| 编辑推荐: |
| 本文来自于csdn,本文就嵌入式C语言在系统开发中,如何更好的利用系统资源,对代码进行优化进行了讨论,希望对您的学习有所帮助。 |
|
1 概述
嵌入式系统是指完成一种或几种特定功能的计算机系统,具有自动化程度高,响应速度快等优点,目前已广泛应用于消费电子,工业控制等领域.嵌入式系统受其使用的硬件以及运行环境的限制,非常注重代码的时间和空间效率,因此选择一种合适的开发语言十分重要.目前,在嵌入式系统开发中可使用的语言很多,其中
C语言应用得最广泛.虽然用 C 语言编程具有许多优点,但基于嵌入式系统的C语言和标准 C语言又有很大区别.接下来我结合嵌入式系统的特点和自己的一些积累,讨论在程序设计中代码优化的一些小技巧.
2 嵌入式C语言的特点
作为一种结构化程序设计语言,C 语言兼顾多种高级语言的特点,具有很强的功能性和可移植性.但在嵌入式系统开发中,出于对低价产品的需求,系统的计算能力和存储容量都非常有限,因此如何利用好这些资源就显得十分重要.开发人员应注意嵌入式
C语言和标准 C 语言的区别,减少生成代码长度,提高程序执行效率,在程序设计中对代码进行优化.
3 C代码在程序中的优化
现在的 C 编译器会自动对代码进行优化,但这些优化是对执行速度和代码长度的平衡.如果要获得更小且执行效率更高的代码,需要程序员手工对代码进行优化.
4 变量类型的定义
不同的数据类型所生成的机器代码长度相差很多,变量类型选取的范围越小运行速度越快,占用的内存越少.能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long
int),能不使用浮点型(float)变量就不要使用浮点型变量.相同类型的数据类型,有无符号对机器代码长度也有影响.因此我们应按照实际需要合理的选用数据类型.当然,在定义变量后不要超过变量的作用范围,如果超过变量的范围赋值,C编译器并不报错,但程序运行结果却错了,而且这样的错误很难发现.
5 算法优化
算法优化指对程序时空复杂度的优化:在 PC 机上进行程序设计时一般不必过多关注程序代码的长短,只需考虑功能的实现,但嵌入式系统就必须考虑系统的硬件资源,在程序设计时,应尽量采用生成代码短的算法,在不影响程序功能实现的情况下优化算法.
6 适当的使用宏
在 C程序中使用宏代码可以提高程序的执行效率.宏代码本身不是函数.但使用起来像函数.函数调用要使用系统的栈来保存数据,同时
CPU 在函数调用时需要保存和恢复当前的现场,进行进栈和出栈操作,所以函数调用也需要 CPU时间.而宏定义就没有这个问题:宏定义仅仅作为预先写好的代码嵌入到当前程序中,不产生函数调用,所占用的仅仅是一些空间,省去了参数压栈,生成汇编语言的
call 调用,返回参数,执行 return等过程,从而提高了程序的执行速度.虽然宏破坏了程序的可读性,使排错更加麻烦,但对于嵌入式系统,为了达到要求的性能,嵌入代码常常是必须的做法.
此外,我们还要避免不必要的函数调用,请看下面的代码:
void str_print( char *str )
{
int i;
for ( i = 0; i < strlen ( str ); i++ )
{
printf("%c",str[ i ] );
}
}
void str_print1 ( char *str )
{
int len;
len = strlen ( str );
for ( i = 0; i < len; i++ )
{
printf("%c",str[ i ] );
}
}
|
请注意,这两个函数的功能相似.然而,第一个函数调用strlen函数多次,而第二个函数只调用函数strlen一次.因此第二个函数性能明显比第一个好.
7 内嵌汇编
程序中对时间要求苛刻的部分可以用内嵌汇编来重写,以带来速度上的显着提高.但是,开发和测试汇编代码是一件辛苦的工作,它将花费更长的时间,因而要慎重选择要用汇编的部分.在程序中,存在一个80-20原则,即20%的程序消耗了80%的运行时间,因而我们要改进效率,最主要是考虑改进那20%的代码.
8 提高循环语言的效率
在 C 语言中循环语句使用频繁,提高循环体效率的基本办法就是降低循环体的复杂性:
(1)在多重循环中,应将最长的循环放在最内层,最短的循环放在最外层.这样可以减少
CPU跨切循环的次数.如例 1-1 的效率比 1-2 的效率要低:
for (j = 0; j < 30; j++)
{
for (i = 0; i < 10; i++)
{
... ...
}
} // 例子 1-1
for (i = 0; i < 10; i++)
{
for (j = 0; j < 30; j++)
{
... ...
}
} // 例子 1-2 |
例 1-1长循环在外层,效率低;例 1-2长循环在内层,效率高.
(2) 如果循环体内有逻辑判断,并且循环次数大,应把循环判断移到循环体外.如例
2-1比例 2-2 多执行了 K-1 次判断,而且由于前者频繁进行判断,打断了循环"流水线"作业,使得编译器不能对循环进行优化处理,降低了效率
for (i = 0; i
< 10000; i++)
{
if (条件)
语句;
else
语句;
} // 例子 2-1 程序简洁但效率低
if (条件)
{
for (i = 0; i < 10000; i++)
语句;
}
else
{
for (i = 0; i < 10000; i++)
语句;
} // 例子 2-2 程序部简洁但效率高
|
9 提高 switch 语句的效率
switch 语句是 C 语言中常用的选择语句, 在编译时会产生if-
else- if 嵌套代码,并按照顺序进行比较,发现匹配时,就跳转到满足条件的语句执行.
当 switch 语句中的 case 标号很多时,为了减少比较的次数,可以把发生频率相对高的条件放到第一位或者把整个
switch 语句转化嵌套 switch 语句.把发生频率高的 case 标号放在最外层的 switch
语句中,发生相对频率相对低的 case 标号放在另外的 switch 语句中.如例 3 中,把发生率高的case
标号放在外层的 switch 语句中,把发生频率低的放在缺省 的(default)内层 switch
语句中
switch (表达式)
{
case 值1:
语句1: break;
case 值2:
语句2:break;
... ...
/*把发生频率低的放在内层的switch语句中*/
default:
switch (表达式)
{
case 值n:
语句n: break;
case 值m:
语句m: break;
... ...
}
}
|
例子3 使用嵌套switch语句提高程序执行效率.
10 避免使用标准库
使用 C语言标准库可以加快开发进度,但由于标准库需要设法处理用户所有可能遇到的情况,所以很多标准库代码很大.比如标准库中的
sprintf函数非常大.这个庞大的代码中有很大一部分用于处理浮点数,如果程序中不需要格式化浮点数值(
如%f),程序设计人员就可以根据实际情况用少量的代码实现这个功能.
11 采用数学方法优化程序
数学是计算机之母,没有数学的依据和基础,就没有计算机的发展,所以在编写程序的时候,采用一些数学方法会对程序的执行效率有数量级的提高.有时候这个问题常常被大家忽略,
对于没有经验的程序员来说更是如此.例如:求 1~100 的和
sum = 100*(100+1)/2; 数学公式. (a1 + an)*n/2
使用C语言的位操作可以减少除法和取模的运算.在计算机程序中数据的位是可以操作的最小数据单位,理论上可以用“位运算”来完成所有的运算和操作.因而,灵活的位操作可以有效地提高程序运行的效率.比如用用位操作区代替除法:比如:128
/ 8 ->> 128 >> 3;
优化算法和数据结构对提高代码的效率有很大的帮助.当然有时候时间效率和空间效率是对立的,此时应分析哪个更重要,
做出适当的折中.另外,在进行优化的时候不要片面的追求紧凑的代码,因为紧凑的代码并不能产生高效率的机器码.
12 存储器分配
由于成本限制,嵌入式系统存储器容量有限.程序中所有的变量,包含的库函数以及堆栈等都使用有限的内存:全局变量在整个程序范围内都有效.程序执行完后才会释放;静态变量的作用范围也是整个程序,只有局部变量中的动态变量在函数执行完后会释放.因此,
在程序中应尽量使用局部变量,提高内存使用效率.程序中堆的大小受限于所有全局数据和栈空间都分配后的剩余量,如果堆太小,程序不能够在需要的时候分配内存.因此在使用
malloc 函数申请内存之后一定要用 free 函数进行释放, 防止内存泄露.
13选择好的无限循环
在编程中,我们常常需要用到无限循环,常用的两种方法是while (1) 和 for (;;).这两种方法效果完全一样,但那一种更好呢?然我们看看它们编译后的代码:
编译前:
while (1);
编译后:
mov eax,1
test eax,eax
je foo+23h
jmp foo+18h
编译前:
for (;;);
编译后:
jmp foo+23h
显然,for (;;)指令少,不占用寄存器,而且没有判断,跳转,比while (1)好.
14 使用Memoization,以避免递归重复计算
考虑Fibonacci(斐波那契)问题,Fibonacci问题是可以通过简单的递归方法来解决:
int fib ( n )
{
if ( n == 0 || n == 1 )
{
return 1;
}
else
{
return fib( n - 2 ) + fib ( n - 1 );
}
}
|
注:在这里,我们考虑Fibonacci 系列从1开始,因此,该系列看起来:1,1,2,3,5,8,…
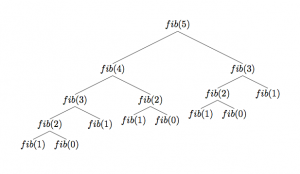
注意:从递归树,我们计算fib(3)函数2次,fib(2)函数3次.这是相同函数的重复计算.如果n非常大,fib函数的效率会比较低.Memoization是一个简单的技术,可以被用在递归,加强计算速度.fibonacci
函数Memoization的代码如下:
int calc_fib
( int n )
{
int val[ n ] , i;
for ( i = 0; i <=n; i++ )
{
val[ i ] = -1; // Value of the first n + 1 terms
of the fibonacci terms set to -1
}
val[ 0 ] = 1; // Value of fib ( 0 ) is set to
1
val[ 1 ] = 1; // Value of fib ( 1 ) is set to
1
return fib( n , val );
}
int fib( int n , int* value )
{
if ( value[ n ] != -1 )
{
return value[ n ]; // Using memoization
}
else
{
value[ n ] = fib( n - 2 , value ) + fib ( n -
1 , value ); // Computing the fibonacci term
}
return value[ n ]; // Returning the value
}
|
除了编程上的技巧外,为提高系统的运行效率,我们通常也需要最大可能地利用各种硬件设备自身的特点来减小其运转开销,例如减小中断次数,利用DMA传输方式等.
对于嵌入式系统,C语言在开发速度,软件可靠性以及软件质量等方面都有着明显的优势.当然代码优化的方法还有很多,这里只是写出了一部分,希望能为开发人员提供一些帮助,也欢迎大家留言交流.
原文:https://blog.csdn.net/u013467442/article/details/47071171
|









