| 编辑推荐: |
本文讲述一些有利于提高xenomai实时性的配置建议,部分针对X86架构,但它们的底层原理相通,同样适用于其他CPU架构和系统,希望对你有用。希望能够帮助大家。
本文来自于微信公众号嵌入式Linux ,由火龙果软件Linda编辑、推荐。 |
|
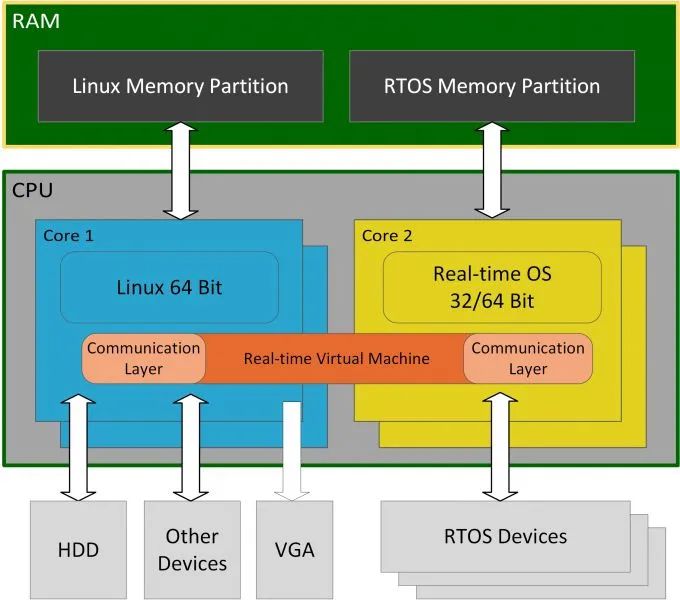
本文讲述一些有利于提高xenomai实时性的配置建议,部分针对X86架构,但它们的底层原理相通,同样适用于其他CPU架构和系统,希望对你有用。
一、前言
1. 什么是实时
“实时”一词在许多应用领域中使用,人们它有不同的解释,并不总是正确的。人们常说,如果控制系统能够对外部事件做出快速反应,那么它就是实时运行的。根据这种解释,如果系统速度快,则系统被认为是实时的。然而,“快”具有相对含义,并未涵盖表征这些类型系统的主要属性。
我们来看一下,在自然界中,生物在栖息地中的实时行为,这些行为与它们的速度无关。例如,乌龟对来自其栖息地的外部刺激的反应,与猫对其栖息地的外部反应一样有效。虽然乌龟比猫慢很多,但就绝对速度而言,它要处理的事件与它可以协调的动作成正比,这是任何动物在环境中生存的必要条件。
相反,如果生物系统所处的环境,引入了速度超过其处理能力的事件,其行为将不再有效,动物的生存也会受到损害。比如,一只苍蝇可以被苍蝇拍捕捉到,一只老鼠可以被陷阱捕捉到,或者一只猫可以被高速行驶的汽车撞倒。在这些例子中,苍蝇拍、陷阱和汽车代表了动物的异常和异常事件,超出了它们的实时能力范围,可能严重危及它们的生存。
前面的例子表明,实时并没有人们想象的那样快,而是与系统运行的环境严格相关。
实时系统是必须在设置的截止时间内对环境中的事件做出反应的系统,否则会产生严重的后果。
再比如,船舶的制导系统可能看起来是一个非实时系统,因为它的速度很低,而且通常有“足够”的时间(大约几分钟)来做出控制决定。尽管如此,根据我们的定义,它实际上是一个实时系统。
2. 实时分类
根据错过截止时间产生的后果,实时任务可以分为三类:
硬实时(Hard real time system)
如果在截止时间之后产生结果,可能对受控系统造成灾难性后果,则该任务是硬实时任务。
硬任务的例子可以在安全关键系统中找到,并且通常与传感、驱动和控制活动有关,例如:
汽车安全气囊的检测与控制;
反导弹系统要求硬实时。反导弹系统由一系列硬实时任务组成。反导系统必须首先探测所有来袭导弹,正确定位反导炮,然后在导弹来袭之前将其摧毁。所有这些任务本质上都是硬实时的,如果反导弹系统有任何一个任务失败都将无法成功拦截来袭导弹。
强实时(Firm real time system)
如果在截止日期之后产生结果对系统无用,但不会造成任何损害,则该任务是强实时任务。
在网络应用程序和多媒体系统中找到,在这些系统中,跳过一个数据包或一个视频帧比长时间延迟处理更重要。因此,它们包括以下内容:
视频播放;
音/视频编解码中,没有在设置的码率时序范围内执行完,产生结果都是无用的丢弃即可,继续下一轮读取;
在线图像处理;
软实时(Soft real time system)
如果实时任务在截止日期之后产生结果仍然对系统有用,尽管会导致性能下降,则该任务是软实时任务。
软任务通常与系统-用户交互有关,有点延迟什么的并不影响,只是体验稍差点。因此,它们包括:
用户界面的命令解释器;
处理来自键盘的输入数据;
在屏幕上显示消息;
网页浏览等;
3.常见的RTOS
小型实时操作系统 UCOS、FreeRTOS、RT-Thread…
大型实时操作系统 RT linux、VxWorks、QNX、sylixOS…

4. latency和jitter
硬实时系统是必须在设置的截止时间内对环境中的事件做出反应的系统。硬实时操作系统应具备的最重要特性之一是确定性、可预期性。
操作系统的实时性能通常用latency或jitter来表示。事件预期发生与实际发生的时间之间的时间称为延迟(latency),实际发生的最大时间与最小时间之间的差值称为抖动(Jitter),两者均可表示实时性。根据实时性的定义,延迟必须是确定的,不能超过deadline,否则将会产生严重的后果。
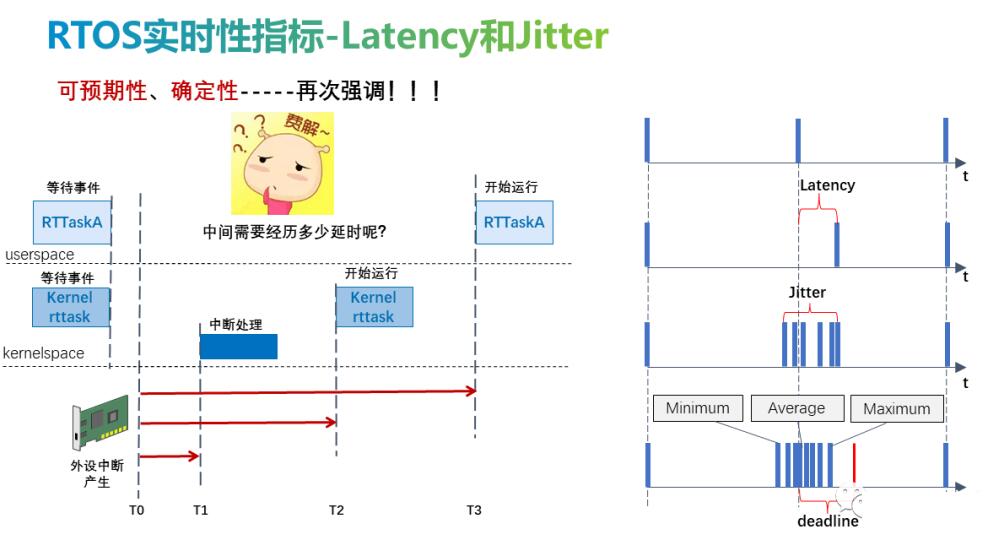
当我们针对实时应用场景评估硬件和实时系统时,通常可以简化为对实时性能和硬件资源的考量,即对于一个应用场景,实时性满足的情况下,硬件性能也满足。
在否决定使用一个实时系统时,需要结合具体应用场景来评估该实时系统是否符合,若不符合则需要考虑对现有系统优化或者更换方案。
二、实时性的影响因素
硬实时操作系统应具备的最重要特性之一是确定性、可预测性,系统应该保证满足所有关键时序约束。然而,这取决于一系列因素,这些因素涉及硬件的架构特征、内核中采用的机制和策略,以及用于实现应用程序的编程语言、软件设计等。
1.硬件
CPU架构
硬件方面,第一个影响调度可预测性的是处理器本身。处理器的内部特性是不确定性的第一个原因,例如指令预取、流水线操作、分支预测、高速缓存存储器和直接存储器访问(DMA)机制。这些特性虽然改善了处理器的平均性能,但它们引入了非确定性因素,这些因素阻止了对最坏情况执行时间WCET(Worst-caseExecutionTime)的精确估计。
高端CPU,如I5、I7实时性不一定有低端的赛扬、atom系列的好,芯片的设计本身定位就是高吞吐量而不是实时性。
Cache
CPU 里的 L1 Cache 或者 L2 Cache,访问延时是内存的 1/15 乃至 1/100,想要追求极限性能,需要尽可能地多从
CPU Cache 里面拿数据,减少cache miss,上面的分配CPU专门对实时任务服务就是对非共享的L1
、L2 Cache的充分优化。
对于L3 Cache,多个cpu核与GPU共享,无法避免非实时任务及GUI争抢L3 Cache对实时任务的影响。
为此intel 推出了资源调配技术(Intel RDT),提供了两种能力:监控和分配。Intel
RDT提供了一系列分配(资源控制)能力,包括缓存分配技术(Cache Allocation Technology,
CAT),代码和数据优先级(Code and Data Prioritization, CDP) 以及
内存带宽分配(Memory Bandwidth Allocation, MBA)。该技术旨在通过一系列的CPU指令从而允许用户直接对每个CPU核心(附加了HT技术后为每个逻辑核心)的L2缓存、L3缓存(LLC--Last
Level Cache )以及内存带宽进行监控和分配。
RDT一开始是为解决云计算的问题,在云计算领域虚拟化环境中,宿主机的资源(包括CPU cache和内存带宽)都是共享的。这带来一个问题就是:如果有一个过度消耗cache的应用耗尽了L3缓存或者大量的内存带宽,将无法保障其他虚拟机应用的性能。这种问题称为
noisy neighbor。
同样对于我们的实时系统也是类似:由于L3 Cache多核共享,如果有一个过度消耗cache的非实时应用耗尽了L3缓存或者大量的内存带宽,将无法保障xenomai实时应用的性能。
以往虚拟化环境中解决方法是通过控制虚拟机逻辑资源(cgroup)但是调整粒度太粗,并且无法控制处理器缓存这样敏感而且稀缺的资源。为此Intel推出了RDT技术。在Intel中文网站的
通过英特尔® 资源调配技术优化资源利用视频形象介绍了RDT的作用。
Intel的Fenghua Yu在Linux Foundation上的演讲 Resource Allocation
in Intel® Resource Director Technology 可以帮助我们快速了解这项技术。
总的来说,RDT让我们实现了控制处理器缓存这样敏感而且稀缺的资源,对我们对实时性能提升有很大帮助(不仅限于xenomai,RTAI、PREEMPT-RT均适用)。
CAT(缓存分配技术,Cache Alocation Technology),对最后一级缓存(L3
Cache)实现分区,用户可以通过限制每个核心能够向其中分配缓存行的LLC数量,将LLC的部分分配给特定核心,使用该技术可以提升实时任务Cahe命中率,减少MSI延迟和抖动,进而提升实时性能。(不是所有intel处理器具有该功能,一开始只有服务器CPU提供该支持,据笔者了解,6代以后的CPU基本支持CAT。关于CAT
见github),对于大多数Linux发行版,可直接安装使用该工具,具体的cache分配策略可根据后面的资源隔离情况进行。
| sudo apt-get
install intel-cmt-cat |
TLB
与cache性质一致。
分支预测
现代 CPU 的流水线级数非常长,一般都在10级以上,指令分支判断错误(Branch Mispredict)的时间代价昂贵。如果判断预测正确,可能只需要一个时钟周期;如果判断错误,就还是需要10-20
左右个时钟周期来重新提取指令。
如下为对同一随机组数,排序与未排序情况下for循环测试:
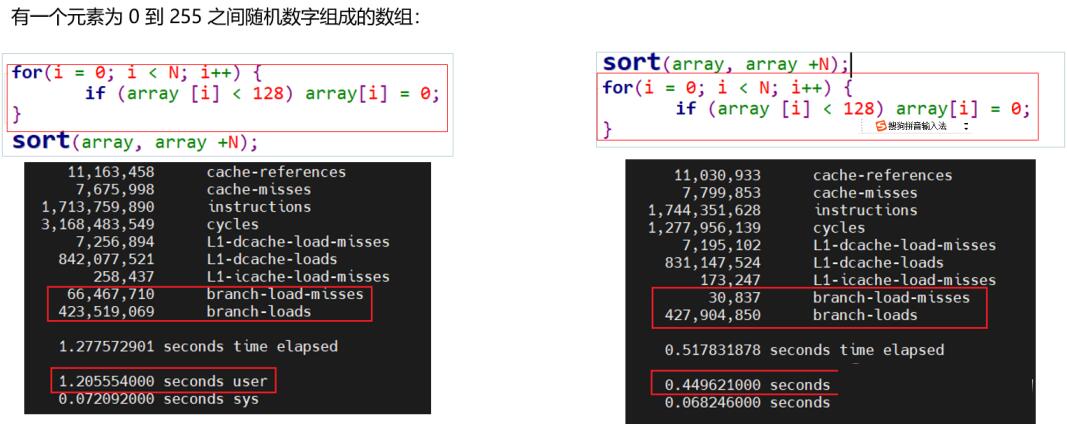
数据有规律和无规律两种情况下同一段代码执行时间相差巨大。
现代 CPU 的分支预测正确率已经可以在一般情况下维持在 95% 以上,所以当分支存在可预测的规律的时候,还是以性能测试的结果为最终的优化依据。
Hyper-Threading
人们对CPU的性能的追求是无止境的,在CPU性能不断优化提高过程中,对于单一流水线,最佳情况下,IPC
也只能到 1。无论做了哪些流水线层面的优化,即使做到了指令执行层面的乱序执行,CPU 仍然只能在一个时钟周期里面取一条指令。
为使IPC>1,诞生了多发射(Mulitple Issue)和超标量(Superscalar)技术,伴随的是每个CPU流水线上各种运算单元的增加。但是当处理器在运行一个线程,执行指令代码时,一方面很多时候处理器并不会使用到全部的计算能力,另一方面由于CPU在代码层面运行前后依赖关系的指令,会遇到各种冒险问题,这样CPU部分计算能力就会处于空闲状态。
为了进一步“压榨”处理器,那就找没有依赖关系的指令来运行好,即另一个程序。一个核可以分成几个逻辑核,来执行多个控制流程,这样可以进一步提高并行程度,这一技术就叫超线程,又称同时多线程(Simultaneous
Multi-Threading,简称 SMT)。
由于超线程技术通过双份的 PC 寄存器、指令寄存器、条件码寄存器,在逻辑层面伪装为2个CPU,但指令译码器和ALU是公用的,这就造成实时任务运行时在CPU执行层面的不确定性,造成非实时线程与实时线程在同一物理核上对CPU执行单元的竞争,影响实时任务实时性。
电源管理与调频
我们知道CPU场效应晶体管FET构成,其简单示意图如下。

当输入高低电平时,CL被充放电,假设充放电a焦耳的能量。因为CL很小,这个a也十分的小,几乎可以忽略不计。为了提高CPU性能,不断提高处理器的时钟频率,但如果我们以1GHz频率翻转这个FET,则能量消耗就是a
× 10^9,这就不能忽略了,再加上CPU中有几十亿个FET,消耗的能量变得相当可观。
| 详细的参考:https://zhuanlan.zhihu.com/p/56864499 |
为了省电,让操作系统随着工作量不同,动态调节CPU频率和电压。但是调频会导致CPU停顿(CPU停顿时间10us~500us不等),运行速度降低导致延迟增加,严重影响实时性能。
除了调频以外,另一个严重影响实时性的是,系统进入更深层次的省电睡眠状态,这时的唤醒延迟长达几十毫秒。
Multi-Core
接收 IRQ 的 CPU 可能不是响应者休眠的 CPU,在这种情况下,前者必须向后者发送重新调度请求,以便它恢复响应者。这通常是通过处理器间中断完成的,也就是IPI,IPI的发送和处理进一步增加了延迟。
中断周期及测试时长
最小 平均 最大
100us 21h 0.086us 0.184us 4.288us |
此外,多核LLC共享,NUMA架构远端内存访问等,均会导致访问延迟不确定。
other
其他影响因素有内存、散热。
提升内存频率可降低内存访问延时;使用双通道内存,这两个内存CPU可分别寻址、读取数据,从而使内存的带宽增加一倍,数据存取速度也相应增加一倍(理论上),内存访问延时得到缩短,进而提升系统的实时性能;
处理器散热设计不好,温度过高时会引发CPU降频保护,系统运行频率降低影响实时性,热设计应确保在高工作量时的温度不会引发降频。
对于X86 CPU,双通道内存性能是单通道内存的2. 5倍以上;正确的热设计可使实时性提升1.4倍以上。
2.BISO(X86平台)
BISO需要针对实时系统进行配置。优化的BIOS设置与使用默认BISO设置的实时性能差距高达9倍。
3.软件
操作系统:调度算法,同步机制,信号量类型,内存管理策略,通信语义和中断处理等。
资源的分配隔离:分配CPU专门对实时任务服务、将多余中断隔离到非实时任务CPU上,分配CPU专门对实时任务服务可使L1
、L2 Cache只为实时任务服务。
实时任务的设计,良好的软件设计能更好的发挥实时性能。
其他,虚拟化、GUI等 。
4. GPU
硬件上GPU与CPU共享L3 Cache ,因此GUI会影响实时任务的实时性。intel建议根据GUI任务的工作负载来固定GPU的运行频率,且频率尽可能低。减小GPU对实时任务实时性的影响。
三、优化措施
原则:降低不确定性,提高可预期性,在此基础上,再提高速度,降低延时。
比如,我们需要在确定的时间内从广州到深圳,如果驾车,途中会遇到多少个红绿灯,有无堵车
等等,有很多不确定性。但是如果我们换坐动车,就比驾车更具确定性,在此基础上我们提高速度,换坐高铁,广州到深圳的延时将变得更小。
1. BIOS[x86]

2. 硬件
除处理器外,内存方面,使用双通道内存,尽可能高的内存频率。
散热当面,针对处理器工作负载设计良好的散热结构, 否则芯片保护会强制降频,频率调整CPU会停顿几十上百us。
3. Linux
xenomai基于linux,xenomai作为一个小的实时核与linux共存,xenomai并未提供完整的硬件管理机制,许多硬件配置是linux
驱动掌管的,必须让linux配置好,给xenomai提供一个好的硬件环境,让xenomai充分发挥其RTOS的优势,主要宗旨:尽可能的不让linux非实时部分影响xenomai,无论是软件还是硬件。
3.1 Kernel CMDLINE
cpu隔离
多核情况下,设置内核参数 isolcpus=[cpu列表],将列表中的CPU从linux内核SMP平衡和调度算法中剔除,将剔除的CPU用于RT应用。如4核CPU平台将第3、4核隔离来做RT应用。
CPU编号从"0"开始,列表的表示方法有三种:numA,numB,...,numN
numA-numN
以及上述两种表示方法的组合:numA,...,numM-numN
例如:isolcpus=0,3,4-7表示隔离CPU0、3、4、5、6、7.
| GRUB_CMDLINE_LINUX="isolcpus=2,3" |
以上只是linux不会调度普通任务到CPU2和3上运行,这是基础,此时还需要设置xenomai方面的CPU隔离,方法一,任务通过函数
pthread_attr_setaffinity_np()设置xenomai任务只在CPU3和4上调度,隔离后的CPU的L1、L2缓存命中率相应的也会得到提高
cpu_set_t cpus;
CPU_ZERO(&cpus);
CPU_SET(2, &cpus);
//将线程限制在指定的cpu2上运行
CPU_SET(3, &cpus);
//将线程限制在指定的cpu3上运行
ret = pthread_attr_setaffinity_np
(&tattr,
sizeof(cpus), &cpus); |
方法二,向xenomai设置内核参数 supported_cpus,指定xenomai支持的CPU,xenomai任务会自动放到cpu2、cpu3上运行。
xenomai 内核参数 supported_cpus与linux不同, supported_cpus是一个16进制数,每bit置位表示支持该CPU,要支持CPU2、CPU3,需要置置位bit2、bit3,即
supported_cpus=0x06(00000110b)。
| GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.supported_cpus=0x06" |
注:linux内核参数 isolcpus=CPU编号列表是基础,否则若不隔离linux任务,后面的xenomai设置将没任何意义。
Full Dynamic Tick
将CPU2、CPU3作为xenomai使用后,由于xenomai调度是完全基于优先级的调度器,并且我们已将linux任务从这两个cpu上剔除,CPU上Tick也就没啥用了,避免多余的Tick中断影响实时任务的运行,需要将这两个cpu配置为Full
Dynamic Tick模式,即关闭tick。通过添加linux内核参数 nohz_full=[cpu列表]配置。
nohz_full=[cpu列表]在使用 CONFIG_NO_HZ_FULL=y构建的内核中才生效。
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.
supported_cpus=0x06 nohz_full=2,3" |
为什么是linux内核参数呢?双核下时间子系统中分析过,每个CPU的时钟工作方式是linux初始化并配置工作模式的,xenomai最后只是接管而已,所以这里是通过linux内核参数配置。
注意:boot CPU(通常是0号CPU)会无条件的从列表中剔除。这是一个坑~
start_kerel()
->tick_init()
->tick_nohz_init()
void __init tick_nohz_init(void)
{
.......
cpu = smp_processor_id();
if (cpumask_test_cpu(cpu, tick_nohz_full_mask))
{
pr_warn("NO_HZ: Clearing %d from
nohz_full
range for timekeeping\n",cpu);
cpumask_clear_cpu(cpu, tick_nohz_full_mask);
}
......
} |
Offload RCU callback
从引导选择的CPU上卸载RCU回调处理,使用内核线程 “rcuox / N”代替,通过linux内核参数
rcu_nocbs=[cpu列表]指定的CPU列表设置。这对于HPC和实时工作负载很有用,这样可以减少卸载RCU的CPU上操作系统抖动。
"rcuox / N",N表示CPU编号,‘x’:'b'是RCU-bh的b,'p'是RCU-preempt,‘s’是RCU-sched。
rcu_nocbs=[cpu列表]在使用 CONFIG_RCU_NOCB_CPU=y构建的内核中才生效。除此之外需要设置RCU内核线程
rcuc/n和 rcub/n线程的SCHEDFIFO优先级值RCUKTHREADPRIO,RCUKTHREADPRIO设置为高于最低优先级线程的优先级,也就是说至少要使该优先级低于xenomai实时应用的优先级,避免xenomai实时应用迁移到linux后,由于优先级低于RCUKTHREAD的优先级而实时性受到影响,如下配置RCUKTHREADPRIO=0。
General setup
--->
RCU Subsystem --->
(0) Real-time priority to use for RCU worker threads
[*] Offload RCU callback processing from boot-selected
CPUs
(X) No build_forced no-CBs CPUs
( ) CPU 0 is a build_forced no-CBs CPU
( ) All CPUs are build_forced no-CBs CPUs
GRUB_CMDLINE_LINUX="isolcpus=2,3 xenomai.
supported_cpus=0x06
nohz_full=2,3 rcu_nocbs=2,3" |
中断
中断隔离
xenomai用户态实时应用运行时,中断优先级最高,CPU必须响应中断,虽然有ipipe会简单将非实时设备中断挂起,但是频繁的非实时设备中断产生可能引入无限延迟,也会影响实时任务的运行。
因此多,核情况下,通过内核参数 irqaffinity==[cpu列表],设置linux设备中断的亲和性,设置后,默认由这些cpu核来处理中断。避免了非实时linux中断影响cpu2、cpu3上的实时应用,将linux中断指定到cpu0、cpu1处理,添加参数:
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.
supported_cpus=0x06
nohz_full=2,3 rcu_nocbs=2,3
irqaffinity=0,1" |
以上只是设置linux中断的affinity,只能确保运行实时任务的CPU2、cpu3不会收到linux非实时设备的中断请求,保证实时性。
要指定cpu来处理xenomai实时设备中断,需要在实时驱动代码中通过函数 xnintr_affinity()设置,绑定实时驱动中断由CPU2、CPU3处理代码如下。
cpumask_t
irq_affinity;
...
cpumask_clear(&irq_affinity)
cpumask_set_cpu(2, &irq_affinity);
cpumask_set_cpu(3, &irq_affinity);
...
if (!cpumask_empty(&irq_affinity)){
xnintr_affinity(&pIp->irq_handle,irq_affinity);
/*设置实时设备中断的affinity*/
}
|
虽然ipipe会保证xenomai 实时中断在任何CPU都会优先处理,在实时设备中断比较少的场合,我觉得把linux中断与实时中断分开比较好;如果实时设备中断数量较多,如果隔离就会造成实时中断间相互影响中断处理的实时性,这时候不指定实时中断处理CPU比较好。
编写xenomai实时设备驱动程序时,中断处理程序需要尽可能的短。
禁用irqbanlance
linux irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于
Performance mode 或 Power-save mode。简单来说irqbalance
会将硬件中断分配到各个CPU核心上处理。
处于 Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个
CPU core,以充分利用 CPU 多核,提升性能。
处于 Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲
CPU 的睡眠时间,降低能耗。
禁用irqbanlance,避免不相干中断发生在RT任务核。发行版不同,配置方式不同,以Ubuntu为例,停止/关闭开机启动如下。
systemctl
stop irqbalance.service
systemctl disable irqbalance.service
|
必要的话直接卸载irqbalance。
| apt-get remove
irqbalance |
x86平台还可添加参数acpi_irq_nobalance禁用ACPI irqbalance.
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.
supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3
irqaffinity=0,1 acpi_irq_nobalance noirqbalance" |
intel 核显配置[x86]
主要针对intel CPU的核显,配置intel核显驱动模块i915,内核参数如下。
GRUB_CMDLINE_LINUX="i915.enable_rc6=0
i915.enable_dc=0 i915.disable_power_well=0
i915.enable_execlists=0
i915.powersave=0" |
nmi_watchdog[x86]
NMI watchdog是Linux的开发者为了debugging而添加的特性,但也能用来检测和恢复Linux
kernel hang,现代多核x86体系都能支持NMI watchdog。
NMI(Non Maskable Interrupt)即不可屏蔽中断,之所以要使用NMI,是因为NMI
watchdog的监视目标是整个内核,而内核可能发生在关中断同时陷入死循环的错误,此时只有NMI能拯救它。
Linux中有两种NMI watchdog,分别是I/O APIC watchdog(nmiwatchdog=1)和Local
APIC watchdog(nmiwatchdog=2)。它们的触发机制不同,但触发NMI之后的操作是几乎一样的。一旦开启了I/O
APIC watchdog(nmi_watchdog=1),那么每个CPU对应的Local APIC的LINT0线都关联到NMI,这样每个CPU将周期性地接到NMI,接到中断的CPU立即处理NMI,用来悄悄监视系统的运行。如果系统正常,它啥事都不做,仅仅是更改
一些时间计数;如果系统不正常(默认5秒没有任何普通外部中断),那它就闲不住了,会立马跳出来,且中止之前程序的运行。该出手时就出手。
避免周期中断的NMI watchdog影响xenomai实时性需要关闭NMI watchdog,传递内核参数
nmi_watchdog=0.
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3
irqaffinity=0,1 acpi_irq_nobalance noirqbalance
i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0
i915.enable_execlists=0 i915.powersave=0 nmi_watchdog=0" |
nosoftlockup
linux内核参数,禁用 soft-lockup检测器。
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3
irqaffinity=0,1 acpi_irq_nobalance noirqbalance
i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0
i915.enable_execlists=0 i915.powersave=0 nmi_watchdog=0
nosoftlockup" |
CPU特性[x86]
intel处理器相关内核参数:
nosmap
nohalt。告诉内核在空闲时,不要使用省电功能PALHALTLIGHT。这增加了功耗。但它减少了中断唤醒延迟,这可以提高某些环境下的性能,例如联网服务器或实时系统。
mce=ignore_ce,忽略machine checkerrors (MCE).
idle=poll,不要使用HLT在空闲循环中进行节电,而是轮询以重新安排事件。这将使CPU消耗更多的功率,但对于在多处理器基准测试中获得稍微更好的性能可能很有用。它还使使用性能计数器的某些性能分析更加准确。
clocksource=tsc tsc=reliable,指定tsc作为系统clocksource.
intel_idle.max_cstate=0 禁用intelidle并回退到acpiidle.
processor.max_cstate = 0intel.max_cstate = 0processor_idle.max_cstate=0
限制睡眠状态c-state。
GRUB_CMDLINE_LINUX="isolcpus=2,3
xenomai.supported_cpus=0x06 nohz_full=2,3 rcu_nocbs=2,3
irqaffinity=0,1 acpi_irq_nobalance noirqbalance
i915.enable_rc6=0 i915.enable_dc=0 i915.disable_power_well=0
i915.enable_execlists=0 nmi_watchdog=0 nosoftlockup
processor.max_cstate=0 intel.max_cstate=0 processor_idle.max_cstate=0
intel_idle.max_cstate=0 clocksource=tsc tsc=reliable
nmi_watchdog=0 nosoftlockup intel_pstate=disable
idle=poll nohalt nosmap mce=ignore_ce" |
3.2 内核构建配置
系统构建时,除以上提到的配置外(CONFIGNOHZFULL = y、CONFIGRCUNOCBCPU=y、RCUKTHREADPRIO=0),其他实时性相关配置如下:
CONFIGMIGRATION=n、CONFIGMCORE2=y[x86]、CONFIGPREEMPT=y、ACPIPROCESSOR
=n[x86]、CONFIGCPUFREQ =n、CONFIGCPUIDLE =n;
经过以上配置后可以使用latency测试,观察配置前后的变化。关于latency,需要注意的是,测试timer-IRQ的latency时,即用
latency-t2命令来测试时,xenomai默认使用cpu0的timer,上面提到boot CPU(通常是0号CPU)会无条件的从
nohz_full=[cpu列表]列表中剔除,所以 latency-t2测试时你会发现没什么变化,还可能会变差了(最坏情况差不多一致,平均值变大了),另外我们将linux中断affinity全都设置为CPU0处理,这些中断或多或少也会影响timer-IRQ的latency。
2021.5添加-- 最近发现xenomai内核定时器affinity为cpu0的问题已被社区修复。
四、软件方面
使用静态编译语言
编写高性能的代码
尽量让分支有规律性,使用likely()/unlikely()或编写无分支代码
利用cache局部性原理,防止伪共享
合理分配任务优先级等待
驱动程序中断处理尽可能短等等
五、优化结果对比
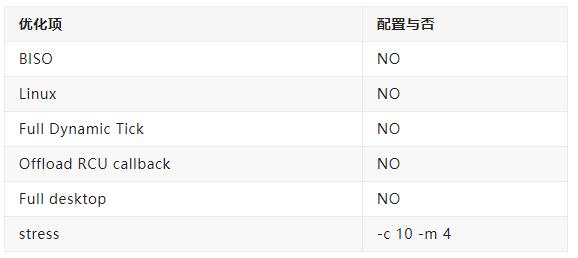
笔者对以上各个条件配置前后对比过实时性改善效果,均有不同程度的优化效果,大家有兴趣也可自行测试。
以下结果基于 i5-7200U 8GB单通道DDR4,64GB emmc5.0,未使用RDT技术。
1-3 在已裁剪桌面下,压力加了内存。
1. 原始性能测试。
只使用了xenomai,CONFIGMIGRATION=n、CONFIGMCORE2=y[x86]、CONFIGPREEMPT=y、ACPIPROCESSOR
=n[x86]、CONFIGCPUFREQ =n、CONFIGCPUIDLE =n。
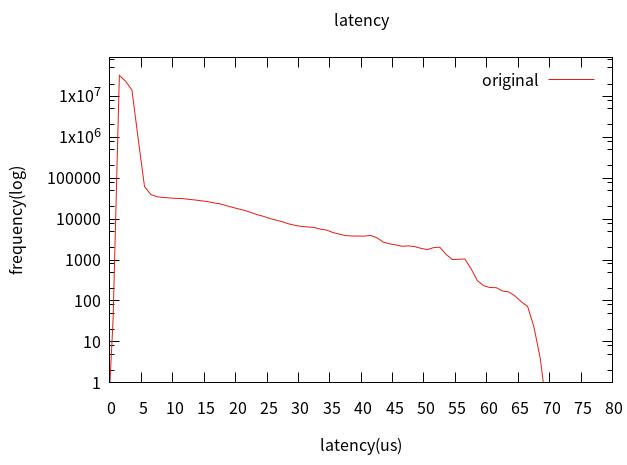
2. 优化BIOS设置。 
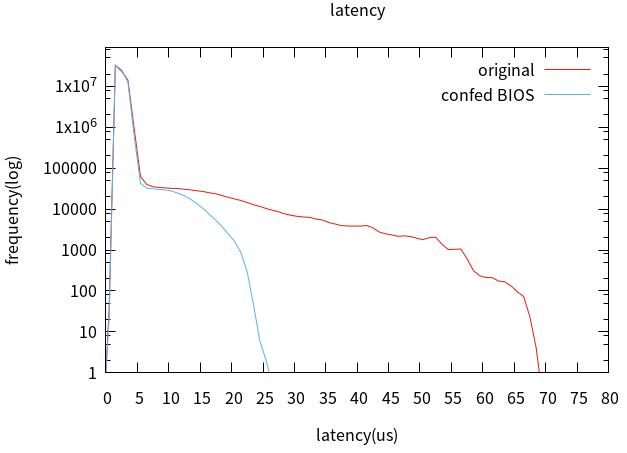
3. Linux配置优化。
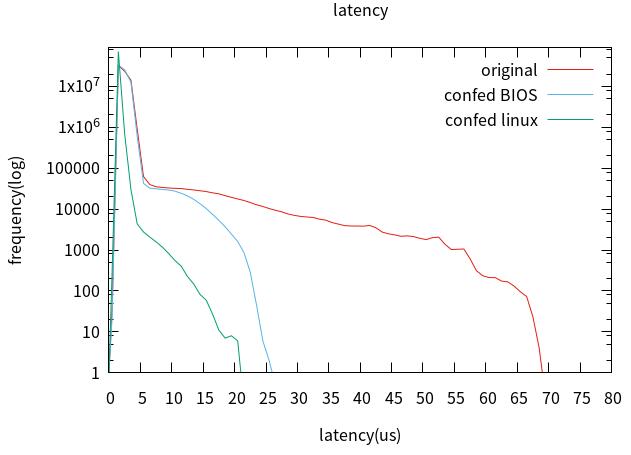
4-6 未添加内存压力
4. 裁剪桌面。
保留完整Ubuntu桌面前,且经所有配置:
裁剪桌面后:
裁剪前后对比:
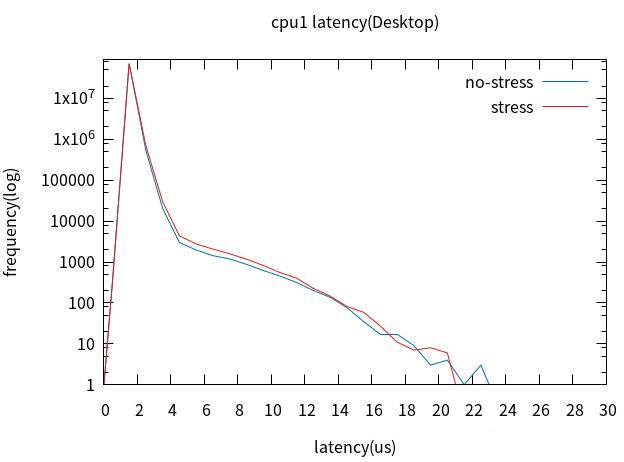
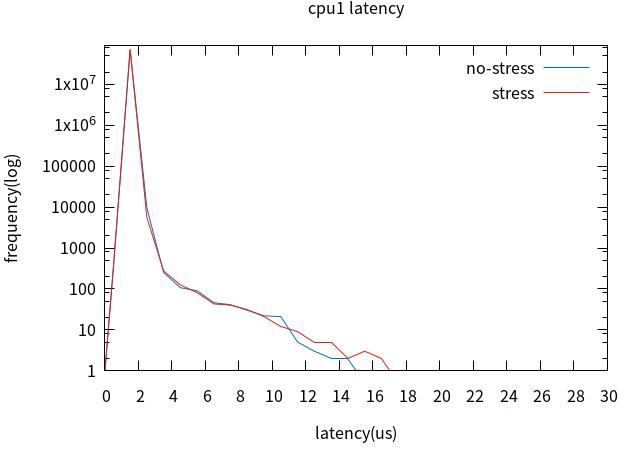
5. Full Dynamic Tick启用前后对比
裁剪桌面后,配置cpu0未启用Full Dynamic Tick,cpu1启用Full Dynamic
Tick,加压与未加压对比。
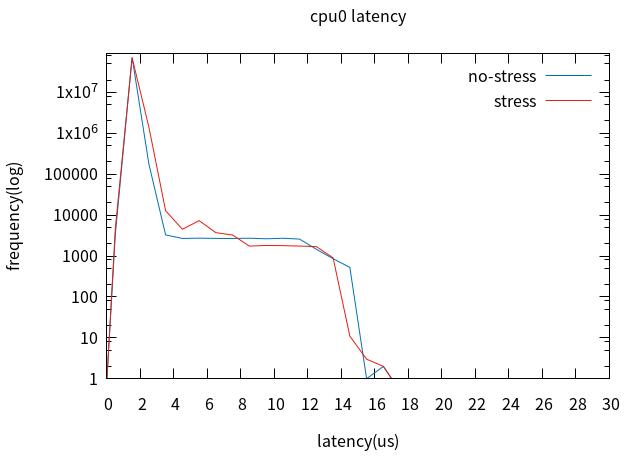
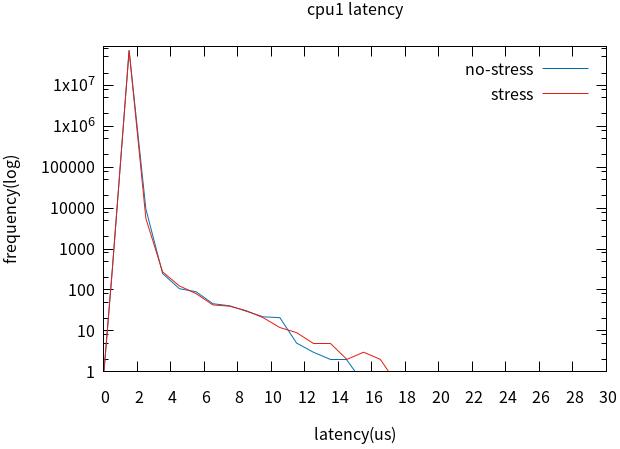
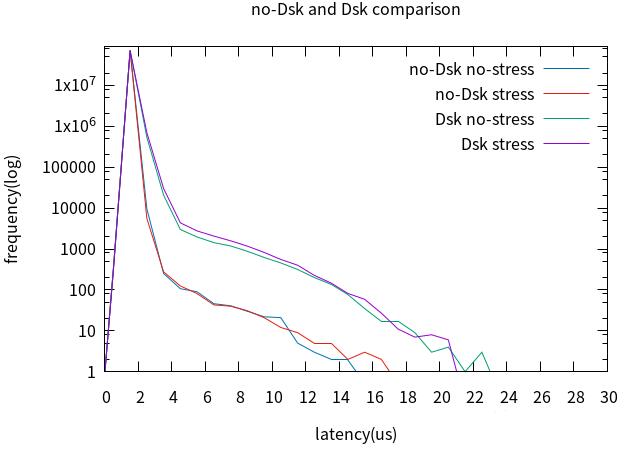
对比cpu0与cpu1,最坏情况没有改善,但4us以上的latency改善明显。
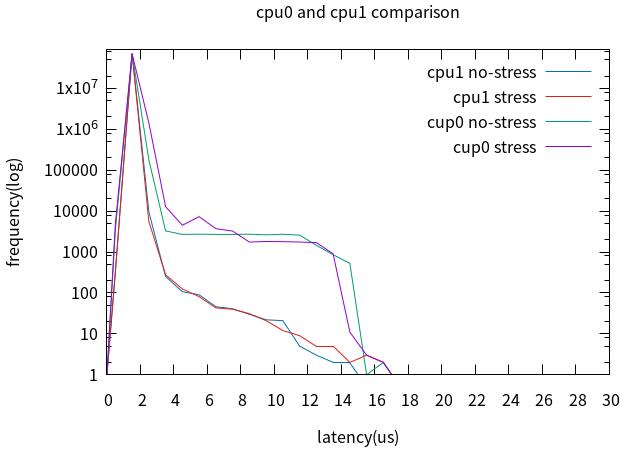
6.桌面、rcu、tick前后比对
带桌面、未启用rcunocb、未启用Full Dynamic Tick-------->裁桌面、启用rcunocb、启用Full
Dynamic Tick;
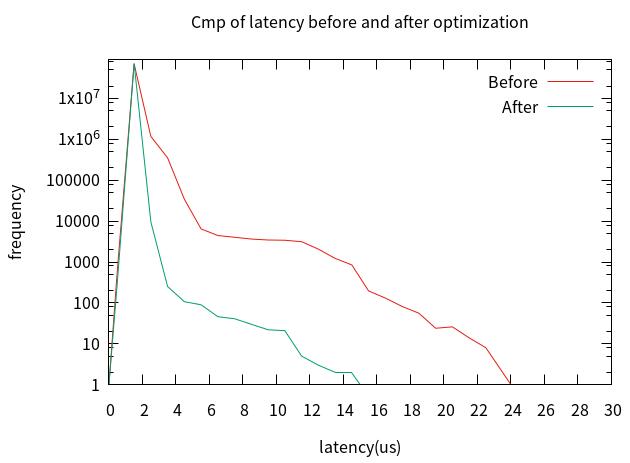
7.总对比 
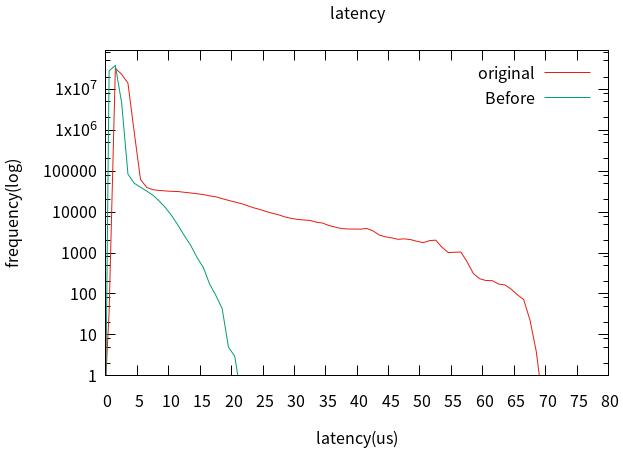
六、实时性能测试
下面直接给出最终的应用空间任务Jitter测试结果,使用的环境如下:
测试条件:在stress压力下测试,同时一个QT应用程序绘制2维曲线图,QT CPU占用率99%。
测试时间:211:04:55
测试命令:
| latency -t0
-p 100 -P 99 -h -g result.txt |
测试应用空间程序,优先级99,任务周期100us,测试结果输出到文件result.txt。经过接近10天的测试后,文件result.txt中latency分布结果如下:
#
211:04:55 (periodic user-mode task, 100 us period,
priority 99)
# ----lat min|----lat avg|----lat
max|-overrun|---msw|
# 0.343| 1.078| 23.110| 0|
0|
# Xenomai version: Xenomai/cobalt
v3.1
# Linux 4.4.200-xeno
......
# I-pipe releagese #20 detected
# Cobalt core 3.1 detected
# Compiler: gcc version 5.4.0
20160609
(Ubuntu 5.4.0-6ubuntu1~16.04.12)
# Build args: --enable-smp
--enable-pshared
--enable-tls
PKG_CONFIG_PATH=:/usr/xenomai/lib/
pkgconfig:/usr/xenomai/lib/pkgconfig0
1
0.5 1599357037
1.5 1621130106
2.5 56618753
3.5 4386985
4.5 3848531
5.5 3556704
6.5 3353649
7.5 3033218
8.5 2560133
9.5 2035075
10.5 1516866
11.5 1038989
12.5 680815
13.5 417124
14.5 224296
15.5 115165
16.5 58075
17.5 27669
18.5 11648
19.5 4648
20.5 1646
21.5 467
22.5 38
23.5 1
|
其中第一列数据表示latency的值,第二列表示该值与上一个值之间这个范围的latency出现的次数,最小0.343us,平均latency
1.078us,最大23.110us。可见xenomai的实时性还是挺不错的。以上只是xenomai应用空间任务的实时性表现,如果使用内核空间任务会更好。当然这只能说明操作系统能提供的实时性能,具体的还要看应用程序的设计等。
此外,该测试基于X86平台,X86处理器的实时性与BIOS有很大关系,通常BIOS配置CPU具有更高的吞吐量,例如超线程、电源管理、CPU频率等,毕竟BIOS不是普通开发者能接触到的,如果能让BIOS对CPU针对实时系统配置的话,实时性会更好。如下图所示,平均抖动几乎在100纳秒以内。
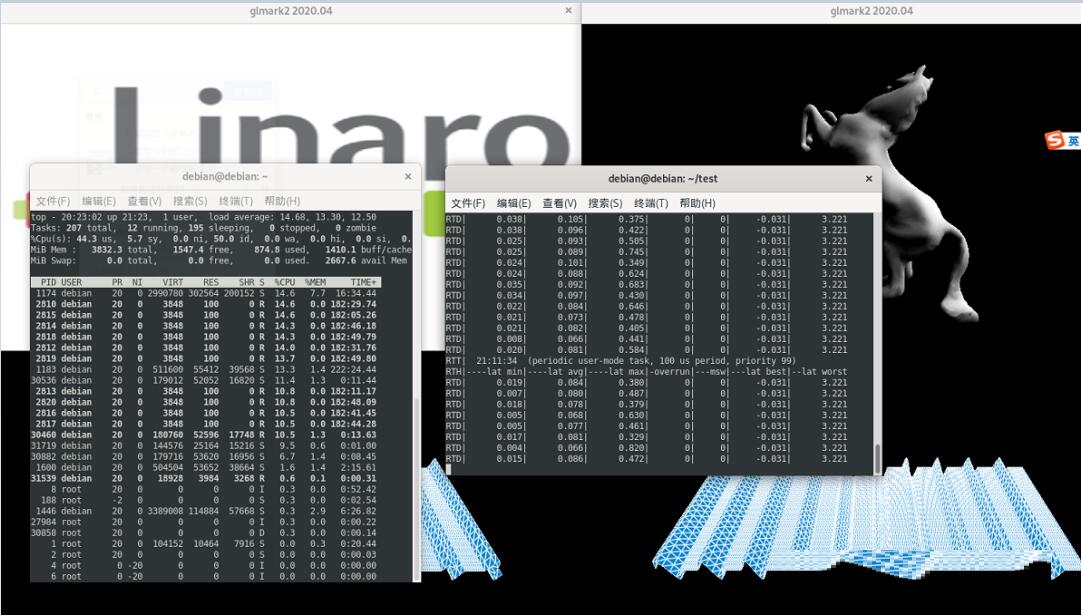
| 






 订阅
订阅