ЦНАВдЦМђНщ
ЦНАВдЦСЅЪєгкжаЙњЦНАВБЃЯе(МЏЭХ)ЙЩЗнгаЯоЙЋЫОЃЌвРЭаЦНАВМЏЭХЙЙНЈЕФН№ШкМАНЁПЕITЩњЬЌШІЃЌЮЊвјааЃЌжЄШЏЃЌБЃЯеЃЌЛЅСЊЭјН№ШкМАвНСЦНЁПЕРрЛњЙЙЬсЙЉАДашИЖЗбЃЌИпПЩгУЃЌИпЕЏадЃЌАВШЋКЯЙцЕФдЦМЦЫуЗўЮёЁЃНсКЯН№ШкМАНЁПЕвЕЮёдкЯЕЭГЃЌКЯЙцвдМАЪ§ОнЗНУцЕФЬиадЃЌЦНАВдЦГ§ЮЊПЭЛЇЬсЙЉПЊЗЂЃЌВтЪдЃЌЩњВњЃЌШндждкФкЕФШЋЬзЛљДЁЩшЪЉЗўЮёЭтЃЌЛЙЬсЙЉЖЈжЦЛЏН№ШкITНтОіЗНАИЁЃ
Дг13ФъЕзСЂЯювдРДЃЌЦНАВН№ШкдЦвЛжБОЁПЩФмзпПЊдДКЭздбаНсКЯЕФТЗЯпЃЌзджїбаЗЂСЫIaaSВуЕФШЋЬзВњЦЗЯпЃЌЮЊН№ШкаавЕПЭЛЇЬсЙЉПЩППЁЂЕЏадЁЂИпаЇЁЂМЏдМЕФЛљДЁМмЙЙВуЗўЮёЁЃ
ШеГЃдЫЮЌЙмРэ
ЛљгкITILЕФСїГЬЙмРэ

ЭМ1 ЦНАВдЦЕФдЫЮЌЙмРэСїГЬЬхЯЕ
ЖрЪ§ЦѓвЕЕФШеГЃЯЕЭГдЫЮЌЖМЪЧзёЪиITILЬхЯЕЁЃдЦМЦЫуИФБфСЫзЪдДНЛИЖгыдЫЮЌзЪдДЕФЗНЪНЃЌдЦЦНЬЈБОЩэвВЪЧаТЕФдЫЮЌЖдЯѓЃЌашвЊПижЦЗчЯеЃЌНтОіЪТМўЃЌИњНјЮЪЬтЃЌЙмРэЦНЬЈзЪдДГиЕФШнСПЁЃ
ЦНАВдЦГаЕЃСЫвЛВПЗжЦѓвЕЛљДЁМмЙЙЕФНЧЩЋЁЃШчЭМ1ЃЌЮЊСЫТњзуН№ШкЦѓвЕЕФИпКЯЙцЬиеїЃЌЦНАВдЦЕФдЫЮЌбЯИёзёЪиITILСїГЬЃЌАДееЦНАВПЦММЕФжЦЖШЙцЗЖвЊЧѓЪЕЪЉБфИќЃЌЪТМўЃЌЮЪЬтЃЌвЕЮёГжајМЦЛЎвдМАШнСПЙмРэЁЃ
АќРЈвбОЭЈЙ§ЙЄОпздЖЏЛЏЕФВйзїЃЌЫљгаЕФЩњВњЧјБфИќЖМашвЊОЙ§УПжмСНДЮЕФФкВПБфИќЦРЩѓЛсвщЪкШЈКѓВХПЩвдДЅЗЂЙЄОпЪЕЪЉЁЃЖдгкЭјТчЕШШЋОжадЕФБфИќИќЪЧашвЊЬсНЛЕНжиДѓБфИќЦРЩѓЯЕСаЛсвщЛёЕУИпМЖжїЙмЩѓХњКѓЗНПЩЪкШЈжДааЁЃ
ЭЌЪБЃЌгЩгквЕЮёЕФПьЫйзЊаЭашЧѓЃЌдЫЮЌЖдЯѓгыдЫЮЌФкШнЕФБфЛЏвВдНРДдНПьЃЌвђДЫдкДЋЭГЕФITILЗчЯеПижЦСїГЬжЎЩЯЃЌЮвУЧНшжњПЊдДЛђздбаПЊЗЂСЫКмЖрдЫЮЌИЈжњЙЄОпЁЃСэвЛЗНУцЃЌдквЕФкШЅIOEЁЂЗжВМЪНЯЕЭГЕФБГОАЯТЃЌДѓСПВЩгУСЫЙЉгІЩЬОКељМЄСвЁЂЭЈгУЕФServerЃЌЭЈгУServerЕФЕЅЛњПЩППадвЊБШвдЭљЕФзЈгУаЁаЭЛњЕШЗўЮёЦїгаЫљЯТНЕЃЌЕЋвЕЮёЭЈЙ§ЗжВМЪНВПЪ№КѓЗДЖјЬсЩ§СЫећИігІгУЕФПЩППадЁЃЃЌвђДЫЕЅвЛЕФЮяРэзЪдДПЩППаджИБъЕФМЏКЯВЂВЛФмгааЇЕиКтСПITЗўЮёПЩППадЃЌЖјашвЊДгЩЯВуЗўЮёЕФећЬхПЩгУжИБъРДЪЕЪЉДДаТгыКтСПЗўЮёПЩППадЃЌетИізЊБфЖдН№ШкММЪѕзЊаЭРДЫЕгШЮЊживЊЁЃ
ЦНАВдЦв§ШыСЫSREдЫЮЌдЦЦНЬЈЯЕЭГЃЌзмНсРДЫЕжааФЫМЯыгаСНЕуЃК1.ДгШэМўЛђМмЙЙВуУцЗжЮіЮЪЬтНтОіЮЪЬтЃЌБмУтв§ШыШЫЕФЙЄзїЛђгАЯьЃЌ2.
ЫљгаБиашЕФВйзїЖМвЊгаЙЄОпжЇГХЃЌБмУтЫцзХЕзВуВйзїЖдЯѓзЪдДЕФдіМгЖјдіМгЙЄзїШЫСІЁЃетИіЫМЯыВЂУЛгаЮЅБГITILРэФюЃЌДгЮвУЧЕФЪЕМљОбщЗжЮіЃЌSREПЩвдзїЮЊITILаТЪБДњЕФЙЄОпЃЌСМКУЕиШкКЯКѓПЩвдгааЇЕижЇГжН№ШквЕЮёдкдЦЩЯЕФПЩППадЁЃ
УХЛЇзджњзЪдДНЛИЖгыд№ШЮЙВЕЃЬхЯЕ
ЦНАВдЦзїЮЊЦНАВМЏЭХЛљДЁМмЙЙЕФбгЩьЃЌЪзЯШЯЃЭћФмЙЛЪЕЯжЯТУцЕФФПБъЃК
1.дЫгЊЛђвЕЮёгУЛЇПЩвджБНгзджњЩъЧызЪдДЃЌЗжжгМЖНЛИЖЁЃВЂНјвЛВНЪЕЯжПьЫйРЉШнФмСІЁЃ
2.ИїИігІгУзЈЛњзЈгУЃЌЯћУ№гІгУМфЕФНЛВцгАЯьЁЃ
3.дкдЦУХЛЇЩЯЪЕЯжШЈЯоПижЦЃЌИїгІгУЕФЫљгаепЖдздМКЕФжїЛњгаЭъШЋЕФЙмРэШЈЃЌдкгЕгаrootШЈЯожЎЩЯИќФмзджїpoweroff/poweronжїЛњЁЃ
дкДЋЭГЕФДѓЮяРэЛњЛЗОГЯТЃЌЛсГіЯжЖрИівЕЮёгІгУЙВЯэвЛЬЈИпадФмжїЛњЁЃдкетжжЛЗОГЯТЃЌгІгУЫљгаепКмФбЕЅЖРЮЊздМКЕФгІгУдкВйзїЯЕЭГВуЕїгХЃЌАВзАШэМўЛђзджњЕФЦєЭЃжїЛњЃЌБиаыЭЈЙ§ШпГЄЕФЩъЧыСїГЬвЊЧѓжїЛњЙмРэдБЪЕЪЉЁЃЭЈЙ§дЦМЦЫуЃЌгІгУЫљгаепЭъШЋЖРЯэздМКЕФдЦжїЛњЃЌВЂПЩвдИљОнвЕЮёашЧѓздгЩЕФЩшжУИїжжВйзїЯЕЭГВЮЪ§ЛђепАВзАШэМўЁЃ
дкДЋЭГЕФащФтЛњЛЗОГЯТЃЌгЩгкVCenterЕШЭГвЛЙмРэЦНЬЈЕФМЏжаШЈЯоЙмРэЃЌвЕЮёгІгУЫфШЛПЩвдгЕгаздМКЖРСЂЕФOSЃЌЕЋЪЧЕБOSашвЊРфЦєЖЏЛђашвЊНјааХфжУЩьЫѕЪБЃЌБиаызпСїГЬЭЈЙ§ащФтЛЗОГЙмРэдБАяжњВйзїЃЌдкЪБаЇЩЯгыаЇТЪЩЯЖМВЛФмТњзуДДаТвЕЮёЕФПьЫйашЧѓЁЃ
ЦНАВдЦзджїбаЗЂСЫвЛЬздЦУХЛЇЯЕЭГЃЌгУЛЇПЩвдЭЈЙ§УХЛЇзджїЕФЙмРэздМКЕФдЦжїЛњЃЌАќРЈжїЛњЕФЦєЭЃЃЌХфжУаоИФвдМАРрЫЦДјЭтЙмРэЕФlocal
consoleЕШЙІФмЁЃЭЌЪБЃЌгЩгкгабЯИёЕФЛљгкзтЛЇгызЪдДзщЕФЪгЭМИєРыгыШЈЯоПижЦЃЌПЩвдШЗБЃУПИігІгУзЪдДзщЙмРэдБжЛФмЙЛПДЕНздМКЯЕЭГЕФжїЛњЃЌБЃжЄСЫзЪдДзщЙмРэдБВйзїгІгУжїЛњКЯЙцЃЌАВШЋЁЃ
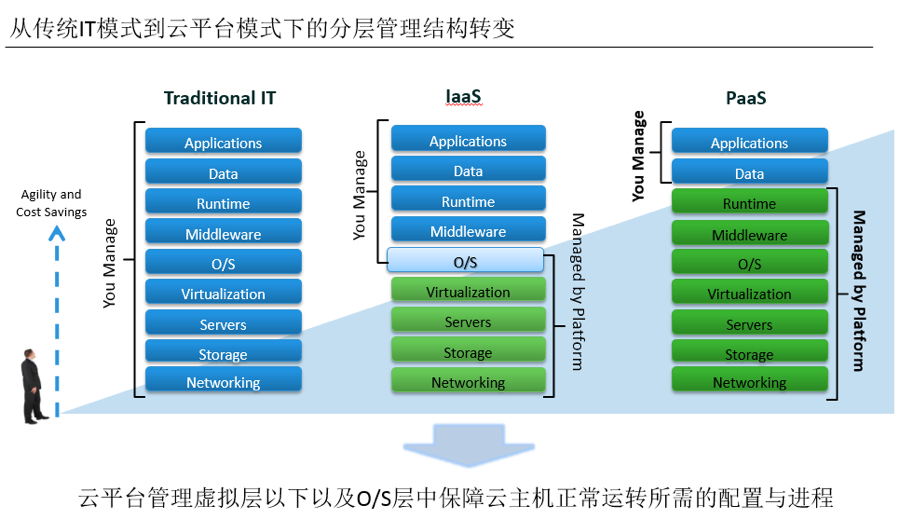
ЭМ2 IaaSФЃЪНЯТЕФд№ШЮЙВЕЃЬхЯЕ
ШчЭМ2ЃЌЭЈЙ§дЦУХЛЇИєРыOSЕФЪгЭМгыВйзїШЈЯоЃЌНЋЖРЯэжїЛњВйзїЫљгаШЈгыЙмРэд№ШЮЩЯИЁЃЌЗжВМЕНВЛЭЌЕФгІгУзЪдДзщЃЌЬсЙЉИјгІгУзЪдДзщЙмРэдБИќМгздгЩЕФСщЛюЖШгыИќАВШЋЕФгІгУжЎМфЕФИєРыЃЌдгаЕФЛљДЁМмЙЙдЫЮЌШЫдБПЩвдМЏжаОЋСІДІРэЦНЬЈВуЕФгХЛЏгыдЫЮЌЃЌДгЖјЬсИпдЫЮЌаЇТЪгыЯЕЭГЮШЖЈадЁЃ
ЫНгадЦ vs ЙЋгадЦ
дквЛПЊЪМЦНАВдЦЪЧвдЙЋгадЦЕФБъзМРДЙцЛЎКЭдЫЮЌЦНАВздМКЕФЫНгадЦЦНЬЈВњЦЗЕФЃЌЕЋЪЧОЙ§СНФъЖрЕФдЫЮЌКЭдНРДдНЖрЕФЩњВњгІгУЩЯдЦЃЌЮвУЧЖдЫНгадЦЕФЖЈЮЛКЭдЫЮЌЗНЪНвВдкВЛЖЯЫМПМКЭИФНјЁЃжївЊгаЯТУцШ§ЕуЃК
1.ЫНгадЦЯрЕБгкЦѓвЕжаЛљДЁМмЙЙЕФЕиЮЛЃЌвђДЫЕквЛМлжЕЕМЯђЮЊЗўЮёвЕЮёгІгУЃЌБЃеЯгІгУПЩгУадЁЃетгыЙЋгадЦЕЅДПзЗЧѓЕЅЛњПЩгУТЪЪЧВЛЭЌЕФЃЌЫНгадЦВЛЕЋвЊЬсЙЉПЩвдНгЪмЕФЕзВузЪдДПЩгУТЪЃЌЭЌЪБвВвЊгаЪжЖЮЗжЩЂЗчЯегАЯьУцЃЌБмУтвьГЃМЏжадкЭЌвЛИіЪБМфЕуЁЃЮвУЧдкКѓајЕФМмЙЙИФдьжаЃЌЮўЩќСЫвЛЖЈЕФЙВЯэзЪдДСщЛюадЃЌЖјзЊЮЊгХЯШБЃеЯЕзВузЪдДИєРыЃЌБмУтгЩгкЕзВуЙВЯэзЪдДвьГЃЖјв§Ц№ЕФДѓУцЛ§ЙЪеЯЗчЯеЁЃ
2.ЫНгадЦгыЩЯВугІгУЙиСЊНєУмЃЌгІгУЭХЖггыдЦЦНЬЈЭХЖгжЎМфЕФЙЕЭЈЦЕЗБЁЃдЦЦНЬЈПЩвдЖдгІгУВПЪ№ЗНЪНЬсГіЙцЗЖЃЌврашвЊгаЪжЖЮгыдЫгЊЭХЖгвЛЭЌбВМьгІгУЕФВПЪ№ЗНЪНЪЧЗёЗћКЯЙцЗЖЁЃвђДЫдЦЩЯгІгУЖддЦЦНЬЈЭХЖгРДЫЕВЛЪЧКкКаЃЌЖјЪЧЛвКаЩѕжСЪЧАзКаЁЃ
3.вЕЮёгІгУгаБрХХДюНЈЃЌПьЫйРЉШнЃЌШнджЭЌВНЃЌЪ§ОнБИЗнЕШашЧѓЃЌетаЉЖМашвЊдЦЦНЬЈВњЦЗеыЖдОпЬхЕФвЕЮёГЁОАПЊЗЂНтОіЗНАИЁЃвђДЫдкКѓЦкЦНАВдЦЕФВњЦЗНЈЩшИќЖрЕФвдЪЕМЪвЕЮёашЧѓЮЊЕМЯђЃЌПЊЗЂСЫБъзМгІгУЯЕЭГБрХХДюНЈЃЌБОЕиХЬЗНАИЃЌдЦжїЛњИДжЦЃЌЮФМўЭЌВНЃЌАДашздЖЏПЊЭЈЗРЛ№ЧНЕШВњЦЗгыЙІФмЁЃ
ЮЊСЫБЃеЯгІгУПЩгУадЃЌЮвУЧЬсЙЉСЫШчЯТЪжЖЮ:
1.ЫЋAZВПЪ№
УПИіЧјгђ(Region)ОљЬсЙЉСЫСНИіПЩгУЧј(Available Zone)ЃЌПЩгУЧјжЎМфдкМЦЫуЭјТчДцДЂШ§ИіВуУцЮяРэИєРыЃЌвЊЧѓгІгУБиаыЗжЩЂВПЪ№дкСНИіПЩгУЧјЃЌЭЈЙ§ELBЗўЮёЗжЩЂСїСПЕНСНИіПЩгУЧјЕФдЦжїЛњЩЯЁЃМДЪЙвЛИіПЩгУЧјгЩгкЮяРэЙЪеЯШЋdownЃЌСэвЛИіПЩгУЧјвВПЩвде§ГЃЬсЙЉЗўЮёЁЃ
2.ЙиСЊадзщ
ЙЫУћЫМвхЃЌОЭЪЧНЋвЛИігІгУМЏШКжаЕФдЦжїЛњЖМЗХЕНЭЌвЛИіЙиСЊадзщФкДђЩЯБъЧЉЃЌдкдЦжїЛњЦєЖЏЪБКѓЬЈЛсЗжЩЂЭЌвЛИіЙиСЊадзщЕФжїЛњЕНВЛЭЌЕФЕзВуЮяРэЗўЮёЦїЩЯЃЌШЗБЃЕЅЬЈЮяРэЗўЮёЦїЕФгВМўЙЪеЯжЛЛсгАЯьЕНвЛИігІгУМЏШКжаЕФвЛЬЈжїЛњЪЕР§ЁЃгІгУЧАЖЫШчЙћгаЪЙгУELBЗўЮёЕФЛАЃЌгІгУПЩгУадВЛЛсЪмЕНгАЯьЃЌЖјжЛЛсМѕаЁгІгУЕФзюДѓЗўЮёШнСПЁЃ
3.ГЌШкКЯМмЙЙ
ЦНАВдЦЬсЙЉЪЙгУГЌШкКЯДцДЂЕФдЦжїЛњЁЃЪЙгУМЦЫуЕЅдЊЮяРэЛњЕФФкжУДѓШнСПДХХЬЬсЙЉШ§ИББОЗжВМЪНДцДЂЃЌЯћГ§СЫiopsМЏжадкФГвЛЬЈДцДЂЩшБИЛђДцДЂТЗОЖЩЯЕФЧщПіЁЃЭЌЪБПижЦвЛИіДцДЂМЏШКЩЯЕФдЦжїЛњЪ§СПЃЌБмУтгЩгкЕзВузЪдДЙЪеЯЕМжТЕФДѓУцЛ§ЙЪеЯЁЃ
ЙЄОпбаЗЂ
ArgusМрПи
МрПиЪЧЯЕЭГЙмРэЕФЛљЪЏЁЃШчЙћМрПиЪЇаЇЃЌдђЮвУЧЮоДгЕУжЊЯЕЭГзДПіШчКЮЃЌЩѕжСЪЧЗёдЫзЊе§ГЃЃЌЫљвдМрПиЯЕЭГашвЊОпБИМЋИпЕФПЩгУадЁЃдкдчЦкЃЌЮвУЧбЁдёЛљгкzabbixНјааЖўПЊЗЂЃЌЕЋЫцзХЦНАВдЦЙцФЃГЌЙ§ЭђЬЈжїЛњвдКѓЃЌzabbixДяЕНСЫадФмЦПОБЃЌЮоЗЈИњЩЯвЕЮёЗЂеЙЕФНХВНЁЃгкЪЧЃЌдкЕїбажЎКѓЃЌЮвУЧбЁдёСЫЖўДЮПЊЗЂopen-falcon
РДжиаТЙЙНЈећИіМрПиЯЕЭГЁЃЫќОпгаИпПЩгУЁЂвзРЉеЙЁЂвзЮЌЛЄЕФЬиадЃЌжЇГжЕкШ§ЗНИцОЏНгШыЁЃ
open-falconЕФИцОЏЖдНгЕНЦНАВздбаЕФЖЫЕНЖЫМрПиЦНЬЈЃЌВЂдкИцОЏеЙЯжЩЯзігХЛЏЁЂЗжЮігыЪеСВЃЌЗНБудЫЮЌШЫдБПьЫйХаЖЯвьГЃРДдДвдМАдвђЁЃЭЌЪБЭЈЙ§open-falconЕФapiЃЌНгШыELKШежОЗжЮігыздбаЕФVMWare
myclientМрПиИцОЏЃЌПЩвдДгШежОгыМЏШКНЧЖШЪЕЪЉМрПиЁЃ
ФПЧАЮвУЧвВдкГЂЪджЧФмЕФЪ§ОнЗжЮігыздЖЏЛжИДЕШВпТдЃЌГігкНїЩїПМТЧЮвУЧЖдздЖЏЛжИДЛЙЪЧБШНЯБЃЪиЃЌМгШыСЫШЫЙЄДЅЗЂЕФВНжшЁЃ
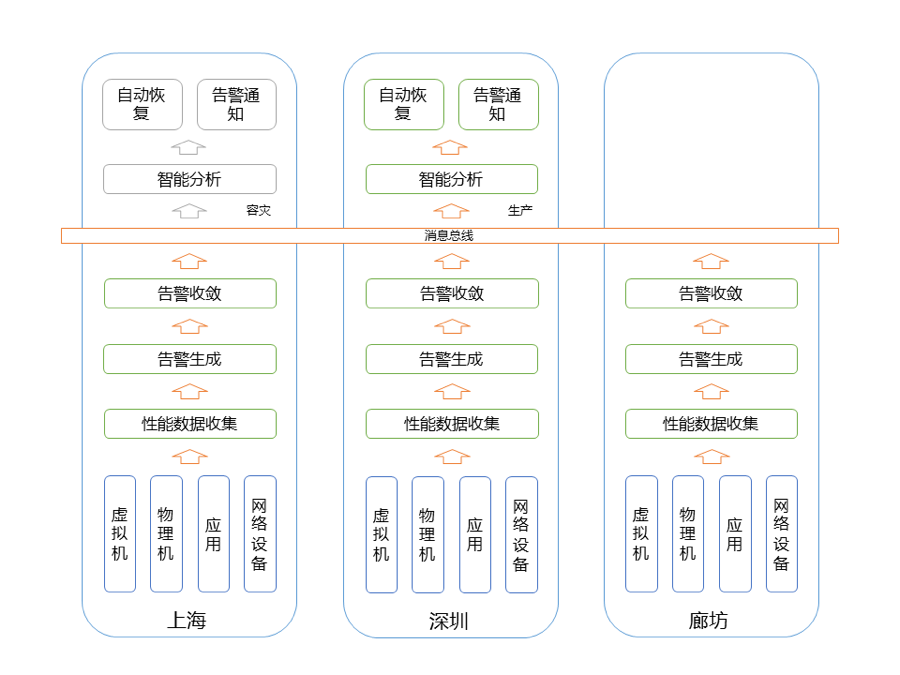
ЭМ3 ArgusЦНЬЈМмЙЙ
AlphaOPS
ЦНАВдЦИјздМКЕФдЫЮЌздЖЏЛЏЦНЬЈКЭдЫЮЌЬхЯЕЦ№СЫИіУћзжНаAlphaOpsЃЌдЂвтЪЧЯЃЭћФмЙЛДяЕНжЧФмдЫЮЌЕФФПБъЁЃ
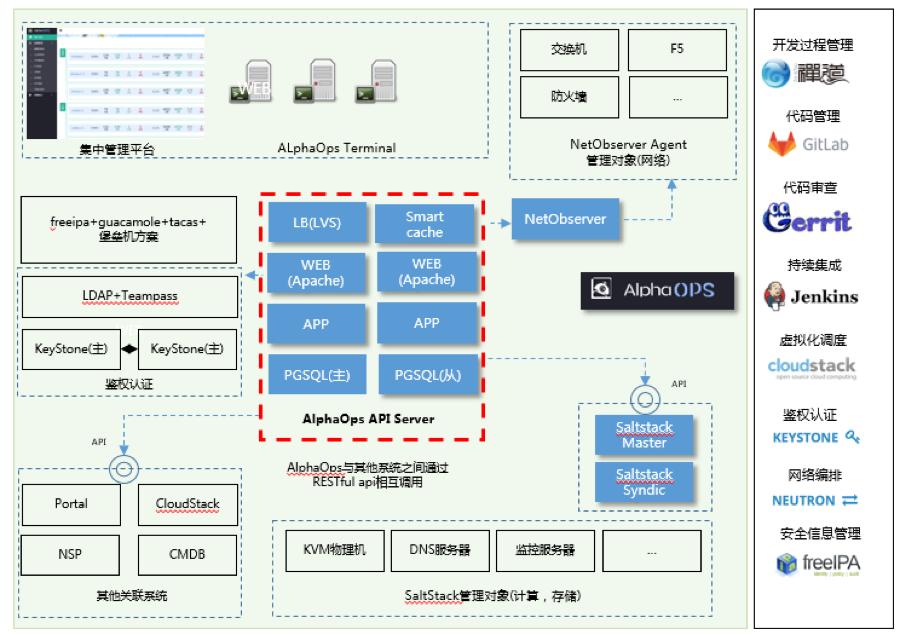
ЭМ4 AlphaOpsЦНЬЈМмЙЙ
ШчЭМ4ЃЌдкЖЈвхAlphaOpsдЫЮЌздЖЏЛЏЕФЪБКђЃЌЮвУЧЖЈвхСЫШ§жжAlphaOpsЕФПЊЗЂФЃЪНЃКМЏжаЙмРэЦНЬЈФЃЪНЃЌНХБОздЖЏЛЏФЃЪНЃЌВњЦЗздДјдЫЮЌФЃЪНЁЃетШ§жжздЖЏЛЏФЃЪНвВПЩвдкЙЪЭAlphaOpsПЊЗЂжаЕФЙЄзїФкШнЁЃ
МЏжаЙмРэЦНЬЈФЃЪН
AlphaOpsгазЈжАЕФдЫЮЌПЊЗЂГЩдБЃЌЫћУЧжївЊИКд№ЪсРэдЦЦНЬЈИїВузщМўжЎМфЕФЙиЯЕЃЌЖдНгвбгаЕФКЫаФгІгУCMDBгызЪдДЙмРэCMDBЃЌеыЖдИпЦЕЛђЧПСвашЧѓЕФдЫЮЌГЁОАПЊЗЂМЏжаЙмРэЦНЬЈЃЌеЙЯжзЪдДжЎМфЕФЙиСЊЙиЯЕгыЦНЬЈШнСПЕФЧїЪЦЃЌХњСПеЙЪОЛђВйзїКЃСПзЪдДЃЌвдМАЪЕЯждЦФкЙмРэЦНЬЈЛљДЁзЪдДЕФздЖЏНЛИЖФмСІЁЃ
AlphaOpsЦНЬЈЛљгкkeystoneПђМмЪЕЯжСЫОЋШЗЕНЪЕУћеЫКХЕФМјШЈЛњжЦЃЌЖддЫЮЌШЫдБзюаЁЪкШЈгыСєДцЫљгаВйзїШежОЁЃдйХфКЯЛљгкFreeIPAЃЌTacacs+ЃЌguacamoleПЊЗЂЕФжЧФмжеЖЫЕЧТМЦНЬЈЃЌдЫЮЌШЫдБПЩвддквЛДЮAlphaOpsЕЧТНбщжЄЩэЗнКѓЃЌУтУмЕЧТНЪкШЈИјздМКЕФБЄРнЛњгыжеЖЫЪЕЪЉВйзїЃЌМѕЩйСЫЛЈЗбдкЩшБИжЎМфЬјзЊЩЯЕФЙЄзїСПЃЌвВМѕЩйСЫЬиШЈеЫЛЇУмТыаЙТЉЕФЗчЯеЁЃЩшБИЕФadminеЫКХИљОнашЧѓЪкШЈЕНИіШЫеЫКХЃЌШ§ИідТздЖЏИќИФвЛДЮЃЌздЖЏНјШыКѓЬЈteampassЪ§ОнПтЃЌдЫЮЌШЫдБВЛашвЊжЊЕРУмТыМДПЩЙмРэЯргІЛљДЁзЪдДЁЃ
НХБОздЖЏЛЏФЃЪН
МЏжаЙмРэЦНЬЈгавЛЖЈЕФЙцЛЎКЭЩшМЦЃЌФмЙЛЪЕЯжНЯЭъећЕФЙІФмЃЌЕЋЮоЗЈТњзудЫЮЌГЁОАЕФЖрбљЛЏгыИіадЛЏашЧѓЃЌвђДЫAlphaOpsЦНЬЈДђЭЈСЫИїИіМЦЫуЃЌДцДЂЃЌЭјТчВњЦЗжЎМфЕФСЌНгКѓЃЌМШЬсЙЉСЫМЏжаЪНдЫЮЌЙмРэЦНЬЈЙЉдЫЮЌШЫдБдкЩЯУцЪЕЪЉвЛМќЪНВйзїЃЌгжЬсЙЉСЫЗНБуЕФweb
serviceНгПкЙЉдЫЮЌШЫдБФмЙЛвРОнИїжжИіадЛђЭЛЗЂдЫЮЌГЁОАдкAlphaOpsЕФЙЄОпTerminalЩЯЗНБуЕиБраДдЫЮЌНХБОЃЌЪЕЯжЖдКЃСПЙцФЃЖдЯѓЕФИпаЇЙмРэЁЃ
ЮЊСЫШЗБЃдЫЮЌНХБОЕФвЛжТадгыПЩЮЌЛЄадЃЌЮвУЧвВвЊЧѓЫљгаЕФНХБОЖМвЊзёбПЊЗЂЙ§ГЬЙцЗЖЃЌЫљгаАцБОаоИФБиаыгЩашЧѓв§ЗЂЃЌАцБОШыПтЙмРэЃЌДњТыЦРЩѓЃЌВЂЧвашвЊзёЪивЛаЉЙВЭЈЕФШежОЃЌШЈЯоЕШЙцЗЖвЊЧѓЁЃ
СэЭтЃЌгЩгкЦНАВдЦЕФдЫЮЌШЫдБЖМОпгаПЊЗЂФмСІЃЌЮвУЧвВвЊЧѓдЫЮЌШЫдБЛ§МЋВЮгыЕНВњЦЗЕФдчЦкПЊЗЂНЈЩшгыМмЙЙЦРЩѓжаЃЌдкВњЦЗПЊЗЂНзЖЮМДв§ШыдЫЮЌВЮгыЃЌШЗБЃВњЦЗЕФПЩППадгыПЩдЫЮЌадЁЃ
ВњЦЗздДјдЫЮЌФЃЪН
ЛљгкПЊдДШэМўзіЖўДЮПЊЗЂЪЕЯжВњЦЗЛЏЪЧКмЖрдЦЦНЬЈНЈЩшЕФбЁдёЃЌЦНАВдЦвВВЛР§ЭтЁЃЮЊСЫШЗБЃетаЉВњЦЗЕФПЩППадгыПЩдЫЮЌадЃЌЮвУЧЖдВњЦЗПЊЗЂЬсГіСЫ3ЬѕвЊЧѓ:
1.ВЛЕЭгк99.95%ЕФПЩгУадЁЃ
2.дкЩшМЦКЭПЊЗЂЙ§ГЬжаПМТЧПЩдЫЮЌадЃЌЬсЙЉRESTfulЕФCRUDвдМАЦєЭЃЕШдЫЮЌAPIНгПкЁЃ
3.дкВњЦЗЗЂЩњвьГЃЪБЕФПьЫйЛжИДШ§АхИЋ(жиЦє/ЧаЛЛ/ЛиЙі)ашвЊбщжЄгааЇЃЌЬсЙЉPOCЛЗОГКЭВтЪдЛЗОГЕФбщжЄНсЙћЁЃ
ЛљгкЩЯЪівЊЧѓПЊЗЂГіРДЕФВњЦЗЬьШЛОпгаПЩдЫЮЌадЃЌКѓајAlphaOpsжЛашвЊЪсРэЛЗОГКѓЃЌЕїгУВњЦЗздЩэЕФAPIМДПЊМДгУЃЌВЂЧвзщжЏЕНИїИідЫЮЌГЁОАжаЁЃ
CMDB
ФПЧАЦНАВдЦЕФCMDBжївЊЗжЮЊСНИіВПЗжЃЌЯђгІгУЗНЯђЕФКЫаФХфжУЙмРэгыЯђЛљДЁзЪдДЗНЯђЕФЛљДЁзЪдДХфжУЙмРэЁЃ
ЦНАВдЦЕФУХЛЇЭЈЙ§зтЛЇгызЪдДзщЕФСНМЖЙмРэЪЕЯжСЫИїИіBUвдМАИїИігІгУЯЕЭГЕНдЦЩЯНЛИЖЮяЕФгГЩфЙмРэЃЌдйМгЩЯЦНАВПЦММдгаЕФМЏШКзЪдДЙмРэЯЕЭГЃЌAlphaOpsЖдетаЉаХЯЂзіСЫОлКЯЃЌЪЕЯжСЫДгЩЯжЎЯТгыДгЯТжСЩЯЕФгІгУгыЕзВузЪдДЕФЙиСЊЙиЯЕЙмРэЁЃдЫЮЌШЫдБФмЙЛПьЫйЕФдкгІгУаХЯЂЕНЫљгаЙиСЊЕФЕзВузЪдДжЎМфНјааЯрЛЅВщбЏЁЃ
ЖдгкЛљДЁзЪдДЕФХфжУЙмРэЃЌжївЊЙмРэСНРраХЯЂ:
1.ЛљДЁзЪдДЕФЪєадЙмРэЁЃШчЮяРэЛњЃЌНЛЛЛЛњЕШЕФХфжУЃЌЮяРэЮЛжУЕШаХЯЂЁЃетВПЗжаХЯЂДѓВПЗжвВгызЪВњЙмРэЯрЙиЃЌдкМИКѕЫљгаЕФCMDBжаЖМЛсЩцМАЕНЁЃ
2.ЛљДЁзЪдДжЎМфЕФЙиСЊЙиЯЕЙмРэЁЃетВПЗжаХЯЂгЩгкДэзлИДдгЃЌаХЯЂСПДѓЃЌМИКѕВЛПЩФмЪжЙЄТМШыЁЃФПЧАЦНАВдЦВЩгУЕФЪЧЪЙгУagentздЖЏВЩМЏЕФЗНЪНРДЙмРэКЭТМШыЯЕЭГЁЃ
СэЭтЃЌеыЖдИїИіЩшБИгыжїЛњздЩэВЮЪ§ЩшжУЕФЖЏЬЌВЩМЏгыЛљЯпЙмРэвВдкЦНАВдЦCMDBЕФПЊЗЂМЦЛЎжаЁЃ
NSP
NSPШЋГЦЪЧЭјТчЗўЮёЦНЬЈЃЈNetwork Service PlatformЃЉЃЌзїЮЊЦНАВдЦЭјТчЕФКЫаФзщМўЃЌЪЕЯжвьЙЙГЇЩЬЩшБИЕФЭГвЛЙмРэЃЌЭјТчЙІФмащФтЛЏЃЌГщЯѓГіЭЈгУвзЖЎЕФЭјТчЙІФмФЃаЭЃЌЮЊдЦУХЛЇКЭЦфЫћЯЕЭГЬсЙЉЭјТчЗўЮёЁЃЭЈЙ§NSPздЖЏЛЏЕФЖдНгЦНАВФкВПЕФЩѓХњЯЕЭГЃЌЭГвЛЕФХфжУЩшМЦКЭМьВщЃЌДяЕНЬсИпЭјТчХфжУаЇТЪКЭМѕЩйШЫЙЄДэЮѓЕФЪТМўЁЃNSPЬсЙЉЕФЗўЮёЙщФЩЮЊвдЯТЫФжжЃК
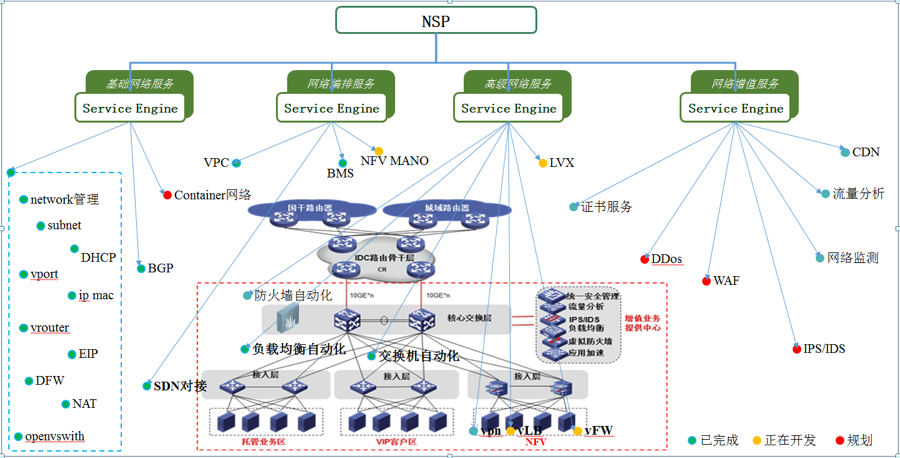
ЭМ5 NSPЙІФмМмЙЙ
1.ЛљДЁЭјТчздЖЏЛЏХфжУЃКNSPЬсЙЉAPIНгПкЃЌЪЕЯжащФтЭјТчКЭЮяРэЭјТчЕФздЖЏЛЏХфжУЃЌЮЊзтЛЇЬсЙЉL2/L3ВуЭјТчЕЏадРЉеЙФмСІЃЛ
2.ЭјТчБрХХЗўЮёЃКзтЛЇVPCЕФЭјТчБрХХЃЌNFVЩшБИЕФБрХХЙмРэЃЌSDNФмСІМЏГЩЕШЁЃ
3.ИпМЖЭјТчЗўЮёЙмРэЃКЬсЙЉЗРЛ№ЧНЁЂИКдиОљКтЁЂVPNЕШИпМЖЭјТчЗўЮёЕФХфжУКЭЙмРэЃЛ
4.ЭјТчдіжЕЗўЮёЃКНгШыЕкШ§ЗНЭјТчЗўЮёЃЌНЋЦфЫћЙЋЫОЬсЙЉЕФдіжЕЭјТчЗўЮёНгШыдЦЦНЬЈЃЌБШШчЭјТчЬНВтЗўЮёЁЂCDNЁЂDDoSЗўЮёЕШЁЃ
VMWare myclient
ЦНАВдЦЕФДЋЭГН№ШкЗжЧјВПЗжЕзВуЪЙгУСЫVMWareзїЮЊащФтЛЏММЪѕЃЌЦНАВдЦЭХЖгздбаСЫвЛЬзmyclientНгПкЃЌЪЕЯжСЫШ§ИіЗНУцЕФФмСІЃК
1.ДгhypervisorВуВЩМЏМрПиаХЯЂЃЌФмЙЛДгШЋОжАбПиащФтЛЏМЏШКЕФНЁПЕзДПігыИцОЏЁЃ
2.зїЮЊcloudstackЕФВЙГфЃЌЪЕЯжСЫжБНгЙмРэVMWareЕФФмСІЃЌдквЛаЉгІМБдЄАИЁЂДѓЙцФЃЧЈвЦЁЂвдМАВЮЪ§ЩшжУЕФГЁОАжаФмЙЛИпаЇЭъГЩздЖЏЛЏВйзїЁЃ
3.ЦНАВМЏЭХЕФДЋЭГЛЗНкЛЙгаКмЖрДцСПЕФЩњВњащФтЛњЁЃЭЈЙ§myclientгыESXiЖдНгЃЌНЋетаЉащФтЛњНгШыЕНЦНАВдЦУХЛЇЃЌдйЪсРэгІгУЫљгаепШЈЯоКѓЃЌФмЙЛДяЕНгы80%гыдЦжїЛњЯрЭЌЕФаЇЙћЁЃ
Lesson Learn/зюМбЪЕМљ
дкЦНАВдЦЕФНЈЩшгыЩњВњЪЙгУЙ§ГЬжаЃЌЮвУЧОРњСЫжїЛњДгСуЕНАйЃЌДгАйЕНЧЇЃЌДгЧЇЕНЭђЕФЙ§ГЬЃЌЪеЛёзюБІЙѓЕФЪЧМмЙЙжЮРэЃЌвЕЮёШыдЦКЭКЃСПдЫЮЌЕФОбщЃЌетжжВЛЖЯЬсИпЕФЙ§ГЬЪЧЦНАВдЦФмЙЛдкЙ§ШЅ2ФъжабИЫйГЩГЄЕФЙиМќЁЃЦфжаеыЖдКЃСПвЕЮёжажївЊгаЯТУцШ§ЬѕаФЕУЁЃ
ЙВЯэзЪдДСЃЖШ
гЩгкдЦМЦЫузюдчЪЧДгащФтЛЏЦ№ВНЃЌЖјащФтЛЏЕФвЛИіживЊБъжОЪЧЪЙгУЕзВуЙВЯэДцДЂЪЕЯжУыЧЈвЦФмСІЃЌвђДЫдкЧАЦкЦНАВдЦвВЪЧВЩгУСЫЙВЯэДцДЂзіЮЊЕзВуДцДЂЁЃдкЙ§ШЅ2ФъЕФЪЙгУжаЗЂЯжЙВЯэДцДЂгаШчЯТСНИіЮЪЬтЃК
1.ЖЈЪБШЮЮёЙВеё
дЦжїЛњЖМЪЧгЩБъзМЛЏЕФOSФЃАхЩњГЩЃЌетаЉФЃАхжаЭЈГЃЖМФкжУСЫвЛаЉЖЈЪБШЮЮёЁЃЕБдЦжїЛњЪ§СПЩЯСЫ5000жЎКѓЃЌУПвЛДЮМИЧЇМИАйИіЖЈЪБШЮЮёЕФЭЌЪБЕїгУЖдгкЕзВуДцДЂРДЫЕЖМЛсЪЧвЛДЮiopsЗчБЉЃЌБиаыЭЈЙ§Ждcron
jobЛђепБЛЕїгУНХБОЕФrandomЦєЖЏДІРэРДЗжЩЂioбЙСІЕНВЛЭЌЕФЪБМфЕуЁЃ
2.ЙВЯэДцДЂвьГЃЪБЕФгАЯьУц
ЕБЭЌвЛИіЙВЯэДцДЂвьГЃЪБЃЌЛљБОЩЯЛсгАЯьЕНЦфЩЯЫљгаЕФЮяРэЛњгыдЦжїЛњЁЃСэвЛЗНУцЃЌОЁЙмЖддЦжїЛњЕФioгаiopsЯоЫйЃЌгЩгкН№ШкаавЕЬиадЃЌДѓВПЗжвЕЮёЗЂЩњдкЙЄзїЪБМфФкБШНЯМЏжаЕФЪБМфЖЮФкЃЌЕБвЛЬзДцДЂЩЯЕФдЦжїЛњЙ§ЖрЃЌЧввЕЮёЗБУІЪБЦкЃЌвЛЦЌУцЛ§ЕФжїЛњЖМДяЕНiopsЩЯЯоЪБЃЌЖдгкЙВЯэДцДЂЕФадФмРДЫЕЪЧвЛИіКмДѓЕФЬєеНЁЃ
вђДЫЃЌДгЗжЩЂЗчЯеЕФНЧЖШашвЊПижЦвЛИіПЩгУЧјФкЕЅИіДцДЂЩшБИЩЯЕФдЦжїЛњИіЪ§ЁЃ
КкЬьЖьЫМЮЌ
СПБфв§Ц№жЪБфЪЧЫљгаЪТЮяЕФЙВЭЈЙцТЩЁЃЕБITЛЗОГЕНДявЛИіЙцФЃКѓЃЌЫљгаПДЦ№РДЪЧЕЭИХТЪЕФЪТМўЖМвЛЖЈЛсЯШКѓЗЂЩњЃЌПЯЖЈЛсЗЂЩњЁЃвђДЫВЛФмвђЮЊвЛИівьГЃПДЦ№РДЗЂЩњЕФИХТЪКмЕЭЛђИаОѕВЛЛсЗЂЩњОЭКіЪгЫќУЧЁЃ
дкОРњСЫ1ЃЌ2ДЮКкЬьЖьИХТЪМЖБ№ЕФЙЪеЯжЎКѓЃЌЦНАВдЦМгЧПСЫеыЖдгІМБдЄАИНЈЩшЕФШЫСІЭЖШыЃЌВЂЧвШЗЖЈСЫЯТУцЕФбщжЄгІМБдЄАИЕФддђЃК
1.ЫљгаЕФЙиСЊзщМўЖМгаПЩФмГіЮЪЬтЃЌВЂЧвгааЉЙиСЊзщМўгаПЩФмЖЬЪБМфФкЛжИДВЛСЫЃЌДЫЪБЛжИДдЄАИЪЧЗёгааЇЁЃ
2.ЫљгаЩцМАздЖЏЛЏДІРэЕФДњТыТпМЖМгаПЩФмЛсГіЮЪЬтЃЌГіЮЪЬтКѓШЫЙЄНщШыЪЧЗёгааЇЁЃ
3.еыЖдИїжжзщМўЃЌЖМашвЊгагааЇЕФЙиСЊЙиЯЕЙмРэЕФCMDBЁЃЫљгаЕФзщМўЖМБиаыгажиЦє/ЧаЛЛдЄАИЃЌЧвБиаывЊЖЈЦкбщжЄЦфгааЇадЁЃ
ИїЯюЗўЮёжИБъЕФШЋОжАбЮе
дЦЦНЬЈБОЩэЕФПЩгУадгыадФмжИБъВЂВЛЪЧвЛжБВЛБфЕФЃЌЫцзХЕзВузЪдДШнСПЕФБфЛЏгыЙцФЃЕФдіДѓЃЌПЩгУадКЭадФмКмгаПЩФмдкФГвЛЬьЛсЗЂЩњЭЛШЛЕФБфЛЏЃЌдкетжЎЧАЖМЛсгавЛаЉеїезВњЩњЁЃ
ФПЧАЮвУЧЭЈЙ§УПШеЕФздЖЏЛЏбВМьЃЌE2EВЛМфЖЯВтЪдгыдкЭјТч/ДцДЂЖЫВПЪ№МрПиРДБЃеЯдЦЦНЬЈећЬхЕФНЛИЖФмСІЃЌПЩгУадгыадФмЃК
1.УПШездЖЏЛЏбВМь
AlphaOpsЦНЬЈздЖЏЗжЮіДгИїИіВуУцЕФВњЦЗЫбМЏЕНЕФаХЯЂЃЌОлКЯКѓеЙЯждкбВМьвГУцЩЯЃЌУПЬьдчАрЭЌЪТЛсШЗШЯбВМьвГУцВЂЧвЗЂГіЙигкШнСПЃЌзЪдДЪЙгУзДПіЕФбВМьБЈИцЁЃ
2.E2EВЛМфЖЯВтЪд
дБОВтЪдЪЧЦЋжигкНјШые§ЪНЩњВњНзЖЮЧАЕФЙІФмадбщжЄгыВЂЗЂЖШбщжЄЃЌЪєгквЛДЮадЙЄзїЕФИХФюЁЃЦНАВдЦЭЈЙ§Robot
Framework+JenkinsЕШГжајМЏГЩгыздЖЏЛЏВтЪдЙЄОпЃЌБраДДгдЦжїЛњЩъЧыЕНИКдиОљКтЩъЧыЕШвЛЯЕСаВтЪдгУР§ЃЌУПЬьВЛМфЖЯЕФЕФдкЩњВњПЩгУЧјЪЕЪЉЖЫЕНЖЫЕФздЖЏЛЏВтЪдЃЌетбљПЩвдЪЕЯжДггУЛЇЕФНЧЖШжБНиСЫЕБЗЂЯжЦНЬЈжаЕФЧБдкЮЪЬтЁЃ
3.ДгЭјТчгыДцДЂОлКЯТЗОЖЕуЪЕЪЉМрПи
ЦНАВдЦдкНгШыНЛЛЛЛњЩЯВПЪ№СЫЖдДэЮѓШежОЕФЗжЮіИцОЏЃЌдкДцДЂЕФПижЦЦїТЗОЖЩЯНгШыСЫCPUЪЙгУТЪИцОЏЃЌДгЦНЬЈЩЯЯТВуЕФШыПкЪЕЯжСЫЖдШЋОжСїСПгыioжИБъЕФМрПиЃЌЕБЗЂЩњСїСПГЌЙ§ЗЇжЕИцОЏКѓЭЈЙ§AlphaOpsЕФадФмЗжЮіЙЄОпПЩвдбИЫйЖЈЮЛЕНЮЪЬтжїЛњЃЌДгЖјВЩШЁБивЊДыЪЉБЃеЯЦНЬЈЮШЖЈадЁЃ
|









