| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“ΣΫι…ήΝΥLinuxΡΎΚΥΦήΙΙΚΆΙΛΉς‘≠άμœξΫβ,œΘΆϊΡζΡήΕ‘»μΦΰΚΆ”≤Φΰ»γΚΈ–≠Ά§ΙΛΉς“‘ΦΑΤτΕ·ΦΤΥψΜζΥυ–ηΒΡΈΡΦΰ”–ΗϋΕύΒΡΝΥΫβ.
±ΨΈΡά¥Ή‘”Ύ†D÷«ΡήΈοΝΣΆχΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
«Α―‘
…η±ΗΒΡΩ…ΩΩ–‘…φΦΑΕύΗωΖΫΟφΘΚΈ»Ε®ΒΡ”≤ΦΰΓΔ”≈–ψΒΡ»μΦΰΦήΙΙΓΔ―œΗώΒΡ≤β ‘“‘ΦΑ –≥ΓΚΆ ±ΦδΒΡΦλ―ι»»ΓΘ’βάοΉ≈÷ΊΧΗ“Μœ¬Ε‘«Ε»κ Ϋ»μΦΰΩ…ΩΩ–‘…ηΦΤΒΡ“Μ–©άμΫβΘ§Ά®Ιΐ“ΜΕ®ΒΡΦΦ«…ΚΆΖΫΖ®ΧαΗΏ»μΦΰΩ…ΩΩ–‘ΓΘ’βάοΥυΥΒΒΡ«Ε»κ Ϋ…η±Η, «÷Η Ι”ΟΒΞΤ§ΜζΓΔARM7ΓΔCortex-M0Θ§M3÷°άύΈΣΚΥ–ΡΒΡ≤βΩΊΜρΙΛΩΊœΒΆ≥ΓΘ
«Ε»κ Ϋ»μΦΰΩ…ΩΩ–‘…ηΦΤ”ΠΗΟ¥”Ζά¥μΓΔ≈–¥μΚΆ»ί¥μ»ΐΖΫΟφΫχ––ΩΦ¬«. ¥ΥΆβ,ΜΙ–ηάμΫβΉ‘ΦΚΥυ Ι”ΟΒΡ±ύ“κΤςΧΊ–‘ΓΘ
¥ΥΈΡ τ≈ΉΉ©“ΐ”ώΓΘ
ΝΦΚΟΒΡ»μΦΰΦήΙΙΓΔ«εΈζΒΡ¥ζ¬κΫαΙΙΓΔ’ΤΈ’”≤ΦΰΓΔ…ν»κάμΫβC”ο―‘ «Ζά¥μΒΡ“ΣΒψΘ§’βάο÷ΜΧΗ“Μ
ΓΑ»ΥΒΡΥΦΈ§ΚΆΨ≠―ιΜΐάέΕ‘»μΦΰΩ…ΩΩ–‘”–Κή¥σ”Αœλ"ΓΘC”ο―‘Ιν“λ«“”–÷÷÷÷œίΎεΚΆ»±œίΘ§–η“Σ≥Χ–ρ‘±ΕύΡξάζΝΖ≤≈Ρή¥οΒΫΫœΈΣΆξ…ΤΒΡΒΊ≤ΫΓΘΓΑ»μΦΰΒΡ÷ ΝΩ «”…≥Χ–ρ‘±ΒΡ÷ ΝΩ“‘ΦΑΥϊΟ«œύΜΞ÷°ΦδΒΡ–≠ΉςΨωΕ®ΒΡΓ±ΓΘ“ρ¥ΥΘ§Ής’Ώ»œΈΣΖά¥μΒΡ÷ΊΒψ «“ΣΩΦ¬«»ΥΒΡ“ρΥΊΓΘ
ΓΑ…ν»κ“ΜΟ≈”ο―‘±ύ≥ΧΘ§≤Μ“ΣΗΓ”Ύ±μΟφΓ±ΓΘ»μΦΰΒΡΩ…ΩΩ–‘Θ§”κΡψάμΫβΒΡ”ο―‘…νΕ»Οή«–œύΙΊΘ§«Ε»κ ΫCΗϋ «»γ¥ΥΓΘ≥ΐΝΥ”ο―‘Θ§Ής’Ώ»œΈΣ«Ε»κ ΫΩΣΖΔΜΙ±Ί–κ…ν»κάμΫβ±ύ“κΤςΓΘ
1.¥Π¥ΠΫ‘œίΎε
Ήν≥θΩΣ Φ±ύ≥Χ ±Θ§≥ΐΝΥ”ΔΈΡ±ξΒψ±ΜΈσ–¥≥…÷–ΈΡ±ξΒψΆβΘ§Ω…Ρή±Μ¥σΦ“Τ’±ι”ωΒΫΒΡ «ΫΪ±»Ϋœ‘ΥΥψΖϊ==Έσ–¥≥…Η≥÷Β‘ΥΥψΖϊ=Θ§¥ζ¬κ»γœ¬Υυ ΨΘΚ
’βάο±Ψ“β «±»Ϋœ±δΝΩx «ΖώΒ»”Ύ≥ΘΝΩ5Θ§ΒΪ «ΈσΫΪΓ·==Γ·–¥≥…ΝΥΓ·=Γ·Θ§if”οΨδΚψΈΣ’φΓΘ»γΙϊ‘Ύ¬ΏΦ≠≈–Εœ±μ¥ο Ϋ÷–≥ωœ÷Η≥÷Β‘ΥΥψΖϊΘ§œ÷‘ΎΒΡ¥σΕύ ΐ±ύ“κΤςΜαΗχ≥ωΨ·Ηφ–≈œΔΓΘ≤ΔΖ«Υυ”–≥Χ–ρ‘±ΕΦΜαΉΔ“βΒΫ’βάύΨ·ΗφΘ§“ρ¥Υ”–Ψ≠―ιΒΡ≥Χ–ρ‘± Ι”Οœ¬ΟφΒΡ¥ζ¬κά¥±ήΟβ¥Υάύ¥μΈσΘΚ
ΫΪ≥ΘΝΩΖ≈‘Ύ±δΝΩxΒΡΉσ±ΏΘ§Φ¥ Ι≥Χ–ρ‘±ΈσΫΪΓ·==Γ·–¥≥…ΝΥΓ·=Γ·Θ§±ύ“κΤςΜα≤ζ…ζ“ΜΗω»ΈΥ≠“≤≤ΜΡήΈό ”ΒΡ”οΖ®¥μΈσ–≈œΔΘΚ≤ΜΩ…Ηχ≥ΘΝΩΗ≥÷ΒΘΓ
+=”κ=+ΓΔ-=”κ=-“≤ «»ί“Ή–¥ΜλΒΡΓΘΗ¥ΚœΗ≥÷Β‘ΥΥψΖϊΘ®+=ΓΔ*=»»ȩΥδ»ΜΩ…“‘ Ι±μ¥ο ΫΗϋΦ”ΦρΫύ≤Δ”–Ω…Ρή≤ζ…ζΗϋΗΏ–ßΒΡΜζΤς¥ζ¬κΘ§ΒΪΡ≥–©Η¥ΚœΗ≥÷Β‘ΥΥψΖϊ“≤ΜαΗχ≥Χ–ρ¥χά¥“ΰΚ§BugΘ§»γœ¬Υυ Ψ¥ζ¬κΘΚ
ΗΟ¥ζ¬κ±Ψ“β «œκ±μ¥οtmp=tmp+1Θ§ΒΪ «ΫΪΗ¥ΚœΗ≥÷Β‘ΥΥψΖϊ+=Έσ–¥≥…=+ΘΚΫΪ’ΐ’ϊ ΐ≥ΘΝΩ1Η≥÷ΒΗχ±δΝΩtmpΓΘ±ύ“κΤςΜα–ά»ΜΫ” ή’βάύ¥ζ¬κΘ§Ν§Ψ·ΗφΕΦ≤ΜΜα≤ζ…ζΓΘ
»γΙϊΡψΡή‘ΎΒς ‘ΫΉΕΈΨΆΖΔœ÷’βΗωBugΘ§Ρψ’φ”ΠΗΟ«λΉΘ“Μœ¬Θ§Ζώ‘ρ’βΚήΩ…ΡήΜα≥…ΈΣ“ΜΗω÷Ί¥σ“ΰΚ§BugΘ§«“≤Μ“Ή±Μ≤λΨθΓΘ
-=”κ=-“≤ «Ά§―υΒάάμΓΘ”κ÷°άύΥΤΒΡΜΙ”–¬ΏΦ≠”κ&&ΚΆΈΜ”κ&ΓΔ¬ΏΦ≠Μρ||ΚΆΈΜΜρ|ΓΔ¬ΏΦ≠Ζ«ΘΓΚΆΈΜ»ΓΖ¥~ΓΘ¥ΥΆβΉ÷ΡΗlΚΆ ΐΉ÷1ΓΔΉ÷ΡΗOΚΆ ΐΉ÷0“≤“ΉΜλœΐΘ§’β÷÷«ιΩωΩ…Ϋη÷ζ±ύ“κΤςά¥Ψά’ΐΓΘ
ΚήΕύΒΡ»μΦΰBUGΉ‘”Ύ δ»κ¥μΈσΓΘ‘ΎGoogle…œΥ―ΥςΒΡ ±ΚρΘ§”––©ΫαΙϊΝ–±μœν÷–¥χ”–“ΜΧθΨ·ΗφΘ§±μΟςGoogle»œΈΣΥϋ¥χ”–Εώ“β¥ζ¬κΓΘ»γΙϊΡψ‘Ύ2009Ρξ1‘¬31»’“Μ¥σ‘γ Ι”ΟGoogleΥ―ΥςΒΡΜΑΘ§ΡψΨΆΜαΩ¥ΒΫΘ§‘ΎΡ«Χλ‘γ≥Ω55Ζ÷÷”ΒΡ ±ΦδΡΎΘ§GoogleΒΡΥ―ΥςΫαΙϊ±ξΟςΟΩΗω’ΨΒψΕ‘ΡψΒΡPCΕΦ «”–ΚΠΒΡΓΘ’β…φΦΑΒΫ’ϊΗωInternet…œΒΡΥυ”–’ΨΒψΘ§Αϋά®GoogleΉ‘ΦΚΒΡΥυ”–’ΨΒψΚΆΖΰΈώΓΘGoogleΒΡΕώ“β»μΦΰΦλ≤βΙΠΡήΆ®Ιΐ‘Ύ“ΜΗω“―÷ΣΙΞΜς’ΏΒΡΝ–±μ…œ≤ι’“’ΨΒψΘ§¥”Εχ Ε±π≥ωΈΘœ’’ΨΒψΓΘ‘Ύ1‘¬31»’‘γ≥ΩΘ§Ε‘’βΗωΝ–±μΒΡΗϋ–¬“βΆβΒΊΑϋΚ§ΝΥ“ΜΧθ–±Ηή(ΓΑ/Γ±)ΓΘΥυ”–ΒΡURLΕΦΑϋΚ§“ΜΧθ–±ΗήΘ§≤Δ«“Θ§Ζ¥Εώ“β»μΦΰΙΠΡήΑ―’βΧθ–±ΗήάμΫβΈΣΥυ”–ΒΡURLΕΦ «Ω…“…ΒΡΘ§“ρ¥ΥΘ§Υϋ”δΩλΒΊΕ‘Υ―ΥςΫαΙϊ÷–ΒΡΟΩΗω’ΨΒψΕΦΧμΦ”“ΜΧθΨ·ΗφΓΘΚή…ΌΦϊΒΫ»γ¥ΥΦρΒΞΒΡ“ΜΗω δ»κ¥μΈσ¥χά¥ΒΡΫαΙϊ»γ¥ΥΤφΙ÷«“”Αœλ»γ¥ΥΙψΖΚΘ§ΒΪ≥Χ–ρΨΆ «’β―υΘ§»ί≤ΜΒΟ“ΜΥΩ ηΚωΓΘ
ΐΉι≥Θ≥Θ“≤ «“ΐΤπ≥Χ–ρ≤ΜΈ»Ε®ΒΡ÷Ί“Σ“ρΥΊΘ§C”ο―‘ ΐΉιΒΡΟ‘Μσ–‘”κ ΐΉιœ¬±ξ¥”0ΩΣ ΦΟή≤ΜΩ…Ζ÷Θ§ΡψΩ…“‘Ε®“εint a[30]Θ§ΒΪ «ΡψΨχ≤ΜΩ…“‘ Ι”Ο ΐΉι‘ΣΥΊa[30]Θ§≥ΐΖ«ΡψΉ‘ΦΚΟς»Ζ÷ΣΒά‘ΎΉω ≤Ο¥ΓΘ
switchΓ≠case”οΨδΩ…“‘ΚήΖΫ±ψΒΡ Βœ÷ΕύΖ÷÷ßΫαΙΙΘ§ΒΪ“ΣΉΔ“β‘ΎΚœ ΒΡΈΜ÷ΟΧμΦ”breakΙΊΦϋΉ÷ΓΘ≥Χ–ρ‘±ΆυΆυ»ί“Ή¬©Φ”break¥”Εχ“ΐΤπΥ≥–ρ÷¥––ΕύΗωcase”οΨδΘ§’β“≤–μ «CΒΡ“ΜΗω»±œί÷°¥ΠΓΘΕ‘”ΎswitchΓ≠case”οΨδΘ§¥”Η≈¬ ¬έ…œΥΒΘ§Ψχ¥σΕύ ΐ≥Χ–ρ“Μ¥Έ÷Μ–η÷¥––“ΜΗωΤΞ≈δΒΡcase”οΨδΘ§ΕχΟΩ“ΜΗω’β―υΒΡcase”οΨδΚσΕΦ±Ί–κΗζ“ΜΗωbreakΓΘ»ΞΗ¥‘”Μ·¥σΗ≈¬ ¬ΦΰΘ§’βΕύ…Ό”––©≤ΜΚœ≥Θ«ιΓΘ
breakΙΊΦϋΉ÷”Ο”ΎΧχ≥ωΉνΫϋΒΡΡ«≤ψ―≠ΜΖ”οΨδΜρ’Ώswitch”οΨδΘ§ΒΪ≥Χ–ρ‘±ΆυΆυ≤ΜΙΜ÷Ί ”’β“ΜΒψΓΘ
1990Ρξ1‘¬15»’Θ§AT&TΒγΜΑΆχ¬γΈΜ”Ύ≈Π‘ΦΒΡ“ΜΧ®ΫΜΜΜΜζΒ±Μζ≤Δ«“÷ΊΤτΘ§“ΐΤπΥϋΝΎΫϋΫΜΜΜΜζΧ±ΜΨΘ§”…¥ΥΦΑ±ΥΘ§“ΜΗωΝ§Ή≈“ΜΗωΘ§ΚήΩλΘ§114Χ®ΫΜΜΜΜζΟΩΝυΟκΒ±Μζ÷ΊΤτ“Μ¥ΈΘ§ΝυΆρ»ΥΨ≈–Γ ±ΡΎ≤ΜΡή¥ρ≥ΛΆΨΒγΜΑΓΘΒ± ±ΒΡΫβΨωΖΫ ΫΘΚΙΛ≥Χ Π÷ΊΉΑΝΥ“‘«ΑΒΡ»μΦΰΑφ±ΨΓΘ ¬ΚσΒΡ ¬Ι Βς≤ιΖΔœ÷Θ§’β «breakΙΊΦϋΉ÷Έσ”Ο‘λ≥…ΒΡΓΘΓΕCΉ®Φ“±ύ≥ΧΓΖΧαΙ©ΝΥ“ΜΗωΦρΜ·ΑφΒΡΈ Χβ‘¥¬κΘΚ
network code()
{
switch(line) {
case THING1:
doit1();
break;
case THING2:
if(x==STUFF) {
do_first_stuff();
if(y==OTHER_STUFF)
break;
do_later_stuff();
} /*¥ζ¬κΒΡ“βΆΦ «ΧχΉΣΒΫ’βάοΓ≠ Γ≠*/
initialize_modes_pointer();
break;
default:
processing();
}/*Γ≠ Γ≠ΒΪ ¬ Β…œΧχΒΫΝΥ’βάοΓΘ*/
use_modes_pointer();/*÷¬ Ιmodes_pointerΈ¥≥θ ΦΜ·*/
} |
Ρ«Ηω≥Χ–ρ‘±œΘΆϊ¥”if”οΨδΧχ≥ωΘ§ΒΪΥϊ»¥ΆϋΦ«ΝΥbreakΙΊΦϋΉ÷ ΒΦ …œΧχ≥ωΉνΫϋΒΡΡ«≤ψ―≠ΜΖ”οΨδΜρ’Ώswitch”οΨδΓΘœ÷‘ΎΥϋΧχ≥ωΝΥswitch”οΨδΘ§÷¥––ΝΥuse_modes_pointer()Κ· ΐΓΘΒΪ±Ί“ΣΒΡ≥θ ΦΜ·ΙΛΉς≤ΔΈ¥Άξ≥…Θ§ΈΣΫΪά¥≥Χ–ρΒΡ ßΑή¬ώœ¬ΝΥΖϋ± ΓΘ
ΫΪ“ΜΗω’ϊ–Έ≥ΘΝΩΗ≥÷ΒΗχ±δΝΩΘ§¥ζ¬κ»γœ¬Υυ ΨΘΚ
±δΝΩaΚΆbœύΒ»¬πΘΩ¥πΑΗ «≤ΜœύΒ»ΒΡΓΘΈ“Ο«÷ΣΒάΘ§16Ϋχ÷Τ≥ΘΝΩ“‘Γ·0xΓ·ΈΣ«ΑΉΚΘ§10Ϋχ÷Τ≥ΘΝΩ≤Μ–η“Σ«ΑΉΚΘ§Ρ«Ο¥8Ϋχ÷ΤΡΊΘΩΥϋ”κ10Ϋχ÷ΤΚΆ16Ϋχ÷Τ±μ ΨΖΫΖ®ΕΦ≤ΜœύΆ®Θ§Υϋ“‘ ΐΉ÷Γ·0Γ·ΈΣ«ΑΉΚΘ§’βΕύ…Ό”–ΒψΤφίβΘΚ»ΐ÷÷Ϋχ÷ΤΒΡ±μ ΨΖΫΖ®Άξ»Ϊ≤ΜœύΆ®ΓΘ»γΙϊ8Ϋχ÷Τ“≤œώ16Ϋχ÷ΤΡ«―υ“‘ ΐΉ÷ΚΆΉ÷ΡΗ±μ Ψ«ΑΉΚΒΡΜΑΘ§Μρ–μΗϋ”–άϊ”ΎΦθ…Ό»μΦΰBugΘ§±œΨΙΡψ Ι”Ο8Ϋχ÷ΤΒΡ¥Έ ΐΩ…ΡήΕΦ≤ΜΜα”–Έσ Ι”ΟΒΡ¥Έ ΐΕύΘΓœ¬Οφ’Ι Ψ“ΜΗωΈσ”Ο8Ϋχ÷ΤΒΡάΐΉ”Θ§ΉνΚσ“ΜΗω ΐΉι‘ΣΥΊΗ≥÷Β¥μΈσΘΚ
a[0]=106; /* °Ϋχ÷Τ ΐ106*/
a[1]=112; /* °Ϋχ÷Τ ΐ112*/
a[2]=052; /* ΒΦ ΈΣ °Ϋχ÷Τ ΐ42Θ§±Ψ“βΈΣ °Ϋχ÷Τ52*/ |
÷Η’κΒΡΦ”Φθ‘ΥΥψ «ΧΊ βΒΡΓΘœ¬ΟφΒΡ¥ζ¬κ‘Υ––‘Ύ32ΈΜARMΦήΙΙ…œΘ§÷¥––÷°ΚσΘ§aΚΆpΒΡ÷ΒΖ÷±π «Εύ…ΌΘΩ
int a=1;
int *p=(int*)0x00001000;
a=a+1;
p=p+1; |
Ε‘”ΎaΒΡ÷ΒΚή»ί≈–Εœ≥ωΫαΙϊΈΣ2Θ§ΒΪ «pΒΡΫαΙϊ»¥ «0x00001004ΓΘ÷Η’κpΦ”1ΚσΘ§pΒΡ÷Β‘ωΦ”ΝΥ4Θ§’β «ΈΣ ≤Ο¥ΡΊΘΩ‘≠“ρ «÷Η’κΉωΦ”Φθ‘ΥΥψ ± «“‘÷Η’κΒΡ ΐΨίάύ–ΆΈΣΒΞΈΜΓΘp+1 ΒΦ …œ «p+1*sizeof(int)ΓΘ≤ΜάμΫβ’β“ΜΒψΘ§‘Ύ Ι”Ο÷Η’κ÷±Ϋ”≤ΌΉς ΐΨί ±ΦΪ“ΉΖΗ¥μΓΘ±»»γœ¬ΟφΕ‘Ν§–χRAM≥θ ΦΜ·Νψ≤ΌΉς¥ζ¬κ:
unsigned int *pRAMaddr; //Ε®“εΒΊ÷Ζ÷Η’κ±δΝΩ
for(pRAMaddr=StartAddr;pRAMaddr
*pRAMaddr=0x00000000; //÷ΗΕ®RAMΒΊ÷Ζ«εΝψ
}
|
”…”ΎpRAMaddr «“ΜΗω÷Η’κ±δΝΩ,Υυ“‘pRAMaddr+=4¥ζ¬κΤδ Β ΙpRAMaddrΤΪ“ΤΝΥ4*sizeof(int)=16ΗωΉ÷ΫΎΘ§Υυ“‘ΟΩ÷¥––“Μ¥Έfor―≠ΜΖΘ§Μα Ι±δΝΩpRAMaddrΤΪ“Τ16ΗωΉ÷ΫΎΩ’ΦδΘ§ΒΪ÷Μ”–4Ή÷ΫΎΩ’Φδ±Μ≥θ ΦΜ·ΈΣΝψΓΘΤδΥϋΒΡ12Ή÷ΫΎ ΐΨίΒΡΡΎ»ίΘ§‘Ύ¥σΕύ ΐΦήΙΙ¥ΠάμΤς÷–ΕΦΜα «ΥφΜζ ΐΓΘ
Ε‘”Ύsizeof()Θ§’βάο«ΩΒςΝΫΒψΘ§ΒΎ“ΜΥϋ «“ΜΗωΙΊΦϋΉ÷Θ§Εχ≤Μ «Κ· ΐΘ§≤Δ«“ΥϋΡ§»œΖΒΜΊΈόΖϊΚ≈’ϊ–Έ ΐΨίΘ®“ΣΦ«ΉΓ «ΈόΖϊΚ≈Θ©ΘΜΒΎΕΰΘ§ Ι”ΟsizeofΜώ»Γ ΐΉι≥ΛΕ» ±Θ§≤Μ“ΣΕ‘÷Η’κ”Π”Οsizeof≤ΌΉςΖϊΘ§±»»γœ¬ΟφΒΡάΐΉ”ΘΚ
void ClearRAM(char array[])
{
int i ;
for(i=0;i
//’βάο”ΟΖ®¥μΈσΘ§array ΒΦ …œ «÷Η’κ
{
array[i]=0x00;
}
}
int main(void)
{
char Fle[20];
ClearRAM(Fle);
//÷ΜΡή«ε≥ΐ ΐΉιFle÷–ΒΡ«ΑΥΡΗω‘ΣΥΊ
} |
Έ“Ο«÷ΣΒάΘ§Ε‘”Ύ“ΜΗω ΐΉιarray[20]Θ§Έ“Ο« Ι”Ο¥ζ¬κsizeof(array)/sizeof(array[0])Ω…“‘ΜώΒΟ ΐΉιΒΡ‘ΣΥΊΘ®’βάοΈΣ20Θ©Θ§ΒΪ ΐΉιΟϊΚΆ÷Η’κΆυΆυ «»ί“ΉΜλœΐΒΡΘ§Εχ«“”–«“÷Μ”–“Μ÷÷«ιΩωœ¬ «Ω…“‘Β±Ήω÷Η’κΒΡΘ§Ρ«ΨΆ « ΐΉιΟϊΉςΈΣΚ· ΐ–Έ≤Έ ±Θ§ ΐΉιΟϊ±Μ»œΈΣ «÷Η’κΓΘΆ§ ±Θ§Υϋ≤ΜΡή‘ΌΦφ»Έ ΐΉιΟϊΓΘΉΔ“β÷Μ”–’β÷÷«ιΩωœ¬Θ§ ΐΉιΟϊ≤≈Ω…“‘Β±Ήω÷Η’κΘ§ΒΪ≤Μ–“ΒΡ «’β÷÷«ιΩωœ¬»ί“Ή“ΐΖΔΖγœ’ΓΘ‘ΎClearRAMΚ· ΐΡΎΘ§ΉςΈΣ–Έ≤ΈΒΡarray[]≤Μ‘Ό « ΐΉιΟϊΝΥΘ§Εχ≥…ΝΥ÷Η’κΓΘsizeof(array)œύΒ±”Ύ«σ÷Η’κ±δΝΩ’Φ”ΟΒΡΉ÷ΫΎ ΐΘ§‘Ύ32ΈΜœΒΆ≥œ¬Θ§ΗΟ÷ΒΈΣ4Θ§sizeof(array)/sizeof(array[0])ΒΡ‘ΥΥψΫαΙϊ“≤ΈΣ4ΓΘΥυ“‘‘ΎmainΚ· ΐ÷–Βς”ΟClearRAM(Fle)Θ§“≤÷ΜΡή«ε≥ΐ ΐΉιFle÷–ΒΡ«ΑΥΡΗω‘ΣΥΊΝΥΓΘ
‘ωΝΩ‘ΥΥψΖϊ++ΚΆΦθΝΩ‘ΥΥψΖϊ--Φ»Ω…“‘Ήω«ΑΉΚ“≤Ω…“‘ΉωΚσΉΚΓΘ«ΑΉΚΚΆΚσΉΚΒΡ«χ±π‘Ύ”Ύ÷ΒΒΡ‘ωΦ”ΜρΦθ…Ό’β“ΜΕ·ΉςΖΔ…ζΒΡ ±Φδ «≤ΜΆ§ΒΡΓΘΉςΈΣ«ΑΉΚ «œ»Ή‘Φ”ΜρΉ‘Φθ»ΜΚσΉω±πΒΡ‘ΥΥψΘ§ΉςΈΣΚσΉΚ ±Θ§ «œ»Ήω‘ΥΥψΘ§÷°Κσ‘ΌΉ‘Φ”ΜρΉ‘ΦθΓΘ–μΕύ≥Χ–ρ‘±Ε‘¥Υ»œ Ε≤ΜΙΜΘ§ΨΆ»ί“Ή¬ώœ¬“ΰΜΦΓΘœ¬ΟφΒΡάΐΉ”Ω…“‘ΚήΚΟΒΡΫβ Ά«ΑΉΚΚΆΚσΉΚΒΡ«χ±πΓΘ
¥ζ¬κ÷¥––ΚσΘ§yΒΡ÷Β «Εύ…ΌΘΩ
’βΗωάΐΉ”≤ΔΖ« «ΆΎΩ’–ΡΥΦ…ηΦΤ≥ωά¥Ή®Ο≈»ΟΡψΫ ΨΓΡ‘÷≠ΒΡCΡ―ΧβΘ®»γΙϊΡψΨθΒΟΉ‘ΦΚΕ‘CœΗΫΎ’ΤΈ’Κή”––≈–ΡΘ§Ήω“Μ–©CΡ―ΧβΦλ―ι“Μœ¬ «Ηω≤Μ¥μΒΡ―Γ‘ώΓΘΡ«Ο¥Θ§ΓΕThe C Puzzle BookΓΖ’β±Ψ ι“ΜΕ®≤Μ“Σ¥μΙΐΓΘΘ©Θ§Ρψ…θ÷ΝΩ…“‘ΫΪ’βΗωΡ―Ε°ΒΡ”οΨδΉςΈΣ≤Μ”―ΚΟ¥ζ¬κΒΡΖ¥ΟφάΐΉ”ΓΘΒΪ «Υϋ“≤Ω…“‘»ΟΡψΗϋΚΟΒΡάμΫβC”ο―‘ΓΘΗυΨί‘ΥΥψΖϊ”≈œ»ΦΕ“‘ΦΑ±ύ“κΤς Ε±πΉ÷ΖϊΒΡΧΑ–ΡΖ®‘≠‘ρΘ§¥ζ¬κy=a+++--b;Ω…“‘–¥≥…ΗϋΟς»ΖΒΡ–Έ ΫΘΚ
Β±Η≥÷ΒΗχ±δΝΩy ±Θ§aΒΡ÷ΒΈΣ8Θ§bΒΡ÷ΒΈΣ1,Υυ“‘±δΝΩyΒΡ÷ΒΈΣ9ΘΜΗ≥÷ΒΆξ≥…ΚσΘ§±δΝΩaΉ‘Φ”Θ§aΒΡ÷Β±δΈΣ9Θ§«ßΆρ≤Μ“Σ“‘ΈΣyΒΡ÷ΒΈΣ10ΓΘ’βΧθΗ≥÷Β”οΨδœύΒ±”Ύœ¬ΟφΒΡΝΫΧθ”οΨδΘΚ
2.ΆφΨΏΑψΒΡ±ύ“κΤς”ο“εΦλ≤ι
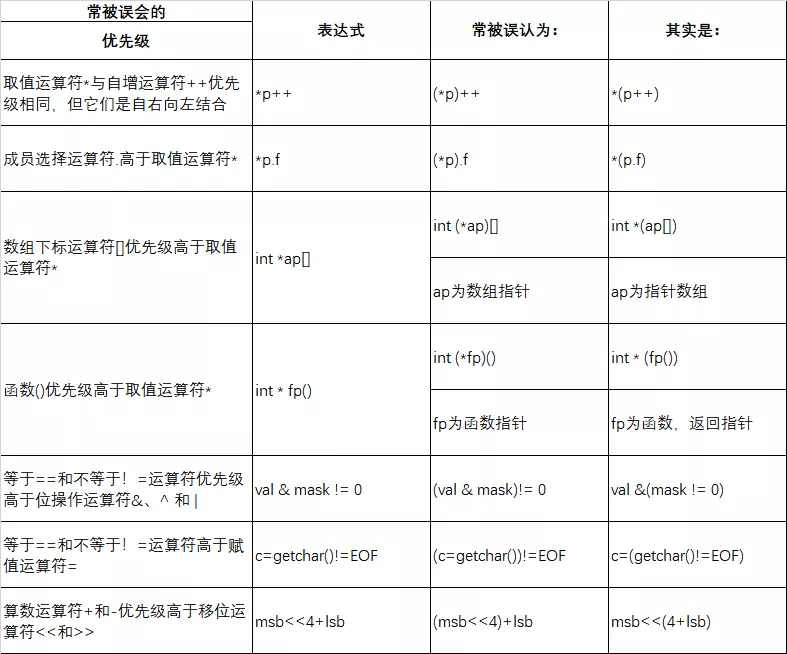
ΈΣΝΥΗϋΦρΒΞΒΡ…ηΦΤ±ύ“κΤςΘ§ΡΩ«ΑΦΗΚθΥυ”–±ύ“κΤςΒΡ”ο“εΦλ≤ιΕΦ±»Ϋœ»θ–ΓΘ§Φ”÷°ΈΣΝΥΜώΒΟΗϋΩλΒΡ÷¥–––߬ Θ§C”ο―‘±Μ…ηΦΤΒΡΉψΙΜΝιΜν«“ΦΗΚθ≤ΜΫχ––»ΈΚΈ‘Υ–– ±Φλ≤ιΘ§±»»γ ΐΉι‘ΫΫγΓΔ÷Η’κ «ΖώΚœΖ®ΓΔ‘ΥΥψΫαΙϊ «Ζώ“γ≥ω»»ΓΘ
C”ο―‘ΉψΙΜΝιΜνΘ§Ε‘”Ύ“ΜΗω ΐΉιa[30]Θ§Υϋ‘ –μ Ι”Οœώa[-1]’β―υΒΡ–Έ Ϋά¥ΩλΥΌΜώ»Γ ΐΉι Ή‘ΣΥΊΥυ‘ΎΒΊ÷Ζ«ΑΟφΒΡ ΐΨίΘΜ‘ –μΫΪ“ΜΗω≥Θ ΐ«Ω÷ΤΉΣΜΜΈΣΚ· ΐ÷Η’κΘ§ Ι”Ο¥ζ¬κ(*((void(*)())0))()ά¥Βς”ΟΈΜ”Ύ0ΒΊ÷ΖΒΡΚ· ΐΓΘC”ο―‘ΗχΝΥ≥Χ–ρ‘±ΉψΙΜΒΡΉ‘”…Θ§ΒΪ“≤”…≥Χ–ρ‘±≥–ΒΘάΡ”ΟΉ‘”…¥χά¥ΒΡ‘π»ΈΓΘœ¬ΟφΒΡΝΫΗωάΐΉ”ΕΦ «Υά―≠ΜΖΘ§»γΙϊ‘Ύ≤Μ≥Θ”ΟΖ÷÷ß÷–≥ωœ÷άύΥΤ¥ζ¬κΘ§ΫΪΜα‘λ≥…Ω¥ΥΤΡΣΟϊΤδΟνΒΡΥάΜζΜρ’Ώ÷ΊΤτΓΘ
a. unsigned char iΘΜ
b. unsigned chari;
for(i=0;i<256;i++) {Γ≠ }
for(i=10;i>=0;i--) { Γ≠ } |
Ε‘”ΎΈόΖϊΚ≈charάύ–ΆΘ§±μ ΨΒΡΖΕΈßΈΣ0~255Θ§Υυ“‘ΈόΖϊΚ≈charάύ–Ά±δΝΩi”ά‘Ε–Γ”Ύ256Θ®ΒΎ“ΜΗωfor―≠ΜΖΈόœό÷¥––Θ©Θ§”ά‘Ε¥σ”ΎΒ»”Ύ0Θ®ΒΎΕΰΗωfor―≠ΜΖΈόœΏ÷¥––Θ©ΓΘ–η“ΣΥΒΟςΒΡ «Θ§Η≥÷Β¥ζ¬κi=256 «±ΜC”ο―‘‘ –μΒΡΘ§Φ¥ Ι’βΗω≥θ÷Β“―Ψ≠≥§≥ωΝΥ±δΝΩiΩ…“‘±μ ΨΒΡΖΕΈßΓΘC”ο―‘Μα«ßΖΫΑΌΦΤΒΡΈΣ≥Χ–ρ‘±¥¥‘λ≥ω¥μΒΡΜζΜαΘ§Ω…Φϊ“ΜΑΏΓΘ
ΦΌ»γΡψ‘Ύif”οΨδΚσΈσΦ”ΝΥ“ΜΗωΖ÷Κ≈ΗΡ±δΝΥ≥Χ–ρ¬ΏΦ≠Θ§±ύ“κΤς“≤ΜαΚή≈δΚœΒΡΑοΟΠ―ΎΗ«Θ§…θ÷ΝΝ§Ψ·ΗφΕΦ≤ΜΧα ΨΓΘ¥ζ¬κ»γœ¬ΘΚ
if(a>b); //’βάοΈσΦ”ΝΥ“ΜΗωΖ÷Κ≈
a=b; //’βΨδ¥ζ¬κ“Μ÷±±Μ÷¥–– |
≤ΜΒΪ»γ¥ΥΘ§±ύ“κΤςΜΙΜαΚω¬‘ΒτΕύ”ύΒΡΩ’ΗώΖϊΚΆΜΜ––ΖϊΘ§ΨΆœώœ¬ΟφΒΡ¥ζ¬κ“≤≤ΜΜαΗχ≥ωΉψΙΜΧα ΨΘΚ
if(n<3)
return //’βάο…ΌΦ”ΝΥ“ΜΗωΖ÷Κ≈
logrec.data=x[0];
logrec.time=x[1];
logrec.code=x[2];
|
’βΕΈ¥ζ¬κΒΡ±Ψ“β «n<3 ±≥Χ–ρ÷±Ϋ”ΖΒΜΊΘ§”…”Ύ≥Χ–ρ‘±ΒΡ ßΈσΘ§return…ΌΝΥ“ΜΗωΫα χΖ÷Κ≈ΓΘ±ύ“κΤςΫΪΥϋΖ≠“κ≥…ΖΒΜΊ±μ¥ο Ϋlogrec.data=x[0]ΒΡΫαΙϊΘ§returnΚσΟφΦ¥ Ι «“ΜΗω±μ¥ο Ϋ“≤ «C”ο―‘‘ –μΒΡΓΘ’β―υΒ±n>=3 ±Θ§±μ¥ο Ϋlogrec.data=x[0];ΨΆ≤ΜΜα±Μ÷¥––Θ§Ηχ≥Χ–ρ¬ώœ¬ΝΥ“ΰΜΦΓΘ
Ω…“‘ΚΝ≤ΜΩΆΤχΒΡΥΒΘ§»θ–ΓΒΡ±ύ“κΤς”ο“εΦλ≤ι‘ΎΚή¥σ≥ΧΕ»…œΉί»ίΝΥ≤ΜΩ…ΩΩ¥ζ¬κΩ…“‘ΥΝΈόΦ…Β§ΒΡ¥φ‘ΎΓΘ
…œΈΡ‘χΧαΒΫ ΐΉι≥Θ≥Θ «“ΐΤπ≥Χ–ρ≤ΜΈ»Ε®ΒΡ÷Ί“Σ“ρΥΊΘ§≥Χ–ρ‘±ΆυΆυ≤ΜΨ≠“βΦδΨΆΜα–¥ ΐΉι‘ΫΫγΓΘ“ΜΈΜΆ§ ¬ΒΡ¥ζ¬κ‘Ύ”≤Φΰ…œ‘Υ––Θ§“ΜΕΈ ±ΦδΚσΨΆΜαΖΔœ÷LCDœ‘ ΨΤΝ…œΒΡ“ΜΗω ΐΉ÷≤Μ’ΐ≥ΘΒΡ±ΜΗΡ±δΓΘΨ≠Ιΐ“ΜΕΈ ±ΦδΒΡΒς ‘Θ§Έ Χβ±ΜΕ®ΈΜΒΫœ¬ΟφΒΡ“ΜΕΈ¥ζ¬κ÷–ΘΚ
int SensorData[30];
Γ≠for(i=30;i>0;i--)
{
SensorData[i]=Γ≠;
Γ≠
}
|
’βάο…υΟςΝΥ”Β”–30Ηω‘ΣΥΊΒΡ ΐΉιΘ§≤Μ–“ΒΡ «for―≠ΜΖ¥ζ¬κ÷–Έσ”ΟΝΥ±Ψ≤Μ¥φ‘ΎΒΡ ΐΉι‘ΣΥΊSensorData[30]Θ§ΒΪC”ο―‘»¥Ρ§–μ’βΟ¥ Ι”ΟΘ§≤Δ–ά»ΜΒΡΑ¥’’¥ζ¬κΗΡ±δΝΥ ΐΉι‘ΣΥΊSensorData[30]Υυ‘ΎΈΜ÷ΟΒΡ÷ΒΘ§ SensorData[30]Υυ‘ΎΒΡΈΜ÷Ο‘≠±Ψ «“ΜΗωLCDœ‘ Ψ±δΝΩΘ§’β’ΐ «œ‘ ΨΤΝ…œΒΡΡ«Ηω÷Β≤Μ’ΐ≥Θ±ΜΗΡ±δΒΡ‘≠“ρΓΘ’φ«λ–“’βΟ¥«αΕχ“ΉΨΌΒΡΖΔœ÷ΝΥ’βΗωBugΓΘ
Τδ ΒΚήΕύ±ύ“κΤςΜαΕ‘…œ ω¥ζ¬κ≤ζ…ζ“ΜΗωΨ·ΗφΘΚΗ≥÷Β≥§≥ω ΐΉιΫγœόΓΘΒΪ≤ΔΖ«Υυ”–≥Χ–ρ‘±ΕΦΕ‘±ύ“κΤςΨ·Ηφ±Θ≥÷ΉψΙΜΟτΗ–Θ§Ωω«“Θ§±ύ“κΤς“≤≤Δ≤ΜΡήΦλ≤ι≥ω ΐΉι‘ΫΫγΒΡΥυ”–«ιΩωΓΘΨΌ“ΜΗωάΐΉ”Θ§Ρψ‘ΎΡΘΩιA÷–Ε®“ε ΐΉιΘΚ
‘ΎΡΘΩιB÷–“ΐ”ΟΗΟ ΐΉιΘ§ΒΪ”…”ΎΡψ“ΐ”Ο¥ζ¬κ≤Δ≤ΜΙφΖΕΘ§’βάοΟΜ”–œ‘ Ψ…υΟς ΐΉι¥σ–ΓΘ§ΒΪ±ύ“κΤς“≤‘ –μ’βΟ¥ΉωΘΚ
»γΙϊ‘ΎΡΘΩιB÷–¥φ‘ΎΚΆ…œΟφ“Μ―υΒΡ¥ζ¬κΘΚ
| for(i=30;i>0;i--){ SensorData[i]=Γ≠; Γ≠} |
’β¥ΈΘ§±ύ“κΤς≤ΜΜαΗχ≥ωΨ·Ηφ–≈œΔΘ§“ρΈΣ±ύ“κΤς―ΙΗυΨΆ≤Μ÷ΣΒά ΐΉιΒΡ‘ΣΥΊΗω ΐΓΘΥυ“‘Θ§Β±“ΜΗω ΐΉι…υΟςΈΣΨΏ”–Άβ≤ΩΝ¥Ϋ”Θ§ΥϋΒΡ¥σ–Γ”ΠΗΟœ‘ Ϋ…υΟςΓΘ
‘ΌΨΌ“ΜΗω±ύ“κΤςΦλ≤ι≤Μ≥ω ΐΉι‘ΫΫγΒΡάΐΉ”ΓΘΚ· ΐfunc()ΒΡ–Έ≤Έ «“ΜΗω ΐΉι–Έ ΫΘ§Κ· ΐ¥ζ¬κΦρΜ·»γœ¬Υυ ΨΘΚ
char * func(char SensorData[30]){
unsignedint iΘΜ
for(i=30;i>0;i--)
{
SensorData[i]=Γ≠;
Γ≠ }}
|
’βΗωΗχSensorData[30]Η≥≥θ÷ΒΒΡ”οΨδΘ§±ύ“κΤς“≤ «≤ΜΗχ»ΈΚΈΨ·ΗφΒΡΓΘ ΒΦ …œΘ§±ύ“κΤς «ΫΪ ΐΉιΟϊSensor“ΰΚ§ΒΡΉΣΜ·ΈΣ÷Ηœρ ΐΉιΒΎ“ΜΗω‘ΣΥΊΒΡ÷Η’κΘ§Κ· ΐΧε « Ι”Ο÷Η’κΒΡ–Έ Ϋά¥ΖΟΈ ΐΉιΒΡΘ§ΥϋΒ±»Μ“≤≤ΜΜα÷ΣΒά ΐΉι‘ΣΥΊΒΡΗω ΐΝΥΓΘ‘λ≥…’β÷÷Ψ÷ΟφΒΡ‘≠“ρ÷°“Μ «C±ύ“κΤςΒΡΉς’ΏΟ«»œΈΣ÷Η’κ¥ζΧφ ΐΉιΩ…“‘ΧαΗΏ≥Χ–ρ–߬ Θ§Εχ«“Θ§ΜΙΩ…“‘ΦρΜ·±ύ“κΤςΒΡΗ¥‘”Ε»ΓΘ
÷Η’κΚΆ ΐΉι «»ί“ΉΗχ≥Χ–ρ‘λ≥…Μ묓ΒΡΘ§Έ“Ο«”–±Ί“ΣΉ–œΗΒΡ«χΖ÷ΥϋΟ«ΒΡ≤ΜΆ§ΓΘΤδ ΒΜΜ“ΜΗωΫ«Ε»œκœκΘ§ΥϋΟ«“≤ «»ί“Ή«χΖ÷ΒΡΘΚΩ…“‘ΫΪ ΐΉιΟϊΒ»Ά§”Ύ÷Η’κΒΡ«ιΩω”–«“÷Μ”–“Μ¥ΠΘ§ΨΆ «…œΟφάΐΉ”ΧαΒΫΒΡ ΐΉιΉςΈΣΚ· ΐ–Έ≤Έ ±ΓΘΤδΥϋ ±ΚρΘ§ ΐΉιΟϊ « ΐΉιΟϊΘ§÷Η’κ «÷Η’κΓΘ
œ¬ΟφΒΡάΐΉ”±ύ“κΤςΆ§―υΦλ≤ι≤Μ≥ω ΐΉι‘ΫΫγΓΘ
Έ“Ο«≥Θ≥Θ”Ο ΐΉιά¥ΜΚ¥φΆ®―Ε÷–ΒΡ“Μ÷Γ ΐΨίΓΘ‘ΎΆ®―Ε÷–Εœ÷–ΫΪΫ” ’ΒΡ ΐΨί±Θ¥φΒΫ ΐΉι÷–Θ§÷±ΒΫ“Μ÷Γ ΐΨίΆξ»ΪΫ” ’Κσ‘ΌΫχ––¥ΠάμΓΘΦ¥ ΙΕ®“εΒΡ ΐΉι≥ΛΕ»ΉψΙΜ≥ΛΘ§Ϋ” ’ ΐΨίΒΡΙΐ≥Χ÷–“≤Ω…ΡήΖΔ…ζ ΐΉι‘ΫΫγΘ§ΧΊ±π «Η…»≈―œ÷Ί ±ΓΘ’β «”…”ΎΆβΫγΒΡΗ…»≈ΤΤΜΒΝΥ ΐΨί÷ΓΒΡΡ≥–©ΈΜΘ§Ε‘“Μ÷ΓΒΡ ΐΨί≥ΛΕ»≈–Εœ¥μΈσΘ§Ϋ” ’ΒΡ ΐΨί≥§≥ω ΐΉιΖΕΈßΘ§Εύ”ύΒΡ ΐΨίΗΡ–¥”κ ΐΉιœύΝΎΒΡ±δΝΩΘ§‘λ≥…œΒΆ≥±άάΘΓΘ”…”Ύ÷–Εœ ¬ΦΰΒΡ“λ≤Ϋ–‘Θ§’βάύ ΐΉι‘ΫΫγ±ύ“κΤςΈόΖ®Φλ≤ιΒΫΓΘ
»γΙϊΨ÷≤Ω ΐΉι‘ΫΫγΘ§Ω…Ρή“ΐΖΔARMΦήΙΙ”≤Φΰ“λ≥ΘΓΘΆ§ ¬ΒΡ“ΜΗω…η±Η”Ο”ΎΫ” ’ΈόœΏ¥ΪΗ–ΤςΒΡ ΐΨίΘ§“Μ¥Έ»μΦΰ…ΐΦΕΚσΘ§ΖΔœ÷Ϋ” ’…η±ΗΙΛΉς“ΜΕΈ ±ΦδΚσΜαΥάΜζΓΘΒς ‘±μΟςARM7¥ΠάμΤςΖΔ…ζΝΥ”≤Φΰ“λ≥ΘΘ§“λ≥Θ¥Πάμ¥ζ¬κ «“ΜΕΈΥά―≠ΜΖΘ®ΥάΜζΒΡ÷±Ϋ”‘≠“ρΘ©ΓΘΫ” ’…η±Η”–“ΜΗω”≤ΦΰΡΘΩι”Ο”ΎΫ” ’ΈόœΏ¥ΪΗ–ΤςΒΡ’ϊΑϋ ΐΨί≤Δ¥φ‘ΎΉ‘ΦΚΒΡ”≤ΦΰΜΚ≥ε«χ÷–Θ§Β±“Μ÷Γ ΐΨίΫ” ’Άξ≥…ΚσΘ§ Ι”ΟΆβ≤Ω÷–ΕœΆ®÷Σ…η±Η»Γ ΐΨίΘ§Άβ≤Ω÷–ΕœΖΰΈώ≥Χ–ρΨΪΦρΚσ»γœ¬Υυ ΨΘΚ
__irq ExintHandler(void)
{
unsignedchar DataBuf[50];
GetData(DataBug); //¥””≤ΦΰΜΚ≥ε«χ»Γ“Μ÷Γ ΐΨί
Γ≠
} |
”…”Ύ¥φ‘ΎΕύΗωΈόœΏ¥ΪΗ–ΤςΫϋΚθΆ§ ±ΖΔΥΆ ΐΨίΒΡΩ…ΡήΦ”÷°GetData()Κ· ΐ±ΘΜΛΝΠΕ»≤ΜΙΜΘ§ ΐΉιDataBuf‘Ύ»Γ ΐΨίΙΐ≥Χ÷–ΖΔ…ζ‘ΫΫγΓΘ”…”Ύ ΐΉιDataBufΈΣΨ÷≤Ω±δΝΩΘ§±ΜΖ÷≈δ‘ΎΕ―’Μ÷–Θ§Ά§‘Ύ¥ΥΕ―’Μ÷–ΒΡΜΙ”–÷–ΕœΖΔ…ζ ±ΒΡ‘Υ––ΜΖΨ≥“‘ΦΑ÷–ΕœΖΒΜΊΒΊ÷ΖΓΘ“γ≥ωΒΡ ΐΨίΫΪ’β–© ΐΨίΤΤΜΒΒτΘ§÷–ΕœΖΒΜΊ ±PC÷Η’κΩ…Ρή±δ≥…“ΜΗω≤ΜΚœΖ®÷ΒΘ§”≤Φΰ“λ≥Θ”…¥Υ≤ζ…ζΓΘ
»γΙϊΈ“Ο«ΨΪ–Ρ…ηΦΤ“γ≥ω≤ΩΖ÷ΒΡ ΐΨίΘ§Μ· ΐΨίΈΣ÷ΗΝνΘ§ΨΆΩ…“‘άϊ”Ο ΐΉι‘ΫΫγά¥–όΗΡPC÷Η’κΒΡ÷ΒΘ§ Ι÷°÷ΗœρΈ“Ο«œΘΆϊ÷¥––ΒΡ¥ζ¬κΓΘ1988ΡξΘ§ΒΎ“ΜΗωΆχ¬γ»δ≥φ‘Ύ“ΜΧλ÷°ΡΎΗ–»ΨΝΥ2000ΒΫ6000Χ®ΦΤΥψΜζΘ§’βΗω»δ≥φ≥Χ–ράϊ”ΟΒΡ’ΐ «“ΜΗω±ξΉΦ δ»κΩβΚ· ΐΒΡ ΐΉι‘ΫΫγBugΓΘΤπ“ρ «“ΜΗω±ξΉΦ δ»κ δ≥ωΩβΚ· ΐgets()Θ§‘≠ά¥…ηΦΤΈΣ¥” ΐΨίΝς÷–Μώ»Γ“ΜΕΈΈΡ±ΨΘ§“≈ΚΕΒΡ «Θ§gets()Κ· ΐΟΜ”–ΙφΕ® δ»κΈΡ±ΨΒΡ≥ΛΕ»ΓΘgets()Κ· ΐΡΎ≤ΩΕ®“εΝΥ“ΜΗω500Ή÷ΫΎΒΡ ΐΉιΘ§ΙΞΜς’ΏΖΔΥΆΝΥ¥σ”Ύ500Ή÷ΫΎΒΡ ΐΨίΘ§άϊ”Ο“γ≥ωΒΡ ΐΨί–όΗΡΝΥΕ―’Μ÷–ΒΡPC÷Η’κΘ§¥”ΕχΜώ»ΓΝΥœΒΆ≥»®œόΓΘ
“ΜΗω≥Χ–ρΡΘΩιΆ®≥Θ”…ΝΫΗωΈΡΦΰΉι≥…Θ§‘¥ΈΡΦΰΚΆΆΖΈΡΦΰΓΘ»γΙϊΡψ‘Ύ‘¥ΈΡΦΰΕ®“ε±δΝΩΘΚ
≤Δ‘ΎΆΖΈΡΦΰ÷–…υΟςΗΟ±δΝΩΘΚextern unsigned longa;
±ύ“κΤςΜαΧα Ψ“ΜΗω”οΖ®¥μΈσΘΚ±δΝΩΓ·aΓ·…υΟςάύ–Ά≤Μ“Μ÷¬ΓΘΒΪ»γΙϊΡψ‘Ύ‘¥ΈΡΦΰΕ®“ε±δΝΩΘΚ
| volatile unsigned int aȧ |
‘ΎΆΖΈΡΦΰ÷–…υΟς±δΝΩΘΚextern unsigned inta;/*»±…ΌvolatileœόΕ®Ζϊ*/
±ύ“κΤς»¥≤ΜΜαΗχ≥ω¥μΈσ–≈œΔΘ®”––©±ύ“κΤςΫωΗχ≥ω“ΜΧθΨ·ΗφΘ©ΓΘ’βάοvolatile τ”Ύάύ–ΆœόΕ®ΖϊΘ§Νμ“ΜΗω≥ΘΦϊΒΡάύ–ΆœόΕ®Ζϊ «constΙΊΦϋΉ÷ΓΘœόΕ®Ζϊvolatile‘Ύ«Ε»κ Ϋ»μΦΰ÷–÷ΝΙΊ÷Ί“ΣΘ§”Οά¥ΗφΥΏ±ύ“κΤς≤Μ“Σ”≈Μ·Υϋ–ό ΈΒΡ±δΝΩΓΘ’βάοΨΌ“ΜΗωΩΧ“βΙΙ‘λ≥ωΒΡάΐΉ”Θ§“ρΈΣœ÷ Β÷–ΒΡvolatile Ι”ΟBug¥σΕΦ“ΰΚ§«“Ρ―“‘άμΫβΓΘ
‘ΎΡΘΩιAΒΡ‘¥ΈΡΦΰ÷–Θ§Ε®“ε±δΝΩΘΚ
| volatile unsigned int TimerCount=0; |
ΗΟ±δΝΩ”Οά¥‘Ύ“ΜΗωΕ® ±ΤςΖΰΈώ≥Χ–ρ÷–Ϋχ––»μΦΰΦΤ ±ΘΚ
| TimerCount++; //ΕΝ»ΓIOΕΥΩΎ1ΒΡ÷Β |
‘ΎΡΘΩιAΒΡΆΖΈΡΦΰ÷–Θ§…υΟς±δΝΩΘΚ
| extern unsigned int TimerCount; //’βά﬩ΒτΝΥάύ–ΆœόΕ®Ζϊvolatile |
‘ΎΡΘΩιB÷–Θ§“Σ Ι”ΟTimerCount±δΝΩΫχ––ΨΪ»ΖΒΡ»μΦΰ―” ±ΘΚ
#include ΓΑ...A.hΓ± // Ήœ»ΑϋΚ§ΡΘΩιAΒΡΆΖΈΡΦΰ
Γ≠
TimerCount=0;
while(TimerCount>=TIMER_VALUE); //―” ±“ΜΕΈ ±Φδ
Γ≠
|
ΒΦ …œΘ§’β «“ΜΗωΥά―≠ΜΖΓΘ”…”ΎΡΘΩιAΆΖΈΡΦΰ÷–…υΟς±δΝΩTimerCount ±¬©ΒτΝΥvolatileœόΕ®ΖϊΘ§‘ΎΡΘΩιB÷–Θ§±δΝΩTimerCount «±ΜΒ±Ήςunsigned intάύ–Ά±δΝΩΓΘ”…”ΎΦΡ¥φΤςΥΌΕ»‘ΕΩλ”ΎRAMΘ§±ύ“κΤς‘Ύ Ι”ΟΖ«volatileœόΕ®±δΝΩ ± «œ»ΫΪ±δΝΩ¥”RAM÷–ΩΫ±¥ΒΫΦΡ¥φΤς÷–Θ§»γΙϊΆ§“ΜΗω¥ζ¬κΩι‘Ό¥Έ”ΟΒΫΗΟ±δΝΩΘ§ΨΆ≤Μ‘Ό¥”RAM÷–ΩΫ±¥ ΐΨίΕχ «÷±Ϋ” Ι”Ο÷°«ΑΦΡ¥φΤς±ΗΖί÷ΒΓΘ¥ζ¬κwhile(TimerCount>=TIMER_VALUE)÷–Θ§±δΝΩTimerCountΫωΒΎ“Μ¥Έ÷¥–– ±±Μ Ι”ΟΘ§÷°ΚσΕΦ « Ι”ΟΒΡΦΡ¥φΤς±ΗΖί÷ΒΘ§Εχ’βΗωΦΡ¥φΤς÷Β“Μ÷±ΈΣ0Θ§Υυ“‘≥Χ–ρΈόœό―≠ΜΖΓΘœ¬ΟφΒΡΝς≥ΧΆΦΥΒΟςΝΥ≥Χ–ρ Ι”ΟœόΕ®ΖϊvolatileΚΆ≤Μ Ι”ΟvolatileΒΡ÷¥––Ιΐ≥ΧΓΘ
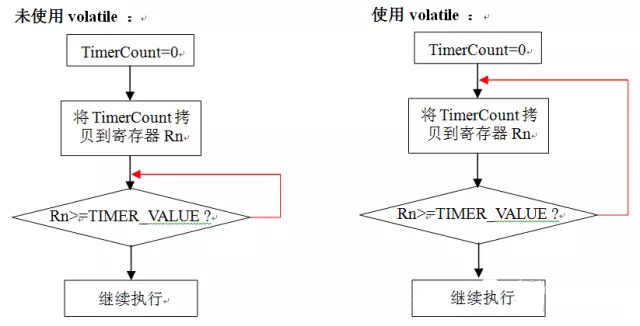
ARMΦήΙΙœ¬ΒΡ±ύ“κΤςΜαΤΒΖ±ΒΡ Ι”ΟΕ―’ΜΘ§Ε―’Μ”Ο”Ύ¥φ¥ΔΚ· ΐΒΡΖΒΜΊ÷ΒΓΔAAPCSΙφΕ®ΒΡ±Ί–κ±ΘΜΛΒΡΦΡ¥φΤς“‘ΦΑΨ÷≤Ω±δΝΩΘ§Αϋά®Ψ÷≤Ω ΐΉιΓΔΫαΙΙΧεΓΔΝΣΚœΧεΚΆC++ΒΡάύΓΘ¥”Ε―’Μ÷–Ζ÷≈δΒΡΨ÷≤Ω±δΝΩΒΡ≥θ÷Β «≤Μ»ΖΕ®ΒΡΘ§“ρ¥Υ–η“Σ‘Υ–– ±œ‘ Ϋ≥θ ΦΜ·ΗΟ±δΝΩΓΘ“ΜΒ©άκΩΣΨ÷≤Ω±δΝΩΒΡΉς”Ο”ρΘ§’βΗω±δΝΩΝΔΦ¥±Μ ΆΖ≈Θ§ΤδΥϋ¥ζ¬κ“≤ΨΆΩ…“‘ Ι”ΟΥϋΘ§“ρ¥ΥΕ―’Μ÷–ΒΡ“ΜΗωΡΎ¥φΈΜ÷ΟΩ…ΡήΕ‘”Π’ϊΗω≥Χ–ρΒΡΕύΗω±δΝΩΓΘ
Ψ÷≤Ω±δΝΩ±Ί–κœ‘ Ϋ≥θ ΦΜ·Θ§≥ΐΖ«Ρψ»ΖΕ®÷ΣΒάΡψ“ΣΉω ≤Ο¥ΓΘœ¬ΟφΒΡ¥ζ¬κΒΟΒΫΒΡΈ¬Ε»÷ΒΗζ‘ΛΤΎΜα”–Κή¥σ≤ν±πΘ§“ρΈΣ‘Ύ Ι”ΟΨ÷≤Ω±δΝΩsum ±Θ§≤Δ≤ΜΡή±Θ÷ΛΥϋΒΡ≥θ÷ΒΈΣ0ΓΘ±ύ“κΤςΜα‘ΎΒΎ“Μ¥Έ‘Υ–– ±«εΝψΕ―’Μ«χ”ρΘ§’βΦ”÷ΊΝΥ¥ΥάύBugΒΡ“ΰ±Έ–‘ΓΘ
unsigned intGetTempValue(void)
{
unsigned int sum; //Ε®“εΨ÷≤Ω±δΝΩΘ§±Θ¥φΉή÷Β
for(i=0;i<10;i++)
{
sum+=CollectTemp();
//Κ· ΐCollectTempΩ…“‘ΒΟΒΫΒ±«ΑΒΡΈ¬Ε»÷Β
}
return (sum/10);
} |
”…”Ύ“ΜΒ©≥Χ–ράκΩΣΨ÷≤Ω±δΝΩΒΡΉς”Ο”ρΦ¥±Μ ΆΖ≈Θ§Υυ“‘œ¬Οφ¥ζ¬κΖΒΜΊ÷ΗœρΨ÷≤Ω±δΝΩΒΡ÷Η’κ «ΟΜ”– ΒΦ “β“εΒΡΘ§ΗΟ÷Η’κ÷ΗœρΒΡ«χ”ρΩ…ΡήΜα±ΜΤδΥϋ≥Χ–ρ Ι”ΟΘ§Τδ÷ΒΜα±ΜΗΡ±δΓΘ
char * GetData(void)
{
char buffer[100]; //Ψ÷≤Ω ΐΉι
Γ≠
return buffer;
}
|
»Ο»Υ–άΈΩΒΡ «Θ§œ÷‘Ύ‘Ϋά¥‘ΫΕύΒΡ±ύ“κΤς“β ΕΒΫΝΥ”ο“εΦλ≤ιΒΡ÷Ί“Σ–‘Θ§±ύ“κΤςΒΡ”ο“εΦλ≤ι“≤‘Ϋά¥‘Ϋ«Ω¥σΘ§±»»γ÷χΟϊΒΡKeil MDK±ύ“κΤς‘ΎΤδ V4.47Μρ“‘…œΑφ±Ψ÷–‘ωΦ”ΝΥΕ·Χ§”οΖ®Φλ≤ι≤ΔΦ”«ΩΝΥ”ο“εΦλ≤ιΘ§Ω…“‘”―ΚΟΒΡΧα ΨΗϋΕύΨ·Ηφ–≈œΔΓΘ
3.≤ΜΚœάμΒΡ”≈œ»ΦΕ
C”ο―‘”–32ΗωΙΊΦϋΉ÷Θ§»¥”–34Ηω‘ΥΥψΖϊΓΘ“ΣΦ«ΉΓΥυ”–‘ΥΥψΖϊΒΡ”≈œ»ΦΕ «άßΡ―ΒΡΓΘ≤ΜΚœάμΒΡ#defineΜαΦ”÷Ί”≈œ»ΦΕΈ ΧβΘ§»ΟΈ Χβ±δΒΟΗϋΦ”“ΰ±ΈΓΘ
±ύ“κΤς‘Ύ±ύ“κΚσΫΪΚξ¥χ»κ,‘≠if”οΨδ±δΈΣ:
#define READSDA IO0PIN&(1<<11)
//Ε®“εΚξΘ§ΕΝIOΩΎp0.11ΒΡΕΥΩΎΉ¥Χ§
//≈–ΕœΕΥΩΎp0.11 «ΖώΈΣΗΏΒγΤΫ
if(READSDA==(1<<11))
{
Γ≠
} |
‘ΥΥψΖϊ'=='ΒΡ”≈œ»ΦΕ «¥σ”Ύ'&'ΒΡΘ§¥ζ¬κIO0PIN&(1<<11)==(1<<11))Β»–ßΈΣIO0PIN&0x00000001ΘΚ≈–ΕœΕΥΩΎP0.0 «ΖώΈΣΗΏΒγΤΫΘ§’β”κ‘≠“βœύ≤ν…θ‘ΕΓΘ
ΈΣΝΥ÷Τ‘λΗϋΕύΒΡ»μΦΰBugΘ§C”ο―‘ΒΡ‘ΥΥψΖϊΒ±»Μ≤ΜΜα÷Μ÷Ι≤Ϋ”Ύ ΐΡΩΖ±ΕύΓΘ‘Ύ¥ΥΜυ¥Γ…œΘ§Α¥’’≥ΘΙφΖΫ Ϋ Ι”Ο ±Θ§Ω…Ρή“ΐΤπΈσΜαΒΡ‘ΥΥψΖϊΗϋ «±»±»Ϋ‘ «ΘΓ»γœ¬±μΥυ ΨΘΚ
4.“ΰ ΫΉΣΜΜΚΆ«Ω÷ΤΉΣΜΜ
’β”÷ «C”ο―‘ΒΡ“Μ¥σΙν“λ÷°¥ΠΘ§Υϋ‘λ≥…ΒΡΈΘΚΠ≥ΧΕ»”κ ΐΉιΚΆ÷Η’κ”–ΒΡ“ΜΤ¥ΓΘ”οΨδΜρ±μ¥ο ΫΆ®≥Θ”ΠΗΟ÷Μ Ι”Ο“Μ÷÷άύ–ΆΒΡ±δΝΩΚΆ≥ΘΝΩΓΘ»ΜΕχΘ§»γΙϊΡψΜλΚœ Ι”Οάύ–ΆΘ§C Ι”Ο“ΜΗωΙφ‘ρΦ·Κœά¥Ή‘Ε·Άξ≥…άύ–ΆΉΣΜΜΓΘ’βΩ…ΡήΚήΖΫ±ψΘ§ΒΪ“≤ΚήΈΘœ’ΓΘ
a.Β±≥ωœ÷‘Ύ±μ¥ο Ϋάο ±Θ§”–ΖϊΚ≈ΚΆΈόΖϊΚ≈ΒΡcharΚΆshortάύ–ΆΕΦΫΪΉ‘Ε·±ΜΉΣΜΜΈΣintάύ–ΆΘ§‘Ύ–η“ΣΒΡ«ιΩωœ¬Θ§ΫΪΉ‘Ε·±ΜΉΣΜΜΈΣunsigned intΘ®‘ΎshortΚΆintΨΏ”–œύΆ§¥σ–Γ ±Θ©ΓΘ’β≥ΤΈΣάύ–ΆΧα…ΐΓΘΧα…ΐ‘ΎΥψ ΐ‘ΥΥψ÷–Ά®≥Θ≤ΜΜα”– ≤Ο¥¥σΒΡΜΒ¥ΠΘ§ΒΪ»γΙϊΈΜ‘ΥΥψΖϊ ~ ΚΆ << ”Π”Ο‘ΎΜυ±Ψάύ–ΆΈΣunsigned charΜρunsigned short ΒΡ≤ΌΉς ΐΘ§ΫαΙϊ”ΠΗΟΝΔΦ¥«Ω÷ΤΉΣΜΜΈΣunsigned charΜρ’Ώunsigned shortάύ–ΆΘ®»ΓΨω”Ύ≤ΌΉς ± Ι”ΟΒΡάύ–ΆΘ©ΓΘ
uint8_t port =0x5aU;
uint8_t result_8;
result_8= (~port) >> 4; |
ΦΌ»γΈ“Ο«≤ΜΝΥΫβ±μ¥ο ΫάοΒΡάύ–ΆΧα…ΐΘ§»œΈΣ‘Ύ‘ΥΥψΙΐ≥Χ÷–±δΝΩport“Μ÷± «unsigned charάύ–ΆΒΡΓΘΈ“Ο«ά¥Ω¥“Μœ¬‘ΥΥψΙΐ≥ΧΘΚ~portΫαΙϊΈΣ0xa5Θ§0xa5>>4ΫαΙϊΈΣ0x0aΘ§’β «Έ“Ο«ΤΎΆϊΒΡ÷ΒΓΘΒΪ ΒΦ …œΘ§result_8ΒΡΫαΙϊ»¥ «0xfaΘΓ‘ΎARMΫαΙΙœ¬Θ§intάύ–ΆΈΣ32ΈΜΓΘ±δΝΩport‘Ύ‘ΥΥψ«Α±ΜΧα…ΐΈΣintάύ–ΆΘΚ~portΫαΙϊΈΣ0xffffffa5Θ§0xa5>>4ΫαΙϊΈΣ0x0ffffffaΘ§Η≥÷ΒΗχ±δΝΩresult_8Θ§ΖΔ…ζάύ–ΆΫΊΕœΘ®’β“≤ «“ΰ ΫΒΡΘΓΘ©Θ§result_8=0xfaΓΘΨ≠Ιΐ’βΟ¥Ιν“λΒΡ“ΰ ΫΉΣΜΜΘ§ΫαΙϊΗζΈ“Ο«ΤΎΆϊΒΡ÷ΒΘ§“―Ψ≠¥σœύΨΕΆΞΘΓ’ΐ»ΖΒΡ±μ¥ο Ϋ”οΨδ”ΠΗΟΈΣΘΚ
| result_8=(unsigned char) (~port) >> 4; /*«Ω÷ΤΉΣΜΜ*/ |
b.‘ΎΑϋΚ§ΝΫ÷÷ ΐΨίάύ–ΆΒΡ»ΈΚΈ‘ΥΥψάοΘ§ΝΫΗω÷ΒΕΦΜα±ΜΉΣΜΜ≥…ΝΫ÷÷άύ–ΆάοΫœΗΏΒΡΦΕ±πΓΘάύ–ΆΦΕ±π¥”ΗΏΒΫΒΆΒΡΥ≥–ρ «long doubleΓΔdoubleΓΔfloatΓΔunsigned long longΓΔlong longΓΔunsigned longΓΔlongΓΔunsigned intΓΔintΓΘ’β÷÷άύ–ΆΧα…ΐΆ®≥ΘΕΦ «ΦΰΚΟ ¬Θ§ΒΪΆυΆυ”–ΚήΕύ≥Χ–ρ‘±≤ΜΡή’φ’ΐάμΫβ’βΨδΜΑΘ§¥”ΕχΉω“Μ–©œκΒ±»ΜΒΡ ¬«ιΘ§±»»γœ¬ΟφΒΡάΐΉ”Θ§intάύ–Ά±μ Ψ16ΈΜΓΘ
uint16_t u16a = 40000; /* 16ΈΜΈόΖϊΚ≈±δΝΩ*/
uint16_t u16b= 30000; /*16ΈΜΈόΖϊΚ≈±δΝΩ*/
uint32_t u32x; /*32ΈΜΈόΖϊΚ≈±δΝΩ */
uint32_t u32y;
u32x = u16a +u16b;
/* u32x = 70000ΜΙ «4464 ? */
u32y =(uint32_t)(u16a + u16b);
/* u32y = 70000 ΜΙ «4464 ? */
|
u32xΚΆu32yΒΡΫαΙϊΕΦ «4464Θ®70000%65536Θ©ΘΓ≤Μ“Σ»œΈΣ±μ¥ο Ϋ÷–”–“ΜΗωΗΏάύ±πuint32_tάύ–Ά±δΝΩΘ§±ύ“κΤςΕΦΜαΑοΡψΑ―Υυ”–ΤδΥϊΒΆάύ±πΕΦΧα…ΐΒΫuint32_tάύ–ΆΓΘ’ΐ»ΖΒΡ ι–¥ΖΫ ΫΘΚ
u32x = (uint32_t)u16a +(uint32_t)u16b;
Μρ’ΏΘΚ
u32x = (uint32_t)u16a + u16b; |
Κσ“Μ÷÷–¥Ζ®‘Ύ±Ψ±μ¥ο Ϋ÷– «’ΐ»ΖΒΡΘ§ΒΪ «‘ΎΤδΥϋ±μ¥ο Ϋ÷–≤Μ“ΜΕ®’ΐ»ΖΘ§±»»γΘΚ
uint16_t u16a,u16b,u16c;
uint32_t u32x;
u32x= u16a + u16b + (uint32_t)u16c;/*¥μΈσ–¥Ζ®Θ§u16a+ u16b»‘Ω…Ρή“γ≥ω*/ |
c.‘ΎΗ≥÷Β”οΨδάοΘ§ΦΤΥψΒΡΉνΚσΫαΙϊ±ΜΉΣΜΜ≥…ΫΪ“Σ±ΜΗ≥”η÷ΒΒΟΡ«Ηω±δΝΩΒΡάύ–ΆΓΘ’β“ΜΙΐ≥ΧΩ…ΡήΒΦ÷¬άύ–ΆΧα…ΐ“≤Ω…ΡήΒΦ÷¬άύ–ΆΫΒΦΕΓΘΫΒΦΕΩ…ΡήΜαΒΦ÷¬Έ ΧβΓΘ±»»γΫΪ‘ΥΥψΫαΙϊΈΣ321ΒΡ÷ΒΗ≥÷ΒΗχ8ΈΜcharάύ–Ά±δΝΩΓΘ≥Χ–ρ±Ί–κΕ‘‘ΥΥψ ±ΒΡ ΐΨί“γ≥ωΉωΚœάμΒΡ¥ΠάμΓΘ
ΚήΕύΤδΥϊ”ο―‘Θ§œώPascal”ο―‘Θ®ΚΟ–ΠΒΡ «C”ο―‘…ηΦΤ’Ώ÷°“Μ‘χΉΪΈΡΚίΚί≈ζΤάΙΐPascal”ο―‘Θ©Θ§ΕΦ≤Μ‘ –μΜλΚœ Ι”Οάύ–ΆΘ§ΒΪC”ο―‘≤ΜΜαœό÷ΤΡψΒΡΉ‘”…Θ§Φ¥±ψ’βΨ≠≥Θ“ΐΤπBugΓΘ
d.Β±ΉςΈΣΚ· ΐΒΡ≤Έ ΐ±Μ¥ΪΒί ±Θ§charΚΆshortΜα±ΜΉΣΜΜΈΣintΘ§floatΜα±ΜΉΣΜΜΈΣdoubleΓΘ
e.C”ο―‘÷ß≥÷«Ω÷Τάύ–ΆΉΣΜΜΘ§»γΙϊΡψ±Ί–κ“ΣΫχ––«Ω÷Τάύ–ΆΉΣΜΜ ±Θ§“Σ»Ζ±ΘΡψΕ‘άύ–ΆΉΣΜΜ”–ΉψΙΜΝΥΫβΘΚ
- ≤ΔΖ«Υυ”–«Ω÷Τάύ–ΆΉΣΜΜΕΦ «”…Ζγœ’ΒΡΘ§Α―“ΜΗω’ϊ ΐ÷ΒΉΣΜΜΈΣ“Μ÷÷ΨΏ”–œύΆ§ΖϊΚ≈ΒΡΗϋΩμάύ–Ά ±Θ§ «ΨχΕ‘Α≤»ΪΒΡΓΘ
- ΨΪΕ»ΗΏΒΡάύ–Ά«Ω÷ΤΉΣΜΜΈΣΨΪΕ»ΒΆΒΡάύ–Ά ±Θ§Ά®ΙΐΕΣΤζ Β± ΐΝΩΒΡΉνΗΏ”––ßΈΜά¥Μώ»ΓΫαΙϊΘ§“≤ΨΆ «ΥΒΜαΖΔ…ζ ΐΨίΫΊΕœΘ§≤Δ«“Ω…ΡήΗΡ±δ ΐΨίΒΡΖϊΚ≈ΈΜΓΘ
- ΨΪΕ»ΒΆΒΡάύ–Ά«Ω÷ΤΉΣΜΜΈΣΨΪΕ»ΗΏΒΡάύ–Ά ±Θ§»γΙϊΝΫ÷÷άύ–ΆΨΏ”–œύΆ§ΒΡΖϊΚ≈Θ§Ρ«Ο¥ΟΜ ≤Ο¥Έ ΧβΘΜ–η“ΣΉΔ“βΒΡ «ΗΚΒΡ”–ΖϊΚ≈ΨΪΕ»ΒΆάύ–Ά«Ω÷ΤΉΣΜΜΈΣΈόΖϊΚ≈ΨΪΕ»ΗΏάύ–Ά ±Θ§Μα≤Μ÷±ΙέΒΡ÷¥––ΖϊΚ≈ά©’ΙΘ§άΐ»γΘΚ
unsigned int bob;
signed char fred = -1;
bob=(unsigned int )fred;
/*ΖΔ…ζΖϊΚ≈ά©’ΙΘ§¥Υ ±bobΈΣ0xFFFFFFFF*/ |
|









