| БрМЭЦМі: |
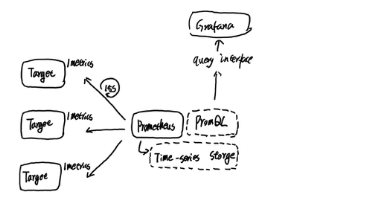
БОЮФДгPrometheusЕФЛљДЁЫЕЦ№ЃЌбЇЯАКЭСЫНтPrometheusЧПДѓЕФЪ§ОнДІРэФмСІЃЌСЫНтШчКЮЪЙгУPrometheusНјааАзКаКЭКкКаМрПиЃЌвдМАPrometheusдкЙцФЃЛЏМрПиЯТЕФНтОіЗНАИЕШЁЃ
БОЮФРДздгкЫбКќЭјЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
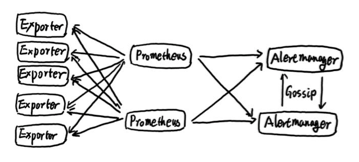
PrometheusЪЧМЬKubernetesКѓЕк2Иіе§ЪНМгШыCNCFЛљН№ЛсЕФЯюФПЃЌШнЦїКЭдЦдЩњСьгђЪТЪЕЕФМрПиБъзМНтОіЗНАИЁЃБОЮФзюКѓНЋДг0ПЊЪМЙЙНЈЭъећЕФKubernetesМрПиМмЙЙЁЃ
МрПиЕФФПБъ
дкЁЖSREЃКGoogleдЫЮЌНтУмЁЗвЛЪщжажИГіЃЌМрПиЯЕЭГашвЊФмЙЛгааЇЕФжЇГжАзКаМрПиКЭКкКаМрПиЁЃЭЈЙ§АзКаФмЙЛСЫНтЦфФкВПЕФЪЕМЪдЫаазДЬЌЃЌЭЈЙ§ЖдМрПижИБъЕФЙлВьФмЙЛдЄХаПЩФмГіЯжЕФЮЪЬтЃЌДгЖјЖдЧБдкЕФВЛШЗЖЈвђЫиНјаагХЛЏЁЃЖјКкКаМрПиЃЌГЃМћЕФШчHTTPЬНеыЃЌTCPЬНеыЕШЃЌПЩвддкЯЕЭГЛђепЗўЮёдкЗЂЩњЙЪеЯЪБФмЙЛПьЫйЭЈжЊЯрЙиЕФШЫдБНјааДІРэЁЃЭЈЙ§НЈСЂЭъЩЦЕФМрПиЬхЯЕЃЌДгЖјДяЕНвдЯТФПЕФЃК
ГЄЦкЧїЪЦЗжЮіЃКЭЈЙ§ЖдМрПибљБОЪ§ОнЕФГжајЪеМЏКЭЭГМЦЃЌЖдМрПижИБъНјааГЄЦкЧїЪЦЗжЮіЁЃР§ШчЃЌЭЈЙ§ЖдДХХЬПеМфдіГЄТЪЕФХаЖЯЃЌЮвУЧПЩвдЬсЧАдЄВтдкЮДРДЪВУДЪБМфНкЕуЩЯашвЊЖдзЪдДНјааРЉШнЁЃ
ЖдееЗжЮіЃКСНИіАцБОЕФЯЕЭГдЫаазЪдДЪЙгУЧщПіЕФВювьШчКЮЃПдкВЛЭЌШнСПЧщПіЯТЯЕЭГЕФВЂЗЂКЭИКдиБфЛЏШчКЮЃПЭЈЙ§МрПиФмЙЛЗНБуЕФЖдЯЕЭГНјааИњзйКЭБШНЯЁЃ
ИцОЏЃКЕБЯЕЭГГіЯжЛђепМДНЋГіЯжЙЪеЯЪБЃЌМрПиЯЕЭГашвЊбИЫйЗДгІВЂЭЈжЊЙмРэдБЃЌДгЖјФмЙЛЖдЮЪЬтНјааПьЫйЕФДІРэЛђепЬсЧАдЄЗРЮЪЬтЕФЗЂЩњЃЌБмУтГіЯжЖдвЕЮёЕФгАЯьЁЃ
ЙЪеЯЗжЮігыЖЈЮЛЃКЕБЮЪЬтЗЂЩњКѓЃЌашвЊЖдЮЪЬтНјааЕїВщКЭДІРэЁЃЭЈЙ§ЖдВЛЭЌМрПижИБъвдМАРњЪЗЪ§ОнЕФЗжЮіЃЌФмЙЛевЕНВЂНтОіИљдДЮЪЬтЁЃ
Ъ§ОнПЩЪгЛЏЃКЭЈЙ§ПЩЪгЛЏвЧБэХЬФмЙЛжБНгЛёШЁЯЕЭГЕФдЫаазДЬЌЁЂзЪдДЪЙгУЧщПіЁЂвдМАЗўЮёдЫаазДЬЌЕШжБЙлЕФаХЯЂЁЃ
ЖјЖдгкЩЯвЛДњМрПиЯЕЭГЖјбдЃЌдкЪЙгУЙ§ГЬжаЭљЭљЛсУцСйвдЯТЮЪЬтЃК
гывЕЮёЭбРыЕФМрПиЃКМрПиЯЕЭГЛёШЁЕНЕФМрПижИБъгывЕЮёБОЩэвВЪЧвЛжжЗжРыЕФЙиЯЕЁЃКУБШПЭЛЇПЩФмЙизЂЕФЪЧЗўЮёЕФПЩгУадЁЂЗўЮёЕФSLAЕШМЖЃЌЖјМрПиЯЕЭГШДжЛФмИљОнЯЕЭГИКдиШЅВњЩњИцОЏЃЛ
дЫЮЌЙмРэФбЖШДѓЃКNagiosетвЛРрМрПиЯЕЭГБОЩэдЫЮЌЙмРэФбЖШОЭБШНЯДѓЃЌашвЊгазЈвЕЕФШЫдБНјааАВзАЃЌХфжУКЭЙмРэЃЌЖјЧвЙ§ГЬВЂВЛМђЕЅЃЛ
ПЩРЉеЙадЕЭЃК МрПиЯЕЭГздЩэФбвдРЉеЙЃЌвдЪЪгІМрПиЙцФЃЕФБфЛЏЃЛ
ЮЪЬтЖЈЮЛФбЖШДѓЃКЕБЮЪЬтВњЩњжЎКѓЃЈБШШчжїЛњИКдивьГЃдіМгЃЉЖдгкгУЛЇЖјбдЃЌЫћУЧПДЕНЕФвРШЛЪЧвЛИіКкКаЃЌЫћУЧЮоЗЈСЫНтжїЛњЩЯЗўЮёеце§ЕФдЫааЧщПіЃЌвђДЫЕБЙЪеЯЗЂЩњКѓЃЌетаЉИцОЏаХЯЂВЂВЛФмгааЇЕФжЇГжгУЛЇЖдгкЙЪеЯИљдДЮЪЬтЕФЗжЮіКЭЖЈЮЛЁЃ
дкЩЯЪіашЧѓжаЃЌЮвУЧПЩвдЬсШЁГівдЯТЖдгквЛИіЭъЩЦЕФМрПиНтОіЗНАИЕФМИИіЙиМќДЪЃКЪ§ОнЗжЮіЁЂЧїЪЦдЄВтЁЂИцОЏЁЂЙЪеЯЖЈЮЛЁЂПЩЪгЛЏЁЃ
Г§ДЫвдЭтЃЌЕБЧАдНРДдНЖрЕФВњЦЗЙЋЫОЧЈвЦЕНдЦЛђепШнЦїЕФЧщПіЯТЃЌЖдгкМрПиНтОіЗНАИЖјбдЛЙашвЊСэЭтвЛИіЙиМќДЪЃКдЦдЩњЁЃ
жївЊФкШн
НёЬьНЋДгвдЯТМИИіЗНУцРДНщЩмЯТвЛДњМрПиНтОіЗНАИPrometheusЪЧШчКЮНтОівдЩЯЮЪЬтЕФЃК
ГѕЪЖPrometheus
ШУЪ§ОнЛсЫЕЛАЃКPromQLгыПЩЪгЛЏ
AlertmanagerгыИцОЏДІРэЃЛ
АзКагыКкКаМрПи
ЙцФЃЛЏМрПиНтОіЗНАИ
Дг0ПЊЪММрПиKubernetesМЏШК
ГѕЪЖPrometheus
PrometheusЪмЦєЗЂгкGoogleЕФBrogmonМрПиЯЕЭГЃЈЯрЫЦЕФKubernetesЪЧДгGoogleЕФBrogЯЕЭГбнБфЖјРДЃЉЃЌДг2012ФъПЊЪМгЩЧАGoogleЙЄГЬЪІдкSoundcloudвдПЊдДШэМўЕФаЮЪННјаабаЗЂЃЌВЂЧвгк2015ФъдчЦкЖдЭтЗЂВМдчЦкАцБОЁЃ2016Фъ5дТМЬKubernetesжЎКѓГЩЮЊЕкЖўИіе§ЪНМгШыCNCFЛљН№ЛсЕФЯюФПЃЌЭЌФъ6дТе§ЪНЗЂВМ1.0АцБОЁЃ2017ФъЕзЗЂВМСЫЛљгкШЋаТДцДЂВуЕФ2.0АцБОЃЌФмИќКУЕигыШнЦїЦНЬЈЁЂдЦЦНЬЈХфКЯЁЃ
Дгhttps://prometheus.io/download/ЛёШЁзюаТЕФnode
exporterАцБОЕФЖўНјжЦАќКѓжБНгдЫааМДПЩЃК
$ node_exporter
INFO[0000] Starting node_exporter (version=0.15.2,
branch=HEAD, revision=98bc64930d34878b84a0f87df
e6e1a6da61e532d) source="
node_exporter.go:43"
INFO[0000] Enabled collectors: source="node_exporter.go:50"
INFO[0000] - time source="node_exporter.go:52"
INFO[0000] - meminfo source="node_exporter.go:52"
INFO[0000] - textfile source="node_exporter.go:52"
INFO[0000] - filesystem source="node_exporter.go:52"
INFO[0000] - netdev source="node_exporter.go:52"
INFO[0000] - cpu source="node_exporter.go:52"
INFO[0000] - diskstats source="node_exporter.go:52"
INFO[0000] - loadavg source="node_exporter.go:52"
INFO[0000] Listening on :9100 source="node_exporter.go:76" |
ЗУЮЪhttp://localhost:9100/metricsЃЌПЩвдПДЕНNode
ExporterЛёШЁЕНЕФЕБЧАжїЛњЕФЫљгаМрПиЪ§ОнЃЌШчЯТЫљЪОЃК
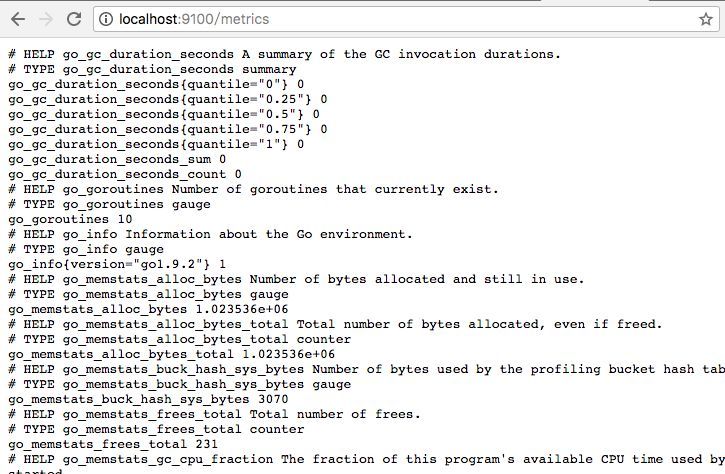
УПвЛИіМрПижИБъжЎЧАЖМЛсгавЛЖЮРрЫЦгкШчЯТаЮЪНЕФаХЯЂЃК
# HELP node_cpu
Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu= "cpu0",mode= "idle"}
362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load13.0703125 |
Node ExporterЭЈЙ§жИБъУћГЦКЭБъЧЉЗЕЛиСЫЕБЧАжїЛњЕФМрПибљБОЪ§ОнЁЃ
Дгhttps://prometheus.io/download/евЕНзюаТАцБОЕФPrometheus
SevrerШэМўАќЃЌФПЧАетРяВЩгУзюаТЕФЮШЖЈАцБО2.x.xЁЃ
ДДНЈХфжУЮФМўprometheus.ymlЃЌШчЯТЫљЪОЃК
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets: [ 'localhost:9100']
- job_name: 'prometheus'
static_configs:
- targets: [ 'localhost:9090'] |
ВЂЦєЖЏPrometheusЃК
$ prometheus
--config.file=prometheus.yml --storage.tsdb.path=/data/prometheus
......
level=info ts=2018-03-11T13:38:06.317645234Z
caller=
main.go:486 msg= "Server is ready to receive
web requests."
level=info ts=2018-03-11T13:38:06.317679086Z
caller=manager.go:59 component= "scrape
manager"msg=
"Starting scrape manager..." |
ЗУЮЪhttp://localhost:9090ЃЌНјШыЕНPrometheus
ServerЁЃЭЈЙ§жИБъУћГЦnode_load1ЃЌПЩвдевЕНЕБЧАВЩМЏЕНЕФжїЛњИКдиЕФбљБОЪ§ОнЁЃ
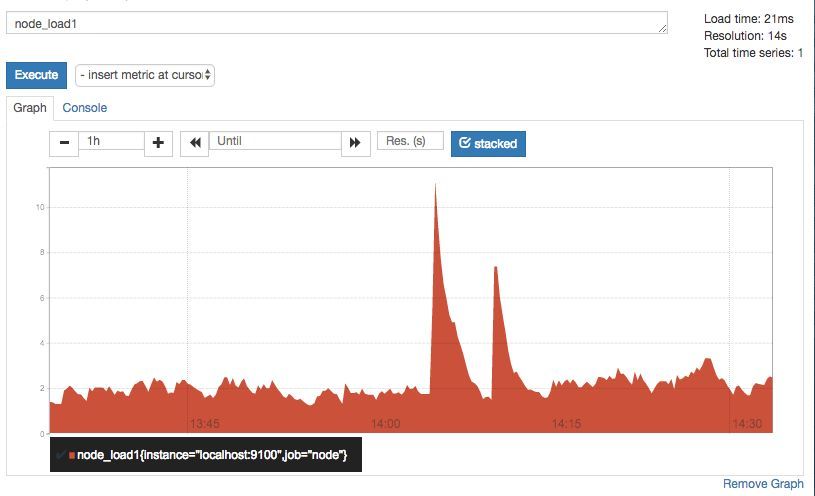
дкЩЯЪіЕФР§згжаЃЌЮвУЧжївЊЪЙгУЕНСЫNode ExporterЪЕР§ШЅЛёШЁжїЛњЕФМрПиЪ§ОнЃЌвЛИідЫааЕФNode
ExporterЪЕР§ГЦЮЊвЛИіTargetЁЃPromthuesжмЦкадЕФДгNode ExporterЪЕР§жаЛёШЁМрПибљБОЃЌВЂБЃДцЕНPromtheusЛљгкБОЕиДХХЬЪЕЯжЕФЪБМфађСаЪ§ОнПтжаЁЃ

дкЪЕМЪЕФгІгУГЁОАжаExporterПЩвдЗжЮЊСНРрЃК
ЖРСЂдЫааЕФЃКРрЫЦгкNode ExporterетжжЃЌЫќВЂВЛжБНгВњЩњЪ§ОнЃЌЫќжЛИКд№ДгЪ§ОндДжаЛёШЁЪ§ОнЃЌВЂвдPrometheusжЇГжЕФИёЪНЗЕЛиМрПиЪ§ОнМДПЩЁЃ
МЏГЩЕНгІгУжаЕФЃКЮЊСЫФмЙЛИќКУЕФМрПиЯЕЭГЕФФкВПдЫаазДЬЌЃЌгааЉПЊдДЯюФПШчKubernetesЃЌETCDЕШжБНгдкФкВПМЏГЩСЫЖдPrometheusЕФжЇГжЃЌЭЈЙ§ФкВПТёЕуЕФаЮЪНЃЌПЩвдИќКУЕФМрПиЗўЮёЕФФкВПдЫаазДЬЌЁЃ
ШУЪ§ОнЫЕЛАЃКPromQLгыЪ§ОнПЩЪгЛЏ
РэНтЪБМфађСа
дкNode ExporterЕФ/metricsНгПкжаЗЕЛиЕФУПвЛааМрПиЪ§ОнЃЌдкPrometheusЯТГЦЮЊвЛИібљБОЁЃВЩМЏЕНЕФбљБОгЩвдЯТШ§ВПЗжзщГЩЃК
жИБъЃЈmetricЃЉЃКжИБъКЭвЛзщУшЪіЕБЧАбљБОЬиеїЕФlabelsetsЮЈвЛБъЪЖЃЛ
ЪБМфДСЃЈtimestampЃЉЃКвЛИіОЋШЗЕНКСУыЕФЪБМфДСЃЌвЛАугЩВЩМЏЪБМфОіЖЈЃЛ
бљБОжЕЃЈvalueЃЉЃК вЛИіfolat64ЕФИЁЕуаЭЪ§ОнБэЪОЕБЧАбљБОЕФжЕЁЃ
PrometheusЛсНЋЫљгаВЩМЏЕНЕФбљБОЪ§ОнвдЪБМфађСаЃЈtime-seriesЃЉЕФЗНЪНБЃДцдкФкДцЪ§ОнПтжаЃЌВЂЧвЖЈЪББЃДцЕНгВХЬЩЯЁЃУПЬѕtime-seriesЭЈЙ§жИБъУћГЦЃЈmetrics
nameЃЉКЭвЛзщБъЧЉМЏЃЈlabelsetЃЉУќУћЁЃШчЯТЫљЪОЃЌПЩвдНЋtime-seriesРэНтЮЊвЛИівдЪБМфЮЊXжсЕФЖўЮЌОиеѓЃК

етжжЖрЮЌЖШЕФЪ§ОнДцДЂЗНЪНЃЌПЩвдбмЩњГіКмЖрВЛЭЌЕФЭцЗЈЁЃ БШШчЃЌШчЙћЪ§ОнРДздВЛЭЌЕФЪ§ОнжааФЃЌФЧУДЮвУЧПЩвддкбљБОжаЬэМгБъЧЉРДЧјЗжРДздВЛЭЌЪ§ОнжааФЕФМрПибљБОЃЌР§ШчЃК
| node_cpu{cpu= "cpu0",mode=
"idle", dc= "dc0"} |
ДгФкВПЪЕЯжЩЯРДПДPrometheusжаЫљгаДцДЂЕФМрПибљБОЪ§ОнУЛгаШЮКЮВювьЃЌОљЪЧвЛзщБъЧЉЃЌЪБМфДСвдМАбљБОжЕЁЃ
ДгДцДЂЩЯРДНВЫљгаЕФМрПижИБъmetricЖМЪЧЯрЭЌЕФЃЌЕЋЪЧдкВЛЭЌЕФГЁОАЯТетаЉmetricгжгавЛаЉЯИЮЂЕФВювьЁЃ
Р§ШчЃЌдкNode ExporterЗЕЛиЕФбљБОжажИБъnode_load1ЗДгІЕФЪЧЕБЧАЯЕЭГЕФИКдизДЬЌЃЌЫцзХЪБМфЕФБфЛЏетИіжИБъЗЕЛиЕФбљБОЪ§ОнЪЧдкВЛЖЯБфЛЏЕФЁЃЖјжИБъnode_cpuЫљЛёШЁЕНЕФбљБОЪ§ОнШДВЛЭЌЃЌЫќЪЧвЛИіГжајдіДѓЕФжЕЃЌвђЮЊЦфЗДгІЕФЪЧCPUЕФРлЛ§ЪЙгУЪБМфЃЌДгРэТлЩЯНВжЛвЊЯЕЭГВЛЙиЛњЃЌетИіжЕЪЧЛсЮоЯоБфДѓЕФЁЃ
ЮЊСЫФмЙЛАяжњгУЛЇРэНтКЭЧјЗжетаЉВЛЭЌМрПижИБъжЎМфЕФВювьЃЌPrometheusЖЈвхСЫ4жаВЛЭЌЕФжИБъРраЭЃЈmetric
typeЃЉЃКCounterЃЈМЦЪ§ЦїЃЉЁЂGaugeЃЈвЧБэХЬЃЉЁЂHistogramЃЈжБЗНЭМЃЉЁЂSummaryЃЈеЊвЊЃЉЁЃ
CounterЃКжЛдіВЛМѕЕФМЦЪ§Цї
CounterЪЧвЛИіМђЕЅЕЋгаЧПДѓЕФЙЄОпЃЌР§ШчЮвУЧПЩвддкгІгУГЬађжаМЧТМФГаЉЪТМўЗЂЩњЕФДЮЪ§ЃЌЭЈЙ§вдЪБађЕФаЮЪНДцДЂетаЉЪ§ОнЃЌЮвУЧПЩвдЧсЫЩЕФСЫНтИУЪТМўВњЩњЫйТЪЕФБфЛЏЁЃPromQLФкжУЕФОлКЯВйзїКЭКЏЪ§ПЩвдгУЛЇЖдетаЉЪ§ОнНјааНјвЛВНЕФЗжЮіЃК
Р§ШчЃЌЭЈЙ§rate()КЏЪ§ЛёШЁHTTPЧыЧѓСПЕФдіГЄТЪЃК
rate( http_requests_total[5m])
GaugeЃКПЩдіПЩМѕЕФвЧБэХЬ
гыCounterВЛЭЌЃЌGaugeРраЭЕФжИБъВржигкЗДгІЯЕЭГЕФЕБЧАзДЬЌЁЃвђДЫетРржИБъЕФбљБОЪ§ОнПЩдіПЩМѕЁЃГЃМћжИБъШчЃКnode_memory_MemFreeЃЈжїЛњЕБЧАПеЯаЕФФкШнДѓаЁЃЉЁЂnode_memory_MemAvailableЃЈПЩгУФкДцДѓаЁЃЉЖМЪЧGaugeРраЭЕФМрПижИБъЁЃ
ЭЈЙ§GaugeжИБъЃЌгУЛЇПЩвджБНгВщПДЯЕЭГЕФЕБЧАзДЬЌЃК
ЖдгкGaugeРраЭЕФМрПижИБъЃЌЭЈЙ§PromQLФкжУКЏЪ§delta()ПЩвдЛёШЁбљБОдквЛЖЮЪБМфЗЕЛиФкЕФБфЛЏЧщПіЁЃР§ШчЃЌМЦЫуCPUЮТЖШдкСНИіаЁЪБФкЕФВювьЃК
| delta(cpu_temp_celsius{host=
"zeus"}[2h]) |
ЛЙПЩвдЪЙгУderiv()МЦЫубљБОЕФЯпадЛиЙщФЃаЭЃЌЩѕжСЪЧжБНгЪЙгУpredict_linear()ЖдЪ§ОнЕФБфЛЏЧїЪЦНјаадЄВтЁЃР§ШчЃЌдЄВтЯЕЭГДХХЬПеМфдк4ИіаЁЪБжЎКѓЕФЪЃгрЧщПіЃК
| predict_linear(node_filesystem_free{job=
"node"}[1h], 4 * 3600) |
ЪЙгУHistogramКЭSummaryЗжЮіЪ§ОнЗжВМЧщПі
дкДѓЖрЪ§ЧщПіЯТШЫУЧЖМЧуЯђгкЪЙгУФГаЉСПЛЏжИБъЕФЦНОљжЕЃЌР§ШчCPUЕФЦНОљЪЙгУТЪЁЂвГУцЕФЦНОљЯьгІЪБМфЁЃетжжЗНЪНЕФЮЪЬтКмУїЯдЃЌвдЯЕЭГAPIЕїгУЕФЦНОљЯьгІЪБМфЮЊР§ЃКШчЙћДѓЖрЪ§APIЧыЧѓЖМЮЌГждк100msЕФЯьгІЪБМфЗЖЮЇФкЃЌЖјИіБ№ЧыЧѓЕФЯьгІЪБМфашвЊ5sЃЌФЧУДОЭЛсЕМжТФГаЉWEBвГУцЕФЯьгІЪБМфТфЕНжаЮЛЪ§ЕФЧщПіЃЌЖјетжжЯжЯѓБЛГЦЮЊГЄЮВЮЪЬтЁЃ
ЮЊСЫЧјЗжЪЧЦНОљЕФТ§ЛЙЪЧГЄЮВЕФТ§ЃЌзюМђЕЅЕФЗНЪНОЭЪЧАДееЧыЧѓбгГйЕФЗЖЮЇНјааЗжзщЁЃР§ШчЃЌЭГМЦбгГйдк010msжЎМфЕФЧыЧѓЪ§гаЖрЩйЖј1020msжЎМфЕФЧыЧѓЪ§гжгаЖрЩйЁЃЭЈЙ§етжжЗНЪНПЩвдПьЫйЗжЮіЯЕЭГТ§ЕФдвђЁЃHistogramКЭSummaryЖМЪЧЮЊСЫФмЙЛНтОіетбљЮЪЬтЕФДцдкЃЌЭЈЙ§HistogramКЭSummaryРраЭЕФМрПижИБъЃЌЮвУЧПЩвдПьЫйСЫНтМрПибљБОЕФЗжВМЧщПіЁЃ
Р§ШчЃЌжИБъprometheus_tsdb_wal_fsync_duration_secondsЕФжИБъРраЭЮЊSummaryЁЃ
ЫќМЧТМСЫPrometheus Serverжаwal_fsyncДІРэЕФДІРэЪБМфЃЌЭЈЙ§ЗУЮЪPrometheus
ServerЕФ/metricsЕижЗЃЌПЩвдЛёШЁЕНвдЯТМрПибљБОЪ§ОнЃК
prometheus_tsdb_wal_fsync_duration_seconds{quantile=
"0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile=
"0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile=
"0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum2.8887161
27000002
prometheus_tsdb_wal_fsync_duration_seconds_count216 |
ДгЩЯУцЕФбљБОжаПЩвдЕУжЊЕБЧАPromtheus ServerНјааwal_fsyncВйзїЕФзмДЮЪ§ЮЊ216ДЮЃЌКФЪБ2.888716127000002sЁЃЦфжажаЮЛЪ§ЃЈquantile=0.5ЃЉЕФКФЪБЮЊ0.012352463ЃЌ9ЗжЮЛЪ§ЃЈquantile=0.9ЃЉЕФКФЪБЮЊ0.014458005sЁЃ
PrometheusЖдгкЪ§ОнЕФДцДЂЗНЪНОЭвтЮЖзХЃЌВЛЭЌЕФБъЧЉОЭДњБэзХВЛЭЌЕФЬиеїЮЌЖШЁЃгУЛЇПЩвдЭЈЙ§етаЉЬиеїЮЌЖШЖдВщбЏЃЌЙ§ТЫКЭОлКЯбљБОЪ§ОнЁЃ
Р§ШчЃЌЭЈЙ§node_load1ЃЌВщбЏГіЕБЧАЪБМфађСаЪ§ОнПтжаЫљгаУћЮЊnode_load1ЕФЪБМфађСаЃК

ШчЙћевЕНТњзуФГаЉЬиеїЮЌЖШЕФЪБМфађСаЃЌдђПЩвдЪЙгУБъЧЉНјааЙ§ТЫЃК

ЭЈЙ§вдБъЧЉЮЊКЫаФЕФЬиеїЮЌЖШЃЌгУЛЇПЩвдЖдЪБМфађСаНјаагааЇЕФВщбЏКЭЙ§ТЫЃЌЕБШЛШчЙћНіНіЪЧетбљЃЌЯдШЛЛЙВЛЙЛЧПДѓЃЌPrometheusЬсЙЉЕФЗсИЛЕФОлКЯВйзївдМАФкжУКЏЪ§ЃЌПЩвдЭЈЙ§PromQLЧсЫЩЛиД№вдЯТЮЪЬтЃК
ЕБЧАЯЕЭГЕФCPUЪЙгУТЪЃП
| avg(irate(node_cpu{mode!=
"idle"}[2m])) without (cpu, mode) |

CPUеМгУТЪЧА5ЮЛЕФжїЛњгаФФаЉЃП
| topk(5, avg(irate(node_cpu{mode!=
"idle"}[2m])) without (cpu, mode)) |

дЄВтдк4аЁЪБКђКѓЃЌДХХЬПеМфеМгУДѓжТЛсЪЧЪВУДЧщПіЃП
| predict_linear(node_filesystem_free{job=
"node"}[2h], 4 * 3600) |
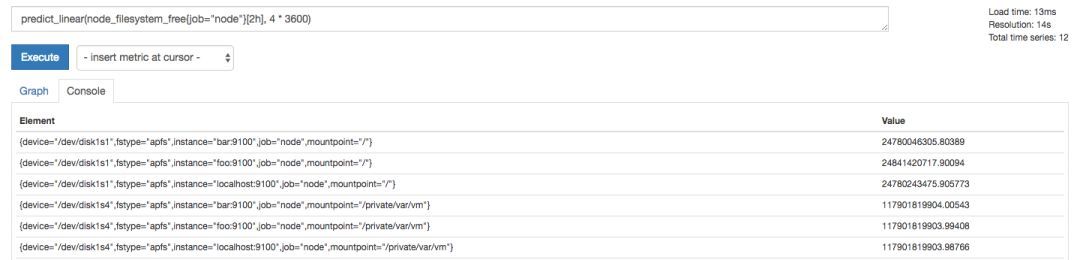
Цфжаavg()ЃЌtopk()ЕШЖМЪЧPromQLФкжУЕФОлКЯВйзїЃЌirate()ЃЌpredict_linear()ЪЧPromQLФкжУЕФКЏЪ§ЃЌirate()КЏЪ§ПЩвдМЦЫувЛЖЮЪБМфЗЕЛиФкЪБМфађСажаЫљгабљБОЕФЕЅЮЛЪБМфБфЛЏТЪЁЃpredict_linearКЏЪ§ФкВПдђЭЈЙ§МђЕЅЯпадЛиЙщЕФЗНЪНдЄВтЪ§ОнЕФБфЛЏЧїЪЦЁЃ
вдGrafanaЮЊР§ЃЌдкGrafanaжаПЩвдЭЈЙ§НЋPromtheusзїЮЊЪ§ОндДЬэМгЕНЯЕЭГжаЃЌКѓдйЪЙгУPromQLНјааЪ§ОнПЩЪгЛЏЁЃдкGrafana
v5.1жаЬсЙЉСЫЖдPromtheus 4жжМрПиРраЭЕФЭъећжЇГжЃЌПЩвдЭЈЙ§Graph PanelЃЌSinglestat
PanelЃЌHeatmap PanelЖдМрПижИБъЪ§ОнНјааПЩЪгЛЏЁЃ
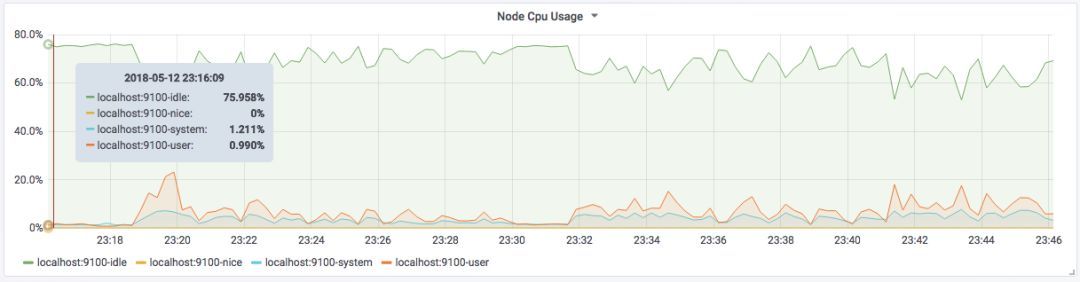
ЪЙгУGraph PanelПЩЪгЛЏжїЛњCPUЪЙгУТЪБфЛЏЧщПіЃК
ЪЙгУSigle PanelЯдЪОЕБЧАзДЬЌЃК
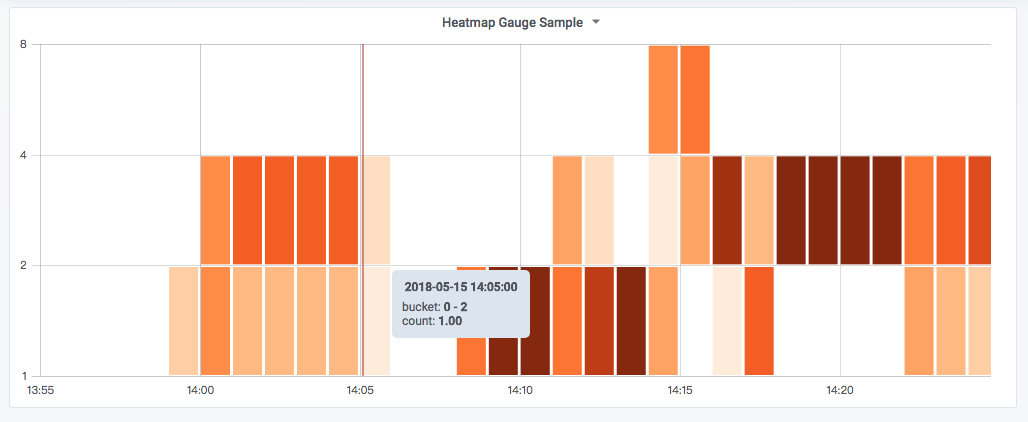
ЪЙгУHeatmap PanelЯдЪОЪ§ОнЗжВМЧщПіЃК
PrometheusЭЈЙ§PromQLЬсЙЉСЫЧПДѓЕФЪ§ОнВщбЏКЭДІРэФмСІЁЃЖдгкЭтВПЯЕЭГЖјбдПЩвдЭЈЙ§PrometheusЬсЙЉЕФAPIНгПкЃЌЪЙгУPromQLВщбЏЯрЙиЕФбљБОЪ§ОнЃЌДгЖјЪЕЯжШчЪ§ОнПЩЪгЛЏЕШздЖЈвхашЧѓЃЌPromQLЪЧPrometheusЖдФкЃЌЖдЭтЙІФмЪЕЯжЕФжївЊНгПкЁЃ
ИцОЏДІРэжааФЃКAlertmanager
ИцОЏдкPrometheusЕФМмЙЙжаБЛЛЎЗжГЩСНИіЖРСЂЕФВПЗжЃКИцОЏВњЩњКЭИцОЏДІРэЁЃ
дкPrometheusПЩвдЭЈЙ§ЮФМўЕФаЮЪНЖЈвхИцОЏЙцдђЃЌPromthuesЛсжмЦкадЕФМЦЫуИцОЏЙцдђжаЕФPromQLБэДяЪНХаЖЯЪЧЗёДяЕНИцОЏДЅЗЂЬѕМўЃЌШчЙћТњзуЃЌдђдкPrometheusФкВПВњЩњвЛЬѕИцОЏЁЃ
ИцОЏЙцдђЮФМўЃЌЭЈЙ§YAMLИёЪННјааЖЈвхЃК
yaml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!=
'idle'}[ 5m]))) by(instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }}
CPU usgae high"
deion: "{{ $labels.instance }} CPU usage
above 85% (current value: {{ $value}})" |
етРяЖЈвхЕБжїЛњЕФCPUЪЙгУТЪДѓгк85%ЪБЃЌВњЩњИцОЏЁЃИцОЏзДЬЌНЋдкPromethuesЕФUIжаНјааеЙЪОЁЃ
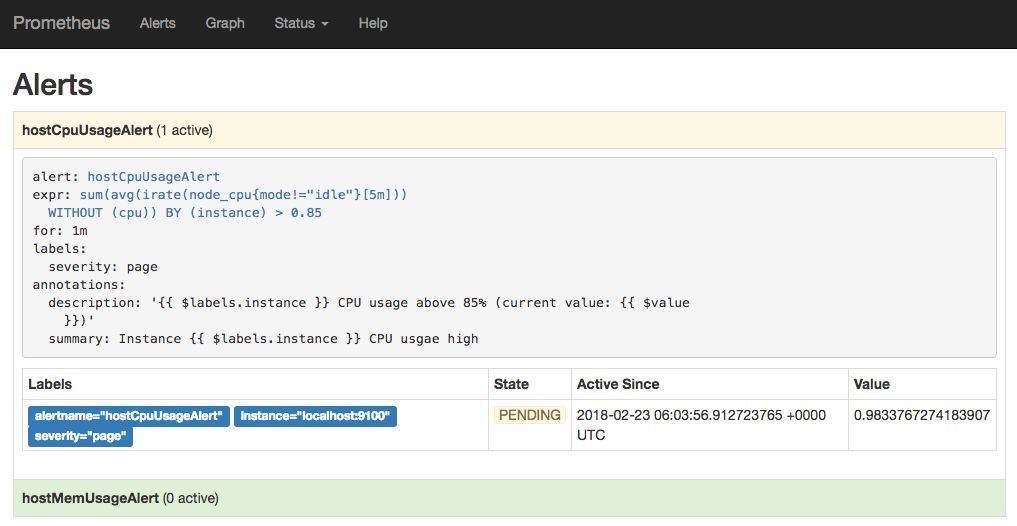
ЕНФПЧАЮЊжЙPromethuesЭЈЙ§жмЦкадЕФаЃбщИцОЏЙцдђЮФМўЃЌДгЖјдкФкВПДІЗЃИцОЏЁЃ
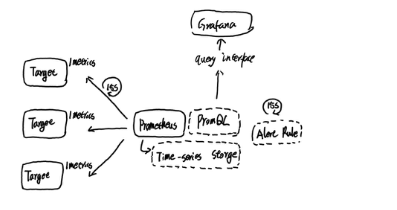
ЖјКѓајЕФИцОЏДІРэдђгЩAlertmanagerНјааЭГвЛДІРэЁЃAlertmanagerзїЮЊвЛИіЖРСЂЕФзщМўЃЌИКд№НгЪеВЂДІРэРДздPrometheus
ServerЃЈвВПЩвдЪЧЦфЫќЕФПЭЛЇЖЫГЬађЃЉЕФИцОЏаХЯЂЁЃAlertmanagerПЩвдЖдетаЉИцОЏаХЯЂНјааНјвЛВНЕФДІРэЃЌБШШчЯћГ§жиИДЕФИцОЏаХЯЂЃЌЖдИцОЏаХЯЂНјааЗжзщВЂЧвТЗгЩЕНе§ШЗЕФНгЪмЗНЃЌAlertmanagerФкжУСЫЖдгЪМўЃЌSlackЕШЭЈжЊЗНЪНЕФжЇГжЃЌЭЌЪБЛЙжЇГжгыWebhookЕФЭЈжЊМЏГЩЃЌвджЇГжИќЖрЕФПЩФмадЃЌР§ШчПЩвдЭЈЙ§WebhookгыЖЄЖЄЛђепЦѓвЕЮЂаХНјааМЏГЩЁЃЭЌЪБAlertManagerЛЙЬсЙЉСЫОВФЌКЭИцОЏвжжЦЛњжЦРДЖдИцОЏЭЈжЊааЮЊНјаагХЛЏЁЃ
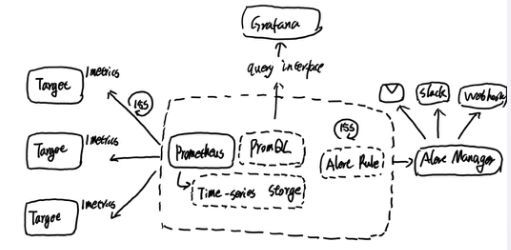
PrometheusзїЮЊЪЧвЛИіПЊдДЕФЭъећМрПиНтОіЗНАИЃЌЦфЖдДЋЭГМрПиЯЕЭГЕФcheck-alertФЃаЭНјааСЫГЙЕзЕФЕпИВЃЌаЮГЩСЫЛљгкжабыЛЏЕФЙцдђМЦЫуЁЂЭГвЛЗжЮіКЭИцОЏЕФаТФЃаЭЁЃ
ЪЙгУBlackboxНјааКкКаМрПи
дкЧАУцЕФВПЗжжаЃЌЮвУЧжївЊНщЩмСЫNode ExporterЕФЪЙгУЃЌЖдгкетРрExporterЖјбдЃЌЫќУЧжївЊМрПиЗўЮёЛђепЛљДЁЩшЪЉЕФФкВПЪЙгУзДЬЌЃЌМДАзКаМрПиЁЃЭЈЙ§ЖдМрПижИБъЕФЙлВьФмЙЛдЄХаПЩФмГіЯжЕФЮЪЬтЃЌДгЖјЖдЧБдкЕФВЛШЗЖЈвђЫиНјаагХЛЏЁЃ
ЖјДгЭъећЕФМрПиТпМЕФНЧЖШЃЌГ§СЫДѓСПЕФгІгУАзКаМрПивдЭтЃЌЛЙгІИУЬэМгЪЪЕБЕФКкКаМрПиЁЃКкКаМрПиМДвдгУЛЇЕФЩэЗнВтЪдЗўЮёЕФЭтВППЩМћадЃЌГЃМћЕФКкКаМрПиАќРЈHTTPЬНеыЁЂTCPЬНеыЕШгУгкМьВтеОЕуЛђепЗўЮёЕФПЩЗУЮЪадЃЌвдМАЗУЮЪаЇТЪЕШЁЃ
КкКаМрПиЯрНЯгкАзКаМрПизюДѓЕФВЛЭЌдкгкКкКаМрПиЪЧвдЙЪеЯЮЊЕМЯђЕБЙЪеЯЗЂЩњЪБЃЌКкКаМрПиФмПьЫйЗЂЯжЙЪеЯЃЌЖјАзКаМрПидђВржигкжїЖЏЗЂЯжЛђепдЄВтЧБдкЕФЮЪЬтЁЃвЛИіЭъЩЦЕФМрПиФПБъЪЧвЊФмЙЛДгАзКаЕФНЧЖШЗЂЯжЧБдкЮЪЬтЃЌФмЙЛдкКкКаЕФНЧЖШПьЫйЗЂЯжвбОЗЂЩњЕФЮЪЬтЁЃ
етРяРрБШУєНнжажјУћЕФУєНнВтЪдН№зжЫўЃЌЖдгкЭъећЕФМрПиЖјбдЃЌЮвУЧашвЊДѓСПЕФАзКаМрПиЃЌгУгкМрПиЗўЮёЕФФкВПдЫаазДЬЌЃЌДгЖјПЩвджЇГжгааЇЕФЙЪеЯЗжЮіЁЃ
ЭЌЪБвВашвЊВПЗжЕФКкКаМрПиЃЌгУгкМьВтжївЊЗўЮёЪЧЗёЗЂЩњЙЪеЯЁЃ
Blackbox ExporterЪЧPrometheusЩчЧјЬсЙЉЕФЙйЗНКкКаМрПиНтОіЗНАИЃЌЦфдЪаэгУЛЇЭЈЙ§ЃКHTTPЁЂHTTPSЁЂDNSЁЂTCPвдМАICMPЕФЗНЪНЖдЭјТчНјааЬНВтЁЃгУЛЇПЩвджБНгЪЙгУgo
getУќСюЛёШЁBlackbox ExporterдДТыВЂЩњГЩБОЕиПЩжДааЮФМўЁЃ
Blackbox ExporterдЫааЪБЃЌашвЊжИЖЈЬНеыХфжУЮФМўЃЌР§Шчblackbox.ymlЃК
modules:
http_2xx:
prober: http
http:
method: GET
http_post_2xx:
prober: http
http:
method: POST |
ЦєЖЏblackbox_exporterМДПЩЦєЖЏвЛИіЬНеыЗўЮёЃК
| blackbox_exporter
--config.file= /etc/prometheus/blackbox.yml |
ЦєЖЏКѓЃЌЭЈЙ§ЗУЮЪhttp://127.0.0.1:9115/probe?module=http
_ 2xx&target = baidu .com ПЩвдЛёЕУ blackbox Жд baidu.comеОЕуЬНВтЕФНсЙћЁЃ
probe_http_duration_seconds{phase=
"connect"} 0.055551141
probe_http_duration_seconds{phase= "processing"}
0.049736019
probe_http_duration_seconds{phase= "resolve"}
0.011633673
probe_http_duration_seconds{phase= "tls"}
0
probe_http_duration_seconds{phase= "transfer"}
3.8919e-05
# HELP probe_http_redirects The number of redirects
# TYPE probe_http_redirects gauge
probe_http_redirects0
# HELP probe_http_ssl Indicates if SSL was used
for the
final redirect
# TYPE probe_http_ssl gauge
probe_http_ssl0
# HELP probe_http_status_code Response HTTP status
code
# TYPE probe_http_status_code gauge
probe_http_status_code200
# HELP probe_http_version Returns the version
of HTTP of the probe response
# TYPE probe_http_version gauge
probe_http_version1.1
# HELP probe_ip_protocol Specifies whether probe
ip protocol
is IP4 or IP6
# TYPE probe_ip_protocol gauge
probe_ip_protocol4
# HELP probe_success Displays whether or not
the probe was a success
# TYPE probe_success gauge
probe_success1 |
дкPrometheusжаПЩвдЭЈЙ§ЬэМгЯьгІЕФМрПиВЩМЏШЮЮёЃЌМДПЩЛёШЁЖдЯргІеОЕуЕФЬНВтНсЙЙбљБОЪ§ОнЃК
- job_name:
'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http: //prometheus.io # Target to probe with
http.
- https: //prometheus.io # Target to probe with
https.
- http: //example.com:8080 # Target to probe
with
http on port 8080.
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1: 9115 |
ЙцФЃЛЏМрПиНтОіЗНАИ
ЕНФПЧАЮЊжЙЃЌЮвУЧСЫНтСЫPrometheusЕФЛљДЁМмЙЙКЭжївЊЙЄзїЛњжЦЃЌШчЯТЫљЪОЃК
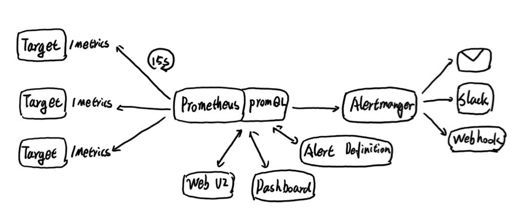
PrometheusжмЦкадЕФДгTargetжаЛёШЁМрПиЪ§ОнВЂБЃДцЕНБОЕиЕФtime-seriesжаЃЌВЂЧвЭЈЙ§PromQLЖдЭтБЉТЖЪ§ОнВщбЏНгПкЁЃ
ФкВПжмЦкадЕФМьВщИцОЏЙцдђЮФМўЃЌВњЩњИцОЏВЂгаAlertmanagerЖдИцОЏНјааКѓајДІРэЁЃ
ФЧУДЮЪЬтРДСЫЃЌетРяPrometheusЪЧЕЅЕуЃЌAlertmanagerвВЪЧЕЅЕуЁЃ
етбљЕФНсЙЙФмЗёжЇГжДѓЙцФЃЕФМрПиСПЃП
ЖдгкPrometheusЖјбдЃЌвЊЯыЭъШЋРэНтЦфИпПЩгУВПЪ№ФЃЪНЃЌЪзЯШЮвУЧашвЊРэНтPrometheusЕФЪ§ОнДцДЂЛњжЦЁЃ
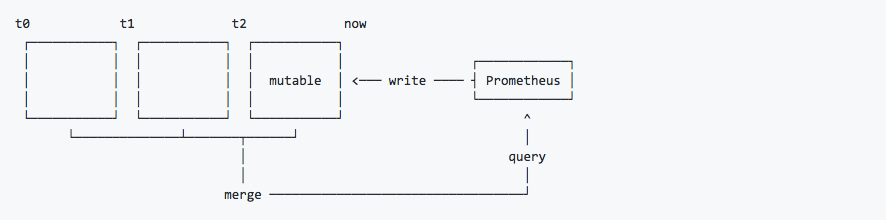
ШчЩЯЫљЪОЃЌPrometheus 2.xВЩгУздЖЈвхЕФДцДЂИёЪННЋбљБОЪ§ОнБЃДцдкБОЕиДХХЬЕБжаЁЃАДееСНИіаЁЪБЮЊвЛИіЪБМфДАПкЃЌНЋСНаЁЪБФкВњЩњЕФЪ§ОнДцДЂдквЛИіПщЃЈBlockЃЉжаЃЌУПвЛИіПщжаАќКЌИУЪБМфДАПкФкЕФЫљгабљБОЪ§ОнЃЈchunksЃЉЃЌдЊЪ§ОнЮФМўЃЈmeta.jsonЃЉвдМАЫїв§ЮФМўЃЈindexЃЉЁЃ
ЕБЧАЪБМфДАПкФке§дкЪеМЏЕФбљБОЪ§ОнЃЌPrometheusдђЛсжБНгНЋЪ§ОнБЃДцдкФкДцЕБжаЁЃЮЊСЫШЗБЃДЫЦкМфШчЙћPrometheusЗЂЩњБРРЃЛђепжиЦєЪБФмЙЛЛжИДЪ§ОнЃЌPrometheusЦєЖЏЪБЛсДгаДШыШежОЃЈWALЃЉНјаажиВЅЃЌДгЖјЛжИДЪ§ОнЁЃДЫЦкМфШчЙћЭЈЙ§APIЩОГ§ЪБМфађСаЃЌЩОГ§МЧТМвВЛсБЃДцдкЕЅЖРЕФТпМЮФМўЕБжаЃЈtombstoneЃЉЁЃ

ЭЈЙ§ЪБМфДАПкЕФаЮЪНБЃДцЫљгаЕФбљБОЪ§ОнЃЌПЩвдУїЯдЬсИпPrometheusЕФВщбЏаЇТЪЃЌЕБВщбЏвЛЖЮЪБМфЗЖЮЇФкЕФЫљгабљБОЪ§ОнЪБЃЌжЛашвЊМђЕЅЕФДгТфдкИУЗЖЮЇФкЕФПщжаВщбЏЪ§ОнМДПЩЁЃЖјЖдгкРњЪЗЪ§ОнЕФЩОГ§ЃЌвВБфЕУЗЧГЃМђЕЅЃЌжЛвЊЩОГ§ЯргІПщЫљдкЕФФПТММДПЩЁЃ
ЖдгкЕЅНкЕуЕФPrometheusЖјбдЃЌетжжЛљгкБОЕиЮФМўЯЕЭГЕФДцДЂЗНЪНФмЙЛШУЦфжЇГжЪ§вдАйЭђЕФМрПижИБъЃЌУПУыДІРэЪ§ЪЎЭђЕФЪ§ОнЕуЁЃЮЊСЫБЃГжздЩэЙмРэКЭВПЪ№ЕФМђЕЅадЃЌPrometheusЗХЦњСЫЙмРэHAЕФИДдгЖШЁЃ
вђДЫЪзЯШЃЌЖдгкетжжДцДЂЗНЪНЖјбдЃЌЮвУЧашвЊУїШЗЕФМИЕуЃК
PrometheusБОЩэВЛЪЪгУгкГжОУЛЏДцДЂГЄЦкЕФРњЪЗЪ§ОнЃЌФЌШЯЧщПіЯТPrometheusжЛБЃСє15ЬьЕФЪ§ОнЁЃ
БОЕиДцДЂвВвтЮЖзХPrometheusздЩэЮоЗЈНјаагааЇЕФЕЏадЩьЫѕЁЃ
ЖјЕБМрПиЙцФЃБфЕУОоДѓЕФЪБКђЃЌЖдгкЕЅЬЈPrometheusЖјбдЃЌЦфжївЊЬєеНАќРЈвдЯТМИЕуЃК
ЗўЮёЕФПЩгУадЃЌШчКЮШЗБЃPrometheusВЛЛсЗЂЩњЕЅЕуЙЪеЯЃЛ
МрПиЙцФЃБфДѓЕФвтЮЖзХЃЌPrometheusЕФВЩМЏJobЕФЪ§СПвВЛсБфДѓЃЈаДЃЉВйзїЛсБфЕУЗЧГЃЯћКФзЪдДЃЛ
ЭЌЪБвВвтЮЖзХДѓСПЕФЪ§ОнДцДЂЕФашЧѓЁЃ
МђЕЅHAЃКЗўЮёПЩгУад
гЩгкPrometheusЕФPullЛњжЦЕФЩшМЦЃЌЮЊСЫШЗБЃPrometheusЗўЮёЕФПЩгУадЃЌгУЛЇжЛашвЊВПЪ№ЖрЬзPrometheus
ServerЪЕР§ЃЌВЂЧвВЩМЏЯрЭЌЕФExporterФПБъМДПЩЁЃ
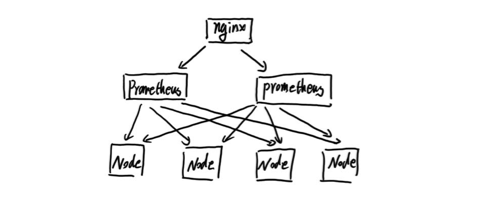
ЛљБОЕФHAФЃЪНжЛФмШЗБЃPrometheusЗўЮёЕФПЩгУадЮЪЬтЃЌЕЋЪЧВЛНтОіPrometheus
ServerжЎМфЕФЪ§ОнвЛжТадЮЪЬтвдМАГжОУЛЏЮЪЬтЃЈЪ§ОнЖЊЪЇКѓЮоЗЈЛжИДЃЉЃЌвВЮоЗЈНјааЖЏЬЌЕФРЉеЙЁЃвђДЫетжжВПЪ№ЗНЪНЪЪКЯМрПиЙцФЃВЛДѓЃЌPromthues
ServerвВВЛЛсЦЕЗБЗЂЩњЧЈвЦЕФЧщПіЃЌВЂЧвжЛашвЊБЃДцЖЬжмЦкМрПиЪ§ОнЕФГЁОАЁЃ
ЛљБОHA + дЖГЬДцДЂ
дкЛљБОHAФЃЪНЕФЛљДЁЩЯЭЈЙ§ЬэМгRemote StorageДцДЂжЇГжЃЌНЋМрПиЪ§ОнБЃДцдкЕкШ§ЗНДцДЂЗўЮёЩЯЁЃ

ЕБPrometheusдкЛёШЁМрПибљБОВЂБЃДцЕНБОЕиЕФЭЌЪБЃЌЛсНЋМрПиЪ§ОнЗЂЫЭЕНRemote
Storage AdaptorЃЌгЩAdaptorЭъГЩЖдЕкШ§ЗНДцДЂЕФИёЪНзЊЛЛвдМАЪ§ОнГжОУЛЏЁЃ
ЕБPrometheusВщбЏЪ§ОнЕФЪБКђЃЌвВЛсДгRemote Storage
AdaptorЛёШЁЪ§ОнЃЌКЯВЂБОЕиЪ§ОнКѓНјааЪ§ОнВщбЏЁЃ
дкНтОіСЫPrometheusЗўЮёПЩгУадЕФЛљДЁЩЯЃЌЭЌЪБШЗБЃСЫЪ§ОнЕФГжОУЛЏЃЌЕБPrometheus
ServerЗЂЩњхДЛњЛђепЪ§ОнЖЊЪЇЕФЧщПіЯТЃЌПЩвдПьЫйЕФЛжИДЁЃ ЭЌЪБPrometheus ServerПЩФмКмКУЕФНјааЧЈвЦЁЃвђДЫЃЌИУЗНАИЪЪгУгкгУЛЇМрПиЙцФЃВЛДѓЃЌЕЋЪЧЯЃЭћФмЙЛНЋМрПиЪ§ОнГжОУЛЏЃЌЭЌЪБФмЙЛШЗБЃPrometheus
ServerЕФПЩЧЈвЦадЕФГЁОАЁЃ
ЛљБОHA + дЖГЬДцДЂ + СЊАюМЏШК
ЕБЕЅЬЈPrometheus ServerЮоЗЈДІРэДѓСПЕФВЩМЏШЮЮёЪБЃЌгУЛЇПЩвдПМТЧЛљгкPrometheusСЊАюМЏШКЕФЗНЪННЋМрПиВЩМЏШЮЮёЛЎЗжЕНВЛЭЌЕФPrometheusЪЕР§ЕБжаМДдкШЮЮёМЖБ№ЙІФмЗжЧјЁЃ
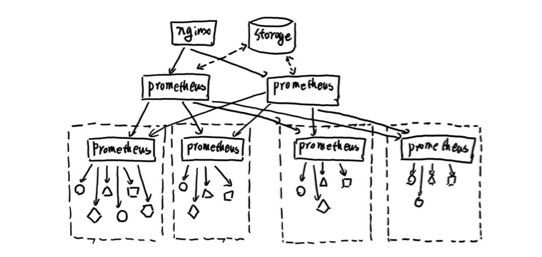
етжжВПЪ№ЗНЪНвЛАуЪЪгУгкСНжжГЁОАЃК
ГЁОАвЛЃКЕЅЪ§ОнжааФ + ДѓСПЕФВЩМЏШЮЮё
етжжГЁОАЯТPrometheusЕФадФмЦПОБжївЊдкгкДѓСПЕФВЩМЏШЮЮёЃЌвђДЫгУЛЇашвЊРћгУPrometheusСЊАюМЏШКЕФЬиадЃЌНЋВЛЭЌРраЭЕФВЩМЏШЮЮёЛЎЗжЕНВЛЭЌЕФPrometheusзгЗўЮёжаЃЌДгЖјЪЕЯжЙІФмЗжЧјЁЃР§ШчвЛИіPrometheus
ServerИКд№ВЩМЏЛљДЁЩшЪЉЯрЙиЕФМрПижИБъЃЌСэЭтвЛИіPrometheus ServerИКд№ВЩМЏгІгУМрПижИБъЁЃдйгаЩЯВуPrometheus
ServerЪЕЯжЖдЪ§ОнЕФЛуОлЁЃ
ГЁОАЖўЃКЖрЪ§ОнжааФ
етжжФЃЪНвВЪЪКЯгыЖрЪ§ОнжааФЕФЧщПіЃЌЕБPrometheus ServerЮоЗЈжБНггыЪ§ОнжааФжаЕФExporterНјааЭЈбЖЪБЃЌдкУПвЛИіЪ§ОнжаВПЪ№вЛИіЕЅЖРЕФPrometheus
ServerИКд№ЕБЧАЪ§ОнжааФЕФВЩМЏШЮЮёЪЧвЛИіВЛДэЕФЗНЪНЁЃетбљПЩвдБмУтгУЛЇНјааДѓСПЕФЭјТчХфжУЃЌжЛашвЊШЗБЃжїPrometheus
ServerЪЕР§ФмЙЛгыЕБЧАЪ§ОнжааФЕФPrometheus ServerЭЈбЖМДПЩЁЃ жааФPrometheus
ServerИКд№ЪЕЯжЖдЖрЪ§ОнжааФЪ§ОнЕФОлКЯЁЃ
ИпПЩгУЗНАИбЁдё
ЩЯУцЕФВПЗжЃЌИљОнВЛЭЌЕФГЁОАбнЪОСЫ3жжВЛЭЌЕФИпПЩгУВПЪ№ЗНАИЁЃЕБШЛЖдгкPrometheusВПЪ№ЗНАИашвЊгУЛЇИљОнМрПиЙцФЃвдМАздЩэЕФашЧѓНјааЖЏЬЌЕїећЃЌЯТБэеЙЪОСЫPrometheusКЭИпПЩгУгаЙи3ИібЁЯюИїздНтОіЕФЮЪЬтЃЌгУЛЇПЩвдИљОнздМКЕФашЧѓСщЛюбЁдёЁЃ

ЖдгкAlertmanagerЖјбдЃЌAlertmanagerМЏШКжЎМфЪЙгУGossipавщЯрЛЅДЋЕнзДЬЌЃЌвђДЫЖдгкPrometheusЖјбдЃЌжЛашвЊЙиСЊЖрИіAlertmanagerЪЕР§МДПЩЃЌЙигкAlertmanagerМЏШКЕФЯъЯИЯъЯИПЩвдВЮПМЃКhttps://github.com
/ yunlzheng / prometheus -book/blob/master/ha/alertmanager-high-availability.md
ЗўЮёЗЂЯжгыдЦдЩњЃКвдKubernetesЮЊР§
ЖдгкжюШчKubernetesетРрШнЦїЛђепдЦЛЗОГЃЌЖдгкPrometheusЖјбдЃЌашвЊНтОіЕФвЛИіживЊЮЪЬтОЭЪЧШчКЮЖЏЬЌЕФЗЂЯжВПЪ№дкKubernetesЛЗОГЯТЕФашвЊМрПиЕФЫљгаФПБъЁЃ

ЖдгкKubernetesЖјбдЃЌШчЩЯЭМЫљЪОЃЌЮвУЧПЩвдАбЕБжаЫљгаЕФзЪдДЗжЮЊМИРрЃК
1.ЛљДЁЩшЪЉВуЃЈNodeЃЉЃКМЏШКНкЕуЃЌЮЊећИіМЏШККЭгІгУЬсЙЉдЫааЪБзЪдД
2.ШнЦїЛљДЁЩшЪЉЃЈContainerЃЉЃКЮЊгІгУЬсЙЉдЫааЪБЛЗОГ
3.гУЛЇгІгУЃЈPodЃЉЃКPodжаЛсАќКЌвЛзщШнЦїЃЌЫќУЧвЛЦ№ЙЄзїЃЌВЂЧвЖдЭтЬсЙЉвЛИіЃЈЛђепвЛзщЃЉЙІФм
4.ФкВПЗўЮёИКдиОљКтЃЈServiceЃЉЃКдкМЏШКФкЃЌЭЈЙ§ServiceдкМЏШКБЉТЖгІгУЙІФмЃЌМЏШКФкгІгУКЭгІгУжЎМфЗУЮЪЪБЬсЙЉФкВПЕФИКдиОљКт
5.ЭтВПЗУЮЪШыПкЃЈIngressЃЉЃКЭЈЙ§IngressЬсЙЉМЏШКЭтЕФЗУЮЪШыПкЃЌДгЖјПЩвдЪЙЭтВППЭЛЇЖЫФмЙЛЗУЮЪЕНВПЪ№дкKubernetesМЏШКФкЕФЗўЮё
вђДЫЃЌдкВЛПМТЧKubernetesздЩэзщМўЕФЧщПіЯТЃЌШчЙћвЊЙЙНЈвЛИіЭъећЕФМрПиЬхЯЕЃЌЮвУЧгІИУПМТЧЃЌвдЯТ5ИіЗНУцЃК
МЏШКНкЕузДЬЌМрПиЃКДгМЏШКжаИїНкЕуЕФkubeletЗўЮёЛёШЁНкЕуЕФЛљБОдЫаазДЬЌЃЛ
МЏШКНкЕузЪдДгУСПМрПиЃКЭЈЙ§DaemonsetЕФаЮЪНдкМЏШКжаИїИіНкЕуВПЪ№Node
ExporterВЩМЏНкЕуЕФзЪдДЪЙгУЧщПіЃЛ
НкЕужадЫааЕФШнЦїМрПиЃКЭЈЙ§ИїИіНкЕужаkubeletФкжУЕФcAdvisorжаЛёШЁИіНкЕужаЫљгаШнЦїЕФдЫаазДЬЌКЭзЪдДЪЙгУЧщПіЃЛ
ДгКкКаМрПиЕФНЧЖШдкМЏШКжаВПЪ№Blackbox ExporterЬНеыЗўЮёЃЌМьВтServiceКЭIngressЕФПЩгУадЃЛ
ШчЙћдкМЏШКжаВПЪ№ЕФгІгУГЬађБОЩэФкжУСЫЖдPrometheusЕФМрПижЇГжЃЌФЧУДЮвУЧЛЙгІИУевЕНЯргІЕФPodЪЕР§ЃЌВЂДгИУPodЪЕР§жаЛёШЁЦфФкВПдЫаазДЬЌЕФМрПижИБъЁЃ
ЖјЖдгкPrometheusетвЛРрЛљгкPullФЃЪНЕФМрПиЯЕЭГЃЌЯдШЛвВЮоЗЈМЬајЪЙгУЕФstatic_configsЕФЗНЪНОВЬЌЕФЖЈвхМрПиФПБъЁЃЖјЖдгкPrometheusЖјбдЦфНтОіЗНАИОЭЪЧв§ШывЛИіжаМфЕФДњРэШЫЃЈЗўЮёзЂВсжааФЃЉЃЌетИіДњРэШЫеЦЮезХЕБЧАЫљгаМрПиФПБъЕФЗУЮЪаХЯЂЃЌPrometheusжЛашвЊЯђетИіДњРэШЫбЏЮЪгаФФаЉМрПиФПБъПиМДПЩЃЌ
етжжФЃЪНБЛГЦЮЊЗўЮёЗЂЯжЁЃ
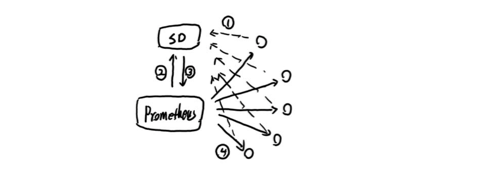
PrometheusЬсЙЉСЫЖдKubernetesЕФЭъећжЇГжЃЌЭЈЙ§гыKubernetesЕФAPIНјааНЛЛЅЃЌPrometheusПЩвдздЖЏЕФЗЂЯжKubernetesжаЫљгаЕФNodeЁЂServiceЁЂPodЁЂEndpointsвдМАIngressзЪдДЕФЯрЙиаХЯЂЁЃ
ЭЈЙ§ЗўЮёЗЂЯжевЕНЫљгаЕФМрПиФПБъКѓЃЌВЂЭЈЙ§PrometheusЕФRelablingЛњжЦЖдетаЉзЪдДНјааЙ§ТЫЃЌmetricsЕижЗЬцЛЛЕШВйзїЃЌДгЖјЪЕЯжЖдИїРрзЪдДЕФШЋздЖЏЛЏМрПиЁЃ
Р§ШчЃЌЭЈЙ§вдЯТСїГЬШЮЮёХфжУЃЌПЩвдздЖЏДгМЏШКНкЕуЕФkubeletЗўЮёжаФкжУЕФcAdvisorжаЛёШЁШнЦїЕФМрПиЪ§ОнЃК
- job_name:
'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: / var/run/secrets/kubernetes.io/
serviceaccount/ca.crtbearer_token_file: / var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes. default.svc: 443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path_
replacement: /api/v1/nodes/${ 1}/proxy/metrics/cadvisor |
гЩЛђепЪЧЭЈЙ§МЏШКжаВПЪ№ЕФblackbox exporterЖдЗўЮёНјааЭјТчЬНВтЃК
- job_name:'kubernetes-services'
metrics_path:/probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role:service
relabel_configs:
- source_labels:[__address_ _]
target_label:__param_target
- target_label:__address_ _
replacement:blackbox-exporter.example. com:9115
- source_labels:[__param_target]
target_label:instance
- action:labelmap
regex:__meta_kubernetes_service_label _(.+)
- source_labels:[__meta_kubernetes_namespace]
target_label:kubernetes_namespace
- source_labels:[__meta_kubernetes_service_name]
target_label:kubernetes_name |
аЁНс
гЩгкЯпЩЯЗжЯэЕФаЮЪНЮоЗЈЪТЮоОоЯИЕФЗжЯэЙигкPrometheusЕФЫљгаФкШнЃЌЕЋЪЧЯЃЭћДѓМвФмЙЛЭЈЙ§НёЬьЕФЗжЯэФмЙЛЖдPrometheusгаИќКУЕФРэНтЁЃ
етРяЮввВНЋЙигкPrometheusЕФЯрЙиЪЕМљЭЈЙ§ЕчзгЪщЕФаЮЪННјааСЫећРэЃКhttps://github.com/yunlzheng/prometheus-bookЃЌЯЃЭћФмЖдДѓМвбЇЯАКЭЪЙгУPrometheusЦ№ЕНвЛЖЈЕФАяжњзїгУЃЌЕБШЛЙигкPrometheusЕФЯрЙиЮЪЬтЃЌвВПЩвдЭЈЙ§Github
IssueРДЯрЛЅНЛСїЁЃ
Q&A
QЃКPrometheusЕФЪ§ОнФмЗёздЖЏЭЌВНЕНInfluxDBжаЃП
AЃКПЩвдЃЌЭЈЙ§remote_writeПЩвдЪЕЯжЃЌПЩвдВЮПМЃКPrometheusЭЈЙ§НЋВЩМЏЕНЕФЪ§ОнЗЂЫЭЕНAdaptorЃЌдйгЩAdaptorЭъГЩЖдЪ§ОнИёЪНЕФзЊЛЛДцДЂЕНInfluxDBМДПЩЁЃ
QЃКPrometheusвЛИіServerзюЖрФмдЫааЖрЩйИіJobЃП
AЃКетИіУЛгазіОпЬхЕФЪдбщЃЌВЛЙ§ашвЊзЂвтЕФЪЧJobШЮЮёСПЃЈаДВйзїЃЉЃЌЛсжБНггАЯьPrometheusЕФадФмЃЌзюКУЪЙгУfederationЪЕЯжЖСаДЗжРыЁЃ
QЃКЧыЮЪИцОЏгЩGrafanaЪЕЯжБШНЯКУЃЌЛЙЪЧAlertmanagerЃЌГЃгУЕФmetricСаБэгаУЛгаЛузмЕФЧхЕЅСДНгЗжЯэЯТЃЌРњЪЗЪ§ОнФЌШЯБЃСєЪБМфШчКЮЩшжУЃП
AЃКGrafanaздЩэЪЧжЇГжЖрЪ§ОндДЃЌPromethuesжЛЪЧЦфжажЎвЛЁЃ
ШчЙћжЛЪЙгУPromthuesФЧгУAlertmanagerОЭКУСЫЃЌРяУцЪЕЯжСЫКмЖрИцОЏШЅжиКЭОВФЌЕФЛњжЦЃЌВЛШЛЪеЕНгЪМўКфеЈвВВЛЬЋКУЁЃ
ШчЙћашвЊЛљгкGrafanaжагУЕНЕФЖржжЪ§ОндДзіИцОЏЕФЛАЃЌФЧОЭгУGrafanaЁЃ
QЃКPrometheusМрПиЪ§ОнЭЦМіДцФФРяЪЧInfluxDBЃЌЛђепESРяУцЃЌInfluxDBЕЅНкЕуУтЗбЃЌЖрНкЕФЫЦКѕЪеЗбЕФЃП
AЃКФЌШЯЧщПіЯТЃЌжБНгЪЧБЃДцЕНБОЕиЕФЁЃШчЙћвЊАбЪ§ОнГжОУЛЏЕНЕкШ§ЗНДцДЂжЛвЊЪЕЯжremote_writeНгПкОЭПЩвдЁЃРэТлЩЯПЩвдЖдНгШЮвтЕФЕкШ§ЗНДцДЂЁЃ
InfluxDBжЛЪЧЙйЗНЬсЙЉЕФвЛИіЪОР§жЎвЛЁЃ
QЃКЧыЮЪЁАдйгаЩЯВуPrometheus ServerЪЕЯжЖдЪ§ОнЕФЛуОлЁЃЁБЪЧБэЪОИУPrometheusЛсЖдЯТВуPrometheusНјааЪ§ОнЪеМЏТ№ЃПЪЙгУЪВУДНгПкЃП
AЃКЧыВЮПМPrometheus FedreationЃЌетРяжївЊЪЧжИгЩвЛВПЗжPrometheusЪЕР§ИКд№ВЩМЏШЮЮёЃЌШЛКѓGlobalЕФPromethe
usЛуМЏЪ§ОнЃЌВЂЖдЭтЬсЙЉВщбЏНгПкЁЃ МѕЩйGlobal PrometheusЕФбЙСІЁЃ
QЃКСНЬЈPrometheus server ПЩЗёгУKeepalivedЃП
AЃКжБНгИКдиОљКтОЭПЩвдСЫЃЌЖдгкPrometheusЖјбдЃЌЪЕР§жЎМфБОЩэВЂУЛгаШЮКЮЕФжБНгЙиЯЕЁЃ
QЃКгУPrometheusМрПивЕЮёЕФAPIНгПкЃЌгаЪВУДКУЕФЗНЗЈТ№ЃЌФмМрПиЪ§ОнПтЕФТ§ВщбЏТ№ЃП
|









