| ±ύΦ≠ΆΤΦω: |
±ΨΫΎ÷ς“ΣΉήΫαΝΥ«Ε»κ ΫCΒΡ“Μ–©”ΟΖ®Θ§Αϋά®ΡΎ¥φΙήάμΓΔΨ≤Χ§ΡΎ¥φΓΔΕ·Χ§ΡΎ¥φΓΔΉς”Ο”ρΓΔΝ¥Ϋ”
ΓΔΡΎ¥φΕ‘ΤκΘ§ΆϊΕ‘ΡζΒΡ―ßœΑ”–ΥυΑο÷ζΓΘ
±ΨΈΡά¥Ή‘”ΎΒγΉ”ΙΛ≥Χ άΫγ-Άχ¬γ’ϊάμΘ§”…ΜπΝζΙϊ»μΦΰAlice±ύΦ≠ΓΔΆΤΦωΓΘ |
|
ΡΎ¥φΙήάμ
Έ“Ο«–η“Σ÷ΣΒάΓΣΓΣ±δΝΩΘ§Τδ Β «ΡΎ¥φΒΊ÷ΖΒΡ“ΜΗω≥ιœώΟϊΉ÷Α’ΝΥΓΘ‘ΎΨ≤Χ§±ύ“κΒΡ≥Χ–ρ÷–Θ§Υυ”–ΒΡ±δΝΩΟϊΕΦΜα‘Ύ±ύ“κ ±±ΜΉΣ≥…ΡΎ¥φΒΊ÷ΖΓΘΜζΤς «≤Μ÷ΣΒάΈ“Ο«»ΓΒΡΟϊΉ÷ΒΡΘ§÷Μ÷ΣΒάΒΊ÷ΖΓΘ
ΡΎ¥φΒΡ Ι”Ο ±≥Χ–ρ…ηΦΤ÷––η“ΣΩΦ¬«ΒΡ÷Ί“Σ“ρΥΊ÷°“ΜΘ§’β≤ΜΫω”…”ΎœΒΆ≥ΡΎ¥φ «”–œόΒΡΘ®”»Τδ‘Ύ«Ε»κ ΫœΒΆ≥÷–Θ©Θ§Εχ«“ΡΎ¥φΖ÷≈δ“≤Μα÷±Ϋ””ΑœλΒΫ≥Χ–ρΒΡ–ß¬ ΓΘ“ρ¥ΥΘ§Έ“Ο«“ΣΕ‘C”ο―‘÷–ΒΡΡΎ¥φΙήάμΘ§”–ΗωœΒΆ≥ΒΡΝΥΫβΓΘ
‘ΎC”ο―‘÷–Θ§Ε®“εΝΥ4ΗωΡΎ¥φ«χΦδΘΚ¥ζ¬κ«χΘΜ»ΪΨ÷±δΝΩΚΆΨ≤Χ§±δΝΩ«χΘΜΨ÷≤Ω±δΝΩ«χΦ¥’Μ«χΘΜΕ·Χ§¥φ¥Δ«χΘ§Φ¥Ε―«χΘΜΨΏΧε»γœ¬ΘΚ
1ΓΔ’Μ«χΘ®stackΘ©ΓΣ ”…±ύ“κΤςΉ‘Ε·Ζ÷≈δ ΆΖ≈ Θ§¥φΖ≈Κ· ΐΒΡ≤Έ ΐ÷ΒΘ§Ψ÷≤Ω±δΝΩΒΡ÷ΒΒ»ΓΘΤδ≤ΌΉςΖΫ ΫάύΥΤ”Ύ ΐΨίΫαΙΙ÷–ΒΡ’ΜΓΘ
2ΓΔΕ―«χΘ®heapΘ© ΓΣ “ΜΑψ”…≥Χ–ρ‘±Ζ÷≈δ ΆΖ≈Θ§ »τ≥Χ–ρ‘±≤Μ ΆΖ≈Θ§≥Χ–ρΫα χ ±Ω…Ρή”…OSΜΊ ’
ΓΘΉΔ“βΥϋ”κ ΐΨίΫαΙΙ÷–ΒΡΕ― «ΝΫΜΊ ¬Θ§Ζ÷≈δΖΫ ΫΒΙ «άύΥΤ”ΎΝ¥±μΓΘ
3ΓΔ»ΪΨ÷«χΘ®Ψ≤Χ§«χΘ©Θ®staticΘ©ΓΣ»ΪΨ÷±δΝΩΚΆΨ≤Χ§±δΝΩΒΡ¥φ¥Δ «Ζ≈‘Ύ“ΜΩιΒΡΘ§≥θ ΦΜ·ΒΡ»ΪΨ÷±δΝΩΚΆΨ≤Χ§±δΝΩ‘Ύ“ΜΩι«χ”ρΘ§
Έ¥≥θ ΦΜ·ΒΡ»ΪΨ÷±δΝΩΚΆΈ¥≥θ ΦΜ·ΒΡΨ≤Χ§±δΝΩ‘ΎœύΝΎΒΡ Νμ“ΜΩι«χ”ρΓΘ - ≥Χ–ρΫα χΚσ”…œΒΆ≥ ΆΖ≈ΓΘ
4ΓΔ≥ΘΝΩ«χ ΓΣ≥ΘΝΩΉ÷Ζϊ¥°ΨΆ «Ζ≈‘Ύ’βάοΒΡΓΘ ≥Χ–ρΫα χΚσ”…œΒΆ≥ ΆΖ≈ΓΘ
5ΓΔ≥Χ–ρ¥ζ¬κ«χΓΣ¥φΖ≈Κ· ΐΧεΒΡΕΰΫχ÷Τ¥ζ¬κΓΘ
Έ“Ο«ά¥Ω¥’≈ΆΦΘΚ
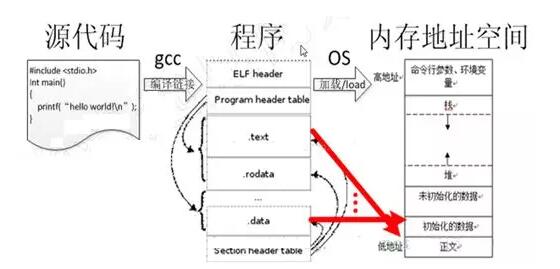
ΆΦ1
Ήœ»Έ“Ο«“Σ÷ΣΒάΘ§‘¥¥ζ¬κ±ύ“κ≥…≥Χ–ρΘ§≥Χ–ρ «Ζ≈‘Ύ”≤≈Χ…œΒΡΘ§ΕχΖ«ΡΎ¥φάοΘΓ÷Μ”–÷¥–– ±≤≈Μα±ΜΒς”ΟΒΫΡΎ¥φ÷–ΘΓΈ“Ο«ά¥Ω¥Ω¥≥Χ–ρΫαΙΙΘ§ELF « «LinuxΒΡ÷ς“ΣΩ…÷¥––ΈΡΦΰΗώ ΫΓΘELFΈΡΦΰ”…4≤ΩΖ÷Ήι≥…Θ§Ζ÷±π «ELFΆΖΘ®ELF
headerΘ©ΓΔ≥Χ–ρΆΖ±μΘ®Program header tableΘ©ΓΔΫΎΘ®SectionΘ©ΚΆΫΎΆΖ±μΘ®Section
header tableΘ©ΓΘΨΏΧε»γœ¬ΘΚ
1ΓΔProgram headerΟη ωΒΡ «“ΜΗωΕΈ‘ΎΈΡΦΰ÷–ΒΡΈΜ÷ΟΓΔ¥σ–Γ“‘ΦΑΥϋ±ΜΖ≈ΫχΡΎ¥φΚσΥυ‘ΎΒΡΈΜ÷ΟΚΆ¥σ–ΓΓΘΦ¥“ΣΦ”‘ΊΒΡ–≈œΔΘΜ
2ΓΔSections±Θ¥φΉ≈object ΈΡΦΰΒΡ–≈œΔΘ§¥”Ν§Ϋ”Ϋ«Ε»Ω¥ΘΚΑϋά®÷ΗΝνΘ§ ΐΨίΘ§ΖϊΚ≈±μΘ§÷ΊΕ®ΈΜ–≈œΔ»»ΓΘ‘ΎΆΦ÷–Θ§Έ“Ο«Ω…“‘Ω¥ΒΫSections÷–Αϋά®ΘΚ
text ΈΡ±ΨΫα ¥φΖ≈÷ΗΝνΘΜ
rodata ΐΨίΫα readonly;
data ΐΨίΫα Ω…ΕΝΩ…–¥ΘΜ
3ΓΔSectionΆΖ±μΘ®section header tableΘ©ΑϋΚ§ΝΥΟη ωΈΡΦΰsectionsΒΡ–≈œΔΓΘΟΩΗωsection‘Ύ’βΗω±μ÷–”–“ΜΗω»κΩΎΘΜΟΩΗω»κΩΎΗχ≥ωΝΥΗΟsectionΒΡΟϊΉ÷Θ§¥σ–Γȧ»»–≈œΔΓΘœύΒ±”Ύ
Υς“ΐΘΓ
Εχ≥Χ–ρ±ΜΦ”‘ΊΒΫΡΎ¥φάοΟφΘ§”÷ «»γΚΈΖ÷≤ΦΒΡΡΊΘΩΈ“Ο«Ω¥Ω¥…œΆΦ÷–ΘΚ
1ΓΔ’ΐΈΡΚΆ≥θ ΦΜ·ΒΡ ΐΨίΚΆΈ¥≥θ ΦΜ·ΒΡ ΐΨίΨΆ «Έ“Ο«ΥυΥΒΒΡ ΐΨίΕΈΘ§’ΐΈΡΦ¥¥ζ¬κΕΈΘΜ
2ΓΔ’ΐΈΡΕΈ…œΟφ «≥ΘΝΩ«χΘ§≥ΘΝΩ«χ…œΟφ «»ΪΨ÷±δΝΩΚΆΨ≤Χ§±δΝΩ«χΘ§Εΰ’Ώ’ΦΨίΒΡΨΆ «≥θ ΦΜ·ΒΡ ΐΨίΚΆΈ¥≥θ ΦΜ·ΒΡ ΐΨίΡ«≤ΩΖ÷ΘΜ
3ΓΔ‘Ό…œΟφΨΆ «Ε―Θ§Ε·Χ§¥φ¥Δ«χΘ§’βάο «…œ‘ω≥ΛΘΜ
4ΓΔΕ―…œΟφ «’ΜΘ§¥φΖ≈ΒΡ «Ψ÷≤Ω±δΝΩΘ§ΨΆ «Ψ÷≤Ω±δΝΩΥυ‘Ύ¥ζ¬κΩι÷¥––Άξ±œΚσΘ§’βΩιΡΎ¥φΜα±Μ ΆΖ≈Θ§’βάο’Μ«χ «œ¬‘ω≥ΛΘΜ
5ΓΔΟϋΝν––≤Έ ΐΨΆ «001÷°άύΒΡΘ§ΜΖΨ≥±δΝΩ ≤Ο¥ΒΡ«ΑΟφΒΡΈΡ’¬“―Ψ≠Ϋ≤ΙΐΘ§”––Υ»ΛΒΡΩ…“‘»ΞΩ¥Ω¥ΓΘ
Έ“Ο«÷ΣΒάΘ§ΡΎ¥φΖ÷ΈΣΕ·Χ§ΡΎ¥φΚΆΨ≤Χ§ΡΎ¥φΘ§Έ“Ο«œ»Ϋ≤Ψ≤Χ§ΡΎ¥φΓΘ
Ψ≤Χ§ΡΎ¥φ
¥φ¥ΔΡΘ–ΆΨωΕ®ΝΥ“ΜΗω±δΝΩΒΡΡΎ¥φΖ÷≈δΖΫ ΫΚΆΖΟΈ ΧΊ–‘Θ§‘ΎC”ο―‘÷–÷ς“Σ”–»ΐΗωΈ§Ε»ά¥ΨωΕ®ΘΚ¥φ¥Δ ±ΤΎ
ΓΔΉς”Ο”ρ ΓΔΝ¥Ϋ”ΓΘ
¥φ¥Δ ±ΤΎ
¥φ¥Δ ±ΤΎΘΚ±δΝΩ‘ΎΡΎ¥φ÷–ΒΡ±ΘΝτ ±ΦδΘ®…ζΟϋ÷ήΤΎΘ©
¥φ¥Δ ±ΤΎΖ÷ΈΣΝΫ÷÷«ιΩωΘ§ΙΊΦϋ «Ω¥±δΝΩ‘Ύ≥Χ–ρ÷¥––Ιΐ≥Χ÷–Μα≤ΜΜα±ΜœΒΆ≥Ή‘Ε·ΜΊ ’ΒτΓΘ
1) Ψ≤Χ§¥φ¥Δ ±ΤΎ Static
‘Ύ≥Χ–ρ÷¥––Ιΐ≥Χ÷–“ΜΒ©Ζ÷≈δΨΆ≤ΜΜα±ΜΉ‘Ε·ΜΊ ’ΓΘ
Ά®≥Θά¥ΥΒΘ§»ΈΚΈ≤Μ‘ΎΚ· ΐΦΕ±π¥ζ¬κΩιΡΎΕ®“εΒΡ±δΝΩΓΘ
Έό¬έ «Ζώ‘Ύ¥ζ¬κΩιΡΎΘ§÷Μ“Σ≤…”ΟstaticΙΊΦϋΉ÷–ό ΈΒΡ±δΝΩΓΘ
2) Ή‘Ε·¥φ¥Δ ±ΤΎ Automatic
≥ΐΝΥΨ≤Χ§¥φ¥Δ“‘ΆβΒΡ±δΝΩΕΦ «Ή‘Ε·¥φ¥Δ ±ΤΎΒΡΘ§Μρ’ΏΥΒ÷Μ“Σ «‘Ύ¥ζ¬κΩιΡΎΕ®“εΒΡΖ«staticΒΡ±δΝΩΘ§œΒΆ≥ΜαΕ«ΤξΉ‘Ε·Ζ«≈δΚΆ ΆΖ≈ΡΎ¥φΘΜ
Ής”Ο”ρ
Ής”Ο”ρΘΚ“ΜΗω±δΝΩ‘ΎΕ®“εΗΟ±δΝΩΒΡΉ‘…μΈΡΦΰ÷–ΒΡΩ…Φϊ–‘Θ®ΖΟΈ Μρ’Ώ“ΐ”ΟΘ©
‘ΎC”ο―‘÷–Θ§“ΜΙ≤”–3÷–Ής”Ο”ρΘΚ
1) ¥ζ¬κΩιΉς”Ο”ρ
‘Ύ¥ζ¬κΩι÷–Ε®“εΒΡ±δΝΩΕΦΨΏ”–ΗΟ¥ζ¬κΒΡΉς”Ο”ρΓΘ¥”’βΗω±δΝΩΕ®“εΒΊΖΫΩΣ ΦΘ§ΒΫ’βΗω¥ζ¬κΩιΫα χΘ§ΗΟ±δΝΩ «Ω…ΦϊΒΡΘΜ
2) Κ· ΐ‘≠–ΆΉς”Ο”ρ
≥ωœ÷‘ΎΚ· ΐ‘≠–Ά÷–ΒΡ±δΝΩΘ§ΕΦΨΏ”–Κ· ΐ‘≠–ΆΉς”Ο”ρΘ§Κ· ΐ‘≠–ΆΉς”Ο”ρ¥”±δΝΩΕ®“ε¥Π“Μ÷±ΒΫ‘≠–Ά…υΟςΒΡΡ©Έ≤ΓΘ
3) ΈΡΦΰΉς”Ο”ρ
“ΜΗω‘ΎΥυ”–Κ· ΐ÷°ΆβΕ®“εΒΡ±δΝΩΨΏ”–ΈΡΦΰΉς”Ο”ρΘ§ΨΏ”–ΈΡΦΰΉς”Ο”ρΒΡ±δΝΩ¥”ΥϋΒΡΕ®“ε¥ΠΒΫΑϋΚ§ΗΟΕ®“εΒΡΈΡΦΰΫαΈ≤¥ΠΕΦ «Ω…ΦϊΒΡΘΜ
Ν¥Ϋ”
Ν¥Ϋ”ΘΚ“ΜΗω±δΝΩ‘ΎΉι≥…≥Χ–ρΒΡΥυ”–ΈΡΦΰ÷–ΒΡΩ…Φϊ–‘Θ®ΖΟΈ Μρ’Ώ“ΐ”ΟΘ©ΘΜ
C”ο―‘÷–“ΜΙ≤”–»ΐ÷÷≤ΜΆ§ΒΡΝ¥Ϋ”ΘΚ
1) Άβ≤ΩΝ¥Ϋ”
»γΙϊ“ΜΗω±δΝΩ‘ΎΉι≥…“ΜΗω≥Χ–ρΒΡΥυ”–ΈΡΦΰ÷–ΒΡ»ΈΚΈΈΜ÷ΟΕΦΩ…“‘±ΜΖΟΈ Θ§‘ρ≥ΤΗΟ±δΝΩ÷ß≥÷Άβ≤ΩΝ¥Ϋ”ΘΜ
2) ΡΎ≤ΩΝ¥Ϋ”
»γΙϊ“ΜΗω±δΝΩ÷ΜΩ…“‘‘ΎΕ®“εΤδΉ‘…μΒΡΈΡΦΰ÷–ΒΡ»ΈΚΈΈΜ÷Ο±ΜΖΟΈ Θ§‘ρ≥ΤΗΟ±δΝΩ÷ß≥÷ΡΎ≤ΩΝ¥Ϋ”ΓΘ
3) Ω’Ν¥Ϋ”
»γΙϊ“ΜΗω±δΝΩ÷Μ «±ΜΕ®“εΤδΉ‘…μΒΡΒ±«Α¥ζ¬κΩιΥυΥΫ”–Θ§≤ΜΡή±Μ≥Χ–ρΒΡΤδΥϊ≤ΩΖ÷ΥυΖΟΈ Θ§‘ρ≥…ΗΟ±δΝΩ÷ß≥÷Ω’Ν¥Ϋ”
Έ“Ο«ά¥Ω¥“ΜΗω¥ζ¬κ ΨάΐΘΚ
#include <stdio.h>
int a = 0;// »ΪΨ÷≥θ ΦΜ·«χ
char *p1; //»ΪΨ÷Έ¥≥θ ΦΜ·«χ
int main()
{
int b; //b‘Ύ’Μ«χ
char s[] = "abc"; //’Μ
char *p2; //p2‘Ύ’Μ«χ
char *p3 = "123456"; //123456\0‘Ύ≥ΘΝΩ«χΘ§p3‘Ύ’Μ…œΓΘ
static int c =0ΘΜ //»ΪΨ÷Θ®Ψ≤Χ§Θ©≥θ ΦΜ·«χ
p1 = (char *)malloc(10);
p2 = (char *)malloc(20); //Ζ÷≈δΒΟά¥ΒΟ10ΚΆ20Ή÷ΫΎΒΡ«χ”ρΨΆ‘ΎΕ―«χΓΘ
strcpy(p1, "123456"); //123456\0Ζ≈‘Ύ≥ΘΝΩ«χΘ§±ύ“κΤςΩ…ΡήΜαΫΪΥϋ”κp3Υυ÷ΗœρΒΡ"123456"”≈Μ·≥…“ΜΗωΒΊΖΫΓΘ
}
1.2Ε·Χ§ΡΎ¥φ
Β±≥Χ–ρ‘Υ––ΒΫ–η“Σ“ΜΗωΕ·Χ§Ζ÷≈δΒΡ±δΝΩ ±Θ§±Ί–κœρœΒΆ≥…ξ«κ»ΓΒΟΕ―÷–ΒΡ“ΜΩιΥυ–η¥σ–ΓΒΡ¥φ¥ΔΩ’ΦδΘ§”Ο”Ύ¥φ¥ΔΗΟ±δΝΩΓΘΒ±≤Μ‘Ύ Ι”ΟΗΟ±δΝΩ ±Θ§“≤ΨΆ «ΥϋΒΡ…ζΟϋΫα χ ±Θ§“Σœ‘ Ψ ΆΖ≈ΥϋΥυ’Φ”ΟΒΡ¥φ¥ΔΩ’ΦδΘ§’β―υœΒΆ≥ΨΆΡήΕ‘ΗΟΩ’Φδ
Ϋχ––‘Ό¥ΈΖ÷≈δΘ§ΉωΒΫ÷ΊΗ¥ Ι”Ο”–œΏΒΡΉ ‘¥ΓΘœ¬ΟφΫι…ήΕ·Χ§ΡΎ¥φ…ξ«κΚΆ ΆΖ≈ΒΡΚ· ΐΓΘ
1.2.1 malloc Κ· ΐ
mallocΚ· ΐ‘≠–ΆΘΚ
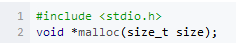
size «–η“ΣΕ·Χ§…ξ«κΒΡΡΎ¥φΒΡΉ÷ΫΎ ΐΓΘ»τ…ξ«κ≥…ΙΠΘ§Κ· ΐΖΒΜΊ…ξ«κΒΫΒΡΡΎ¥φΒΡΤπ ΦΒΊ÷ΖΘ§»τ…ξ«κ ßΑήΘ§ΖΒΜΊNULLΓΘΈ“Ο«Ω¥œ¬Οφ’βΗωάΐΉ”ΘΚ

Ι”ΟΗΟΚ· ΐ ±Θ§”–œ¬ΟφΦΗΒψ“ΣΉΔ“βΘΚ
1Θ©÷ΜΙΊ–Ρ…ξ«κΡΎ¥φΒΡ¥σ–ΓΘΜ
2Θ©…ξ«κΒΡ «“ΜΩιΝ§–χΒΡΡΎ¥φΓΘΦ«ΒΟ“ΜΕ®“Σ–¥≥ω¥μ≈–ΕœΘΜ
3Θ©œ‘ Ψ≥θ ΦΜ·ΓΘΦ¥Έ“Ο«≤Μ÷Σ’βΩιΡΎ¥φ÷–”– ≤Ο¥ΕΪΈςΘ§“ΣΕ‘Τδ«εΝψΘΜ
1.2.2 freeΚ· ΐ
‘ΎΕ―…œΖ÷≈δΒΡΕνΡΎ¥φΘ§–η“Σ”ΟfreeΚ· ΐœ‘ Ψ ΆΖ≈Θ§Κ· ΐ‘≠–Ά»γœ¬ΘΚ
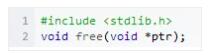
Ι”Οfree(),“≤”–œ¬ΟφΦΗΒψ“ΣΉΔ“βΘΚ
1Θ©±Ί–κΧαΙ©ΡΎ¥φΒΡΤπ ΦΒΊ÷ΖΘΜ
Βς”ΟΗΟΚ· ΐ ±Θ§±Ί–κΧαΙ©ΡΎ¥φΒΡΤπ ΦΒΊ÷ΖΘ§≤ΜΡήΙΜΧαΙ©≤ΩΖ÷ΒΊ÷ΖΘ§ ΆΖ≈ΡΎ¥φ÷–ΒΡ“Μ≤ΩΖ÷ «≤Μ‘ –μΒΡΓΘ
2Θ©mallocΚΆfree≈δΕ‘ Ι”ΟΘΜ
±ύ“κΤς≤ΜΗΚ‘πΕ·Χ§ΡΎ¥φΒΡ ΆΖ≈Θ§–η“Σ≥Χ–ρ‘±œ‘ Ψ ΆΖ≈ΓΘ“ρ¥ΥΘ§malloc”κfree «≈δΕ‘ Ι”ΟΒΡΘ§±ήΟβΡΎ¥φ–Ι¬©ΓΘ
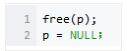
p = NULL «±Ί–κΒΡΘ§“ρΈΣΥδ»Μ’βΩιΡΎ¥φ±Μ ΆΖ≈ΝΥΘ§ΒΪ «p»‘÷Ηœρ’βΩιΡΎ¥φΘ§±ήΟβœ¬¥ΈΕ‘pΒΡΈσ≤ΌΉςΘΜ
3Θ©≤Μ‘ –μ÷ΊΗ¥ ΆΖ≈
“ρΈΣ’βΩιΡΎ¥φ±Μ ΆΖ≈ΚσΘ§Ω…Ρή“―ΝμΖ÷≈δΘ§’βΩι«χ”ρ±Μ±π»Υ’Φ”ΟΘ§»γΙϊ‘Ό¥Έ ΆΖ≈Θ§Μα‘λ≥… ΐΨίΕΣ ßΘΜ
1.2.3 ΤδΥϋœύΙΊΚ· ΐ
callocΚ· ΐΖ÷≈δΡΎ¥φ–η“ΣΩΦ¬«¥φ¥ΔΈΜ÷ΟΒΡάύ–ΆΓΘ
reallocΚ· ΐΩ…“‘Βς’ϊ“ΜΕΈΕ·Χ§Ζ÷≈δΡΎ¥φΒΡ¥σ–Γ
1.3Ε―ΚΆ’Μ±»Ϋœ
1Θ©…ξ«κΖΫ Ϋ
stack: ”…œΒΆ≥Ή‘Ε·Ζ÷≈δΓΘ άΐ»γΘ§…υΟς‘ΎΚ· ΐ÷–“ΜΗωΨ÷≤Ω±δΝΩ int b; œΒΆ≥Ή‘Ε·‘Ύ’Μ÷–ΈΣbΩΣ±ΌΩ’Φδ
heap: –η“Σ≥Χ–ρ‘±Ή‘ΦΚ…ξ«κΘ§≤Δ÷ΗΟς¥σ–ΓΘ§‘Ύc÷–mallocΚ· ΐ
,»γp1 = (char *)malloc(10);
2Θ©…ξ«κΚσœΒΆ≥ΒΡœλ”Π
’ΜΘΚ÷Μ“Σ’ΜΒΡ Θ”ύΩ’Φδ¥σ”ΎΥυ…ξ«κΩ’ΦδΘ§œΒΆ≥ΫΪΈΣ≥Χ–ρΧαΙ©ΡΎ¥φΘ§Ζώ‘ρΫΪ±®“λ≥ΘΧα Ψ’Μ“γ≥ωΓΘ
Ε―ΘΚ Ήœ»”ΠΗΟ÷ΣΒά≤ΌΉςœΒΆ≥”–“ΜΗωΦ«¬ΦΩ’œ–ΡΎ¥φΒΊ÷ΖΒΡΝ¥±μΘ§Β±œΒΆ≥ ’ΒΫ≥Χ–ρΒΡ…ξ«κ ±Θ§Μα±ιάζΗΟΝ¥±μΘ§―Α’“ΒΎ“ΜΗωΩ’Φδ¥σ”ΎΥυ…ξ«κΩ’ΦδΒΡΕ―ΫαΒψΘ§»ΜΚσΫΪΗΟΫαΒψ¥”Ω’œ–ΫαΒψΝ¥±μ÷–…Ψ≥ΐΘ§≤ΔΫΪΗΟΫαΒψΒΡΩ’ΦδΖ÷≈δΗχ≥Χ–ρΘ§ΝμΆβΘ§Ε‘”Ύ¥σΕύ ΐœΒΆ≥Θ§Μα‘Ύ’βΩιΡΎ¥φΩ’Φδ÷–ΒΡ ΉΒΊ÷Ζ¥ΠΦ«¬Φ±Ψ¥ΈΖ÷≈δΒΡ¥σ–ΓΘ§’β―υΘ§¥ζ¬κ÷–ΒΡdelete”οΨδ≤≈Ρή’ΐ»ΖΒΡ ΆΖ≈±ΨΡΎ¥φΩ’ΦδΓΘΝμΆβΘ§”…”Ύ’“ΒΫΒΡΕ―ΫαΒψΒΡ¥σ–Γ≤Μ“ΜΕ®’ΐΚΟΒ»”Ύ…ξ«κΒΡ¥σ–ΓΘ§œΒΆ≥ΜαΉ‘Ε·ΒΡΫΪΕύ”ύΒΡΡ«≤ΩΖ÷÷Ί–¬Ζ≈»κΩ’œ–Ν¥±μ÷–ΓΘ
3Θ©…ξ«κ¥σ–ΓΒΡœό÷Τ
’ΜΘΚ’Μ «œρΒΆΒΊ÷Ζά©’ΙΒΡ ΐΨίΫαΙΙΘ§ «“ΜΩιΝ§–χΒΡΡΎ¥φΒΡ«χ”ρΓΘ’βΨδΜΑΒΡ“βΥΦ «’ΜΕΞΒΡΒΊ÷ΖΚΆ’ΜΒΡΉν¥σ»ίΝΩ «œΒΆ≥‘Λœ»ΙφΕ®ΚΟΒΡΘ§’ΜΒΡ¥σ–Γ «2MΘ®“≤”–ΒΡΥΒ «1MΘ§Ήή÷° «“ΜΗω±ύ“κ ±ΨΆ»ΖΕ®ΒΡ≥Θ ΐΘ©Θ§»γΙϊ…ξ«κΒΡΩ’Φδ≥§Ιΐ’ΜΒΡ Θ”ύΩ’Φδ ±Θ§ΫΪΧα ΨoverflowΓΘ“ρ¥ΥΘ§Ρή¥”’ΜΜώΒΟΒΡΩ’ΦδΫœ–ΓΓΘ
Ε―ΘΚΕ― «œρΗΏΒΊ÷Ζά©’ΙΒΡ ΐΨίΫαΙΙΘ§ «≤ΜΝ§–χΒΡΡΎ¥φ«χ”ρΓΘ’β «”…”ΎœΒΆ≥ «”ΟΝ¥±μά¥¥φ¥ΔΒΡΩ’œ–ΡΎ¥φΒΊ÷ΖΒΡΘ§Ή‘»Μ «≤ΜΝ§–χΒΡΘ§ΕχΝ¥±μΒΡ±ιάζΖΫœρ «”…ΒΆΒΊ÷ΖœρΗΏΒΊ÷ΖΓΘΕ―ΒΡ¥σ–Γ ήœό”ΎΦΤΥψΜζœΒΆ≥÷–”––ßΒΡ–ιΡβΡΎ¥φΓΘ”…¥ΥΩ…ΦϊΘ§Ε―ΜώΒΟΒΡΩ’Φδ±»ΫœΝιΜνΘ§“≤±»Ϋœ¥σΓΘ
4Θ©…ξ«κ–߬ ΒΡ±»Ϋœ
’Μ”…œΒΆ≥Ή‘Ε·Ζ÷≈δΘ§ΥΌΕ»ΫœΩλΓΘΒΪ≥Χ–ρ‘± «ΈόΖ®ΩΊ÷ΤΒΡΓΘ
Ε― «”…newΖ÷≈δΒΡΡΎ¥φΘ§“ΜΑψΥΌΕ»±»Ϋœ¬ΐΘ§Εχ«“»ί“Ή≤ζ…ζΡΎ¥φΥιΤ§,≤ΜΙΐ”ΟΤπά¥ΉνΖΫ±ψΓΘ
5Θ©Ε―ΚΆ’Μ÷–ΒΡ¥φ¥ΔΡΎ»ί
’ΜΘΚ‘ΎΚ· ΐΒς”Ο ±Θ§ΒΎ“ΜΗωΫχ’ΜΒΡ «÷ςΚ· ΐ÷–ΚσΒΡœ¬“ΜΧθ÷ΗΝνΘ®Κ· ΐΒς”Ο”οΨδΒΡœ¬“ΜΧθΩ…÷¥––”οΨδΘ©ΒΡΒΊ÷ΖΘ§»ΜΚσ «Κ· ΐΒΡΗςΗω≤Έ ΐΘ§‘Ύ¥σΕύ ΐΒΡC±ύ“κΤς÷–Θ§≤Έ ΐ «”…”“ΆυΉσ»κ’ΜΒΡΘ§»ΜΚσ «Κ· ΐ÷–ΒΡΨ÷≤Ω±δΝΩΓΘΉΔ“βΨ≤Χ§±δΝΩ «≤Μ»κ’ΜΒΡΓΘ
Β±±Ψ¥ΈΚ· ΐΒς”ΟΫα χΚσΘ§Ψ÷≤Ω±δΝΩœ»≥ω’ΜΘ§»ΜΚσ «≤Έ ΐΘ§ΉνΚσ’ΜΕΞ÷Η’κ÷ΗœρΉνΩΣ Φ¥φΒΡΒΊ÷ΖΘ§“≤ΨΆ «÷ςΚ· ΐ÷–ΒΡœ¬“ΜΧθ÷ΗΝνΘ§≥Χ–ρ”…ΗΟΒψΦΧ–χ‘Υ––ΓΘ
Ε―ΘΚ“ΜΑψ «‘ΎΕ―ΒΡΆΖ≤Ω”Ο“ΜΗωΉ÷ΫΎ¥φΖ≈Ε―ΒΡ¥σ–ΓΓΘΕ―÷–ΒΡΨΏΧεΡΎ»ί”…≥Χ–ρ‘±Α≤≈≈ΓΘ
6Θ©¥φ»Γ–߬ ΒΡ±»Ϋœ
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa «‘Ύ‘Υ–– ±ΩΧΗ≥÷ΒΒΡΘΜ
Εχbbbbbbbbbbb «‘Ύ±ύ“κ ±ΨΆ»ΖΕ®ΒΡΘΜ
ΒΪ «Θ§‘Ύ“‘ΚσΒΡ¥φ»Γ÷–Θ§‘Ύ’Μ…œΒΡ ΐΉι±»÷Η’κΥυ÷ΗœρΒΡΉ÷Ζϊ¥°(άΐ»γΕ―)ΩλΓΘ
±»»γΘΚ
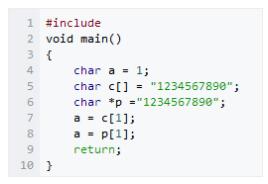
Ε‘”ΠΒΡΜψ±ύ¥ζ¬κ
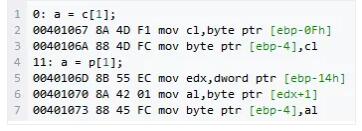
ΒΎ“Μ÷÷‘ΎΕΝ»Γ ±÷±Ϋ”ΨΆΑ―Ή÷Ζϊ¥°÷–ΒΡ‘ΣΥΊΕΝΒΫΦΡ¥φΤςcl÷–Θ§ΕχΒΎΕΰ÷÷‘ρ“Σœ»Α―÷Η’κ÷ΒΕΝΒΫedx÷–Θ§‘ΌΗυΨίedxΕΝ»ΓΉ÷ΖϊΘ§œ‘»Μ¬ΐΝΥΓΘ
7Θ©ΉνΚσΉήΫα
Ε―ΚΆ’ΜΒΡ«χ±πΩ…“‘”Ο»γœ¬ΒΡ±»”ςά¥Ω¥≥ωΘΚ
’ΜΨΆœώΈ“Ο«»ΞΖΙΙίάο≥‘ΖΙΘ§÷ΜΙήΒψ≤ΥΘ®ΖΔ≥ω…ξ«κΘ©ΓΔΗΕ«°ΓΔΚΆ≥‘Θ® Ι”ΟΘ©Θ§≥‘±ΞΝΥΨΆΉΏΘ§≤Μ±ΊάμΜα«–≤ΥΓΔœ¥≤ΥΒ»ΉΦ±ΗΙΛΉςΚΆœ¥ΆκΓΔΥΔΙχΒ»…®Έ≤ΙΛΉςΘ§ΥϊΒΡΚΟ¥Π «ΩλΫίΘ§ΒΪ «Ή‘”…Ε»–ΓΓΘ
Ε―ΨΆœσ «Ή‘ΦΚΕ· ÷Ήωœ≤ΜΕ≥‘ΒΡ≤Υκ»Θ§±»Ϋœ¬ιΖ≥Θ§ΒΪ «±»ΫœΖϊΚœΉ‘ΦΚΒΡΩΎΈΕΘ§Εχ«“Ή‘”…Ε»¥σΓΘ
2ΓΔΡΎ¥φΕ‘Τκ
2.1 #pragma pack(n) Ε‘Τκ”ΟΖ®œξΫβ
1. ≤Ο¥ «Ε‘ΤκΘ§“‘ΦΑΈΣ ≤Ο¥“ΣΕ‘Τκ
œ÷¥ζΦΤΥψΜζ÷–ΡΎ¥φΩ’ΦδΕΦ «Α¥’’byteΜ°Ζ÷ΒΡΘ§¥”άμ¬έ…œΫ≤ΥΤΚθΕ‘»ΈΚΈάύ–ΆΒΡ±δΝΩΒΡΖΟΈ Ω…“‘¥”»ΈΚΈΒΊ÷ΖΩΣ ΦΘ§ΒΪ ΒΦ «ιΩω «‘ΎΖΟΈ ΧΊΕ®±δΝΩΒΡ ±ΚρΨ≠≥Θ‘ΎΧΊΕ®ΒΡΡΎ¥φΒΊ÷ΖΖΟΈ Θ§’βΨΆ–η“ΣΗςάύ–Ά ΐΨίΑ¥’’“ΜΕ®ΒΡΙφ‘ρ‘ΎΩ’Φδ…œ≈≈Ν–Θ§Εχ≤Μ «Υ≥–ρΒΡ“ΜΗωΫ”“ΜΗωΒΡ≈≈Ζ≈Θ§’βΨΆ «Ε‘ΤκΓΘ
Ε‘ΤκΒΡΉς”ΟΚΆ‘≠“ρΘΚΗςΗω”≤ΦΰΤΫΧ®Ε‘¥φ¥ΔΩ’ΦδΒΡ¥Πάμ…œ”–Κή¥σΒΡ≤ΜΆ§ΓΘ“Μ–©ΤΫΧ®Ε‘Ρ≥–©ΧΊΕ®άύ–ΆΒΡ ΐΨί÷ΜΡή¥”Ρ≥–©ΧΊΕ®ΒΊ÷ΖΩΣ Φ¥φ»ΓΓΘΤδΥϊΤΫΧ®Ω…ΡήΟΜ”–’β÷÷«ιΩωΘ§
ΒΪ «Ήν≥ΘΦϊΒΡ «»γΙϊ≤ΜΑ¥’’ ΚœΤδΤΫΧ®“Σ«σΕ‘ ΐΨί¥φΖ≈Ϋχ––Ε‘ΤκΘ§Μα‘Ύ¥φ»Γ–߬ …œ¥χά¥Υπ ßΓΘ±»»γ”––©ΤΫΧ®ΟΩ¥ΈΕΝΕΦ «¥”≈ΦΒΊ÷ΖΩΣ ΦΘ§»γΙϊ“ΜΗωint–ΆΘ®ΦΌ…ηΈΣ
32ΈΜœΒΆ≥Θ©»γΙϊ¥φΖ≈‘Ύ≈ΦΒΊ÷ΖΩΣ ΦΒΡΒΊΖΫΘ§Ρ«Ο¥“ΜΗωΕΝ÷ήΤΎΨΆΩ…“‘ΕΝ≥ωΘ§Εχ»γΙϊ¥φΖ≈‘ΎΤφΒΊ÷ΖΩΣ ΦΒΡΒΊΖΫΘ§ΨΆΩ…ΡήΜα–η“Σ2ΗωΕΝ÷ήΤΎΘ§≤ΔΕ‘ΝΫ¥ΈΕΝ≥ωΒΡΫαΙϊΒΡΗΏΒΆΉ÷ΫΎΫχ––Τ¥¥’≤≈ΡήΒΟΒΫΗΟint ΐΨίΓΘœ‘»Μ‘ΎΕΝ»Γ–ß¬ …œœ¬ΫΒΚήΕύΓΘ’β“≤ «Ω’ΦδΚΆ ±ΦδΒΡ≤©όΡΓΘ
2.Ε‘ΤκΒΡ Βœ÷
Ά®≥ΘΘ§Έ“Ο«–¥≥Χ–ρΒΡ ±ΚρΘ§≤Μ–η“ΣΩΦ¬«Ε‘ΤκΈ ΧβΓΘ±ύ“κΤςΜαΧφΈ“Ο«―Γ‘ώ ±ΚρΡΩ±ξΤΫΧ®ΒΡΕ‘Τκ≤Ώ¬‘ΓΘΒ±»ΜΘ§Έ“Ο«“≤Ω…“‘Ά®÷ΣΗχ±ύ“κΤς¥ΪΒί‘Λ±ύ“κ÷ΗΝνΕχΗΡ±δΕ‘÷ΗΕ® ΐΨίΒΡΕ‘ΤκΖΫΖ®ΓΘ
ΒΪ «Θ§’ΐ“ρΈΣΈ“Ο«“ΜΑψ≤Μ–η“ΣΙΊ–Ρ’βΗωΈ ΧβΘ§Υυ“‘“ρΈΣ±ύΦ≠ΤςΕ‘ ΐΨί¥φΖ≈ΉωΝΥΕ‘ΤκΘ§ΕχΈ“Ο«≤ΜΝΥΫβΒΡΜΑΘ§≥Θ≥ΘΜαΕ‘“Μ–©Έ ΧβΗ–ΒΫΟ‘ΜσΓΘΉν≥ΘΦϊΒΡΨΆ «struct ΐΨίΫαΙΙΒΡsizeofΫαΙϊΘ§≥ωΚθ“βΝœΓΘΈΣ¥ΥΘ§Έ“Ο«–η“ΣΕ‘Ε‘ΤκΥψΖ®ΥυΝΥΫβΓΘ
Ής”ΟΘΚ
÷ΗΕ®ΫαΙΙΧεΓΔΝΣΚœ“‘ΦΑάύ≥…‘±ΒΡpacking alignment;
”οΖ®ΘΚ
#pragma pack( [show] | [push | pop]
[, identifier], n )
ΥΒΟςΘΚ
1>packΧαΙ© ΐΨί…υΟςΦΕ±πΒΡΩΊ÷ΤΘ§Ε‘Ε®“ε≤ΜΤπΉς”ΟΘΜ
2>Βς”Οpack ±≤Μ÷ΗΕ®≤Έ ΐΘ§nΫΪ±Μ…η≥…Ρ§»œ÷ΒΘΜ
3>“ΜΒ©ΗΡ±δ ΐΨίάύ–ΆΒΡalignmentΘ§÷±Ϋ”–ßΙϊΨΆ «’Φ”ΟmemoryΒΡΦθ…ΌΘ§ΒΪ «performanceΜαœ¬ΫΒΘΜ
3.”οΖ®ΨΏΧεΖ÷Έω
1>showΘΚΩ…―Γ≤Έ ΐΘΜœ‘ ΨΒ±«Αpacking aligmentΒΡΉ÷ΫΎ ΐΘ§“‘warning
messageΒΡ–Έ Ϋ±Μœ‘ ΨΘΜ
2>pushΘΚΩ…―Γ≤Έ ΐΘΜΫΪΒ±«Α÷ΗΕ®ΒΡpacking alignment ΐ÷ΒΫχ––―Ι’Μ≤ΌΉςΘ§’βάοΒΡ’Μ «the
internal compiler stackΘ§Ά§ ±…η÷ΟΒ±«ΑΒΡpacking alignmentΈΣnΘΜ»γΙϊnΟΜ”–÷ΗΕ®Θ§‘ρΫΪΒ±«ΑΒΡpacking
alignment ΐ÷Β―Ι’ΜΘΜ
3>popΘΚΩ…―Γ≤Έ ΐΘΜ¥”internal compiler
stack÷–…Ψ≥ΐΉνΕΞΕΥΒΡrecordΘΜ»γΙϊΟΜ”–÷ΗΕ®nΘ§‘ρΒ±«Α’ΜΕΞrecordΦ¥ΈΣ–¬ΒΡpacking
alignment ΐ÷ΒΘΜ»γΙϊ÷ΗΕ®ΝΥnΘ§‘ρnΫΪ≥…ΈΣ–¬ΒΡpacking aligment ΐ÷ΒΘΜ»γΙϊ÷ΗΕ®ΝΥidentifierΘ§‘ρinternal
compiler stack÷–ΒΡrecordΕΦΫΪ±Μpop÷±ΒΫidentifier±Μ’“ΒΫΘ§»ΜΚσpop≥ωidentitierΘ§Ά§ ±…η÷Οpacking
alignment ΐ÷ΒΈΣΒ±«Α’ΜΕΞΒΡrecordΘΜ»γΙϊ÷ΗΕ®ΒΡidentifier≤Δ≤Μ¥φ‘Ύ”Ύinternal
compiler stackΘ§‘ρpop≤ΌΉς±ΜΚω¬‘ΘΜ
4>identifierΘΚΩ…―Γ≤Έ ΐΘΜΒ±Ά§push“ΜΤπ Ι”Ο ±Θ§Η≥”ηΒ±«Α±Μ―Ι»κ’Μ÷–ΒΡrecord“ΜΗωΟϊ≥ΤΘΜΒ±Ά§pop“ΜΤπ Ι”Ο ±Θ§¥”internal
compiler stack÷–pop≥ωΥυ”–ΒΡrecord÷±ΒΫidentifier±Μpop≥ωΘ§»γΙϊidentifierΟΜ”–±Μ’“ΒΫΘ§‘ρΚω¬‘pop≤ΌΉςΘΜ
5>nΘΚΩ…―Γ≤Έ ΐΘΜ÷ΗΕ®packingΒΡ ΐ÷ΒΘ§“‘Ή÷ΫΎΈΣΒΞΈΜΘΜ»± Γ ΐ÷Β «8Θ§ΚœΖ®ΒΡ ΐ÷ΒΖ÷±π «1ΓΔ2ΓΔ4ΓΔ8ΓΔ16ΓΘ
4.÷Ί“ΣΙφ‘ρ
1>Η¥‘”άύ–Ά÷–ΗςΗω≥…‘±Α¥’’ΥϋΟ«±Μ…υΟςΒΡΥ≥–ρ‘ΎΡΎ¥φ÷–Υ≥–ρ¥φ¥ΔΘ§ΒΎ“ΜΗω≥…‘±ΒΡΒΊ÷ΖΚΆ’ϊΗωάύ–ΆΒΡΒΊ÷ΖœύΆ§ΘΜ
2>ΟΩΗω≥…‘±Ζ÷±πΕ‘ΤκΘ§Φ¥ΟΩΗω≥…‘±Α¥Ή‘ΦΚΒΡΖΫ ΫΕ‘ΤκΘ§≤ΔΉν–ΓΜ·≥ΛΕ»ΘΜΙφ‘ρΨΆ «ΟΩΗω≥…‘±Α¥Τδάύ–ΆΒΡΕ‘Τκ≤Έ ΐΘ®Ά®≥Θ «’βΗωάύ–ΆΒΡ¥σ–ΓΘ©ΚΆ÷ΗΕ®Ε‘Τκ≤Έ ΐ÷–Ϋœ–ΓΒΡ“ΜΗωΕ‘ΤκΘΜ
3>ΫαΙΙΓΔΝΣΚœΜρ’ΏάύΒΡ ΐΨί≥…‘±Θ§ΒΎ“ΜΗωΖ≈‘ΎΤΪ“ΤΈΣ0ΒΡΒΊΖΫΘΜ“‘ΚσΟΩΗω ΐΨί≥…‘±ΒΡΕ‘ΤκΘ§Α¥’’#pragma
pack÷ΗΕ®ΒΡ ΐ÷ΒΚΆ’βΗω ΐΨί≥…‘±Ή‘…μ≥ΛΕ»ΝΫΗω÷–±»Ϋœ–ΓΒΡΡ«ΗωΫχ––ΘΜ“≤ΨΆ «ΥΒΘ§Β±#pragma pack÷ΗΕ®ΒΡ÷ΒΒ»”ΎΜρ’Ώ≥§ΙΐΥυ”– ΐΨί≥…‘±≥ΛΕ»ΒΡ ±ΚρΘ§’βΗω÷ΗΕ®÷ΒΒΡ¥σ–ΓΫΪ≤Μ≤ζ…ζ»ΈΚΈ–ßΙϊ;
4>Η¥‘”άύ–ΆΘ®»γΫαΙΙΘ©’ϊΧεΒΡΕ‘Τκ<ΉΔ“β «ΓΑ’ϊΧεΓ±> «Α¥’’ΫαΙΙΧε÷–≥ΛΕ»Ήν¥σΒΡ ΐΨί≥…‘±ΚΆ#pragma
pack÷ΗΕ®÷Β÷°ΦδΫœ–ΓΒΡΡ«Ηω÷ΒΫχ––ΘΜ’β―υ‘Ύ≥…‘± «Η¥‘”άύ–Ά ±Θ§Ω…“‘Ήν–ΓΜ·≥ΛΕ»ΘΜ
5>ΫαΙΙ’ϊΧε≥ΛΕ»ΒΡΦΤΥψ±Ί–κ»ΓΥυ”ΟΙΐΒΡΥυ”–Ε‘Τκ≤Έ ΐΒΡ’ϊ ΐ±ΕΘ§≤ΜΙΜ≤ΙΩ’Ή÷ΫΎΘΜ“≤ΨΆ «»ΓΥυ”ΟΙΐΒΡΥυ”–Ε‘Τκ≤Έ ΐ÷–Ήν¥σΒΡΡ«Ηω÷ΒΒΡ’ϊ ΐ±ΕΘ§“ρΈΣΕ‘Τκ≤Έ ΐΕΦ «2ΒΡn¥ΈΖΫΘΜ’β―υ‘Ύ¥Πάμ ΐΉι ±Ω…“‘±Θ÷ΛΟΩ“ΜœνΕΦ±ΏΫγΕ‘ΤκΘΜ
5.Ε‘ΤκΒΡΥψΖ®
”…”ΎΗςΗωΤΫΧ®ΚΆ±ύ“κΤςΒΡ≤ΜΆ§Θ§œ÷“‘±Ψ»Υ Ι”ΟΒΡgcc version
3.2.2±ύ“κΤςΘ®32ΈΜx86ΤΫΧ®Θ©ΈΣάΐΉ”Θ§ά¥Χ÷¬έ±ύ“κΤςΕ‘struct ΐΨίΫαΙΙ÷–ΒΡΗς≥…‘±»γΚΈΫχ––Ε‘ΤκΒΡΓΘ
‘ΎœύΆ§ΒΡΕ‘ΤκΖΫ Ϋœ¬Θ§ΫαΙΙΧεΡΎ≤Ω ΐΨίΕ®“εΒΡΥ≥–ρ≤ΜΆ§Θ§ΫαΙΙΧε’ϊΧε’ΦΨίΡΎ¥φΩ’Φδ“≤≤ΜΆ§Θ§»γœ¬ΘΚ
…ηΫαΙΙΧε»γœ¬Ε®“εΘΚ

ΫαΙΙΧεA÷–ΑϋΚ§ΝΥ4Ή÷ΫΎ≥ΛΕ»ΒΡint“ΜΗωΘ§1Ή÷ΫΎ≥ΛΕ»ΒΡchar“ΜΗωΚΆ2Ή÷ΫΎ≥ΛΕ»ΒΡshort–Ά ΐΨί“ΜΗωΓΘΥυ“‘A”ΟΒΫΒΡΩ’Φδ”ΠΗΟ «7Ή÷ΫΎΓΘΒΪ «“ρΈΣ±ύ“κΤς“ΣΕ‘ ΐΨί≥…‘±‘ΎΩ’Φδ…œΫχ––Ε‘ΤκΓΘΥυ“‘ Ι”Οsizeof(strcut
A)÷ΒΈΣ8ΓΘ
œ÷‘ΎΑ―ΗΟΫαΙΙΧεΒς’ϊ≥…‘±±δΝΩΒΡΥ≥–ρΓΘ

’β ±ΚρΆ§―υ «ΉήΙ≤7ΗωΉ÷ΫΎΒΡ±δΝΩΘ§ΒΪ «sizeof(struct B)ΒΡ÷Β»¥ «12ΓΘ
œ¬ΟφΈ“Ο« Ι”Ο‘Λ±ύ“κ÷ΗΝν#progma pack (value)ά¥ΗφΥΏ±ύ“κΤςΘ§ Ι”ΟΈ“Ο«÷ΗΕ®ΒΡΕ‘Τκ÷Βά¥»Γ¥ζ»± ΓΒΡΓΘ

sizeof(struct C)÷Β «8ΓΘ
–όΗΡΕ‘Τκ÷ΒΈΣ1ΘΚ

sizeof(struct D)÷ΒΈΣ7ΓΘ
Ε‘”Ύchar–Ά ΐΨίΘ§ΤδΉ‘…μΕ‘Τκ÷ΒΈΣ1Θ§Ε‘”Ύshort–ΆΈΣ2Θ§Ε‘”Ύint,float,doubleάύ–ΆΘ§ΤδΉ‘…μΕ‘Τκ÷ΒΈΣ4Θ§ΒΞΈΜΉ÷ΫΎΓΘ
6.ΥΡΗωΗ≈Ρν÷Β
1> ΐΨίάύ–ΆΉ‘…μΒΡΕ‘Τκ÷ΒΘΚΨΆ «…œΟφΫΜ¥ζΒΡΜυ±Ψ ΐΨίάύ–ΆΒΡΉ‘…μΕ‘Τκ÷ΒΓΘ
2>÷ΗΕ®Ε‘Τκ÷ΒΘΚ#progma pack (value) ±ΒΡ÷ΗΕ®Ε‘Τκ÷ΒvalueΓΘ
3>ΫαΙΙΧεΜρ’ΏάύΒΡΉ‘…μΕ‘Τκ÷ΒΘΚΤδ ΐΨί≥…‘±÷–Ή‘…μΕ‘Τκ÷ΒΉν¥σΒΡΡ«Ηω÷ΒΓΘ
4> ΐΨί≥…‘±ΓΔΫαΙΙΧεΚΆάύΒΡ”––ßΕ‘Τκ÷ΒΘΚΉ‘…μΕ‘Τκ÷ΒΚΆ÷ΗΕ®Ε‘Τκ÷Β÷––ΓΒΡΡ«Ηω÷ΒΓΘ
”–ΝΥ’β–©÷ΒΘ§Έ“Ο«ΨΆΩ…“‘ΚήΖΫ±ψΒΡά¥Χ÷¬έΨΏΧε ΐΨίΫαΙΙΒΡ≥…‘±ΚΆΤδΉ‘…μΒΡΕ‘ΤκΖΫ ΫΓΘ”––ßΕ‘Τκ÷ΒN «Ήν÷’”Οά¥ΨωΕ® ΐΨί¥φΖ≈ΒΊ÷ΖΖΫ ΫΒΡ÷ΒΘ§Ήν÷Ί“ΣΓΘ”––ßΕ‘ΤκNΘ§ΨΆ «±μ ΨΓΑΕ‘Τκ‘ΎN…œΓ±Θ§“≤ΨΆ «ΥΒΗΟ ΐΨίΒΡΓ±¥φΖ≈Τπ ΦΒΊ÷Ζ%N=0Γ±.
Εχ ΐΨίΫαΙΙ÷–ΒΡ ΐΨί±δΝΩΕΦ «Α¥Ε®“εΒΡœ»ΚσΥ≥–ρά¥≈≈Ζ≈ΒΡΓΘΒΎ“ΜΗω ΐΨί±δΝΩΒΡΤπ ΦΒΊ÷ΖΨΆ « ΐΨίΫαΙΙΒΡΤπ ΦΒΊ÷ΖΓΘΫαΙΙΧεΒΡ≥…‘±±δΝΩ“ΣΕ‘Τκ≈≈Ζ≈Θ§ΫαΙΙΧε±Ψ…μ“≤“ΣΗυ
ΨίΉ‘…μΒΡ”––ßΕ‘Τκ÷Β‘≤’ϊ(ΨΆ «ΫαΙΙΧε≥…‘±±δΝΩ’Φ”ΟΉή≥ΛΕ»–η“Σ «Ε‘ΫαΙΙΧε”––ßΕ‘Τκ÷ΒΒΡ’ϊ ΐ±ΕΘ§ΫαΚœœ¬ΟφάΐΉ”άμΫβ)ΓΘ’β―υΨΆ≤ΜΡήάμΫβ…œΟφΒΡΦΗΗωάΐΉ”ΒΡ÷ΒΝΥΓΘ
άΐΉ”Ζ÷ΈωΘΚ
Ζ÷ΈωάΐΉ”BΘΜ

ΦΌ…ηB¥”ΒΊ÷ΖΩ’Φδ0x0000ΩΣ Φ≈≈Ζ≈ΓΘΗΟάΐΉ”÷–ΟΜ”–Ε®“ε÷ΗΕ®Ε‘Τκ÷ΒΘ§‘Ύ± ’ΏΜΖΨ≥œ¬Θ§ΗΟ÷ΒΡ§»œΈΣ4ΓΘ
ΒΎ“ΜΗω≥…‘±±δΝΩbΒΡΉ‘…μΕ‘Τκ÷Β «1Θ§±»÷ΗΕ®Μρ’ΏΡ§»œ÷ΗΕ®Ε‘Τκ÷Β4–ΓΘ§Υυ“‘Τδ”––ßΕ‘Τκ÷ΒΈΣ1Θ§Υυ“‘Τδ¥φΖ≈ΒΊ÷Ζ0x0000ΖϊΚœ0x0000%1=0.
ΒΎΕΰΗω≥…‘±±δΝΩaΘ§ΤδΉ‘…μΕ‘Τκ÷ΒΈΣ4Θ§Υυ“‘”––ßΕ‘Τκ÷Β“≤ΈΣ4Θ§Υυ“‘÷ΜΡή¥φΖ≈‘ΎΤπ ΦΒΊ÷ΖΈΣ0x0004ΒΫ0x0007’βΥΡΗωΝ§–χΒΡΉ÷ΫΎΩ’Φδ÷–Θ§ΖϊΚœ0x0004%4=0,
«“ΫτΩΩΒΎ“ΜΗω±δΝΩΓΘ
ΒΎ»ΐΗω±δΝΩc,Ή‘…μΕ‘Τκ÷ΒΈΣ2Θ§Υυ“‘”––ßΕ‘Τκ÷Β“≤ «2Θ§Ω…“‘¥φΖ≈‘Ύ0x0008ΒΫ0x0009
’βΝΫΗωΉ÷ΫΎΩ’Φδ÷–Θ§ΖϊΚœ0x0008%2=0ΓΘΥυ“‘¥”0x0000ΒΫ0x0009¥φΖ≈ΒΡΕΦ «BΡΎ»ίΓΘ‘ΌΩ¥ ΐΨίΫαΙΙBΒΡΉ‘…μΕ‘Τκ÷ΒΈΣΤδ±δΝΩ÷–Ήν¥σΕ‘Τκ÷Β(’βάο «bΘ©Υυ“‘ΨΆ «4Θ§Υυ“‘ΫαΙΙΧεΒΡ”––ßΕ‘Τκ÷Β“≤ «4ΓΘΗυΨίΫαΙΙΧε‘≤’ϊΒΡ“Σ«σΘ§0x0009ΒΫ0x0000=10Ή÷ΫΎΘ§Θ®10ΘΪ2Θ©ΘΞ4ΘΫ0ΓΘΥυ“‘0x0000AΒΫ0x000B“≤ΈΣΫαΙΙΧεBΥυ’Φ”ΟΓΘΙ B¥”0x0000ΒΫ0x000BΙ≤”–12ΗωΉ÷ΫΎ,sizeof(struct
B)=12;
Ά§άμ,Ζ÷Έω…œΟφάΐΉ”CΘΚ

ΒΎ“ΜΗω±δΝΩbΒΡΉ‘…μΕ‘Τκ÷ΒΈΣ1Θ§÷ΗΕ®Ε‘Τκ÷ΒΈΣ2Θ§Υυ“‘Θ§Τδ”––ßΕ‘Τκ÷ΒΈΣ1Θ§ΦΌ…ηC¥”0x0000ΩΣ ΦΘ§Ρ«Ο¥b¥φΖ≈‘Ύ0x0000Θ§ΖϊΚœ0x0000%1=0;
ΒΎΕΰΗω±δΝΩΘ§Ή‘…μΕ‘Τκ÷ΒΈΣ4Θ§÷ΗΕ®Ε‘Τκ÷ΒΈΣ2Θ§Υυ“‘”––ßΕ‘Τκ÷ΒΈΣ2Θ§Υυ“‘Υ≥–ρ¥φΖ≈‘Ύ0x0002ΓΔ0x0003ΓΔ0x0004ΓΔ0x0005ΥΡΗωΝ§–χΉ÷ΫΎ÷–Θ§ΖϊΚœ0x0002%2=0ΓΘ
ΒΎ»ΐΗω±δΝΩcΒΡΉ‘…μΕ‘Τκ÷ΒΈΣ2Θ§Υυ“‘”––ßΕ‘Τκ÷ΒΈΣ2Θ§Υ≥–ρ¥φΖ≈‘Ύ0x0006ΓΔ0x0007÷–Θ§ΖϊΚœ0x0006%2=0ΓΘΥυ“‘¥”0x0000ΒΫ0x00007Ι≤ΑΥΉ÷ΫΎ¥φΖ≈ΒΡ «CΒΡ±δΝΩΓΘ
”÷CΒΡΉ‘…μΕ‘Τκ÷ΒΈΣ4Θ§Υυ“‘CΒΡ”––ßΕ‘Τκ÷ΒΈΣ2ΓΘ”÷8%2=0,C÷Μ’Φ”Ο0x0000ΒΫ0x0007ΒΡΑΥΗωΉ÷ΫΎΓΘΥυ“‘sizeof(struct
C)=8.
9.2.2Ή÷ΫΎΕ‘ΤκΕ‘≥Χ–ρΒΡ”Αœλ
œ»»ΟΈ“Ο«Ω¥ΦΗΗωάΐΉ”Α…(32bit,x86ΜΖΨ≥,gcc±ύ“κΤς):
…ηΫαΙΙΧε»γœ¬Ε®“εΘΚ

œ÷‘Ύ“―÷Σ32ΈΜΜζΤς…œΗς÷÷ ΐΨίάύ–ΆΒΡ≥ΛΕ»»γœ¬:
char:1(”–ΖϊΚ≈ΈόΖϊΚ≈Ά§)
short:2(”–ΖϊΚ≈ΈόΖϊΚ≈Ά§)
int:4(”–ΖϊΚ≈ΈόΖϊΚ≈Ά§)
long:4(”–ΖϊΚ≈ΈόΖϊΚ≈Ά§)
float:4 double:8
Ρ«Ο¥…œΟφΝΫΗωΫαΙΙ¥σ–Γ»γΚΈΡΊ?
ΫαΙϊ «:
sizeof(strcut A)÷ΒΈΣ8
sizeof(struct B)ΒΡ÷Β»¥ «12
ΫαΙΙΧεA÷–ΑϋΚ§ΝΥ4Ή÷ΫΎ≥ΛΕ»ΒΡint“ΜΗωΘ§1Ή÷ΫΎ≥ΛΕ»ΒΡchar“ΜΗωΚΆ2Ή÷ΫΎ≥ΛΕ»ΒΡshort–Ά ΐΨί“ΜΗω,B“≤“Μ―υ;Α¥άμΥΒA,B¥σ–Γ”ΠΗΟΕΦ «7Ή÷ΫΎΓΘ÷°Υυ“‘≥ωœ÷…œΟφΒΡΫαΙϊ «“ρΈΣ±ύ“κΤς“ΣΕ‘ ΐΨί≥…‘±‘ΎΩ’Φδ…œΫχ––Ε‘ΤκΓΘ…œΟφ «Α¥’’±ύ“κΤςΒΡΡ§»œ…η÷ΟΫχ––Ε‘ΤκΒΡΫαΙϊ,Ρ«Ο¥Έ“Ο« «≤Μ «Ω…“‘ΗΡ±δ±ύ“κΤςΒΡ’β÷÷Ρ§»œΕ‘Τκ…η÷ΟΡΊ,Β±»ΜΩ…“‘.άΐ»γ:
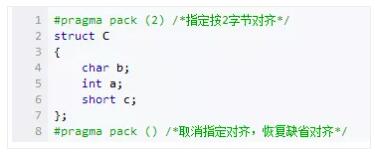
sizeof(struct C)÷Β «8ΓΘ
–όΗΡΕ‘Τκ÷ΒΈΣ1ΘΚ

sizeof(struct D)÷ΒΈΣ7ΓΘ
ΚσΟφΈ“Ο«‘ΌΫ≤Ϋβ#pragma pack()ΒΡΉς”Ο.
2.3–όΗΡ±ύ“κΤςΒΡΡ§»œΕ‘Τκ÷Β
1>‘ΎVC IDE÷–Θ§Ω…“‘’β―υ–όΗΡΘΚ[Project]|[Settings],c/c++―ΓœνΩ®CategoryΒΡCode
Generation―ΓœνΒΡStruct Member Alignment÷––όΗΡΘ§Ρ§»œ «8Ή÷ΫΎΓΘ
2>‘Ύ±ύ¬κ ±Θ§Ω…“‘’β―υΕ·Χ§–όΗΡΘΚ#pragma pack .ΉΔ“β: «pragmaΕχ≤Μ «progma.
»γΙϊ‘Ύ±ύ≥ΧΒΡ ±Κρ“ΣΩΦ¬«ΫΎ‘ΦΩ’ΦδΒΡΜΑ,Ρ«Ο¥Έ“Ο«÷Μ–η“ΣΦΌΕ®ΫαΙΙΒΡ ΉΒΊ÷Ζ «0,»ΜΚσΗςΗω±δΝΩΑ¥’’…œΟφΒΡ‘≠‘ρΫχ––≈≈Ν–Φ¥Ω…,Μυ±ΨΒΡ‘≠‘ρΨΆ «Α―ΫαΙΙ÷–ΒΡ±δΝΩΑ¥’’
άύ–Ά¥σ–Γ¥”–ΓΒΫ¥σ…υΟς,ΨΓΝΩΦθ…Ό÷–ΦδΒΡΧν≤ΙΩ’Φδ.ΜΙ”–“Μ÷÷ΨΆ «ΈΣΝΥ“‘Ω’ΦδΜΜ»Γ ±ΦδΒΡ–ß¬ ,Έ“Ο«œ‘ ΨΒΡΫχ––Χν≤ΙΩ’ΦδΫχ––Ε‘Τκ,±»»γ:”–“Μ÷÷ Ι”ΟΩ’ΦδΜΜ ±ΦδΉω
Ζ® «œ‘ ΫΒΡ≤ε»κreserved≥…‘±ΘΚ
reserved≥…‘±Ε‘Έ“Ο«ΒΡ≥Χ–ρΟΜ”– ≤Ο¥“β“ε,Υϋ÷Μ «ΤπΒΫΧν≤ΙΩ’Φδ“‘¥οΒΫΉ÷ΫΎΕ‘ΤκΒΡΡΩΒΡ,Β±»ΜΦ¥ Ι≤ΜΦ”’βΗω≥…‘±Ά®≥Θ±ύ“κΤς“≤ΜαΗχΈ“Ο«Ή‘Ε·Χν≤ΙΕ‘Τκ,Έ“Ο«Ή‘ΦΚΦ”…œΥϋ÷Μ «ΤπΒΫœ‘ ΫΒΡΧα–―Ής”Ο.
2.4Ή÷ΫΎΕ‘ΤκΩ…Ρή¥χά¥ΒΡ“ΰΜΦ
¥ζ¬κ÷–ΙΊ”ΎΕ‘ΤκΒΡ“ΰΜΦΘ§ΚήΕύ «“ΰ ΫΒΡΓΘ±»»γ‘Ύ«Ω÷Τάύ–ΆΉΣΜΜΒΡ ±ΚρΓΘάΐ»γ:
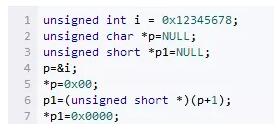
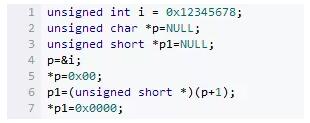
ΉνΚσΝΫΨδ¥ζ¬κΘ§¥”Τφ ΐ±ΏΫγ»ΞΖΟΈ unsignedshort–Ά±δΝΩΘ§œ‘»Μ≤ΜΖϊΚœΕ‘ΤκΒΡΙφΕ®ΓΘ
‘Ύx86…œΘ§άύΥΤΒΡ≤ΌΉς÷ΜΜα”Αœλ–߬ Θ§ΒΪ «‘ΎMIPSΜρ’Ώsparc…œΘ§Ω…ΡήΨΆ «“ΜΗωerror,“ρΈΣΥϋΟ«“Σ«σ±Ί–κΉ÷ΫΎΕ‘Τκ.
»γΙϊ≥ωœ÷Ε‘ΤκΜρ’ΏΗ≥÷ΒΈ Χβ Ήœ»≤ιΩ¥
1). ±ύ“κΤςΒΡbig littleΕΥ…η÷Ο
2). Ω¥’β÷÷ΧεœΒ±Ψ…μ «Ζώ÷ß≥÷Ζ«Ε‘ΤκΖΟΈ
3). »γΙϊ÷ß≥÷Ω¥…η÷ΟΝΥΕ‘Τκ”κΖώ,»γΙϊΟΜ”–‘ρΩ¥ΖΟΈ ±–η“ΣΦ”Ρ≥–©ΧΊ βΒΡ–ό Έά¥±ξ÷ΨΤδΧΊ βΖΟΈ ≤ΌΉςΓΘ
ARMœ¬ΒΡΕ‘Τκ¥Πάμ
from DUI0067D_ADS1_2_CompLib type qulifiers
”–≤ΩΖ÷’ΣΉ‘ARM±ύ“κΤςΈΡΒΒΕ‘Τκ≤ΩΖ÷Ε‘ΤκΒΡ Ι”Ο:
1.__align(num)
’βΗω”Ο”Ύ–όΗΡΉνΗΏΦΕ±πΕ‘œσΒΡΉ÷ΫΎ±ΏΫγΓΘ‘ΎΜψ±ύ÷– Ι”ΟLDRDΜρ’ΏSTRD ±ΨΆ“Σ”ΟΒΫ¥ΥΟϋΝν__align(8)Ϋχ–––ό Έœό÷ΤΓΘά¥±Θ÷Λ ΐΨίΕ‘œσ «œύ”ΠΕ‘ΤκΓΘ’βΗω–ό ΈΕ‘œσΒΡΟϋΝνΉν¥σ «8ΗωΉ÷ΫΎœό÷Τ,Ω…“‘»Ο2Ή÷ΫΎΒΡΕ‘œσΫχ––4Ή÷ΫΎΕ‘Τκ,ΒΪ «≤ΜΡή»Ο4Ή÷ΫΎΒΡΕ‘œσ2Ή÷ΫΎΕ‘ΤκΓΘ
__align «¥φ¥Δάύ–όΗΡ,Υϊ÷Μ–ό ΈΉνΗΏΦΕάύ–ΆΕ‘œσ≤ΜΡή”Ο”ΎΫαΙΙΜρ’ΏΚ· ΐΕ‘œσΓΘ
2.__packed
__packed «Ϋχ––“ΜΉ÷ΫΎΕ‘Τκ
l ≤ΜΡήΕ‘packedΒΡΕ‘œσΫχ––Ε‘Τκ
l Υυ”–Ε‘œσΒΡΕΝ–¥ΖΟΈ ΕΦΫχ––Ζ«Ε‘ΤκΖΟΈ
l floatΦΑΑϋΚ§floatΒΡΫαΙΙΝΣΚœΦΑΈ¥”Ο__packedΒΡΕ‘œσΫΪ≤ΜΡήΉ÷ΫΎΕ‘Τκ
l __packedΕ‘Ψ÷≤Ω’ϊ–Έ±δΝΩΈό”Αœλ
l «Ω÷Τ”…unpackedΕ‘œσœρpackedΕ‘œσΉΣΜ· «Έ¥Ε®“ε,’ϊ–Έ÷Η’κΩ…“‘ΚœΖ®Ε®
“εΈΣpackedΓΘ
__packed int* p; //__packed int ‘ρΟΜ”–“β“ε
2.5Ε‘ΤκΜρΖ«Ε‘ΤκΕΝ–¥ΖΟΈ ¥χά¥Έ Χβ
__packed struct STRUCT_TEST
{char a;int b;char c;
} ;
//Ε®“ε»γœ¬ΫαΙΙ¥Υ ±bΒΡΤπ ΦΒΊ÷Ζ“ΜΕ® «≤ΜΕ‘ΤκΒΡ,‘Ύ’Μ÷–ΖΟΈ bΩ…Ρή”–Έ Χβ,“ρΈΣ’Μ…œ ΐΨίΩœΕ® «Ε‘ΤκΖΟΈ [from
CL]
//ΫΪœ¬Οφ±δΝΩΕ®“ε≥…»ΪΨ÷Ψ≤Χ§≤Μ‘Ύ’Μ…œ
static char* p;static struct STRUCT_TEST a;void Main()
{
__packed int* q; //¥Υ ±Ε®“ε≥…__packedά¥–ό ΈΒ±«Αq÷ΗœρΈΣΖ«Ε‘ΤκΒΡ ΐΨίΒΊ÷Ζœ¬ΟφΒΡΖΟΈ ‘ρΩ…“‘
p = (char*)&a;
q = (int*)(p+1);
*q = 0x87654321; /*
ΒΟΒΫΗ≥÷ΒΒΡΜψ±ύ÷ΗΝνΚή«ε≥ΰ
ldr r5,0x20001590 ; = #0x12345678
[0xe1a00005] mov r0,r5
[0xeb0000b0] bl __rt_uwrite4 //‘Ύ¥Υ¥ΠΒς”Ο“ΜΗω–¥4byteΒΡ≤ΌΉςΚ· ΐ
[0xe5c10000] strb r0,[r1,#0] //Κ· ΐΫχ––4¥Έstrb≤ΌΉς»ΜΚσΖΒΜΊ±Θ÷ΛΝΥ ΐΨί’ΐ»ΖΒΡΖΟΈ
[0xe1a02420] mov r2,r0,lsr #8
[0xe5c12001] strb r2,[r1,#1]
[0xe1a02820] mov r2,r0,lsr #16
[0xe5c12002] strb r2,[r1,#2]
[0xe1a02c20] mov r2,r0,lsr #24
[0xe5c12003] strb r2,[r1,#3]
[0xe1a0f00e] mov pc,r14
*/ /*
»γΙϊqΟΜ”–Φ”__packed–ό Έ‘ρΜψ±ύ≥ωά¥÷ΗΝν «’β―υ÷±Ϋ”ΜαΒΦ÷¬ΤφΒΊ÷Ζ¥ΠΖΟΈ ßΑή
[0xe59f2018] ldr r2,0x20001594 ; = #0x87654321
[0xe5812000] str r2,[r1,#0]
*/
//’β―υΩ…“‘Κή«ε≥ΰΒΡΩ¥ΒΫΖ«Ε‘ΤκΖΟΈ «»γΚΈ≤ζ…ζ¥μΈσΒΡ
//“‘ΦΑ»γΚΈœϊ≥ΐΖ«Ε‘ΤκΖΟΈ ¥χά¥Έ Χβ
//“≤Ω…“‘Ω¥ΒΫΖ«Ε‘ΤκΖΟΈ ΚΆΕ‘ΤκΖΟΈ ΒΡ÷ΗΝν≤ν“λΒΦ÷¬–߬ Έ Χβ
|









