Έ“Ο«“―Ψ≠”κ ΐΑΌΟϊΩΆΜßΚœΉςΘ§ΈΣΥϊΟ«ΒΡΜΖΨ≥ΙΙΫ®ΝΥΦύΩΊ’ΜΘ§Υυ“‘Έ“Ο«“―Ψ≠ΝΥΫβ ≤Ο¥ «Ω…––ΒΡΘ§ ≤Ο¥ «≤ΜΩ…––ΒΡΓΘ’β–©ΚœΉςΒΡΫαΙϊΩ…ΡήΜα»ΟΡψ¥σ≥‘“ΜΨΣΘ§±»»γΈ“Ο«ΖΔœ÷‘ΎΦύΩΊΒΡ ±ΚρΘ§“«ΤςΚΆ”Π”Ο≥Χ–ρΤδ Β «“Μ―υ÷Ί“ΣΒΡΓΘ ±ΨΈΡΫΪΫι…ή»γΚΈΫ®ΝΔ“ΜΗωΚαœρά©’ΙΓΔΗΏΕ»Ω…ΩΩΒΡΦύΩΊœΒΆ≥ά¥¥Πάμ ΐΆρΗω»ίΤςΥυ–η“ΣΒΡœΗΫΎΘ§≤Δ«“ΜΙΫΪΖ÷œμ“Μœ¬Μυ¥ΓΦήΙΙΘ§…ηΦΤ―Γ‘ώΚΆ»®ΚβΓΘΈ“ΫΪΫι…ήΒΡΈεΗωΖΫΟφ»γœ¬ΘΚ
1.œΒΆ≥≤βΝΩΘΜ
2.ΫΪ ΐΨί”κ”Π”Ο≥Χ–ρΘ§÷ςΜζΚΆ»ίΤςœύΙΊΝΣΘΜ
3.άϊ”Ο–≠ΒςΤςΘΜ
4.ΨωΕ®“Σ¥φ¥ΔΒΡ ΐΨίΘΜ
5.»γΚΈ‘ΎΦ·ΉΑœδΜ·ΜΖΨ≥÷–Ττ”ΟΙ ’œ≈≈≥ΐΘΜ
Ήœ»ΡψΒΟΝΥΫβΘ§Sysdig «“ΜΦ“Ήω»ίΤςΦύΩΊΒΡΙΪΥΨΓΘΩΣ‘¥œνΡΩ‘ –μΡζΩ¥ΒΫΒΞΗω÷ςΜζ…œΒΡΟΩΗωœΒΆ≥Βς”ΟΙΐ≥ΧΓΔ≤Έ ΐΓΔ”––ßΗΚ‘ΊΚΆΝ§Ϋ”ΓΘ
…Χ“Β≤ζΤΖΫΪΥυ”–’β–© ΐΨίΉΣΜ·ΈΣ ΐ«ßΗω÷Η±ξΘ§ΈΣΟΩΗω»ίΤςΚΆ÷ςΜζΧαΙ© ΐΨίΘ§≤ΔΜψΉήΥυ”– ΐΨίΘ§≤ΔΈΣΡζΧαΙ©“«±μΑεΘ§±®Ψ·ΚΆάύΥΤhtopΒΡΜΖΨ≥ΓΘ Έ“Ο«¥”»ίΤςΕ‘ΦύΩΊœΒΆ≥ΒΡ”ΑœλΩΣ ΦΘ§…ν»κΝΥΫβ“Μ–©œΗΫΎΓΘ
ΈΣ ≤Ο¥ΥΒ»ίΤςΗΡ±δΝΥΦύΩΊΒΡΙφ‘ρ
»ίΤςΒΡΙΠΡήΖ«≥Θ«Ω¥σΘ§ΧΊΒψ»γœ¬ΘΚ ΦρΒΞ–‘ΘΚΒδ–ΆΒΡΒΞΗωΫχ≥ΧΘΜ ΧεΜΐ–ΓΘΚΧεΜΐ «VM¥σ–ΓΒΡ1/10Θ§±μ ΨΥϋΟ« «±ψ–· ΫΒΡΘΜ Έό“άάΒ–‘ΘΚΉιΦΰ÷°ΦδΈό“άάΒ–‘ΘΜ Ε·Χ§–‘ΘΚΩλΥΌΒΡΤτΕ· ±ΦδΘΜ ±Θ≥÷»ίΤςΒΡΦρΒΞ–‘ «ΤδΦέ÷Β÷ς’≈ΒΡΚΥ–ΡΘ§“≤ «ΈΔΖΰΈώΒΡ÷Ί“ΣΙΙΫ®ΩιΓΘΒΪ «’β÷÷ΦρΒΞ–‘ «”–¥ζΦέΒΡΓΘ¥”opsΒΡΫ«Ε»ά¥Ω¥Θ§Ρζ–η“Σ‘Ύ»ίΤςΡΎΫχ––…ν»κΒΡΩ… ”–‘Θ§Εχ≤ΜΫωΫω «÷ΣΒάΡ≥–©»ίΤς¥φ‘ΎΓΘ ΡζΒΡ»ίΤς“≤ΚήΩ…Ρή”…“ΜΗω±ύ≈δœΒΆ≥Ιήάμ(œκœκKubernetesΜρswarm)Θ§»γΙϊΡζ’ΐ‘Ύ‘Υ––PaaSΘ§Ρ«Ο¥ΡζΒΡΩΣΖΔ»Υ‘±Ω…ΡήΜα‘Ύ»ΈΚΈ ±ΚρΆΤΕ·–¬ΒΡ”Π”Ο≥Χ–ρΘ§Εχ≤ΜΆ®÷ΣΤΫΧ®Ά≈Ε”ΓΘ ΚΟΝΥΘ§œ÷‘ΎΈ“Ο«÷ΣΒά’ΐ‘Ύ¥Πάμ’β–©–ΓΒΡΚΎΚ–Ή”Θ§ΥϋΟ«≥ωœ÷Θ§ΥάΆωΘ§≤Δ«“±ΜΡψΒΡ±ύ≈δœΒΆ≥ΒΡΆΜΖΔΤφœκΥυΗ–Ε·ΓΘΡζΒΡΩΣΖΔ»Υ‘±Ω…“‘Ή‘”…ΒΊΧμΦ”ΚΆ–όΗΡΥϊΟ«ΒΡ”Π”Ο≥Χ–ρΓΘΡψΒΡΙΛΉς «»Ζ±ΘΙΪΥΨΒΡ”Π”Ο≥Χ–ρ‘Υ––’ΐ≥ΘΘ§Ηϋ≤Μ“ΣΥΒ”– ΐΨίά¥ΫβΨωΈ ΧβΓΘ»ΟΈ“Ο«ΩΣ Φ¥ρΤΤΦύΩΊΒΡΧτ’ΫΓΘ
“«Τς–η“ΣΆΗΟς
1.‘ΎΨ≤Χ§Μρ–ιΡβΜΖΨ≥÷–Θ§»Ο¥ζάμ‘Ύ÷ςΜζ…œ‘Υ––ΚήΦρΒΞΘ§≤ΔΗυΨίœύΙΊ”Π”Ο≥Χ–ρ≈δ÷Ο¥ζάμΓΘ
»ΜΕχΘ§‘ΎΦ·ΉΑœδΜ·ΒΡΜΖΨ≥÷–Θ§’β÷÷ΖΫΖ®≤Δ≤ΜΤπΉς”ΟΘΚ
2.≤ΜΡήΫΪ¥ζάμΖ≈‘ΎΟΩΗω»ίΤς÷–Θ®≤ΜΤΤΜΒ»ίΤςΒΡΦϋ÷ΒΘ©ΘΜ
ΥφΉ≈”Π”Ο≥Χ–ρΒΡ≥ωœ÷ΚΆ‘Υ––Θ§ΩΣΖΔ’Ώ≤ΜΡή ÷Ε·≈δ÷Ο¥ζάμ≤εΦΰά¥ ’Φ·œύΙΊΒΡ”Π”ΟΦΕ±π÷Η±ξΘΜ Υυ“‘Έ“Ο« ‘ΆΦ Ι“«ΤςΒΡΙΠΡή±Ί–κΨΓΩ…ΡήΆΗΟςΘ§ΨΓΩ…Ρή…ΌΒΡ»ΥΈΣΗ…‘ΛΓΘ Μυ¥Γ…η ©÷Η±ξΘ§”Π”Ο÷Η±ξΘ§ΖΰΈώœλ”Π ±ΦδΘ§Ή‘Ε®“ε÷Η±ξΚΆΉ ‘¥/Άχ¬γάϊ”Ο¬ ”ΠΗΟ‘Ύ»ίΤςΡΎ≤Μ–η“Σ»ΈΚΈœϊΚΡΒΡ«ιΩωœ¬ΨΆΩ…“‘Άξ≥…ΓΘ
ΥϋΒ±»Μ≤Μ”ΠΗΟ“Σ«σΟΩΗωΗΫΦ”»ίΤςΒΡΉ‘–ΐœρ…œΓΘ Βœ÷’β“ΜΡΩ±ξ”–ΝΫ÷÷Ω…ΡήΖΫΖ®ΓΘ Ήœ» «podsΘ§’β «Kubernetes¥¥‘λΒΡ“ΜΗωΗ≈ΡνΓΘpod «“ΜΉιΙ≤œμΙΪΙ≤Οϊ≥ΤΩ’ΦδΒΡ»ίΤςΓΘ“ρ¥ΥΘ§“ΜΗω»ίΤςΡΎΒΡ»ίΤςΩ…“‘Ω¥ΒΫœύΆ§»ίΤς÷–ΒΡΤδΥϊ»ίΤς’ΐ‘ΎΉω ≤Ο¥ΓΘΕ‘”ΎΦύ ”¥ζάμΘ§’βΆ®≥Θ±Μ≥ΤΈΣΓΑsidecarΓ±»ίΤςΓΘ
ΚΟ¥Π÷°“Μ «‘ΎKubernetes÷–Θ§’β «œύΕ‘»ί“ΉΒΡ ¬«ιΓΘ»ΜΕχΘ§»±Βψ «:»γΙϊΜζΤς…œ”–ΚήΕύΒΡpodsΘ§Ή ‘¥œϊΚΡΨΆΜαΚήΗΏΓΣΓΣ’β”–ΒψœώΟΩΗωΫχ≥ΧΕΦ”–“ΜΗωΦύΩΊ¥ζάμΘ§Εχ«“ΡζΜΙ¥¥Ϋ®ΝΥ“άάΒœνΘ§“‘ΦΑ‘Ύ’βΗωpod÷–ΗΫΦ”ΒΡΙΞΜς±μΟφΓΘ’β“βΈΕΉ≈Θ§»γΙϊΡζΒΡΦύ ”sidecarΨΏ”––‘ΡήΓΔΈ»Ε®–‘ΜρΑ≤»Ϊ–‘Έ ΧβΘ§ΥϋΨΆΜαΕ‘ΡζΒΡ”Π”Ο≥Χ–ρ‘λ≥…―œ÷ΊΤΤΜΒΓΘ
ΒΎΕΰ÷÷ΡΘ Ϋ «ΟΩΗω÷ςΜζΘ§ΆΗΟςΒΡ“«ΤςΓΘ ’βΗωΆΗΟςΒΡ“«Τςάϊ”ΟΒΞΗω≤β ‘Βψ≤ΕΜώΥυ”–”Π”Ο≥Χ–ρΘ§»ίΤςΘ§Ά≥ΦΤ–≈œΔΚΆ÷ςΜζ÷Η±ξΘ§άϊ”ΟΡΎΚΥ÷–ΒΡΗζΉΌΒψ…η±ΗΘ§≤ΔΫΪΤδΖΔΥΆΒΫΟΩΗω÷ςΜζΒΡ»ίΤςΫχ––¥ΠάμΚΆ¥Ϊ δΓΘ
’βœϊ≥ΐΝΥΫΪΥυ”–ΡΎ»ί±δ≥…Ά≥ΦΤ ΐΨίΒΡ–η«σΘ§’β «Έ“Ο«Ω¥ΒΫ–μΕύ»ΥΥυΉΖ«σΒΡΓΘ ”κsidecarΡΘ–Ά≤ΜΆ§Θ§ΟΩΗω÷ςΜζ¥ζάμΦΪ¥σΒΊΦθ…ΌΝΥΦύ ”¥ζάμΒΡΉ ‘¥œϊΚΡΘ§≤Δ«“≤Μ–η“Σ–όΗΡ”Π”Ο≥Χ–ρ¥ζ¬κΓΘΒΪ «Θ§Υϋ»Ζ Β–η“Σ“ΜΗωΧΊ»®»ίΤςΚΆ“ΜΗωΡΎΚΥΡΘΩιΓΘ
ΚΥ–Ρ…η±Η «»γΚΈ‘ΥΉςΒΡ
ContainerVision «»ΟSysdig»γ¥Υ≤ΜΆ§ΒΡ“ΜΗω÷Ί“Σ“ρΥΊΘ§Υυ“‘»ΟΈ“Ο«Μ®Βψ ±Φδ»ΞΝΥΫβ“Μœ¬Υϋ «‘θΟ¥‘Υ––ΒΡΑ…ΓΘ’β“Μ≤ΩΖ÷Έ“ΫΪ÷ΊΒψΫ≤“Μœ¬ΩΣ‘¥œνΡΩ «»γΚΈ‘ΥΉςΒΡΓΘΡψΟ«÷–ΒΡ¥σΕύ ΐ»ΥΩ…ΡήΜα≥…ΈΣΒΎ“Μ≈ζ Ι”Ο’βΗωΑφ±ΨΒΡΘ§Υυ“‘ΕΝΆξ’βΤΣΈΡ’¬“‘ΚσΘ§Ρψ”ΠΗΟΜα”–Ηϋ…νΩΧΒΡάμΫβΓΘ
SysdigΒΡΦήΙΙΚΆlibpcap/tcpdump/wiresharkΖ«≥ΘœύΥΤΘ®’β≤Μ ««…ΚœΘ§“ρΈΣSysdig «”…wiresharkΒΡΙ≤Ά§¥¥Ϋ®’Ώ÷°“Μ¥¥Ϋ®ΒΡΘ©ΓΘ Ήœ» «”…sysdig-probe’βΟ¥“ΜΗω–Γ–Ά«ΐΕ·Τς‘ΎΡΎΚΥ÷–»Ξ≤ΕΜώ ¬ΦΰΘ§Υϋ Ι”ΟΒΡΡΎΚΥΙΛΨΏ «tracepointsΓΘtracepoints ΙΒΟΩ…“‘Α≤ΉΑ¥”ΡΎΚΥ÷–ΒΡΧΊΕ®ΙΠΡήΒς”ΟΒΡΓΑ¥Πάμ≥Χ–ρΓ±ΓΘ
ΡΩ«ΑΘ§sysdigΉΔ≤αΫχ»κΚΆΆΥ≥ωΒΡœΒΆ≥Βς”ΟΒΡΗζΉΌΒψ“‘ΦΑΫχ≥ΧΒςΕ» ¬ΦΰΓΘ Sysdig-probeΕ‘’β–© ¬ΦΰΒΡ¥Πάμ≥Χ–ρ «Ζ«≥ΘΦρΒΞΒΡ
- ΥϋΫωœό”ΎΫΪ ¬ΦΰœξœΗ–≈œΔΗ¥÷ΤΒΫΙ≤œμΜΚ≥ε«χ÷–Θ§“‘Ι©“‘Κσ Ι”ΟΓΘ ±Θ≥÷¥Πάμ≥Χ–ρΦρΒΞΒΡ‘≠“ρΩ…“‘œκœώΘ§ «–‘ΡήΘ§“ρΈΣ‘≠ ΦΒΡΡΎΚΥ÷¥––±ΜΓΑΕ≥ΫαΓ±Θ§÷±ΒΫ¥Πάμ≥Χ–ρΖΒΜΊΓΘΓΘ
«ΐΕ·ΤςΨΆ «ΗΚ‘πΉω’β–© ¬ΒΡΘ§ΤδΥϋΒΡ≤ΜΩ…ΥΦ“ιΒΡ ¬«ι «ΖΔ…ζ‘ΎUser≤ψΓΘ Event Buffer±ΜΡΎ¥φ”≥…δΒΫ”ΟΜßΩ’ΦδΘ§’β―υΨΆ≤Μ–η“Σ»ΈΚΈΗ±±ΨΦ¥Ω…Ϋχ––ΖΟΈ Θ§¥”ΕχΉν¥σœόΕ»ΒΊΦθ…ΌCPU Ι”Ο¬ ΚΆΜΚ¥φΓΘlibscapΚΆlibsinsp’βΝΫΗωlibΧαΙ©ΝΥΕΝ»ΓΓΔΫβ¬κΚΆΫβΈω ¬ΦΰΒΡ÷ß≥÷ΓΘΨΏΧεά¥ΥΒΘ§libscapΧαΙ©ΝΥΗζΉΌΈΡΦΰΙήάμΙΠΡήΘ§ΕχlibsinspΑϋΚ§Η¥‘”ΒΡΉ¥Χ§ΗζΉΌΙΠΡή(άΐ»γΘ§ΡζΩ…“‘ Ι”ΟΈΡΦΰΟϊΕχ≤Μ «FDΚ≈)Θ§ΜΙΩ…“‘Ιΐ¬Υ ¬ΦΰΫβ¬κΘ§Lua
JIT±ύ“κΤςά¥‘Υ––chisels»»ΓΘΉνΚσΘ§sysdigΑ―ΥϋΉςΈΣ“ΜΗωΦρΒΞΒΡΑϋΉΑΤςΖ≈‘Ύ’β–©Ωβ÷–ΓΘ ΒΪ «Θ§»γΙϊsysdigΘ§libsinspΜρlibscap≤ΜΙΜΩλΘ§ΈόΖ®Ηζ…œά¥Ή‘ΡΎΚΥΒΡ ¬ΦΰΝςΡΊΘΩsysdigΜαœώstraceΡ«―υΒΦ÷¬œΒΆ≥±δ¬ΐ¬πΘ®¥œΟςΒΡΕΝ’ΏΜαΈ Θ©ΘΩΒ±»Μ≤ΜΩ…ΡήΓΘ‘Ύ’β÷÷«ιΩωœ¬Θ§ ¬ΦΰΜΚ≥ε«χΜα±ΜΧν¬ζΘ§sysdig-probeΩΣ Φ“≈¬©¥Ϊ»κΒΡ ¬ΦΰΓΘ
Υυ“‘ΡψΜαΕΣ ß“Μ–©ΗζΉΌ–≈œΔΘ§ΒΪΜζΤςΚΆ‘Υ––ΒΡΤδΥϊΫχ≥Χ≤ΜΜαΦθ¬ΐΓΘ ’β «»γΙϊsysdigΦήΙΙΒΡΙΊΦϋ”≈ ΤΘ§“ρΈΣ’β≤ΜΫω“βΈΕΉ≈Ω…“‘‘Λ≤βΗζΉΌΒΡΩΣœζΘ§ΜΙ“βΈΕΉ≈‘Ύ…ζ≤ζΜΖΨ≥÷–‘Υ––Θ§«ιΩω“≤Μα±»Ϋœά÷ΙέΘ§Εχ«“chisels≤Μ–η“ΣœώDTracesΒΡDΫ≈±ΨΡ«―υΨ≠ΙΐΉ–œΗΒΡ”≈Μ·ΓΘ≥ΐ¥Υ÷°ΆβΘ§chiselsΜΙΩ…“‘άϊ”ΟΈΣLua±ύ–¥lib(œκ“ΣΫΪchiselsΒΡ ΐΨί¥ΪΒίΒΫRedisΘΩ”Ο’βΗωlibΨΆΩ…“‘ΉωΒΫΘΓ)ΓΘœκ‘Ύ’βΗωΈ Χβ…œ…‘ΈΔ…ν»κ“ΜΒψΘ§Ω…“‘‘ΡΕΝDTrace
vs strace vs sysdig: A technical discussionΓΘ
ΩΣ‘¥Ι ’œ≈≈≥ΐΙΛΨΏΦ»ΈΣ”ΟΜßΧαΙ©ΝΥΟϋΝν––ΫγΟφΘ§“≤ΧαΙ©ΝΥ’κΕ‘ΒΞΗω÷ςΜζΜυ”ΎcursesΒΡΥυ”– ΐΨί(»γœ¬ΥυΦϊ)ΒΡΫ”ΩΎΓΘ
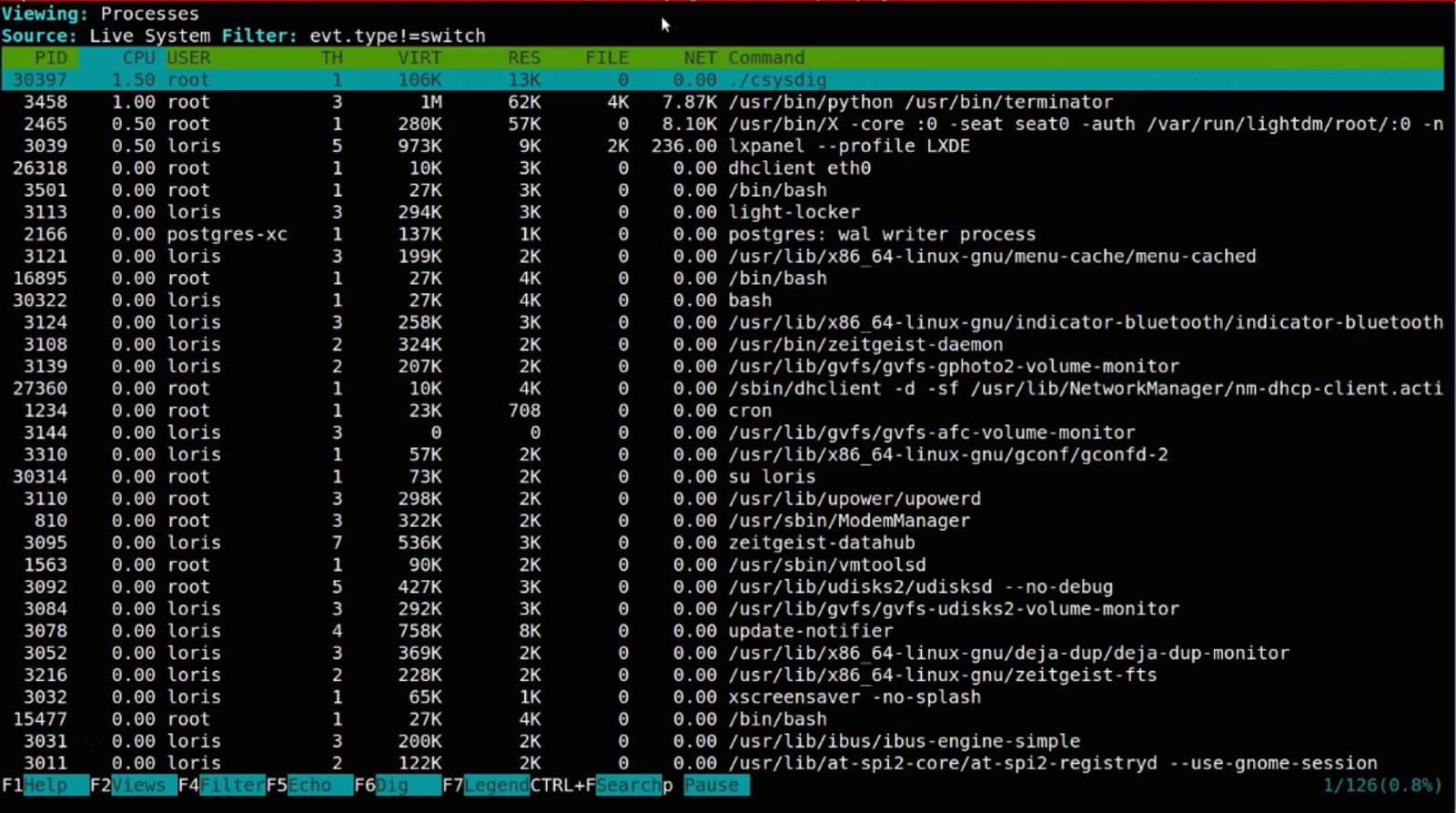
Ε‘”ΎΈ“Ο«ΒΡΦύΩΊ≤ζΤΖΘ§Έ“Ο« Ι”ΟΆ§―υΒΡœΒΆ≥Ϋχ––Βς”ΟΘ§ΫχΕχ¥”Ε―’Μ÷–Χα»ΓœύΙΊΒΡ÷Η±ξΘ§≤Δ‘ΎΖ÷≤Φ ΫΜΖΨ≥÷–¥¥Ϋ®“ΜΗωάύΥΤhtopΒΡΫγΟφΓΘ
»ΜΕχΈ“Ο«œύ–≈Θ§»γΙϊ¥Πάμ»ίΤςΒΡΜΑΘ§ΫωΫωΩΩΚβΝΩ±ξΉΦΨΆ≤ΜΙΜΝΥΓΘ “ρ¥Υ»ΟΈ“Ο«ΧΗ“ΜΧΗ’β“Μ«–ΒΡ“β“εΓΘ
»γΚΈΫΪ ΐΨίΙΊΝΣΒΫ”Π”ΟΘ§÷ςΜζΘ§»ίΤςΚΆOrchestrators
ΥφΉ≈ΜΖΨ≥Η¥‘”–‘ΒΡ‘ωΦ”Θ§Μυ”Ύ‘Σ ΐΨίΙΐ¬ΥΓΔΖ÷ΕΈΚΆΖ÷ΉιΕ»ΝΩΒΡΡήΝΠ «÷ΝΙΊ÷Ί“ΣΒΡΓΘ±ξΦ«Ω…“‘Αο÷ζ”ΟΜß’Ι Ψ≥ω”Π”Ο≥Χ–ρΧεœΒΫαΙΙΒΡ¬ΏΦ≠άΕΆΦΘ§ΒΪ «≤ΜΑϋά®»ίΤς‘Υ––ΒΡΈοάμœ÷ ΒΓΘάΐ»γΘ§ΡζΩ…“‘Ά®Ιΐdev/prodΓΔserviceΓΔpodΜρΤδΥϋΒΡά¥Ϋχ––Μ°Ζ÷ΓΘ Ρζ”ΠΗΟΡήΙΜΕ·Χ§ΒΊ―Γ‘ώΜρ‘Ύ÷Η±ξ…œΫχ––±ξΦ«ΓΣΓΣ“‘≤ψ¥ΈΫαΙΙΟϋΟϊΒΡΓΔΒψΖ÷ΗτΒΡ÷Η±ξΟϊ≥ΤΚΆ‘ΛΕ®“εΒΡΨέΚœ’ΐ‘Ύ÷πΫΞœϊ ßΓΘΕ·Χ§―Γ‘ώ ΙΡζΡήΙΜΩλΥΌΜΊ¥π”–ΙΊΖΰΈώ–‘ΡήΒΡΈ ΧβΘ§Μρ’Ώ…ν»κΒΫΟϊ≥ΤΩ’Φδ…θ÷Ν»ίΤς÷–ΓΘ Ω…“‘œκΒΫ”–ΝΫ÷÷ΖΫ ΫΩ…“‘”Οά¥±ξΦ«÷Η±ξΘΚœ‘ Ϋ±ξ«©Θ®“Σ¥φ¥ΔΒΡ τ–‘Θ©vs“ΰ Ϋ±ξ«©Θ®–≠ΒςΤςΘ©ΓΘΡζ”ΠΗΟ”–Μζ÷ΤΚΆΉνΦ―ΉωΖ®ά¥ΧμΦ”Ος»ΖΒΡ±ξ«©Θ§“‘±ψΆ≈Ε”÷–ΒΡ»ΈΚΈ»ΥΕΦΩ…“‘ΗυΨίΗςΉ‘ΒΡ–η«σΫχ––ΧμΦ”ΓΘΒΪ «Ρ§»œ«ιΩωœ¬”ΠΗΟ≤ΕΜώ“ΰ Ϋ±ξΦ«ΓΘΚσΟφΒΡ“ΜΒψΖ«≥Θ÷Ί“ΣΘ§“ρΈΣΥϋ «œ¬“ΜΗωΙέΒψΒΡ÷Ί“ΣΉι≥…≤ΩΖ÷ΓΘ
ΥφΉ≈≤ζΤΖΒΡΖΔ’ΙΘ§Έ“Ο«ΖΔœ÷ΖΔœ÷Ρ§»œ«ιΩωœ¬Θ§Ά®≥ΘΜαΧμΦ”12-25Ηω±ξ«©ΓΘ ”–ΒΡ”ΟΜßΩ…ΡήΜα”ΟΗϋΕύΓΘ ΫΪΟΩΗωΕάΧΊΒΡ±ξ«©ΉιΚœ ”ΈΣ“ΜΗωΒΞΕάΒΡ÷Η±ξΘ§Ρζ–η“ΣΗυΨί–η“ΣΕ‘”ΟΜßΫχ––¥φ¥ΔΘ§¥ΠάμΚΆΒς”ΟΓΘ
’β”–“Μ–©œύΒ±÷Ί¥σΒΡ”ΑœλΘ§Έ“Ο«‘Ύœ¬ΟφΒΡΓΑΨωΕ®“Σ¥φ¥ΔΒΡΡΎ»ίΓ±÷–Χ÷¬έΓΘ
Leveraging Orchestrators
¥”Ηυ±Ψ…œΗΡ±δΝΥ»ίΤςΒΡΒςΕ»ΙήάμΖΫΖ®Θ§≤Δ‘Ύ¥ΥΙΐ≥Χ÷–”ΑœλΝΥ”ΟΜßΒΡΦύ ”≤Ώ¬‘ΓΘΈό¬έ «KubernetesΓΔSwarmΜΙ «MesosΘ§ΡζΕΦΫΪΩ¥ΒΫ”κΦύ ”ΖΫΖ®άύΥΤΒΡ±δΜ·ΓΘΒΞΗω»ίΤς±δΒΟ≤ΜΡ«Ο¥÷Ί“ΣΘ§ΕχΖΰΈώΒΡ–‘Ρή±δΒΟΗϋ÷Ί“ΣΓΘΗΟΖΰΈώ”…–μΕύ»ίΤςΉι≥…Θ§Ηϋ÷Ί“ΣΒΡ «Θ§–≠ΒςΤςΩ…“‘ΗυΨί–η“Σ“ΤΕ·’β–©»ίΤςΘ§“‘¬ζΉψ–‘ΡήΚΆΫΓΩΒ–η«σΓΘΨΏΧεά¥ΥΒΘ§Ε‘”ΎΦύΩΊœΒΆ≥”–ΝΫΗωΚ§“ε: ΦύΩΊœΒΆ≥±Ί–κΗυΨί–≠ΒςΤςΒΡ‘Σ ΐΨίΘ§“ΰ ΫΒΊ±ξΦ«Υυ”–÷Η±ξΓΘ’β ”Ο”ΎœΒΆ≥Ε»ΝΩΓΔ»ίΤςΕ»ΝΩΓΔ”Π”Ο≥Χ–ρΉιΦΰΕ»ΝΩΘ§…θ÷Ν «Ε®÷ΤΒΡΕ»ΝΩΓΘ Ή‘Ε®“εΕ»ΝΩ–η“Σ÷ΊΗ¥:ΡζΒΡΩΣΖΔ»Υ‘±”ΠΗΟΡήΙΜΦρΒΞΒΊ δ≥ωΕ®÷ΤΒΡΕ»ΝΩΘ§ΕχΦύ ”œΒΆ≥”ΠΗΟ±Θ≥÷Ή¥Χ§Θ§ΙΊ”ΎΕ»ΝΩά¥Ή‘ΚΈ¥ΠΓΘ»γΙϊΡζ“άάΒ”ΎΓΑΉνΦ― ΒΦυΓ±ά¥Ϋχ––±ξ֫ȧѫϥ±Ρζ’φ’ΐ–η“ΣΫβΨωΈ ΧβΒΡ ±ΚρΘ§ΡζΒΡΕ»ΝΩ±ξΉΦΫΪ «Έό”ΟΒΡΓΘΗϋΕύΙΊ”Ύ’βΗωΜΑΧβΓΘ Οϊ“ε…œ”–ΝΫ÷÷ΖΫΖ®:“άάΒ”Ύ–≠ΒςΤςΖΔ≥ωΒΡ ¬Φΰά¥±ξΦ«»ίΤςΘ§Μρ’ΏΗυΨί»ίΤςΒΡ ‘ΧΫά¥»ΖΕ®”Π”Ο≥Χ–ρΓΘΚσ’Ώ‘ΎΡψΒΡΦύΩΊœΒΆ≥÷––η“ΣΗϋΕύΒΡ÷«ΡήΘ§ΒΪΜα≤ζ…ζΗϋΩ…ΩΩΒΡΫαΙϊΓΘ’β «“ρΈΣΡζΒΡœΒΆ≥Βς”Ο≤ΜΜαΥΒΜ―ΓΣΡζΩ…“‘«αΥ…ΒΊΫΪΥϋΟ«”κ‘Υ––÷–ΒΡ”Π”Ο≥Χ–ρΝΣœΒΤπά¥ΓΘΩΦ¬«ΒΫΈ“Ο«ΒΡ“«±μΘ§ΡψΩ…“‘≤¬≤βSysdig―Γ‘ώΝΥΚσ“Μ÷÷ΖΫΖ®ΓΘ “ΣΝΥΫβΗϋΕύΙΊ”ΎKubernetesΚΆKubernetesΒΡ–≈œΔΘ§«κΒψΜςΓΑΦύ ”Kubernetes:œξœΗΒΡ÷ΗΡœΓ±
ΨωΕ®–η“Σ¥φ¥ΔΡΡ–© ΐΨίΘΚΓΑΥυ”–ΒΡ ΐΨίΓ±
Νμ“Μ÷÷ΥΒΖ®ΨΆ «ΓΑ ’Φ·Υυ”–ΒΡ ΐΨίΓ±Θ§ «Υυ”–ΒΡ ΐΨίΘ§ΟΜ”–Ιΐ¬ΥΙΐΒΡΘ§ΟΜΨ≠Ιΐ»ΈΚΈ¥ΠάμΒΡΓΘ ΡψΒΟ≥–»œ’β―υ“ΜΗω ¬ ΒΘ§Ρ«ΨΆ «ΥφΉ≈ΡψΒΡœΒΆ≥±δΒΟ‘Ϋά¥‘ΫΗ¥‘”Θ§»μΦΰ±δΒΟ‘Ϋά¥‘ΫΖ÷≤Φ ΫΘ§–η“Σ ’Φ·ΒΡ ΐΨί“≤‘Ϋά¥‘ΫΕύΓΘ±ξΦ«ΨΆ «ΉνΚΟΒΡάΐΉ”ΘΚΥϋΟ«ΒΡ ΐΝΩ «Ρ«–©±Ί–κ“Σ¥φ¥ΔΒΡ÷Η±ξΒΡ ΐ±ΕΓΘ Β±»ΜΘ§»γΙϊΫωΫω÷Μ¥φ¥ΔΫΎΒψ”Π”Ο≥Χ–ρKubernetes≤Ω πΒΡΤΫΨυ÷Β/Ήν–Γ÷Β/Ήν¥σ÷Β/ 95thΑΌΖ÷ΈΜ’β–©Θ§÷Η±ξΒΡ ΐΝΩ”ΠΗΟ“≤ΜαΫΒœ¬ά¥ΓΘΥϋΡήΚήΟςœ‘ΒΊΦθ…Ό÷Η±ξ ’Φ·Θ§¥φ¥ΔΚΆΦΤΥψΓΘ ΒΪ «ΥφΉ≈Μυ¥ΓΒΡΡΎ»ί‘Ϋά¥‘ΫΗ¥‘”Θ§¥φ¥ΔΥυ”– ΐΨίΒΡ÷Ί“Σ–‘“≤ΨΆ‘Ϋά¥‘ΫΗΏΘ§≤Δ“‘“Μ÷÷‘ –μΫχ––ΝΌ ±Ζ÷ΈωΚΆΙ ’œ≈≈≥ΐΒΡΖΫ ΫΫχ––¥φ¥ΔΓΘάΐ»γΘ§»γΙϊ‘Ύ÷°«ΑΧαΒΫΒΡΡ«ΗωΫΎΒψ”Π”Ο≥Χ–ρ÷–”–Φδ–Σ–‘ΜΚ¬ΐΒΡœλ”Π ±ΦδΘ§ΗΟ‘θΟ¥ΑλΡΊ?Ρψ‘θΟ¥÷ΣΒά’β «¥ζ¬κ÷–ΒΡœΒΆ≥–‘Έ ΧβΘ§Μρ «frtizΒΡ»ίΤςΈ ΧβΘ§ΜΙ «AWSΒΡΈ Χβ?Ά®Ιΐ≤Ω πά¥ΨέΚœΥυ”–’β–©–≈œΔΘ§ΫΪ≤ΜΜαΗχΡζΉψΙΜΒΡΫβΨωΖΫΑΗΓΘ Β±»ΜΘ§’β÷÷ΖΫΖ®≤ζ…ζΒΡΈ Χβ≤Δ≤ΜΝν»ΥΨΣ―»:Ρζ–η“Σ ’Φ·¥σΝΩΒΡ ΐΨίΓΘΜΙ–η“Σ ’Φ·÷Η±ξΚΆ ¬ΦΰΓΘΡψ±Ί–κΦα≥÷Θ§ Ι”ΟΜßΩ…“‘Υφ ±ΖΟΈ ΓΘ‘Ύ’βάοΘ§Έ“Ο«“≤ΉωΝΥ“Μ–©÷Ί¥σΒΡ…ηΦΤΨω≤Ώ: Έ“Ο«»œΈΣΘ§‘ΎΟΩΗωΖΰΈώΜρΟΩΗω”Π”Ο≥Χ–ρΜΖΨ≥÷–≤Ω πΫœ–ΓΒΡΓΔΗτάκΒΡΚσΕΥ «≤ΜΚœάμΒΡΓΘ Ε‘Έ“Ο«ά¥ΥΒΘ§’βΥΤΚθ≤Μ «“Μ÷÷Ω…ΙήάμΒΡΖΫΖ®ά¥‘Υ––(‘Ύ‘ΤΜΖΨ≥÷–)Θ§Μρ’Ώ»ΟΩΆΜßΙήάμ(‘ΎΈ“Ο«ΒΡ»μΦΰΒΡΡΎ≤Ω≤Ω π÷–)ΓΘ»γΙϊΡζœκ÷ΣΒάΈΣ ≤Ο¥’β «“ΜΗω–η“ΣΩΦ¬«ΒΡΈ ΧβΘ§Ρ«Ο¥ΡζΫΪΩ¥ΒΫœώΤ’¬όΟΉ–όΥΙ’β―υΒΡΩΣ‘¥œνΡΩ ΒΦ …œ «Ρ§»œΒΡΚσΕΥΡΘ–ΆΘ§“ρ¥ΥΆ®ΙΐΤ» ΙΗϋΕύΒΡΙήάμΙΛΉςœρ”ΟΜßΧαΙ©ΗϋΕύΒΡΙήάμΙΛΉςΘ§¥”Εχ“ΐΖΔΝΥΕ‘Ω……λΥθ–‘ΒΡΙΊΉΔΓΘœύΖ¥Θ§Έ“Ο«œΘΆϊΙΙΫ®“ΜΗωΥ°ΤΫΩ……λΥθΒΡΚσΕΥΘ§Έ“Ο«ΒΡ”Π”Ο≥Χ–ρΩ…“‘ΗυΨί”ΟΜßΜρΖΰΈώά¥Ητάκ ΐΨίΓΔ÷Η ΨΑεΓΔΨ·±®Β»ΓΘ ΈΣΝΥΧαΙ©ΟΜ”– ±Φδœό÷ΤΒΡ±ΘΝτΘ§Έ“Ο«ΨωΕ®‘Ύ“ΜΕΈ ±ΦδΡΎΙωΕ· ΐΨίΓΘΈ“Ο«ΫΪΆξ’ϊΒΡΫβΈω ΐΨί¥φ¥Δ6Ηω–Γ ±Θ§»ΜΚσ‘Ύ¥Υ÷°ΚσΩΣ ΦΨέΚœ ΐΨίΓΘ(Έ“Ο«ΜΙ”–“ΜΗωΫβΨωΖΫΑΗΘ§Ω…“‘‘ΎΨ·±®ΒΡ÷ήΈß¥φ¥ΔΆξ’ϊΒΡΖ÷±φ¬ ΐΨίΓΘ«κ≤Έ‘Ρœ¬“ΜΫΎΓΘ)
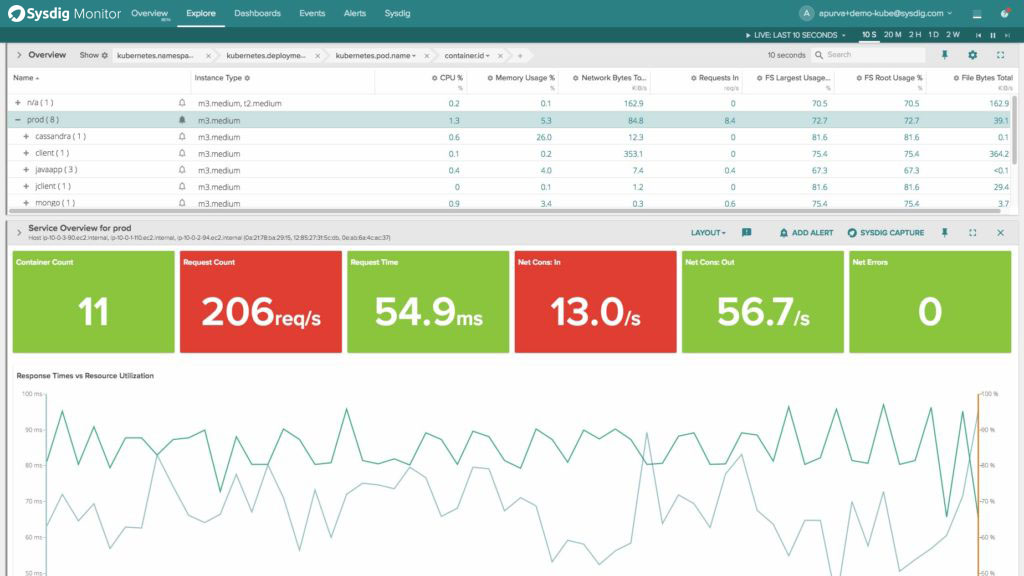
Υδ»ΜΈ“Ο«ΒΡΚσΕΥΦΧ–χΖΔ’ΙΘ§ΒΪΫώΧλΥϋ”…Υ°ΤΫΩ……λΥθΒΡCassandra(÷Η±ξ)ΓΔΒ·–‘Υ―Υς( ¬Φΰ)ΚΆRedis(ΖΰΈώ¥ζάμ)Ήι≥…ΓΘΜυ”Ύ’β–©ΉιΦΰΒΡΙΙΫ®ΧαΙ©ΝΥΚήΗΏΒΡΩ…ΩΩ–‘ΚΆΙφΡΘΘ§Ω…“‘¥φ¥ΔΕύΡξΒΡ ΐΨίά¥Ϋχ––≥ΛΤΎ«ς ΤΖ÷ΈωΚΆΖ÷ΈωΓΘΥυ”– ΐΨίΕΦΩ…“‘Ά®ΙΐREST
APIΖΟΈ ΓΘ’ϊΗωΚσΕΥΩ…“‘Ά®ΙΐsysΆΎΩύΒΡ‘ΤΖΰΈώά¥ Ι”ΟΘ§“≤Ω…“‘‘ΎΥΫ”–‘Τ÷–≤Ω πΘ§“‘ΜώΒΟΗϋ¥σΒΡΑ≤»Ϊ–‘ΚΆΗτάκ–‘ΓΘΗΟ…ηΦΤ‘ –μΡζ±ήΟβ‘Υ––“ΜΗωœΒΆ≥ά¥Φύ ”ΚΆΝμ“ΜΗωœΒΆ≥Ϋχ––≥ΛΤΎΖ÷ΈωΜρ ΐΨί±ΘΝτΓΘ
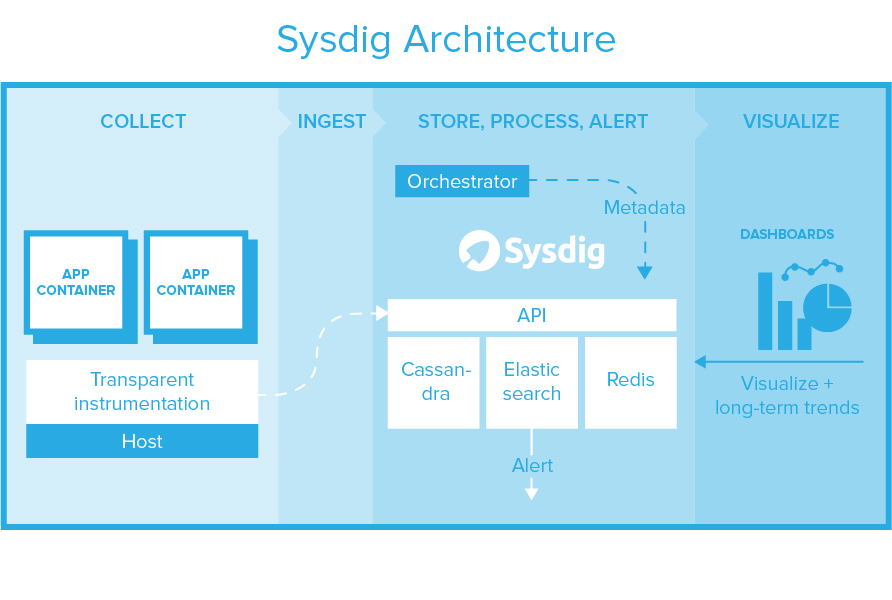
»γΚΈ‘ΎΦ·ΉΑœδΜ·ΒΡΜΖΨ≥÷–Ττ”ΟΙ ’œ≈≈≥ΐ
»ίΤς…ηΦΤ ±ΕΦ «–Γ«…«α±ψΒΡΓΘ ’βΕ‘”ΎΩ…≤Ω π–‘ΚΆΩ…÷ΊΗ¥–‘ΕΦ «Ζ«≥ΘΚΟΒΡΘ§ΒΪ“≤Μα”ΑœλΡζΕ‘»ίΤςΫχ––Ι ’œ≈≈≥ΐΒΡΖΫ ΫΓΘ ΜΙΦ«ΒΟΡψΒΡάœ≈σ”―sshΓΔtopΓΔpsΓΔifconfigΒ»¬π?ΡψΩ…Ρή≤ΜΜαΑ―ΥϋΟ«Ζ≈‘ΎΡψΒΡ»ίΤςάοΓΘ»γΙϊΡζ‘Ύ“ΜΗω ήΩΊΒΡPaaSΜΖΨ≥÷–‘Υ––Θ§Φ¥ Ι’β–©ΙΛΨΏ «Ω…”ΟΒΡΘ§Ρζ“≤Ω…ΡήΈόΖ®ΖΟΈ ΥϋΘ§≤Δ«“Γ≠Γ≠Έ“Ο«ΧαΒΫΒΡ»ίΤς”–ΒΡΩ…Ρή“―Ψ≠≤Μ¥φ‘ΎΝΥ?»γΙϊ–≠ΒςΤς’ΐ‘Ύ÷¥––ΥϋΒΡΙΛΉςΘ§Ρ«Ο¥‘ΎΡζΫχ––Ι ’œ≈≈≥ΐ÷°«ΑΘ§’βΗω»ίΤςΩ…Ρή“―Ψ≠ΚήΨΟΝΥΓΘ ΦρΕχ―‘÷°Θ§Μώ»ΓΥυ–η“ΣΒΡ–≈œΔΫΪΜα±δΒΟΚήΗ¥‘”ΓΘ≥ΐ¥Υ÷°ΆβΘ§¥”–≠ΒςΤς÷–ΜώΒΟ Β±ΒΡ…œœ¬ΈΡ «÷ΝΙΊ÷Ί“ΣΒΡΓΘ“ρ¥ΥΘ§»ΟΩΣΖΔ»Υ‘±ΡήΙΜΜώΒΟ’β–©…ν»κΒΡ–≈œΔ «Ζ«≥Θ±Ί“ΣΒΡΘ§άμœκ«ιΩωœ¬≤ΜΜαΤΤΜΒ…ζ≤ζΜΖΨ≥ΓΘ±Ί–κΫβΨω’βΗωΈ ΧβΘ§“ρΈΣΈ“Ο«»œΈΣΦρΜ·Ι ’œ≈≈≥ΐΚΆΕ‘»ίΤςΙΛΉςΗΚ‘ΊΫχ––ΦύΩΊ“Μ―υ÷Ί“ΣΓΘ ’βΨΆ «ΩΣ‘¥SysdigΒΡ»ίΤςΙ ’œ≈≈≥ΐΙΛΨΏΓΘ Υϋ≤ΕΜώ÷ςΜζ…œΒΡΟΩΗωΒΞ“ΜœΒΆ≥Βς”ΟΒΡΡήΝΠΩ…“‘…ν»κΝΥΫβ”Π”Ο≥Χ–ρΘ§»ίΤςΘ§÷ςΜζΚΆΆχ¬γΒΡ‘Υ––«ιΩωΓΘ ΡήΙΜ”κ“ΒΈώΝς≥ΧΙήάμΕ‘Ϋ”Θ§“≤ΨΆ“βΈΕΉ≈ΥϋΩ…“‘ ’Φ·œύΙΊΒΡ‘Σ ΐΨίΘ§“‘±ψΡζΩ…“‘≤ΕΜώΖ÷≤Φ ΫœΒΆ≥ΒΡ…œœ¬ΈΡΚΆΉ¥Χ§Θ§Εχ≤ΜΫωΫω «ΒΞΗωΜζΤςΒΡΉ¥Χ§ΓΘ
ΉνΚσΘ§SysdigΫΪΥυ”–ΡΎ»ί»Ϊ≤Ω≤ΕΜώΒΫΈΡΦΰ÷–ΒΡΙΠΡή“βΈΕΉ≈ΡζΩ…“‘¥”prod≤ΕΜώ ΐΨίΘ§ΒΪΩ…“‘‘Ύ± Φ«±ΨΒγΡ‘…œΫχ––Ι ’œ≈≈≥ΐΓΘ
ΡψΩ…“‘‘Ύ»ίΤς≤Μ‘ΎΒΡ ±ΚρΉωΚήΨΟΘ§Β±ΡψΒΡ¥ΠΨ≥≤Δ≤Μ «Ζ«≥ΘΫτΦ±ΒΡ ±ΚρΘ§ΡψΩ…“‘Ήω“ΜΗω’ΐ»ΖΒΡ ¬ΚσΖ÷ΈωΓΘ
άΐ»γΘ§”…”ΎΡζ‘ΎΧΊΕ®»ίΤς…œΩ¥ΒΫ¥σΝΩΒΡΆχ¬γΝ§Ϋ”Εχ ’ΒΫΨ·±®Θ§ Έ“Ο«ΒΡΦύΩΊΖΰΈώ÷–ΒΡΨ·±®Ω…“‘¥ΞΖΔ≤ΕΜώΘ§‘ΎΗΟ÷ςΜζ…œΦ«¬ΦΥυ”–œΒΆ≥Βς”Ο“ΜΕΈ ±ΦδΓΘ
ΧΫΥς‘ΎcSysdig÷–Θ§ΡζΩ…“‘Μώ»Γ’ΐ»ΖΒΡ»ίΤς…œœ¬ΈΡΘ§»ΜΚσ…ν»κΤδΆχ¬γΝ§Ϋ”ΘΚ
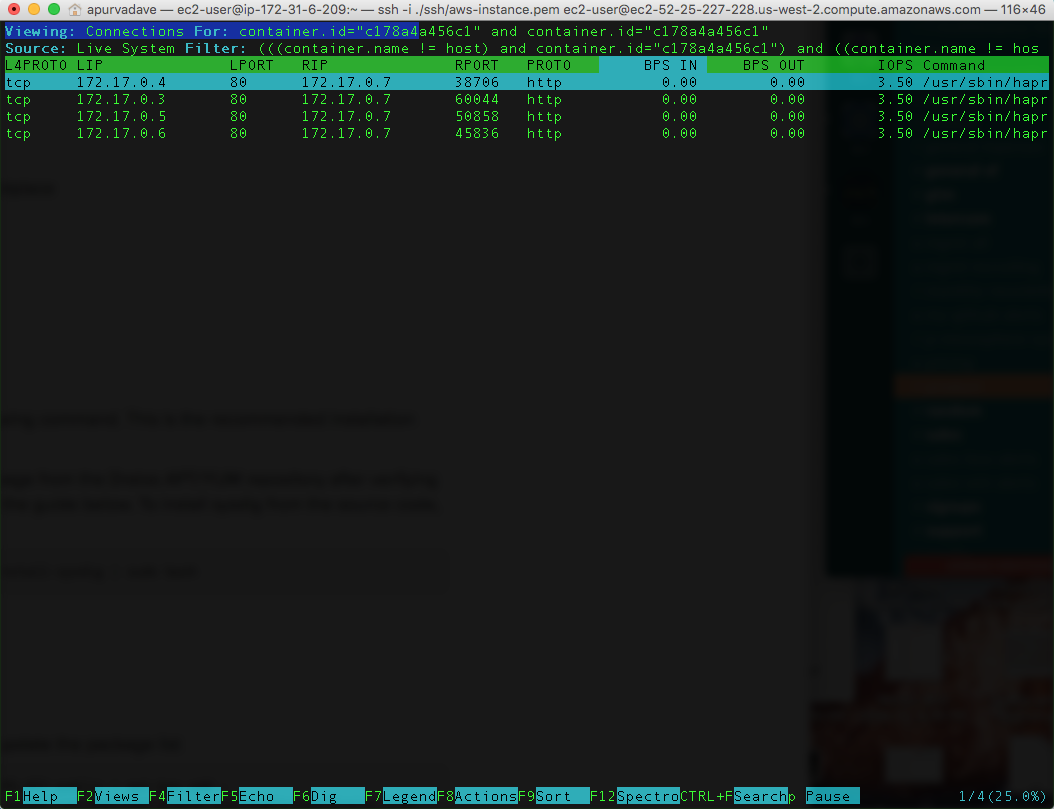
“ΣΝΥΫβΩΣ‘¥sysdigΩ…“‘Ήω ≤Ο¥Θ§«κ≤ιΩ¥Kubernetes DNSΖΰΈώΒΡΙΛΉς‘≠άμΓΘ
Ϋα¬έ
ΙΙΫ®“ΜΧΉΗΏΕ»Ω……λΥθΒΡΖ÷≤Φ ΫΦύΩΊœΒΆ≥≤Δ≤Μ «“ΜΦΰ»ί“ΉΒΡ ¬«ιΓΘ≤ΜΙήΡψ «―Γ‘ώΉ‘ΦΚΉωΜΙ «άϊ”Ο±π»ΥΒΡœΒΆ≥Θ§Έ“œύ–≈ΡζΫΪ≤ΜΒΟ≤ΜΉω≥ω–μΕύ”κΈ“Ο«“Μ―υΒΡ―Γ‘ώΓΘ ΉήΒΡά¥ΥΒΘΚ
1.»γΚΈ≤βΝΩœΒΆ≥?
2.»γΚΈ”κ–≠ΒςΤςΕ‘Ϋ”ΘΩ
3.»γΚΈΦρΜ· ΐΨί”κΉ‘Ε®“ε÷Η±ξΘΩ
4.ΨωΕ®±ΘΝτ ≤Ο¥ΘΩ
5. «ΖώΡήΙΜ‘ΎΕ·Χ§ΒΡΓΔΕΧ‘ίΒΡΜΖΨ≥÷–Ϋχ––Ι ’œ≈≈≥ΐΘΩ
|









