| ±ύΦ≠ΆΤΦω: |
±ΨΈΡ÷ς“ΣΫι…ήΝΥ ≤Ο¥ «Ϋχ≥ΧΘΩ ≤Ο¥ «Ϋχ≥ΧΆ®–≈ΘΩΫχ≥ΧΆ®–≈ΒΡ”Π”Ο≥ΓΨΑΓΔΫχ≥ΧΆ®–≈ΒΡΖΫ Ϋ“‘ΦΑΗςΫχ≥ΧΦδΆ®–≈ΒΡ‘≠άμΦΑ Βœ÷Β»œύΙΊΡΎ»ίΓΘ
ΈΡά¥Ή‘”Ύ≤©ΩΆ‘ΑΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
Ϋχ≥ΧΒΡΗ≈Ρν
Ϋχ≥Χ «≤ΌΉςœΒΆ≥ΒΡΗ≈ΡνΘ§ΟΩΒ±Έ“Ο«÷¥––“ΜΗω≥Χ–ρ ±Θ§Ε‘”Ύ≤ΌΉςœΒΆ≥ά¥Ϋ≤ΨΆ¥¥Ϋ®ΝΥ“ΜΗωΫχ≥Χ,‘Ύ’βΗωΙΐ≥Χ÷–Θ§ΑιΥφΉ≈Ή ‘¥ΒΡΖ÷≈δΚΆ ΆΖ≈ΓΘΩ…“‘»œΈΣΫχ≥Χ «“ΜΗω≥Χ–ρΒΡ“Μ¥Έ÷¥––Ιΐ≥ΧΓΘ
Ϋχ≥ΧΆ®–≈ΒΡΗ≈Ρν
Ϋχ≥Χ”ΟΜßΩ’Φδ «œύΜΞΕάΝΔΒΡΘ§“ΜΑψΕχ―‘ «≤ΜΡήœύΜΞΖΟΈ ΒΡΓΘΒΪΚήΕύ«ιΩωœ¬Ϋχ≥ΧΦδ–η“ΣΜΞœύΆ®–≈Θ§ά¥Άξ≥…œΒΆ≥ΒΡΡ≥œνΙΠΡήΓΘΫχ≥ΧΆ®Ιΐ”κΡΎΚΥΦΑΤδΥϋΫχ≥Χ÷°ΦδΒΡΜΞœύΆ®–≈ά¥–≠ΒςΥϋΟ«ΒΡ––ΈΣΓΘ
Ϋχ≥ΧΆ®–≈ΒΡ”Π”Ο≥ΓΨΑ
ΐΨί¥Ϊ δΘΚ“ΜΗωΫχ≥Χ–η“ΣΫΪΥϋΒΡ ΐΨίΖΔΥΆΗχΝμ“ΜΗωΫχ≥ΧΘ§ΖΔΥΆΒΡ ΐΨίΝΩ‘Ύ“ΜΗωΉ÷ΫΎΒΫΦΗ’ΉΉ÷ΫΎ÷°ΦδΓΘ
Ι≤œμ ΐΨίΘΚΕύΗωΫχ≥Χœκ“Σ≤ΌΉςΙ≤œμ ΐΨίΘ§“ΜΗωΫχ≥ΧΕ‘Ι≤œμ ΐΨίΒΡ–όΗΡΘ§±πΒΡΫχ≥Χ”ΠΗΟΝΔΩΧΩ¥ΒΫΓΘ
Ά®÷Σ ¬ΦΰΘΚ“ΜΗωΫχ≥Χ–η“ΣœρΝμ“ΜΗωΜρ“ΜΉιΫχ≥ΧΖΔΥΆœϊœΔΘ§Ά®÷ΣΥϋΘ®ΥϋΟ«Θ©ΖΔ…ζΝΥΡ≥÷÷ ¬ΦΰΘ®»γΫχ≥Χ÷’÷Ι ±“ΣΆ®÷ΣΗΗΫχ≥ΧΘ©ΓΘ
Ή ‘¥Ι≤œμΘΚΕύΗωΫχ≥Χ÷°ΦδΙ≤œμΆ§―υΒΡΉ ‘¥ΓΘΈΣΝΥΉςΒΫ’β“ΜΒψΘ§–η“ΣΡΎΚΥΧαΙ©ΥχΚΆΆ§≤ΫΜζ÷ΤΓΘ
Ϋχ≥ΧΩΊ÷ΤΘΚ”––©Ϋχ≥ΧœΘΆϊΆξ»ΪΩΊ÷ΤΝμ“ΜΗωΫχ≥ΧΒΡ÷¥––Θ®»γDebugΫχ≥ΧΘ©Θ§¥Υ ±ΩΊ÷ΤΫχ≥ΧœΘΆϊΡήΙΜάΙΫΊΝμ“ΜΗωΫχ≥ΧΒΡΥυ”–œί»κΚΆ“λ≥ΘΘ§≤ΔΡήΙΜΦΑ ±÷ΣΒάΥϋΒΡΉ¥Χ§ΗΡ±δΓΘ
Ϋχ≥ΧΆ®–≈ΒΡΖΫ Ϋ
ΙήΒά( pipe )ΘΚ
ΙήΒάΑϋά®»ΐ÷÷:
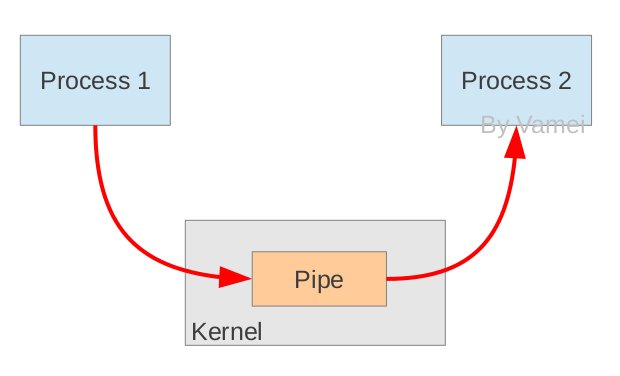
Τ’Ά®ΙήΒάPIPEΘΚ Ά®≥Θ”–ΝΫ÷÷œό÷Τ,“Μ «ΒΞΙΛ,÷ΜΡήΒΞœρ¥Ϊ δ;Εΰ «÷ΜΡή‘ΎΗΗΉ”Μρ’Ώ–÷ΒήΫχ≥ΧΦδ Ι”Ο.
ΝςΙήΒάs_pipe: »Ξ≥ΐΝΥΒΎ“Μ÷÷œό÷Τ,ΈΣΑκΥΪΙΛΘ§÷ΜΡή‘ΎΗΗΉ”Μρ–÷ΒήΫχ≥ΧΦδ Ι”ΟΘ§Ω…“‘ΥΪœρ¥Ϊ δ.
ΟϋΟϊΙήΒά:name_pipeΘΚ»Ξ≥ΐΝΥΒΎΕΰ÷÷œό÷Τ,Ω…“‘‘Ύ–μΕύ≤Δ≤ΜœύΙΊΒΡΫχ≥Χ÷°ΦδΫχ––Ά®―Ε.
–≈Κ≈ΝΩ( semophore ) ΘΚ
–≈Κ≈ΝΩ «“ΜΗωΦΤ ΐΤςΘ§Ω…“‘”Οά¥ΩΊ÷ΤΕύΗωΫχ≥ΧΕ‘Ι≤œμΉ ‘¥ΒΡΖΟΈ ΓΘΥϋ≥ΘΉςΈΣ“Μ÷÷ΥχΜζ÷ΤΘ§Ζά÷ΙΡ≥Ϋχ≥Χ’ΐ‘ΎΖΟΈ Ι≤œμΉ ‘¥ ±Θ§ΤδΥϊΫχ≥Χ“≤ΖΟΈ ΗΟΉ ‘¥ΓΘ“ρ¥ΥΘ§÷ς“ΣΉςΈΣΫχ≥ΧΦδ“‘ΦΑΆ§“ΜΫχ≥ΧΡΎ≤ΜΆ§œΏ≥Χ÷°ΦδΒΡΆ§≤Ϋ ÷ΕΈΓΘ
œϊœΔΕ”Ν–( message queue ) ΘΚ
œϊœΔΕ”Ν– «”…œϊœΔΒΡΝ¥±μΘ§¥φΖ≈‘ΎΡΎΚΥ÷–≤Δ”…œϊœΔΕ”Ν–±ξ ΕΖϊ±ξ ΕΓΘœϊœΔΕ”Ν–ΩΥΖΰΝΥ–≈Κ≈¥ΪΒί–≈œΔ…ΌΓΔΙήΒά÷ΜΡή≥–‘ΊΈόΗώ ΫΉ÷ΫΎΝς“‘ΦΑΜΚ≥ε«χ¥σ–Γ ήœόΒ»»±ΒψΓΘ
–≈Κ≈ ( sinal ) ΘΚ
–≈Κ≈ «“Μ÷÷±»ΫœΗ¥‘”ΒΡΆ®–≈ΖΫ ΫΘ§”Ο”ΎΆ®÷ΣΫ” ’Ϋχ≥ΧΡ≥Ηω ¬Φΰ“―Ψ≠ΖΔ…ζΓΘ
Ι≤œμΡΎ¥φ( shared memory ) ΘΚ
Ι≤œμΡΎ¥φΨΆ «”≥…δ“ΜΕΈΡή±ΜΤδΥϊΫχ≥ΧΥυΖΟΈ ΒΡΡΎ¥φΘ§’βΕΈΙ≤œμΡΎ¥φ”…“ΜΗωΫχ≥Χ¥¥Ϋ®Θ§ΒΪΕύΗωΫχ≥ΧΕΦΩ…“‘ΖΟΈ ΓΘΙ≤œμΡΎ¥φ «ΉνΩλΒΡ
IPC ΖΫ ΫΘ§Υϋ «’κΕ‘ΤδΥϊΫχ≥ΧΦδΆ®–≈ΖΫ Ϋ‘Υ–––߬ ΒΆΕχΉ®Ο≈…ηΦΤΒΡΓΘΥϋΆυΆυ”κΤδΥϊΆ®–≈Μζ÷ΤΘ§»γ–≈Κ≈ΝΫΘ§≈δΚœ Ι”ΟΘ§ά¥ Βœ÷Ϋχ≥ΧΦδΒΡΆ§≤ΫΚΆΆ®–≈ΓΘ
ΧΉΫ”Ή÷( socket ) ΘΚ
ΧΉΫβΩΎ“≤ «“Μ÷÷Ϋχ≥ΧΦδΆ®–≈Μζ÷ΤΘ§”κΤδΥϊΆ®–≈Μζ÷Τ≤ΜΆ§ΒΡ «Θ§ΥϋΩ…”Ο”Ύ≤ΜΆ§ΜζΤςΦδΒΡΫχ≥ΧΆ®–≈ΓΘ
ΗςΫχ≥ΧΦδΆ®–≈ΒΡ‘≠άμΦΑ Βœ÷
ΙήΒά
ΙήΒά «»γΚΈΆ®–≈ΒΡ
ΙήΒά «”…ΡΎΚΥΙήάμΒΡ“ΜΗωΜΚ≥ε«χΘ§œύΒ±”ΎΈ“Ο«Ζ≈»κΡΎ¥φ÷–ΒΡ“ΜΗω÷ΫΧθΓΘΙήΒάΒΡ“ΜΕΥΝ§Ϋ”“ΜΗωΫχ≥ΧΒΡ δ≥ωΓΘ’βΗωΫχ≥ΧΜαœρΙήΒά÷–Ζ≈»κ–≈œΔΓΘΙήΒάΒΡΝμ“ΜΕΥΝ§Ϋ”“ΜΗωΫχ≥ΧΒΡ δ»κΘ§’βΗωΫχ≥Χ»Γ≥ω±ΜΖ≈»κΙήΒάΒΡ–≈œΔΓΘ“ΜΗωΜΚ≥ε«χ≤Μ–η“ΣΚή¥σΘ§Υϋ±Μ…ηΦΤ≥…ΈΣΜΖ–ΈΒΡ ΐΨίΫαΙΙΘ§“‘±ψΙήΒάΩ…“‘±Μ―≠ΜΖάϊ”ΟΓΘΒ±ΙήΒά÷–ΟΜ”––≈œΔΒΡΜΑΘ§¥”ΙήΒά÷–ΕΝ»ΓΒΡΫχ≥ΧΜαΒ»¥ΐΘ§÷±ΒΫΝμ“ΜΕΥΒΡΫχ≥ΧΖ≈»κ–≈œΔΓΘΒ±ΙήΒά±ΜΖ≈¬ζ–≈œΔΒΡ ±ΚρΘ§≥Δ ‘Ζ≈»κ–≈œΔΒΡΫχ≥ΧΜαΒ»¥ΐΘ§÷±ΒΫΝμ“ΜΕΥΒΡΫχ≥Χ»Γ≥ω–≈œΔΓΘΒ±ΝΫΗωΫχ≥ΧΕΦ÷’ΫαΒΡ ±ΚρΘ§ΙήΒά“≤Ή‘Ε·œϊ ßΓΘ
ΙήΒά «»γΚΈ¥¥Ϋ®ΒΡ
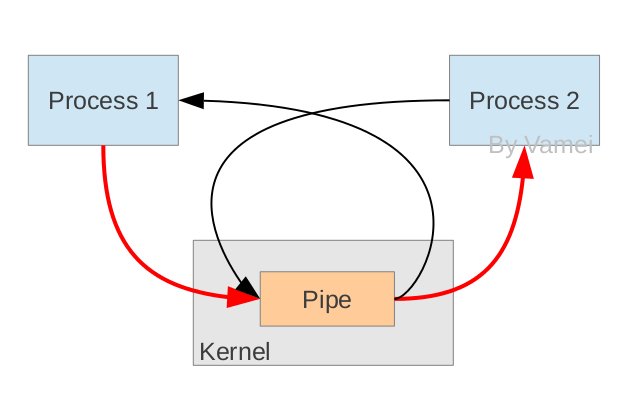
¥”‘≠άμ…œΘ§ΙήΒάάϊ”ΟforkΜζ÷ΤΫ®ΝΔΘ§¥”Εχ»ΟΝΫΗωΫχ≥ΧΩ…“‘Ν§Ϋ”ΒΫΆ§“ΜΗωPIPE…œΓΘΉνΩΣ ΦΒΡ ±ΚρΘ§…œΟφΒΡΝΫΗωΦΐΆΖΕΦΝ§Ϋ”‘ΎΆ§“ΜΗωΫχ≥ΧProcess
1…œ(Ν§Ϋ”‘ΎProcess 1…œΒΡΝΫΗωΦΐΆΖ)ΓΘΒ±forkΗ¥÷ΤΫχ≥ΧΒΡ ±ΚρΘ§ΜαΫΪ’βΝΫΗωΝ§Ϋ”“≤Η¥÷ΤΒΫ–¬ΒΡΫχ≥Χ(Process
2)ΓΘΥφΚσΘ§ΟΩΗωΫχ≥ΧΙΊ±’Ή‘ΦΚ≤Μ–η“ΣΒΡ“ΜΗωΝ§Ϋ” (ΝΫΗωΚΎ…ΪΒΡΦΐΆΖ±ΜΙΊ±’; Process 1ΙΊ±’¥”PIPEά¥ΒΡ δ»κΝ§Ϋ”Θ§Process
2ΙΊ±’ δ≥ωΒΫPIPEΒΡΝ§Ϋ”)Θ§’β―υΘ§ Θœ¬ΒΡΚλ…ΪΝ§Ϋ”ΨΆΙΙ≥…ΝΥ»γ…œΆΦΒΡPIPEΓΘ
ΙήΒάΆ®–≈ΒΡ Βœ÷œΗΫΎ
‘Ύ Linux ÷–Θ§ΙήΒάΒΡ Βœ÷≤ΔΟΜ”– Ι”ΟΉ®Ο≈ΒΡ ΐΨίΫαΙΙΘ§Εχ «Ϋη÷ζΝΥΈΡΦΰœΒΆ≥ΒΡfileΫαΙΙΚΆVFSΒΡΥς“ΐΫΎΒψinodeΓΘΆ®ΙΐΫΪΝΫΗω
file ΫαΙΙ÷ΗœρΆ§“ΜΗωΝΌ ±ΒΡ VFS Υς“ΐΫΎΒψΘ§Εχ’βΗω VFS Υς“ΐΫΎΒψ”÷÷Ηœρ“ΜΗωΈοάμ“≥ΟφΕχ Βœ÷ΒΡΓΘ»γœ¬ΆΦ
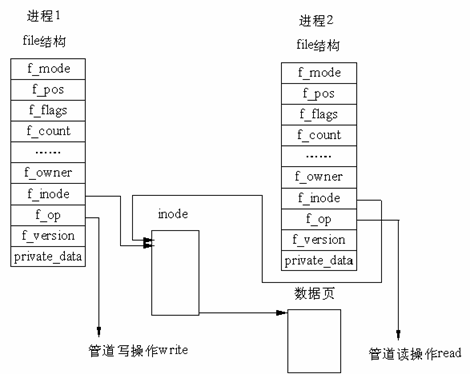
”–ΝΫΗω file ΐΨίΫαΙΙΘ§ΒΪΥϋΟ«Ε®“εΈΡΦΰ≤ΌΉςάΐ≥ΧΒΊ÷Ζ «≤ΜΆ§ΒΡΘ§Τδ÷–“ΜΗω «œρΙήΒά÷––¥»κ ΐΨίΒΡάΐ≥ΧΒΊ÷ΖΘ§ΕχΝμ“ΜΗω «¥”ΙήΒά÷–ΕΝ≥ω ΐΨίΒΡάΐ≥ΧΒΊ÷ΖΓΘ’β―υΘ§”ΟΜß≥Χ–ρΒΡœΒΆ≥Βς”Ο»‘»Μ «Ά®≥ΘΒΡΈΡΦΰ≤ΌΉςΘ§ΕχΡΎΚΥ»¥άϊ”Ο’β÷÷≥ιœσΜζ÷Τ Βœ÷ΝΥΙήΒά’β“ΜΧΊ β≤ΌΉςΓΘ
ΙΊ”ΎΙήΒάΒΡΕΝ–¥
ΙήΒά Βœ÷ΒΡ‘¥¥ζ¬κ‘Ύfs/pipe.c÷–Θ§‘Ύpipe.c÷–”–ΚήΕύΚ· ΐΘ§Τδ÷–”–ΝΫΗωΚ· ΐ±»Ϋœ÷Ί“ΣΘ§Φ¥ΙήΒάΕΝΚ· ΐpipe_read()ΚΆΙήΒά–¥Κ· ΐpipe_wrtie()ΓΘΙήΒά–¥Κ· ΐΆ®ΙΐΫΪΉ÷ΫΎΗ¥÷ΤΒΫ
VFS Υς“ΐΫΎΒψ÷ΗœρΒΡΈοάμΡΎ¥φΕχ–¥»κ ΐΨίΘ§ΕχΙήΒάΕΝΚ· ΐ‘ρΆ®ΙΐΗ¥÷ΤΈοάμΡΎ¥φ÷–ΒΡΉ÷ΫΎΕχΕΝ≥ω ΐΨίΓΘΒ±»ΜΘ§ΡΎΚΥ±Ί–κάϊ”Ο“ΜΕ®ΒΡΜζ÷ΤΆ§≤ΫΕ‘ΙήΒάΒΡΖΟΈ Θ§ΈΣ¥ΥΘ§ΡΎΚΥ Ι”ΟΝΥΥχΓΔΒ»¥ΐΕ”Ν–ΚΆ–≈Κ≈ΓΘ
Β±–¥Ϋχ≥ΧœρΙήΒά÷––¥»κ ±Θ§Υϋάϊ”Ο±ξΉΦΒΡΩβΚ· ΐwrite()Θ§œΒΆ≥ΗυΨίΩβΚ· ΐ¥ΪΒίΒΡΈΡΦΰΟη ωΖϊΘ§Ω…’“ΒΫΗΟΈΡΦΰΒΡ
file ΫαΙΙΓΘfile ΫαΙΙ÷–÷ΗΕ®ΝΥ”Οά¥Ϋχ–––¥≤ΌΉςΒΡΚ· ΐΘ®Φ¥–¥»κΚ· ΐΘ©ΒΊ÷ΖΘ§”Ύ «Θ§ΡΎΚΥΒς”ΟΗΟΚ· ΐΆξ≥…–¥≤ΌΉςΓΘ–¥»κΚ· ΐ‘ΎœρΡΎ¥φ÷––¥»κ ΐΨί÷°«ΑΘ§±Ί–κ Ήœ»Φλ≤ι
VFS Υς“ΐΫΎΒψ÷–ΒΡ–≈œΔΘ§Ά§ ±¬ζΉψ»γœ¬ΧθΦΰ ±Θ§≤≈ΡήΫχ–– ΒΦ ΒΡΡΎ¥φΗ¥÷ΤΙΛΉςΘΚ
ΡΎ¥φ÷–”–ΉψΙΜΒΡΩ’ΦδΩ…»ίΡ…Υυ”–“Σ–¥»κΒΡ ΐΨίΘΜ
ΡΎ¥φΟΜ”–±ΜΕΝ≥Χ–ρΥχΕ®ΓΘ
»γΙϊΆ§ ±¬ζΉψ…œ ωΧθΦΰΘ§–¥»κΚ· ΐ Ήœ»ΥχΕ®ΡΎ¥φΘ§»ΜΚσ¥”–¥Ϋχ≥ΧΒΡΒΊ÷ΖΩ’Φδ÷–Η¥÷Τ ΐΨίΒΫΡΎ¥φΓΘΖώ‘ρΘ§–¥»κΫχ≥ΧΨΆ–ίΟΏ‘Ύ
VFS Υς“ΐΫΎΒψΒΡΒ»¥ΐΕ”Ν–÷–Θ§Ϋ”œ¬ά¥Θ§ΡΎΚΥΫΪΒς”ΟΒςΕ»≥Χ–ρΘ§ΕχΒςΕ»≥Χ–ρΜα―Γ‘ώΤδΥϊΫχ≥Χ‘Υ––ΓΘ–¥»κΫχ≥Χ ΒΦ ¥Π”ΎΩ…÷–ΕœΒΡΒ»¥ΐΉ¥Χ§Θ§Β±ΡΎ¥φ÷–”–ΉψΙΜΒΡΩ’ΦδΩ…“‘»ίΡ…–¥»κ ΐΨίΘ§ΜρΡΎ¥φ±ΜΫβΥχ ±Θ§ΕΝ»ΓΫχ≥ΧΜαΜΫ–―–¥»κΫχ≥ΧΘ§’β ±Θ§–¥»κΫχ≥ΧΫΪΫ” ’ΒΫ–≈Κ≈ΓΘΒ± ΐΨί–¥»κΡΎ¥φ÷°ΚσΘ§ΡΎ¥φ±ΜΫβΥχΘ§ΕχΥυ”––ίΟΏ‘ΎΥς“ΐΫΎΒψΒΡΕΝ»ΓΫχ≥ΧΜα±ΜΜΫ–―ΓΘ
ΙήΒάΒΡΕΝ»ΓΙΐ≥ΧΚΆ–¥»κΙΐ≥ΧάύΥΤΓΘΒΪ «Θ§Ϋχ≥ΧΩ…“‘‘ΎΟΜ”– ΐΨίΜρΡΎ¥φ±ΜΥχΕ® ±ΝΔΦ¥ΖΒΜΊ¥μΈσ–≈œΔΘ§Εχ≤Μ «Ήη»ϊΗΟΫχ≥ΧΘ§’β“άάΒ”ΎΈΡΦΰΜρΙήΒάΒΡ¥ρΩΣΡΘ ΫΓΘΖ¥÷°Θ§Ϋχ≥ΧΩ…“‘–ίΟΏ‘ΎΥς“ΐΫΎΒψΒΡΒ»¥ΐΕ”Ν–÷–Β»¥ΐ–¥»κΫχ≥Χ–¥»κ ΐΨίΓΘΒ±Υυ”–ΒΡΫχ≥ΧΆξ≥…ΝΥΙήΒά≤ΌΉς÷°ΚσΘ§ΙήΒάΒΡΥς“ΐΫΎΒψ±ΜΕΣΤζΘ§ΕχΙ≤œμ ΐΨί“≥“≤±Μ ΆΖ≈ΓΘ
LinuxΚ· ΐ‘≠–Ά
| #include <unistd.h>
int pipe(int filedes[2]); |
filedes[0]”Ο”ΎΕΝ≥ω ΐΨίΘ§ΕΝ»Γ ±±Ί–κΙΊ±’–¥»κΕΥΘ§Φ¥close(filedes[1]);
filedes[1]”Ο”Ύ–¥»κ ΐΨίΘ§–¥»κ ±±Ί–κΙΊ±’ΕΝ»ΓΕΥΘ§Φ¥close(filedes[0])ΓΘ
≥Χ–ρ ΒάΐΘΚ
int main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if(pipe(fd) 0){ /* œ»Ϋ®ΝΔΙήΒάΒΟΒΫ“ΜΕ‘ΈΡΦΰΟη ωΖϊ */
exit(0);
}
if((pid = fork()) 0) /* ΗΗΫχ≥ΧΑ―ΈΡΦΰΟη ωΖϊΗ¥÷ΤΗχΉ”Ϋχ≥Χ */
exit(1);
else if(pid > 0){ /* ΗΗΫχ≥Χ–¥ */
close(fd[0]); /* ΙΊ±’ΕΝΟη ωΖϊ */
write(fd[1], "\nhello world\n", 14);
}
else{ /* Ή”Ϋχ≥ΧΕΝ */
close(fd[1]); /* ΙΊ±’–¥ΕΥ */
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
} |
ΟϋΟϊΙήΒά
”…”ΎΜυ”ΎforkΜζ÷ΤΘ§Υυ“‘ΙήΒά÷ΜΡή”Ο”ΎΗΗΫχ≥ΧΚΆΉ”Ϋχ≥Χ÷°ΦδΘ§Μρ’Ώ”Β”–œύΆ§Ήφœ»ΒΡΝΫΗωΉ”Ϋχ≥Χ÷°Φδ (”–«Ή‘ΒΙΊœΒΒΡΫχ≥Χ÷°Φδ)ΓΘΈΣΝΥΫβΨω’β“ΜΈ ΧβΘ§LinuxΧαΙ©ΝΥFIFOΖΫ ΫΝ§Ϋ”Ϋχ≥ΧΓΘFIFO”÷Ϋ–ΉωΟϋΟϊΙήΒά(named
PIPE)ΓΘ
Βœ÷‘≠άμ
FIFO (First in, First out)ΈΣ“Μ÷÷ΧΊ βΒΡΈΡΦΰάύ–ΆΘ§Υϋ‘ΎΈΡΦΰœΒΆ≥÷–”–Ε‘”ΠΒΡ¬ΖΨΕΓΘΒ±“ΜΗωΫχ≥Χ“‘ΕΝ(r)ΒΡΖΫ Ϋ¥ρΩΣΗΟΈΡΦΰΘ§ΕχΝμ“ΜΗωΫχ≥Χ“‘–¥(w)ΒΡΖΫ Ϋ¥ρΩΣΗΟΈΡΦΰΘ§Ρ«Ο¥ΡΎΚΥΨΆΜα‘Ύ’βΝΫΗωΫχ≥Χ÷°ΦδΫ®ΝΔΙήΒάΘ§Υυ“‘FIFO ΒΦ …œ“≤”…ΡΎΚΥΙήάμΘ§≤Μ”κ”≤≈Χ¥ρΫΜΒάΓΘ÷°Υυ“‘Ϋ–FIFOΘ§ «“ρΈΣΙήΒά±Ψ÷ …œ «“ΜΗωœ»Ϋχœ»≥ωΒΡΕ”Ν– ΐΨίΫαΙΙΘ§Ήν‘γΖ≈»κΒΡ ΐΨί±ΜΉνœ»ΕΝ≥ωά¥Θ§¥”Εχ±Θ÷Λ–≈œΔΫΜΝςΒΡΥ≥–ρΓΘFIFO÷Μ «Ϋη”ΟΝΥΈΡΦΰœΒΆ≥(file
system,ΟϋΟϊΙήΒά «“Μ÷÷ΧΊ βάύ–ΆΒΡΈΡ??Θ§“ρΈΣLinux÷–Υυ”– ¬ΈοΕΦ «ΈΡΦΰΘ§Υϋ‘ΎΈΡΦΰœΒΆ≥÷–“‘ΈΡΦΰΟϊΒΡ–Έ Ϋ¥φ‘ΎΓΘ)ά¥ΈΣΙήΒάΟϋΟϊΓΘ–¥ΡΘ ΫΒΡΫχ≥ΧœρFIFOΈΡΦΰ÷––¥»κΘ§ΕχΕΝΡΘ ΫΒΡΫχ≥Χ¥”FIFOΈΡΦΰ÷–ΕΝ≥ωΓΘΒ±…Ψ≥ΐFIFOΈΡΦΰ ±Θ§ΙήΒάΝ§Ϋ”“≤Υφ÷°œϊ ßΓΘFIFOΒΡΚΟ¥Π‘Ύ”ΎΈ“Ο«Ω…“‘Ά®ΙΐΈΡΦΰΒΡ¬ΖΨΕά¥ Ε±πΙήΒάΘ§¥”Εχ»ΟΟΜ”–«Ή‘ΒΙΊœΒΒΡΫχ≥Χ÷°ΦδΫ®ΝΔΝ§Ϋ”
Κ· ΐ‘≠–ΆΘΚ
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *filename, mode_t mode);
int mknode(const char *filename, mode_t mode
| S_IFIFO, (dev_t) 0 ); |
Τδ÷–filename «±Μ¥¥Ϋ®ΒΡΈΡΦΰΟϊ≥ΤΘ§mode±μ ΨΫΪ‘ΎΗΟΈΡΦΰ…œ…η÷ΟΒΡ»®œόΈΜΚΆΫΪ±Μ¥¥Ϋ®ΒΡΈΡΦΰάύ–Ά(‘Ύ¥Υ«ιΩωœ¬ΈΣS_IFIFO)Θ§dev «Β±¥¥Ϋ®…η±ΗΧΊ βΈΡΦΰ ± Ι”ΟΒΡ“ΜΗω÷ΒΓΘ“ρ¥ΥΘ§Ε‘”Ύœ»Ϋχœ»≥ωΈΡΦΰΥϋΒΡ÷ΒΈΣ0ΓΘ
≥Χ–ρ ΒάΐΘΚ
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
int res = mkfifo("/tmp/my_fifo", 0777);
if (res == 0)
{
printf("FIFO created/n");
}
exit(EXIT_SUCCESS);
} |
≤ΈΩΦΈΡœΉ
LinuxΫχ≥ΧΦδΆ®–≈÷°ΙήΒά(pipe)ΓΔΟϋΟϊΙήΒά(FIFO)”κ–≈Κ≈(Signal)
–≈Κ≈ΝΩ
≤Ο¥ «–≈Κ≈ΝΩ
ΈΣΝΥΖά÷Ι≥ωœ÷“ρΕύΗω≥Χ–ρΆ§ ±ΖΟΈ “ΜΗωΙ≤œμΉ ‘¥Εχ“ΐΖΔΒΡ“ΜœΒΝ–Έ ΧβΘ§Έ“Ο«–η“Σ“Μ÷÷ΖΫΖ®ΓΘ±»»γ‘Ύ»Έ“Μ ±ΩΧ÷ΜΡή”–“ΜΗω÷¥––œΏ≥ΧΖΟΈ ¥ζ¬κΒΡΝΌΫγ«χ”ρΓΘΝΌΫγ«χ”ρ «÷Η÷¥–– ΐΨίΗϋ–¬ΒΡ¥ζ¬κ–η“ΣΕά’Φ ΫΒΊ÷¥––ΓΘΕχ–≈Κ≈ΝΩΨΆΩ…“‘ΧαΙ©’β―υΒΡ“Μ÷÷ΖΟΈ Μζ÷ΤΘ§»Ο“ΜΗωΝΌΫγ«χΆ§“Μ ±Φδ÷Μ”–“ΜΗωœΏ≥Χ‘ΎΖΟΈ ΥϋΘ§“≤ΨΆ «ΥΒ–≈Κ≈ΝΩ «”Οά¥Βς–≠Ϋχ≥ΧΕ‘Ι≤œμΉ ‘¥ΒΡΖΟΈ ΒΡΓΘ
–≈Κ≈ΝΩ «“ΜΗωΧΊ βΒΡ±δΝΩΘ§≥Χ–ρΕ‘ΤδΖΟΈ ΕΦ «‘≠Ή”≤ΌΉςΘ§«“÷Μ‘ –μΕ‘ΥϋΫχ––Β»¥ΐΘ®Φ¥P(–≈Κ≈±δΝΩ))ΚΆΖΔΥΆΘ®Φ¥V(–≈Κ≈±δΝΩ))–≈œΔ≤ΌΉςΓΘΉνΦρΒΞΒΡ–≈Κ≈ΝΩ «÷ΜΡή»Γ0ΚΆ1ΒΡ±δΝΩΘ§’β“≤ «–≈Κ≈ΝΩΉν≥ΘΦϊΒΡ“Μ÷÷–Έ ΫΘ§Ϋ–ΉωΕΰΫχ÷Τ–≈Κ≈ΝΩΓΘΕχΩ…“‘»ΓΕύΗω’ΐ’ϊ ΐΒΡ–≈Κ≈ΝΩ±Μ≥ΤΈΣΆ®”Ο–≈Κ≈ΝΩΓΘ
–≈Κ≈ΝΩΒΡΙΛΉς‘≠άμ
”…”Ύ–≈Κ≈ΝΩ÷ΜΡήΫχ––ΝΫ÷÷≤ΌΉςΒ»¥ΐΚΆΖΔΥΆ–≈Κ≈Θ§Φ¥P(sv)ΚΆV(sv),ΥϊΟ«ΒΡ––ΈΣ «’β―υΒΡΘΚ
P(sv)ΘΚ»γΙϊsvΒΡ÷Β¥σ”ΎΝψΘ§ΨΆΗχΥϋΦθ1ΘΜ»γΙϊΥϋΒΡ÷ΒΈΣΝψΘ§ΨΆΙ“ΤπΗΟΫχ≥ΧΒΡ÷¥––
V(sv)ΘΚ»γΙϊ”–ΤδΥϊΫχ≥Χ“ρΒ»¥ΐsvΕχ±ΜΙ“ΤπΘ§ΨΆ»ΟΥϋΜ÷Η¥‘Υ––Θ§»γΙϊΟΜ”–Ϋχ≥Χ“ρΒ»¥ΐsvΕχΙ“ΤπΘ§ΨΆΗχΥϋΦ”1.
ΨΌΗωάΐΉ”Θ§ΨΆ «ΝΫΗωΫχ≥ΧΙ≤œμ–≈Κ≈ΝΩsvΘ§“ΜΒ©Τδ÷–“ΜΗωΫχ≥Χ÷¥––ΝΥP(sv)≤ΌΉςΘ§ΥϋΫΪΒΟΒΫ–≈Κ≈ΝΩΘ§≤ΔΩ…“‘Ϋχ»κΝΌΫγ«χΘ§ ΙsvΦθ1ΓΘΕχΒΎΕΰΗωΫχ≥ΧΫΪ±ΜΉη÷ΙΫχ»κΝΌΫγ«χΘ§“ρΈΣΒ±Υϋ ‘ΆΦ÷¥––P(sv) ±Θ§svΈΣ0Θ§ΥϋΜα±ΜΙ“Τπ“‘Β»¥ΐΒΎ“ΜΗωΫχ≥ΧάκΩΣΝΌΫγ«χ”ρ≤Δ÷¥––V(sv) ΆΖ≈–≈Κ≈ΝΩΘ§’β ±ΒΎΕΰΗωΫχ≥ΧΨΆΩ…“‘Μ÷Η¥÷¥––ΓΘ
LinuxΒΡ–≈Κ≈ΝΩΜζ÷Τ
LinuxΧαΙ©ΝΥ“ΜΉιΨΪ–Ρ…ηΦΤΒΡ–≈Κ≈ΝΩΫ”ΩΎά¥Ε‘–≈Κ≈Ϋχ––≤ΌΉςΘ§ΥϋΟ«≤Μ÷Μ «’κΕ‘ΕΰΫχ÷Τ–≈Κ≈ΝΩΘ§œ¬ΟφΫΪΜαΕ‘’β–©Κ· ΐΫχ––Ϋι…ήΘ§ΒΪ«κΉΔ“βΘ§’β–©Κ· ΐΕΦ «”Οά¥Ε‘≥…ΉιΒΡ–≈Κ≈ΝΩ÷ΒΫχ––≤ΌΉςΒΡΓΘΥϋΟ«…υΟς‘ΎΆΖΈΡΦΰsys/sem.h÷–ΓΘ
semgetΚ· ΐ
ΥϋΒΡΉς”Ο «¥¥Ϋ®“ΜΗω–¬–≈Κ≈ΝΩΜρ»ΓΒΟ“ΜΗω“―”––≈Κ≈ΝΩΘ§‘≠–ΆΈΣΘΚ
int semget(key_t
key, int num_sems, int sem_flags);
|
ΒΎ“ΜΗω≤Έ ΐkey «’ϊ ΐ÷ΒΘ®Έ®“ΜΖ«ΝψΘ©Θ§≤ΜœύΙΊΒΡΫχ≥ΧΩ…“‘Ά®ΙΐΥϋΖΟΈ “ΜΗω–≈Κ≈ΝΩΘ§Υϋ¥ζ±μ≥Χ–ρΩ…Ρή“Σ Ι”ΟΒΡΡ≥ΗωΉ ‘¥Θ§≥Χ–ρΕ‘Υυ”––≈Κ≈ΝΩΒΡΖΟΈ ΕΦ «ΦδΫ”ΒΡΘ§≥Χ–ρœ»Ά®ΙΐΒς”ΟsemgetΚ· ΐ≤ΔΧαΙ©“ΜΗωΦϋΘ§‘Ό”…œΒΆ≥…ζ≥…“ΜΗωœύ”ΠΒΡ–≈Κ≈±ξ ΕΖϊΘ®semgetΚ· ΐΒΡΖΒΜΊ÷ΒΘ©Θ§÷Μ”–semgetΚ· ΐ≤≈÷±Ϋ” Ι”Ο–≈Κ≈ΝΩΦϋΘ§Υυ”–ΤδΥϊΒΡ–≈Κ≈ΝΩΚ· ΐ Ι”Ο”…semgetΚ· ΐΖΒΜΊΒΡ–≈Κ≈ΝΩ±ξ ΕΖϊΓΘ»γΙϊΕύΗω≥Χ–ρ Ι”ΟœύΆ§ΒΡkey÷ΒΘ§keyΫΪΗΚ‘π–≠ΒςΙΛΉςΓΘ
ΒΎΕΰΗω≤Έ ΐnum_sems÷ΗΕ®–η“ΣΒΡ–≈Κ≈ΝΩ ΐΡΩΘ§ΥϋΒΡ÷ΒΦΗΚθΉή «1ΓΘ
ΒΎ»ΐΗω≤Έ ΐsem_flags «“ΜΉι±ξ÷ΨΘ§Β±œκ“ΣΒ±–≈Κ≈ΝΩ≤Μ¥φ‘Ύ ±¥¥Ϋ®“ΜΗω–¬ΒΡ–≈Κ≈ΝΩΘ§Ω…“‘ΚΆ÷ΒIPC_CREATΉωΑ¥ΈΜΜρ≤ΌΉςΓΘ…η÷ΟΝΥIPC_CREAT±ξ÷ΨΚσΘ§Φ¥ ΙΗχ≥ωΒΡΦϋ «“ΜΗω“―”––≈Κ≈ΝΩΒΡΦϋΘ§“≤≤ΜΜα≤ζ…ζ¥μΈσΓΘΕχIPC_CREAT
| IPC_EXCL‘ρΩ…“‘¥¥Ϋ®“ΜΗω–¬ΒΡΘ§Έ®“ΜΒΡ–≈Κ≈ΝΩΘ§»γΙϊ–≈Κ≈ΝΩ“―¥φ‘ΎΘ§ΖΒΜΊ“ΜΗω¥μΈσΓΘ
semgetΚ· ΐ≥…ΙΠΖΒΜΊ“ΜΗωœύ”Π–≈Κ≈±ξ ΕΖϊΘ®Ζ«ΝψΘ©Θ§ ßΑήΖΒΜΊ-1.
semopΚ· ΐ
ΥϋΒΡΉς”Ο «ΗΡ±δ–≈Κ≈ΝΩΒΡ÷ΒΘ§‘≠–ΆΈΣΘΚ
int semop(int
sem_id, struct sembuf *sem_opa, size_t num_sem_ops);
|
sem_id «”…semgetΖΒΜΊΒΡ–≈Κ≈ΝΩ±ξ ΕΖϊΘ§sembufΫαΙΙΒΡΕ®“ε»γœ¬ΘΚ
|
struct sembuf{
short sem_num;//≥ΐΖ« Ι”Ο“ΜΉι–≈Κ≈ΝΩΘ§Ζώ‘ρΥϋΈΣ0
short sem_op;//–≈Κ≈ΝΩ‘Ύ“Μ¥Έ≤ΌΉς÷––η“ΣΗΡ±δΒΡ ΐΨίΘ§Ά®≥Θ «ΝΫΗω ΐΘ§“ΜΗω «-1Θ§Φ¥PΘ®Β»¥ΐΘ©≤ΌΉςΘ§
//“ΜΗω «+1Θ§Φ¥VΘ®ΖΔΥΆ–≈Κ≈Θ©≤ΌΉςΓΘ
short sem_flg;//Ά®≥ΘΈΣSEM_UNDO, Ι≤ΌΉςœΒΆ≥ΗζΉΌ–≈Κ≈Θ§
//≤Δ‘ΎΫχ≥ΧΟΜ”– ΆΖ≈ΗΟ–≈Κ≈ΝΩΕχ÷’÷Ι ±Θ§≤ΌΉςœΒΆ≥ ΆΖ≈–≈Κ≈ΝΩ
}; |
semctlΚ· ΐ
| int semctl(int
sem_id, int sem_num, int command, ...); |
»γΙϊ”–ΒΎΥΡΗω≤Έ ΐΘ§ΥϋΆ®≥Θ «“ΜΗωunion semumΫαΙΙΘ§Ε®“ε»γœ¬ΘΚ
| union semun{
int val;
struct semid_ds *buf;
unsigned short *arry;
}; |
«ΑΝΫΗω≤Έ ΐ”κ«ΑΟφ“ΜΗωΚ· ΐ÷–ΒΡ“Μ―υΘ§commandΆ®≥Θ «œ¬ΟφΝΫΗω÷Β÷–ΒΡΤδ÷–“ΜΗω
SETVALΘΚ”Οά¥Α―–≈Κ≈ΝΩ≥θ ΦΜ·ΈΣ“ΜΗω“―÷ΣΒΡ÷ΒΓΘp ’βΗω÷ΒΆ®Ιΐunion semun÷–ΒΡval≥…‘±…η÷ΟΘ§ΤδΉς”Ο «‘Ύ–≈Κ≈ΝΩΒΎ“Μ¥Έ Ι”Ο«ΑΕ‘ΥϋΫχ––…η÷ΟΓΘ
IPC_RMIDΘΚ”Ο”Ύ…Ψ≥ΐ“ΜΗω“―Ψ≠Έό–ηΦΧ–χ Ι”ΟΒΡ–≈Κ≈ΝΩ±ξ ΕΖϊΓΘ |









