| 编辑推荐: |
本期主要介绍了GPU部署到硬件相关内容。希望对您的学习有所帮助。
本文来自于微信公众号TrustZone,由火龙果软件Linda编辑、推荐。 |
|
前言
前几天我们过了一遍,现在的GPU在逻辑上应该包含哪些功能模块?
当然要直接设计成硬件,必然会遇到很多问题,成本,性能,功耗,性能等。
下面就来探讨一下这些问题的解决方法,回到最基本的图形流水线,

这是我的第一个带有基本的可编程流水线CPU的显卡。

2003年的geforce fx 5600。在硬件上他有两个vertex shader单元,四个pixel
shader单元,所以当顶点和像素的工作量是1:2的时候,他能发挥出最高效率。

如果一堆很小的三角形挤在一起,顶点很多像素很少,

或者全屏就有一个巨大的三角形,顶点很少,像素很多,

它就会出现负载不平衡的情况。一部分忙死,另一部分闲死。随着渲染的内容和流水线越来越复杂,如果全都堆到硬件上,负载平衡出问题只会是早晚的事情。

现在我们来想想vertex shader单元和pixel shader单元究竟有什么不同。

在2005年以前,人们的想法是vertex shader需要做32位浮点精度的计算,因为坐标得要有那么高的精度。但是vertex
shader不需要读取纹理。Pixel shader则做好相反,基本只和颜色打交道,精度不用太高,但是需要读取纹理。

这个想法使得两者在硬件上分开了,但是随着需求的发展,他们的界限逐渐变得模糊。大规模地形渲染的需求使得vertex
shader得能读取纹理。

用pixel shader做通用计算的需求,使得pixel shader也需要32位浮点精度的支持。结果就是两个单元都有一样的纹理采样器以及一样运算器,虽看起来两者都变复杂了,但一次性提高了。

这时候,人们发现一个方法可以同时解决。
前面提到的两个问题,那就是共享,这叫做统一shader架构,unified shader architecture。

他用同样的硬件单元来执行各种shader,

不需要再区分vertex shader专用的硬件单元,还是pixel shader专用的硬件单元。
注意,在流水线里他们仍然是不同的阶段,只是用一致的硬件单元来执行。


那么什么时候执行vertex的,什么时候执行pixel shader呢?这里需要的是调度器。当你需要x个verdex
shader单元。或y个pixel shader单元的时候,

调度器会根据硬件上究竟有多少统一的shader单元动态分配给你所需要的。如此一来,负载平衡的问题被动态调度解决了,GPU硬件也可以因为共享而变得简单一致。同样的道理,我们可以继续拆。

一般来说,一个shader里纹理采样的次数远低于计算。所以采样器的数量可以少于运算器。那就拆出来共享,交给调度器去分配。其他固定流水线单元,也都可以这样来安排。
在新出的GeForce RTX 3090 Ti上,就有10752个统一shader,336个采样器,112个光栅化和像素操作单元。


即便有那么多类型的shader,硬件的执行单元都是一样的。那么,为什么GPU动不动就是成千上万个核,CPU有几十个核就了不起了。GPU真的有那样惊人的核数吗?

是也不是。主要还是因为它们对“核”定义不同,首先提两个计算机体系结构的概念,

单指令单数据流SISD和单指令多数据流SIMD。
这里拿大家比较熟的公路来作类比,指令类比于红绿灯,数据类比于车,数据流类比于路面。


在SISD里,每条公路就一个车道,一个红绿灯控制路上车辆的走向。

在SIMD里,有多个车道,共享同一个红绿灯,路上的车走向必须一致。

CPU上的一个核是SISD的,带有一定的SIMD指令集作为补充。比如SSE指令集,可以对4个数做同样的操作,相当于4车道。现在的AVX-512指令集,宽度到了16。

GPU上的一个核,指的只是SIMD里的一条通路,也就是一个车道。
现在的GPU都至少是SIMD的,而且宽度很大,有16、32、64、甚至128的。

逻辑上可以认为这么多个GPU线程在同一个时刻总是执行同样的指令。这样的一组线程称为warp或者wave。

所以说,CPU的核数,指的是一共有多少条路。GPU的核数,指的是一共有多少个车道。两个定义并不同,不能直接比较。

如果都用GPU对核的定义,那么CPU的核数,需要至少乘上SSE的宽度4。
反过来,如果都用CPU对核的定义,那么GPU的核数至少需要除掉warp的宽度。

GPU上这样的核,称为流处理器,streaming processor。

一组流处理器,加上控制器和片上内存等,成为一个功能相对完整的streaming multi-processor。

NVIDIA的RTX 30系列GPU。一个SM包含128个SP,4个采样器。一堆SM成了GPU上的主要组成部分。常看到的切一刀,就是指同系列的不同款GPU,高端的3090
Ti有84个SM,低端的3050就切到了20个。

SM数量有所不同。

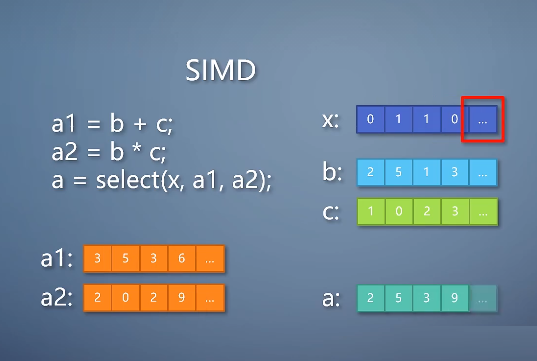
在SISD的时候,x、a、b、c都是标量。 根据x的值来决定a是相加还是相乘就行了,很简单。

但如果是宽度为32的SIMD的情况,x、a、b、c实际上都对应了宽度32的向量里的一个分量,而且32个车道都得做同样的操作。
现在的GPU已经有分支指令,如果x的每个分量都一样,那还好办,GPU只要执行一个分支,这时候分支造成的开销可以忽略不计。

但如果这32个车道的x并不相同,就叫做分支分歧。

这个时候为了保证SIMD,就得把代码展开成这个这样:

这里select是一个SIMD的选择操作,可以根据x向量里每一个分量,选择从a1还是a2提取一个分量。换句话说,在SIMD展开的情况下,我们需要两个分支都执行,每个分量从结果里选择一个,抛弃另一个。这就等于浪费了计算。这个浪费除了不可避免地增加时间之外,还会增加功耗。
为了改变这种情况,MIMD也被多多少少用到了这里。

传统的MIMD,相当于让每个车道都有自己的红绿灯,并把路面做成立交桥的形式。左拐的左拐,直行的直行,同时完成,没有浪费。但这样复杂度高了不知道多少,往往得不偿失。

而NVIDIA在GPU上做的MIMD,是一个取巧的方式。它基本还是SIMD的,没有立交桥,但每个车道有单独的红绿灯。轮到左拐的时候,直行车道亮红灯。

在这种情况下,有分支分歧的话仍然会花费两边都执行的时间,但每个车道只执行一个分支里的代码,并没有计算上的浪费,功耗降下来了,
如果计算是很宽的,内存也得跟得上。独立显卡有自己的内存,称为显存。与CPU对应的这边的内存就称为主存。

常见显存的类型是GDDR,硬件位宽是128-512位,高于主存DDR的32-64位。也是用同样的多车道原理,一次读写很宽的数据。这样的显存被设计成用高延迟换取高吞吐量的。延迟往往在百纳秒这个数量级,比主存高很多。
等于说当你要读取显存的数据时,它得等成团之后再一批发给你。如果就这么等着,会严重影响GPU的执行效率。
这里调度的思想再显神功。

来看一个简单的程序,它执行一些计算,
读取了一下内存,再执行一些计算。在GPU上,一个warp执行到Read()的时候,需要等上一阵子才能拿到结果。

所以这时候SM里有个组件叫做warp调度器,可以把这个warp暂停下来。激活下一个warp来执行。当这个新warp又到了Read,就再暂停,最早被暂停的那个warp如果已经完成了读取,就又被激活,继续往下执行。这称为用计算掩盖访存。

这样的调度使得GPU的线程数量可以远远大于核的数量。
SM内部会有一个寄存器空间,每个wrap都会占用一部分用于局部变量等。要是整个空间都被沾满了,就没法再调用更多地wrap进来。只能真的停下来等内存读取。

这就是访存实在无法被计算掩盖的情况,会降低效率,需要修改算法或数据大小来减少访存才能优化上去。

CPU上的超线程也使用了类似的思路,通过调度把局部单元尽量占满,使得硬件线程数可以高于核数。

这里我们可以看到CPU和GPU的第四个大区别:CPU计算的延迟小,GPU计算的吞吐量大。
• 简单来说,就是CPU相当于一辆轿车。上车就开,直奔目的地,但一趟运不了几个人。
• GPU相当于一辆公交车,得花很多时间上人,每一站还得停。但一趟能把很多人送到目的地。
这个特点使得它们在不同场合有着不同的适用性。也因为GPU可以大量使用计算掩盖访存,对cache的要求小了很多。

而CPU为了降低访存的延迟,需要很大的芯片面积做多级cache.

Cache的功耗很大,因此GPU的这种设计也能进一步降低功耗。
好了,我们粗略看了一下在硬件层面GPU的原理,
尤其是GPU巨大计算量的来源。
那么程序如何使用GPU呢?
下一期将会深入软件的部分,涉及到驱动层、图形API层、应用层,把整个栈串起来。 |







 订阅
订阅