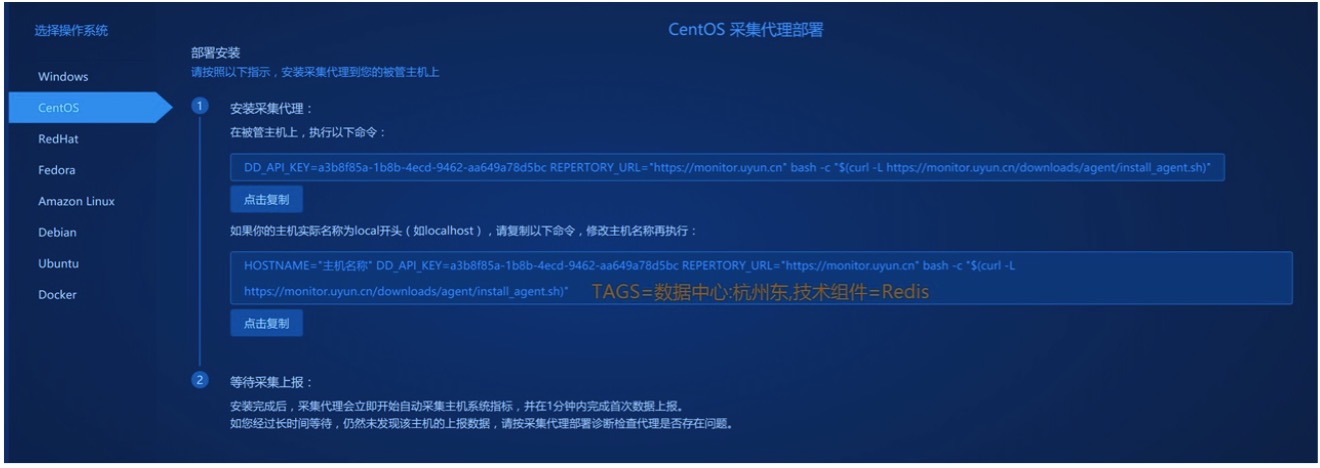
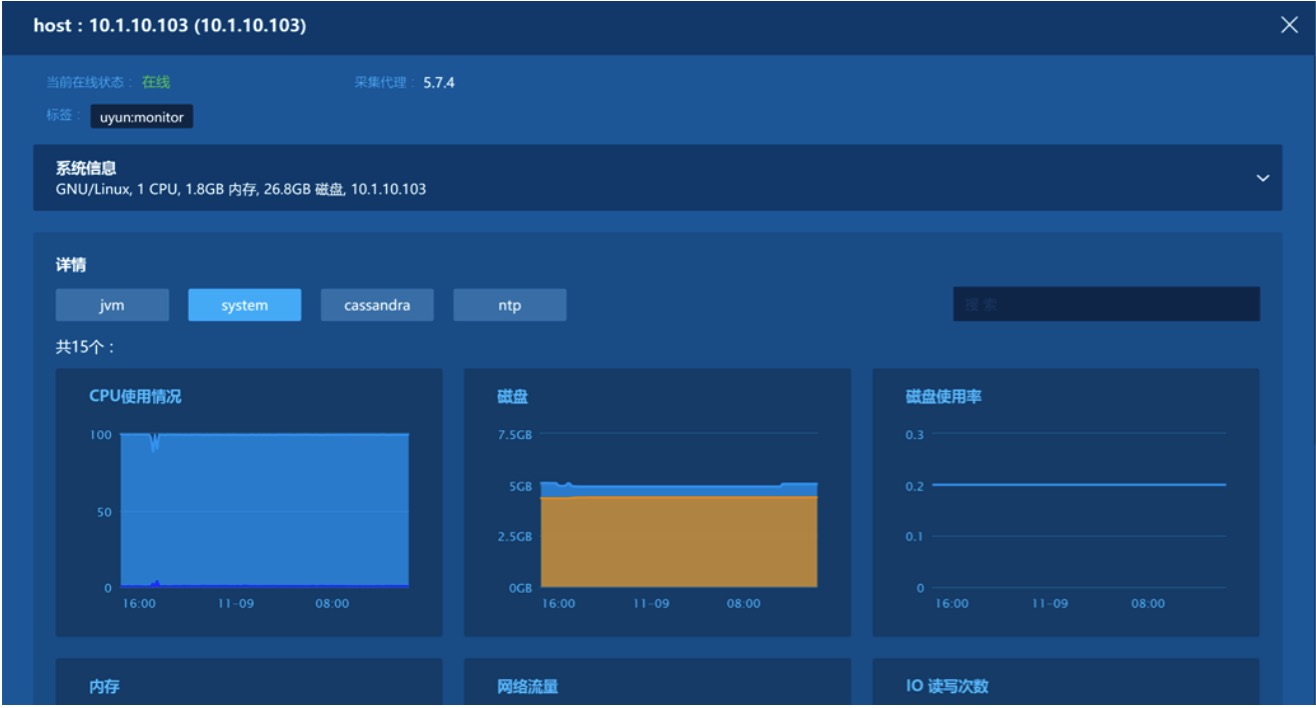
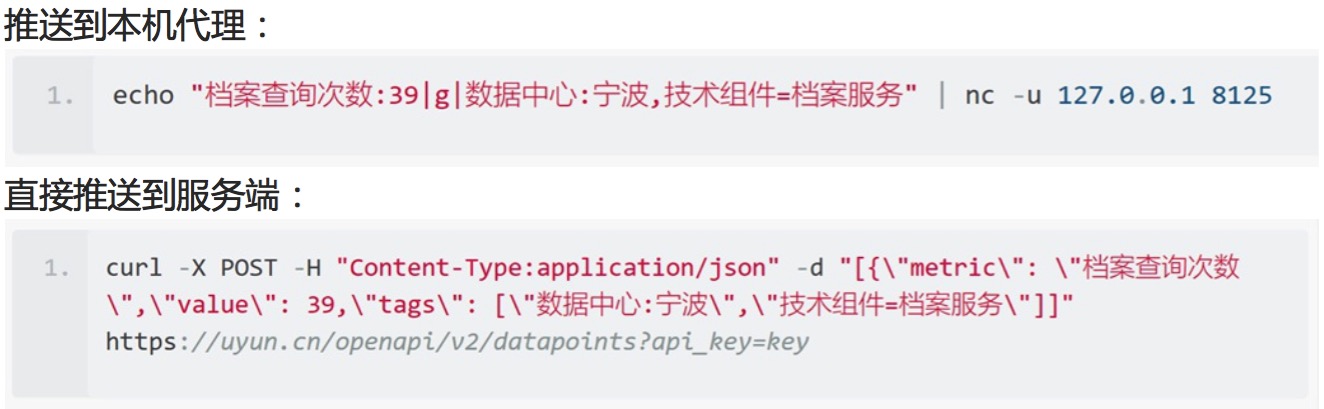
| БрМЭЦМі: |
| БОЮФРДдДcnblogsЃЌЗжБ№ДгвдЯТ3ИіЮЌЖШРДЗжЯэЃК1ЁЂдЦЪБДњМрПиЗжЮіЕФОНОГЃЛ2ЁЂЪЙгУБъЧЉБъМЧМрПиЪ§ОнЕФЮЌЖШЃЛ3ЁЂМрПиЪ§ОнгІгУГЁОАЁЃ |
|
дЦЪБДњМрПиЗжЮіЕФОНОГ
дкащФтЛЏгыШнЦїММЪѕЙуЗКгІгУЕФЧщПіЯТЃЌдЫЮЌЖдЯѓДѓЙцФЃЕидіГЄЃЌМрПиЦНЬЈУПЬьДцДЂЕФжИБъЖМвдвкМЦЃЌЫљвдМрПиЪ§ОнШчНёвбОГЩСЫДѓЪ§ОнЁЃДЋЭГЕФМрПиЙЄОпдкетжжГЁОАЯТЃЌЖдгкЪ§ОнЕФЬсШЁЗжЮіЃЌвбОСІВЛДгаФЃЌЗДЖјГЩЮЊСЫдЫЮЌЕФИКЕЃЁЃ
ЮвУЧгУвЛИіЕфаЭЕФЛЅСЊЭјЕЕАИЗжЮігІгУОйР§ЫЕУїЃК
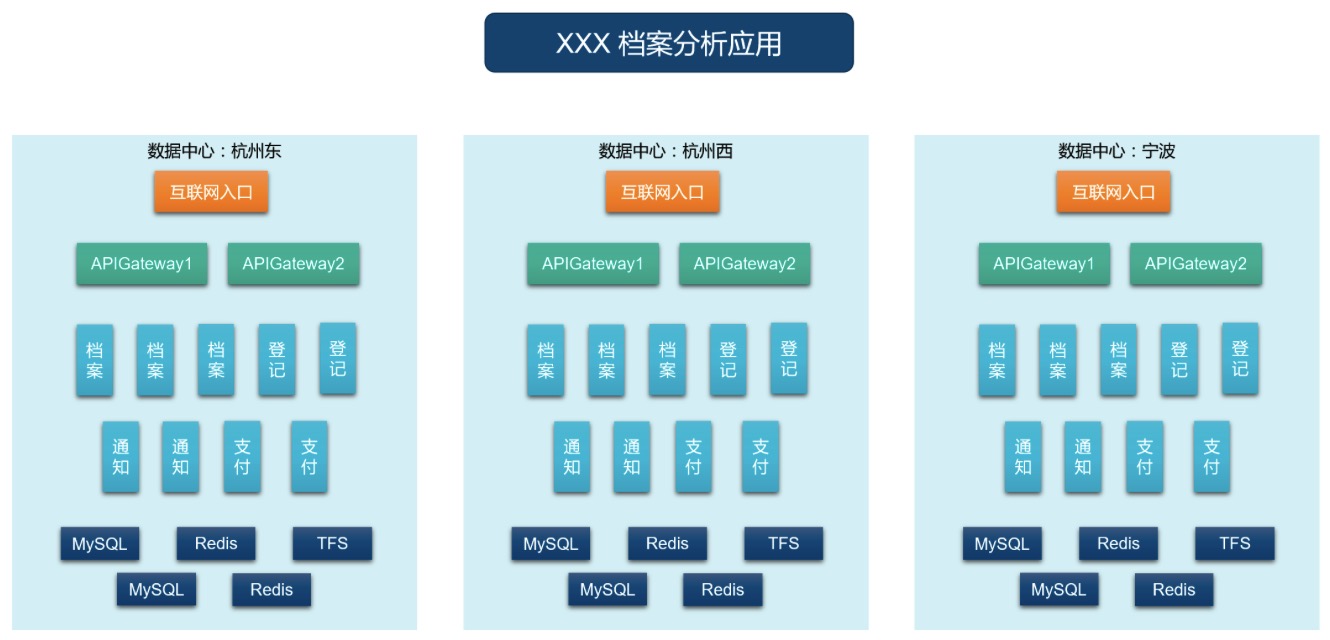
етИігІгУжЇГжШнджгыИКдиОљКтЃЌЫќВПЪ№дкШ§ИіЪ§ОнжааФЃЌВЂЭЌЪБЬсЙЉЗўЮёЃЛ
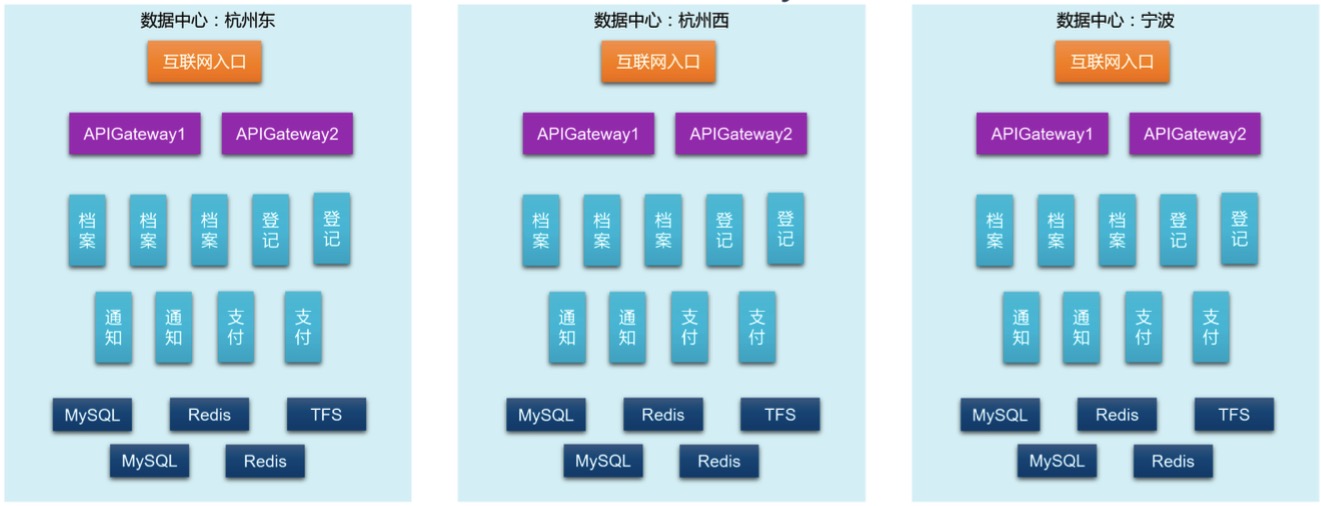
гІгУАДЮЂЗўЮёЫМЯыЩшМЦЃЌФкВПЛЎЗжЮЊЖрИіММЪѕзщМўЃЌАќРЈAPIGatewayЁЂЕЕАИЁЂЕЧМЧЁЂЭЈжЊЁЂжЇИЖМАвЛаЉЪ§ОнПтЗўЮё
ММЪѕзщМўПЩЕЏадРЉЫѕШн
етбљЕФгІгУФПЧАКмГЃМћЃЌЫќгаетбљвЛаЉЬиеїЃК
БфЃКМмЙЙБфЁЂЪЕР§Бф
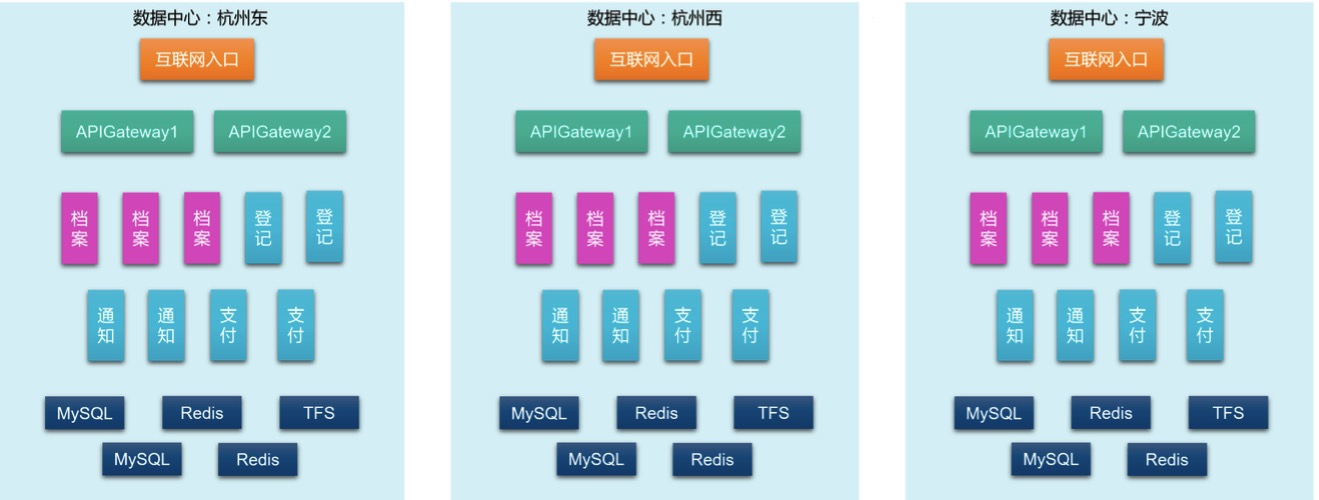
гЩгкбаЗЂУПжмЖМдкЕќДњЃЌПЩФмЫцЪБЖММгдіМгаТЕФММЪѕзщМўжжРрЃЌШчдіМгвЛИіMongoDBзїЮЊЮФЕЕРрЪ§ОнДцДЂЃЛЭЌЪБгЩгкЕЏадРЉЫѕШнЃЌУПИіММЪѕзщМўЕФЪЕР§ЪБПЬвВдкБфЃЌБШШчЯТЭМЃЌОЭМѕЩйСЫвЛИіЕЕАИЗўЮёЃЌдіМгСЫвЛИіжЇИЖЗўЮёЃК
етИјМрПиДјРДСЫФбЬтЃКШчКЮМрПиОГЃБфЛЏЕФФПБъЃП Д№АИЪЧЃКМрПиХфжУздЖЏЛЏЃЌЫцЛљДЁМмЙЙРЉеЙЃЌВЂБъМЧМрПиФПБъЁЃ
дкZabbixгыUYUN MonitorВњЦЗжаЃЌЖМПЩвдЪЙгУздЖЏВПЪ№гыЗЂЯжРДЪЕЯжздЖЏРЉеЙМрПиЁЃZabbixжївЊЪЙгУБъМЧгыздЖЏЗжзщЕФЗНЪНЃЌЖјMonitorдђЪЙгУБъЧЉЕФЗНЪНЃК
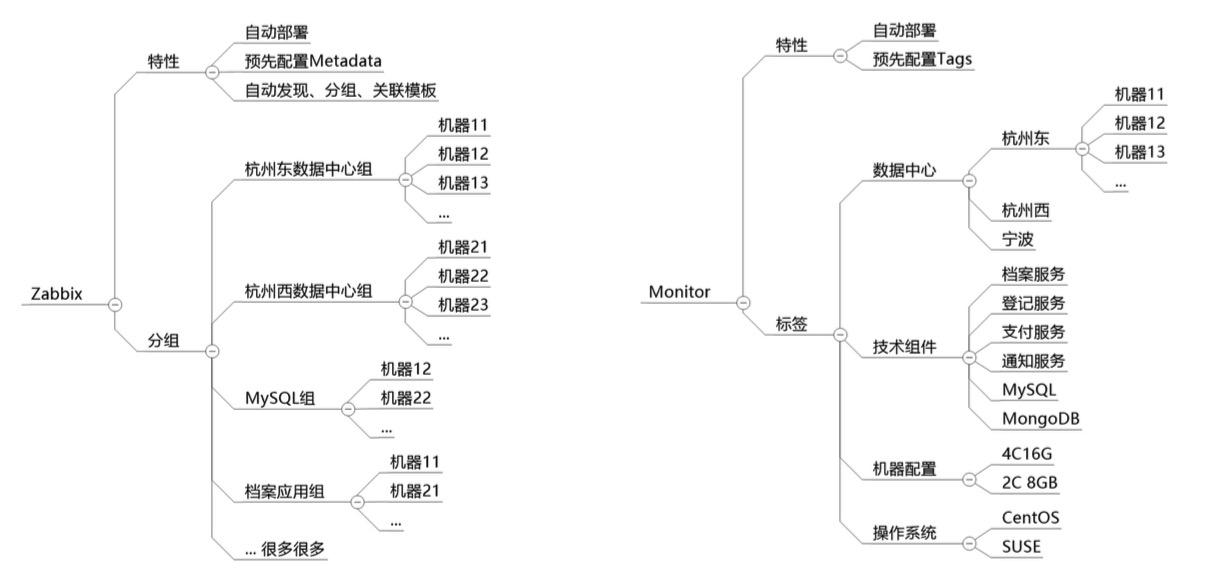
ЖрЃКжжРрЖрЁЂЪЕР§Жр
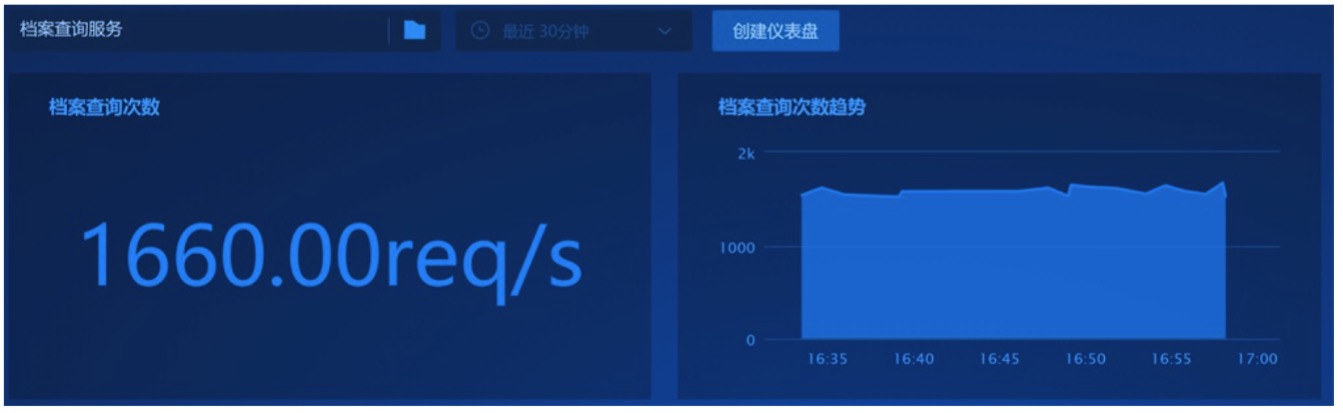
вЛИіЙЋЫОПЩФмДцдк30ЖрИіетбљЕФМЏШКгІгУЃЌЫќЪЙгУЩЯАйжжММЪѕзщМўЃЌЪ§ЧЇИіащФтЛњЛђШнЦїЪЕР§ЁЃШчДЫДѓЕФЙцФЃЃЌДјРДСЫОоДѓЕФМрПиИДдгЖШЃЌаТЕФФбЬтЪЧЃКЮвУЧБфЕУИќФбдЄВтЕФЙЪеЯеяЖЯГЁОАЃЁ
ЮвУЧОйМИИіОпЬхЕФГЁОАРДЫЕУїетЕуЃК
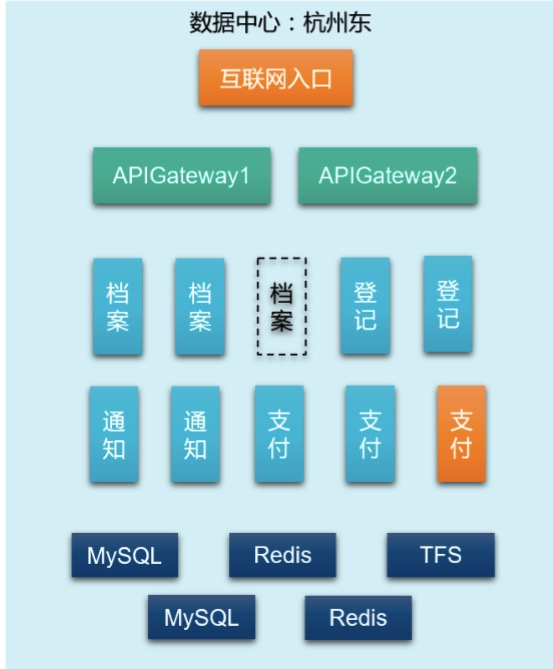
ГЁОА1ЃКЮвЯывЊжЊЕРЫљгаЕФЕЕАИВщбЏДЮЪ§
ЕЕАИВщбЏДЮЪ§ЪЧКтСПећИігІгУвЕЮёСПЕФвЛИіживЊжИБъЃЌетИіГЁОАЕФФбЕуЪЧЕЕАИЗўЮёЪЧЖрЪЕР§ЕФЃЌВЂЧвЗжВМдкЖрИіЪ§ОнжааФЁЃеыЖдетИіГЁОАЃЌЮвУЧЕФНтЬтЫМТЗЪЧЃККЯМЦЫљгаЪ§ОнжааФЕФЫљгаЕЕАИЗўЮёЕФВщбЏAPIЕїгУДЮЪ§ЃЌМДЯТЭМжаЫљгаКьЩЋВПЗнЃК
ЪЙгУZabbixЪБЃЌПЩвдАДШчЯТВНжшЃК
ДДНЈвЛИіЕЕАИЗўЮёgroupЃЌАќКЌЫљгаЪ§ОнжааФЕФЫљгаЕЕАИЗўЮё
ДДНЈвЛИіitemЃЌЪЙгУЛуОл groupfunc КЯМЦ group ФкЕФЫљгаВщбЏAPIЕїгУДЮЪ§
ЪЙгУUYUM MonitorЪБЃЌдђХфжУШчЯТзжЗћДЎМДПЩЃК
m=sum:ВщбЏAPIЕїгУДЮЪ§{ММЪѕзщМў=ЕЕАИЗўЮё}
ЪЕЯжаЇЙћЃК
ГЁОА2ЃКЮвЯыжЊЕРAPIGateway TCPСЌНгЪ§Ш§ИіжааФЕФИїздеМБШ
ЭЈЙ§СЌНгЪ§еМБШЃЌЮвУЧПЩвдЗжЮіГіИїИіЪ§ОнжааФЕФИКдиЪЧЗёОљКтЁЃЦфНтЬтЫМТЗЪЧЃКЖРСЂКЯМЦУПИіЪ§ОнжааФЕФAPIGateway
TCPСЌНгЪ§ЃЌМДШчЯТКьЩЋВПЗнЃК
ЪЙгУZabbixЪБЃЌПЩвдАДШчЯТВНжшХфжУЃК
ДДНЈШ§ИіЪ§ОнжааФAPIGateway group g1. КМжнЖЋ APIGateway group
g2. КМжнЮї APIGateway group g3. ФўВЈ APIGateway group
ДДНЈЖдгІitem ЗжБ№ЭГМЦЦфTCPСЌНгЪ§КЯМЦ
ЪЙгУUYUM MonitorЪБЃЌЛЙЪЧХфжУШчЯТзжЗћДЎМДПЩЃК
m=sum:TCPСЌНгЪ§{Ъ§ОнжааФ=*,ММЪѕзщМў=APIGateway}
ЪЕЯжаЇЙћЃК

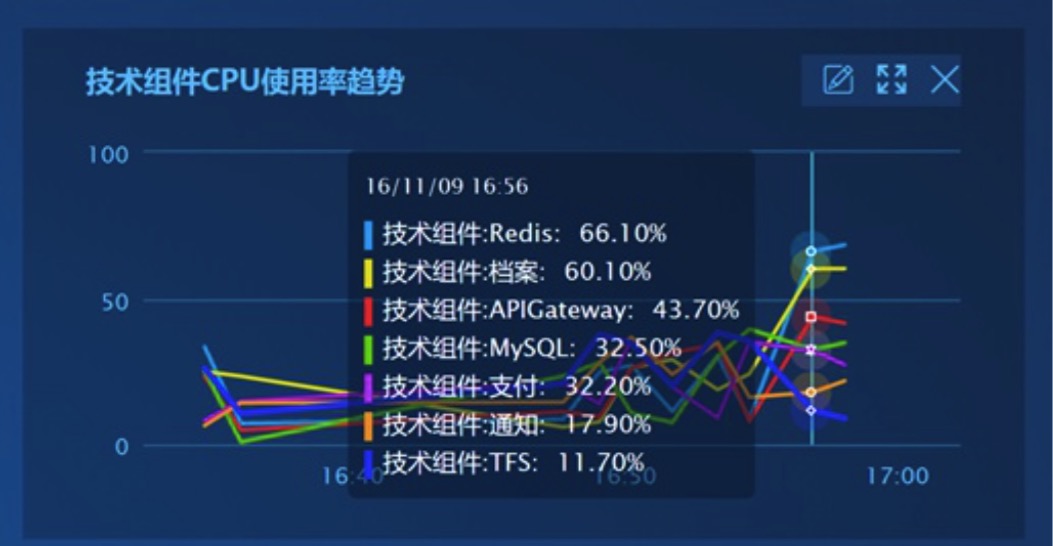
ГЁОА3ЃКЮвЯыжЊЕРИїжжЗўЮёЕФжїЛњCPUЦНОљРћгУТЪЧїЪЦ
ЭЈЙ§НЋвЛаЉММЪѕзщМўЕФCPUРћгУТЪдквЛИіЧїЪЦЭМжаЯдЪОЃЌЮвУЧПЩвдРћгУжИБъМфЕФе§ЯрЙиадЃЌРДЗжЮізщМўМфЕФгАЯьЃЌБШШчЕЕАИЗўЮёЕФCPUРћгУТЪЩ§ИпЪБЃЌЬсЙЉЦфЪ§ОнЕФRedisЗўЮёCPUЪЙгУТЪвВдкЩ§ИпЁЃЦфНтЬтЫМТЗЮЊЃКЗжБ№ЮЊУПжжЗўЮёЧѓЕУЦфжїЛњCPUЦНОљРћгУТЪЃЌВЂдквЛИіЧїЪЦЭМжаеЙЪОЁЃ
ЪЙгУZabbixЪБЃЌПЩвдАДШчЯТВНжшХфжУЃК
ДДНЈИїИіММЪѕзщМўЖдгІЕФgroupЃЌАќКЌЃКЪЧAPIGatewayЁЂЕЕАИЁЂЕЧМЧЁЂЭЈжЊЁЂжЇИЖЁЂMySQLЕШЕШ
ДДНЈЖдгІitem ЗжБ№ЭГМЦЦфжїЛњCPUРћгУТЪЦНОљжЕ
ЖјЪЙгУUYUM MonitorЪБЃЌвРШЛЪЧХфжУШчЯТзжЗћДЎЃК
Ц№ЪМЪБМф=30ЗжжгЧА&m=avg:жїЛњCPUРћгУТЪ{ММЪѕзщМў=*}
ЪЕЯжаЇЙћЃК
ЪЙгУБъЧЉБъМЧМрПиЪ§ОнЕФЮЌЖШ
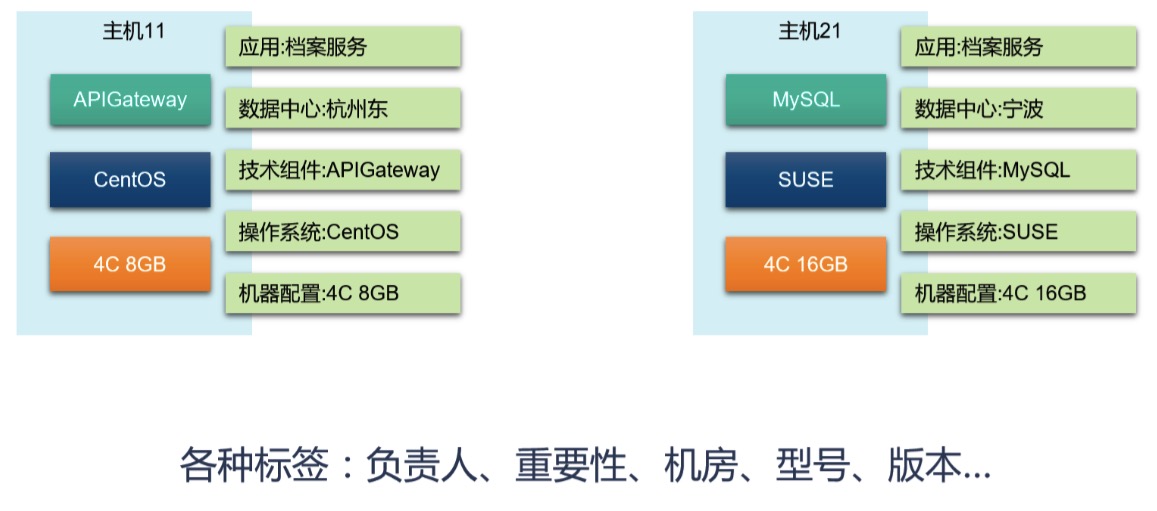
ЮвУЧПЩвдПДГіЃЌZabbixгыMonitorеыЖдвЛаЉЪ§ОнЕФЬсШЁЗНЪНЪЧВЛвЛбљЕФЁЃZabbixИќЖрЕФЪЧЪЙгУGroupЗжзщЕФЗНЪНЃЌРДЪсРэФГаЉЮЌЖШЭЌРраЭЕФаХЯЂЃЌетжжЗНЪНЪЧЮвУЧЙ§ШЅЙпгУЕФЃЌзщжЏвЛПУЪїРДГщЯѓЪРНчЁЃ
ЕЋЪЧЃЌЪРНчЦфЪЕЪЧЦНЕФЃЌИїжжЪТЮяЪЕМЪЩЯЪЧЦНЕШДцдкЕФЃЌжЛЪЧЫќУЧгазХИїздЕФЬиадЖјвбЁЃЫљвдЃЌЮвУЧЫљашвЊЕФжЛЪЧАДашгУетаЉЬиадБъЧЉРДЬсШЁЫќУЧЁЃОйР§РДЫЕЃЌЯТЭМОЭПЩвдПДЕНСНИіжїЛњЕФИїжжБъЧЉЃК
ЪЙгУUYUN MonitorЪБЃЌПЩвдАДКмЖржжВЛЭЌЕФЗНЪНРДНЈСЂБъЧЉЃЌАќРЈЃК
1ЁЂАВзАДњРэЪБжИЖЈ
2ЁЂВщПДжїЛњаХЯЂЪБжИЖЈ
3ЁЂвдМАЭЈЙ§здЖЈвхНХБОЭЦЫЭжИБъЪБжИЖЈ ЭЦЫЭЕНБОЛњДњРэЃК
дкЮЊМрПиЖдЯѓНЈСЂКУетаЉБъЧЉКѓЃЌЮвУЧОЭПЩвдГфЗжЪЙгУБъЧЉДјРДЕФБуРћЃЌЫцашВщбЏЃЌВЛдЄЩшГЁОАЁЃ
МрПиЪ§ОнгІгУГЁОА
аТвЛДњЕФМрПиЯЕЭГЃЌЦфБОжЪЪЕМЪЩЯЪЧвЛИіМрПиДѓЪ§ОнЪеМЏгыЗжЮіЦНЬЈЃЌЫќВЛЯоЖЈМрПиЕзВуЕФЪ§ОнРДдДвдБуШЋУцИВИЧдЫЮЌЖдЯѓЃЌЭЈЙ§КЃСПДцДЂгыСщЛюЕФЪ§ОнЬсШЁФмСІЃЌЮЊЩЯВуЕФИїжждЫЮЌГЁОАЃЌЬсЙЉШчДѓЦСПЩЪгЛЏЁЂБЈОЏЁЂЗжЮіБЈБэЕШЙІФмЁЃ
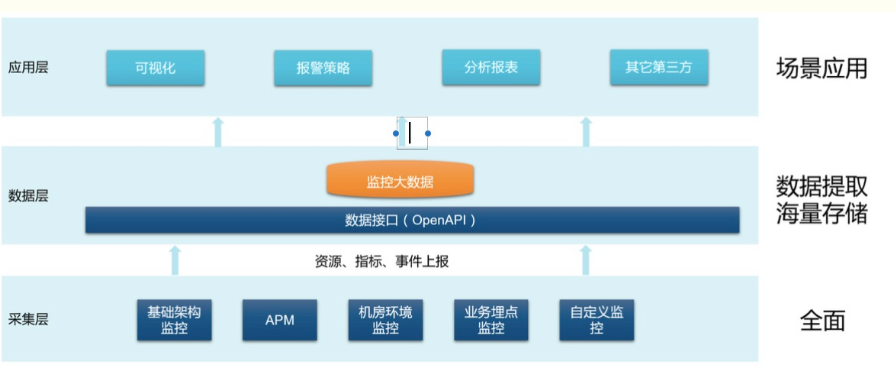
UYUN Monitor вВЬсЙЉСЫЖржжЩЯВуЕФдЫЮЌЗжЮіЙІФмЃЌАќРЈЃК
1ЁЂИіадЗсИЛЕФвЧБэХЬЃЌФмСщЛюЬсШЁИїРрМрПиЪ§ОнАДЖржжЗНЪНеЙЯж
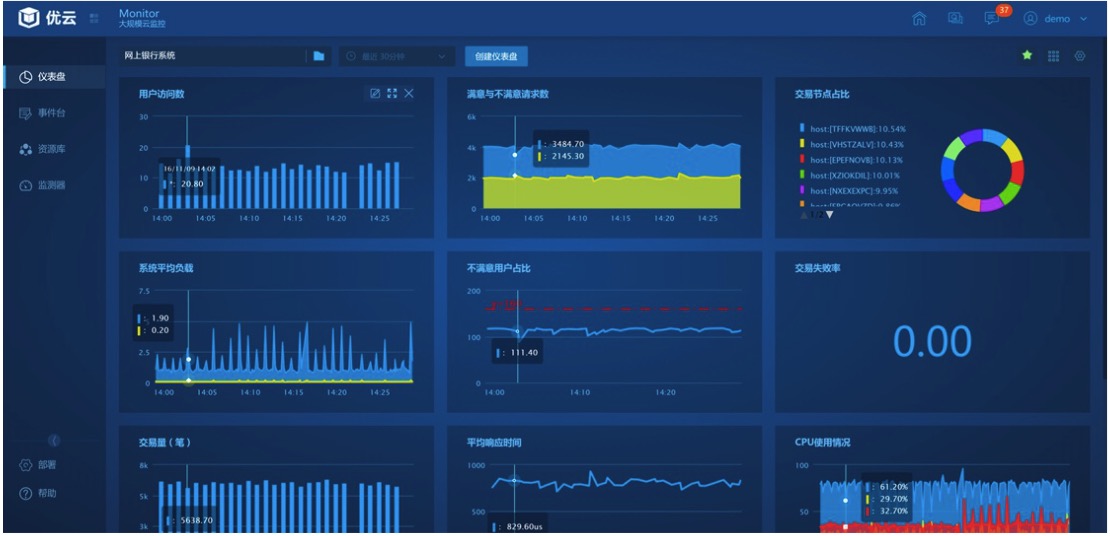
2ЁЂжИБъЕФуажЕМьВщВпТдЃЌФмЖдМЏШКжИБъНјаазлКЯЛуОлгыИцОЏ
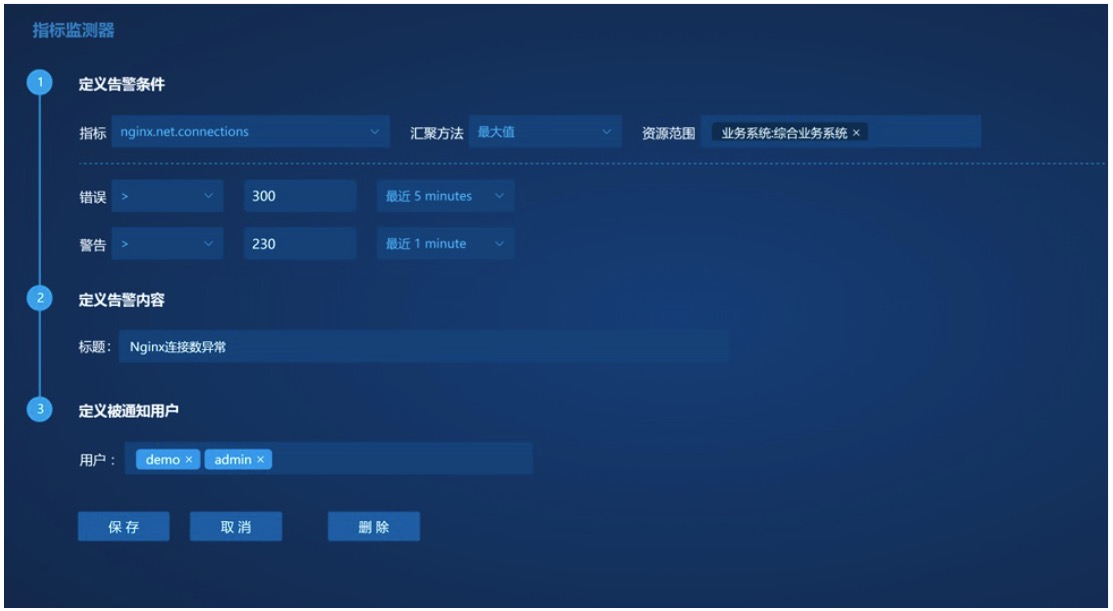
3ЁЂЕкШ§ЗНЪ§ОнВщбЏOpenAPIЃЌЬсЙЉЪ§ОнЕФЖўДЮЯћЗбШыПк
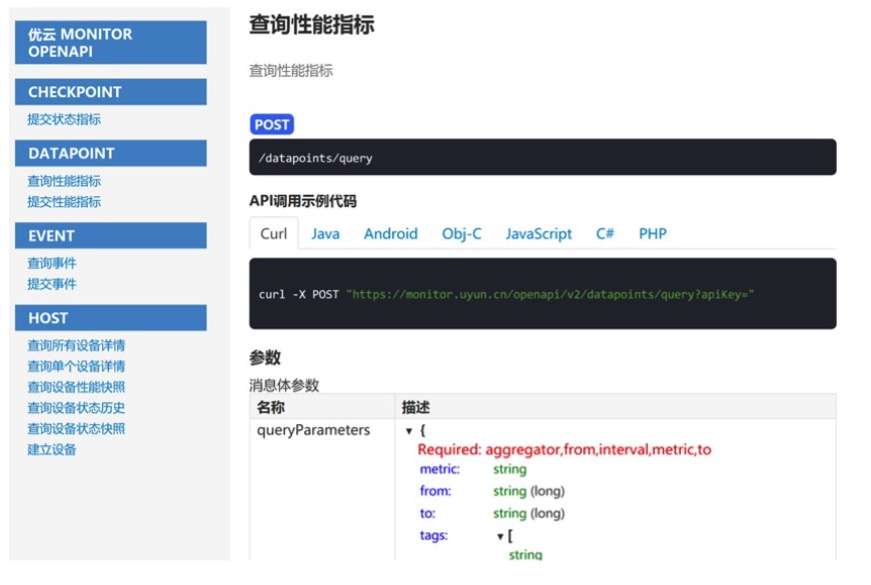
ПЩвдПДГі,УцЖддЦЪБДњ,ЮвУЧЖдМрПиЯЕЭГЕФвЊЧѓвбОВњЩњСЫБфЛЏ,МрПиЯЕЭГЪЕМЪЩЯвбОзЊБф ЮЊвЛИіМрПиДѓЪ§ОнЪеМЏгыЗжЮіЦНЬЈ,ЫќВЛЯоЖЈМрПиЕзВуЕФЪ§ОнРДдДвдБуШЋУцИВИЧдЫЮЌЖдЯѓ,
ЭЈЙ§КЃСПДцДЂгыСщЛюЕФЪ§ОнЬсШЁФмСІ,ЮЊЩЯВуЕФИїжждЫЮЌГЁОА,ЬсЙЉШчДѓЦСПЩЪгЛЏЁЂБЈОЏЁЂ ЗжЮіБЈБэЕШЙІФмЁЃ
БОДЮжїЬтЁЖМрПиДѓЪ§ОнЕФЬсШЁгыЗжЮіЁЗЕФЗжЯэЯЃЭћЖдДѓМвгаЫљАяжњЃЌгХдЦУєНндЫЮЌДѓНВЬУУцЯђдЫЮЌСьгђЕФММЪѕЗжЯэЁЂзюМбЪЕМљНЋВЛЖЈЦкгыДѓМвМћУцЃЌОДЧыЦкД§ЁЃ |









