| 编辑推荐: |
本文主要介绍了进程基本概念、进程的实现及进程的生命周期。希望对您的学习有所帮助。
本文来自微信公众号Linux阅码场,由火龙果软件Linda编辑、推荐。 |
|
一、进程基本概念
进程是计算机里面最重要的概念之一。操作系统的目的就是为了运行进程。那么到底什么是进程,操作系统又是如何实现进程和管理进程的呢?
1.1 进程与程序
进程是程序的执行过程。程序是静态的,是存在于外存之中的,电脑关机后依然存在。进程是动态的,是存在于内存之中的,是程序的执行过程,电脑关机后就不存在进程了。进程的内容来源于程序,进程的启动过程就是把程序从外存加载到内存的过程。程序文件是有格式的,UNIX-Like操作系统的通用程序文件格式是ELF。程序文件是从源码文件编译过来的,源码文件很多是用C或者C++书写的。关于编译系统,请参看《深入理解编译系统》,关于C和C++,请参看《深入理解C与C++》。
1.2 进程与线程
进程是操作系统分配和管理系统资源的基本单位。进程本来也是程序执行的基本单位,但是自从有了线程之后就不是了。现在线程是程序执行的基本单位,代表一个执行流,一个进程可以有多个执行流。最初的时候,一个进程就只有一个执行流,也就是主线程,此时进程就是线程,线程就是进程。当程序需要多个执行流的时候,采取的都是多进程的方式。但是创建一个新进程是一个很耗费资源的事情,而且多个进程之间还要进行进程间通信也很费事。于是人们便想到了开发进程内并发机制,也就是在一个进程内能同时存在多个执行流(线程)。不同的人设计的进程内并发机制并不相同。按照线程的管理是否实现在内核里,进程内并发机制可以分为两大类,分别是内核级线程(内核级线程也被叫做轻量级进程)和用户级线程,注意这两个名词都带个级,它们是进程内并发机制的两个子类,并不是具体的线程。内核级线程下的线程,按照运行主体是在内核空间还是在用户空间可以分为内核线程和用户线程。用户级线程下的线程,按照运行主体是在内核空间还是在用户空间也可以分为内核线程和用户线程,但是由于用户级线程实现在用户空间,所以它的线程不可能存在于内核空间。内核级线程下的用户线程一般被叫做用户线程,简称线程。用户级线程下的用户线程如果再叫用户线程或者线程就会产生混淆,于是就被叫做协程或者纤程。如下图所示:
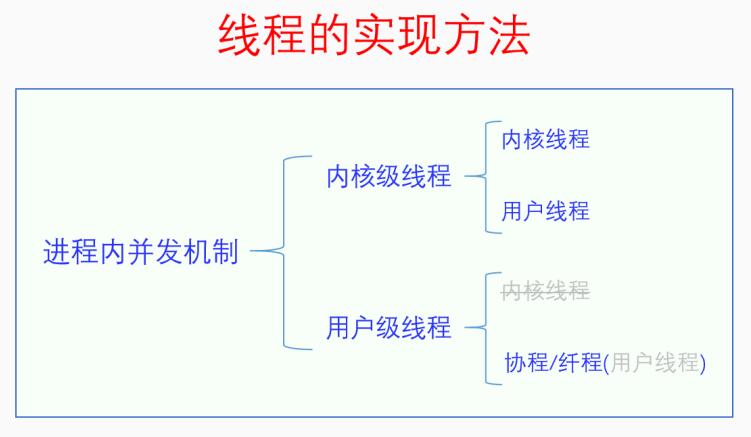
这两种实现多线程的方法各有优缺点。在用户空间实现的话,优点是简单,不用改内核,只需要实现一个库就行了,创建线程开销小,缺点是线程之间做不到真并发,一个线程阻塞就会阻塞同一进程的所有其它线程。在内核空间实现的话,缺点是麻烦,需要改内核,创建线程开销大,但是优点是能做到真并发,一个进程的多个线程可以同时在多个CPU上运行,能充分利用CPU。当然这两者并不是对立的,它们可以同时实现,一个进程可以有多个内核级线程,一个内核级线程又可以有多个用户级线程,编程者可以灵活选择使用哪种多线程方式。
1.3 进程与内核
进程与内核在同一个虚拟地址空间中,但是在不同的子空间,进程是在用户空间,内核是在内核空间。整个系统只有一个内核空间,但是却有很多用户空间,不过当前用户空间永远只有一个(对于一个CPU来说)。虽然内核空间和用户空间在同一个空间中,但是它们的权限并不相同。内核空间处于特权模式,用户空间处于非特权模式。内核可以随意访问和操作用户空间,但是用户空间对内核空间却是看得见摸不着。内核空间可以做很多特权操作,用户空间没有权限做,但是有些时候又需要做,所以内核为用户空间开了一个口子,就是系统调用,用户空间可以通过系统调用来请求内核的服务。关于系统调用请参看《深入理解Linux系统调用与API》。
下面我们用一张图来总结内核和进程之间的关系:
这个图是在讲进程调度的时候画的,但是用在这里表示进程和内核的关系也很合适。
1.4 进程与内存
对于内核来说,内存是有虚拟内存和物理内存之分的。但是对于进程来说,这些都是透明的,进程只需要知道自己独占一个用户空间的内存就可以了,它不知道也不需要知道自己是否运行在虚拟内存上。如果非要说进程知道物理内存和虚拟内存,那么进程也只能分配和管理虚拟内存,它没法分配管理物理内存,因为物理内存对它来说是透明的。内核在合适的时候会为进程分配相应的物理内存,保证进程在访问内存的时候一定会有对应的物理内存,但是进程对此毫不知情,也管不了。
进程需要内存的时候可以通过系统调用brk、sbrk、mmap来向内核申请分配虚拟内存。但是直接使用系统调用来分配管理内存显然很麻烦效率也低,为此libc向进程提供了malloc库,malloc提供了malloc、free等几个接口供进程使用。这样进程需要内存的时候就可以直接使用malloc去分配内存,使用完了就用free去释放内存,不用考虑分配效率、内存碎片等问题了。目前比较流行的malloc库有ptmalloc、jemalloc、scudo等。
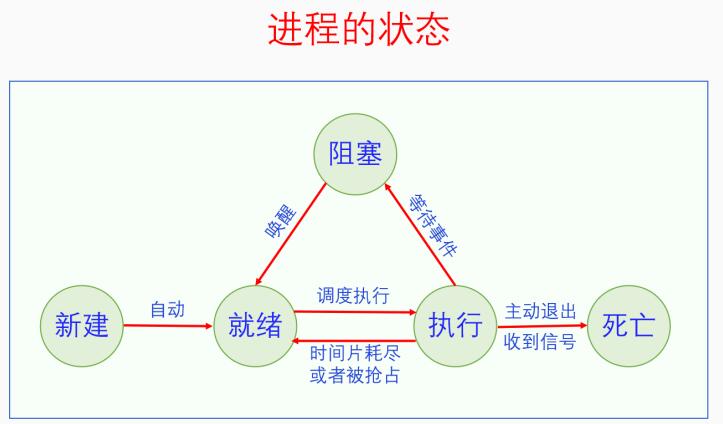
1.5 进程运行状态
很多操作系统的书籍上都会讲进程的运行状态,有的讲的是三态,有的讲的是五态。其实两者并不矛盾,三态只有进程运行时的状态,五态把进程的新建和死亡状态也算上去了,如下图所示:
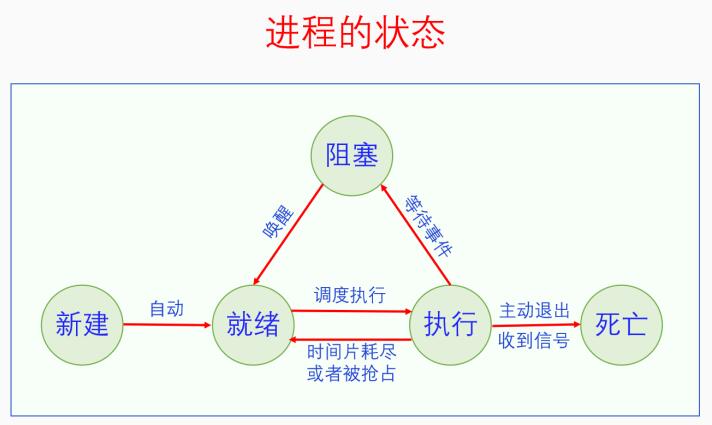
进程刚创建之后处于新建态,但是新建态不是持久状态,它会立马转变为就绪状态。然后进程就会一直处于就绪、执行、阻塞三态的循环之中。就绪态会由于进程调度而转为执行态;执行态会由于时间片耗尽而转为就绪态,也会由于等待某个事件而转为阻塞态;阻塞态会由于某个事件的发生而转为就绪态。最后进程可能会由于主动退出或者发生异常而死亡。死亡态也不是一个持久态,进程死亡之后就不存在了。
1.6 进程亲缘关系
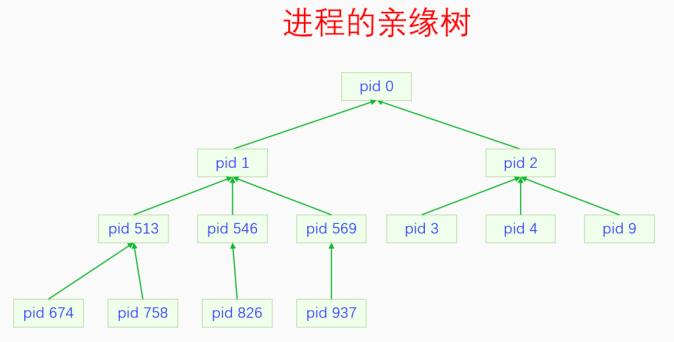
所有进程都通过父子关系连接而构成一颗亲缘树,这颗树的树根是init进程(pid
1)。Init进程是第一个用户空间进程,所有的用户空间进程都是init进程的子孙进程。Init进程的父进程是零号进程,零号进程是在代码中通过硬编码创建的,其它所有的进程都是通过fork创建的。这里为什么叫做零号进程呢?因为零号进程的职责发生过变化,在系统刚启动的时候,零号进程是BSP(bootstrap
process),start_kernel函数就是在零号进程中运行的。当系统初始化完成的时候,零号进程退化为了idle进程。当我们只强调零号进程的身份而不关心它的职责的时候,就叫它零号进程。当后面我们强调它的idle职责的时候,就叫它idle进程。
零号进程有两个亲儿子,除了init之外,还有一个是kthreadd(pid
2)。Kthreadd是一个内核线程,它是所有其它内核线程的父进程。内核线程比较特殊的点在于它只运行在内核空间,所以所有的内核线程都可以看做是同一个进程下的线程,因为内核空间只有一个。但是每个内核线程在逻辑意义上又是一个独立的进程,它们执行独立的任务,有着独立的进程人格。所以当我们说一个内核线程的时候,心里也要明白它是一个单独的进程,是一个只有主线程的单线程进程。
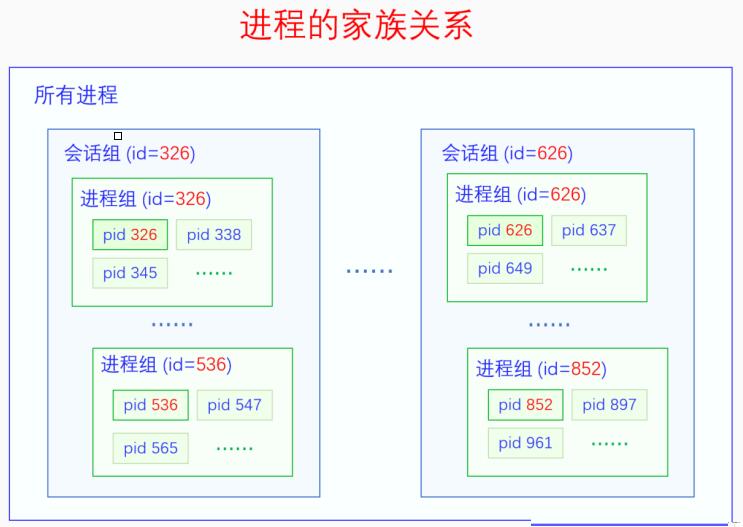
我们来画一下进程的亲缘关系:
进程除了父子这种血缘关系之外,还存在着家族关系。一个是大家族关系,会话组(session),一个是小家族关系,进程组(process
group)。会话组的产生来源于早期的大型计算机,当时一个公司或者一个科研单位只能买得起一台大型机。然后每个人都通过一个终端连接到这个大型机,用自己的用户名和密码登录上去。每个用户都有自己的用户id,一个用户运行的所有的程序构成了一个会话组。有了会话组的概念,就可以方便我们把一个用户运行的所有进程作为一个整体进行管理。进程组的产生来源于命令行操作的作业管理。什么是作业管理呢?就是把一行命令的执行整体作为一个作业。一行命令的执行不一定只有一个进程,比如命令
ps -ef | grep
bash,就有两个进程,我们需要有个概念把这两个进程作为一个整体来处理,这个概念就是进程组。有了进程组的概念,作业管理就比较方便了,比如Ctrl+C就是给当前正在执行的命令(进程组)发信号,进程组中的每个进程都会收到信号。
一个进程诞生的时候默认继承父进程的会话组和进程组,但是进程可以通过系统调用(setsid,setpgrp)创建新的会话组或者进程组。会话组的第一个进程叫做这个会话组的组长,进程组的第一个进程叫做这个进程组的组长,会话组的id等于会话组组长的pid,进程组的id等于进程组组长的pid。一个进程只有当它不是某个进程组组长的时候,它才可以调用setpgrp创建新的进程组,同时它也成为了这个新建的进程组的组长。这个也很好理解,只有臣子造反当皇帝,哪有皇帝自己造自己的反重新创建一个朝代的。同理,只有不是会话组组长的进程才能通过setsid创建新的会话组,并成为这个会话组组长。而且在这个新的会话组里也不能没有进程组啊,于是还会创建一个进程组,这个会话组组长还会成为这个新建的进程组的组长,这也要求了这个进程之前不能是进程组组长。所以只有既不是进程组组长又不是会话组组长的进程才能创建新的会话组。
任何一个进程,它必然属于某个进程组,而且只能同时属于一个进程组。任何一个进程,它必然属于某个会话组,而且只能属于一个会话组。任何一个进程组,它的所有进程必须都属于同一个会话组。一个进程所属的会话组只有两种来源,要么是继承而来的,要么是自己创建的,进程是不能转会话组的。不过一个进程是可以转进程组的,但是只能在同一个会话组中的进程组之间转。因此我们可以得出一个结论,一个会话组的所有进程肯定都是其会话组组长的子孙进程,一个进程组的所有进程一般情况下都是其进程组组长的子孙进程。
我们来画一下进程的家族关系:
二、进程的实现
明白了进程的基本概念之后,我们来看一看Linux是怎么实现进程的。按照标准的操作系统理论,进程是资源分配的单位,线程是程序执行的单位,内核里用进程控制块(PCB
Process Control Block)来管理进程,用线程控制块(TCB Thread Control
Block)来管理线程。那么Linux是按照这个逻辑来实现进程的吗?我们来看一下。
2.1 基本原理
Linux内核并不是按照标准的操作系统理论来实现进程的,在内核里找不到典型的进程控制块和线程控制块。内核里只有一个task_struct结构体,初学内核的人会很疑惑这是代表进程还是代表线程呢。之所以会这样,是由于历史原因造成的。Linux最开始的时候是不支持多线程的,也可以认为此时一个进程只能有一个线程就是主线程,因此线程就是进程,进程就是线程。所以最初的时候,task_struct既代表进程又代表线程,因为进程和线程没有区别。但是后来Linux也要支持多线程了,我们在1.2节中讨论过,多线程的实现方法可以在内核实现,也可以在用户空间实现,也可以同时实现,Linux选择的是在内核实现。为了最大限度地利用已有的代码,尽量不对代码做大的改动,Linux选择的方法是:task_struct既是线程又是进程的代理。注意这句话,task_struct既是线程又是进程的代理(不是进程本身)。Linux并没有设计单独的进程结构体,而是用task_struct作为进程的代理,这是因为进程是资源分配的单位,线程是程序执行的单位,同一个进程的所有线程共享相同的资源,因此我们让同一个进程下的所有线程(task_struct)都指向相同的资源不就可以了嘛。线程在执行的时候会通过task_struct里面的指针访问资源,同一个进程下的线程自然就会访问到相同的资源,而且这么做还有很大的灵活性。
我们下面再来强调一下这句话,以加深对这句话的理解。
task_struct既是线程又是进程的代理(不是进程本身)。
2.2 进程结构体
当我们明白了task_struct既是线程又是进程的代理之后,再来理解task_struct就容易多了。task_struct的字段由两部分组成,一部分是线程相关的,一部分是进程相关的,线程相关的一般是直接内嵌其它数据,进程相关的一般是用指针指向其它数据。线程代表的是执行流,所以task_struct的线程相关部分是和执行有关的,进程代表的是资源分配,所以task_struct的进程相关部分是和资源有关的。我们可以想一下和执行有关的都有哪些,和资源有关的都哪些?可以很轻松地想到,和执行有关的肯定是进程调度相关的数据啊(进程调度虽然叫进程调度,但实际上调度的是线程)。和资源相关的,最重要的首先肯定是虚拟内存啊,其次是文件系统。
下面我们来看一下task_struct的定义:
linux-src/include/linux/sched.h
struct task_struct
{
#ifdef CONFIG_THREAD_INFO_IN_TASK
struct thread_info thread_info;
#endif
unsigned int __state;
void *stack;
unsigned int flags;
int on_cpu;
unsigned int cpu;
int recent_used_cpu;
int wake_cpu;
int on_rq;
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_mask;
struct sched_info sched_info;
struct list_head tasks;
struct mm_struct *mm;
struct mm_struct *active_mm;
struct vmacache vmacache;
int exit_state;
int exit_code;
int exit_signal;
pid_t pid;
pid_t tgid;
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
unsigned long nvcsw;
unsigned long nivcsw;
u64 start_time;
u64 start_boottime;
unsigned long min_flt;
unsigned long maj_flt;
char comm[TASK_COMM_LEN];
struct fs_struct *fs;
struct files_struct *files;
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked;
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending;
struct thread_struct thread;
}; |
这个结构体定义有700多行,本文把一些暂时用不到的都删除了,现在还有70多行,我们来看一下大概都有哪些内容。先看和进程相关的,首先最重要的是虚拟内存空间信息mm、active_mm,这两个都是指针,对于用户线程来说两个指针的值永远都是相同的,同一个进程的所有线程都指向相同的mm,这个值就表明了同一个进程的线程都在同一个用户空间。其次比较重要的是文件管理相关的两个字段fs和files,也都是指针,fs代表的是文件系统挂载相关的,这个不仅是同进程的所有线程都相同,而且整个系统默认的值都一样,除非使用了mount
命名空间,files代表的是打开的文件资源,这个是同进程的所有线程都相同。然后我们再来看一下信号相关的,信号有的数据是进程全局的,有的是线程私有的,信号的处理是进程全局的,所以signal、sighand两个字段都是指针,同进程的所有线程都指向同一个结构体,信号掩码是线程私有的,所以blocked直接是内嵌数据。进程相关的数据基本就这些,下面我们来看一下线程相关的数据。首先是进程的运行退出状态,有几个字段,__state、on_cpu、cpu、exit_state、exit_code、exit_signal。然后是和线程调度相关的几个字段,有和优先级相关的rt_priority、static_prio、normal_prio、prio,有和调度信息统计相关的两个结构体,se、sched_info。还有两个非常重要的字段我们下一节讲。
2.3 进程标识符
task_struct里面有两个重要的字段pid、tgid。我们在用户空间的时候也有pid、tid,那么用户空间的pid是不是就是内核的pid呢,那tgid又是啥呢。很多初学内核的人会认为用户空间的pid就是内核的pid,刚开始我也是这么认为的,给我的内核学习带来了很大的困扰。实际上用户空间的tid是内核空间pid,用户空间的pid是内核空间的tgid,内核空间的tgid是内核里主线程的pid。为什么会这样呢?主要还是前面讲的问题,task_struct既是线程又是进程的代理,没有单独的进程结构体。当进程创建时,也就是进程的第一个线程创建时,会为task_struct分配一个pid,就是主线程的tid,然后进程的pid也就是字段tgid会被赋值为主线程的tid。此后再创建的线程都会继承父线程的tgid,所以在每个线程中都能直接获取进程的pid。
我们在这里画个图总结一下进程与线程的关系、pid与tgid之间的关系:
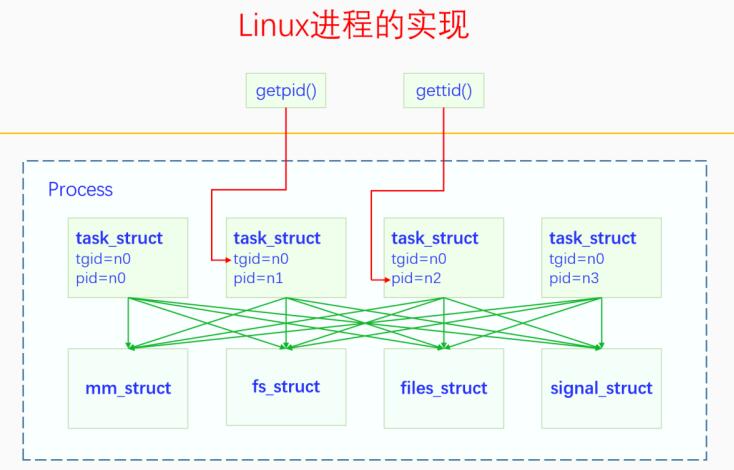
Linux里面虽然没有进程结构体,但是所有tgid相同、虚拟内存等资源相同的线程构成一个虚拟的进程结构体。创建进程的第一个线程(task_struct)就是同时在创建进程,其对应的mm_struct、files_struct、signal_struct等资源都会被创建出来。创建进程的第二个线程那就是纯粹地创建线程了。
2.4 进程的状态
进程的状态在Linux中是如何表示的呢?task_struct中有两个字段用来表示进程的状态,__state和exit_state,前者是总体状态,后者是进程在死亡时的两个子状态。
我们来看一下代码中的定义:
linux-src/include/linux/sched.h
| /*
Used in tsk->state: */
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE
0x0001
#define TASK_UNINTERRUPTIBLE
0x0002
#define __TASK_STOPPED 0x0004
#define __TASK_TRACED 0x0008
/* Used in tsk->exit_state:
*/
#define EXIT_DEAD 0x0010
#define EXIT_ZOMBIE 0x0020
#define EXIT_TRACE (EXIT_ZOMBIE
| EXIT_DEAD)
/* Used in tsk->state again:
*/
#define TASK_PARKED 0x0040
#define TASK_DEAD 0x0080
#define TASK_WAKEKILL 0x0100
#define TASK_WAKING 0x0200
#define TASK_NOLOAD 0x0400
#define TASK_NEW 0x0800 |
其中TASK_RUNNING代表的是Runnable和Running状态。在Linux中不是用flag直接区分Runnable和Running状态的,它们都用TASK_RUNNING表示,区分它们的方法是进程是否在运行队列的当前进程字段上。Blocked状态有两种表示,TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,它们的区别是前者在睡眠时能被信号唤醒,后者不能被信号唤醒。表示死亡的状态是TASK_DEAD,它有两个子状态EXIT_ZOMBIE、EXIT_DEAD,这两个状态在3.6中讲解。
三、进程的生命周期
了解了进程的基本概念,明白了进程在Linux中的实现,下面我们再来看一看进程的生命周期。进程的生命周期和进程的五态转化有关联,但是又不完全相同。我们先来回顾一下进程的五态转化图。
进程从无到有要经历新建的状态,在Linux上创建进程和加载程序是两个不同的步骤。刚创建出来的进程和父进程几乎是一模一样,要想执行新的程序还得经历装载的过程。程序装载完成之后就会进入就绪、执行、阻塞的循环了,这个是进程调度里面的内容。实际上程序在main函数之前还经历了两个过程,分别是so的加载和程序本身的初始化。进程执行到最后总会经历死亡,无论是主动退出还是意外死亡。下面我们就详细分析一下进程的这几个生命周期。
3.1 进程的创建
Linux上创建进程和我们直观想象的不同,我们一般想象的是有个类似create_process的系统调用,可以直接创建进程并执行新的程序。但是在UNIX-like的系统上,创建进程和执行新的程序是分开的,fork是用来创建进程的,创建的进程和父进程是同一个程序,然后可以在子进程中通过exec系统调用来执行你想要执行的程序。UNIX为什么要这么设计呢?有两个原因,一是当时还没有多线程,使用fork可以实现多进程;二是fork之后可以进行一些操作再用exec装载新程序,可以提高灵活性。我们这节只讲fork,在下一节讲exec。
我们先来看一下fork的接口定义:
| #include
<unistd.h>
pid_t fork(void); |
fork系统调用不接受任何参数,返回值是个pid。第一次接触fork的人难免会有疑惑,fork是怎么创建进程的呢?答案是fork会返回两次,在父进程中返回一次,在子进程中返回一次,在父进程中返回的是子进程的pid,在子进程中返回的是0,如果创建进程失败则返回-1。估计很多人还是难以理解这是什么意思。下面我们再举个例子用代码来演示一下。
| #include
<stdio.h>
#include <sys/wait.h>
#include <unistd.h>
#include <signal.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
pid_t pid = fork();
if(pid == -1) {
printf("fork error, exit\n");
exit(-1);
} else if(pid == 0) {
printf("I am child process,
pid:%d\n", getpid());
pause();
} else {
printf("I am parent process,
pid:%d, my child is pid:%d\n", getpid(),
pid);
waitpid(pid, NULL, 0);
}
} |
从这个例子中,我们可以看到fork的用法,当fork返回值为0时代表是子进程,我们可以在这里做一些要在子进程中做的事。
那么fork系统调用是怎么实现的呢?让我们来看一下代码:
linux-src/kernel/fork.c
SYSCALL_DEFINE0(fork)
{
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
pid_t kernel_clone(struct kernel_clone_args
*args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
pid_t nr;
/*
* For legacy clone() calls, CLONE_PIDFD uses
the parent_tid argument
* to return the pidfd. Hence, CLONE_PIDFD and
CLONE_PARENT_SETTID are
* mutually exclusive. With clone3() CLONE_PIDFD
has grown a separate
* field in struct clone_args and it still doesn't
make sense to have
* them both point at the same memory location.
Performing this check
* here has the advantage that we don't need
to have a separate helper
* to check for legacy clone().
*/
if ((args->flags & CLONE_PIDFD) &&
(args->flags & CLONE_PARENT_SETTID) &&
(args->pidfd == args->parent_tid))
return -EINVAL;
/*
* Determine whether and which event to report
to ptracer. When
* called from kernel_thread or CLONE_UNTRACED
is explicitly
* requested, no event is reported; otherwise,
report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if (args->exit_signal != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current,
trace)))
trace = 0;
}
p = copy_process(NULL, trace, NUMA_NO_NODE,
args);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the
thread pointer
* might get invalid after that point, if the
thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, args->parent_tid);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run,
tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
} |
内核本身有fork的系统调用,但是glibc的fork API是用clone系统调用来实现的,我们知道这一点就行了,实际上它们最后调用的代码还是一样的,所以我们还用fork系统调用来讲解,没有影响。可以看到fork系统调用什么也没做,直接调用的kernel_clone函数,kernel_clone以前叫做do_fork,现在改名了。kernel_clone的逻辑也很简单,就是做了两件事,一是copy_process复制task_struct,二是wake_up_new_task唤醒新进程。copy_process会根据flag来决定新的task_struct是自己创建新的mm_struct、files_struct等结构体,还是和父线程共享这些结构体,由于我们这里是创建进程,所以这些结构体都会创建新的。系统调用执行完成后就会返回,返回值是子进程的pid。而子进程被wake_up之后会被调度执行,它返回到用户空间时返回值是0。
3.2 进程的装载
新的进程刚刚创建之后执行的还是旧的程序,想要执行新的程序的话还得使用系统调用execve。execve会把当前程序替换为新的程序。下面我们先来看一下execve的接口:
| #include
<unistd.h>
int execve(const char *pathname,
char *const argv[], char *const envp[]); |
第一个参数是要执行的程序的路径,可以是相对路径也可以是绝对路径。第二个参数是程序的参数列表,我们在命令行执行命令时后面跟的参数会被放到这里。第三个参数是环境变量列表,在命令行执行程序时bash会被自己的环境变量放到这里传给子进程。
除此之外,libc还提供了几个API可以用来执行新的进程,它们的功能是一样的,只是参数有所差异,这些API的实现还是使用的系统调用execve。
#include <unistd.h>
extern char **environ;
int execl(const char *pathname, const char *arg,
... /*, (char *) NULL */);
int execlp(const char *file, const char *arg,
... /*, (char *) NULL */);
int execle(const char *pathname, const char *arg,
... /*, (char *) NULL, char *const envp[] */);
int execv(const char *pathname, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]); |
下面我们来看一下execve系统调用的实现:
linux-src/fs/exec.c
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv
};
struct user_arg_ptr envp = { .ptr.native = __envp
};
return do_execveat_common(AT_FDCWD, filename,
argv, envp, 0);
}
static int do_execveat_common(int fd, struct
filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
struct linux_binprm *bprm;
int retval;
if (IS_ERR(filename))
return PTR_ERR(filename);
/*
* We move the actual failure in case of RLIMIT_NPROC
excess from
* set*uid() to execve() because too many poorly
written programs
* don't check setuid() return code. Here we
additionally recheck
* whether NPROC limit is still exceeded.
*/
if ((current->flags & PF_NPROC_EXCEEDED)
&&
is_ucounts_overlimit(current_ucounts(), UCOUNT_RLIMIT_NPROC,
rlimit(RLIMIT_NPROC))) {
retval = -EAGAIN;
goto out_ret;
}
/* We're below the limit (still or again),
so we don't want to make
* further execve() calls fail. */
current->flags &= ~PF_NPROC_EXCEEDED;
bprm = alloc_bprm(fd, filename);
if (IS_ERR(bprm)) {
retval = PTR_ERR(bprm);
goto out_ret;
}
retval = count(argv, MAX_ARG_STRINGS);
if (retval < 0)
goto out_free;
bprm->argc = retval;
retval = count(envp, MAX_ARG_STRINGS);
if (retval < 0)
goto out_free;
bprm->envc = retval;
retval = bprm_stack_limits(bprm);
if (retval < 0)
goto out_free;
retval = copy_string_kernel(bprm->filename,
bprm);
if (retval < 0)
goto out_free;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp,
bprm);
if (retval < 0)
goto out_free;
retval = copy_strings(bprm->argc, argv,
bprm);
if (retval < 0)
goto out_free;
retval = bprm_execve(bprm, fd, filename, flags);
out_free:
free_bprm(bprm);
out_ret:
putname(filename);
return retval;
}
static int bprm_execve(struct linux_binprm
*bprm,
int fd, struct filename *filename, int flags)
{
struct file *file;
int retval;
retval = prepare_bprm_creds(bprm);
if (retval)
return retval;
check_unsafe_exec(bprm);
current->in_execve = 1;
file = do_open_execat(fd, filename, flags);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
sched_exec();
bprm->file = file;
/*
* Record that a name derived from an O_CLOEXEC
fd will be
* inaccessible after exec. This allows the code
in exec to
* choose to fail when the executable is not
mmaped into the
* interpreter and an open file descriptor is
not passed to
* the interpreter. This makes for a better user
experience
* than having the interpreter start and then
immediately fail
* when it finds the executable is inaccessible.
*/
if (bprm->fdpath && get_close_on_exec(fd))
bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE;
/* Set the unchanging part of bprm->cred
*/
retval = security_bprm_creds_for_exec(bprm);
if (retval)
goto out;
retval = exec_binprm(bprm);
if (retval < 0)
goto out;
/* execve succeeded */
current->fs->in_exec = 0;
current->in_execve = 0;
rseq_execve(current);
acct_update_integrals(current);
task_numa_free(current, false);
return retval;
out:
/*
* If past the point of no return ensure the
code never
* returns to the userspace process. Use an existing
fatal
* signal if present otherwise terminate the
process with
* SIGSEGV.
*/
if (bprm->point_of_no_return && !fatal_signal_pending(current))
force_fatal_sig(SIGSEGV);
out_unmark:
current->fs->in_exec = 0;
current->in_execve = 0;
return retval;
}
static int exec_binprm(struct linux_binprm
*bprm)
{
pid_t old_pid, old_vpid;
int ret, depth;
/* Need to fetch pid before load_binary changes
it */
old_pid = current->pid;
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
/* This allows 4 levels of binfmt rewrites
before failing hard. */
for (depth = 0;; depth++) {
struct file *exec;
if (depth > 5)
return -ELOOP;
ret = search_binary_handler(bprm);
if (ret < 0)
return ret;
if (!bprm->interpreter)
break;
exec = bprm->file;
bprm->file = bprm->interpreter;
bprm->interpreter = NULL;
allow_write_access(exec);
if (unlikely(bprm->have_execfd)) {
if (bprm->executable) {
fput(exec);
return -ENOEXEC;
}
bprm->executable = exec;
} else
fput(exec);
}
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
return 0;
}
static int search_binary_handler(struct linux_binprm
*bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
retval = prepare_binprm(bprm);
if (retval < 0)
return retval;
retval = security_bprm_check(bprm);
if (retval)
return retval;
retval = -ENOENT;
retry:
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (bprm->point_of_no_return || (retval !=
-ENOEXEC)) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1])
&&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x",
*(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
} |
linux-src/fs/binfmt_elf.c
static int load_elf_binary(struct
linux_binprm *bprm)
{
struct file *interpreter = NULL; /* to shut gcc
up */
unsigned long load_addr = 0, load_bias = 0;
int load_addr_set = 0;
unsigned long error;
struct elf_phdr *elf_ppnt, *elf_phdata, *interp_elf_phdata
= NULL;
struct elf_phdr *elf_property_phdata = NULL;
unsigned long elf_bss, elf_brk;
int bss_prot = 0;
int retval, i;
unsigned long elf_entry;
unsigned long e_entry;
unsigned long interp_load_addr = 0;
unsigned long start_code, end_code, start_data,
end_data;
unsigned long reloc_func_desc __maybe_unused =
0;
int executable_stack = EXSTACK_DEFAULT;
struct elfhdr *elf_ex = (struct elfhdr *)bprm->buf;
struct elfhdr *interp_elf_ex = NULL;
struct arch_elf_state arch_state = INIT_ARCH_ELF_STATE;
struct mm_struct *mm;
struct pt_regs *regs;
retval = -ENOEXEC;
/* First of all, some simple consistency checks
*/
if (memcmp(elf_ex->e_ident, ELFMAG, SELFMAG)
!= 0)
goto out;
if (elf_ex->e_type != ET_EXEC &&
elf_ex->e_type != ET_DYN)
goto out;
if (!elf_check_arch(elf_ex))
goto out;
if (elf_check_fdpic(elf_ex))
goto out;
if (!bprm->file->f_op->mmap)
goto out;
elf_phdata = load_elf_phdrs(elf_ex, bprm->file);
if (!elf_phdata)
goto out;
elf_ppnt = elf_phdata;
for (i = 0; i < elf_ex->e_phnum; i++,
elf_ppnt++) {
char *elf_interpreter;
if (elf_ppnt->p_type == PT_GNU_PROPERTY)
{
elf_property_phdata = elf_ppnt;
continue;
}
if (elf_ppnt->p_type != PT_INTERP)
continue;
/*
* This is the program interpreter used for shared
libraries - * for now assume that this is an
a.out format binary.
*/
retval = -ENOEXEC;
if (elf_ppnt->p_filesz > PATH_MAX || elf_ppnt->p_filesz
< 2)
goto out_free_ph;
retval = -ENOMEM;
elf_interpreter = kmalloc(elf_ppnt->p_filesz,
GFP_KERNEL);
if (!elf_interpreter)
goto out_free_ph;
retval = elf_read(bprm->file, elf_interpreter,
elf_ppnt->p_filesz,
elf_ppnt->p_offset);
if (retval < 0)
goto out_free_interp;
/* make sure path is NULL terminated */
retval = -ENOEXEC;
if (elf_interpreter[elf_ppnt->p_filesz -
1] != '\0')
goto out_free_interp;
interpreter = open_exec(elf_interpreter);
kfree(elf_interpreter);
retval = PTR_ERR(interpreter);
if (IS_ERR(interpreter))
goto out_free_ph;
/*
* If the binary is not readable then enforce
mm->dumpable = 0
* regardless of the interpreter's permissions.
*/
would_dump(bprm, interpreter);
interp_elf_ex = kmalloc(sizeof(*interp_elf_ex),
GFP_KERNEL);
if (!interp_elf_ex) {
retval = -ENOMEM;
goto out_free_ph;
}
/* Get the exec headers */
retval = elf_read(interpreter, interp_elf_ex,
sizeof(*interp_elf_ex), 0);
if (retval < 0)
goto out_free_dentry;
break;
out_free_interp:
kfree(elf_interpreter);
goto out_free_ph;
}
elf_ppnt = elf_phdata;
for (i = 0; i < elf_ex->e_phnum; i++,
elf_ppnt++)
switch (elf_ppnt->p_type) {
case PT_GNU_STACK:
if (elf_ppnt->p_flags & PF_X)
executable_stack = EXSTACK_ENABLE_X;
else
executable_stack = EXSTACK_DISABLE_X;
break;
case PT_LOPROC ... PT_HIPROC:
retval = arch_elf_pt_proc(elf_ex, elf_ppnt,
bprm->file, false,
&arch_state);
if (retval)
goto out_free_dentry;
break;
}
/* Some simple consistency checks for the
interpreter */
if (interpreter) {
retval = -ELIBBAD;
/* Not an ELF interpreter */
if (memcmp(interp_elf_ex->e_ident, ELFMAG,
SELFMAG) != 0)
goto out_free_dentry;
/* Verify the interpreter has a valid arch */
if (!elf_check_arch(interp_elf_ex) ||
elf_check_fdpic(interp_elf_ex))
goto out_free_dentry;
/* Load the interpreter program headers */
interp_elf_phdata = load_elf_phdrs(interp_elf_ex,
interpreter);
if (!interp_elf_phdata)
goto out_free_dentry;
/* Pass PT_LOPROC..PT_HIPROC headers to arch
code */
elf_property_phdata = NULL;
elf_ppnt = interp_elf_phdata;
for (i = 0; i < interp_elf_ex->e_phnum;
i++, elf_ppnt++)
switch (elf_ppnt->p_type) {
case PT_GNU_PROPERTY:
elf_property_phdata = elf_ppnt;
break;
case PT_LOPROC ... PT_HIPROC:
retval = arch_elf_pt_proc(interp_elf_ex,
elf_ppnt, interpreter,
true, &arch_state);
if (retval)
goto out_free_dentry;
break;
}
}
retval = parse_elf_properties(interpreter
?: bprm->file,
elf_property_phdata, &arch_state);
if (retval)
goto out_free_dentry;
/*
* Allow arch code to reject the ELF at this
point, whilst it's
* still possible to return an error to the code
that invoked
* the exec syscall.
*/
retval = arch_check_elf(elf_ex,
!!interpreter, interp_elf_ex,
&arch_state);
if (retval)
goto out_free_dentry;
/* Flush all traces of the currently running
executable */
retval = begin_new_exec(bprm);
if (retval)
goto out_free_dentry;
/* Do this immediately, since STACK_TOP as
used in setup_arg_pages
may depend on the personality. */
SET_PERSONALITY2(*elf_ex, &arch_state);
if (elf_read_implies_exec(*elf_ex, executable_stack))
current->personality |= READ_IMPLIES_EXEC;
if (!(current->personality & ADDR_NO_RANDOMIZE)
&& randomize_va_space)
current->flags |= PF_RANDOMIZE;
setup_new_exec(bprm);
/* Do this so that we can load the interpreter,
if need be. We will
change some of these later */
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
if (retval < 0)
goto out_free_dentry;
elf_bss = 0;
elf_brk = 0;
start_code = ~0UL;
end_code = 0;
start_data = 0;
end_data = 0;
/* Now we do a little grungy work by mmapping
the ELF image into
the correct location in memory. */
for(i = 0, elf_ppnt = elf_phdata;
i < elf_ex->e_phnum; i++, elf_ppnt++)
{
int elf_prot, elf_flags;
unsigned long k, vaddr;
unsigned long total_size = 0;
unsigned long alignment;
if (elf_ppnt->p_type != PT_LOAD)
continue;
if (unlikely (elf_brk > elf_bss)) {
unsigned long nbyte;
/* There was a PT_LOAD segment with p_memsz
> p_filesz
before this one. Map anonymous pages, if needed,
and clear the area. */
retval = set_brk(elf_bss + load_bias,
elf_brk + load_bias,
bss_prot);
if (retval)
goto out_free_dentry;
nbyte = ELF_PAGEOFFSET(elf_bss);
if (nbyte) {
nbyte = ELF_MIN_ALIGN - nbyte;
if (nbyte > elf_brk - elf_bss)
nbyte = elf_brk - elf_bss;
if (clear_user((void __user *)elf_bss +
load_bias, nbyte)) {
/*
* This bss-zeroing can fail if the ELF
* file specifies odd protections. So
* we don't check the return value
*/
}
}
}
elf_prot = make_prot(elf_ppnt->p_flags,
&arch_state,
!!interpreter, false);
elf_flags = MAP_PRIVATE;
vaddr = elf_ppnt->p_vaddr;
/*
* If we are loading ET_EXEC or we have already
performed
* the ET_DYN load_addr calculations, proceed
normally.
*/
if (elf_ex->e_type == ET_EXEC || load_addr_set)
{
elf_flags |= MAP_FIXED;
} else if (elf_ex->e_type == ET_DYN) {
/*
* This logic is run once for the first LOAD
Program
* Header for ET_DYN binaries to calculate the
* randomization (load_bias) for all the LOAD
* Program Headers, and to calculate the entire
* size of the ELF mapping (total_size). (Note
that
* load_addr_set is set to true later once the
* initial mapping is performed.)
*
* There are effectively two types of ET_DYN
* binaries: programs (i.e. PIE: ET_DYN with
INTERP)
* and loaders (ET_DYN without INTERP, since
they
* _are_ the ELF interpreter). The loaders must
* be loaded away from programs since the program
* may otherwise collide with the loader (especially
* for ET_EXEC which does not have a randomized
* position). For example to handle invocations
of
* "./ld.so someprog" to test out a
new version of
* the loader, the subsequent program that the
* loader loads must avoid the loader itself,
so
* they cannot share the same load range. Sufficient
* room for the brk must be allocated with the
* loader as well, since brk must be available
with
* the loader.
*
* Therefore, programs are loaded offset from
* ELF_ET_DYN_BASE and loaders are loaded into
the
* independently randomized mmap region (0 load_bias
* without MAP_FIXED).
*/
if (interpreter) {
load_bias = ELF_ET_DYN_BASE;
if (current->flags & PF_RANDOMIZE)
load_bias += arch_mmap_rnd();
alignment = maximum_alignment(elf_phdata, elf_ex->e_phnum);
if (alignment)
load_bias &= ~(alignment - 1);
elf_flags |= MAP_FIXED;
} else
load_bias = 0;
/*
* Since load_bias is used for all subsequent
loading
* calculations, we must lower it by the first
vaddr
* so that the remaining calculations based on
the
* ELF vaddrs will be correctly offset. The result
* is then page aligned.
*/
load_bias = ELF_PAGESTART(load_bias - vaddr);
total_size = total_mapping_size(elf_phdata,
elf_ex->e_phnum);
if (!total_size) {
retval = -EINVAL;
goto out_free_dentry;
}
}
error = elf_map(bprm->file, load_bias +
vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
if (BAD_ADDR(error)) {
retval = IS_ERR((void *)error) ?
PTR_ERR((void*)error) : -EINVAL;
goto out_free_dentry;
}
if (!load_addr_set) {
load_addr_set = 1;
load_addr = (elf_ppnt->p_vaddr - elf_ppnt->p_offset);
if (elf_ex->e_type == ET_DYN) {
load_bias += error - ELF_PAGESTART(load_bias
+ vaddr);
load_addr += load_bias;
reloc_func_desc = load_bias;
}
}
k = elf_ppnt->p_vaddr;
if ((elf_ppnt->p_flags & PF_X) &&
k < start_code)
start_code = k;
if (start_data < k)
start_data = k;
/*
* Check to see if the section's size will overflow
the
* allowed task size. Note that p_filesz must
always be
* <= p_memsz so it is only necessary to check
p_memsz.
*/
if (BAD_ADDR(k) || elf_ppnt->p_filesz >
elf_ppnt->p_memsz ||
elf_ppnt->p_memsz > TASK_SIZE ||
TASK_SIZE - elf_ppnt->p_memsz < k) {
/* set_brk can never work. Avoid overflows.
*/
retval = -EINVAL;
goto out_free_dentry;
}
k = elf_ppnt->p_vaddr + elf_ppnt->p_filesz;
if (k > elf_bss)
elf_bss = k;
if ((elf_ppnt->p_flags & PF_X) &&
end_code < k)
end_code = k;
if (end_data < k)
end_data = k;
k = elf_ppnt->p_vaddr + elf_ppnt->p_memsz;
if (k > elf_brk) {
bss_prot = elf_prot;
elf_brk = k;
}
}
e_entry = elf_ex->e_entry + load_bias;
elf_bss += load_bias;
elf_brk += load_bias;
start_code += load_bias;
end_code += load_bias;
start_data += load_bias;
end_data += load_bias;
/* Calling set_brk effectively mmaps the pages
that we need
* for the bss and break sections. We must do
this before
* mapping in the interpreter, to make sure it
doesn't wind
* up getting placed where the bss needs to go.
*/
retval = set_brk(elf_bss, elf_brk, bss_prot);
if (retval)
goto out_free_dentry;
if (likely(elf_bss != elf_brk) && unlikely(padzero(elf_bss)))
{
retval = -EFAULT; /* Nobody gets to see this,
but.. */
goto out_free_dentry;
}
if (interpreter) {
elf_entry = load_elf_interp(interp_elf_ex,
interpreter,
load_bias, interp_elf_phdata,
&arch_state);
if (!IS_ERR((void *)elf_entry)) {
/*
* load_elf_interp() returns relocation
* adjustment
*/
interp_load_addr = elf_entry;
elf_entry += interp_elf_ex->e_entry;
}
if (BAD_ADDR(elf_entry)) {
retval = IS_ERR((void *)elf_entry) ?
(int)elf_entry : -EINVAL;
goto out_free_dentry;
}
reloc_func_desc = interp_load_addr;
allow_write_access(interpreter);
fput(interpreter);
kfree(interp_elf_ex);
kfree(interp_elf_phdata);
} else {
elf_entry = e_entry;
if (BAD_ADDR(elf_entry)) {
retval = -EINVAL;
goto out_free_dentry;
}
}
kfree(elf_phdata);
set_binfmt(&elf_format);
#ifdef ARCH_HAS_SETUP_ADDITIONAL_PAGES
retval = ARCH_SETUP_ADDITIONAL_PAGES(bprm, elf_ex,
!!interpreter);
if (retval < 0)
goto out;
#endif /* ARCH_HAS_SETUP_ADDITIONAL_PAGES */
retval = create_elf_tables(bprm, elf_ex,
load_addr, interp_load_addr, e_entry);
if (retval < 0)
goto out;
mm = current->mm;
mm->end_code = end_code;
mm->start_code = start_code;
mm->start_data = start_data;
mm->end_data = end_data;
mm->start_stack = bprm->p;
if ((current->flags & PF_RANDOMIZE)
&& (randomize_va_space > 1)) {
/*
* For architectures with ELF randomization,
when executing
* a loader directly (i.e. no interpreter listed
in ELF
* headers), move the brk area out of the mmap
region
* (since it grows up, and may collide early
with the stack
* growing down), and into the unused ELF_ET_DYN_BASE
region.
*/
if (IS_ENABLED(CONFIG_ARCH_HAS_ELF_RANDOMIZE)
&&
elf_ex->e_type == ET_DYN && !interpreter)
{
mm->brk = mm->start_brk = ELF_ET_DYN_BASE;
}
mm->brk = mm->start_brk = arch_randomize_brk(mm);
#ifdef compat_brk_randomized
current->brk_randomized = 1;
#endif
}
if (current->personality & MMAP_PAGE_ZERO)
{
/* Why this, you ask??? Well SVr4 maps page
0 as read-only,
and some applications "depend" upon
this behavior.
Since we do not have the power to recompile
these, we
emulate the SVr4 behavior. Sigh. */
error = vm_mmap(NULL, 0, PAGE_SIZE, PROT_READ
| PROT_EXEC,
MAP_FIXED | MAP_PRIVATE, 0);
}
regs = current_pt_regs();
#ifdef ELF_PLAT_INIT
/*
* The ABI may specify that certain registers
be set up in special
* ways (on i386 %edx is the address of a DT_FINI
function, for
* example. In addition, it may also specify
(eg, PowerPC64 ELF)
* that the e_entry field is the address of the
function descriptor
* for the startup routine, rather than the address
of the startup
* routine itself. This macro performs whatever
initialization to
* the regs structure is required as well as
any relocations to the
* function descriptor entries when executing
dynamically links apps.
*/
ELF_PLAT_INIT(regs, reloc_func_desc);
#endif
finalize_exec(bprm);
START_THREAD(elf_ex, regs, elf_entry, bprm->p);
retval = 0;
out:
return retval;
/* error cleanup */
out_free_dentry:
kfree(interp_elf_ex);
kfree(interp_elf_phdata);
allow_write_access(interpreter);
if (interpreter)
fput(interpreter);
out_free_ph:
kfree(elf_phdata);
goto out;
} |
execve系统调用的逻辑比较复杂,这里就简单解析一下。函数首先会调用alloc_bprm分配一个linux_binprm结构体,这个结构体记录着可执行程序的一些信息。在alloc_bprm会创建一个新的mm_struct,此后进程就会用这个新的虚拟内存空间了,还会创建一个vma作为主线程的栈,初始大小为4k。然后调用bprm_execve,bprm_execve会调用exec_binprm,exec_binprm会调用search_binary_handler,在search_binary_handler里会通过函数指针load_binary调用最后的函数load_elf_binary。
在load_elf_binary里,会先对ELF文件头部信息进行解析。然后会加载解释器(interpreter)。什么是解释器呢?一个程序往往并不是只有可执行程序,而是由一个可执行程序加上n个so组成。so是在程序启动时动态加载的,可能很多人会认为这个工作是由内核完成的,实际上这个工作是由一个so完成的,这个so就叫做程序解释器,在教科书上往往被叫做加载器,也有叫动态链接器的。X86_64上的解释器文件是/lib64/ld-linux-x86-64.so.2,这一般是个软连接文件,它会指向真正的解释器。内核负责加载解释器,解释器负责加载所有其它的so。很多人可能认为进程返回用户空间之后就要直接执行main函数了,实际上还早着呢。进程返回用户空间首先执行的是解释器的入口函数,解释器执行完了之后会执行可执行程序的入口函数,入口函数执行完了之后才会去执行main函数。这个正是我们下面两节要讲的内容。
3.3 进程的加载
这一节要讲的是解释器的加载过程,这个过程也被叫做动态链接。加载器的实现是在Glibc里面。我们这里就是大概介绍一下加载器的逻辑,具体的细节大家可以去看参考文献中的书籍。ELF格式的可执行程序和共享库里面有一个段叫做.dynamic,这个段里面会记录程序所依赖的所有so。so里面的.dynamic段也会记录自己所依赖的所有so。解释器会通过深度优先或者广度优先的方法找到一个程序所依赖的所有so,然后加载它们。加载一个so会首先解析它的ELF头部信息,然后通过mmap为它的数据段代码段分配内存,并设置不同的读写执行权限。最后会对so进行重定位,重定位包括全局数据重定位和函数重定位。
3.4 进程的初始化
进程完成加载之后不是直接就执行main函数的,而是会执行ELF文件的入口函数。这个入口函数叫做_start,_start完成一些基本的设置之后会调用__libc_start_main。__libc_start_main完成一些初始化之后才会调用main函数。你会发现,我们上学的时候讲的是程序执行的时候会首先执行main函数,实际上在main函数执行之前还发生了很多很复杂的事情,只不过这些事情系统都帮我们悄悄地做了,如果我们想要研究透彻的话还是很麻烦的。
__libc_start_main的具体细节请参看:
http://dbp-consulting.com/tutorials/debugging/linuxProgramStartup.html
3.5 进程的运行
程序在运行的时候会不停地经历就绪、运行、阻塞的过程,具体情况请参看《深入理解Linux进程调度》。
3.6 进程的死亡
进程执行到最后总会死亡的,进程死亡的原因可以分为两大类,正常死亡和非正常死亡。
正常死亡的情况有:
1.main函数返回。
2.进程调用了exit、_exit、_Exit 等函数。
3.进程的所有线程都调用了pthread_exit。
4.主线程调用了pthread_exit,其他线程都从线程函数返回。
非正常死亡的情况有:
1.进程访问非法内存而收到信号SIGSEGV。
2.库程序发现异常情况给进程发送信号SIGABRT。
3.在终端上输入Ctrl+C给进程发送信号SIGINT。
4.通过kill命令给进程发送信号SIGTERM。
5.通过kill -9命令给进程发送信号SIGKILL。
6.进程收到其它一些会导致死亡的信号。
main函数返回本质上也是调用的exit,因为main函数外还有一层函数__libc_start_main,它会在main函数返回后调用exit。exit的实现调用的是系统调用exit_group,pthread_exit的实现调用的是系统调用exit。这里就体现出了API和系统调用的不同。进程由于信号原因而死的,其死亡方法也是内核在信号处理中调用了系统调用exit_group,只不过是直接调用的函数,没有走系统调用的流程。系统调用exit的作用是杀死线程,系统调用exit_group的作用是杀死当前线程,并给同进程的所有其它线程发SIGKILL信号,这会导致所有的线程都死亡,从而整个进程也就死了。每个线程死亡的时候都会释放对进程资源的引用,最后一个线程死亡的时候,资源的引用计数会变成0,从而会去释放这个资源。总结一下就是进程的第一个线程创建的时候会去创建进程的资源,进程的最后一个线程死亡的时候会去释放进程的资源。
进程死亡的过程可以细分为两步,僵尸和火化,对应着进程死亡的两个子状态EXIT_ZOMBIE和EXIT_DEAD。进程只有被火化之后才算是彻底死亡了。就像人死了需要被家属送去殡仪馆火化并注销户口一样,进程死了也需要亲属送去火化并注销户口。僵尸进程虽然已经死了,但是并没有火化和注销户口,此时进程的各种状态信息还能查得到,进程被火化之后其户口也就自动注销了,内核中的相关函数、proc文件系统以及ps命令就查不到它的信息了。对于进程来说只有父进程有权力去火化子进程,如果父进程一直不去火化子进程,那么子进程就会一直处于僵尸状态。父进程火化子进程的方法的是什么呢?就是系统调用wait、waitid、waitpid、wait3、wait4。如果父进程提前死了怎么办呢?子进程会被托孤给init进程,由init进程负责对其火化。任何进程死亡都会经历僵尸状态,只不过大部分情况下这个状态持续时间都非常短,用户空间感觉不到。当父进程没有对子进程wait的时候,子进程就会一直处于僵尸状态,不会被火化,这时候用户空间通过ps命令就可以看到僵尸状态的进程了。僵尸进程不是没有死,而是死了没人送去火化,所以杀死僵尸进程的说法是不对的。清理僵尸进程的方法是kill其父进程,父进程死了,僵尸进程会被托孤给init进程,init进程会立马对其进行火化。
当一个进程的exit_group执行完成之后,这个进程就变成了僵尸进程。僵尸进程是没有用户空间的,也不可能再执行了。僵尸进程的文件等所有资源都被释放了,唯一剩下的就是还有一个task_struct结构体。如果父进程此时去wait子进程或者之前就已经在wait子进程,此时wait会返回,task_struct会被销毁,这个进程就彻底消失了。
下面然我们来看看exit_group系统调用的代码:
linux-src/kernel/exit.c
SYSCALL_DEFINE1(exit_group,
int, error_code)
{
do_group_exit((error_code & 0xff) <<
8);
/* NOTREACHED */
return 0;
}
void
do_group_exit(int exit_code)
{
struct signal_struct *sig = current->signal;
BUG_ON(exit_code & 0x80); /* core dumps
don't get here */
if (signal_group_exit(sig))
exit_code = sig->group_exit_code;
else if (!thread_group_empty(current)) {
struct sighand_struct *const sighand = current->sighand;
spin_lock_irq(&sighand->siglock);
if (signal_group_exit(sig))
/* Another thread got here before we took the
lock. */
exit_code = sig->group_exit_code;
else {
sig->group_exit_code = exit_code;
sig->flags = SIGNAL_GROUP_EXIT;
zap_other_threads(current);
}
spin_unlock_irq(&sighand->siglock);
}
do_exit(exit_code);
/* NOTREACHED */
}
void __noreturn do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
/*
* We can get here from a kernel oops, sometimes
with preemption off.
* Start by checking for critical errors.
* Then fix up important state like USER_DS and
preemption.
* Then do everything else.
*/
WARN_ON(blk_needs_flush_plug(tsk));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
/*
* If do_exit is called because this processes
oopsed, it's possible
* that get_fs() was left as KERNEL_DS, so reset
it to USER_DS before
* continuing. Amongst other possible reasons,
this is to prevent
* mm_release()->clear_child_tid() from writing
to a user-controlled
* kernel address.
*/
force_uaccess_begin();
if (unlikely(in_atomic())) {
pr_info("note: %s[%d] exited with preempt_count
%d\n",
current->comm, task_pid_nr(current),
preempt_count());
preempt_count_set(PREEMPT_ENABLED);
}
profile_task_exit(tsk);
kcov_task_exit(tsk);
ptrace_event(PTRACE_EVENT_EXIT, code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit.
Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING))
{
pr_alert("Fixing recursive fault but reboot
is needed!\n");
futex_exit_recursive(tsk);
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
io_uring_files_cancel();
exit_signals(tsk); /* sets PF_EXITING */
/* sync mm's RSS info before statistics gathering
*/
if (tsk->mm)
sync_mm_rss(tsk->mm);
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
/*
* If the last thread of global init has exited,
panic
* immediately to get a useable coredump.
*/
if (unlikely(is_global_init(tsk)))
panic("Attempted to kill init! exitcode=0x%08x\n",
tsk->signal->group_exit_code ?: (int)code);
#ifdef CONFIG_POSIX_TIMERS
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
#endif
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss,
tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm();
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_shm(tsk);
exit_files(tsk);
exit_fs(tsk);
if (group_dead)
disassociate_ctty(1);
exit_task_namespaces(tsk);
exit_task_work(tsk);
exit_thread(tsk);
/*
* Flush inherited counters to the parent - before
the parent
* gets woken up by child-exit notifications.
*
* because of cgroup mode, must be called before
cgroup_exit()
*/
perf_event_exit_task(tsk);
sched_autogroup_exit_task(tsk);
cgroup_exit(tsk);
/*
* FIXME: do that only when needed, using sched_exit
tracepoint
*/
flush_ptrace_hw_breakpoint(tsk);
exit_tasks_rcu_start();
exit_notify(tsk, group_dead);
proc_exit_connector(tsk);
mpol_put_task_policy(tsk);
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held();
if (tsk->io_context)
exit_io_context(tsk);
if (tsk->splice_pipe)
free_pipe_info(tsk->splice_pipe);
if (tsk->task_frag.page)
put_page(tsk->task_frag.page);
validate_creds_for_do_exit(tsk);
check_stack_usage();
preempt_disable();
if (tsk->nr_dirtied)
__this_cpu_add(dirty_throttle_leaks, tsk->nr_dirtied);
exit_rcu();
exit_tasks_rcu_finish();
lockdep_free_task(tsk);
do_task_dead();
} |
linux-src/kernel/signal.c
int zap_other_threads(struct
task_struct *p)
{
struct task_struct *t = p;
int count = 0;
p->signal->group_stop_count = 0;
while_each_thread(p, t) {
task_clear_jobctl_pending(t, JOBCTL_PENDING_MASK);
count++;
/* Don't bother with already dead threads
*/
if (t->exit_state)
continue;
sigaddset(&t->pending.signal, SIGKILL);
signal_wake_up(t, 1);
}
return count;
} |
四、回顾总结
在本文中我们学习了进程的基本概念,知道了进程在Linux上是怎么实现的,也明白了进程的各个生命周期的活动。下面我们再来看一下进程的实现图,回顾一下:
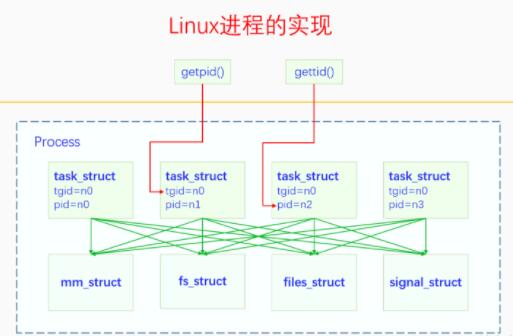
在Linux中没有严格的进程线程之分,内核没有实现进程控制块,只有一个task_struct,它既是线程又是进程的代理。当进程的第一个线程创建的时候,此时进程被创建,进程相应的资源结构体会被创建。当进程的最后一个线程死亡的时候,进程相应的所有资源都会被释放,进程就死亡了。 |







 订阅
订阅