| 编辑推荐: |
本文首先对背景做了个介绍,接下来对全链路监控介绍,包括:核心概念,应用场景以及PYTHON
tonardo实现方式等内容。
本文来源testwo.com,由火龙果Anna编辑推荐。
|
|
背景介绍
随着搜索系统的扩大和微服务的流行,一次请求涉及的服务往往是很多次调用,这些模块,通常是由不同团队,甚至是不同语言编写的,所以,可能部署在数十台服务器、横跨多个数据中心。因此,在排查问题时,就不能人工对调用链路通过日志分析问题,我们需要轻松的获取到调用链上的每次请求的情况,以便能快速定位和分析问题。
所以全链路监控的目标是
链路追踪、定位故障
各阶段耗时可视化
服务依赖调用梳理
数据分析,链路优化
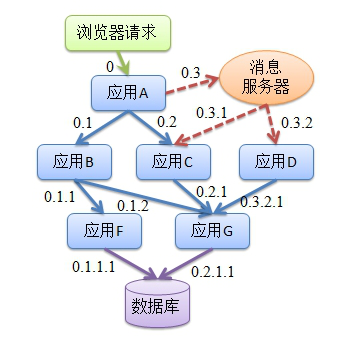
全链路监控介绍
核心概念
SPAN
基本工作单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它,uuid较为方便,span中还有其他的数据,例如描述信息,时间戳,key-value对的(Annotation)tag信息,parent_id等,其中parent-id可以表示span调用链路来源。
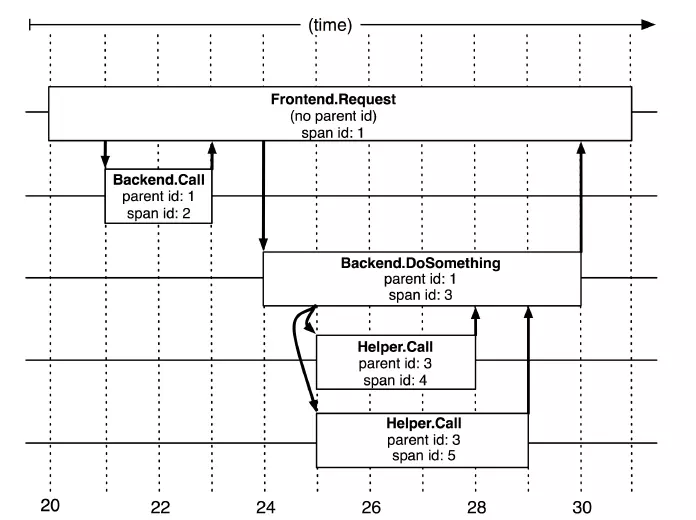
上图说明了span在一次大的跟踪过程中是什么样的。Dapper记录了span名称,以及每个span的ID和父ID,以重建在一次追踪过程中不同span之间的关系。如果一个span没有父ID被称为root
span。所有span都挂在一个特定的跟踪上,也共用一个跟踪id。
TRACE
类似于 树结构的Span集合,表示一次完整的跟踪,从请求到服务器开始,服务器返回response结束,跟踪每次rpc调用的耗时,存在唯一标识trace_id。比如:你运行的分布式大数据存储一次Trace就由你的一次请求组成。
每种颜色的note标注了一个span,一条链路通过TraceId唯一标识,Span标识发起的请求信息。树节点是整个架构的基本单元,而每一个节点又是对span的引用。节点之间的连线表示的span和它的父span直接的关系。虽然span在日志文件中只是简单的代表span的开始和结束时间,他们在整个树形结构中却是相对独立的。
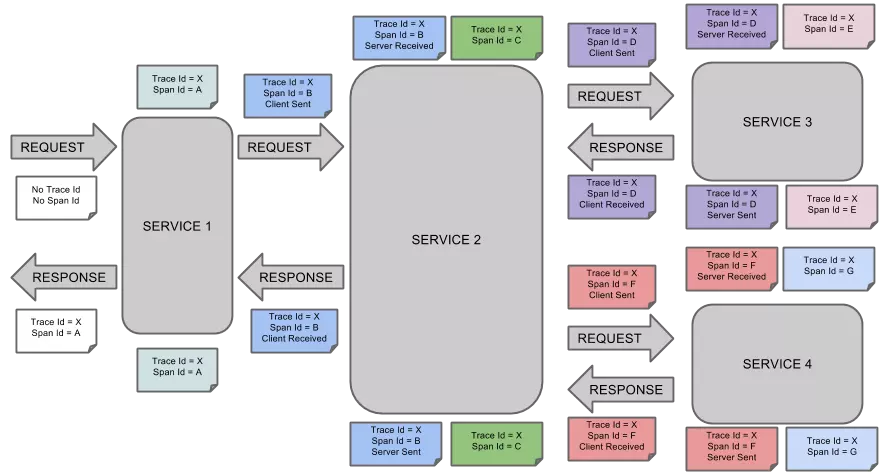
注解,用来记录请求特定事件相关信息(例如时间),一个span中会有多个annotation注解描述。通常包含四个注解信息:
cs:Client Start,表示客户端发起请求
sr:Server Receive,表示服务端收到请求
ss:Server Send,表示服务端完成处理,并将结果发送给客户端
cr:Client Received,表示客户端获取到服务端返回信息
应用场景
性能分析
应用级别的tps,平均耗时,慢调用等
分析应用的错误率,服务错误率、超时率的top10
服务总采集数,成功次数,错误次数,平均耗时,最大耗时,超时次数
链路查询,查看每次接口请求的调用链,反应接口性能,方便优化服务
拓扑分析
应用拓扑,分析应用与应用之间的调用关系,依赖关系
场景拓扑
服务级别的拓扑关系,直接反应核心服务的性能
报警
对应用指标数据、服务指标数据进行报警,实时监控应用
应用日志,JVM,主机监控,心跳
整合其他数据综合分析,快速定位问题
PYTHON tonardo实现方式
全链路监控的实现,核心在于数据的采集和推送,而数据采集又是核心的核心,最简单的方式无非是将全链路监控代码写到代码中,但这样随着业务的扩大,我们不能在每次写代码时,都再多写一部分非业务代码,所以,数据的采集要做到对业务代码的侵入性最小。
在Java中,有AOP这一方式,可以实现对代码无侵入的方式进行数据采集及推送。
在PYTHON中,有一种语法叫做装饰器,可以用@xxx的语法,对某一方法进行注解,可以实现在方法执行前后,执行自定义方法,来获取方法执行时间、异常捕获等操作,但是,装饰器对方法的装饰是独立的,但像trace_id或parent_id这样的需要传递的参数,要通过参数的方式传递给下一个函数。这样势必要对代码有侵入,所以,最终我们仅实现了tornado调用的数据采集及推送。
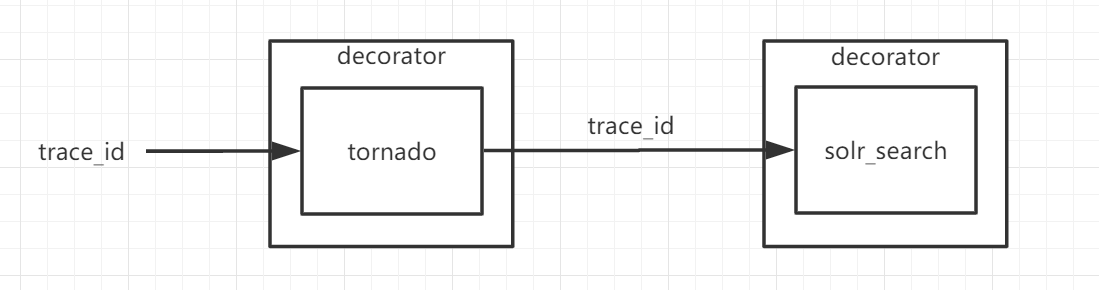
最终方案
装饰器的实现主要有两个类,一个是gtrace_decorator.py,一个是gtrace_push.py,gtrace_decorator负责数据采集,gtrace_push负责数据推送。
gtrace_decorator.py
def __call__(self, func, *args, **kwargs):
@wraps(func)
def _wrapper(*args, **kwargs):
start_time = int(round(time.time() * 1000000))
trace_id = self._get_request_param_value ('trace_id',
*args, **kwargs)
if not trace_id:
return func(*args, **kwargs)
trace_id = trace_id[0]
span_id = trace_id[0:16]
parent_id = trace_id[16:]
name = func.__name__
try:
result = func(*args, **kwargs)
end_time = int(round(time.time() * 1000000))
duration = end_time - start_time
message = self.build_base_message (span_id, trace_id,
parent_id,
name, start_time, duration)
self.gtrace_push.push(message)
return result
except Exception as exception:
end_time = int(round(time.time() * 1000000))
duration = end_time - start_time
message = self.build_base_message(span_id, trace_id,
parent_id,
name, start_time, duration)
self.push_error (message, exception, end_time)
if self._get_request_param_value ('debug', *args,
**kwargs):
raise Exception (traceback.format_exc())
else:
raise Exception(exception.message)
return _wrapper
|
gtrace_push.py
class GtracePush(object):
last_push_time = timeutil.current_milli_time()
gtrace_topic = 'gtrace'
span_list = span_list_pb2.SpanList()
def __init__(self, cfg):
self.kafka_wrapper = KafkaWrapper (cfg, 'KafkaGtrace',
core='')
self.producer = self.kafka_wrapper.get_producer (self.gtrace_topic)
def push(self, message):
self.add_span_message(message)
if self._is_ok_status():
self.producer.produce (self.span_list.SerializeToString())
self._init_param()
|
数据采集中trace_id的采集是获取http请求headers中的trace_id,数据推送是推送至kafka中。
达到一定阀值或定时上报,目前是队列达到512k,或者时间超过2秒就上报。 采用protobuf压缩上报。
PROTOBUF压缩方式
什么是protobuf
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比
XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单来说,protobuf是一种类似于json的,跨平台的,传输效率更高的数据传输方式。
protobuf如何使用
syntax = "proto3";
message Span {
string parentId = 1;
string id = 2;
string traceId = 3;
Kind kind = 4;
Reference reference = 5;
string name = 6;
sint64 timestamp = 7;
sint64 duration = 8;
string serviceName = 9;
string ip = 10;
repeated Pair baggages = 11;
repeated Pair tags = 12;
repeated Log logs = 13;
message Pair {
string key = 1;
string value = 2;
}
message Log {
sint64 timestamp = 1;
string key = 2;
string value = 3;
}
enum Kind {
SERVER = 0;
CLIENT = 1;
PRODUCER = 2;
CONSUMER = 3;
KIND_UNKNOWN = 4;
}
enum Reference {
CHILD_OF = 0;
FOLLOWS_FROM = 1;
REFERENCE_UNKNOWN = 2;
}
}
message SpanList {
repeated Span spans = 1;
} |
1.先写一个如上述代码的数据对象, .proto结尾的文件。
2.将.proto文件编译成.py文件。
3.import编译后的python文件,像处理java中的BO一样给各个字段赋值。
4.通过SerializeToString()方法序列化后推送至kafka
总结
全链路监控可以让我们对我们的服务的可控性更高,能够更容易的分析出调用过程中的问题,节约开发人员的时间。虽然现有的全链路监控只监控了tonardo调用的入口方法,但随着后面的不断优化,相信我们在python的全链路监控上能做的更加完善。
|








