| 编辑推荐: |
文章重点讲解4个部分内核任务,实现策略,内核组成部分,内核特别之处。
本文来自于cnblogs:从零开始学架构,由火龙果软件依然编辑推荐。 |
|
一、内核的任务
纯技术层面上,内核是硬件与软件的之间的一个中间层。作用是将应用程序的请求传递给硬件,并充当底层驱动程序,对系统中的各种设备和组件进行寻址。
从应用程序视角上看,内核可以被认为是一台增强的计算机,将计算机抽象到一个高层次上。应用程序与硬件本没有联系,只与内核有联系,内核是应用程序所知道的层次结构中的最底层。
当若干程序在同一系统中并发运行时,也可以将内核视为资源管理程序。内核负责将可用共享资源分配到各个系统进程,同时保证系统的完整性。
将内核视为库,其提供了一组面向系统的命令。通常系统调用用于向计算机发送请求。
二、实现策略
在操作系统的实现方面,有两种主要的泛型:微内核和宏内核。
微内核:只有最基本的功能直接由内核实现。所有其他的功能(譬如文件系统、内存管理等)都委托给一些独立的进程,这些进程通过明确定义的通信接口与内核通信。这种设计方式优点包括:动态可扩展性和在运行时切换重要组件。但由于在各个组件之间支持复杂通信需要额外的CPU时间,所以尽管微内核在各研究领域早已成为活跃主题,但在使用性方面进展甚微。
宏内核:宏内核是构建系统内核的传统方法。这种方法中,内核的全部代码包括所有子系统(如内存管理、文件系统、设备驱动程序)都打包到一个文件中。内核中每个函数都可以访问内核所有其他部分,容易导致源代码中出现复杂的嵌套。
当前宏内核的性能仍强于微内核,Linux采取的是宏内核的设计模式。但是也进行了一定程度上的改进,系统运行中,模块可以插入到内核代码中,也可以移除。
三、内核的组成部分
图1概述了组成完整Linux系统的各个层次,以及内核所包含的一些重要子系统。
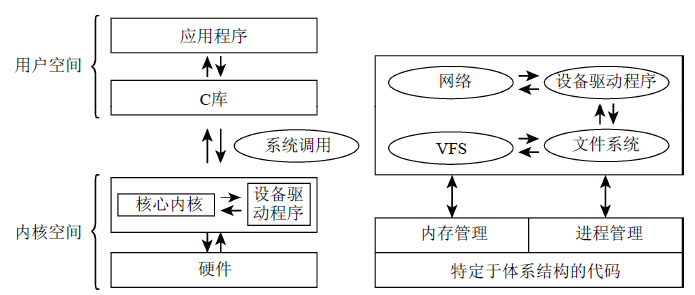
图1 Linux内核的高层次概述以及完整的Linux系统中的各个层次
1、进程、进程切换、调度
进程:传统上UNIX操作系统下运行的应用程序、服务器及其他程序都称为进程。每个进程都在CPU的虚拟内存中分配地址空间。各个进程的地址空间是完全独立的。Linux是多任务系统,支持并发执行的若干进程。系统中同时真正在运行的进程数目最多不超过CPU的数目。
进程切换:进程之间的切换。内核借助CPU的帮助,负责进程切换的技术细节。通过在撤销进程的CPU资源之前保存进程所有与状态相关的要素,并将进程置于空闲状态。重新激活进程时,将保存的状态原样恢复。
调度:内核必须确定如何在现存进程之间共享CPU时间。重要进程得到的CPU时间多一点,次要进程少一点,确定哪个进程运行多长时间的过程称为调度。
2、UNIX进程
Linux对进程采用了一种层次系统,每个进程都依赖于一个父进程。内核启动init程序作为第一个进程,负责进一步系统初始化工作,init是进程树的根,所有进程都直接或间接起源于该进程(在linux系统终端输入pstree查看进程树)。
树型结构的扩展方式与新进程创建方式密切相关。UNIX操作系统中创建新进程的机制有两个,分别是fork和exec。fork可以创建当前进程的一个副本,除了PID,子进程完全复制父进程的内存内容。在Linux中,采用写时复制(copy
on write)技术,将内存复制操作延迟到父进程或子进程向某内存页面写入数据之前,在只读访问的情况下父进程和子进程共用一个内存页,提高了执行效率。exec将一个新程序加载到当前进程的内存中并执行,旧程序的内存页被刷出,其内容替换为新数据,开始执行新程序。
线程:有时也称为轻量级进程。本质上一个进程可能由若干线程组成,这些线程共享同样的数据和资源,但可能执行程序中不同的代码路径。Linux用clone方法创建线程,工作方式类似于fork,但是会检查确认哪些资源与父进程共享,哪些资源为线程独立创建。细粒度的资源分配扩展了一般线程的概念,在一定程度上允许线程与进程之间的连续转换。
命名空间:传统的Linux使用了许多全局量,启用命名空间后,以前的全局资源具有了不同的分组。每个命名空间可以包含一个特定的PID集合,或可以提供文件系统的不同视图,在某个命名空间中挂载的卷不会传播到其他命名空间中。(并非内核的所有部分都完全支持命名空间)命名空间的经典作用之一:可以通过称为容器的命名空间来建立系统的多个视图,一台物理机中可以运行多个虚拟机。与完全的虚拟解决方案(如KVM)相比,计算机上多了一个内核来管理所有的容器。
3、地址空间与特权级别
由于内存区域是通过指针寻址,因此CPU的字长决定了所能管理的地址空间的最大长度。以32位系统为例,可以管理232B=4GB的内存。
地址空间的最大长度与实际可用的物理内存数量无关,因此被称为虚拟地址空间。从系统中每个进程的角度看,地址空间中只有自身一个进程,无法感知到其他进程的存在。Linux将虚拟地址空间划分为两个部分,分别为内核空间和用户空间,如图2所示。
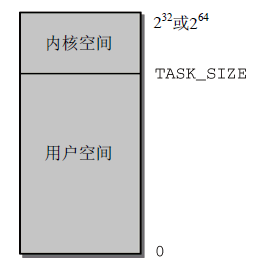
图2 虚拟地址空间的划分
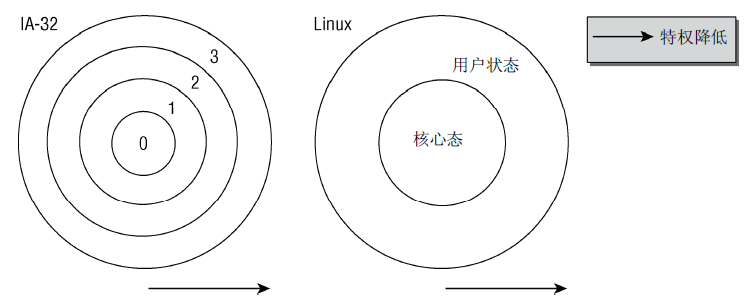
图3特权级别的环状系统
系统中每个进程都有自身的虚拟地址范围,从0到TASK_SIZE,用户空间之上的区域保留给内核专用。以IA-32为例,地址空间在3GB处划分,每个进程虚拟地址空间都是3GB,内核空间由1GB可用。此划分与内存数量无关。由于地址空间虚拟化的结果,每个用户进程都认为自身有3GB内存。各个系统进程的用户空间彼此完全分离。(64位计算机可管理巨大的理论虚拟地址空间,操作系统中倾向于使用小于64的位数,实际使用的如42为或47位等,这样做可以节省一些CPU的工作量)。
特权级别:内核把虚拟地址空间划分为两个部分,因此能够保护各个系统进程,使之彼此分离。所有现代的CPU都提供了几种特权级别,进程可以驻留在某一个特权级别。IA-32体系结构使用4种特权级别构成的系统,各级别可以看作是环,如图3所示。Intel处理器有4种特权级别,Linux只使用两种不同的状态:核心态和用户状态。两种状态的关键差别在于用户状态禁止访问内存空间。从用户状态到核心态的切换通过系统调用的特定转换手段完成,且系统调用的执行因具体系统而不同。图4概述了不同的执行上下文(详细讨论见下一篇博客)。此外,在多处理器系统中,线程启动时可以指定CPU,并限制只能在特定CPU上运行。
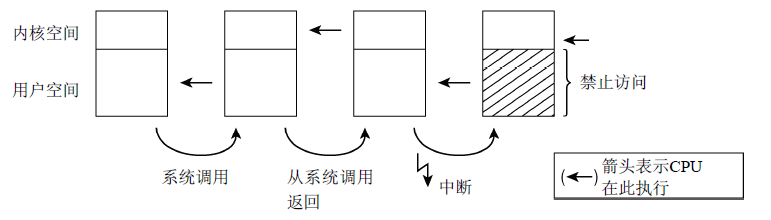
图4 在核心态和用户态执行(CPU大多时间在执行用户空间中代码,当应用程序执行系统调用时切换到核心态,此时,内核可以访问虚拟地址空间用户部分。系统调用结束后CPU回到用户状态。硬件中断也可以使CPU切换到核心态,这种情况下内核不能访问用户空间)
大多情况下,单个虚拟地址空间就比系统中可用的物理内存大。此外,每个进程也都有自身的虚拟地址空间,因此,内核和CPU必须考虑如何将实际可用的物理内存映射到虚拟地址空间的区域。Linux内核中用页表来为物理地址分配虚拟地址。虚拟地址关系到进程的用户空间和内核空间,而物理地址则用来寻址实际可用的内存。原理如图5所示。两个进程的虚拟地址空间都被划分为很多等长的部分(页),物理内存同样进行划分。
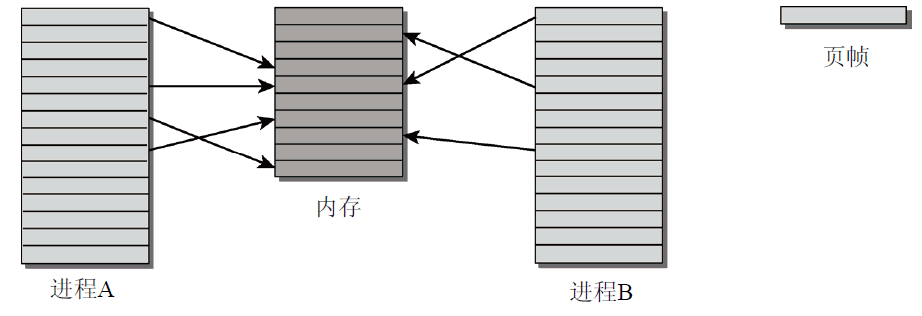
图5 虚拟地址和物理地址
物理内存页经常称为页帧,页则指虚拟地址空间中的划分单位。虚拟地址空间和物理内存之间的映射也使得进程之间的隔离有一点点松动(内核负责将虚拟地址空间映射到物理地址空间,决定哪些内存区域在进程之间共享哪些不共享)。图5表明并非虚拟地址空间的所有页都映射到某个页帧(可能是因为页没有使用,或者数据尚不需要使用而没有载入)。
4、页表
用来将虚拟地址空间映射到物理地址空间的数据结构称为页表,对于页表的管理采用多级分页模型。如图6所示,将虚拟地址划分成4部分,这样需要一个三级页表。(当前Linux内核采用了四级页表)此处以三级页表为例,虚拟地址的第一部分称为全局页目录(Page
Global Directory, PGD),用于索引进程中的一个数组(每个进程有且仅有一个);虚拟地址的第二个部分称为PMD(Page
Middle Directory),并通过PGD中的数组项找到对应的PMD之后,使用PMD来索引PMD;虚拟地址的第三部分称为PTE(Page
Table Entry),用作页表的索引,页表的数组项指向页帧,虚拟内存页和页帧之间的映射由此完成;虚拟内存的最后一部分称为偏移量,它指定了页内部的一个字节的位置。每个地址都指向地址空间中唯一定义的某个字节。
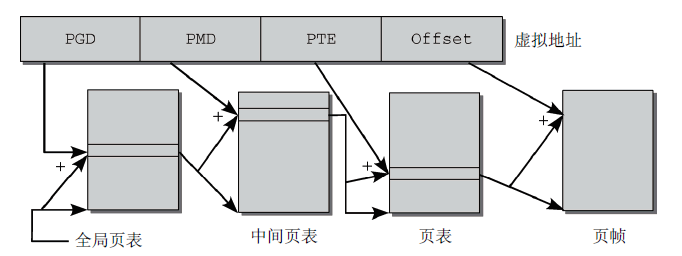
图6 分配虚拟地址
页表对虚拟地址空间中不需要的区域,不必创建中间页目录或页表,节省了大量的内存。但是每次访问内存时,必须逐级访问多个数组才能将虚拟地址转化为物理地址。
CPU试图使用MMU(Memory Management Unit)优化内存访问操作;同时对于地址转换中出现最高频的那些地址,保存到地址转换后备缓冲器(Translation
Lookaside Buffer)的CPU高速缓存中。在许多体系结构中高速缓存的运转是透明的,但某些体系结构则需要内核专门处理。
与CPU交互:IA-32体系结构在将虚拟地址映射到物理地址时,只用了两级页表,64位体系结构中需要三级或四级页表,内核与体系结构无关的部分总是假定使用四级页表。对于只支持二级或三级页表的CPU来说,内核中体系结构相关代码必须通过空页表对缺少的页表进行仿真。
内存映射:内存映射是一种重要的抽象手段。映射方法可以将任意来源的数据传输到虚拟地址空间中,作为映射目标的地址空间区域,可以像普通内存那也用通常的方法访问。内核在时限设备驱动程序时,直接使用了内存映射,外设的输入/输出可以映射到虚拟地址空间的区域中,对相关内存区域的读写会由系统重定向到设备,简化了驱动程序的实现。
5、物理内存的分配
内核分配内存时,会记录页帧已分配或空闲状态,以免两个进程使用同样的内存区域。内核只分配完整的页帧,将内存划分为更小的部分工作则委托给用户空间中的标准库。
内核采用伙伴系统进行快速检测内存中的连续区域。系统中的内存块总是两两分组,每组中两个内存块称为伙伴。若两个伙伴都空闲,则将其合并为一个更大内存块,作为下一层次上的某个内存块的伙伴。图7师范了伙伴系统,初始大小为8页。从上到下,如果系统需要8个页帧,则将16个页帧组成的块分为两个伙伴,往下类似...。
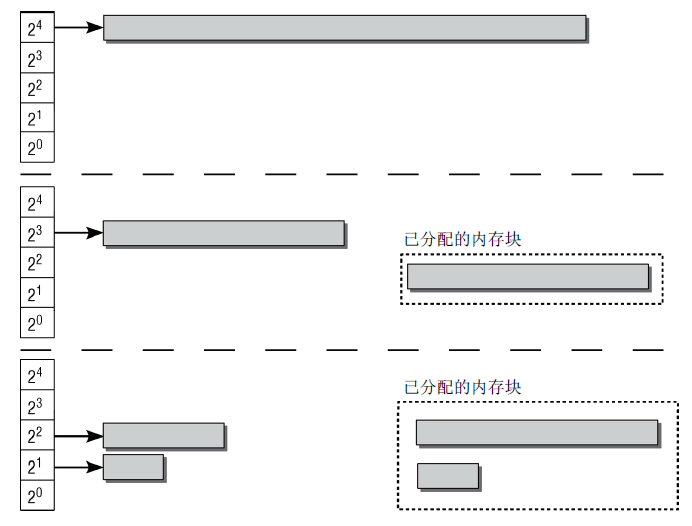
图7 伙伴系统
内核本身经常需要比完整页帧小得多的内存块,由于内核无法使用标准库函数,因此在伙伴系统的基础上,设置了内存管理层,将伙伴系统提供的页划分为更小的部分,此外还为频繁使用的小对象设置了slab缓存。slab缓存自动维护与伙伴系统的交互,在缓存用尽时会请求信的页帧。图8综述了伙伴系统、slab分配器以及内核其他方面之间的关联。
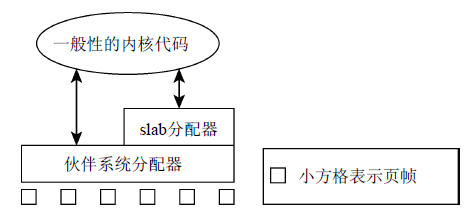
图8 页帧的分配由伙伴系统进行,而slab分配器则负责分配小内存以及提供一般性的内核缓存
页面交换通过利用磁盘空间作为扩展内存,增大了可用内存。内核需要更多内存时,不经常使用的页可用写入硬盘,再需要访问的时候通过缺页异常机制,将相应的页切换回内存。
页面回收用于将内存映射被修改的内容与底层的块设备同步。有时简称数据回写。
6、计时
全局变量jiffies_64和jiffies(分别是64位和32位)为内核的时间坐标,会按恒定的时间间隔递增。(对其的更新操作可使用底层体系结构提供的各种定时器机制执行)
基于jiffies的计时相对粒度较粗,在底层硬件能力允许的前提下,内核可使用高分辨率的定时器提供额外的计时手段,能够以纳秒级的精确度和分辨率计量时间。
计时的周期可以动态改变,动态改变计时周期对于供电受限的系统(比如笔记本电脑和嵌入式系统)是很有用的。
7、系统调用
系统调用是用户进程与内核交互的经典方法。POSIX标准定义了许多系统调用,以及这些系统调用在所有遵从POSIX的系统包括Linux上的语义。传统的系统调用按不同类别分组,为:
进程管理:创建新进程,查询信息,调试。
信号:发送信号,定时器以及相关处理机制。
文件:创建、打开和关闭文件,从文件读取和向文件写入,查询信息和状态。
目录和文件系统:创建、删除和重命名目录,查询信息,链接,变更目录。
保护机制:读取和变更UID/GID,命名空间的处理。
定时器函数:定时器函数和统计信息。
用户进程要从用户状态切换到核心态,并将系统关键任务委派给内核执行,系统调用是必由之路。(不同的是不同的硬件平台提供的切换机制不尽相同)
8、设备驱动程序、块设备和字符设备
设备驱动程序用于与系统链接的输入/输出装置通信,如硬盘、软驱、各种借口、声卡等。
外设可以分为块设备和字符设备。
块设备:应用程序可以随机访问设备数据,程序可自行确定读取数据的位置。数据的读写只能以块的倍数(通常512B)进行,不支持基于字符的寻址。(应用:硬盘)
字符设备:提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取。相反,此类设备支持按字节/字符来读写数据。(应用:调制解调器)
由于内核为提高系统性能,广泛使用了缓存机制,块设备驱动程序比字符设备复杂。
9、网络
由于在网络通信期间,数据打包到了各种协议层中。接收到数据时,内核必须针对各协议层的处理,对数据进行拆包与分析,然后将有效数据传递给应用程序;发送数据时,内核必须首先根据各协议层的要求打包数据,才能发送。Linux使用了源于BSD的套接字抽象,以支持通过文件接口处理网络连接。套接字可以看作为应用程序、文件接口、内核的网络实现之间的代理。
10、文件系统
Linux系统由大量文件组成,其数据存储在硬盘或其他块设备。存储使用了层次式文件系统。Linux支持许多不同的文件系统:标准的Ext2、Ext3和Ext4文件系统、ReiserFS、XFS、VFAT(为兼容DOS)等等。不同的文件系统基于不同的概念抽象。此外内核必须提供一个VFS(Virtual
Filesystem或Virtual Filesystem Switch),将各种底层文件系统的具体特性与应用层隔离。如图9所示,VFS既是向下的接口(所有文件系统都必须实现该接口),同时也是向上的接口(用户进程通过系统调用最终能够访问文件系统功能)。
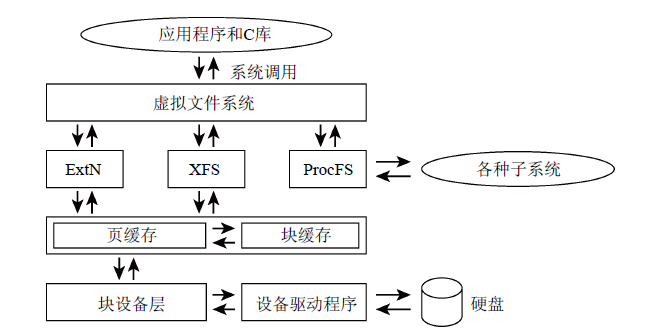
图9 虚拟文件系统层、文件系统实现和块设备层之间的互操作
11、模块和热插拔
模块用于在运行时动态向内核添加功能(如设备驱动程序、文件系统、网络协议等),消除了宏内核与微内核相比一个重要的不利之处。模块也可以在运行时从内核写在,方便了开发新内核组件。
模块本质上也是普通程序,它必须提供某些代码段在模块初始化和终止时执行,以便向内核注册和注销模块。模块代码可以像编译到内核中的代码一样,访问内核所有函数和数据。
对支持热插拔而言,模块本质上是必须的。某些总线(比如USB)允许在系统运行时连接设备,无需重启,系统检测到设备时,通过加载对应的模块,将驱动添加到内核中。(某些模块开不开源有争论)
12、缓存
内核使用缓存来改进性能。从低速的块设备读取的数据会暂时保持在内存中,应用程序下次访问数据时,可以绕过低速的块设备。由于内核通过基于页的内存映射来实现对块设备的访问,因此缓存也按页组织,称为页缓存。块缓存用于缓存没有组织成页的数据,如今已被页缓存取代。
13、链表处理
C程序中重复出现的一项任务是对双向链表的处理,内核同样需要处理这样的链表。内核提供了一个标准链表,可用于将任何类型的数据结构彼此连接起来(非类型安全)。加入链表的数据结构必须包含一个类型为list_head的成员,其中包含了正向和反向指针。链表的起点是list_head的实例,通常用LIST_HEAD(list_name)宏来声明初始化。图10为内核建立的标准双链表示意图。对链表进行操作时,内核定义了一些API。
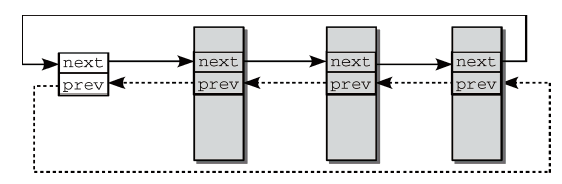
图10 标准双链表
list_add(new,head):在紧接head之后插入new元素。
list_add_tail(new,head):在head之前(即链表末尾)插入new元素。
list_del(entry):从链表中删除一项。
list_empty(head):检测链表是否为空。
list_splice(list,head):在head后插入list链表,合并两个链表。
list_entry(ptr,type,member):查找链表元素。(ptr为指向数据结构list_head的指针,type是该数据结构的类型,member是数据结构中表示链表元素的成员名)
list_for_each(pos,head):遍历链表所有元素。
14、对象管理和引用计数
内核中许多地方需要跟踪记录C语言中结构的实例,这会导致代码复制。因此,在内核2.5开发期间,采用一般性的方法来管理内核对象,它不止是为了防止代码复制,同时也为内核不同部分管理的对象提供了一致的视图,在许多部分可以有效地使用相关信息。一般性的内核对象机制可用于执行:引用计数;管理对象链表;集合加锁;将对象属性导出到用户空间(通过sysfs文件系统)。
(1)一般性的内核对象
一般性的内核对象抽象成了一个结构体kobject,用作内核对象的基础。
struct kobject{
struct kref kref; //用于简化引用计数的管理
struct list_head entry; //标准链表元素
struct kobject * parent; //一个指向父对象的指针
struct kset * kset; //将对象与其他对象放置到一个集合时需要
struct kobj_type *ktype; //提供了包含kobject数据结构更多详细信息
struct sysfs_dirent * sd;
} |
kobject与面向对象语言(C++/Java)中的对象概念的性质相似。kobject抽象提供了在内核使用面向对象技术的可能性。
(2)对象集合
很多情况下,需要将不同的内核对象归类到集合中(比如所有字符设备集合,所有基于PCI的设备集合等)。
1 struct kset{
2 struct kobj_type * ktype;
//指向kset中各内核对象的公用kobj_type结构,提供了与sysfs文件系统的接口
3 struct list_head list;//当前集合的内核对象链表
4 ...
5 struct kobject kobj;
6 struct kset_uevent_ops * uevent_ops; //提供了若干函数指针,将集合状态传递给用户层
7 } |
kset是内核对象应用的第一个例子,它对kobject的管理是在kset中嵌入了一个kobject的实例kobj,它与集合中包含的各个kobject无关,只是用来管理kset对象本身。
(3)引用计数
引用计数用于检测内核中有多少地方使用了某个对象。每当内核的一个部分需要某个对象所包含的信息时,该对象引用计数加1,如果不再需要,则引用计数减1。当计数为0时,内核知道不再需要该对象,便从内存中将其释放。(对引用计数的操作为原子操作)
15、数据类型
(1)类型定义
内核使用typedef定义各种数据类型,避免依赖于体系结构相关的特性。(比如sector_t用于指定块设备扇区编号,pid_t表示进程ID,_s8(8位有符号数),_u8(8位无符号数)等)
(2)字节序
现代计算机采用大端序(big endian)或小端序(little endian)格式。大端序中,高位在低字节;小端序中低位在低字节。内核提供了各种函数和宏,可以在CPU使用的格式与特定表示法之间转换。
(3)per_cpu变量
per_cpu变量是通过DEFINE_PER_CPU(name,type)声明,在有若干CPU的SMP系统上,会为每个CPU分别创建变量的一个实例。用于某个特定CPU的实例可以通过get_cpu(name,cpu)获得,其中smp_processor_id()可以返回当前活动处理器ID。采用per_cpu变量好处
:所需数据很可能存在于处理器缓存中,因此可以快速访问;绕过了多处理器系统中使用可能被所有CPU同时访问的变量的通信问题。
(4)访问用户空间
源代码中多处指针标记为_user,表示对用户空间程序设计未知,在没有进一步预防措施时,不能轻易访问这些指针指向的区域。因为内存是通过页表映射到虚拟地址空间的用户空间部分的,不是由物理内存直接映射的,内核需要确保指针所指的页帧确实存在于物理内存中。
四、内核特别之处
调试内核通常比调试用户层程序困难。
内核提供了许多辅助函数,类似于用户空间的C语言库,但内核领域中的东西总是朴素得多。
用户层程序错误可能会导致segmentation fault或core dump,但内核错误会导致整个系统故障。
必须考虑到内核运行的许多体系结构上根本不支持非对齐的内存访问。
所有内核代码都必须是并发安全的。对于多处理器计算机的支持,Linux内核代码必须是可冲入和线程安全的。
内核代码必须在小端序和大端序计算机上都能够工作。
大多数的体系结构根本不允许在内核中执行浮点计算,因此计算需要想办法用整型来替代。
|









