| БрМЭЦМі: |
| БОЮФРДдДwww.tuicool.comЃЌЫцзХздЖЏЛЏдЫЮЌЫЎЦНЕФЬсИпЃЌвЛИіЛљДЁЕФдЫЮЌШЫдБЮЌЛЄГЩАйЩЯЧЇЬЈНкЕувбОВЛЪЧЬЋФбЕФЪТЧщЃЌЕБШЛЃЌеташвЊвРППгкЮШЖЈЁЂИпаЇЕФздЖЏЛЏдЫЮЌЬхЯЕЁЃ |
|
1 ЧАбдНщЩм
БОЦЊЮФеТМДЪЧВћЪіШчКЮРћгУ bitbucket pipeline НсКЯ
Amazon S3 ДцДЂЪЕЯжЯюФПЕФздЖЏЙЙНЈЁЂздЖЏЗЂВМвдМАвьГЃБЈОЏЕШЭъећЕФздЖЏЛЏСїГЬДІРэЁЃВЛЭЌгкГЃМћЕФздЖЏЛЏЯюФПвЛАуЗўЮёгкОжгђЭјЬхЯЕЃЌгаКмДѓЕФВЂЗЂЯожЦгыЭјТчДјПэЯожЦЃЌБОЦЊНщЩмВЂЪЕЯжЕФдЫЮЌЬхЯЕВЛДцдкЭјТчЦПОБЃЌПЩвджЇГХЙугђЭјдЫЮЌздЖЏЛЏЃЌВЂЧвжЇГжИпВЂЗЂЁЂЩ§МЖЫйЖШПьЁЂМмЙЙЮШЖЈПЩРЉеЙадЧПЕШгХЕуЁЃ
2.1 гІгУИХЪі
БОМмЙЙжаЩцМАЕНЕФжївЊгІгУгаЃК
BitbucketЃКвЛжжЛљгк Git зіАцБОПижЦЕФДњТыЭаЙмЦНЬЈЃЌЦфЫћБШНЯСїааЕФЦНЬЈга GithubЁЂGitLabЁЂCodingЁЃBitbucket
жЇГж pipeline ЙІФмЃЌетвВЪЧЮвУЧздЖЏЛЏЬхЯЕ CIЃЈГжајМЏГЩЃЉ/CDЃЈГжајНЛИЖЃЉЕФЛљДЁЁЃ
Amzaon S3ЃКAWS ЙйЭјНщЩмЪЧЃКЁАЬсЙЉСЫвЛИіМђЕЅ Web ЗўЮёНгПкЃЌПЩгУгкЫцЪБдк Web
ЩЯЕФШЮКЮЮЛжУДцДЂКЭМьЫїШЮКЮЪ§СПЕФЪ§ОнЁБЁЃМђЖјбджЎЃЌОЭЪЧ Amazon S3 ЬсЙЉвЛИіЭјТчДцДЂЦНЬЈЃЌЮвУЧПЩвдРћгУЦфЬсЙЉЕФ
Web API НјааФкШнЕФДцДЂгыЗУЮЪЁЃ
Docker HubЃКФПЧА Docker ЙйЗНЮЌЛЄЕФвЛИіЙЋЙВ Docker ОЕЯёВжПтЃЌЖјдкЮвУЧЕФздЖЏЛЏЬхЯЕжаЃЌвВЪЧЛљгкЛљДЁЕФ
Docker ОЕЯёЫљзіЕФЖўДЮПЊЗЂЁЃ
AnsibleЃКвЛИіЛљгк SSH АВШЋШЯжЄЕФХњСПВйзїЙЄОпЃЌЯрБШНЯгк saltstack ЦфВйзїЁЂВПЪ№вдМАЮЌЛЄБШНЯМђЕЅЃЌЕЋЪЧСЌНгЫйЖШНЯТ§ЁЃ
SlackЃКгХауЕФЦѓвЕазїЭЈбЖЦНЬЈЃЌЮвУЧПЩвдРћгУЦфЬсЙЉЕФНгПкНјааздЖЏЛЏжДааНсЙћЕФЯћЯЂЭЈжЊгыеЙЪОЁЃ
2.2 ВжПтНсЙЙгыВжПтШЈЯоИХЪі
ЮвУЧНЋвЛИіВњЦЗЯюФПЃЈProjectXЃЉИљОнТпМЙІФмВЛЭЌВ№ЗжВ№ЗжГЩШєИЩИіЖРСЂЕФФЃПщЃЌУПИіФЃПщДцДЂдквЛИіЖРСЂЕФВжПтжаЁЃСэЭтЃЌЮвУЧИљОнВжПтЕФЮЌЛЄепВЛЭЌНЋВжПтЗжЮЊдДТыПтЃЈsource
repositoryЃЉЁЂЗЂВМПтЃЈrelease repositoryЃЉЁЂећКЯПтЃЈdistribution
repositoryЃЉЁЃБШШчЮвУЧЕФЯюФП ProjectX ЖдгІЕФећКЯВжПтЮЊ ProjectX.dist
ЃЌИУЯюФПжагаИіЙІФмФЃПщЮЊ ModuleX ЃЌеыЖдетИіФЃПщашвЊгадДТыВжПтЃЈModuleX.srcЃЉвдМАЗЂВМВжПтЃЈModuleX.relЃЉЁЃ
ЦфжадДТыПтЃЈКѓМђГЦ SRC ВжПтЃЉгЩбаЗЂШЫдБЮЌЛЄЃЌМДЬсЙЉФГИіЙІФмФЃПщЕФдДДњТыЁЂФЃПщЙІФмНщЩмгыЪЙгУЫЕУїЕШаХЯЂЁЃПЊЗЂШЫдБЖддДТыПтПЩЖСаДЃЌдЫЮЌШЫдБПЩЖСЃЛЗЂВМПтЃЈКѓМђГЦ
REL ВжПтЃЉгЩЯЕЭГдЫЮЌШЫдБЮЌЛЄЃЌЬсЙЉдДТыЃЈМйЩшдДТыЮЊБрвыаЭгябдЃЉБрвыКѓЕФЖўНјжЦЮФМўАВзАГЬађЁЃдЫЮЌШЫдБЖдЗЂВМПтПЩЖСаДЃЌПЊЗЂШЫдБЮоШЈЯоЃЛећКЯПтЃЈКѓМђГЦ
DIST ВжПтЃЉдђЪЧНЋВЛЭЌЕФВжПтФЃПщАДеевЛЖЈЕФТпМЫГађзщКЯЦ№РДЃЌаЮГЩвЛИіЭъећЕФВњЦЗЯюФПЁЃдЫЮЌШЫдБЖдећКЯПтПЩЖСаДЃЌПЊЗЂШЫдБЮоШЈЯоЁЃВњЦЗЯюФПЕФ
Git ВжПтТпМЗжВуНсЙЙЪОвтЭМШчЯТЃК
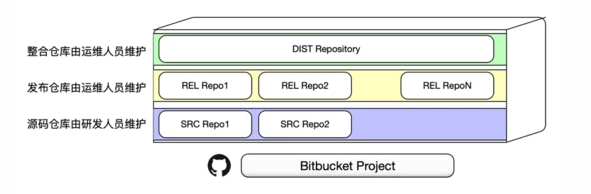
ЭМ 1 Git ВжПтТпМЗжВуНсЙЙЪОвтЭМ
вЛИіЯюФПгЩвЛИі DIST ВжПтЁЂN Иі SRC ВжПтЁЂN+M Иі REL ВжПтзщГЩЁЃжЛгавЛИіећКЯВжПтЃЌетИіКмКУРэНтЃЌЕЋЪЧ
SRC гы REL ВжПтЕФЙиЯЕШчКЮРэНтФиЃПвЛАуРДЫЕвЛИі SRC ВжПтЛсЖдгІвЛИі REL ВжПтЃЌМДбаЗЂШЫдБжЛИКд№ЬсЙЉдДДњТыЃЌжСгкШчКЮАВзАЕНЯЕЭГЁЂАВзАЕНЯЕЭГЕФФФИіФПТМЁЂвдМАШчКЮжЦЖЈАВШЋБИЗнВпТдЁЂШежОЛиЙіВпТдЕШЮЪЬтдђВЛашвЊЙизЂЃЌетаЉгЩЯЕЭГдЫЮЌШЫдБНЋИУГЬађЕФжДааВпТдвдГЬађЛђепНХБОЕФаЮЪНДцдкЖдгІЕФ
REL ЗЂВМПтжаЃЌвђДЫвЛИі SRC ВжПтЛсгавЛИіЯргІЕФ REL ВжПтгыжЎЖдгІЁЃЕЋЪЧвЛИі REL ВжПтгаПЩФмЪЧВЛашвЊ
SRC ВжПтЕФЃЌБШШчЮвУЧдкЯЕЭГжаЛсв§ШыФГИіПЊдДГЬађЃЈШч NginxЃЉЃЌЮЊСЫЯюФПЕФЮШЖЈадЃЌЮвУЧЛсАб Nginx
жИЖЈАцБОЕФ RPM АВзААќзїЮЊвЛИіЮФМўДцДЂжС REL ВжПтжаЃЌетбљетИіВжПтЦфЪЕОЭВЛашвЊдДТыПтМД SRC
ВжПтЃЌЕЋЪЧШчЙћЮвУЧвЊЖд Nginx зіЖўДЮбаЗЂЃЌШЛКѓдйБрвыГЩЖўНјжЦЮФМўЃЌдђашвЊЖюЭтДДНЈ SRC ВжПтгУгкДцДЂдДДњТыЁЃ
2.3 МмЙЙжДааСїГЬИХЪі
ЕБПЊЗЂепНЋДњТыЭЦЫЭжС Bitbucket ЩЯЕФдДТыВжПтжЎКѓЃЌЛсДЅЗЂ SRC ВжПтЕФ pipeline
ЃЌЕїгУжИЖЈЕФ Docker Image ЃЈвЛАуашвЊЮвУЧзіЖўДЮаоИФЁЂЗЂВМВХФмЪЙгУЃЉЭъГЩдДТыздЖЏБрвыЁЂДђАќЃЌЮвУЧЖЈвхДђАќЮФМўУћЭЌЖўНјжЦЮФМўУћМгЩЯжИЖЈЕФбЙЫѕКѓзКЃЈБШШч
ModuleX.src жаЬсЙЉСЫвЛИіЖўНјжЦГЬађЮЊ modulex-client ЃЌФЧУДИУФЃПщДђАќУћГЦМДЮЊ
modulex-client.tar.gzЃЉЃЌВЂЧвДцДЂжС Amazon S3 ДцДЂЭАжаЃЛШЛКѓдЫЮЌШЫдБашвЊИљОнГЬађЕФХфжУЮФЕЕЃЈгЩбаЗЂШЫдБЬсЙЉЯргІЕФ
README ЮФМўЃЌжИУїГЬађШчКЮАВзАЁЂШчКЮжИЖЈХфжУЮФМўЕШЃЉПЊЗЂЯргІЕФАВзАГЬађЃЌШЛКѓНЋАВзАГЬађЭЦЫЭжС
REL ВжПтжаЁЃетЭЌбљЛсДЅЗЂ REL ВжПтЕФ pipeline ЃЌЭЈЙ§ЕїгУЯргІЕФ Docker Image
НЋАВзАНХБОДђАќДцДЂжС Amazon S3 жаЃЌЭЌбљЃЌЮвУЧвВашвЊЖЈвхЗЂВМПтПтЕФДђАќЮФМўУћЭЌЗЂВМВжПтУћГЦЃЈШЅЕє
.rel КѓзКЃЉМгЫйжИЖЈЕФбЙЫѕКѓзКЃЈБШШч ModuleX.rel ДђАќжЎКѓЕФУћГЦЮЊ ModuleX.tar.gzЃЉЁЃетбљдк
S3 жаОЭгаСЫБрвыКѓЕФЖўНјжЦГЬађЃЌвдМАИУГЬађЕФАВзАНХБОЃЌЮвУЧдк DIST ВжПтЕФећКЯГЬађжажЛашвЊИљОнСНИіАќЕФ
S3 ДцДЂЮЛжУНЋЦфЯТдиЯТРДЃЌжДааАВзАНХБОМДЭъГЩИУФЃПщЕФАВзАЃЌЖдгкЦфЫћФЃПщвВЪЧШчДЫЁЃDIST ВжПтжЛашвЊвЛИіећКЯГЬађНЋЫљгаЕФзгФЃПщЃЈВжПтЃЉАДеевЛЖЈЕФТпМЫГађзщКЯЦ№РДЃЌОЭПЩвдЭъГЩСЫвЛИіЯюФПЕФЗЂВМЁЃжСДЫЃЌЮвУЧвбОФмЙЛЭъГЩвЛИіЁААыздЖЏЁБЕФЯюФПАВзАЃЌдЫЮЌШЫдБжЛашвЊНЋ
DIST ВжПтжаЕФећКЯГЬађЯТдиЕННкЕуВЂжДааЃЌећКЯГЬађЛсШЅЯргІЕФ Amazon S3 ДцДЂЩЯЯТдиИїИіВжПтЕФАВзАГЬађгыЖўНјжЦЮФМўЃЈШчЙћгаЕФЛАЃЉЃЌШЛКѓжДааИїИіФЃПщЕФАВзАГЬађЃЌетбљЕБЫљгаЕФФЃПщАВзАХфжУЭъГЩКѓЃЌвЛИіЭъећЕФЯюФПОЭвбОе§ГЃдЫааЦ№РДСЫЁЃ
НгЯТРДЃЌЮвУЧПЩвдНшжњздЖЏЛЏжДааЙЄОпЃЈШч AnsibleЁЂPuppetЁЂSaltstack ЕШЃЉгы
pipeline ЭъГЩНкЕуЕФздЖЏЛЏХњСПВПЪ№ЁЃМДЯЕЭГдЫЮЌШЫдБНЋећКЯНХБОЬсНЛжС DIST ВжПтКѓЃЌЛсДЅЗЂВжПтЕФ
pipeline ЃЌНЋећКЯНХБОгыЦфЫћЯрЙиЮФМўЃЈШчЯюФПАцБОаХЯЂЁЂзгФЃПщв§гУаХЯЂЃЌвдМАЯргІЕФДцДЂаХЯЂЕШЃЉЭЦЫЭжСАВзАСЫздЖЏЛЏжДааЙЄОпЕФжаПиНкЕуЃЌжаПиНкЕуНЋАВзАЛђепИќаТШЮЮёЗжЗЂЕНзгНкЕуЩЯЃЌМЬЖјЭъГЩШЋЧђНкЕуГжајМЏГЩгыГжајЗЂВМЁЃ
ЕБЭъГЩНкЕуЕФЗЂВМШЮЮёжЎКѓЃЌЮвУЧашвЊЖдЗЂВМНсЙћЃЈЬиБ№ЪЧЪЇАмНсЙћЃЉзігааЇМрПигыЭЈжЊЗДРЁЁЃДгжаПиЦНЬЈЗЂВМШЮЮёЕННкЕужДааЃЌжСЩйАќКЌСНИіЙиМќНкЕуЃКвЛЪЧжаПиЦНЬЈФмЗёГЩЙІНЋШЮЮёЯТЗЂЕНБЛПиНкЕуЃЌЖўЪЧБЛПиНкЕуФмЗёГЩЙІжДааЯТЗЂШЮЮёЁЃЧАвЛИіЙиМќНкЕуПЩвдЭЈЙ§жаПиЦНЬЈЕФЗжЗЂШЮЮёжДааНсЙћЃЈЛђепШежОЃЉЕУжЊЃЌКѓвЛИіЙиМќНкЕуПЩвдЭЈЙ§БЛПиНкЕуЕФШЮЮёжДаазДЬЌЃЈЛђепШежОЃЉЕУжЊЁЃМмЙЙЕФжДааСїГЬЭМШчЯТЃК
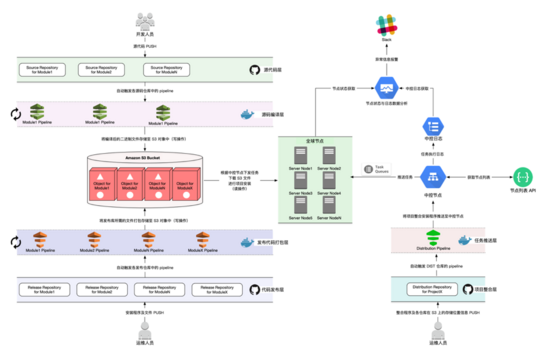
ЭМ 2 МмЙЙжДааСїГЬЭМ
3 МмЙЙЪЕЯж
3.1 Amazon S3 ДцДЂЙцдђ
ЮвУЧашвЊжЦЖЈ S3 Bucket ДцДЂЭАНсЙЙЙцдђЃЌвдБугкКѓЦкГЬађПЩвдАДееетбљЕФЙцдђЭъГЩздЖЏДцДЂгыЛёШЁЁЃЪзЯШЃЌвЛИіЯюФПЖдгІвЛИіДцДЂЭАЃЌМД
Amazon S3 BucketЃЛЦфДЮЃЌУПИізгВжПтЃЈФЃПщЃЉЪЧИУДцДЂЭАЯТЕФвЛИіЖдЯѓЃЈПЩвдМђЕЅЕФРэНтЮЊвЛИіФПТМЃЉЃЌЖјЩЯЮФЬсЕНЕФдДТыВжПтБрвыКѓДђАќЕФЖўНјжЦЮФМўЃЌвдМАЗЂВМВжПтДђАќЕФАВзАХфжУЕШЮФМўНдДцДЂдкИУФПТМжаЁЃШчЙћЮвУЧМЬајвдЩЯЮФЬсЕНЕФ
ProjectX ЯюФПЮЊР§ЃЌФЧУДЕБЧАДцДЂЭАЕФНсЙЙШчЯТЃК
rojectX:
- ModuleX
- modulex-client.tar.gz
- ModuleX.tar.gz |
Ѕp
етбљвбОПЩвдТњзуЕЅИіФЃПщЙІФмЕФаХЯЂДцДЂЃЌЕЋЪЧжЛФмДцДЂзюНќвЛДЮДђАќНсЙћЁЃШчЙћЮвЯыДцДЂжЎЧАЗЂВМЕФФГИіАцБОЃЌдђВЛФмЪЕЯжЃЌЩшжУВЛФмЙЛНјааИУАцБОЕФШЮКЮВтЪдОЭЛсБЛЭЦЩЯЩњВњЯЕЭГЃЌетЯдШЛВЛКЯРэЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧИјДцДЂЭАгжМгСЫвЛВуЁАЗжжЇЁБгыЁААцБОПижЦЁБЕФНсЙЙИХФюЁЃЖдгкЗжжЇЃЌвЛАуЮвУЧдкЩњВњПЊЗЂжажСЩйЖМЛсгаСНИі
git ЗжжЇЃЌМД master гы developer ЗжжЇЃЌЦфжа developer ЗжжЇДњТыгУгкЙІФмВтЪдЃЌЕБВтЪдЭЈЙ§жЎКѓЬсНЛЕН
master ЗжжЇЃЌгУгке§ЪНАцБОЗЂВМЁЃвђДЫЮвУЧдк S3 ДцДЂЭАжаФЃПщЖдЯѓЯТЃЌгжаТдіСЫвЛВуФПТМНсЙЙЃЌdeveloper
ФПТМгы master ФПТМЃЌеыЖдВтЪдДњТыЃЌЮвУЧЮоашДцДЂжЎЧАЕФАцБОЃЌжЛБЃСєЕБЧАзюаТДњТыМДПЩЃЌвђДЫжБНгНЋДђАќКѓЕФЮФМўДцДЂжС
developer ФПТМЯТМДПЩЬцЛЛжЎЧАЕФВтЪдГЬађЁЃЕЋЪЧЖдгкЗЂВМАцЃЌдђашвЊБЃСєРњЪЗАцБОЃЌвдБуПьЫйЛиЙіЃЌЛђепгЩгкФГаЉЦфЫћФЃПщв§гУСЫЕБЧАФЃПщЕФФГИіжИЖЈАцБОЃЌЖјЕМжТИУАцБОБиаыБЃСєЁЃвђДЫ
master ЗжжЇгы developer ВЛЭЌЃЌВЛФмЭЈЙ§МђЕЅЕФДДНЈвЛИі master ФПТМРДНтОіЮЪЬтЃЌЛљгкДЫЃЌЮвУЧЖд
mater ЗжжЇжЦЖЈСЫвЛИіЙцдђЃЌМДвЛЕЉКЯВЂСЫ developer ЗжжЇЃЌБиаыДђЩЯЯргІЕФ tag аХЯЂЃЈЗёдђЮоЗЈДЅЗЂ
PIPELINE ЭъГЩздЖЏЙЙНЈЃЉЃЌДцДЂЭАЙІФмФЃПщЯТВЛдйвд master зїЮЊжїЗжжЇДђАќГЬађЕФЗХжУФПТМЃЌЖјЪЧвд
tag УћГЦзїЮЊЗХжУФПТМЁЃетбљЕФЛАЃЌЮвУЧОЭПЩвдЭЈЙ§ tag аХЯЂЃЌЛёжЊФГИіФПТМЯТДцДЂЕФЪЧФФИі tag
ЕФЗЂВМДњТыЃЌетбљЕБЧАЕФДцДЂЭАФПТМНсЙЙШчЯТЃК
ProjectX:
- ModuleX
- developer
- modulex-client.tar.gz
- ModuleX.tar.gz
- 1.0.0
- modulex-client.tar.gz
- ModuleX.tar.gz
- 2.0.0
- modulex-client.tar.gz
- ModuleX.tar.gz
- ModuleY
- developer
- moduley-client.tar.gz
- ModuleY.tar.gz
- 3.2.0
- moduley-client.tar.gz
- ModuleY.tar.gz |
Ѕp
3.2 ВжПтФПТМНсЙЙгыЙІФмЫЕУї
дДТыВжПтЃЈsource repositoryЃЉЃКВжПтУћГЦвд ЁЎ.srcЁЏ зїЮЊКѓзКЃЌАќКЌдДДњТыЁЂPIPELINE
ЮФМўЃЈзЂвтЃКbitbucket ЕФ PIPELINE ЮФМўУћГЦБиаыЪЧ bitbucket-pipelines.ymlЃЉЁЂГЬађХфжУЮФМўФЃАхЃЈШчЙћашвЊЕФЛАЃЉЁЂCHANGELOG
гы README ЕШЫЕУїЮФМўЃЌвдБудЫЮЌШЫдБПЊЗЂЯргІЕФАВзАХфжУГЬађЁЃ
ЗЂВМВжПтЃЈrelease repositoryЃЉЃКВжПтУћГЦвд ЁЎ.relЁЏ зїЮЊКѓзКЃЌАќКЌдДТыБрвыКѓЕФЖўНјжЦГЬађАВзАгыХфжУГЬађЃЈНХБОЃЉЁЂЩ§МЖГЬађЁЂХфжУЮФМўЁЂдДТыПтАцБОаХЯЂЃЈАВзАГЬађОЭЪЧИљОнетИіАцБОЃЈЛђепЫЕЪЧ
tagЃЉаХЯЂШЅ S3 ЩЯЛёШЁЯргІ tag УћГЦФПТМЯТЕФДђАќЮФМўЃЉЁЃ
ећКЯВжПтЃЈdistribution repositoryЃЉЃКВжПтУћГЦвд ЁЎ.distЁЏ зїЮЊКѓзКЃЌАќКЌећКЯГЬађЃЈАВзАгыЩ§МЖЃЉЁЂЮЌЛЄвЛИіЯюФПЃЈprojectЃЉЫљашЕФФЃПщСаБэвдМАИїФЃПщЕФАцБОаХЯЂЃЌећКЯГЬађИљОнИїИіФЃПщСаБэЕФАцБОаХЯЂДг
Amazon S3 ЕФДцДЂЩЯЯТдиЯргІФЃПщЕФжИЖЈАцБОЃЌЭЈЙ§жДааИїФЃПщЕФАВзАНХБОЃЌЭъГЩИїИіФЃПщЕФАВзАЁЃ
ФЃПщАцБОаХЯЂЮФМўЃЈrepo-infoЃЉЃКИУЮФМўДцдкгк REL ВжПтгы DIST ВжПтжаЃЌТњзу yaml
ЮФМўИёЪНЁЃИУЮФМўдк rel ВжПтжажївЊгУгкМЧТМИУФЃПщЕФдДТы tag аХЯЂЃЈКѓУцШчЮоЬиЪтЪ§ТыЃЌЭЌЁАЗЂВМАцБОаХЯЂЁБЭЌвхЃЉЃЌЗЂВМПтЗжжЇЛђАцБОаХЯЂЃЌвдМАвРРЕФЃПщЕФЗЂВМАцБОаХЯЂЃЌЮФМўИёЪНШчЯТЃК
Repo-Info ЮФМўХфжУФЃАхЃЌЦфжа
repo_name ПЩвдРэНтЮЊЕЅИіФЃПщЙІФмдк git жаЕФВжПтУћГЦ
rel_branch: [developer|rel_tag_info] # ЩњВњЛЗОГжЛФм
developer OR rel_tag_info ЖўбЁвЛ
src_branch: [developer|src_tag_info] # ЩњВњЛЗОГжЛФм
developer OR src_tag_info ЖўбЁвЛ
depend_list: [none] # ЩњВњЛЗОГжЛФмЪЧ none Лђеп ЯТУцЕФ KEY-VALUES
ЖўбЁвЛ
repo_name1: 1.2.3
repo_name2: 1.1.1
repo_name3: 1.1.2
repo_name4: 2.1.3
repo_name5: 3.1.3 |
Ѕp
ЭЈЙ§ЩЯУцЕФИёЪНЖЈвхЃЌ rel ВжПтжаЕФАВзАНХБООЭПЩвдШЅ S3 ДцДЂЩЯЛёШЁдДТыАВзААќЃЌвдМАФГИіАцБОЕФвРРЕФЃПщАВзААќЁЃМђЕЅЫЕУїЯТХфжУЮФМўИїИіВЮЪ§ЕФКЌвхЃК
rel_branch: гУгкжИЖЈ REL ВжПтЕФДђАќЮФМўДцЗХЮЛжУЃЌШчЙћЪЧ developer дђБэЪОДцДЂдк
S3 ЩЯФЃПщУћГЦФПТМЯТЃЌdeveloper ФПТМжаЃЌгУгкЩњВњВтЪдЃЛЖјШчЙћЪЧ rel_tag_info
дђБэЪОДцДЂдк S3 ЩЯФЃПщУћГЦФПТМЯТЃЌЖдгІ tag УћГЦФПТМжаЃЌгУгкЩњГЩЗЂВМЁЃвђЮЊжЛгадкВтЪдЭЈЙ§жЎКѓЃЌВХЛсКЯВЂЕН
master ЗжжЇЃЌЖј master ЗжжЇвВжЛгадкДђЩЯ tag жЎКѓЃЌВХЛсДЅЗЂ pipeline ЭъГЩздЖЏЙЙНЈЃЌНЋЖдгІЕФДђАќЮФМўДцДЂдквдЕБЧА
tag ЮЊУћГЦЕФФПТМЯТЁЃЫљвдЃЌS3 ДцДЂжа tag ФПТМЯТЕФДђАќЮФМўЃЌОљЪЧЩњВњЗЂВМАцБОЁЃ src_branch:
гУгкжИЖЈ SRC ВжПтЕФДђАќЮФМўДцЗХЮЛжУЃЌгы rel_branch ЩшМЦРэФюЯрЭЌЃЌВтЪдЗжжЇЛсДцДЂдк
developer ФПТМЯТЃЌе§ЪНЗЂВМАцБОЛсДцДЂдквд tag аХЯЂзїЮЊУћГЦЕФФПТМЯТЁЃ depend_list:
гУгкжИЖЈИУФЃПщЕФвРРЕФЃПщЃЈЛђепЫЕЪЧПтЃЉЃЌШчЙћжЕЮЊ ЁЎnoneЁЏ ЃЌБэЪОИУФЃПщУЛгавРРЕФЃПщЃЌПЩвджБНгАВзАЁЃШчЙћВЛЪЧ
ЁЎnoneЁЏ ЃЌдђашвЊжИЖЈвРРЕФЃПщЕФУћГЦЃЌвдМАЯргІвРРЕФЃПщЕФАцБОаХЯЂЁЃашвЊзЂвтЕФЪЧЃЌетРяЕФФЃПщАцБОаХЯЂЮвУЧЙцЖЈжЛФмЪЙгУ
tag аХЯЂЃЌвВОЭЪЧжЛФмжИЖЈФГИіФЃПщЕФЗЂВМАцЃЌЖјВЛФмЪЙгУ developer ЯТЕФДђАќЮФМўЃЌМДИУФЃПщЕФВтЪдАцЃЌвђЮЊвРРЕФЃПщзїЮЊвЛИіЕзВуФЃПщЃЌБиаыБЃжЄЮШЖЈЕФЧАЬсЯТВХФмБЛЦфЫћЩЯВуФЃПщЫљв§гУЃЌвВВХФмБЃжЄЩЯВуФЃПщЕФЮШЖЈадЁЃ
Жјдк DIST ВжПтжаЕФ repo-info ЮФМўЃЌЮФМўИёЪНЭЌбљТњзу yaml гяЗЈЃЌЮФМўЕФФкШнВЮЪ§ТдгаЕїећЃЌвдЯТЮЊФЃАхЮФМўЃК
ranch: [developer|rel_tag_info]
# ЩњВњЛЗОГжЛФм developer OR rel_tag_info ЖўбЁвЛ
sub_repo: [none] ## ШчЙћЪЧ none ЃЌдђВЛЛсгаЯТУцашвЊАВзАЕФВжПтСаБэаХЯЂ
repo_name1: 1.2.3
repo_name2: 1.1.1
repo_name3: 1.1.2
repo_name4: 2.1.3
repo_name5: 3.1.3
upgrade_list: [none] # ШчЙћЪЧ none ЃЌдђВЛЛсгаЯТУцашвЊЩ§МЖЕФВжПтСаБэаХЯЂ
repo_name3: 1.1.3
repo_name4: 2.1.4
repo_name5: 4.0.0 |
Ѕp
Цфжа rel_branch гыдк REL ВжПтжаЕФКЌвхвЛбљЃЌгУгкБэЪО DIST ВжПтДцДЂдк Amazon
S3 ЩЯЕФЮЛжУЃЌЕЋЪЧашвЊзЂвтЕФЪЧ DIST ВжПтЪЧУЛга src_branch ЕФЃЌвђЮЊетИіВжПтОЭЪЧзЈУХгУгкИїИізгФЃПщЕФећКЯЃЌВЛДцШЮКЮДњТыЃЌжЛБЃСєИїФЃПщАцБОЃЈвВМДЪЧДцДЂЃЉаХЯЂЁЃ
sub_repoЃК БэЪОетИіЯюФПЃЈProjectЃЉгЩФФаЉФЃПщзщГЩЃЌИїФЃПщЕФАцБОЪЧЪВУДЃЌећКЯНХБООЭЪЧИљОн
sub_repo ЕФаХЯЂНјааЖдгІЕФЙІФмФЃПщЛёШЁгыАВзАЕФЃЌетРяашвЊзЂвтЕФЪЧЃЌФЃПщАВзАЛсДцдкЫГађЙиЯЕЃЌетРяашвЊЧјБ№ЖдД§вРРЕЙиЯЕЁЃвРРЕЙиЯЕЪЧШБЩйФГИіФЃПщЛсЕМжТЕБЧАФЃПщЮоЗЈдЫааЃЌЛђепВПЗжЙІФмВЛФмЪЙгУЃЛЖјЫГађЙиЯЕЃЌдђЪЧТпМЙиЯЕЃЌШБЩйФГИіЛђепЫГађВЛЖдВЛЛсЕМжТСэвЛИіЮоЗЈАВзАЃЌжЛЪЧећИівЕЮёТпМЩЯЛсДцдквЛЖЈЕФЮЪЬтЁЃОйИіР§згЃЌЮвУЧБрвы
nginx ашвЊ gcc ПтЃЌБиаыЯШАВзА gcc ПтВХФмБрвыАВзА nginxЃЌетОЭЪЧвРРЕЙиЯЕЁЃЖј nginx
дкНгЪеПЭЛЇЖЫЧыЧѓКѓЃЌПЩФмЛсНЋЧыЧѓзЊИј php ДІРэЃЌphp ПЩФмЛсШЅВйзїЪ§ОнПтЃЌЮвУЧвЛАуАВзАЕФЪБКђЃЌОЭЛсЯШАВзАЪ§ОнПтЃЌЕЋЪЧетСНепжЎМфЕФАВзАОЭВЛДцдквРРЕЙиЯЕЃЌЖјЪЧвЛжжЫГађЙиЯЕЁЃШчЙћЯШАВзА
nginx ШЛКѓдкАВзАЪ§ОнПтЃЌПЩФмжЛЛсЕМжТвЕЮёВЛФмДІРэЖЏЬЌЧыЧѓЖјвбЃЌЖјВЛЛсгАЯьСНИігІгУЕФе§ГЃАВзАЁЃ
upgrade_listЃК гУгкжИЖЈЯюФПЩ§МЖЃЈвВМД DIST ВжПтЩ§МЖЃЉЩцМАЕНФФаЉФЃПщЕФИќаТЃЌЁЎnoneЁЏ
БэЪОЮоЩ§МЖашЧѓЃЌШчЙћЮЊПеЃЌдђашвЊИљОнЯТУцЕФВжПтУћГЦЃЌЯТдиЯргІЕФзгФЃПщЃЌжДааРяУцЕФЩ§МЖНХБОЃЈ upgrade.sh
ЃЉЁЃ
3.3 АВзАгыЩ§МЖ
дкЮвУЧЖЈвхЭъ Amazon S3 ДцДЂЙцдђЃЌВЂЧвдкЗЂВМПтгыећКЯПтжаЬсЙЉСЫФЃПщаХЯЂЃЌИїИіФЃПщЕФАВзАЛђЩ§МЖГЬађОЭПЩвдРћгУетаЉаХЯЂЕН
S3 ЩЯЛёШЁЯргІЕФДђАќЮФМўЃЌетИіЮФМўЛсАќКЌдДТыБрвыКѓЕФЖўНјжЦЮФМўЃЈШчЙћгаЕФЛАЃЉКЭеыЖдИУЖўНјжЦЮФМўЕФАВзАХфжУНХБОЃЌетбљЮвУЧжЛашЕНШУећКЯВжПтИљОн
repo-info ЮФМўжажаЕФ sub_repo ФЃПщаХЯЂЕН S3 ЩЯЯТдиИїИіФЃПщЕФДђАќЮФМўЃЌжДааИїздЕФАВзАгыЩ§МЖНХБОМДПЩЁЃжСгкФГИіФЃПщвРРЕФФаЉФЃПщЃЌдђВЛгУдк
DIST ПтжаДІРэЃЌжЛашвЊдкжДааЕЅИіФЃПщЕФАВВПЪ№зАЃЈ deploy.sh ЃЉЛђЩ§МЖНХБОЃЈ upgrade.sh
ЃЉМДПЩЃЌвђЮЊетИіФЃПщЪЧзюЧхГўздМКвРРЕФФаЉФЃПщЕФЃЌдкетРяДІРэвВЪЧзюЧхЮњЁЂМђЕЅЕФЁЃЯТЭМЮЊЯюФПЕФАВзАСїГЬЃЌЩ§МЖСїГЬгыАВзАСїГЬРрЫЦЃЌжЛВЛЙ§АВзАСїГЬЪЧЯТдиИїИіФЃПщЃЌжДааИїФЃПщЕФАВзАНХБОЃЌЖјЩ§МЖЪЧжДааИїФЃПщЕФЩ§МЖНХБОЁЃ
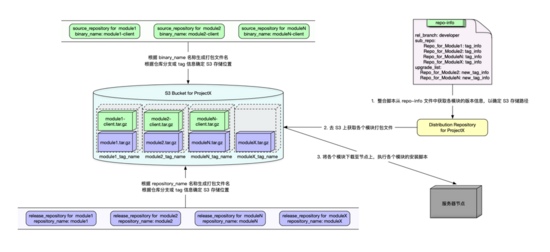
ЭМ 3 ЯюФПАВзАгыЩ§МЖСїГЬЭМ
3.4 PIPELINE ЙцдђжЦЖЈ
Bitbucket жЇГж pipeline ЙІФмЃЌдкТњзуЬѕМўЪБДЅЗЂФГжжВйзїЃЌетИіВйзїЮвУЧПЩвдМђЕЅЕФРэНтЮЊЕїгУ
docker ОЕЯёЭъГЩФГжжааЮЊЃЌБШШчБрвыЁЂДђАќЁЂЩЯДЋжС S3 ДцДЂЕШЁЃетРяЮвУЧЫљашвЊВћЪіЕФЪЧЃЌШчКЮжЦЖЈ
pipeline ЕФДЅЗЂЙцдђЃПвЊЛиД№етИіЮЪЬтЃЌЮвУЧЪзЯШвЊХЊУїАзРћгУ pipeline ЕФФПЕФЃЌМДЮвУЧЯЃЭћЕБПЊЗЂШЫдБ
push ДњТыЪБЃЌФмЙЛЭъГЩДњТыЕФздЖЏБрвыЁЂДђАќЁЂЗЂВМЁЂВтЪдЁЂвдМАЩЯЯпЕШааЮЊЁЃЦфжаДњТыБрвыЁЂДђАќЁЂЗЂВМЕШааЮЊЪЧЭГвЛЕФЃЌЖјВтЪдгыЩЯЯпЪЧзюжеВЛЭЌЕФСНИіФПЕФЃЌетбљЮвУЧОЭЯёашвЊЩшЖЈВЛЭЌЕФЙцдђРДДЅЗЂВтЪдгыЩЯЯпЕФВЛЭЌааЮЊЁЃИљОн
bitbucket ЕФ ЙйЗНЮФЕЕ жаЙигк pipeline ЕФДЅЗЂЬѕМўЃЌПЩвдЗжЮЊШ§жжЃЈЪЕМЪЩЯЪЧЫФжжЃЌЕЋЪЧ
bookmarks ЪЧеыЖд Mercurial ЃЌЮвУЧднВЛЬжТлЃЉЃЌЯТУцМђЕЅЫЕЯТетШ§жжЃК
default ЃКМДвЛЕЉгУЛЇ push ДњТыМДЛсДЅЗЂЕБЧА pipeline ЁЃ
tags: МДвЛЕЉгУЛЇЮЊДњТыДђЩЯ tag БъЧЉЪБОЭЛсДЅЁЃ
branchesЃК МДвЛЕЉгУЛЇЭљжИЖЈЗжжЇЩЯЬсНЛДњТыЪБОЭЛсДЅЗЂЁЃ
НсКЯЮвУЧЩшЖЈЕФздЖЏЛЏжДааТпМЃЌашвЊЪЙгУ tags гы branch зїЮЊДЅЗЂЬѕМўЃЌbranch ЩшжУЮЊ
developer ЗжжЇЃЌетбљЕБПЊЗЂШЫдБНЋДњТыЬсНЛЕН developer ЗжжЇЪБЛсСЂПЬДЅЗЂ pipeline
ЃЌжДааЯрЙиЕФБрвыЁЂДђАќЁЂЗЂВМЁЂВтЪдЙЄзїЁЃtags дђгУгкДЅЗЂВтЪджЎКѓЕФЗЂВМЃЌМДвЛЕЉЮвУЧдкЗжжЇЩЯДђЩЯ
tag БъЧЉЃЌОЭЛсздЖЏДЅЗЂ pipeline ЭъГЩБрвыЁЂДђАќЁЂЗЂВМЁЂЩЯЯпЙЄзїЁЃетРяашвЊзЂвтЕФЪЧЃЌbitbucket
pipeline ЮоЗЈЧјЗж tag ЪЧРДздгк master ЗжжЇЛђеп developer ЕШШЮвтЗжжЇЃЌжЛвЊМьВтЕНга
tag ВњЩњЃЌМДЛсДЅЗЂ pipeline ЃЌЫљвдДђ tag ЪБвЛЖЈвЊЩїжиЃЌЮвУЧЙцЖЈЃКБиаыдк developer
ЗжжЇЭъГЩГфЗжВтЪджЎКѓЃЌВХФм pull request ЕН master ЗжжЇЃЌЖјЫљгаЕФ tag вВБиаыЪЧДђдк
master ЗжжЇЩЯЕФЁЃЕБШЛЃЌвтЭтВЛПЩБмУтЃЌЮвУЧзіСЫЯрЙиЕФПМТЧЃЌШчЙћвђЮЊЮѓВйзїЛђепВтЪдВЛГфЗжЕМжТЕБЧААцБОВПЪ№ЕНЪЕМЪЩњВњНкЕуВЛФме§ГЃЪЙгУЃЌжЛашвЊ
rerun ЩЯИі tag ЕФ pipeline МДЛсжиаТДђАќЗЂВМРЯАцБОЁЃ
3.5 вЛдДЖрДцЮЪЬт
дкНВЪіИУЮЪЬтЧАЃЌЮвУЧЯШРДСФвЛИівЕЮёГЁОАЃЌЙЋЫОбаЗЂСЫвЛИіЕзВуЕФЛљДЁЙІФмФЃПщЃЌШчКЮБЛСНИіЩѕжСЖрИіЯюФПЫљв§гУЃЌзюМђЕЅЕФзіЗЈЪЧНЋетИіФЃПщзїЮЊДњТыЕФвЛВПЗжжБНгЬсЙЉИјИїИіЯюФПЪЙгУЃЌетОЭШнвздьГЩЩњВњжаОГЃгіЕНЕФЖрдДЮЪЬтЃЌКѓЦкЫцзХгЩгкИїЯюФПЕФЗЂеЙЃЌПЩФмЛсЖдв§ШыЕФЛљДЁФЃПщЙІФмзіЕїећЃЌФЧУДЕїећКѓЕФЛљДЁФЃПщОЭВЛдйФмЙЛБЃжЄБЛЦфЫћЯюФПЫљЭЈгУЃЌФЧУДаоИФКѓЕФДњТыЬсНЛЕНФФФиЃПжЛФмНЈСЂаТВжПтЬсНЛСЫЃЌетбљЮвУЧДгЮЌЛЄвЛИіЛљДЁПтОЭБфГЩСЫЮЌЛЄЖрИіЛљДЁПтЃЌПЊЗЂЛљДЁФЃПщЕФФПЕФБОРДОЭЪЧГщЯѓЙІФмЁЂДњТыИДгУЁЂЬсИпПЊЗЂаЇТЪЃЌетЯдЪОЪТгыдИЮЅЁЃ
ЕБШЛеыЖдетжжЖрдДЮЪЬтЃЌБШНЯГЃМћЕФНтОіАьЗЈЪЧЪЙгУ subtree Лђеп submodule ЕФЗНЪННЋВжПтв§ШыЕНЯюФПжаЃЌsubtree
ЛсжБНгНЋДњТыв§ШыЃЌетбљЛсЕМжТЮвКмФбПьЫйЕФжИЖЈЕБЧАЯюФПв§ШыЕФЪЧФФИіАцБОЕФЛљДЁФЃПщЁЃsubmodule
ПЩвдРэНтЮЊв§ШыЕФЪЧвЛИіжИеыЃЌжИЯђФГИіАцБОЕФЛљДЁПтЃЌетдквЛЖЈГЬЖШЩЯФмЙЛДяЕНЮвУЧЕФФПЕФЃЌЕЋЪЧвЛЕЉБЛЖрИіЯюФПЛђепЖрМЖЃЈЬиБ№ЪЧЖрМЖв§гУЃЉв§гУЃЌШчЙћИќаТЛљДЁФЃПщЃЌдђв§гУИУФЃПщЕФЫљгаЩЯМЖФЃПщашвЊвЛМЖвЛМЖжиаТв§ШыЃЌМђжБОЭЪЧиЌУЮЁЃЖјЮвУЧЪЕЯжЕФЭЈЙ§ВжПтжажИЖЈв§гУЛљДЁФЃПщАцБОЕФЗНЪНОЭЗЧГЃМђЕЅСЫЃЌЕБЛљДЁФЃПщИќаТЪБЃЌв§гУФЃПщШчЙћВЛашвЊИќаТЃЌдђВЛгУаоИФздЩэЕФвРРЕВжПтАцБОаХЯЂЃЌШчЙћашвЊЪЙгУаТАцБОЛљДЁПтЃЌжЛашвЊНЋвРРЕПтЕФАцБОКХаоИФЮЊЯывЊв§гУЕФАцБОКХМДПЩЃЌ
S3 ДцДЂЭАжаДцЗХСЫЫљгаЕФЮШЖЈАцБОЃЌВйзїЗЧГЃжЎМђЕЅЁЃетбљЮвУЧжЛашвЊДгвЛИідДЬсЙЉДњТыЃЌОЭПЩвдБЛЖрИіЯюФПв§гУЃЌЖјЧвПЩвдв§гУВЛЭЌАцБОЃЌЛЅЯрВЛгАЯьЁЃ
ЮвУЧжЊЕРЃЌвЛИіЭъећЕФЯюФПашвЊЖрИіВЛЭЌЕФФЃПщЃЌЮвУЧЪЧЪЙгУДцДЂЭАЕФЗНЪННЋИїИіФЃПщДђАќДцЗХЃЌФЧУДвВОЭЪЧЫЕУПИіДцДЂЭАжаЖМАќКЌСЫЫљгаЕФФЃПщДђАќЮФМўЃЌвдМАВЛЭЌАцБОЕФДђАќЮФМўЃЌФЧУДЕБвЛИіЛљДЁФЃПщдкДЅЗЂСЫ
pipeline ЭъГЩздЖЏБрвыДђАќжЎКѓЃЌШчЙћЗжЗЂЕНВЛЭЌЕФДцДЂЭАжаФиЃПетОЭЪЧЮвУЧНгЯТРДвЊЬжТлЕФЁАвЛдДЖрДцЮЪЬтЁБЁЃ
етРяЮвУЧашвЊв§Шы pipeline жаБфСПЕФИХФюЃЌЮвУЧДг bitbucket ЙигкБфСПЕФ ЙйЗНЮФЕЕ
жаПЩвдЕУжЊЃЌpipeline ПЩвдЪЙгУ bitbucket ФкжУЕФБфСПЃЌЕБШЛЮвУЧвВПЩвдздМКЖЈвхБфСПЃЌШчЙћБфСПУћГЦЯрЭЌЃЌЛсвдздЖЈвхБфСПЮЊзМЃЈзМШЗЕФЫЕЃЌЛсвдзюКѓЩљУїЕФБфСПЮЊзМЃЌЕЋЪЧФкжУБфСПЩљУїЪЧдкздЖЈвхБфСПЩљУїжЎЧАОЭЭъГЩЕФЃЉЁЃетбљЮвУЧОЭПЩвдРћгУБфСПЕФЗНЪНЃЌИјВЛЭЌЕФДцДЂЭАЩшЖЈВЛЭЌЕФБфСПУћГЦЃЌФЧУДДђАќДцДЂжЎКѓдйИљОнВЛЭЌЕФБфСПУћГЦНЋЮФМўДцДЂжС
S3 ЩЯМДПЩЁЃетбљЮвУЧОЭашвЊЙцЗЖФГаЉздЖЈвхБфСПЃЌетаЉБфСПзЈУХгУгк pipeline ЃЌЖјВЛФмБЛЦфЫћНХБОЖЈвхЃЌетаЉБфСПгаЃК
Бэ 1 PIPELINE здЖЏЙЙНЈБфСПЖЈвх
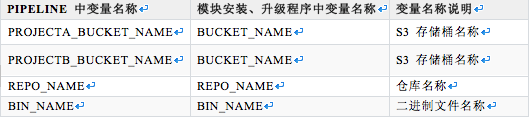
ЩЯЪіБэИёЃЌзѓБпЕквЛСаБэЪОашвЊдк bitbucket ЕФУПИіФЃПщВжПтжаЖЈвхЮЊ pipeline ЪЙгУЕФБфСПЃЌЕкЖўСаБэЪОУПИіФЃПщЕФАВзАгыЩ§МЖГЬађжаЖЈвхЕФБфСПЃЌЕкШ§СаБэЪОИУБфСПЕФКЌвхЁЃЯТУцЮвУЧДгЩЯЕНЯТНтЪЭетМИИіБфСПЕФКЌвхвдМАгУЗЈЃК
S3 ДцДЂЭАУћГЦЃКгУгкИцЫп pipeline дкЭъГЩДђАќжЎКѓЗЂЭљФФИіДцДЂЭАЁЃЖдгквЛдДЖрДцЕФЮЪЬтЃЌвВЪЧдкДЫДІНтОіЕФЁЃЪзЯШгЩгкЮвУЧЪЧДгвЛИідДВжПтДђАќв§ШыЕНВЛЭЌЯюФПжаЃЌФЧУДетЗнДњТыдкдДВжПтжаОЭЪЧЮЈвЛЧвЭЈгУЕФЃЌвђДЫЮвУЧЖЈвхСЫБфСПЁАBUCKET_NAMEЁБ
зїЮЊДцДЂЭАУћГЦЃЌгаашвЊЛёШЁ S3 ДцДЂЩЯЕФЮФМўЪБЃЌгУБфСПДњЬцЃЛСэЭтЃЌЮвУЧЭЈЙ§дк bitbucket
ЕФВЛЭЌЯюФПВжПтжаЩшжУВЛЭЌЕФДцДЂЭАУћГЦБфСПЃЌдк pipeline жаНЋBUCKETNNAMEЬцЛЛГЩ
{PROJECTA_BUCKET_NAME} Лђеп ${PROJECTB_BUCKET_NAME}ЃЌРДНЋдДЮФМўжаЕФДцДЂЭАУћГЦаоИФЮЊЕБЧАЯюФПЕФДцДЂЭАУћГЦЃЌВЂЧвЗЂЫЭжСЖдгІЕФДцДЂЭАЯТЃЌЪОР§ДњТыШчЯТЃК
# ЛљДЁФЃПщ REL ВжПтжаЕФДњТыЃЈdeploy.sh
гы upgrade.sh ОљАќКЌШчЯТДњТыЃЉНиШЁ
BUCKET_NAME=''
# ЛёШЁдДТыВжПтДђАќКѓЕФЮФМў
aws s3 cp s3://$ {BUCKET_NAME}/$ {REPO_NAME}/$ {BITBUCKET_TAG}/$ {BIN_NAME}.tar.gz
./ |
Ѕp
ДгЩЯУцЕФДњТыжаЃЌЮвУЧПЩвдПДЕНЃЌЛёШЁ S3 ЩЯДцДЂЕФЮФМўЃЌашвЊЫФИіБфСПЃЌМДЃК
BUCKETNAMEЁЂ{REPO_NAME}ЁЂ BITBUCKETTAGЁЂ{BIN_NAME}ЃЌЦфжаГ§СЫ
BITBUCKETTAGЭтЃЌЦфгрЕФШ§ИіЖМЪЧЮв УЧдкЩЯУцздМКЖЈвхЕФЁЃЩдКѓЛсЖдетМИИіВЮЪ§ЕФЪЙгУзіЫЕУїЃЌЮвУЧМЬајЬжТл
BITBUCKETTAGЭтЃЌЦфгрЕФШ§ИіЖМЪЧЮвУЧдкЩЯУцздМКЖЈвхЕФЁЃЩдКѓЛсЖдетМИИіВЮЪ§ЕФЪЙгУзіЫЕУїЃЌЮвУЧМЬајЬжТл{BUCKET_NAME}
ЕФЪЙгУЁЃетРяЮвУЧПДЯТ pipeline жаЕФВПЗжДњТыЃЌОЭЛсУїАзЪЧШчКЮНшжњгы bitbucket ЕФБфСПЖЈвхЃЌЭъГЩВЛЭЌдДЕФЖрДцДЂЮЪЬтСЫЁЃ
# bitbucket-pipelines.yml
жаВПЗжДњТы
script:
# ЗЂЫЭДцДЂЭА BUCKET_A жаЕФДђАќЮФМў
- export AWS_ACCESS_KEY_ID =${BUCKETA_S3KEY} AWS_SECRET_ACCESS_KEY =${BUCKETA_S3SECRET}
- sed -i 's#\${REPO_NAME} #'${REPO_NAME}'#g ; s#\$ {BUCKET_NAME} #'$ {PROJECTA_BUCKET_NAME}'#g'
deploy.sh upgrade.sh
- tar czf ${REPO_NAME}.tar.gz etc repo-info deploy.sh
upgrade.sh
- aws s3 cp ${REPO_NAME}.tar.gz s3:// ${PROJECTA_BUCKET_NAME} /${REPO_NAME}/ ${BITBUCKET_TAG}/
# ЗЂЫЭДцДЂЭА BUCKET_B жаЕФДђАќЮФМў
- export AWS_ACCESS_KEY_ID= ${BUCKETB_S3KEY} AWS_SECRET_ACCESS_KEY =${BUCKETB_S3SECRET}
- sed -i 's#\${REPO_NAME} #'${REPO_NAME}'#g ; s#\${BUCKET_NAME}#'${PROJECTB_BUCKET_NAME}'#g'
deploy.sh upgrade.sh
- tar czf ${REPO_NAME}.tar.gz etc repo-info deploy.sh
upgrade.sh
- aws s3 cp ${REPO_NAME}
|
Ѕp
ЪзЯШашвЊЫЕУїЕФвЛЕуЪЧЃЌЩЯУцЕФ pipeline ЪЙгУЕФ docker ОЕЯёЪЧ atlassian/pipelines-awscli
ЃЌгЩ aws ЙйЗНЬсЙЉЃЌЦфжаБфСП AWS_ACCESS_KEY_ID гы AWS_SECRET_ACCESS_KEY
ЗжБ№БэЪОЗУЮЪДцДЂЭЈЕФ key КЭ secret ЃЌУПИіДцДЂЭАЕФ key КЭ secret ОљВЛвЛбљЃЌОпЬхЧыВЮПМ
AWS IAM ЃЌДЫДІВЛдйзИЪіЁЃ
ЮвУЧЭЈЙ§дк bitbucket ЩЯЩшжУБфСП PROJECTABUCKETNAMEКЭ{PROJECTB_BUCKET_NAME}
РДЬцЛЛНХБОжа ${BUCKET_NAME} ЃЌвдНЋДцДЂдкФГИіЭАЯТЕФЯюФПНХБОПЩвде§ШЗЕФЪЪХфИУЯюФПЁЃ
НгЯТРДЮвУЧЫЕЯТЦфгрЕФМИИіБфСПЃК
ВжПтУћГЦЃКМД ${REPO_NAME}ЃЌашвЊдк bitbucket ЕФУПИіВжПтжаЩшЖЈЃЌжївЊгаСНИіФПЕФЃЌвЛЪЧШЗЖЈ
S3 ЩЯЕФДцДЂЮЛжУЃЛЖўЪЧШЗЖЈ REL ВжПтДђАќКѓЕФУћГЦЁЃ
ЖўНјжЦЮФМўУћГЦЃКМД BINNAMEЃЌЭЌбљашвЊдкbitbucketЕФУПИіВжПтжаЩшЖЈЃЌФПЕФгыBINNAMEЃЌЭЌбљашвЊдкbitbucketЕФУПИіВжПтжаЩшЖЈЃЌФПЕФгы{REPO_NAME}
вЛбљЃЌгУгкШЗШЯ SRC ЮФМўДђАќКѓЕФУћГЦЃЌвбОдк S3 ЩЯЕФЮФМўДцДЂЮЛжУЁЃ
ЖјБфСП ${BITBUCKET_TAG} дђЪЧ bitbucket ФкжУЕФБфСПЃЌЪЧгУгкЛёШЁзюНќвЛДЮВжПт
tag УћГЦЕФЃЌетИіВЛашвЊЮвУЧЪжЖЏЩшЖЈЃЌжЛашвЊжБНгдк pipeline жав§гУМДПЩЁЃ
злЩЯЫљЪіЃЌЮвУЧЭЈЙ§ЙцЖЈБфСПУћГЦЃЌвдМАРћгУ bitbucket pipeline ФкжУБфСПЁЂздЖЈвхБфСПЃЌНтОіСЫЭЌвЛЗнЪ§ОндДЪЪХфВЛЭЌЯюФПЕФЮЪЬтЁЃетбљВЛЭЌЕФЯюФПећКЯГЬађЃЌдкИїздЕФЯюФПжав§ШыЕФФЃПщОЭЪЧвдМАЪЪХфКУЕФГЬађЃЌПЩвджБНггУгкЯюФПЕФАВзАгыЩ§МЖЁЃФЧУДНгЯТРДЃЌЮвУЧОЭПЊЪМЬжТлЯюФПЕФздЖЏЛЏВПЪ№ЁЃ
3.6 здЖЏЛЏВПЪ№
дкЮвУЧЭъГЩ Amazon S3 ДцДЂЙцдђЁЂВжПтНсЙЙЁЂАВзАгыЩ§МЖТпМСїГЬЁЂPIPELINE ЕШЙцдђФкШнЩшЖЈвдМАвЛдДЖрДцЮЪЬтНтОіжЎКѓЃЌЮвУЧвбОПЩвдПьЫйБуНнЕФЭъГЩЕЅИіФЃПщЁЂВПЗжФЃПщвдМАећИіЯюФПЕФАВзАгыИќаТВйзїЃЌЕЋЪЧетЛЙашвЊШЫЙЄВЮгыЃЌНгЯТРДЮвУЧОЭЬжТлШчКЮРћгУХњСПЛЏВПЪ№ЙЄОпЃЌЭъГЩШЋЧђНкЕуЕФздЖЏЛЏВПЪ№ЁЃ
ЪзЯШЮвУЧЖдХњСПЛЏВПЪ№ЙЄОпНјаабЁдёЃЌЕБЧАБШНЯШШУХЕФга saltstack ЁЂpuppetЁЂansible
ЕШЃЌЮЊСЫНЕЕЭЮЌЛЄГЩБОвдМАПьЫйВПЪ№ЃЌЮвУЧНсКЯЕБЧАЩњВњЛЗОГЯжзДвдМАЩњВњНкЕуЪ§СПЃЌбЁдёСЫЧсБуПьНнЕФ ansible
зїЮЊХњСППижЦЦНЬЈЃЌЫќЪЧЛљгк ssh авщЭъГЩШЮЮёЗжЗЂЃЌЫљвдАВШЋадЛЙЪЧБШНЯИпЕФЃЌСэЭтВЛашвЊПЭЛЇЖЫЃЌВйзїМђЕЅЁЂбЇЯАГЩБОЕЭЕШЬиЕуЃЌЖМЪЧЮвУЧЯжЯТБШНЯашвЊЕФЁЃЕБШЛЃЌКѓЦкЫцзХздЖЏЛЏЦНЬЈЙІФмЕФВЛЖЯЭъЩЦЃЌвдМАдЫЮЌНкЕуЪ§СПЕФдіМгЁЂЖддЫЮЌЪБаЇадЕФвЊЧѓЬсИпЕШвђЫиЃЌПЩФмашвЊИќЛЛжаПиЦНЬЈЛђепздбаИУЦНЬЈЃЌетЫфЪЧКѓЛАЃЌЕЋЪЧЮвдкЩшМЦЕБЧАЕФздЖЏЛЏдЫЮЌЬхЯЕЪБвбОНЋИУЮЪЬтПМТЧНјШЅЃЌНЋећИіЬхЯЕНјааФЃПщЛЏЗжИюЃЌгыжаПиЦНЬЈжЎМфЕФёюКЯадНЕЕНзюЕЭЃЌетбљвдКѓЮоТлЪЙгУКЮжжжаПиЦНЬЈЃЌЖМВЛЛсЖдЯжгаЬхЯЕдьГЩЬЋДѓВЈЖЏЃЌвдДяЕННЕЕЭгАЯьЁЂПьЫйЕќДњЩЯЯпЕФФПЕФЁЃ
НгЯТРДЮвУЧОЭЬжТлШчКЮРћгУ Ansible ЭъГЩШЋЧђНкЕуЕФздЖЏЙЙНЈгыИќаТЃЌКЫаФТпМДІРэСїГЬШчЯТЃК ЮЊСЫВЛВњЩњЦчвхЃЌЮвУЧвдНкЕуздЖЏЙЙНЈзїЮЊЫЕУїЖдЯѓЃЌздЖЏИќаТгыжЎРрЫЦЁЃЕБЮвУЧОіЖЈВЩгУ
ansible зїЮЊХњСПВПЪ№ЙЄОпКѓЃЌОЭашвЊИљОнвЕЮёТпМЩшМЦЯргІЕФ ansible жДааНХБОМД playbook
ЃЌНХБОашвЊОпБИХаЖЯФГИіНкЕуЪЧЗёТњзуАВзАЛђепИќаТЬѕМўЕФФмСІЁЃЮЊСЫДяЕНетИіФПЕФЃЌЮвУЧЭЈЙ§дкНкЕуЩЯДДНЈ images.yaml
ЮФМўЃЌФЃАхШчЯТЃК
# ЖЈвх image АцБОаХЯЂ
image:
version: 2.1.0
status: building |
Ѕp
ЮвУЧЖдОЕЯёЮФМўв§ШыЁАНкЕузДЬЌЁБгыЁАНкЕуАцБОЁБЕФИХФюЃЌВЂЧвНЋНкЕузДЬЌЗжЮЊЃКНкЕузДЬЌЮФМўВЛДцдкЁЂbuildingЃЈНкЕуЙЙНЈжаЃЉЁЂmaintainЃЈНкЕуЮЌЛЄжаЃЉЁЂfailureЃЈЪЇАмЃЉЁЂactiveЃЈПЩгУЃЉЁЃЖдгкетЮхИізДЬЌЃЌЦфвтвхШчЯТЃК
НкЕузДЬЌЮФМў images.yaml ВЛДцдкЃКМДЮвУЧШЮЮёИУНкЕуЮЊаТНкЕуЃЌЛсЖдИУНкЕужДааАВзАВйзїЃЈетИізДЬЌЮФМўзїЮЊздЖЏЛЏжДааЕФживЊТпМХаЖЯвРОнЃЌЪЧОјЖдВЛдЪаэБЛШЫЮЊИЩдЄЕФЃЌМДЪЙЪЧЮѓВйзїЃЌГЬађвВЛсздЖЏжиНЈИУНкЕуЃЌвдБЃжЄНкЕуКѓЦкЕФПЩЮЌЛЄадЃЉЁЃ
buildingЃЈНкЕуЙЙНЈжаЃЉЃКетЪЧЕБЖдвЛИіаТНкЕуНјааЯюФПАВзАЪБЃЌЛсаТді images.yaml
ЮФМўЃЌВЂНЋзДЬЌжЕаоИФЮЊ buildingЃЌЦфЪЕЮвУЧдк DIST ВжПтжаДцДЂЕФ imags.yaml
ЮФМўГѕЪМзДЬЌОЭЪЧ building ЃЌетвВЪЧЗћКЯЮвУЧЕФжДааТпМЃЌАВзАЪБжБНгНЋИУЮФМўЗХжУЕНжИЖЈЮЛжУМДПЩЁЃ
maintainЃЈНкЕуЮЌЛЄжаЃЉЃК етжжзДЬЌЪЧгЩНкЕуЕФ active
зЊБфЃЌМДНкЕуЗћКЯИќаТЮЌЛЄЬѕМўЃЌдђЛсНЋ active аоИФЮЊ maintain ЁЃ
failureЃЈЪЇАмЃЉЃКБэЪОНкЕуАВзАЛђепИќаТЪЇАмЃЌашвЊНјааШЫЙЄИЩдЄЁЃ
activeЃЈПЩгУЃЉЃКНтЪЭНкЕуАВзАЛђепИќаТГЩЙІЃЌПЩвде§ГЃЬсЙЉЗўЮёЁЃ
ФЧУД ansible ЪЧШчКЮИљОнЩЯУцЕФЮхжжзДЬЌЃЌРДОіЖЈИУНкЕуЪЧЗёФмЙЛНјааАВзАЛђепИќаТЃПШчКЮБмУтЖде§дкЮЌЛЄЕФНкЕудйДЮДЅЗЂЮЌЛЄжДааЮЌЛЄГЬађЃПAnsible
ЕФХаЖЯвРОнЪЧЃЌНкЕузДЬЌЮФМўВЛДцдкЃЌжБНгжДааАВзАВйзїЃЌАВзАВйзїгЩ DIST ЕФАВзАГЬађжДааЃЌИУГЬађжДааЭъЛсХаЖЯБОДЮжДааЪЧЗёГЩЙІЃЌГЩЙІдђНЋНкЕузДЬЌгЩ
building аоИФЮЊ active ЃЌВЛГЩЙІдђаоИФЮЊ failure ЁЃетбљЃЌЮвУЧОЭФмЕУГі failure
зДЬЌЪЧгЩгкећКЯВжПтЕФАВзАЃЈЛђепИќаТЃЉНХБОЕМжТЃЌЖјИњ ansible ЮоЙиЃЌвВОЭВЛгІИУдйШУ ansible
МЬајЖд failure зДЬЌЕФНкЕуЯТЗЂАВзАЛђепИќаТШЮЮёЁЃвђДЫЃЌЮвУЧЕУГіНсТлЃЌansible жЛЛсЖдаТНкЕужДааАВзАВйзїЃЌжЛгІИУЖд
active зДЬЌЕФНкЕужДааЩ§МЖВйзїЃЈЕБШЛетЪЧБивЊЬѕМўЃЌЖјВЛЪЧГфЗжЬѕМўЃЌЗёдђНкЕуЛсвЛжБДІдк maintain
Ињ active МфЧаЛЛЃЉЁЃвђДЫЮвУЧЭЈЙ§в§ШыЁАНкЕуАцБОЁБЕФИХФюЃЌРДзїЮЊСэЭтвЛИіХаЖЯЪЧЗёПЩвдНјааЩ§МЖВйзїЕФБивЊЬѕМўЁЃЮвдкПЊЗЂ
ansible playbook НХБОЪБЃЌв§ШыСЫЁАПЩИќаТНкЕуАцБОЁБЕФБфСПЃЈИУБфСПЭЈЙ§ playbook
ЕФБфСПЮФМўДцДЂЃЌвђДЫУПДЮЩ§МЖЯюФПаоИФећКЯВжПтЪБЃЌвВашвЊаоИФИУБфСПЮФМўжаЙигкЁАПЩИќаТНкЕуЁББфСПЕФжЕЃЉЃЌМДжЛгаЕБетИіБфСПгыОЕЯёЮФМўжаЕФНкЕуАцБОЯрЦЅХфЪБЃЌВХЛсТњзуЩ§МЖЬѕМўЁЃМДЃЌЮвУЧХаЖЯНкЕуЪЧЗёгІИУЩ§МЖЛсЖдНкЕузДЬЌгыНкЕуАцБОХаЖЯЃЌжЛгаНкЕузДЬЌЮЊ
active ЧвНкЕуАцБОгы ansible жаЖЈвхЕФПЩЩ§МЖАцБОЫљЦЅХфЃЌВХЛсжДааЩ§МЖВйзїЁЃ
НгЯТРДЃЌЮвУЧМЬајЬжТлаТАцБОЗЂВМЮЪЬтЁЃЕБЮвУЧШЗЖЈвЊЗЂВМаТАцБОЪБЃЌЛсИљОнБОДЮАцБОжаИїИіФЃПщЕФЕїећаоИФ
DIST ВжПтЕФ repo-info аХЯЂЁЂansible playbook жДааЮФМўЁЂCHANGELOG
ЁЂ README ЕШаХЯЂЃЌЕБШЛЃЌПЩФмЛЙашвЊаоИФ DIST ВжПтжаЕФАВзАНХБОЁЃЮЊЪВУДЫЕПЩФмФиЃПИљОнЧАУцЕФЩшМЦТпМЃЌ
DIST ВжПтжаЕФАВзАНХБОжЛИКд№ИљОн repo-info ЮФМўДг S3 ЩЯЛёШЁИїИіФЃПщЕФАВзААќЃЌШЛКѓжДааИїАВзААќжаЕФВПЪ№НХБОМДПЩЁЃетбљЕФЛАЃЌЦфЪЕ
DIST ВжПтЕФАВзАНХБОжЛашвЊжДаавЛИібЛЗЃЌвРДЮЖСШЁ repo-info жаФЃПщаХЯЂЃЌШЛКѓЯТдиЮФМўЁЂАВзАЮФМўМДПЩЁЃЮоТлЪЧаТдіЁЂЩОГ§ЁЂаоИФЙІФмФЃПщЃЌжЛашвЊЖд
repo-info жаИУФЃПщЕФФкШнНјааЯргІЕФаТдіЁЂЩОГ§ЁЂаоИФМДПЩЃЌЖјВЛБиШЅаоИФећКЯНХБОЕФФкВПТпМЃЌетбљМЋДѓЕФНЕЕЭСЫЮЌЛЄ
DIST ВжПтЕФШЫдБЫЎЦНЁЃвВОЭЪЧЫЕЃЌОјДѓЖрЪ§ЧщПіЯТЖМВЛашвЊаоИФ DIST ВжПтЕФАВзАНХБОЃЌЕЋЪЧгааЉЧщПіЯТПЩФмашвЊЕЅЖРДІРэФГИіФЃПщЃЌР§ШчетИіФЃПщЕФДІРэТпМгыЦфЫћФЃПщВЛЭЌЃЌФЧУДОЭашвЊЕїећећКЯНХБОЃЌвдМцШнИУФЃПщЁЃОйИізюМђЕЅЕФР§згЃЌМйЩшФЃПщ
C дкжДааВПЪ№ГЬађЪБЃЌашвЊИјИУГЬађДЋЕнжИЖЈВЮЪ§ЃЌФЧУДетОЭгыЦфЫћФЃПщЕФДІРэТпМВЛЭЌЃЌБиаыЕЅЖРЩшЖЈЁЃ
змЖјбджЎЃЌЮвУЧашвЊИљОнНЋвЊЗЂВМЕФАцБОзіећКЯВжПтЕФЪЪХфЃЌШЛКѓНЋДњТыЬсНЛжС DIST ВжПт developer
ЗжжЇЃЌДЅЗЂ pipeline ЃЌНЋВжПтжажИЖЈЮФМўЃЈАќРЈ playbook вдМАЦфБфСПХфжУЮФМўЁЂimages.yamlЁЂАВзАгыЩ§МЖНХБОЁЂВжПт
repo-info ЮФМўЕШЃЉЭЦЫЭжС ansible ПижЦНкЕуЕФФГИіФПТМЯТЃЌansible ЛсЖЈЦкжДааИУФПТМЯТЕФ
playbook ЮФМўЃЌНјааШЋЧђНкЕуШЮЮёЗжЗЂЃЌЖдТњзуАВзАЛђепЩ§МЖЕФНкЕуНјааздЖЏЛЏАВзАгыИќаТВйзїЁЃзлЩЯЫљЪіЃЌansible
жДааздЖЏЛЏАВзАгыЩ§МЖСїГЬЭМШчЯТЃК
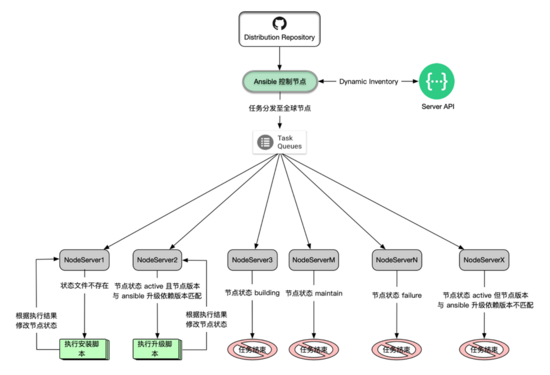
ЭМ 4 Ansible жДааздЖЏЛЏАВзАгыЩ§МЖСїГЬЭМ
ећИіСїГЬПЩвдИХРЈЮЊЃК
(1). ЪЪХф DIST ВжПтФкШнЃЌДЅЗЂ pipeline ЭЦЫЭжС ansible ПижЦНкЕуЁЃ
(2). Ansible жДаа DIST ВжПтжа playbook ЮФМўЃЌШЋЧђНкЕуЯТЗЂШЮЮёЁЃ
(3). РћгУ playbook ТпМЖдИїНкЕуНјаазДЬЌХаЖЯЃЌОіЖЈжДааАВзАЁЂИќаТГЬађЛђепжежЙШЮЮёЁЃ
(4). ЖдгкжДааАВзАЛђепИќаТГЬађЕФНкЕуЃЌЛсИљОнГЬађЕФжДааНсЙћаоИФНкЕузДЬЌЮЊ active Лђ failure
ЁЃ
3.7 МрПигыБЈОЏ
ЕБЮвУЧРћгУ bitbucket pipeline + ansible ЭъГЩШЋЧђНкЕуЕФГжајМЏГЩгыГжајЗЂВМжЎКѓЃЌНгЯТРДашвЊНтОіЕФЮЪЬтОЭЪЧМрПиЁЃашвЊзЂвтЕФЪЧЃЌетРяЮвУЧЬсЕНЕФМрПиЪЧжИ
CI/CD НсЙћЕФМрПиЃЌЖјВЛЪЧГЃЙцЕФНкЕуСїСПЁЂФкДцЁЂCPU ЕШадФмМрПиЁЃЭЈЙ§ЩЯУцЕФЗжЮіЮвУЧжЊЕРДг ansible
ЛёШЁзюаТЕФ playbook ЕННЋШЮЮёЭЦЫЭжСШЋЧђНкЕужДааЃЌПЩвдЗжЮЊСНИіЛЗНкЃЌЕквЛЪЧ ansible
НЋШЮЮёЭЦЫЭжСШЋЧђИїНкЕуЩЯЃЌНјааАВзАЛђИќаТТпМХаЖЯЃЛЕкЖўЪЧ ansible жДааЭъХаЖЯТпМКѓЃЌЗћКЯАВзАЛђИќаТЕФНкЕуЛсжДааЯргІЕФНХБОНјааАВзАЛђепЩ§МЖЃЌШЛКѓНХБОИљОнздЩэЕФжДааНсЙћЖдНкЕузДЬЌНјаааоИФЁЃетбљЕФЛАЃЌЮвУЧЕФМрПивВгІИУДЅМАЕНетСНИіЛЗНкЃЌЕквЛЁЂAnsible
ЪЧЗёГЩЙІНЋШЮЮёЭЦЫЭжСШЋЧђИїНкЕуЃЛЕкЖўЁЂНкЕудкНгЪеЕН ansible ЭЦЫЭЕФШЮЮёКѓЃЌЪЧЗёГЩЙІжДааСЫАВзАЛђЩ§МЖНХБОЁЃЖдгкЕквЛИіЕуЃЌЮвУЧПЩвдЭЈЙ§ЗжЮі
ansible ЕФжДааШежОЛёШЁЃЛЖдгкЕкЖўЕудђПЩвдДгИїНкЕузДЬЌжаЛёШЁЁЃетбљОЭаЮГЩСЫМрПиБЈОЏЕФПђМмЃЌМДЮвУЧЪзЯШЖд
ansible playbook ШежОжа recap НсЙћНјааЗжЮіЃЌЖдЦфжаВњЩњЪЇАмЃЈБШШч failedЁЂunreachableЃЉЕФжїЛњНкЕуНјааБЈОЏЃЛШЛКѓЭЈЙ§
ssh ЕФЗНЪНСЌНгдЖГЬНкЕуЃЌЖдзДЬЌжЕЮЊ failure вВНјааБЈОЏЃЌБЈОЏЦНЬЈЮвУЧЪЙгУ slack ЃЌЦфЬсЙЉСЫИпаЇЕФБЈОЏНгПкЃЈЮвУЧЖдИУНгПкгжзіСЫЖўДЮПЊЗЂЃЌЪЙЦфЙІФмИќМгЗсИЛЃЉЃЌЕїгУЦ№РДЗЧГЃМђЕЅЃЌШчЯТЪЧЗЂЫЭ
slack ЕФБЈОЏаХЯЂШчЯТЃК
ЪБМф: 2018-10-25
08:17:46,282
жїЛњ: 192.168.10.129
Ansible жДаазДЬЌ: success
НкЕузДЬЌ:failure |
Ѕp
НтЪЭвЛЯТБЈОЏаХЯЂИїЬѕФПЕФКЌвхЃК
ЪБМфЃКБэЪО ansible ЭЦЫЭШЮЮёЕНИУНкЕуЕФЪБМфЃЌвд ansible ЗўЮёЦїЪБМфЮЊзМЁЃ
жїЛњЃКБэЪО ansible е§дкНЋШЮЮёЭЦЫЭжСФФЬЈНкЕуЁЃ
Ansible жДаазДЬЌЃКБэЪОДг ansible ЖдИУжїЛњЯТЗЂШЮЮёЕФзДЬЌЃЌзДЬЌжЕга unreachableЁЂ
failedЁЂsuccessЁЃ Цфжа unreachable БэЪО ansible гыетЬЈНкЕуСЌНгЪЇАмЃЛ
failed БэЪОЫфШЛ ansible ПЩвдГЩЙІСЌНгЕНИУНкЕуЃЌВЂЧвжДаа playbook жаЕФШЮЮёЃЌЕЋЪЧвђЮЊФГаЉдвђЕМжТШЮЮёжДааЪЇАмЃЛsuccess
БэЪО ansible ГЩЙІСЌНгЕНИУНкЕуЃЌВЂЧвНЋ playbook жаЕФШЮЮёвРДЮГЩЙІжДааЭъЁЃЖјИљОнЮвУЧжЎЧАЕФЩшМЦЃЌНкЕуЕФЩ§МЖЛђепАВзАЃЌЪЧгЩ
ansible ЕїгУЩ§МЖЛђАВзАНХБОШЅжДааЕФЃЌвђДЫ ansible жДаазДЬЌГЩЙІЃЌВЂВЛФмБэЪОНкЕуБЛГЩЙІАВзАЛђепЩ§МЖСЫЃЌЮвУЧашвЊМЬајЖдНкЕузДЬЌНјааХаЖЯЁЃ
НкЕузДЬЌЃКБэЪОИїИіНкЕуЩЯ images.yaml ЮФМўжаМЧТМЕФНкЕузДЬЌаХЯЂЃЌга activeЁЂfailureЁЂbuildingЁЂmaintain
ЫФИіЃЌСэЭтМгЩЯНкЕузДЬЌЮФМўВЛДцдкгыСЌНгдЖГЬНкЕуЪЇАмЃЌвЛЙВгаСљИізДЬЌжЕЃЌЕЋЪЧ activeЁЂbuildingЁЂmaintain
ЮЊе§ГЃзДЬЌЃЌвђДЫЛсВњЩњБЈОЏааЮЊЕФНкЕузДЬЌга failureЁЂНкЕузДЬЌЮФМўВЛДцдквдМАСЌНгдЖГЬНкЕуЪЇАмШ§жжЁЃ
злЩЯЫљЪіЃЌЯТУцЕФЧщПіааЮЊЛсВњЩњБЈОЏааЮЊЃК
(1). Ansible СЌНгдЖГЬНкЕуЪЇАм
(2). НкЕуЩЯжДаа playbook ЪЇАм
(3). НкЕуЩЯжДааАВзАЛђепЩ§МЖНХБОЪЇАм
ЫфШЛЮвУЧЩшМЦЕФБЈОЏТпМЛљБОЩЯКИЧСЫДѓЖрЪ§ПЩФмГіЯжЕФДэЮѓЃЌЕЋВЂВЛЪЧКмбЯНїЃЌЮвУЧвВЛсМЬајХЌСІШЅжЦЖЈИќЖрЮЌЖШЕФМрПиЃЌвдЬсИпМрПиЕФгааЇадЁЃ
4 ЕБЧАМмЙЙЕФгХШБЕуЗжЮі
4.1 МмЙЙгХЕуЗжЮіЃК
ШЈЯоЗжХфЧхЮњ
ЮвУЧЭЈЙ§Жд Git ВжПтЪЕааШ§ВуТпМЗжВуЃЌНЋПЊЗЂШЫдБгыдЫЮЌШЫдБШЈЯозіСЫбЯИёЕФЧјЗжЃЌЪЙЦфПЩвдКмКУЕФазїЖјВЛЛсЛЅЯрИЩШХЁЃ
здЖЏЛЏГЬЖШНЯИпЃЌЧвдЫЮЌГЩБОЕЭ
ЭЈЙ§РћгУ Bitbucket pipeline + Amazon S3 + Ansible ЪЕЯжСЫздЖЏЛЏГжајМЏГЩгыГжајВПЪ№ЃЌЧввђЮЊИїИіЙІФмФЃПщДђАќДцЗХдк
S3 жаЃЌжаПиНкЕуНіЭЦЫЭ DIST ВжПтжаЕФМИИіЮФБОЮФМўЕНИїНкЕуЩЯЃЌШЛКѓдкУПИіНкЕуЩЯжДааАВзАЛђЩ§МЖНХБОМДПЩЃЌИїИіНкЕуЛсДг
S3 ЩЯЯТдиЯргІЕФФЃПщЮФМўНјааАВзАЛђЩ§МЖЃЌетбљЖджаПиНкЕуЕФЮяРэгВМўадФмвЊЧѓЗЧГЃЕЭЁЃзнЙлетИідЫЮЌЯюФПЃЌДг
bitbucket ДњТыВжПтЃЌЕН Amazon S3 ДцДЂЃЌдйЕН ansible жаПиНкЕуЗўЮёЦїЃЌећИідЫЮЌГЩБОДѓИХдк
20 - 30 $/Month ЁЃСэЭтЃЌгЩгкздЖЏЛЏСїГЬОЙ§ИпЖШГщЯѓгыФЃПщЛЎЗжЃЌЖдВйзїШЫдБЕФММФмвЊЧѓвВДѓДѓНЕЕЭЃЌетвВМѕЧсСЫдЫЮЌГЩБОЁЃ
жЇГжЙугђЭјздЖЏЛЏдЫЮЌЃЌВЛДцдкЭјТчЦПОБЃЌВЂЗЂФмСІЗЧГЃЧП
ДЋЭГЕФздЖЏЛЏдЫЮЌЦНЬЈвЛАуЪЧУцЯђОжгђЭјЕФЃЌвЛАуЕФжДааСїГЬЪЧАбДњТыЯТдижСгыЭЌвЛОжгђЭјФкЕФжаПиНкЕуЃЌШЛКѓгЩжаПиНкЕуНЋЦфЭЦЫЭОжгђЭјФкЕФЫљгаНкЕуЃЌетОЭЖджаПиНкЕуЕФЭјТчДјПэДјРДСЫМЋДѓЕФПМбщЃЌвђЮЊвЛИіЯюФПЩЯЯпЃЌЫљгаЙІФмФЃПщЕФАВзААќЩйдђМИЪЎезЃЌЖрдђАйезЩѕжСЕН
GB МЖБ№ЃЌетЪЧИљБОУЛЗЈЪЕЯжЙугђЭјздЖЏЛЏВПЪ№ЕФЃЌвђДЫДЋЭГздЖЏЛЏдЫЮЌЦНЬЈвЛАуЖМЛсгаБШНЯбЯжиЕФЭјТчЦПОБЃЌШЮЮёВЂЗЂДІРэФмСІНЯЕЭЁЃЖјЮвУЧЭЈЙ§МмЙЙгХЛЏЃЌШУжаПиЦНЬЈжЛЭЦЫЭЪ§СПКмаЁЕФЮФБОЮФМўЃЌПЩвдЧсЫЩДяЕНМИЪЎЩѕжСЩЯАйИіШЮЮёВЂЗЂЃЌвРШЛВЛЛсЖджаПиНкЕудьГЩЬЋДѓЕФбЙСІЁЃИїИіНкЕудкжДааАВзАЛђепЩ§МЖНХБОЪБЃЌЛсДг
Amazon S3 ЩЯЯТдиЮФМўЃЌЖј S3 ЫљжЇГжЕФЯТааДјПэЪЧВЛДцдкШЮКЮЯТдиЩЯЕФЦПОБЕФЁЃ
ФЃПщв§ШыЗЧГЃСщЛюМђЕЅ
ЛљДЁФЃПщЕФв§ШывЛАуЪЧБШНЯЭЗЬлЕФЮЪЬтЃЌЮвУЧЭЈЙ§НшжњгкЮяРэДцДЂЕФаЮЪНЃЌвдМАДцДЂЙцдђЩшЖЈЃЌПЩвдЧсЫЩЪЕЯжЖрИіЯюФПЖдФГИіФЃПщВЛЭЌАцБОЕФв§гУЃЌЧвЪ§ОндДНівЛИіЃЌВЛЛсдьГЩКѓЦкЕФЖрдДЮЪЬтЁЃ
АцБОЩ§МЖгыЛиЙіЗЧГЃБуНн
ЮвУЧЖдећИідЫЮЌСїГЬНјааИпЖШГщЯѓЛЏЁЂФЃПщЛЏЃЌЯюФПЛђепЕЅИіФЃПщЕФАВзАгыЩ§МЖШЋВПвРППгкИїздЕФВжПтаХЯЂЮФМўЃЌМД
repo-info ЮФМўЃЌЩ§МЖЛђепЛиЙіВйзїЃЌНіашвЊаоИФХфжУЮФМўжа S3 ДцДЂЕФжИЯђМДПЩЃЌУыМЖЭъГЩАцБОЩ§МЖгыЛиЙіЁЃ
МрПиБЈОЏаЮГЩздЖЏЛЏСїГЬБеЛЗЃЌАВШЋадНЯИп
МрПиЪЧЖдећИідЫЮЌПђМмЕФТпМВЙГфЃЌПЩвдАяжњЮвУЧМђЕЅЧвИпаЇевЕНЮЪЬтЕуЃЌЬсЩ§ећИіздЖЏЛЏСїГЬЕФАВШЋПЩППадЁЃ
4.2 МмЙЙШБЕуЗжЮіЃК
Лљгк ansible ДІРэЃЌСЌНгЫйЖШНЯТ§ЃЌНкЕуЪ§дкЧЇЬЈвдФк
гЩгкжаПиЦНЬЈВЩгУ ansible зїЮЊХњСПЛЏВйзїЙЄОпЃЌЫљвдвВЛсЪмЕНЦфадФмЕФгАЯьЁЃAnsible ЪЧЛљгк
ssh СЌНгЖдИїНкЕуНјааВйзїЃЌетОЭЕМжТСЫСЌНгЫйЖШБШНЯТ§ЃЌЧвЮЌЛЄСПМЖвЛАудкЧЇЬЈвдФкЁЃ
МрПигыЗжЮіЦНЬЈВЛЙЛЧПДѓ
ФПЧАМрПиЦНЬЈЪЧЛљгкСНИіКЫаФЮЌЖШНјааЕФЃЌЫфШЛПЩвдЗЂЯжОјДѓЖрЪ§ГЃМћЕФздЖЏЛЏВПЪ№ВњЩњЕФЮЪЬтЃЌЕЋЪЧЮЌЖШЬЋаЁЃЌгіЕНБШНЯИДдгЕФЧщПіЮоЗЈЪЕЯжгааЇМрПиЃЌЖјЮвУЧвВе§ХЌСІДгЦфЫћЮЌЖШШЅЙЅПЫетвЛМрПиФбЬтЁЃ
5 ЯТИіАцБОашвЊзіЪВУД
ЕБЧАЕФздЖЏЛЏдЫЮЌЬхЯЕжЇГжЖржждЦЦНЬЈЁЂжЇГжЙугђЭјЃЌФмЙЛТњзужааЁЦѓвЕЃЈХњСПВйзїНкЕудк 1000 ЬЈвдФкЃЉЕФШеГЃдЫЮЌЙЄзїЃЌЕЋЪЧдкИУЬхЯЕЕФЙЙНЈгыгІгУжаЃЌЗЂЯжСЫвЛаЉЮЪЬтЃЌСэЭтЛЙгавЛаЉаТЕФЯыЗЈЯЃЭћФмЙЛВЙГфНјРДЃЌЮвУЧНЋетаЉЗХдкЯТИіАцБОжаЪЕЃЌетаЉЮЪЬтЛђЯыЗЈАќРЈЕЋВЛЯогквдЯТетаЉЃК
ЬсИпМрПиеЙЪОФмСІЃК
МрПиЮЌЖШВЛЙЛЗсИЛШЋУцЃЌШнвздьГЩФГаЉЮЪЬтЕФвХТЉЁЃЯТИіАцБОЮвУЧЛсДгФПБъНсЙћЕФЗНЯђГіЗЂЃЈБШШчЕБЧААцБОКХЁЂЕБЧАгУЛЇСЌНгЪ§ЁЂЕБЧАСїСПЕШЃЉЃЌзіе§ЯђЦЅХфМрПиЃЌФтв§Шы
elasticsearch ЦНЬЈЃЌЖдетаЉФПБъЪ§ОнНјааВЩМЏЃЌЭЌЪБвВНЋЖдАВзАгыЩ§МЖШежОНјааЪеМЏЁЂвдгУгкЗжЮігыНсЙћеЙЪОЃЌзюжеДяЕНЩюЖШЖЈЮЛЧБдкЕФЮЪЬтЕФФПЕФЁЃ
ЬсИпжаПиНкЕуСЌНгЫйЖШ
НкЕуСЌНгЫйЖШБШНЯТ§ЃЌansible playbook ТпМХаЖЯЬЋМђЕЅЃЌВЛЬЋЪЪКЯИДдгФЃаЭДІРэЁЃЯТИіАцБОгІИУЛсЕїећХњСПЛЏВПЪ№ЙЄОпЃЌвдЬсИпТпМХаЖЯФмСІгыНкЕуВПЪ№ЫйЖШЁЃ
в§Шы CMDB ЯЕЭГЃЌЪЕЯжНкЕуЗжзщ
ЕБЧАНкЕуЩаЮДЗжзщЃЌШЫЙЄВЛИЩдЄЕФЧщПіЯТЃЌЮоЗЈзіЛвЖШЩЯЯпЁЃетЖдЩњВњЗЂВМЪМжеЪЧвЛИівўЛМЃЌЯТИіАцБОгІИУЛсЩшМЦВЂв§ШыКЯЪЪЕФзЪВњЙмРэЯЕЭГЃЌФтЭЈЙ§в§Шы
tag ЕФЗНЪННтОіетвЛЮЪЬтЁЃ
в§ШыБЄРнЛњгыЩѓМЦЯЕЭГ
етвЛЙІФмЫфШЛгыЕБЧААцБОВЛДцдкжБНгЙиЯЕЃЌЕЋЪЧШЗФмЙЛНтОідЫЮЌжаОГЃГіЯжЕФНкЕуШЈЯоЗжХфЛьТвЁЂЪТЙЪд№ШЮОРВјВЛЧхЁЂвдМАШЫдБРыжАШЋЧђНкЕуаоИФУмТыЕШЫіЫщЮЪЬтЁЃЭЈЙ§БЄРнЛњЛњжЦЃЌПЩвдЭГвЛЕЧТМШыПкЃЌдіМгНгШыЕФАВШЋадЃЛСэЭтПЩвддкБЄРнЛњжаЖдШЫдБШЈЯоНјаабЯИёЗжзщЁЂМЧТМгУЛЇВйзїааЮЊЕШЃЌетЖМЪЧБъзМдЫЮЌСїГЬашвЊНтОіЕФЪТЧщЁЃ |









