дкеЙПЊе§ЮФжЎЧАЃЌЮвУЧЯШЗжЯэвЛЯТМЧТМЦЌЁЖГЌМЖЙЄГЇЃКвЫМвМвОгЁЗЕФЙЪЪТЃЌвЫМвзїЮЊШЋЧђжЊУћЕФМвОпСьЕМЦЗХЦЃЌдкШЋЧђМИЪЎИіЙњМвКЭЕиЧјЃЌгЕгаЪ§АйИіЩЬГЁЁЃвЫМвЕФШЋЧђЛЏВЩЙККЭжБЯњФЃЪНЃЌФмЙЛШЁЕУШчДЫОоДѓЕФГЩЙІЃЌгывЫМвдкДДАьГѕЦкЃЌОЭШЗСЂЕФБъзМЛЏЩшМЦРэФюгаЙиЁЃ
дквЫМвЃЌШчЙћвЛИіВњЦЗВЛФмБЛБтЦНЛЏАќзАдЫЪфЃЌФЧУДМДЪЙЩшМЦдйОЋУюЃЌвВВЛЛсБЛХњСПЩњВњЁЃЩшМЦКЭдЫЪфЭЌбљживЊ!
МсГжЁИПЩдЫЪфадЁЙЕФЩшМЦРэФюЃЌНЕЕЭСЫВњЦЗЕНДяжеЖЫгУЛЇЕФГЩБОЁЃБувЫЁЂПьНнЕФЬхбщЃЌНјвЛВНЭЦЖЏзХвЫМвЕФГжајЗЂеЙЁЃ
ЭЌбљЕФЃЌЙцФЃЛЏЕФдЫЮЌЃЌВЛФмдйЪЧМћеаВ№еаЃЌзЗзХвЕЮёТњЪРНчХмЃЌгІИУШЋОжЭГГяЃЌНЋЖрБфЕФвЕЮёашЧѓГщЯѓЮЊИпЖШЭГвЛЕФдЫЮЌФЃаЭЃЌЭЈЙ§ЦНЬЈРДЬхЯЕЛЏЕФжЇГХЁЃЮвУЧЯЃЭћФмгаетУДвЛИіБъзМЛЏЕФФЇЗЈЯфзгЃЌАбЮвУЧЕФДњТыЃЌДђАќНјШЅЃЌдЫааЁЂЮЌЛЄЁЂРЉШнЁЂШнджЖМЪЧСїЫЎЯпЕФЗНЪНздЖЏЛЏНјааЁЃ
ИљОн"ьиРэТл"
1.вЛИіЙТСЂЕФЯЕЭГЃЌЪМжеЛсЧїЯђгкдНРДдНТвЃЈЮоађЛЏЃЉЕФЗНЯђЗЂеЙ
2.ШчЙћвЊШУвЛИіЯЕЭГБфЕУИќгаађЃЌБиаыгаЭтВПФмСПЕФЪфШы
ЫљвдЖдгкЮвУЧЖЏщќМИЧЇЩЯЭђЬЈЕФЛЅСЊЭјаавЕРДНВЃЌМгЩЯЬигаЕФЁИПьЫйЪдДэЁЙРэФюМгГжЃЌетИіХгДѓЕФЁЂДэзлИДдгЕФЯЕЭГЃЌзмЪЧЧуЯђгкдНРДдНТвЁЃетОЭашвЊЮвУЧИёЭтЭЖШыОЋСІЃЌВХФмШУЯЕЭГГЏзХгаађЕФЗНЯђЗЂеЙЁЃШчЙћЮвУЧдкЩшМЦЛђепПЊЗЂНзЖЮЃЌЧЗЯТИќЖрЕФеЎЃЌТёЯТИќЖрЕФПгЃЌФЧУДдкВњЦЗЕФдЫааЮЌЛЄНзЖЮЃЌОЭвЊМгБЖГЅЛЙетаЉММЪѕеЎЮёЁЃеЎзмЪЧдкФЧРяЃЌжЛЪЧдкФФИіНзЖЮЛЙЕФЮЪЬтЃЌsystems
do not run themselvesЁЃ
ЙцФЃЛЏЕФЛЅСЊЭјдЫЮЌ
ОГЃЛсгаШЫЮЪЃЌ1ИіШЫжЇГХ10ЬЈЗўЮёЦїКЭ1ИіШЫжЇГХ2000ЬЈЗўЮёЦїЃЌЕНЕзФФИіИќФбвЛаЉЃПЕБдЫЮЌжЇГХЬхЯЕВЛЭъЩЦЃЌвЕЮёФЃПщЖМВЛЭЌЙЙЃЌМрПиЗНЪНЁЂВПЪ№ЗНЪНАйЛЈЦыЗХЃЌ1ИіШЫвЊжЇГХ10ЬЈЗўЮёЦїЃЌОЭвбОЦЃгкгІИЖЃЌДІгквЊБРРЃЕФБпдЕСЫЃЛЯрЗДЃЌШчЙћЫљгаЕФЗўЮёЃЌЖМЪЧЭЌбљЕФМрПиЗНЪНЁЂВПЪ№ЗНЪНЃЌЭЌЪБдЫЮЌжЇГжЬхЯЕЖМЪЧздЖЏЛЏЕФЃЌФЧУД1ИіШЫжЇГХ2000ЬЈЗўЮёЦїЃЌвВЪЧЧсЫЩМггфПьЕФЁЃ
вдЕЮЕЮЮЊР§ЃЌдкЫФФъЪБМфРяЃЌДгзюГѕжЛгаЫФЬЈЗўЮёЦїЃЌЗЂеЙЕНЯждкЕФЪ§ЭђЬЈЩшБИЃЌдкетбљЕФЗЂеЙЫйЖШЯТЃЌЯдШЛЮвУЧвЊВЩгУЙцФЃЛЏЕФдЫзїЗНЪНЃЌЬсИпдЫЮЌаЇТЪЃЌздЖЏЛЏвЛЧаЪЧАкдкЮвУЧУцЧАЮЈвЛЕФГіТЗЁЃвЛЧаЯЕЭГЕФЩшМЦЃЌЖМЪЧдкТњзувЛЖЈМйЩшЧАЬсЯТЕФВњЮяЃЌЖјздЖЏЛЏЕФЧАЬсЃЌЧЁЧЁОЭЪЧЁАБъзМЛЏЁБЁЃ
змжЎЃЌдквЛИіЭГвЛЕФБъзМКЭЪЕМљв§ЕМЯТЃЌЫљгаШЫШЅОЁПЩФмППТЃЃЌФЧУДЪТЧщЛсБфЕУМђЕЅКмЖрЃЁ
ЫљвдЃЌАыФъЪБМфРяЃЌЮвУЧжївЊЮЇШЦзХШ§ИіЗНУцдкЭЦНјЗўЮёБъзМЛЏЕФЪТЧщЃК

ХфжУЙмРэ
ГЃМћЕФХфжУАќРЈвдЯТвЛаЉФкШн
1.ИїжжПЊЙиЃЌБШШчНЕМЖЕФПЊЙиЁЂdebugПЊЙиЁЂabВтЪдЕФПЊЙиЕШ
2.ИїжжПЩХфВЮЪ§ЃЌБШШчГЌЪБЪБМфЁЂВЂЗЂЪ§ЁЂШежОМЖБ№ЕШ
3.ЩЯЯТгЮСЌНгаХЯЂ
ЩЯЯТгЮЕФСЌНгаХЯЂЃЌгыЛЗОГЕФёюКЯЖШзюИпЃЌЪЧзюИДдгЁЂзюЖрБфЁЂзюФбДІРэЕФВПЗжЁЃЮвУЧПДПДДѓМввЛАуЖМЪЧдѕУДРДЖдИЖЩЯЯТгЮСЌНгаХЯЂЕФЁЃ
1.ЭЈЙ§LVSРДЙмРэЃЌМД vip:port -> real-server-ip:port
СаБэЁЃетжжЗНАИЕФКУДІОЭЪЧГфЗжРћгУСЫLVSЕФИпПЩгУЬиадвдМАИКдиОљКтЁЂНЁПЕМьВщФмСІЃЌНЋЩЯЯТгЮЕФёюКЯзЊвЦЕНLVSЕФХфжУжаЁЃетбљЕФЛЕДІвВЯдЖјвзМћЃЌХфжУЙмРэЫфШЛМЏжаЛЏСЫЃЌЕЋЪЧСїСПвВМЏжаЛЏСЫЃЌДцдкбЯжиЕФЕЅЕуЗчЯеЁЃ
2.ЭЈЙ§NginxРДЙмРэЃЌМДip:port/server/location
-> upstreamСаБэЃЌИУЗНАИЕФгХШБЕуЃЌЭЌLVSЗНАИЃЌжЛВЛЙ§ЪЧЙЄзїдкЦпВуАеСЫЁЃ
3.ЭЈЙ§DNSРДЙмРэЃЌМАdomain -> ipСаБэЃЌИУЗНАИИКдиОљКтВпТдЬЋЕЅвЛЃЌЭЌЪБЧаЛЛЫйЖШЬЋТ§ЁЃ
4.ЭЈЙ§zookeeper/etcdРДЙмРэЃЌетЪЧЗЧГЃОЕфЕФЗНАИЃЌГЩЪьЖШНЯИпЃЌжЛВЛЙ§дкЭјТчЗЂЩњЗжЧјЕФЪБКђШнвзГіЮЪЬтЁЃ
5.ЭЈЙ§БОЕиХфжУЮФМўРДЙмРэЃЌетЪЧзюдЪМЕФЗНАИСЫЃЌЩЯЯТгЮЕФСЌНгаХЯЂЃЌжБНгаДдкФЃПщЕФХфжУЮФМўжаЃЌЩЂТфдкФПБъЗўЮёЦїЩЯЁЃЪЙЕУећИіЭиЦЫЙиЯЕВЛЧхЮњЃЌЙЪеЯЧаЛЛЫйЖШТ§ЁЃ
еыЖдетаЉЯжЪЕЧщПіЃЌЮвУЧЦШЧаашвЊНЈЩшХфжУЙмРэЃЌРДНтОіЃК
1.ДњТыЃЈХфжУЃЉКЭЛЗОГНтёюКЯЃЌгУЛЇаДКУДњТыЃЌВЛгУдйЙизЂВтЪдЛЗОГЁЂЯпЩЯЖрЬзМЏШКЕФВювьадЃЌВЛгУЙизЂЪЕР§ОпЬхХмдкФФаЉзЪдДЩЯЁЃ
2.ХфжУМЏжаЛЏЙмРэЃЌЪЙЕУЮвУЧОпгаздЖЏЛЏЭиЦЫЕФФмСІЃЌвдМАПьЫйЧаЛЛЕФФмСІЁЃ
3.жЇГжМДЪБЩњаЇЁЂНЁПЕМьВщЁЂИКдиОљКтЁЃ
ДЫЭтЃЌздЖЏзЂВсКЭЗЂЯжЃЌетаЉЬиадЖМПЩвддкЯжгаЕФЛљДЁЩЯЃЌЗНБуЕФЕўМгЁЃЖдгкдЫЮЌЕФЯЕЭГКЭЛљДЁЩшЪЉНЈЩшЃЌРэФюЕФвЛжТадКЭбгајадЗЧГЃживЊЃЌЕБЧАЕФШЮКЮвЛИіЗНАИЃЌЖМвЊГфЗжПМТЧКЭЮДРДШ§ФъЕФГЄдЖЗНЯђЪЧЗёвЛжТЃЌНёЬьЫљзіЕФЙЄзїЪЧЗёдкЮЊГЄдЖФПБъЦЬТЗЃЌзюМЩЛфЕФЧщПіОЭЪЧКѓРДЕФЗНАИашвЊВЛЭЃЕФЭЦЗдчЯШЕФЗНАИЃЌвЕЮёЕФИФдьГЩБОЪЧвЊжиЕуПМТЧЕФЁЃ
МрПи
МрПиЪЧећИідЫЮЌЛЗНкЃЌФЫжСећИіВњЦЗЩњУќжмЦкжазюживЊЕФвЛЛЗЃЌЪТЧАМАЪБдЄОЏЗЂЯжЙЪеЯЃЌЪТКѓЬсЙЉЯшЪЕЕФЪ§ОнгУгкзЗВщЖЈЮЛЮЪЬтЃЌЗжЮівЕЮёжИБъЕШЁЃ
ФЧУДВаПсЕФЯжЪЕЧщПіЪЧдѕбљЕФФиЃП
1.дкЯпШежОЗжЮіЃЌЪЙгУИїжже§дђБэДяЪНРДЬсШЁЯрЙижИБъ
2.етжжЗНАИЃЌЖЈжЦЛЏГЬЖШИпЃЌЮЌЛЄГЩБОИпЃЌЪдЯыЯыЃЌЙ§СЫШ§ИідТЃЌУцЖдФуЫљХфжУЕФвЛДѓЖбе§дђБэДяЪНЙцдђЃЌФугагТЦјШЅУцЖдКЭЮЌЛЄТ№ЃПЭЌЪБдкЯпЗжЮіШежОЃЌЛсЖддкЯпЗўЮёЦїдьГЩНЯДѓЕФадФмЯћКФЁЃ
3.РыЯпШежОЗжЮі
4.ИУЗНАИЪБаЇадНЯЕЭЃЌЖдШежОЕФёюКЯИпЃЌЭЌЪБДѓСПШежОЕФДЋЪфЗжЮіашвЊЕФзЪдДЯћКФвВЪЧЗЧГЃПЩЙлЕФЃЌВЛЙЛОМУЃЌВЛЙЛЧсСПЁЃ
5.ЪЕР§здЩэБЉТЖЯрЙиstatusНгПк
етжжЗНЪНЃЌРэФювбОНЯЮЊЯШНјСЫЃЌбаЗЂдкЩшМЦКЭПЊЗЂФЃПщЕФЪБКђЃЌОЭвбОГфЗждЄМћЕНСЫашвЊБЉТЖФФаЉжИБъЃЌРДгааЇЕФМрПиздЩэЕФдЫаазДЬЌКЭИїжжЭГМЦаХЯЂЃЌЕЋЪЧвЛЧЇИіШЫблРягавЛЧЇИіЙўФЗРзЬиЃЌУПЮЛбаЗЂЭЌбЇЖМгаздМКЕФМћНтЃЌгкЪЧетаЉНгПкЪфГіИёЪНКЭвтвхИїВЛЯрЭЌЃЌШБЗІвЛжТадЕФЙцЗЖЃЌдкећЬхдЫЮЌЕФВуУцЃЌдьГЩРЇФбЁЃ
6.ИїжжЁИЭтЙвЁЙаЮЪНЕФМрПиГЬађ
етжжгІИУЪЧзюдуИтЁЂзюТфКѓЕФЗНЪНСЫЃЌбаЗЂдкЩшМЦКЭПЊЗЂФЃПщЕФЪБКђЃЌУЛгавЛЫПЫПЕФЁАМрПиЁБвтЪЖЃЌУЛгаБЉТЖздЩэЕФзДЬЌКЭаХЯЂЃЌЩѕжСвВУЛгаДђгЁЯрЙиживЊШежОЃЌЕШЕНетбљЕФДњТыЩЯЯпКѓЃЌВХЯыЦ№РДЃЌЪЧВЛЪЧашвЊМгвЛаЉМрПиЁЃФЧУДЖдгкетаЉМШГЩЪТЪЕЃЌЪмЯогквЕЮёЕФбЙСІЃЌдЫЮЌжЛФмХзШДддђКЭЕзЯпЃЌЮоФЮЭзаЃЌШЛКѓЯыОЁИїжжХдУХзѓЕРЕФАьЗЈЃЌИјвЕЮёФЃПщаДМрПиЭтЙвЁЃетаЉЭтЙвКЭУПИіФЃПщздЩэЬиадНєУмёюКЯЃЌвЕЮёвЛВЛаЁаФИФСЫЃЌМрПиЭтЙвОЭЕУИњзХИФЃЛЭЌЪБШчЙћУПИівЕЮёФЃПщЖМетУДИуЃЌЛљБОЩЯетаЉвЕЮёОЭДІгкЪТЪЕЩЯЕФЁАВЛПЩдЫЮЌЁБзДЬЌСЫЁЃ
ПДЭъЩЯУцЕФМИжжЧщПіЗжЮіЃЌдйвЛДЮЫЕУїЃЌЙцФЃЛЏЕФдЫЮЌЃЌВЛФмЪЧМћеаВ№еаЃЌгІИУШЋОжЭГГяЁЃеыЖдМрПиЃЌЮвУЧЬсСЖСЫСНЬѕЛљБОддђЃК
1.МсГжвЕЮёжИБъВЩМЏЪЧДњТыЕФвЛВПЗжддђВЛЖЏвЁЃЌЬсИпжИБъИВИЧТЪ
2.МрПиЗНЪНКЭжИБъвЊБъзМЛЏЃЌЙЄОпжЇГХЯЕЭГЛЏ
ддђ1ЃЌУЛгаШЫБШФЃПщЕФбаЗЂШЫдБЃЌИќЧхГўЦфЙЄзїЛњжЦЃЌИќЙиаФЦфдЫаазДЬЌЃЌФЃПщздЩэЕФПЩдЫЮЌадОЭЪЧДњТыЙІФмЕФживЊзщГЩВПЗжЁЃУПДЮвЕЮёТпМВПЗжЕФДњТыБфИќЃЌЖМгІИУАщЫцзХМрПижИБъВЩМЏЕФЯргІИќИФЁЃ
гаСЫддђ1ЃЌЛЙдЖдЖВЛЙЛЃЌУЛгаКУЕФЙЄОпКЭЬхЯЕжЇГХЃЌЬсИпжИБъИВИЧТЪОЭЪЧвЛОфПеЛАЁЃдкдЫЮЌВуУцЃЌгІИУжЦЖЈЭГвЛЕФМрПиБъзМЃЌЭЦааЭГвЛЕФзюМбЪЕМљЃЌЬсЙЉЭГвЛЧПДѓБуНнЕФmetrics
libПтжЇГХЁЃетбљВХФмИќШнвзЕФЭЦНјздЖЏЛЏНјГЬЃЌвдМАИќИпЕФМрПижИБъИВИЧЖШЁЃ
ЬИЬИМрПиБъзМЛЏЃЌБъзМШчКЮЖЈвхЃП
1.УПИівЕЮёЕФУПИіНгПкЃЌЖМвЊПЩБЛМрПи
2.УПИіНгПкЕФМрПижИБъЃЌБиаыжСЩйАќКЌЃК
cps
latency-50th/75th/95th/99th...
error_rate
error_count
3.ПЩвддк2ЕФЛљДЁЩЯЃЌРЉГфЯрЙиздЖЈвхжИБъЃЌБШШчЃК
caller
callee
етбљОЭПЩвдЯИЛЏЕНЕїгУЙиЯЕМЖБ№ЕФЪ§Он
4.ЫљгаЕФжИБъЩЯБЈЃЌВЩгУжїЖЏpushЛњжЦЃЌЮоашдЄЯШзЂВс
гаСЫЩЯУцЕФвЛаЉБъзМЛЏЕФжИЕМЫМЯыЃЌЮвУЧОЭПЩвдзХЪжПЊЗЂlibПтЃЌЭЦНјвЕЮёФЃПщНгШыСЫЁЃвдnginxЮЊР§ЃЌМрПижИБъВЩМЏЃЌПЩвдВЮПМЮвУЧЕФЪЕЯжhttp://book.open-falcon.org/zh/usage/ngx_metric.html
ЃЌВЩМЏЕНЕФжИБъАќРЈЃК
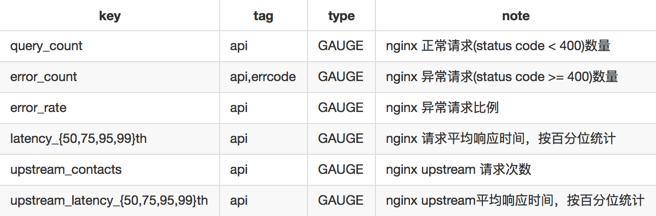
nginxжИБъБъзМЛЏ
1.api tag: МДnginx request uriЃЌИїЭГМЦЯюАДееuriЧјЗжЁЃЕБapiЮЊБЃСєзж__serv__ЪБЃЌДњБэnginxЫљгаЧыЧѓЕФзлКЯЭГМЦ
2.error_countЁЂupstreamЭГМЦЯюИљОнЪЕМЪЧщПіЃЌШчЙћУЛгадђВЛЛсЪфГі
гаСЫетаЉБъзМЛЏЕФжИБъЃЌКмЩйЕФМИИіИцОЏВпТдОЭФмИВИЧЕНОјДѓЪ§ЕФвЕЮёФЃПщЃЌЖјВЛгУЕЃаФеыЖдУПИівЕЮёЬэМгВЛЭЌЕФИцОЏВпТдЁЃЭЌЪБПЩвдеыЖдУПИівЕЮёЃЌИљОнВЛЭЌЕФгУЛЇЃЌНЈСЂИїздЕФdashboardЃЌБШШчеыЖдРЯАхЁЂбаЗЂЁЂдЫЮЌЁЂВтЪдЃЌЙизЂЕФdashboardВржиЕуЖМгаЫљВЛЭЌЁЃ

УПИіЗўЮёЖМвЊгаздМКЕФДѓХЬ
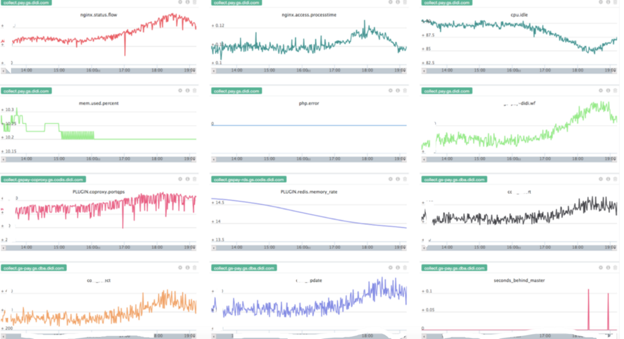
ДѓХЬПЩФмГЄетбљ

ДѓХЬвВПЩФмГЄетбљ
ВПЪ№
ЫЕЦ№РДКмМђЕЅЃЌВПЪ№ОЭЪЧНЋДњТыЁЂХфжУЁЂЪ§ОнЃЌдквЛзщзЪдДЩЯЃЌБЃГжИјЖЈЪ§СПЕФЪЕР§дкдЫааЁЃ
ЕЋЃЌЯжЪЕЪЧЙЧИаЕФЃЌДцдкзХетбљФЧбљЕФЭДЕуЃК
1.аТвЕЮёНгШыЙЕЭЈГЩБОИп
2.ЛЗОГвРРЕЖрЃЈPHP/java/golang/c++ЃЉ
3.ЩЯЯТгЮСЌНгаХЯЂЙмРэТвЃЈЭиЦЫВЛУїШЗЃЌЩЂТфдкИїИіФПБъЗўЮёЦїЩЯЃЉ
4.гУЛЇЬхбщВЛЭГвЛЃЈБрвыДђАќЁЂЗЂЕЅЁЂЩѓКЫЁЂжДааЁЂЙлВьИїИіЛЗНкЭбНкЃЉ
5.діСПИќаТДцдкаЭЌЩЯЕФЮЪЬт
ВПЪ№КЭБфИќЃЌЮвУЧЕФвЛаЉддђЃК
1.вдАцБОЮЊЗЂВМЕЅЮЛ
2.ЭГвЛЕФНгШыСїГЬКЭДђАќЙцЗЖЃЈвВПЩвдКмЗНБуЕФЙЙНЈЮЊdocker imageЃЉ
3.МЏжаЛЏЕФХфжУЙмРэЃЌХфжУгыЯпЩЯЛЗОГНтёю
4.ЭГвЛЕФЩЯЯпСїГЬКЭМьВщЛњжЦЃЈpreviewЁЂаЁСїСПЁЂМЏГЩМрПиИцОЏЁЂМЏГЩЧїЪЦЭМЃЉ
5.ШежОвРРЕНтёюЃЈЭјТчШежОЃЉ
ПЩвддЄМћЃЌОЙ§МсГжВЛаИЕФБъзМЛЏИФдьЃЌЯпЩЯЗўЮёЃК
1.ХфжУКЭЛЗОГНтёюСЫ
2.МрПиБъзМЛЏСЫ
3.ВПЪ№ЙцЗЖЛЏСЫ
4.ШежОЭјТчЛЏСЫ
5.Ъ§ОнserviceЛЏСЫ
6.ЪЕР§здЗЂЯжСЫ
7.зЪдДШнЦїЛЏСЫ
8.ШЋздЖЏЛЏЕїЖШЃЌЫГЪЦЖјЮЊАеСЫЁЃ
|









