| БрМЭЦМі: |
| БОЮФРДдДЭјТчЃЌБОЮФНЋЗжЯэаЏГЬдкAIOpsЗНУцЕФвЛаЉЬНЫїКЭЕфаЭЕФЪЕМљГЁОАЃЌЯЃЭћЭЈЙ§ЗжЯэЃЌШУДѓМвЖдAIOpsвдМАФПЧАаавЕЗЂеЙЫЎЦНгаИіКъЙлЕФШЯЪЖЁЃ |
|
аЏГЬЕФгІгУЪ§СПжкЖрЁЂМмЙЙИДдгЃЌЙцФЃаЇгІКЭЪБМфЮЌЖШЩЯЕФЛ§РлЛсЕМжТдЫЮЌЪ§ОнЃЈШежОЁЂМрПиЪ§ОнЁЂгІгУаХЯЂЕШЃЉЬхСПвьГЃХгДѓЃЌДЋЭГЛљгкОбщЙцдђЕФЗНЪНвбОВЛФмКмКУЕиЪЄШЮФГаЉЬиЖЈЕФдЫЮЌГЁОАЁЃЬиБ№ЪЧдкДѓЪ§ОнЪБДњБГОАЯТЃЌетжжЬєеНгШЮЊбЯОўЁЃ
БОЮФНЋЗжЯэаЏГЬдкAIOpsЗНУцЕФвЛаЉЬНЫїКЭЕфаЭЕФЪЕМљГЁОАЃЌЯЃЭћЭЈЙ§ЗжЯэЃЌШУДѓМвЖдAIOpsвдМАФПЧАаавЕЗЂеЙЫЎЦНгаИіКъЙлЕФШЯЪЖЃЌвВИјЖдAIOpsИааЫШЄЕФаЁЛяАщвЛаЉНшМјКЭЦєЗЂЁЃ
дЫЮЌУцСйЕФЬєеН

дЫЮЌЪ§ОнЕФЬхСПЫцзХдЫЮЌЙцФЃЕФПьЫйдіГЄГЪЯжГіБЌЗЂЪНЕидіГЄЁЃГ§СЫЖдГжајНЛИЖЁЂГжајМЏГЩЁЂзЪдДЕїЖШЁЂМрПиФмСІЕШЬсГіКмИпЕФвЊЧѓЭтЃЌУцЖдКЃСПЕФдЫЮЌЪ§ОнЃЌЦфВщевКЭЛёШЁГЩБОвВБфЕУЗЧГЃИпЁЃ
СэЭтЃЌдЫЮЌЪ§ОнЕФМлжЕКЭЪ§ОнГЩБОжЎМфШчКЮЦНКтЁЂШчКЮШЁЩсЃЌвдМАШчКЮЭкОђгаМлжЕЕФаХЯЂЃЌвВИјдЫЮЌЬсГіСЫвЛЖЈЕФЬєеНЁЃ
AIOpsЕФРэНтЁЂЖЈЮЛКЭЯжзД
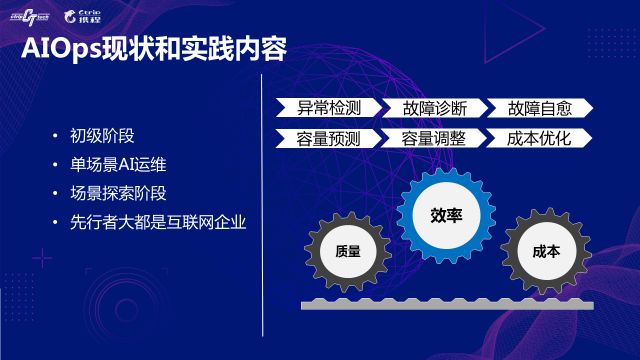
НсКЯздЩэЪЕМљвдМАЭЈЙ§ЖдаавЕећЬхЫЎЦНЕФЗжЮіЃЌНщЩмЯТЖдAIOpsЕФРэНтЁЂЖЈЮЛКЭЯжзДЃЌвдМАЗЂеЙAIOpsУцСйЕФвЛаЉЬєеНЁЃ
дЫЮЌММЪѕЕФЗЂеЙЧїЪЦ
КЭдЫЮЌаавЕжаЦеБщЕФОРњвЛбљЃЌаЏГЬЕФдЫЮЌЗНЪНжївЊОРњСЫЃКШЫШтдЫЮЌЕФНХБОдЫЮЌЪБДњЃЌеыЖдЬиЖЈдЫЮЌГЁОАЕФЙЄОпЛЏдЫЮЌЪБДњЃЌДђЭЈЖЫЕНЖЫгІгУНЛИЖЕФздЖЏЛЏдЫЮЌЪБДњЃЌЕНЯждке§дкНјаажаЕФжЧФмЛЏдЫЮЌЪБДњЁЃ
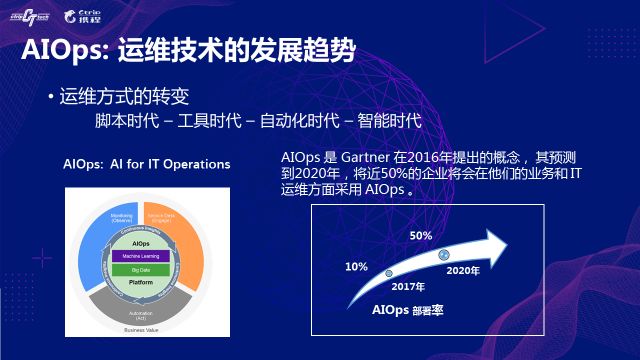
AIOpsЪєгкПчСьгђНсКЯЕФММЪѕЃЌе§ЪНБЛЬсГіЪЧдк2016ФъЃЌЫцКѓгаЖрМвЛЅСЊЭјЙЋЫОВЮгыЪЕМљЃЌ2018ФъБЛвЕФкГЦЮЊAIOpsЕФдЊФъЁЃ
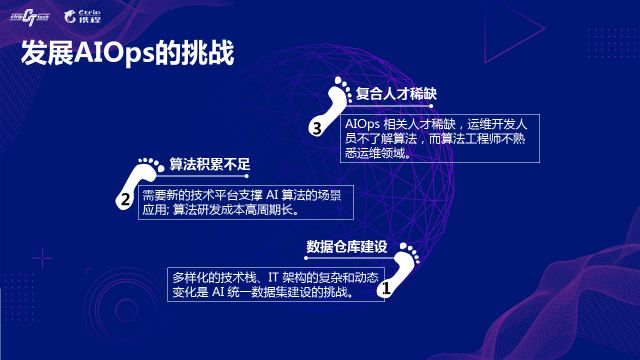
дЫЮЌШЫдБЙЙГЩзЊБф
аавЕжаЖдШЫдБЕФЙЙГЩЩЯвВАДеежАФмЕФВржиЕуВЛЭЌЃЌЛЎЗжЮЊдЫЮЌЙЄГЬЪІЁЂдЫЮЌПЊЗЂЙЄГЬЪІКЭдЫЮЌAIЙЄГЬЪІЃЌДѓМвзЈвЕСьгђВЛЭЌЃЌЗжЙЄЕФВрживВВЛЭЌЁЃ
ДгИіШЫРэНтПДЃЌетжжЛЎЗжДѓЖрЪ§ЧщПіЯТжЛЪЧвЛжжТпМЛЎЗжЃЌР§ШчвЛИіШЫПЩвдЩэМцЖржжНЧЩЋЃЌЖјетжжИДКЯаЭЕФШЫВХЪЧФПЧАЗЧГЃНєШБЕФЁЃ

AIOpsЯжзДМАЪЕМљФкШн
ДгаавЕЗжЯэЕФзюМбЪЕМљФкШнПДЃЌAIOpsжївЊЮЇШЦжЪСПЁЂаЇТЪКЭГЩБОетШ§ИіЗНУцеЙПЊЃЌЪЕМљАќРЈвьГЃМьВтЕНеяЖЯздгњЃЌвдМАШнСПЕНГЩБОЕФгХЛЏЁЃ
ДгаавЕећЬхЪЕМљЫЎЦНРДПДЃЌФПЧАЕФAIOpsЛЙДІгкГѕМЖНзЖЮЃЌЪЕМљЕФФкШнжївЊЛЙЪЧеыЖдЕЅИігІгУЕФГЁОАеЙПЊЁЃ
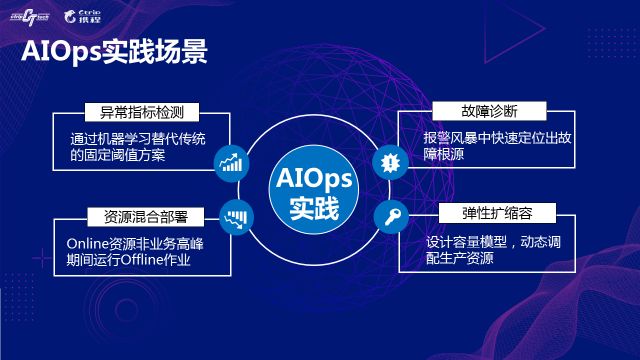
ЗЂеЙAIOpsЕФЬєеН
вђЮЊЪЧПчСьгђНсКЯЕФММЪѕЃЌЫљвдЗЂеЙЕФФбЖШвВжївЊЪЧСНИіСьгђЕФжЊЪЖЖМашвЊгаБШНЯЩюПЬЕФРэНтКЭШЯЪЖЁЃЪ§ОнжЪСПКЭЫуЗЈЛ§РлЪЧвЛЗНУцЬєеНЃЌИДКЯаЭШЫВХЕФЯЁШБЪЧСэвЛЗНУцЁЃ
AIOpsдкаЏГЬЕФЬНЫїгыЪЕМљГЁОАНщЩм
ЕЅГЁОАЪЕМљЗНУцТоСаСЫМИИіЯрЖдГЩЪьЕФНтОіЗНАИЁЃ
ЪзЯШЪЧгІгУМрПижИБъЕФжЧФмвьГЃМьВтЁЃДЋЭГЛљгкЙцдђЗНЪНЕФИцОЏЗКЛЏФмСІВюЃЌОГЃЛсЕМжТИцОЏТЉИцЛђепЮѓИцЃЌжЧФмИцОЏЪЧЭЈЙ§ЛњЦїбЇЯАЕФЗНЪНЬцДњДЋЭГЛљгкЙЬЖЈуажЕЕФИцОЏЗНЪНЁЃ
ЕБМьВтЕНгІгУжИБъвьГЃжЎКѓЃЌЮвУЧЭЈЙ§жЧФмгІгУеяЖЯЯЕЭГЃЌеяЖЯЯЕЭГЪЧЛљгкзЈМвОбщКЭЯрЙиадМьВтЕШЫуЗЈЪЕЯжЕФЙЪеЯЗжЮіеяЖЯЯЕЭГЃЌПЩвдПьЫйЖЈЮЛЙЪеЯИљдДЃЌДгЖјДяЕНПьЫйжЙЫ№ЁЃ
СэвЛЪЕМљГЁОАЪЧдкЯпзЪдДКЭРыЯпзївЕжЎМфЕФЛьКЯВПЪ№ЃЌЛљгкЖддкЯпгІгУЕФзЪдДКЭРыЯпзївЕЕФЛЯёЃЌЗжЪБЖЏЬЌЕиНЋРыЯпзївЕЕїЖШЕНдкЯпзЪдДЩЯдЫааЃЌДгЖјДяЕНЬсЩ§дкЯпзЪдДРћгУТЪЕФФПЕФЃЌЭЌЪБвВЬсИпСЫРыЯпзївЕЕФжДаааЇТЪЁЃ
зюКѓвЛИівЊНщЩмЕФЪЧжЧФмЕЏадРЉЫѕШнЃЌЭЈЙ§ЖдЯпЩЯзЪдДЙЙНЈШнСПФЃаЭЃЌЖЈЦкЩњГЩШнСПБЈИцЃЌИљОнШнСПБЈИцздЖЏжДааРЉШнКЭЫѕШнЁЃ
ДгAIOpsећЬхМмЙЙЩшМЦКЭЙцЛЎЗНУцЃЌжївЊЗжЮЊЫФИіТпМВуЪЕЯжЁЃздЖЅЯђЯТЗжБ№АќРЈЃКдЫЮЌKPIВуЁЂдЫЮЌГЁОАНтОіЗНАИВуЁЂЦНЬЈздЖЏЛЏВуЁЂвдМАЕзВуЛљДЁМмЙЙКЭЪ§ОнМрПиВуЁЃ
ЕзВуЗўЮёЮЊЩЯДЮЕФЪЕЯжЬсЙЉФмСІКЭЦНЬЈжЇГХЃЌЮДРДжиЕужївЊЛсЗХдкЦНЬЈФмСІЕФНЈЩшКЭгХЛЏЁЂвдМАИќЖржЧФмЛЏдЫЮЌГЁОАЕФЭкОђЗНУцЁЃ
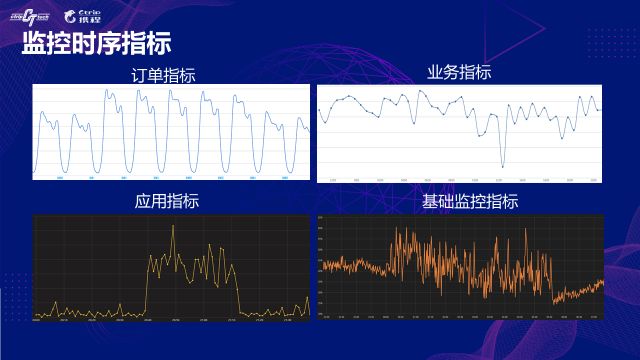
ОпЬхЕФЪЕМљдЫЮЌГЁОАвдМрПиЪБађЕФвьГЃМьВтКЭгІгУЕФжЧФмеяЖЯЮЊР§еЙПЊНщЩмЃК
МрПиЪБађЕФвьГЃМьВт
Ъ§ОнЬхСПКмаЁЕФЪБКђЃЌЛљгкЙцдђЕФИцОЏЗНЪНЩаПЩЪЄШЮЃЌЕБЪ§ОнЬхСПВЛЖЯдіГЄжЎКѓЃЌЙцдђЕФЗКЛЏФмСІОЭЛсБфШѕЁЃзіМрПиЪБађЕФжЧФмвьГЃМьВтжївЊЪЧЮЊСЫЬсИпИцОЏЕФжЪСПЃЌМѕЩйЮѓБЈКЭТЉИцЪ§СПЁЂЬсИпИцОЏЕФМАЪБадЁЂНЕЕЭуажЕЙмРэЕФИДдгЖШЁЃ
МрПиЪБађжИБъ
ЪзЯШзмНсЯТГЃМћЕФМрПиЪБађжИБъЃЌаЏГЬЪЧЙњФкзюДѓЕФдкЯпТУгЮЛЅСЊЭјЙЋЫОЃЌКЭДѓВПЗжЛЅСЊЭјЙЋЫОвЛбљЃЌМрПижИБъИљОнЙІФмЕФВЛЭЌжївЊЗжЮЊвдЯТМИРрЃК
1.ЖЉЕЅжИБъЃЌвВЪЧзюКЫаФЕФМрПижИБъЃЌДгМрПиЧњЯпПДгаЗЧГЃЧПЕФжмЦкадЃЛ
2.гІгУжИБъКЭвЕЮёжИБъЃЌДѓВПЗжЪЧПЊЗЂЛљгкПђМмжаМфМўзіЕФвЛаЉвЕЮёТёЕуЁЃетаЉжИБъе§ГЃЧщПіЯТЖМЛсБэЯжЕФКмЦНЮШЃЌЕБгаЭЛЗЂзДПіЛђвьГЃЪБЃЌжИБъЛсОчСвЖЖЖЏЃЛ
3.ЛљДЁМрПижИБъЃЌЩцМАЕзВуИїжжРраЭЕФМрПиЃЌАќРЈЗўЮёЦїCPUЁЂФкДцЁЂДХХЬIOЁЂЭјТчIOЕШжИБъЃЌвдМАDBЁЂRedisЁЂДњРэЁЂЭјТчЕШЯрЙиМрПижИБъЁЃ
вьГЃМьВтСїГЬ
ЧАУцЬсЕНСЫГЃМћМИжжМрПиЪБађРраЭЃЌЦфжазюФмЙЛМАЪБЗДгГгІгУНЁПЕГЬЖШЕФОЭЪЧгІгУЕФМрПижИБъЃЈДэЮѓЪ§ЁЂЧыЧѓСПвдМАЯргІЪБМфЕШЃЉЃЌвВЪЧгІгУдЫЮЌзюЙиаФЕФжИБъЁЃ
вьГЃМьВтЪЕМљЕФжївЊФкШнвВЪЧдкЮЇШЦвЕЮёжИБъИњгІгУжИБъеЙПЊЕФЃЌвђЮЊаЏГЬЕФгІгУЪ§СПжкЖрЃЌетВПЗжжИБъЕФЪ§СПвВЪЧЗЧГЃХгДѓЃЌЗЧГЃОпгаЬєеНадЁЃетРяЮвУЧжївЊНщЩмДгЪ§ОнСїЯђЕФНЧЖШРДНщЩмЯТЪБађжИБъЕФвьГЃМьВтЁЃ
1.Ъ§ОндДХфжУЃКЖдгквЛИіЭЈгУЕФвьГЃМьВтЦНЬЈЖјбдЃЌД§МьВтЕФЪБађЪ§ОндДПЩФмДцдкВЛЭЌЕФЮяРэНщжЪЩЯЃЌвВПЩФмЪЧВЛЭЌЕФЯЕЭГжаЃЌЮЊСЫБмУтЖдвЕЮёЯЕЭГЕФЧжШыадЃЌвьГЃМьВтЕФТпМвЛАуЖМЪЧХдТЗРДЪЕЯжЁЃЪзЯШашвЊНЋетаЉВЛЭЌЯЕЭГЁЂВЛЭЌДцДЂНщжЪжаЕФЪБађНјааВЩМЏЃЈЪ§ОндДПЩвдЪЧDBЁЂHBaseЁЂЯћЯЂЁЂAPIЁЂвдМАЬиЖЈЕФМрПиЯЕЭГЕШЃЉЃЌдквьГЃМьВтЦНЬЈжаБЃДцвЛЖЮИББОЪ§ОнЃЌСєзїЙЙНЈЪ§ОнВжПтЪЙгУЁЃ
2.Ъ§ОнМЏЙ§ТЫЃКЪЕМљжаЮвУЧВЂВЛЛсЖдЫљгаЕФЪ§ОнМЏЖМХфжУжЧФмМьВтЫуЗЈЃЌЪЧвђЮЊдкКмЖрецЪЕЕФГЁОАжаЃЌгааЉжИБъКмФбгУБЛвьГЃМьВтЕФЫуЗЈМьВтЃЌжївЊЕФдвђЪЧЪ§ОнжЪСПВЛИпЃЌгаЫуЗЈОРњЕФЕРгбгІИУЖМЧхГўЃЌЪ§ОнжЪСПЕФКУЛЕОіЖЈСЫЫуЗЈаЇЙћЕФЩЯЯоЁЃЮвУЧЛсЪТЯШХфжУСЫвЛИіЪ§ОнМЏЙ§ТЫФЃПщЃЌЙ§ТЫЕєвЛаЉЪ§ОнжЪСПВЛИпЕФЪ§ОнМЏЁЃЪЕЯжЕФдРэжївЊЪЧЛљгкЪ§ОнМЏЕФвЛНзКЭЖўНзЭГМЦСПЁЂЦЋЖШЁЂЗхЖШЁЂаХЯЂьиЕШжИБъЃЌНЋТњзувЛЖЈЭГМЦЬиадЕФЪ§ОнМЏЩИбЁЕНКѓајСїГЬДІРэЁЃ
3.вьГЃМьВтЫуЗЈМЏЃКеыЖддЄЩИбЁЛЗНкЙ§ТЫЕУЕНЕФЪ§ОнМЏЃЌЮвУЧзМБИСЫГЃМћЕФвьГЃМьВтЫуЗЈМЏЃЌетаЉЫуЗЈДѓЖМЪЧЭЈгУЕФЛњЦїбЇЯАЫуЗЈИљОнЪЕМЪЧщПіКЭашвЊзіСЫвЛЖЈЕФЖўДЮЖЈжЦЃЌИќЯъЯИЕФНщЩмЮвУЧЛсдкНгЯТРДЕФФкШнжаеЙПЊЁЃ
4.ИцОЏзДЬЌЛњЃКетИіФЃПщЕФЙІФмжївЊЪЧНЋЪБађвьГЃзЊБфЮЊвЛИігааЇЕФИцОЏЁЃДгЪТЙ§МрПиИцОЏЕФЕРгбгІИУгаРрЫЦЕФЙВЪЖЃЌвьГЃЪ§ОнДгЭГМЦНЧЖШПДжЛЪЧРыШКНЯдЖЕФЗжВМЃЌФмВЛФмЕБзівЛИівЕЮёИцОЏДІРэФиЃПДѓВПЗжЪБКђЪЧашвЊвЕЮёЭЌЪТРДИјГіЙцдђЃЌНЋвЛИіЮогявхЕФЪБађвьГЃзЊБфГЩвЛИівЕЮёИцОЏЁЃР§ШчНЋСЌајШ§ДЮЛђЮхДЮЕФЪБађвьГЃзЊБфГЩвЛИівЕЮёИцОЏЃЌСЌајЖрЩйДЮжЎКѓЛжИДИцОЏЃЌЭЌЪБИцОЏзДЬЌЛњЛсЮЌЛЄУПИіИцОЏЕФЩњУќжмЦкЃЌБмУтжиИДЕФИцОЏЭЈжЊЕШЁЃ
5.ИцОЏжЪСПЦРМлЃКИцОЏжЪСПЕФЦРЙРПЩвдЫЕЪЧзюОпЬєеНадЕФЙЄзїСЫЁЃвЛЗНУцЃЌЮвУЧМьВтЕФжИБъЛљБОЖМЪЧЮоБъзЂЕФЪ§ОнМЏЃЌВњЩњЕФИцОЏзМШЗгыЗёБиаыгаШЫРДХаЖЯЃЛСэвЛЗНУцЃЌвђЮЊгІгУЪ§СПжкЖрЃЌУПЬьЕФИцОЏСПвВЗЧГЃЕФХгДѓЃЌППШЫСІж№ИіШЅХаЖЯМИКѕЪЧВЛПЩФмЪЕЯжЕФЁЃШчЙћВЛзіИцОЏжЪСПЕФЦРМлЃЌОЭЮоЗЈаЮГЩБеЛЗЃЌЫуЗЈаЇЙћвВЮоЗЈЕУЕНКѓајЕФгХЛЏгыЬсЩ§ЁЃФПЧАЕФЦРМлвЛЗНУцЪЧППзЈМвОбщГщбљХаЖЯЃЌвЛЗНУцЪЧгЪМўНЋИцОЏЭЦЫЭИјМрПиИКд№ШЫЃЌЭЈЙ§вЛЖЈЕФНБРјЛњжЦЕїЖЏгУЛЇРДЗДРЁИцОЏНсЙћЁЃ
вьГЃМьВтЫуЗЈНщЩм
ЯАЙпЩЯЃЌАДееД§МьВтЕФЪ§ОнМЏгаЮоБъЧЉБъзЂПЩвдЗжЮЊМрЖНЪНбЇЯАЁЂЮоМрЖНбЇЯАвдМААыМрЖНбЇЯАЃЛАДееЫуЗЈФЃаЭгаЮоВЮЪ§НЋЫуЗЈЗжЮЊгаВЮФЃаЭКЭЮоВЮФЃаЭЁЃ
ОпЬхЫуЗЈЛљБОЖМЪЧДѓМвЖњЪьФмЯъЕФЃЌЦфжаДѓВПЗжЫуЗЈдкЪЕМЪЪЙгУЕФЪБКђЖМзіЙ§вЛаЉЖўДЮПЊЗЂКЭВЮЪ§гХЛЏЃЌР§ШчФГаЉГЁОАЯТЮвУЧашвЊНЋгаЕФЫуЗЈИФаДГЩЕнЙщЗНЪНЪЕЯжЃЌгУРДЪЪХфСїЗНЪНЕФДІРэЁЃ

ЩЯУцжЛЪЧТоСаСЫВПЗжЫуЗЈЃЌОпЬхЕФЪЕЯжЫуЗЈвЊдЖЖргкетМИжжЁЃЕЋОЭетаЉвьГЃМьВтЫуЗЈЕФЫМЯыНјааЗжРрЕФЛАЃЌЮоЭтКѕСНДѓРрЃК
вЛРрЪЧМрЖНЪНЕФвьГЃМьВтЃЌетРрЫуЗЈЕФЪ§ОнМЏвђЮЊвбОДђЩЯСЫБъЧЉЕФЃЌЗжГЩСЫбЕСЗЪ§ОнМЏКЭВтЪдЪ§ОнМЏЃЌРћгУбЕСЗЪ§ОнМЏКЭЖдгІЕФБъЧЉбЕСЗГіФЃаЭЃЌШЛКѓРћгУбЇЯАЕНЕФФЃаЭдйЖдВтЪдЪ§ОнМЏНјааМьВтЃЛ
СэЭтвЛРрЫуЗЈПЩвдЙщНсЮЊЛљгкЗжВМКЭЭГМЦЬиадЕФвьГЃМьВтЃЌетРраЭЕФЫуЗЈеыЖдЕФЪЧЮоБъзЂЪ§ОнМЏЕФМьВтЃЌвЛИіКмМђЕЅЕФЕРРэЃЌЮвУЧвЊХаЖЯФГИіжИБъе§ГЃгыЗёЃЌвЛЖЈашвЊКЭФГИіЛљзМНјааБШЖдЃЌетИіЛљзМПЩвдЪЧЙЬЖЈуажЕЃЌвВПЩвдЪЧЖЏЬЌуажЕЁЃЛљгкЗжВМКЭЭГМЦЬиадЕФвьГЃМьВтЪЙгУЕФЛљБОЖМЪЧЖЏЬЌЛЏЕФуажЕЁЃ
дкДѓВПЗжЕФЪЕМљГЁОАжаЃЌМрПижИБъЖМЪЧУЛгаБъЧЉБъзЂЕФЃЌетРяЮвУЧжиЕуНщЩмЯТЛљгкЗжВМКЭЭГМЦЬиадЕФвьГЃМьВтдРэЁЃ
ЮвУЧЬсЕНЕФОјДѓВПЗжМрПижИБъЃЌОЙ§ЭГМЦЗжЮіКѓЖМЪЧФмЙЛНќЫЦТњзуе§ЬЌЗжВМЛђепГЌИпЫЙЗжВМЁЃРћгУЭГМЦЬиадзівьГЃМьВтжївЊЪЧПДЗжВМЧщПіЃЌЪБМфжсЩЯЕФМрПиађСаЭЖгАЕНзнжсЩЯЃЌОЭПЩвдЕУЕНЯргІЕФИХТЪУмЖШЗжВМКЏЪ§ЃЌбљзгШчЯТЭМЫљЪОЁЃ
ПЩвдПДЕНЫЎЦНЗНЯђКмИпЕФЕуЃЌЖдгІЕФИХТЪУмЖШЗЧГЃаЁЃЌЖјДѓВПЗжМрПиЪ§ОнЕФЗжВМЖМБШНЯМЏжаЁЃжБЙлЕФПДЃЌСЌајЖрДЮаЁИХТЪЪТМўЗЂЩњОЭПЩвдШЯЮЊЪЧвьГЃЪТМўЁЃ
ЮвУЧНшжњЙЄвЕЩЯГЃгУЕФ3SigmaЃЈБъзМВюЃЉзМдђзїЮЊЪЧЗёЪЧвьГЃЕуЕФМьбщБъзМЃЌЖдБъзМЕФе§ЬЌЗжВМЖјбдЃЌ3SigmaзМдђПЩвдАќРЈећИібљБОМЏ99.7%ЕФЗжВМЃЌвВОЭЪЧЫЕгаЧЇЗжжЎШ§ЕФбљБОЛсБЛХаЖЈЮЊвьГЃЁЃ
ЖдгкГЌИпЫЙЗжВМЃЌвВОЭЪЧаЮзДЩЯБШБъзМе§ЬЌЗжВМИќМтЕФЗжВМЃЌПЩФмВЛгУ3SigmaЃЌ2SigmaЩѕжС1SigmaОЭПЩвдТњзуМьВташЧѓЁЃГ§СЫЪЙгУБъзМВюЭтЃЌЫФЗжЮЛВювВЪЧОГЃБЛгУзївьГЃМьВтЕФЖЏЬЌуажЕЁЃ
ЯТУцЪЧДгЮвУЧЩњВњЯЕЭГРяНиШЁЕФвЛеХЭМЃЌЪЧФГИігІгУЕФФГЯюМрПижИБъЃЌЪњзХЕФащЯпБъЪЖЕФЪБМфЕуДњБэИУжИБъгаМрПиИцОЏЁЃПЩвдПДЕНе§ГЃЧщПіЯТетИіжИБъЪЧБШНЯаЁЃЌАДеевдЭљЙЬЖЈуажЕЕФИцОЏЗНЪНКмФбЗЂЯжетРрЙЪеЯЃЌвђЮЊЙЬЖЈуажЕЖЏщќОЭЪЧГЩАйЩЯЧЇЕФЩшжУуажЕЃЌЯёетжжCaseЃЌКмШнвзТЉЕєИцОЏЃЌЕЋЪЧЭЈЙ§ЗжВМКЭЭГМЦЬиадРДМьВтОЭКмШнвзЗЂЯжвьГЃЁЃ 
ЧАУцНщЩмСЫЛљгкЗжВМКЭЭГМЦЬиадЕФвьГЃМьВтЙцдђЃЌдРэЩЯОЭЪЧЛљгкN SigmaзМдђЗНЪНЪЕЯжЕФЖЏЬЌуажЕЃЌЦфжаЖЏЬЌуажЕЪЧИљОндЄВтЛљЯпКЭNБЖБъзМВюМЦЫуЕУЕНЕФЁЃНгЯТРДетИіЫуЗЈжївЊЪЧИњДѓМвЗжЯэЯТЃЌЮвУЧЪЧШчКЮЛљгкЪБЦЕБфЛЛЕУЕНдЄВтЛљЯпЁЃ
ЪБЦЕБфЛЛЖдКмЖрШЫРДНВПЩФмЪЧИіБШНЯФАЩњЕФИХФюЃЌгУЕНЕФММЪѕНазіИЕРявЖБфЛЛЁЃДѓМвПЩФмЛђЖрЛђЩйЖМгавЛЕугЁЯѓЃЌИпЕШЪ§бЇгавЛеТМЖЪ§ЃЌдјОЬсЕНЙ§ИЕРявЖМЖЪ§ЁЃЯЕЭГНВНтИЕЪЯБфЛЛЕФММЪѕЪЧдкаХКХДІРэетУХПЮГЬРяБпНщЩмЕФЁЃ
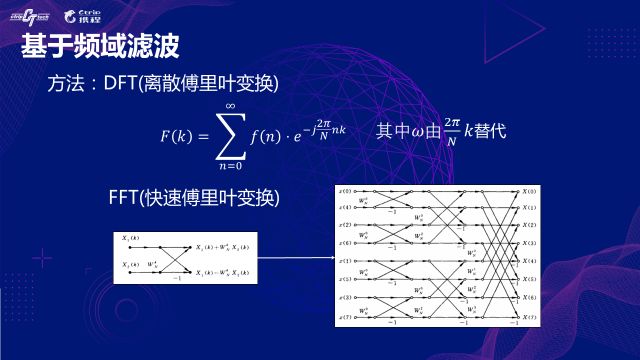
РэНтИЕЪЯБфЛЛЕФЮяРэвтвхЪЧКмгаЬєеНадЃЌетРяМђЕЅНщЩмЯТШчКЮгІгУКЭЪЕЯжЃЌОпЬхЪЕЯжашвЊЖдМрПиађСаМгДАЃЌШЛКѓзіРыЩЂИЕРявЖБфЛЛЁЃЯТУцвВИјГіСЫОпЬхЕФМЦЫуЙЋЪНЃЌЕЋгЩгкжБНгМЦЫуЯрЕБЕФИДдгЃЌЪЕЯжЩЯЖМЪЧЭЈЙ§зіПьЫйИЕРявЖБфЛЛЪЕЯжЯТЕФЃЌМђГЦFFTЁЃКмЖрБрГЬгябдЖМгаЯжГЩЕФКЏЪ§ПтЪЕЯжЁЃ
ЭЈЙ§ЧАУцНщЩмЕФЪБЦЕзЊЛЛММЪѕЃЌНЋМрПиЪБађБфЛЛЕНЦЕТЪгђжЎКѓдйЖдЦЕЦззіЯргІЕФЙ§ТЫЃЌШЅГ§ЕєЦЕТЪНЯИпЕФГЩЗжЃЌШЛКѓдкЪБМфгђжиЙЙЪБађЃЌОЭПЩвдЕУЕНвЛЬѕЯрЖдЦНЮШЕФЛљЯпСЫЁЃ
етРяЕФЧАЬсМйЩшОЭЪЧЮвУЧЕФМрПижИБъе§ГЃЧщПіЯТЖМЪЧЦНЮШЕФЃЌНЅБфЕФЁЃДгЮвУЧЩњВњЯЕЭГРяБпНиШЁСЫвЛЖЮЛљгкЦЕгђТЫВЈЕФМрПиНсЙћЃЌЛЦЩЋЕФЧњЯпЪЧдЪМЕФМрПижИБъЃЌТЬЩЋЕФЧњЯпЪЧЭЈЙ§ЦЕгђТЫВЈжЎКѓЕФЛљЯпЃЌПЩвдПДЕНЪЧвЛЬѕЗЧГЃЦНЛЌКЭЮШЖЈЕФЧњЯпЁЃДгЭМжаПЩвдПДЕНЃЌЪЙгУетИіММЪѕПЩвдгааЇЕФЬоГ§ЕєвьГЃМрПиЕуЃЌШЗБЃЛљЯпЦНЮШЁЃ

ЛљгкЪБЦЕБфЛЛЕФММЪѕЃЌГ§СЫЧАУцНВЕНЕФПЩвдЙ§ТЫЕєЪБађжаЕФИпЦЕГЩЗжЩњГЩБШНЯЦНЮШЛљЯпЪБађЭтЃЌЛЙПЩвдздЖЏЗЂЯжЪБађЪЧгаАќКЌжмЦкадЬиеїЁЃ
вдетЗљЭМЮЊР§ЮЊР§ЃЌетЪЧДгЩњВњЯЕЭГРяБпНиШЁЕФвЛЖЮецЪЕЕФМрПижИБъЁЃжБЙлЕФПДЃЌШЗЪЕЪЧДцдкУїЯдЕФжмЦкадЃЌЯждкЮвУЧвЊзіЕФЪТЧщЪЧШУГЬађздЖЏЕФРДЪЖБ№етИіжИБъЕФжмЦкЁЃ
ЪзЯШЖдетИіЪБађзівЛИіздЯрЙиЃЌШчЭМжаЕк2ЗљЫљЪОЃЌШЛКѓШЅЕєздЯрЙиађСажаЦЕТЪЙ§ЕЭКЭЙ§ИпЕФГЩЗжЃЌдйШЅЕєОљжЕЃЌШчЭМжаЕк3ЗљЫљЪОЃЌетЪБКђНсЙћПДЩЯШЅгаЕуНгНќе§ЯвВЈЕФаЮзДЁЃзюКѓдйЖдЩЯУцЕФНсЙћзівЛДЮЪБЦЕБфЛЛОЭПЩвдЕУЕНЖдгІађСаЕФЦЕТЪЦзЃЌШчзюКѓвЛЗљЭМЫљЪОЁЃ 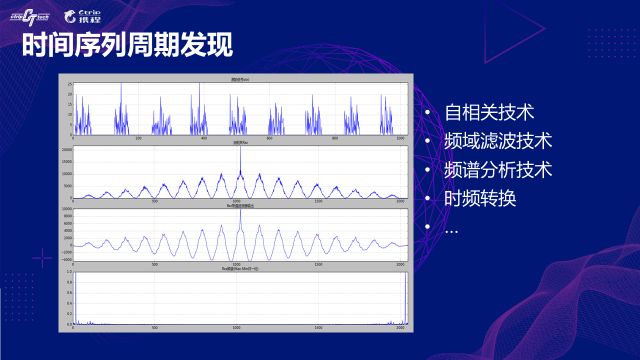
ЦЕТЪЦззѓгвЖдГЦЃЌЕЅЮЛвЛАуШЁКезШЃЌЦЕЦзЩЯгаУїЯдЕФЦзЯпОЭЫЕУїЖдгІЕФЪБМфађСаДцдкБШНЯЧПЕФжмЦкадЃЌЭЈЙ§вЛЖЈЕФЪ§бЇЙЋЪНзЊЛЛЃЌОЭПЩвдМЦЫуГіЯргІЕФжмЦкДѓаЁЁЃ
вьГЃМьВтЪЕМљЕФОбщзмНс
еыЖдЧАУцНщЩмЕФЙигквьГЃжИБъМьВтЪЕМљФкШнЃЌЮвУЧМђЕЅзмНсЯТЪЕМљЕФГЩЙћКЭЛ§РлЕФвЛаЉОбщЃЌвдМАЪЖБ№ЕНЕФвЛаЉЮЪЬтЁЃ
ЭЈЙ§жЧФмЛЏИцОЏЕФЪЕМљЃЌгІгУИцОЏЕФзМШЗТЪЁЂейЛиТЪЯрБШжЎЧАЛљгкЙцдђКЭЙЬЖЈуажЕЗНЪНЕФИцОЏЕУЕНСЫКмДѓЕФЬсЩ§ЁЃ
ЯждкаЏГЬФЌШЯЕФгІгУИцОЏЗНЪНвбОШЋЬцЛЛГЩСЫжЧФмИцОЏЁЃДѓВПЗжЪЕМљГЁОАжаЃЌетаЉЪБађЪ§ОнЖМЪЧУЛгаБъзЂЕФЃЌЖМЪЧашвЊНсКЯЛљгкЗжВМКЭЭГМЦЬиадЕФвьГЃМьВтЗНЪНЁЃ
СэЭтВЂВЛЪЧЫљгаЕФЪБађЖМЪЧвЊВЩгУжЧФмЛЏЕФЗНЪНБЛМьВтЃЌетРяЩцМАЕНЫуСІКЭГЩБОЕФЭЖШыЃЌШчЙћЛљгкЙцдђЕФЗНЪНПЩвдТњзуФГаЉГЁОАЯТЕФИцОЏМьВтЃЌФЧУДзіжЧФмЛЏМьВтЕФвтвхОЭВЛЪЧКмДѓЃЌзіГЩетМўЪТжївЊЛЙЪЧЮЊСЫНтОіЁАЭДЕуЁБЁЃ

СэЭтОЭЪЧВЛЭЌЪБађЕФЬиеїПЩФмгаЫљВЛЭЌЃЌЖјВЛЭЌЕФЫуЗЈЪЪгУГЁОАвВгаЫљВювьЃЌЫљвдеыЖдВЛЭЌЬиеїЕФЪ§ОнМЏОЭашвЊХфжУВЛЭЌЕФМьВтЫуЗЈЁЃ
дйЬсвЛЯТМьВтНсЙћЕФжЪСПЦРЙРЮЪЬтЃЌЖдгкУЛгаБъЧЉБъзЂЕФЪ§ОнМЏРДЫЕЃЌвЛжБЪЧвЛИіФбЕуКЭЬєеНЃЌжЛгаетИіЛЗНкДђЭЈЃЌвьГЃМьВтВХЫуЪЧеце§ЕФБеЛЗСЫЁЃвВжЛгаВЛЖЯЕиЪеМЏКЭРћгУЗДРЁНсЙћЃЌетМўЪТВХФмдНРДдНжЧФмЁЃ
гІгУИцОЏЕФжЧФмеяЖЯ
ЮвУЧЯШРДПДвЛИіР§згЃЌЯТУцЪЧвЛеХДѓСПгІгУИцОЏЪБЕФгІгУДѓХЬНиЭМЃЌБъКьЕФУПИіЗНИёБэЪОЕБЧАгаИцОЏЕФгІгУЁЃЪЕМЪгІгУжЎМфЕФЕїгУДэзлИДдгЃЌОПОЙЪЧФФИігІгУЛђЪВУДВйзїЕМжТСЫДЫДЮЙЪеЯЃЌашвЊФмПьЫйХХВщГіЙЪеЯдвђЃЌетбљОЭПЩвдЮЊЭјеОПьЫйЛжИДКЭжЙЫ№ЁЃ 
зїЮЊМсЖЈЕФЮЈЮяжївхвђЙћТлепЃЌЮвУЧЯраХЭђЪТНдгавђЙћЁЃНшжњзЈМвОбщЃЌЮвУЧАбЫљгаПЩФмЛсгАЯьЕНФГИігІгУвьГЃЕФвђЫиТоСаГіРДЃЌУПИізгЯюГЦЮЊвЛИівђзгЗжЮіЦїЃЌЦфжаАќРЈСЫгІгУЗЂВМЁЂХфжУБфИќЁЂЕїгУСДвьГЃЁЂДњРэЙЪеЯЁЂЪ§ОнПтЗЂВМЁЂDNSЙЪеЯЁЂИКдиОљКтЦїЙЪеЯЁЂЭјТчБфИќЕШЕШЁЃ 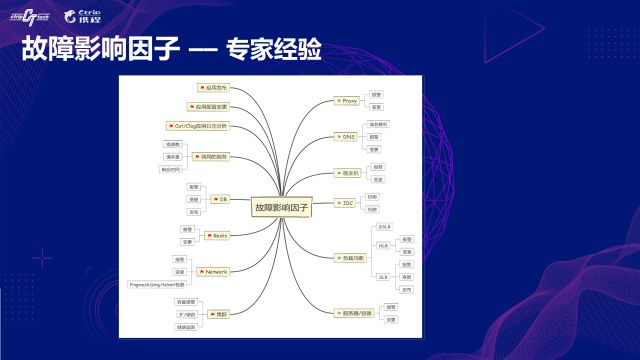
УПЕБЗЂЩњгІгУИцОЏЕФЪБКђЃЌОЭЛсздЖЏДЅЗЂвђзгЗжЮіЦїЗжЮіЁЃв§згЗжЮіЦїжївЊЪЧзідЫЮЌЪТМўМАИцОЏЕШКЭгІгУИцОЏЕФЙиСЊЗжЮіЃЌЗжЮіНсЙћгУАйЗжжЦДђЗжИјГіЁЃ
жївЊЕФЫуЗЈгаСНИіЃКвЛжжЪЧЛљгкЦЄЖћбЗЯрЙиЯЕЪ§МЦЫуЕУЕНЕФЯрЙиЯЕЪ§ЃЛСэЭтвЛжжЪЧЛљгкБДвЖЫЙЙЋЪНМЦЫуЕУЕНЕФКѓбщИХТЪЁЃетСНжжММЪѕМЦЫуЕФНсЙћЃЌЦфОјЖджЕЖМЪЧдк0КЭ1жЎМфЃЌЯрЕБгкЖдНсЙћзіСЫЙщвђЛЏЕФДІРэЃЌШЛКѓЖдетИіНсЙћдйГЫвд100ОЭПЩвджБНгМЦЫуГівђзгЗжЮіЦїЪфГіЕФЙиСЊЗжЪ§ЁЃ 
гІгУЕФЯрЙиадДђЗжЁЂОлКЯ
вђзгЗжЮіЦїжжРрЬиБ№ЖрЃЌетРяЮвУЧвдгІгУИцОЏжИБъКЭЗЂВМЪТМўжЎМфЕФЙиСЊЗжЮіЮЊР§ЃЌЫЕУїЯТЯрЙиадДђЗжЕФдРэЁЃ 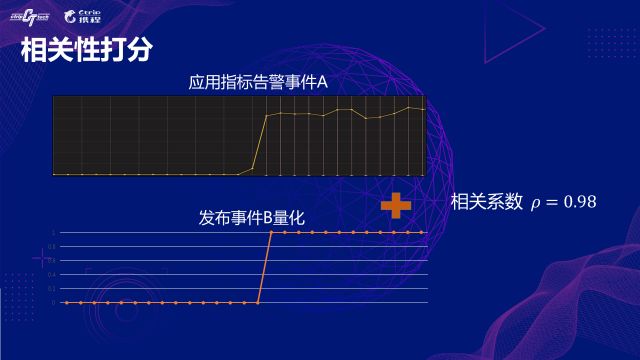
ЩЯУцЛЦЩЋЕФЧњЯпДњБэСЫФГИіИцОЏгІгУЕФМрПижИБъЃЌМЧзіађСаAЃЛЯТУцЕФКьЩЋЕФЧњЯпДњБэСЫЗЂВМЪТМўдкЪБМфЮЌЖШЩЯЕФСПЛЏНсЙћЃЌМЧзіађСаBЁЃДЫЪБЮвУЧОЭЕУЕНСЫAКЭBСНИіЪБМфађСаЃЌШЛКѓМЦЫуЯТЦЄЖћбЗЯрЙиЯЕЪ§МДПЩМЦЫуЕУГіЙиСЊЗжЮіНсЙћЁЃ
ЭЌбљЕФЫМТЗЮвУЧЛЙПЩвддЫгУЕНЖрИіИцОЏгІгУжЎМфЕФЙиСЊадЗжЮіЁЃЭМжаЩЯЯпСНЬѕЧњЯпЗжБ№ДњБэСЫСНИіИцОЏгІгУЕФМрПижИБъађСаЃЌЖдетСНИіМрПиЪБађжБНгМЦЫуЦЄЖћбЗЯрЙиЯЕЪ§ЃЌМДПЩЧѓЕУСНИіИцОЏжЎМфЕФЙиСЊГЬЖШЁЃ
СэЭтЃЌЮвУЧЛЙЛсЭЈЙ§ПђМмжаМфМЧТМЕФТёЕуЪ§ОнЗжЮіСНИігІгУжЎМфЪЧЗёДцдкЕїгУЙиЯЕЃЌдйНсКЯжЎЧАМЦЫуЕУЕНЕФЯрЙиЯЕЪ§ЃЌвдДЫРДЭъГЩНЋЖрИігІгУИцОЏЪТМўНјааОлКЯКЭЪеСВЁЃ 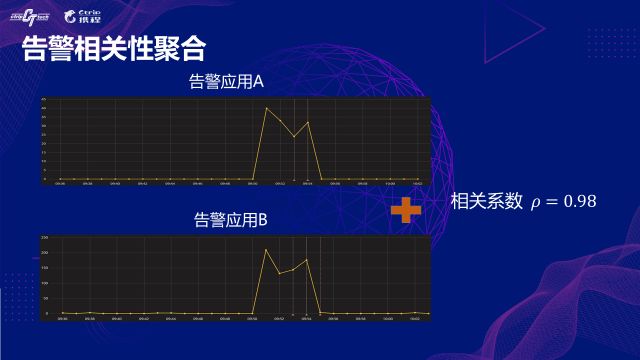
КѓбщИХТЪДђЗж
РћгУКѓбщИХТЪДђЗжЃЌашвЊЛ§РлЯрЕБГЄЪБМфЕФРњЪЗдЫЮЌЪТМўКЭЙиСЊгІгУИцОЏЕФЪ§ОнЃЌМЧТМВЂЪеМЏдкдЫЮЌжЊЪЖПтЁЃетРяЮвУЧжївЊЖдБДвЖЫЙЙЋЪНЕФЪЙгУзіЯТЫЕУїЃЌЪЙгУБДвЖЫЙЙЋЪНЕФФПЕФжївЊЪЧЯЃЭћДгЫЦШЛИХТЪМЦЫуЕУГіКѓбщИХТЪЁЃ
ЫЦШЛИХТЪЪЧПЩвдЭЈЙ§ЖджЊЪЖПтЕФбЕСЗКЭбЇЯАЕУГіЕФФГИідЫЮЌЪТМўЗЂЩњЕФЪБКђЃЌИїгІгУИцОЏЗЂЩњЕФИХТЪЃЛКѓбщИХТЪИеКУЪЧЗДЙ§РДЕФЃЌЪЧдкгІгУИцОЏЕФЪБКђЃЌФГИідЫЮЌЪТМўЗЂЩњЕФИХТЪДѓаЁЃЌЖјетаЉдЫЮЌЪТМўДѓВПЗжЧщПіЯТОЭЪЧЖдгІгІгУИцОЏЕФИљдДЁЃ

ЩЯУцЮвУЧНщЩмСЫЖржжЙЪеЯЙиСЊЕФЗНЗЈКЭЪЕЯжЁЃЪЕМЪаЇЙћШчКЮФиЃПетЗљЭМЪЧДгЮвУЧЩњВњЯЕЭГРяБпНиЕФвЛеХЙЪеЯЪБКђПьЫйЖЈЮЛИљдДЕФПьХФЁЃ
ФГЬьФГЪБЭЛШЛгаКмЖргІгУИцОЏЭЌЪБИцОЏЃЌдкЮвУЧЙЪеЯеяЖЯЯЕЭГжавЛМќЗжЮіОЭЕУГіСЫЭМжаЕФНсЙћЃЌЖЈЮЛЕФНсЙћЗЧГЃУїЯдЕижИЯђСЫжаМфФГИігІгУЃЌЖјетИігІгУЕБЪБЙиСЊЕНе§дкзіЗЂВМЁЃ
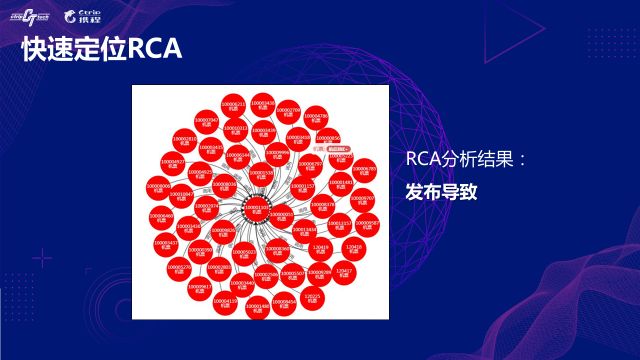
ЙЪеЯеяЖЯзмНс
КЭЧАУцгІгУИцОЏЕФжЧФмМьВтЪЕМљвЛбљЃЌЮвУЧзмНсЯТЙЪеЯжЧФмеяЖЯЕФЪЕМљГЩЙћЁЂОбщКЭЪЖБ№ЕНЕФвЛаЉЮЪЬтЁЃ
ФПЧАДѓВПЗжЙЪеЯЗЂЩњЪБЃЌЮвУЧвбОПЩвдПьЫйЕФЖЈЮЛГіЙЪеЯИљдДЃЌДѓДѓЫѕЖЬСЫЛжИДЙЪеЯЕФЪБМфЁЃвђзгЗжЮіЦїЕФЩшМЦЁЂзЈМвОбщжЊЪЖПтЕФЙЙНЈЁЂЙиСЊДђЗжЁЂЕїгУСДЭкОђЕШЖМЪЧЗЧГЃЙиМќЕФММЪѕЕуЁЃ
вЊЬсЕНЕФвЛЕуЪЧЃЌеяЖЯжЪСПЕФНсЙћЦРЙРКЭИцОЏжЪСПЕФНсЙћЦРЙРРрЫЦЃЌвВЪЧвЛИіММЪѕФбЕуЁЃЮДРДЕФМЦЛЎЪЧЫцзХЗДРЁЪ§ОнЕФВЛЖЯЛ§РлвдМАжЊЪЖПтЕФЭъЩЦЃЌЯраХетИіЮЪЬтЛсж№ВНЕУЕНИќКУЕиНтОіЁЃ

AIOpsЮДРДеЙЭћ
ЭЈЙ§аЏГЬдкAIOpsЗНУцЕФЪЕМљКЭЬНЫїЃЌзюКѓМђЕЅзмНсЯТЮвУЧдкAIOpsЗНУцЕФвЛаЉЫМПМКЭеЙЭћЁЃ
AIЪЧЁАЫћЩНжЎЪЏЁБЃКAIOpsЪЧвЛИіПчСьгђНсКЯЕФММЪѕЃЌAIжЛЪЧНтОідЫЮЌЮЪЬтЕФвЛжжЫМТЗКЭЙЄОпЃЌЪЕМљЕФГіЗЂЕуКЭТфНХЕуЛЙЪЧOpsЁЃСэЭтЃЌНЯИпЕФздЖЏЛЏГЬЖШЪЧAIOpsЪЕМљЕФЧАЬсЁЃ
ЪЕМљвЛЖЈвЊНсКЯздЩэГЁОАЃКЮвУЧвЛжБЪЧжїеХГЁОАгХЯШЕФддђЃЌЪЕМљAIOpsЃЌЪзЯШвЛЖЈвЊУїШЗздЩэдЫЮЌЙ§ГЬжаЕФГЁОАКЭЭДЕуЃЌВЛФмИњЗчЃЛОЏЬшФУРДжївхЃЌAIOpsФПЧАУЛгаУїШЗКЭЭГвЛЕФЪЕМљЙцЗЖЃЌЪЕМљЧАзюКУвЊИуЧхГўЛњжЦКЭдРэЃЌБивЊЕФЪБКђзівЛаЉЖўДЮПЊЗЂЁЃ
НєИњаавЕЖЏЬЌЃКДѓаЭЛЅСЊЭјЦѓвЕгаЯрЕБЕФВЦСІКЭШЫСІзіетМўЪТЧщЃЌЖјЧввЛАувВКмРжвтЗжЯэЯрЙиЕФЪЕМљОбщЁЃНєЫцаавЕЕФвЛаЉзюМбЪЕМљЃЌНсКЯздЩэГЁОАЗжЮіЬжТлТфЕиЕФПЩааадЃЌПЩвдБмУтДѓЗНЯђЩЯзпЭфТЗЁЃ
бЇЪѕНчИњЙЄвЕНчИїЙБЯзвЛАыСІСПЃКетЪЧЧхЛЊХсЕЄНЬЪкдкИїжжAIOpsЛсвщЩЯЗжЯэЕФЪБКђвЛжБКєгѕЕФЃЌбЇЪѕНчЙБЯзЫуЗЈЃЌЙЄвЕНчЙБЯзЪ§ОнКЭГЁОАЃЌзюжеЪЕЯжAIOpsЕФУРКУдИОАЁЃ

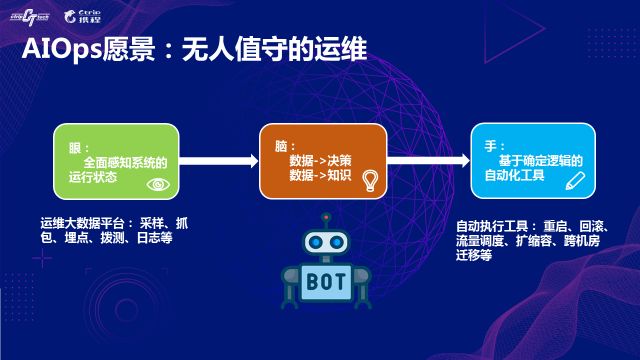
AIOpsзмЬхРДЫЕЪЧвЛИіБШНЯаТКЭГѕЦкЕФММЪѕЃЌдЄВт5ЕН10ФъКѓЃЌдЫЮЌБиНЋЪЧСэЭтвЛЗЌОАЯѓЁЃЯраХЭЈЙ§ЙЙНЈУєШёЕФЁАблЁБЁЂжЧЛлЕФЁАФдЁБвдМАздЖЏЛЏЕФЁАЪжЁБЃЌЁАЮоШЫжЕЪиЕФдЫЮЌЁБЕФУРКУдИОАжеНЋФмЪЕЯжЁЃ
|









