、 M1层 (模型)、M2层(元模型或语言层)、M3层(元-元模型或语言描述层)。目前存在其他变体,且关于IRDS元金字塔是否足够精确的争论仍在继续——因为它是一维的,而多维模型金字塔已被提出[2]。然而,目前IRDS元金字塔仍是MDE的主流元模型架构。
在M3层,IRDS/OMG元金字塔采用元对象设施(MOF)作为元-元模型,其核心概念与ERD类似。MDA的典型模型(CIM、PIM、PSM)位于M1层,均由M2层的元模型(CIM-MM、PIM-MM、PSM-MM)规范——这些元模型是UML的方言,通过包含模型元素标记(构造型和标记值)的概要文件扩展UML核心。
每个元模型涵盖PSM的不同主题领域:CIM-MM涵盖需求,PIM-MM涵盖平台无关概念,PSM-MM则添加平台相关问题。尽管这些模型都是规定性的(即采用实例关系),但问题依然存在:依赖“被描述关系”的本体论应如何融入元金字塔?这正是下一节要探讨的主题。
9.4 MDE与本体论
本节讨论描述性结构模型(尤其是本体论)在模型驱动过程中的作用。首先分析领域本体论和上层本体论的不同角色,提出上层本体论也可作为语言描述的观点;其次,提出将CIM的部分内容作为本体论嵌入MDA元金字塔(即支持本体论的元金字塔)的方案——这实际上构建了第一个支持本体论的MDE巨型模型[10],并讨论其概念优势;最后,一方面,该巨型模型为扩展的、支持本体论的软件过程提供了思路;另一方面,MDA和MOF领域的工具构建技术可被迁移到本体论领域。
9.4.1 领域本体论与上层本体论
支持本体论的元金字塔的核心思想是:MDE中的大多数模型是规范,但可在不同元层级整合本体论作为描述性分析模型。由于本体论的描述性本质使其与规范有所区别,标准的M0-M3元金字塔可从仅使用规范模型扩展为同时使用本体论。
本体论在不同元层级可能承担不同角色。文献中对本体论的类型有不同划分:“本体论”一词源于哲学,用于描述“存在”:
本体论是对存在的系统阐述[18]。
我们将这种对存在的系统阐述称为“世界本体论”,即对世界(所有现存概念)的概念化。通常,世界本体论分为上层本体论(概念本体论、框架本体论)和多个下层本体论(领域本体论):上层本体论提供分类和描述的基本概念,领域本体论描述世界的特定领域[19,41]。索瓦(Sowa)对领域本体论的描述如下:
本体论的研究对象是某一领域中存在或可能存在的事物类别。此类研究的成果(即本体论)是一份目录,列出了从使用语言L讨论领域D的人的视角出发,被假定存在于目标领域D中的事物类型。本体论中的类型代表了语言L在讨论领域D的主题时所使用的谓词、词义或概念及关系类型[40]。
相比之下,上层本体论可定义如下:
上层本体论仅限于元概念、通用概念、抽象概念和哲学概念,因此具有足够的通用性,能够(在高层级)涵盖广泛的领域。上层本体论不包含特定领域的概念,但提供了一种结构和一组通用概念,领域本体论(如医学、金融、工程等领域)可基于这些结构和概念构建[21]。
通常,领域本体论中的概念继承自上层本体论中的概念。为了提高互操作性和可理解性,部分研究人员试图构建标准化的上层本体论,所有可能的领域本体论都可从中继承[33]。如果存在包含建模概念的标准化上层本体论,所有领域本体论都可依赖标准化的概念词汇表。
9.4.2 不同元层级上本体论与系统模型的关系
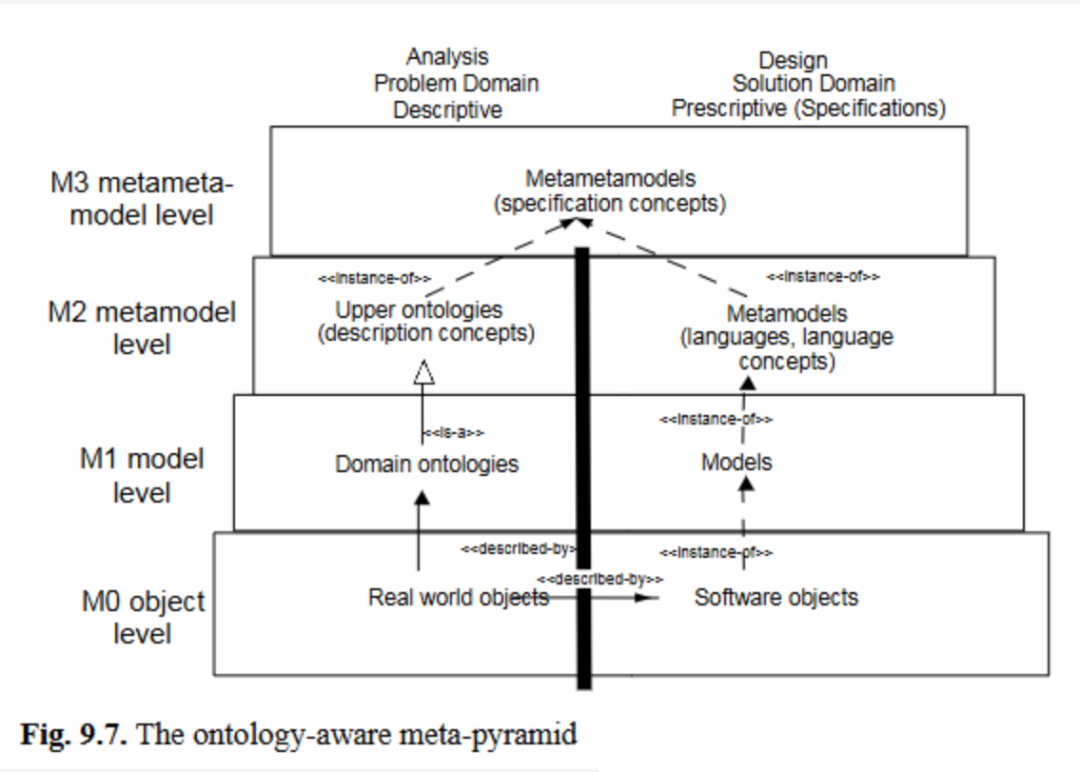
基于上述术语区分,可将不同类型的本体论与元金字塔中的元层级相关联:领域本体论位于M1层,对应模型;上层本体论(包括标准化的上层本体论)应位于M2层,因为它为本体论提供了语言支持。图9.7总结了这一观点,展示了不同元层级上的描述性模型和规定性模型这两个维度。
有趣的是,在本体论一侧,M1层与M2层通过继承关系连接,而非实例关系。我们认为,这一可能是无意识做出的历史性选择,源于描述性与规定性的本质差异:M1层领域本体论中的概念需要表达其与M2层上层本体论建模概念的相似性,而“是-关系”足以精确表达这一相似性(参见图9.4),因此本体论领域选择“是-关系”连接元层级;而规范模型中的概念需要表达其是基于规范模型构建的,这显然是一种比“是-关系”更具体的关系,这也是IRDS领域采用实例关系的原因。
我们认为,在支持本体论的元金字塔的描述性一侧的M3层,也应采用规范元语言(图9.7)。描述或规范本体论语言的语言不能是描述性的,因为本体论语言并非既定存在,而是人工语言。因此,用于表示本体论语言的模型应是规定性的。我们主张,本体论领域和系统模型领域可使用相同的元语言。
事实上,图9.7中并不强制要求继承关系。尽管通常领域本体论中的概念继承自上层框架本体论中的概念,但我们建议,为了更好地区分本体论概念与规范模型中的概念,本体论建模应通过“被描述关系”在本体论概念之间建立因果关联。这将与规范一侧使用的实例关系形成平行结构,并保留本体论建模的核心原则——描述性。由于与规范维度的结构平行,这种元金字塔的优势在于能够轻松建立本体论与规范之间的关联,尤其是在MDE中应用该元金字塔时。
9.4.3 本体论在MDA中的应用
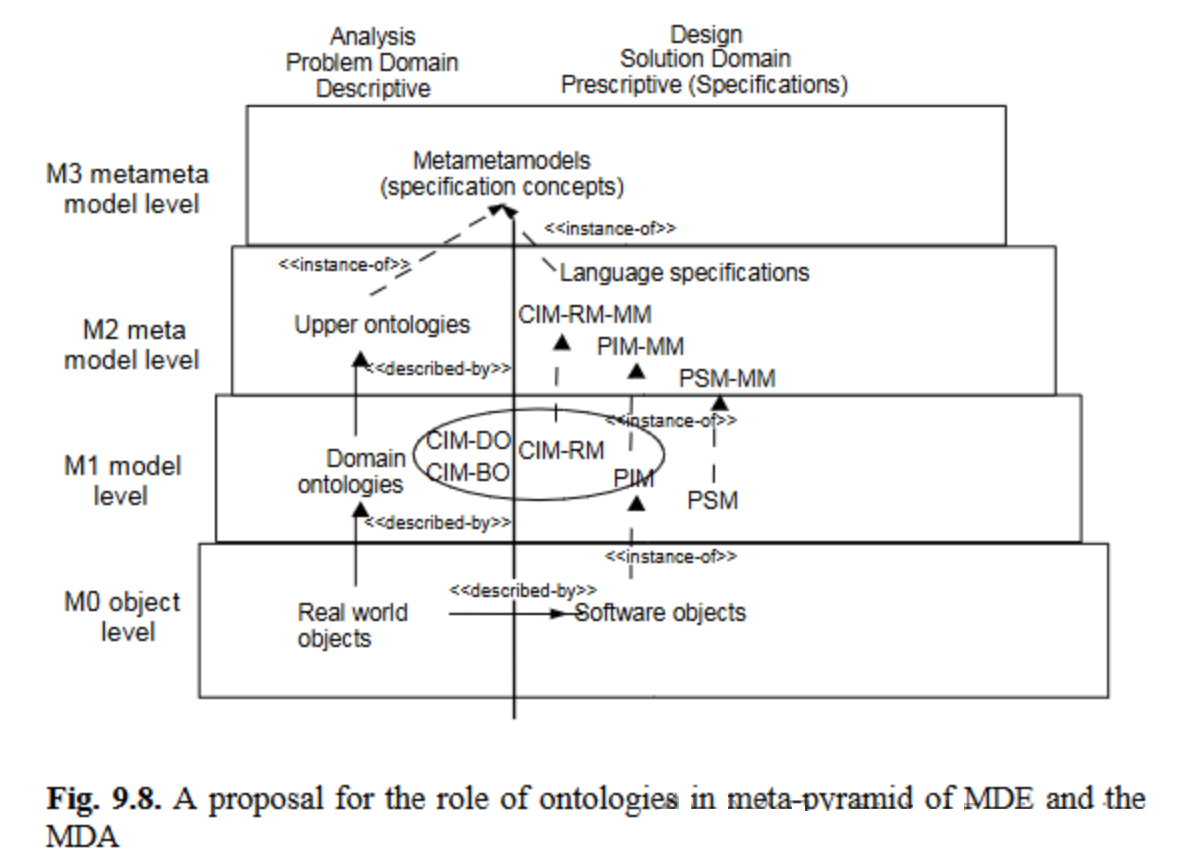
这种支持本体论的元金字塔允许围绕本体论组织基于MDA的模型,其中CIM扮演着特殊角色。
CIM从系统用户的视角包含系统相关信息,是一种分析模型,通常包含领域模型、业务模型和需求(图9.1)[30]。描述性模型与规定性模型之间的鸿沟在CIM中尤为明显:CIM的领域模型可选择作为领域本体论(图9.8中的CIM-DO);捕捉应在所有软件产品中遵循的企业业务规则的业务模型,也可被视为领域本体论(即企业规则的领域本体论,图9.8中的CIM-BO)。然而,CIM中涉及需求的部分无法通过本体论涵盖,因为这些需求规定了待构建系统的要求,因此这部分规范被归为图9.8中的CIM-RM(规范模型)。这一差异也是为何仅CIM的规范部分(CIM-RM)需要元模型的原因:CIM-DO或CIM-BO的概念描述现有事物,可能继承自语言或概念本体论层级的概念;而CIM-RM中的概念是CIM元模型的实例,因为它们规范了系统的功能部分。
通常,CIM通过手动添加操作型模型元素扩展为PIM。因此,至少CIM-DO和CIM-BO扮演着标准化分析模型的角色,其元素可从PIM中追溯[1]:
在系统的MDA规范中,CIM需求应能追溯到实现这些需求的PIM和PSM构造,反之亦然[30]。
因此,MDA可从本体论中获益:通过曾作为CIM一部分的标准化领域本体论和业务本体论,能够以清晰、系统的方式建立与PIM规范的关联。
9.4.4 支持本体论的元金字塔的概念优势
支持本体论的元金字塔还具有其他多项优势:
首先,它为模型驱动软件开发过程提供了更具体的框架。设计人员从标准化的分析模型(本体论)入手——这些本体论可能在项目启动前很久就已定义。这些领域模型和业务模型被逐步精化为设计模型:首先添加需求以形成完整的CIM,然后精化为PIM,最后通过多个PSM常规地推进至实现。将本体论用作分析模型有助于提高软件产品的可靠性,因为这些模型经过了良好的工程设计、被广泛使用,因此具有较高的可信度,避免了自建领域分析带来的风险。
其次,本体论作为分析模型为软件架构师、客户和领域专家提供了更统一的词汇表,有助于改善软件订购方与构建方之间的沟通理解。此外,本体论的标准化提高了应用程序的互操作性——使用同一本体论的应用程序包含共同的核心词汇表。最后,领域本体论和业务本体论可在多个软件产品中复用,尤其可作为软件产品线[1]的核心——围绕该核心可构建多个产品,并复用领域术语。总体而言,这提高了软件过程中的复用性。
在MDA中明确区分描述性模型和规定性模型也具有优势:建模过程变得更加简单,因为设计人员和领域专家总能明确“真实性的来源”——源于模型还是源于现实?规范模型需局限于对人造事物(被构建的事物)的建模,而本体论可专注于对真实事物(现存的事物)的描述。(这一点在CIM中尤为明显,CIM实际上同时包含描述性模型和规定性模型。)
最后,支持本体论的元金字塔区分了概念模型与行为模型。围绕领域概念或领域结构进行软件建模,并逐步添加行为,这种方式更为便捷。本质上,这支持了MDA的核心思想之一——精化。
9.4.5 基于支持本体论的元金字塔的工具
支持本体论的元金字塔不仅实现了语义网与MDE的概念整合,还允许对比两种范式的工程实践,进而开发通用工具。
在MDE中,类型系统通过接口定义语言(IDL)[39]进行协调。基于两个类型系统的元模型(M2层),可自动生成类型系统1中的对象与类型系统2中的对象之间的转换代码(M1层)。这是IDL编译器的核心功能,通过支持数据的序列化和反序列化,促进了组件与服务之间的互操作性。目前,基于本体论的应用程序之间的互操作性仍是一个未解决的问题,但将IDL工具迁移到本体论语言中可能是一种可行的解决方案。
将M1层模型划分为平台相关的主题领域(CIM、PIM、PSM)这一结构化原则,可被应用于本体论领域。由于该原则最初是为了支持产品族中的模型复用(CIM和PIM分别在多个PIM和PSM中复用),因此可实现抽象本体论在本体论族中的复用。领域并非总是相互独立的,而是常常存在重叠,这意味着应开发可在多个领域间共享的抽象本体论,并通过添加领域差异精化为具体本体论。尽管“平台”这一概念是否是抽象的合适标准仍有待观察,但MDE工具(如MDE代码生成器)可轻松迁移到这类本体论族中。
本体论和本体论语言的成功应用表明,规范模型中可引入逻辑。这也是实践中本体论常被滥用为规定性用途的原因之一。然而,更有益的做法是在本体论语言和规范语言中明确反映开放世界假设和封闭世界假设的作用:对于特定建模语言,能否切换假设?如果假设与建模语言正交,工具的复用程度如何?
在MDE领域,XMI标准[32]简化了元数据交换。本质上,XMI在M2层定义了UML元模型、XML模式定义和编程语言(如Java)之间的元模型映射。基于这些映射,可自动将类图的UML模型序列化为树形的XML模型,还可自动生成采用受限形式继承的Java类模型。XMI为元数据仓库(如MDR[43]或Eclipse-MDR[15])奠定了基础,这些仓库有望成为未来CASE工具和集成软件开发环境的核心。基于支持本体论的元金字塔,XMI技术可被迁移到本体论仓库中。
图9.8提出了一种适用于本体论领域和规范领域的通用元语言。显然,这种元语言应基于表达能力强的逻辑:如果逻辑是可判定的(如OWL-DL),则可构建可判定的工具技术;如果逻辑是不可判定的,则表达能力更强,可能更具实用性。或许可以定义一种兼容的逻辑语言层级结构,兼顾表达能力和使用灵活性。这种语言层级结构无疑将为描述性本体论领域和规定性规范领域的工具开发提供极大帮助。
9.4.6 支持本体论的MDE巨型模型
上述支持本体论的元金字塔可被称为支持本体论的MDE巨型模型:
巨型模型是描述元金字塔的模型[11]。
巨型模型位于元金字塔之外,描述元金字塔的所有层级,对元金字塔的所有层级都具有全局影响。因此,本文提出的巨型模型为理解MDE中本体论与元模型的关系提供了新的视角:本体论可与元金字塔中的规范模型和元模型系统地关联起来。区分“被描述关系”和“实例关系”这两种表示关系至关重要,因为这能在所有层级上将本体论与规范模型区分开来。总体而言,我们提出以下主张:
- 支持本体论的MDA应将领域本体论和业务本体论作为CIM的一部分;
- 支持本体论的MDE应在元金字塔中额外融入本体论作为描述性模型的维度,并在所有层级维持描述性模型与规定性模型之间的关联。
9.5 相关工作
将元模型与本体论相结合的研究之一是[35],该研究将软件过程和度量本体论扩展为可构建软件的元模型,证明了本体论在元建模场景中的实用性。
前文提到的标准元金字塔在文献中并非没有争议。如果改变文献中提出的某些元金字塔设计原则,可得到其他形式的元金字塔。相似关系在元金字塔中扮演核心角色:由于可定义不同类型的相似关系,因此会产生不同的模型层级结构。
法夫尔(Favre)将“实例关系”拆分为“表示关系”(representationOf)和“成员关系”(member-of)[9]:模型表示语言,系统是该语言的元素。这形成了一种相对模型层级结构,不受限于四个层级,其中某些复合模式表示更复杂的相似关系(如实例关系或被描述关系)。
如果n+1层的每个元素都是n层恰好一个元素的实例,则该元金字塔被称为“严格的”[2]。在严格相似关系下,元金字塔必须是列表或树结构,本质上是一维的。基于这一区分,[2]定义了一种非严格的元金字塔,由两个维度构成矩阵:矩阵的一个维度以物理(技术、语言)实例化为特征,语言相似性描述建模的规范语言方面(即哪种语言构造是哪种语言概念的实例);语言相似性与逻辑(本体论)相似性相区分,逻辑相似性构成矩阵的另一个维度(矩阵式元金字塔)。本体论相似性描述现实世界概念的相似性(例如,狗是哺乳动物,菲多是狗)。显然,这一维度与我们提出的描述性本体论维度相对应。然而,[2]并未区分规定性模型与描述性模型,也未进一步区分不同形式的相似关系。未来的研究将结合这两种方法;目前,尚不清楚二维矩阵式方法与本文提出的描述性和规定性平行维度方法哪种将占主导地位。
9.6 结论
本体论并非万能钥匙。它们可在软件过程中用作描述性的标准化领域模型、领域特定语言和建模(描述)语言,但不应与软件系统的规范混淆。在MDE中,这两种模型都是必需的,且相互补充。现在是时候开发合适的巨型模型,明确本体论在MDE中的角色了。本章提出了一种方法,但这只能作为中间步骤——因为我们局限于标准的IRDS元金字塔。其他更复杂的元金字塔已存在,且必须扩展为支持本体论的形式。
9.7 致谢
本研究部分得到了欧盟信息社会技术(IST)计划的资助(项目编号:IST-2003-506779-REWERSE[4])。
参考文献
- 阿斯曼(Aßmann),U.,语义应用中的复用。收录于诺伯特·艾辛格(Norbert Eisinger)和扬·马卢辛斯基(Jan Małuszynski)编著的《推理网:第一届国际暑期学校(2005年7月,德国柏林)》,《计算机科学讲义》第3564卷,施普林格出版社,2005年。
- 阿特金森(Atkinson),C.,库恩(Kühne),T.,模型驱动开发:元建模基础。《IEEE软件》,20(5):36-41,2003年。
- 史密斯(Smith),B.,威廉姆斯(Williams),J.,舒尔茨-克雷默(Schulze-Kremer),S.,基因本体论的本体论基础。收录于《美国医学信息学会2003年年会论文集》,2003年。网址:http://www.gene-ontology.org
- 布里(Bry),F. 等,语义网环境中的规则(REWERSE)。欧盟第六框架计划项目(编号:IST-2004-506779)。网址:http://www.rewerse.net
- 坎福拉(Canfora),G.,加西亚(García),F.,皮亚蒂尼(Piattini),M.,鲁伊斯(Ruiz),F.,维萨焦(Visaggio),C.A.,软件过程成熟度改进框架的应用。《软件:实践与经验》,36(3):283-304,2005年3月,威立出版社(美国纽约)。
- 陈品山(Chen, P.P.-S.),实体-关系模型:数据的统一视图。《数据库系统汇刊》,1(1):9-36,1976年。
- 德兰萨特(Deransart),P.,儒尔丹(Jourdan),M.,洛罗(Lorho),B.,属性语法:定义、系统与文献综述。《计算机科学讲义》第323卷,施普林格出版社(德国柏林),1988年。
- 德韦德齐奇(Devedzic),V.,理解本体工程。《ACM通讯》,45(4):136-144,2002年。
- 法夫尔(Favre),J.-M.,模型(驱动)(逆向)工程基础:模型。技术报告(第1-3卷),法国格勒诺布尔约瑟夫·傅立叶大学LSR-IMAG实验室ADELE团队,2004年。
- 法夫尔(Favre),J.-M.,巨型建模与词源学——一段词汇的故事:五千年间从MED到MODEL再到MDE。收录于《达格斯图尔软件工程项目转换技术研讨会论文集》(DROPS 04101,编号05161),IFBI出版社,2005年。
- 法夫尔(Favre),J.-M.,阮(Nguyen),T.,通过转换建模软件演化的巨型模型。《理论计算机科学电子笔记》,127(3):59-74,2005年。
- 弗拉彻(Flatscher),R.,EIA/CDIF中的元建模:元-元模型与元模型。《ACM建模与计算机仿真汇刊》,12(4):322-342,2002年。
- 弗里茨松(Fritzson),P.,恩格尔松(Engelson),V.,Modelica:用于系统建模与仿真的统一面向对象语言。收录于埃里克·尤尔(Eric Jul)编著的《ECOOP '98——面向对象编程》,《计算机科学讲义》第1445卷,第67-90页,施普林格出版社(德国柏林),1998年。
- 加西亚(García),F.,鲁伊斯(Ruiz),F.,皮亚蒂尼(Piattini),M.,波洛(Polo),M.,软件维护评估与改进的概念架构。收录于马里奥·皮亚蒂尼(Mario Piattini)和华金·菲利佩(Joaquim Filipe)编著的《企业信息系统IV(ICEIS)》,第219-226页,克卢维尔学术出版社(荷兰多德雷赫特),2002年。
- 吉尔(Geer),D.,Eclipse成为主流Java集成开发环境。《IEEE计算机》,38(7):16-18,2005年。
- 戈德法布(Goldfarb),S.F.,《SGML手册》。牛津大学出版社(英国牛津),1990年。
- 古斯(Goos),G.,怀特(Waite),W.M.,《编译器构造》。施普林格出版社(德国柏林),1984年。
- 格鲁伯(Gruber),T.R.,可移植本体规范的转换方法。《知识获取》,5(2):199-220,1993年。
- 吉扎尔迪(Guizzardi),G.,赫雷(Herre),H.,瓦格纳(Wagner),G.,概念建模的一般本体论基础。收录于S.斯帕卡皮特拉(S. Spaccapietra)、S.T.马奇(S.T. March)和Y.神林(Y. Kambayashi)编著的《第21届国际概念建模大会(ER 2002)》,《计算机科学讲义》第2503卷,第65-78页,施普林格出版社(德国柏林),2002年。
- 霍罗克斯(Horrocks),I.,帕特尔-施耐德(Patel-Schneider),P.,范哈默伦(van Harmelen),F.,从SHIQ和RDF到OWL:一种网络本体语言的构建。《网络语义学杂志》,1(1):7-26,2003年。
- 电气和电子工程师协会(IEEE),标准上层本体知识交换格式。技术报告,2003年。网址:http://suo.ieee.org/suo-kif.html
- 国际标准化组织(ISO)和国际电工委员会(IEC),信息技术——信息资源字典系统(IRDS)。国际标准ISO/IEC 10027,1990年。
- 卡恩(Kahn),G.,自然语义。技术报告第601号,法国国家信息与自动化研究所(INRIA),1987年2月。
- 基扎莱斯(Kiczales),G.,面向方面编程。《ACM计算调查》,28(4),1996年12月。
- 基扎莱斯(Kiczales),G.,德·里维埃雷斯(des Rivières),J.,鲍布罗(Bobrow),D.G.,《元对象协议的艺术》。麻省理工学院出版社(美国马萨诸塞州剑桥),1991年。
- 拉尔斯多特-尼尔森(Larsdotter-Nilsson),E.,弗里茨松(Fritzson),P.,使用Modelica对离散、连续和混合生物及生化系统进行建模。收录于《第三届生物学、医学和生物医学工程建模与仿真大会论文集》(黎巴嫩巴拉曼德大学,2003年5月)。
- 尼德尔曼(Needleman),M.H.,都柏林核心元数据元素集。《连续出版物评论》,24(3-4):131-135,爱思唯尔出版社,1998年。
- 弗里德曼(Fridman),N.,穆森(Musen),M.A.,本体论管理框架中的本体论版本控制。《IEEE智能系统》,19(4):6-13,2004年。
- 对象管理组织(OMG),公共仓库元模型(CWM),2000年2月10日。
- 对象管理组织(OMG),《MDA指南》,2003年6月。网址:http://www.omg.org/mda
- 对象管理组织(OMG),《UML 2.0对象约束语言(OCL)规范》,2003年。网址:http://www.omg.org/docs/ptc/03-10-14.pdf
- 对象管理组织(OMG),《XML元数据交换(XMI)》,2002年1月。网址:http://www.omg.org/technology / documents/format/xmi.htm
- 皮斯(Pease),A.,奈尔斯(Niles),I.,特克诺利奇公司(Teknowledge Corporation),迈向标准上层本体论。收录于《形式化本体论在信息系统中的应用大会(FOIS)论文集》(美国缅因州奥甘奎特),ACM出版社,2001年10月。
- 皮德(Pidd),M.,《思维工具——管理科学中的建模》。威立出版社(美国纽约),2000年。
- 鲁伊斯(Ruiz),F.,比斯卡伊诺(Vizcaíno),A.,皮亚蒂尼(Piattini),M.,加西亚(García),F.,软件维护项目管理的本体论。《国际软件工程与知识工程杂志》,14(3):323-349,2004年。
- 谢尔(Scheer),A.-W.,《ARIS——业务流程框架》。施普林格出版社(德国柏林),1998年。
- 申克(Schenck),D.,《EXPRESS语言参考手册》。技术报告ISO TC184/SC4/WG1 N466工作文档,国际标准化组织(ISO),1990年3月。
- 赛德维茨(Seidewitz),E.,模型的含义。《IEEE软件》,20:26-32,2003年9月。
- 西格尔(Siegel),J.,OMG概述:企业计算中的CORBA与OMA。《ACM通讯》,41(10):37-43,1998年10月。
- 索瓦(Sowa),J.F.,本体论网站。网址:http://www.jfsowa.com/ontology/index.htm
- 索瓦(Sowa),J.F.,《知识表示:逻辑、哲学与计算基础》。布鲁克斯·科尔出版社(美国贝尔蒙特),2000年。
- 斯托伊(Stoy),J.E.,《指称语义学:程序设计语言理论的斯科特-斯特拉切方法》。麻省理工学院出版社(美国马萨诸塞州剑桥),1977年。
- 瑟维耶(Surveyer),J.,Sun公司加入开源Java集成开发环境行列:NetBeans Java IDE评测。《应用开发趋势》,11(9):48-48,2004年。
- 万维网联盟(W3C),《可扩展标记语言(XML)1.0》。技术报告REC-xml19980210,1998年2月。
- 维尔特(Wirth),N.,通过逐步精化进行程序开发。《ACM通讯》,14(4):221-227,1971年。
| 






 订阅
订阅