| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“ΣΫ≤ΫβΝΥΜυ¥Γ÷Σ ΕΓΔΜΚ¥φΟϋ÷–ΓΔΜΚ¥φ“Μ÷¬ΓΔ≥Χ–ρ–‘ΡήΒ»œύΙΊΡΎ»ίΓΘ
±ΨΈΡά¥Ή‘”ΎcsdnΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
“ΜΓΔ Μυ¥Γ÷Σ Ε
Ήœ»Θ§¥σΦ“ΕΦ÷ΣΒάœ÷‘ΎCPUΒΡΕύΚΥΦΦ θΘ§ΕΦΜα”–ΦΗΦΕΜΚ¥φΘ§œ÷‘ΎΒΡCPUΜα”–»ΐΦΕΡΎ¥φΘ®L1Θ§L2Θ§
L3Θ©Θ§»γœ¬ΆΦΥυ ΨΓΘ
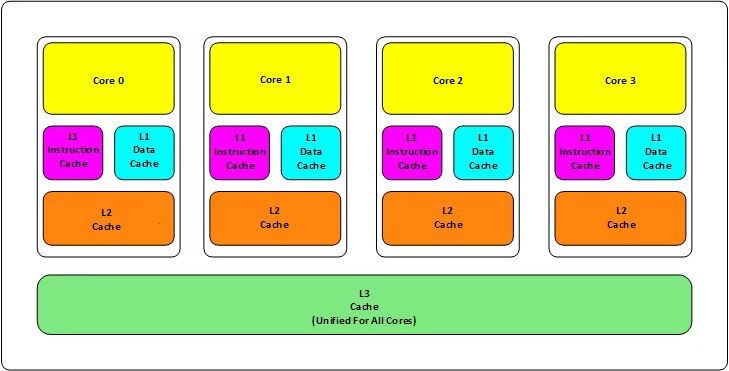
Τδ÷–ΘΚ L1ΜΚ¥φΖ÷≥…ΝΫ÷÷Θ§“Μ÷÷ «÷ΗΝνΜΚ¥φΘ§“Μ÷÷ « ΐΨίΜΚ¥φΓΘL2ΜΚ¥φΚΆL3ΜΚ¥φ≤ΜΖ÷÷ΗΝνΚΆ ΐΨίΓΘ
L1ΚΆL2ΜΚ¥φ‘ΎΟΩ“ΜΗωCPUΚΥ÷–Θ§L3‘ρ «Υυ”–CPUΚΥ–ΡΙ≤œμΒΡΡΎ¥φΓΘ
L1ΓΔL2ΓΔL3ΒΡ‘ΫάκCPUΫϋΨΆ‘Ϋ–ΓΘ§ΥΌΕ»“≤ΨΆ‘ΫΩλΘ§‘ΫάκCPU‘ΕΘ§ΥΌΕ»“≤‘Ϋ¬ΐΓΘ
‘ΌΆυΚσΟφΨΆ «ΡΎ¥φΘ§ΡΎ¥φΒΡΚσΟφΨΆ «”≤≈ΧΓΘΈ“Ο«ά¥Ω¥“Μ–©ΥϊΟ«ΒΡΥΌΕ»ΓΘ
L1ΒΡ¥φ»ΓΥΌΕ»ΘΚ4ΗωCPU ±÷”÷ήΤΎ
L2ΒΡ¥φ»ΓΥΌΕ»ΘΚ11ΗωCPU ±÷”÷ήΤΎ
L3ΒΡ¥φ»ΓΥΌΕ»ΘΚ39ΗωCPU ±÷”÷ήΤΎ
RAMΡΎ¥φΒΡ¥φ»ΓΥΌΕ»ΘΚ107ΗωCPU ±÷”÷ήΤΎ Έ“Ο«Ω…“‘Ω¥ΒΫΘ§L1ΒΡΥΌΕ» «RAMΒΡ27±ΕΘ§L1ΚΆL2ΒΡ¥φ»Γ¥σ–ΓΜυ±Ψ…œ «KBΦΕΒΡΘ§L3‘ρ «MBΦΕ±πΒΡΓΘάΐ»γΘ§Intel
Core i7-8700K, «“ΜΗω6ΚΥΒΡCPUΘ§ΟΩΚΥ…œΒΡL1 «64KBΘ® ΐΨίΚΆ÷ΗΝνΗς32KBΘ©,L2 «256KΘ§L3”–2MBΓΘ
Έ“Ο«ΒΡ ΐΨί¥”ΡΎ¥φœρ…œΘ§œ»ΒΫL3Θ§‘ΌΒΫL2Θ§‘ΌΒΫL1Θ§ΉνΚσΒΫΦΡ¥φΤςΫχ––ΦΤΥψΓΘΡ«Ο¥Θ§ΈΣ ≤Ο¥Μα…ηΦΤ≥…»ΐ≤ψΘΩ’βάο”–“‘œ¬ΦΗΖΫΟφΒΡΩΦ¬«ΘΚ
ΈοάμΥΌΕ»Θ§»γΙϊ“ΣΗϋ¥σΒΡ»ίΝΩΨΆ–η“ΣΗϋΕύΒΡΨßΧεΙήΘ§≥ΐΝΥ–ΨΤ§ΒΡΧεΜΐΜα±δ¥σΘ§Ηϋ÷Ί“ΣΒΡ «¥σΝΩΒΡΨßΧεΙήΜαΒΦ÷¬ΥΌΕ»œ¬ΫΒΘ§“ρΈΣΖΟΈ ΥΌΕ»ΚΆ“ΣΖΟΈ ΒΡΨßΧεΙήΥυ‘ΎΒΡΈΜ÷Ο≥…Ζ¥±»ΓΘ“≤ΨΆ «Β±–≈Κ≈¬ΖΨΕ±δ≥Λ ±Θ§Ά®–≈ΥΌΕ»Μα±δ¬ΐΘ§’βΨΆ «ΈοάμΈ ΧβΓΘ
ΝμΆβ“ΜΗωΈ Χβ «Θ§ΕύΚΥΦΦ θ÷–Θ§ ΐΨίΒΡΉ¥Χ§–η“Σ‘ΎΕύΗωCPUΫχ––Ά§≤ΫΓΘΈ“Ο«Ω…“‘Ω¥ΒΫΘ§cacheΚΆRAMΒΡΥΌΕ»≤νΨύΧΪ¥σΓΘΥυ“‘Θ§ΕύΦΕ≤ΜΆ§≥Ώ¥γΒΡΜΚ¥φ”–άϊ”ΎΧαΗΏ’ϊΧεΒΡ–‘ΡήΓΘ ’βΗω άΫγ”ά‘Ε «ΤΫΚβΒΡΘ§“ΜΟφ±δΒΟ”–ΕύΙβœ Θ§Νμ“ΜΖΫΟφ“≤Μα±δΒΟ”–ΕύΚΎΑΒΘ§Ϋ®ΝΔΕύΦΕΒΡΜΚ¥φΘ§“ΜΕ®ΨΆΜα“ΐ»κΤδΥϋΒΡΈ ΧβΓΘ’βάο”–ΝΫΗω±»Ϋœ÷Ί“ΣΒΡΈ ΧβΓΘ
“ΜΗω «±»ΫœΦρΒΞΒΡΜΚ¥φΟϋ÷–¬ ΒΡΈ Χβ
Νμ“ΜΗω «±»ΫœΗ¥‘”ΒΡΜΚ¥φΗϋ–¬ΒΡ“Μ÷¬–‘Έ Χβ ”»Τδ «ΒΎΕΰΗωΈ ΧβΘ§‘ΎΕύΚΥΦΦ θœ¬Θ§’βΨΆΚήœώΖ÷≤Φ ΫœΒΆ≥ΝΥΘ§“ΣΟφΕ‘ΕύΗωΒΊΖΫΫχ––Ηϋ–¬ΓΘ
ΕΰΓΔ ΜΚ¥φΟϋ÷– Ήœ»Θ§Έ“Ο«–η“ΣΝΥΫβ“ΜΗω θ”οCache LineΓΘΜΚ¥φΜυ±Ψ…œά¥ΥΒΨΆ «Α―ΚσΟφΒΡ ΐΨίΦ”‘ΊΒΫάκΉ‘ΦΚΉνΫϋΒΡΒΊΖΫΘ§Ε‘”ΎCPUά¥ΥΒΘ§Υϋ «≤ΜΜα“ΜΗωΉ÷ΫΎ“ΜΗωΉ÷ΫΎΒΡΦ”‘ΊΒΡΓΘ“ρΈΣ’βΖ«≥ΘΟΜ”––߬ Θ§“ΜΑψά¥ΥΒΕΦ «“Σ“ΜΩι“ΜΩιΒΡΦ”‘ΊΒΡΘ§Ε‘”Ύ’β―υ“ΜΩι“ΜΩιΒΡ ΐΨίΒΞΈΜΘ§ θ”οΫ–ΓΑCache
LineΓ±ΓΘ“ΜΑψά¥ΥΒΘ§“ΜΗω÷ςΝςΒΡCPUΒΡCache Line «64 Bytes(“≤”–ΒΡCPU”Ο32BytesΚΆ128Bytes),64Bytes“≤ΨΆ «16Ηω32ΈΜΒΡ ΐΉ÷,’βΨΆ «CPU¥”ΡΎ¥φ÷–άΧ ΐΨί…œά¥ΒΡΉν–Γ ΐΨίΒΞΈΜΓΘ±»»γΘΚCache
Line «Ήν–ΓΒΞΈΜΘ®64BytesΘ©Θ§Υυ“‘œ»Α―CacheΖ÷≤ΦΕύΗωCache LineΓΘ±»»γΘΚL1”–32KBΘ§Ρ«Ο¥
32KB/64B = 512ΗωCache LineΓΘ ΜΚ¥φ–η“ΣΑ―ΡΎ¥φάοΒΡ ΐΨίΖ≈Ϋχά¥Θ§”ΔΈΡΫ–CPU AssociativityΘ§CacheΒΡ ΐΨίΖ≈÷Ο≤Ώ¬‘ΨωΕ®ΝΥΡΎ¥φ÷–ΒΡ ΐΨίΜαΩΫ±¥ΒΫCPU
Cache÷–ΒΡΡΡΗωΈΜ÷Ο…œΘ§“ρΈΣCacheΒΡ¥σ–Γ‘Ε‘Ε–Γ”ΎΡΎ¥φΘ§Υυ“‘Θ§–η“Σ”–“Μ÷÷ΒΊ÷ΖΙΊΝΣΥψΖ®Θ§ΡήΙΜ»ΟΡΎ¥φ÷–ΒΡ ΐΨί±Μ”≥…δΒΫCache÷–ΓΘ’βΗωΨΆ”–ΒψœώΡΎ¥φΒΊ÷Ζ¥”¬ΏΦ≠ΒΊ÷ΖΒΫΈοάμΒΊ÷ΖΒΡ”≥…δΖΫΖ®ΓΘΒΪ «≤ΜΆξ»Ϊ“Μ―υΓΘ
Μυ±Ψ…œΜα”–“‘œ¬ΒΡ“Μ–©ΖΫΖ®
»ΈΚΈ“ΜΗωΡΎ¥φΒΡ ΐΨίΩ…“‘±ΜΜΚ¥φ‘Ύ»ΈΚΈ“ΜΗωCache LineάοΘ§’β÷÷ΖΫΖ® «ΉνΝιΜνΒΡΘ§ΒΪ «Θ§»γΙϊΈ“Ο«“Σ÷ΣΒά“ΜΗωΡΎ¥φ «Ζώ¥φ‘Ύ”ΎCache÷–ΓΘΈ“Ο«ΨΆ–η“ΣΫχ––O(n)Η¥‘”Ε»ΒΡCache±ιάζΘ§’β «ΟΜ”––߬ ΒΡΓΘ
Νμ“Μ÷÷ΖΫΖ®Θ§ΈΣΝΥΫΒΒΆΜΚ¥φΥ―ΥςΥψΖ®ΒΡ ±ΦδΗ¥‘”Ε»Θ§Έ“Ο«“Σ Ι”Οœώhash table’β―υΒΡ ΐΨίΫαΙΙΘ§ΉνΦρΒΞΒΡhash
tableΨΆ «ΓΑ«σΡΘ‘ΥΥψΓ±ΓΘ±»»γΘ§Έ“Ο«ΒΡL1 Cache”–512ΗωCache Line,Ρ«Ο¥ΙΪ ΫΨΆ «(ΡΎ¥φΒΊ÷Ζ
mod 512) *64ΨΆΩ…“‘÷±Ϋ”’“ΒΫΥυ‘ΎΒΡCacheΒΊ÷ΖΒΡΤΪ“ΤΝΥΓΘΒΪ «Θ§’β―υΒΡΖΫ Ϋ–η“Σ≥Χ–ρΕ‘ΡΎ¥φΒΊ÷ΖΒΡΖΟΈ Ζ«≥ΘΒΡΤΫΨυΘ§≤Μ»ΜΜα‘λ≥…―œ÷ΊΒΊ≥εΆΜΓΘΥυ“‘Θ§’β≥…ΝΥ“ΜΗωΖ«≥ΘάμœκΒΡ«ιΩωΝΥΓΘ
ΈΣΝΥ±ήΟβ…œ ωΒΡΝΫ÷÷ΖΫΑΗΒΡΈ ΧβΘ§”Ύ «ΨΆ“Σ»ί»Χ“ΜΕ®ΒΡhash≥εΆΜΘ§“≤ΨΆ≥ωœ÷ΝΥN-WayΙΊΝΣΓΘ“≤ΨΆ «Α―Ν§–χΒΡNΗωCache
LineΑσ≥…“ΜΉιΘ§»ΜΚσΘ§œ»’“ΒΫœύΙΊΒΡΉιΘ§»ΜΚσ‘Ό‘ΎΉιΡΎ’“ΒΫœύΙΊΒΡCache LineΓΘ’βΫ–Set AssociativityΓΘ»γœ¬ΆΦΥυ Ψ
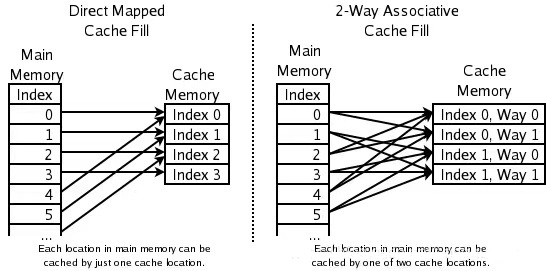
Ε‘”Ύ N-Way ΉιΙΊΝΣΘ§Ω…Ρή”–Βψ≤ΜΚΟάμΫβΓΘ’βάοΨΌΗωάΐΉ”Θ§≤ΔΕύΥΒ“Μ–©œΗΫΎΘ®≤Μ»ΜΚσΟφΒΡ¥ζ¬κΡψΜα≤ΜΡήάμΫβΘ©Θ§Intel
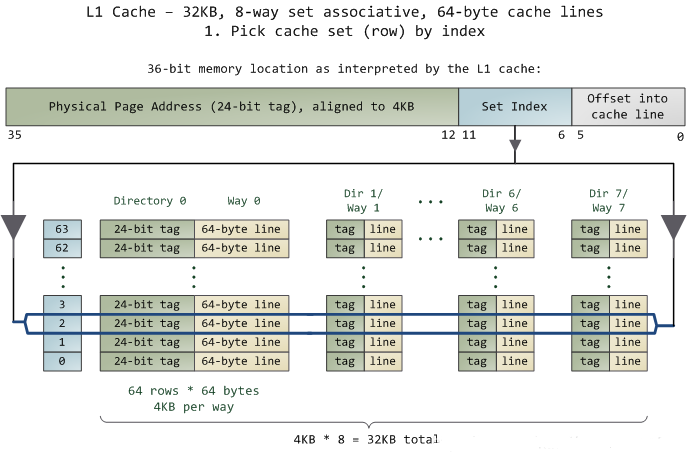
¥σΕύ ΐ¥ΠάμΤςΒΡL1 CacheΕΦ «32KBΘ§8-Way ΉιœύΝΣΘ§Cache Line «64 BytesΓΘ’β“βΈΕΉ≈
32KBΒΡΩ…“‘Ζ÷≥…Θ§32KB / 64 = 512 Χθ Cache LineΘΜ
“ρΈΣ”–8 WayΘ§”Ύ «ΜαΟΩ“ΜWay ”– 512 / 8 = 64 Χθ Cache LineΘΜ
”Ύ «ΟΩ“Μ¬ΖΨΆ”– 64 x 64 = 4096 Byts ΒΡΡΎ¥φΓΘ
ΈΣΝΥΖΫ±ψΥς“ΐΡΎ¥φΒΊ÷Ζ
TagΘΚΟΩΧθ Cache Line «ΑΕΦΜα”–“ΜΗωΕάΝΔΖ÷≈δΒΡ 24 bitsά¥¥φΒΡ tagΘ§ΤδΨΆ «ΡΎ¥φΒΊ÷ΖΒΡ«Α24bitsΘΜ
IndexΘΚΡΎ¥φΒΊ÷ΖΚσ–χΒΡ6Ηωbits‘ρ «‘Ύ’β“ΜWayΒΡ «Cache Line Υς“ΐΘ§2^6 = 64
Η’ΚΟΩ…“‘Υς“ΐ64ΧθCache LineΘΜ
OffsetΘΚ‘ΌΆυΚσΒΡ6bits”Ο”Ύ±μ Ψ‘ΎCache Line άοΒΡΤΪ“ΤΝΩ
Υς“ΐΙΐ≥Χ»γœ¬ΆΦΥυ ΨΘΚ
Β±ΡΟΒΫ“ΜΗωΡΎ¥φΒΊ÷ΖΒΡ ±ΚρΘ§œ»ΡΟ≥ω÷–ΦδΒΡ 6bits ά¥Θ§’“ΒΫ «ΡΡΉιΘΜ
»ΜΚσ‘Ύ’β“ΜΗω8ΉιΒΡcache line÷–Θ§‘ΌΫχ––O(n) Θ§n=8
ΒΡ±ιάζΘ§÷ς «“ΣΤΞ≈δ«Α24bitsΒΡtagΓΘ»γΙϊΤΞ≈δ÷–ΝΥΘ§ΨΆΥψΟϋ÷–Θ§»γΙϊΟΜ”–ΤΞ≈δΒΫΘ§Ρ«ΨΆ «cache
missΘ§»γΙϊ «ΕΝ≤ΌΉςΘ§ΨΆ–η“ΣΫχœρΚσΟφΒΡΜΚ¥φΫχ––ΖΟΈ ΝΥΓΘL2ΚΆL3Ά§―υ «’β―υΒΡΥψΖ®ΓΘΕχΧ‘Χ≠ΥψΖ®”–ΝΫ÷÷Θ§“Μ÷÷ «ΥφΜζΘ§Νμ“Μ÷÷ «LRUΓΘ
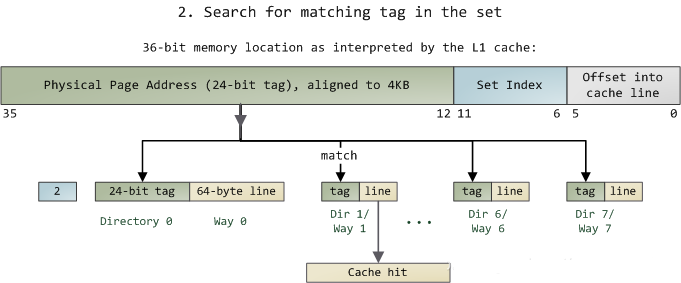
’β“≤“βΈΕΉ≈ΘΚ
L1 Cache Ω…”≥…δ 36bits ΒΡΡΎ¥φΒΊ÷ΖΘ§“ΜΙ≤ 2^36 = 64GBΒΡΡΎ¥φ
Β±CPU“ΣΖΟΈ “ΜΗωΡΎ¥φΒΡ ±ΚρΘ§Ά®Ιΐ’βΗωΡΎ¥φ÷–ΦδΒΡ6bits Ε®ΈΜ «ΡΡΗωsetΘ§Ά®Ιΐ«Α 24bits
Ε®ΈΜœύ”ΠΒΡCache LineΓΘ
ΨΆœώ“ΜΗωhash TableΒΡ ΐΨίΫαΙΙ“Μ―υΘ§œ» «O(1)ΒΡΥς“ΐΘ§»ΜΚσΫχ»κ≥εΆΜΥ―ΥςΓΘ “ρΈΣ÷–ΦδΒΡ 6bitsΨωΕ®ΝΥ“ΜΗωΆ§“ΜΗωsetΘ§Υυ“‘Θ§Ε‘”Ύ“ΜΕΈΝ§–χΒΡΡΎ¥φά¥ΥΒΘ§ΟΩΗτ4096ΒΡΡΎ¥φΜα±ΜΖ≈‘ΎΆ§“ΜΗωΉιΡΎΘ§ΒΦ÷¬ΜΚ¥φ≥εΆΜΓΘ ¥ΥΆβΘ§Β±”– ΐΨίΟΜ”–Οϋ÷–ΜΚ¥φΒΡ ±ΚρΘ§CPUΨΆΜα“‘Ήν–ΓΈΣCache LineΒΡΒΞ‘ΣœρΡΎ¥φΗϋ–¬ ΐΨίΓΘΒ±»ΜΘ§CPU≤Δ≤Μ“ΜΕ®÷Μ «Ηϋ–¬64BytesΘ§“ρΈΣΖΟΈ ÷ς¥φ Β‘Ύ «ΧΪ¬ΐΝΥΘ§Υυ“‘Θ§“ΜΑψΕΦΜαΕύΗϋ–¬“Μ–©ΓΘΚΟΒΡCPUΜα”–“Μ–©‘Λ≤βΒΡΦΦ θΘ§»γΙϊ’“ΒΫ“Μ÷÷patternΒΡΜΑΘ§ΨΆΜα‘Λœ»Φ”‘ΊΗϋΕύΒΡΡΎ¥φΘ§Αϋά®÷ΗΝν“≤Ω…“‘‘ΛΦ”‘ΊΓΘ’βΫ–
Prefetching ΦΦ θΓΘ±»»γΘ§Ρψ‘Ύfor-loopΖΟΈ “ΜΗωΝ§–χΒΡ ΐΉιΘ§ΡψΒΡ≤Ϋ≥Λ «“ΜΗωΙΧΕ®ΒΡ ΐΘ§ΡΎ¥φΨΆΩ…“‘ΉωΒΫprefetchingΓΘ
ΝΥΫβ’β–©œΗΫΎΘ§Μα”–άϊ”ΎΈ“Ο«÷ΣΒά‘Ύ ≤Ο¥«ιΩωœ¬”–Ω…“‘ΒΦ÷¬ΜΚ¥φΒΡ ß–ßΓΘ
»ΐΓΔΜΚ¥φ“Μ÷¬
Ε‘”Ύ÷ςΝςΒΡCPUά¥ΥΒΘ§ΜΚ¥φΒΡ–¥≤ΌΉςΜυ±Ψ…œ «ΝΫ÷÷≤Ώ¬‘
Write BackΘΚ–¥≤ΌΉς÷Μ‘ΎCache…œΘ§»ΜΚσ‘ΌflushΒΫΡΎ¥φ…œ
Write ThroughΘΚ–¥≤ΌΉςΆ§ ±–¥ΒΫcacheΚΆΡΎ¥φ…œΓΘ ΈΣΝΥΧαΗΏ–¥ΒΡ–‘ΡήΘ§“ΜΑψά¥ΥΒΘ§÷ςΝςΒΡCPUΘ®»γΘΚIntel Core i7/i9Θ©≤…”ΟΒΡ «Write
BackΒΡ≤Ώ¬‘Θ§“ρΈΣ÷±Ϋ”–¥ΡΎ¥φ Β‘Ύ «ΧΪ¬ΐΝΥΓΘ ΚΟΝΥΘ§œ÷‘ΎΈ Χβά¥ΝΥΘ§»γΙϊ”–“ΜΗω ΐΨί x ‘Ύ CPU ΒΎ0ΚΥΒΡΜΚ¥φ…œ±ΜΗϋ–¬ΝΥΘ§Ρ«Ο¥ΤδΥϋCPUΚΥ…œΕ‘”Ύ’βΗω ΐΨί
x ΒΡ÷Β“≤“Σ±ΜΗϋ–¬Θ§’βΨΆ «ΜΚ¥φ“Μ÷¬–‘ΒΡΈ ΧβΓΘ “ΜΑψά¥ΥΒΘ§‘ΎCPU”≤Φΰ…œΘ§Μα”–ΝΫ÷÷ΖΫΖ®ά¥ΫβΨω’βΗωΈ ΧβΓΘ
Directory –≠“ιΓΘ’β÷÷ΖΫΖ®ΒΡΒδ–Ά Βœ÷ «“Σ…ηΦΤ“ΜΗωΦ·÷– ΫΩΊ÷ΤΤςΘ§Υϋ «÷ς¥φ¥ΔΤςΩΊ÷ΤΤςΒΡ“Μ≤ΩΖ÷ΓΘΤδ÷–”–“ΜΗωΡΩ¬Φ¥φ¥Δ‘Ύ÷ς¥φ¥ΔΤς÷–Θ§Τδ÷–ΑϋΚ§”–ΙΊΗς÷÷±ΨΒΊΜΚ¥φΡΎ»ίΒΡ»ΪΨ÷Ή¥Χ§–≈œΔΓΘΒ±ΒΞΗωCPU
Cache ΖΔ≥ωΕΝ–¥«κ«σ ±Θ§’βΗωΦ·÷– ΫΩΊ÷ΤΤςΜαΦλ≤ι≤ΔΖΔ≥ω±Ί“ΣΒΡΟϋΝνΘ§“‘‘Ύ÷ς¥φΚΆCPU Cache÷°ΦδΜρ‘ΎCPU
CacheΉ‘…μ÷°ΦδΫχ–– ΐΨίΆ§≤ΫΚΆ¥Ϊ δΓΘ
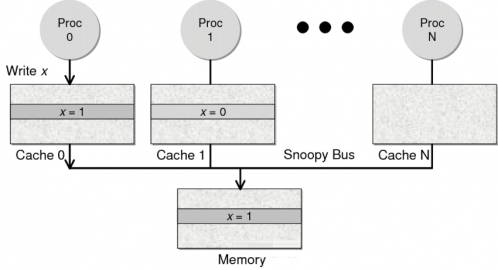
Snoopy –≠“ιΓΘ’β÷÷–≠“ιΗϋœώ «“Μ÷÷ ΐΨίΆ®÷ΣΒΡΉήœΏ–ΆΒΡΦΦ θΓΘCPU
CacheΆ®Ιΐ’βΗω–≠“ιΩ…“‘ Ε±πΤδΥϋCache…œΒΡ ΐΨίΉ¥Χ§ΓΘ»γΙϊ”– ΐΨίΙ≤œμΒΡΜΑΘ§Ω…“‘Ά®ΙΐΙψ≤ΞΜζ÷ΤΫΪΙ≤œμ ΐΨίΒΡΉ¥Χ§Ά®÷ΣΗχΤδΥϋCPU
CacheΓΘ’βΗω–≠“ι“Σ«σΟΩΗωCPU Cache ΕΦΩ…“‘ΓΑΩζΧΫΓ± ΐΨί ¬ΦΰΒΡΆ®÷Σ≤ΔΉω≥ωœύ”ΠΒΡΖ¥”ΠΓΘ»γœ¬ΆΦΥυ ΨΘ§”–“ΜΗωSnoopy
BusΒΡΉήœΏΓΘ
“ρΈΣDirectory–≠“ι «“ΜΗω÷––Ρ ΫΒΡΘ§Μα”––‘ΡήΤΩΨ±Θ§Εχ«“Μα‘ωΦ”’ϊΧε…ηΦΤΒΡΗ¥‘”Ε»ΓΘΕχSnoopy–≠“ιΗϋœώ «ΈΔΖΰΈώ+œϊœΔΆ®―ΕΘ§Υυ“‘Θ§œ÷‘ΎΜυ±ΨΕΦ « Ι”ΟSnoopyΒΡΉήœΏΒΡ…ηΦΤΓΘ
‘ΎΖ÷≤Φ ΫœΒΆ≥÷–Έ“Ο«“ΜΑψ”ΟPaxos/Raft’β―υΒΡΖ÷≤Φ Ϋ“Μ÷¬–‘ΒΡΥψΖ®ΓΘΕχ‘ΎCPUΒΡΈΔΙέ άΫγάοΘ§‘ρ≤Μ±Ί Ι”Ο’β―υΒΡΥψΖ®ΓΘ“ρΈΣCPUΒΡΕύΗωΚΥΒΡ”≤Φΰ≤Μ±ΊΩΦ¬«Άχ¬γΜαΕœΜα―”≥ΌΒΡΈ ΧβΓΘΥυ“‘Θ§CPUΒΡΕύΚΥ–ΡΜΚ¥φΦδΒΡΆ§≤ΫΒΡΚΥ–ΡΨΆ «“ΣΙήάμΚΟ ΐΨίΒΡΉ¥Χ§ΨΆΚΟΝΥΓΘ
’βάοΫι…ήΦΗΗωΉ¥Χ§–≠“ιΘ§œ»¥”ΉνΦρΒΞΒΡΩΣ ΦΘ§MESI–≠“ιΘ§’βΗω–≠“ιΗζΡ«Ηω÷χΟϊΒΡΉψ«ρ‘ΥΕ·‘±ΟΖΈςΟΜ ≤Ο¥ΙΊœΒΘ§Τδ÷ς“Σ±μ ΨΜΚ¥φ ΐΨί”–ΥΡΗωΉ¥Χ§ΘΚModifiedΘ®“―–όΗΡΘ©,
ExclusiveΘ®Εά’ΦΒΡΘ©,SharedΘ®Ι≤œμΒΡΘ©Θ§InvalidΘ®Έό–ßΒΡΘ©ΓΘ MESI ’β÷÷–≠“ι‘Ύ ΐΨίΗϋ–¬ΚσΘ§Μα±ξΦ«ΤδΥϋΙ≤œμΒΡCPUΜΚ¥φΒΡ ΐΨίΩΫ±¥ΈΣInvalidΉ¥Χ§Θ§»ΜΚσΒ±ΤδΥϋCPU‘Ό¥ΈreadΒΡ ±ΚρΘ§ΨΆΜα≥ωœ÷
cache miss ΒΡΈ ΧβΘ§¥Υ ±‘Ό¥”ΡΎ¥φ÷–Ηϋ–¬ ΐΨίΓΘ¥”ΡΎ¥φ÷–Ηϋ–¬ ΐΨί“βΈΕΉ≈20±ΕΥΌΕ»ΒΡΫΒΒΆΓΘΈ“Ο«Ρή≤ΜΡή÷±Ϋ”¥”Έ“Ητ±ΎΒΡCPUΜΚ¥φ÷–Ηϋ–¬ΘΩ «ΒΡΘ§’βΨΆΩ…“‘‘ωΦ”ΚήΕύΥΌΕ»ΝΥΘ§ΒΪ «Ή¥Χ§ΩΊ÷Τ“≤ΨΆ±δ¬ιΖ≥ΝΥΓΘΜΙ–η“ΣΕύά¥“ΜΗωΉ¥Χ§ΘΚOwner(Υό÷ς)Θ§”Ο”Ύ±ξΦ«Θ§Έ“ «Ηϋ–¬ ΐΨίΒΡ‘¥ΓΘ”Ύ «Θ§≥ωœ÷ΝΥ
MOESI –≠“ιΓΘ MOESI–≠“ι‘ –μ CPU Cache ΦδΆ§≤Ϋ ΐΨίΘ§”Ύ «“≤ΫΒΒΆΝΥΕ‘ΡΎ¥φΒΡ≤ΌΉςΘ§–‘Ρή «Ζ«≥Θ¥σΒΡΧα…ΐΘ§ΒΪ «ΩΊ÷Τ¬ΏΦ≠“≤Ζ«≥ΘΗ¥‘”ΓΘ Υ≥±ψΥΒ“Μœ¬Θ§”κ MOESI –≠“ιάύΥΤΒΡ“ΜΗω–≠“ι « MESIFΘ§Τδ÷–ΒΡ F « ForwardΘ§Ά§―υ «Α―Ηϋ–¬ΙΐΒΡ ΐΨίΉΣΖΔΗχ±πΒΡ
CPU Cache ΒΪ «Θ§MOESI ÷–ΒΡ Owner Ή¥Χ§ ΚΆMESIF ÷–ΒΡ Forward Ή¥Χ§”–“ΜΗωΖ«≥Θ¥σΒΡ≤Μ“Μ―υΓΣΓΣ
OwnerΉ¥Χ§œ¬ΒΡ ΐΨί «dirtyΒΡΘ§ΜΙΟΜ”––¥ΜΊΡΎ¥φΘ§ForwardΉ¥Χ§œ¬ΒΡ ΐΨί «cleanΒΡΘ§Ω…“‘ΕΣΤζΕχ≤Μ”ΟΝμ––Ά®÷ΣΓΘ –η“ΣΥΒΟςΒΡ «Θ§AMD”ΟMOESIΘ§Intel”ΟMESIFΓΘΥυ“‘Θ§F Ή¥Χ§÷ς“Σ «’κΕ‘ CPU
L3 Cache …ηΦΤΒΡΘ®«ΑΟφΈ“Ο«ΥΒΙΐΘ§L3 «Υυ”–CPUΚΥ–ΡΙ≤œμΒΡΘ©ΓΘ
ΥΡΓΔ≥Χ–ρ–‘Ρή
ΝΥΫβΝΥΈ“Ο«…œΟφΒΡ’β–©ΕΪΈςΚσΘ§Έ“Ο«ά¥Ω¥“Μœ¬Ε‘”Ύ≥Χ–ρΒΡ”ΑœλΓΘ
Ψάΐ“Μ
Ήœ»Θ§ΦΌ…ηΈ“Ο«”–“ΜΗω64M≥ΛΒΡ ΐΉιΘ§…ηœκ“Μœ¬œ¬ΟφΒΡΝΫΗω―≠ΜΖΘΚ
const int LEN
= 64*1024*1024;
int *arr = new int[LEN];
for (int i = 0; i < LEN; i += 2) arr[i] *=
i;
for (int i = 0; i < LEN; i += 8) arr[i] *=
i;
|
Α¥Έ“Ο«ΒΡœκΖ®Θ§ΒΎΕΰΗω―≠ΜΖ“Σ±»ΒΎ“ΜΗω―≠ΜΖ…Ό4±ΕΒΡΦΤΥψΝΩΓΘΤδ”ΠΗΟ“ΣΩλ4±ΕΒΡΓΘΒΪ ΒΦ ≈ήœ¬ά¥≤Δ≤Μ «Θ§‘ΎΈ“ΒΡΜζΤς…œΘ§ΒΎ“ΜΗω―≠ΜΖ–η“Σ128ΚΝΟκΘ§ΒΎΕΰΗω―≠ΜΖ‘ρ–η“Σ122ΚΝΟκΘ§œύ≤νΈόΦΗΓΘ’βάοΉν÷ς“ΣΒΡ‘≠“ρΨΆ «
Cache LineΘ§“ρΈΣCPUΜα“‘“ΜΗωCache Line 64BytesΉν–Γ ±ΒΞΈΜΦ”‘ΊΘ§“≤ΨΆ «16Ηω32bitsΒΡ’ϊ–ΆΘ§Υυ“‘Θ§Έό¬έΡψ≤Ϋ≥Λ «2ΜΙ «8Θ§ΕΦ≤ν≤ΜΕύΓΘΕχΚσΟφΒΡ≥ΥΖ®Τδ Β «≤ΜΚΡCPU ±ΦδΒΡΓΘ
ΨάΐΕΰ
Ϋ”œ¬ά¥Θ§Έ“Ο«‘Όά¥Ω¥Ηω ΨάΐΓΘœ¬Οφ «“ΜΗωΕΰΈ§ ΐΉιΒΡΝΫ÷÷±ιάζΖΫ ΫΘ§“ΜΗω÷π––±ιάζΘ§“ΜΗω «÷πΝ–±ιάζΘ§’βΝΫ÷÷ΖΫ Ϋ‘Ύάμ¬έ…œά¥ΥΒΘ§―Α÷ΖΚΆΦΤΥψΝΩΕΦ «“Μ―υΒΡΘ§÷¥–– ±Φδ”ΠΗΟ“≤ «“Μ―υΒΡΓΘ
const int row
= 1024;
const int col = 512
int matrix[row][col];
//÷π––±ιάζ
int sum_row=0;
for(int _r=0; _r<row; _r++) {
for(int _c=0; _c<col; _c++){
sum_row += matrix[_r][_c];
}
}
//÷πΝ–±ιάζ
int sum_col=0;
for(int _c=0; _c<col; _c++) {
for(int _r=0; _r<row; _r++){
sum_col += matrix[_r][_c];
}
} |
»ΜΕχΘ§≤Δ≤Μ «Θ§‘ΎΈ“ΒΡΜζΤς…œΘ§ΒΟΒΫœ¬ΟφΒΡΫαΙϊΓΘ ÷π––±ιάζΘΚ0.083ms ÷πΝ–±ιάζΘΚ1.072ms ÷¥–– ±Φδ”– °ΦΗ±ΕΒΡ≤νΨύΓΘΤδ÷–ΒΡ‘≠“ρΘ§ΨΆ «÷πΝ–±ιάζΕ‘”ΎCPU Cache ΒΡ‘ΥΉςΖΫ Ϋ≤Δ≤Μ”―ΚΟΘ§Υυ“‘Θ§ΗΕ≥ωΨό¥σΒΡ¥ζΦέΓΘ
Ψάΐ»ΐ
Ϋ”œ¬ά¥Θ§Έ“Ο«ά¥Ω¥“Μœ¬ΕύΚΥœ¬ΒΡ–‘ΡήΈ ΧβΘ§≤ΈΩ¥»γœ¬ΒΡ¥ζ¬κΓΘΝΫΗωœΏ≥Χ‘Ύ≤ΌΉς“ΜΗω ΐΉιΒΡΝΫΗω≤ΜΆ§ΒΡ‘ΣΥΊΘ®Έό–ηΦ”ΥχΘ©Θ§œΏ≥Χ―≠ΜΖ1000Άρ¥ΈΘ§ΉωΦ”Ζ®≤ΌΉςΓΘ‘Ύœ¬ΟφΒΡ¥ζ¬κ÷–Θ§Έ“ΗΏΝΝΝΥ“Μ––Θ§ΨΆ «p2÷Η’κΘ§“ΣΟ¥ «p[1]Θ§Μρ «
p[30]Θ§άμ¬έ…œά¥ΥΒΘ§Έό¬έΖΟΈ ΡΡΝΫΗω ΐΉι‘ΣΥΊΘ§ΕΦ”ΠΗΟ «“Μ―υΒΡ÷¥–– ±ΦδΓΘ
void fn (int*
data) {
for(int i = 0; i < 10*1024*1024; ++i)
*data += rand();
}
int p[32];
int *p1 = &p[0];
int *p2 = &p[1]; // int *p2 = &p[30];
thread t1(fn, p1);
thread t2(fn, p2);
|
»ΜΕχΘ§≤Δ≤Μ «Θ§‘ΎΈ“ΒΡΜζΤς…œ÷¥––œ¬ά¥ΒΡΫαΙϊ «ΘΚ Ε‘”Ύ p[0] ΚΆ p[1] ΘΚ570ms Ε‘”Ύ p[0] ΚΆ p[30]ΘΚ105ms ’β «“ρΈΣ p[0] ΚΆ p[1] ‘ΎΆ§“ΜΧθ Cache Line …œΘ§Εχ p[0] ΚΆ p[30]
‘ρ≤ΜΩ…Ρή‘ΎΆ§“ΜΧθCache Line …œ Θ§CPUΒΡΜΚ¥φΉν–ΓΒΡΗϋ–¬ΒΞΈΜ «Cache LineΘ§Υυ“‘Θ§’βΒΦ÷¬Υδ»ΜΝΫΗωœΏ≥Χ‘Ύ–¥≤ΜΆ§ΒΡ ΐΨίΘ§ΒΪ «“ρΈΣ’βΝΫΗω ΐΨί‘ΎΆ§“ΜΧθCache
Line…œΘ§ΨΆΜαΒΦ÷¬ΜΚ¥φ–η“Σ≤ΜΕœΫχ‘ΎΝΫΗωCPUΒΡL1/L2÷–Ϋχ––Ά§≤ΫΘ§¥”ΕχΒΦ÷¬ΝΥ5±ΕΒΡ ±Φδ≤ν“λΓΘ
|









