| 主题简介
本次分享主要分为两部分:
第一部分引入运维工程师的能力理论定义;
第二部分介绍DevOps的能力模型,其中引用了第一部分的定义。
部分内容可能形而上学,所以带好枕头被褥,困了就眯一会儿,后面有点小精彩。
引言
运维工作是实践性的学科和工作,即便没有高深的理论也可以开展工作,继而从事这个工作的朋友不缺乏实际动手的能力。
但从事物的发展规律性和普遍性来看,从实践出发的Ops恰恰缺乏必要的理论指导和思想探究。
本文是我对运维工作的理论、思考和定义的总结,同时给出DevOps相关概念的定义,明确其工作范畴,能力要求,产出标准以及演进建议。一家之言尚未完善,抛砖引玉,欢迎讨论。
从一次面试开始
问题1
问:如何通过Python或者Shell给Nginx添加/删除一个虚拟站点?
答:通过Python或者Shell在nginx.conf里添加server区块,然后如何如何……
问题2
问:如何使用Python将文本日志结构化
答:通过python的os.system调用awk。(哭,韩国的整容术用到运维上了,给awk整成python……)
这是最近真实的面试案例。上述两个问题的回答,让我很不开心:
问题1的回答,说明面试者不具备运维的工程能力,更不具备架构能力;
问题2的回答,说明面试者不具备程序的架构能力,甚至对语言理解和标准库的学习都不到位。
从案例里我总结了两个核心的定义:工程能力和架构能力。下面先给出这两个定义。
工程能力当然是运维工!程!师所必需具备的。我对工程能力的定义是:
分解问题的能力;
定义执行序列的能力;
制定可重入操作行为的能力。
架构能力,本人解释为:
懂“不该”懂的;
想“不该”想的;
做“不该”做的。
比如程序猿懂了业务,想了部署,做了高可用的规划应该算得上架构狮了。
1. 分解问题的能力
针对问题1的分解逻辑如下:
nginx是如何管理虚拟站点的,是否具有模块化能力?
在具有模块能力的情况下,如何实现虚拟站点模块的添加?
如何定义规则来命名虚拟站点,以保证可重入,在规则不变的情况不会再重复添加(还要支持upstream等等)?
python要实现什么样的功能,shell要完成什么样的工作?
添加完成后,如何验证其生效?
删除的行为是否要彻底删除配置文件,抑或者留一个副本?
2. 定义执行序列的能力
有些操作是高危操作或者是不可逆的,比如修改sudoers文件。在基于sudo管理的系统下,如果一旦sudoers被改坏是灾难性的。因此定义执行序列是:
在 Terminal下开一个窗口切换到root下;
在另外的窗口下进行对sudoers/sudoers.d的修改或者添加;
一旦试验过程中sudoers被改坏,可以用root账户直接改回来;
以上流程虽然简单,但是这跟飞机起飞前拔掉起落架的闩是一样致命的。
3. 制定可重入操作的能力
系统的管理和系统的状态的获取是两个不同方向的工作:
管理是把指令传递给系统,修改系统的状态和信息;查看系统的状态是从系统获取信息。
这两个不同向的操作行为就导致了状态和信息同步的问题。解决这个问题的方法有很多,但是稳定可靠,兼容性好的方法不多,我的方法是保证操作的可重入性。
即在同等的条件下,对于系统发出的指令,执行n+1次(n>0)的效果是相同的。
这样,即便我可能知道系统状态和信息是不一致的,但是由于操作行为是可重入的,我可以最终把状态和信息一致化。
以上展开了工程能力的解释。
由于架构能力涉及面广,交叉学科众多,此处暂不作展开说明。
DevOps的能力模型
我们先介绍相关能力模型:操作系统能力模型和应用系统能力模型,然后再由此引出DevOps能力模型。
操作系统能力模型
除操作系统核心提供的基本功能外,还给我们提供了以下功能(以Linux为例):
访问控制,实现基于角色的最小粒度访问控制,此为系统管理的基础,能力模型的关键之一;
权利托管,基于角色和命令的可配置授权机制,提供了可控的,可定制的提权的方案;
导入式的可插拔配置能力(通过类include指令), 比如 /etc/security/limits.d,/etc/sudoers.d,
此为自动化重要设施;
包管理能力,包括二进制和源码包的依赖管理等;
shell编程的支持。
应用系统能力模型
除操作系统能力模型提供的功能之外,还给我们提供了以下功能:
导入式配置能力,如nginx的 /etc/nginx/sites-available/;
系统状态侦测能力,如php-fpm的ping/pong;
热装载能力,例如很多服务的reload功能;
高可用性以及故障恢复能力,例如MySQL的高可用配置,以及其binlog的恢复能力;
5,其他必要特性,视不同的业务系统而定。
DevOps能力模型
由此,我们给出DevOps能力模型的定义:
了解其所管理的操作系统的能力模型(Linux,Windows),掌握系统编程语言(Shell)并能利用其能力用于DevOps工作;
了解其管理的应用系统的能力模型(Mysql, Nginx等),掌握系统编程语言(Shell)并能利用其能力用于DevOps工作;
具备前文提到的工程能力,掌握系统编程语言(Shell)和通用语言(Python/Ruby等),并能利用其编程能力将工程能力提到三种能力程序化,并进一步实现自动化;
了解工作场景和业务场景,以及业务的关键指标,使DevOps工作有的放矢,贴近业务。
评估DevOps是否合格的标准:
具备DevOps能力模型提到的各项要求;
其产出的代码脚本能够适应普遍需求,并且该代码脚本符合前文的可重入要求,即执行n和n+1次的效果相同;
其产出的代码脚本能够供其他代码脚本使用,此条尤为重要。
DevOps的级别:
符合DevOps能力模型1:为初级DevOps,可以使用shell做DevOps的一般性系统级别的工作,在一些第三方工具(Ansible/Fabric)的帮助下管理大量服务器;
符合DevOps能力模型2:为中级DevOps,可以使用shell做DevOps的应用系统的部署和优化工作,并能通过其产出的脚本大批量管理应用系统
符合DevOps能力模型3:为高级DevOps,可以使用shell和通用语言进行广泛的DevOps的工作,可以完成完整的业务流程的定义和开发,能够熟练抽象并编写供其他DevOps使用的接口。
符合DevOps能力模型4:为架构师级别的DevOps,根据业务需求,规划系统部署架构;根据业务指标要求优化部署结构和性能,保证高可用等;定义脚本代码接口,制定开发规范和操作规范。
理论的东西说完了,下面是探讨下Dev和Ops的现状,Ops的演进,Dev的演进以及三项补充内容。
Dev和Ops的现状
Dev和Ops是实践性的工作,因此即便不是一名DevOps,或许你也在做着Dev或者Ops的工作。只是这不是真正的DevOps。让我们看两个场景:
Dev的风格是力求用Python/Ruby这类通用编程语言整合一堆的API,实现一套大系统,搞定一切Ops的工作;他们每天的工作就是在找Libs和看各种API的文档,满脑子设计思想。这种思维是Dev思维;
Ops的风格是力求从命令行的角度,甚至脚本都不用,一行一行的把命令敲下去完成工作;或者快速的写一个一次性脚本搞定;他们还喜欢自己编译各种系统,满世界下源码包,喜欢自己搞几个参数优化一下;他们只关心当下的结果,不关心以后的重复利用和持续集成。
这是我以前的工作中遇到的真实情况。
现在情况变了,自从Dev和Ops弄在一起变成DevOps后,又出现了几个自动化工具,搞的现在Dev不好好写代码了,Ops也不好好的写命令行,都去学习自动化工具去了。
这不是DevOps的王道。这是错误的。
即便把所有的自动化工具,不管是Ansible还是Puppet或者其他学的再熟,也只是学会了一个工具而已,很可能DevOps没当成,却变成工具的奴隶。
DevOps是先有思想,而后有工具。
现在崇尚工具的思路是非常可怕的,很多初学者误以为学会了这些自动化工具就可以把运维做好,而忽视基本功的学习,空学工具,只重其招,不重其义。
下面分享下两者的演进。
Ops的演进
案例1:以在RedHat上安装Nginx为例子,网上很多文章的步骤大概如下:
PCRE库的安装:wget, tar, configure, make,make install
OpenSSL库的安装,wget, tar, configure, make,make install
nginx安装,wget, tar, configure, make,make install
这种做法早些年是非常流行的,而且很多人对于在configure后面带的那些参数很是自得,屡试不爽。
时至今日这种方法仍然在很多初学者那里非常流行,而这种做法就是严重的反DevOps的做法。
案例2:以给Nginx增加一个虚拟站点www.devops.org为例,很多初学者一上来就打开nginx.conf开始改,这同样是严重反DevOps的。
这可能是因为一来nginx官方文档是这么改的,二来很多文章也是这么转载,或者原创这么写的。
案例3:再以网络性能优化的为例,很多Ops同学直接冲到/etc/sysctl.conf这里面疯狂的修改一通,添加了各种参数。
这仍然是反DevOps的。一来过不久以后也不知道哪些是自己改的,哪些的默认的,二来如果想用脚本批量更新也是大问题。
针对上面提到的,我认为DevOps应该是这么做的:
对于案例1:首先根据自己的系统设置好nginx的源,而设置源的方法也不是直接冲到/etc/yum.conf,而是建立一个/etc/yum.repos.d/nginx.repo文件,用于保存nginx的源信息。然后然后通过yum
install nginx 安装。(如果一定非得必须特定版本,稍后讨论)。
对于案例2:给Nginx添加一个虚拟站点。RPM包的结构如下
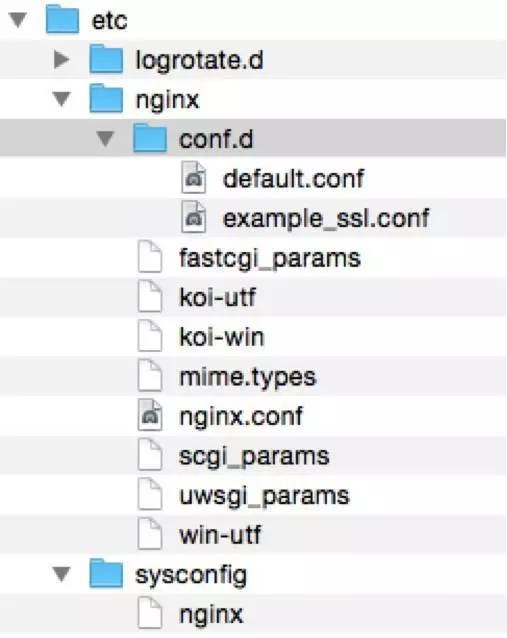
尽管这个结构不是很令人满意,但是仍然可以将就。
至少我们可以看出Redhat的潜在建议是让我们把新的站点放在conf.d下面,我建议的命名是www.devops.org.conf。
那么问题来了,如果我要暂时关闭这个站点怎么办呢?在这个结构下,我们只要把www.devops.org.conf从conf.d里移出来再reload一下就可以了……对,是移出来,不是删除。因为我们后面可能还要用。
此时www.devops.org.conf放在nginx目录下,显得有点格格不入,那么我们干脆建一个文件夹叫disabled-sites,把www.devops.org.conf放在disabled-sites下面得了,以后要是再启用该站点,就直接符号连接到conf.d下面。
再演进一步我们就有了如下的结构:
把站点放在sites-*里。available里放置所有站点的配置文件,通过符号连接到enabled目录下启用。
如果要临时关闭站点,可以删除enabled下的符号连接。这个结构就非常适合DevOps用脚本进行管理。
对于案例3:关于sysctl的修改,DevOps方法是在/etc/sysctl.d下面,按照命名规则添加一个文件,把需要添加的参数放到新文件即可。
这样一来可以方便查看自己修改了哪些,便于确认,二来可以持续集成,通过文件的形式保留自己思考的路径。
通过上面3个事例的演进,我们已经清晰的感觉到,上面三个步骤现在可以马上用脚本自动化起来。但是演进之前确实很难办到。
如果没有Ops的演进,再牛X的Dev他也无法完成自动批量管理以上的业务需求。
Dev的演进
我作为Dev的时间要比作为Ops的时间长很多。8年前从Windows转到Unix-like下,我们看下两个不同系统下,Dev的思路的差别。
写过Windows程序的人都有一个非常坚定的信念就是API,Windows系统下事无巨细都会有对应的API,尤为著名的是注册表的API,还有一个典型的是服务API(Windows
Services)。
你要改个啥配置,要创建一个Service都必须得用API来完成。复杂点的比如写一个端口扫描的要用到socket和多线程的API等等。这个端口扫描说来业务逻辑本身很简单,倒是程序逻辑搞的复杂的不得了。
而Unix-like的系统,沿袭着Unix的哲学其Dev的思路又是另外一套。修改配置,直接冲到文件里改,创建一个daemon/service直接写个shell脚本放到系统即可,完全不必要API。
所有的一切无论是在Dev还是Ops面前都是一目了然。前面提到的端口扫描更是直接用python/ruby/shell
直接调用nmap搞定,效率高,功能强大,稳定性和兼容性都不错。
我认为这是Dev要借鉴的,也是思想上最大的差别。
统统用API做出来的东西,一是容易让Ops一头雾水,搞不清楚,很难参与,二是有些功能实现起来要达到足够的性能,强大,稳定以及良好的兼容性是非常困难的。
nmap第一版本是1997.9发布的,历经18个年头,这样的工具我们一朝一夕是难以实现的。
关于Dev转DevOps的建议
鉴于以上的讨论,我给Dev即将转到DevOps的同学们的建议是:
试做一个有经验的Ops,放下编程语言,从命令行开始,从Shell开始;
理解操作系统的哲学,Unix-like下管道连接一切命令,文件代表一切配置;
理解Ops的核心指标,比如高可用,兼容稳定,可重入,故障容灾;
在坚持Ops-style的前提下,通过程序设计思想将DevOps的代码脚本的产出层次化,模块化,使之达到高复用;
Dev和Ops的另外一个区别是,以往Dev注重的是具体功能开发,而Ops天生要关注的是系统的整体管理。
功能开发注重逻辑的正确,1+1=2;但是Ops要求业务和结果导向,有时1+1可能是无穷大,比如磁盘满了。
补充1:编程语言和Shell在DevOps的关系
从自动化部署工具来看他们的关系,Python/Ruby通过业务逻辑把产生出相关文件和Shell语句通过下面两种方式执行:
基于ssh;
基于Agent(姑且认为是RPC的一种方式)。
因此Python/Ruby作用是:编排和启动Shell语句的作用;具体实现功能,则仍是Shell语句。
根据这种关系,我们不难发现以上两种方式存在现实的局限性:
众多命令执行情况下,ssh效率不高;
Agent效率虽然高,但是开发和调试成本很高,另外Agent对于Ops是透明、不可控的,一线Ops在Agent出了问题后,很难介入调试。
我的建议是在shell做文章,即基于shell脚本的机制完成远端业务逻辑的工作,通过ssh或者agent调用脚本执行功能,这样提高了效率又便于Ops参与脚本的编写和调试。
结论:DevOps的落点是Ops,Python/Ruby的落点是shell和commands。
Python/Ruby的优势是业务逻辑,文件处理等,莫用Python/Ruby去实现shell和commands擅长的。
补充2:编程语言在DevOps的意义
Python/Ruby体现的重要性是程序设计的思想,shell和commands的重要性在于,系统最终由他们改变。
以前是Ops玩shell和commands,现在是DevOps通过Python/Ruby玩shell和commands,所以本质还是shell和commands。
就像互联网和传统行业一样,有互联网传统行业转的更好,但是没有互联网传统行业一样转;而如果没有传统行业,估计饭都吃不上,互联网也就不存在了。
补充3:操作系统能力模型
根据前面的结论,我认为DevOps的核心竞争是在Shell和Commands的竞争。而操作系统能力的提升也将是Shell和commands的提升。
试想如果没有yum/apt,没有sed,没有iptables,没有virsh这样的指令,我们是否寸步难行?答案当然是肯定的。
有人说,可以通过c/python/ruby实现,反正都有api,这是错误的轮子思路。
我可以肯定的说,我们几乎没有能力超越先贤们历经数十年累积的成果。即便可以我们做出来类似的东西,也很难超越这些既有的工具,这些工具优秀之处除了智慧,还有时间以及实践的检验。
但是有一件事我们是可以做的,就是把操作系统业务能力提升起来。我认为的操作系统能力模型里,唯缺此一项。
我们不需要再写一个iptables,sed,yum/apt,我们可以包装他们,通过命令的组合和逻辑的判断,衍生出专用的业务能力。
RedHat下有不少好的例子,比如service iptables save的功能。此功能的意义如下:
提供了统一的调用方式,并且封装业务逻辑,便于其他脚本使用;
统一的文件存放位置,便于自动加载,管理和备份;
同时提供了restore的命令。
这就是一种操作系统的能力。这种能力在Linux的一些分支上是没有的,我们就必须自己编写脚本实现此功能。但是写来写去,写得最好也就是跟RedHat大同小异,但是却花了我们的宝贵的时间。
试想在拥有这种能力的RedHat上面,DevOps开发一个批量保存iptables的功能是否更容易呢?
|






