| 编辑推荐: |
本文主要介绍了开源监控框架Prometheus的安装、配置、添加监控等详细的实现集群监控过程,希望对您的学习有所帮助。
本文来自于51cto,由火龙果软件Luca编辑、推荐。 |
|
1、Prometheus 对比 Zabbix
和 Zabbix 类似,Prometheus 也是一个近年比较火的开源监控框架,和 Zabbix不同之处在于
Prometheus 相对更灵活点,模块间比较解耦,比如告警模块、代理模块等等都可以选择性配置。服务端和客户端都是开箱即用,不需要进行安装。Zabbix则是一套安装把所有东西都弄好,很庞大也很繁杂。
Zabbix 的客户端 agent 可以比较方便的通过脚本来读取机器内数据库、日志等文件来做上报。而
Prometheus 的上报客户端则分为不同语言的SDK和不同用途的 exporter 两种,比如如果你要监控机器状态、mysql性能等,有大量已经成熟的
exporter 来直接开箱使用,通过http通信来对服务端提供信息上报(server去pull信息);
而如果你想要监控自己的业务状态,那么针对各种语言都有官方或其他人写好的 sdk 供你使用,都比较方便,不需要先把数据存入数据库或日志再供
zabbix-agent 采集。
Zabbix 的客户端更多是只做上报的事情,push 模式。而 Prometheus 则是客户端本地也会存储监控数据,服务端定时来拉取想要的数据。界面来说
zabbix 比较陈旧,而 prometheus 比较新且非常简洁,简洁到只能算一个测试和配置平台。要想获得良好的监控体验,搭配
Grafana 还是二者的必走之路。
2、安装 Prometheus
Prometheus 有很多种安装方式,可以在官网看到,这里只介绍下载安装包解压的方式,因为 Prometheus
是“开箱即用”的,也就是说解压安装包后就可以直接使用了,不需要再执行安装程序,很方便。
可以去 Prometheus 的官网下载页面获取最新版本的信息,比如现在的最新版本是2.7.2,那就下载相应系统的安装包,然后解压
$ wget https://github.com/prometheus/prometheus
/releases/download/v2.7.2/prometheus-2.7.2.linux-amd64.tar.gz
$ tar xvfz prometheus-2.7.2.linux-amd64.tar.gz
|
解压后当前目录就会出现一个相应的文件夹,进入该文件夹,然后就可以直接运行Prometheus
server了!
$ cd prometheus-2.7.2.linux-amd64
// 查看版本
$ ./prometheus --version
// 运行server
$ ./prometheus --config.file=prometheus.yml |
命令中的 prometheus.yml 文件其实就是配置文件,也在当前目录下,在其中可以配置一些东西。
3、配置 Prometheus
上文说了,prometheus.yml 是配置文件,打开可以看到不多的几十行文字,类似下面:
$ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval
to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every
15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default
(10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them
according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one
endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>`
to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090'] |
其大致分为四部分:
global:全局配置,其中 scrape_interval 表示抓取一次数据的间隔时间,evaluation_interval
表示进行告警规则检测的间隔时间;
alerting:告警管理器(Alertmanager)的配置,目前还没有安装Alertmanager;
rule_files:告警规则有哪些;
scrape_configs:抓取监控信息的目标。一个 job_name 就是一个目标,其 targets
就是采集信息的 IP 和端口。这里默认监控了 Prometheus 自己,可以通过修改这里来修改 Prometheus
的监控端口。
Prometheus 的每个 exporter 都会是一个目标,它们可以上报不同的监控信息,比如机器状态,或者
mysql 性能等等,不同语言 sdk 也会是一个目标,它们会上报你自定义的业务监控信息。
4、Prometheus 界面
运行后,在浏览器访问[机器IP:端口]就可以查看 Prometheus 的界面了,这里的机器IP是你运行
Prometheus 的机器,端口是上面配置文件中配置的监控自己的端口。打开后界面如下:
如果访问不了,看看是不是端口没有打开或者允许外网访问。
界面非常简单(所以我们还需要Grafana),上面标签栏中,Alerts是告警管理器,暂时还没安装。Graph是查看监控项的图表,也是访问后的默认页面,Status中可以查看一些配置、监控目标、告警规则等。
在 Graph 页面,由于我们默认已经监控了 Prometheus 自己,所以已经可以查看一些监控图表,比如在输入框输入“promhttp_metric_handler_requests_total”,执行Execute,下面的小标签中切换到Graph就能看到“/metrics”访问次数的折线图。
5、添加机器状态监控
我们尝试添加第一个监控exporter——监控当前机器自身的状态,包括硬盘、CPU、流量等。因为Prometheus已经有了很多现成的常用exporter,所以我们直接用其中的node_exporter。注意了,这里名字虽然叫node_exporter,但跟nodejs没有任何关系,在Prometheus看来,一台机器或者说一个节点就是一个node,所以该exporter是在上报当前节点的状态。node_exporter本身也是一个http服务,可以供
prometheus server 调用(pull)来获取监控的信息,安装方法同样是下载安装包后解压直接运行:
// 下载最新版本,可以在github的release中对最新版本右键获取下载链接
$ wget https://github.com/prometheus/node_exporter/
releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
// 解压
$ tar xvfz node_exporter-0.17.0.linux-amd64.tar.gz
// 进入解压出的目录
$ cd node_exporter-0.17.0.linux-amd64
// 运行监控采集服务
$ ./node_exporter |
运行后可以看到在监听9100端口。这样就可以采集了,现在先访问试试能不能有没有成功运行:这里也可以看出其实每个exporter本身都是一个http服务,server端会定时来访问获取监控信息。访问成功的话,我们去prometheus的配置文件(prometheus.yml)中,加上这个target:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'server'
static_configs:
- targets: ['localhost:9100'] |
可以看到,就是在 scrape_configs 模块中加一个job,命好名,配置好监听的IP和端口即可,然后重新运行
prometheus,在标签栏的 Status → Targets 中可以看到多了一个:
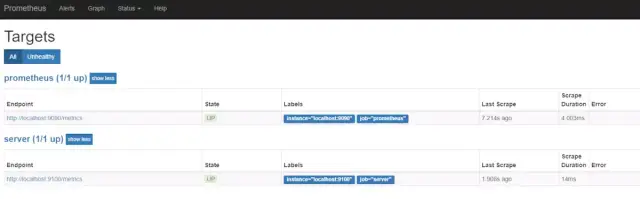
如果新加的 target 的 status 是“UP”的话,就说明监听成功了。
此时去Graph中,输入框输入node可以发现有很多 node 开头的监控项了,都是和机器状态有关的,可以自己执行看一看。
安装 Grafana
因为 Prometheus 的界面看起来非常简单,所以我们还需要 Grafana 这个非常强大也是最常用的监控展示框架。
我们还是用下载二进制包的方式来进行安装,这种方式不需要你当前的linux用户拥有sudo权限,也不需要你知道
root 密码。如果你有这些权限,那就使用 yum 等其他直接的安装方式吧,安装说明见 Grafana
的官方安装页面
我们直接下载并解压:
$wget [https://dl.grafana.com/oss/release/grafana-6.0.0.linux-amd64.tar.gz](https://dl.grafana.com/oss/release/grafana-6.0.0.linux-amd64.tar.gz)
$ tar -zxvf grafana-6.0.0.linux-amd64.tar.gz
这个页面给出的是最新版本的安装命令,右上角可以选择切换其他版本的安装命令。 |
解压后会出现 grafana-6.0.0 目录,进入该目录,然后就可以运行
Grafana 了:
$ cd grafana-6.0.0
// 启动Grafana。$ ./bin/grafana-server web |
通过log信息可以看到Grafana默认运行在3000端口,这个也可以通过配置文件进行修改:创建名为
custom.ini 的配置文件,添加到 conf 文件夹,复制 conf/defaults.ini
中定义的所有设置,然后修改自己想要修改的。
在 Grafana 展示监控信息
安装并启动Grafana后,浏览器输入 IP:3000 来访问Grafana,管理员账号密码默认是admin/admin。首次登陆会让你修改管理员密码,然后就可以登录查看了。
在界面左边是一竖排选项,选择设置图标中的Data Source,添加Prometheus的数据源,URL
就填上面你给 Prometheus Server 设置的ip+端口号就行了,如果没改过且在本机运行的话,那就是
localhost:9090。
此时可以添加 dashboard,也就是监控面板了,在刚配好的 Prometheus Data Source的设置中有一个标签就是
dashboard,我们导入 Prometheus 2.0 Stats 这个面板,就能看到我们Prometheus的一些基本监控情况了,这其实就是导入了一个别人写好的面板配置,并且连接我们自己
Prometheus 的监控数据做展示。还记得我们上面还运行了一个 node exporter 吧,现在我们展现一下这个监控信息,左边竖排点击加号图标中的
Import,来导入其他别人写好的面板。在Grafana的官方面板页面其实可以看到很多别人配置好的面板,我们找到自己想要的面板,比如这个node
exporter 的:
复制右边那个面板ID,然后在 Import 界面输入ID,Load 后配置好数据源为我们的Prometheus,就可以出现我们自己机器的状态监控面板了,很炫酷吧。
这个面板需要安装一个饼图的插件(页面上有说明),安装 Grafana
插件的方法为:
// 进入Grafana/bin目录
./grafana-cli plugins install [插件名]
// 安装成功后重启Grafana |
面板中的每个图都是可以编辑的,也可以设置告警,Grafana 告警支持多种方式,我们最常用的就是邮件和
webhook 了,所以其实不太需要用 Prometheus 的告警。 |









