| БрМЭЦМі: |
| БОЮФРДдДИпаЇдЫЮЌ
ЃЌдкБОЮФжаНщЩмСЫ58жЧФмМрПиЯЕЭГНЈЩшОРњвдМАМрПиЯЕЭГЕФКЫаФЙІФмЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
МрПиЯЕЭГИХЪі
58жЧФмМрПиЯЕЭГЕФФПБъЪЧЮЊМЏЭХЦьЯТИївЕЮёЯпЬсЙЉСщЛювзгУЕФМрПиВњЦЗЃЌЭЈЙ§ИВИЧЭјТчВуЁЂЗўЮёЦїВуЁЂЯЕЭГВуЁЂгІгУВуЁЂвЕЮёВуЕФСЂЬхЛЏМрПиЬхЯЕЃЌЪЕЯж7*24ЮоЫРНЧЕФЪЕЪБМрПиЃЌБЃеЯЙЋЫОИїВњЦЗЕФЮШЖЈдЫааЁЃ
Г§ДЋЭГМрПиВњЦЗжЇГжЕФЪ§ОнВЩМЏЁЂДцДЂЁЂИцОЏЁЂеЙЪОЕШЙІФмЭтЃЌ58жЧФмМрПиЯЕЭГЛЙжЇГжСЫЙиМќжИБъЕФжЧФмдЄВтКЭвьГЃМьВтЁЂИцОЏКЯВЂЁЂИцОЏЙиСЊЗжЮіЁЂЙЪеЯздгњЁЂЙЪеЯдЄОЏЁЂздЖЏЛЏЬэМгМрПиЁЂСщЛюЕФздЖЈвхМрПиЕШЙІФмЁЃ
МрПиЯЕЭГКЫаФЙІФм
ЭјеОПЩФмГіЯжИїжжЗУЮЪвьГЃЃЌдьГЩЙЪеЯЕФвђЫиЖржжЖрбљЃЌдкетУДЖрПЩФмЙЪеЯЕФЧщПіЯТЃЌБЃеЯЭјеОЕФЗўЮёЮШЖЈадБиаывЊвРРЕжЧФмЕФМрПиЯЕЭГЁЃ
ЮвУЧЯШРДПДвЛЯТМрПиЯЕЭГЕФКЫаФЙІФмЃК
1ЁЂВЩМЏЪ§ОнЃКВЩМЏашвЊМрПиЕФжИБъЪ§ОнЃЌР§ШчЃКЗўЮёЦїЕФзЪдДЪЙгУТЪЃЌгІгУЗўЮёЕФЗўЮёзДЬЌЕШЃЛ
2ЁЂЩшжУИцОЏВпТдЃКСщЛюХфжУЕФИцОЏВпТдЃЛ
3ЁЂЗЂЫЭИцОЏЃКжЇГжЖржжИцОЏЗНЪНЃЌЧввЊЧѓИцОЏзМШЗЃЌЪ§СПНЯЩйЃЛ
4ЁЂЪ§ОнВщПДЃКЖрЮЌЖШМрПиЪ§ОнЕФВщПДЁЃ
ЮвУЧЯЃЭћМрПиЯЕЭГГЩЮЊЯпЩЯЗўЮёЕФЪиЛЄЩёЃЌЫ§ЪЧЗўЮёЮШЖЈадЕФживЊБЃеЯЁЃЦНЪБЃЌМрПиЯЕЭГЪЧдЫЮЌКЭбаЗЂЁЂВтЪдШЫдБЕФблОІЃЌажњЮвУЧПьЫйЗЂЯжКЭХХВщЙЪеЯЃЛЭЈЙ§НЋдЫЮЌЪ§ОнНјааСПЛЏКЭПЩЪгЛЏЃЌБугкММЪѕШЫдБЖдЭјеОНјаагХЛЏЁЃ
СэЭтЃЌЮвУЧЛЙвЊЧѓМрПиЯЕЭГОпгавЛЖЈЕФжЧФмЃЌПЩвдИљОнДѓСПаХЯЂИјГігаМлжЕЕФНсТлЃЌР§ШчЃКИцОЏЕФЙиСЊЗжЮіЁЂЙЪеЯЕФИљвђЗжЮіЁЂздЖЏИјГіЯЕЭГЕФгХЛЏНЈвщЕШЁЃ
СЂЬхЛЏЕФМрПиЬхЯЕ
ИљОнДѓаЭЭјеОЕФЭЈгУМмЙЙЃЌЮвУЧЙЙНЈСЫСЂЬхЛЏЕФМрПиЬхЯЕЃЌШчЯТЭМЫљЪОЃК
МрПизнЯђИВИЧСЫЃК
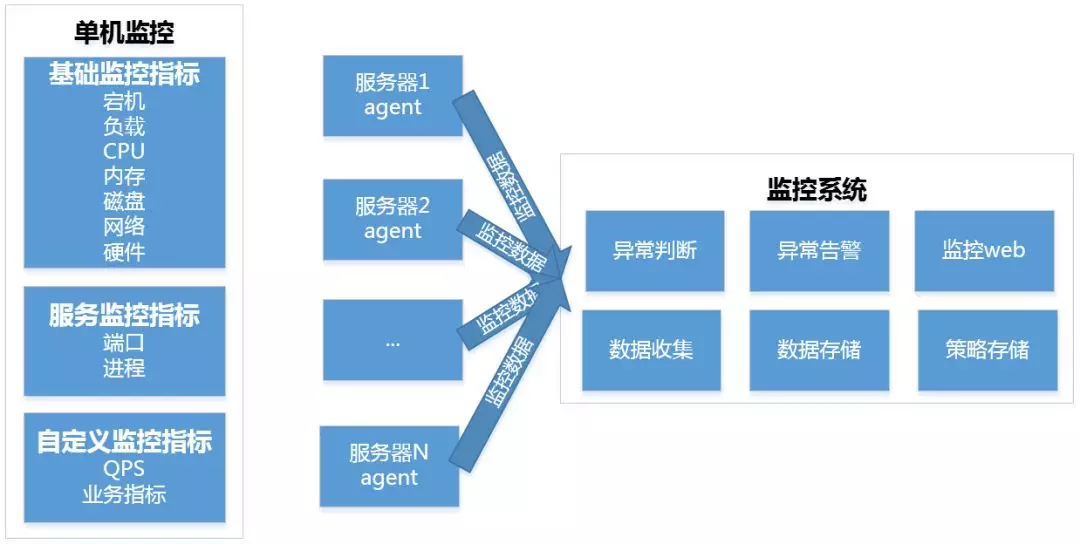
1ЁЂЭјТчВуЃКЭјТчЩшБИхДЛњЃЌзЪдДЪЙгУТЪЃЌСїСПЃЌЗўЮёжЪСПЃЌзЈЯпЕШЃЛ
2ЁЂЗўЮёЦїВуЃКхДЛњЃЌЮоЗЈЕЧТНЃЌгВМўЙЪеЯЕШЃЛ
3ЁЂЯЕЭГВуЃКзЪдДЪЙгУТЪЃЈCPUЁЂФкДцЁЂДХХЬЁЂЭјТчЕШЃЉЃЛ
4ЁЂгІгУВуЃКЖЫПкДцЛюЃЌНјГЬДцЛюЃЌНгПкзДЬЌЃЌЗўЮёQPSЕШЃЛ
5ЁЂвЕЮёВуЃКPVЁЂUVЁЂЖЉЕЅСПЃЌГЩНЛЖюЕШвЕЮёжИБъЁЃ
КсЯђИВИЧСЫЃК
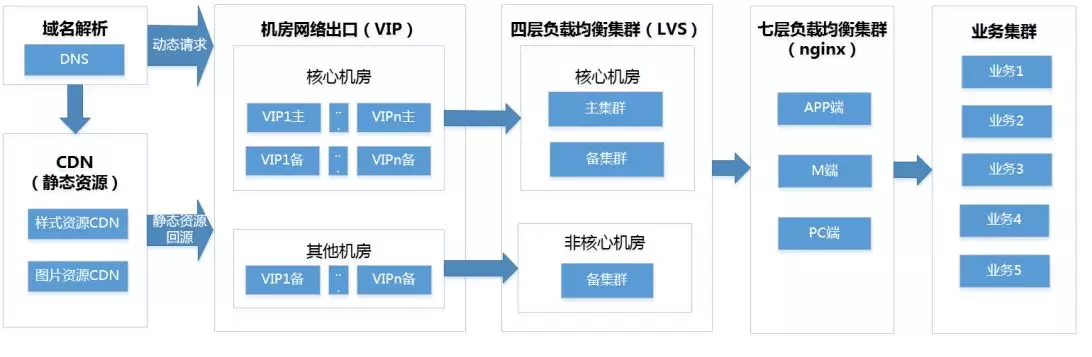
гУЛЇЖЫЃКжиЕувГУцЙиМќжИБъЃЈПЩгУадЃЌЪзЦСЪБМфЃЌШЋВПМгдиЪБМфЕШЃЉЃЌDNSНйГжЃЌСДТЗНйГжЃЌвГУцГіДэЃЌвГУцГЌЪБЕШЃЛ
ЛњЗПЭјТчГіПкЖЫЃКVIPСЌЭЈадМрПиЃЌвГУцМрПиЃЌНгПкМрПиЕШЃЛ
СїСПНгШыЖЫЃКЭјеОзмЭјТчСїСПЁЂШ§ЖЫЃЈAPPЖЫЁЂMЖЫЁЂPCЖЫЃЉЭјТчСїСПЕШЃЛдкNginxЩЯЪЕЪБЭГМЦЕФгђУћЮЌЖШЁЂМЏШКЮЌЖШЪ§ОнЃЛ
вЕЮёМЏШКЖЫЃКЕЅЛњМрПиЃЈзнЯђЃКЗўЮёЦїВуЃЌЯЕЭГВуЃЌгІгУВуЃЌвЕЮёВуЃЉЃЌМЏШКМрПиЃЈвГУцЁЂНгПкМрПиЃЌNginxШежОМрПиЃЛКЫаФжИБъАќРЈЃКПЩгУадЃЌЯьгІЪБМфЃЉЁЃ
МрПивЕЮёФЃаЭ
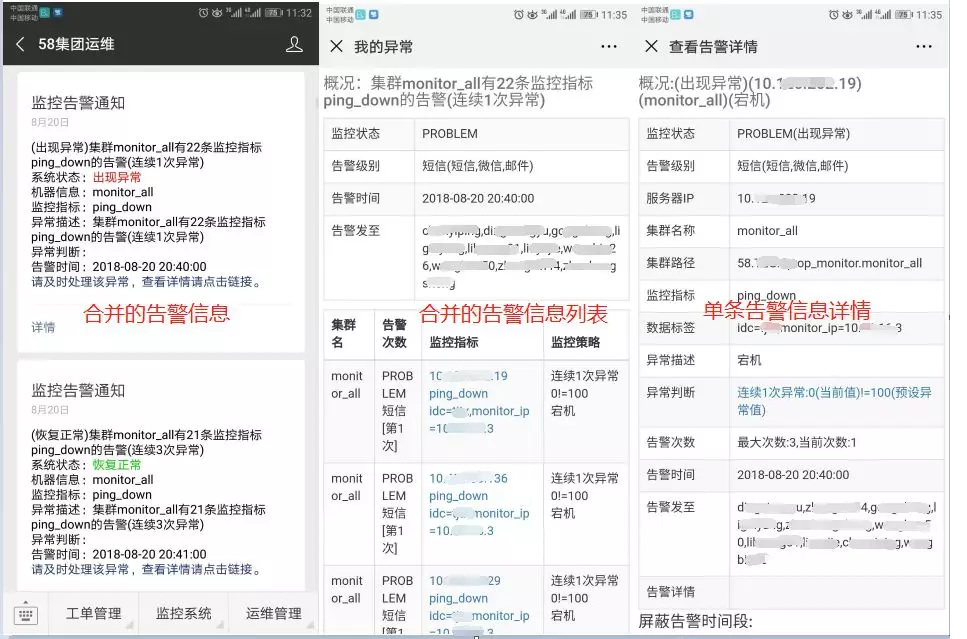
гЩгкЛЅСЊЭјЙЋЫОЕФЗўЮёЦїЪ§СПЗЧГЃЖрЃЌЭљЭљЖМДяЕНЭђЬЈЁЂЩѕжСМИЪЎЭђЬЈЃЌЬсЙЉЭЌвЛИіЗўЮёЕФНкЕуЃЈЗўЮёЦїЛђШнЦїЃЉЕФЪ§СПЗЧГЃЖрЃЌЮЊСЫБугкЙмРэЃЌЮвУЧЪЙгУСЫЛљгкМЏШКЕФМрПиФЃаЭЁЃ
ЮвУЧНЋЬсЙЉЭЌбљЙІФмЁЂВПЪ№ЭЌбљЗўЮёЁЂМрПиЗНЗЈвЛжТЕФвЛзщЗўЮёНкЕуГЦЮЊвЛИіМЏШКЃЌЫљгаМрПиХфжУЯюЃЈНкЕуСаБэЃЌМрПиФЃАхЃЌИцОЏНгЪеШЫЃЉгыМЏШКЙиСЊЁЃИУМрПиЙмРэФЃаЭШчЯТЭМЫљЪОЃК
етжжМрПивЕЮёФЃаЭПЩвддЪаэвЕЮёЗЧГЃЗНБуЕФИќаТИїжжМрПиХфжУЯюЁЃР§ШчЃКЖдЗўЮёНјааРЉШнЛђНЋЙЪеЯНкЕуЬоГ§ЪБЃЌжЛашвЊДгНкЕуСаБэжазіБфИќМДПЩЃЌЮоашИќИФЦфЫћЯюЃЛашвЊдіМгЁЂаоИФЛђЩОГ§ИцОЏВпТдЕФЪБКђЃЌНіашЙизЂВпТдЕФБфИќЃЌЮоашЙизЂЦфЫћаХЯЂЃЛгУЛЇЖЉдФЛђШЁЯћЖЉдФИцОЏЕФЪБКђЃЌНіНігАЯьИцОЏзщжаЕФгУЛЇСаБэЃЌгыЦфЫћЯюЮоЙиЁЃЯЕЭГећЬхИљОнМЏШКЙиСЊЕФНкЕуСаБэЁЂМрПиФЃАхжаЕФВпТдЁЂИцОЏНгЪеШЫСаБэШЅЪЕЪБЕФЯТЗЂЕНИцОЏПижЦФЃПщЃЌЖдИцОЏВњЩњгАЯьЁЃ
ЬсЙЉИќКУЕФгУЛЇЬхбщ
гУЛЇПЩвддкPCАцЕФМрПиЯЕЭГЪЙгУМрПиЯЕЭГЕФЫљгаЙІФмЁЃЮЊСЫЗНБугУЛЇЕФЪЙгУЃЌЮвУЧЕФНчУцЗжЮЊШ§ИіЧјгђЃЌЗжБ№ЪЧВЫЕЅЁЂЗўЮёЪїКЭвЕЮёеЙЪОЧјЁЃВЫЕЅЙЉгУЛЇбЁдёвЊЪЙгУЕФЙІФмЃЌбЁдёСЫЗўЮёЪїЕФФГИіНкЕуОЭШЗЖЈСЫЙизЂЕФвЕЮёЗЖЮЇЃЌЧАСНепШЗЖЈСЫвЕЮёеЙЪОЧјеЙЯжЪВУДЪ§ОнКЭЙІФмЁЃШчЯТЭМЫљЪОЃК

ЮЊСЫЗНБудквЦЖЏГЁОАЪЙгУМрПиЯЕЭГЃЌЛЙЬсЙЉСЫЮЂаХАцЕФМрПиЯЕЭГЁЃдкЮЂаХИцОЏжаЃЌПЩвдЗНБуПДЕНИцОЏЯъЧщЃЌМАИцОЏЯрЙиЕФМрПижИБъЕФЪ§ОнЪгЭМЃЌСэЭтЛЙПЩвдЖдЮоашДІРэЕФИцОЏзіЦСБЮИцОЏВйзїЃЌБИзЂИцОЏЕФДІРэНјеЙЃЌБугкЖрИіИКд№ШЫЭЌВНЯћЯЂЕШЁЃ
ЖрЮЌЖШМрПиЗНЗЈ
ЮЊСЫШЗБЃЗЂЯжИїЮЌЖШЕФвьГЃЃЌЮвУЧЪЙгУСЫЖрЮЌЖШЕФМрПиЗНЗЈЃЌАќРЈШчЯТВуМЖЃК
1ЁЂЛљДЁМрПиЃКЗўЮёЦїхДЛњЁЂзЪдДЪЙгУТЪЁЂЭјТчжЪСПЃЛ
2ЁЂЗўЮёМрПиЃКЖЫПкзДЬЌЃЌНјГЬзДЬЌЃЛ
3ЁЂздЖЈвхМрПиЃКЖржжЖрбљИіадЛЏМрПижИБъЃЛ
4ЁЂЙІФмМрПиЃКвГУцМрПиЁЂНгПкМрПиЃЛ
5ЁЂПЩгУадМрПиЃКМЏШКЮЌЖШЁЂгђУћЮЌЖШЕФПЩгУадЁЂЯьгІЪБМфЕШЃЛ
6ЁЂвЕЮёжИБъжЧФмМрПиЃКЖдЗДгГвЕЮёдЫааЧщПіЕФКъЙлЪ§ОнзіжЧФмдЄВтЁЂвьГЃМьВтЁЃ
ЯТУцЗжБ№НщЩмвЛЯТЪЕЯждРэЁЃ
ЛљДЁМрПиЁЂЗўЮёМрПиЁЂздЖЈвхМрПи
ЩЯЪіШ§жжРраЭЕФМрПиЪ§ОнЖМгЩВПЪ№дкЗўЮёЦїЩЯЕФМрПиagentНјааВЩМЏЃЌЪ§ОнВЩМЏКѓзіЪ§ОнЕФДцДЂКЭвьГЃХаЖЯЃЌНјЖјзіЪгЭМеЙЪОКЭвьГЃИцОЏЁЃ
Ъ§ОнВЩМЏЪОвтЭМЃК
вГУцЁЂНгПкМрПи
ЭјеОЕФЪзвГЃЌЛђепживЊЕФСаБэвГЁЂЯъЧщвГЪЧЖдгУЛЇЬхбщгАЯьНЯДѓЕФвГУцЃЛAPPЖЫЮЊСЫеЙЯжЪ§ОнашвЊЕїгУНгПкЛёШЁЪ§ОнЃЌНгПкЕФПЩгУадвВЪЧЗЧГЃгАЯьгУЛЇЬхбщЕФЁЃЮЊСЫМАЪБЁЂзМШЗЕФЗЂЯжЙиМќЕФвГУцЁЂНгПкЕФЙІФмЪЧЗёе§ГЃЃЌЮвУЧПЊЗЂСЫИУЯюЙІФмЁЃ
ЮЊСЫМАЪБЗЂЯжЭјеОгУЛЇФмЙЛИажЊЕНЕФвьГЃЃЌЮвУЧЭЈЙ§гђУћНтЮіГіРДЕФVIPЃЌДгЭтЭјЗУЮЪжИЖЈЕФвГУцЛђНгПкЃЌВЂбщжЄгђУћНтЮіЁЂНЈСЂСЌНгЁЂHTTPзДЬЌТыЁЂЯьгІЪБМфЕШжИБъЁЃВЂЖдвГУцМрПибщжЄЪ§ОнГЄЖШЁЂЪЧЗёАќКЌжИЖЈЙиМќДЪЕШжИБъЃЛЖдНгПкМрПибщжЄвЕЮёзДЬЌЗЕЛиТыЁЂНгПкжаЬиЖЈзжЖЮЕФЪ§ОнГЄЖШЕШжИБъЁЃ
гЩгкЯждкЕФЗўЮёвЛАуЖМЪЧАДееМЏШКНјааВПЪ№ЃЌЕЅИіНкЕуГіЯжЮЪЬтЃЌNginxЛсзіжиЪдЃЌЩйСПНкЕуГіЯжЮЪЬтЭтВПгУЛЇВЛЛсИажЊЕНвьГЃЁЃЮЊСЫМАЪБЗЂЯжИУРрЮЪЬтЃЌЮвУЧИљОнгУЛЇХфжУЕФВЮЪ§ЃЌАДееЗўЮёЦїЕФЮЌЖШНјааЬНВтЃЌИУжжМрПиЗНЪНФмЙЛМАЪБЗЂЯжЗўЮёЦїМЖБ№ЕФвьГЃЃЌДгЖјНјааЙЪеЯЕФдЄОЏЁЃ
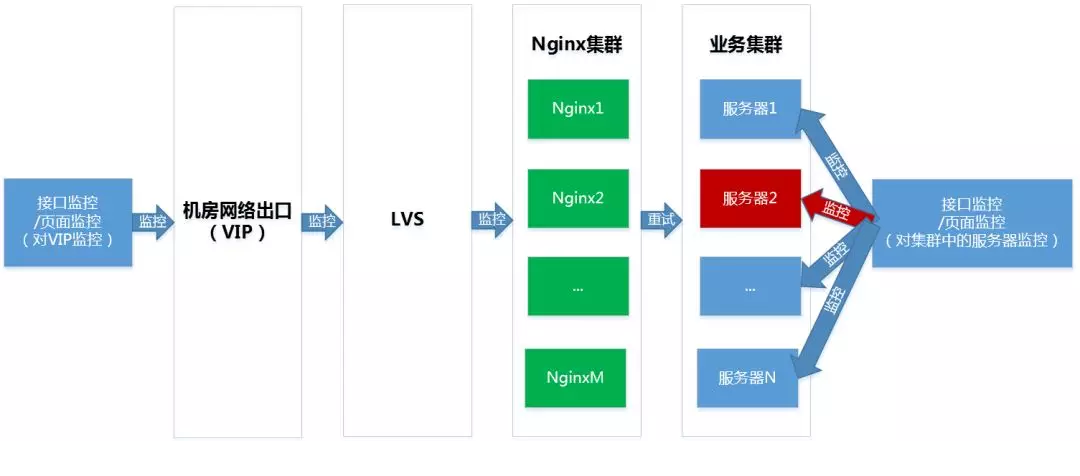
МЏШКЁЂгђУћПЩгУадМрПи
ЭјеОЕФЫљгаСїСПОЙ§ЫФВуИКдиОљКтЩшБИЁЂNginxМЏШКзЊЗЂЕНКѓЖЫвЕЮёМЏШКЁЃдкNginxМЏШКЩЯПЩвдПДЕНКѓЖЫвЕЮёМЏШКЕФдЫаазДПіЃЌЮвУЧЭЈЙ§ЪЕЪБЪеМЏКЭДЋЪфNginxШежОЃЌЪЙгУStormМЏШКЪЕЪБМЦЫуМЏШКЮЌЖШКЭгђУћЮЌЖШЕФИїжжзДЬЌТыЪ§СПКЭБШР§ЁЂЯьгІЪБМфЕШжИБъЃЌНјЖјзіЪ§ОнеЙЪОКЭвьГЃИцОЏЁЃВЂдкМЏШКЮЌЖШвВАДееЗўЮёЦїЭГМЦСЫЩЯЪіжИБъЃЌПЩвдЗЂЯжИіБ№ЗўЮёЦїЕФвьГЃЃЌзіЕНЖдМЏШКЙЪеЯЕФдЄОЏЁЃ
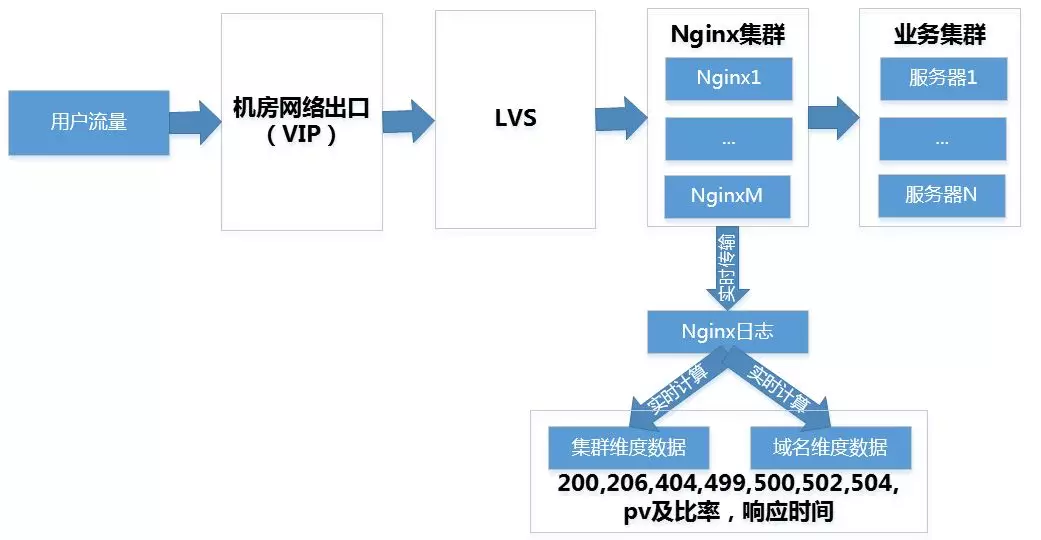
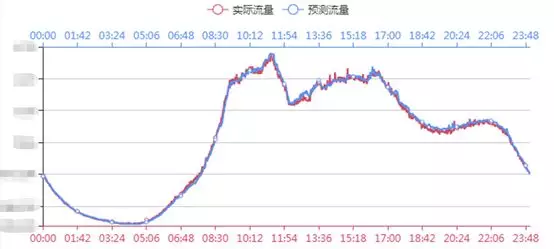
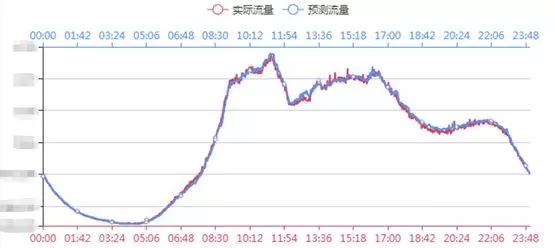
вЕЮёжИБъжЧФмМрПи
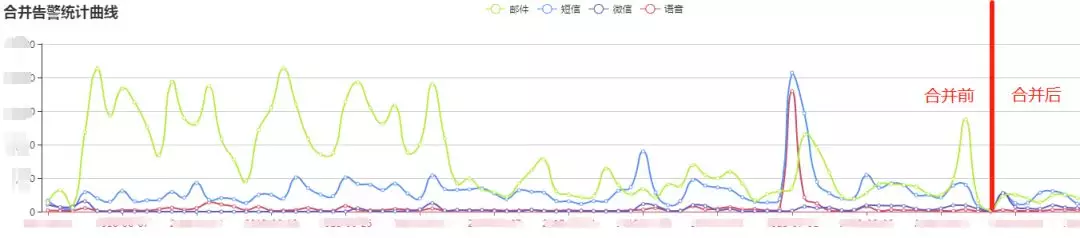
вЛаЉКъЙлЕФвЕЮёжИБъЭљЭљФмЙЛИќзМШЗЁЂгааЇЕФЗДгГвЕЮёЕФдЫаазДПіЁЃЮвУЧЖдетаЉЙиМќЕФвЕЮёжИБъЪЙгУСЫЛњЦїбЇЯАЯрЙиЕФММЪѕЃЌЖдЪ§ОнзіСЫдЄВтКЭвьГЃМьВтЁЃИУВПЗжНЋдкБОЮФжаЩдКѓЕФжЧФмМрПиВПЗжЯъЯИНщЩмЁЃ
ЖрЮЌЖШМрПиЗНЗЈзмНс
злЩЯЫљЪіЃЌЮвУЧЖдИїЮЌЖШЕФМрПиЗНЗЈЙщФЩзмНсШчЯТЃК
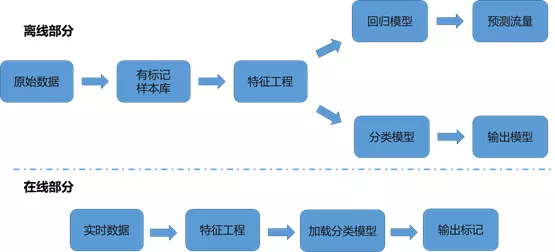
ећЬхМмЙЙ
ЮвУЧвдopen-falconЮЊЛљДЁЃЌДђдьСЫЛљДЁЕФМрПиЯЕЭГЃЌЛљБОНсЙЙШчЯТЃК

ЮвУЧдкЛљДЁМрПиЯЕЭГЕФЛљДЁЩЯзіСЫДѓСПЕФгХЛЏЁЂЩ§МЖЃЈЭМжаЛЦЩЋВПЗжЃЉЃЌдіМгСЫДѓСПгыжЧФмМрПиЯрЙиФЃПщЃЈЭМжаКьЩЋВПЗжЃЉЁЃ
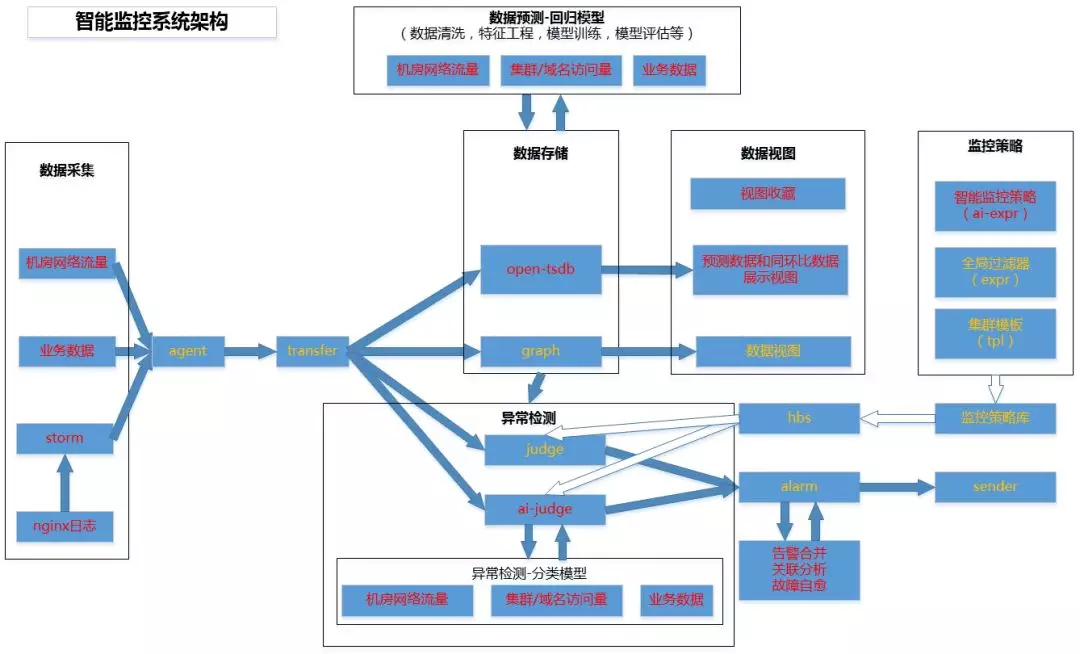
жЧФмМрПиЪЕМљ
жЧФмМрПизмЬхЙцЛЎ
ЮвУЧЯЃЭћзіЕНЖдМрПивЕЮёЕФШЋСїГЬИВИЧЃЌШчЯТЭМЫљЪОЃК

ЙЪеЯдЄОЏЃКЦНЪБзіКУЯЕЭГгХЛЏЃЌЙЪеЯЧАПЩвдЗЂГіЙЪеЯдЄОЏЃЛ
ЙЪеЯИцОЏЃКФмЖджмЦкадБфЛЏжИБъНјаадЄВтКЭвьГЃМьВтЃЌЧвгаИцОЏЗжМЖЃЛ
ИцОЏКЯВЂЃКжЇГжАДееКЯЪЪЕФЮЌЖШЖдИцОЏНјааКЯВЂЃЌеЙЯжИХПіаХЯЂЃЛ
ИљвђЗжЮіЃКжЧФмЖдЙЪеЯИљвђНјааЗжЮіЃЌИјГізюПЩФмЕФдвђЃЌИЈжњШЫзіОіВпЃЛ
ЙЪеЯздгњЃКПЩвдИљОнЙЪеЯдвђбЁдёКЯЪЪЕФЙЪеЯздгњВпТдВЂжДааЃЌздЖЏНтОіЙЪеЯЁЃ
ЙиМќжИБъЕФжЧФмдЄВтКЭвьГЃМьВт
вЛаЉКъЙлЕФвЕЮёжИБъЭљЭљФмЙЛИќзМШЗЁЂгааЇЕФЗДгГвЕЮёЕФдЫаазДПіЃЌР§ШчЃКЛњЗПЭјТчСїСПЃЌвЕЮёЗУЮЪСПЃЌЖЉЕЅЪ§ЃЌГЩНЛЖюЕШжИБъЁЃЮвУЧЖдетаЉЙиМќЕФвЕЮёжИБъЪЙгУСЫЛњЦїбЇЯАЯрЙиЕФММЪѕЃЌЖдЪ§ОнзіСЫдЄВтКЭвьГЃМьВтЁЃШчЯТЪЧвЛИівЕЮёжИБъЕФЪ§ОнЪгЭМЃК
1ЁЂашЧѓБГОАЃКећЬхЙцТЩадНЯЧПЁЂЖЬЦкаЁЗљВЈЖЏНЯЖрЕФЙиМќжИБъЃЌВЛЪЪКЯЪЙгУОВЬЌуажЕЃЛ
2ЁЂЪЪгУГЁОАЃКЭјТчГіПкСїСПЛђвЕЮёЕФНјГіСїСПЃЌМЏШККЭгђУћЕФЗУЮЪСПЃЌКъЙлвЕЮёЪ§ОнЃЛ
3ЁЂашЧѓЃКАДЬьЖдСїСПЕФЬсЧАдЄВтЃЌЖдЪЕЪБСїСПЕФвьГЃМьВтЃЛ
4ЁЂММЪѕЗНАИЃКЪЙгУЛиЙщФЃаЭАДЬьдЄВтСїСПБфЛЏЧїЪЦЃЌЪЙгУЗжРрФЃаЭЖдЪЕЪБСїСПзівьГЃМьВтЁЃ
ШчКЮЪЙгУЛњЦїбЇЯАЕФЗНЗЈ
ЪЙгУЛњЦїбЇЯАЕФЗНЗЈЗжЮЊЫФДѓВНжшЃКУїШЗЮЪЬтЃЌДІРэЪ§ОнЃЌбЕСЗФЃаЭЃЌЪЙгУФЃаЭЁЃАДееШчЯТЕФЗНЪНгыЮвУЧЕФвЕЮёНсКЯЦ№РДЃК
СїСПдЄВтМАвьГЃМьВтММЪѕПђМм
дкММЪѕПђМмЩЯЗжЮЊРыЯпВПЗжКЭдкЯпВПЗжЃЌШчЯТЭМЫљЪОЃК
жЧФмдЄВтЕФаЇЙћШчЯТЭМЫљЪОЃЌПЩвдПДЕНдЄВтЪ§ОнгыЪЕМЪЪ§ОнЕФЮЧКЯГЬЖШНЯИпЃЌдЄВтЕФаЇЙћЛЙЪЧБШНЯКУЕФЁЃ
жЧФмвьГЃМьВтЕФаЇЙћШчЯТЭМЫљЪОЃЌЛљгкЪ§ОнвьГЃГЬЖШНЋвьГЃЗжЮЊЃКЦеЭЈвьГЃЁЂбЯживьГЃЁЂЖИБфвьГЃЁЃ
ЦеЭЈЕФвьГЃвЛАуЪЧвЛаЉЭЛЗЂЕФЪ§ОнУЋДЬЃЌвЛАуВЛживЊЁЃ
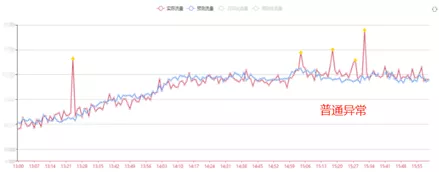
ШчЙћЪЕМЪСїСПГжајЦЋРые§ГЃжЕЃЌЮвУЧНЋЦфЪЖБ№ЮЊбЯживьГЃЃЌетЪЧашвЊЯрЙибаЗЂКЭдЫЮЌШЫдБЙизЂЕФЃЌПЩФмЛсдьГЩЙЪеЯЁЃ
ЕБЪ§ОнГіЯжЭЛШЛЯТНЕЪБЃЌвЛАуГіЯжСЫбЯжиЕФЪТЙЪЁЃР§ШчЃКЛњЗПГіПкЕФДјПэБЛЙЅЛїСїСПДђТњЃЌЯЕЭГГіЯжбЯжиЮЪЬтЕШЁЃетжжвьГЃЪЧашвЊдЫЮЌКЭбаЗЂШЫдБМАЪБжЊЯўЁЂСЂМДДІРэЕФЁЃ
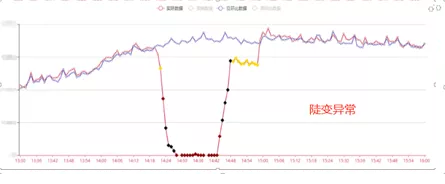
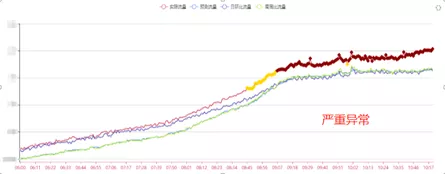
ЮвУЧдкЪЕЯжСЫвьГЃМьВтЕФЛљДЁЩЯЃЌгжЖдвьГЃзіСЫЗжМЖЃЌВЂЪЕЯжСЫИцОЏЗжМЖЃЌВЛЭЌМЖБ№ЕФвьГЃЪЙгУВЛЭЌЕФИцОЏЗНЪНЁЃР§ШчЃКЖИБфвьГЃЪЙгУгявєЕФЗНЪНИцОЏЃЌбЯживьГЃЪЙгУЖЬаХЁЂЮЂаХЕФЗНЪНИцОЏЁЃ
ИУвьГЃМьВтФЃаЭгаНЯКУЕФЦеЪЪадЃК
1ЁЂЪЪгУгкВЛЭЌЪ§СПМЖЕФЪ§ОнЃЛ
2ЁЂЪЪгУгкВЛЭЌБфЛЏЙцТЩЕФЪ§ОнЃЛ
3ЁЂЪЪгУгкВЛЭЌвЕЮёЕФЪ§ОнЃЛ
жЧФмИцОЏКЯВЂ
ШчЙћУПИівьГЃЖМЗЂЫЭвЛЬѕИцОЏЃЌФЧУДИцОЏЕФЪ§СПНЋЪЧЗЧГЃЖрЕФЃЌЖдШЫЕФИЩШХвВЪЧНЯДѓЕФЃЌашвЊШЫЖдДѓСПЪ§ОнзіДІРэВХФмЕУЕНгаМлжЕЕФаХЯЂЁЃЮвУЧЭЈЙ§жЧФмИцОЏКЯВЂЕФЗНЪННтОіСЫИУЮЪЬтЁЃ
1ЁЂКЯВЂЪБМфДАПкЃКМцЙЫКЯВЂаЇЙћКЭИцОЏЪБаЇадЃЌКЯВЂЪБМфДАПкЮЊ1ЗжжгЃЛ
2ЁЂКЯВЂЪевцЃКБмУтКЃСПИцОЏКфеЈЃЌПьЫйеЦЮеЙЪеЯЧщПіЃЌИЈжњОіВпЙЪеЯИљвђЃЛ
3ЁЂКЯВЂВпТдЃКЯрЭЌгУЛЇЃЈЖдЭЌвЛИіШЫЕФИцОЏКЯВЂЃЉЃЌЯрЭЌзДЬЌЃЈвьГЃЃЌЩ§МЖЃЌЛжИДЕШЃЉЃЌЯрЭЌИцОЏЗНЪНЃЈгявєЁЂЖЬаХЁЂЮЂаХЁЂгЪМўЃЉЃЛ
4ЁЂКЯВЂЮЌЖШЃКИљОнМЏШККЯВЂЃЌИљОнIPКЯВЂЃЌИљОнЭјЖЮКЯВЂЃЌИљОнвьГЃжжРрКЯВЂЃЈхДЛњЁЂЖЫПкВЛЭЈЕШЃЉЃЌИљОнЫожїЛњгыащФтЛњЕФЙиЯЕКЯВЂЁЃ
ЮвУЧВЩгУСЫЛљгкЛљФсжЕЕФздДДИцОЏКЯВЂЫуЗЈЃК

ЫуЗЈЕФжДааВНжшМђЪіЃК
1ЁЂБщРњШЋВПБИбЁЮЌЖШЃЌШЗШЯЕБЧАКЯВЂЮЌЖШЃЛ
2ЁЂЛљгкКЯВЂЮЌЖШЛЎЗжЪ§ОнМЏЃЌМЬајбЁдёКЯВЂЮЌЖШЃЛ
3ЁЂЕНДяЭЃжЙЬѕМўКѓЭЃжЙЁЃ
ИцОЏКЯВЂЪїгЩИљНкЕуЯђЯТЩњГЩЃЌШчЭМЫљЪОЃК
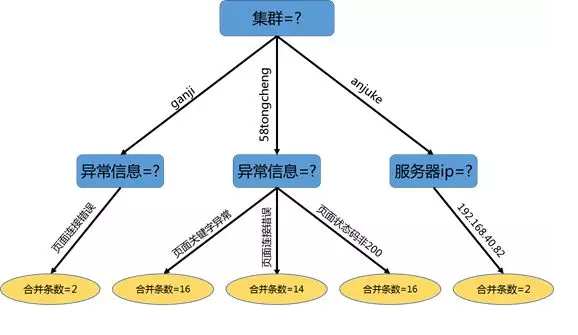
жЧФмИцОЏКЯВЂаЇЙћ
ЯТЭМЫљЪОЮЊИцОЏКЯВЂЫуЗЈЩЯЯпЧАКѓИцОЏЪ§СПЕФЖдБШЭМЃК
дкБЃжЄСЫКмИпЕФИцОЏКЯВЂжЪСПЕФЧАЬсЯТЃЌИцОЏЪ§СПМѕЩй76.65%ЁЃДгЯТЭМжаПЩвдПДЕНЃЌЯЕЭГИљОнКЯВЂЕФЖрЬѕИцОЏИјГіСЫКЯВЂКѓИцОЏИХПіаХЯЂЃЌИУаХЯЂвбОДяЕНЛђГЌГіШЫгыШЫжЎМфЙЕЭЈДЋЕнЕФаХЯЂСПЃЌБугкММЪѕШЫдБПьЫйХаЖЯвьГЃЕФгАЯьУцКЭгАЯьГЬЖШЁЃ
жЧФмИцОЏЙиСЊЗжЮі
ЭјеОжаДѓСПЗўЮёЕФЙиСЊЙиЯЕЪЧЗЧГЃИДдгЕФЃЌШчЙћГіЯжЙЪеЯЃЌКмФбдкДѓСПаХЯЂжаПьЫйЁЂзМШЗЕФХаЖЯЙЪеЯЕуЁЃЮЊСЫНтОіИУЮЪЬтЃЌЮвУЧЪдЭМгУжЧФмЕФЗНЪНзіИцОЏЕФЙиСЊЗжЮіЁЃЙиСЊЕФИцОЏЪТМўжЎМфгавЛЖЈЕФЯрЙиадЃК
1ЁЂвьГЃЪТМўЕФЪБМфЯрЙиадЃКЙиСЊЕФвьГЃдкЯрСкЕФЪБМфЖЮФкГіЯжЃЛ
2ЁЂвьГЃЪТМўжЎМфЕФЯрЙиадЃКЗўЮёжЎМфДцдкЕїгУЛђвРРЕЙиЯЕЃЛ
3ЁЂвьГЃЪТМўгыБфИќЪТМўЕФЯрЙиадЃКБфИќВйзїЕМжТЗўЮёГіЯжвьГЃЪТМўЁЃ
ОйвЛИіЪЕМЪЕФР§згЃК
58КЭAPPЖЫСїСПдквЛИіЪБМфЖЫФкГіЯжНЯДѓЕФдіГЄЃЌШчЯТЭМЫљЪОЃК
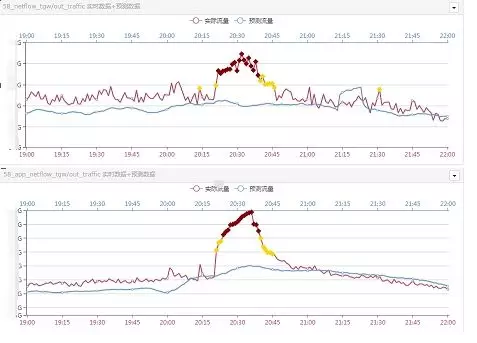
ЯрЙиЕФМЏШКЗУЮЪСПвВГіЯжБфЛЏЃЌШчЯТЭМЫљЪОЃК
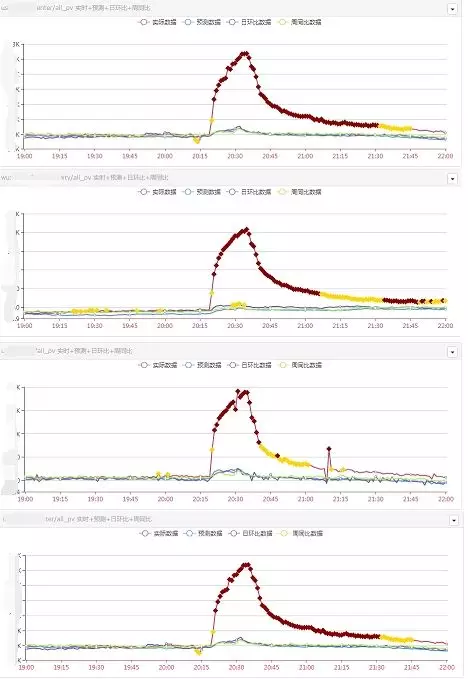
АДееДЋЭГЕФЗНЗЈЃЌдЫЮЌШЫдБвЊХХВщзмСїСПЕФБфЛЏЪЧгЩгкФФаЉвЕЮёКЭМЏШКв§Ц№ЕФЃЌашвЊКФЗбДѓСПЕФЪБМфКЭОЋСІЃЌДгДѓСПЕФМЏШКжаШЅзіЪ§ОнЕФЗжЮіЁЃЮвУЧЪЙгУЦЄЖћбЗЯрЙиЯЕЪ§ЕФЗНЗЈЃЌЖдДѓСППЩФмгаЙиСЊЕФМрПижИБъзіЯрЙиЖШМЦЫуЃЌДгЖјПьЫйЕФЗЂЯжИцОЏжЎМфЕФЙиСЊЁЃдкЮЂаХИцОЏаХЯЂжаЃЌВЛЕЋФмПДЕНИцОЏЕФЯъЧщЃЌЛЙПЩвдПДЕНЯЕЭГИљОнЫуЗЈздЖЏИјГіЕФИљвђЗжЮіЃЌЧвФмПДЕНЪ§ОнЕФБфЛЏЧїЪЦЁЃЕуЛїИљвђЗжЮіПЩвдПДЕНЭМаЮЛЏеЙЪОЕФИцОЏЙиСЊЙиЯЕЃЌШчЯТЭМЫљЪОЃК
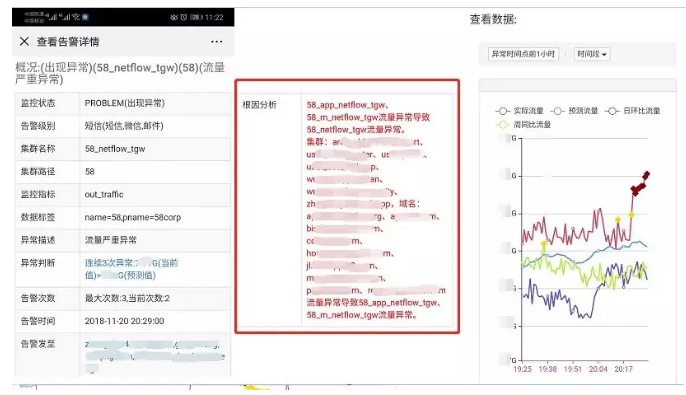
ДЋЭГМрПигыжЧФмМрПиЕФВюБ№
зюКѓзівЛИізмНсЃЌдкИїЗНУцЖдБШвЛЯТДЋЭГЕФМрПиКЭжЧФмМрПиЕФВюБ№ЃК
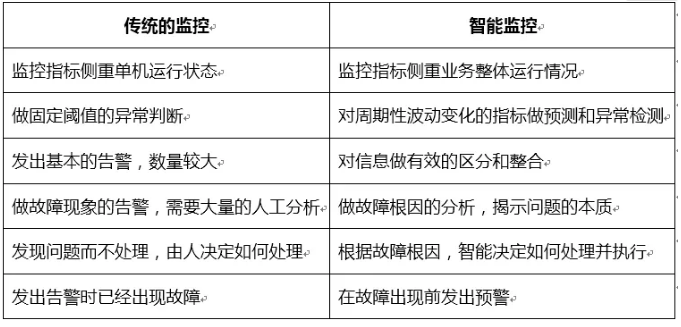
58жЧФмМрПиЯЕЭГНЈЩшОРњСЫЖрИіНзЖЮЃКздЖЏЛЏЁЂСЂЬхЛЏЁЂВњЦЗЛЏЁЂжЧФмЛЏЁЃ
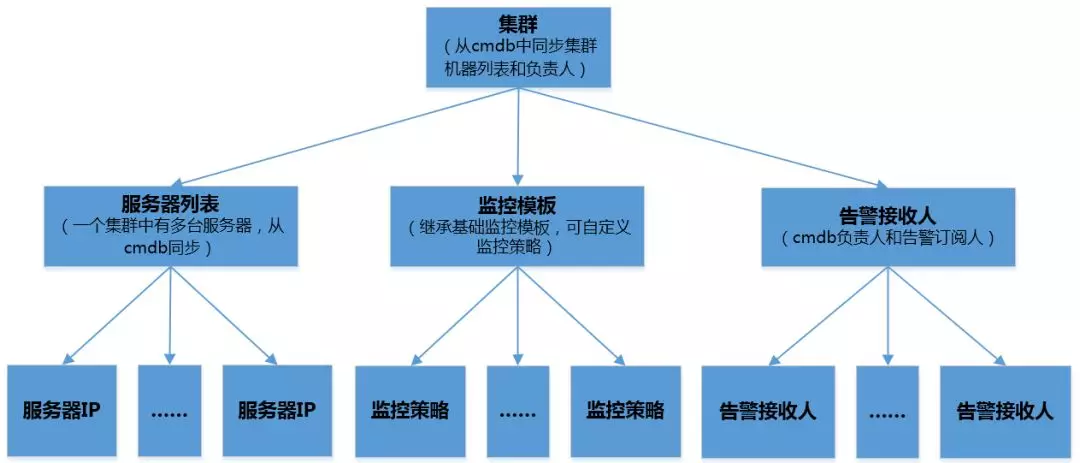
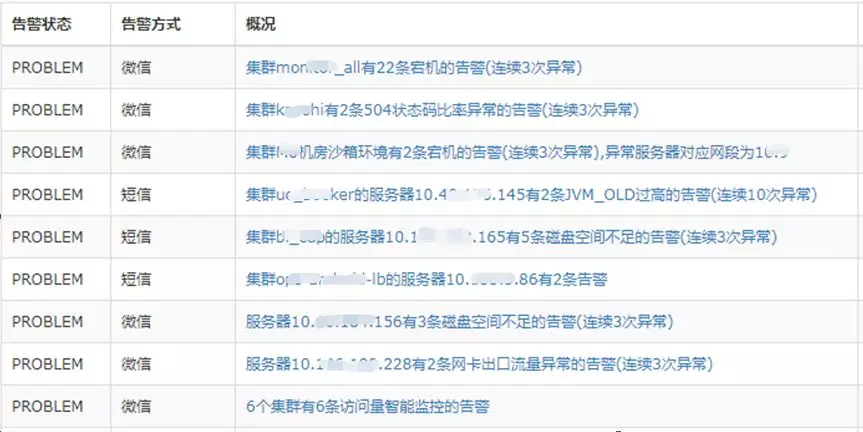
здЖЏЛЏЃКБЃжЄМрПиЯЕЭГЛљДЁМрПиЬэМгЕФздЖЏЛЏЃЌДгCMDBЯЕЭГздЖЏЭЌВНМЏШКУћГЦЁЂИКд№ШЫаХЯЂЁЂНкЕуСаБэЃЌздЖЏЙиСЊЛљДЁЕФМрПиФЃАхЃЌБЃжЄСЫЛљДЁЗўЮёЦїМрПиЕФздЖЏЛЏЁЃ
СЂЬхЛЏЃКжИЖдМрПиИВИЧЕФСЂЬхЛЏЃЌДгКсЯђКЭзнЯђСНИіЮЌЖШБЃжЄСЫЖдЭјеОЕФСЂЬхЛЏМрПиЁЃ
ВњЦЗЛЏЃКЫцзХМрПиЯЕЭГЕФЙІФмдНРДдНЗсИЛЁЂдНРДдНЧПДѓЃЌЪЙгУУХМїдНРДдНИпЃЌЮЊСЫШУФкВПгУЛЇЗНБуЁЂгааЇЕФЪЙгУЃЌЮвУЧзіСЫДѓСПЬсЩ§гУЛЇЬхбщЕФЙЄзїЁЃ
жЧФмЛЏЃКЫцзХЭјеОжаЗўЮёЦїЪ§СПЕФдіМгКЭвЕЮёИДдгГЬЖШЕФдіГЄЃЌвРППДЋЭГЕФЗНЪНвбОВЛФмгааЇЕФТњзуашЧѓСЫЃЌЮвУЧв§ШыСЫШЫЙЄжЧФмЯрЙиЕФММЪѕЃЌгыдЫЮЌЯрЙиЕФвЕЮёЯрНсКЯЃЌж№НЅГЏзХжЧФмЛЏЕФЗНЯђЧАНјЁЃ |









