| 编辑推荐: |
本文主要介绍异构ADS芯片的背景、任务调度的模型与实现及任务调度洞察,希望对您的学习有所帮助。
本文来自微信公众号车端,由火龙果软件Linda编辑、推荐。 |
|
1 异构ADS芯片的背景
ADS因其减少交通事故和无人驾驶的能力而备受关注。传统的ADAS功能在当今市场上已经被广泛应用,例如自动紧急刹车和车道保持,是当检测到危险时,通过对制动、加速以及转向的简单控制来实现的。而对于最新的ADAS功能,例如自适应巡航和智能泊车,则需要对车辆的转向以及速度进行更加精确的控制。但是,这些高级的功能只能在限定的场景或者区域运行。在不久的将来,更高级的
ADS系统有望在更广泛的区域(如拥挤的城市街道、路况复杂的乡村街道)支持更智能的控制,如自动紧急转向和自动代客泊车[1]。
ADS可以控制车辆的移动,它们可以从多个传感器(例如摄像头、Radar、Lidar)的输入中识别物体,并根据识别的结果做出车辆控制的决策。Figure
1是ADS应用的示例[2]。
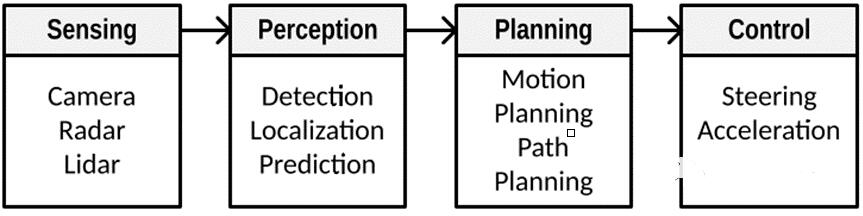
Figure 1. ADS应用的示例
该示例包含四个流程:
a.在Sensing过程中, ADS系统接收来自多个传感器的信息;
b.在Perception过程中,ADS系统对行人、车辆、路面、红绿灯、交通标志等物体进行检测和分类,识别其位置,预测周围物体的行为;
c.在Planning过程中,ADS系统利用Perception过程的结果规划出车俩的路径;
d.在Control过程中,ADS系统通过控制转向、加速和制动来控制车俩的运动
为了实现目标检测和运动轨迹预测,图像识别和机器学习是ADS系统的必备技术。深度学习的引入,可以实现更高的检测精度和跟踪更多的目标[3]-[7]。但是,这也使得ADS系统变得更加复杂。此外,预计未来的ADS系统可以更进一步的控制车辆,使得全自动驾驶成为可能。因此,ADS的应用程序需要大算力、高性能和低功耗的SoC芯片。
为了同时兼顾高性能和低功耗,ADAS/ADS的芯片通常会采用异构的SoC架构。Figure 2是NVIDIA的Orin系列芯片的架构图[8]。该SoC内部有Arm
Cortex-A78AE CPU,NVIDIA Ampere GPU,NVDLA,vision accelerator等多种加速器。
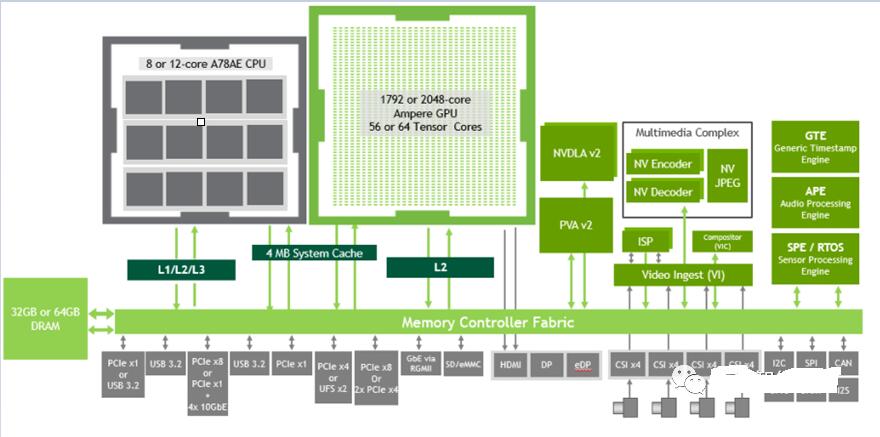
Figure 2. Jetson AGX Orin Series Functional Block
Diagram
2 任务调度的模型与实现
构建一个拥有大量异构加速器的软硬件系统并非易事。Figure 3是一个异构SoC系统示例,其中包含使用shared
memory的CPU和多种加速器[9]。由于加速器可能需要使用CPU生产的数据,因此内存的coherence和consistence的设计十分具有挑战。并且操作系统的堆栈、编译器以及调度器都需要重新设计,加速器的粒度也需要仔细定义。因此,编程模型的选择、调度器的设计是ADS系统的重要问题,好编程模型和调度器可以极大的提高算法在ADS芯片中的运算效率。
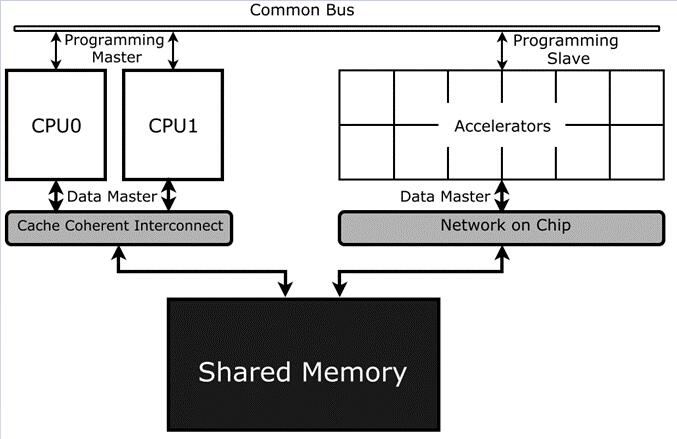
Figure 3. 异构SoC系统示例
学界和工业界一直在寻找不同级别的并行编程模型来提高计算性能,通常的并行编程模型有ILP (Instruction
Level Parallelism)、TLP (Thread Level Parallelism)和DLP
(Data Level Parallelism),如Figure 4。这三种并行模型均与计算机体系结构的发展相吻合。处理器中的指令乱序调度使得ILP的能力大幅增长;多核的设计使得TLP变尤为重要;vector计算单元的增加,例如GPGPU,使得DLP得到有效利用。
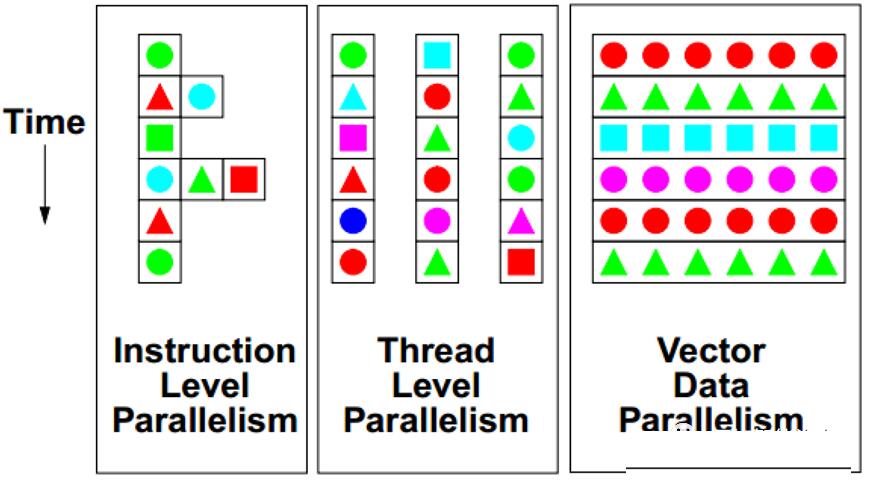
Figure 4. ILP、TLP和DLP示意图
异构ADS芯片拥有大量的专用异构加速器。ILP、TLP和DLP并不能充分发挥异构加速器的计算潜能,因此选择一种新的编程模型作为ADS算法和芯片的接口迫在眉睫。异构加速器的使用天然为task作为计算单元铺平了道路,TLP
(Task Level Parallelism)也顺理成章的被引入进来。其中,task是将一组指令定义成原语的抽象层级,该原语可以在程序中重复使用。用户的线程可以由多个task组成,通常一个task是由芯片中一种加速器执行的。如Figure
5所示,多个task可以根据不同的算法和应用场景构成DAG实现细粒度并行,task之间的边表示依赖关系。
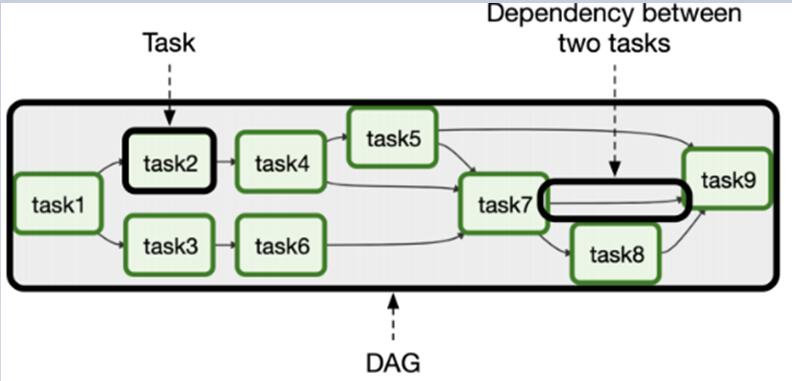
Figure 5. 由多个task构成的DAG
通常,基于task的并行计算环境由两个组件组成:
(1)任务并行API和
(2)任务runtime系统[10]。
前者定义了开发人员描述并行性、依赖性、数据分发等的方式,而后者定义了环境的效率和能力。runtime确定了支持的体系结构、调度的目标、调度策略和异常处理等。但是,这种基于软件的调度器具有固有的缺点:
a.在CPU上运行调度程序实例是一种开销,当任务粒度较小、加速器数量很多时,软件调度会占用大量的CPU资源,并且使得端到端的计算效率发生显著下降;
b.任务在加速器上执行结束,必须通过具有长延迟的中断来通知CPU,进一步导致调度的latency变大;
c.调度的软件开销、延迟开销导致无法编译出细粒度的任务,导致无法利用细粒度的并行性;
Figure 6是不同的任务粒度对OmpSs软件调度器加速效果的影响[11]。在前半段,当任务粒度变小时,Speedup是逐渐上升的;当任务粒度逐渐降低到某个点时,调度开销已经无法被计算掩盖,Speedup开始下降。
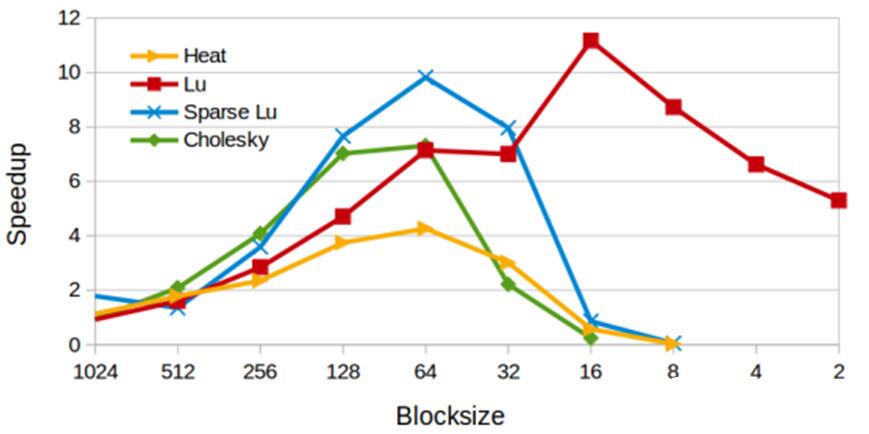
Figure 6. OmpSs在不同任务粒度下的加速器效果
如果ADS系统中包含一个SoC级别的硬件任务调度器,则可以大大减轻上述缺点,编译器可以编译出细粒度的任务来充分利用细粒度的并行。Figure
7是在Figure 3的基础上,将HTS (Hardware Task Scheduler)加入到包含CPU和各种加速器的系统中[9]。
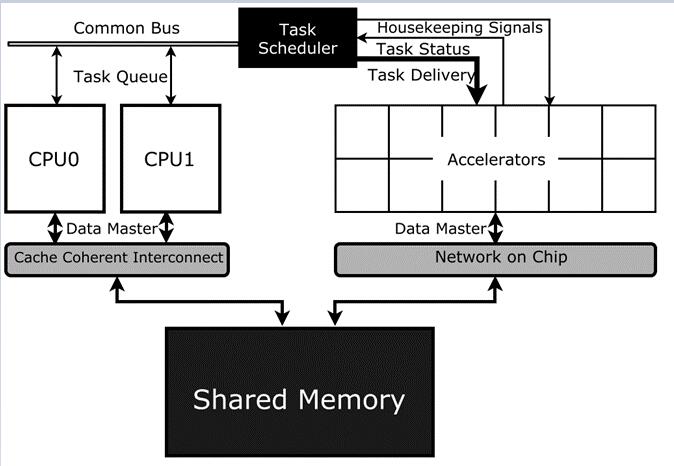
Figure 7 包含HTS的异构SoC系统
CPU可以将任务和任务间的依赖关系都推送到HTS,CPU只需要轮询任务完成队列、处理异常等。HTS会维护若干个任务队列,类似与OoO
CPU中执行的指令。HTS会维护整个系统中每个加速器的忙闲状态,并将任务发送给空闲的加速器上。
当任务执行结束时,加速器写任务完成描述符来通知HTS,这比中断处理快几个数量级。HTS可以处理任务间的依赖关系,当某个任务依赖解除时,HTS会以无序的方式调度该任务,这可以在异构ADS系统中带来巨大的速度提升。如Figure
8所示,HTS的调度相比于runtime带来显著性能提升[9]。
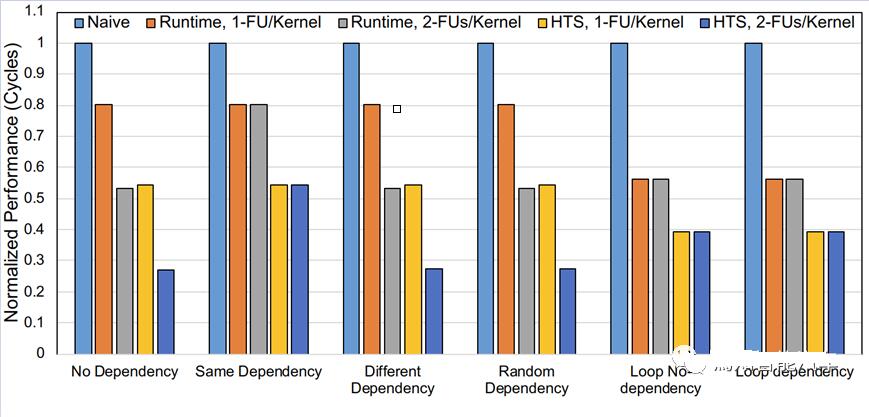
Figure 8. HTS相比于runtime带来的性能提升
因此,任务调度可以显著提升ADS芯片的计算效率。
3 任务调度洞察
业内已经有一些将任务调度应用到ADS的示例了。
Apollo Cyber RT是一个专为自动驾驶设计的开源runtime框架。它是基于中心化的计算模型,针对自动驾驶场景的延迟低、并发高和吞吐高进行了专门优化。Cyber
RT在Apollo中主要的作用是一个消息中间件,作为RTOS和自动驾驶各个模块的中间通信接口。Cyber
RT在Apollo架构中如Figure 9所示。
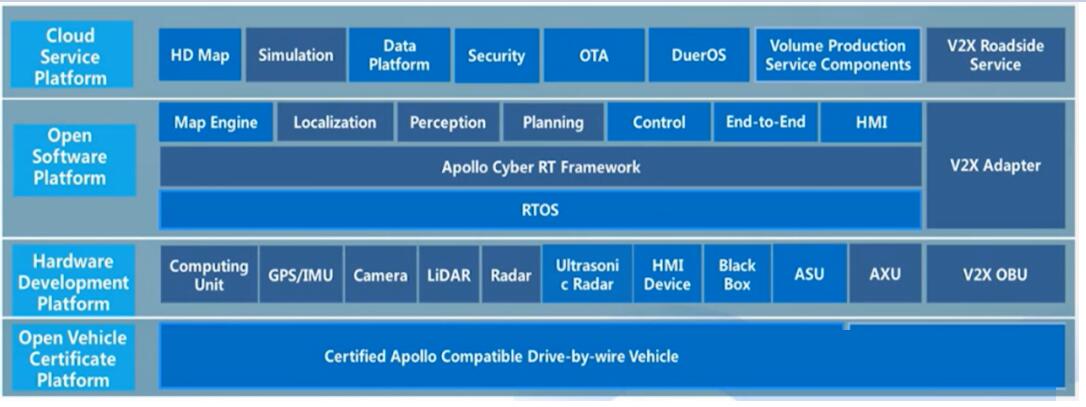
Figure 9. Apollo架构
Cyber RT的运行流程如Figure 10所示。编译器会将算法编译成DAG,每个算法都可以进行优先级、运行时间及使用资源等方面的配置;Cyber
RT可以结合DAG创建任务,并为每个任务分配一个coroutine;调度器根据调度任务类型以及调度策略等将任务放入对于Processor的队列中进行运算。
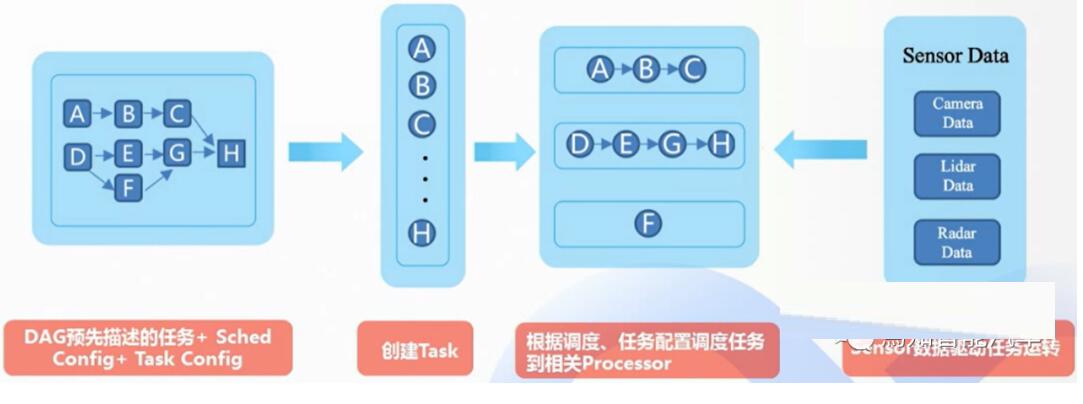
Figure 10. Cyber RT运行流程
Cyber RT的调度逻辑如Figure 11所示。每个Processor均有一个任务队列,由Scheduler将队列中的任务编排好;任务在哪个Processor上运行,哪些任务先运行,哪些后运行,均由调度器统一调度;任务执行发生阻塞时,支持context
switch;支持Thread级的高低优先级抢占。
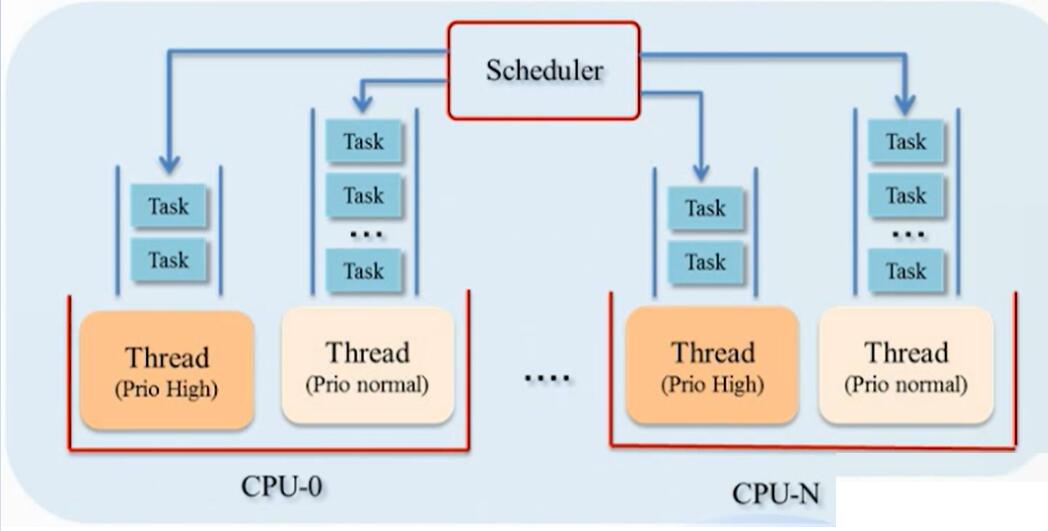
Figure 11. 调度策略
相比于Apollo纯软件调度,Ascend提供了软硬件结合的调度方案。Ascend开发软件栈支持原生的可微分编程范式和原生的执行模式,在开发效率和计算效率之间进行了折中。一方面,开发者可以轻易的将DNN模型部署到各种Ascend设备上,这些设备也可以配备不同的Ascend
core上。开发者可以使用high-level的编程模型实现一次性的开发和按需部署。另一方面,拥有更多架构知识的专家可以利用low-level的编程模型和库进一步提高计算效率。Ascend的开发软件栈如Figure
12所示[12]。
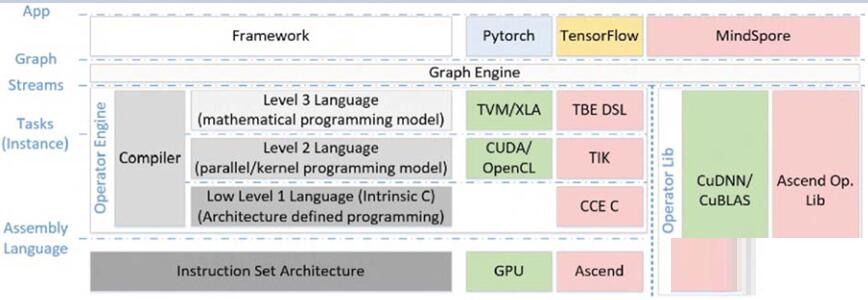
Figure 12. Ascend开发软件栈
Pytorch、Tensorflow和MindSpore等DNN开发框架处于整个开发软件栈的顶端。MindSpore是Ascend
core的专用框架。它可以充分的利用Ascend的计算资源,实现很高的计算效率。这些DNN开发框架的输出被称为“Graph”,它表示算法中粗粒度的依赖关系。然后,如Figure
13所示,Graph Engine会对“Graph”进行切分,将适合CPU逻辑处理的算子切分到CPU子图,将计算密集型算子切分到专用加速器子图[13],即被转换成Stream。其中,Stream是由若干个有序的Task组成[12]。
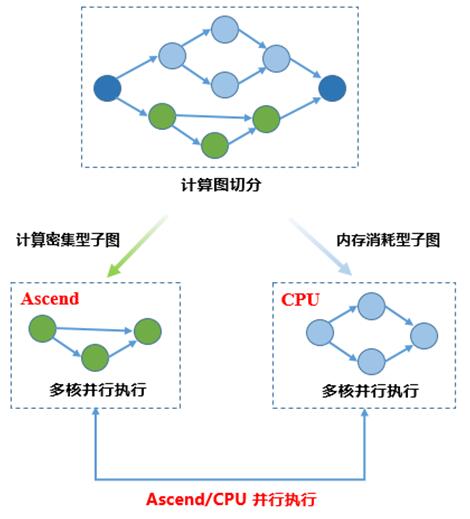
Figure 13. Graph切分示例
TBE (Tensor Boost Engine) DSL (Domain Specific Language)是用Level-3编程模型开发的,可以让没有硬件知识的用户也可以在这个级别编写代码,也称为数学编程级别。在编译器的帮助下,可以从TBE
DSL描述中自动生成实例Tasks[12]。
程序员还可以在parallel/kernel level (Level-2)编程模型中开发实例task。此级别类似于GPU
的 CUDA 或 OpenCL。它引入了所谓的TIK (Tensor Iterator Kernel)接口,用于使用
Python 进行并行编程。专用的编译器技术,称为Auto Tiling,用于将大的task转换为小的task,以适应
Ascend 架构。在强化学习算法的帮助下,该技术通过智能搜索合法映射空间,为任何程序提供最佳的映射和调度[12]。
如Figure 12所示,编程模型的Level-1是C编程接口,也称为CCE-C (Cube-based
Compute Engine)。在这个Level,架构的所有设计细节都是向开发者公开的。开发者可以在C代码中嵌入汇编,从而充分的利用硬件加速能力[12]。
如上文所述,APP在不同Level的编程模型会被转换为不同的表达形式,即Stream、Task和Block,如Figure
14所示[12]。所有的这些表达在不同级别的调度器中并行执行,详细介绍如下:
应用层:多个应用可以在同一个Ascend SoC上并行执行。
Stream/Task层:图编译器会将每个应用编译成多个Stream,每个Stream中有多个Task。多个Stream的Task可以在TS
(Task Scheduler)的调度下并行执行,同一个Stream的Task串行执行。TS在Ascend
SoC如Figure 15所示[14]。
Block层:每个Task可以被分成若干个Block(需要由开发者或编译器显式描述),不同的Block可以被分发到不同的Core上执行。
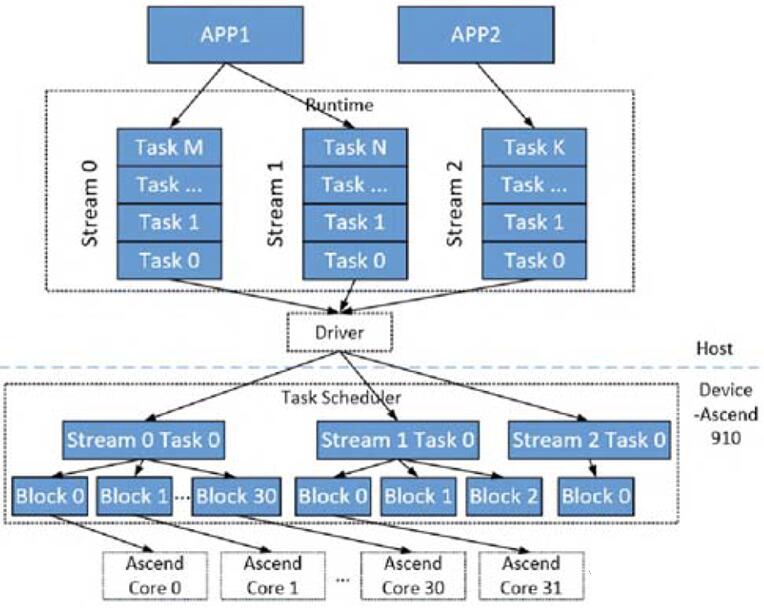
Figure 14. Ascend调度层级
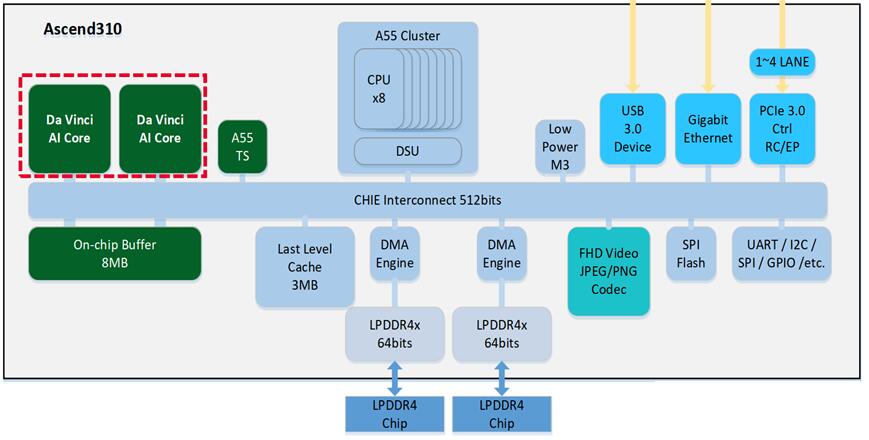
Figure 15. Ascend 310 SoC架构图 | 






 订阅
订阅