| ����
����ǰ��άӭ��ҵ���ϵ�һ���ںϣ��Ӷ����ƺ�˵�IT�����������ϡ���Ϊϵͳ���������ϵ���������л���Ҳ�в�𣬵���ϵͳǨ�ƺ���ʹ�ã�����ڲ��ı䵱ǰ����ģʽ������£���Ҫ�ؽ���������άƽ̨��ϵ�����и��죬�����ɴ˶���������ҵ��չ������չ�����Ľ������ȥ�˽�ƽ̨�ӹ�ȥ�����ڣ��µ���Ʒ�������ںϵ�������ϵ��?������ƺ��ƽ̨�ִ�����ʲô���ı仯?�ڽ���Ĺ����У��Ŷ��ֻ����ʲô�����ĵú�����?
��ǰ��״
�ں�ʱ�ڱ����˷�������ϵͳ��ҵ����ȣ�DB������ִ��ƽ̨���������ģ���ʹ����������⣺
1. ���л�����ͬ������ϵͳ��Ҫ���رౣ֤����ƽ̨���ȶ�����
2. ��������ϵͳ��ǿ����CMDB���豸��ҵ��Ĺ�ϵ���Ӷ��ܿط�������
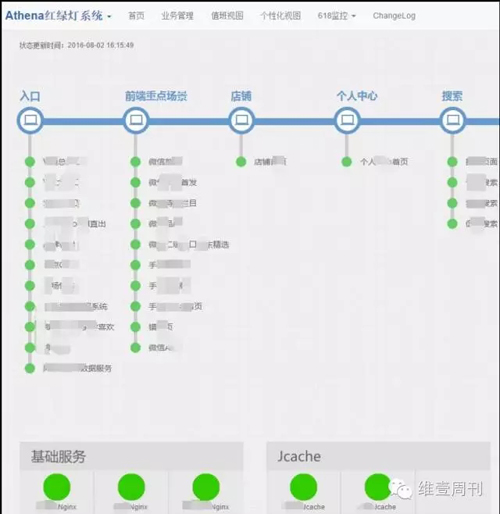
���Ϊ�˱�֤ҵ���ܹ�������������Ҫ�ؽ��ؼ�·�������������Ŭ����Ŀǰ��ϵ��ɴ��¿��������ʾ���������ں�֮ǰ���̵�ϵͳ���������´��ƽ̨��
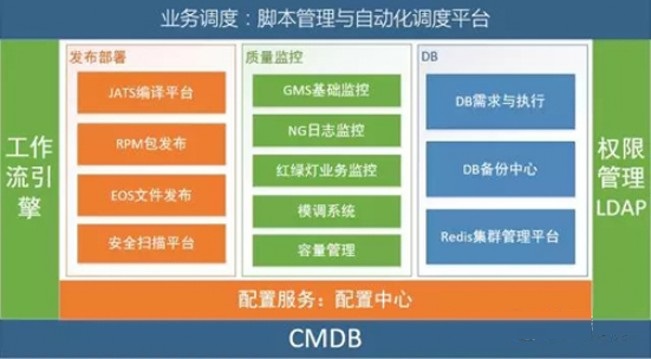
1. CMDB
��������������˾���ƣ�ͨ���ײ�CMDB�����豸��ҵ���豸���˵Ĺ�ϵ���豸�������ڡ�����״̬�ļ�¼����������Դ����ϵͳ�Ľ�ɫ�ṩ��Ϣ����������ϵͳ���á�����CMDB���ݵ�ά��������ͨ������ϵͳ������������֤����ȷ�ԣ�������RPM�������������� 
��Ϊ�ں�ǰϵͳ������CMDBΪҵ����CMDB����������ؽ�ʱҲ��ҵ��CMDBΪĿ�ꡣ
2. ��������
��������Ϊ������������Ҫϵͳ����������·�ɺ�DB·����Ϣ�������ؾ��⡢ҵ�����֡��Լ�����ҵ����Ļ������á�ҵ�����á�DB·�ɷ������Զ��л���������Ϣ�İ汾�������·����Լ��豸��ɫ�Ĺ�����ͨ������agent����������ĵ�Ŀ������ڴ���·������¼ܹ�ͼ����ͼ��ʾ��
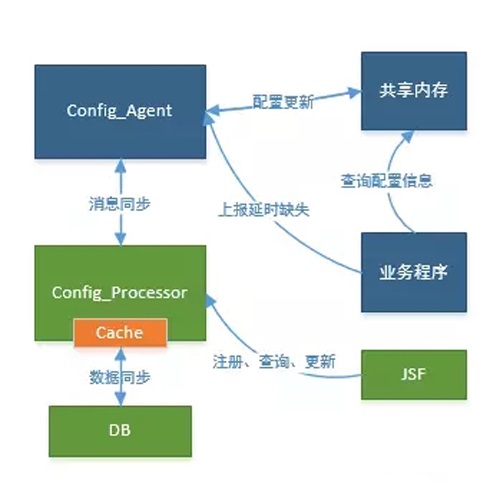
Configprocessor���ö��߳�ģ�ͣ����д���configagent��jsf�������û�ͨ���Ż������������IJ��ύ��DB����server��ȡ��agent��serer���ֳ����ӣ��ᶨ�ڷ��ͱ��ع����ڴ��ʱ�����server��server�ж�ʱ����Ƿ��ʱ����ʱ�����µ������ļ����ݵ�agent��agent��������Ϣ�����������ڴ沢ˢ��ʱ���������serverҲ��������������Ϣ�·���agent�������ڴ���ά������������֤���²���ͻ�������������Ļ�֧�ְ��������ܣ������ý��лҶȡ�
3. ����ϵͳ
������豸������ִ�к��ļ��·�������ϵͳ�κε��ļ����������·�������������ͨ������ϵͳȥ�������������ĺô����ǿ��٣�Ȩ�ɿ��ҷ�����־ͳһ������DB�����Զ�ִ��ƽ̨����������������ƽ̨������Ͻ���DBA������������Ϻ�����ƽ̨��SQL���Ϊ�ű���ͨ������ƽ̨���ݵ�Ŀ�Ķ�ִ�У������ؽ����
4. Ӧ�ó�������
Ӧ�ò������Dz��õ���RPM�ķ�����ĿǰҲ��ҵ�����еIJ��ÿ�Դ��������������Ҫ�Ŀ��ǵ��ǣ�
1. RPM��Ϊ��Դ��ͨ�õķ����Ѿ��dz����죬��������������spec�ļ��а�װǰ����װ��ж�غ�ȸ��εĶ������ж���
2. ͨ����spec�ļ��б�ע��������ĸ�����Ժܺõعܿذ�����Ȩ��
3. ͨ����spec�ж���Requires�����Է���Ĺ���������ϵ��ƽ̨����ά�����ӵİ�������
Ŀǰ�з�ͨ��JATS��C++�����б��룬Ȼ��ͨ��RPM������ɹ��Ķ������ļ�����RPM���Ĵ����ͨ�����������豸��ɫ(dev��gamma��idc)
����Ա(���������ԣ���ά)��ɫ���ж��岢����Ӧ�������ܿط������̡�EOS������Ӫ��Ա��ҳ��Ƭ��CDN�ķ����ͻع���ͨ���������������豸��ɫ���ٽ�����Ӧҳ��Ƭ�ļ����·�����ȫɨ�����CGI��������ɨ�裬��ʱ��������©��ɨ�裬��֤ҵ��ȫ��
5. �������ƽ̨
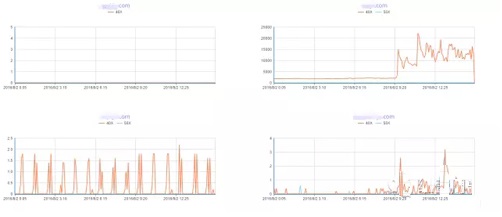
GMS�������ƽ̨����openfalcon��Դ�ģ���ʵ�����docker���л����������Զ���ļ�ظ澯����־���Ŀǰ����ƽ̨��ͨ������־�IJɼ����˺�ͳ�ƣ�����GMS�������ƽ̨����nginx��־���м�أ����̵�ϵͳ���Ϊҵ��ά�ȵļ�أ�ͨ�����ŵĿ������ϱ�ϸ����ҵ��Ľ���״̬������ģ��ϵͳ�����������ĵ�ҵ�����ù�ϵ��ɵ������������͵��û��ڵĿ�����ͳ�ơ���������ͨ��GMS������ص����ݣ������豸��ҵ��ά�ȵĸ����ʼ���ߵ��ع�����
6. DB����ƽ̨
���ڲ�DB����ҪΪmysql��redis������Χ������������DB�����Զ���ִ�У��������ĺ�����redis��Ⱥ��ʵ��������
���������Щƽ̨�Ĵ�����������´��²�����
�ںϷ���
ҵ�������Ժ�ҵ����Ҫ���ٵ�����Ч��Ϊ�ȣ�ͨ����ϵͳ����������������ȷ���˴��¶������������ķ�����������ײ��CMDB��ʼ���ϣ��������ϵͳǿ�����Ĺؼ�·������ȥ����ȱ�ٲ��֡���һ�����Ǿ����ؽ�һ��С�͵�CMDB�����ڽ�����������ϵͳ�Ĺؼ�����;�ڶ���Ϊȷ������ϵͳ������ת���Ա�֤ҵ����ٵ�������;�������������������ϵ�����������������������ܣ�
��һ�Σ��ؽ�С��CMDB
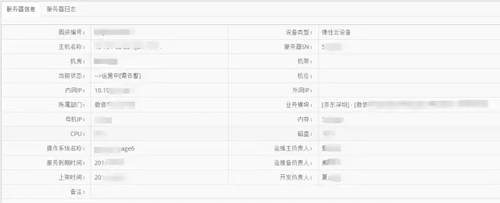
����CMDBϵͳ����;��ͨ����Ϊ���㣬���������ʩ����Դ����ϵͳ������ҵ�����Դ����ϵͳ�����ھ�������ҵ������Ҫƫ��ҵ��㣬���ϵͳ������Ҫƫ������ҵ������ʩ�����ɼ��Ž��й�����Ϊ�˿���ƥ������ϵͳʵ�ֺ�������CMDB��ҵ���ʾ����֮ǰ��ʽ������ģ�������й�������������ҵ������ģ����б�ʾ����ͼ��ʾ��

��Ϊ����ҵ�����Դ���������ݱ䶯Ƶ������ά���Էdz���Ҫ����ҵ����û�л����Զ����֣����˻�ȡȨ������£���Ҫͨ����Դ��������֤����ȷ��ͨ�������ṩAPI������Դ������ά��������ά���豸״̬���豸�������������ڼ��ϵͳ���ж�������;ά��ģ�黷����������RPM��ϵͳ�İ������ж�������IDC���������ڷ����Ĺܿأ��Ӷ�����֤��CMDB�ݵ�ȷ�ԡ�
ĿǰCMDB����23�����ԣ������豸����(IP��������Ϣ������)���豸��ҵ���ϵ(ҵ��ģ�飬������Ⱥ)���豸���˵Ĺ�ϵ(��ά�����ˣ������з�)���豸����״̬(ά������Ӫ)����������(��ת��¼)�ȣ�������ʾ�˵�ǰ�豸�Ļ���Ȼ���ﻹ��Ҫ��RPM���������������Ľ����������������������������Ϣ�ȡ�
�ڶ��Σ�ȷ������ϵͳ������ת
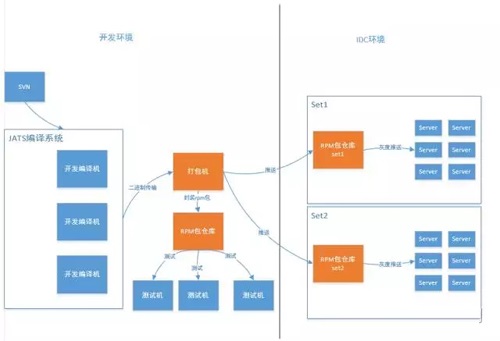
����ϵͳ��ҪΪ�������ĺͷ�������ϵͳ��ƪ����������ֻ����RPMϵͳ��Ŀǰϵͳ��ɴ��������Ϣ�Ǽǣ��汾������������ع���Ȩ���Ƶȶ�����Ŀǰ������1200���������ʱ����֧�ַ���7w�Σ�
�ܺõ�������ճ��������ͽ������ݵ����ܹ����£�
dashboard���£�
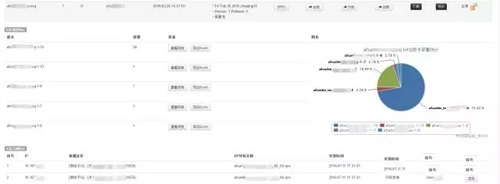
Ŀǰ����Ҳ�ڿ��Ƕ��ִ�RPMϵͳ�ĸ��죬����Ѿ����ģӦ��docker����ν���������docker��ֽ�ϣ�����docker���ٽ�������������Ҫ�Ż��ĵط���
�����Σ������Ż�������
ҵ��ϵͳ���ú����ǿ�ʼ�������䣬���ȿ���������������Ҫ�ǽ���һ�����¶��ϵ����廯��أ���ά��Ҫ�����������Ĵ�������ṩAPI��
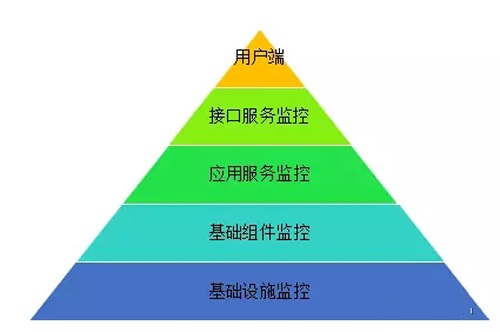
�κμ�أ�����Ϊ�ȣ�������ػ�۸���������Դ�����������ϣ���ҪΪCMDB���ɼ�agent���������ĵ��ù�ϵ������UMP�����ϱ�������߽��й�����
������ʩ��ͻ���������ϵͳ
���ֿ���֮�������С��Դ��openfalcon�������˸��졣��������£�
1. agentͬʱ����ʵ�����docker
2. ��ͨCMDB���½�API����δ������ϵͳ�������ݹ�������ͨ���еĸ澯����(�ʼ������š���)
3. ��ϵͳ�������Ҫ����Ӧ��/ģ��ļ��
4. ��չ���������صĹ��ܣ���nginx��mysql��redis����������������ر��ռ�
5. ������������ʹ��
ϵͳ�����ڼ����ٵĵ�һ��������Ǿ�����ʱ���ڴ��ģ����docker������ڴ�ͳ�IJɼ�agent�������ã�Ϊ�˱��ⲻͬ�����豸����Ϊ��ͬϵͳ���������agent�˽����˸��죬��ȡ��ͬ�㱨��ʽ��ͬ�ɼ���ʽ�����ڶ�ĸ��û��Ȩ���·ţ����Ͼ���ƽ̨������ʵ�����ȡ��ͳ�ɼ���docker����api���ݲ����ϣ��Զ�����������ͳһ���Ӷ�������ʽ��ʵ����ͳһ��
Ŀǰ����ϱ��豸������������CPU���ڴ棬�����ʣ��ش��ʣ��ļ��ڵ㣬coredump�ȣ�����Է��������������ϱ����ݣ�����nginx��nginx.conn.active��
nginx.conn.reading�ȡ�
Ϊ�˱�֤�澯��Ч�ԣ�����ͨ����ͬӦ�õĸ��Ի���ز��ԣ�ά��ÿ�ջ����澯����20-50֮�䣬�Ӷ���֤��ά�Ը澯�����жȡ���ͼΪdashboard��
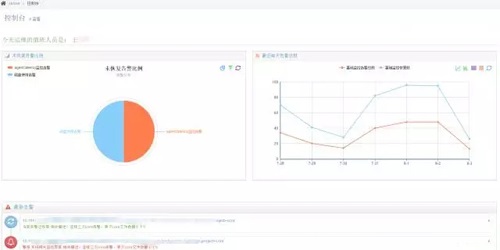
����ͼ����ģ����ۺ���ͼ���û��ڴ������ĺ���Ա��ж����ֵ����ж�Ҫ����ͼ�����жȣ�������ǽ�������Ϊ������ͼ����Ϊ�ڶ�����ṩ���ƵIJ鿴
��ͼ�����صIJ������̣���nginxΪ����
��־����Ŀǰ�������ƣ����ڼܹ������ԣ���Ҫ��nginx��־�����δ�����������ռ������˿�����������log-viewer���ö���̴��������ڴ�����־����ʱ��Ϣ����ӵ����Ŀǰ�ܹ�ͼ���£�
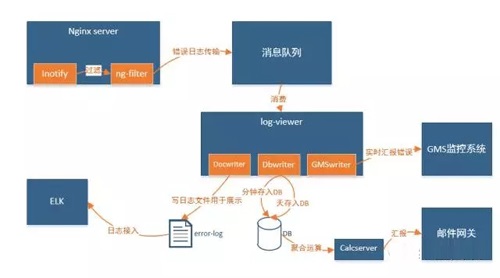
��־�����е�������������أ�
Ӧ�ò���
ͨ�����̵�ϵͳ���е������ݼ��ŵ�UMPҵ����ϵͳ�����������ϣ�ֱ�۵İ��պ������ɫ����ʾ
�ӿڲ���
�ӿڲ���ϵͳ�������ĵ��������ģ����������ù�ϵ���ٸ���ump�ϱ����������ǰ������
�ĵ�
���Ž��뾩������ϵ֮�������������ӣ�����ô����ƽ̨����˼ά�������Ż����ǵ�ƽ̨������˵��ϸ���Ĺ����ͼ�أ���������Docker�������Ƕ�֪��Ŀǰ�����ǹ���Dockerʹ�������͵Ĺ�˾��Docker��Ϊһ���µ�IT����ԭ�еij�������CMDB����ء����ݷ�����ƽ̨��������µ���ϵ��Ҫ��
��ʵ��������ʹ����������Ī����������ϵͳ���ϵ������ˣ�������һ���ʱ�����������ε����ϡ�Ǩ�ƺ���ҵ�����ߡ������漰���ײ��������ǧ̨��ҵ��ģ��300�����Ӧ��100���������Ǩ�ƣ�����ս�������������ջ����ĵá�
��άϵͳ�Ĵ������һ������ά����Ӫ����ת����̡�
��ͨ�������Ծ�����豸�ͳ����ҵ����й淶������������ij�������ϵͳ���ɼ����������������֮�������������ϵͳ����һ��������Ч�ʣ���������Ϊҵ���ṩ����IJο�֧���Ǹ���һ����Ҫ˼��������;�����������RPM����һ�����ٽ��������ÿ������⣬��θ���ϸ���ռ���־��������ʹ�з����Լ���CGIʹ���и�����˽⣬��Щ������ά��Ҫ���ǵ����⡣
CMDB�ķֲ�������Ҫ
һ��Ҫ��CMDB���ֳ�������Դ������CMDB��ҵ����CMDB�������ϲ�Ӧ�õ�CMDB��������ײ������Դ���CMDB�����ڣ�ͨ���Լ���һ�������Զ������ֺ���ά�����ϵ������CMDB���ݡ�ǿ�������ϲ���ά����ƽ̨Ǩ�Ƶ�����ϰ���
���϶��µ�ҵ������������������¶��ϵ�ϵͳ����ֶ���֮
��һ����ҵ���ں��зdz����ԣ�����һ����Գ�����м�ϵͳʱ����β��ܱ�֤ϵͳ�ȶ����Դ�Ϊ������չ����һ������϶��·�����������Ҫ���������¶��ϵĽ��衣
ÿ��ϵͳ����һ����Դ�أ�ͨ��ϵͳ����������Դ�ع��������̻�ϵͳ����֤ϵͳ��Чȷ����ת������������Ϊһ������ƽ̨
ϵͳ����������ά���dz���Ҫ����ǿϵͳ�������Ǽ���ϵͳά����һ����Ҫ��ʽ��Ҳ���̻�ƽ̨�Ĺؼ�·��������RPMϵͳ�����CMDB���������ݲɼ��˵������ṩ������ء�����������CMDB���߽�Ϻ�����ΪIT��Ӫ������֧�š�
��άϵͳ����ƶ���ѯ�з���ҵ���Ʒ����
�������ѯ��ֻ���������ϵģ�Ҳ��ʹ���ϵģ�ҵ���з��Ͳ�Ʒ������Ϊ����û���һ�ˣ���ԭ����ƣ�ϵͳʹ�������Ӱ���û�����άҪרҵ���ο���άƽ̨���û�Ҳ�����з���һ�����û������ϵͳ�Ƚ������ƹ�ʹ�ã�Ҳ�����ܵ���������Ȼ���ǵ��κ�ϵͳ��Ҫ�ѷ�����ڷ�������λ�ã�)
��άƽ̨����Ҳ��һ���������ݽ��Ĺ���
���û��ҵ��������û�д˴�ƽ̨�ĵ���;���û��Docker���ٵ����룬�������RPMƽ̨�����ݽ��������άƽ̨����Ҳ��ҵ�����ܹ�һ��������ҵ��ͼ����ı仯������Ҳ��ǿ����Ӧ�ԡ� |






