| БрМЭЦМі: |
| РДздзїепХэЖЌЃЌAIOpsЃЌвВОЭЪЧЛљгкЫуЗЈЕФITдЫЮЌЃЈAlgorithmic
IT OperationsЃЉЃЌЪЧгЩGartnerЖЈвхЕФаТРрБ№ЃЌдДздвЕНчжЎЧАЫљЫЕЕФITOAЃЈIT
Operations and AnalyticsЃЉЁЃ |
|

1.ИХЪіЃКЮвУЧРы AIOps РэЯыЭѕЙњЛЙгаЖрдЖ
ЗжЫФИіФЃПщЃЌЪзЯШЮвУЧСЫНтКЭвЛЦ№ЬНЬжвЛЯТЃЌДѓМвЖМдкЬс AIOpsЃЌЮвУЧ
AIOps РэЯыЭѕЙњЕНЕзРыдлУЧЯждкЛЙгаЖрдЖЃЌЮвУЧвЛЦ№ЬНЬжвЛЯТЁЃ

ЮвУЧЬНЬжетИіЮЪЬтЪБКђПМТЧУЮЯыЛђепРэЯыЪЧЪВУД:
ЕквЛИіЃЌЮвУЧВЛБГЙјЃЌЮвЯраХдкзљзідЫЮЌЕФЭЌбЇПЯЖЈгаБГЙјЕФОРњЃЌШчЙћЮвУЧЪЕЪЉ AIOps ШУДѓМвВЛгУдйБГЙјСЫЃЌетЫуЪЧЕквЛИіРэЯыЁЃ
ЕкЖўИіРэЯыЃЌВЛгУдйЦ№вЙЃЈАывЙБЛНаабЃЉЃЌетИіЪТЧщОГЃЛсЗЂЩњЁЃЮвЕФЭХЖгЃЌАќРЈЮвздМКЃЌвВЛсгЩгкЯпЩЯЮЪЬтАывЙЦ№РДВйзїЯпЩЯЗўЮёЃЌЮвУЧЯЃЭћгаСЫAIOpsжЎКѓетЪЧвЊЪЕЯжЕФЕкЖўИіРэЯыЃЛ
ЕкШ§ИіРэЯыЃЌЮвУЧВЛгУШЅ7ЁС24аЁЪБжЕАрЃЌгШЦф618ЁЂЙњЧьЁЂЫЋЪЎвЛЁЂЫЋЪЎЖўЃЌИїжжНкШеЗЧГЃЖрЃЌетжжЧщПіЯТвЊжЕАрЃЌЯЃЭћгаСЫAIOpsетЬзЛњжЦКѓЃЌВЛашвЊдйзіХХАрЁЂжЕАрЃЌЭъШЋЛњЦїздЖЏжДааШЫЙЄвЊИЩЕФЪТЧщЃЌетЪЧЮвУЧМљааAIOpsЕФШ§ДѓРэЯыЁЃ

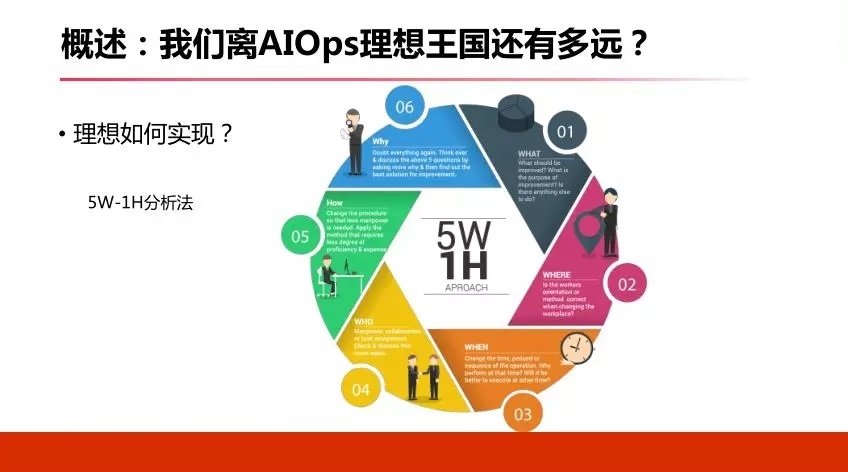
ИеВХжЊЕРЮвУЧРэЯыЃЌФЧдѕУДШЅЪЕЯжФиЃПЮвУЧПЩвдЭЈЙ§етбљЗжЮіЗНЗЈЃК5W-1HЗжЮіЗНЗЈЃЌетИіРэТлдкЙЋЫООгЊЙмРэЗНУцгУЕУЗЧГЃЖрЃЌзіШЮКЮЪТЧщвЊЮЪ5ИіWЃЌ1ИіHЁЃ
ЕквЛИіWЃЌЮвУЧзіЪВУДЁЃЕкЖўИіЃЌдкФФИіЕиЗНзіЁЃЕкШ§ИіЃЌЪВУДЪБКђПЊЪМзіЁЃЕкЫФИіЃЌЫШЅзіЃЌДѓМвЮЪЭъетаЉЮЪЬтаФРявбОгаД№АИЃЌЫШЅзіЃЌдЫЮЌШЅзіAIOpsЁЃ
ЮвУЧдѕУДШЅзіКЭЮЊЪВУДЪЧЮвУЧзіЃЌЖјВЛЪЧБ№ШЫШЅзіФиЃПНгЯТРДЮвУЧЬНЬжетИіЮЪЬтЁЃ

етОЭЛиЕНСЫетИіЮЪЬтЃЌЮвУЧРэЯыЕНЕздѕУДШЅЪЕЯжФиЃПЮвОѕЕУД№АИЪЧетбљЕФЃКcodingЃЌжЎЧАзідЫЮЌЕФЭЌбЇаДНХБОЛђепзіЛњЦїдЫЮЌЃЌЯждкЮвУЧзі
AIOps Лђеп DevOpsЃЌЮвУЧНјШыСЫПЊЗЂСьгђЃЌЫљвдЮвУЧвЊВЛЭЃаДДњТыШЅЪЕЯжздМКЕФРэЯыЁЃ
гаСЫРэЯыжЎКѓЃЌЮвУЧгжгаСЫЗНЗЈЃЌЕНЕзЛЙвЊЖрОУВХФмЪЕЯжРэЯыФиЃЌетРяПЩвдВЮПМНшжњгкПЕВЈжмЦкРэТлЁЃ
етЪЧвЛИіЖэТоЫЙЗЧГЃГіУћОМУбЇЬЉЖЗШЫЮяЬсГіЕФжмЦкИХФюЃЌЪЧжИЮвУЧЩчЛсЕФОМУЗЂеЙДцдкжмЦкадВЈЖЏЕФЬиЕуЁЃ
БШШчЫЕЮвУЧЕФОМУЭЈГЃЛсОРњВЈЙШЕНВЈЗхЙ§ГЬЃЌУПДЮЫЅЭЫЕНаЫЪЂашвЊПЦММИяУќЕФЭЦЖЏЃЌБШШчеєЦћЛњЁЂЬњТЗЃЌЛЙгавЛаЉЕчЦјЙЄвЕЃЌЕНITЃЌдйЕНЮвУЧЯждкAIЃЌетЪЧЭЦЖЏЮвУЧНЈСЂетбљвЛИіаТжмЦкЕФММЪѕжЇГХЁЃ
етИіРэТлШЯЮЊЃЌвЛИіжмЦкДѓИХвЊ50ФъЃЌгЩДЫПЩМћЃЌЖдгкAIЃЌЮвУЧЯждкИеПЊЪМЃЌЫљвдЮвУЧе§ДІгкетИіЪБДњзюПЊЪМЃЌДѓМвЭЖЩэ
AIOps НЋЗЧГЃгаЛњЛсЁЃ
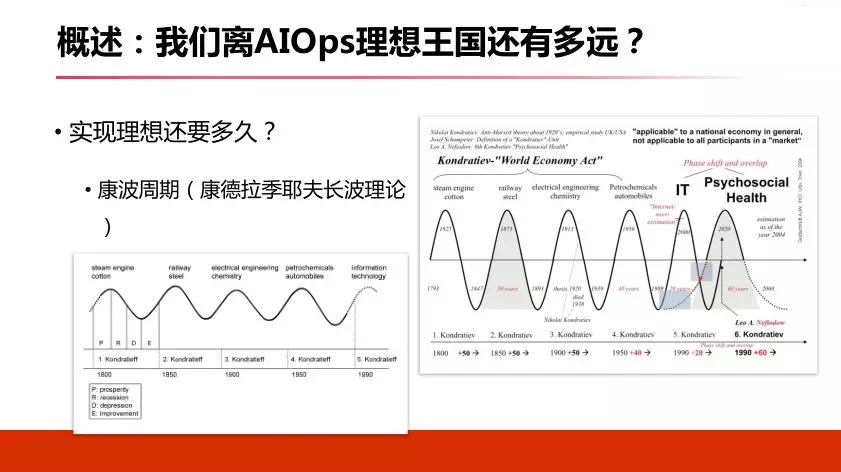
2. зМБИЃКвджеЮЊЪМЃЌПДзМФПБъ
ИеВХЬсЕНЮвУЧдЫЮЌДгПЊЪМВЛгУаДДњТыЃЌЕНаДНХБОЃЌЕНЮвУЧПЩвдзіSREЙЄзїЃЌдйзіПЊЗЂDevOpsЃЌдйзі AIЃЌЮвУЧдЫЮЌНЧЩЋЗЂЩњзХБфЛЏЁЃДгзюПЊЪМЕФдЫЮЌЕНдЫЮЌЙЄГЬЪІЃЌдйЕНПЊЗЂЙЄГЬЪІЃЌдйЕНДѓЪ§ОнЙЄГЬЪІЃЌзюКѓЖМБфГЩЫуЗЈЙЄГЬЪІЃЌЫљвдОЭЪЧетбљвЛИіНЧЩЋЕФБфЛЏЙ§ГЬЃЌЮвУЧДІгкетИіAIЪБДњЃЌЮвОѕЕУЗЧГЃКУЕФЁЃ
ИеВХЮвУЧЬИСЫРэЯыЃЌгаСЫРэЯыжЎКѓЃЌЮвУЧЩшЖЈЪЕЪЉФПБъЃЌЫљвдЯждкЮвУЧЬНЬжвЛЯТдѕУДШЅЪЕЪЉФПБъЃЌвЊЯШСЫНтвЛЯТЮвУЧаавЕЕФЯжзДЃЌОпЬхЕФФПБъЪЧЪВУДЃЌЮвУЧЪЕЪЉ
AIOps Ш§МнТэГЕЪЧЪВУДЁЃ

ЮвУЧПДвЛЯТаавЕЯжзДЃЌЕквЛЬнЖгЃЌПДЙњФкЕквЛЬнЖгЃЌBATДѓМвЖМШЯПЩЕФЁЃЕБШЛЛЙгаBATXJЃЌЛЙгаATMЃЌЛЙгаXXXЃЌЛЙгаКмЖрЦѓвЕЃЌБШШчFacebookЁЂGoogleЕШЦѓвЕЁЃ
ЮвУЧИњЕквЛЬнЖгБШЩдЮЂРЇФбвЛЕуЃЌЫћУЧЬиЕуЪЧШЫЖрЁЂБјЧПТэзГЃЌЧЎЖрЁЂЬхСПДѓЁЂЦ№ВНдчЃЌБ№ШЫБШЮвУЧДЯУїЃЌЦ№ВНЛЙБШЮвУЧдчЃЌЮвУЧДяЕНЫћУЧетбљНзЖЮЃЌБШШчИеВХАЂРяКЭАйЖШЭЌбЇЗжЯэЕФММЪѕЃЌЮвУЧДяЕНЫћУЧОГНчПЩФмЛЙдчзХФиЁЃЖдгкЕквЛЬнЖгРДНВЃЌЮвУЧПЩФмзЗИЯЫћУЧЩдЮЂРЇФбвЛЕуЁЃ

длУЧПДЕкЖўЬнЖгЃЌЕкЖўЬнЖгЮвУЧШЯЮЊЪажЕ100вкЕН500вкжЎМфЕФЦѓвЕЃЌБШШчЮЂВЉЁЂЫбКќЁЂЭјвзЃЌетаЉЦѓвЕИќзЂжигквЕЮёЃЌЙЄГЬМмЙЙДгСуПЊЪМЁЃ
вЊИњЫћУЧЭЌЬЈОКММЃЌдлУЧгаЁЖЦѓвЕМЖ AIOps ЪЕЪЉНЈвщЁЗЃЌАќРЈЮвУЧГіЕФжЧФмдЫЮЌетБОЪщЃЌДгетаЉВФСЯРяУцКЭИпаЇдЫЮЌЙЋжкКХРяУцбЇЕНКмЖрЖЋЮїЃЌПЩвдДгСуДюНЈздМКЕФ
AIOps ЯЕЭГЁЃ

ЧјБ№ОЭЪЧетбљЃЌЖдгкЕквЛЬнЖгРДНВЃЌBATКНПеФИНЂЃЌдьИїжжТжДЌДѓХкЃЌЫљгаСуВПМўздМКШЅИуЁЃ
ЖдгкЮвУЧЕкЖўЬнЖгРДНВЃЌЮвУЧзіСЫЪВУДЪТЧщФиЃПЮвУЧгУСЫКмЖрПЊдДЕФЖЋЮїЃЌЖдгкЮЂВЉРДНВгУСЫЗЧГЃЖрПЊдДЃЌБШШч
Redis МЏШКЮвУЧЪЧЙњФкзюДѓЕФЃЌЮвУЧвВгУСЫЦфЫћКмЖрЕФПЊдДШэМўЁЃ

ЮвУЧЗЂЯжЕквЛЬнЖгКЭЕкЖўЬнЖгЧјБ№жЎКѓЃЌОЭПЩвдЩшЖЈЮвУЧздМКФПБъЃЌУїШЗдЫЮЌФПБъЕНЕзЪЧЪВУДЃЌетИіКмживЊЁЃЮвУЧСаСЫМИЕуЃЌвЛАуДѓМвОѕЕУЮШЖЈадЁЂПЩППадЃЌадФмЪЧЮвУЧзідЫЮЌЕФФПБъЃЌЪЕМЪЩЯЮвУЧвЊПМТЧЕФЪЧЃЌЖдгкЮШЖЈадРДНВЃЌгаЪБКђдЫЮЌЪЧВЛФмЭъШЋИЩдЄЕФЁЃ

ЮШЖЈадвЛАуЪЧжИвЛИіЯЕЭГЮШЖЈадЛђепЗўЮёЮШЖЈадЃЈГіЙЪеЯЕФИХТЪЃЉЃЌПЩФмИњПЊЗЂКмгаЙиЯЕЃЌЫћаДвЛИіДњТыгаBUGЃЌЮШЖЈадОЭВЛИпЁЃЮвУЧдЫЮЌгІИУШЅЯыАьЗЈЬсИпПЩгУадЃЌЮвУЧЙизЂЕФзюживЊжИБъгІИУЪЧЯЕЭГЕФПЩгУадЁЃ
ПЩгУадЕФЖЈвхЪЧетбљЃЌгаСНИівђЫигАЯьПЩгУадЃКЙЪеЯГіЯжЕФМфИєЪБМфЃЌМфИєЪБМфШчЙћдНГЄЃЌПЩгУаддНИпЁЃ
ЕкЖўЃЌЙЪеЯЕФаоИДЪБМфЃЌаоИДЫйЖШдНПьЃЌПЩгУаддНИпЁЃ
дЫЮЌвЊзіЕФЙЄзїЃЌвЛЪЧвЊШЅРГЄЮвУЧЙЪеЯГіЯжЕФМфИєЪБМфЁЃЕкЖўЃЌвЛЕЉГіЙЪеЯЕФЪБКђЃЌЮвУЧФмЙЛПьЫйШЅаоИДЃЌетСНЕуе§КУПЩвдЭЈЙ§здЖЏЛЏЗНЪНКЭжЧФмЛЏЗНЪНФмЙЛНтОіЕФЮЪЬтЁЃ

ЮвУЧИеВХЬсЕНдЫЮЌЕФКЫаФФПБъЪЧвЊЬсИпПЩгУадЃЌЯТУцЮвУЧСФвЛЯТЪЕЯж AIOps гаШ§МнТэГЕЁЃ
ЕквЛЃЌИажЊВуЃЌМрПиЦНЬЈЃЌЮвЯраХЫљгазідЫЮЌЦНЬЈЖМжЊЕРМрПиЦНЬЈЪЧЪВУДбљзгЃЌашвЊгавЛИіБЈОЏЦНЬЈЃЌашвЊгавЛИіCI/CDЦНЬЈЃЌздЖЏЛЏЦНЬЈЁЃCI/CDЦНЬЈИКд№зюжежДааЃЌгаСЫВпТджЎКѓЃЌАбетИіВпТдЪЕЪЉЕНЯпЩЯЃЌашвЊетШ§МнТэГЕЃЌжЛгаетШ§МнТэГЕЗЧГЃГфЗжЧщПіЯТЃЌВЂМнЦыЧ§ЃЌШ§МнТэГЕПЊзуТэСІЧщПіЯТВХФмЪЕЪЉ
AIOps МЦЛЎЁЃ

3. ЦєГЬЃКДг0ПЊЪМЃЁЙЙНЈAIOpsДѓЮшЬЈ

3.1 гЕгаЪ§Он
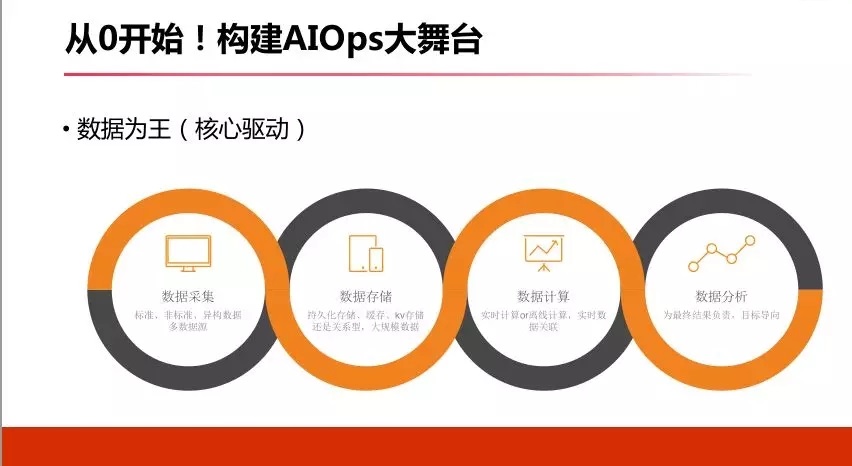
ЧАУцНВСЫетУДЖрЃЌПДвЛЯТдѕУДЪЕЪЉШ§МнТэГЕЃЌДгСуЕНвЛдѕУДДюНЈетИіЦНЬЈЁЃ
ЮвУЧПДвЛЯТЯжзДЃЌЮвУЧЫљгаЕФЦѓвЕЛђепжааЁЦѓвЕЃЌЮвУЧвЊЖдееЕФПДЃЌЮвУЧЦѓвЕЕНЕзДѓЪ§ОнЙЋЫОЃЌФуЕФЪ§ОнСПДѓЪ§ОнЃЌЛЙЪЧгаЪ§ОнЁЃШЫЙЄжЧФмЃЌЛЙЪЧжЧФмШЫЙЄЁЃ
ЧАЖЮЪБМфгавЛИіЖЮзгЫЕЯждкКмЖрШЫЙЄжЧФмПЭЗўЃЌКѓУцЙЭСЫвЛАяШЫзіШЫЙЄПЭЗўЕФЃЌШЫЙЄжЧФмПЭЗўЪЕМЪЩЯЪЧжЧФмПЭЗўЃЌКѓУцгавЛЖбПЭЗўШЫдБГфЕБЛњЦїЃЌЫљвдЮвУЧвЊПДЧхГўЕНЕзЪЧЗёашвЊAIЃЌгаПЩФмЮвУЧжЛашвЊвЛаЉЙцдђОЭИуЖЈЃЌБЈОЏОлКЯЛђепИљвђЗжЮігаЙцдђОЭИуЖЈЃЌВЛашвЊЬЋИпЩюЫуЗЈЃЌЮвУЧвЊШЯЧхздМКЫљУцСйЕФОпЬхЮЪЬтЁЃ

ЦфДЮзі AIOps вЛЖЈвЊЗЧГЃжиЪгЪ§ОнЃЌЮвУЧетБОЪщвВЗЧГЃЯъЯИЬНЬжСЫЪ§ОнживЊадЃЌвЊвдЪ§ОнЮЊЭѕЁЃШчЙћУЛгаЪ§ОнЃЌКѓУцЫљгаЗжЮіМЦЫуЁЂФЃаЭЁЂЫуЗЈЃЌЮвУЧЮоДгЬИЦ№ЃЌЪ§ОнзюПЊЪМвЛЖЈвЊАбЙиКУЃЌДгЪ§ОнВЩМЏЁЂДцДЂЁЂМЦЫуЃЌдйЕНЗжЮіЃЌвЛЖЈвдЪ§ОнЮЊЭѕЁЃ
3.2 ВЩМЏЪ§Он
ДгВЩМЏетЖЫЃЌЮвУЧПЩвдгУПЊдДЙЄОпЗЧГЃЖрЁЃдкЮЂВЉзюПЊЪМЪЧетИіЃЌЫцзХадФмдіГЄЫќгаКмЖрЮЪЬтЃЌЮвУЧж№НЅЧЈвЦЃЌЯждкгУЮвУЧздбаЕФвЛИіАцБОЁЃ
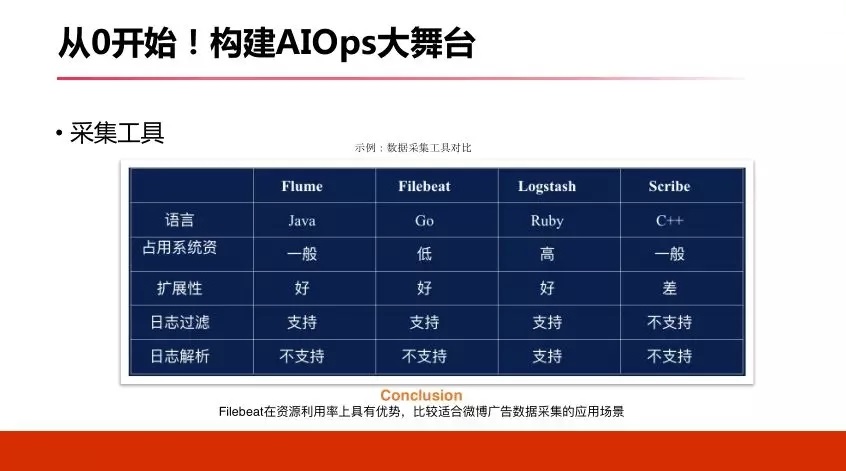
здбаАцБОжЇГжздЖЏСїСППижЦЃЌЮвУЧБЃжЄЪ§ОнВЛЖЊЪЇЃЌФмЙЛжЇГжИїжжЪЪХфЃЌШЛКѓБЃжЄЮвУЧЪ§ОнИљОнздМКЙцдђШЅНјаавЛаЉМђЕЅЕФЧхЯДЁЃ
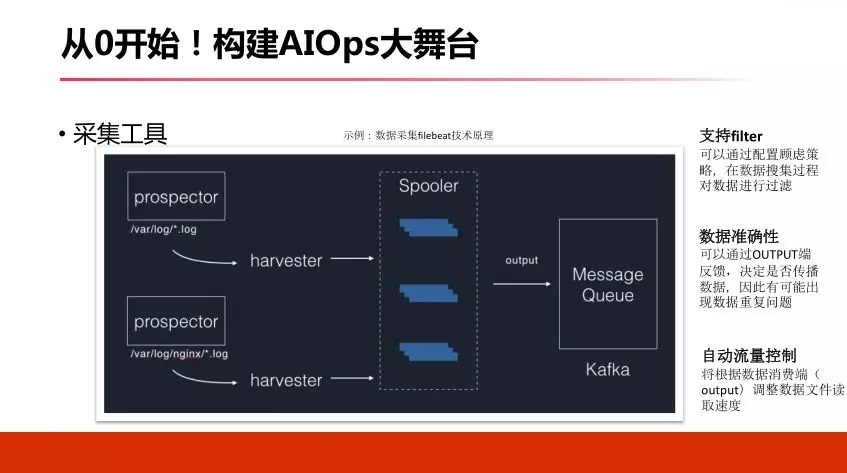
етЪЧЮвУЧЖдВЩМЏЖЫЕФадФмВтЪдЁЃ
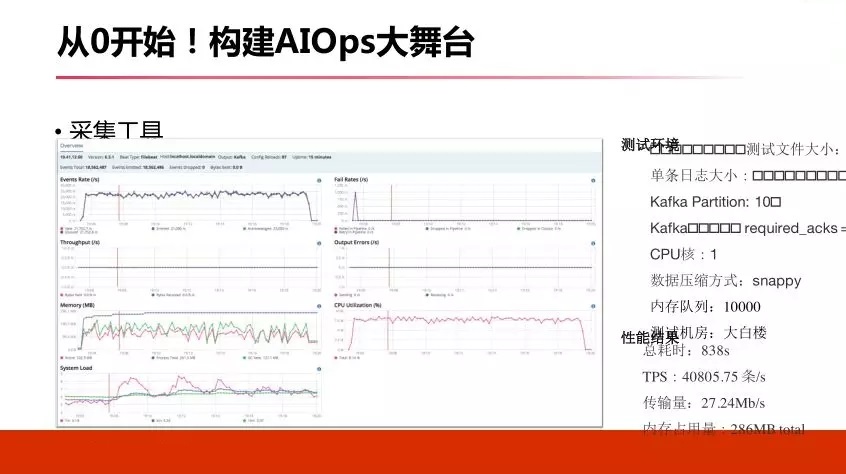
ИеВХЬсЕНЫљгаЪ§ОнВЩМЏЖЫЃЌЪ§ОнВЩМЏдкЪЕЪЉЪБКђЃЌгШЦфДгСуЕНвЛашвЊзЂвтЕФЕиЗНЁЃ
ЕквЛЃЌВЩМЏЕФЭЌЪБвЊзіЪ§ОндЄДІРэЃЌвЛЖЈзіЪ§ОнДІРэЃЌЗёдђЫљгаЪ§ОнЗХЕНДцДЂРяУцШЅЃЌКѓУцЗжЮіМЦЫуЛсДјРДКмДѓЮЪЬтЃЌвЊдкзюПЊЪМЪБКђЖдЪ§ОнНјааЗЧГЃбЯИёЕФДІРэЁЃЭЌЪБЮвУЧШЅЭЦЖЏШежОЕФБъзМЛЏЃЌШчЙћПЊЪММмЙЙВЛКЯРэЃЌзюжеИФдьГЩБОЗЧГЃИпЁЃ
ЩЯДЮИњЕЮЕЮЙЋЫОЕФЭЌбЇНЛСїЃЌЫћУЧзіЕФвЛИіtraceЯЕЭГЛЈСЫСНФъЪБМфЃЌЯпЩЯЕФвЛИіЯЕЭГЃЌДђЭЈЫљгавЕЮёЯЕЭГжЎМфЕФЧХСКЃЌвЊНЈСЂетИіЁЃШчЙћФуПЊЪМУЛгаПМТЧЕНетаЉЃЌКѓУцФуПЩФмашвЊЛЈЯрЕБГЄЪБМфЙЙНЈКЭЭъЩЦетбљЕФЯЕЭГЁЃ
ЮвУЧзюПЊЪМЪ§ОндДЭЗвЊзЂвтетЕуЃЌдѕУДБЃСєЪ§ОнФмЙЛе§ШЗКЭПьЫйВЩМЏЕНЁЃЭЌЪБЮвУЧвЊШУдЫЮЌФмЙЛгАЯьПЊЗЂКЭВњЦЗЃЌетЕугаБивЊЧПЕївЛЯТЃЌЗЧГЃживЊЕФЁЃ
дЫЮЌвўВидкПЊЗЂЃЈRDЃЉКѓУцЃЌПЊЗЂвўВидкВњЦЗКѓУцЃЌВњЦЗвўВидквЕЮёдЫгЊКѓУцЃЌЮвУЧдЫЮЌРывЕЮёЕФСДТЗКмГЄЃЌУЛгаАьЗЈжБНггАЯьвЕЮёЃЌПЊЗЂЛђепВњЦЗЫЕЩЯЯпевдЫЮЌЃЌСЂТэШУФуЩЯЯпзіЯпЩЯБфИќЃЌЮвУЧЪЧБШНЯБЛЖЏЕФЁЃ
ЮвЯждкЫљдкЕФЭХЖгдкГЂЪдИФБфетбљЕФЯжзДЃЌЮвУЧЯЃЭћдЫЮЌАбЮвУЧгАЯьЗЖЮЇЧАжУЃЌАбЮвУЧЪ§ОнЧАжУЃЌдкВњЦЗЩшМЦЙцЛЎНзЖЮЃЌвЊИцЫпЫћУЧШежОгІИУдѕУДзіЃЌЯЕЭГгІИУдѕУДЩшМЦЃЌЮвУЧашвЊНЈСЂетбљвЛИіЛњжЦЃЌШУдЫЮЌЙЄзїФмЙЛЫГРћеЙПЊЁЃ
3.3 ДцДЂЪ§Он
ДцДЂЃЌЮветПщВЛгУЬЋЖрНВСЫЃЌШчЙћЖдДѓЪ§ОнБШНЯСЫНтгІИУЗЧГЃЧхГўЃЌБШШчДцДЂгаКмЖрЕФЗНЗЈЃЌЖдгкШШЪ§ОндѕУДДцДЂЃЌЖдгкЪБађЪ§ОндѕУДДцДЂЁЃ

ЖдгкЪ§ОнЕФМЦЫуЃЌЮвУЧетРяУцПМТЧМИИіЗЧГЃЙиМќЕФЮЪЬтЃЌИеВХЫЕЮвУЧЪ§ОнВЩМЏЭъСЫжЎКѓдѕУДШЅзіЪ§ОнЕФМЦЫуЃЌетРяУцвЊзЂвтКУМИИіЮЪЬтЃЌБШШчЮвУЧЪЕЪБМЦЫуЯЕЭГдѕУДШЅжЇГжЖржжЮЌЖШЕФОлКЯЛђепЙиСЊЃЌетИіЪЧЯрЖдБШНЯРЇФбЕФЁЃЖдгкЪЕЪБЯЕЭГРДНВЃЌЮвУЧЙизЂСНИіЕуЁЃ
ЕквЛЃЌЪБаЇадЃЌдѕУДПьЫйШЅЭъГЩЁЃ
ЕкЖўЃЌЙизЂЮвУЧЪ§ОнЕФзМШЗадЃЌЪЕЪБСїЪ§ОнКмФббщжЄзМШЗадЃЌВЛЯёРыЯпЪ§ОнЃЌАДЬьжиХметИіЃЌЪЕЪБЪ§ОнКмФббщжЄЃЌЮвУЧБиаыЭЈЙ§ЛњжЦЛђепМмЙЙВуУцШЅБЃжЄЁЃ
ЮвУЧгавЛИіЫузгЃЌЭЈЙ§ВЛЭЌЫузгЭъГЩВЛЭЌЮЌЖШЪ§ОнЙиСЊКЭОлКЯЃЌЭЈЙ§ХфжУЗНЪНПЩвдЪЕЯжЯпЩЯЕФСщЛюБфИќЃЌБШШчаТдівЛИіЪ§ОнжИБъЙиСЊЃЌФужЛашвЊИФЯТХфжУИуЖЈЃЌВЛашвЊдйЩЯЯпЗЂВМЁЃ
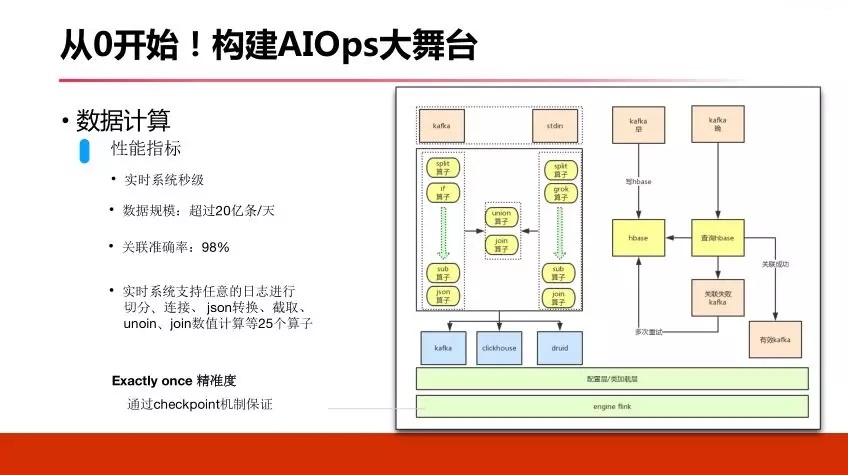
3.4 БЈОЏЯЕЭГ
ЖдгкЕкЖўМнТэГЕЃЌБЈОЏЯЕЭГЃЌЮвУЧОѕЕУзюЙиМќвЛЕуЃЌетРяУцгаПЊдДЕФетИіПЩвдгУЁЃЮвУЧКЫаФЫМЯыАбБЈОЏМЏГЩМрПиЦНЬЈРяУцШЅЃЌЭЈЙ§МрПивГУцПЩЪЧЛЏКЭБЈОЏЙцдђЃЌетСНИівЊДђЭЈЃЌПЊЗЂЭЌбЇХфСЫвЛИіМрПиЭМЃЌЫћЯЃЭћИљОнетИіЧїЪЦЩшЖЈЫћздМКЕФБЈОЏуажЕЛђепЪЧХфжУЃЌетСНИіашвЊФмЙЛзіЕНЙиСЊЁЃ
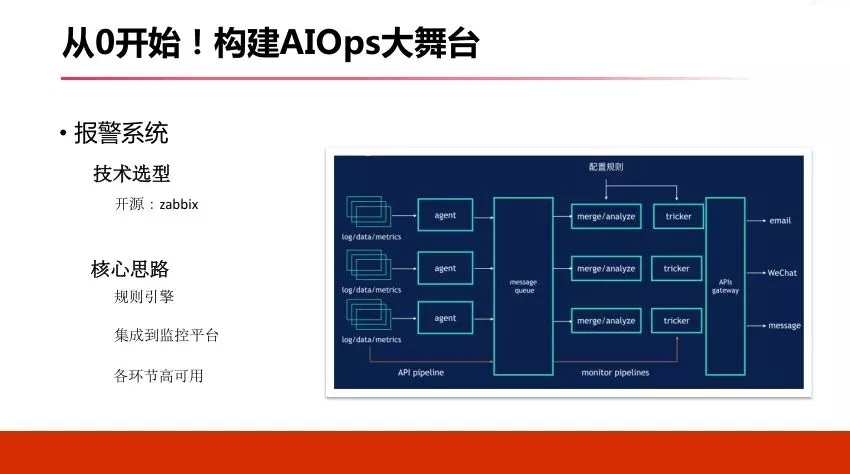
3.5 CI/CDЯЕЭГ
ЕкШ§МнТэГЕЃЌCI/CDЯЕЭГЃЌетИіЯЕЭГКмЙиМќвЛЕуЃЌЫќвЊФмШЅМЏГЩЮвУЧQAЕФздЖЏЛЏВтЪдЙІФмЃЌЗёдђЮвУЧдкЫљгаЕФЯпЩЯБфИќЪБКђЖМЛсШЅзіздЖЏЛЏВтЪдЃЌШчЙћФуУЛгаздЖЏЛЏЕФВтЪдЛЗНкЃЌФуКмФбБЃжЄЮвУЧЯпЩЯЕФЗЂВМжЪСПЁЃ
ИеВХЭѕвеЬсЕНЮвУЧЯпЩЯга40%ЖрЕФЮЪЬтЃЌвђЮЊЯпЩЯБфИќЕМжТЃЌЯжЪЕжаПЩФмИќЕБЃЌАйЗжжЎАЫОХЪЎЖМЪЧЯпЩЯБфИќЕМжТЁЃвђДЫЮвУЧБиаыгавЛЬзЛњжЦШЅБЃжЄЫљгаЕФБфИќЪЧАВШЋЃЌЪЧУЛгаЮЪЬтЕФЁЃ
ДгИеВХЪ§ОнЕФВЩМЏЕНЮвУЧЪ§ОнЕФДцДЂЃЌдйЕНЪ§ОнЕФМЦЫуЃЌдйЕНЦфЫћБЈОЏКЭМрПиЃЌећИіЯЕЭГШчЙћКЯдквЛЦ№ЃЌЪЧетбљвЛИіМмЙЙЃЌетЪЧЮвУЧПЩвдЪЕЪЉМмЙЙЃЌВЛЪЧBATКмФбКмКмИпЩюМмЙЙЃЌКмЖрФЃПщПЩвдЭЖШыПЊдДПђМмШЅЭъГЩЁЃ
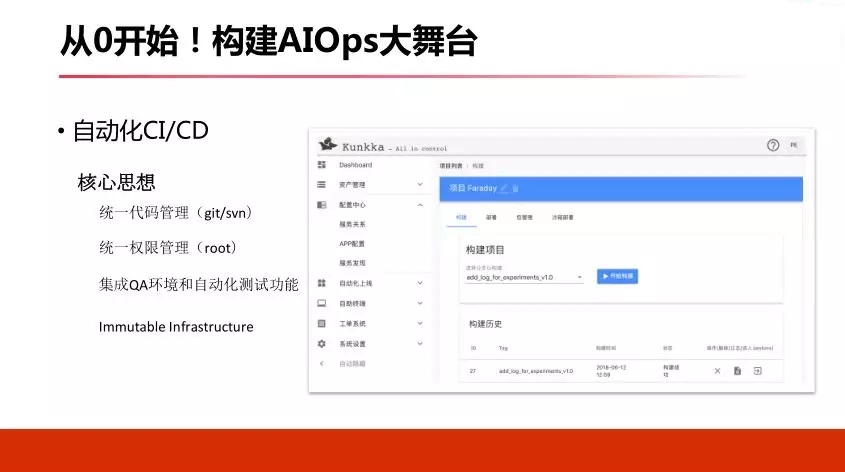
3.6 ЯпЩЯЯЕЭГ
зюЯТУцЪЧЮвУЧЯпЩЯЕФЯЕЭГЃЌЯпЩЯЯЕЭГВњЩњКмЖрЪ§ОнЃЌетИіЪ§ОнЭЈЙ§вЛаЉДцДЂНщжЪЃЌЮвУЧПЭЛЇЖЫЪеМЏЃЌЪеМЏвдКѓНјШыЪЕЪБЖгСаЃЌдйгЩЪЕЪБЯЕЭГНјааЯћЗбЃЌЦкМфПЩФмНјааЪ§ОнЕФЙиСЊКЭОлКЯЃЌЪЕЪБЪ§ОнНјШыГжајЪ§ОнЕФДцДЂв§ЧцЃЌБШШчетРяУцЕФетаЉЃЌКмЖрЁЃдйЭЈЙ§ВщбЏв§ЧцЃЌПЩФмашвЊНЈСЂвЛЬзЛКДцЛњжЦЃЌзюжеНјааПЩЪгЛЏЃЌетИіМрПиЯЕЭГОЭГіРДСЫЁЃ
МрПиЯЕЭГГіРДжЎКѓЃЌЮвУЧШЅХфКЯЮвУЧЕФБЈОЏЃЌЮвУЧашвЊгаБЈОЏЕФВпТдЃЌетИіВпТджБНгДЅЗЂЮвУЧЯпЩЯБфИќЃЌЮЂВЉРяУцгаИіУћШЫГіЙьСЫЃЌЮвУЧЖдЯЕЭГНјааНЕМЖЛђепРЉШнЃЌетИіВйзївЊЭЈЙ§ВпТджБНгШЅгАЯьЕНЯпЩЯБфИќЯЕЭГЃЌCI/CDБфИќЯЕЭГЃЌзюжегАЯьЮвУЧЯпЩЯЁЃ
ЭЌЪБетРяУцгавЛЬѕТпМЃЌЮвУЧЛЙашвЊвЛИіБъзЂЯЕЭГЃЌЖдгкЪЕМЪБЈОЏЙцдђгаЮѓБЈЧщПіЃЌЖдгкетаЉаХЯЂНјШыБъзЂЯЕЭГЃЌзюжеШЅЗДРЁЮвУЧЯпЩЯЕФЬиеїРяУцШЅЃЌетЪЧвЛИіећЬхЕФМмЙЙЧщПіЁЃ
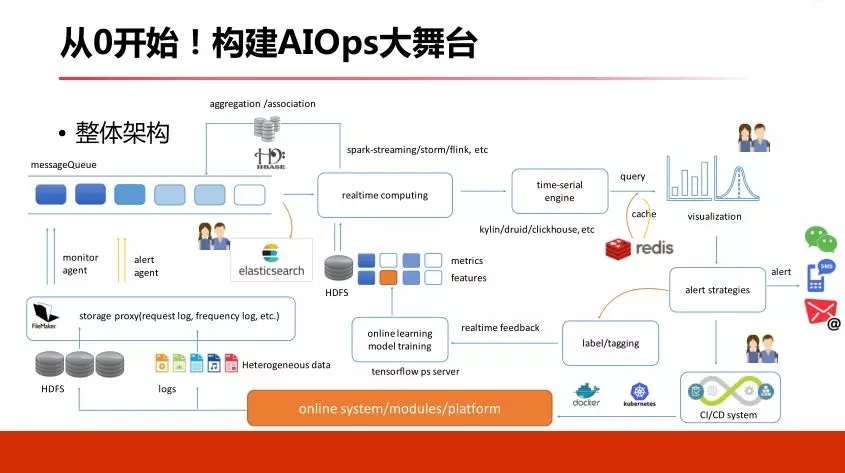
4. БЌЗЂЃКжЧФмОіВпЃЌОіЪЄЧЇРя

4.1 ФЃаЭЫуЗЈ
ЧАУцКмЖрРЯЪІНВСЫжЧФмдЫЮЌИљвђЗжЮіКЭвьГЃМьВтЃЌЦфЪЕМђЕЅРДНВЃЌФуВЛФУЫуЗЈРДНВЃЌЖдгквьГЃМьВтЃЌЦфЪЕКмМђЕЅЁЃБШШчЛљгкЭГМЦЕФФЃаЭЃЌЛљгкЭГМЦФЃаЭвЛЖЈЗжЮіЪ§ОнЭГМЦЕФЙцТЩЃЌЛђепЫќЕФИХТЪЗжВМЃЌетЪЧБиаывЊгаЃЌВЛвЛЖЈЪЧЫљгаЕФЪ§ОнЖМПЩвдФУетИіЭГМЦФЃаЭРДШЅзіЁЃФуШЅЗжЮіЗЂЯжетИіЪ§ОнЪєгке§ЬЌЗжВМЃЌОЭПЩвдгУетИіЗНЗЈзіМьВтЁЃ
ШчЙћУЛгаЗжВМЁЂУЛгаЙцТЩЃЌФуПЩФмжЛФмАДееЦфЫћЗНЗЈЃЌБШШчЛљгкСйНќЖШЛђепУмЖШЕФЗНЗЈЁЃСйНќЖШКмМђЕЅЃЌПЩвдРэНтвьГЃЪ§ОнКЭе§ГЃЪ§ОнЃЌЫќЪЧвЛИіЗжРрЕФЮЪЬтЃЌе§ГЃЪ§ОндквЛЖбЃЌвьГЃЪ§ОндквЛЖбЃЌвьГЃЪ§ОнОрРыБШНЯЖЬЃЌетРяУцПЩвдгУЗжРрЫуЗЈЁЃ
ЛљгкУмЖШвВЪЧвЛбљЃЌЮявдРрОлЃЌОлдквЛЦ№УмЖШИќИпвЛаЉЃЌЫќКЭвьГЃЕуУмЖШЛсИќаЁвЛаЉЃЌЭЈЙ§етСНжжЗНЪНЖМПЩвдзіЁЃЛљгкСйНќЖШКЭУмЖШЗНЗЈзіЃЌЮвУЧбЁKжЕПЩФмРЇФбвЛаЉЃЌМЦЫуИДдгЗЧГЃИпЁЃ
гвБпЮвУЧЭЈЙ§ЛљгкЖРСЂЩСжЕФЫуЗЈзіМьВтаЇЙћЃЌЮвУЧЗЂЯжетИіЫуЗЈФмЙЛДјРДЕФаЇЙћЃЌЮвУЧзМШЗТЪПЩвдДяЕН90%вдЩЯЃЌетРявЛЖЈвЊЬсЕНвЛЕуЃЌЮвУЧвьГЃМьВтВЛФмЭъШЋЬцДњЃЌЮвУЧЯЃЭћЭЈЙ§ЫуЗЈЬсИпдЫЮЌЕФаЇТЪЁЃ
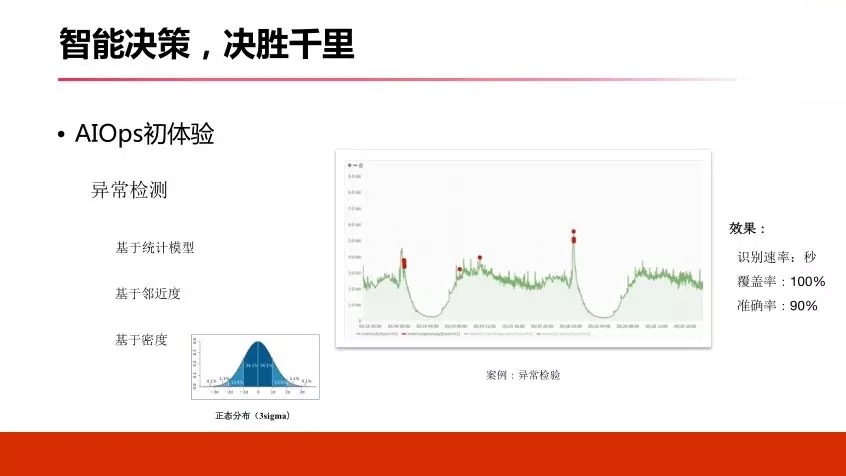
4.2 БЈОЏОлКЯ
ЖдгкБЈОЏЕФОлКЯЃЌетРяУцБЈОЏОлКЯЃЌЮвУЧЯЃЭћБЈГіРДЕФОЏЃЌИеВХЬсЕНгаИіУћШЫГіЙьСЫЃЌПЩФмЕМжТвЛЖбЯЕЭГЖМГіСЫЮЪЬтЃЌетвЛЖбЯЕЭГПЩФмГЩЧЇЩЯАйЬЈЛњЦїЗЂБЈОЏаХЯЂЃЌВЛжЊЕРИУдѕУДДІРэСЫЃЌЖдгкетбљЕФЧщПіЃЌЮвУЧашвЊгУБЈОЏОлКЯЕФЗНЗЈЁЃ
БШШчЮвУЧгУЕФAIЗНЗЈЃЌЛљгкЪєадЙщФЩЃЌБШШчФГЬЈЛњЦїГіСЫЮЪЬтЃЌетЬЈЛњЦїДцДЂЗўЮёЃЌЫќЕМжТДцДЂЗўЮёВППЩгУЃЌДцДЂЗўЮёЩЯВувЕЮёжЇГХЗЂВЉЮФЃЌЛсЕМжТЗЂВЉЮФЛсЪмЕНгАЯьЁЃ
ЙщФЩЦ№РДЃЌетИіЛњЦїБЈОЏЃЌДцДЂГіСЫЮЪЬтЃЌЗЂВЉЮФЪмЕНгАЯьЃЌЮвУЧЙщФЩЦ№РДжЛашвЊЗЂвЛЬѕБЈОЏЕФЖЬаХЙ§РДОЭааСЫЃЌЮвУЧЯждкЗЂВЉЮФЪЧвьГЃЕФЃЌашвЊЫШЅДІРэЃЌетбљОЭПЩвдМЋДѓЕФНЕЕЭЮвУЧЕФБЈОЏЬѕЪ§ЁЃ
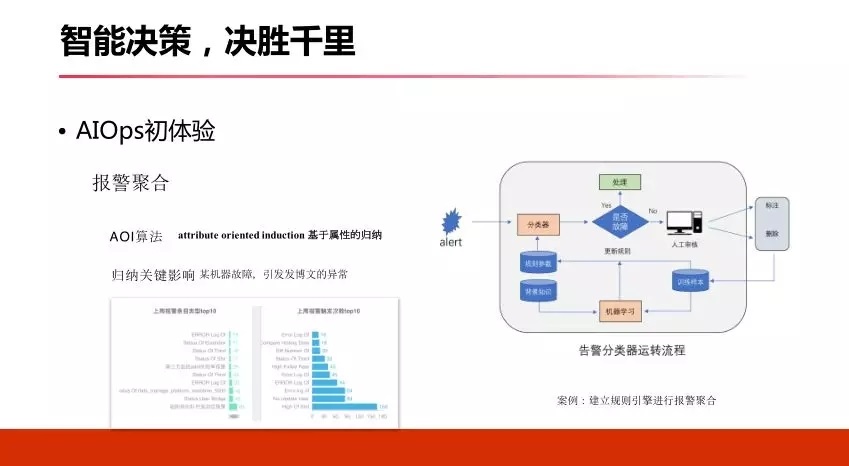
4.3 ИљвђЗжЮі
ЖдгкИљвђЗжЮіЃЌе§КУКЭБЈОЏОлКЯЪЧвЛИіЗДЕФЗНЯђЃЌИеВХЪЧздЯТЖјЩЯШЅзіЙщФЩЃЌИљвђЗжЮіздЩЯЖјЯТзіЗжЮіКЭХаЖЯЃЌзюГЃМћЕФЗНЗЈОіВпЪїЃЌвВЪЧзюМђЕЅЕФАьЗЈЁЃ
ЗЂВЉЮФГіСЫЮЪЬтЃЌЫќПЩФмЪЧДцДЂЗўЮёЕМжТЃЌДцДЂЗўЮёдЫааФФаЉЛњЦїЩЯЃЌФФаЉЛњЦїГіСЫЮЪЬтЃЌздЩЯЖјЯТХаЖЯОпЬхЕФдвђЁЃ
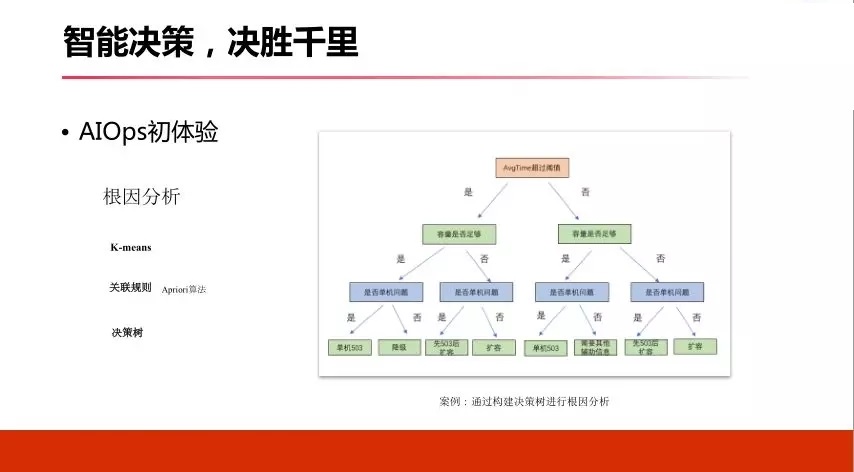
ЛЙгавЛаЉЙиСЊЗжЮіЃЌетРяУцВЛеЙПЊНВСЫЁЃ
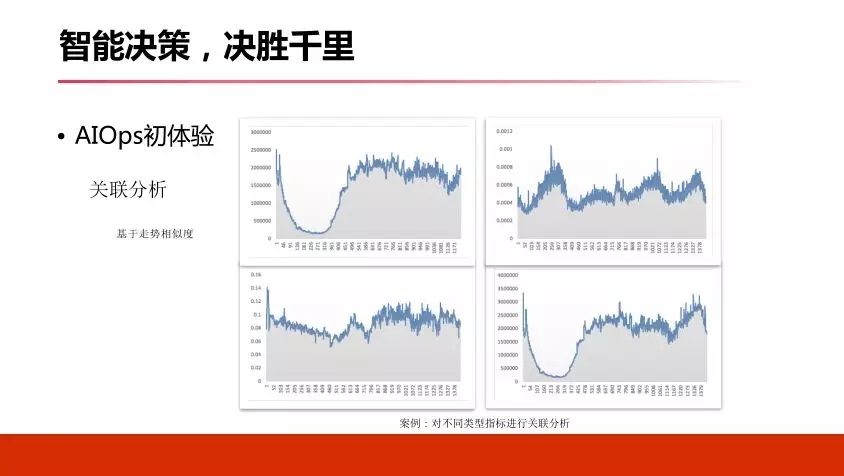
4.4 дЄВт
ЮвОѕЕУAIOpsЕФЮДРДЃЌгІИУЪЧдЄВтЃЌКмЩйгаШЫжиЕуНВЃЌЮввЊжиЕуНВвЛЯТетвЛПщЃЌЮвУЧАбзцЪІвВАсГіРДЃЌжюИ№ССЫћдкШ§ЙњЪБЦкКмКУдЫгУЕНСЫдЄВтетжжММЪѕЃЌБШШчГрБкжЎеНЁЂВнДЌНшМ§КЭНшЖЋЗчЕФЙЪЪТДѓМвЖњЪьФмЯъЃЌжюИ№ССЭЈЙ§дЄВтЕФЗНЗЈЃЌдЄВтЕН11дТЗнЖЌжСЪБКђгаДѓЗчЁЃИљОнЪВУДРДЕФЃПИљОнРњЪЗЪ§ОнЭГМЦЧщПіЕУРДЁЃ
ЪБађЪ§ОнПЩвддЫгУРДдЫЮЌЃЌЮвУЧгУЪБађЪ§ОнПДРњЪЗЧщПіРДдЄВтЮДРДЁЃЮвУЧПДЪБађЪ§ОнЛљБОЬиЕуЃЌЫќвЛАуЛсгаетбљМИИіЬиЕуЁЃ
ЕквЛИіЃЌЮвУЧПЩФмгааЉЧїЪЦадЃЌЯђЩЯЛђепЯђЯТЁЃгвБпЕФЭМжмЦкЕФБфЛЏЃЌЫќПЩФмЛЙгавЛаЉМОНкадЕФдвђЃЌПЩФмИДдгвЛЕуЫцЛњЕФПДВЛЕНЙцТЩЃЌЫќДѓИХгаетаЉЬиЕуЁЃ

ЖдгкГжајЪ§ОнЕФдЄВтЃЌЦфЪЕЮвУЧгаКмЖржжЗНЗЈЁЃЕквЛжжЗНЗЈЗЧГЃМђЕЅЃЌФУРњЪЗЕФNИіЕуРДШЅзіЦНОљЃЌБШШчЙуИцЕФЪеШыЁЃЮвУЧевЧАЦпЬьМгЦ№РДГ§вдЦпЃЌОЭПЩвдЕУЕНУїЬьДѓИХЪеШыЧщПіЁЃ
ПМТЧОрРыЪБМфзюНќЕФЪ§ОнПЩФмЖддЄВтНсЙћгАЯьИќДѓЃЌЮвУЧПЩвдМгШЈЃЌАбРызюНќЪБМфЕуШЈжиМгДѓЃЌМгШЈЦНОљЁЃ
МгШЈЦНОљЗЈбЁдёNИіЕуЃЌNЕФбЁдёБШНЯРЇФбЃЌЫљвдЮвУЧОЭгажИЪ§ЦНЛЌЗжЗЈЃЌАбРњЪЗNИіЕуЖМбЁГіРДЃЌВЂЧввВЪЧИљОнРыЕБЧАЪБМфдННќЃЌЩшЖЈШЈжидНДѓЃЌЮвУЧЕкШ§жжЗНЗЈЁЃ
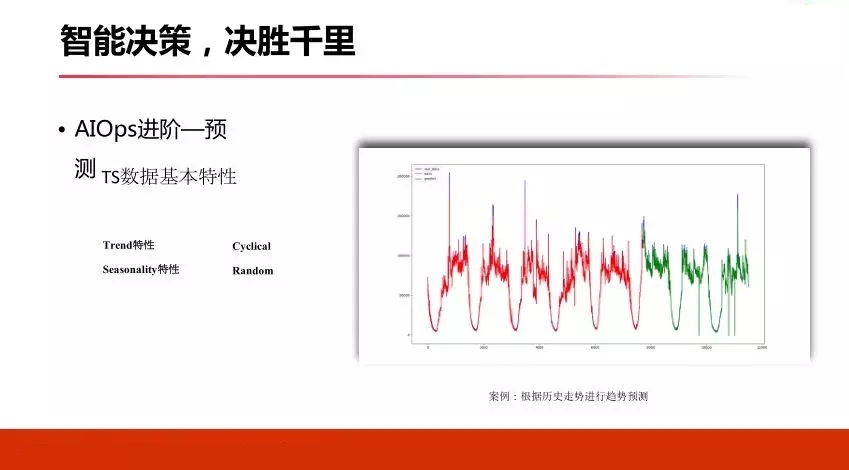
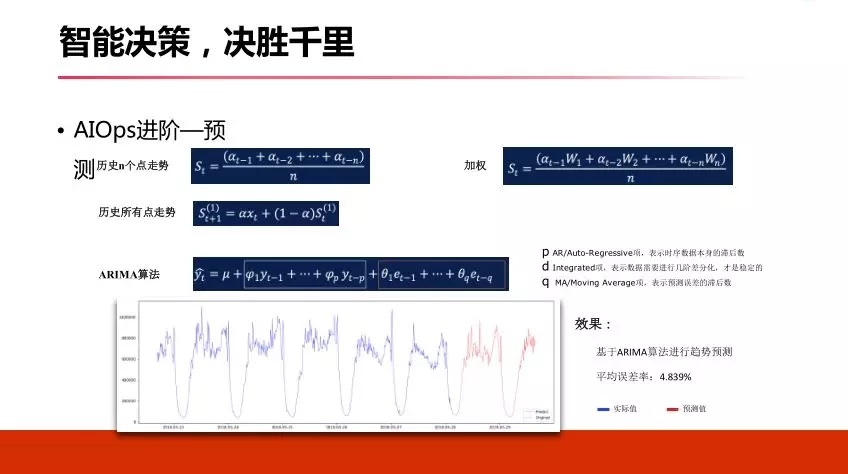
ЛЙгаЦфЫћвЛаЉЗНЗЈЃЌБШШчARIMAЫуЗЈЃЌетаЉЫуЗЈЕФвЛаЉВЮЪ§ЩшЖЈЖМВЂВЛЭъУРЃЌБШШчARIMAРяУцашвЊЩшЖЈPDQЃЌетИіЭЈГЃЗЧГЃРЇФбЃЌвВгавЛаЉздЖЏЛЏАьЗЈЃЌЫќВЛвЛЖЈЪЪКЯЫљгаГЁОАЃЌетИіЕиЗНЮвУЧгУСЫARIMAзіСЫЖдгкЙуИцЕФЦиЙтСПзіСЫЧїЪЦдЄВтЃЌаЇЙћЦНОљЮѓВюдк4.8зѓгвСПЁЃ
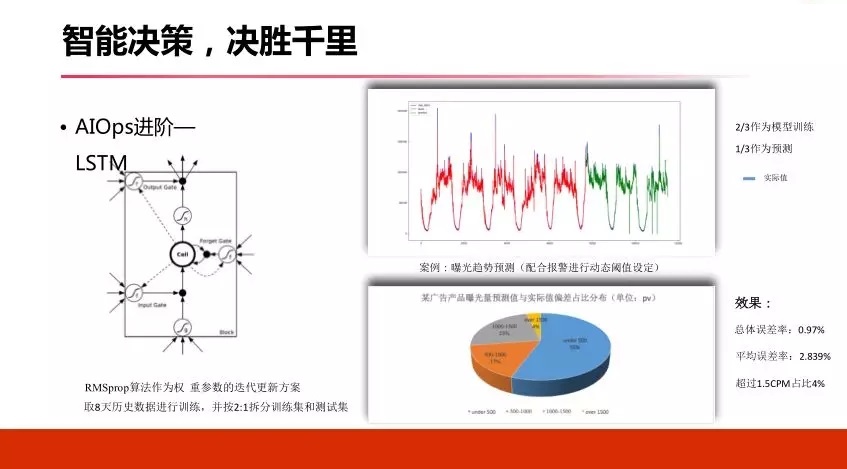
ЛЙгавЛжжАьЗЈЃЌLSTMЃЌЮвУЧЧыГізюИпДѓЩЯЕФЫуЗЈГіРДЃЌЮвУЧИуЩюЖШбЇЯАЃЌИеВХЬсЕНЕФФЧаЉДЋЭГАьЗЈЃЌОіВпЪїЪВУДЕФЁЃ
ЮвУЧдЄВтПЩвдгУЕНвЛаЉИпЩюЕФЫуЗЈЃЌLSTMЃЌЫќЗЧГЃЪЪКЯгкзіЧїЪЦдЄВтЃЌЫќПЩвдАбРњЪЗЕФЪ§ОнаХЯЂЃЌЛђепвЛаЉЬиеїВЖЛёНјРДЃЌВЂЧвЭЈЙ§вХЭќУХЃЌЫќгавХЭќУХЛњжЦЃЌПЩвдАбРњЪЗЪ§ОнЬиеїгабЁдёадЕФаЏДјНјРДЁЃ
ЭЈЙ§етИіЃЌЮвУЧвВзіСЫаЇЙћЃЌЮвУЧвВЪЧФУСЫЙуИцУПЬьЕФЧыЧѓЪ§ОнзіСЫЗжЮіЃЌЗЂЯжСЫЮвУЧзмЕФЮѓВюТЪдк0.97ЃЌЦНОљЮѓВюдк2.839ЃЌБШИеВХЕФЕЅДПгУФЧИіЫуЗЈаЇЙћКУКмЖрЁЃ
ЛЙгаКмЖрЯрЙиЕФзЪдДЃЌДѓМвПЩвдЙизЂвЛЯТЃЌБШШчСГЪщЁЂЭЦЬиЁЂЙШИшгаПЊдДЫуЗЈЃЌДѓМвЖМПЩвдШЅСЫНтвЛЯТЁЃвдЩЯЪЧЮвЗжЯэЕФШЋВПФкШнЃЌаЛаЛДѓМвЃЁ

|









