| БрМЭЦМі: |
| БОЮФРДдДinfoqЃЌЮФеТДгЖрИіЗНУцНщЩмШчЃКМрПиЮЌЖШЃЌМрПиЯЕЭГЩшМЦЃЌЪ§ОнУцАхЃЌPrometheus
ЕФгІгУЪЕМљЕШЗНУцЃЌЯъЯИШчЯТЃК |
|
БГОА
360 дкзіШнЦїЛЏЦНЬЈжЎЧАЃЌгавЛИіЛљгкаЁУзПЊдДЕФ Open-Falcon НјааЖўДЮПЊЗЂЕФРЯМрПиЯЕ (Wonder)ЃЌетИіЯЕЭГГаРПСЫЙЋЫОЫљгаЕФЮяРэЛњКЭащФтЛњЕФМрПиШЮЮёЁЃЫцзХШнЦїММЪѕЕФЦеМАЃЌвдШнЦїЕФЗНЪНдкДДНЈгІгУЪБЃЌгЩгк
Kubernetes ШнЦїБрХХЯЕЭГВПЪ№ЕФЗўЮёОпгаЕЏадРЉШнЕФЬиадЃЌЖјРЯЕФМрПиЯЕЭГЮоЗЈИажЊетаЉЖЏЬЌДДНЈЕФЗўЮёЃЌвбОВЛЪЪКЯШнЦїЛЏЕФГЁОАЃЌЫљвд
360 ЭХЖгОЭДюНЈСЫвЛЬзПЩвджЇГжЗўЮёЗЂЯжЕФаТМрПиЯЕЭГЁЃ
ФПЧА 360 вЛЙВга 5 Иі k8s ЯпЩЯМЏШКЃЌЗжВМдкББОЉЩЯКЃКЭЩюлкЃЌДЫЭтЛЙгавЛаЉ GPU МЏШКЁЃ
ШнЦїЦНЬЈЙЙНЈвдКѓДјРДСЫвдЯТМИИіЗНУцЕФКУДІЃК
НкЪЁзЪдДЁЃДЋЭГвЛЬЈЮяРэЛњжЛФмВПЪ№вЛИіЪЕР§ЃЌащФтЛњФмВПЪ№МИИіЗўЮёЃЌЖјЪЙгУШнЦївЛЬЈЛњЦїЩЯФмВПЪ№МИЪЎИіЗўЮёЁЃ
ЬсИпаЇТЪЁЃ1. ЫѕЖЬСїГЬЁЃРЯЯЕЭГвЊдіМгЛњЦїашвЊЬсЧАЩъЧыЃЌЖјЪЙгУ Kubernetes ШнЦїЦНЬЈжЛвЊећИізЪдДГиРягаГфзуЕФзЪдДЃЌВЛгУЬсНЛдЄЫуОЭПЩвджБНгЪЙгУЁЃ2.
ЕЏадРЉШнЁЃдкСїСПИпЗхЦкЃЌШнЦїЦНЬЈПЩвдПьЫйРЉШнЃЛдкСїСПВЛЖрЕФЪБЖЮЃЌПеЯаЕФзЪдДПЩвдДІРэЦфЫћРыЯпШЮЮёЃЌЖдзЪдДЕФРћгУТЪИпЁЃ
ИпПЩгУЁЃШнЦїЦНЬЈПЩвдБЃжЄдЫааЕФЗўЮёЪ§СПзмЪЧФмДяЕНдЄЦкЁЃ
МѕЧсдЫЮЌИКЕЃЁЃжЎЧАЫљгаЕФВПЪ№ЩЯЯпЛюЖЏЖМЪЧдЫЮЌРДзіЁЃШнЦїЦНЬЈЩЯЯпКѓЃЌПЊЗЂШЫдБПЩвджБНгдкГЬађЭъГЩжЎКѓНЋЦфжЦзїГЩОЕЯёЃЌздМКОЭПЩвдНјааВПЪ№ЁЃ
ЕБШЛШЮКЮЪТЧщВЛПЩФмжЛгаКУЕФвЛУцЃЌШнЦїЦНЬЈвВЛсДјРДЯргІЕФФбЖШЁЃШнЦїЦНЬЈЖдЗўЮёЕФЕїЖШОпгаЖЏЬЌадЃЌетОЭашвЊМрПиЯЕЭГФмЖЏЬЌИажЊЗўЮёЪЕР§ТфдкФФРяЃЌетЪЧМрПиЙЄзїжаЕФвЛИіФбЕуЁЃ
360 ШнЦїЦНЬЈЕФМрПиЮЌЖШ
360 ШнЦїЦНЬЈЕФМрПиЯЕЭГЖдвЕЮёЕФММЪѕжИБъНјааМрПиЃЌВњЦЗЪЧДгШ§ИіЮЌЖШНјааЩшМЦЕФЃК
ШнЦї: етЪЧзюаЁЕФСЃЖШЁЃ
Pod: вЛИі Pod РяУцПЩвдгаЖрИіШнЦїЁЃ
гІгУ: вЛИігІгУРяПЩФмЛсгаЖрИі PodЁЃ
Г§СЫетаЉММЪѕжИБъМрПиЃЌ360 ШнЦїЦНЬЈЕФМрПиЯЕЭГЛЙжЇГжздЖЈвхМрПиЁЃгааЉвЕЮёПЩФмашвЊдкздМКЕФГЬађРяДђЕуЃЌБШШчвЊЕїЕкШ§ЗННгПкЃЌВщПДбгЪБКЭЕїгУЕФДЮЪ§ЕШЁЃДѓЦНЬЈЩЯВЛЭЌвЕЮёЖдЪ§ОнЕФашЧѓВЛЭЌЃЌЮЊСЫДяЕНвЕЮёашЧѓЃЌжЇГжздЖЈвхМрПиЛЙЪЧКмБивЊЕФЁЃаТПЊЗЂЕФвЕЮёПЩвддкздМКЕФГЬађРяв§Шы
Prometheus ЯрЙиЕФ SDK НјааДђЕуЃЌ360 ЕФШнЦїЦНЬЈОЭЛсНЋетаЉ metrics ЪеМЏЩЯРДЁЃ
СэЭтЃЌУЛгаЪЙгУ Prometheus ЕФРЯЯЕЭГдкПЊЗЂЪБУЛгадкГЬађРяДђЕуЕФЙІФмЃЌетЪБвЕЮёПЩвдеыЖдздМКЕФашЧѓвд
sidecar ЕФЗНЪНдкГЬађЕФБпдЕаД exporter РДВЩМЏИУНјГЬЫљгаЕФМрПиЪ§ОнЃЌexporter
вд metrics ЕФаЮЪНБЈИцИј PrometheusЃЌPrometheus НјаазЅШЁЁЃ
МрПиЯЕЭГЩшМЦ
360 ШнЦїЦНЬЈМрПиЯЕЭГМмЙЙЭМШчЯТЃК
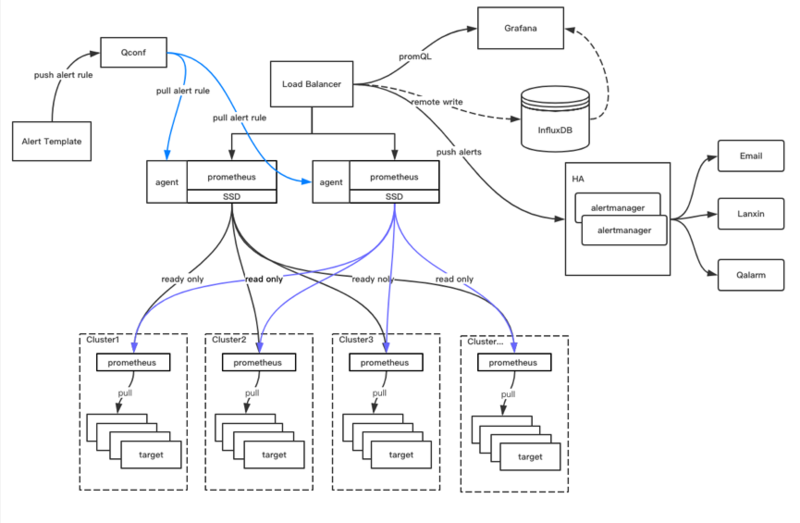
ШежОМрПи
360 ШнЦїЦНЬЈМрПиЯЕЭГЕФШежОМрПиЪЙгУЕФЪЧ ELK ММЪѕеЛЃЌЕЋЪЧНјааСЫЖўДЮПЊЗЂЁЃЭХЖгздМКаДСЫ Log
controller зщМўЃЌИУзщМўЛсЪЕЪБЕи watch Kubernetes API Server
ЕФ Deployment зЪдДЖдЯѓЕФзДЬЌБфЛЏЁЃЕБвЕЮёдкДДНЈгІгУЪБЃЌЪЧвд Kubernetes deployment
ЕФзЪдДЖдЯѓРДДДНЈЕФЁЃLog controller ЛсИажЊЕНетИізЪдДЕФДДНЈЃЌжЊЕРетИі deployment
ЯТгаЖрЩй Pod вбОДІгк Ready зДЬЌЁЃЕБ Log controller ИажЊЕНаТДДНЈЕФ Pod
вбОДІгк Ready зДЬЌвдКѓЃЌЛсИљОнгУЛЇдкДДНЈ Pod ЪБжИЖЈЕФецЪЕШежОЪеМЏТЗОЖЦДНгГЩЫќдкЮяРэЛњЩЯЕФОјЖдТЗОЖЃЌШЛКѓНЋзщзАКУЕФХфжУВЂЭЦЫЭЕН
360 здбаЕФХфжУжааФ QConf жаЁЃ
360 дк Kubernetes МЏШКЕФУПИі Node НкЕуЖМЛсВПЪ№вЛИіЖўДЮПЊЗЂЕФ LogstashЃЌИУ
Logstash ЛсЖЈЦкЃЈУПИєЪЎУыЛђепЮхУыЃЌЪБМфПЩХфжУЃЉШЅХфжУжааФ (Qconf) РШЁзюаТЕФХфжУЁЃРШЁЭъХфжУжЎКѓЃЌLogstash
ЛсИљОнзюаТЕФХфжУАбЯрЙиЕФЕФШежОЪеМЏЕНЙЋЫОЕФ QbusЃЈЖд Kafka НјааАќзАЕФВњЦЗЃЉжаЃЌвВОЭЪЧЪ§ОнвбОНјШыЕН
Kafka СЫЁЃжЎКѓгУЛЇПЩвддк HULK ЫНгадЦЦНЬЈ (ФкВПЕФЫНгадЦЦНЬЈ) ПЊЭЈ ES ЗўЮёЃЌЖдШежОНјааМьЫїЗжЮіЛђЖдЦфЫћШежОжИЖЈЪ§ОнНјааМрПиЁЃ
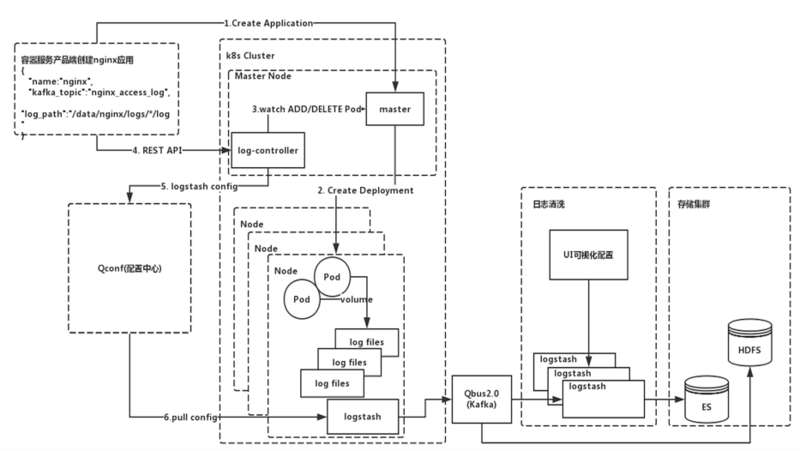
Ъ§ОнУцАх
360 ШнЦїЦНЬЈМрПиЯЕЭГЕФЪ§ОнУцАхЪЙгУЕФЪЧ GrafanaЃЌВЂЖдЦфдіМгСЫ LDAP гУЛЇШЯжЄЁЃПЩвдЯдЪОФкДцЃЌЗУЮЪСПЃЌSIO,
GPU ЕШМрПиЪ§ОнжИБъЁЃ
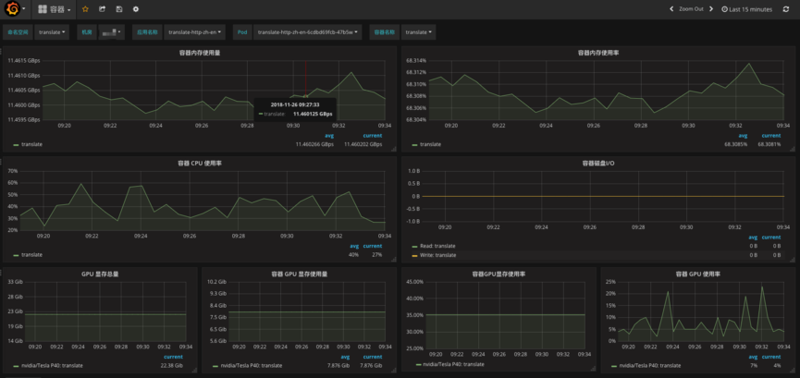
гІгУМЖБ№ЛљДЁМрПижИБъ:
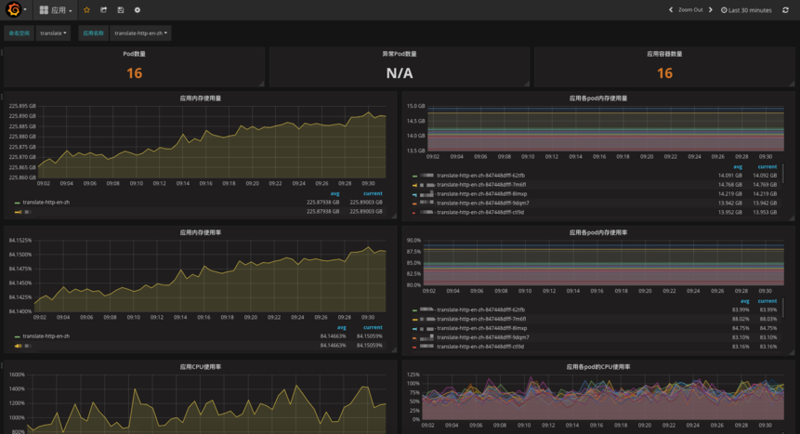
Pod МЖБ№ЛљДЁМрПижИБъ:
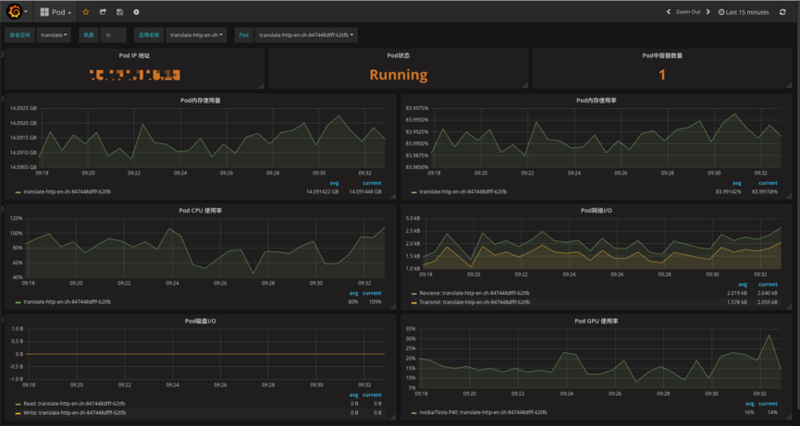
ШнЦїМЖБ№ЛљДЁМрПижИБъ:
Prometheus ЕФЛљБОдРэЪЧЭЈЙ§ HTTP авщжмЦкадзЅШЁБЛМрПизщМўЕФзДЬЌЃЌШЮвтзщМўжЛвЊЬсЙЉЖдгІЕФ
HTTP НгПкОЭПЩвдНгШыМрПиЁЃВЛашвЊШЮКЮ SDK ЛђепЦфЫћЕФМЏГЩЙ§ГЬЁЃетбљзіЗЧГЃЪЪКЯзіащФтЛЏЛЗОГМрПиЯЕЭГЃЌБШШч
VMЁЂDockerЁЂKubernetes ЕШЁЃЪфГіБЛМрПизщМўаХЯЂЕФ HTTP НгПкБЛНазі exporter
ЁЃФПЧАГЃгУЕФзщМўДѓВПЗжЖМга exporter ПЩвджБНгЪЙгУЃЌБШШч HAproxyЁЂNginxЁЂMySQLЁЂLinux
ЯЕЭГаХЯЂ (АќРЈДХХЬЁЂФкДцЁЂCPUЁЂЭјТчЕШЕШ)ЁЃ
БЈОЏ
БЈОЏЯЕЭГЪЙгУЕФЪЧ Prometheus здДјЕФ Alertmanager зщМўЃЌЕЋЪЧЖдЦфНјааЖўДЮПЊЗЂЃЌМЏГЩСЫ
360 здМКЕФБЈОЏЯЕЭГ (Qalram)ЃЌВЂЧвПЩвдЭЈЙ§ 360 здМКЕФМДЪБЭЈаХЙЄОпЃЈРЖаХЃЉЪЕЪБНгЪеБЈОЏаХЯЂЃЌгбКУЗНБуПьНнЁЃ
360 ШнЦїЦНЬЈМрПиЯЕЭГбЁаЭЖдБШ
дкЙЙНЈШнЦїЦНЬЈЕФЙ§ГЬжаЃЌ360 ЭХЖгЖдМрПиЯЕЭГЕФМИжжГЃгУЕФПЊдДЗНАИНјааЙ§бЁаЭЖдБШЃЌжївЊЕїбаСЫ K8s
ЩчЧјЕФ HeapsterЃЈK8s АВзАЙ§ГЬжаФЌШЯАВзАЕФВхМўЃЉКЭ PrometheusЁЃ
Heapster+InlfuxDB+Heapster здДјБЈОЏЯЕЭГЕФЗНАИгаИіШБЕуЃКЫќЪЧеыЖд K8s
ШнЦїМЖБ№вдМА Code МЖБ№ЕФММЪѕжИБъМрПиЃЌЮоЗЈЪЕЯжвЕЮёЯЕЭГЪ§ОнЕФМрПиЃЌПЩРЉеЙадВЛЬЋгбКУЃЌВЂЧвЕБЮДРДЪ§СПМЖДѓЪБЃЌВЛЗНБуРЉШнЁЃ
зюКѓЭХЖгбЁдёСЫ Prometheus дЦдЩњМрПиЗНАИЁЃЫфШЛ Prometheus дкГжОУЛЏЗНУцзіЕФЛЙВЛЙЛКУЃЌЕЋЪЧ
Prometheus ИќЪЪКЯдЦдЩњЩњЬЌЁЃвђЮЊШнЦїЪЧЖЏЬЌБфЛЏЕФЃЌЮЂЗўЮёМмЙЙЯТвЛИіЪЕР§ЕФЖрИіИББОвВЪЧЖЏЬЌБфЛЏЕФЃЌPrometheus
ЕФ Pull ЗНЪНИќЪЪКЯЖЏЬЌБфЛЏЕФГЁОАЁЃ
Prometheus ЕФгІгУЪЕМљ
ИпПЩгУ
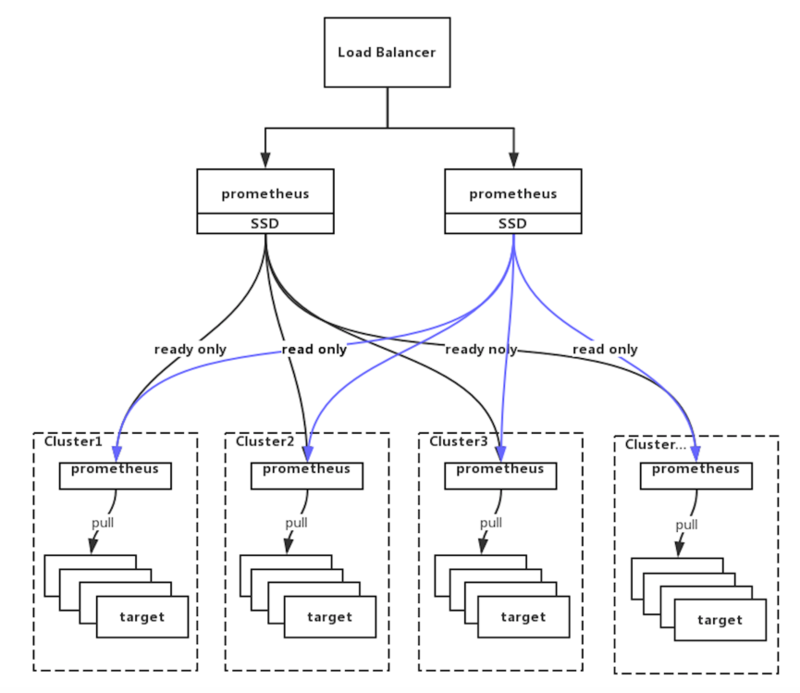
ЯждкгЩгкУПИіЛњЗПЕФЛњЦїЪ§СПВЛЫуЬЋЖрЃЌЕБЧАЕФЩшМЦЗНЪНЪЧдкУПИіЛњЗПВПЪ№вЛЬз Prometheus ЪЕР§гУгкзЅШЁФПБъЕФМрПиЪ§ОнЃЌЭЌЪБдкУПИіЛњЗПЕФЩЯвЛВуЛсВПЪ№СНЬз
Prometheus РДзіИпПЩгУ (HA). етбљЩЯВуЕФ Prometheus жЛвЊШЅЯТВузЅШЁЙиаФЕФ
metrics ОЭПЩвдЁЃетбљзіЕФКУДІ:
Й§ТЫЕєЩЯВуВЛЙиаФЕФМрПиЪ§ОнЃЌМѕЧсЪ§ОнДцДЂЕФбЙСІЁЃ
ЖдИїИіЛњЗПЕФЪ§ОнНјааОлКЯЃЌВЂЭГвЛЖдЭтЬсЙЉЭГвЛЕФБЈОЏЃЌЪгЭМВщбЏНгПкЁЃ
гЩгк promethues ЪЕР§дЫаадкБОЕиЃЌБОЕиЕФДХХЬПеМфгаЯоЃЌФЌШЯжЛБЃСєзюНќ 15 ЬьЕФМрПиЪ§ОнЃЌЕЋЪЧЯыВщбЏзюНќвЛИідТЃЌЛђепАыФъЕФЪ§ОнЃЌетИіашЧѓЪЧзіВЛЕНЕФЁЃЫљвдНЋ
prometheus ЕФЪ§ОнгжШыЕНСЫдЖГЬДцДЂ InfluxDB вЛЗнЃЌгУгкЪ§ОнЕФВщбЏЪЙгУЁЃ
БЈОЏ
Prometheus ЕФБЈОЏЛљгкХфжУЮФМўаЮЪНЕФЁЃетжжЧщПіЯТЃЌЛљДЁаджИБъПЩвдВњЦЗЛЏЁЃ360 ЭХЖгЖЈжЦСЫХфжУФЃАцЃЌгУЛЇжЛашвЊЬюОпЬхЕФМрПижЕОЭПЩвдСЫЁЃ
еыЖдвЕЮёМрПиЃЌгУЛЇашвЊбЇЯА Prometheus ЕФ promQLЃЌетЪЧгЩгкВЛЭЌЕФвЕЮёМрПиЕФашЧѓВЛЭЌЃЌУЛгаАьЗЈИјвЕЮёЭГвЛЕФВњЦЗЛЏЗўЮёЃЌжЛФмАДвЕЮёздМКжЦЖЈБЈОЏЙцдђШЅЯТЗЂБЈОЏЁЃ
ЖдгкздЖЈвхвЕЮёЃЌШУвЕЮёздМКаДИцОЏЃЌЭГвЛЕФХфжУЮФМўЛсЩЯБЈЕН QConfЁЃ
дЫаадкСНЬЈ Prometheus ЛњЦїЩЯ Agent ЛсЪЕЪБЕФ watch ХфжУжааФ (Qconf)
ЪЧЗёгааТЕФХфжУЩњГЩЃЌШчЙћДцдкдђЛс Pull БЈОЏЙцдђЃЌВЂ reload Prometheus ЪЕР§ЁЃ
ЮЊЪВУДвЊЪЙгУПЊдДЯЕЭГ
вЛАуЙЋЫОЖМгаздбаЕФМрПиЯЕЭГЃЌДѓЖрЪ§МрПиЯЕЭГЖМЪЧЛљгкПЊдДЯюФППЊЗЂЕФЁЃЮЊЪВУД 360 вЊЪЙгУ PrometheusЃП
дк K8s ДѓЙцФЃЪЙгУЕФНёЬьЃЌећИіШнЦїдЦЕФЩњЬЌЭЦМіЪЙгУ PrometheusЁЃ
НкЪЁШЫСІГЩБОЁЃЙЋЫОПЊЗЂвЛЬзМрПиЯЕЭГашвЊЭЖШыШЫСІЃЌШчЙћКѓЦкПЊЗЂШЫдБСїЪЇЃЌКѓЦкЕФЮЌЛЄЪЧИіДѓЮЪЬтЁЃЕЋЪЧЪЙгУПЊдДМрПиЯЕЭГЃЌдкЩчЧјЛюдОЕФЧщПіЯТЯюФПвВгаБЃжЄЃЌВЂЧвЮвУЧвВЛсдкЪЙгУЙ§ГЬжаЛиРЁЩчЧјЁЃ
360 ШнЦїЦНЬЈМрПиЯЕЭГбнНјЗНЯђ
ФПЧАЕФМрПиЯЕЭГећЬхМмЙЙЖдгкШнЦїЦНЬЈРДЫЕПЩРЉеЙадБШНЯКУЁЃЮДРДЫцзХМЏШКЙцФЃВЛЖЯРЉДѓЃЌЕЅИіМЏШКжЛгавЛИі Prometheus
ЪЕР§вЊДІРэЕФ Job Ъ§СПБЌЗЂЪБЃЌPrometheus ЕФадФмОЭЛсБфВюЁЃетИіЪБКђПЩвдеыЖдВЛЭЌЕФШЮЮёРраЭЃЌдквЛИіМЏШКРяВПЪ№ЖрИі
PrometheusЃЌУПвЛИі Prometheus жЛЙиаФздМКЕФШЮЮёЃЌПЩПиадЛсДѓДѓЬсЩ§ЃЌЭЌЪБећИіМмЙЙЕФКсЯђРЉеЙБШНЯЗНБуЁЃ
СэЭт Prometheus ДцдкГжОУЛЏЕФЮЪЬтЃЌЮДРДЛЙашвЊЖд Prometheus НјааЪ§ОндЖГЬДцДЂЃЈдкЩЯУцЕФМмЙЙЭМжаЪЙгУЕФащЯпБъзЂВПЗжЃЉЁЃ
Г§СЫЪ§ОнЃЌ360 вВдкЬНЫї AIOpsЃЌПЩвдЖдМрПиЯЕЭГЪеМЏЕНЕФЪ§ОнНјааДІРэЃЌЬНЫїЙЪеЯЖЈЮЛКЭИљвђЗжЮіЕШЁЃ
ЦеЭЈЭХЖгШчКЮЙЙНЈМрПиЯЕЭГЃП
360 МрПиЭХЖгШЯЮЊЃЌЙЋЫОЕФМрПиЯЕЭГвЊИљОнЙЋЫОЕФЙцФЃКЭвЕЮёГЁОАРДЖЈЃЌВЛПЩФмвЛЬзЗНАИжБНгФУРДОЭжБНгЪЙгУЁЃ
ЖдгкЪЙгУЙЋгадЦВЂЧвЙцФЃНЯаЁЕФЙЋЫОЃЌЙЋгадЦБОЩэОЭгаМрПиЯЕЭГЁЃШчЙћЙЋЫОздМКгаЗўЮёЦїЃЌЕЋЪЧСПВЛДѓЃЌМђЕЅДюНЈвЛИіаЁаЭ
HA ЕФМрПиЯЕЭГОЭЭъШЋПЩвдТњзуМрПиЕФашЧѓСЫЁЃМмЙЙЕФбнБфЪЧЫцзХвЕЮёЙцФЃЕФдіГЄЖјВЛЖЯЕФбнБфИФНјЕФЁЃетЪБОЭашвЊИљОнОпЬхЕФЧщПіЃЌШЅбЁдёЪЪКЯздМКЦНЬЈЕФМмЙЙЗНАИЁЃ |









