| 编辑推荐: |
本文讲述SR-IOV原理以及基于SR-IOV的IO虚拟化,希望能够帮助大家。
本文来自于 Linux阅码场,由火龙果软件Alice编辑、推荐。 |
|
一、背景
SR-IOV(Single Root I/O Virtualization)是由PCI-SIG组织定义的PCIe规范的扩展规范《Single Root I/O Virtualization and Sharing Specification》,目的是通过提供一种标准规范,为VM(虚拟机)提供独立的内存空间、中断、DMA数据流,当前最新版本为1.1。
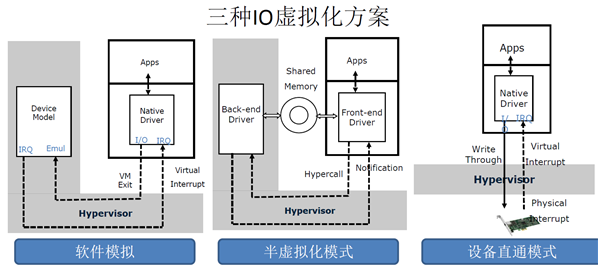
图1.1
IO虚拟化有软件模拟、基于virtio的半虚拟化和设备直通三种方式,见图1.1,其中设备直通实现了数据面加速,允许物理PCIe设备可以直接访问虚拟机的GuestOS中运行相应驱动分配的物理地址(GPA)。
SR-IOV的出现,支持了单个物理PCIe设备虚拟出多个虚拟PCIe设备,然后将虚拟PCIe设备直通到各虚拟机,以实现单个物理PCIe设备支撑多虚拟机的应用场景,如图1.2。
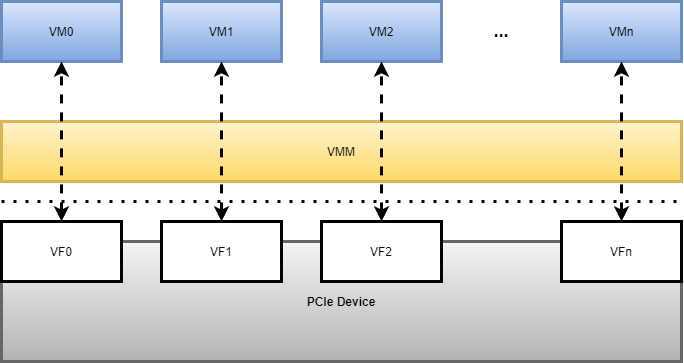
图1.2
二、SR-IOV原理
2.1 硬件实现
2.1.1 SR-IOV基本结构
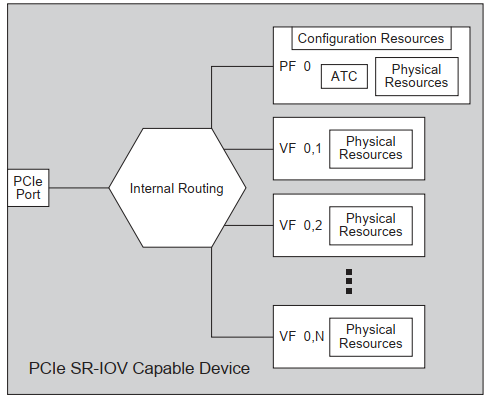
SR-IOV是在PCIe规范的基础上实现的,SR-IOV协议引入了两种类型功能的概念:物理功能 (Physical Function, PF)和虚拟功能 (Virtual Function, VF),基本结构见图2.1.1。
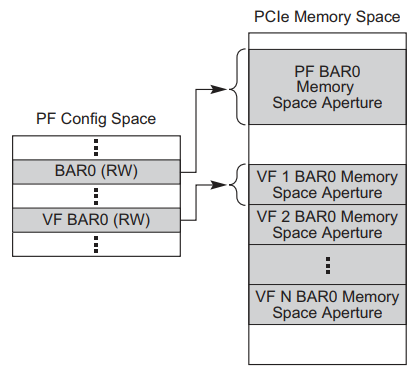
图2.1.1
PF用于支持 SR-IOV 功能的 PCI 功能,如 SR-IOV 规范中定义,PF 包含 SR-IOV 功能配置结构体,用于管理 SR-IOV 功能。PF 是全功能的 PCIe 功能,可以像其他任何 PCIe 设备一样进行发现、管理和处理。PF 拥有完全配置资源,可以用于配置或控制 PCIe 设备。
VF是与PF关联的一种功能,是一种轻量级 PCIe 功能,可以与物理功能以及与同一物理功能关联的其他 VF 共享一个或多个物理资源。VF 仅允许拥有用于其自身行为的配置资源。
2.1.2 VF的BAR空间资源
VF的BAR空间是PF的BAR空间资源中规划的一部分,VF不支持IO空间,所以VF的BAR空间也需要映射到系统内存,VF的BAR空间的物理资源排布如图2.1.2:
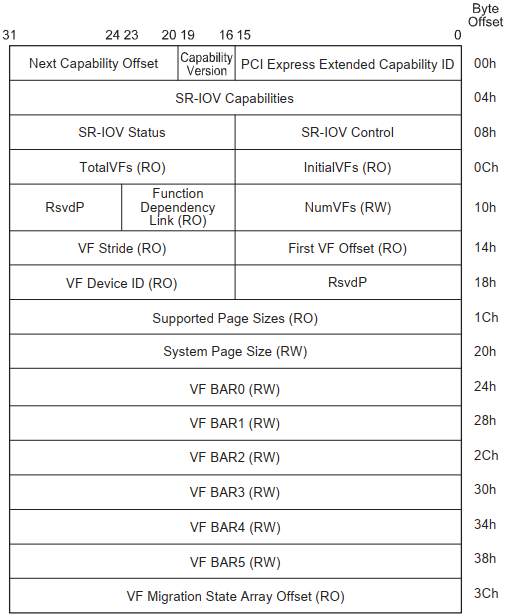
图2.1.2
2.1.3 PF的SR-IOV Extended Capabilities 配置
PF的PCIe扩展配置空间 SR-IOV Extended Capability支持对SR-IOV功能进行配置,如图2.1.3:
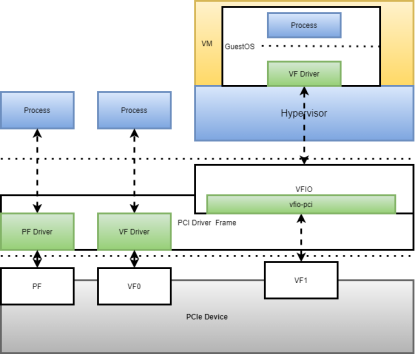
图2.1.3
其中SR-IOV Control 字段的bit0位是SR-IOV的使能位,默认为0,表示关闭,如果需要开启SR-IOV功能,需要配置为1。
TotalVFs字段表示PCIe Device支持VF的数量。
NumVFs字段表示开启VF的数量,此值不应超过PCIe Device支持的VF的数量TotalVFs的值。
First VF Offset字段表示第一个各VF相对PF的Routing ID(即Bus number、Device number、Function number)的偏移量。
VF Stride字段表示相邻两个VF的Routing ID的偏移量。
其他字段含义详见《Single Root I/O Virtualization and Sharing Specification Revision 1.1》。
2.2 软件支持
Linux系统下,基于SR-IOV有三种应用场景:HostOS使用PF、HOstOS使用VF、将VF直通到VM(虚拟机),见图2.2.1:
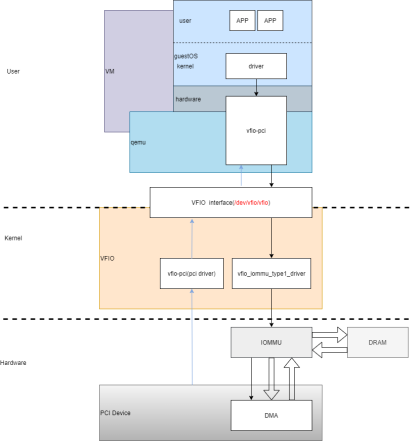
图2.2.1
Linux系统中PCI驱动框架drivers/pci/iov.c提供了一系列对SR-IOV Extended Capability的配置接口函数,PCIe Device需要有相应的PF驱动和VF驱动,PF驱动支持配置SR-IOV,VF驱动需要实现相应的PCIe Device的业务功能(例如NIC或GPU),VFIO中的vfio-pic是一个简易符合VFIO框架PCIe驱动。
三、基于SR-IOV的IO虚拟化
3.1 基于QEMU/KVM的PCIe设备直通框架
在QEMU/KVM的虚拟化架构下,PCIe设备直通的软硬件系统架构由下往上有如下几部分(见图3.1):
PCIe Device(支持SR-IOV功能)
l IOMMU
l VFIO
l Hypervisor(QEMU/KVM)
l VF Driver(运行在GuestOS中)
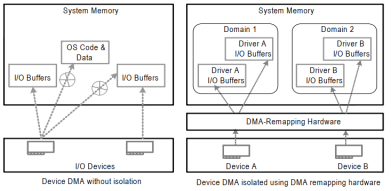
图3
3.1.1 IOMMU
IOMMU(I/O Memory Management Unit)是一个内存管理单元,主要针对外设访问系统内存市进行内存管理,像intel VT-d、AMD的IOMMU及ARM的SMMU都具有相同功能。IOMMU支持PCIe Device虚拟化的两个基础功能: 地址重映射 和 中断重映射 。
3.1.1.1 DMA物理地址重映射
(DMA Remapping )
1)地址空间隔离
在没有iommu的时候,用户态驱动可以通过设备dma可以访问到机器的全部的地址空间,如何保护机器物理内存区对于用户态驱动框架设计带来挑战。引入iommu以后,iommu通过控制每个设备dma地址到实际物理地址的映射转换,可以实现地址空间上的隔离,使设备只能访问规定的内存区域,见图3.1.1.1.1。
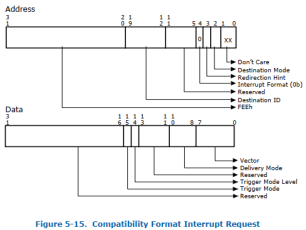
图3.1.1.1.1
2)GPA(虚拟机物理地址) --> HPA(宿主机物理地址)
物理PCI设备通过直通的方式进入到虚拟机的客户机时,客户机设备驱动使用透传设备的DMA访问虚拟机内存物理地址时,IOMMU会进行 GPA-->HPA的转换,详细转换细节在下一章节分析。
3.1.1.2 中断重映射
以Intel VT-d为例,提出了两个机制支持中断重映射:
引入两种中断请求格式
兼容模式和重映射模式,Bit4位为0来表征为不可重映射中断,Bit4位为
1来表征为可重映射中断,见图3.1.1.2.1和图3.1.1.2.2。
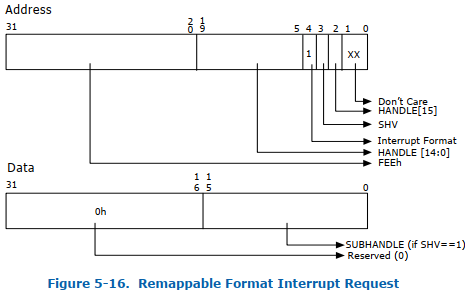
图3.1.1.2.1
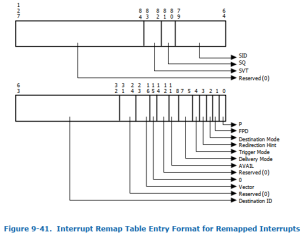
图3.1.1.2.2
引入Interrupt Remapping Table Entry (IRTE)
Interrupt Remapping Table Entry是一个二级表,需要先通过Interrupt Remapping Table Address Register来找到Interrupt Remapping Table Entry所在的地址,Interrupt Remapping Table Entry的格式如图3.1.1.2.3:
图3.1.1.2.3
IOMMU中断重映射的实质是将来自PCIe设备的中断(包括来自IOAPIC和PCIe设备的MSI/MSI-X等)拦截下来判断是否为重映射中断,如果是重映射中断会通过查询中断映射表(Interrupt Remapping Table Entry)找到真正的中断路由信息然后发送给物理CPU。
3.1.2 VFIO
VFIO(Virtual Function I/O)是基于IOMMU为HostOS的用户空间暴露PCIe设备的配置空间和DMA。VFIO的组成主要有以下及部分,见图3.1.2.1:
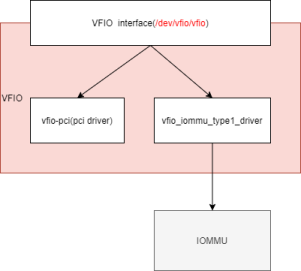
图3.1.2.1
l VFIO Interface:
VFIO通过设备文件向用户空间提供统一访问接口:
• Container文件描述符:打开/dev/vfio字符设备可得
• IOMMU group文件描述符:打开/dev/vfio/N文件可得
• Device文件描述符:向IOMMU group文件描述符发起相关ioctl可得
l vfio_iommu_type1_driver:
为VFIO提供了IOMMU重映射驱动,向用户空间暴露DMA操作。
l vfio-pci:
vfio支持pci设备直通时以vfio-pci作为pci设备驱动挂载到pci总线, 将pci设备io配置空间、中断暴露到用户空间。
3.1.3 QEMU/KVM PCI设备直通
QEMU/KVM 的PCI设备直通QEMU的核心工作主要有两部分:
1) 读取PCIe设备信息
通过VFIO接口读取PCIe设备的配置空间和DMA信息,
2) 为虚拟机创建虚拟PCIe设备
为虚拟机创建虚拟PCIe设备,虚拟PCIe设备的寄存器规划和DMA信息是物理PCIe设备在虚拟机中的映射。
QEMU中PCI设备直通时vfio-pci注册流程见图3.1.3.1:
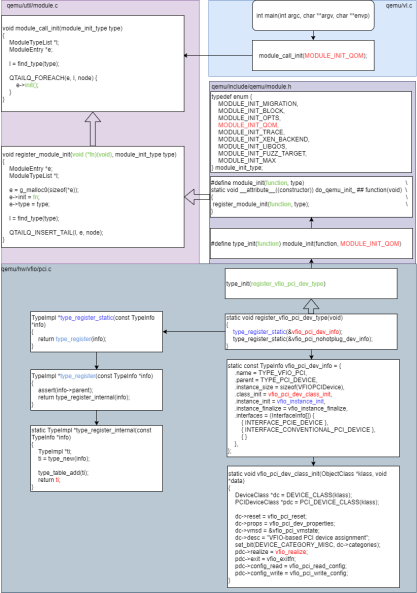
QEMU中PCI设备直通时vfio-pci初始化流程见图3.1.3.2:
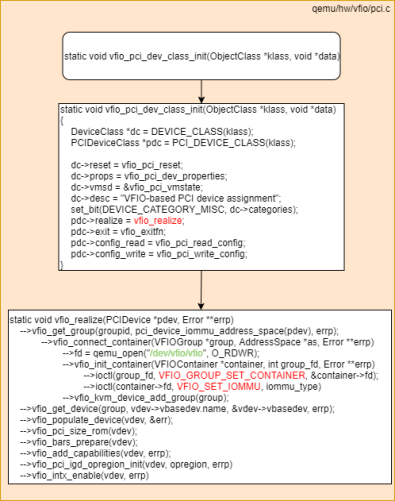
图3.1.3.2
3.2 PCI设备直通数据面加速
PCI设备直通时,GuestOS中的设备驱动操作虚拟PCI设备的DMA时,QEMU会将上述操作通过VFIO接口下发给物理PCI设备的DMA,物理设备DMA收到GuestOS中的物理地址GPA,通过IOMMU的映射,找到Host主机物理内存的物理地址HPA,达到物理PCI设备直接访问GuestOS中的GPA,从而达到数据数据面加速。
3.2.1 GPA->HPA的映射过程
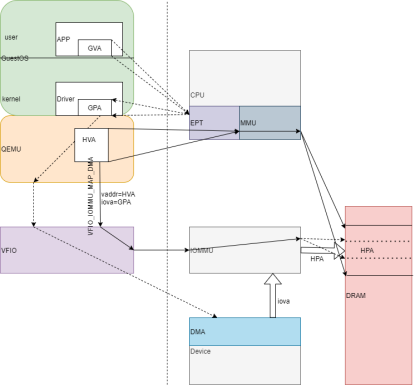
对于直通的设备,QEMU创建虚拟机时需要两方面的地址映射,见图3.2.1.1:
1)VM在创建时GuestOS的内存需要QEMU调用KVM最终通过EPT和MMU建立GVA->GPA->HPA的映射;
2)QEMU进行VM的虚拟PCI设备初始化时,会将HVA和GPA下发给IOMMU,
让IOMMU建立GPA到HPA的映射关系。
当GuestOS中直通设备的驱动分配内存并配置DMA时,QEMU通过VFIO接口将GPA下发到PCI Device的DMA,DMA读取数据时经由IOMMU映射,找到相应的HPA。
| 






 订阅
订阅